
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Design and Implementation of Police Equipment Knowledge Query System
Department of Information Technology and Cyber Security, People’s Public Security University of China, Beijing, 102623, China
* Corresponding Author: Xin Li. Email:
Journal of Quantum Computing 2022, 4(2), 63-74. https://doi.org/10.32604/jqc.2022.027715
Received 25 January 2022; Accepted 23 March 2023; Issue published 16 May 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In the field of public security, the standardized use of police equipment can better assist the public security police in performing their duties. With the advancement of science and technology of the times, police equipment is also constantly developing, and more and more new types of police equipment have appeared. Nowadays, there are a large number and variety of police equipment, and public security police are facing the challenge of mastering and updating equipment knowledge. This article builds a knowledge base of police equipment based on the knowledge of opening source data on the Internet, uses a variety of databases to store knowledge, and presents knowledge of police equipment in the form of knowledge queries, innovatively applying the concept of knowledge base to police Knowledge of equipment in science. Knowledge is presented in three modules: encyclopedia knowledge, question answering knowledge, and product knowledge, which can answer the description questions and experience questions of police equipment. The query accuracy rate for the physical problems of police equipment is 70%, and the query accuracy rate of the experience problems of police equipment is 90%. The design and implementation of the system solves the problem of knowledge fusion in the field of police equipment in opening source data, and at the same time can help the police to sort out the knowledge structure of police equipment, fully understand the police equipment, and better serve public security Field related work.Keywords
In recent years, the anti-terrorism situation abroad has become increasingly serious, and violent and terrorist incidents have often been reported in some places. Similarly, in China, similar violent and terrorist incidents also happen occasionally, causing great harm to the society, the update and improvement of police equipment is playing an increasingly important role. In recent years, China’s police equipment production enterprises gradually increased, from the beginning of only a few types of police equipment to the development of all kinds of police equipment. With the continuous research and development of intelligent police equipment, the scale of police equipment in China has been expanding. Some manufacturers have developed many new equipment through emerging technologies such as biometrics, cloud computing and Internet of Things to meet the needs of domestic police [1].
In order to be able to better uphold order of security of the state, to prevent violence could events, security forces need to be able to skillfully use modern police technology and equipment to deal with emergency public safety emergency, so police equipment technology in the field of police information updating and timely grasp modern police equipment knowledge has become the issue in the field of public security police at present a problem. Constructing police equipment knowledge base and applying it in the way of equipment knowledge query can effectively help police to understand police equipment knowledge.
Knowledge mapping is a technical method that uses graph models to describe knowledge and help model the relationships between everything in the world. Knowledge graph is a computable model of entity relationship, which can be used to identify and discover the acquired data and deduce the complex relationship between entities and attributes. Knowledge mapping is widely used, including language understanding, semantic search, intelligent question answering, language understanding [2] and decision analysis. The construction of knowledge graph includes knowledge representation [3], graph database, natural language processing, machine learning and other technologies [4].
Knowledge graph aims to describe the relationship between entities in the real world, and is a form of representation that converts a large number of unstructured or semi-structured texts into structured knowledge through a series of operations such as entity extraction [5], attribute extraction and relationship extraction [6]. It can express a series of complex relationships in an intuitive and understandable form, which is similar to the relationship between the knowledge we humans store in the brain, and is more in line with human learning habits. The construction of knowledge graph can help people to sort out the knowledge structure and dig out the correlation between domain knowledge. According to the knowledge representation and knowledge reasoning of knowledge graph, the key points of knowledge can be learned systematically and efficiently from the massive and chaotic knowledge system [7]. The concept was first formally proposed by Google in May 2012, with the initial purpose of improving the search engine’s capabilities and improving users’ search experience. Now, with the development of artificial intelligence technology, knowledge graph technology has been widely used in intelligent search, intelligent question answering, personalized recommendation and other fields [8,9].
This chapter mainly introduces the construction of police equipment knowledge and police equipment knowledge query system implementation work, first introduced the system’s overall framework, then each step of the system is respectively, knowledge ontology construction is discussed in detail, knowledge extraction and knowledge storage, knowledge integration and query platform to build the implementation details.
The construction process of the Q&A system is shown in Fig. 1:
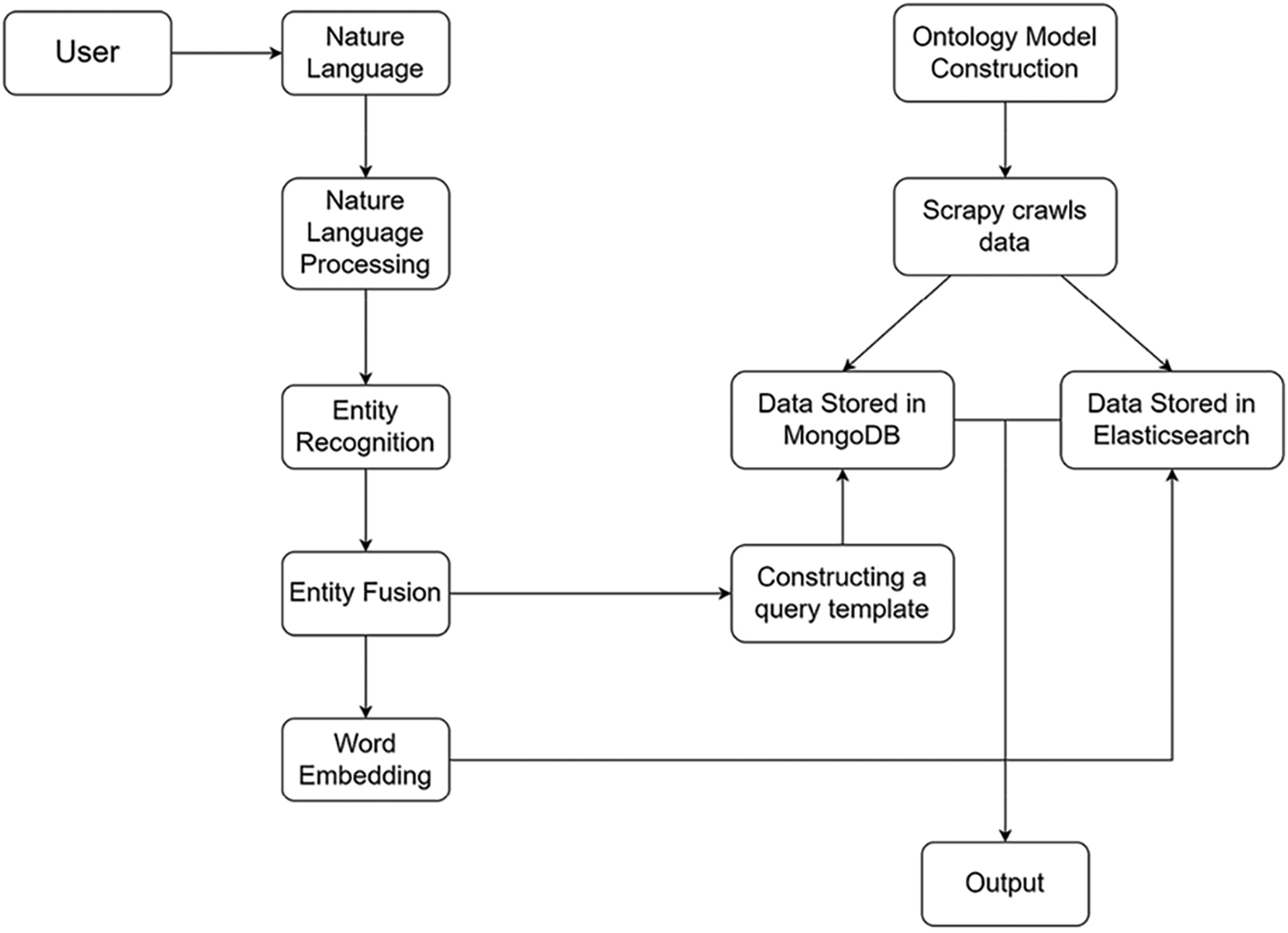
Figure 1: System construction process
The system is introduced from the perspective of foreground and background:
At the front desk interface, the user input in the search input box natural language questions, system will submit questions for background to natural language processing and knowledge reasoning, jump to the query results page, return to the three kinds of results, respectively is: the entity name and data related to the answer, and the input question the most relevant question and answer on the answer, and query equipment the most relevant equipment information [10].
In the background page, the system performs word segmentation and named entity recognition according to the natural language questions, divides the questions into words, and identifies the police equipment entities [11]. Then, syntactic dependency analysis is carried out to find out the dependency between named entities and attributes. According to the characteristic words and their relations of questions, the database query template statements constructed by rules are used to retrieve the results in the knowledge base of equipment encyclopedia. In order to ensure the accuracy of the returned results, this paper collected the question pairs data in Baidu know, matched the input questions with the question pairs, and returned the two answers with the highest similarity with the question pairs. At the end of the return result page, we recommend the equipment products according to the equipment entity names obtained from the previous entity recognition, and recommend the three most relevant equipment. In each recommendation, detailed description of the product is displayed, as well as detailed information about the manufacturer [12].
Knowledge base construction process:
Firstly, knowledge extraction is carried out. The system uses crawler to acquire the equipment encyclopedia knowledge, commodity knowledge and equipment-related question and answer knowledge from the opening source data of the Internet, and then cleans the obtained data and reprocesses it [13].
Secondly, knowledge fusion and storage. According to the knowledge characteristics of different data collected and the expected return form of search results [14], the system decided to build the police equipment knowledge base into three aspects: encyclopedic knowledge, question and answer knowledge and commodity knowledge. In this paper, the equipment encyclopedia knowledge is used for entity alignment, and the entity fusion is compared with the words with the same or close meaning of the entity and stored in the MongoDB database. Select * from ElasticSearch [15], select * from ElasticSearch, select * from ElasticSearch, select * from ElasticSearch. As for commodity knowledge, its data source is commodity data in the website of police equipment. As this data is presented in a structured form on the website, in data extraction, this paper will crawl the data directly according to the webpage display for structured storage, and each commodity entity has attributes and corresponding attribute values. The commodity data is cleaned and stored in MongoDB [16].
3.2 Ontology Construction of Police Equipment Domain
According to the process, the ontology of police equipment field is firstly constructed. The construction of ontology is a specification obtained by defining terms in ontology, attributes of entity concepts and constraints of attributes [17,18]. Ontology can be used to arrange hierarchical relations among concepts and determine clear knowledge structure, which is the core part of knowledge graph and the basis of knowledge graph construction [19]. Moreover, the knowledge base can be constructed by adding the exact attribute information and the instance of attribute constraint definition to the constructed ontology to avoid excessive redundancy and error.
In the field of police equipment, the knowledge type is relatively single and the definition of equipment attributes is relatively similar, so in the process of ontology modeling, artificial modeling is used to complete the description and definition of ontology and attributes in the field of police equipment. The object of application of this knowledge base is the police who use the police equipment. Considering the occasions that the police use the equipment, the effectiveness of the equipment and the nature of the equipment itself, the core concept of the police equipment is determined by combining the professional knowledge of the public security.
First of all, as shown in Fig. 2, according to the role of police equipment and effectiveness, it can be divided into the law enforcement eod equipment, protective equipment, security equipment, Anti-terrorism ChuTu, JiZhen equipment, communications equipment, anti-terrorism ChuTu equipment surveillance equipment, police, traffic police equipment, a total of nine categories under each equipment categories and subdivision of the variety of specific equipment in detail. For example, under the law enforcement equipment, there are batons, police pass, scene law enforcement recorder and other equipment. In the specific equipment category is its respective attributes, such as equipment role, equipment material, manufacturer, etc.
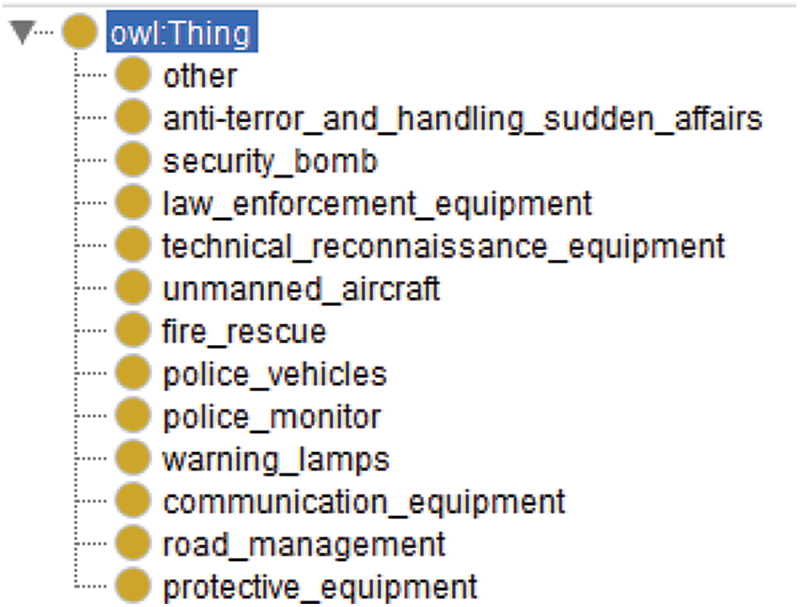
Figure 2: Police equipment body structure
This ontology modeling uses Protege software class for ontology construction [20]. Protege software is a specialized ontology development tool as well as a knowledge-based editor. It provides the construction of ontology concepts, relations and attributes, and can construct ontology model of domain knowledge at the conceptual level.
3.3 Police Equipment Knowledge Extraction
The system is constructed based on the open source police equipment related data on the network. The knowledge data sources include: Police equipment encyclopedia knowledge of Baidu Encyclopedia and Wikipedia, question and answer knowledge in Baidu Know, and equipment products in police equipment network.
The system encyclopedia knowledge is extracted from Baidu encyclopedia encyclopaedia entries. According to the structure of the URL of the encyclopedia, the lexical dictionary of police equipment terms is firstly constructed. As shown in Fig. 3, from the analysis of the page structure of the encyclopedia, it can be found that the page content of the encyclopedia entry is not described according to a strict and uniform structure, and the page structure will change with different entries. The main changes are the detailed introduction at the back of the catalog. For the structured part of the header to the directory, crawls by tag attributes. For the contents after the directory, the .next_siblings() function is used to iterate over the subsequent parallel nodes of the directory node, and the subheadings and contents of this part of the contents are crawled and cleaned according to the tag attributes. The crawler is connected with MongoDB, and the rule data extracted by keywords in the thesaurus is packaged and stored in MongoDB. Q&A knowledge comes from Baidu know about police equipment questions and answers. Firstly, we construct the URL pool according to the URL structure known by Baidu, combined with the thesaurus of related problems to be searched. Crawls each URL associated with the keyword. However, there are still a lot of noises in the data obtained at this time, so further processing is needed. Regular expressions are constructed and Python scripts are used to clean the data, leaving only questions and answers with useless information such as the nickname and time of the responder. Python is used to export the data to JSON format, and the data is stored in the ElasticSearch search engine for indexing. Police equipment website is the most authoritative professional portal website about police equipment in China, committed to the government and police equipment enterprises. There are relatively complete police equipment product information and equipment product production enterprise information. This project collects and analyzes the relevant information of the police equipment website. After analysis, each type of equipment is listed on the home page of the product center of this website. Enter according to the link of each equipment, which is the link of the list of equipment products of each type. The information to be collected includes: equipment product name, equipment type, equipment picture, equipment product introduction, equipment manufacturer, enterprise contact information, enterprise type, and enterprise address. This page is semi-structured data, and you can browse all the information of the site without logging in. We use crawler’s scrapy framework to crawl the site data, and use xpath language to traverse and locate tags and attributes in the web page. First, obtain the URLS of all types of equipment on the home page of the product center, store them in the list, traverse the URLS with yield iteration generator, and then enter the detailed page of equipment products, obtain their attribute values according to the rules of the tag, and use the function class ItemLoader in Scrapy to clean the data and remove redundant Spaces in the data. And merge part of the data. Finally, the crawled data is stored in JSON format.

Figure 3: Police equipment encyclopedia entry page
3.4 Police Equipment Knowledge Storage
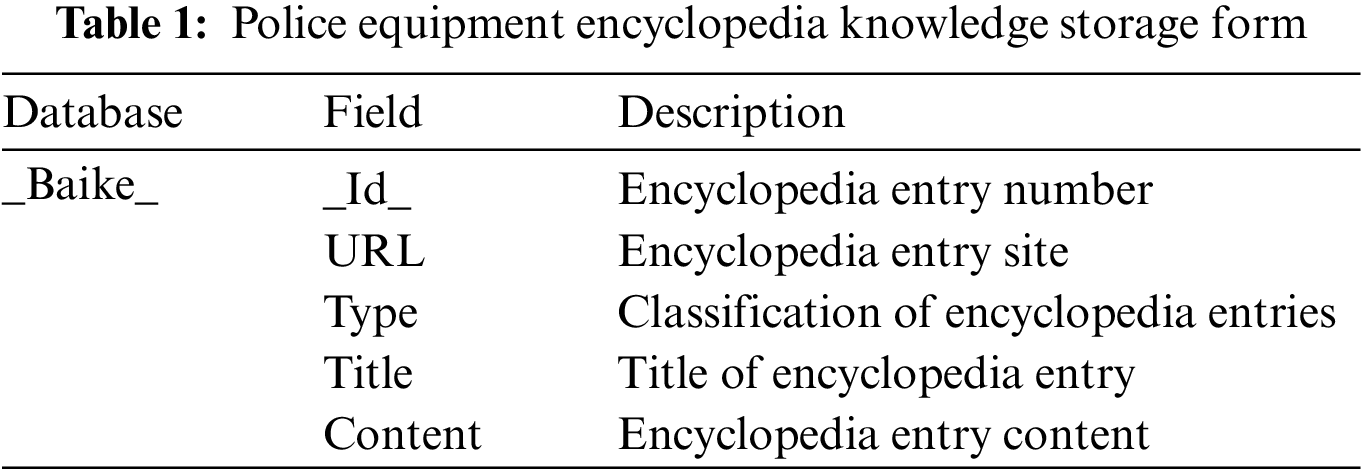
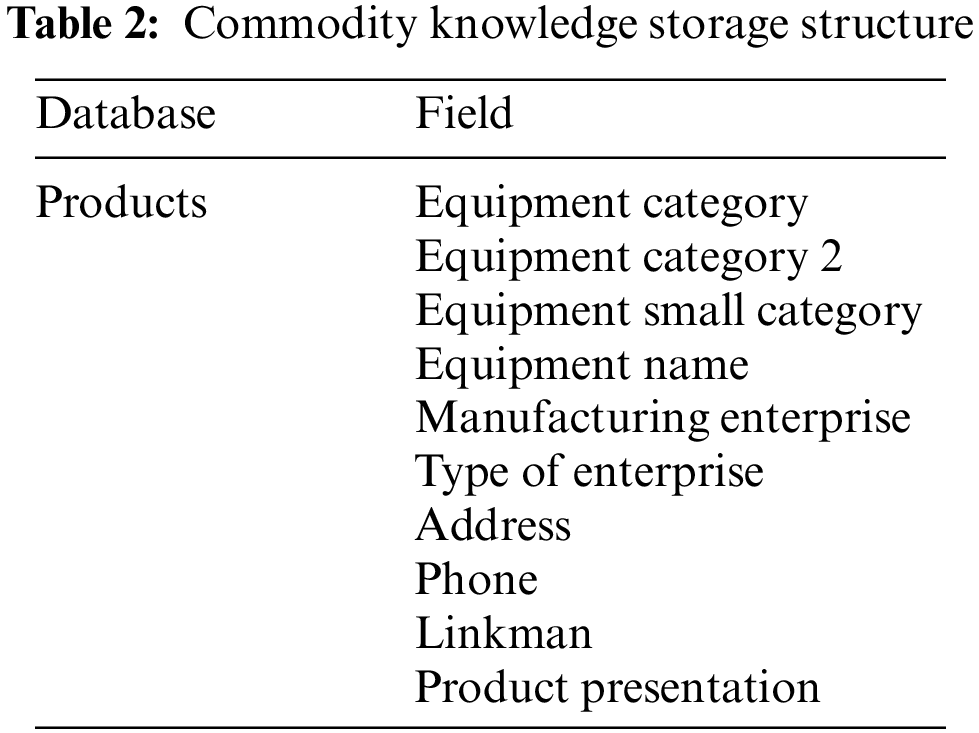
The encyclopedic knowledge and commodity knowledge stored by MongoDB are shown in Tables 1 and 2. In Table 1, there are five parts: ID of encyclopedic entry, website of encyclopedic entry, classification of encyclopedic entry, title of encyclopedic entry and content of encyclopedic entry. The commodity fields in Table 2 include equipment category, equipment category 2, equipment sub-category, equipment name, manufacturer, enterprise type, address, contact number, contact person and product introduction, altogether ten.
The form of ES index is shown in Table 3. In ES, an index represents a record in the database, and attributes such as index and properties must be marked in the index. This system uses version 7.4.2 of Elasticsearch to build the index, and uses Kibana tool to monitor the data import in real time.

3.5 Police Equipment Knowledge Integration
Collect the knowledge base of knowledge from various platforms, due to different sources of knowledge and form is different, so a lot of time will lead to more than a righteous word phenomenon appeared, such as the law enforcement recorder can also use “police law enforcement recorder” and “the law enforcement recorder” to express, so when searching a word can match the current search term, You can’t find other keywords that have similar meanings. This requires knowledge fusion technology, which combines and merges information from different sources to form unified knowledge identification and association. A good knowledge fusion method can effectively avoid information islands and make knowledge connection more comprehensive [21]. This system carries on the knowledge fusion to the knowledge base through the manual construction of synonyms database. In the specific field of police equipment, the noun terms of equipment are relatively unified, and the number of synonyms of equipment is not large, so it can be constructed manually, and the word database constructed manually will be more accurate.
We used Synonyms, which is a good Chinese Synonyms toolkit that can be used in many transactions related to natural language understanding: text alignment, system recommendation algorithms, text similarity calculation, semantic offset calculation, etc. [22]. Both a Synonyms table and a word vector model are Synonyms, in which a large Synonyms table is held, and in which both of the words that exist in the synonym-tree, CNKI, and synonym-are easier to use and have better feedback [23,24].
Then we de-weight the entries, compare the similarity between questions and answers, and integrate knowledge. In this way, we integrate all kinds of encyclopedic knowledge, question and answer knowledge and product knowledge, greatly reducing the redundant information in the knowledge base, while supplementing and enriching some knowledge [25].
4 System Testing and Presentation
Test environment: Win10 system, Python3.6.2 installed, Python installed libraries: Web framework flask-1.0.2, Harbin Institute of Technology LTP pyLTP-0.2.1, MongoDB database, Elasticsearch-7.4.2 index.
In order to verify the accuracy of knowledge query system, this paper tests the system.
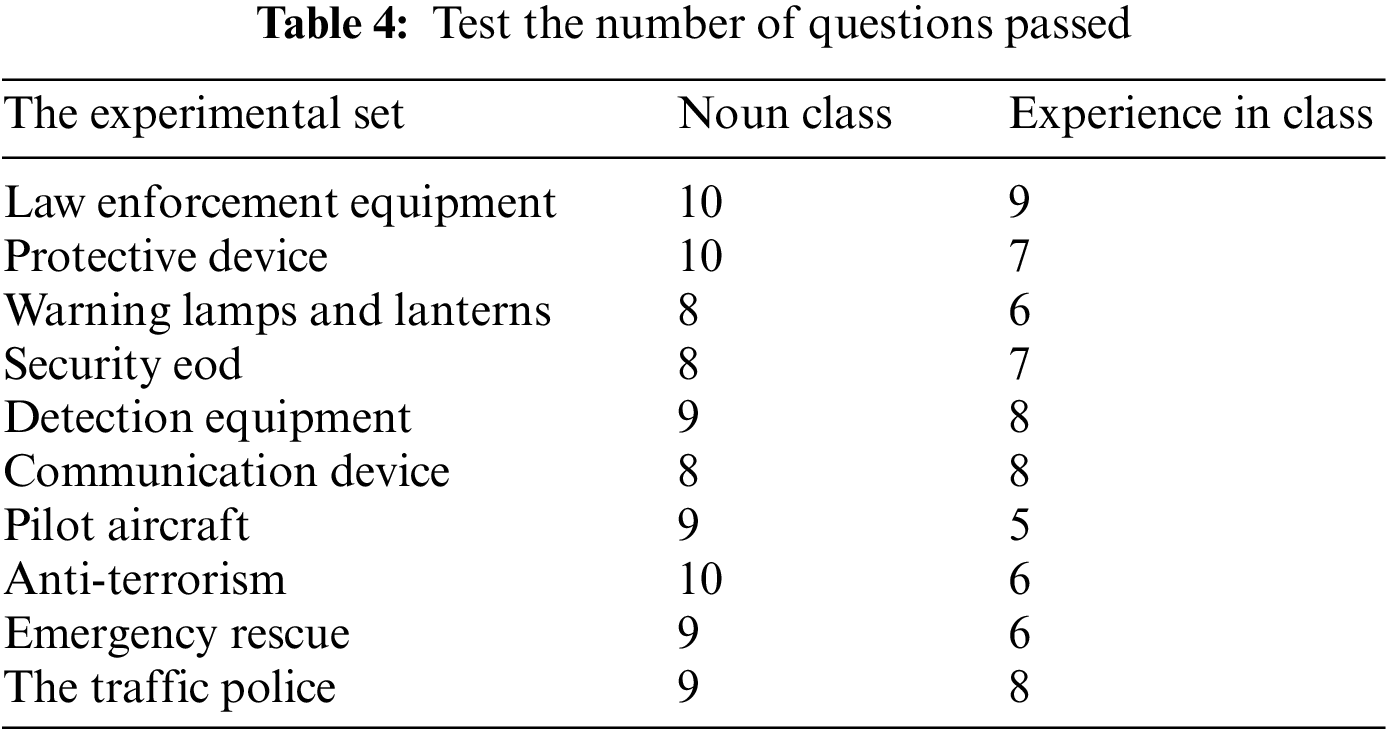
The knowledge base used in the experiment is the knowledge base of police equipment field constructed in the early stage of this paper, which includes three kinds of knowledge constructed before. Since there is no standard question and answer corpus in the field of police equipment at present, this paper decides to conduct tests according to equipment category and question type respectively. According to the equipment category, it can be divided into law enforcement equipment, protective equipment, warning lamps, security check and explosive disposal, technical investigation equipment, communication equipment, unmanned aircraft, anti-terrorism and emergency response, emergency rescue and police traffic. The problem type can be divided into: noun class, experience class problem. The questions of each equipment type can be divided into two types, such as the noun questions of law enforcement equipment and the experiential questions of law enforcement equipment. There are 20 types, 10 questions in each category, and a total of 200 questions.
Experimental test data put forward questions for the grassroots police, according to the questions raised by the police and the results returned by the system to test the accuracy of the system equipment query. If the answers are accurate and can effectively solve practical problems for the police, the test is considered to have passed.
As shown in Tables 4 and 5, it can be seen from the experimental results that the accuracy rate of noun questions is higher (90%), while that of experiential questions is generally higher (70%). It shows that the data in the encyclopedia knowledge base of the system is relatively comprehensive. However, as the data source of the Q&A knowledge comes from Baidu, the range of questions asked by users is large, so there are gaps in questions in some fields, resulting in the average accuracy of experiential questions. In addition, the system takes a long time to run, because the word vector has a slow loading speed and occupies a large memory during the word vector comparison.

This paper first introduces the background of domain knowledge graph and the research status of the technology required to construct the knowledge graph, and objectively analyzes the status quo and future prospects in the field of police equipment in the public security industry. The tools needed to build the build system were then introduced. According to the general framework of domain knowledge base, this paper innovatively constructs the knowledge of police equipment domain into domain knowledge base.
Firstly, the knowledge base of police equipment domain is constructed. According to the opening source data on the Internet, using scrapy crawler technology to collect the relevant knowledge of police equipment, a total of three kinds of knowledge including encyclopedia knowledge, question and answer knowledge and commodity knowledge were collected. And according to the different types of knowledge, different knowledge storage methods are carried out. For example, encyclopedia knowledge and commodity knowledge are stored in MongoDB database, and Q&A knowledge is stored in ElasticSearch index. In this paper, entity fusion technology is adopted for the named entities and equipment, and a synonym thesaurus of named entities is constructed, which can better match named entities in natural language questions with named entities in knowledge base.
Secondly, this paper constructs the police equipment query system according to the above knowledge base. When users input natural language, named entity recognition can be carried out, and the identified entity can be matched with the constructed rules, that is, the database query template, to match the encyclopedia knowledge of the entity in the database and the knowledge of related equipment commodities. The post-word vector technique compares questions from natural language to questions from ElasticSearch indexes. The top two responses with the highest scores are selected as the results.
Finally, this paper uses the Flask framework and bootstrap to design and implement the visualization of the system. The final police equipment query results are presented in three parts, which are the introduction of the encyclopedic knowledge of the equipment entity, the best answer to the question matching, and the commodity recommendation of the equipment entity.
After testing, the system has realized high accuracy and strong practicability of police equipment query system. Through the design of multiple modules to achieve a complete knowledge of the problem. This system can facilitate the police to have a more complete understanding of police equipment knowledge.
The system has the following problems in application:
(1) The quantity and quality of knowledge need to be improved. As the police equipment domain knowledge base is a vertical domain knowledge base belonging to the public security industry, some data cannot be disclosed. In addition, the knowledge acquisition this time comes from the open source data on the Internet, resulting in a limited amount of acquired data and low quality of some data.
(2) The operation efficiency of the system is not high. Because the system is in the user input questions began to perform a series of operations such as natural language processing technology and database search and question comparison. When the word vector technology is used, the high accuracy of the word vector leads to a long preloading time. As a result, the system takes too long to run during the search.
In this paper, knowledge graph technology is innovatively applied to the field of police equipment, realizing the concept of knowledge management of police equipment, and it can be applied to the public in the form of knowledge query. However, this experiment is only a foundation, and there is still a lot of room for improvement in the construction process.
In the background technology of the system, the system will try to use Trans series of technology to train the word vector in the field and improve the accuracy of entity recognition. At the same time, the type of knowledge and the amount of data in the field of police equipment should be expanded to improve and enrich the knowledge base in the field of police equipment. In terms of the query function of police equipment knowledge, the author will try to use Bert model or bi-LSTM model and other deep learning algorithm models to strengthen the natural language analysis of the query and improve the query efficiency of the query platform.
In terms of user’s query experience, the system will optimize the website page in the future, design a more beautiful and generous page, and add some reference pictures of police equipment, so that users can have a more intuitive and comprehensive understanding of knowledge and enhance the sense of user experience.
Based on the field of police equipment, this study has a further understanding of the construction and application of knowledge base, and realized that this is a very worthy of serious research. In addition to knowledge graph technology itself, more deep learning technology and natural language processing technology are needed to construct knowledge graph better. This research is only a starting point for the research in this field. This paper will combine the above ideas to make up for the shortcomings in the follow-up work, innovate and improve, continue to explore in this field, and make its own contribution to the cause of public security.
Acknowledgement: We would like to thank teachers Yuan Deyu and Sun Haichun for their helpful discussion and feedback, as well as the team’s technical support.
Funding Statement: This work was supported by Ministry of public security technology research program [Grant No. 2020JSYJC22ok], Fundamental Research Funds for the Central Universities (No. 2021JKF215), Open Research Fund of the Public Security Behavioral Science Laboratory, People’s Public Security University of China (2020SYS03), and Police and people build/share a smart community (PJ13-201912-0525).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. L. J. Che, L. W. Tang, S. J. Deng and X. J. Su, “Construction and application of military equipment knowledge graph based on encyclopedia knowledge,” Journal of Ordnance Equipment Engineering, vol. 40, no. 1, pp. 148–153, 2019. [Google Scholar]
2. W. Guo, R. Jia and Y. Zhang, “Semantic link network based knowledge graph representation and construction,” Journal on Artificial Intelligence, vol. 3, no. 2, pp. 73–79, 2021. [Google Scholar]
3. T. Li, H. Li, S. Zhong, Y. Kang, Y. Zhang et al., “Knowledge graph representation reasoning for recommendation system,” Journal of New Media, vol. 2, no. 1, pp. 21–30, 2020. [Google Scholar]
4. Q. Nie, X. Sheng, N. Zhang and J. Wang, “Construction of a nautical knowledge graph based on multiple data sources,” Journal of Coastal Research, vol. 94, no. sp1, pp. 223–226, 2019. [Google Scholar]
5. P. Han, M. Zhang, J. Shi, J. Yang and X. Li, “Chinese Q&A community medical entity recognition with character-level features and self-attention mechanism,” Intelligent Automation & Soft Computing, vol. 29, no. 1, pp. 55–72, 2021. [Google Scholar]
6. W. X. Hao, “Study on the construction of health knowledge graph of traditional Chinese medicine,” M.S. Dissertation, Beijing Jiaotong University, China, 2017. [Google Scholar]
7. D. Zhang, Q. Jia, S. Yang, X. Han, C. Xu et al., “Traditional Chinese medicine automated diagnosis based on knowledge graph reasoning,” Computers, Materials & Continua, vol. 71, no. 1, pp. 159–170, 2022. [Google Scholar]
8. Q. Wang, Z. D. Mao, B. Wang and L. Guo, “Knowledge graph embedding: A survey of approaches and applications,” IEEE Transactions on Knowledge and Data Engineering, vol. 29, no. 1, pp. 2724–2743, 2017. [Google Scholar]
9. Z. L. Xu, Y. P. Sheng, L. R. He and Y. F. Wang, “Review on knowledge graph techniques,” Journal of University of Electronic Science and Technology of China, vol. 45, no. 4, pp. 589–606, 2016. [Google Scholar]
10. T. Wang, “Research on distributed information collection strategy for financial credit,” M.S. Dissertation, Nanjing University, China, 2016. [Google Scholar]
11. L. H. Lei, X. E, F. Yang, J. Zhou and C. X. Liu, “Discussion on web front-end development technology,” Computer Knowledge and Technology, vol. 10, no. 23, pp. 5458–5459, 2014. [Google Scholar]
12. L. H. Lei, X. E., F. Yang, J. Zhou and C. X. Liu, “Design and implementation of educational administration system based on opening source framework flask,” China Computer & Communication, vol. 23, no. 20, pp. 107–109, 2016. [Google Scholar]
13. B. Shi, “Research on key technologies of semantic search engine for semantic web,” Ph.D. Dissertation, Beijing University of Technology, China, 2010. [Google Scholar]
14. S. Wang, D. Wang, D. K. Zhang and F. Zhang, “Construction and querying of ancient poet knowledge graph,” Journal of Physics: Conference Series, vol. 1237, no. 3, pp. 032047, 2019. [Google Scholar]
15. S. N. Hao and L. J. Zhao, “A recommendation system architecture based on elastic search,” Computer Knowledge and Technology, vol. 13, no. 36, pp. 230–232, 2017. [Google Scholar]
16. F. P. Yu, “Design and implementation of distributed storage optimization for college entrance examination data,” M.S. Dissertation, Shandong Normal University, China, 2017. [Google Scholar]
17. H. L. Wei, “The application of text sentiment analysis in product review,” M.S. Dissertation, Beijing Jiaotong University, China, 2014. [Google Scholar]
18. Z. Y. Hu and Y. S. Hu, “Design of information extraction system based on domain main body,” Value Engineering, vol. 29, no. 14, pp. 158–159, 2010. [Google Scholar]
19. J. Song, P. Q. Wang, J. F. Qi and X. H. Li, “The research of ontology’s create on equipment domain,” Microcomputer Information, vol. 25, no. 15, pp. 17–18+3, 2009. [Google Scholar]
20. J. Y. Ding, Q. S. Zhao, B. Y. Xia and Z. G. Zou, “The method study of armament knowledge graph’s establishment based on opening source data,” Command Control & Simulation, vol. 40, no. 2, pp. 22–26, 2018. [Google Scholar]
21. C. H. Zhang, M. Zhou, X. Han, Z. Hu and Y. Ji, “Knowledge graph embedding for hyper-relational data,” Tsinghua Science and Technology, vol. 22, no. 2, pp. 185–197, 2017. [Google Scholar]
22. P. Y. Zhang, C. M. Chen and B. Huang, “Texts similarity algorithm based on subtrees matching,” Pattern Recognition and Artificial Intelligence, vol. 27, no. 3, pp. 226–234, 2014. [Google Scholar]
23. H. Y. Zhou and Z. Zhang, “The review of Chinese word segmentation technology,” Journal of Anyang Normal University, vol. 12, no. 2, pp. 54–56, 2010. [Google Scholar]
24. J. T. Tang, F. Li and C. S. Guo, “Research of new word pattern recognition in network monitoring public opion,” Computer Technology and Development, vol. 22, no. 1, pp. 119–121+125, 2012. [Google Scholar]
25. F. F. Liu and Z. J. Wang, “Research on recognition of Tibetan names based on hierarchical features,” Application Research of Computers, vol. 35, no. 9, pp. 2583–2587+2596, 2018. [Google Scholar]
Cite This Article
 Copyright © 2022 The Author(s). Published by Tech Science Press.
Copyright © 2022 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools