DOI:10.32604/cmc.2022.021125
| Computers, Materials & Continua DOI:10.32604/cmc.2022.021125 | |
| Article |
Fusion of Infrared and Visible Images Using Fuzzy Based Siamese Convolutional Network
1Department of Electrical Engineering, National Taipei University of Technology, Taipei, 10608, Taiwan
2Department Virtualization, School of Computer Science, University of Petroleum & Energy Studies, Dehradun, India
3College of Computer Science and Information technology, King Faisal University, 36362, Saudi Arabia
4College of Computing and Informatics, Saudi Electronic University, Riyadh, 11673, Saudi Arabia
*Corresponding Author: Deepika Koundal. Email: koundal@gmail.com
Received: 24 June 2021; Accepted: 03 August 2021
Abstract: Traditional techniques based on image fusion are arduous in integrating complementary or heterogeneous infrared (IR)/visible (VS) images. Dissimilarities in various kind of features in these images are vital to preserve in the single fused image. Hence, simultaneous preservation of both the aspects at the same time is a challenging task. However, most of the existing methods utilize the manual extraction of features; and manual complicated designing of fusion rules resulted in a blurry artifact in the fused image. Therefore, this study has proposed a hybrid algorithm for the integration of multi-features among two heterogeneous images. Firstly, fuzzification of two IR/VS images has been done by feeding it to the fuzzy sets to remove the uncertainty present in the background and object of interest of the image. Secondly, images have been learned by two parallel branches of the siamese convolutional neural network (CNN) to extract prominent features from the images as well as high-frequency information to produce focus maps containing source image information. Finally, the obtained focused maps which contained the detailed integrated information are directly mapped with the source image via pixel-wise strategy to result in fused image. Different parameters have been used to evaluate the performance of the proposed image fusion by achieving 1.008 for mutual information (MI), 0.841 for entropy
Keywords: Convolutional neural network; fuzzy sets; infrared and visible; image fusion; deep learning
The infrared sensors or multi-sensors are used to capture the infrared and visible images. As different objects like the environment, people, and animals emit thermal or infrared radiations which are further used for the detection of target and parametric inversion. These images have a lesser effect and insensitive to the illumination variations and disguise. Thus, it overcomes the hurdles while detecting the targets by working day and night [1]. But the most important visible feature such as texture information get lost due to the small spatial resolution of the infrared images, as a result objects contain insufficient details. This is due to the temperature-based nature of the object. The objects that are warmer and colder than the background is easier to detect. On the contrary, visible images deal with the spectral resolution and sensitivity to the effect of changing brightness or illumination in the scene. It illustrates the perceptual scenes for the human eyes and human vision system (HVS) [2]. Sharpened high spatial resolution VS images depicts the important information on the geometric details of the objects, and thus helps for overall recognition [3]. But mostly, a target cannot be easily identified due to the changing environmental and poor lighting conditions like objects covered in smoke, disguises, night time, and disordered background. Sometimes background and targets are similar due to which obtained information is insufficient. Hence, IR/VS images offer integrative advantages.
Therefore, there is a need for an automatic fusion method that can fuse the two complementary images into a single image, i.e., integration of thermal radiations of the IR and texture appearance of the VS images to produce an enhanced vision of an image [4,5]. Furthermore, the main aim is to obtain the fused image with abundant VS image details and chief thermal targets from the IR images. Hence, the goal of the IR/VS image fusion is to preserve the useful features of IR and VS images.
In recent years, more attention has been paid towards the field of IR and VS image fusion. Many researchers presented a lot of IR/VS image fusion approaches which are roughly classified into various categories as multi-scale decomposition (MST), principal component analysis (PCA), sparse representation (SR), fuzzy sets (FS), and deep learning (DL). In consideration to this problem, the main motivation behind this work was to extend the research in the direction of the examination of the fused image to be helpful in the object tracking, object detection, biometric recognition, and RGB-infrared fusion tracking. Therefore, goal is to propose a reliable automatic anti-noise infrared/visible image fusion technique for generating a fused image that has the largest degree of visual representation of environmental scenes to be used in.
Major contributions of this study are: (1) The unique integration of fuzzification and siamese CNN based infrared/visible fusion technique for the integration of complementary infrared/visible images has been put forward. (2) Fuzzification has been done using the fuzzy sets to model various uncertainties efficiently for problems like ambiguousness, vagueness, unclearness, and distortion present in the image by the determination of the membership grade of the background environment as well as target detection. Whereas, feature classification has been done by the CNN model with the extraction of the low level as well as high level infrared/visible features. Furthermore, fusion rules are also automatically generated to fuse the obtained features. (3) The proposed technique is more reliable and robust as compared to the classical infrared/visible technique due to its advantage of making it less laborious. (4) A publically accessible dataset consisted of 78 infrared/visible images has been used for the experiments. (5) The qualitative as well as quantitative evaluation has been done using six classical infrared/visible techniques such as discrete cosine transform (DCT), anisotropic diffusion & karhunen-loeve (ADKL), guided filter (GF), random walk (RW), principal component analysis (PCA), and convolutional neural network (CNN) methods by using five metrics, i.e., mutual information (MI), entropy
The key motivation of this research is to combine the advantages of the spatial domain (CNN) and fuzzy based method to achieve the accurate extraction of IR targets while maintaining the background features of VS images which is not easy to attain as there occurs various challenges during this process. Efficacious evaluation of the quality of pixels has been done with the extraction of target features and background features in order to integrate them for the generation of clear focused fused image. Additionally, it is a laborious task. Then, investigation of the determination of the pixels belongingness is an issue of relevance. Furthermore, from the literature, it has been analyzed that FS represented the uncertain features. Therefore, indeterminacies, noise, and imprecision present in the images can be considered as a problem of fuzzy image processing. Subsequently, due to the powerful ability of the CNN for automatic data extraction, this research work generated the data-driven decision maps with the utilization of CNN. Hence, as per the literature, no attempt has been made to integrate the FS with CNN for IR/VS image fusion. Therefore, in this research work, an attempt has been made to propose a novel fuzzy CNN based IR/VS image fusion method for the fusion of images. The key contributions of this study are outlined as follows.
• It helped to integrate different modality images to produce a clear more informative fused image.
• It also improved the infrared image recognition quality of the modern imaging system.
• Subjective and objective experimental analysis have been performed.
The remaining structure of this study is presented as follows: Section 2 briefly describes the background and related approaches for infrared/visible image fusion. In Section 3 detailed description of the proposed technique methodology is given. Section 4 presents the dataset, evaluation metrics, and validates the experimental results by doing an extensive comparison with existing techniques. In Section 5, concluding remarks and future works discussion is drawn.
In the past, numerous techniques for infrared/visible fusion had been developed like pyramid decomposition [6], and DCT [7]. But, they were not suitable methods as they produced oversampling, high redundancy, and so many other problems. Whereas, histogram-based methods [8,9] produced unsatisfactory results due to their inability to amplify gray levels of the images as well as background distortion. Hence, they produced the low-quality fused images. Bavirisetti et al. [10] introduced the edge preserving ADKL transform technique. Although, good results were obtained but still the qualitative as well as quantitative results needs to be improved and along with this it was a labor-intensive method. Further, Liu et al. [11] presented the convolutional sparse representation method whose main drawback was that only the last layer was used for the extraction of features which resulted in the loss of the most useful information. Hence, it was a crude method. Liu et al. [12] developed a variation model which was based on saliency preservation. Only seven image sets were used, which were the main limitation of this study. Many non-subsampled contourlet transform (NSCT) approaches [13,14] were developed. However, these methods gave satisfactory fused images but there were many drawbacks like the process was cumbersome and tedious. The decomposition of the image and reconstruction of the fused image was computationally intensive and was not a feasible method to be used in real time applications. Yang et al. [15] developed the guided filter (GF) technique for the measurement of visual features of the image. Although a better-quality of fused image was obtained but still subjective and quantitative results need to be enhanced. Only five sets of infrared/visible images with three evaluation metrics were used for the validation purpose. Ma et al. [16] developed a boosted RW method for the effective estimation of the two-scale focus maps. The quality of the fused image needed to be improved. Afterwards, Shahdoosti et al. [17] introduced a hybrid technique with an integration of PCA and spatial PCA techniques with the usage of an optimal filter. Subsequently, obtained the synthesized results similar to the corresponding multisensors observed at the high-resolution level. Liu et al. [18] developed the DL framework for the integration of multi-focus images which was computationally intensive. They have exhibited their applications on other types of modalities such as infrared/visible image fusion. Many other DL based techniques were introduced for the fusion of different modality images. Li et al. [19] presented a fusion framework based on DenseNet. Four convolution layers were included in the encoder block. Shallow features were extracted by one of the convolutional layers. Another three layers constituted the Dense block were used to obtain both shallow and deep image features. Then, Li et al. [20] fused the visible and infrared images using VGG network. In this approach, middle layer information were utilized but the information loss during the integration of features limited the model’s performance. Ma et al. [21] propounded an image fusion method based on generative adversarial network (GAN). Whereas, adversarial network was adopted to extract more visible details of the images. Zhang et al. [22] designed a transform domain based convolutional neural network approach constituting both feature extraction and reconstruction blocks. In this architecture, 2 CNN layers utilized to obtain features of an image for fusion, and then reconstructions of image features were done to generate fused images. Xu et al. [23] developed the U2Fusion architecture for the fusion of images. This method was based on DenseNet [24] where vital information were retained by the designed information measurement. Zhao et al. [25] attained the fused images by the designing of self-supervised feature adaption architecture. Moreover, fuzzy set-based approaches [26–28] were also used due to their very strong mathematical operations to deal with the fuzzy concepts even whose quantitative illustration was not possible. Thus, on the basis of the literature study, the above limitations motivated us to hybridize the advantages of fuzzy sets with deep learning concepts. The presented work focused on the development of an automatic effective infrared/visible image fusion technique for enhancing the vision of the fused image. With this incorporation, this method preserved vital information.
In order to handle the former problems, hybridization of the fuzzy set and Siamese CNN has been employed to fuse the infrared/visible images. The proposed technique is presented as follows.
Zadeh et al. [29] introduced the concept of a fuzzy set which is a very useful mathematical expression to handle an object with some kinds of imprecision and uncertainties like distortion, vague boundaries, ambiguity, blurriness, uneven brightness, and poor illumination [30]. When the infrared/visible images are captured by sensors, there occurs an ambiguity in image pixels. Their belongingness to the target or background is considered to be a typical problem. Therefore, this problem has been solved by the use of fuzzy sets that further helps to solve the existence of intermediate values by the assignment of a degree of truth ranges from 0 to 1 typically deals with an uncertain problem.
For the processing of an image, input images L and M was converted from pixel domain to fuzzy domain. Eq. (1) illustrated the image representation. Let’s assume an image L as for illustration.
where
The membership grade describes the element’s degree of belongingness to a FS. Here, 1 indicates the elements with complete belongingness to a FS, whereas 0 implies it’s belonginess to the fuzzy set. Summation of all the membership functions of the element ‘L’ is 1 as represented below.
where,
As input grayscale image includes darker, brighter, and gray level pixels whose value ranges from 0 to 255. Therefore, image mapping has been done from pixel scale to fuzzy domain by assigning triangular membership function.
Now, image having pixel values between 0 to 255 was converted to 0 to 1 indicating the pixel fuzziness.
where
The triangular membership function of the image has been applied whose mathematical representation is shown in Eq. (3). Now, the image having pixel values between 0 to 255 is converted to 0 to 1 indicating the pixel fuzziness. The membership grade describes the element’s degree of belongingness to a fuzzy set. Here, 1 indicates the elements with complete belongingness to a fuzzy set, whereas 0 implies that it does not belong to the fuzzy set. The calculation of membership value i.e., the process of fuzzification is given by Eq. (3).
So, by using the above equation, pixels having minimum intensity value are assigned 0 whilst pixels having maximum value are assigned 1, and the uncertainty, as well as ambiguity are removed. Hence, the uncertainty was removed without diminishing the image quality.
The proposed Siamese CNN or convNet model designed for the fusion of IR/VS images is described here. It is designed to automatically learn mid and high level abstractions of the data presented in the two heterogeneous images. By the use of the Siamese network, the same weights were shared between two different branches. One branch was used to handle the infrared image and the other was to process the visible image. Each branch has step-wise stages of CNN such as convolution layer, max pooling, flattening, and full connection, i.e., fully connected layer.
These layers generate the feature maps parallel to each level of abstraction of features from an image [31]. The CNN framework configuration for infrared/visible image fusion is used as a stack of varied convolutional layers consisting of 3 convolutional layers, one max pooling, two FC layers, and one output softmax layer. Therefore, the above-discussed features have been captured by using three convolutional filters with a feature detector size of 3
Then, features extracted from the previous CNN layers are concatenated by the fully connected (FC) layer. Subsequently, pooled feature maps are obtained by the flattening of the pooling layers. The last layer consists of the output neuron which assigns a probability to the image. CNN gives scalar output whose value ranges from 0 to 1.
The proposed technique for the fusion scheme consisted of five steps: fuzzification, focus detection by the feature map generations, segmentation, unwanted region removal, and infrared/visible image fusion. This attempt has been made to generate a fused image consisting of all its useful features as illustrated by the schematic block diagram of the proposed technique for infrared/visible image fusion in Fig. 1.

Figure 1: Schematic block diagram of the proposed infrared/visible image fusion
Firstly, L and M, the infrared/visible images, respectively are fed to the fuzzy set. Then, the fuzzification has been done by doing the processing of the information presented in the image, followed by
For the first three convolutional layers, the fixed stride of 1 has been used. Max pooling has been applied for the localization of the parts of the images using a window size of 2
Thus, during the fusion, the network which has been trained using the patch size of 16
If 0 <
Moreover,
Now, more detailed information is contained in the focus map of the image which is near to 0 or 1 values. From Fig. 2, it can be observed that the obtained focus map constitutes of correctly classified gray pixels, as shown in the white background.
Further processing of the focus map has been done to preserve the maximum of useful features i.e., only to have focused parts i.e., black or white. For this purpose, the maximum method has employed a 0.6 threshold value to segment
The obtained binary map contained some misclassified pixels and unwanted small objects or holes as clearly seen in Fig. 1. Therefore, for the removal of some of the misclassified pixels from the
Here, the area threshold value is manually adjusted to 0.03 i.e., the threshold for area is given in Eq. (8).
Now the computed

Figure 2: Fused image generated without using GF and with the use of GF
where r is set as 5, eps is 0.2. This initial fused image is used as a guidance image for the calculation of
Lastly, the pixel-wise weighted average method has been used to obtain the resultant single fused image as described in Fig. 1 using Eq. (10).
where,
The proposed algorithm for infrared/visible image fusion is described in detail in Algorithm 1.

In this research work, both subjective and objective assessment has been done for the validation of the superiority of the proposed technique. For this purpose, six pre-existing infrared/visible image fusion techniques such as DCT [7], ADKL [10], GF [15], DL [18], RW [16], and PCA [17] have been compared.
In this, IR/VS images are obtained under changing environmental conditions. The publically available datasets are acquired from RoadScene [23], TNO [32], and CVC-14 [33] datasets. The experimental results have been conducted using 78 sets of infrared/visible images. Simulations are conducted in Matlab R2016a, 64-bit using PC with processor Intel® Core™ i5-3470 CPU, 16.0 GB RAM.
The RoadScene dataset consisted of total 221 IR/VS sets of images. Images are of rich road traffic spots. For an instance, pedestrians, roads, and vehicles. These highly representative spots are acquired from naturalistic driving videos. These images have no uniform resolution.
The TNO dataset is common publically used for the IR/VS research. It includes the varied military relevant scenes images that has registered with distinct multi-band cameras with non-uniform resolution.
The CVC-14 dataset included pedestrian scenes that is highly utilized for the manufacturing of autonomous driving technologies. It is composed of two pair of sequence, namely day and night pairs, respectively. Total are 18710 images, among which 8821 is the daytime sequence and 9589 as the nighttime sequence. All images have resolution of 640
4.2 Performance Evaluation Metrics
Towards this approach,
Entropy
where, ‘S’ represents the number of gray levels i.e., 256 and
MI: It tells about the transfer of the quantity of important useful information from the given input source images to the single fused image.
where, two source input images are described by A′ and B′, F′ is the fused image. Joint histograms of the source input and fused output image are denoted by
Edge information: It calculates the transference of the visual as well as edge information from the two input source images to the fused image.
where,
Image structural similarity: It describes the amount of structural information preservation into the resultant single image. It tells about the similarity between the given input images with resultant single fused images.
where,
Human Perception: The IF method is dependent on the perception of humans which is calculated using human perception. Input as well as output images are filtered using a contrast sensitivity filter. Then, the calculation of the contrast preservation map is done. It is represented in Eq. (15).
where
All metrics values have ranges in the [0, 1] interval [29]. 0 indicates low-quality image whereas, 1 implies high-quality image.
In this study, Siamese CNN has been presented. It consisted of two branches having the same neural structure with the same weights for the extraction of the features of two different infrared/visible images. The network training has been done by using a framework of caffe [40]. Xavier algorithm is used for the weight’s initialization of each convolutional layer.
Training has been done on 50,000 natural images derived from the ImageNet dataset [41]. Due to the lack of a labeled datasets, a Gaussian filter has been used to obtain the blurred version of the images. After that, for every blurred version of the image, 20 sets of 16
where,
• Random flipping: both horizontal and vertical flipping is done.
• Rotation: both horizontal as well as vertical rotation of images is done by 90° and 180°.
• Gaussian filter: blurring of images are obtained for noise smoothening.
The fusion result on the six different sets of infrared/visible images has been attained. Based on the fused images, it can be observed that infrared images have apparent objects and visible images have an obvious background. The techniques such as GF, DL, RW, PCA, and ADKL failed in retaining the objects presented in the images well.
From Fig. 3, it can be noted that in Figs. 3I–3III, the fused images produced by DL, PCA, and ADKL are low-intensity images, hence, not able to keep the intensities of the object information. They contained blurriness and artifacts in the images as shown by the area in red boxes. Thus, unclear and poor quality of images have been obtained. The visual quality of images obtained from RW and GF methods are worst because there is information loss and the upper right corner of these images seemed to be darker than the original image with some distortion too. The image produced by DCT is better as compared to above-discussed techniques but is also incapable to extract all the information. Thus, the proposed technique overcame these problems very well as shown in Figs. 3I–3III by producing images of enhanced quality.
It is evident from the Figs. 3IV–3VI that the fused image produced by the proposed technique contained more detailed information of the target image depicting image characteristics as well. By contrast, DL, ADKL, and DCT generated a noisy, blurred image with a poor quality of fused image. The DCT technique produced some distortion giving the distorted image. From the fused images of GF, RW, and PCA it can be analyzed that all the contents from the source images are not transferred to the resultant output images. On comparative analysis of the proposed technique with the other techniques, it has been analyzed that other techniques exhibited the loss of contrast, brightness, edges as well as incapable of fusing many types of features among two different heterogeneous images. Thermal radiations of the infrared and target object of the visible image has not been retained by these techniques and most of the information got damaged. Hence, the proposed technique has outperformed all other techniques by producing the better fused image.

Figure 3: Qualitative fused images on 6 infrared/visible image pairs, (a)–(i) represents infrared image, visible image, fused output by DL, fused output by PCA, fused output by ADKL, fused output by DCT, fused output by RW, fused output by GF, and fused output by proposed technique in (I)–(VI)
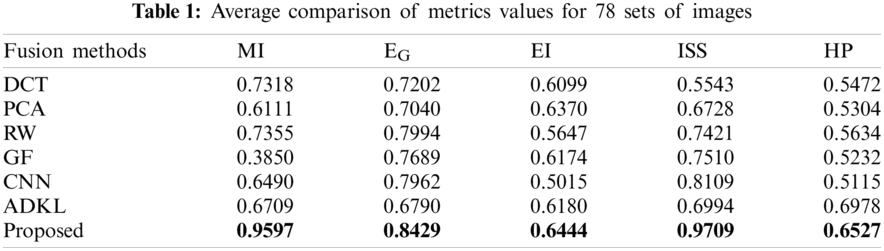
For further illustrations of the fusion effects, five evaluation metrics such as MI, HP, ISS,
Therefore, from the above discussions, it can be concluded that the proposed technique attained the highest values in terms of every metric as shown in bold in Tab. 1. Hence, it has outperformed the other traditional infrared/visible image fusion techniques.
5 Conclusion and Future Directions
This paper designed an infrared/visible image fusion technique based on the fuzzification and convolutional neural network. The main goal of this study is to solve the issue regarding the maintenance of thermal radiation features in the pre-existing IR/VS based methods. Therefore, benefits of two theories have been taken with the integration of FS and CNN to devise a new strong and adaptable technique into a single scheme. The proposed technique firstly retained the details of the thermal radiation of the infrared images, whereas simultaneously accumulated the visibility in the visible image. Therefore, correct target location can be observed which further helped in the processing and also vital for increasing precision and focused ability of the output image. This technique dealt with 78 sets of infrared/visible images. Furthermore, high quality and enhanced image has been produced even under bad illumination and varied expressions. The main goal behind this work is the designing of the advanced automatic technique to obtain the fused image containing contour, brightness, and texture information between IR/VS images to illustrate clear target features of the infrared image while distinctly visible background which will be further helpful in the military surveillance and object detection. The subjective, as well as objective evaluation, indicated that the proposed technique has given a higher performance in comparison to the existing techniques in feature extraction and information gathering.
In the future, we intend on the optimization of the developed technique with the hybridization of the neuro fuzzy and CNN. Moreover, this technique can be more generalized for the fusion of more than two images at the same time by adapting the convolutional operations. Also, we intend to extend this research in other domains as well.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |