
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Distributed Federated Split Learning Based Intrusion Detection System
1 Department of Computer Science, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
2 Department of Computer Science, Faculty of Computer Science and Engineering, University of Hail, Hail, 55476, Saudi Arabia
* Corresponding Author: Rasha Almarshdi. Email:
Intelligent Automation & Soft Computing 2024, 39(5), 949-983. https://doi.org/10.32604/iasc.2024.056792
Received 31 July 2024; Accepted 23 September 2024; Issue published 31 October 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The Internet of Medical Things (IoMT) is one of the critical emerging applications of the Internet of Things (IoT). The huge increases in data generation and transmission across distributed networks make security one of the most important challenges facing IoMT networks. Distributed Denial of Service (DDoS) attacks impact the availability of services of legitimate users. Intrusion Detection Systems (IDSs) that are based on Centralized Learning (CL) suffer from high training time and communication overhead. IDS that are based on distributed learning, such as Federated Learning (FL) or Split Learning (SL), are recently used for intrusion detection. FL preserves data privacy while enabling collaborative model development. However, FL suffers from high training time and communication overhead. On the other hand, SL offers advantages in terms of computational resources, but it faces challenges such as communication overhead and potential security vulnerabilities at the split point. Federated Split Learning (FSL) has proposed overcoming the problems of both FL and SL and offering more secure, efficient, and scalable distribution systems. This paper proposes a novel distributed FSL (DFSL) system to detect DDoS attacks. The proposed DFSL enhances detection accuracy and reduces training time by designing an adaptive aggregation method based on the early stopping strategy. However, the increased number of clients leads to increasing communication overheads. We further propose a Multi-Node Selection (MNS) based Best Channel-Best -Norm (BC-BN2) selection scheme to reduce communication overhead. Two DL models are used to test the effectiveness of the proposed system, including a Convolutional Neural Network (CNN) and CNN with Long Short-Term Memory (LSTM) on two modern datasets. The performance of the proposed system is compared with three baseline distributed approaches such as FedAvg, Vanilla SL, and SplitFed algorithms. The proposed system outperforms the baseline algorithms with an accuracy of 99.70% and 99.87% in CICDDoS2019 and LITNET-2020 datasets, respectively. The proposed system’s training time and communication overhead are 30% and 20% less than the baseline algorithms.Keywords
The Internet of Things (IoT) is the most important technology, and it has grown exponentially. IoT is a set of technologies that connect a wide range of IoT devices and generate a large volume of data with features of larger size, higher velocity, and heterogeneity [1]. At the same time, the evolution of 5G networks has given strength to the growth of the IoT. 5G is characterized by higher capacity and lower latency to facilitate communication of billions of devices over the Internet. Therefore, the 5G network should be integrated with modern technologies to provide exceptional services [2]. One of the important 5G-enabling technologies is Multiple-Input-Multiple-Output (MIMO), which has been used in recent years to provide high spectral efficiency and high throughput [3].
The growth of 5G-based IoT (5G-IoT) comes with challenges related to IoT data, such as security and privacy, and they also have an impact on computational complexity and cost in data storage and data processing. An important IoT domain that needs 5G features in transmission and channel utilization is the Internet of Medical Things (IoMT) [4]. The IoMT is a latency-sensitive application expected to be deployed based on 5G technologies. It will have a great role in maintaining the sustainability of smart cities [5]. Fig. 1 describes the 5G-IoMT architecture, including three layers: sensing layer, fog computing layer, and cloud computing layer. First, the data is collected using various sensors or medical devices in the sensing layer. These devices are resource-constrained and have low computation power. The data is passed to the fog computing layer via communication protocols, where more powerful computing fog servers process it to avoid latency. The data is transmitted in the 5G structure through multiple Base Stations (BSs) that employ fog computing. Finally, the data is transmitted from the fog computing layer to the cloud computing layer to store and update the patient’s data [6].
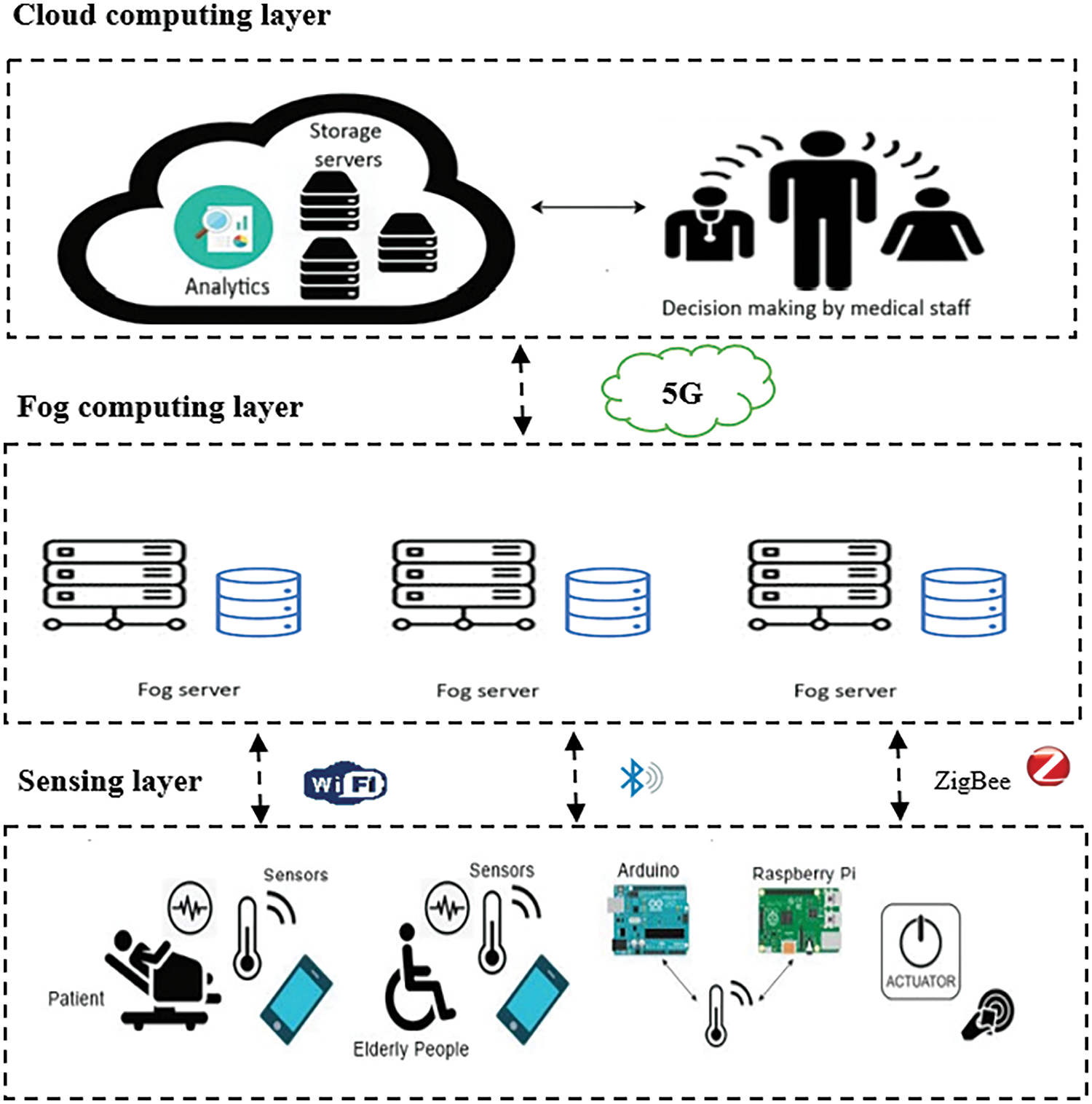
Figure 1: 5G-IoMT system architecture
The significant increase in transmitting a large volume of data across distributed networks makes security one of the most important challenges in IoMT. Recently, Distributed Denial of Service (DDoS) attacks have increased dramatically, leading to significant consequences [7]. One of the most popular real examples of DDoS against medical institutions was in 2016 when the attacker used malware to breach the Banner Health network in Arizona and access the patient’s information, including patient’s social numbers, dates of services, and information related to the insurance. The attack went undetected for a month, with 3.7 million patients affected. It cost $1.25 million to resolve the data breach issue [8].
Intrusion Detection Systems (IDSs) based on the Centralized Learning (CL) approach are widely used to detect security attacks. CL is a traditional learning approach where the data is uploaded from each connected client device to the cloud server to train the entire model and distribute it to all devices [9]. IDSs using Machine Learning (ML) methods are impractical in the new network environment, and they are not effective in detecting attacks in massive and distributed environments. Although centralized systems based on Deep Learning (DL) achieve acceptable accuracy, they include limitations such as connectivity, bandwidth, latency, communication overhead, computation power, and distributed data security. In addition, it is not scalable to the size of IoMT [10].
IDSs based on distributed learning, such as Federated Learning (FL) or Split Learning (SL), are used in distributed environments to overcome the limitations of CL. FL is an efficient approach that trains the model with its local data among multiple clients and shares the model update with the server. FL preserves data privacy while enabling collaborative model development. However, FL suffers from high training time and communication overhead [11]. On the other hand, SL splits the model into two parts, one for clients and one for servers, which reduces the computational cost and can help reduce training time [12]. SL offers advantages in terms of computational resources, but it faces challenges such as communication overhead and potential security vulnerabilities at the split point. Both FL and SL are not efficient when the number of clients increases, having heterogeneous datasets, and with constraints on communication resources. Federated Split Learning (FSL) is emerging research combining FL and SL that could solve problems of both FL and SL and offer more secure, efficient, and scalable distribution systems [13]. Most existing IDSs are not scalable to the network size. It suffers from low detection accuracy, training time, and communication overhead. These issues have negatively affected the throughput of real-time applications such as IoMT, and we need to solve them urgently.
Recently, a user selection strategy has been used to reduce communication overheads. In FL, different selection schemes have been proposed in [14], including four schemes. The first scheme is Best Channel (BC), where the user is selected based only on the channel condition. The second scheme is Best
Motivated by the above, this paper proposed a distributed FSL (DFSL) system to detect DDoS attacks, enhancing detection accuracy and reducing training time and communication overhead. Three research questions were formulated as follows:
Q1: How do we distribute the detection model with high detection accuracy and low training time?
Q2: How can the communication overhead of the system be reduced?
Q3: How can we test the effectiveness of the proposed system?
To address the research questions of this paper, the following contributions were identified:
1. Propose a novel distributed FSL (DFSL) system to detect DDoS attacks in IoMT. An adaptive aggregation method is designed based on the early stopping strategy to reduce training time and enhance detection accuracy.
2. Propose a Multi-Node Selection (MNS) based Best Channel-Best
3. Test the system performance using Convolutional Neural Network (CNN) and a hybrid model that combines the CNN and long Short-Term Memory (LSTM), on two modern datasets such as CICDDoS2019 and LITNET-2020, and compare the performance with baseline distributed approaches such as FedAvg, Vanilla SL, and SplitFed algorithms.
The paper is organized as follows. A brief overview of FL, SL, FSL, and related works is provided in Section 2. Section 3 describes the problem formulation. The proposed work of the DFSL system and MNS scheme are described in Section 4. Section 5 describes the dataset description and data preprocessing. The performance results and comparative analysis are presented in Section 6. The discussion is presented in Section 7. Finally, the conclusion and future work is described in Section 8.
This section described a background for the FL, SL, and FSL approaches. Then, related works that are based on ML, CL, and distributed learning IDS in IoMT networks are presented.
In Federated Learning (FL) [16], the model is trained at each client in parallel with its local data for its local epochs. After that, the local model updates are sent to the server for model aggregation. The server aggregates the received local updates, generates the global model update, and sends it back to the clients so they can train for the next round. After receiving the global model update, each client trains the global parameters on its local data and sends its local update to the server. This process continues until the model converges. Federated Averaging (FedAvg) algorithm [17] is the popular centralized aggregation algorithm in FL. FedAvg algorithm considers a weighted average of the gradients for the model updates. Based on the FedAvg procedure, as shown in Fig. 2, the server initializes the global model parameter
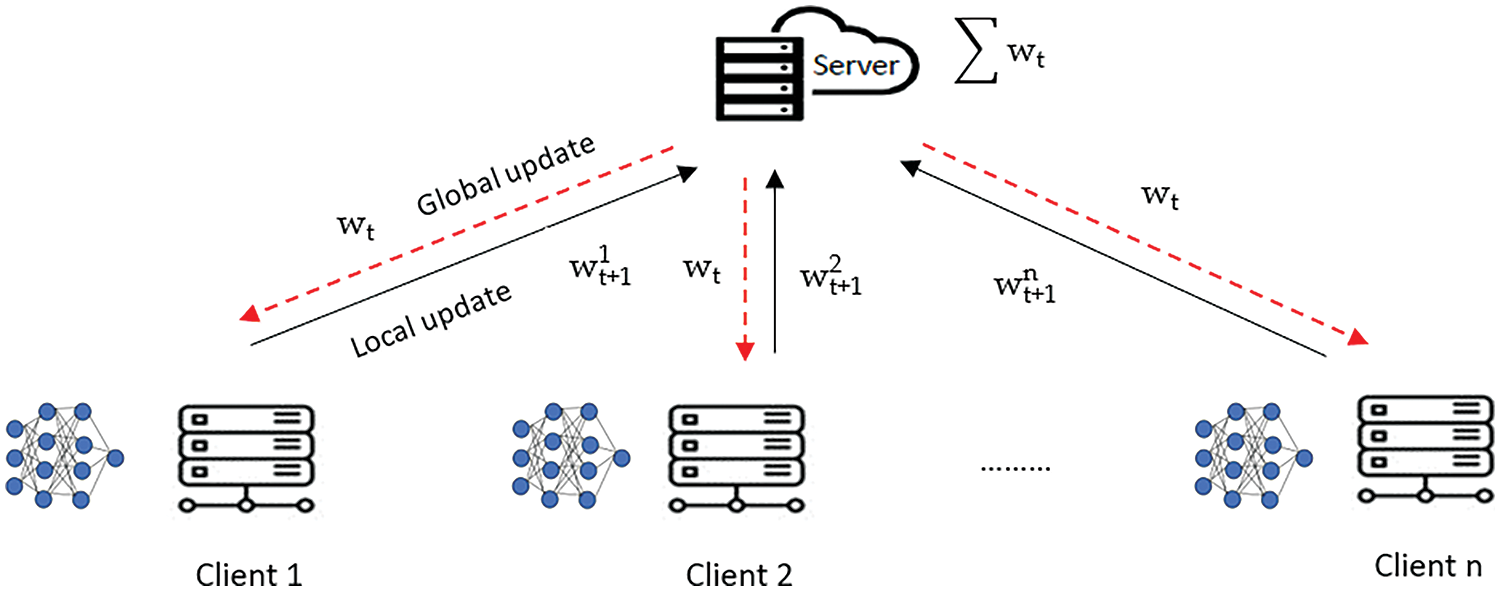
Figure 2: FedAvg architecture
where
where
where
In Split Learning (SL), the model is trained sequentially with its local data. The training raw data is stored in the client, and the server cannot access the raw data. Four SL configuration strategies include Vanilla SL, U-shaped SL, Vertically SL, and two-part SL configurations. Vanilla SL [18] is the most popular SL algorithm where the model is partitioned into at least two parts and shares labels. The first part runs on the client
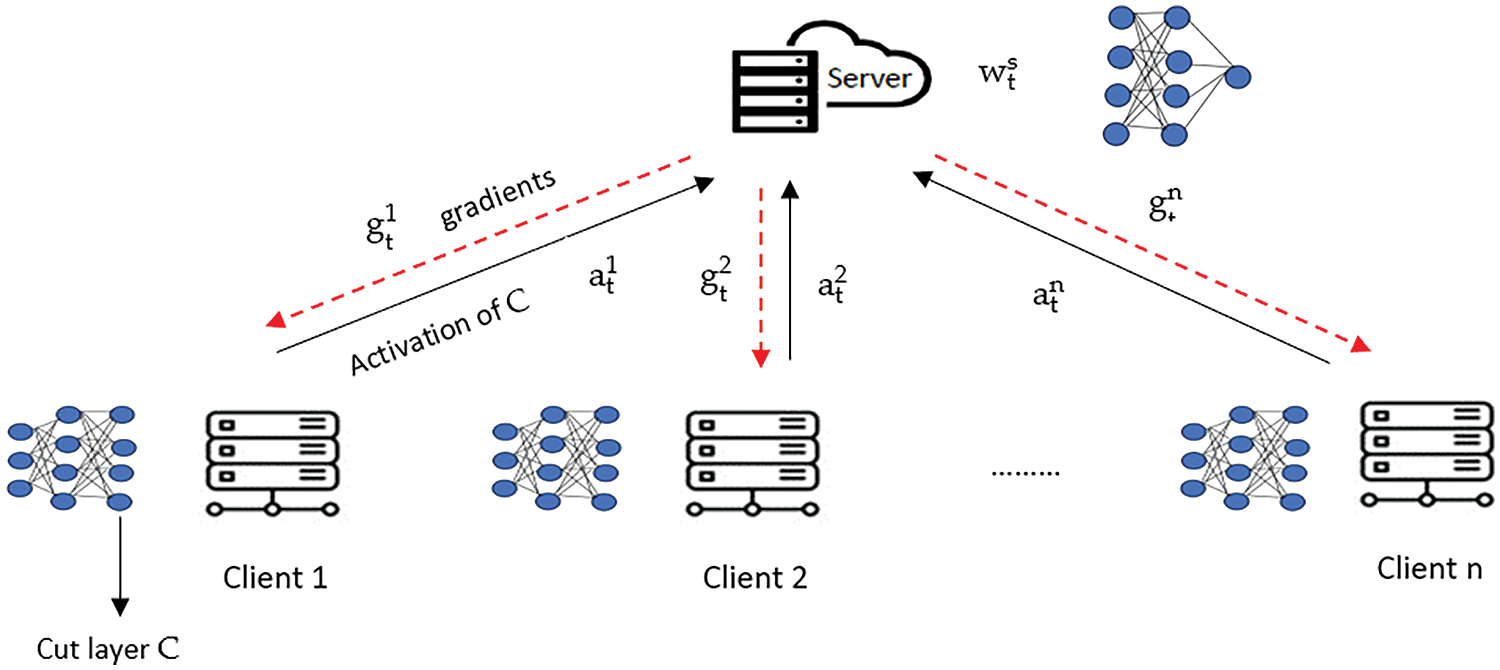
Figure 3: Vanilla SL architecture
U-shaped SL is another split configuration similar to Vanilla SL but without label sharing. Because the client does not share the label, the client completes learning. In U-shaped SL, the client has one or more bottom layers and one or two top layers, whereas the middle layers are allocated by the server. Vertically SL is a way to train a split model with different data without sharing data. Each client trains a part of the model up to the cut layer
Federated Split Learning (FSL) is a promising distributed learning that combines FL and SL approaches and takes advantage of the two approaches. It trains the model in parallel among multiple distributed clients in FL and splits the entire model between the clients and server in SL. SplitFed is the first method in FSL that eliminates the drawbacks of FL and SL. Unlike FL, the model is portioned and trained among the clients and the server to reduce training time. On the other hand, it does their training in parallel to reduce computation time and enhance learning performance, as in FL. It works similarly to the classic SL setting, except the existing fed server on the client side performs federated aggregation [20]. MiniBatch-SFL is proposed to incorporate MiniBatch SGD to FSL, where the clients train the client-side model in an FL fashion, and the server trains the server side and analyzes the convergence of the data [21]. A Communication and Storage Efficient FSL (CSE-FSL) strategy is proposed using the auxiliary network to update the local model at the client while keeping only a single model at the server, which helps to avoid the communication of gradients from the server and reduces the server resource requirement [22]. Finally, a comparison of the FL and SL settings regarding communication efficiency is explained in [23].
The following presents the most current IDS for detecting attacks in the IoMT environment.
Saheed et al. [24] developed an efficient IDS in IoMT based on Deep Recurrent Neural Network (DRNN) and ML models such as Random Forest (RF), Decision Tree (DT), K-Nearest Neighbors (KNN), and ridge classifiers. The goal is to classify and forecast unexpected cyber-attacks. They evaluated the developed IDS with the NSL-KDD dataset, and it outperformed the existing approaches with an accuracy of 99.76%. Manimurugan et al. [25] proposed a DL-based method Deep Belief Network (DBN) algorithm for IDS in IoMT. The CICIDS2017 dataset is used to test the proposed algorithm. The results achieved 96.67% accuracy for the DoS/DDoS class, 95.21% precision, 97.34% recall, 0.97 F-measure, and 97.31% detection rate. Usman et al. [26] proposed a framework that divides an underlying wireless multimedia sensor network into many clusters in IoMT. Each cluster has a cluster head, which is responsible for protecting the privacy data via data and location coordinates aggregation. Then, the aggregated data are processed on the cloud using Artificial Neural Network (ANN). The proposed P2DCA framework is implemented with the CICIDS2017 dataset and compared with the existing schemes. It achieved 150 min training time, 350 MB communication overhead, and 95.56% accuracy. Ren et al. [27] proposed Data Optimization IDS (DO-IDS) to identify the anomaly behaviors in the network. The proposed DO-IDS used hybrid data optimization. They used Isolation Forest (iForest) in data sampling and Genetic Algorithm (GA) to optimize the sampling ratio. The RF and GA are used in feature selection to obtain the optimal subset. The DO-IDS is tested using the RF classifier with the UNSW-NB15 dataset; it scored an accuracy of 92.8% and a false alarm rate of 0.330.
Some of the studies used the CL approach to detect attacks. Gudla et al. [28] proposed a Deep Intelligent DDoS Detection Scheme (DI-ADS) for IoT applications. The model is implemented in the fog layer to predict the behavior of the fog devices. The scheme was implemented using Multilayer Perceptron (MLP) on a dataset for Software Defined System called DDoS-SDN that consists of three types of DDoS attacks. The results showed the accuracy of 97.84% and 1000 min training time. Priyadarshini et al. [29] proposed a source-based DDoS defense mechanism in fog and cloud environments. The defender module is deployed at the SDN controller to detect abnormal behavior in the network and transport layer. The detection model is implemented using LSTM on CTU-13 Botnet and ISCX 2012 IDS datasets. The accuracy of the model was 87.67% and 87.96% for CTU-13 Botnet and ISCX 2012 IDS, respectively. Zhang et al. [30] proposed a DDoS detection model based on Bidirectional LSTM (BiLSTM) at edge computing. The model achieves information extraction using the BiLSTM network and automatically learns the characteristics of the attack traffic in the original data traffic. The proposed model, called power IoT, was implemented in their data and achieved an accuracy of 95%, 250 min training time, and 520 MB communication overhead.
For distributed learning, little works addresses the security in IoMT using FL, SL, and FSL approaches. Verma et al. [31] proposed an FL Deep Intrusion Detection (FLDID) framework in smart industries. The proposed framework builds a collaborative model to detect DDoS attacks. They used CNN+LSTM+MLP in the detection model with the X-IIoTID dataset. The proposed framework outperforms the other approaches with 99.22% accuracy and 3042 s training time. Rey et al. [32] proposed an FL framework to detect malware in IoT devices. The N-BaIoT dataset is used and is designed for network traffic of multiple IoT devices. Two different DL models, MLP and Autoencoders (EA), are used for detection. The performance of the models is compared with the traditional approach, which shares its data with the server, and with the traditional approach, which does not share its data. The performance of the proposed framework scored an accuracy of 95% and 88 MB communication overhead. Alhasawi et al. [33] introduced a federated learning-based approach to detect DDoS attacks known as FL for decentralized DDoS Attack Detection (FL-DAD). The detection model used CNN to effectively identify DDoS attacks on the CICIDS2017 dataset. The model is compared with centralized detection methods, and it achieved 99.3% accuracy, 48.3 s training time, and 390.2 MB communication overhead with the maximum number of nodes.
Yu et al. [34] proposed a Pseudo-Client ATack (PCAT) based on SL to detect DDoS attacks with more challenging situations where the client model is unknown to the server. They investigated the inherent privacy leakage via the server model in SL, where the server model can easily steal the data. The server trains a small part from the dataset, about 0.1%–5%, for the same learning task. The performance is evaluated using the Deep Neural Network (DNN) model on the MINIST dataset with a two-part SL strategy, where the results scored an accuracy of 96.98%. Abuadbba et al. [35] examined the SL on the 1D CNN model to detect DDoS attacks. They tested the model with medical ECG data and added two mitigation techniques. The first technique adds more hidden layers to the client side. The second technique applies various privacy. The model achieved 98% accuracy and 20 min training time.
Khan et al. [36] performed the first empirical analysis of the SplitFed algorithm. They used SplitFed to design a strong detection model. The CIFAR10 and FEMNIST datasets are used with Alexnet and VGG11 models to perform the training process. The results of the Alexnet and VGG11 in the CIFAR10 dataset, the accuracy scored 62.4% and 73%, respectively. For the custom model in the FEMNIST dataset, the accuracy scored 81%. The communication overhead scored 150 and 200 MB for both datasets. Li et al. [37] proposed an attack detection approach FSL in real IoT scenarios. The proposed approach for the construction of global models of various time series in the context of data isolation has the ability to detect attacks. The experiment is applied to the CNN model and MNIST dataset. It achieved an accuracy of 93.56%, precision of 92.78%, recall of 93.19%, and F-measure of 92.98%.
All related works that are mentioned above are summarized in Table 1.

Three important criteria to improve IoMT networks are detection accuracy, latency, and communication overhead. Most existing works that address the security in IoMT based on ML, CL, and distributed learning suffer from low detection accuracy, high training time, and high communication overhead, which is not acceptable for real-time and latency-sensitive applications such as IoMT. In addition, most of the datasets are out of date and related to different types of security attacks; there is a lack of datasets related to DDoS attacks. To solve the problems of existing attack detection, we propose a distributed FSL (DFSL) system to detect DDoS attacks in the IoMT environment, supporting the existing issues. An adaptive aggregation method based on the early stopping strategy is proposed to enhance detection accuracy and reduce training time. In addition, to improve the communication overhead, we propose a Multi-Node Selection (MNS) based BC-BN2 scheme with three selection metrics. The proposed system is evaluated using two modern DDoS datasets, CICDDoS2019 and LITNET-2020.
As mentioned above, IDS based on ML and CL has multiple challenges, including learning performance, training time, and communication overhead. The first Optimization Problem (
Although the FL may enhance learning performance, it suffers from high training time, which takes a long time to compute. The term computation refers to the number of training epochs/rounds
where
A distributed FSL (DFSL) system with an adaptive aggregation method based on the early stopping strategy is proposed to solve
where
A Multi-Node Selection (MNS) based BC-BN2 selection scheme is proposed to solve
4 Proposed Distributed FSL System
This section describes the details of the proposed distribution FSL (DFSL) system. First, the channel model is illustrated. Then, the DFSL system procedure is introduced. Then, the MNS scheme is explained. Finally, model convergence and complexity analysis are described.
The channel model of the proposed distributed FSL (DFSL) is based on uplink massive MIMO technology. The massive MIMO technology has been used in recent years with 5G to achieve high spectral efficiency and throughput, which is needed for IoMT networks. As shown in Fig. 4, the channel model consists of multiple clients, a base station with multiple antennas, and one server. The clients are fog nodes represented as

Figure 4: System channel model
where
The proposed DFSL is based on the FSL approach to maximize detection accuracy and reduce training time. Fig. 5 shows the DFSL system framework. Because the IoMT devices are resource-constrained and limited in computations, our DFSL algorithm works on fog nodes which have high computation capabilities and can avoid latency in computations. The proposed system works in three phases including initialization and model splitting, local model training, and adaptive aggregation.

Figure 5: Proposed DFSL framework
4.2.1 Initialization and Model Splitting
The server randomly selects the nodes randomly and broadcasts the initial global parameter

Figure 6: Two-part SL (a) CNN; (b) CNN+LSTM
After model splitting, each node with its smashed data computes activation
The local model updates on the node side are calculated as
An adaptive aggregation method is proposed to reduce training time and enhance detection accuracy. When training a model, the weights are the most important parameter for learning the model. The objective of the nodes’ local training process is to find the weight that enhances the global model’s accuracy on the local training sets. Therefore, the proposed adaptive aggregation adopts a computation amount controlled strategy that performs a certain number of model training steps per round to each node. This controlled strategy is based on the gap between the current local model’s accuracy and loss on the training set, as well as the maximum achievable accuracy and minimum achievable loss.
Unlike FedAvg, which perform fixed computation (
Our idea is that FedAvg’s convergence can be improved by using the max score of accuracy and loss in the training set to smartly stop the training at a certain point and to set the values for
The adaptive aggregation works in three steps. First, the server determines the maximum score
The
Second, the current
Finally, the stopping counter
Subsequently, the server aggregates the selected local updates to obtain the global model updates. The global model aggregation is calculated as
The workflow of the proposed DFSL system is described in Algorithm 1.

The fog nodes are connected to a wireless network via a radio communication link with constrained bandwidth. Although the DFSL reduces communication overhead by sharing model parameters rather than raw training data, the transmission of complex models from many nodes still generates much traffic. The goal is to reduce the number of nodes participating in each communication round to reduce overall communication overhead. One common technique to reduce the communication overhead in a distributed network is the node selection technique.
Based on the BC-BN2 which selects the nodes based on two metrics including the importance of local update and channel quality, the proposed MNS scheme selects the nodes based on three metrics. These metrics include the importance of local update, channel quality, and the nearest distance from the server. Selecting nodes with important local update helps to improve the model performance and get an accurate model. On the other hand, selecting the node with good channel quality and the nearest distance from the server improves communication and reduces communication time consumption.
For selecting nodes with the importance of local update, the nodes need to compare their local updates with the global update to determine the importance of its update in each communication round. The issue here is we cannot know if the global update is relevant or not until all local updates are aggregated. So, we can use the previous global update for comparison. To ensure the correct relevance between the previous global update and the current local update, we take the difference between two sequential global updates because the model training does not always have constant model convergence in each communication round. The normalized difference between two previous sequential global updates is measured as
where
A larger normalized difference means a larger divergence between the two updates. To ensure no large divergence between the two updates, the CNN and CNN+LSTM models are trained and measured for the cumulative distribution of the normalized divergence of the two global updates. As shown in Fig. 7, we see that for CNN, more than 98% of the difference is less than 0.3, where the maximum difference is 0.5. For CNN+LSTM, more than 99% has a difference of less than 0.2, where the maximum difference is 0.4. We can ensure that the previous global update can be used for the current global update. This prediction does not require more communications because each node maintains the global update made in the previous round. The current local update is compared to the previous round’s global update. The relevance between the local and global update is determined by computing the number of parameters with the same sign (gradients) in the two updates and normalizing the result by the total number of parameters. The relevance between the two updates is formulated as
where

Figure 7: Cumulative distribution of CNN and CNN+LSTM
Now, the nodes that have the important local update are denoted as
where
When the
The nearest distance between the node
where
Finally, finding the nearest neighbor nodes, the
Because the first round doesn’t have a previous global update, the nodes are selected randomly. The proposed algorithm starts from the second round, only node

In this section, the fundamental convergence analysis that affects the node side and server side on its training is performed. First, the technical assumptions are made. Then, the convergence result is presented.
A. Assumptions
First, we make the following four assumptions for convergence analysis.
Assumption 1. (ℓ-smooth) Each local loss function
Assumption 2. (
Assumption 3. (Unbiased and bounded stochastic gradient with bounded variance). Let
Further, the expected squared norm is bounded by
Assumption 4. (Partial participation). As discussed before, only subset of nodes is selected to participate in model aggregation in each communication round
B. Convergence result
Based on the previous assumptions, the following results are obtained.
Theorem 1. Based on Assumptions 1–4, we assume
where
Proof. By defining
Then by ℓ-smooth of
The convergence of the model is stable without extra communication overhead. Moreover, the convergence performance doesn’t affect the number of selected nodes, but the speed of convergence increases with the increasing number of selected nodes. The convergence rate achieves an order of
Suppose the total number of nodes is
1. Node-side computation complexity: The computation complexity of each local update is based on the number of samples updated in each round and the number of communication rounds. The time complexity of local updates for each node is
2. Server-side computation complexity: The computation on the server side is divided into model training, model aggregation, and weight update. For model training, as on the node side, the time complexity of local updates for each node is
3. Communication overhead analysis: Four communications between the node and server, including forward propagation transmission from the node to the server, backward propagation transmission from server to the node, aggregation from node to the server, and global update from server to the nodes. The time complexity for the first three communications is
5 Data Description and Preprocessing
This section describes the datasets used in implementation and data preprocessing, including different techniques.
The CICDDoS2019 [38] and LITNET-2020 [39] datasets are used to direct this work. These datasets are designed for the types of DDoS attacks. The details of the CICDDoS2019 and LITET-2020 datasets are as follows.
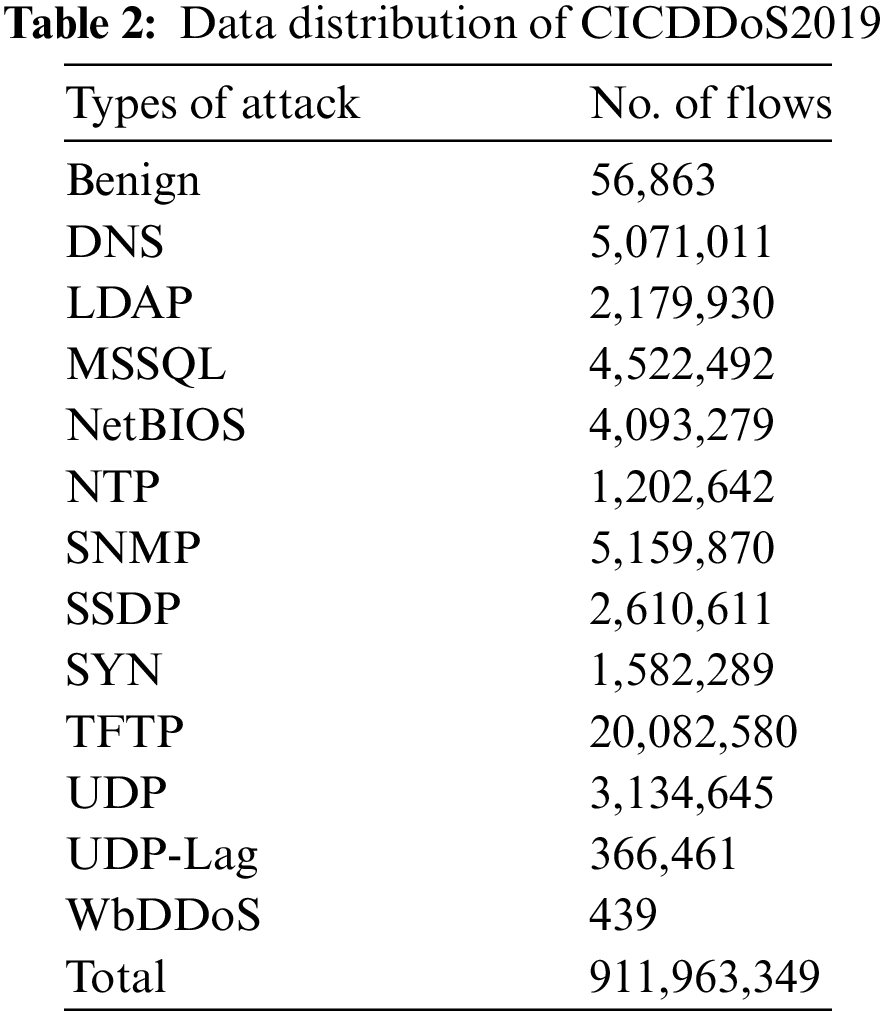
A new network intrusion dataset has been selected named CICDDoS2019, designed in 2019; the dataset consists of a large number of various types of DDoS attacks that can be carried out using Transmission Control Protocol (TCP) and User Datagram Protocol (UDP) at the application layer. The taxonomy of the DDoS attacks in the dataset is implemented in terms of reflection-based and exploitation-based attacks. The dataset is organized in two days for training and testing evaluation. The training set contains 12 different types, and the testing set contains 7 types of DDoS attacks. The dataset has more than 80 features, which were extracted using the CICFlowMeter tool. The distribution of the CICDDoS2019 data is described in Table 2.
The LITNET-2020 NetFlow is a new dataset obtained from a real-world academic network. The network topology of the dataset consists of two parts: senders and collectors. The senders are Cisco routers and Fortige (FG-1500D) firewalls, which were utilized to process NetFlow data and send it to the collectors. The collector is a server with appropriate software that is responsible for receiving, storing, and filtering data. The LITNET-2020 dataset represented real-world examples of normal and attack traffic with 12 types of DDoS attacks. The total flow of the data samples is 45,492,310 flows, categorized into normal data with 45,330,333 flows and attack data with 5,328,934 flows. The LITNET-2020 dataset consists of 85 network features divided into 49 features that are specified to the NetFlow V9 protocol, 15 features are supplemented by the data extender, 19 features are offered to recognize attack types, and 2 additional features to determine the attack type and normal traffic. The distribution of attacks in the dataset. The distribution of LITNET-2020 data is described in Table 3.
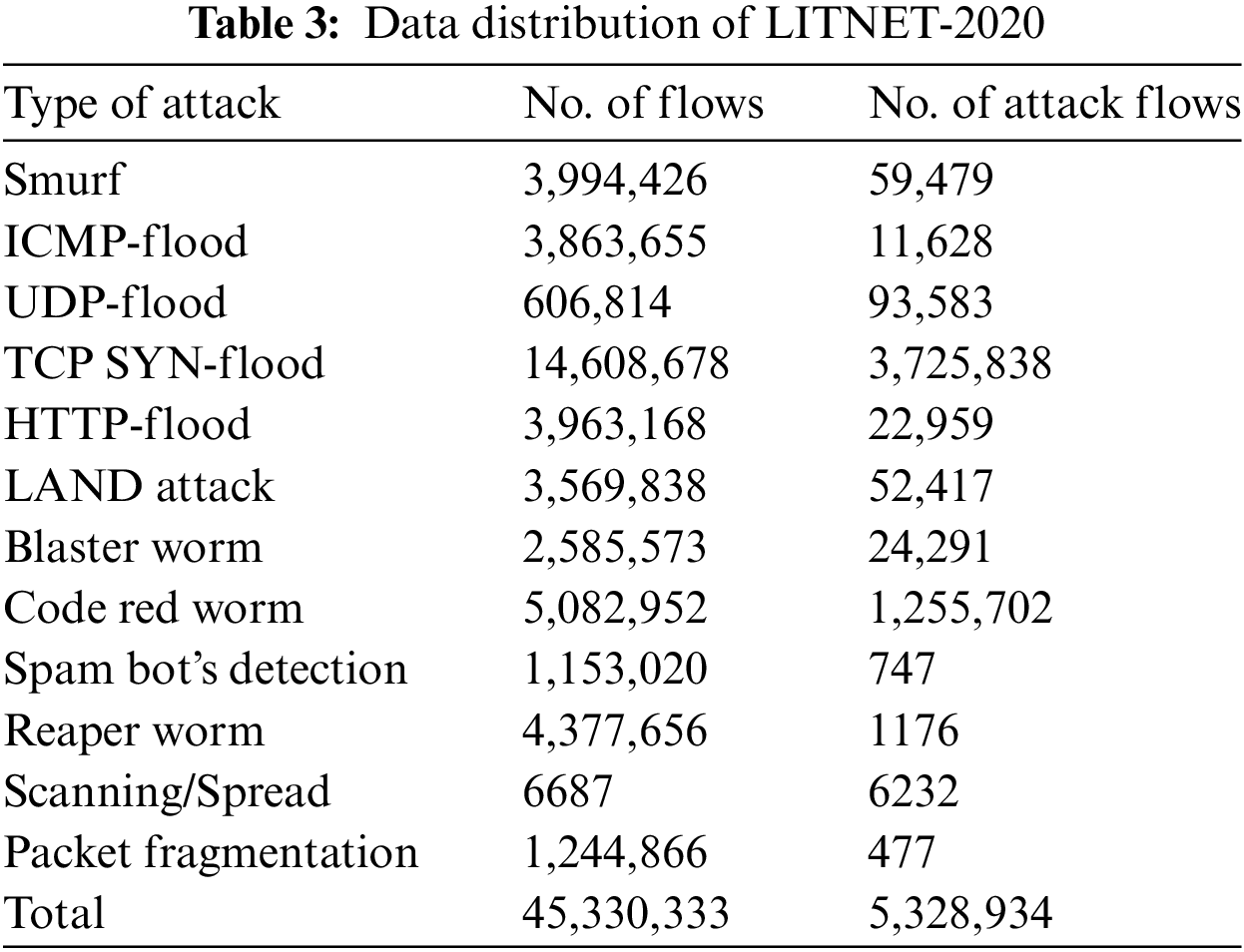
In data preprocessing, we divide the task into five steps, including features mapping, computing the missing value, feature selections, data normalization, and data imbalance.
The data features in IoMT don’t contain only numeric values. So, a mapping technique is required to convert the categorical values to numeric values. One-Hot Encoding (OHE) technique converts the categorical features to integer format to be more expressive. The OHE transforms a single value with
The datasets always consist of many missing values, which come from different reasons such as data failure or corruption during its recording, unreliable data transmission, and system maintenance and storage issues. The missing value is calculated using a linear interpolation method as
The
where
Feature selection improves the quality of prediction during the selection of feature inputs. Feature selection is the process of converting the set of features into a subset that contains the features that are important to solve the detection problem and discard the unneeded features. In this paper, a Mutual Information (MI) technique is used for features selection. The criteria of selecting features are the dependency where the features that have high dependencies between them are noted as best features. The MI procedure is shown in the following steps:
Step 1: From the training set sample, the input-output variables can be represented as
Step 2: The MI value between input and output variables
where
Step 3: Remove the values which are less than other values and maintain the remaining values in vector
Step 4: Define the number of selected features represented as
Step 5: Select the variable with the highest MI value as the first variable in
Step 6: Repeat Steps 4 and 5 until all variables are chosen.
Normalization is a scaling method used to convert all features into a common scale. The minimum and maximum values range of the continuous feature in CICDDoS2019 and LITNET-2020 are different. A Min-Max is a popular method used to facilitate arithmetic processing, and the range of values of each feature is uniformly linearly mapped in the range between 0 and 1. The Min-Max scaling method can be defined as
where
The CICDDoS2019 and LITNET-2020s datasets are not perfectly balanced. The imbalanced dataset is solved using a Synthetic Minority Over-sampling Technique (SMOTE) [40]. SMOTE is an over-sampling technique used to avoid overfitting; it allows the generation of synthetic samples for the minority categories. It is based on the KNN algorithm, where it takes a sample from the dataset and considers its nearest neighbors in the feature map. If
where
This section describes the experimental setup and the comparative analysis of the proposed DFSL system with baseline distributed algorithms such as FedAvg, Vanilla SL, and SplitFed with different experiments.
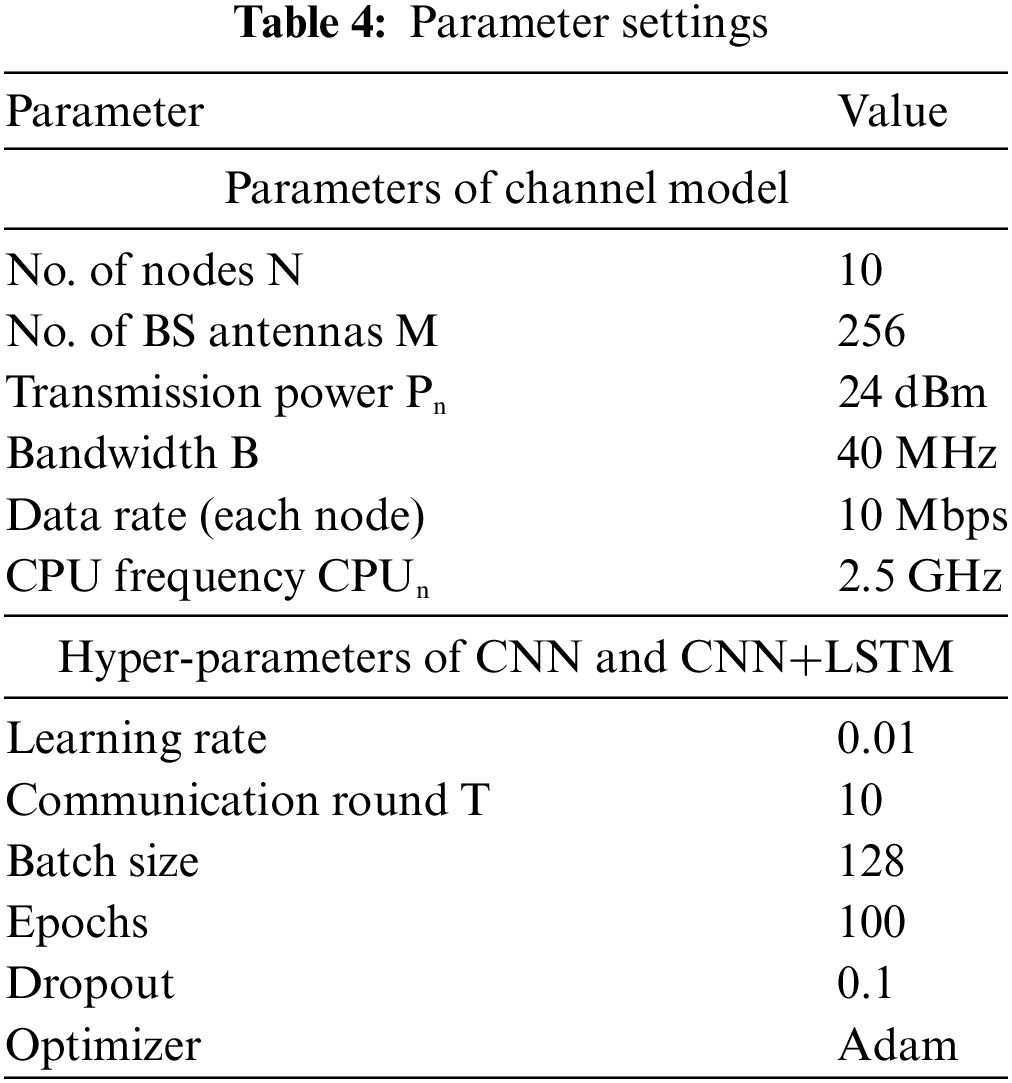
The experiment in this work is conducted with the following practical setting: Python version 3.7.3 and PyTorch library version 1.2 with Anaconda and CUDA version 10.1. We use a Dell laptop with CPU i5-1235U, 64-bit, GPU GTX 1050, and OS (Windows 11). The system consists of 10 fog nodes distributed at different distances from the server. We assume all fog nodes have the same computing capabilities. We use the 80:20 ratio (80% for the training set and 20% for the testing set). Using a high training set helps to ensure that the model is trained on enough datasets to capture the patterns and relationships in the data, and to learn more complex patterns. The tasks are assumed to be independent of each other. The parameter settings that are used in implementation are described in Table 4.
The proposed DFSL is compared with a baseline of distributed learning algorithms such as FedAvg, Vanilla SL, and SplitFed. The experiment is implemented with two datasets (CICDDoS2019 and LITNET-2020) on CNN and CNN+LSTM models to test the effectiveness of the proposed DFSL. The learning performance is implemented and compared based on four scenarios. First, the training loss and accuracy are tested with different cut layers. Second, the training time and communication overhead are tested with different numbers of nodes. Third, the adaptive aggregation of the DFSL will be compared with different aggregation methods. Finally, the proposed MNS scheme will be compared with different selection schemes.
6.2.1 Experiment 1: Performance Analysis of the DFSL with Different Cut Layers
The first experiment evaluates the proposed DFSL with different metrics such as loss, accuracy, and detection rate with different cut layers. Changing the cut layer point plays a huge role in the model’s effectiveness to get better results. We consider two types of model splitting represented by
As shown in Fig. 8, the loss of DFSL outperforms FedAvg, Vanilla SL, and SplitFed with 0.07 and 0.02 at

Figure 8: Loss performance of CNN and CNN+LSTM (a) CICDDoS2019; (b) LITNET-2020

Figure 9: Accuracy performance of CNN and CNN+LSTM (a) CICDDoS2019; (b) LITNET-2020
In contrast, there is no big variation between FedAvg and SplitFed, as both apply the same aggregation strategy. For Vanilla SL, it scored the worst values in terms of loss, accuracy, and detection rate. It is very sensitive to data distribution. In fact, for both FedAvg and Vanilla SL, some knowledge forgetting while learning is evident when trained in non-IID settings.
When comparing the DFSL with the other approaches, we note that our DFSL has more hyper-parameters to tune when the cut layer is large. We conclude that a carefully specified way of determining the maximum accuracy and loss score and comparing it with average scores for each local update can benefit the most when applied in the DFSL system.
As shown in Tables 5 and 6, we observe that the proposed DFSL can detect DDoS attacks effectively enhancing learning performance. Based on these results, using the
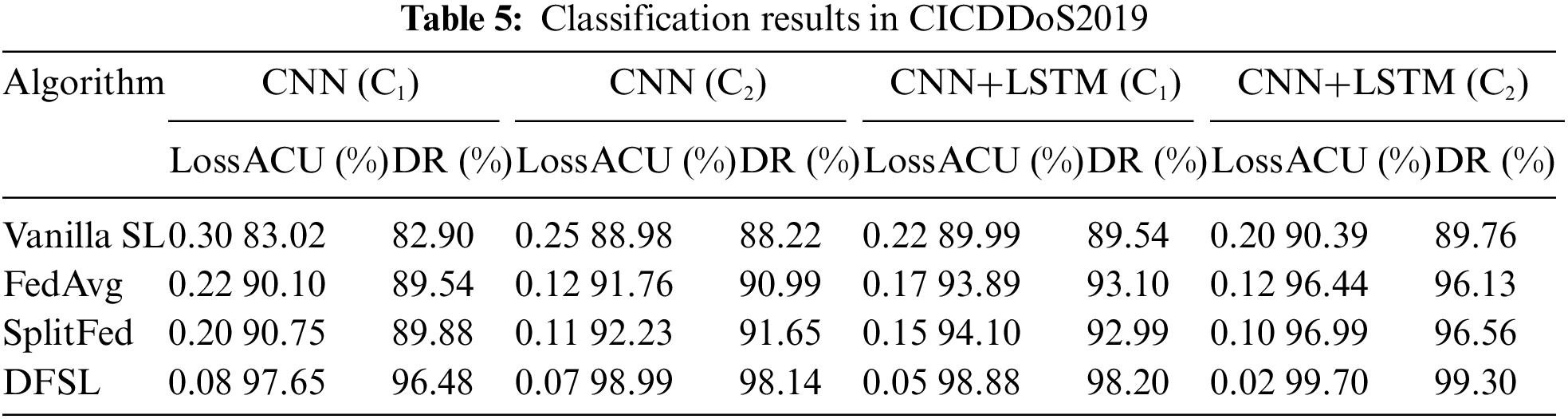
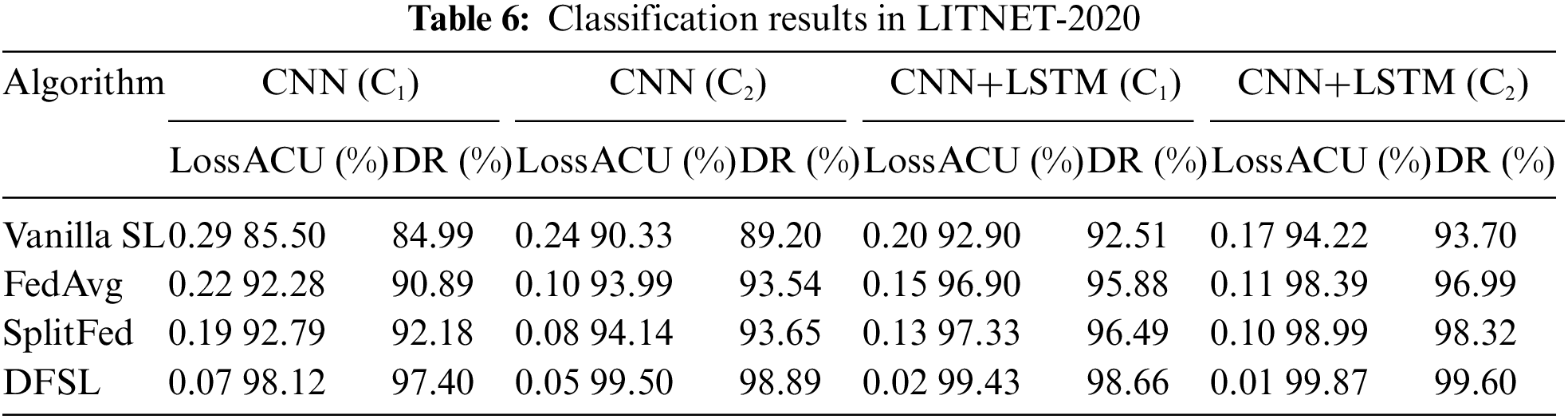
6.2.2 Experiment 2: Performance Analysis of the DFSL with Different Number of Nodes
In this experiment, the training time and communication overhead are tested. We test the training time and communication overhead with different numbers of nodes, including
Fig. 10 shows the training time performance in CICDDoS2019 and LITNET-2020. The FedAvg has the highest training time compared with Vanilla SL, SplitFed, and DFSL, with 60 and 80 min in CICDDoS2019 and LITNET-2020, respectively, when the number of nodes is 10. The reason behind this is that in FedAvg, the allocated bandwidth to each node is decreasing. SplitFed achieves the highest training time after FedAvg with 60 and 80 min in CICDDoS2019 and LITNET-2020, respectively, when the number of nodes is 10. The Vanilla SL achieves acceptable results with 47 and 55 min in CICDDoS2019 and LITNET-2020, respectively. Compared to FedAvg, Vanilla SL, and SplitFed, DFSL spends less training time. The DFSL dynamically tunes the amount of computation assigned to the selected nodes at each round of training, resulting in a significant reduction in the overall training time per round. It achieves a total training time of 18 and 38 min in both datasets.

Figure 10: Training time performance (a) CICDDoS2019; (b) LITNET-2020
Fig. 11 shows the communication overhead in CICDDoS2019 and LITNET-2020. In terms of communication overhead, the performance degrades with increasing the number of nodes. When the nodes are 10, the DFSL has the lowest communication overhead with 25 and 31 MB in CICDDoS2019 and LITNET-2020, respectively. In contrast, FedAvg, Vanilla SL, and SplitFed with random node selection have high communication overhead. The Vanilla SL achieves 64 and 79 MB in CICDDoS2019 and LITNET-2020, respectively. The FedAvg has better performance than Vanilla SL, it achieved 50 and 64 MB in CICDDoS2019 and LITNET-2020, respectively. For SplitFed, it outperforms FedAvg and Vanilla SL with 59 and 70 MB. Finally, the DFSL with the proposed MNS scheme performs effectively on the performance. Selecting only the nodes with important update, good channel quality, and the nearest distance from the server reduces the communication overhead.
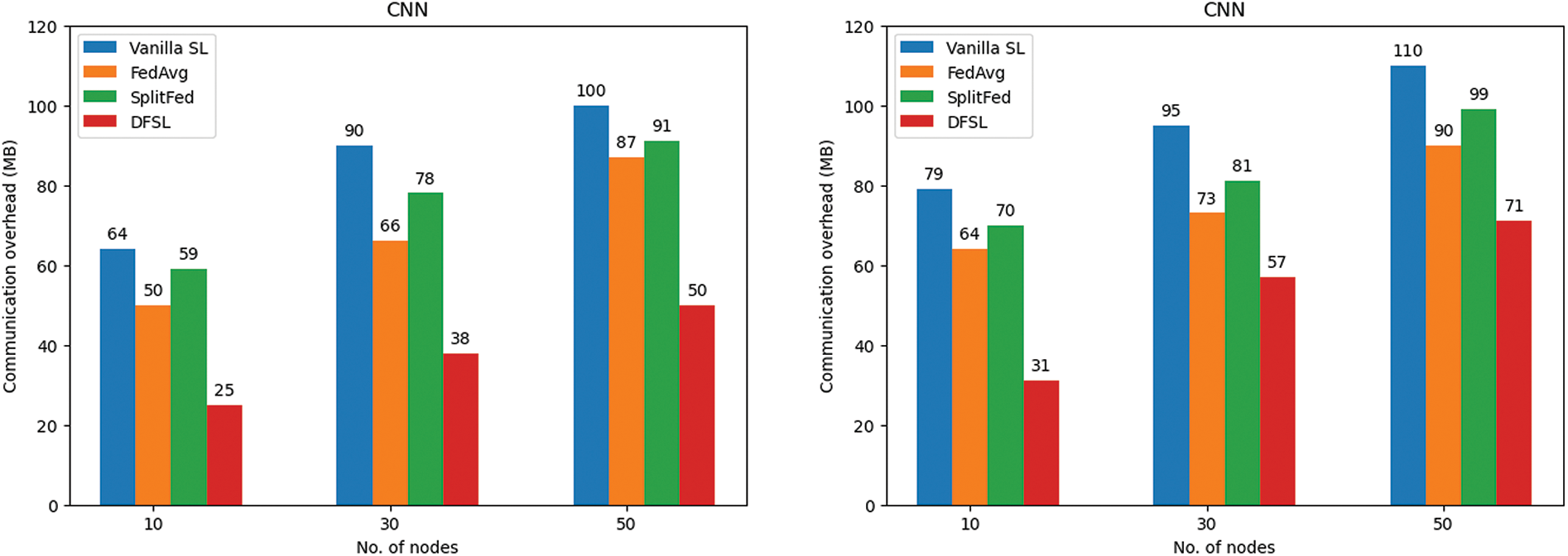
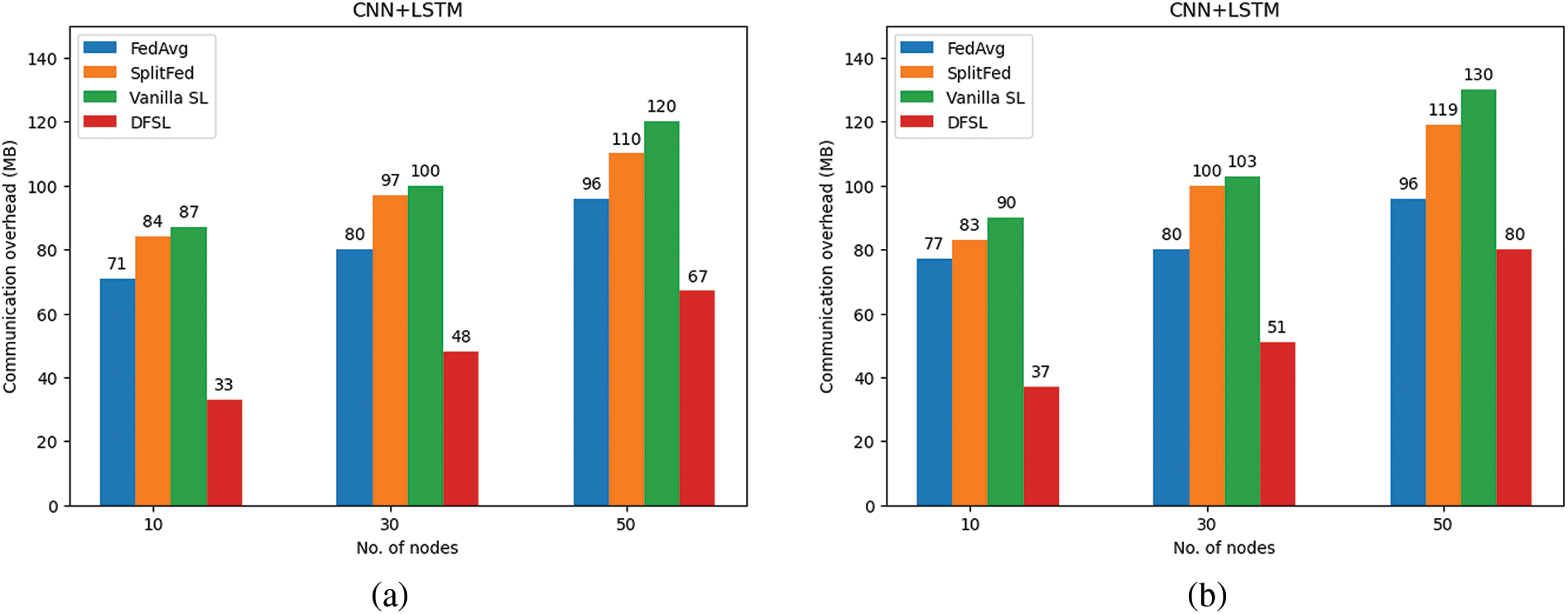
Figure 11: Communication overhead performance (a) CICDDoS2019; (b) LITNET-2020
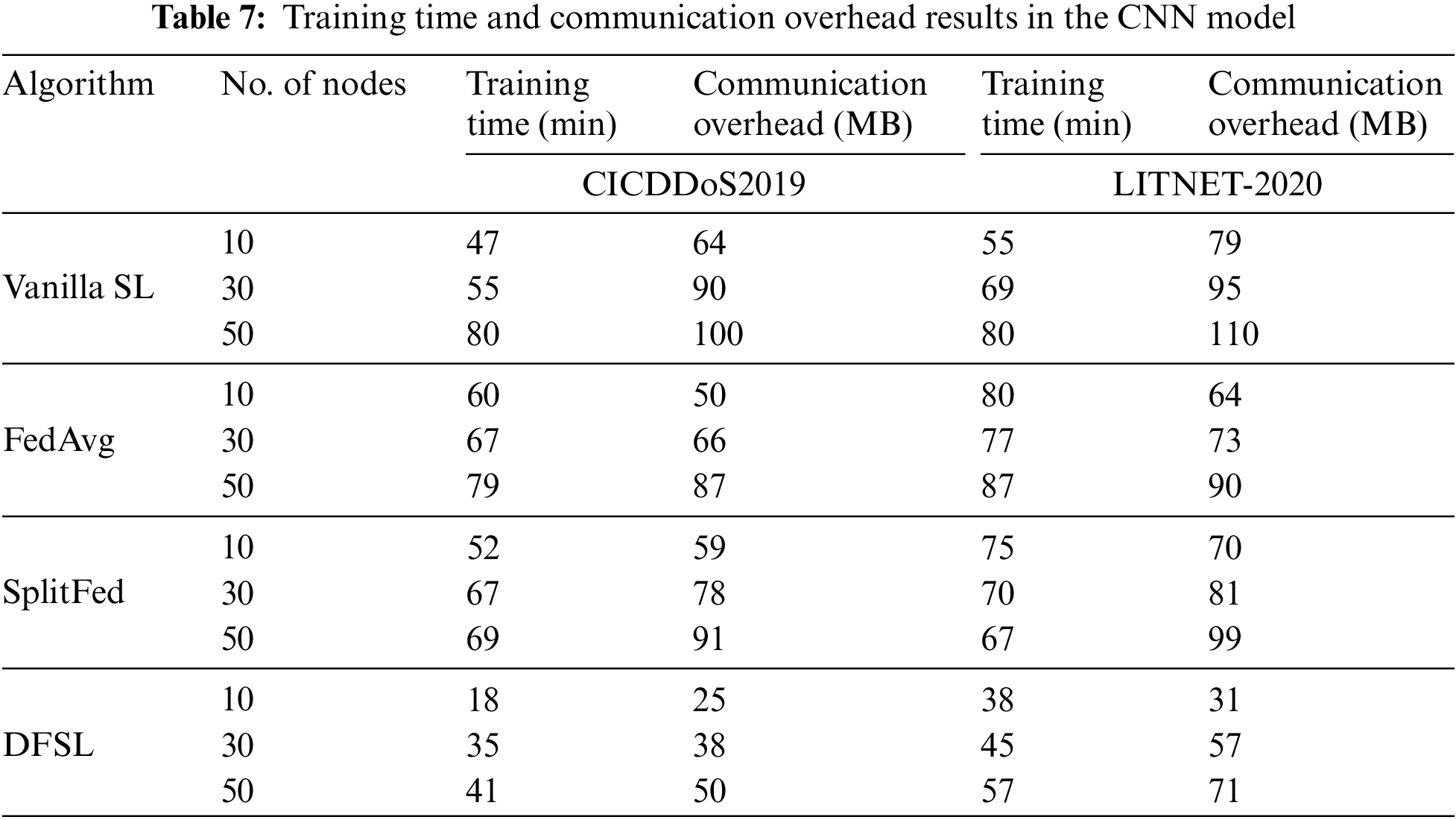
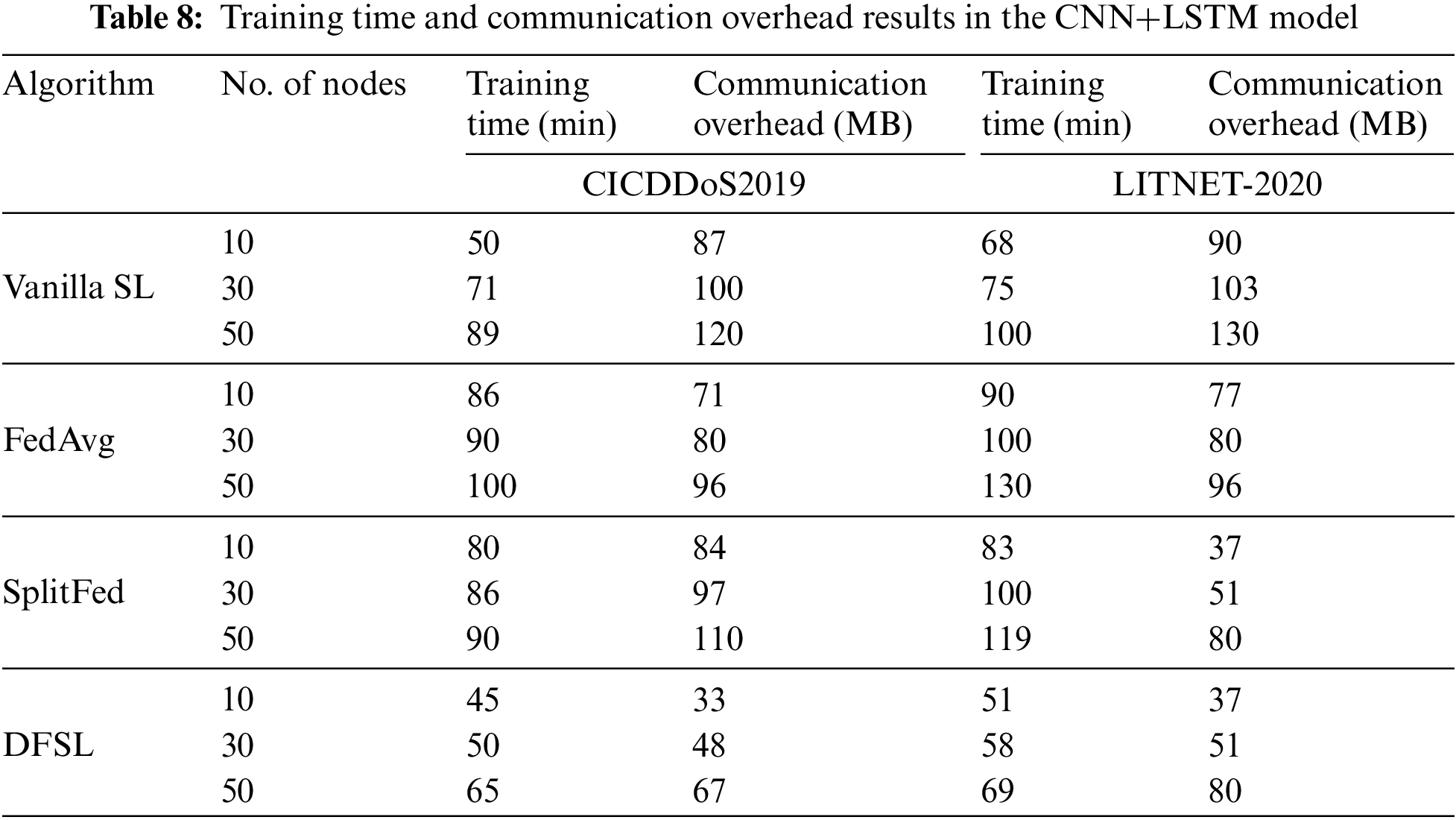
Tables 7 and 8 summarize the training time and communication overhead results with the increasing number of nodes for CNN and CNN+LSTM in CICDDoS2019 and LITNET-2020.
6.2.3 Comparing the Proposed Adaptive Aggregation with Other Aggregation Methods
The proposed adaptive aggregation in DFSL is compared with the three aggregation methods: geometric median [41], Krum aggregation function [42], and Fourier Transform [43], as shown in Table 9. We find that our aggregation method is more effective compared with the other methods. Determining the maximum score for accuracy and loss in each round enhances learning performance and makes the convergence more stable. Finally, we observe that our aggregation method gives more convergence stability without need for extra communications..
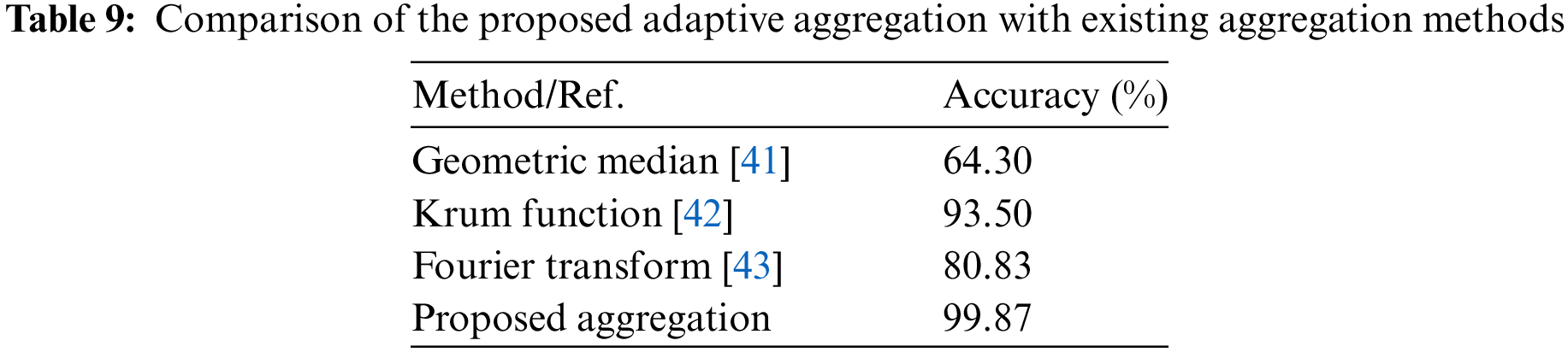
6.2.4 Comparing the Proposed MNS Scheme with Other Selection Schemes
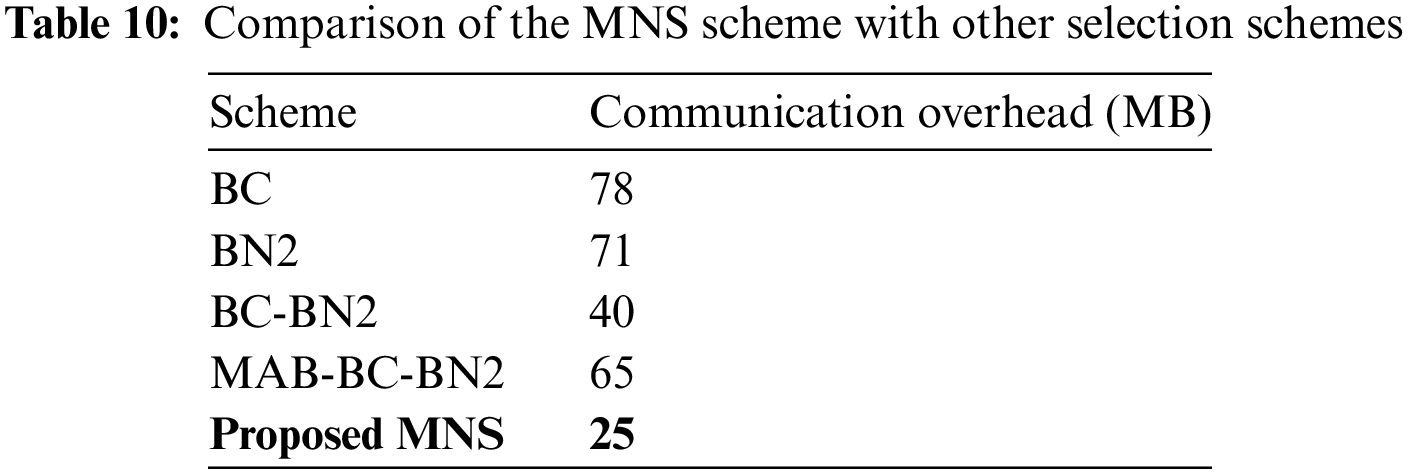
The proposed MNS scheme is compared with other selection schemes, such as BC, BN2, BS-BN2, and MAB-BC-BN2 schemes, as shown in Table 10. The MNS proves its effectiveness in reducing communication overhead compared with the other selection schemes. The dynamic selection of irrelevant updates and their exclusion during the training process helps to save computation and communication resources. Testing the performance of the MNS scheme by increasing the number of nodes proves that the MNS can be deployed in real-world IoMT with negligible additional computation overhead and thus can be implemented on a large scale.
The above sections explain experiments in scenario with different nodes, including 10, 30, and 50 nodes, to test the training time and communication overhead. We assess DFSL’s performance across increasing DFSL sizes, measuring main metrics such as accuracy and convergence time (including ten rounds). To create the DFSL of extra sizes, we have increased the number of nodes up to 90 nodes.
The experiment has been executed 10 times for each DFSL size at each iteration. Fig. 12 shows the average accuracy and convergence time in LITNET-2020 dataset. The Figure shows that DFSL has consistent performance stability when the number of nodes increases. Furthermore, these results validate our proposed DFSL is stable with a large number of nodes.
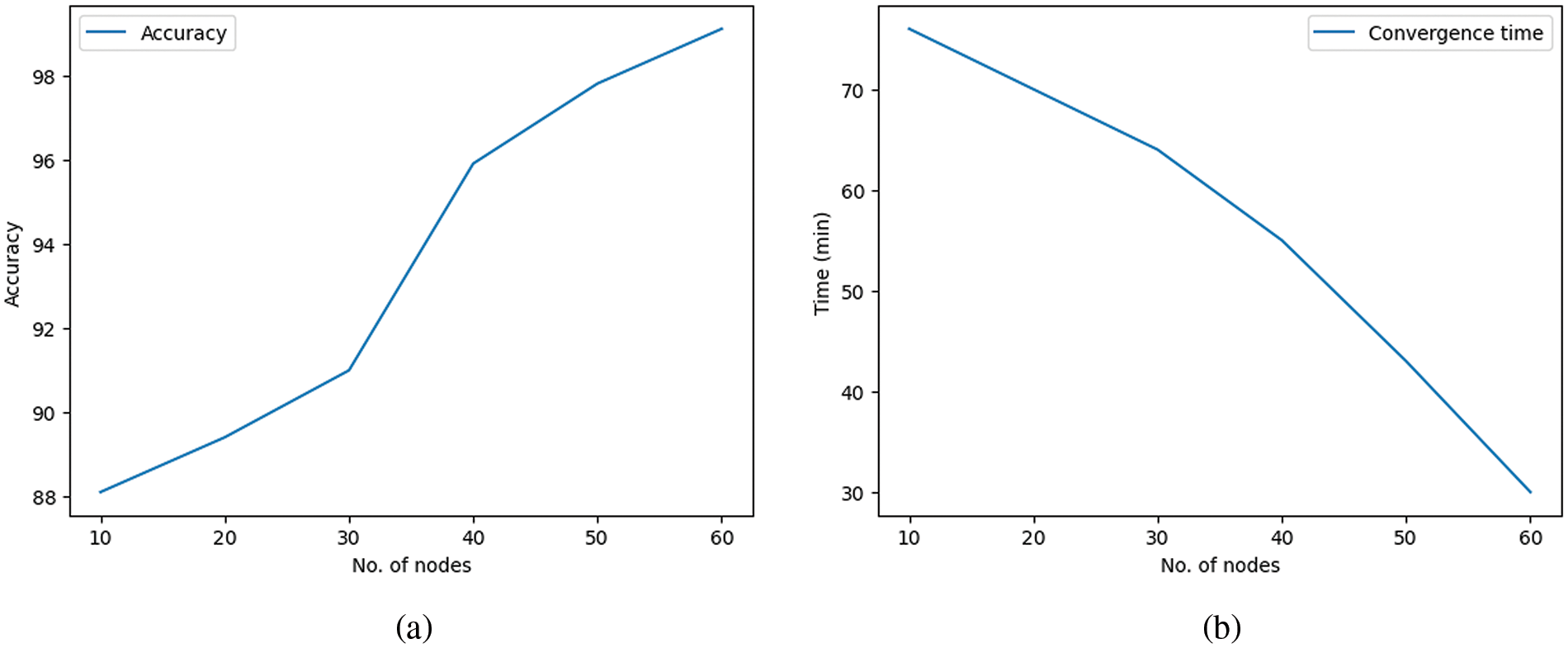
Figure 12: Scalability performance of the DFSL (a) accuracy; (b) convergence time
Therefore, with a few numbers of nodes, a low value on a few training sets can significantly impact on the overall average. In scenarios with more nodes, DFSL learns all attacks more accurately, although it consistently produces an accuracy below 0.93 when the number of nodes is 90.
The global model’s ability to perform well greatly impacts the DFSL process’s convergence time. By adding new nodes, the global model is learned more quickly, which has proven critical for the process’s convergence.
In summary, the experiments’ results prove that the DFSL detects DDoS attacks with low loss value and high detection accuracy compared with the FedAvg, Vanilla SL, and SplitFed. In addition, it achieved low training time and communication overhead compared with FedAvg, Vanilla SL, and SplitFed.
In the first experiment, the DFSL training enhanced the model’s performance in terms of loss and accuracy when more layers were trained at the node side. We observe that the model’s performance achieves high accuracy and low loss by applying the early stopping strategy. In addition, we observe that the performance in LITNET-2020 is better than CICDDoS2019 performance; it contains more features and data to train. In the second experiment, stopping the model at a certain point when the model stops improvement helps to reduce training time. In contrast, the proposed MNS scheme helps to reduce communication overheads. It aims to decrease the communication rounds where only the important local update with good channel quality and the nearest node are selected for aggregation. It dynamically selects the relevant updates during the training process to avoid consuming computation and communication resources.
The model performance in CICDDoS2019 is better than LITNET-2020 in the second experiment, where more features need more training time and communication to transmit the model parameters.
Even though the proposed framework achieves acceptable results in terms of loss, accuracy, training time, and communication overhead, there are four implementation challenges and limitations of the proposed system, including:
1. Achieving consistent accuracy: The data heterogeneity in IoMT across different nodes makes it a challenge to maintain constant accuracy results. Some nodes that have more heterogeneity rates need more training time for convergence.
2. Anomalies data complexity: Notwithstanding our preprocessing efforts, some nodes sporadically presented anomalous data patterns. These could be attributed to distinct local network behaviors, which sometimes inject noise through model training.
3. Real-time data: Although the proposed system is examined with two non-IID datasets proposed for DDoS attacks, it needs to be examined on real-time data to test its effectiveness.
4. Real-time application: Although the proposed system is simulated by PyTorch, it needs to be examined in a real-time IoMT application.
A novel distributed FSL (DFSL) system is proposed in this paper to detect Distributed Denial of Service (DDoS) attacks in the IoMT networks while enhancing detection accuracy and reducing training time and communication overhead. The proposed system uses Federated Split Learning (FSL) to take advantage of each approach. The proposed system is tested on two DL models, including the Convolutional Neural Network (CNN) and a hybrid model that combines CNN and Long Short-Term Memory (LSTM) to determine the best model to detect DDoS attacks and test the effectiveness of the system. The procedure of the proposed system starts with initialization and model splitting, local model training, and adaptive aggregation. The adaptive aggregation method is designed based on the early stopping strategy to enhance learning performance and reduce training time. In addition, a Multi-Node Selection (MNS) based BC-BN2 selection scheme is proposed to reduce communication overhead with three selection metrics: the importance of local update, channel quality, and the nearest distance from the server. The performance results of the proposed system are compared with a baseline of distributed learning such as FedAvg, Vanilla SL, and SplitFed algorithms with different cut layers and increasing number of nodes. The results show the effectiveness of the proposed system where it can detect DDoS with an accuracy of 99.70% and 99.87%, and it achieved 18 and 38 min training time and 25 and 31 MB communication overhead in CICDDoS2019 and LITNET-2020, respectively. In future work, we aim to address the current limitations. We will further explore advanced convergence strategies with robust anomalous data management. In addition, we will deploy the proposed system in real IoMT scenarios to assess its feasibility in resource-constrained devices and networks.
Acknowledgement: The authors would like to extend their sincere thanks and gratitude to the supervisor for his support and direction of this research.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm their contribution to the paper as follows: study conception and design: Rasha Almarshdi; data collection: Rasha Almarshdi; analysis and interpretation of results: Rasha Almarshdi, Etimad Fadel, Nahed Alowidi, Laila Nassef; draft manuscript preparation: Rasha Almarshdi, Etimad Fadel, Nahed Alowidi, Laila Nassef. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data supporting the contributions of this study are open-source and available at https://www.unb.ca/cic/datasets/ddos-2019.html and https://epubl.ktu.edu/object/elaba:61188126/ (accessed on 22 September 2024).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. A. Chelloug and M. A. El-Zawawy, “Middleware for Internet of Things: Survey and challenges,” Intell. Autom. Soft Comput., vol. 24, no. 2, pp. 309–318, 2018. doi: 10.1080/10798587.2017.1290328. [Google Scholar] [CrossRef]
2. D. Wang, D. Chen, B. Song, N. Guizani, X. Yu and X. Du, “From IoT to 5G I-IoT: The next generation IoT-based intelligent algorithms and 5G technologies,” IEEE Commun. Mag., vol. 56, no. 10, pp. 114–120, Oct. 2018. doi: 10.1109/MCOM.2018.1701310. [Google Scholar] [CrossRef]
3. S. Markkandan, S. Sivasubramanian, J. Mulerikkal, N. Shaik, B. Jackson and L. Naryanan, “Massive MIMO codebook design using gaussian mixture model based clustering,” Intell. Autom. Soft Comput., vol. 32, no. 1, pp. 361–375, 2022. doi: 10.32604/iasc.2022.021779. [Google Scholar] [CrossRef]
4. N. Javaid, A. Sher, H. Nasir, and N. Guizani, “Intelligence in IoT-based 5G networks: Opportunities and challenges,” IEEE Commun. Mag., vol. 56, no. 10, pp. 94–100, Oct. 2018. doi: 10.1109/MCOM.2018.1800036. [Google Scholar] [CrossRef]
5. M. Deepender, U. Shrivastava, and J. K. Verma, “A study on 5G technology and its applications in telecommunications,” IEEE Xplore, vol. 7, pp. 365–371, 2021. doi: 10.1109/ComPE53109.2021.9752402. [Google Scholar] [CrossRef]
6. A. Sonavane, A. Khamparia, and D. Gupta, “A systematic review on the internet of medical things: Techniques, open issues, and future directions,” Comput. Model. Eng. Sci., vol. 137, no. 2, pp. 1525–1550, 2023. doi: 10.32604/cmes.2023.028203. [Google Scholar] [CrossRef]
7. H. -C. Chen and S. -S. Kuo, “Active detecting DDoS attack approach based on entropy measurement for the next generation instant messaging app on smartphones,” Intell. Autom. Soft Comput., vol. 25, no. 1, pp. 217–228. doi: 10.31209/2018.100000057. [Google Scholar] [CrossRef]
8. S. Innes, “Banner Health paid $1.25 million to resolve Federal Data Breach Probe,” The Arizona Republic, 2023. Accessed: Feb. 03, 2023. [Online]. Available: https://www.azcentral.com/story/money/business/health/2023/02/04/banner-health-paid-1-25-million-to-resolve-federal-data-breach-probe/69871530007/. [Google Scholar]
9. Y. Ko, K. Choi, H. Jei, D. Lee, and S. Kim, “ALADDIN: Asymmetric centralized training for distributed deep learning,” in Proc. 30th ACM Int. Conf. Inform. Knowl. Manage., 2021, pp. 863–872. doi: 10.1145/3459637.3482412. [Google Scholar] [CrossRef]
10. S. Kamei and S. Taghipour, “A comparison study of centralized and decentralized federated learning approaches utilizing the transformer architecture for estimating remaining useful life,” Reliability Eng. Syst. Saf., vol. 233, May 2023, Art. no. 109130. doi: 10.1016/j.ress.2023.109130. [Google Scholar] [CrossRef]
11. N. N. Thilakarathne et al., “Federated learning for privacy-preserved medical internet of things,” Intell. Autom. Soft Comput., vol. 33, no. 1, pp. 157–172, 2022. doi: 10.32604/iasc.2022.023763. [Google Scholar] [CrossRef]
12. O. Gupta and R. Raskar, “Distributed learning of deep neural network over multiple agents,” J. Netw. Comput. Appl., vol. 116, pp. 1–8, Aug. 2018. doi: 10.1016/j.jnca.2018.05.003. [Google Scholar] [CrossRef]
13. Z. Zhang, A. Pinto, V. Turina, F. Esposito, and I. Matta, “Privacy and efficiency of communications in federated split learning,” IEEE Trans. Big Data, vol. 9, no. 5, pp. 1380–1391, Oct. 2023. doi: 10.1109/TBDATA.2023.3280405. [Google Scholar] [CrossRef]
14. M. M. Amiria, D. Gunduzb, S. R. Kulkarni, and H. V. Poor, “Convergence of update aware device scheduling for federated learning at the wireless edge,” IEEE Trans. Wirel. Commun., vol. 20, no. 6, pp. 3643–3658, 2021. doi: 10.1109/TWC.2021.3052681. [Google Scholar] [CrossRef]
15. X. Liu, Y. Deng, and T. Mahmoodi, “Wireless distributed learning: A new hybrid split and federated learning approach,” IEEE Trans. Wirel. Commun., vol. 22, no. 4, pp. 2650–2665, 2022. doi: 10.1109/twc.2022.3213411. [Google Scholar] [CrossRef]
16. T. Li, A. K. Sahu, A. Talwalkar, and V. Smith, “Federated learning: Challenges, methods, and future directions,” IEEE Signal Process. Mag., vol. 37, no. 3, pp. 50–60, May 2020. doi: 10.1109/MSP.2020.2975749. [Google Scholar] [CrossRef]
17. L. Collins, H. Hassani, A. Mokhtari, and S. Shakkottai, “FedAvg with fine tuning: Local updates lead to representation learning,” May 2022. doi: 10.48550/arxiv.2205.13692. [Google Scholar] [CrossRef]
18. J. Shen, X. Wang, N. Cheng, L. Ma, C. Zhou, and Y. Zhang, “Effectively heterogeneous federated learning: A pairing and split learning based approach,” in GLOBECOM 2023–2023 IEEE Glob. Commun. Conf., Kuala Lumpur, Malaysia, Dec. 2023, pp. 5847–5852. doi: 10.1109/GLOBECOM54140.2023.10437666. [Google Scholar] [CrossRef]
19. P. Vepakomma, O. Gupta, T. Swedish, and R. Raskar, “Split learning for health: Distributed deep learning without sharing raw patient data,” in Proc. Int. Conf. Learn. Rep. (ICLR) Workshop AI Social Good, 2019, pp. 1–7. doi: 10.48550/arXiv.1812.00564. [Google Scholar] [CrossRef]
20. C. Thapa, P. C. M. Arachchige, S. Camtepe, and L. Sun, “SplitFed: When federated learning meets split learning,” Proc. AAAI Conf. Artif. Intell., vol. 36, no. 8, pp. 8485–8493, Jun. 2022. doi: 10.1609/aaai.v36i8.20825. [Google Scholar] [CrossRef]
21. C. Huang, G. Tian, and M. Tang, “When minibatch SGB meets splitfed learning: Convergence analysis and performance evaluation,” 2023. doi: 10.48550/arXiv.2308.11953. [Google Scholar] [CrossRef]
22. Y. Mu and C. Shen, “Communication and storage efficient federated split learning,” in Proc. : ICC 2023-IEEE Int. Conf. Commun., May 2023, pp. 2976–2981. doi: 10.1109/icc45041.2023.10278891. [Google Scholar] [CrossRef]
23. A. Singh, P. Vepakomma, O. Gupta, and R. Raskar, “Detailed comparison of communication efficiency of split learning and federated learning,” 2019, arXiv:1909.09145. [Google Scholar]
24. Y. K. Saheed and M. O. Arowolo, “Efficient cyber attack detection on the internet of medical things-smart environment based on deep recurrent neural network and machine learning algorithms,” IEEE Access, vol. 9, pp. 161546–161554, 2021. doi: 10.1109/ACCESS.2021.3128837. [Google Scholar] [CrossRef]
25. M. Manimurugan, S. Al-Mutairi, M. M. Aborokbah, N. Chilamkurti, S. Ganesan and R. Patan, “Effective attack detection in internet of medical things smart environment using a deep belief neural network,” IEEE Access, vol. 8, pp. 77396–77404, 2020. doi: 10.1109/ACCESS.2020.2986013. [Google Scholar] [CrossRef]
26. M. Usman, M. A. Jan, X. He, and J. Chen, “P2DCA: A privacy-preserving-based data collection and analysis framework for IoMT applications,” IEEE J. Sel. Areas Commun., vol. 37, no. 6, pp. 1222–1230, Jun. 2019. doi: 10.1109/JSAC.2019.2904349. [Google Scholar] [CrossRef]
27. J. Ren, J. Guo, W. Qian, H. Yuan, X. Hao and J. Hu, “Building an effective intrusion detection system by using hybrid data optimization based on machine learning algorithms,” Secur. Commun. Netw., vol. 2019, pp. 1–11, Jun. 2019. doi: 10.1155/2019/7130868. [Google Scholar] [CrossRef]
28. S. P. K. Gudla, S. K. Bhoi, S. R. Nayak, and A. Verma, “DI-ADS: A deep intelligent distributed denial of service attack detection scheme for fog-based IoT applications,” Math. Probl. Eng., vol. 2022, pp. 1–17, Aug. 2022. doi: 10.1155/2022/3747302. [Google Scholar] [CrossRef]
29. R. Priyadarshini and R. K. Barik, “A deep learning based intelligent framework to mitigate DDoS attack in fog environment,” J. King Saud Univ.-Comput. Inf. Sci., vol. 34, no. 3, pp. 825–831, 2022. doi: 10.1016/j.jksuci.2019.04.010. [Google Scholar] [CrossRef]
30. Y. Zhang, Y. Liu, X. Guo, Z. Liu, X. Zhang and K. Liang, “A BiLSTM-based DDoS attack detection method for edge computing,” Energies, vol. 15, no. 21, Oct. 2022, Art. no. 7882. doi: 10.3390/en15217882. [Google Scholar] [CrossRef]
31. P. Verma, J. G. Breslin, and D. O’Shea, “FLDID: Federated learning enabled deep intrusion detection in smart manufacturing industries,” Sensors, vol. 22, no. 22, Nov. 2022, Art. no. 8974. doi: 10.3390/s22228974. [Google Scholar] [PubMed] [CrossRef]
32. V. Rey, P. M. Sánchez Sánchez, A. Huertas Celdrán, and G. Bovet, “Federated learning for malware detection in IoT devices,” Comput. Netw., vol. 204, Feb. 2022, Art. no. 108693. doi: 10.1016/j.comnet.2021.108693. [Google Scholar] [CrossRef]
33. Y. Alhasawi and S. Alghamdi, “Federated learning for decentralized DDoS attack detection in IoT networks,” IEEE Access, vol. 12, pp. 42357–42368, Jan. 2024. doi: 10.1109/ACCESS.2024.3378727. [Google Scholar] [CrossRef]
34. F. Yu, B. Zeng, K. Zhao, Z. Pang, and L. Wang, “Chronic poisoning: Backdoor attack against split learning,” Proc. AAAI Conf. Artif. Intell., vol. 38, no. 15, pp. 16531–16538, Mar. 2024. doi: 10.1609/aaai.v38i15.29591. [Google Scholar] [CrossRef]
35. S. Abuadbba et al., “Can we use split learning on 1D CNN models for privacy preserving training?,” in Proc. 15th ACM Asia Conf. Comput. Commun. Secur., 2020, pp. 305–318. doi: 10.1145/3320269.3384740. [Google Scholar] [CrossRef]
36. M. A. Khan, V. Shejwalkar, A. Houmansadr, and F. M. Anwar, “Security analysis of SplitFed learning,” in Proc. ACM Conf. Embed. Netw. Sens. Syst., Nov. 2022. doi: 10.1145/3560905.3568302. [Google Scholar] [CrossRef]
37. F. Li, J. Lin, and H. Han, “FSL: Federated sequential learning-based cyberattack detection for industrial Internet of Things,” Ind. Artif. Intell., vol. 1, Mar. 2023, Art. no. 4. doi: 10.1007/s44244-023-00006-2. [Google Scholar] [CrossRef]
38. I. Sharafaldin, A. H. Lashkari, S. Hakak, and A. A. Ghorbani, “Developing realistic distributed denial of service (DDoS) attack dataset and taxonomy,” in Proc. 2019 Int. Carnahan Conf. Secur. Technol. (ICCST), IEEE, Oct. 2019, pp. 1–8. doi: 10.1109/CCST.2019.8888419. [Google Scholar] [CrossRef]
39. R. Damasevicius et al., “LITNET-2020: An annotated real-world network flow dataset for network intrusion detection,” Electronics, vol. 9, no. 5, May 2020, Art. no. 800. doi: 10.3390/electronics9050800. [Google Scholar] [CrossRef]
40. A. Fernandez, S. Garcia, F. Herrera, and N. V. Chawla, “SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary,” J. Artif. Intell. Res., vol. 61, pp. 863–905, Apr. 2018. doi: 10.1613/jair.1.11192. [Google Scholar] [CrossRef]
41. K. Pillutla, S. M. Kakade, and Z. Harchaoui, “Robust aggregation for federated learning,” IEEE Trans. Signal Process., vol. 70, pp. 1142–1154, 2022. doi: 10.1109/TSP.2022.3153135. [Google Scholar] [CrossRef]
42. R. Taheri et al., “Robust aggregation function in federated learning,” in Proc. 6th Int. Conf. Inform. Knowl. Syst., Cham, Springer Nature Switzerland, 2023, pp. 168–175. doi: 10.1007/978-3-031-51664-1_12. [Google Scholar] [CrossRef]
43. E. M. Campos, A. Jose, L. Ramos, and A. Skarmeta, “FedRDF: A robust and dynamic aggregation function against poisoning attacks in federated learning,” 2024. doi: 10.48550/arXiv.2402.10082. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools