
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Intrusion Detection Method Based on Active Incremental Learning in Industrial Internet of Things Environment
1 School of Software, Nanjing University of Information Science and Technology, Nanjing, 210044, China
2 Cyberspace Institute Advanced Technology, Guangzhou University, Guangzhou, 510006, China
3 Jiangsu Collaborative Innovation Center of Atmospheric Environment and Equipment Technology (CICAEET), Nanjing University of Information Science and Technology, Nanjing, 210044, China
* Corresponding Author: Zilong Jin. Email:
Journal on Internet of Things 2022, 4(2), 99-111. https://doi.org/10.32604/jiot.2022.037416
Received 03 November 2022; Accepted 06 December 2022; Issue published 28 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Intrusion detection is a hot field in the direction of network security. Classical intrusion detection systems are usually based on supervised machine learning models. These offline-trained models usually have better performance in the initial stages of system construction. However, due to the diversity and rapid development of intrusion techniques, the trained models are often difficult to detect new attacks. In addition, very little noisy data in the training process often has a considerable impact on the performance of the intrusion detection system. This paper proposes an intrusion detection system based on active incremental learning with the adaptive capability to solve these problems. IDS consists of two modules, namely the improved incremental stacking ensemble learning detection method called Multi-Stacking model and the active learning query module. The stacking model can cope well with concept drift due to the diversity and generalization selection of its base classifiers, but the accuracy does not meet the requirements. The Multi-Stacking model improves the accuracy of the model by adding a voting layer on the basis of the original stacking. The active learning query module improves the detection of known attacks through the committee algorithm, and the improved KNN algorithm can better help detect unknown attacks. We have tested the latest industrial IoT dataset with satisfactory results.Keywords
Under the background of intelligence, the industrial Internet of Things (IIot) is transforming industrial production environments by connecting sensors, brakes, and other devices to enable them to operate more efficiently and reliably. The rapid development of artificial intelligence technology has brought more new possibilities for the intelligence of Industrial Control Systems (ICS) [1]. Especially the development of various technologies such as sensors, 5g networks, cloud computing, and edge computing, there will be more and more machines, equipment, and sensors connected to IIot gateways and local routers in the future, which may contain critical data in the industrial production process. which could be extremely costly for factories if stolen or tampered with by lawless. Network security is all about preventing network attacks. Intrusion detection systems (IDS) are currently one of the most effective and commonly used methods. Fig. 1 depicts all layers in the IIoT, including the perception layer, the networking layer, the application layer, and the solution based on the IDS network architecture. The process includes data collection, data preprocessing, concrete implementation, training, and validation. The security database stores the collected signatures of various attacks, and the data is preprocessed and sent to IDS for detection. IDS and Next Generation Firewall (NGFW) work together to maintain the security of IIoT [2].
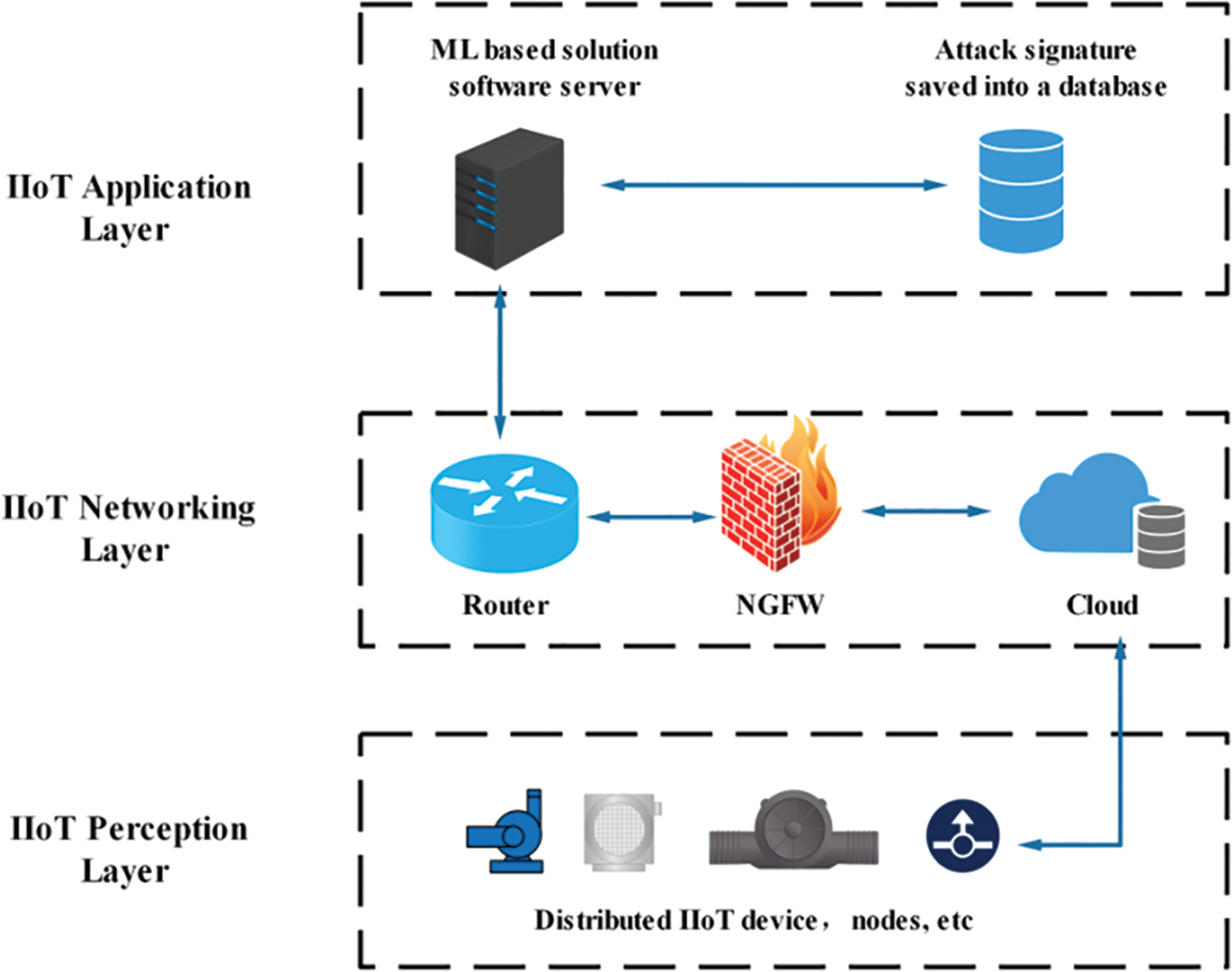
Figure 1: Solution based on IDS network architecture in IIOT environment
Network traffic as a stream of data comes from one or more data sources [3], with high frequency and large data volume, and many data will not be saved. It is important to note that with the advancement of artificial intelligence, a variety of attack generation tools came into being. Network criminals will often skillfully use these tools to generate various attacks, and some of these attacks can skillfully evade detection [4].
IDS based on batch learning has poor adaptability, because it cannot learn new attacks unless it is retrained, which causes a waste of time [5]. For huge data streams, it is not possible to load them into memory at once for training for batch learning. Incremental learning-based techniques are a good solution to these problems. During incremental learning, the models are updated accordingly to changes in the data [6], and there is no need to store all the training data at once.
Incremental learning also faces some challenges, the biggest of which is the problem of conceptual drift [7]. In the training prediction process, we often assume that the data has independent identical distribution properties so that the machine learning algorithm can learn the distribution properties of the data in the training set. However, the joint probability distribution of real data streams tends to change, which may affect the classifier’s performance [8,9].
To address these issues, this paper proposes a hybrid intrusion detection framework based on incremental ensemble learning and active learning. First, we propose an improved stacking ensemble learning detection method called Multi-Stacking. Stacking usually has two layers, the basic layer is composed of multiple heterogeneous classifiers, and the generalization layer is usually composed of one meta classifier. The diversity of base classifiers and generalization options in stacking can help solve concept drift. We further improve the model accuracy and generalization ability by adding a voting layer between the base layer and the generalization layer, which consists of multiple voting policies. In active learning, we first cull the noisy and hard-to-classify data by a committee algorithm and then continue to detect unknown attacks in the normal traffic obtained from the Multi-Stacking classification by an improved KNN algorithm. We store the culled data in markers and retrain the three-layer stacking model to improve its performance and ability to detect unknown attacks.
This paper is organized as follows: In Section 2, related work will be discussed. And our proposed method is introduced elaborately in Section 3. Section 4 gives the experimental results of the proposed scheme. Finally, a conclusion is given in Section 5.
Traditional machine learning methods, despite their limitations, are simpler and more convenient in terms of optimizing model changes and adjusting hyperparameters while having better learning and detection capabilities. Anand Sukumar et al. [10] proposed an intrusion detection method, IGKM, which uses a genetic algorithm (GA) to obtain the optimal k value of the k-means algorithm. Kanimozhi et al. [11] proposed a logistic regression (LR) method based on the opposite truncated fuzzy mean, which uses logistic regression for feature selection, greatly improving the training efficiency, but it is easy to produce overfitting when the number of tuples is insufficient.
The popular deep learning method has strong detection ability and is the first choice for researchers to design intrusion detection systems. Amjad et al. [12] proposed a deep learning architecture combining auto coder and LSTM for detecting known and unknown attacks in networks. Singla et al. [13] proposed adversarial domain adaptation for intrusion detection in the absence of labeled data. Experiments show that this method can maintain good accuracy in the absence of labeled training data.
Ensemble learning models are also commonly used in intrusion detection by combining multiple weak classifiers into a single strong classifier. Miah et al. [14] use cluster-based undersampling and random forest classifier to classify a few types of network attacks/intrusions. This method is a multi-level classification method, which can deal with highly unbalanced big data to correctly identify minority/rare class intrusions. Zheng et al. [15] proposed a stacking-based intrusion detection method that greatly exceeds the detection capability of a single classifier by combining SVM, BPNN, K-Means, and XGBoost into a set of base classifiers.
Incremental learning is to learn samples one by one in chronological order to partially update the learning model. The Hoeffding tree (HT) is a type of decision tree (DT) that uses the Hoeffding bound to incrementally adapt to data streams [16]. Compared to a DT that chooses the best split, the HT uses the Hoeffding bound to calculate the number of necessary samples to select the split node. Thus, the HT can update its node to adapt to newly incoming samples. However, the HT does not have mechanisms to address specific types of drift. The Extremely Fast Decision Tree (EFDT) [17], also named Hoeffding Anytime Tree (HATT), is an improved version of the HT that splits nodes as soon as it reaches the confidence level instead of detecting the best split in the HT. This splitting strategy makes the EFDT adapt to concept drifts more accurately than the HT, but its performance still needs improvement.
Due to the variable attack behavior, traditional IDS based on batch learning algorithms cannot be dynamically adjusted in the face of changes in the network environment and often require retraining of the model, which poses many problems and issues, for which incremental learning is a good solution. Xu et al. [18] proposed an incremental KNN-SVM method where the model is able to maintain a short prediction time during the update process. Wang et al. [19] proposed a small-sample class-incremental learning method to facilitate the class-incremental learning strategy of DNN through a meta-learning method, which is suitable for cases where there are few new class samples.
In the above research scheme, Few intrusion detection methods consider adapting a system to an attack that actually occurs in the environment. Some attack types, even if learned, may hardly occur in the environment in the future. At this point, our intrusion detection system does not need to learn. The IDS based on active incremental learning in this paper can quickly adapt and learn the types of attacks that exist in the current environment.
This section details the proposed intrusion detection method based on active incremental integrated learning. IDS mainly consists of two modules. Multi stacking method module and active learning module. Active learning is responsible for guiding and optimizing the multi stacking method module in the detection process. Fig. 2 describes the specific process.
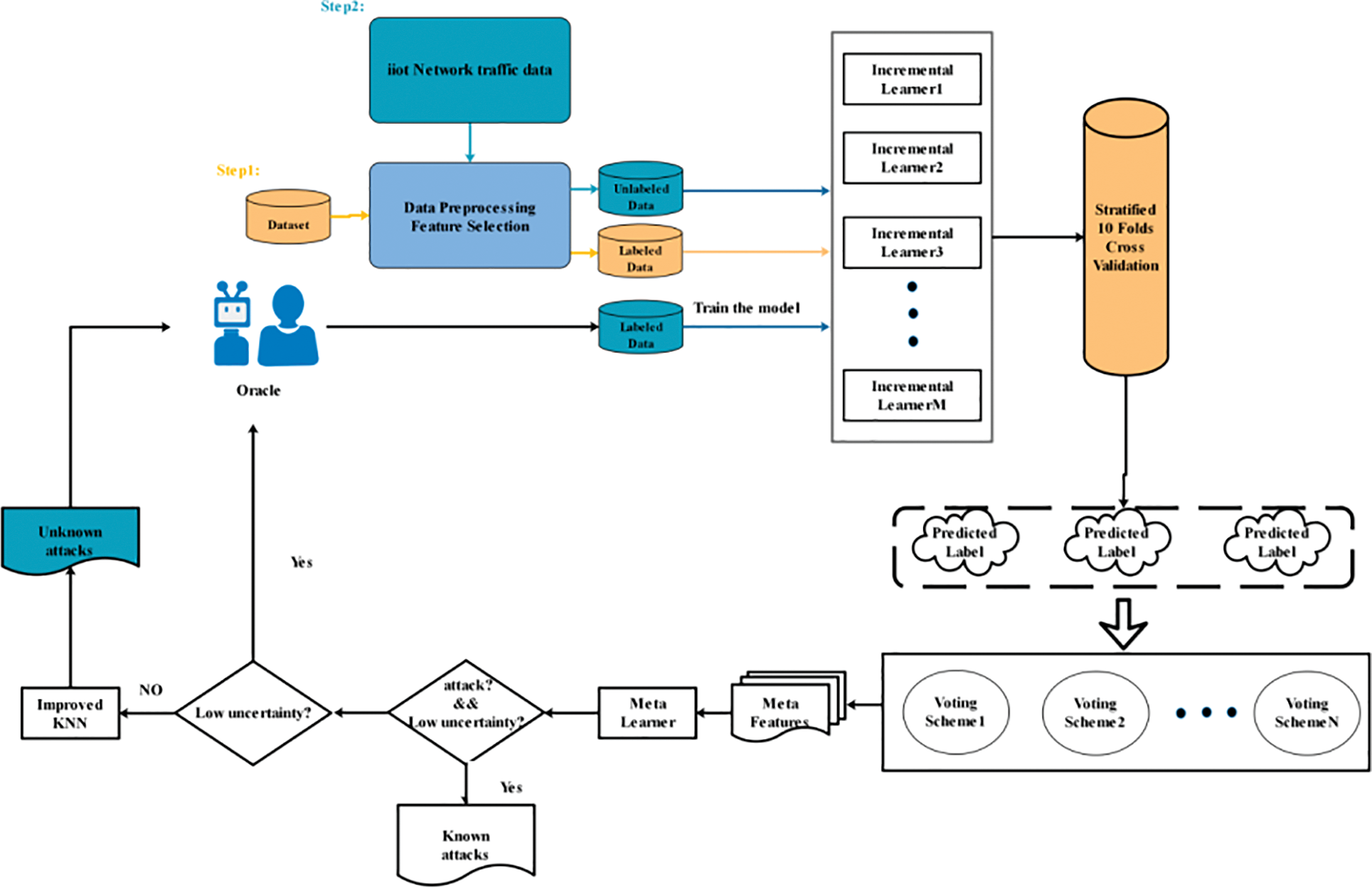
Figure 2: IDS detection framework based on active incremental learning
Stacking ensemble learning can effectively address the problem of concept drift due to the diversity of its base classifiers and generalization selection. We improve the input value of the meta classifier by adding combined voting to the output of the traditional base classifier to increase the accuracy of the model.
For the industrial IoT security dataset
In our proposed Multi-Stacking method, the first layer is a base layer composed of a set of base learners, denoted as
The industrial IoT attack dataset was divided into five parts, where

3.2 Active Learning of Data Query Strategies
3.2.1 Committee Query Algorithm
The base classifier in Multi-Stacking, as a committee member in the committee query algorithm, is defined as
where
We improve the KNN algorithm to make it efficient for detecting unknown attacks. The proposed method censors the unknown attacks from the normal traffic obtained from the Multi-Stacking model classification by excluding the normal traffic by relative distance. In the industrial IoT dataset
Therefore, the hypersphere is defined as:
For all hyperspheres in Di, define Hi as the set of hyperspheres in Qi:
Then we determine the category of the traffic by calculating the distance between the analysis traffic and the hypersphere. The discriminant formula is as follows:
where t is the set threshold,
Next, the discriminant values of the samples were voted on by Plural voting and the final flow class results were as follows:
where
After the classified unknown attacks are labeled by active learning, the KNN detector can be further updated. The specific algorithm is shown in Algorithm 2.

In this section, we perform a series of experiments to evaluate the proposed IDS.
We choose Edge-IIoTset, a comprehensive reality network security data set of the latest industrial IoT applications [20], in which the data is generated by a variety of IIoT devices, such as soil moisture sensors, pH sensors, flame sensors, and digital sensors used to sense temperature and humidity. The dataset was generated from 21 November 2021 to 10 January 2022 and overall contains a total of 20952,648 data and 1,176 features, 61 of which have high relevance. The dataset collects a total of fourteen attacks related to IoT and IIoT connectivity protocols, which are grouped into five threats, including DoS/DDoS attacks, information gathering, man-in-the-middle attacks, injection attacks, and malware attacks [21].
The Area Under the ROC Curve (AUC) is plotted to validate the effectiveness of the proposed active incremental learning method based on Multi-Stacking, with the value of AUC ranging from 0 to 1, the closer to 1, the better the model validity. The Area Under the ROC Curve (ROC) is plotted by the false positive rate (TPR) and the false positive rate (FPR) for a given model. TPR and FPR are defined as follows:
Each component in the above formula is defined as follows:
• TP: Indicates traffic that is correctly classified as attack.
• TN: Indicates traffic that is correctly classified as normal.
• FP: Indicates traffic that is incorrectly as attack.
• FN: Indicates traffic that is incorrectly as normal.
In this section, we study the influences of three parameters: the number of labeled data n, the number of nearest neighbors L, and the threshold t. We choose the appropriate parameters by fixing other parameters and evaluating the performance of the model for different parameters at different values.
Formula (1) expresses that if the threshold t is set too small, more normal traffic will be misjudged as attack traffic, which will add many unnecessary labels. If the value of t is too large, some attack traffic will be missed. Therefore, our primary goal is to ensure a higher TPR and then select a smaller t value as far as possible. Fig. 3a shows the effect of the t value on the TPR. When t is 0.98, it can not only achieve a higher TPR but also ensure that the value of t is as tiny as possible. Fig. 3b shows the influence of the number of nearest neighbors L on the TPR. When L is less than 7, the range of change is relatively large, and when L is greater than 7, it tends to be stable. The calculation cost can be reduced by adequately using a smaller number of nearest neighbors. Therefore, we choose seven as the number of nearest neighbors.
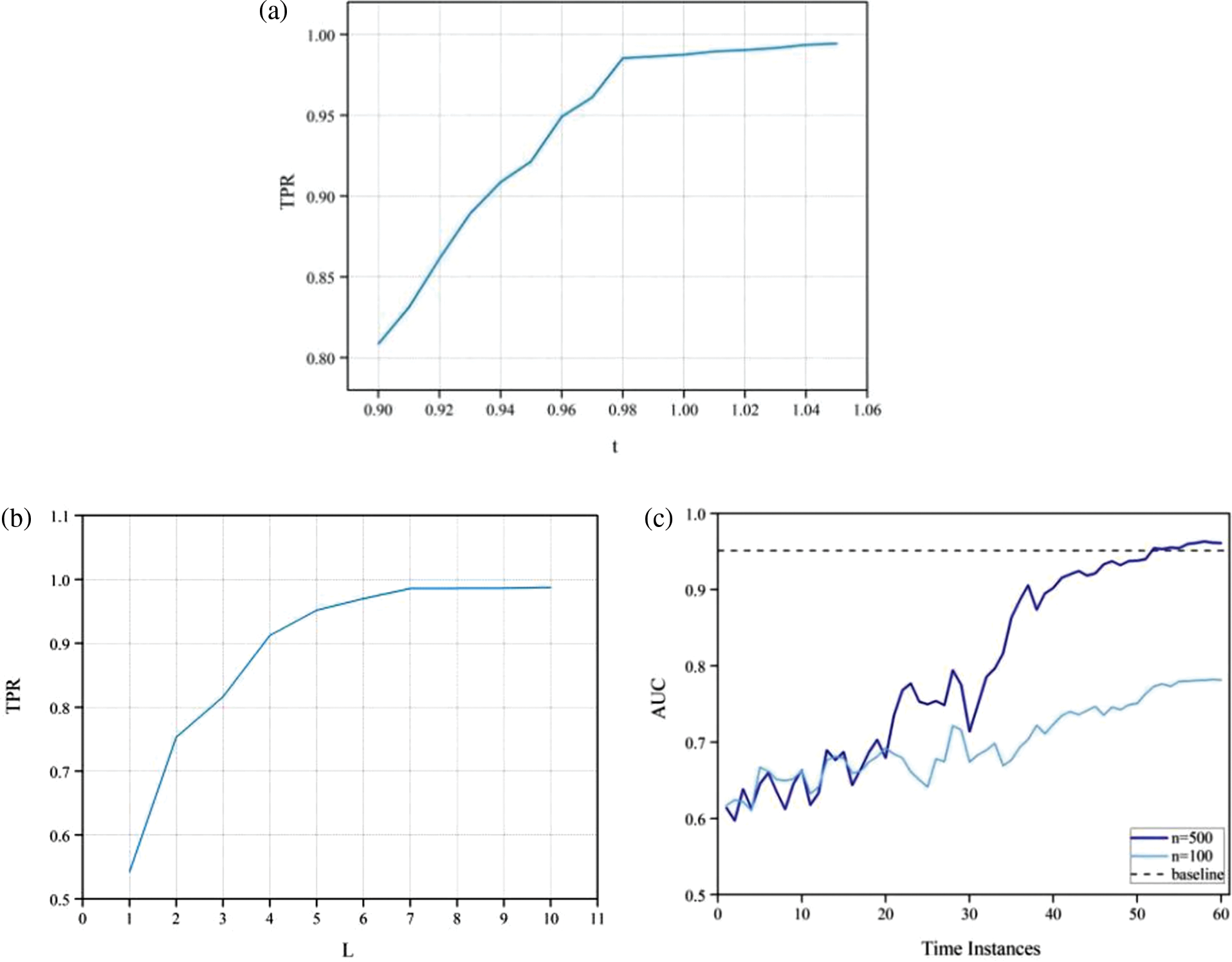
Figure 3: Influences of parameters: (a) Influence of threshold t. (b) Influence of number of nearest neighbors L. (c) Influences of number of labeled data n
Fig. 3c shows the AUC of the active incremental learning method on the test set with the different number of labels n. It can be seen that the detection performance is low at the beginning because many attacks in the test set belong to unknown attacks and are difficult to detect. Still, over time, the AUC has significantly improved, indicating that active incremental learning has good adaptability in actual detection. Using the number of labels for n of 100 and 500, equivalent to 2% and 10% of the training set, and using the complete data for AUC comparisons at different time instances. The higher the labeling rate is, the better the effect will be. When n is 500, the final AUC can reach the AUC obtained by using the complete training set. Therefore, the same effect of all labels can be achieved by sampling labels, and the label cost can also be significantly reduced.
Fig. 4 mainly shows two groups of active incremental learning methods. The detection models are the Multi-Stacking method and the Stacking method of this paper and the change in AUC at different time instances for the removal of the committee algorithm. The addition of the combined voting layer brings a considerable improvement in the detection of the stacking model. There are few new attacks in 40 to 50 time instances. We can see that the detection of known attacks by the model can be improved by the committee algorithm by re-labeling noisy data and by labeling indistinguishable samples. The performance in 50 to 60 even slightly exceeds that of the model trained with all data, because some noise data in the data set are detected.
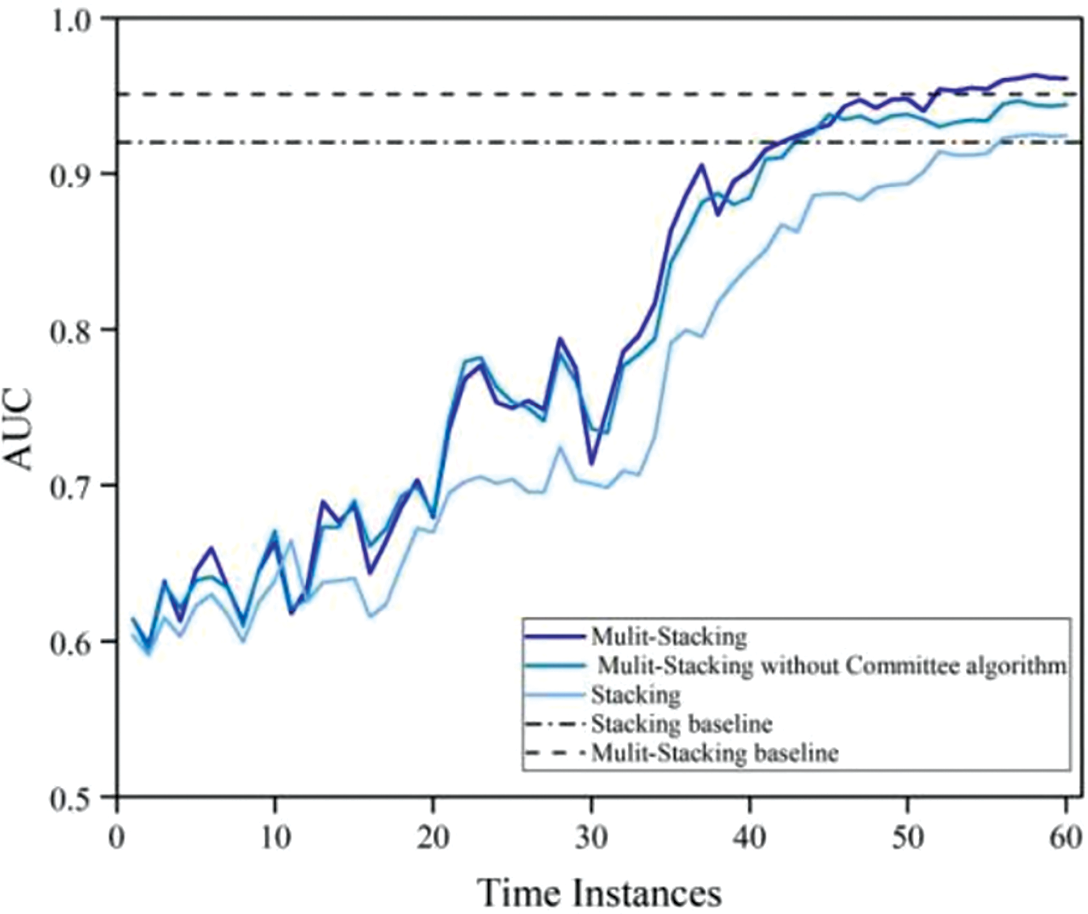
Figure 4: Performance of the Multi-Stacking, Stacking, and Multi-Stacking without Committee algorithm under different time instances
In Fig. 5, Multi-Stacking is replaced with other machine learning methods, and conducted several experiments to compare the performance of the final model in the test set for different numbers of time instances. We can see that the Multi-Stacking model is indeed a significant improvement in detection and outperforms several other standard machine learning methods selected.
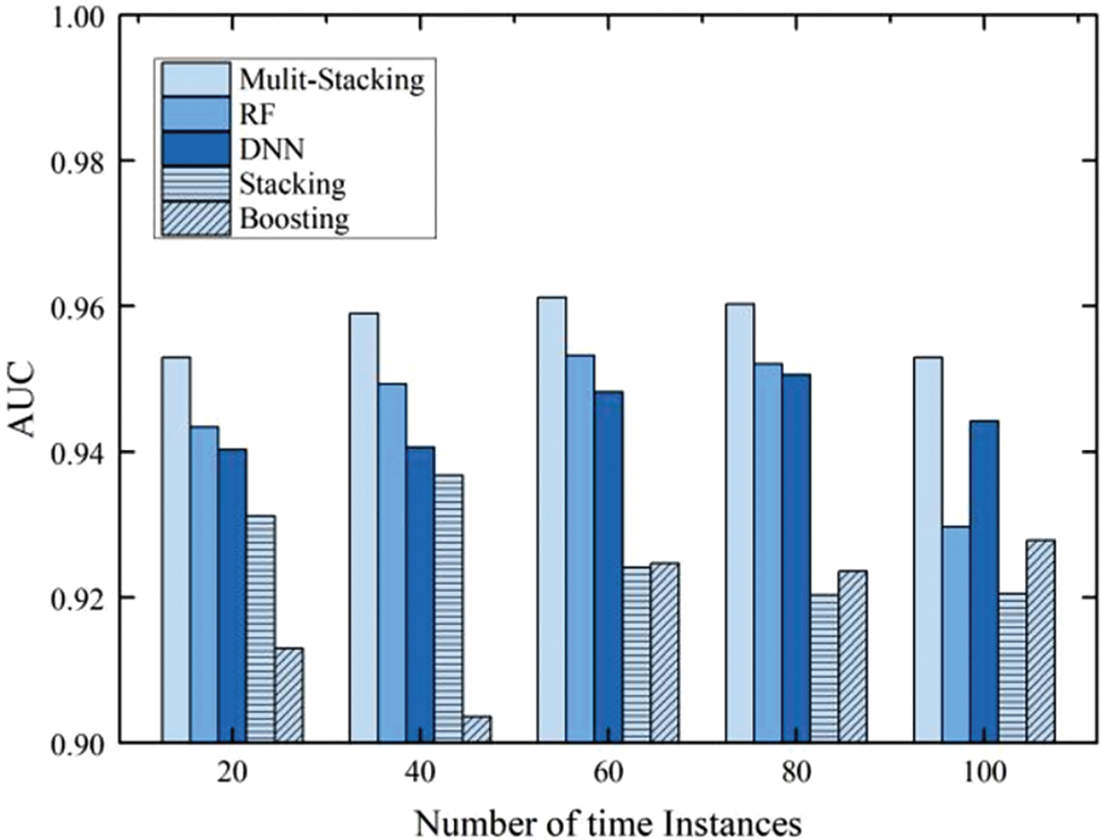
Figure 5: Performance of the final model under different number of time instances
In this paper, An intrusion detection framework was proposed based on active ensemble learning, using an improved KNN and committee algorithm as the active learning query algorithm. The improved KNN is responsible for helping to find potential unknown attacks, and the committee algorithm is mainly responsible for finding some noisy data in the datasets and in the crowd sourcing process. Active learning is responsible for “teaching” the ensemble learning model to identify more attack types and improve the detection accuracy of known attacks, so the proposed IDS is adaptive. In order to fit this incremental learning model, the existing stacking model was chosen and improved, which copes well with conceptual drift in a realistic detection environment. By adding a voting layer between the base layer and the generalization layer of the stacking model, the Multi-Stacking model has higher accuracy and also copes well with concept drift.
In the future, we intend to further improve the Multi-Stacking method. The limitation of Multi-Stacking is that the added voting layer requires additional data processing and a small amount of extra execution time. Therefore, the following work considers the parallel processing of the integration layer and the voting layer to make up for this shortcoming. Feature selection is also one of the improvement directions we consider. Improving the existing feature selection method can help us perform real-time detection more efficiently and improve detection accuracy.
Funding Statement: This work was sponsored by the National Natural Science Foundation of China under Grants 62271264, 61972207, and 42175194, and the Project through the Priority Academic Program Development (PAPD) of Jiangsu Higher Education Institution.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. F. Rodriguez-Diaz, “Industry 4.0: The industrial Internet of Things,” Computing Reviews, vol. 58, no. 4, pp. 228–229, 2017. [Google Scholar]
2. F. F. Alruwaili, “Intrusion detection and prevention in industrial IoT: A technological survey,” in Proc. of Int. Conf. on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Mauritius, pp. 1–5, 2021. [Google Scholar]
3. I. Sharafaldin, A. H. Lashkari and A. A. Ghorbani, “Toward generating a new intrusion detection dataset and intrusion traffic characterization,” in Proc. of ICISSp, Hyderabad, India, pp. 1–5, 2018. [Google Scholar]
4. N. Moustafa, J. Slay and G. Creech, “Novel geometric area analysis technique for anomaly detection using trapezoidal area estimation on large-scale networks,” IEEE Transactions on Big Data, vol. 5, no. 4,pp. 481–494, 2019. [Google Scholar]
5. Z. Xiaorong, W. Dianchun, L. Jin and T. Wei, “Incremental learning in the application of intrusion detection,” in Proc. of 2009 WRI Global Congress on Intelligent Systems, Xiamen, China, pp. 549–553, 2009. [Google Scholar]
6. S. Shalev-shwartz, “Online learning: Theory, algorithms, and applications,” Ph.D. dissertation, University of Hebrew, Israel, 2007. [Google Scholar]
7. F. Chu, Y. Wang and C. Zaniolo, “An adaptive learning approach for noisy data streams,” in Proc. of Fourth IEEE Int. Conf. on Data Mining (ICDM), Brighton, UK, pp. 351–354, 2004. [Google Scholar]
8. J. Dromard, G. Roudiere and P. Owezarski, “Online and scalable unsupervised network anomaly detection method,” IEEE Transactions on Network and Service Management, vol. 14, no. 1, pp. 34–47, 2016. [Google Scholar]
9. L. Boukela, G. Zhang, S. Bouzefrane and J. Zhou, “An outlier ensemble for unsupervised anomaly detection in honeypots data,” Intelligent Data Analysis, vol. 24, no. 4, pp. 743–758, 2020. [Google Scholar]
10. J. V. Anand Sukumar, I. Pranav, M. Neetish and J. Narayanan, “Network intrusion detection using improved genetic K-means algorithm,” in Proc. of 2018 Int. Conf. on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, pp. 2441–2446, 2018. [Google Scholar]
11. P. Kanimozhi and T. Aruldoss Albert Victoire, “Oppositional tunicate fuzzy C-means algorithm and logistic regression for intrusion detection on cloud,” Concurrency and Computation: Practice and Experience, vol. 34, no. 4, pp. 13, 2022. [Google Scholar]
12. M. Amjad, H. Zahid, S. Zafar and T. Mahmood, “A novel deep learning framework for intrusion detection system,” in Proc. of 2019 Int. Conf. on Advances in the Emerging Computing Technologies (AECT), Al Madinah Al Munawwarah, Saudi Arabia, pp. 1–6, 2020. [Google Scholar]
13. A. Singla, E. Bertino and D. Verma, “Preparing network intrusion detection deep learning models with minimal data using adversarial domain adaptation,” in Proc. of the 15th ACM Asia Conf. on Computer and Communications Security (ACM Asia CCS), Taipei, Taiwan, pp. 127–140, 2020. [Google Scholar]
14. M. O. Miah, S. Shahriar Khan, S. Shatabda and D. M. Farid, “Improving detection accuracy for imbalanced network intrusion classification using cluster-based under-sampling with random forests,” in Proc. of 2019 1st Int. Confe. on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, pp. 1–5, 2019. [Google Scholar]
15. X. Zheng, Y. Wang, L. Jia, D. Xiong and J. Qiang, “Network intrusion detection model based on chi-square test and stacking approach,” in Proc. of 2020 7th Int. Conf. on Information Science and Control Engineering (ICISCE), Changsha, China, pp. 894–899, 2020. [Google Scholar]
16. P. Domingos and G. Hulten, “Mining high-speed data streams,” in Proc. of the Sixth ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Boston, MA, USA, pp. 71–80, 2000. [Google Scholar]
17. C. Manapragada, G. I. Webb and M. Salehi, “Extremely fast decision tree,” in Proc. of the 24th ACM SIGKDD Int. Conf. on Knowledge Discovery & Data Mining, London, UK, pp. 1953–1962, 2018. [Google Scholar]
18. B. Xu, S. Chen, H. Zhang and T. Wu, “Incremental KNN-SVM method in intrusion detection,” in Proc. of 2017 8th IEEE Int. Conf. on Software Engineering and Service Science (ICSESS), Beijing, China,pp. 712–717, 2017. [Google Scholar]
19. T. Wang, Q. Lv, B. Hu and D. Sun, “A few-shot class-incremental learning approach for intrusion detection,” in Proc. of 2021 Int. Conf. on Computer Communications and Networks (ICCCN), Athens, Greece, pp. 1–8, 2021. [Google Scholar]
20. Edge-iiotset dataset, https://www.kaggle.com/mohamedamineferrag/edgeiiotset-cyber-security-dataset-of-iot-iiot, 2022. [Google Scholar]
21. M. A. Ferrag, O. Friha, D. Hamouda, L. Maglaras and H. Janicke, “Edge-IIoTset: A new comprehensive realistic cyber security dataset of IoT and IIoT applications for centralized and federated learning,” IEEE Access, vol. 10, no. 1, pp. 40281–40306, 2022. [Google Scholar]
Cite This Article
 Copyright © 2022 The Author(s). Published by Tech Science Press.
Copyright © 2022 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools