DOI:10.32604/cmc.2021.018303
| Computers, Materials & Continua DOI:10.32604/cmc.2021.018303 | |
| Article |
ECC: Edge Collaborative Caching Strategy for Differentiated Services Load-Balancing
1School of Design, Hunan University, Changsha, China
2School of Computer Science and Engineering, Sun Yat-Sen University, Guangzhou, China
3Department of Computing, Imperial College London, UK
*Corresponding Author: Fang Liu. Email: fangl@hnu.edu.cn
Received: 04 March 2021; Accepted: 19 April 2021
Abstract: Due to the explosion of network data traffic and IoT devices, edge servers are overloaded and slow to respond to the massive volume of online requests. A large number of studies have shown that edge caching can solve this problem effectively. This paper proposes a distributed edge collaborative caching mechanism for Internet online request services scenario. It solves the problem of large average access delay caused by unbalanced load of edge servers, meets users’ differentiated service demands and improves user experience. In particular, the edge cache node selection algorithm is optimized, and a novel edge cache replacement strategy considering the differentiated user requests is proposed. This mechanism can shorten the response time to a large number of user requests. Experimental results show that, compared with the current advanced online edge caching algorithm, the proposed edge collaborative caching strategy in this paper can reduce the average response delay by 9%. It also increases the user utility by 4.5 times in differentiated service scenarios, and significantly reduces the time complexity of the edge caching algorithm.
Keywords: Edge collaborative caching; differentiated service; cache replacement strategy; load balancing
With the advent of 5G era, the number of edge network devices has greatly increased, and the amount of data that needs to be processed or cached on the edge is explosively increasing. For example, Intel reported that the data generated by an autonomous vehicle in one day was 4TB in 2016. Cisco predicted that by 2021, the growth rate of mobile data to be processed will far exceed the capacity of data centers. There are currently billions of IoT devices connected to the Space, Air, Ground, and Sea (SAGS) network, and a large amount of data is generated [1]. If all these data were up-loaded to the cloud for processing, it would certainly not be able to meet the low latency requirements of complex applications, such as on-board applications. Also, it is well known that there is a serious mismatch in I/O speed between the CPU and the disk. Adding a memory cache between the two can solve this problem. Therefore, the edge cache in the network path between cloud and Internet of Things (IoT) devices is a good choice to reduce network latency. Yu et al. [2] proposed an algorithm based on the “IoT-Edge-Cloud” three-layer multi-hop model to evenly distribute computing tasks to network devices to process large amounts of data with huge potential value generated by IoT devices. Moreover, Liu et al. [3] proposed a matrix-based data sampling to alleviate the problems of data redundancy and high energy consumption that artificial intelligence is facing in collecting and processing big data.
Besides the latency issues, with the growth of network users, the traditional cloud-IoT or Cloud-Edge-IoT transmission architecture will cause some problems such as overloading of edge servers, single point failure of transmission links, and redundant transmission (such as hot videos) on resource-limited links.
In view of the above defects, there has been much research on the strategy of caching the most popular content locally according to the popularity of content, and a lot of work follows the Zipf distribution [4]. These methods can solve some of the above problems, but Zwolenski points out that the popularity of content on the Internet is easy to change greatly in a certain period of time, and it is easy to cause great deviation by using popularity [5]. In addition, Zhou et al. [6] proposed a new type of mobile photo selection scheme for congestion detection to reduce data redundancy on the server.
With the proliferation of Internet online requests, service providers will face the challenge of huge bandwidth overhead and the quality of service for users will be difficult to guarantee. Deploying the service close to the user and running the service cache on the edge server can effectively reduce access latency and improve the user’s utility.
There is no doubt that collaborative caching strategy can reduce the probability of obtaining services from the original server. However, there are few effective caching schemes for caching the hottest services locally according to the popularity of services. It is worth noting that this is based on services. Taking services as the research object, the heat of services in different nodes is different for a period of time, which will lead to different loads on nodes (i.e., the requested number of the services). It is necessary to keep services load balance to prevent the server from going down. Not only does it reduce the service access delay but also improves the user’s experience.
At present, most of the work doesn’t consider the difference of user requests, that is, the demand of the Internet for differentiated services. For example, some users are VIPs who can prior to occupying server resources but some are not. Nielsen, a global monitoring and data analysis company, pointed out that 39% of consumers are willing to buy products with better quality but relatively expensive prices, while 15% of consumers are willing to buy products with basic functions but relatively cheap prices, and 1% of consumers are willing to buy low-priced products at the expense of quality [4]. Therefore, providing differentiated services can bring higher commercial benefits to service providers. In addition, most of the existing work does not consider the extra cost of a large number of sudden service requests on edge nodes, such as queuing delay, which will greatly increase the average access delay and lead to a bad experience for users. Caching services or applications which users frequently request to collaborative edge nodes can effectively reduce average access latency and network traffic [7–9].
In the Internet online request service scenario, we will supplement the differentiated Internet services and the average queuing delay of mass emergent requests at edge collaborative nodes, in order to meet the differentiated service demands of users, reduce the average request access delay and improve user experience.
The characteristics of the edge collaborative caching strategy proposed in this paper are as follows:
• Our research object is different from the traditional file or content caching problem. We study the service caching problem in the Internet scenario where common content popularity model such as Zipf is not applicable to this scenario.
• The congestion of services in the node will damage user experience. When a user requests a service and the service runs on the edge node to answer the request, it needs to occupy node resources, such as CPU and memory resources. So the high concurrency of the service may easily cause other services to wait or even the node to go down, extremely increasing average access time of services.
• The node selection is divided into two stages where service should be placed. Referring to the characteristics of multi-node cooperative architecture (local cache hit delay < neighbor node hit delay < < cloud delay), when the service request frequency is low, it is randomly placed including the neighbor nodes and the local node. When the service request frequency reaches a large threshold, the service prefetching is placed in the local node.
• The same service delay, different user benefits. Differentiated services are common in Internet service scenarios. While considering the average access latency, we also need to consider the user benefits. Based on a real dataset, we classify different user requests into eight levels. Take it into cache replacement stage, optimizing the utility of users.
• The assumption of node blocking in point b and the assumption of differentiated service in point d above have been verified in real Google Trace (it is observed that there is blocking phenomenon and request level classification), and experiments are carried out based on this Trace, which reduces the delay and improves the user benefit.
Our key contributions of this paper are listed as follows:
• We specifically describe the online request application scenario of distributed edge cache, analyzes the Google data set, and finds that introducing relaying mechanism in nodes with relatively balanced must break the load balance. In particular, some cache algorithms without considering load balancing have too much queueing delay in some hot nodes, which leads to too much average access delay and too little benefit for users.
• By optimizing the average access time of online service requests and differentiated services for user requests, we propose a collaborative edge caching algorithm with differentiated services and load balancing. Compared with the classical cache replacement algorithm and the advanced online edge cache algorithm, analyzes the effectiveness of our proposal.
The rest of the paper is organized as follows. Section 2 introduces the related work. Section 3 introduce our system modeling and problem formulation. We present effective algorithms in Section 4. Experiments and performance evaluations are in Section 5. Finally, Section 6 concludes this paper and discusses the future work.
Among the traditional online caching algorithms, the most widely used is LRU [10]. With low spatial complexity, it performs well in cache hit ratio evaluation because online requests often have the characteristics of “locality principle.” On the edge cooperative cache scenario, LRU which is naturally modified also performs well in hit ratio evaluation [9]. Edge caching technology has developed rapidly and it can be traced back to content distribution network technology [11]. In recent years, many excellent works were proposed on edge caching research. According to the use of tools or the field of studies, it can be divided into three kinds: D2D (Device-to-Device) communication aided edge caching [12,13], Game theory aided edge caching which reduces operator cost or increases profits [14], and edge collaborative caching which reduces the service response/access time [8,9].
D2D communication aided edge caching. Golrezaei et al. [11] proposed an architecture for caching popular video content based on the edge caching net-work assisted by D2D, and proved that D2D communication can effectively improve system throughput. On the D2D aided edge network, Wang et al. proposed an effective hierarchical collaborative caching algorithm for un-loading network traffic, which takes the social behavior and preferences of mobile users and cache content size into account [12]. Besides, it is also a popular method to establish game models for edge cache network and it takes system cost and benefit as the optimization goal. Li et al. [13] on the edge of the small commercial network, proposed that the competition relation between NEP (network equipment providers) and VSP (video service provider) can be built as a Stackelberg Game model. By describing the cache equipment rental and deployment strategy, it optimizes the benefit of the NEP and VSP.
Game theory aided edge caching. Cao et al. [14] conducted auction modeling for the content delivery relationships among SP (service providers), users and content providers on edge cache network, and reduced the cost of SP and maximized the revenue of SP by using Myerson optimal auction model. Wu et al. [15] devised a distributed game-theoretical mechanism with resources sharing among network service providers with the objective to minimize the social cost of all network service providers, by introducing a novel cost sharing model and a coalition formation game.
Edge collaborative caching. Tan et al. [8] studied online service caching in the multiple edge node collaboration scenario, and proposed an asymptotic optimal cache replacement algorithm with the goal of optimizing network traffic and other costs. Ma et al. pointed out that due to the heterogeneity of edge resource capacity and the inconsistency of edge storage computing capacity, it is difficult to make full use of edge resource storage and computing capacity in the absence of collaboration between edge nodes. To solve this problem, they considered edge collaborative caching based on Gibbs sampling and Water falling algorithm, reducing the service outsourcing traffic and response time [4]. Hao et al. [7] proposed an edge intelligent algorithm in the heterogeneous Internet of Things architecture to jointly optimize the wireless communication cost, the collaborative cache and the computing unloading cost in the edge cloud, so as to minimize the total delay of the system. Wu et al. [16] proposed Edge-oriented Collaborative Caching (ECC) in information centric networking (ICN). In ECC, edge devices (such as edge server, micro data center, etc.) cache file contents while routers only maintain file cache indexes which are used to redirect subsequent requests towards the cached file content. Ren et al. [17] proposed a hybrid collaborative caching (Hy-CoCa) design that places cache in nodes, node groups and nodes in the network according to content popularity to further reduce delay and energy consumption.
There have been some researches on edge service caching algorithms, but the difference of service requirements has not been considered. In addition, most studies have ignored the unbalanced load of a large number of user requests on the edge server, which may cause congestion on edge servers, or even server downtime.
3 System Modeling and Problem Formulation
From the collaborative model of edge caching, it can be divided into cloud-edge, edge-edge and edge-IoT collaboration. The system proposed in this paper is based on the mode of cloud-edge and edge-edge collaboration to study the cooperative caching strategy. In this model, we study the cooperative caching strategy applied by Internet service in edge nodes. It is reasonable to assume that the cloud center has configured with all Internet service applications. Due to the limited storage capacity of edge nodes, the installation configuration can only be performed in the node after downloading/acquiring source files (or application installation packages) from the cloud center. Usually, due to the limited capacity of edge nodes, after installing new service applications, edge nodes will discard their source files (or application installation packages).
In the system architecture in Fig. 1, when an Internet user issues a request for application services which were deployed in the cloud or edge nodes, edge nodes will respond to the request with four different actions according to their cache hits. Denote the user request as
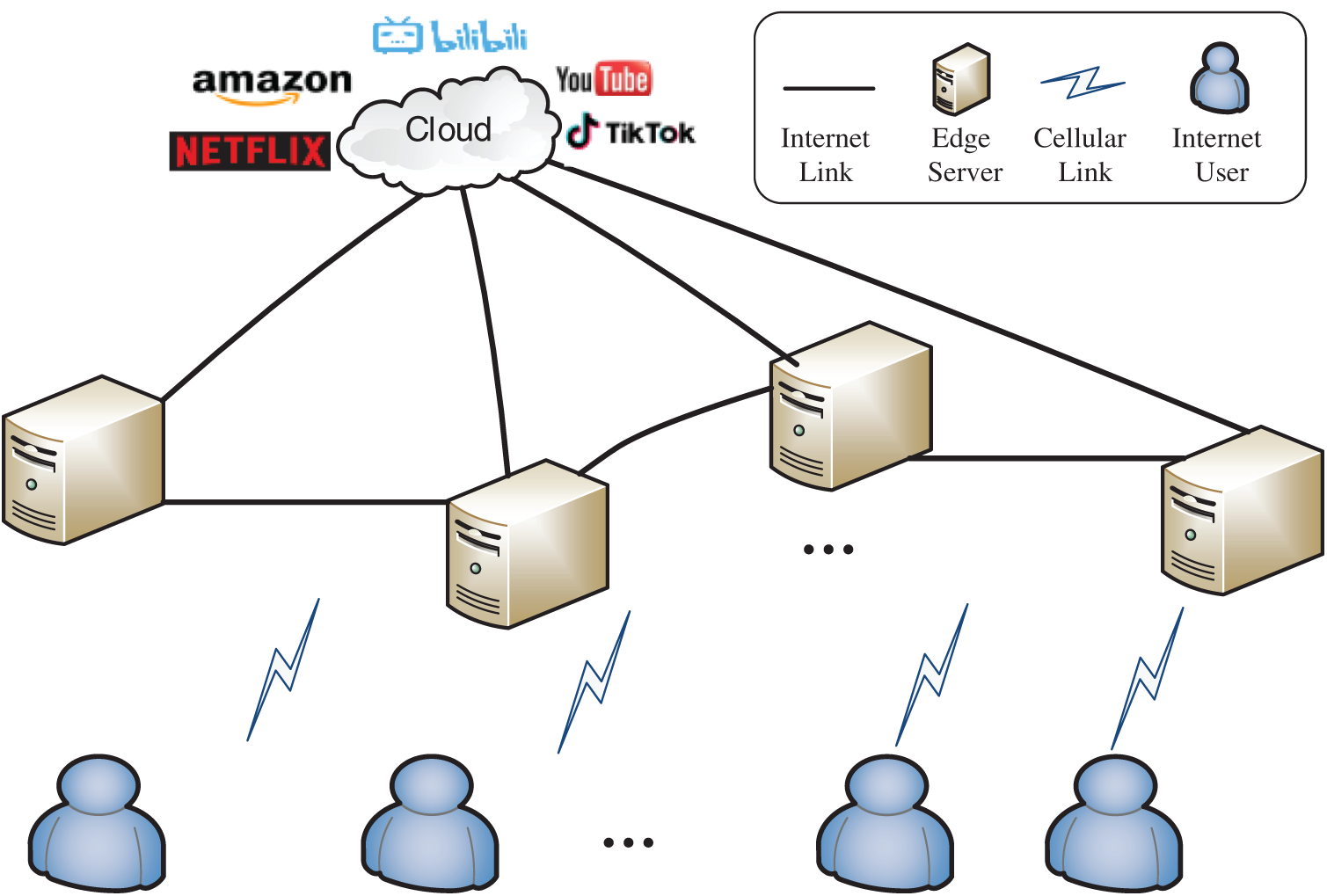
Figure 1: An example for edge collaborative caching system
First, if the local edge node s, such as the base station, router and other devices with storage and networking capacity, has deployed the service, the user request
Second, if the local edge node s is not hit, and the neighbor node
Third, if none of the edge nodes are hit, the local node s will send request
Fourth, if the local node or neighbor node does not hit multiple times, the edge node s and
It is reasonable to assume that all service applications (i.e., files, for simple) are accessible in the cloud center, and that the edge nodes have limited cache space, so only some files can be cached. Suppose there are m edge nodes in the cache system, denoted as the node set
As mentioned above, the high concurrency of the service may easily cause request congestion. When a request is blocked in a node, there is a queueing delay. Define the queueing ratio for the user’s request, called the mean blocking rate pqueueing, as shown in Eq. (1).
where nqueueing represents the number of requests blocking the queue, and nrequest represents the number of requests.
Define the total queueing delay of the request in the node as shown in Eq. (2).
where K is the number of queueing tasks and tavgQ is the average queuing delay, which is usually set to 100 milliseconds (
Cache hit ratio hr is an essential performance indicator for cache system evaluation, and its definition is shown in Eq. (3).
where hlocal represents the number of local hits, hrelay represents the number of relay hits, and nrequest represents the number of requests.
Furthermore, average access delay tavg is also an essential performance indicator for cache system evaluation, and its definition is shown in Eq. (4).
Among them,
In addition, we observe the load balancing of nodes with the edge node load variance va, which is defined as Eq. (5) and represents the stability of node response delay. From the perspective of users, the greater the variance of node load, the greater the delay difference of service response request perceived by users (i.e., the delay of user request response is sometimes large and sometimes small).
where AVG(hc) is the function that finds the average number of loads on all nodes.
As mentioned above, differentiated services are common in Internet service application scenarios. In order to meet the needs of differentiated services and optimize user benefits, we analyzed the relationship between the priority and frequency of user requests in the Google dataset and found that they are not inversely proportional, as shown in Fig. 2. Considering the priority and frequency of user requests, the definition of service level of user requests is shown in Eq. (6).
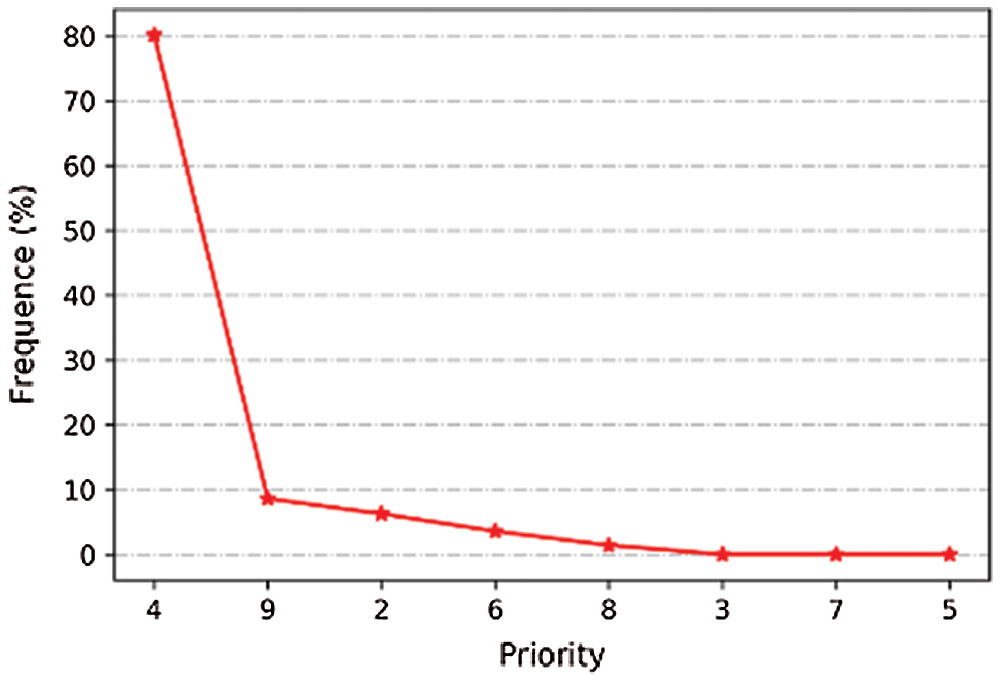
Figure 2: Priority and frequency of user request in google dataset
When the user request
Since different service requests have different user utility, in order to improve sum of user utility, we can replace the services with lower cumulative utility first. If the cumulative utility is the same, then consider the least recently used (LRU) strategy to replace the least recently used service.
4 Distributed Edge Collaborative Caching Mechanism
Similar to the memory cache in a computer, edge caching process can be roughly divided into three stages, data prefetch, node selection and cache replacement stage. In particular, we optimize an algorithm for node selection stage based on the hot load node of probability choice node (i.e., Select-the-node-with-probability), and boost a differentiated service cache replacement algorithm for cache replacement stage based on the recent minimum user benefit respectively (i.e., LUULRU-Fetch).

Above, lines 5 to 11 in algorithm 1 show how to obtain random numbers for the node selection stage. Where, line 5 of the algorithm represents the maximum number of loads MAX(hc) within the node load count table hc, and
Differentiated services are common in Internet scenarios. For example, compared with normal users, VIPs can get superior service quality and better user experience. In order to meet the needs of differentiated services, we put forward differentiated service strategies.

Edge collaborative caching strategy is proposed as follows (overall strategy, integrating differentiated service strategy and load balancing strategy). Combined with the node load balancing strategy and differentiated service strategy proposed above in the three stages of the cache replacement process (data prefetching, node selection and cache replacement). The specific algorithm is shown in Algorithm 3.

In the input section of Algorithm 3,
Lines 1 to 7 of algorithm 3 describe the response action of edge node or neighbor node, or cloud service/response when the user request r access f. In line 4, hc(s) represents the number of requests/loads processed in the node s,
Lines 9 to 15 of Algorithm 3 describe the cache replacement (also known as cache update) process. Lines 9 to 12 describe that after prefetching f, Algorithm 1 (Select-node-with-probability (r)) is used for node selection, and finally Algorithm 2 (LUULRU-Fetch) is used for cache replacement.
Lines 13 to 15 of Algorithm 3, similar to lines 9 to 12, describe the process after prefetching f, selecting the current node, and finally using algorithm 2 (LUULRU-Fetch) for cache replacement.
Based on the Task Event Table [18] in the real Data set Google Cluster Data 2011-2, we conducted a large number of experimental tests and performance analysis compared with the baselines. Due to probabilistic selection existing in some baselines and the proposed algorithm, we conducted 10 times and analyzed the results of the proposed algorithm improvements. Specifically, the baselines are the advanced Camul [8] and the classic LRUwithRelay and LRUwithoutRelay algorithms. The baselines are used to test and analyze important performance indicators such as hit ratio, average access delay and so on.
Considering the system shown in Fig. 1, we set some important parameters and explain them as follows. According to the experimental test results of Maheshwari et al. on edge cloud system in 2018, we set tl = 1, tr = 10, tb = 100, and the unit of time was simply set as milliseconds (ms) [19]. Refer to Camul [8], the ratio of operation cost of FETCH and bypass is 10, so set tf = 1000 ms. Due to the huge difference between the two poles of queueing delay in Google Cluster Data 2011-2, which is 1us

5.2 Additional Overhead Analysis of Algorithms
Suppose there are n user requests, m nodes in the system, and each node has e slots. Compared with the traditional LRU algorithm, the extra space overhead of each algorithm is shown in Tab. 2.

In short, the space overhead of each algorithm is: LRUwithoutRelay < LRUwithRelay < Proposal < Camul.
Observe the experimental results, as shown in Fig. 3, and explore the impact of the number of cache nodes on the algorithm performance: (a) with the increase in the number of nodes, similar to other algorithms with relaying mechanism, the hit ratio of proposal is almost unchanged; (b) As the number of nodes increases, the number of queueing tasks in each node decreases, the queueing delay decreases, and the hit ratio slightly increases, so the average access delay decreases; (c) As the number of nodes increases, the number of local hits decreases and the number of relaying hits increases for the algorithm with relaying mechanism. According to user utility Eq. (7), it can be seen that the user utility decreases. In addition, for LRUwithoutRelay algorithm, since nodes do not have relaying mechanism and fetch delay are relatively more, its user utility is usually low. (d) Except for LRUwithoutRelay which does not have the relaying mechanism and remains the load balance of original traces, which leads to the lowest load variance, the proposals are all better than the other two algorithms. (e) In terms of the algorithm’s time overhead, Proposal is obviously superior to Camul, and even slightly superior to LRUwithRelay algorithm when the number of nodes is large.
Based on the experimental results, as shown in Fig. 4, we can analyze the impact of cache node capacity on algorithm performance: (a) the hit ratio of each algorithm increases with the increase of cache size, and the proposal is very close to Camul. (b) With the increase of cache capacity, the average access delay of LRUwithoutRelay decreases. The benefits brought by relaying mechanism make the other three algorithms not significantly changed. (c) Since user utility of LRUwithoutRelay is far less than 0 in small capacity, it is not shown here. It can be seen from Fig. 4c that proposal is superior to other algorithms. (d) With the exception of LRUwithoutRelay, the proposal is superior to other algorithms in terms of the load variance of performance indicators. (e) Since the classical LRUwithoutRelay algorithm is the simplest, it has the lowest time cost. LRUwithRelay is similar to the proposal, while Camul needs to record the status of the slot in the node, so its time cost increases with the increase of cache capacity.
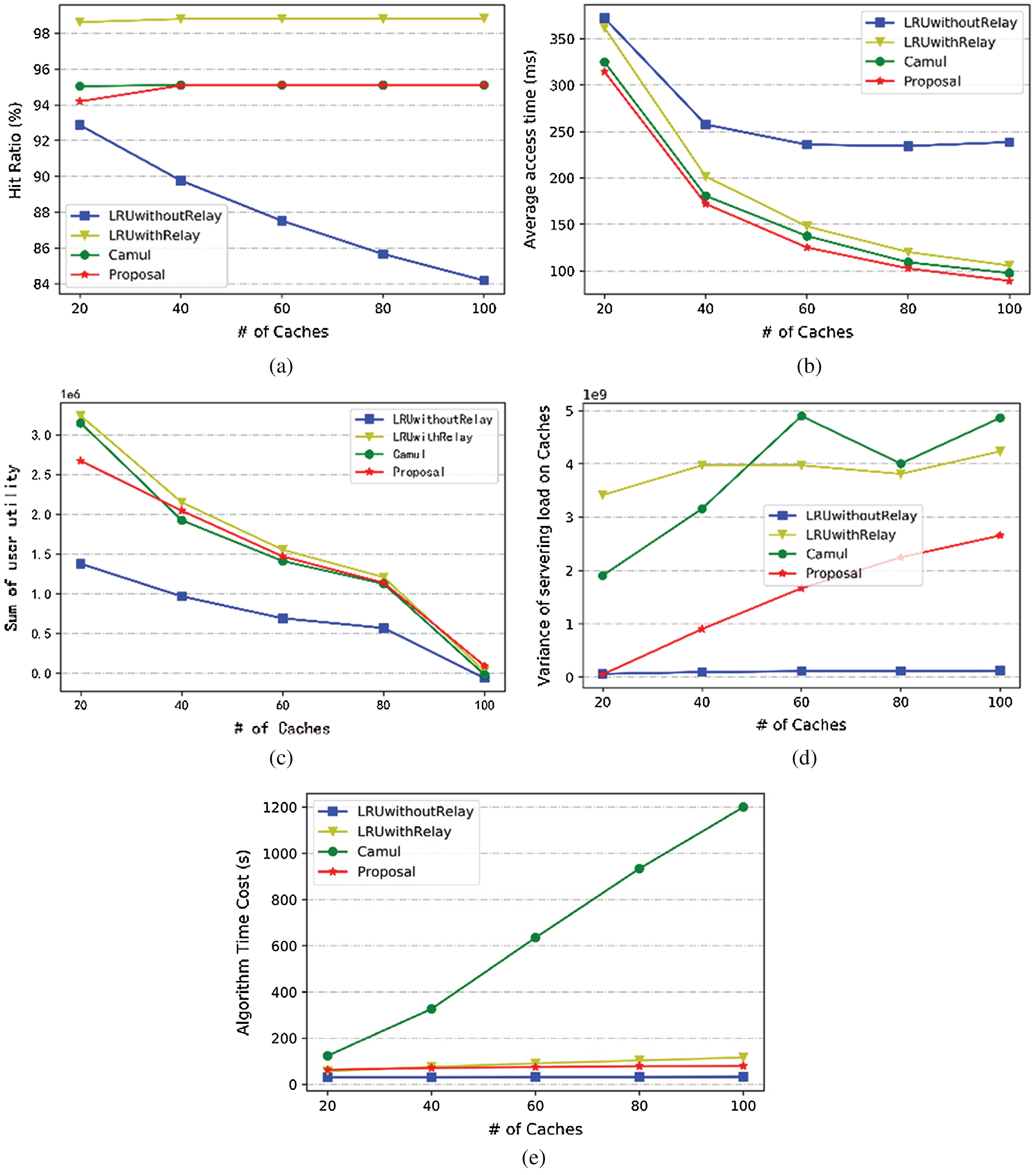
Figure 3: Impact of cache number
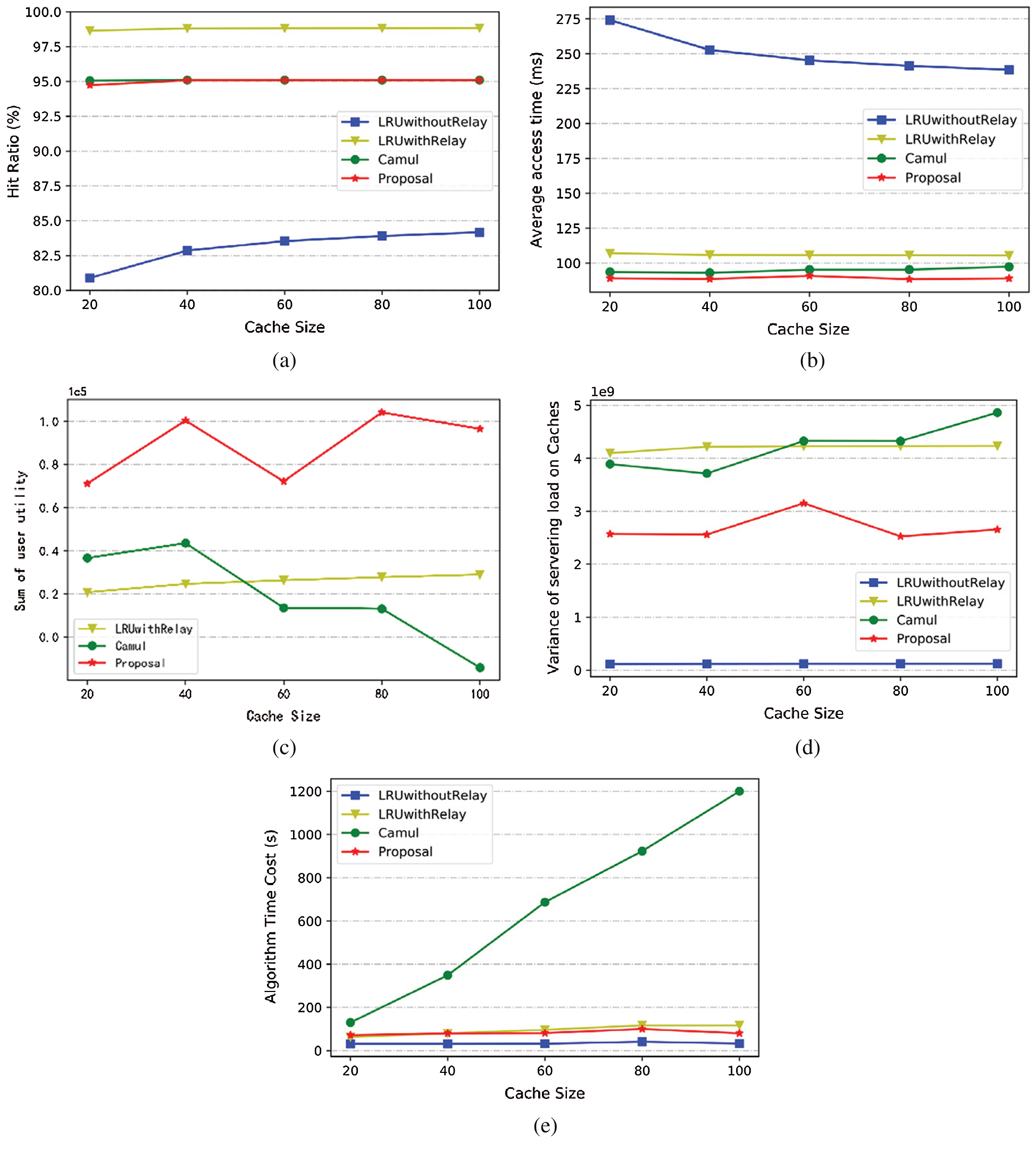
Figure 4: Impact of cache size
5.3.3 Impact of Average Queueing Delay
As shown in Fig. 5, the experiment shows the effect of average queuing delay on the performance of the algorithm: (a) it can be found that with the increase of average queueing delay, the average access delay of all algorithms increases gradually. The more balanced the algorithm is, the slower the increase rate is. (b) With the increase of average queueing delay, the user utility of each algorithm decreases gradually. In addition, when the average queueing delay is within a reasonable range of 60 ms
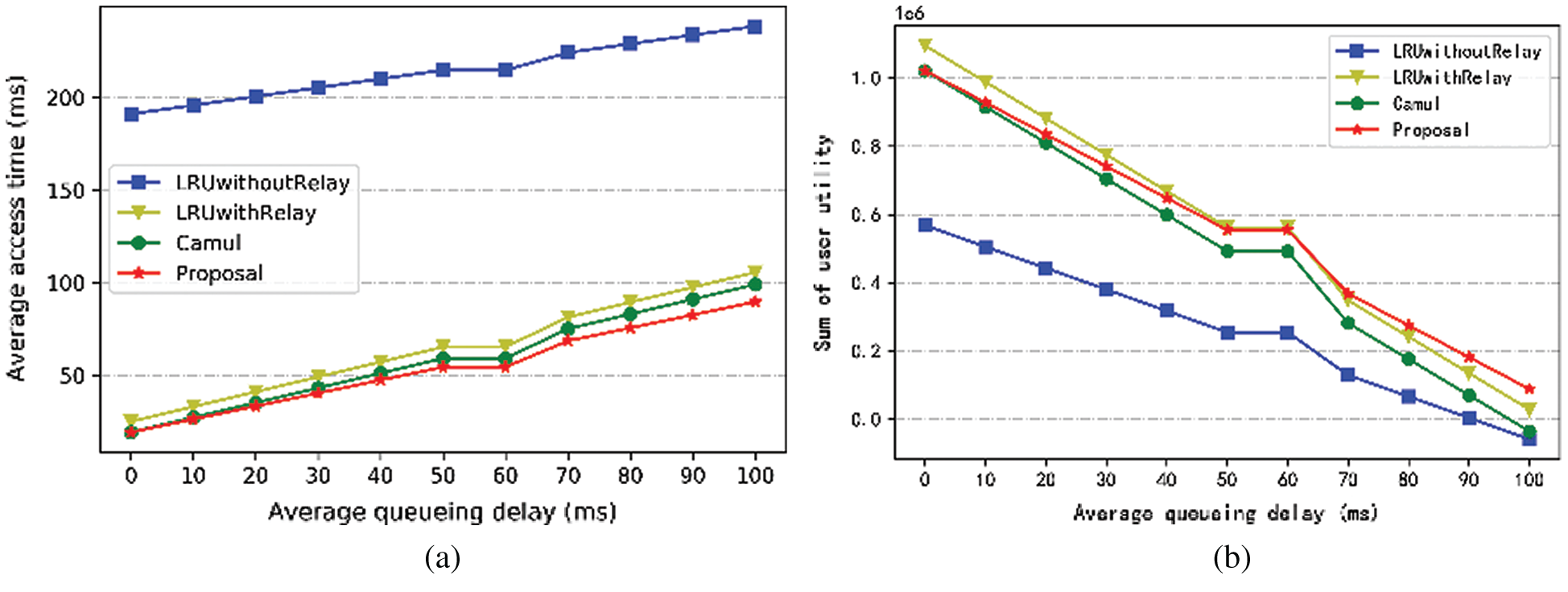
Figure 5: Impact of average queueing delay
In addition, as can be seen from Figs. 3a and 4a, the proposal is not superior to LRUwithoutRelay on an important indicator of cache hit ratio. This is because LRUwithRelay with relaying mechanism treats all nodes as a whole, and its content repetition proportion between nodes is 0, while the content repetition between proposal and Camul is greater than 0. Besides, LRUwithoutRelay regards each node as independent and its content repetition between nodes is the highest.
This paper describes the online request scenario of edge collaborative caching, analyzes the Google data set and finds that the introduction of relaying mechanism in nodes with relatively balanced load must increase the variance of node service load. However, some cache algorithms without considering load balancing have large queueing delay in some nodes, which leads to large average access delay and low utility for users.
By optimizing the average access delay of online service requests and differentiated services scenes, we proposed an edge collaborative caching algorithm based on differentiated services and load balancing. Based on differentiation of Internet service scenarios and the introduction of relaying mechanisms, we considered serious request queuing delays from the node load imbalance, compared to the classic cache replacement algorithm and the current advanced online edge caching algorithm. The experimental results show that our proposal not only guarantees the load balancing server process the request, but also reduces the average user requests access latency, improving the utility of users.
By caching the requested content, multiple nodes can provide services for users to speed up transfer. In the future, we will study the influence of single point transmission and coordinated multiple points (CoMP) transmission on edge cache, such as energy consumption and computational complexity, so as to find a compromise between cooperative multi-point transmission and single point transmission.
Funding Statement: This work is supported by the National Natural Science Foundation of China (62072465) and the Key-Area Research and Development Program of Guang Dong Province (2019B010107001).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |