DOI:10.32604/cmc.2022.019586
| Computers, Materials & Continua DOI:10.32604/cmc.2022.019586 | |
| Article |
Dynamic Hand Gesture Recognition Using 3D-CNN and LSTM Networks
1Department of Electrical Engineering, HITEC University Taxila, Pakistan
2Department of Computer Science, HITEC University Taxila, Pakistan
3College of Computer Engineering and Sciences, Prince Sattam Bin Abdulaziz University, Al-Khraj, Saudi Arabia
4Department of Forensic Sciences, College of Criminal Justice, Naif Arab University for Security Sciences, Riyadh, Saudi Arabia
5Department of Information Technology, Albaha University, Albaha, Saudi Arabia
6School of Computing, Edinburgh Napier University, UK
*Corresponding Author: Jawad Ahmad. Email: J.Ahmad@napier.ac.uk
Received: 18 April 2021; Accepted: 27 July 2021
Abstract: Recognition of dynamic hand gestures in real-time is a difficult task because the system can never know when or from where the gesture starts and ends in a video stream. Many researchers have been working on vision-based gesture recognition due to its various applications. This paper proposes a deep learning architecture based on the combination of a 3D Convolutional Neural Network (3D-CNN) and a Long Short-Term Memory (LSTM) network. The proposed architecture extracts spatial-temporal information from video sequences input while avoiding extensive computation. The 3D-CNN is used for the extraction of spectral and spatial features which are then given to the LSTM network through which classification is carried out. The proposed model is a light-weight architecture with only 3.7 million training parameters. The model has been evaluated on 15 classes from the 20BN-jester dataset available publicly. The model was trained on 2000 video-clips per class which were separated into 80% training and 20% validation sets. An accuracy of 99% and 97% was achieved on training and testing data, respectively. We further show that the combination of 3D-CNN with LSTM gives superior results as compared to MobileNetv2 + LSTM.
Keywords: Convolutional neural networks; 3D-CNN; LSTM; spatio-temporal; jester; real-time hand gesture recognition
Gestures are primary tool of symbolic communication and natural form in which humans express themselves more effectively. They vary from simple to more complex actions which allow us to communicate with others. Due to rapid development in the field of deep learning and computer vision technology, the use of biological characteristics of human beings have become a focus for shifting human-computer interaction from traditional ways to new methods. As the most flexible body part of a human body is hand, therefore, hand gestures can express rich and various form of communication between humans and machines. They are widely used for communication between humans and computers or other electronic devices such as smart phones, robotics, auto-mobile infotainment system, etc. Gesture recognition can replace human-computer interaction from touch or wired-controlled input devices [1].
There are two types of gestures as shown in Fig. 1, static gesture [2], in which there is no change in body pose or arm; only the hand is kept still with some specific pose over time. In the second case, the arm with hand moves and there are a set of poses that vary according to the time interval. This is referred to as dynamic gesture [3]. Hand gesture detection methods generally have three main steps: (i) pre-processing (ii) feature extraction and (iii) gesture recognition. Gesture recognition requires hand movement in a video stream. It is done by first transforming video sequence into frames and then going through feature extraction steps and finally recognizing the hand gestures.
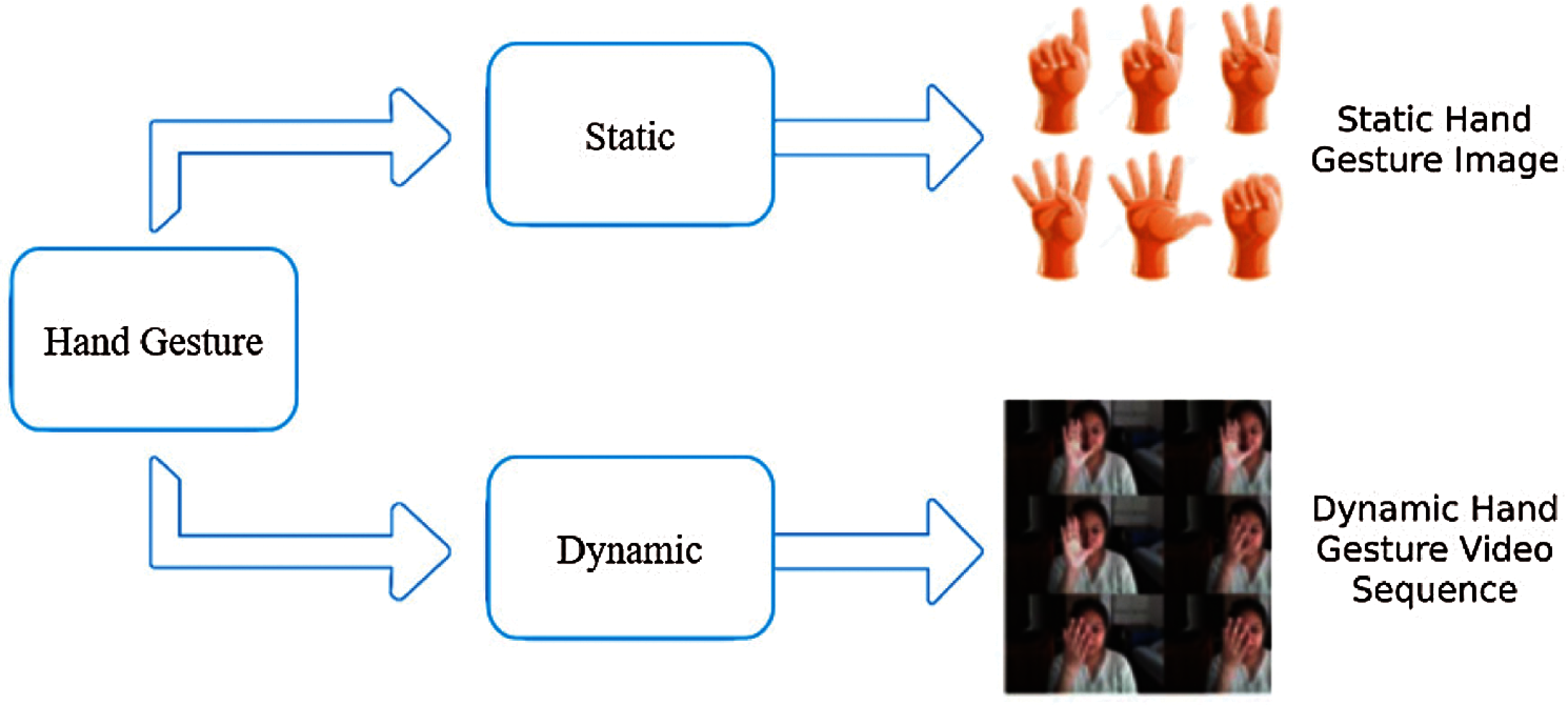
Figure 1: Type of hand gestures
Different sensors have different sensing capabilities. Mostly, a single sensor is used for gesture based interactive technology. Raw data needs to be collected by the sensors before the gesture recognition process start. There can be many other ways to get this data, for example, using a contact-less sensor such as a radar for hand movement detection or a wearable sensor such as a glove, which can measure the pressure applied by the fingers around the wrist [4,5]. Image based approaches mimic the use of eyes to recognize objects in this world. Similarly, robots or human-machine interaction needs cameras to see and recognize things. Initial research in image-based gesture recognition had limitations due to low accuracy, poor real-time recognition and algorithm complexity. With the passage of time, these issues were addressed due to faster computers and advancement in the field of artificial intelligence, especially, deep learning.
Deep Learning (DL) is a developing field and is a sub-category of machine learning inspired by the function of human brain and its structure. It uses multiple hidden neural network layers for better learning of a model. It can learn the features of an object accurately and easily under complex surrounding or background. The Convolutional-Neural-Network (CNN) is a very famous DL model which is used in image-based applications. Nowadays, DL is used in visual object detection and recognition, speech recognition and many other applications [6–8]. In recent years, many hand gesture recognition methods have been proposed using deep learning techniques. Fig. 2 shows the basic steps for automatic recognition of hand gestures.
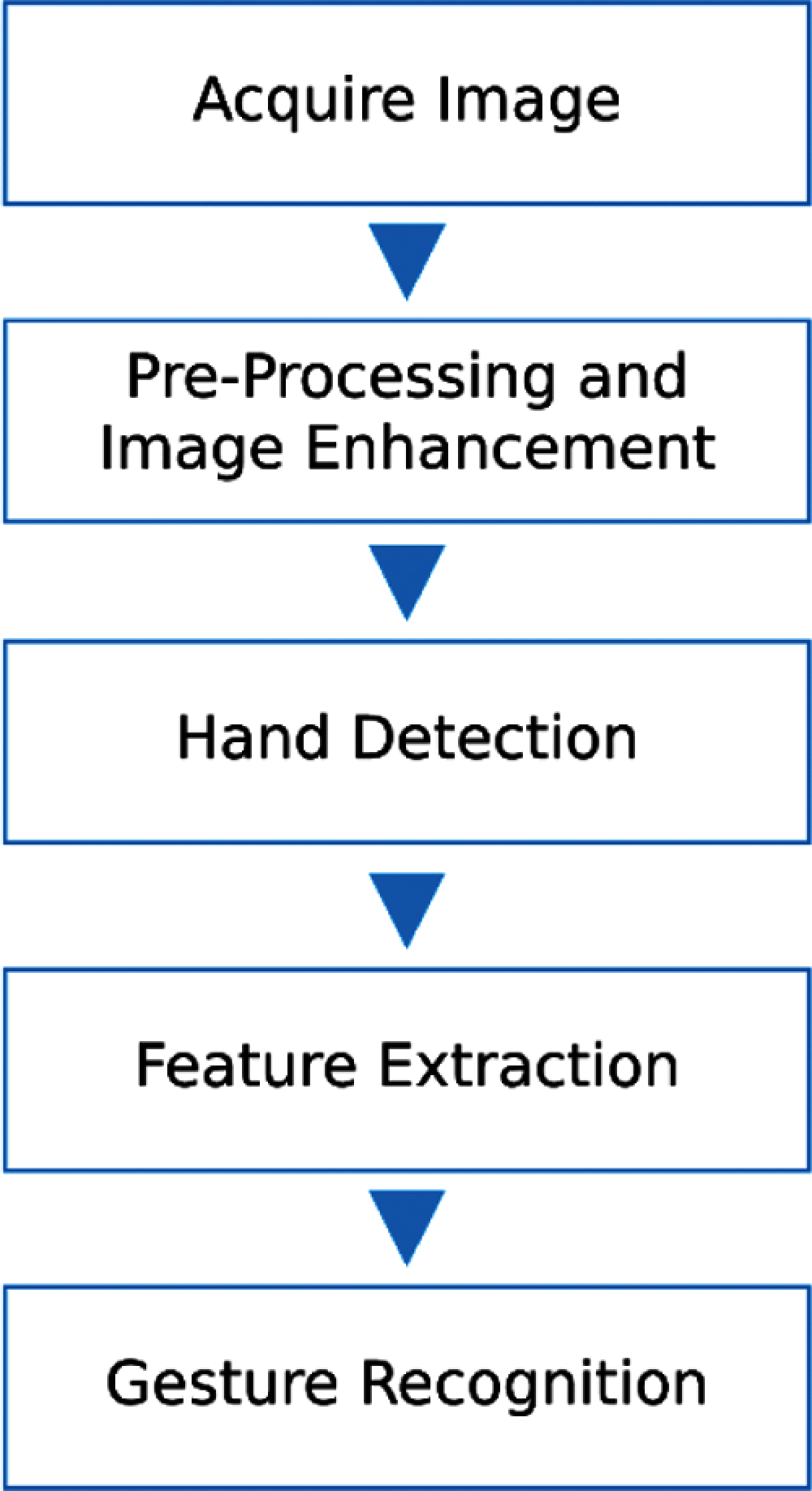
Figure 2: Basic steps for automatic gesture recognition
As shown in Fig. 2, hand gesture recognition process is divided into four steps; image acquisition, image enhancement, hand detection, feature extraction and finally gesture classification. Input images are collected in the form of multiple frames for dynamic gestures, whereas for static gestures, a single image can also be used. Image enhancement techniques are applied to increase the quality of input images. To apply deep learning based gesture recognition, the dataset needs to be large; therefore to enrich the input dataset, data augmentation is employed in this work using scaling, translating, rotating and shearing techniques.
Dynamic gesture recognition falls under the category of video classification since the dataset is mostly available in the form of video frames. Hence both spatial and temporal domains features are used. Dynamic gesture recognition is a difficult task because the images obtained from video recordings does not have consistent pixels; the camera is not fixed at one position and every person performs the same gesture in a different way. Gesture includes different background with hand and arm continuous movement due to which it is not easy for an algorithm to predict the gestures with very high accurately.
In this paper, a deep learning-based model which is combination of 3D-CNN and LSTM is proposed for recognizing dynamic hand gestures. To evaluate the proposed technique, the 20BN-jester dataset [9] is used. The 20BN-jester consists of 148,092 labeled video clips showing different people performing different dynamic hand gestures. The dataset has approximately 5000 video clips per class which are separated into training, validation and test sets. Due to computational restrictions, only 15 classes have been used in this paper. As discussed in the later section of the paper, the proposed model attained an accuracy of 97% on unseen data taken from the test set.
The remaining paper is organized as follows. In Section 2, work of other researchers using deep learning methods for gesture recognition is discussed. In Section 3, the proposed technique which is based on 3D-CNN and LSTM for the recognition of dynamic hand gesture is presented. In Section 4, experimental results are discussed along with different optimizers and hyper parameters used in this work. In addition, the prediction results are also shown for the new unseen data during the testing phase. Finally, Section 5 concluded the paper.
Learning spatio-temporal features is critical for performance to be stable in human hand gesture or action recognition. Several deep neural networks based models have been introduced recently [10]. However, gesture recognition is significantly different from action recognition. The background information in an action recognition task is helpful for correct prediction of any action, but for gesture recognition, the background may be same for all gestures, which is a challenging issue for accurate prediction. Hand gesture recognition focuses more on the hand movement rather than the background.
Hand gesture recognition methods have been introduced to correctly identify and track hand postures. Many methods have been proposed for hand gesture recognition in recent years. Zhao et al. [11] presented a technique based on computer vision for real-time hand gesture recognition. Adaptive skin color and motion detection is used to identify hand regions. Hand images are extracted using the Histograms of Oriented Gradients (HOG). The characteristic local distribution of edges and intensity gradients are used to describe hand gestures. PCA-LDA is utilized to project the extracted HOG features into a low-dimensional subspace. Later, these features are classified using K-Nearest-Neighbors (KNN). A total of ten different gestures are classified with an accuracy of 91%. Chung et al. [12] proposed a technique for gesture recognition based on CNN. The technique recognizes hand gesture using a webcam. Color space and different morphology operation are used to differentiate gestures from complex background. To track the gesture movement, kernel correlation filters are used. The processed images are then fed into two different models; the VGG-Net and the AlexNet. The VGG-Net attained a better recognition rate as compared to the AlexNet. The recognition accuracy attained by the VGG-Net is 95.61%.
Bao et al. [13] proposed a two-dimensional CNN model for recognition of gestures. A nine-layer CNN is used to directly categorize hand gesture present in the images without preprocessing segmentation of the region of interest. The presented technique is able classify seven different types of hand gestures in real-time. The system achieved 97.1% accuracy with simple background and 85.3% accuracy was attained when the images had complex background. Neethu et al. [14] have also used CNN based classification technique for gesture recognition. The hand, which is the region of interest, is first separated from the background followed by adaptive histogram equalization to increase the contrast of the input image. Further, to segment fingers, connected component analysis is used. To classify different hand gestures, the segmented finger tips are fed to the CNN. The proposed technique attains an accuracy of 96.2% for gesture recognition with complex background.
Apart from 2D-CNN approaches for the effective recognition of hand gestures, 3D-CNNs are also used by researchers. In [15], a three-dimensional convolutional network (3D-ConvNets) with an attention mechanism technique is proposed for learning of spatio-temporal features. The model was trained on the UCF-101 and HMDB-51 datasets. The authors claim that 3DConvNets are better than simple 2D-CNNs for spatial-temporal learning of features. The 3D-CNN with Resnet101 architecture and softmax classifier achieved an accuracy of 95.5% on the UCF-101 dataset.
Molchanov et al. [16] proposed a robust hand gesture classification algorithm which uses 3D-CNN with augmentation techniques in spatio-temporal domain for reducing overfitting. Their model when used on the VIVA challenge dataset, attained classification precision of 77.5%. In [17], the researchers introduced two models for hand gesture recognition. The first model consists of CNN and an RNN-LSTM network. When the model was fed with color channel, it achieved an accuracy of 83%, whereas when the depth channel data was introduced, the accuracy was 89%. The second model consists of two parallel merged CNN and RNN with LSTM fed by RGB-depth dataset. This second model achieved 93% accuracy. Hakim et al. [18] used a 3D-CNN model followed by LSTM to extract the spatial-temporal features of 23 hand gestures, which includes 13 static and 11 dynamic. After the classification stage, a finite-state machine (FSM) is fused with the 3D-CNN+LSTM model to supervise the categorical decision. The dataset used was a combination of RGB and depth data. The model achieved an accuracy rate of 97.8% on subset class of eight gestures while recognition with the FSM model improved to 91% from 85% in real-time.
Nguyen et al. [19] proposed a two-stream convolution network model on 6 classes out of 25 using the 20BN-jester dataset. MobileNet-V2 followed by LSTM was used for spatio-temporal features extraction. The MobileNet-V2 is used because of its smaller number of training parameters due to which it took less time for training than other models mentioned in the paper. This model achieved precision of 91.25% which is a bit less than other models, but it greatly reduced the execution time and memory resources. In [20], the authors designed a low memory and power budget architecture for hand gestures recognition from video streams. The model has two parts: (1) A light-weight CNN architecture for extracting features and, (2) A deep CNN classifier for the classification of detected hand gestures. The authors used Levenshtein distance as the evaluation metric to classify hand gestures in real-time. ResNeXt-101 model is used on two publicly available datasets—the NVIDIA Hand Gesture and Ego-Gesture dataset. The model achieved an accuracy of 94.04% and 83.82%, respectively.
In [21], the authors proposed a deep deformable 3D-CNN with an impressive accuracy and real-time dynamic hand gesture recognition processing. The authors proposed three types of 3D-CNN models; Modified C3D, deformed ResNext3D-101 and InceptionResNet3D-v2 to learn the spatio-temporal information from video sequences. A spatio-temporal deformable CNN module is considered for three different datasets, Jester, Ego-Gesture and Chalearn-IsoGD. The model pays attention to learn more discriminative portions in a video sequence in both spatial and temporal domains. The 3D-CNN models have more training parameters which makes it computationally expensive and time consuming. Pigou et al. [22] emphasis that learning of temporal information is crucial for dynamic real-time gesture recognition. They proposed a model which consists of a residual network, batch normalization and exponential linear units (ELUs) for simple RGB dataset. It is concluded from their work that temporal information and LSTM is very important for getting accurate gesture prediction while dealing with dynamic gestures. However, RNN-based models can lead to some difficulties during training such as exploding or vanishing gradient. When using LSTM alone for hand gesture recognition, the model can ignore the low-level spatial or temporal information. It is because of this reason; a 3D-CNN coupled with LSTM is used in this work.
It is a challenging task to learn temporal and spatial information for gesture recognition with only one model [23]. To address this problem, a new architecture which consists of a 3D-CNN followed by LSTM and a Softmax classifier is proposed in this paper as shown in Fig. 3. This architecture has several steps such as data-loading, data-augmentation, training and testing.
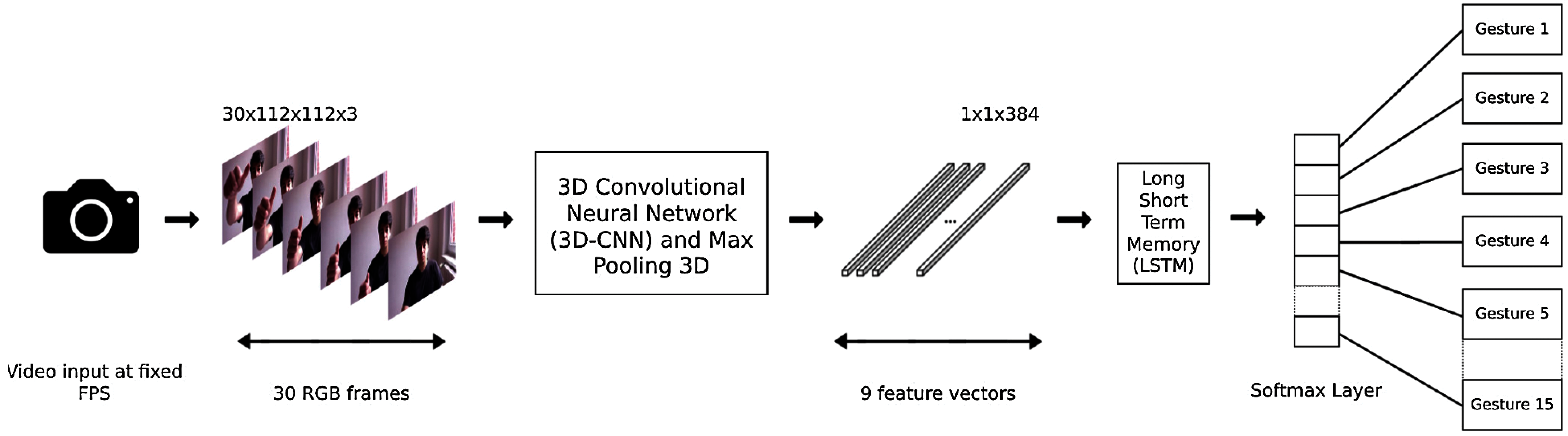
Figure 3: The proposed model pipeline
The proposed model pipeline consists of fusing two models, a 3D-CNN and an LSTM. The original frame size of the dataset has a height of 100 pixels and variable width; therefore, the input frames are first resized to 112 × 112 pixels during data loading. The 3D-CNN network is used to learn spatial information from successive video frames. The output of the 3D-CNN produces feature maps which are converted into vector that has 9 time-steps; also known as length of sequence and 384 features, it is then fed into the LSTM model as it accepts input with number of samples, time steps, and features information. In this model the number of sample taken per sequence is 1. To learn the temporal information from video frames, an LSTM network is used for the classification of hand gestures.
Various video datasets are available publicly, however for this research, the 20BN-Jester, which is a very large-scale real-world dataset has been used. This dataset is generated by 1376 different actors in different unconstrained environments. It contains over 148,092 short video clips of 3 s length. Each video has 27 or more frames, which makes this the largest hand gesture dataset with more than 5 million frames in total. Due to time constraints and memory resources restriction, only 15 out of 27 hand gestures are used in this work. The original dataset has more than 4000 videos per class, however, 2000 random videos per class are chosen, which are further divided into 80% training and 20% validation set.
Video sequences of the 20BN-jester dataset have different length. For data preparation, the first step is to unify all the video-clips. Every video is limited to 30 frames per video. The dataset has videos of different length varying from 27 to 46 frames. Only 30 frames for each video clip have been adopted to train the model. The overall dataset contains 30,000 folders for 15 classes and each class has 2000 folders or samples. The dataset is separated into 80% training and 20% validation sets, respectively. All video frames are resized to 112 × 112 pixels during loading of data for training.
Deep learning models need more data for improved training and subsequent performance. To achieve this, data augmentation techniques are used to modify the current dataset and create more variations of the images which will improve the model learning. The data augmentation techniques used in this work are explained below.
Image augmentation uses affine transformation to modify the geometric structure of images, preserving the ratios of distances and collinearity. It is often used in deep learning to increase training data quantity. In this work, each frame is first translated by −20% to +20% per axis. Then images are scaled by 80% to 120% of their original size. In addition, shearing and rotation operations are also performed for each frame. Besides affine transformations, contrast normalization and additive Gaussian noise are also applied to each frame. Contrast normalization is applied uniformly for each per image.
Adding noise to small dataset can increase the dataset and reduce overfitting and has a regularizing effect. When the neural network tries to learn very high frequency spatio-temporal features or patterns that occur a lot, the model is usually over fitted. To avoid such a scenario, data augmentation is performed by using the additive Gaussian noise with zero mean. Eq. (1) below shows the PDF distribution of Gaussian noise.
where x is the gray value (0 to 255), σ is the standard deviation and μ is the mean. We can improve the learning capabilities of the model by adding the right amount of noise to the image. In this work, Gaussian noise between ranges 0.0 to 0.05 per channel is added. Tab. 1 shows that before applying data augmentation, the model was over-fitting. On the other hand, after data augmentation, a significant improvement in training-validation accuracy and loss can be observed.

3.4 Learning Spatio-Temporal Features
Nowadays, deep learning based techniques are being widely used to perform gesture recognition tasks more accurately. A number of researchers have used CNN models to classify static gestures, however, for dynamic gesture recognition, CNN based models do not have high accuracy. The combination of learning both spatial and temporal features is a necessary requirement for dynamic gesture classification. To achieve this, a six-layer 3D-CNN model is used in this work which can extract temporal features by preserving the spatial information of the video frames. It is pertinent to mention that similar networks have been used in video classification problems, for example, [24] to extract short-term temporal information from input video frames. Merely using a 3D-CNN model for dynamic hand gesture recognition is not good enough to learn long-term spatio-temporal information from video datasets. Therefore, another network which can learn the long-term temporal information is needed. In this work, a combination of 3D-CNN followed by an LSTM network is used, as shown in Fig. 4.
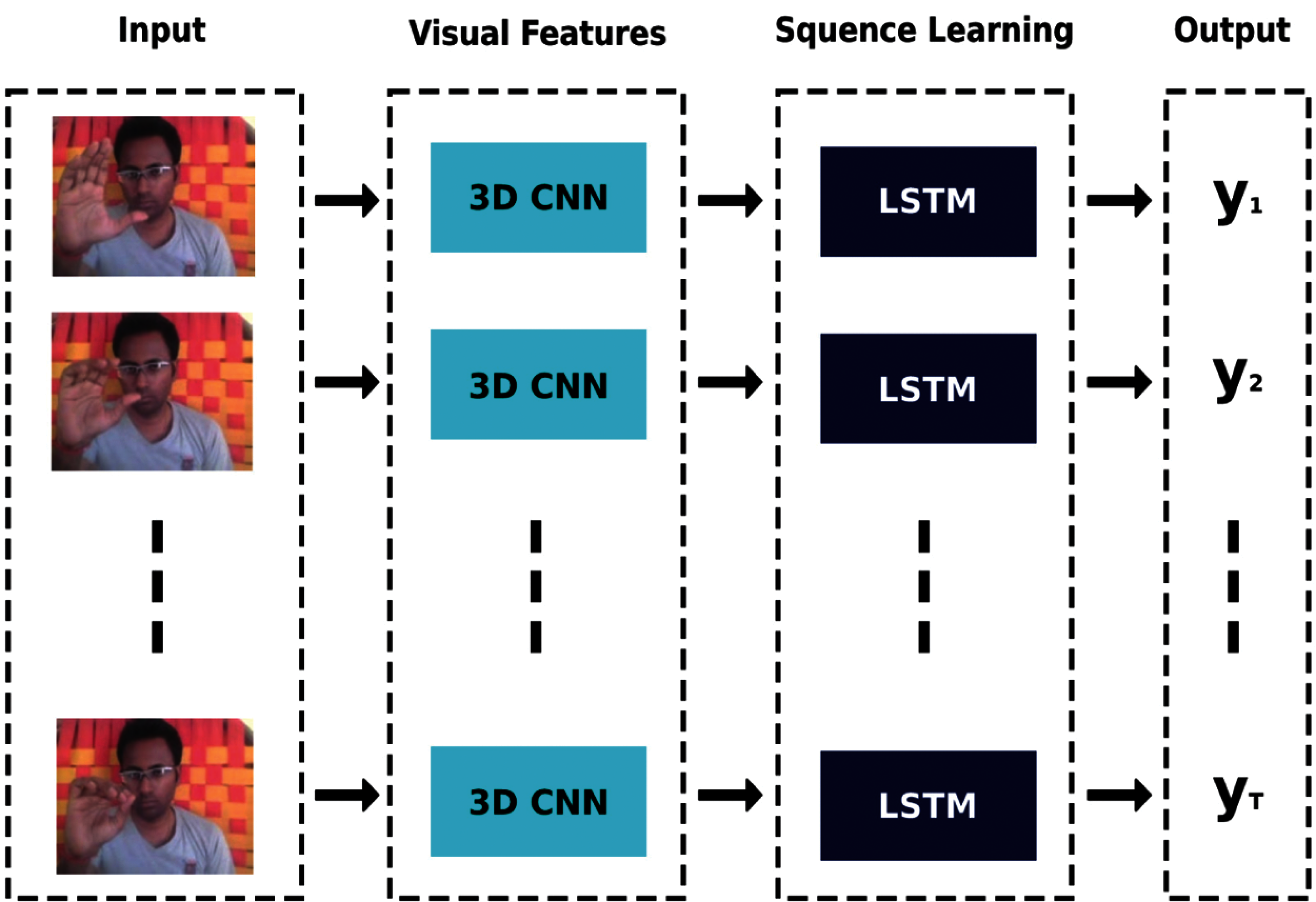
Figure 4: The proposed model general diagram
The structure of an LSTM unit consists of input/output and forget/cell gates which controls the learning process as shown in Fig. 5. These gates are adjusted with the help of sigmoid functions to control the opening and closing during the learning process. The long-term memory in LSTM is known as the Cell state. It controls the information to be stored within an LSTM cell from the previous intervals. The remembering vector is called the forget gate which modifies the cell gate. If the forget gate output state is 0, it tells the cell gate to forget the information, and if 1, it tells the cell gate to keep it in the cell state.
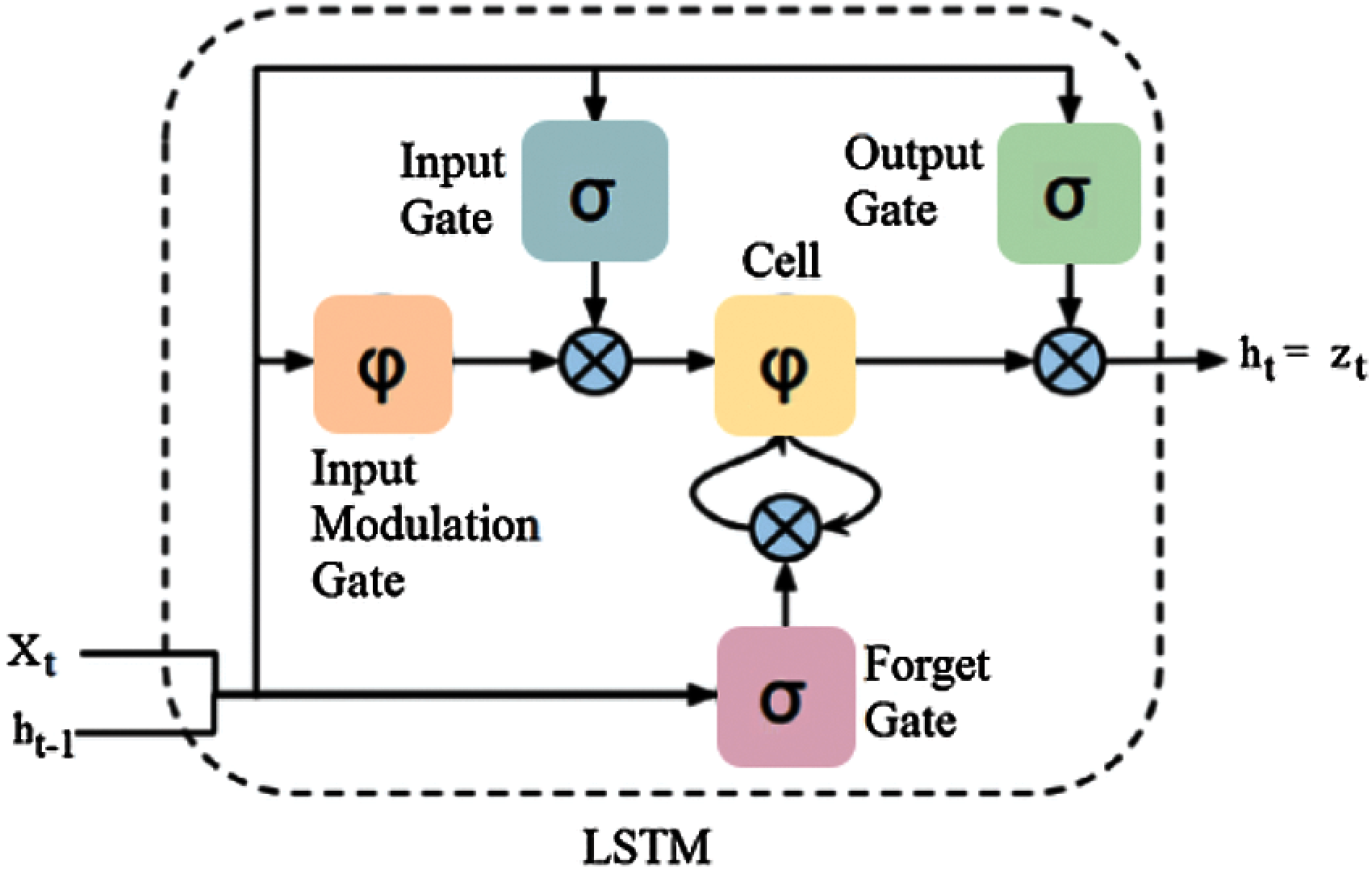
Figure 5: A typical long short-term memory unit
Eqs. (2) to (7) illustrate the learning process inside an LSTM unit [25].
where, “

Figure 6: The proposed 3D-CNN + LSTM architecture
The features obtained from the 3D-CNN layers passes to the L2 batch normalization layer and are then fed to the LSTM layer. This is followed by a dropout layer to avoid overfitting and finally the fully connected layer followed by output Softmax layer as shown in Fig. 6. L2 batch normalization is applied to obtain higher learning rates and to accelerate the initialization process for training and to reduce overfitting of the model. Batch Normalization as shown by Eq. (8) is carried out by using mean and variance of training data batches before the activation layer on the input.
where,
L2 regularization is a method used in deep learning with sum of square of scale weights which are added to the loss function as a penalty condition to be minimized as shown by Eq. (9). L2 regularization ensures that the scale of weights should be close to zero. L2 regularization is also known as the “weight decay regularization”.
Each Conv3D has a kernel size (3 × 3 × 3), stride and pooling size (2 × 2 × 2) except for the first layer which is 1 × 2 × 2. This layer preserves the temporal details. Feature maps have three different filter depths; 32, 64 and 128 which reduces the training parameters to approximately 3 million. Features are extracted by the 3D-CNN model and are then fed to the LSTM first layer with a unit size of 512. A dropout layer is added after the LSTM layer with a value 0.5 and then the probability results are computed using the softmax function.
4 Experimental Results and Discussion
This section presents the experimental results of the proposed scheme. Simulation is carried out using Google Colab GPU Tesla T4 with 16 GB memory and RAM of 25 GB. The deep learning framework Keras has been used to implement the proposed architecture. Tab. 2 shows a comparison of the proposed 3D-CNN + LSTM model with other models in terms of accuracy, precision and recall using the 20BN-jester dataset for 15 classes. For the MobileNet-V2 + LSTM model, pre-trained weights of the ImageNet dataset [26] were used which gave a validation accuracy of 84% at 20 epochs. The results however did not improve further with validation loss not going below 0.25. The accuracy was reasonable but the real-time gestures prediction through a webcam was not accurate. After this, L2 batch normalization was introduced to MobilNet-V2+LSTM model and the accuracy improved to 87%, which was better but not acceptable as compared to other techniques proposed in the literature. A light-weighted model consisting of 3D-CNN+LSTM with L2-batch normalization was used which had 3.7 million training parameters. The combination of two models and normalization technique for sequential video dataset produce competitive results as shown in table below.

Further, we have implemented our model with three optimizers: Adam, SGD (stochastic gradient descent) and Adadelta and the results obtained from these experiments are shown in Fig. 7.

Figure 7: Comparison of different optimizers
As shown in Fig. 7, the Adam optimization technique achieved a validation accuracy of 95.2%, whereas the Stochastic Gradient Descent (SGD) optimizer achieved a lower accuracy. Adadelta optimizer with our proposed 3D-CNN+LSTM model achieved the best accuracy. The learning rate for all three optimizers is ‘0.00001’. In Figs. 8 and 9, the accuracy and loss curves are shown with ‘Adadelta’ optimizer.
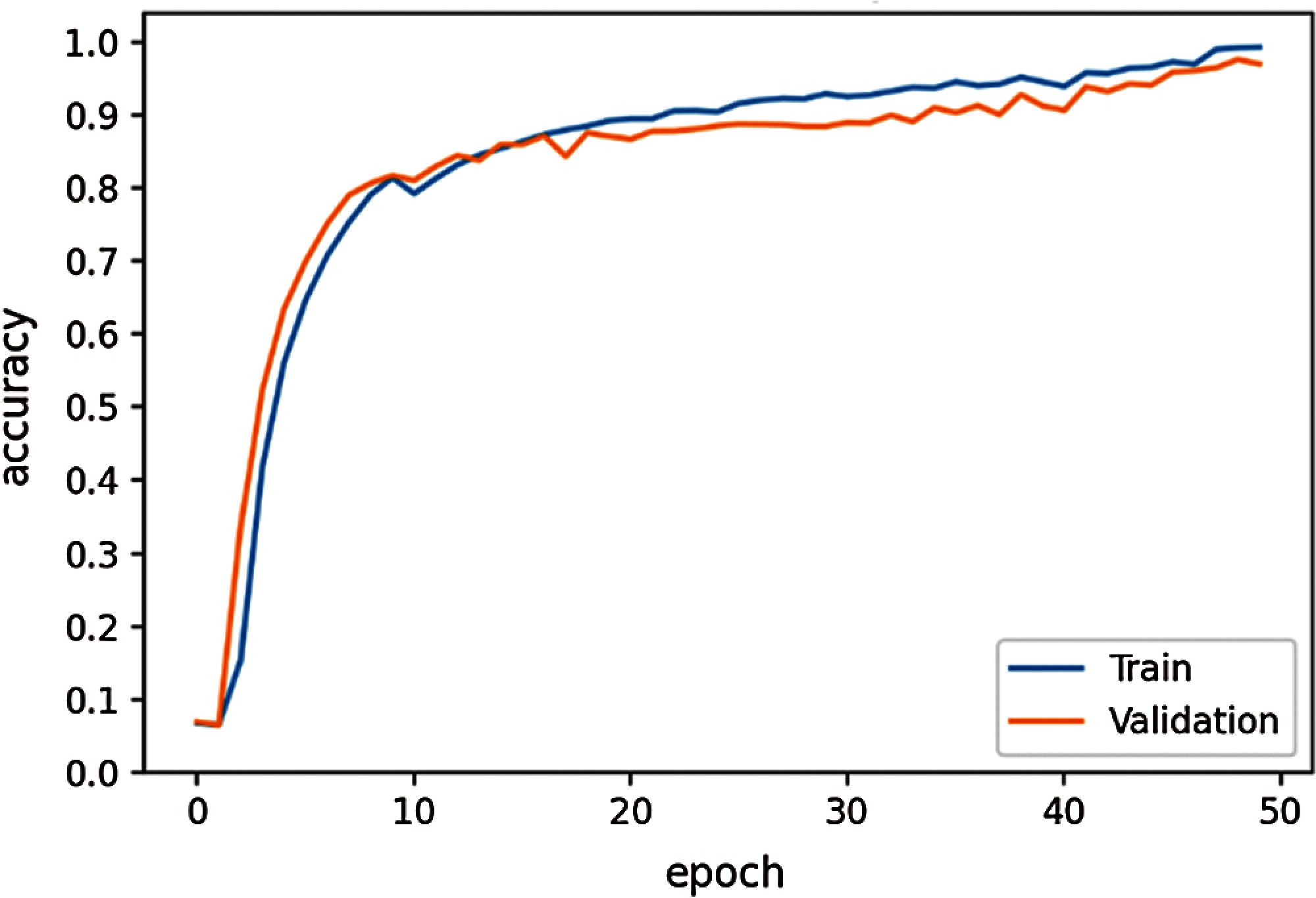
Figure 8: Model accuracy
From the model accuracy and model loss curves, it takes 50 epochs to reach the desired loss as the model was trained from scratch. For the first 4 epochs, the accuracy remained unchanged with very high loss. Later, after 6 epochs, the model achieved higher accuracy. The batch size kept for this training was 32 due to which it took many hours for training since the model was loading dataset in batches of 32. In addition, data augmentation was also carried out due to which it took almost 36 h to train the whole dataset for 50 epochs. With early stopping technique, training was stopped when the validation accuracy of 97.5% and loss of 0.09 was achieved. To avoid overfitting, L2 regularization together with batch normalization were used.

Figure 9: Model loss
Testing Results: For testing, 600 video-clips were chosen from the test folder of the 20BN-jester dataset. Each class has 40 or less video clips. Prediction results of the proposed model for unseen data are shown in Tab. 3. The results show that the model achieved 97% test accuracy on the unseen data. The model produced good results on 15 most difficult classes taken from 20BN-jester dataset.

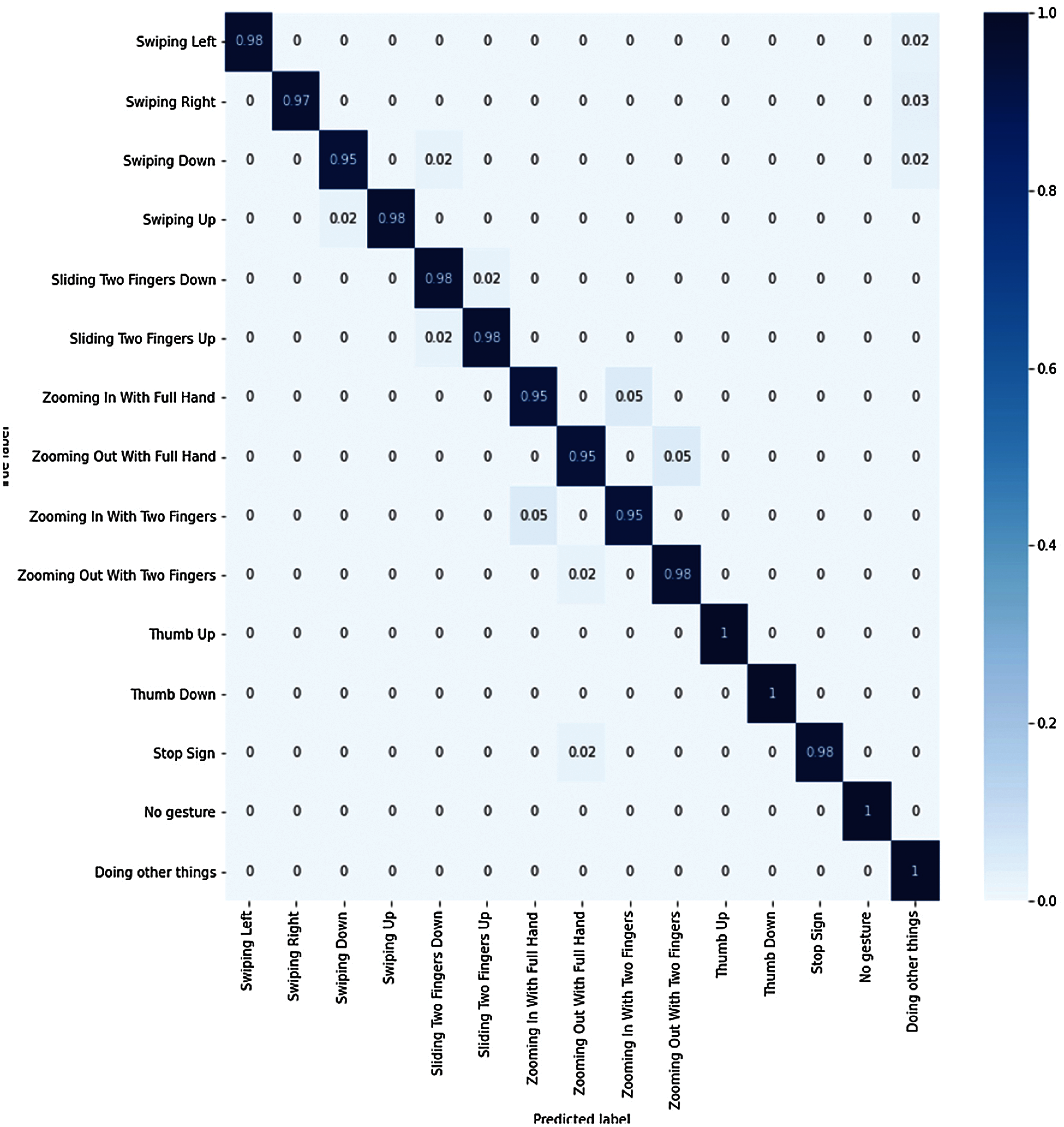
Figure 10: Confusion matrix
From a total 600 video-clips, 41 were classified as “Swiping Left” gesture. In actual, 40 video clips belong to swiping left class, hence the model predicted 40 clips correctly but 1 video clip was predicted false positive, therefore the recall is 98% for this class. Similarly for all the remaining classes, classification results are shown in Tab. 3. The model misclassified other classes as “Doing Other Things” class, therefore precision for this specific class is low but recall is very high. The prediction results in Tab. 3 show that the model achieved 97% average test accuracy on the unseen data which is close to the validation accuracy of 97.5%. The confusion matrix obtained after making predictions on the new data using the proposed model is shown in Fig. 10.
The confusion matrix shows that most of the predictions are accurate. For the first gesture, “Swiping Left”, the model predicted 98% of the video clips as true positive while only 2% were predicted as true negative. Similarly, for the “Swiping Right” gesture, 97% of the video clips were predicted as true positive while only 3% were predicted as true negative. The simplest gesture among all classes is the “thumb up” gesture, which was predicted 100% correctly. Results for the remaining gestures are also shown in Fig. 10 with true positive, true negative and false negative information.
A new deep-learning model is proposed that learns spatial-temporal features of dynamic hand gesture sequences in a video-stream. The architecture consists of a 3D-CNN followed by an LSTM network which learns both spatial and temporal features of all video frames under complex background and lighting conditions. The proposed model was trained on a subset of 20BN-jester dataset that contained 15 classes with unique hand gestures. The Combination of 3D-CNN with LSTM gives better results as compared to MobileNetv2 + LSTM. To avoid overfitting, batch normalization and L2 regularization has been used. The proposed model achieved 99% training, 97.5% validation and 97% predictive accuracy during real-time testing. In the future, more advanced deep learning [27–31] techniques will be applied for human gesture recognition.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |