
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Comparison among Classical, Probabilistic and Quantum Algorithms for Hamiltonian Cycle Problem
1 Computer Science Department, Università di Torino, Torino, Italy
2 Computer Science Department, ITIS Avogadro Serale, Torino, Italy
3 Computer Engineering Department (DII), Università Degli Studi di Pisa, Pisa, 56122, Italy
4 Justonearth SRL, Roma, 00168, Italy
5 Physics Deparment E.Fermi, Università Degli Studi di Pisa, Pisa, 56127, Italy
* Corresponding Author: Giuseppe Corrente. Email:
Journal of Quantum Computing 2023, 5, 55-70. https://doi.org/10.32604/jqc.2023.044786
Received 09 August 2023; Accepted 02 November 2023; Issue published 14 December 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The Hamiltonian cycle problem (HCP), which is an NP-complete problem, consists of having a graph G with nodes and m edges and finding the path that connects each node exactly once. In this paper we compare some algorithms to solve a Hamiltonian cycle problem, using different models of computations and especially the probabilistic and quantum ones. Starting from the classical probabilistic approach of random walks, we take a step to the quantum direction by involving an ad hoc designed Quantum Turing Machine (QTM), which can be a useful conceptual project tool for quantum algorithms. Introducing several constraints to the graphs, our analysis leads to not-exponential speedup improvements to the best-known algorithms. In particular, the results are based on bounded degree graphs (graphs with nodes having a maximum number of edges) and graphs with the right limited number of nodes and edges to allow them to outperform the other algorithms.Keywords
A Hamiltonian cycle is a cycle in an undirected or directed graph that visits each vertex exactly once. Hamiltonian cycle problem (HCP) is the problem to determine if a Hamiltonian cycle exists in a given graph.
HCP is in NP, and precisely it is NP-complete. Shortly, the first proposition indicates that while it is almost impossible to find an efficient solution for HCP, it is straight in polynomial, often linear, complexity time to control if a given item is a solution or not. Obviously, generating and checking all possible solutions to find a correct one has exponential time complexity, and it is very difficult to obtain with little error margin a solution for them in another way, heuristics for example.
NP-complete problems are a class of decision problems within NP for which any other problem in NP can be reduced to them in polynomial time. In other words, if you could solve any NP-complete problem in polynomial time, you could solve all problems in NP in polynomial time. Therefore, a polynomial solution, more precisely an exact solution, given to HCP in its general formulation, would imply that
A simple deterministic solution to the HPC, for example, is the following: given a Graph with N vertices, generate all permutation of its vertices which begin with 1, and this phase has complexity
So, the whole complexity is
In the simplest scenarios, that involve small graphs, this class of solutions is broadly used [2,3]. With larger graphs, though, a deterministic approach is computationally infeasible. Therefore, probabilistic and quantum algorithms come into play [4]; they do not guarantee finding a Hamiltonian cycle if one exists, but they can be effective in practice. In fact, the trade-off is between computational time, and the quality of the solution; these methods can provide reasonably good solutions within a reasonable time frame for many real-world instances of the HCP. The algorithms also differ by the class of graphs they are appliable to, because some of them are designed to give better solutions on HCP graph models with several constraints (such as the degree of nodes) than the ones that work on every graph. We will see some of these approaches in the Related Works section.
Overall, in this article, we compare the most relevant algorithms and results between them and with others designed by ourselves, using HCP as a benchmark and a hint to compare different approaches and models of computation.
We know [5] that for the sparse locally connected graphs, HCP is solvable in polynomial complexity time. Sparse locally connected graphs are graphs for which
In [7], they designed a distributed algorithm that with high probability computes a Hamiltonian cycle in a random graph
Another way to use probability in HCP solutions is to consider random walks in graphs. This type of research implies to construct a geometric polytope based on the graph to be examined, and using its extreme points, meaning points that do not lie in any open line segment joining two points, as starting point to analyze. Very positive experimental results were shown in [8] by using this type of approach.
In [9], they showed a quantum computing model in which Hadamard gates are used to obtain all permutations of vertices in a superposition way. Then the Grover algorithm is applied to search for an eventual Hamiltonian cycle. So, in [9], the authors solved HCP for a general graph with high probability, but only a quadratic speedup is obtained compared to the deterministic model of searching classically among all possible solutions. The complexity time of this solution remains exponential.
As they showed in [10], for an adiabatic quantum computing model, it is possible to use a particular methodology to obtain some code effectively testable on an existing prototype, the so-known D-Wave. They map the Hamiltonian cycle problem in QUBO problem, the mathematical algorithm for which D-Wave is designed. However, they did not observe an exponential speed-up over the number of nodes of the graph. They also underline problems with noise preparing and testing their examples.
Another quantum information technique for graph algorithms is quantum random walks. For example, in [11] quantum random walks were described for very particular graphs, such as hypercubes and a few tree-based graphs. However, using quantum walks for a generic graph was proved impossible [12].
Based on all these results, we reached the conclusion that very significant results in computational time are reached by restricting the graph classes on the problem instances.
The brute force algorithm presented in the introduction has a time-complexity of
In addition, many heuristics and strategic approaches exist for TSP, such as Ant Colony Optimization Algorithm, Particle Swarm Optimization Algorithm, Artificial Bee Colony Algorithm and recently Genetic Algorithm [15,16], but they do not find the exact solution efficiently; they only search for one solution near to the optimal. Alternatively, also for TSP, as for HCP, quantum annealing algorithms have been proposed [17–19], but they still have too many limitations regarding noise and number of nodes of the graph that have to be elaborated [17].
In the following sections we will present our proposed probabilistic and quantum algorithms.
3 Methods and Algorithms Design
3.1 A Probabilistic Approach for HCP
Using a random walk approach on a graph G, we consider a memory-less path in which, if at the
Then we show:
1. // Legend:
2. // Node is the class of every node
3. //
4. //
5. //
6. //
7. //
8. //
9. // chooseRandomNode() is the function that takes a node and returns the next one according to our approach
10. // getRandom() is a function that returns a random index in an array with a weight based on its values (in this // case the probability)
11.
12. Node chooseRandomNode(Node
13. float probabilityArray[
14. for (i = 0; i <
15. if (
16. probabilityArray[i] =
17. }
18. else {
19. probabilityArray[i] = 0;
20. }
21. }
22. int randomIndex = getRandom(probabilityArray);
23. return
24. }
25.
26. int main() {
27.
28. for (t = 1; (t < n &&
29.
30. if (t == n && (vt, v1) == 1){
31. printf(“(v1, v2, …., vn, v1) is an Hamiltonian cycle for G”);
32. break;
33. }
34.
35. }
36.
37. return 0;
Follows:
Theorem 1. Consider a random walk on a graph G starting at node v1 that follows the stop conditions stated in the above algorithm. Let
Proof. The first part is simple to prove. If the condition in line 30 in the algorithm above is true, we have arrived at the
We now prove the second statement of our theorem. It simply follows from the relative marking rule (line 29) of the algorithm above. The probability is calculated as product of independent events probabilities. Our algorithm’s iteration steps depend on one another. Still, this dependence is already implicit in the term
Corollary 1. Considering the rate of success of our algorithm for each Hamiltonian cycle in the graph, and given that each random walk is
where, for the sake of simplicity we chose
Furthermore, if L is a lower bound to the number of Hamiltonian cycles of
Proof. Given
We have designed in such way a probabilistic algorithm that, with high probability, solves for a generic graph G with a better time complexity than classical brute-force deterministic algorithm presented in the introduction assuming simply that:
However, we remain in an exponential time complexity.
Comparing our algorithm to the quantum computational search algorithm shown in [9], we also can do better but only with the following stronger assumption:
We are not discussing here the advantage of decreasing the degree from
Furthermore, to outperform respectively the best-known classical [13] and quantum [14] algorithm for HCP, the following conditions must be true:
3.2 The Quantum Version of Our Probabilistic Algorithm
In this chapter, we show a few quantum versions of our algorithms in a QTM format, as we already did for some known algorithm in [20].
We give the following definition of a Quantum Turing Machine [20,21].
A Quantum Turing Machine (QTM for short) M can be seen as the quantum version of a Turing Machine, usually described by the 7-tuple
■ Q is the (finite) set of internal states {
■
■
■
■ F (a subset of
Here we itemize other relevant features:
■ A tape is a pair of strings
■
■ A configuration of M is a triple in
■ The initial configuration is represented as
■ A final configuration is
A QTM-computation [15] is a (finite) set of configurations
Consequently, for each configuration
where
Note that after the first step, the starting configuration
We now want to give a quantum version of our algorithm.
We start with the definition of the following QTM:
■
■
■
■
Each symbol refers to the previous generic definition of a QTM, H and
Note that with this definition each cell of the tape may contain not only a single symbol and their superposition, but also partial or full paths of the graph and their superposition.
Then, we define
where
Let
And finally:
In Eq. (20), f returns H only if
Now a measure on the input tape, precisely in the cell relative to the cursor position, that is the
Function
When it is not possible, f writes the
The probability of finding H as a result, given the previously defined f, is greater than zero only if the graph is Hamiltonian. In this case, a read operation on the whole tape would result in a Hamiltonian cycle.
Theorem 2. The probability of a hit result in the final measure for the above quantum algorithm is:
Proof. Indeed, the time of evolution of our algorithm, if we exclude the latest step, the measurement, is exactly
Corollary 2. The complexity of the above quantum algorithm derives from the repeated number of its executions and measure operations. This must be proportional to the inverse of the probability given in Theorem 2.
Corollary 3. The complexity of the probabilistic and quantum algorithms of Theorem 1 and Theorem 2 respectively are the same.
This follows from what is stated in [22], when quantum computation is not used with all or a large part of its features, often the respective algorithms do not perform computationally faster than probabilistic ones for a similar problem. More in general, we can say that in order to obtain a quantum advantage, it is necessary to rely on purely quantum features rather than trying to replicate a classical version of our problem within a quantum framework.
3.3 A Quantum Interference-Based Algorithm for HCP
If we want a better result, we may relax some QTM conditions and admit the following modification to the last rules Eqs. (20) and (21), substituting them with the following ones:
where
Due to Eqs. (23)–(25), if we read the symbol
The presence of negative interference allows us to access more paths and, if the graph is Hamiltonian, the result of measurement is H with higher probability. Consequently, the complexity of our algorithm is better than the one from the previous algorithm version.
Theorem 3. The time complexity of the algorithm with the new rules Eqs. (23)–(25) instead of Eqs. (20) and (21) is:
Proof. The
Consequently, we can derive Eq. (26) from our definition of
So, we have a quadratic speedup, the same obtained applying to our algorithm a quantum search of Grover type [22–24], for example in a similar manner that in [9].
Now we explain better the oracle function of our quantum algorithm.
Note that, given that
where as in the non-quantum case,
If all the neighbors of i have been visited, and if the length of the path is less then n (number of G nodes) or there is no edge
On the left-hand side of Fig. 1, we can see a graph G with two partial paths in superposition. We suppose
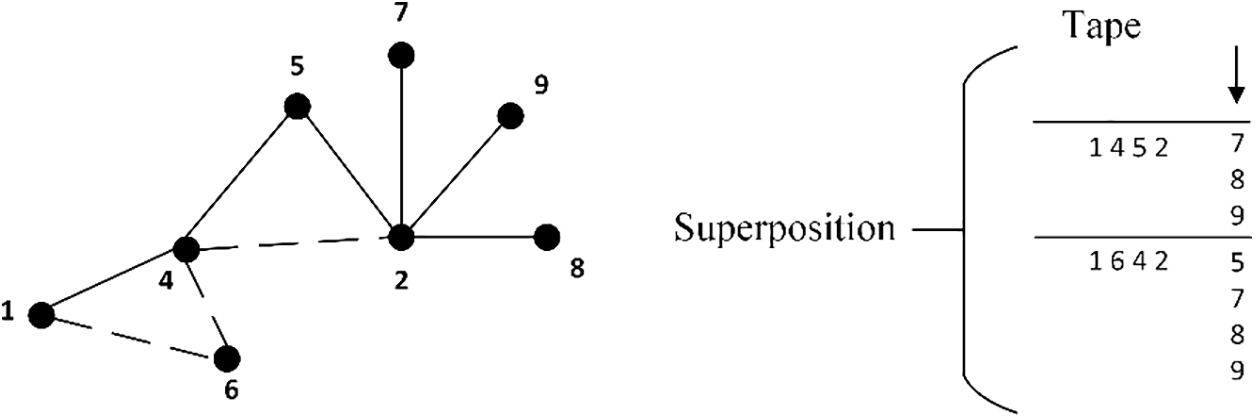
Figure 1: An example of superposition of two visited paths in a part of the graph G and on the tape, and of the next node choice. Three possible choices are added to the first path and four to the second. The resulting superposition of seven paths is the result of this choice
On the right-hand side of Fig. 1, we consider the two possible partial paths:
All these paths are possible, then they are in superposition. The chosen one will be overwritten on the tape, each weighted with their appropriate amplitude. At each phase, the path length of all superposition paths will be the same. If a path terminates before visiting all possible nodes, from the rules derives that the terminating positions will be filled with the
The oracle function
In Fig. 2, we show an overview of all the algorithms, classic, probabilistic and quantum ones, shown schematically in Table 1. On the y-axis we represent the expected execution time steps in logarithmic scale. On the x-axis we represent the number of nodes. The first thing that catches the eye is that the classical algorithms can all be over-performed in terms of time complexity by the quantum ones. The brute force classical algorithm (b-f classic) is better than our classical algorithm only for the maximum degree graph class; while obviously the brute force quantum algorithm (b-f quantum) is always better than b-f classic labelled algorithm, this latter being the brute force algorithm that analyzes classically all the possible permutations of the G vertices. B-f quantum is a quantum search-based algorithm that works on all possible permutations; it can be over-performed by our probabilistic algorithm applied to graphs whose degree is limited by the base-ten logarithm of the number of nodes (our d-log10) and obviously by our quantum version with the same graphs class (q-our d-log10).
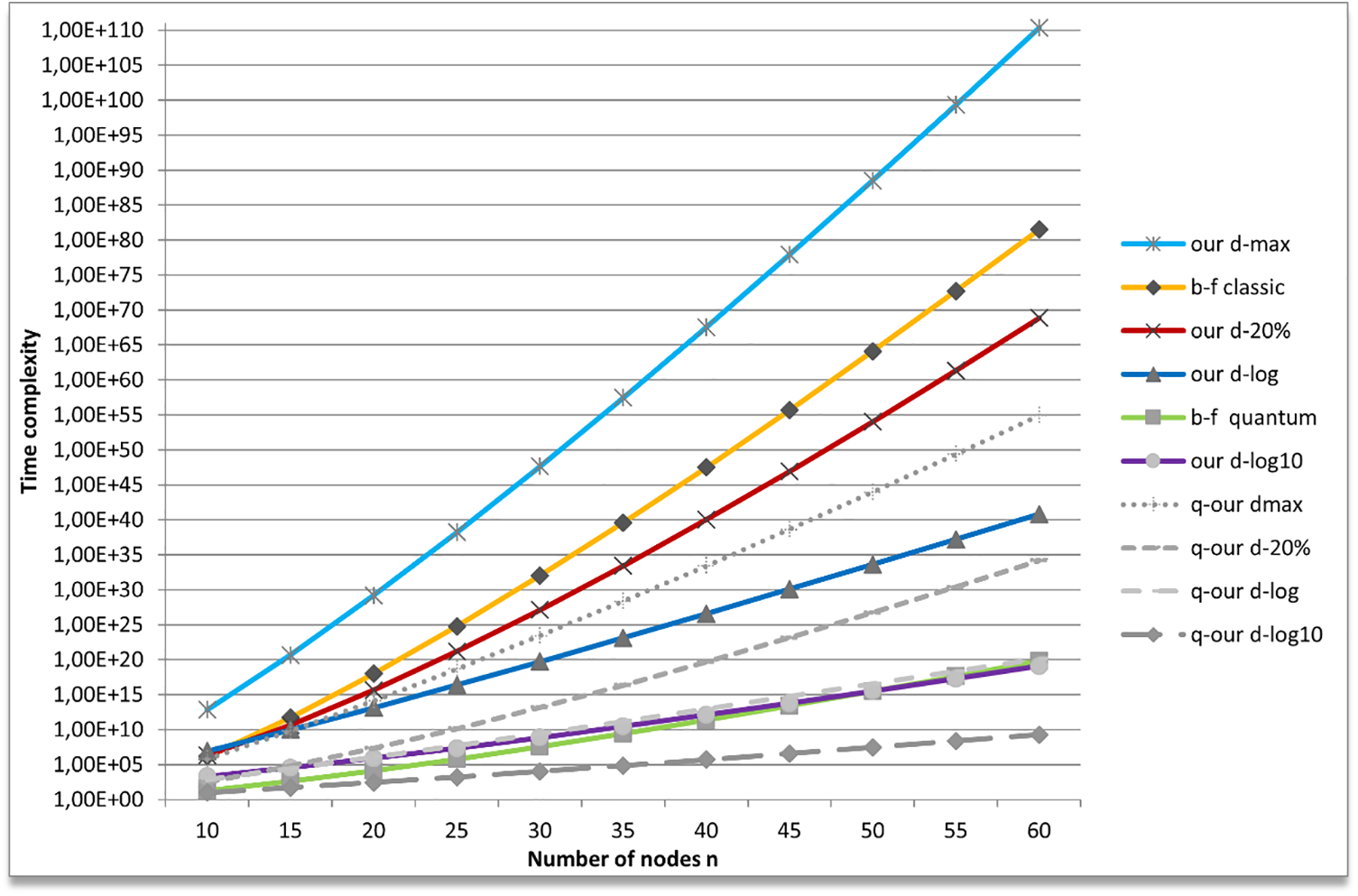
Figure 2: Comparison between our probabilistic algorithm and different quantum and brute force algorithms

Following the same criteria, with the labels our d−20% and our d-log, we represent time complexity of our algorithm with parameter d, the maximum degree of the graph nodes, given as limited respectively to the
In Fig. 3, we compare our algorithms with best classical and best quantum known algorithms, respectively indicated with labels best cl and best q. These are over-performed only by the quantum version of our algorithm. Indeed, Figs. 2 and 3 show that only our quantum algorithm applied to base-ten logarithm limited degree graph class, labelled q-our d-log10, among those examined, is better than best classical and quantum known algorithms.
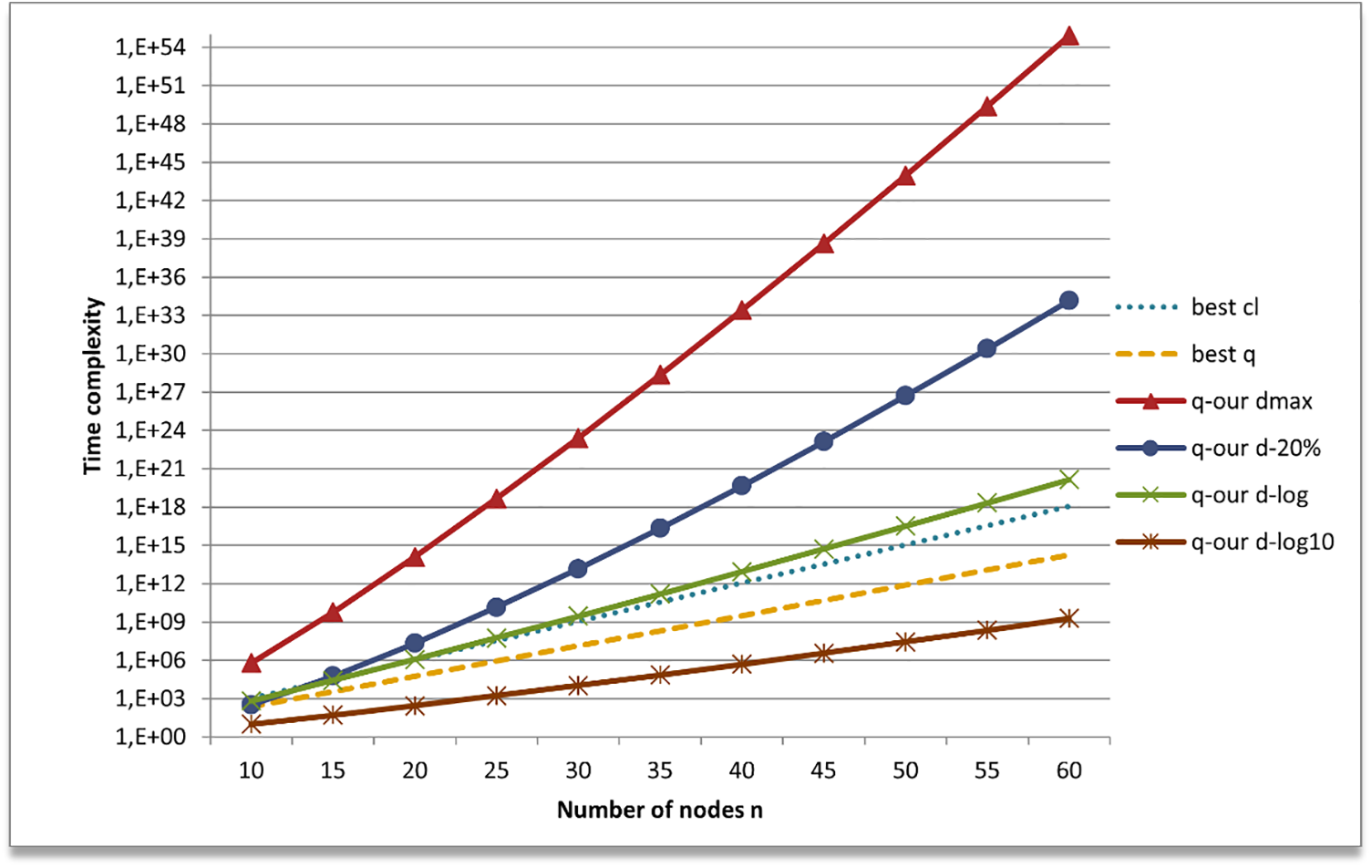
Figure 3: Comparison between our probabilistic quantum algorithm and the best-known classic and quantum ones
Moreover, if we limit n to a few hundreds, our quantum algorithm can achieve the same time complexity of q-our d-log10 for every class of graph following this relation:
while our algorithm performs better than best known algorithms also for n that tends to infinity if
We have designed and analyzed a probabilistic algorithm for a Hamiltonian Cycle Problem (HCP), even if without obtaining for the general case a relevant improvement. We also designed two quantum versions of our algorithm, respectively without and with negative interference added. We compared them, the latter in particular, with a classical and a quantum algorithm. In this case, for some classes of graphs, for example, the upper bounded degree graphs, with the assumption of the validity of Eq. (31), our algorithm performs better. It outperforms not only the quantum algorithm based on Grover searches on all permutations, but also the best classical and quantum already known algorithms for HCP.
Anyway, we can obtain a quadratic speedup with our quantum algorithm with respect to the classic version of it, only if we use also quantum negative interference and not only quantum superposition.
An interesting aspect arising from this work is the possibility of comparing probabilistic with quantum computational models. Indeed, this work can also be seen as a hybrid approach combining quantum and probabilistic elements. Also, it is worth deepening our knowledge of our version of a QTM, as it is a valid tool for algorithm design. Further studies should be done to compare our algorithm with that written specifically for graphs of bounded average degree, for example those in [25,26].
Another theme that emerges from this work is the exploration of other NP problems and determining under what conditions, with constraints on the original problem or extensions of the quantum model, they become tractable.
Acknowledgement: Author Vittoria Stanzione acknowledges the support of the project PNRR-HPC, Big Data and Quantum Computing–CN1 Spoke 10, CUP I53C22000690001.
Funding Statement: This work received the funding from the project PNRR-HPC, Big Data and Quantum Computing–CN1 Spoke 10, CUP I53C22000690001.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Giuseppe Corrente; algorithms design and refinement: Giuseppe Corrente, Carlo Vincenzo Stanzione, Vittoria Stanzione; analysis and interpretation of results: Giuseppe Corrente, Carlo Vincenzo Stanzione, Vittoria Stanzione; draft manuscript preparation: Giuseppe Corrente, Carlo Vincenzo Stanzione, Vittoria Stanzione. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. J. Dutka, “The early history of the factorial function,” Archive for History of Exact Sciences, vol. 43, pp. 225–249, 1991. [Google Scholar]
2. E. L. Altschuler, M. Lades and R. Stong, “Finding Hamiltonian cycles,” Science, vol. 273, pp. 413–415, 1996. [Google Scholar]
3. P. Baniasadi, V. Ejov, J. A. Filar, M. Haythorpe and S. Rossomakhine, “Deterministic “Snakes and ladders” heuristic for the Hamiltonian cycle problem,” Mathematical Programming Computation, vol. 6, pp. 55–75, 2014. [Google Scholar]
4. A. Mahasinghe, R. Hua, M. J. Dinneen and R. Goyal, “Solving the Hamiltonian cycle problem using a quantum computer,” in Proc. of the Australasian Computer Science Week Multiconf. (ACSW’19), New York, NY, USA, Association for Computing Machinery, pp. 1–9, 2019. [Google Scholar]
5. A. S. van Aardt, A. P. Burger, M. Frick, C. Thomassen and P. de Wet, “Hamilton cycles in sparse locally connected graphs,” Discrete Applied Mathematics, vol. 257, pp. 276–288, 2019. [Google Scholar]
6. M. Haythorpe, “On the minimum number of Hamiltonian cycles in regular graphs,” Experimental Mathematics, vol. 27, no. 4, pp. 426–430, 2018. [Google Scholar]
7. V. Turau, “A distributed algorithm for finding Hamiltonian cycles in random graphs in O(logn) time,” Theoretical Computer Science, vol. 846, pp. 61–74, 2020. [Google Scholar]
8. T. Kalinowski and S. Mohammadian, “Feasible bases for a polytope related to the hamilton cycle problem,” arXiv preprint arXiv:1907.12691, 2019. [Google Scholar]
9. V. C. Raj and M. S. Shivakumar, “Applying quantum algorithm to speed up the solution of Hamiltonian cycle problems,” in IFIP TC12 Int. Conf. on Intelligent Information Processing, Boston, Springer, vol. 228, pp. 53–61, 2006. [Google Scholar]
10. A. Mahasinghe, R. Hua, M. J. Dinneen and R. Goyal, “Solving the Hamiltonian cycle problem using a quantum computer,” in Proc. of the Australasian Computer Science Week Multiconference, pp. 1–9, 2019. https://doi.org/10.1145/3290688.3290703 [Google Scholar] [CrossRef]
11. S. E. Venegas-Andraca, “Quantum walks: A comprehensive review,” Quantum Information Processing, vol. 11, pp. 1015–1106, 2012. [Google Scholar]
12. A. Glos and J. A. Miszczak, “The role of quantum correlations in Cop and Robber game,” Quantum Studies: Mathematics and Foundations, vol. 6, no. 1, pp. 15–26, 2019. [Google Scholar]
13. M. Held and R. Karp, “A dynamic programming approach to sequencing problems,” Journal of SIAM, vol. 10, pp. 196–210, 1962. [Google Scholar]
14. A. Amabainis, K. Balodis, J. Iraids, M. Kokainis and J. Vihrovs, “Quantum speedups for exponential-time dynamic programming algorithms,” 2018. https://doi.org/10.48550/arXiv.1807.05209 [Google Scholar] [CrossRef]
15. T. Kaur, A. K. Lamba and R. Talwar, “A review: Optimized solutions for travelling sales person problem,” International Journal of Engineering Trends and Applications (IJETA), vol. 8, no. 3, pp. 36–40, 2021. [Google Scholar]
16. C. Dahiya and S. Sangwan, “Literature review on travelling salesman problem,” International Journal of Research, vol. 5, no. 16, pp. 1152–1155, 2018. [Google Scholar]
17. S. Jain, “Solving the traveling salesman problem on the D-wave quantum computer,” Frontiers in Physics-Quantum Engineering and Technology, vol. 9, pp. 760783, 2021. https://doi.org/10.3389/fphy.2021.760783 [Google Scholar] [CrossRef]
18. R. H. Warren, “Solving the traveling salesman problem on a quantum annealer,” SN Applied Sciences, vol. 2, pp. 75, 2020. [Google Scholar]
19. E. Stogiannos, C. Papalitsas and T. Andronikos, “Experimental analysis of quantum annealers and hybrid solvers using benchmark optimization problems,” Mathematics, vol. 10, pp. 1294, 2022. [Google Scholar]
20. G. Corrente, “Translation of quantum circuits into quantum turing machines for Deutsch and Deutsch-Jozsa problems,” Journal of Quantum Computing, vol. 2, no. 3, pp. 137–145, 2020. [Google Scholar]
21. S. Guerrini, S. Martini and A. Masini, “Quantum turing machines: Computations and measurements,” Applied Sciences, vol. 10, pp. 5551, 2020. [Google Scholar]
22. J. Gruska, “Algorithms,” in Quantum Computing. USA: McGraw-Hill, pp. 101–148, 1999. [Google Scholar]
23. G. Corrente, “Reflections on probabilistic compared to quantum computational devices,” International Journal of Parallel, Emergent and Distributed Systems, pp. 251–261, 2020. https://doi.org/10.1080/17445760.2020.1805610 [Google Scholar] [CrossRef]
24. L. Grover, “A fast quantum mechanical algorithm for database search,” in Proc. of the Twenty-Eighth Annual ACM Symp. on Theory of Computing, pp. 212–219, 1996. https://doi.org/10.1145/237814.237866 [Google Scholar] [CrossRef]
25. M. Cygan and M. Pilipczuk, “Faster exponential-time algorithms in graphs of bounded degree,” Information and Computation, vol. 243, pp. 75–85, 2015. [Google Scholar]
26. M. Feldman, “Algorithms for bounded degree graphs,” in Algorithms for Big Data. Israel: The Open University of Israel, pp. 267–307, 2020. https://doi.org/10.1142/9789811204746_0012 [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools