DOI:10.32604/cmc.2022.013956
| Computers, Materials & Continua DOI:10.32604/cmc.2022.013956 | |
| Article |
Prediction of Extremist Behaviour and Suicide Bombing from Terrorism Contents Using Supervised Learning
Department of Computer Science, University of Engineering and Technology, 54890, Lahore
*Corresponding Author: Nasir Mahmood. Email: nasir202003@yahoo.com
Received: 30 August 2020; Accepted: 16 March 2021
Abstract: This study proposes an architecture for the prediction of extremist human behaviour from projected suicide bombings. By linking ‘dots’ of police data comprising scattered information of people, groups, logistics, locations, communication, and spatiotemporal characters on different social media groups, the proposed architecture will spawn beneficial information. This useful information will, in turn, help the police both in predicting potential terrorist events and in investigating previous events. Furthermore, this architecture will aid in the identification of criminals and their associates and handlers. Terrorism is psychological warfare, which, in the broadest sense, can be defined as the utilisation of deliberate violence for economic, political or religious purposes. In this study, a supervised learning-based approach was adopted to develop the proposed architecture. The dataset was prepared from the suicide bomb blast data of Pakistan obtained from the South Asia Terrorism Portal (SATP). As the proposed architecture was simulated, the supervised learning-based classifiers naïve Bayes and Hoeffding Tree reached 72.17% accuracy. One of the additional benefits this study offers is the ability to predict the target audience of potential suicide bomb blasts, which may be used to eliminate future threats or, at least, minimise the number of casualties and other property losses.
Keywords: Extremism; terrorism; suicide bombing; crime prediction; pattern recognition; machine learning; supervised learning
Crime is a politico-socio-economic problem that adversely affects people worldwide, marring the social welfare and progress of the masses. Law enforcement agencies need to formulate crime policies and strategic plans to prevent crimes and reduce crime rates. However, they face the challenge of effectively extracting relevant knowledge from a large volume of criminal data and reports [1]. Knowledge discovery (KD) and data mining from this mass of data require sophisticated analytical processing. This KD is ultimately used to provide practical decision-making support to law enforcement agencies. Nevertheless, the analytical processing of large amounts of data is complicated for humans [2]. Therefore, scholars have proposed numerous techniques to automate a significant part of or the entire analytical process. Crime data mining is a well-known set of measures to automatically extract hidden knowledge from dimensional databases [3].
In comparison to other crimes, terrorism—an aggregate of brutality—is a more complex and versatile framework that directly affects harmony, the daily schedule of nations, and social orders. It is utilised to produce widespread, global dread among nations’ citizenry [4]. Acts of terrorism encompass a broad range of activities, including criminal communication, planning, transportation, logistics, reconnaissance of targets, harbouring, providing materials and items such as weapons, and supporting other relevant materials and finances. Acts of terrorism by extremist or terrorist organisations create psychological pressure amongst civilians and governments; the military, due to the casualties; and property losses, social unrest, and economic disruption [5]. There is no universal consensus on the cause and roots of terrorism [6]. According to the Global Terrorism Database (GTD) maintained by the University of Maryland, more than 61,000 incidents occurred between 2000 and 2014, resulting in 140,000 casualties. Meanwhile, the Global Terrorism Index (GTI) reported an increase in terrorism from 65 countries in 2015 to 77 countries in 2016, indicating more devastation than over the last 17 years [7].
After the terrorist attacks on the World Trade Centre and the Pentagon on 11 September 2001, the former President of the United States, George Walker Bush, introduced the phrase ‘war against terror’. The campaign was launched with the US and UK invasion of Afghanistan. The attack engendered mass displacement in Afghanistan and compelled the country’s people to take refuge in the religiously, ethnically, linguistically and culturally associated tribal areas of Pakistan. This cross-border displacement of people from Afghanistan to Pakistan caused social, political and economic upheaval, leading to a rise in militancy and extremism, drone attacks, internally displaced persons (IDPs) and suicide bombing attacks [1].
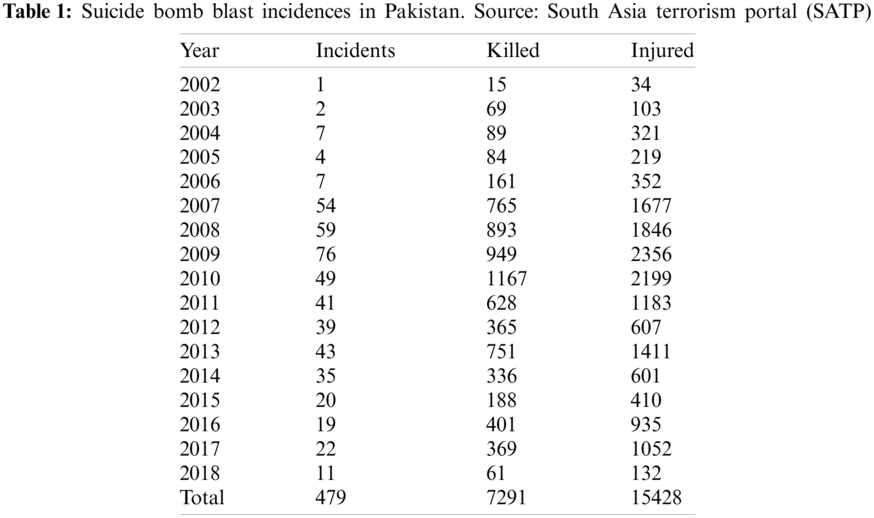
Pakistan has been an active target of terrorist activities for the past 18 years. Between 2001 and 2010, the country’s anti-terrorist activities incurred a total of $68 billion. Moreover, in 2009, 300,000 IDPs were recorded in the wake of different forms of terrorist acts, including target killings, military operations, planted bombs and suicide attacks [2]. Suicide bombing is a terrorist practice targeting military personnel, famous personalities, religious sites and civilians. These attacks are usually carried out using vehicles or by individuals wearing vests and carrying explosives [1]. Tab. 1 illustrates the data regarding suicide attacks in Pakistan from 8 May 2002 to 17 June 2018.
Crime and terrorism are common problems in almost every society because they affect the quality of life and economic growth. They bring fear and disrupt the population’s unity by breaking social associations. The discipline of criminology involves the study of crime and criminal behaviour and a process that aims to identify a crime’s characteristics, motives and hidden patterns. The emergence of modern techniques, such as machine learning (ML) and data mining, and the availability of a high volume of crime and terrorist datasets, have enabled the identification and prediction of crimes [8]. The predictive capability of crime, facilitated by the effective implementation of security policies, can assist crime prevention [9].
There is substantial statistical proof that crime and terrorism are predictable not because criminals and terrorists operate in their comfort zone; rather, a frequency of variables make their methods work well. The most significant theories supporting this hypothesis include criminal behaviour theory, routine activity theory, rational choice theory, and crime pattern theory. These theories are consolidated to form a blended theory. The proposed research is based on the crime pattern theory [8].
Data is characterised as an assortment of facts and figures, statistics, and measurements that can be utilised for references and examinations to reach determinations. Information assortment is a pivotal and deliberate way to deal with data from various sources to obtain an exact image of a region of intrigue. It assists in answering research questions, formulating a hypothesis and drawing conclusions. The objective of information assortment is to collect high-quality evidence that will then be converted to allow for an information-rich investigation, permitting the structure of persuasive and tenable responses to explore questions. Accurate data collection is key to ensuring the morality of the study. Information assortment is of particular significance in the domain of terrorism and related fear-based oppressive exercises. Exact and reliable information can help to stop psychological warfare exercises and execute security approaches that can forestall the development of fear-based oppressor gatherings [10].
ML is a sub-domain of artificial intelligence that uses the computational statistical model. It is widely used to design intelligent algorithms that can learn from previous data or knowledge to make future predictions or decisions. ML answers two fundamental questions related to artificial intelligence: namely, how can computer systems automatically improve themselves through experience, and what are the basic statistical, computational information laws that govern all the learning systems? Learning problems can be defined as problems surrounding the improvement of performance measures through training experience. Applications of ML include computer vision, email filtering, predictive analytics, natural language processing, optical character recognition and pattern recognition [11].
Supervised learning (SL) techniques require a sufficient amount of labelled training data for classification or to label unseen test data. In contrast, deep learning (DL) techniques emerged recently from artificial neural networks (ANNs), requiring minimal engineering by hand. Thus, the latter methods can benefit from an increase in the amount of available computation and data compared with classical ML techniques and external neural networks. Supervised ML algorithms are frequently used to recognise, understand and translate human languages to extract meaningful information [11], and ML and analytics have contributed to the development of many medical, financial, technological, and business-and science-related applications. ML has also proven to be a vital means of understanding, analysing and predicting criminal and terrorist behaviour [12]. Previous studies have concentrated on theoretical models to develop a hypothesis about causes and consequent effects. ML algorithms are innovative and have predictive capabilities: ML can add robustness to the variables of a sample by validating actual predictive capabilities. Furthermore, ML can rank variables by the influence of predictive accuracy, giving a sense of the importance of a particular variable [6].
Understanding crime is the objective of many types of research and studies. While numerous benchmark datasets are available, it is difficult to extract some attributes, such as the number of casualties and expected injuries, from the crime and terrorism data. Some non-linear models have been proposed to find a correlation between crime data and urban matrices. However, because of non-Gaussian distributions and multi-correlation in urban indicators, it is common to find controversial conclusions about the influence of some urban indicators on crime [13]. ML methods frequently rely on supervised classification learning, which includes support vector machines (SVMs), ANNs, the naïve Bayes classifier (NB), and maximum entropy [14]. The knowledge gained from the ML and data mining approaches and techniques can help law enforcement agencies prevent or decrease criminal and terrorist activities in society [8].
This study adopts and recommends the SL-based approach to predict the target audience (target class) of suicide bombers using the suicide bomb blast data of Pakistan available on the SATP. The study has the following objectives:
• Analysing Pakistan’s suicide bombing data to understand and extract valid attacker behavioural variables available in the data.
• Designing an accurate dataset to train and test the system efficiently (useful for future studies).
• Finding the maximum results through the twin operations of training and testing by applying simple SL algorithms.
The literature review for this study covers three significant dimensions of terrorist events and data: suicide bombing, previously proposed suicide bombing and crime prediction techniques, and the use of ML for crime prediction.
The primary aim of qualitative research by Abbasi et al. [1] was to analyse the social, economic and physiological implications and repercussions for Pakistan after 9/11 and the ensuing war against terror. This study’s major findings included a relationship between religious extremist behaviour and suicide bombing, external invasion, and internal displacement. The study provided a better understanding of suicide bombing culture and other useful statistical details of terrorist events.
Rasheed et al. [10] discussed the existing sources of suicide bombing data and datasets, presenting a vital case study of a data collection related to suicide bombings in Pakistan. Important contributions made by the study included new variables, such as explosion types, explosives, perpetrators, motives, etc. These variables, of course, explain the phenomena of suicide attacks. Agarwal et al. [7] provided useful insights by tracking patterns and trends [10] in their analysis of a historical dataset of the GTD. They predicted the factors that can potentially correlate with the menace of terrorism. Different data mining and ML techniques, including SVMs, random forest (RF), and logistic regression (LR), were employed to analyse the dataset and predict the would-be terrorist groups, the success or failure of the attacks, and their effects on external factors. In the implementation, k-means clustering and dummy classifiers showed an improvement, while RF with the GTD and dummy classifiers with the GTD peaked to the marks of 0.82 and 0.56, respectively [7].
Gao et al. [5] also used the GTD to compare five classification ML algorithms: the decision tree (DT), LR, a Gaussian Bayesian Network (GBN), RF and AdaBoost. The experiment results showed that classification based on the DT had the highest precision at 94.8%. Moreover, the GBN could list all the possibilities according to the probabilities and showed 94.7% of the results [5]. In another study, Mehmood et al. [2] acquired data concerning terrorism in Pakistan between 1998 and 2012 from the SATP. The methodology included a cluster analysis based on statistical correlation, followed by data pre-processing. The clusters were discovered over event and target; event and method were used in terrorism, and a more significant clustering grouped the distinct combination into separate clusters. The clusters were analysed according to three dimensions: the period, geography and type of terrorist events. The authors found that some critical terrorist activities, including suicide bomb attacks after 2012, reshaped the architecture of terrorism networks and events in Pakistan.
Soliman et al. [4] proposed a hybrid computational intelligent algorithm as a decision support tool for the phenomenon of terrorism. The algorithm was based on different decision support tools and data mining techniques and aimed to improve the previously proposed algorithms inspired by meta-heuristics. The algorithm could predict the terrorist groups responsible for terrorist attacks on different regions of Egypt from 1996 to 2017. The accuracy of the prediction model with the neural network (NN) decision-maker was recorded at 74.77% with a mean square error (MSE) = 0.018 at iteration 10 = 0.0860. Although the proposed algorithm provided a marked accuracy, it involved complex implementation details [4].
Basuchoudhary et al. [6] argued that ML could explain the phenomenon of terrorism since it can replace the missing data in scientifically validated ways. ML can help to reduce the multidimensionality of the most commonly used variables with no causal effect, explaining why it can identify causal variables. In another study, Basuchoudhary et al. [6] outlined how ML could be a vital part of the iterative knowledge-building process. Greitzer et al. [15] asserted that insider attacks could be detected based on psychological, behavioural, physical and sociotechnical indicators and factors mapped into a domain ontology. The proposed solution incorporated the technical indicators from the previous work. The ontology was derived from the taxonomy of the domain knowledge [15].
Moreover, Nguyen et al. [12] put forward a crime forecasting method that predicted crimes based on location and time. The techniques comprised data acquisition, pre-processing, linking data with demographic data, and prediction using ML techniques including SVMs, RF, gradient boosting machines (GBMs), and NNs. The results obtained by the classifiers SVMs, RF, GBMs and NNs using scaled conjugate back-propagation and resilient back-propagation were 79.39%, 65.79%, 61.67%, 74.02%, and 74.24%, respectively. The data was provided by the Portland Police Bureau and the public government source American Factfinder [12].
Kang [9] proposed a feature-level data fusion technique with the environmental context based on a deep neural network (DNN). The dataset consisted of online databases of crime statistics, demographics, meteorological data and images in Chicago, Illinois. Experimental performance results showed that this DNN model was more accurate in predicting crime than other prediction models [9]. Meanwhile, a study by Ahishakiye et al. [8] considered developing a crime prediction prototype model using the DT (J48) algorithm since the related literature has argued that it is the most efficient ML algorithm for predicting crime data. From the experimental results, the J48 algorithm predicted the unknown category of crime data at an accuracy of 94.25%, a rate high enough for the system to be relied upon to predict future crimes. The dataset, entitled ‘Crime and Communities’, was acquired from the UCI Machine Learning Repository.
Azizan et al. [14] developed a terrorism detection technique using ML through sentiment analysis on the microblogging social website Twitter. Terrorists and people who support terrorism demonstrate patterns in these sentiments, which run through the very fabric of the comments, tweets, or messages they post. This study built upon the current sentimental analysis methods and techniques by using ML for crime prediction. The NB accuracy was recorded at between 85% to 96% [14]. Alves et al. [13] obtained accurate predictions through statistical learning, suggesting that crime prediction depends on urban matrices and indicators. The proposed model provided a better solution to predicting crime with good accuracy and identifying the importance of the feature. It also held, even under small perturbation, on the training dataset [15]. This approach showed up to 97% accuracy using RF classifiers. Furthermore, the importance of urban indicators was ranked and clustered in groups of equal influence in the data sample analysed [13].
Using ML, Singh et al. [16] were able to predict terrorist attacks by country and region. This study was carried out upon the GTD. Six ML algorithms were applied to the selected dataset to achieve 82% accuracy using NB and LR. Gerber [17] argued that the importance of GPS-tagged tweets for crime prediction has been ignored in the literature; fewer types of crime have been discussed, and the performance comparison of previously proposed and currently used hot-spot models on Twitter have not been addressed. Finally, Lim et al. [18] conducted experiments to demonstrate that a criminal network link prediction model based on deep reinforcement learning (DRL) outperformed the GBM model with a relatively smaller dataset. AUC scores were 0.85, 0.82, and 0.76 for the DRL criminal network link prediction model, compared with the GBM model scores of JUANES, MAMBO, and JAKE, respectively. The experiments indicated that the DRL method was capable of a better predictive performance than conventional SL under the same hyper-parameter setting. Further research should focus on confirming whether the SL technique’s predictive precision would be stronger over a larger dataset and number of training iterations [18].
Fig. 1 shows the steps involved in the current study. Its details are discussed below.
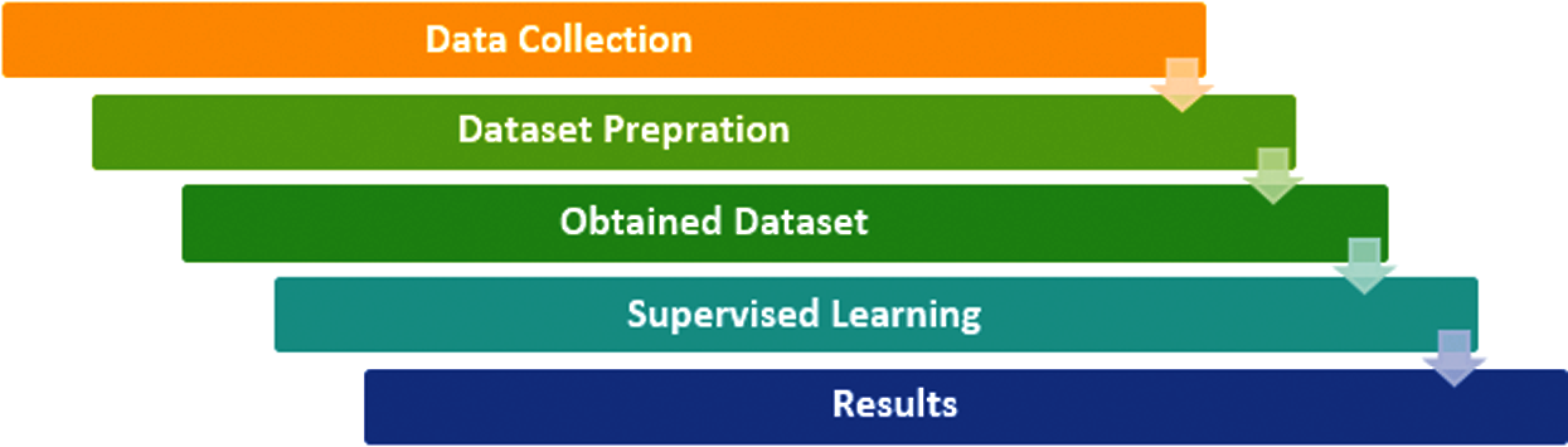
Figure 1: Proposed model
The data were collected from the SATP, which launched in March of 2000. The SATP is the largest comprehensive, searchable and continually updated database on terrorism, low-intensity warfare, and ethnic/communal/sectarian strife in South Asia. The project is the initiative of the Institute for conflict management (ICM). The ICM provides consultancy services on terrorism and internal security to various governments. It was established in 1997 in New Delhi, India, and was registered as a non-profit, non-governmental organisation supported by voluntary contributions and project aid [10]. SATP has data of 479 suicide bomb blast incidents from 2002 to 2018. Tab. 2 contains sample data of the first five suicide bomb blasts in 2017.
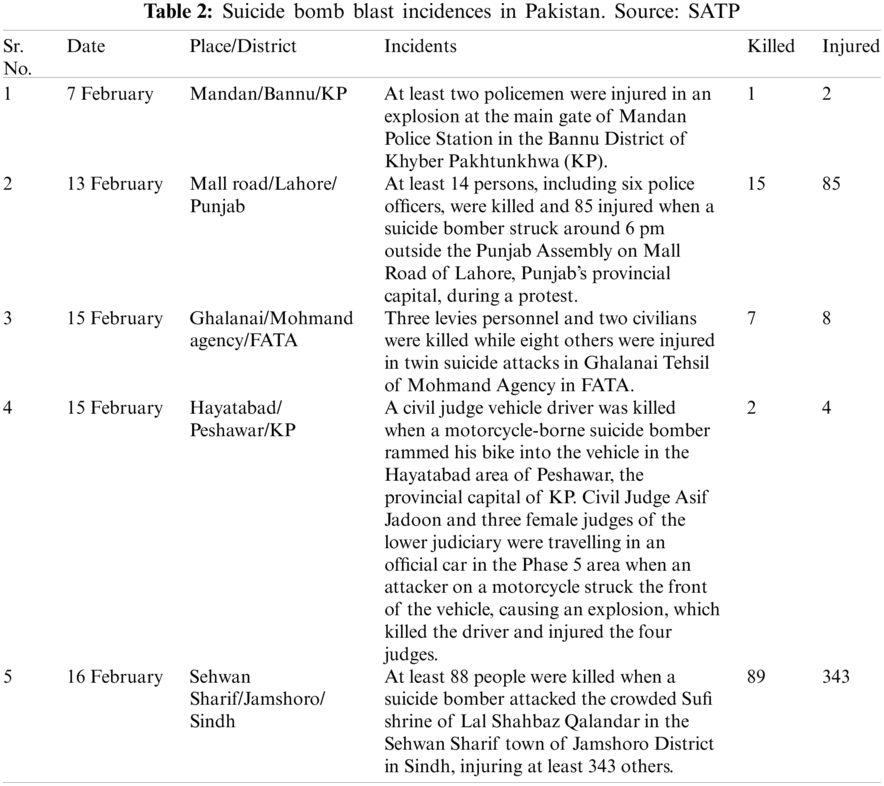
There were four steps to the dataset preparation phase, all of which are shown in Fig. 2 and explained in further detail below.
The data’s initial investigation revealed that 479 suicide bombing incidents took place in Pakistan from 2002 to 2018. These incidents claimed the lives of more than 7,291 people, while 15,428 people were injured. The preliminary analysis indicated five attributes to the data: the year and date, the location (district), incident detail, number of people killed, and the number of people injured.
The dataset preparation was accomplished in four steps. The phases involved in the data preparation are illustrated in Fig. 2.

Figure 2: Steps involved in dataset preparation
3.2.3 Knowledge Discovery and Extracted Variables
After pre-processing, important behavioural information and attributes were identified and extracted from the available data. For example, the ‘selected date’ attribute provided a further valuable discovery: that the attacker chose specific days of the week for the attacks. Similarly, the chosen incident filed (alpha-numeric text) presented some novel and critical attributes, such as blast type, target type, and attack space, as illustrated in Fig. 3.
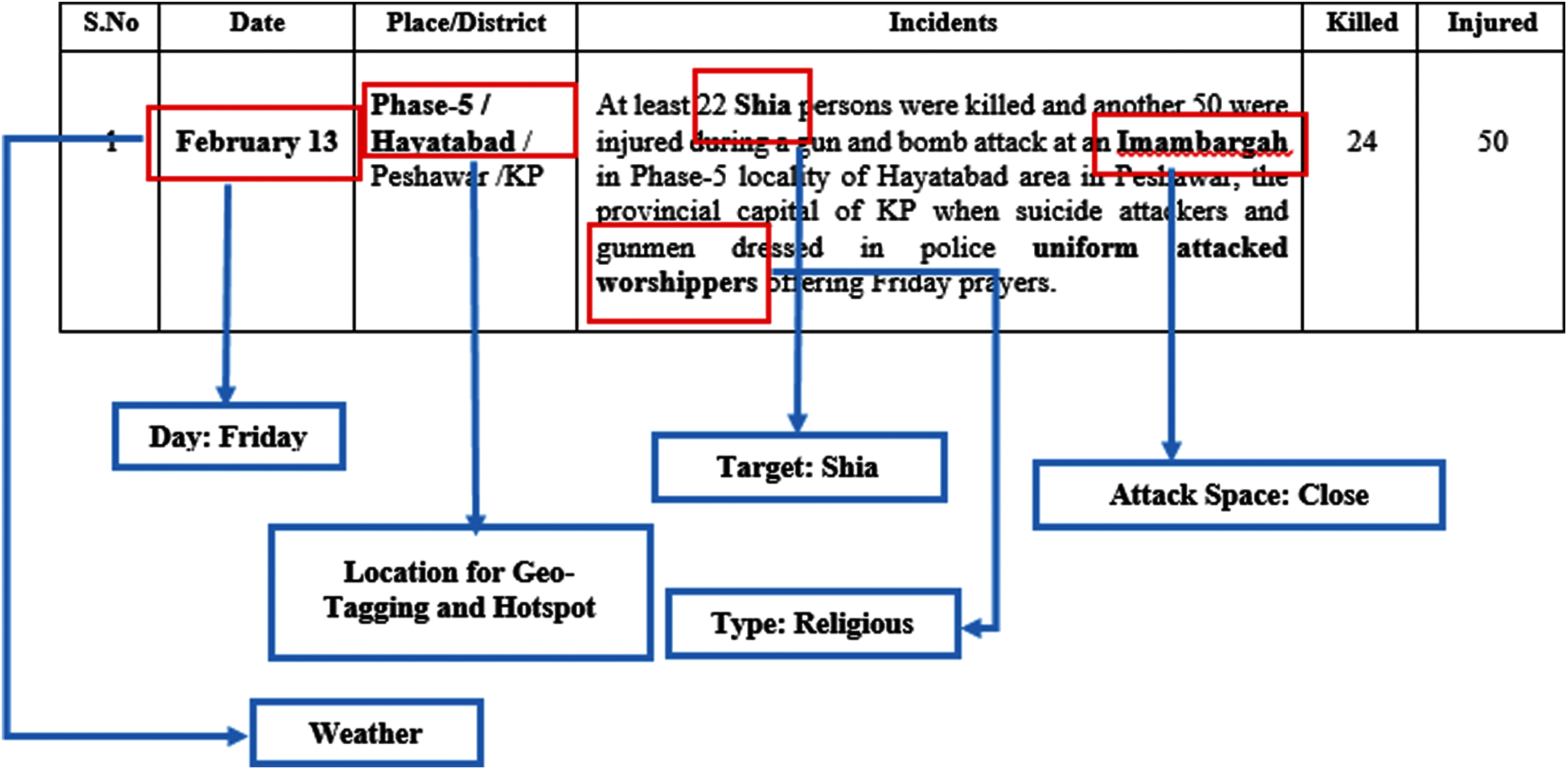
Figure 3: Novel attributes discovered in collected data
The behavioural attributes of the attacker were extracted from the dataset, as shown in Tab. 3.
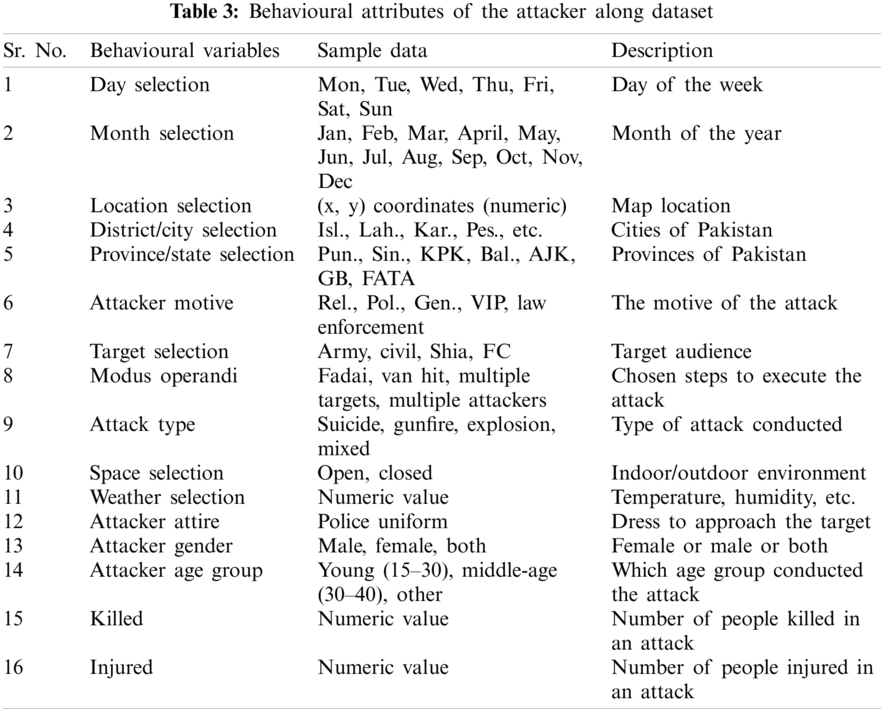
The data obtained via the SATP recorded 479 suicide bomb blasts. There were, however, missing values and duplication in the available data; thus, the obtained dataset includes 454 instances. The dataset’s most important attributes include the month, day, state/province, district/city, and blast type. Tab. 4 presents the preliminary analysis and complete detail of the obtained dataset.
Tab. 4 demonstrates some of the fundamental and most notable patterns from the dataset. The most critical days of the week in Pakistan are Friday, with weight 93, followed by Monday and Thursday with weights 81 and 78. November, December, February, and March are the most critical months, with weights of 47, 45, 51, and 45, respectively. KPK (Khyber Pakhtunkhwa), the third most populated province of Pakistan, is the most affected province, with 224 incidences recorded. This is followed by FATA (the territory that has now been merged with KPK), with 79 incidences recorded, and Punjab (the most populated province of Pakistan), with 63 incidences reported. The most affected city is Peshawar (capital of the province KPK) with 69 blasts, followed by Quetta (capital of the province Baluchistan) with 40 blasts, and Karachi (the most populated city and economic hub of Pakistan with a seaport; the capital of the province Sindh) with 27 blasts. Variable blast type represents the main agenda or motive (for instance, political or religious) of the attack. The most recorded blast type is ‘Law_Enf’, the forces that maintain law and order in the country. These forces were the prime targets of the suicide bomb blasts, with a count of 219. These blasts also claimed a further 165 and 43 lives by targeting the general public and religious ceremonies.
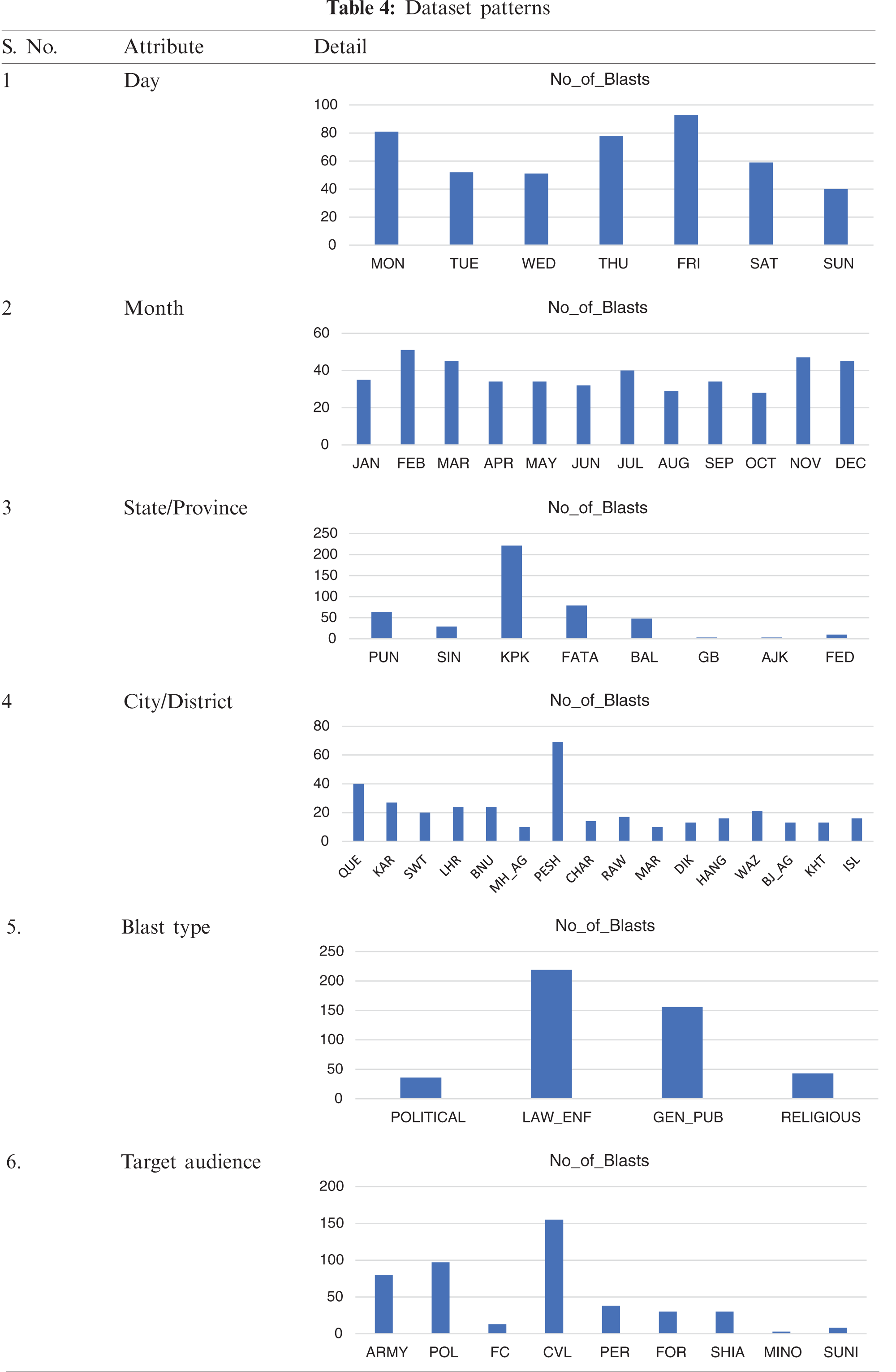
The dataset contains nine labelled classes. Each class represents a particular target audience of a suicide blast in which an instance belongs. These nine labelled classes are ARMY (Pakistan Armed Forces), POL (police), FC (Frontier Core, which is the core of the Pakistan Army), CVL (civilians), PER (personalities), FOR (armed forces, such as Khasadar Force and the Military Police, which is appointed to protect Pakistan’s borders and primarily tribal areas), SHIA (the second biggest religious sect in Pakistan), MINO (minorities, such as Christians, Sikhs, etc.) and SUNI (the most prominent religious sect in Pakistan). The most recorded class is civilians with a count of 155, followed by police and the Pakistan Armed Forces with the counts of 90 and 87, respectively. For this study, the dataset has been divided into 75% of the training set (339 instances) and 25% of the testing set (115 instances).
Supervised and unsupervised learning are the two main branches of ML. SL is still the most esteemed branch of pattern recognition in the ML field [19]. Supervised machine learning, also called the classification learning approach, is used for analysing training or labelled data to map unseen instances of data for future classification. Features extracted from recognition units train a classifier that learns to differentiate between different pattern classes [20]. SL techniques require a sufficient amount of labelled training data for classification or to label unseen test data [21].
Conversely, DL, which recently emerged from ANNs, requires minimal engineering by hand and can thus take advantage of an increase in the amount of available computation and data compared with classical ML techniques and external neural networks [22]. The results generated by the SL approach are discussed in the next section.
WEKATM (the Waikato Environment for Knowledge Analysis) version 3.8.4, considered one of the most efficient ML and data mining tools, was used to determine the overall efficiency of the proposed method and dataset. Different algorithms are available for SL, including Bayes, Function, Lazy, Meta, Rules, Tree, etc. In this study, the proposed technique and dataset’s efficiency was demonstrated using different, widely used algorithms; nevertheless, results could also be generated using other SL algorithms.
The Bayesian network consists of a structural model and a set of conditional probabilities. Bayesian-based algorithms are often used for classification problems in which learning is done by constructing a classifier from a set of training instances with labelled classes [23,24]. Bayes algorithms are simple, supervised probabilistic classifier algorithms [21] used for binary or multiclass classification based on Bayes’ theorem.
The NB algorithm is a simple supervised probabilistic classifier algorithm used for binary or multiclass classification. This algorithm is highly scalable.
In Bayes’ theorem, the probability of a hypothesis (h) given data (D) can be expressed as:
From Eqs. (1) and (2), we get:
Bayes’ theorem can be defined as:
Using Eq. (3),
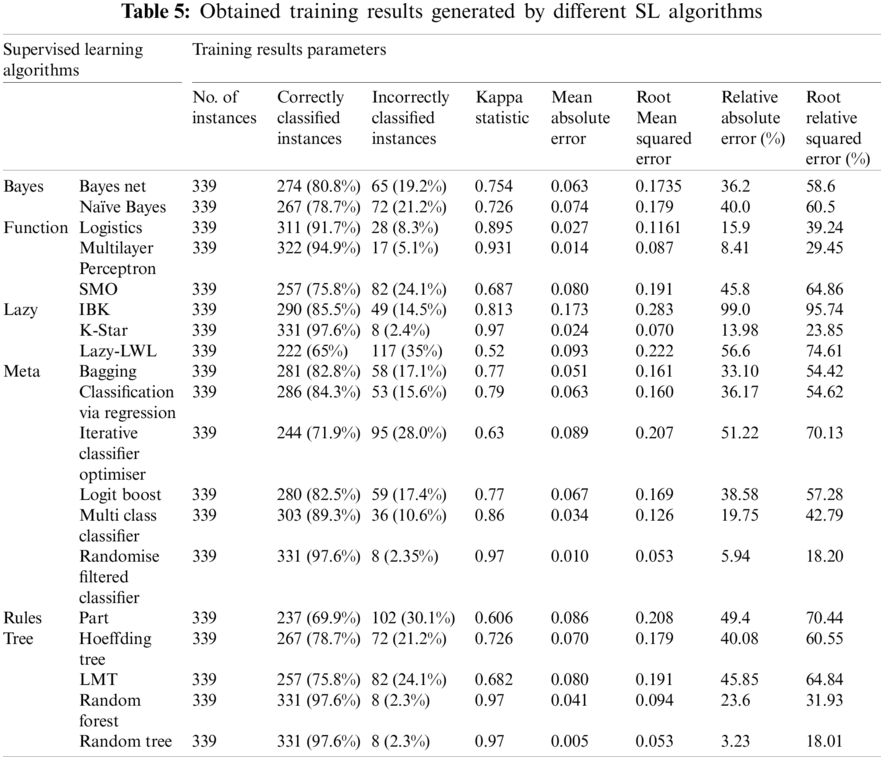
NB algorithms, alongside other SL algorithms, generated the training results, as shown in Tab. 5. This study’s primary objective is to train the system to classify different alphabets and characters and their different writing styles into accurate classes. It is suitable to use information retrieval measures to evaluate the overall accuracy of the proposed system. The two main information retrieval measures are break-even points and the F-score. The F-score measures the effect of a system’s performance on a particular class, whereas the break-even point is a value where precision and recall become equal: it is not, therefore, a good indicator of classification performance. However, accuracy is a valid parameter to measure the system’s overall performance [19]. The measures of F-score and accuracy are illustrated below:
True positive (Tp) = No. of characters correctly classified to the class
True negative (Tn) = No. of characters correctly rejected to the class
False positive (Fp) = No. of characters incorrectly rejected to the class
False negative (Fn) = No. of characters incorrectly classified to the class
By using the terms mentioned above, we can generate measurement factors as:
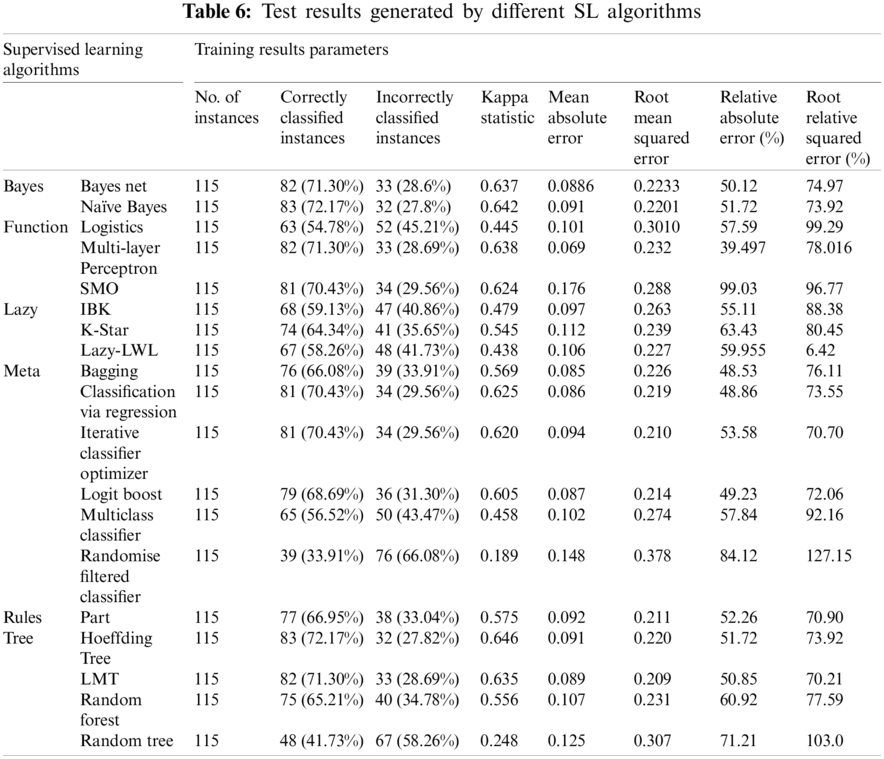
Some classes are not shown in Tabs. 6 and 7, such as F1–1 and F8–2, depicting that the instances belonging to these classes are part of the test set (i.e., the training set and test set are not overlapping). The precise accuracy by level using the NB algorithm is illustrated in Tab. 6.
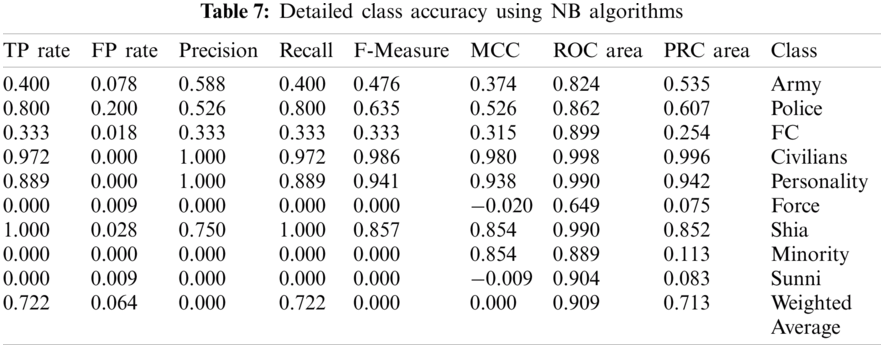
Figure 4: Training results using NB algorithm
The training results generated by the NB algorithm are shown in Fig. 4 as a sample. Tab. 6 presents the comparison of results obtained using the different supervised algorithms, and Tab. 7 demonstrates the detailed accuracy by class using the NB algorithm.
Different algorithms, such as NB, SMO, and the Hoeffding Tree, gave accuracies of 72.17%, 71.30%, and 72.17%, respectively. Other SL algorithms, such as LMT, Logit Boost and Iterative Classifier Optimiser, also show promising results. These results can help predict a specific class of people who may become victims of suicide bomb blasts. With the help of simple variables, including the day, month, province, and city, the target can be predicted, allowing for the prevention of these attacks altogether or, at least, minimising the casualty rates and damages. In the future, establishing more information about the impact of suicide bombing would be useful for developing proficient datasets and improving the exactness of results.
Furthermore, more variables can be introduced for accurate predictions. Results can also be generated using different SL classifiers and algorithms and JRip, OneR, WAODE, etc. Criminal and suicide attacker profiling could be accomplished if the data are available, and an accurate target audience of a suicide bomb blast can be achieved using SL classifiers. Indeed, SL classifiers (e.g., NB and SMO) are generating significant results. The present study helps predict the target class of the suicide blast, which would aim to prevent or reduce the impact of damages, including casualties and loss of properties.
The ontology will be developed to explain concepts of behavioural aspects in the terrorism domain for machines, law enforcement personnel and researchers. An ontology is an explicit specification of a conceptualisation [25]. The ontology of the terrorism domain will focus on concepts, relationships, and mapping by observing specific standards and principles. ML and data mining techniques will be used to predict and classify the incidents and groups’ involvement on the basis of features extracted from the dataset using this domain ontology.
Acknowledgement: Thanks to our families and colleagues, who supported us morally.
Funding Statement:The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |