DOI:10.32604/cmc.2021.016713
| Computers, Materials & Continua DOI:10.32604/cmc.2021.016713 | |
| Article |
A Mixture Model Parameters Estimation Algorithm for Inter-Contact Times in Internet of Vehicles
1School of Computer and Communication Engineering, University of Science and Technology Beijing, Beijing, 100083, China
2Beijing Advanced Innovation Center for Materials Genome Engineering, School of Computer and Communication Engineering, University of Science and Technology Beijing, 100083, China
3Shunde Graduate School of University of Science and Technology Beijing, Foshan City, 528300, Guangdong, China
4Beijing Engineering and Technology Center for Convergence Networks and Ubiquitous Services, University of Science and Technology Beijing, Beijing, 100083, China
5Commonwealth Scientific and Industrial Research Organization, Canberra, 2600, Australia
*Corresponding Author: Wei Huangfu. Email: huangfuwei@ustb.edu.cn
Received: 08 January 2021; Accepted: 09 February 2021
Abstract: Communication opportunities among vehicles are important for data transmission over the Internet of Vehicles (IoV). Mixture models are appropriate to describe complex spatial-temporal data. By calculating the expectation of hidden variables in vehicle communication, Expectation Maximization (EM) algorithm solves the maximum likelihood estimation of parameters, and then obtains the mixture model of vehicle communication opportunities. However, the EM algorithm requires multiple iterations and each iteration needs to process all the data. Thus its computational complexity is high. A parameter estimation algorithm with low computational complexity based on Bin Count (BC) and Differential Evolution (DE) (PEBCDE) is proposed. It overcomes the disadvantages of the EM algorithm in solving mixture models for big data. In order to reduce the computational complexity of the mixture models in the IoV, massive data are divided into relatively few time intervals and then counted. According to these few counted values, the parameters of the mixture model are obtained by using DE algorithm. Through modeling and analysis of simulation data and instance data, the PEBCDE algorithm is verified and discussed from two aspects, i.e., accuracy and efficiency. The numerical solution of the probability distribution parameters is obtained, which further provides a more detailed statistical model for the distribution of the opportunity interval of the IoV.
Keywords: Internet of vehicles; opportunistic networks; inter-contact times; mixture model; parameters estimation
The concept of the Internet of Vehicles (IoV) is closely related to the Internet of Things (IoT) [1–5]. It takes vehicles as the objects of information perception and control. With the help of the new generation of information and communication technologies, the IoV realizes the network connections among the vehicles, people, roads, and service platforms. Thus improve the vehicle driving experience, traffic efficiency, and social traffic service level. The IoV is one of the important branches of the opportunity network [6]. Since vehicles are usually in motion, the instantaneous opportunity communication formed when two vehicles meet is an important way of data transmission in the IoVs. The statistical model of inter-contact times is one of the basic problems of the IoVs [7].
Communication opportunity interval is affected by many factors, including but not limited to vehicle movement model and location distribution, vehicle density, broad geographic distribution, communication accessibility, etc. The previous scholars mainly considered establishing the vehicle movement model and mine the statistical model of communication opportunity interval through theory or simulation. In a Random Waypoint Mobility (RWM) model [8], it was found through simulation that the inter-contact time interval of moving points obeyed exponential distribution [9]. Based on the RWM model and a Random Direction Mobility (RDM) model [10], it was proved that in a finite boundary movement space, the inter-contact time interval was an exponential distribution, while in the unbounded condition, the inter-contact time interval was an approximate power-law distribution [11].
With the development of big data technology, more scholars tended to collect the actual spatial-temporal data sets of vehicle movement, and then used big data mining techniques to determine the statistical model of the data [12,13]. References [14–17] analyzed the inter-contact time interval extracted from the movement trajectory data of buses and taxis in Beijing and Shanghai, respectively. Reference [14] held that the inter-contact time interval of the taxi approximately follows the exponential distribution. References [15,16] both believed that it was a segmented distribution. Only reference [17] proposed that it was the mixture normal distribution. Although the above conclusions based on spatial-temporal big data were not consistent, most of them adopted single statistical distribution or segmented statistical distribution for data analysis. In fact, the IoV are affected by many factors. The sample data of the vehicle movement trajectory is complex and changeable, which may come from a population with different properties. Therefore, a single statistical distribution is difficult to describe the characteristics of actual data. However, the segmented distribution model to describe the vehicle inter-contact time interval is essentially a superficial description of the overall sampled data, so it is difficult to express the complex composition contained in the data.
For the mixture statistical distribution of spatial-temporal big data, a parameter estimation algorithm with low computational complexity based on Bin Count (BC) and Differential Evolution (DE) (PEBCDE) is proposed. BC is used to count all data in a small number of intervals, and a small number of calculated values are used as statistics for the next step of parameter estimation. DE is used to solve nonlinear optimization problems similar to the Expectation Maximization (EM) algorithm [18]. Due to the adoption of BC and DE algorithms, although the accuracy is lower than the EM algorithm, a faster parameter estimation of the statistical model for vehicle inter-contact times is realized. Based on this characteristic, the PEBCDE algorithm proposed in this paper can be used for the online calculation of vehicle-mounted systems. The real-time data received by the vehicles are further calculated to improve the model and obtain more accurate parameter estimation results. In addition, BC parameters can be adjusted to control the accuracy of the algorithm, to optimize the balance between calculated amount and accuracy.
The rest of this paper is arranged as follows. Section 2 describes the related work. Sections 3 and 4 introduce the system model and the algorithm. Analysis and simulation results will be described and displayed in Section 5. Section 6 gives the conclusions of this paper and an outlook for future work.
For the estimation of a high-dimensional latent variable model, a novel semi-stochastic variance-reduced gradient designed for the Q-function in the EM algorithm was proposed [19]. Compared with the state-of-the-art algorithm, the new algorithm had a certain reduction in the overall computational complexity. Reference [20] modified the EM algorithm, by attaching a truncation step to the expectation step (E-step) and maximization step (M-step), the convergence rate was effectively improved. According to the modified algorithm, the article also gave a decorrelated score statistic about the low dimensional components of the high dimensional parameters.
Reference [21] focused on global convergence rates for stochastic EM methods. In a sufficient statistics space, the EM method can be studied as a scaled-gradient method. On this basis, the author introduced a new incremental version. For a particular model, such as a mixture model of two Gaussians, it had been researched [22]. The article proved the convergence of the sequence of iterates in that model. The author also studied the initial parameter settings. Inspired by variance reduced stochastic gradient descent algorithms, Variance Reduced Stochastic EM (sEM-vr) algorithm was developed [23]. The sEM-vr computed the full batch expectation as a control variate, which reduced the variance of minibatch. Comparing with other gradient-based and Bayesian algorithms, this algorithm achieved a faster convergence speed. Given low-rank mixture regression and regression with missing covariates, it specialized in a general framework [24]. Using the state-of-the-art high-dimensional prescriptions to regular the M-step did not guarantee balance. Aregularization method was proposed considering optimization and statistical error.
The actual spatial-temporal big data often have missing or hidden variables, the traditional methods are difficult to accurately estimate the parameters, and the data may come from different populations. The single distribution model cannot accurately reflect the nature of the data, and it is difficult to mine the effective information of the data. A more reasonable approach is to explore the mixture distribution model of data [25]. The mixture distribution model is a combination of several different statistical distributions according to a certain probability. It is a new combination model combining the properties and characteristics of multiple branches. The mixture distribution model can simulate a large amount of data effectively and make the data distribution model more accurate.
At present, the EM algorithm is usually used for the parameter estimation of mixture statistical distribution modeling [26,27]. It is one of the classical algorithms in the field of data mining and solves the problem that the maximum likelihood estimation is difficult to optimize due to the hidden variables in the actual statistical model. However, the EM algorithm needs to iterate several times to achieve the ideal effect, and each iteration process requires the participation of all data. Therefore, the algorithm has high computational complexity and it is difficult to adapt to the massive spatiotemporal big data scene. Besides, the addition of probability is introduced into the mixture distribution, which calculates logarithmic likelihood very complicated and difficult to obtain closed solutions. As a result, every step of EM iteration becomes a sub-problem of nonlinear optimization, and the computational complexity of EM is increased.
In this paper, BC and DE are introduced to reduce the computational complexity of mixture distribution parameter estimation. Bin counting and DE based on a small amount of data are used to replace the EM algorithm with a large number of data to realize the optimization of the opportunity interval distribution model of the IoVs.
In this paper, based on the longitude and latitude trajectory data of Beijing taxis in May 2010, the algorithm of data cleaning and extraction of inter-contact times interval is presented [16]. Assume that a large sample set
where, k denotes the number of branches, fi(x) denotes the probability density function of the
The EM algorithm is widely used in parameter estimation of mixture models. The likelihood function can be simplified by introducing suitable potential data. It first assumes that the known observed data of the total sample number N is X, and the potential data is
(1) Set the initial value
(2) Step E: Calculate the conditional expectation of the likelihood function based on the complete data set of the hidden variable Y, denoted as the auxiliary function Q.
where
(3) Step M: Evaluate
The operations of Step E and Step M above are iterated alternately until
The basic flow of a parameter estimation algorithm based on BC and DE proposed in this paper is as follows: (1) First, the total sample data is segmented according to a certain interval, and the number of sampled data in each segment is counted. The statistical probability of each segment is calculated by the mixture distribution probability density function (including parameters), and the probability of event occurrence is calculated by multinomial distribution; (2) the event probability calculated in the previous step is taken as the objective function, and the parameter value at the maximum of the objective function is iterated through DE algorithm.
4 Design of the PEBCDE Algorithm
4.1 Segment and Calculate the Maximum Probability Objective Function
Suppose the probability density function of the total data set is
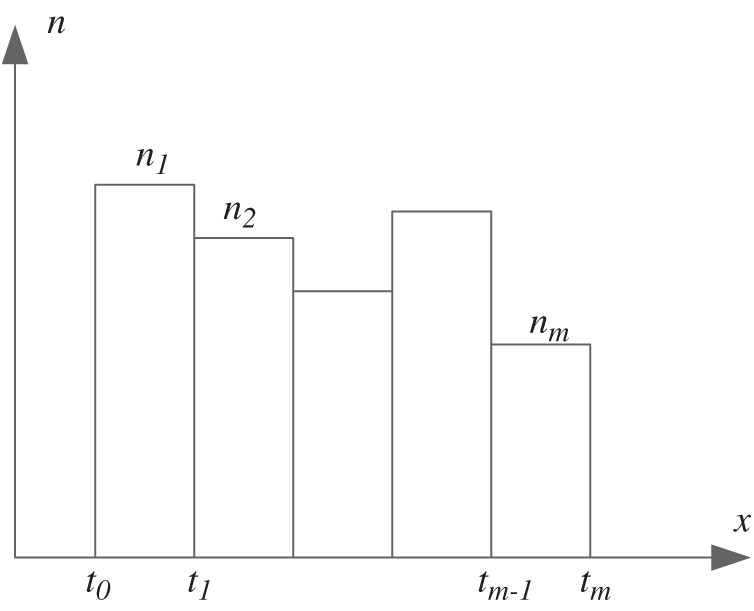
Figure 1: Segmental statistical schematic diagram of the sampled data
If special cases such as the existence of impulse function in probability distribution are not considered, then the probability of data points in the interval
The probability that ni out of N data points are in the interval
According to the multinomial distribution, the occurrence probability P is exactly given as
The time complexity of this step is
4.2 Solve the Estimated Parameters by DE
DE algorithm is a heuristic parallel search method based on group difference. In this step, DE algorithm is used to solve the estimated parameters so that Eq. (5) can obtain the maximum value. First, we initialize the population. In the solution space, M individuals are generated randomly and uniformly, and each individual is composed of K chromosomes. As the
Mutation operation:
In the
where F denotes the scaling factor used to control the influence of the difference factor.
Crossover operation:
Crossover operation increases the diversity of population as follows,
where
After completing the mutation and crossover operation,
The flow of DE algorithm is shown in Fig. 2.
The size of the statistic values that DE algorithm needs to process at each step is m, much smaller than N. Therefore, the algorithm is fast in solving the problem and is very suitable for solving the probability distribution type where it is difficult to find the closed solution. When the number of iterations and individuals are fixed, the time complexity of DE algorithm is only related to the number of segments m, which is close to

Figure 2: The flow of DE algorithm
This section analyzes and verifies the effectiveness of the proposed algorithm in the system model. Firstly, the correctness of the algorithm is verified and the accuracy of the algorithm is analyzed. Correctness is verified by comparing the similarity between the given model data and the evaluation model data. The accuracy of the algorithm is observed by modeling and analyzing the ideal data. Based on ensuring the effectiveness and availability of the algorithm, we further apply the algorithm to the actual data set to analyze and verify the actual effect of the PEBCDE algorithm on the movement trajectory data of Beijing taxis. Then, we compare the operation efficiency of the traditional EM algorithm and the proposed PEBCDE algorithm under different parameters, and summarize the performance of the algorithm as a whole.
The simulation experiment is implemented in Python (version 3.7.3) and on an AMD RyzenTM7 3700X processor with 3.60 GHz CPU 16 GB RAM running on the platform Microsoft Window 10.
5.1 Correctness and Accuracy Verification
In this subsection, the simulated data obey a Gaussian mixture distribution with

The parameters of the statistical model obtained by the PEBCDE algorithm are
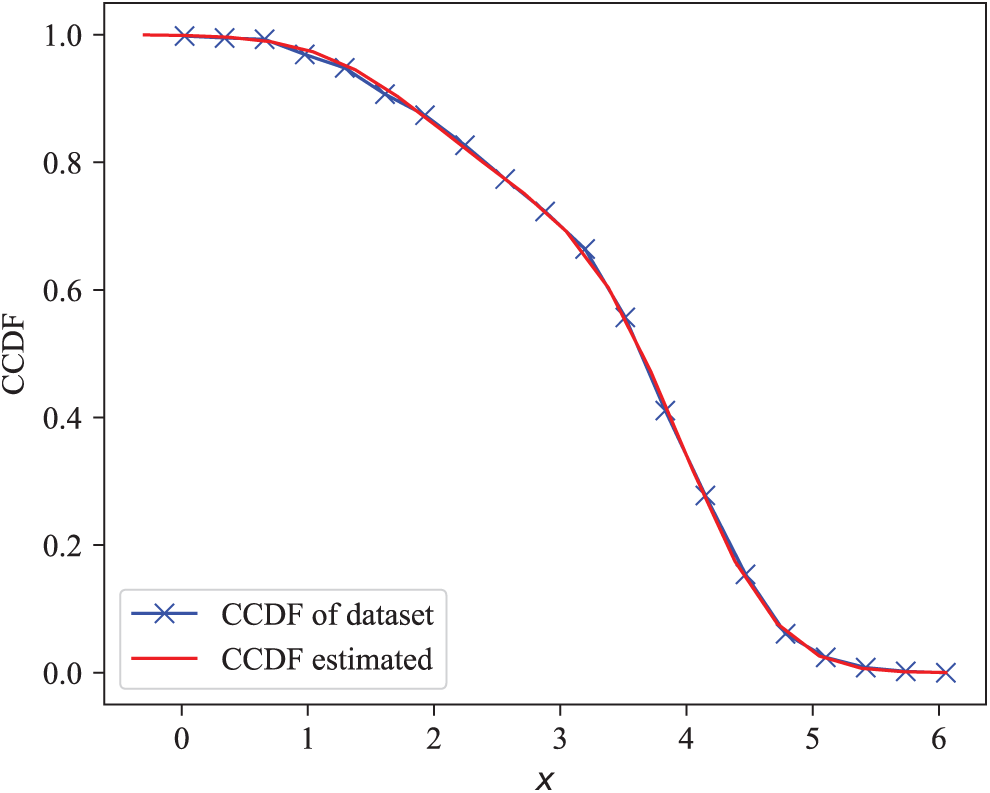
Figure 3: Modeling and comparison of simulation data
The specific iteration of some parameters is shown in Fig. 4. The solid lines represent the actual value of parameters, and the lines with markers represent the value change of the estimated parameter. Each parameter oscillates around the actual value and converges.
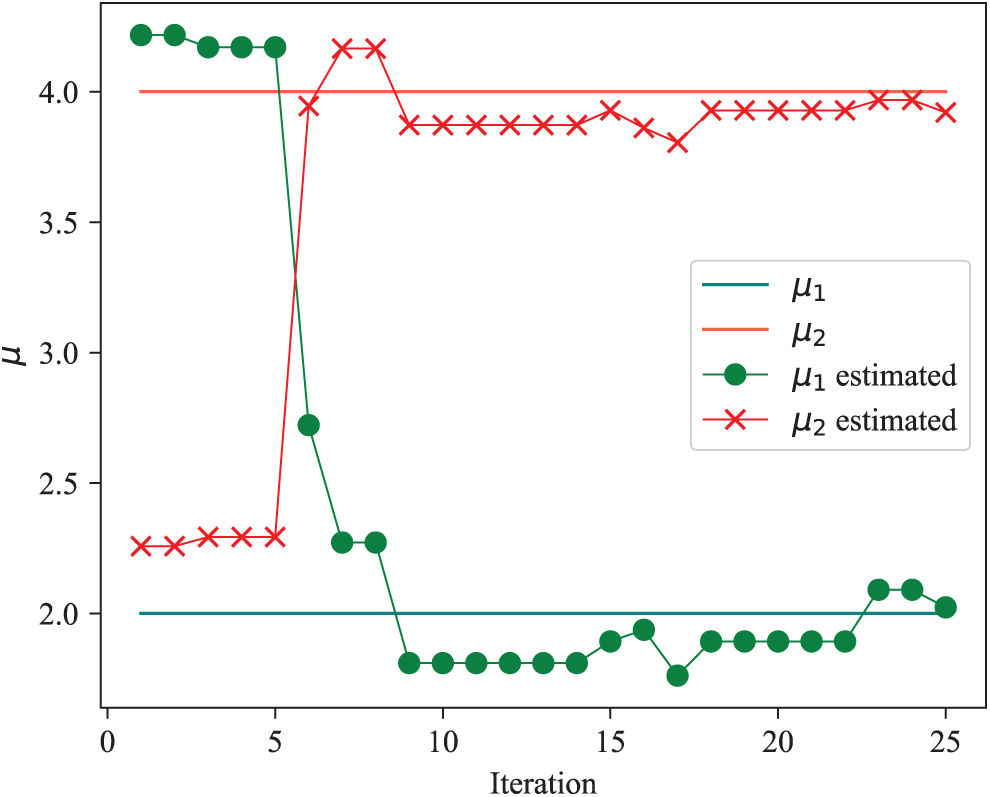
Figure 4: The convergence of mean values of both branches per iteration
In the initial stage of data processing, the PEBCDE algorithm needs to segment all the data. The difference in the number of bins leads to different degrees of information loss of part of the raw data, resulting in the different effects on the calculation accuracy. However, the process can also be speeded up, allowing users to adjust the accuracy of calculations to suit their specific needs. Kolmogorov Smirnov (KS) test is used to evaluate the accuracy of the model obtained by the algorithm. The results are shown in Fig. 5. It can be clearly seen that the accuracy of the algorithm has been improved with the increase of the number of bins. It is important to note that the more the number of bins is, the better the algorithm performs. Therefore, after convergence, the KS statistical result with 32 bin is slightly higher than that with 8 bin. This shows that when the number of bins reaches a certain degree, the basically accurate results based on the segmented data can be achieved.
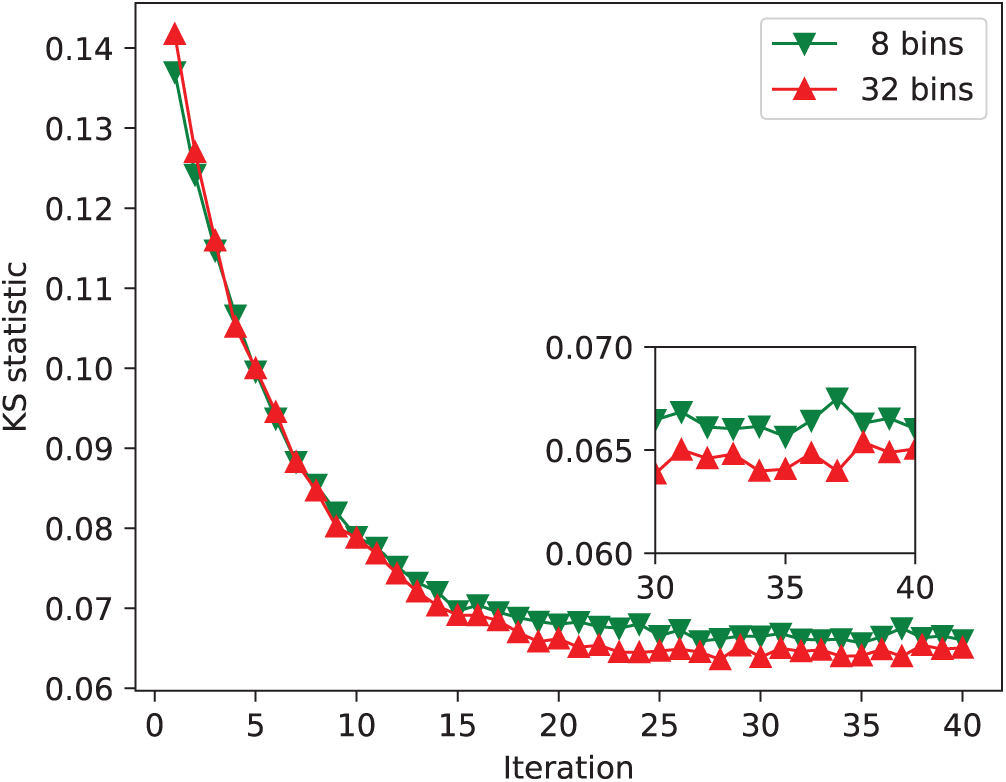
Figure 5: Comparison of KS statistics with different bin counts
5.2 Analysis of Actual Taxi Data
Based on the latitude and longitude trajectory data of Beijing taxis in May 2010, this subsection conducted statistical modeling for the time interval of the IoV communication opportunities. Taking as an example the trajectories of, 100 taxis which were randomly selected from all the data sets, we analyzed the statistical model in the case of the number of vehicles mentioned above.
Through multiple tests and analysis, we believe that the communication opportunity interval between vehicles obeys the mixture of lognormal distribution. The statistical model of different vehicle densities can be fitted with the Gaussian mixture distribution of different parameters. Fig. 6 showed the KS statistics of the actual values under different bin counts and algorithms. All the fitted parameters of the Gaussian mixture distribution passed KS test, and the fitting conditions were good.
Figure 6: Taxi real communication opportunity interval modeling comparison
If the time span of a single iteration is used as the unit, the EM algorithm had the fastest initial speed. After more than 10 iterations, the EM algorithm basically converged, and a relatively ideal result was obtained. By comparison of the results of the PEBCDE algorithm with 8 and 32 bins, it holds that the greater the number of bins is, the faster the PEBCDE algorithm was converges. Then, similar to the EM algorithm, it fell into the near optimal solution after a number of iterations. Here after about 20 iterations, the near optimal solution was obtained.
The EM algorithm requires all data in the data set to participate in the calculation. When the amount of data is very large, the calculation speed is slow and it is difficult to deal with massive big data scene. This subsection analyzes the operation efficiency of the EM algorithm and the proposed PEBCDE algorithm.
When the EM algorithm is used for parameter estimation of Gaussian mixture model, the responsiveness of sub-model k to the observed data yj needs to be calculated during step E. The number of calculations is the dimension N of the observed data. Considering that the number of iterations is Ni, the time complexity of the algorithm is
Firstly, let us set the size of the data volume to 1000 and 100000, respectively, to obtain the running times of the EM algorithm and the PEBCDE algorithm. As shown in Fig. 7, when the amount of data was small, EM algorithm runs fast. However, when the amount of data increased to a certain extent, EM algorithm runs slowly. The running time of the PEBCDE algorithm only increase with the increase of the number of segments because the second step, i.e., DE algorithm, is independent of the data size and only related to the number of segments. Thus PEBCDE is highly efficient for mixture statistical modeling of big data.
Figure 7: The comparison of running time with different algorithms
In this paper, the PEBCDE algorithm based on BC and DE is proposed to overcome the disadvantages of the EM algorithm in parameter estimation of big data mixture model. Through modeling and analysis of simulation data and instance data, the PEBCDE algorithm is verified from two aspects of accuracy and efficiency. The research shows that the computational complexity of the PEBCDE algorithm is significantly reduced. As the increase of data volume, every iteration round of the EM algorithm needs all the data, while the PEBCDE algorithm only needs to traverse all the data once. Therefore, when the amount of data is large, the running time of the PEBCDE algorithm is far less than that of the EM algorithm.
It is worth noting that the PEBCDE algorithm sacrifices precision to some extent compared with the EM algorithm. This is because differences between data within the same interval are ignored after interval calculation. Therefore, the first few moments of the data can be obtained by improving the PEBCDE algorithm combining moment estimation in the first step, and then applied to DE algorithm in the second stage, to further improve the accuracy of this algorithm.
Acknowledgement: We gratefully acknowledge anonymous reviewers who read drafts and made many helpful suggestions.
Funding Statement: This work was supported by the Fundamental Research Funds for the Central Universities (Grant No. FRF-BD-20-11A), and the Scientific and Technological Innovation Foundation of Shunde Graduate School, USTB (Grant No. BK19AF005).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |