
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Causality-Driven Common and Label-Specific Features Learning
1 School of Intelligent Transportation Modern Industry, Anhui Sanlian University, Hefei, 230601, China
2 Heyetang Middle School, Jinhua, 322010, China
* Corresponding Author: Yuting Xu. Email:
Journal on Artificial Intelligence 2024, 6, 53-69. https://doi.org/10.32604/jai.2024.049083
Received 27 December 2023; Accepted 04 March 2024; Issue published 05 April 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In multi-label learning, the label-specific features learning framework can effectively solve the dimensional catastrophe problem brought by high-dimensional data. The classification performance and robustness of the model are effectively improved. Most existing label-specific features learning utilizes the cosine similarity method to measure label correlation. It is well known that the correlation between labels is asymmetric. However, existing label-specific features learning only considers the private features of labels in classification and does not take into account the common features of labels. Based on this, this paper proposes a Causality-driven Common and Label-specific Features Learning, named CCSF algorithm. Firstly, the causal learning algorithm GSBN is used to calculate the asymmetric correlation between labels. Then, in the optimization, both -norm and -norm are used to select the corresponding features, respectively. Finally, it is compared with six state-of-the-art algorithms on nine datasets. The experimental results prove the effectiveness of the algorithm in this paper.Keywords
Multi-label learning [1] (MLL) is one of the hot research areas in machine learning, which alleviates the problem that instances covering multiple concepts or semantics in numerous real-world application scenarios cannot be accurately handled by traditional single-label algorithms. In real life, MLL has also long been applied in several domains, such as text classification [2], image annotation [3], protein function detection [4] and personalized recommendation [5], to name a few. With the rapid development of the Internet, data is gradually characterized by high dimensional distribution [6]. This can lead to the problem of dimensional catastrophe suffered by multi-label algorithms for data learning.
Label-specific feature (LSF) learning can effectively solve this problem, which is to establish the label-specific relation between labels and features by learning the connection between features and labels. The core idea is that each label should have a specific feature corresponding to it, i.e., the specific features of the label are learned. In multi-label learning,
Label correlation [7] (LC) has long been commonly used in LSF learning, which effectively improves the classification performance of LSF learning algorithms. However, the correlation calculated by cosine similarity is symmetric, and ignore the asymmetric correlation may introduce redundant information in the model. Cosine similarity is also highly susceptible to dimensional catastrophe. As the amount of data increases, the Euclidean distance metric deteriorates. In the process of calculation, the label relevance calculated by cosine similarity is highly susceptible to the a priori knowledge of the labels. Most of the labels in multi-label datasets rely on manual expert marking. With the increase of data volume and the influence of experts’ experience, it is inevitable that there will be omission and miss labeling in the process of marking. For such incomplete datasets, the LC computed by cosine similarity methods are inevitably mixed with many spurious correlations. Therefore, it is necessary to adopt the causal learning [8] algorithm to measure the asymmetric correlation between labels.
In LSF learning, most algorithms only consider the private features of labels and do not consider the common features of labels [9]. However, when we classify two similar labels, the LC of the similar labels are also similarly strongly correlated, but the computed weight matrices are not necessarily similar. As shown in Fig. 1. The labels
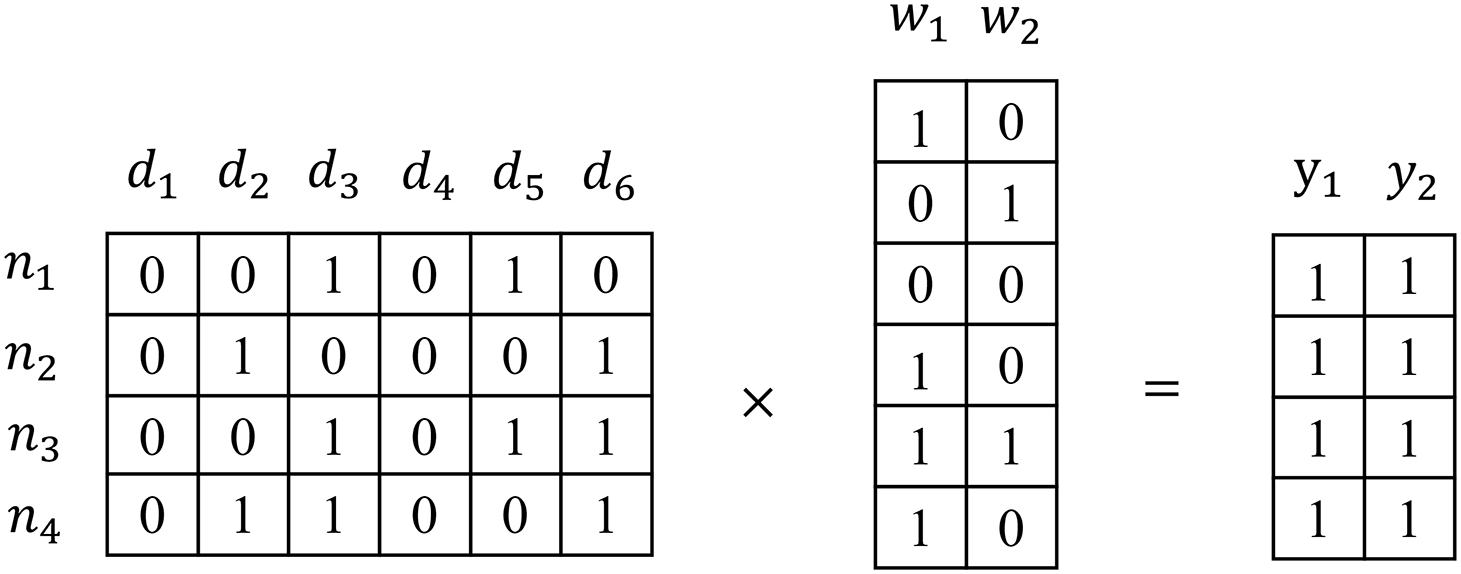
Figure 1: The process of addressing the label-specific feature
Based on the above analysis, we propose a causality-driven common and LSF learning. The main contributions of this paper are as follows:
1) We propose a novel CCSF method, which use
2) We use a causal learning algorithm to compute asymmetric label correlations, discarding the traditional way of combining correlation matrix and neighbor matrix, which reduces the influence of original labels.
The remaining sections are organized as follows. Section 2 summarizes some state-of-the-art domestic and international research. The proposed framework and model optimization of CCSF are presented in Section 3. Section 4 analyzes the experimental results and other related experiments. Finally, the conclusion is presented in Section 5.
Traditional MLL considers that all labels are distinguished based on the same features. However, this categorization is not reasonable and brings a lot of redundant information in the process of categorization, and the classification results are often sub-optimal. Zhang et al. proposed the LSF learning algorithm LIFT [10], which considers that each label is classified based on specific features. Compared with the traditional classification methods, it effectively improves the classification performance of MLL algorithm. But the algorithm does not take into account the correlation between labels. We consider that each label does not exist independently, but has a strong or weak correlation with other labels. The LLSF [11] algorithm proposed by Huang et al. uses the cosine similarity method to measure the correlation between labels. Two strongly correlated labels, whose LSF are also strongly correlated, which further improves the performance of the LSF learning algorithm. By different methods to measure the correlation between labels, Cheng et al. proposed the FF-MLLA [12] algorithm, which utilizes the Minkowski distance to measure the inter-sample similarity based on LC, and uses the singular value decomposition and the limit learning machine to classify multiple labels. The LF-LPLC [13] algorithm proposed by Weng et al. uses the nearest-neighbor technique to consider the local correlation of labels on the basis of the LSF learning algorithm. The algorithm not only enriches the semantic information of labels, but also solves the imbalance problem of labels. The MLFC [14] algorithm proposed by Zhang et al. further improves the performance of the LSF learning algorithm by uniting LSF learning and LC to obtain LSF for each label. For the missing label problem occurring in LSF learning algorithms, the LSML [15] algorithm proposed by Huang et al. utilizes the correlation between labels and has better experimental results not only on the complete dataset, but also on the missing label dataset. Zhao et al. proposed the LSGL [16] algorithm, which considers not only global but also local correlations between labels. LSGL algorithm, based on the assumption that both global and local correlations coexist, has more accurate classification performance than the LSF learning algorithm, which only considers local correlations.
However, most of the above algorithms use cosine similarity to measure out symmetric correlations in the learning of LSF. In fact, the correlation between labels is mostly asymmetric. As the data dimension increases, the Euclidean distance metric becomes less effective. ACML [17] algorithm proposed by Bao et al. and CCSRMC [18] algorithm proposed by Zhang et al. measure the asymmetric correlation between labels using the DC algorithm in causal learning, which are both effective in improving the classification performance of MLL. Luo et al. proposed the MLDL [19] algorithm to fully utilize the structural relationship between features and labels. Not only does it use bi-Laplace regularization to mine the local information of the labels, but it also employs a causal learning algorithm to explore the intrinsic causal relationships between the labels. The BDLS [20] algorithm proposed by Tan et al. introduces a bi-mapping learning framework in LSF learning and uses a causal learning algorithm to calculate the asymmetric correlation between labels, which also effectively improves the classification performance of the LSF learning algorithm. However, the above LSF learning only considers the private features of labels and not the common features of labels. CLML [9] algorithm proposed by Li et al. first uses a norm in the LSF framework to extract the common features of the labels. Subsequently, the GLFS [21] algorithm proposed by Zhang et al. builds a group-preserving optimization framework for feature selection by learning the common features of similar labels and the private features of each label using K-means clustering. Based on the above analysis, we adopt a causal learning algorithm to learn asymmetric LC among labels in LSF learning framework. The
3 CCSF Model Construction and Optimization
In MLL,
where
where
LC has been widely used in LSF learning algorithms, which can effectively improve the classification performance of MLL algorithms. But cosine similarity [22] all calculates symmetric correlations. Indeed, correlations between labels are asymmetric [23]. In this paper, we use a globally structured causal learning algorithm GSBN [24]. First, Markov Blanket (MB) or Parent and Child (PC) part-to-whole structure learning for each label is obtained. Then a directed acyclic graph (DAG) framework is constructed using MB or PC learning.
With the constraint of causal LC, assuming that
where
Therefore, we add causal constraints based on Eq. (2). The core formula of the CCSF algorithm can be written as:
where
Considering the non-smoothness of the
where
The CCSF model is a convex optimization problem. Due to the non-smoothness of the
where
For any matrices
where
Let
The optimization algorithm proposed by Lin et al. [27] points out that
In Eq. (13),
where
According to
Therefore, the Lipschitz constant for the CCSF model is:
The CCSF algorithm framework is as following:

The validation method is as follows.

The time complexity analysis of CCSF and comparison algorithms is shown in Table 1, where

To validate the effectiveness of the algorithm proposed in this paper, five cross-validations were performed on nine multi-label benchmark datasets. The datasets are from different domains, the details of which are shown in Table 2.
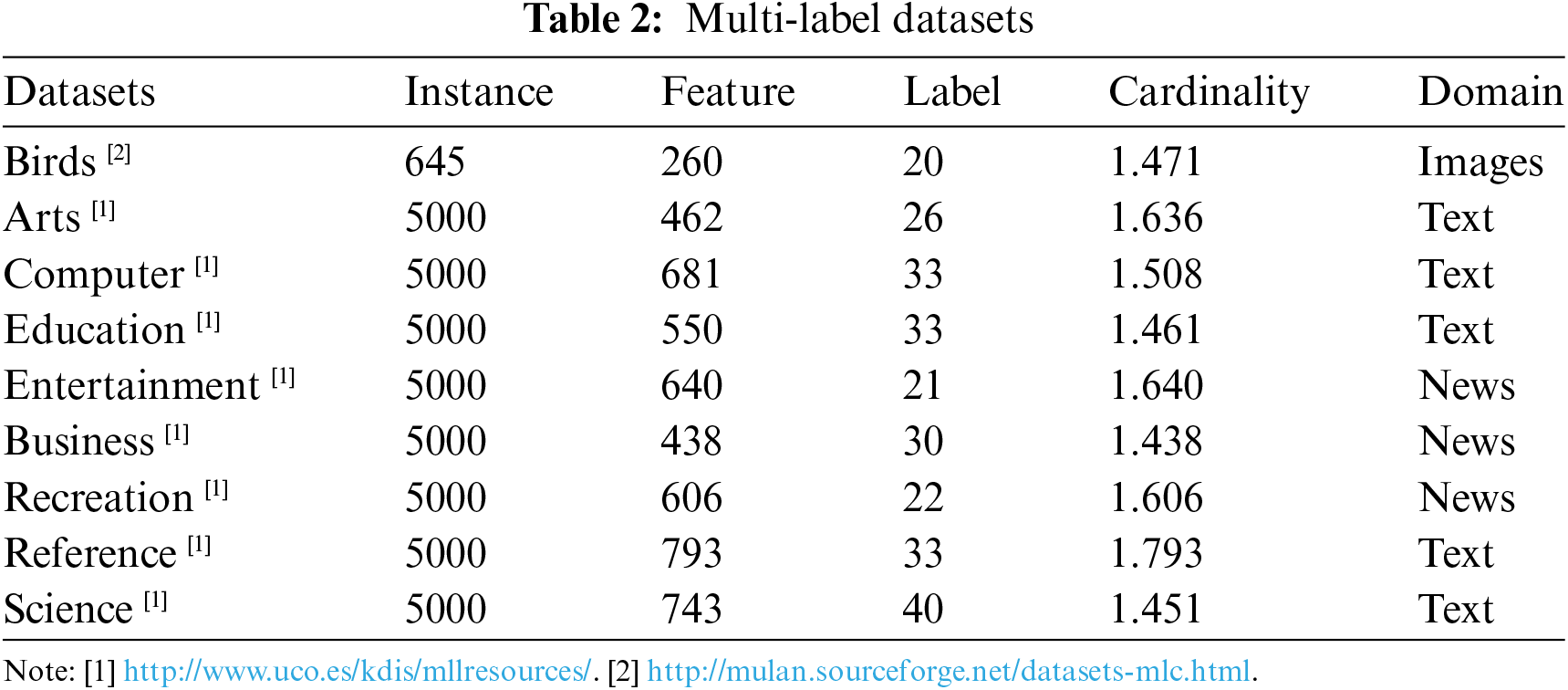
4.2 Results and Comparison Algorithms
The experimental codes are implemented in MatlabR2021a, with a hardware environment of IntelCore (TM) i5-11600KF 3.90 GHz CPU, 32 G RAM, and an operating system of Windows 10.
In order to compare the effectiveness of CCSF algorithms, six commonly used evaluation metrics in MLL are selected in this paper, which are Hamming Loss (HL), Average Precision (AP), One Error (OE), Ranking Loss (RL), Coverage (CV), and AUC (AUC). Among them, the smaller the HL, OE, RL, CV metrics the better, the larger the AP and AUC metrics the better the experimental effect. Specific formulas and meanings can be found in the literature [28,29]. The parameters of the comparison algorithm are set as follows:
1) In LSGL [16] algorithm,
2) The parameters interval of the ACML [17] algorithm are
3) Numbers of nearest neighbors in the FF-MLLA [12] algorithm are
4) The parameters of LSML [15] are set as follows
5) The parameters of LLSF [11] are set to
6) The parameters of LSI-CI [30] are set to
7) The parameters of CCSF are set as
The experimental results of the CCSF algorithm on 9 datasets with 6 state-of-the-art algorithms under 6 different metrics are given in Table 2, where “
1) As can be seen from Table 3, out of the 54 sets of experimental results, the CCSF algorithm is superior in 49 sets, with a superiority rate of 90.74%. The CCSF algorithm significantly outperforms the other compared algorithms on all 8 datasets. The variance of the CCSF algorithm is smaller, which also proves that the CCSF algorithm is more stable. On the Birds dataset, the CCSF algorithm and the ACML algorithm are equally dominant, due to the fact that both algorithms use causal learning algorithms to compute asymmetric correlations between labels. While the Birds dataset is small, it is difficult to extract more common features of the labels, and the experimental effect dominance is not obvious compared to the larger dataset.
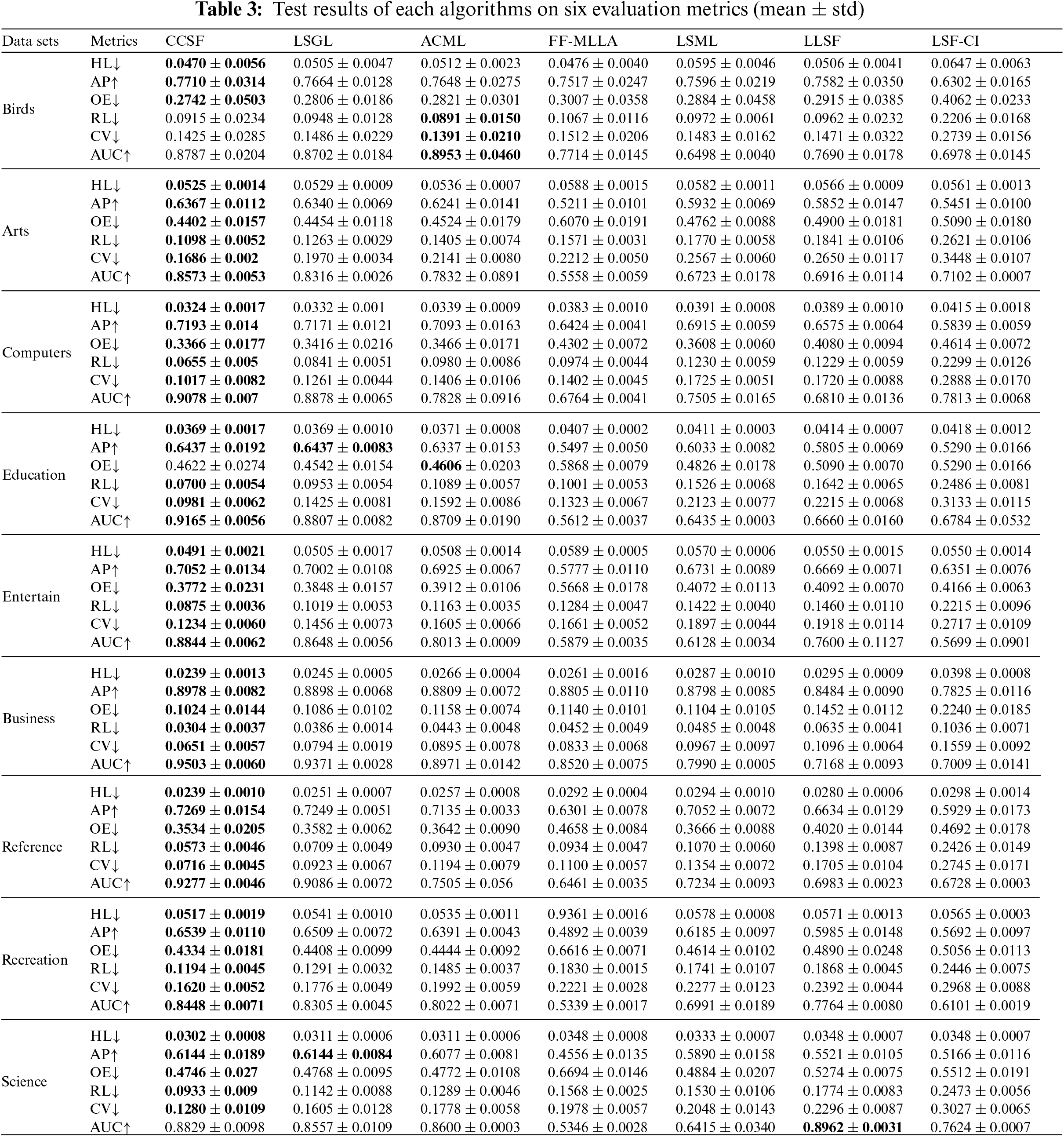
2) The CCSF algorithm significantly outperforms the ACML algorithm on these 54 sets of experimental results. This is because the ACML algorithm only takes into account the asymmetric relationship between the labels and does not take into account the fact that the common features of the labels also have a very significant role in multi-label classification.
3) The CCSF algorithm significantly outperforms the traditional LLSF algorithm and the LSGL algorithm. The reason is that the LLSF algorithm only considers the global correlation of labels. The LSGL algorithm is superior to the LLSF algorithm, which is because the LSGL algorithm not only considers the global correlation of labels, but also considers the local correlation of labels. Both of them do not consider the causal relationship between the labels and do not take into account that the common features of labels can effectively improve the performance of multi-label classification algorithms. However, we adopt a global causality and do not consider the local causality between labels, which is also a defect of the algorithm in this paper.
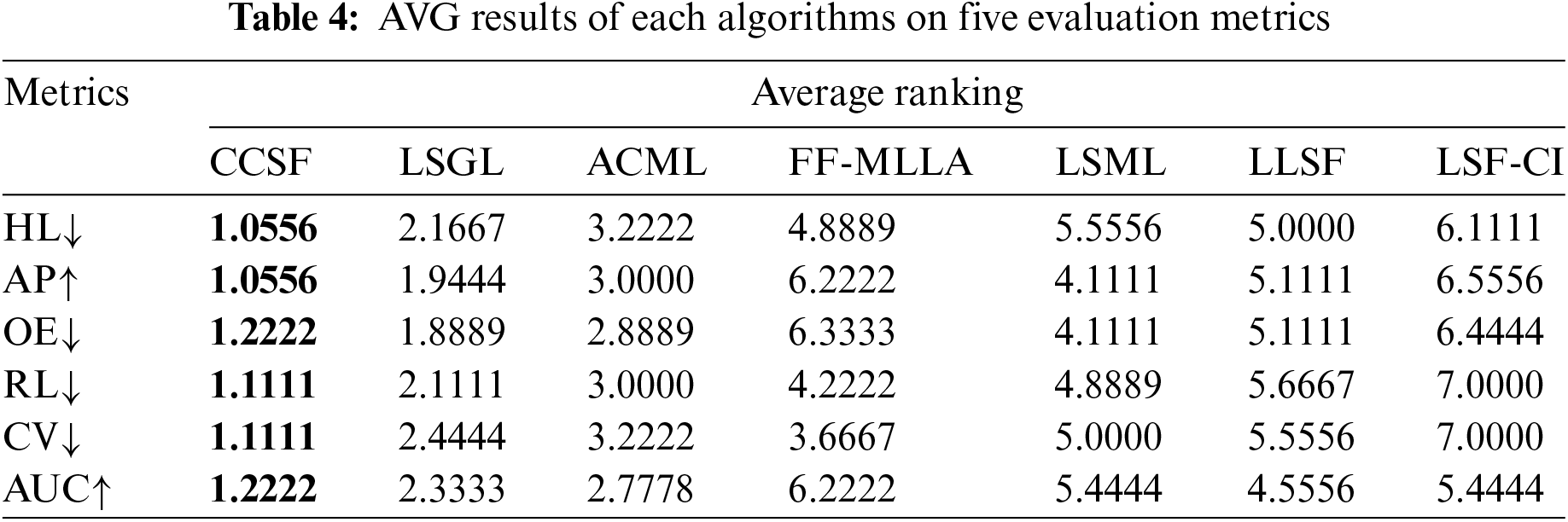
4) The experimental results of the CCSF algorithm for the average ranking of six evaluation metrics on nine datasets are demonstrated in Table 4, which also fully proves that the adoption of causal correlation and common features of labels can effectively improve the classification performance of the LSF model.
4.3 Parameter Sensitivity Analysis
The CCSF algorithm has three main hyperparameters.
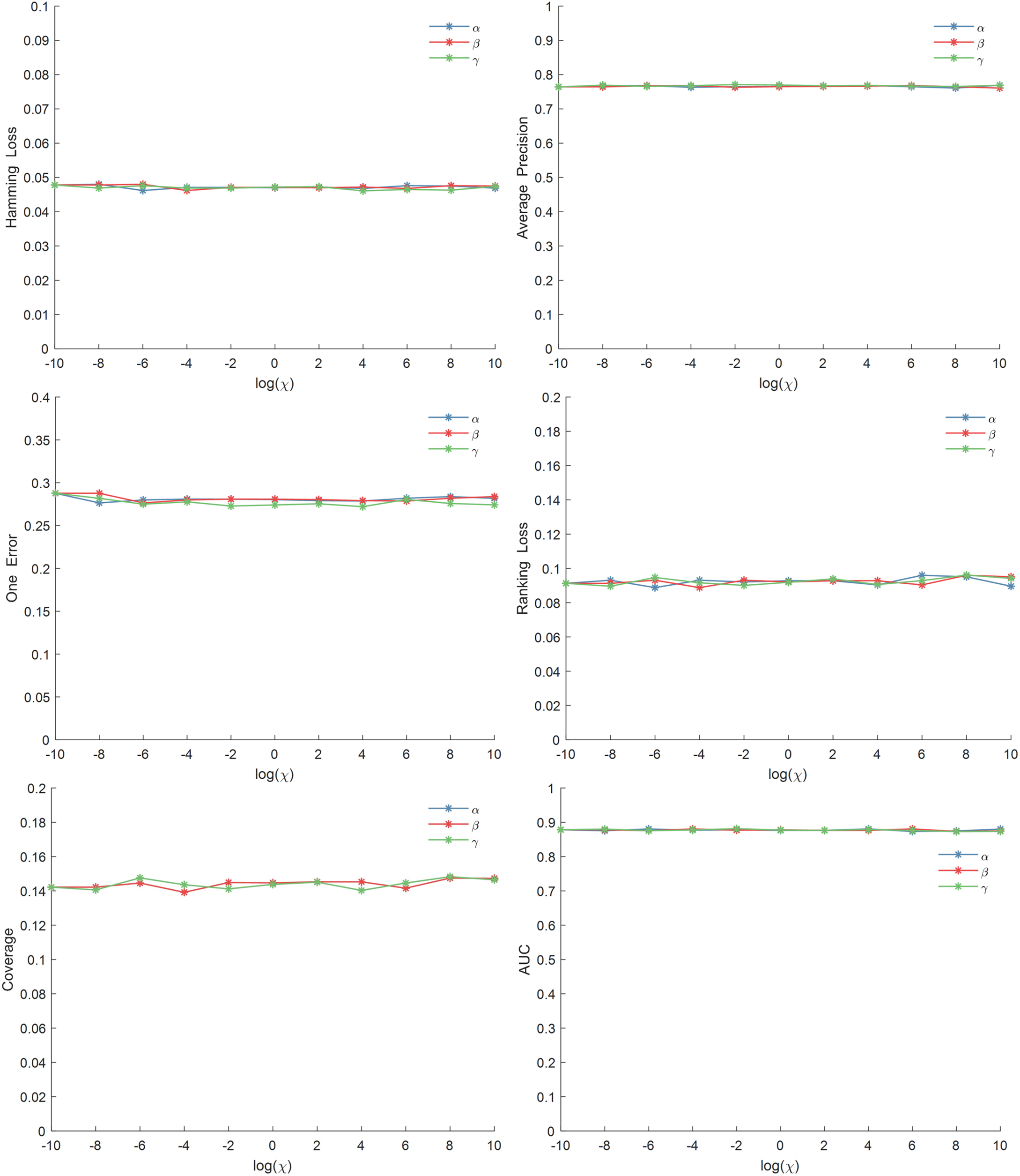
Figure 2: Parameter sensitivity analysis on the Birds dataset
In order to verify that introducing common features of labels in the model can effectively improve the performance of multi-label LSF learning algorithms. We conducted component analysis experiments on nine datasets. We compare the CCSF algorithm, which combines the common and private features of label, with the CSF algorithm, which considers only the private features of label. The experimental results are shown in Fig. 3, where the CCSF algorithm outperforms the CSF algorithm on multiple datasets. This indicates that considering the common and private features of labels can effectively improve the performance of LSF algorithm. It also demonstrates that common feature learning of labels introduced into multi-label classification algorithms can improve the accuracy of the algorithms.
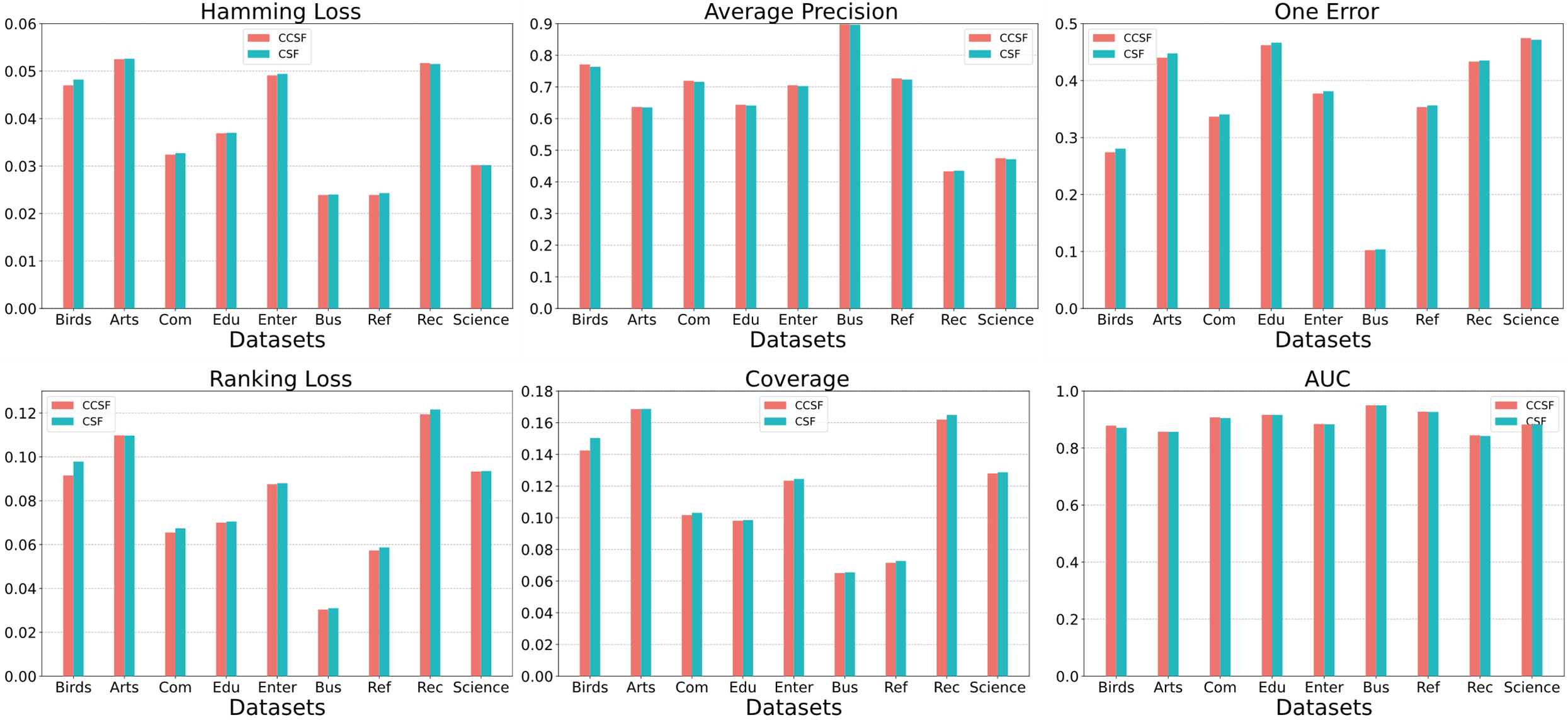
Figure 3: Component analysis on nine datasets
4.5 Statistical Hypothesis Testing
The statistical hypothesis tests in this paper are all based on a significance level of

Nemenyi test [32] is then used to compare the CCSF algorithm with the other six algorithms on all datasets. A significant difference exists when the difference between the average rankings of the two algorithms on all datasets is greater than the Critical Difference (CD) and vice versa. CD value is calculated as follows:
where
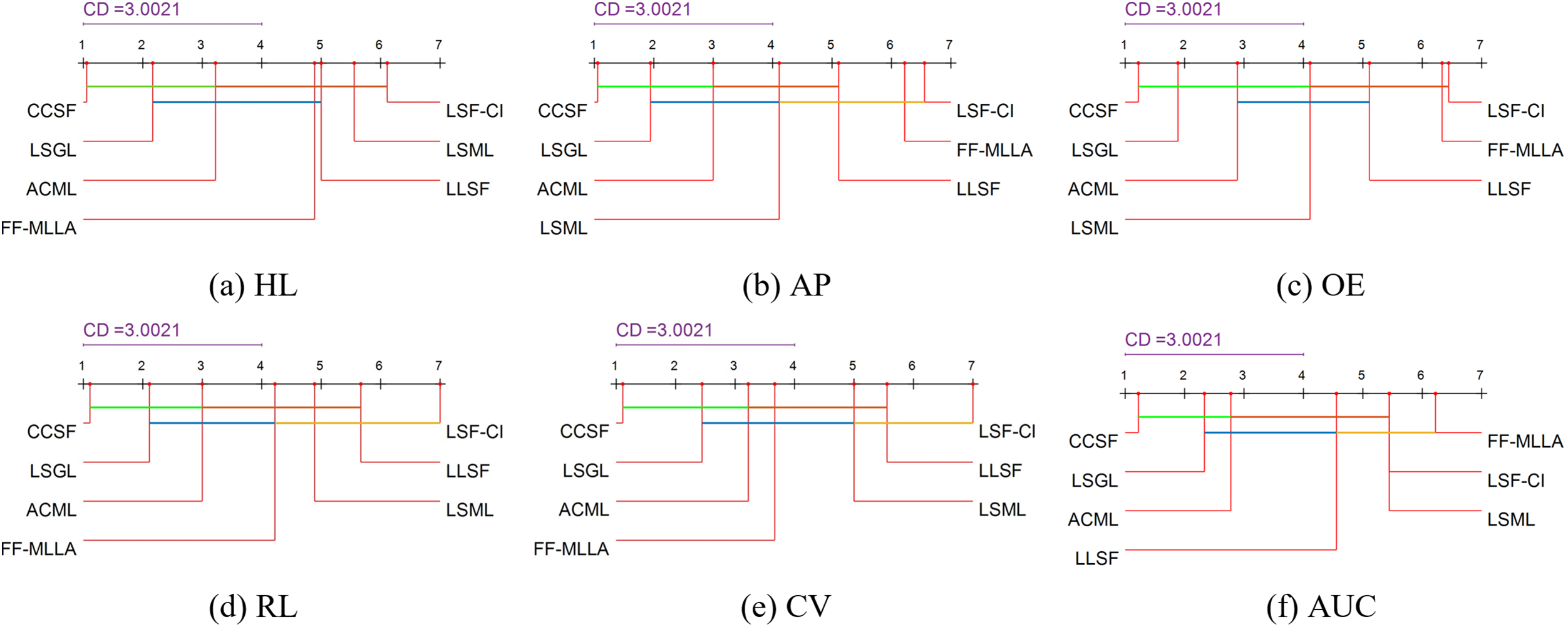
Figure 4: Performance comparison of the CCSF algorithm and the comparison algorithm
In this paper, the sentiment dataset and the yeast dataset are selected for convergence analysis. As can be seen in Fig. 5, after about forty iterations, the experimental results tend to converge. We conducted the same experiment on other datasets. The convergence results are also similar.
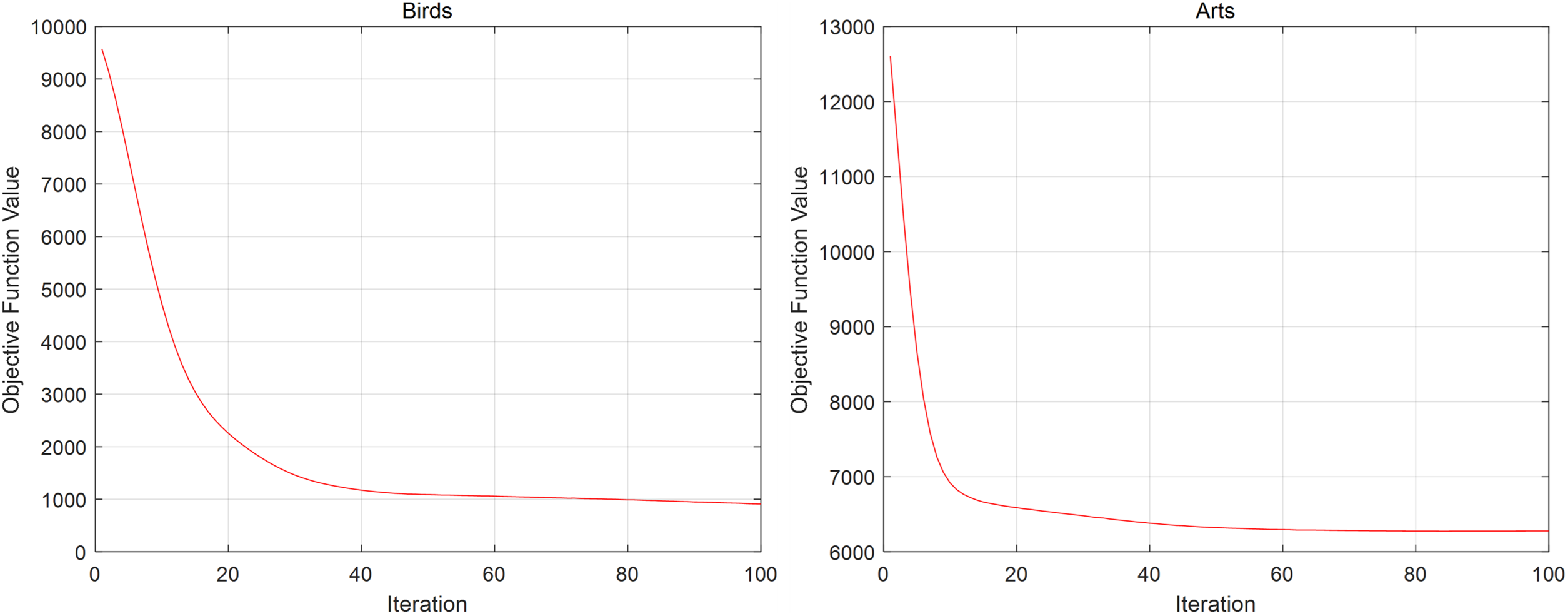
Figure 5: Convergence of CCSF
In response to the fact that most of the current LSF learning does not consider the common features of the labels. And only symmetric LC is considered in the calculation of LC. The result is the introduction of much redundant information when classification is performed, which reduces the classification performance of MLL algorithms. Based on the above problem, we use
Acknowledgement: None.
Funding Statement: 2022 University Research Priorities, No. 2022AH051989.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Y. T. Xu and D. Q. Zhang; analysis and interpretation of results: H. B. Guo and Y. T. Xu; draft manuscript preparation: Y. T. Xu and M. Y. Wang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: All datasets are publicly available for download. The download URL is in Section 4.1.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. L. Zhang and Z. H. Zhou, “A review on multi-label learning algorithms,” IEEE Trans. Knowl. Data Eng., vol. 26, no. 8, pp. 1819–1837, 2013. doi: 10.1109/TKDE.2013.39. [Google Scholar] [CrossRef]
2. W. Wei et al., “Automatic image annotation based on an improved nearest neighbor technique with tag semantic extension model,” Procedia Comput. Sci., vol. 183, no. 24, pp. 616–623, 2021. doi: 10.1016/j.procs.2021.02.105. [Google Scholar] [CrossRef]
3. T. Qian, F. Li, M. S. Zhang, G. N. Jin, P. Fan and W. Dai, “Contrastive learning from label distribution: A case study on text classification,” Neurocomput., vol. 507, no. 7, pp. 208–220, 2022. doi: 10.1016/j.neucom.2022.07.076. [Google Scholar] [CrossRef]
4. W. Q. Xia et al., “PFmulDL: A novel strategy enabling multi-class and multi-label protein function annotation by integrating diverse deep learning methods,” Comput. Biol. Med., vol. 145, pp. 105465, 2022. doi: 10.1016/j.compbiomed.2022.105465. [Google Scholar] [PubMed] [CrossRef]
5. S. H. Liu, B. Wang, B. Liu, and L. T. Yang, “Multi-community graph convolution networks with decision fusion for personalized recommendation,” in Pacific-Asia Conf. Knowl. Discov. Data Min., Chengdu, China, 2022, pp. 16–28. [Google Scholar]
6. J. L. Miu, Y. B. Wang, Y. S. Cheng, and F. Chen, “Parallel dual—channel multi-label feature selection,” Soft Comput., vol. 27, no. 11, pp. 7115–7130, 2023. doi: 10.1007/s00500-023-07916-4. [Google Scholar] [CrossRef]
7. Y. B. Wang, W. X. Ge, Y. S. Cheng, and H. F. Wu, “Weak-label-specific features learning based on multidimensional correlation,” J. Nanjing Univ. (Natural Sci.), vol. 59, no. 4, pp. 690–704, 2023 (In Chinese). [Google Scholar]
8. K. Yu et al., “Causality-based feature selection: Methods and evaluations,” ACM Comput. Surv., vol. 53, no. 5, pp. 1–36, 2020. [Google Scholar]
9. J. H. Li, P. P. Li, X. G. Hu, and K. Yu, “Learning common and label-specific features for multi-Label classification with correlation information,” Pattern Recogn., vol. 121, no. 8, pp. 108257, 2022. doi: 10.1016/j.patcog.2021.108259. [Google Scholar] [CrossRef]
10. M. L. Zhang and L. Wu, “LIFT: Multi-label learning with label-specific features,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 1, pp. 107–120, 2015. doi: 10.1109/TPAMI.2014.2339815. [Google Scholar] [PubMed] [CrossRef]
11. J. Huang, G. Li, Q. Huang, and X. D. Wu, “Learning label specific features for multi-label classification,” in 2015 IEEE Int. Conf. Data Min., Atlantic City, NJ, USA, 2015, pp. 181–190. [Google Scholar]
12. Y. S. Cheng, K. Qian, Y. B. Wang, and D. W. Zhao, “Multi-label lazy learning approach based on firefly method,” J. Comput. Appl., vol. 39, no. 5, pp. 1305–1311, 2019 (In Chinese). [Google Scholar]
13. W. Weng, Y. J. Lin, S. X. Wu, Y. W. Li, and Y. Kang, “Multi-label learning based on label-specific features and local pairwise label correlation,” Neurocomput., vol. 273, no. 9, pp. 385–394, 2018. doi: 10.1016/j.neucom.2017.07.044. [Google Scholar] [CrossRef]
14. J. Zhang et al., “Multi label learning with label-specific features by resolving label correlation,” Knowl.-Based Syst., vol. 159, no. 8, pp. 148–157, 2018. doi: 10.1016/j.knosys.2018.07.003. [Google Scholar] [CrossRef]
15. J. Huang et al., “Improving multi-label classification with missing labels by learning label-specific features,” Inf. Sci., vol. 492, no. 1, pp. 124–146, 2019. doi: 10.1016/j.ins.2019.04.021. [Google Scholar] [CrossRef]
16. D. W. Zhao, Q. W. Gao, Y. X. Lu, and D. Sun, “Learning multi-label label-specific features via global and local label correlations,” Soft Comput., vol. 26, no. 5, pp. 2225–2239, 2022. doi: 10.1007/s00500-021-06645-w. [Google Scholar] [CrossRef]
17. J. C. Bao, Y. B. Wang, and Y. S. Cheng, “Asymmetry label correlation for multi-label learning,” Appl. Intell., vol. 55, no. 6, pp. 6093–6105, 2022. doi: 10.1007/s10489-021-02725-4. [Google Scholar] [CrossRef]
18. C. Zhang, Y. S. Cheng, Y. B. Wang, and Y. T. Xu, “Interactive causal correlation space reshape for multi-label classification,” Int. J. Interact. Multimed. Artif. Intell., vol. 7, no. 5, pp. 107–120, 2022. doi: 10.9781/ijimai.2022.08.007. [Google Scholar] [CrossRef]
19. J. Luo, Q. W. Gao, Y. Tan, D. W. Zhao, Y. X. Lu and D. Sun, “Multi label learning based on double Laplace regularization and causal inference,” Comput. Eng., vol. 49, pp. 49–60, 2023 (In Chinese). [Google Scholar]
20. Y. Tan, D. Sun, Y. Shi, L. Gao, Q. Gao and Y. Lu, “Bi-directional mapping for multi-label learning of label-specific features,” Appl. Intell., vol. 52, no. 7, pp. 8147–8166, 2022. doi: 10.1007/s10489-021-02868-4. [Google Scholar] [CrossRef]
21. J. Zhang et al., “Group-preserving label-specific feature selection for multi-label learning,” Expert. Syst. Appl., vol. 213, pp. 118861, 2023. doi: 10.1016/j.eswa.2022.118861. [Google Scholar] [CrossRef]
22. L. L. Zhang, Y. S. Cheng, Y. B. Wang, and G. S. Pei, “Feature-label dual-mapping for missing label-specific features learning,” Soft Comput., vol. 25, no. 14, pp. 9307–9323, 2021. doi: 10.1007/s00500-021-05884-1. [Google Scholar] [CrossRef]
23. P. Zhao, S. Y. Zhao, X. Y. Zhao, H. T. Liu, and X. Jia, “Partial multi-label learning based on sparse asymmetric label correlations,” Knowl.-Based Syst., vol. 245, pp. 108601, 2022. doi: 10.1016/j.knosys.2022.108601. [Google Scholar] [CrossRef]
24. D. Margaritis and S. Thrun, “Bayesian network induction via local neighborhoods,” in Proc. Conf. Neural Inf. Process. Syst., Harrahs and Harveys, Lake Tahoe, USA, 2000, pp. 505–511. [Google Scholar]
25. A. Argyriou, T. Evgeniou, and M. Pontil, “Multi-task feature learning,” in Annual Conf. Neural Inf. Process. Syst., Vancouver, British Columbia, Canada, 2006, pp. 41–48. [Google Scholar]
26. A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM J. Imaging Sci., vol. 2, no. 1, pp. 183–202, 2009. doi: 10.1137/080716542. [Google Scholar] [CrossRef]
27. Z. C. Lin, A. Ganesh, J. Wright, L. Q. Wu, M. M. Chen and Y. Ma, “Fast convex optimization algorithms for exact recovery of a corrupted low-rank matrix,” Coordinated Sci. Lab. Report, vol. 246, pp. 2214, 2009. [Google Scholar]
28. D. W. Zhao, Q. W. Gao, Y. X. Lu, and D. Sun, “Learning view-specific labels and label-feature dependence maximization for multi-view multi-label classification,” Appl. Soft Comput., vol. 124, no. 8, pp. 109071, 2022. doi: 10.1016/j.asoc.2022.109071. [Google Scholar] [CrossRef]
29. K. Qian, X. Y. Min, Y. S. Cheng, and F. Min, “Weight matrix sharing for multi-label learning,” Pattern Recogn., vol. 136, pp. 109156, 2023. doi: 10.1016/j.patcog.2022.109156. [Google Scholar] [CrossRef]
30. H. R. Han, M. X. Huang, Y. Zhang, X. G. Yang, and W. G. Feng, “Multi-label learning with label specific features using correlation information,” IEEE Access, vol. 7, pp. 11474–11484, 2019. doi: 10.1109/ACCESS.2019.2891611. [Google Scholar] [CrossRef]
31. J. Demsar, “Statistical comparisons of classifiers over multiple data sets,” J. Mach Learn. Res., vol. 7, no. 1, pp. 1–30, 2006. [Google Scholar]
32. D. Zhao, H. Li, Y. Lu, D. Sun, D. Zhu and Q. Gao, “Multi label weak-label learning via semantic reconstruction and label correlations,” Inf. Sci., vol. 623, no. 8, pp. 379–401, 2023. doi: 10.1016/j.ins.2022.12.047. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools