DOI:10.32604/cmc.2022.021186
| Computers, Materials & Continua DOI:10.32604/cmc.2022.021186 | |
| Article |
Graph Transformer for Communities Detection in Social Networks
1Department of Computer Science and Engineering, ANU College of Engineering and Technology, Guntur,522510, India
2Statistics and Operations Research Department, College of Science, King Saud University, Riyadh, 11451, Kingdom of Saudi Arabia
3LBEF Campus, Kathmandu, 44600, Nepal
4Department of Computer Science and Engineering, ANU, Guntur, 522510, India
5Operations Research Department, Faculty of Graduate Studies for Statistical Research, Cairo University, Giza, 12613, Egypt
6Wireless Intelligent Networks Center (WINC), School of Engineering and Applied Sciences, Nile University, Giza, 12588, Egypt
*Corresponding Author: Ali Wagdy Mohamed. Email: aliwagdy@gmail.com
Received: 26 June 2021; Accepted: 13 August 2021
Abstract: Graphs are used in various disciplines such as telecommunication, biological networks, as well as social networks. In large-scale networks, it is challenging to detect the communities by learning the distinct properties of the graph. As deep learning has made contributions in a variety of domains, we try to use deep learning techniques to mine the knowledge from large-scale graph networks. In this paper, we aim to provide a strategy for detecting communities using deep autoencoders and obtain generic neural attention to graphs. The advantages of neural attention are widely seen in the field of NLP and computer vision, which has low computational complexity for large-scale graphs. The contributions of the paper are summarized as follows. Firstly, a transformer is utilized to downsample the first-order proximities of the graph into a latent space, which can result in the structural properties and eventually assist in detecting the communities. Secondly, the fine-tuning task is conducted by tuning variant hyperparameters cautiously, which is applied to multiple social networks (Facebook and Twitch). Furthermore, the objective function (cross-entropy) is tuned by L0 regularization. Lastly, the reconstructed model forms communities that present the relationship between the groups. The proposed robust model provides good generalization and is applicable to obtaining not only the community structures in social networks but also the node classification. The proposed graph-transformer shows advanced performance on the social networks with the average NMIs of 0.67 ± 0.04, 0.198
Keywords: Social networks; graph transformer; community detection; graph classification
The concept of networks is widely used in various disciplines, such as social networks, protein to protein interactions, knowledge graphs, recommendation systems, etc. The social network analysis is studied due to the development of big data techniques, where the communities are categorized into groups based on their relationship. In biological networks, interconnectivity among protein molecules can result in similar protein-protein interactions which may depict similar functionality. In general, a community is a collection of the closely related entity in terms of the similarity among individuals. With the increase of social media utility, social network mining becomes one of the crucial topics in both industry and academia. With the growth of the network topology, the complexity of information mining increases. Therefore, it is challenging to detect and segregate the communities by analyzing individual clusters [1]. Moreover, it is also a sophisticated task to understand the topological properties of a cluster in a network as well as the information that they carry simultaneously. The graphs (networks) community detection refers to collecting a set of closely related nodes based on either the spatial location of nodes or topological characteristics. Hence, understanding the network behavior in detail is the key to mine information for detecting appropriate communities.
A variety of works study how to detect the communities in large-scale networks such as deep walk [2], skip-gram with negative sub-sampling [3], and matrix factorization methods [4,5]. However, with the advance of deep learning, the encoder-decoder structures are utilized to be a stacked autoencoder and preserve the proximities, which can achieve great performance. It can also provide a solution for image reconstruction in computer vision and language translation NLP. Hence, this paradigm is important for graph neural networks (GNN), and the graph autoencoder can provide an encoder and a decoder. The graph is represented by mapping the encoder into a latent space. Furthermore, the decoder reconstructs the latent representations to generate the new graph with varying embedding structures. Various researchers have focused on this direction. Some of them utilize transformers to improve the embedding quality of the model, considering the equivalent relationship with the encoder. The embedding feature vector is created by tuning the parameters rigorously optimally. In this paper, we aim to provide a robust solution by cautiously considering every constraint in detail. The graph transformer is implemented in Section 4.
Deep Neural Network for graph representations (DNGR) [6] utilizes a stacked autoencoder [7] for finding patterns in the community by encoding a graph to the Positive Point-wise Mutual Information (PPMI) matrix. The procedure is initiated with the stacked denoising autoencoders in largely connected networks. Subsequently, structural deep network embedding (SDNE) [8] imparts stacked autoencoders for preserving the node proximities. The first-order and the second-order proximities are preserved together by providing two objective functions for encoder and decoder separately. The objective function for the encoder preserves the first-order node proximity.
where
where
However, DNGR and SDNE only preserve the topological information and fail to extract the information regarding the nodes’ attributes. To solve this problem, graph autoencoders in [9] import a graph convolutional network to leverage the information capturing ability of nodes.
where Z represents the graph embedding space. Then the decoder tries to extract the information on the relationship of nodes from Z by reconstructing an adjacency matrix, i.e.,
where
Note that the reconstruction of the adjacency matrix may cause overfitting of the model. To this end, researchers make efforts to detect communities through either understanding the structural properties of the nodes or extracting information from underlying relationships among nodes.
The above-mentioned research introduces the auto-encoder and encoder-decoder architecture to learn representations in a graph structure. Similarly, in the language processing, especially for the sequence transduction task, a Long Short-Term Memory (LSTM) architecture has been developed for the machine translation task [10]. Moreover, the neural machine translation (NMT) attracts attention from researchers since it can greatly improve the translation accuracy [11]. A variety of local and global attention paradigms are introduced to investigate the attention layers in NMT [12]. It is demonstrated that the attention in NMT is a deterministic factor for performance improvement. In addition, the transformer is proposed for NMT, which has a similar encoder-decoder architecture and is self-attention [13].
Besides the neural sequence transduction tasks, the transformers tend to provide numerous other applications, such as pre-trained machine translation [14], ARM to text-generation [15], and document classification [16]. Furthermore, the transformers can provide advanced performance in large-scale image recognition [17] and object detection in 3D videos [18]. It is even widely utilized in the domain of graph neural networks. Hu et al. [19] are motivated by the transformers and propose a heterogeneous graph transformer architecture for extracting complex networks variances from the node and edge dependent parameters. An HG Sampling algorithm is proposed to train the mini-batch samples in the large-scale academic dataset named Open Academic Graph (OAG), of which heterogeneous transformer is able to rise the baseline performance from 9% to 19% in the paper-filed classification task.
Some research focuses on designing models which provide hardware acceleration to fasten the training of the large-scale network. Auten et al. [20] provide a unique proposition to improve the performance of graph neural networks with Central Processing Unit (CPU) clusters instead of Graphical Processing Units (GPU). The authors consider some standard benchmark models, and the proposed architecture for computing the factorization can improve the performance of graph traversal greatly. Jin et al. [21] study a graph neural network named Pro-GNN, which learns the community structures underlying a network by defending against adversarial attacks. The model is able to tackle the problem of perturbations in large-scale networks. It presents high performance for some of the standard datasets, such as Cora, Citeseer, Pubmed, even though the perturbation rate is high. Ma et al. [22] investigate a graph neural network that can learn the representations dynamically, i.e., DyGNN. They address the problem of static graphs and propose a dynamic GNN model that performs well on both link prediction and node classification. Compared with the benchmark models, the DyGNN model shows better performance on link prediction with UCI and Epinions datasets. Moreover, for the case training ratios vary from 60–100% on the Epinions dataset, the model outperforms the individual models. El-Kenawy et al. [23] propose a modified binary Grey Wolf Optimizer (GWO) algorithm for selecting the optimal subset of features. It utilizes the Sandia frequency shift (SFS) technique, where the diffusion process is based on the Gaussian distribution method. In this way, the values can be converted to binary by sigmoid. Eid et al. [24] propose a new feature selection approach based on the Sine Cosine algorithm which obtains unassociated characteristics and optimum features. In 2021, El-Kenawy et al. [25] propose a method for disease classification based on the Advanced Squirrel Search Optimization algorithm. They employ a Convolutional Neural Network model with image augmentation for feature selection. However, most of the state-of-the-art models are focusing on specific domains. It means they cannot represent heterogeneous graphs information and are suitable for static graphs with deep neural networks.
This work is inspired by the transformers, which is applicable to various domains. The contributions of this paper are summarized as follows.
1. Firstly, the transformer is applied to downsample the first-order proximities of the graph into a latent space, which can preserve the structural properties and eventually assist in detecting the communities.
2. The fine-tuning task is conducted by tuning various hyperparameters cautiously, which can be widely competent on multiple social networks, e.g., Facebook and Twitter. In addition, the objective function, i.e., cross-entropy, is tuned by L0 regularization.
3. Finally, the learned representations are employed for node classification, which can be applicable to general scenarios.
In this section, we aim to introduce the implementation of methodology and the process involved in this paper. The process is illustrated in Fig. 1, including (a) definitions of the basic notations and the related terms; (b) implementation of the graph-transformer for both graph clustering and classification tasks; (c) discussions on the insights of transformers in detail which present the self-attention mechanism, and residual connectivity with its relative connection to GNN for detecting communities by using the first-order proximity.

Figure 1: The model diagram of the proposed model
Here, the required definitions and notations in the paper are described as follows.
Graph A graph is a collection of nodes and their relative connectivity. G <V, E> is used to denote a graph, where the pair < V, E > is a collection of nodes and edges. V
First-Order Proximity The first-order proximity determines the relationship between two specific nodes in the given graph G. Specifically, if an edge exists between the node pair (vi , vj), the first-order proximity is equal to w; otherwise, it is set to 0, i.e., null. Note that w depends on the connectivity of nodes in the given graph. If the edge of the graph is weighted, w will denote the edge weight; otherwise, it is regarded as 1.
Adjacency Matrix A square matrix is constructed according to the first-order proximity of nodes in the given graph and is represented as A. The value of the first-order proximity is placed by checking individual node pairs. In this way, a complete set of node pair samples is selected.
In this sub-section, the transformer and its internal working principle are explained first. The graph structures of the first-order proximity are subsequently learned. The transformers are guided with self-attention which has an encoder and a decoder structure. The encoder part consists of two attention blocks. One is a multi-head intra-attention network, and the other is a position-wise fully-connected feed-forward network. These two blocks are sequentially connected with multiple units. Each layer has a definite set of residual connections and successive layer normalization to overhaul covariate shifts in recurrent neural networks [26,27]. Fig. 2 demonstrates the internal working of the transformer.
where
where
where S is an input to the feed-forward neural network layer as mentioned in Fig. 2.
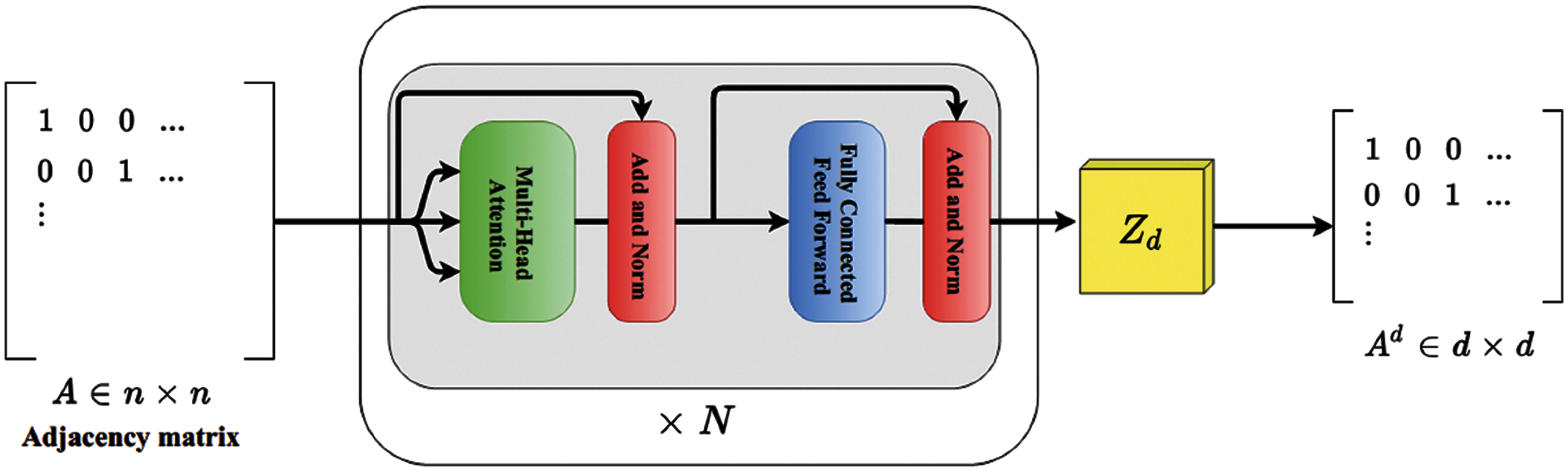
Figure 2: The internal working model diagram of the transformer
Eq. (7) represents the linear transformation of the input x, i.e., densely connected neurons. ReLU is an activation function to push the feed to the next layer, i.e.,
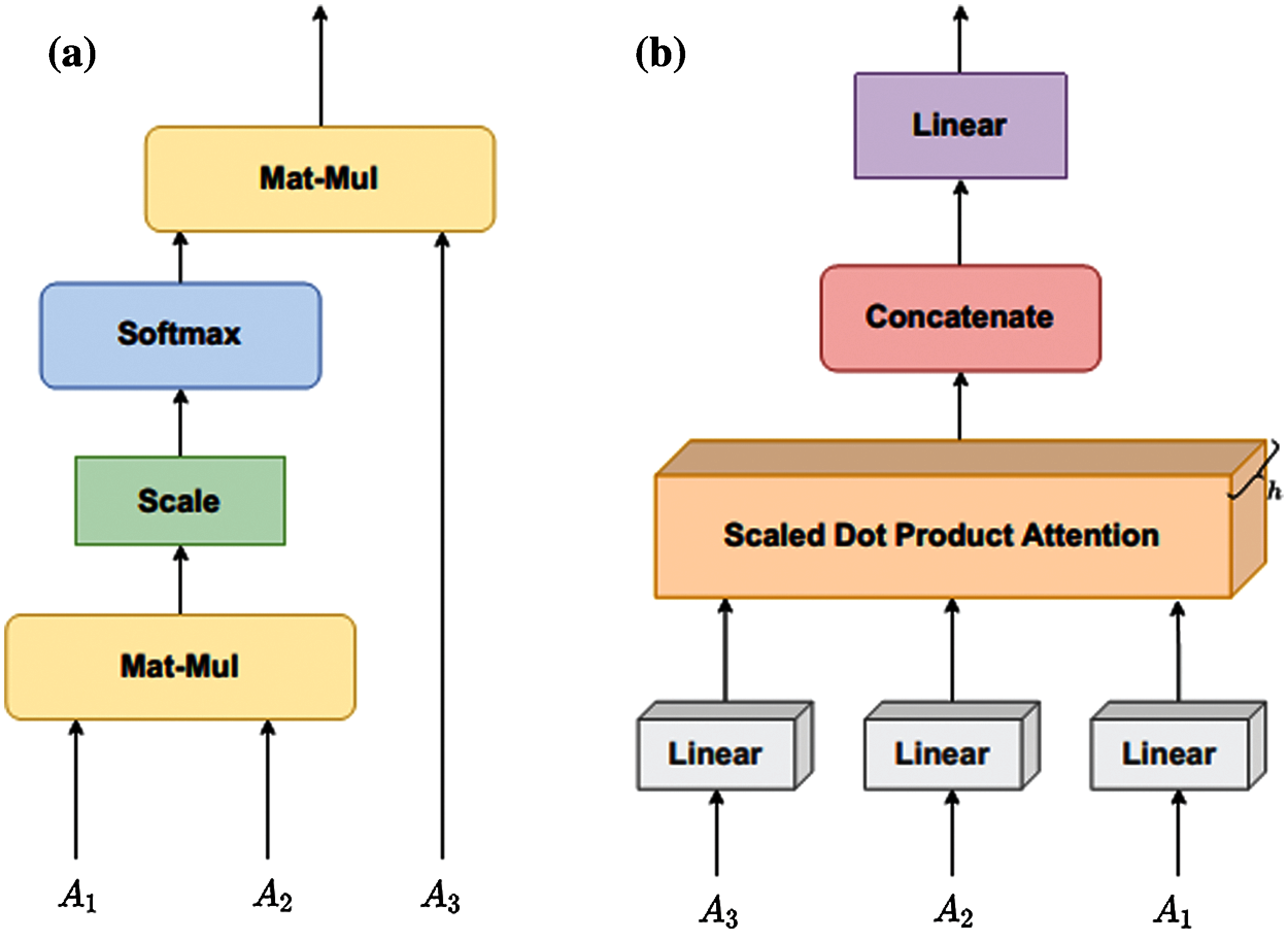
Figure 3: The information flow of the proposed model. (a) Scaled dot product attention (b) Multi head attention
4.3 Fine-Tuning of the Graph-Transformer
In this sub-section, the parameter settings are introduced for the graph transformer, as well as the corresponding tuning process.
1. The individual attention layers and their layer partitions are illustrated in Fig. 3, where h in Fig. 3b denotes the number of the attention heads utilized and is set to 2.
2. To obtain the structure, the adjacency matrix is the input of the graph-transformer and positional encoding, as shown in Figs. 2 and 3. It is constructed by query, key, and value. Note that the embeddings here are generic, and the whole first-order proximity is derived from the latent space.
3. The hidden layers for each attention head are set to 2. The dimension of the transformer model is decreased to 128, where the shape of the adjacency matrix is reduced from n × n to n × 128. n represents the number of nodes in the given graph G.
4. The number of attention heads is set to 2. For appropriate regularization, the graph-transformer dropout [kk] and layer normalization layers are added, where the drop rate is set to 50% for effective generalization during the testing phase.
5. The objective function for evaluating the loss is categorical cross-entropy. And the Adam optimizer is involved with an initial learning rate of 4.5 × 10−5. Note that the learning is multiplied by 0.9 after a certain number of iterations (≈ 10 epochs). Since the model can reach convergence, no further increment in the learning rate is required.
The above-mentioned parameters are tuned internally in the network, and the objective function is regularized with a cautious optimization.
Objective Function Optimization It is known that A is sparse, if the sparse matrix is reconstructed without appropriate regularization. It can mislead the reconstruction of the matrix and result in a number of zeros in the matrix. To solve the problem, we introduce an appropriate penalty on neural networks. Generally, Ridge (
where
θ is the dimension of the parametric factor, Λ is a weighting agent for the regularization, and
To evaluate the proposed methodology, a set of vertex-level algorithms with the ground truth of communities are considered. The statistics of datasets are listed in Tab. 1. The ground-truth of communities in the datasets can assist in both community detection and graph classification. Moreover, the collaboration network, web network, and social networks in the datasets are considered. The raw adjacency matrix is constructed with available nodes and edges. The networks considered are acquired from the publicly available resources [29,30].

In this sub-section, whether the structure is preserved by the embeddings of the graph-transformer is investigated first. To this end, the latent space embeddings are evaluated with the standard graph clustering metrics. Normalized Mutual Information (NMI) [31] is chosen to be the standard metric for the cluster quality evaluation, due to its improvement on the relative normalized mutual information. The library of Karate Club [32] is utilized as a benchmark, which can obtain fast and reliable reproducible results with consistency.
The evaluation procedure is comparatively different from the proposed method. Firstly, a set of nodes are trained on the graph transformer. Only 50% of the nodes are trained in the network and the remaining ones are used for testing. The results are obtained over 10-times repetitive experiments, of which the mean deviations are shown in Tab. 2.
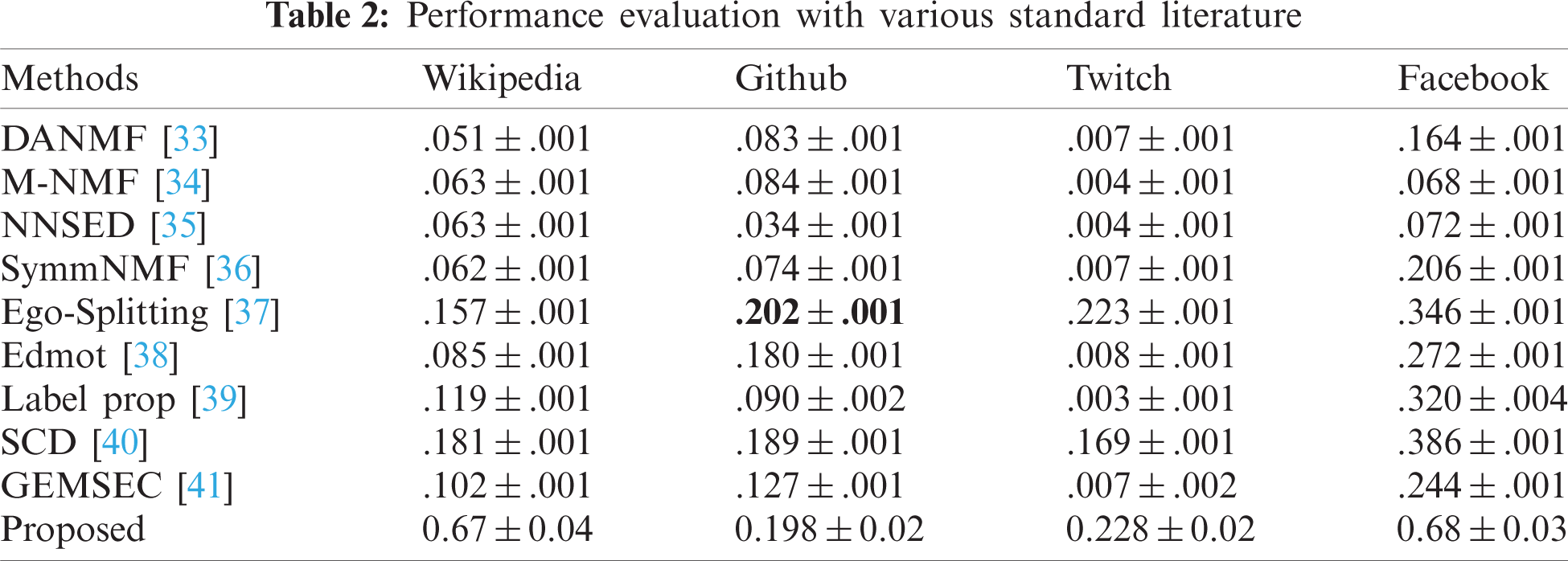
A set of standard models for community detection algorithms are utilized to validate the work. The first five models in Tab. 2 [33–37] are proposed for overlapping communities, whereas the remaining methods are designed for non-overlapping communities. It is observed that the proposed graph-transformer tends to have effective outcomes for the datasets. The results present the resilience of the model which can balance the performance of different communities appropriately. The average NMIs for Wikipedia crocodiles, Github Developers, Twitch England, and Facebook Page-Page networks are 0.67 ± 0.04, 0.198
Subsequently, the latent node embeddings of graph-transformer are investigated for node classification. Due to the availability of ground truth labels for the individual networks, the task is evaluated as similar as the clustering problem. The nodes are equally divided into two sets for training and test, respectively. The training convergence is studied accordingly. It is observed that, in most of the scenarios, the model can converge very fast and obtain the optimal accuracy within about 10 epochs. To present the learning ability of the graph-transformer, the accuracy and loss curves are illustrated in Fig. 5. The accuracy and loss values on node classification for the selected networks are listed in Tab. 3.
This section aims to illustrate the drawbacks of the proposed work. Firstly, in some intricate scenarios, reducing dimensions can be problematic. Small data with higher sparsity can mislead the predictability, as the small-scale data cannot draw inferences generically. As a result, the dimensionality should not be selected for the case with small data samples. Secondly, the proposed work mainly focuses on undirected, homogeneous, and unweighted graphs. Thirdly, the method shall be fine-tuned to a specific dataset, as the constructed adjacency matrix varies with different network structures. It means that the problems of dynamically evolving networks cannot be solved, since an increasing number of nodes leads to the incensement of the adjacency matrix dimensions, in terms of width and length.
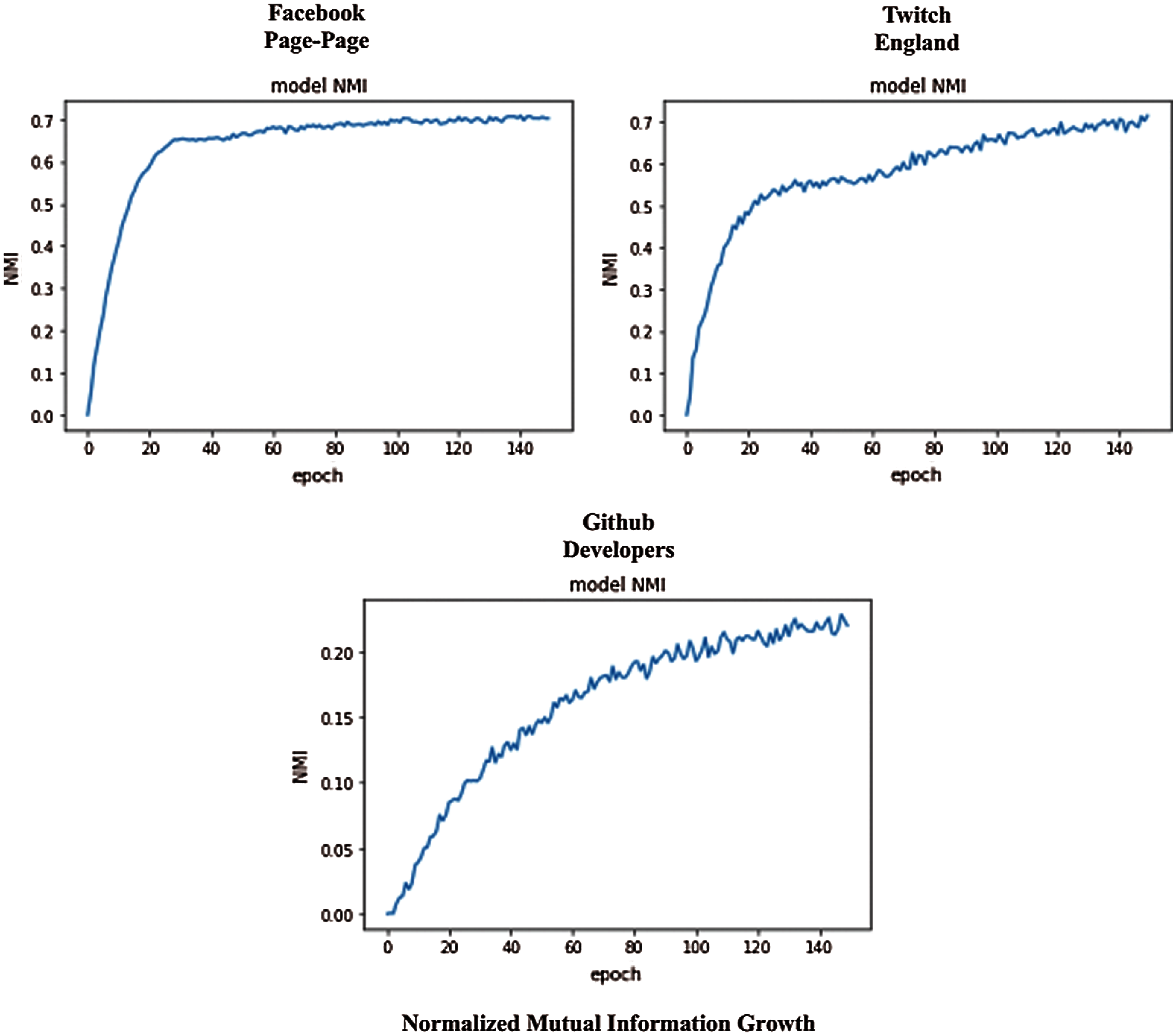
Figure 4: NMI growth (Test) for the selected networks with several epochs
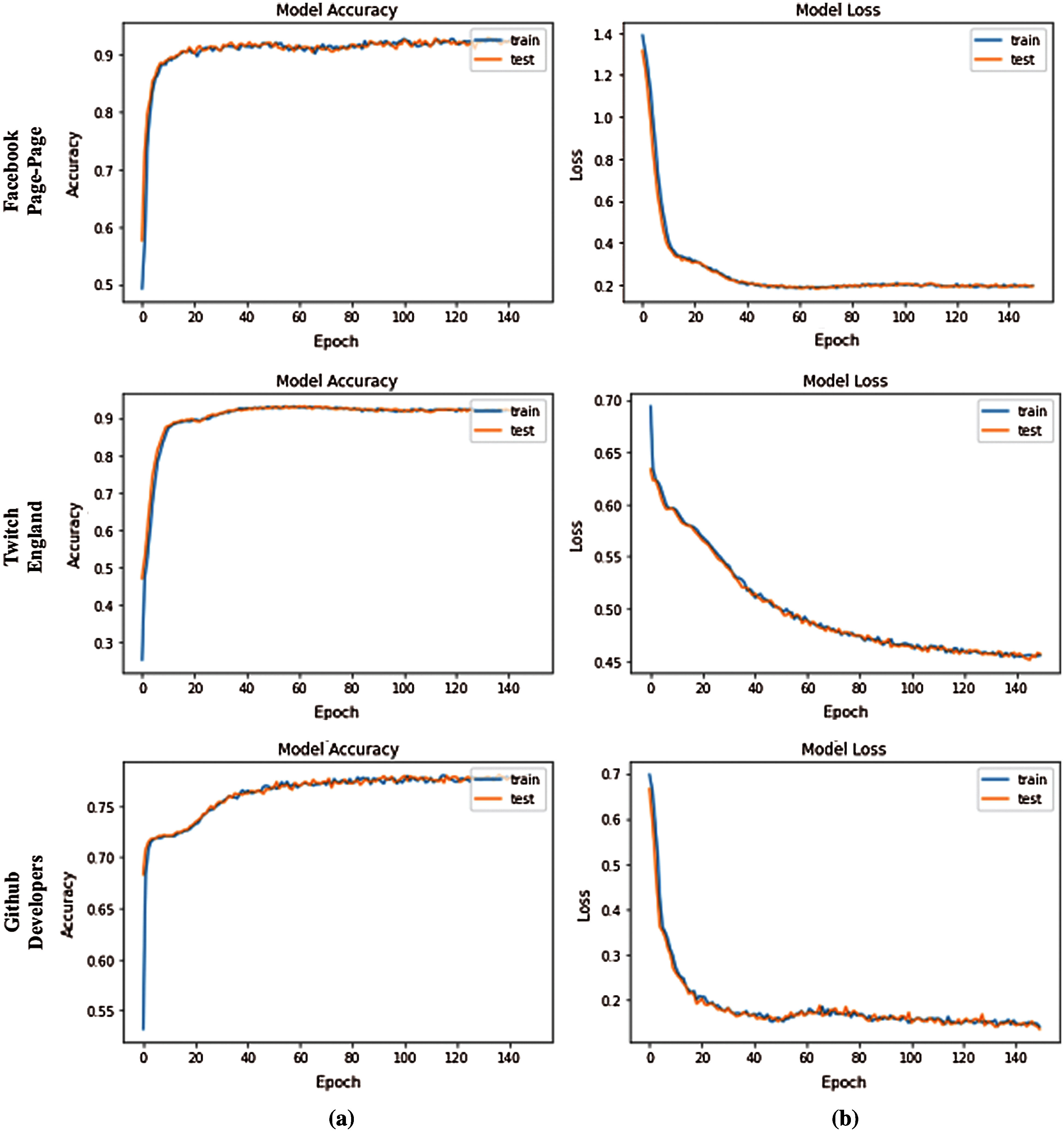
Figure 5: The individual accuracy plot and the loss decay plot of the networks. (a) Accuracy plots (b) Loss plots

Hence, it is recommended to build a very small model or a naive model for the unseen samples. The parametric weights are required to be dealt with carefully. It means that the specified attention layers should be added to extract temporal patterns, and the parameters are required to be tuned based on the real-life network.
It is possible to improve the performance by using various dimensionality reduction techniques, especially for the graph-transformer techniques. The attention heads and self-attention mechanisms are important with a balanced criterion. The structure of the complete graph can be captured with the assistant of the local patterns, which leads to the communities containing the global and local structural patterns. The objective function obliges to provide appropriate learning through stochastic optimization.
It is observed that, even on variant tasks, the proposed method can outperform the existing task invariant domain. Hence, the objective function can provide a domain invariant characterization with higher generalization. The proposed mechanism tends to have advanced performance on social network data for both detecting communities and node classification.
Acknowledgement: The authors extend their appreciation to King Saud University for funding this work through Researchers Supporting Project number RSP-2021/305, King Saud University, Riyadh, Saudi Arabia.
Funding Statement: The research is funded by the Researchers Supporting Project at King Saud University (Project# RSP-2021/305).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |