
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Chaotic Elephant Herd Optimization with Machine Learning for Arabic Hate Speech Detection
1 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Mecca, 24382, Saudi Arabia
3 Prince Saud AlFaisal Institute for Diplomatic Studies, Riyadh, 12735, Saudi Arabia
4 Department of Computer Science, College of Computing and Information Technology, Shaqra University, Shaqra, 11911, Saudi Arabia
5 Department of Information Systems, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
6 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt New Cairo, New Cairo, 11835, Egypt
7 Department of Computer and Self Development, Preparatory Year Deanship, Al-Kharj, 16278, Saudi Arabia
* Corresponding Author: Abdelwahed Motwakel. Email:
Intelligent Automation & Soft Computing 2024, 39(3), 567-583. https://doi.org/10.32604/iasc.2023.033835
Received 29 June 2022; Accepted 14 October 2022; Issue published 11 July 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In recent years, the usage of social networking sites has considerably increased in the Arab world. It has empowered individuals to express their opinions, especially in politics. Furthermore, various organizations that operate in the Arab countries have embraced social media in their day-to-day business activities at different scales. This is attributed to business owners’ understanding of social media’s importance for business development. However, the Arabic morphology is too complicated to understand due to the availability of nearly 10,000 roots and more than 900 patterns that act as the basis for verbs and nouns. Hate speech over online social networking sites turns out to be a worldwide issue that reduces the cohesion of civil societies. In this background, the current study develops a Chaotic Elephant Herd Optimization with Machine Learning for Hate Speech Detection (CEHOML-HSD) model in the context of the Arabic language. The presented CEHOML-HSD model majorly concentrates on identifying and categorising the Arabic text into hate speech and normal. To attain this, the CEHOML-HSD model follows different sub-processes as discussed herewith. At the initial stage, the CEHOML-HSD model undergoes data pre-processing with the help of the TF-IDF vectorizer. Secondly, the Support Vector Machine (SVM) model is utilized to detect and classify the hate speech texts made in the Arabic language. Lastly, the CEHO approach is employed for fine-tuning the parameters involved in SVM. This CEHO approach is developed by combining the chaotic functions with the classical EHO algorithm. The design of the CEHO algorithm for parameter tuning shows the novelty of the work. A widespread experimental analysis was executed to validate the enhanced performance of the proposed CEHOML-HSD approach. The comparative study outcomes established the supremacy of the proposed CEHOML-HSD model over other approaches.Keywords
In recent times, the Arab world has been getting much attention from various multi-national predictors as it is an important performer in international politics and the global economy [1]. Opinion mining has become an important research phenomenon, especially for the problems faced in politics, market movements and oil and gas prices. It gained a significant amount of interest after the Arab spring movement. Reflecting this, the accessibility of social networking media has increased in Arabic countries, which led to the generation of huge volumes of Arabic texts on the internet. As per the ‘Internet World Stats’, Arabic is the 4th commonly-applied language on the internet after English, Chinese and Spanish [2]. Notwithstanding this, Sentiment Analysis (ASA)-related studies in the Arabic language are too few, mainly because of the lack of sentiment resources in the Arabic language [3,4]. This is because the bilingual methodologies are simply incompetent for the Arabic language, which has unique characteristics compared to the English language in terms of grammar and structure [5]. The studies pertaining to the Arabic language SA find it challenging to accomplish the outcomes due to different formats of the language and tits free writing style. Most of the time, the Arabic language-based interactions on social networking platforms are generated in local dialects [6,7]. But, monolingual studies that take the Arabic language texts into consideration mainly disregard the dialects and the Arabic texts that contain Latin letters. The existing resources and their respective tools only consider the current version of Arabic (MSA). As a result, imitation cannot be executed since it produces low performance in real-time applications [8]. The real-time value of the SA approach for the study corresponds to the outcome, replicated with them [9].
Hate speech is the usage of insulting, offensive and abusive language towards individuals or a group of people [10]. The aim of hate speech is to disseminate hatred and discriminate the opposition based on their gender, race, disability or religion. The European Court of Human Rights (ECHR) recognizes the conception of hate speech as the usage of words or expressions that incite, spread or encourage hatred against an individual or a group of people based on xenophobia or race and some kind of intolerance against minorities or immigrants (Court) [11]. Being a microblogging site, Twitter is a social networking platform that facilitates the end users to express their opinions and discuss easily interactive concepts [12]. The increased penetration of social media networks results in the generation of massive volumes of data that are analysed through smart Machine Learning (ML) algorithms. Data mining and ML techniques are used to interpret such huge volumes of data, which in turn provides the capability to understand the hidden patterns of the data [13]. Therefore, the prospective is high for the identification of hatred information patterns. Natural Language Processing (NLP) techniques employ employing dissimilar statistical pre-processing methods. The NLP technique aims to transform the text dataset into a dataset that is possibly used by ML algorithms [14]. The NLP process includes various sub-processes such as stemming, data normalization, feature extraction and tokenization. But it also faces numerous challenges while handling sophisticated languages.
Aljarah et al. [15] proposed a method involving NLP and ML techniques for detecting cyber hate speech in the context of the Arabic language on the Twitter platform. This work considered a group of tweets encompassing sports, orientation, Islam, racism, journalism and terrorism. Distinct emotions and features were extracted from the dataset and arranged under 15 distinct data classes. In literature [16], the authors developed an NN-based classification of tweets expressed in seven different languages under hate or non-hate categories. This study covered the texts in one or more one languages, too, simultaneously. The study utilized CNNs and character-level representations. In the study conducted earlier [17], the authors examined the capabilities of CNN, CNN-LSTM and BiLSTM-CNN DL networks for automatic classification and recognising hateful content posted on social media. In this study, the deep network was trained and tested using the ArHS dataset, that had a total of 9,833 tweets. These tweets were recognized and categorized as hateful speech in the Arabic language.
Aldjanabi et al. [18] examined numerous aggressive and hate speeches on Arab social media to develop an accurate aggressive and hate speech recognition method. To be specific, this study established a classification method to define offensive content and hate speech with the help of the Multi-Task Learning (MTL) technique. This technique was developed on the basis of the pre-trained Arabic language method. In literature [19], the authors focused only on the technical features of designing an automated model such as monitoring and detecting hate speech made in the Arabic language. This study used the data collected from several companies that utilize it to prevent hate speech and cyberbullying. Also, the researchers utilized deep RNNs to detect and classify hate speeches.
The current study develops a Chaotic Elephant Herd Optimization with Machine Learning for Hate Speech Detection (CEHOML-HSD) model in the context of the Arabic language. The presented CEHOML-HSD model follows different sub-processes. At the initial stage, the CEHOML-HSD model undergoes data pre-processing with the help of the TF-IDF vectorizer. Secondly, the Support Vector Machine (SVM) model is applied to detect and classify hate speech made in the Arabic language. At last, the CEHO technique is employed for optimal fine-tuning of the SVM parameters. This study introduces the CEHO algorithm by combining the chaotic functions with the classical EHO algorithm. A widespread experimental analysis was executed to validate the enhanced performance of the proposed CEHOML-HSD model.
In this study, a novel CEHOML-HSD approach is proposed for the identification and categorization of the Arabic text into hate speech and normal. The proposed CEHOML-HSD model follows data pre-processing with the help of the TF-IDF vectorizer at the initial stage. Next, the SVM technique is used to detect and classify the hate speech made in the Arabic language. Finally, the CEHO technique is employed to modify the SVM parameters optimally. Fig. 1 showcases the overall processes involved in the CEHOML-HSD approach.
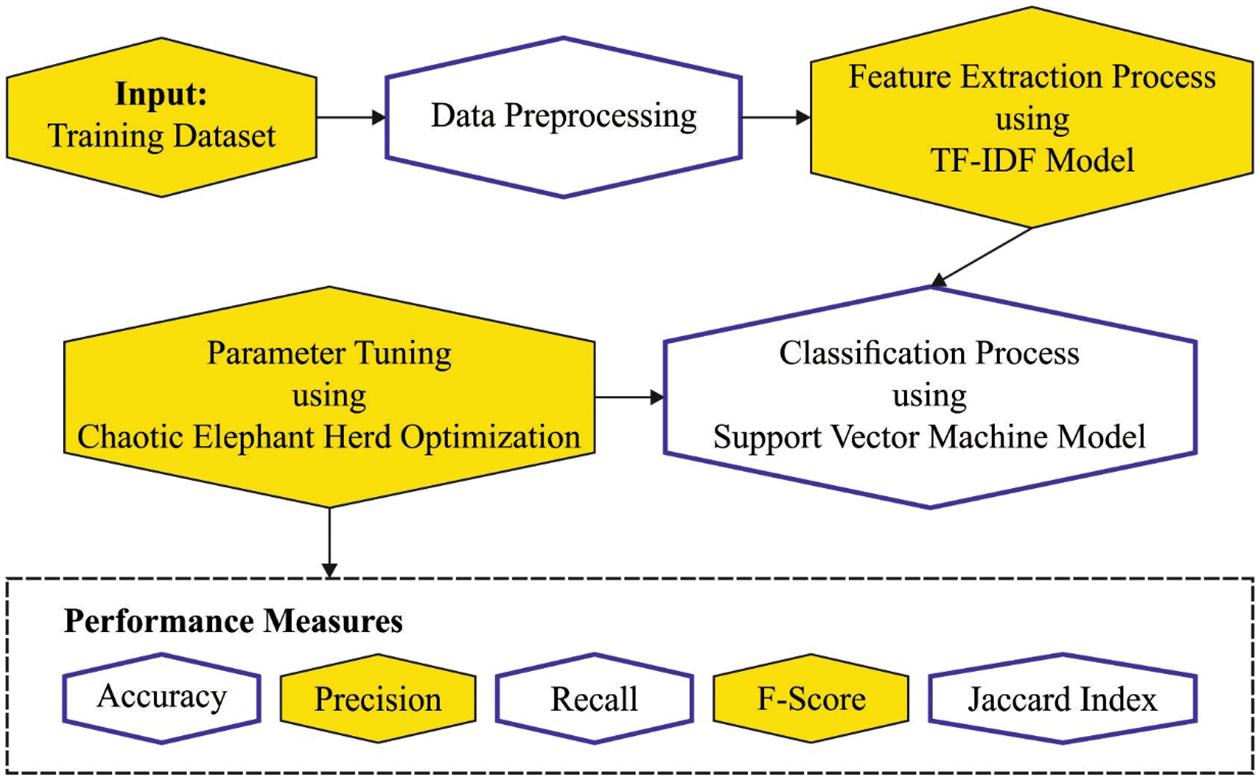
Figure 1: Overall processes of the CEHOML-HSD approach
Data pre-processing commences after the tweets are collected with the help of R language and Twitter APIs. Then, the data is annotated by two volunteers, after which the clean data is obtained without any redundant or irrelevant tweets. Then, the tweets are tokenized, normalized and vectorised for feature representation. During the data cleaning process, all the hashtags, non-Arabic characters, punctuation marks, numerals, diacritics, symbols, Arabic stop words and web addresses are filtered. Tweets’ normalization is a procedure in which the Arabic characters are transformed so that the characters can be written in a standard writing manner to a colloquial-writing manner. Predominantly, the arithmetical features indicate the statistical dimensions of the words. The feature collections are represented as vectors; hence, the process is termed text vectorization.
2.2 Hate Speech Detection Using SVM Model
Next, the SVM model is used to detect and classify the hate speeches made in Arabic. The SVM is a classifier approach that determines the decision to separate data points from distinct classes [20]. This procedure aims to increase the width of the ‘street’ by splitting it into two classes.
In Eq. (1),
To increase the margin size, it is necessary to minimize the
In Eq. (2),
It is to be noted that the constraints are divided as follows:
The abovementioned optimization issue is a quadratic convex optimization issue with a linear constraint that can be resolved by a quadratic programming solver. The SVM is expanded to obtain a non-linear classifier in which a kernel is employed in the input dataset and the input the mapped with high-dimensional feature spaces.
In comparison with
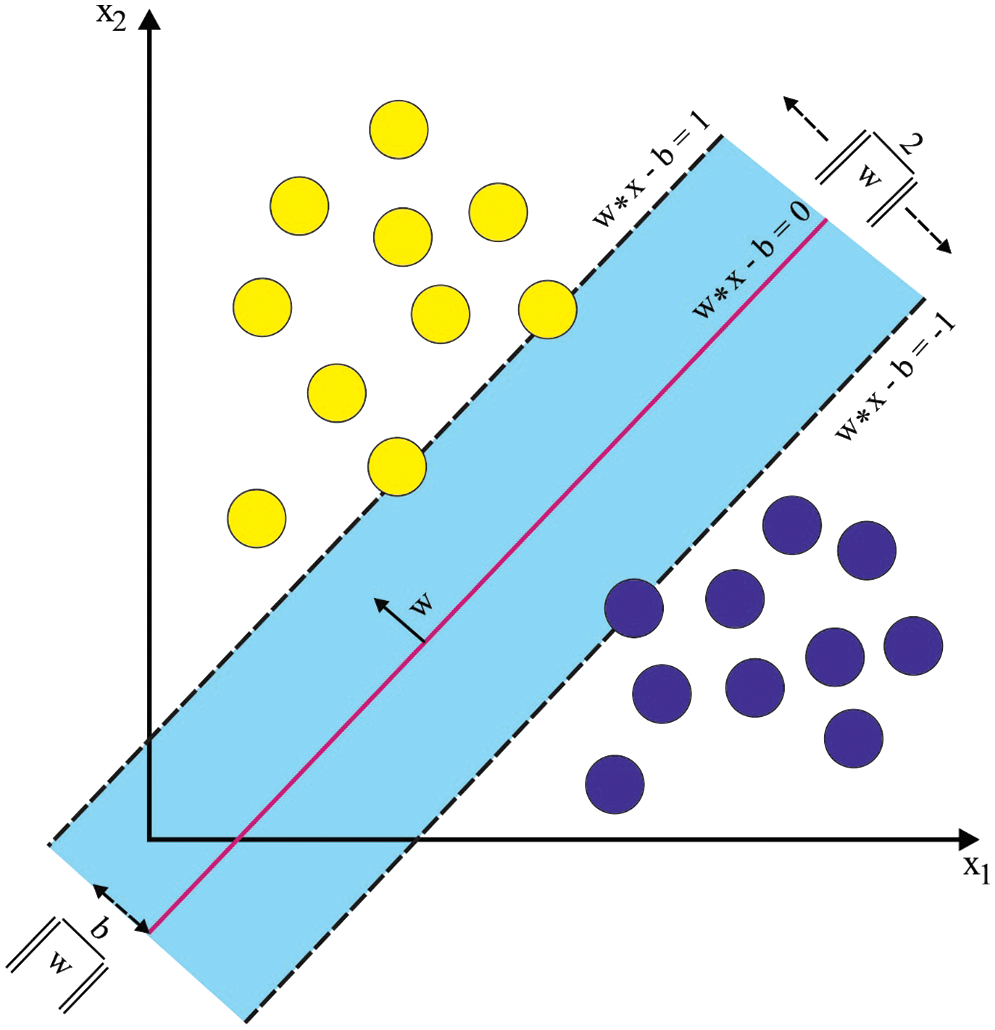
Figure 2: SVM hyperplane
2.3 Parameter Tuning using CEHO Algorithm
Finally, the CEHO algorithm is introduced as a combination of chaotic functions and the classical EHO algorithm. The elephant herding behavior is utilized in implementing the EHO approach [21]. This section discusses the elephant herding behaviour in detail. The single-elephant population is divided into multiple clans. Each clan follows the matriarchy process i.e.; a female elephant leads the clan. In every population, a specific male elephant leaves the clan to live an isolated life farther from the clan. Concerning Swarm Intelligence (SI) approach, the clan indicates the local search process, whereas the male elephant that leaves the clan denotes the global search. The matriarch pattern is the solution (elephant) with better fitness value in the clan. On the contrary, the movement of the male elephants represents the solution with the worst fitness value. EHO approach is determined as discussed herewith. The elephant population is classified into
In Eq. (4),
In every generation, the solution changes as follows. A member
In Eq. (5),
In Eq. (6),
Here,
In Eq. (8),
The circle map is determined as follows:
In Eq. (9), for
The sinusoidal map is determined as follows:
In Eq. (10), for
The presented chaotic map is applied in the CEHO algorithm for generating chaos sequences. Then, the random numbers are replaced in Eqs. (4)–(6) with the numbers attained from the chaos sequence.

In this section, the proposed CEHOML-HSD model was experimentally validated and the results are discussed in detail. The model was validated using a dataset composed of Arabic text under two classes: hate and normal.
Table 1 and Fig. 3 depict the overall hate speech detection outcomes accomplished by the proposed CEHOML-HSD model under 500 epochs. The results infer that the proposed CEHOML-HSD model accomplished superior performance in each aspect. In hate class, the proposed CEHOML-HSD model offered an

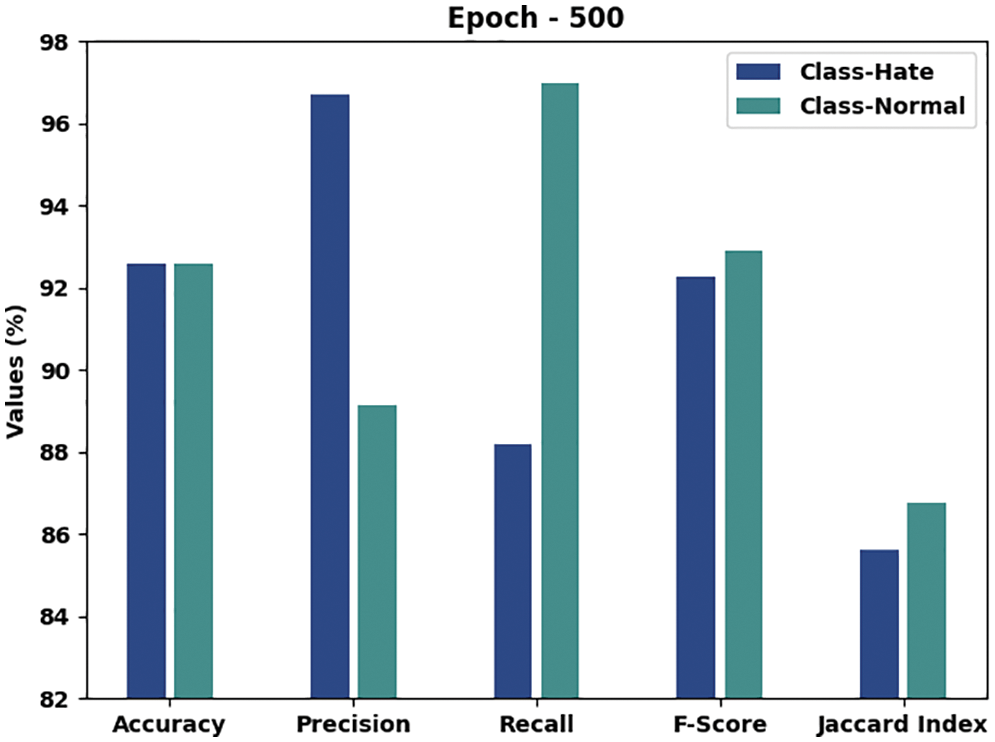
Figure 3: Results of the analysis of the CEHOML-HSD approach under 500 epochs
Table 2 and Fig. 4 demonstrate the overall hate speech detection outcomes achieved by the proposed CEHOML-HSD model with 1000 epochs. The outcomes imply that the proposed CEHOML-HSD system accomplished improved outcomes under each aspect. In hate class, the presented CEHOML-HSD approach offered an
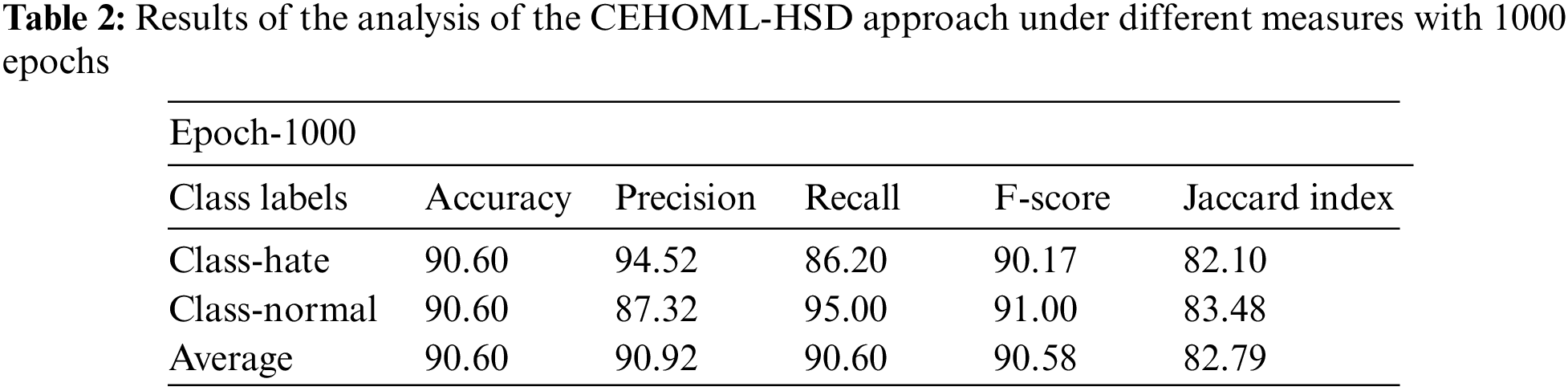
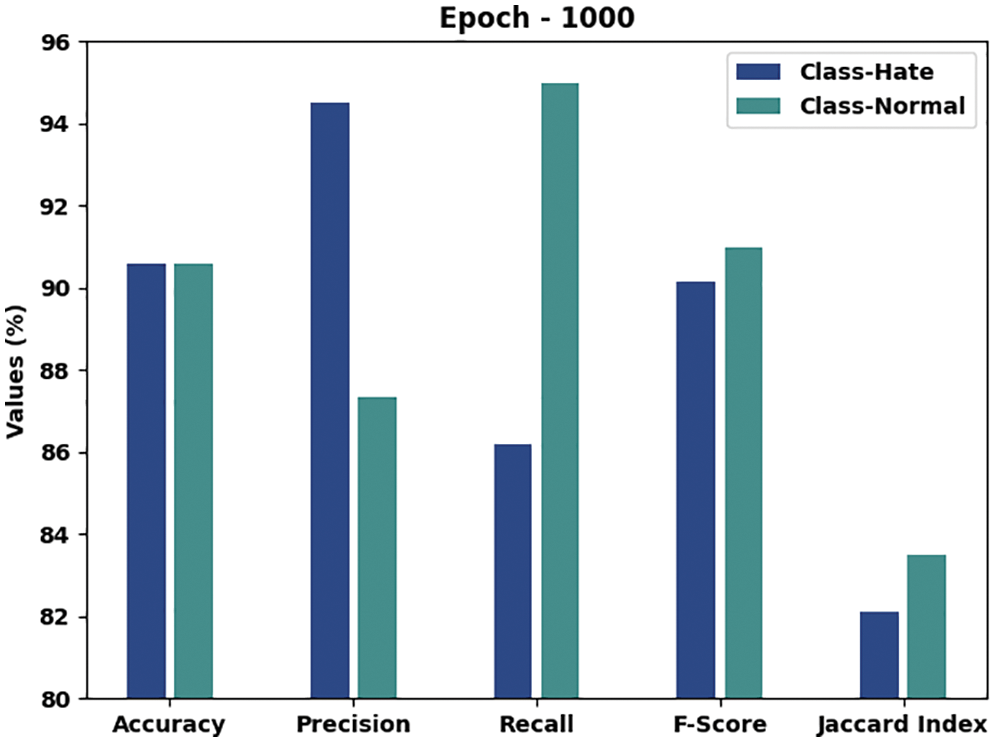
Figure 4: Results of the analysis of the CEHOML-HSD approach under 1000 epochs
Table 3 and Fig. 5 illustrate the overall hate speech detection outcomes attained by the proposed CEHOML-HSD technique with 1500 epochs. The results demonstrate that the proposed CEHOML-HSD model accomplished enhanced results under each aspect. In hate class, the proposed CEHOML-HSD approach obtained an
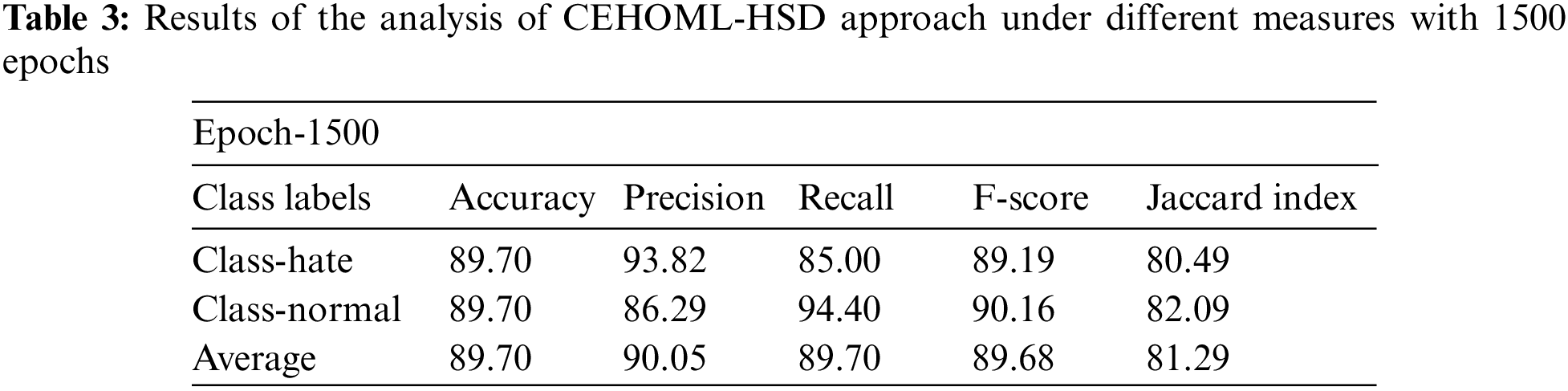
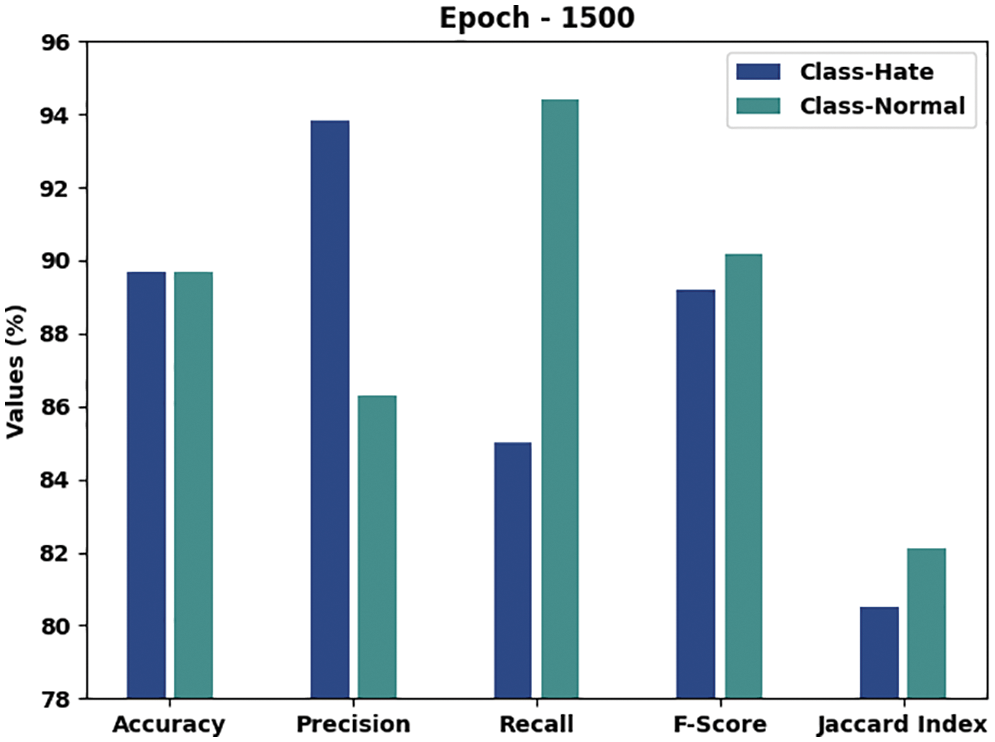
Figure 5: Results of the analysis of CEHOML-HSD approach under 1500 epochs
Table 4 and Fig. 6 showcase the overall hate speech detection outcomes produced by the proposed CEHOML-HSD model with 2000 epochs. The outcomes depict that the proposed CEHOML-HSD system accomplished exemplary performance under each aspect. In hate class, the proposed CEHOML-HSD method achieved an
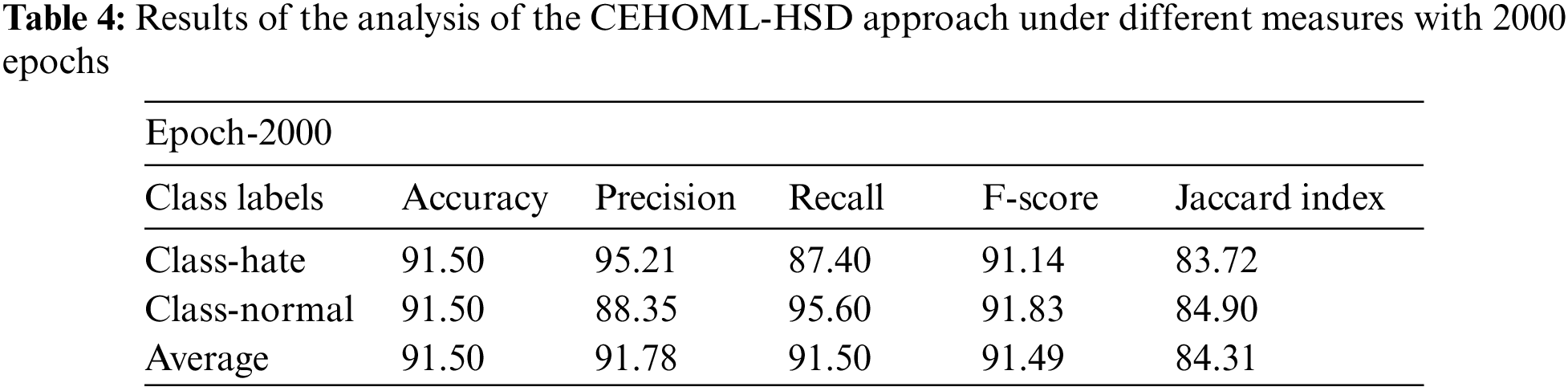
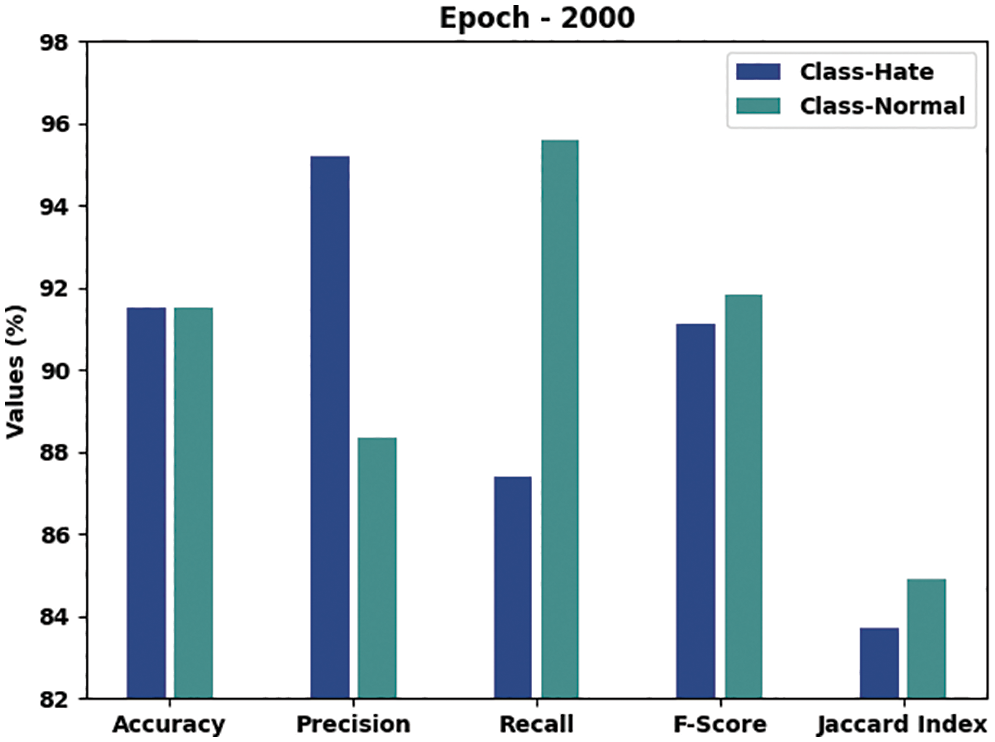
Figure 6: Results of the analysis of CEHOML-HSD approach under 2000 epochs
Both Training Accuracy (TA) and the Validation Accuracy (VA) values, acquired by the proposed CEHOML-HSD methodology on the test dataset, are depicted in Fig. 7. The experimental outcomes expose that the proposed CEHOML-HSD system achieved high TA and VA values. In contrast, the VA values were superior to TA.
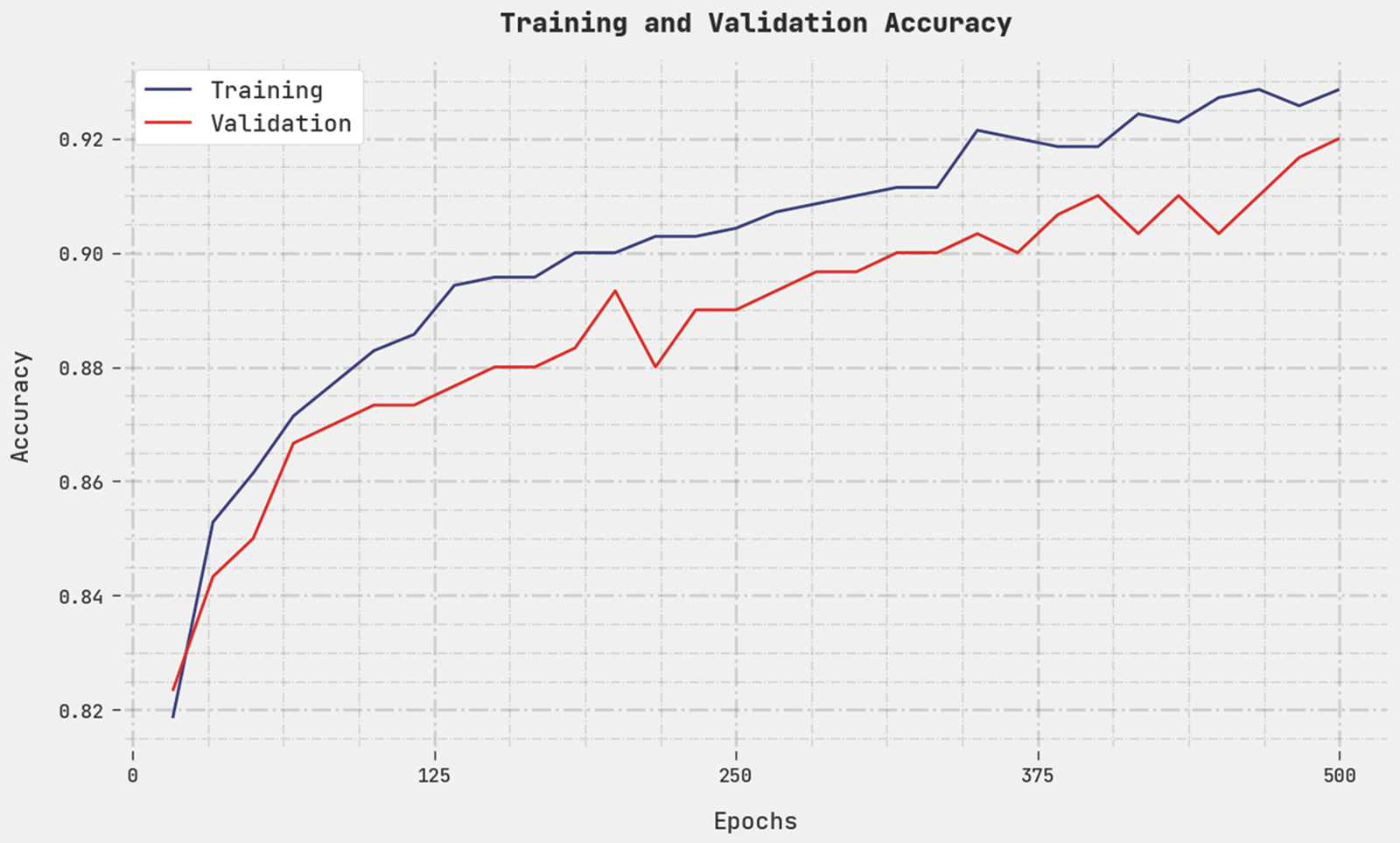
Figure 7: TA and VA analyses results of CEHOML-HSD methodology
Both Training Loss (TL) and the Validation Loss (VL) values, accomplished by the proposed CEHOML-HSD approach on the test dataset, are represented in Fig. 8. The experimental outcomes reveal that the proposed CEHOML-HSD algorithm achieved the minimal TL and VL values whereas the VL values were lesser than TL.

Figure 8: TL and VL analyses results of CEHOML-HSD methodology
A clear precision-recall inspection was conducted upon the CEHOML-HSD method using the test dataset, and the results are depicted in Fig. 9. The figure implies that the proposed CEHOML-HSD methodology produced high precision-recall values under all the classes.
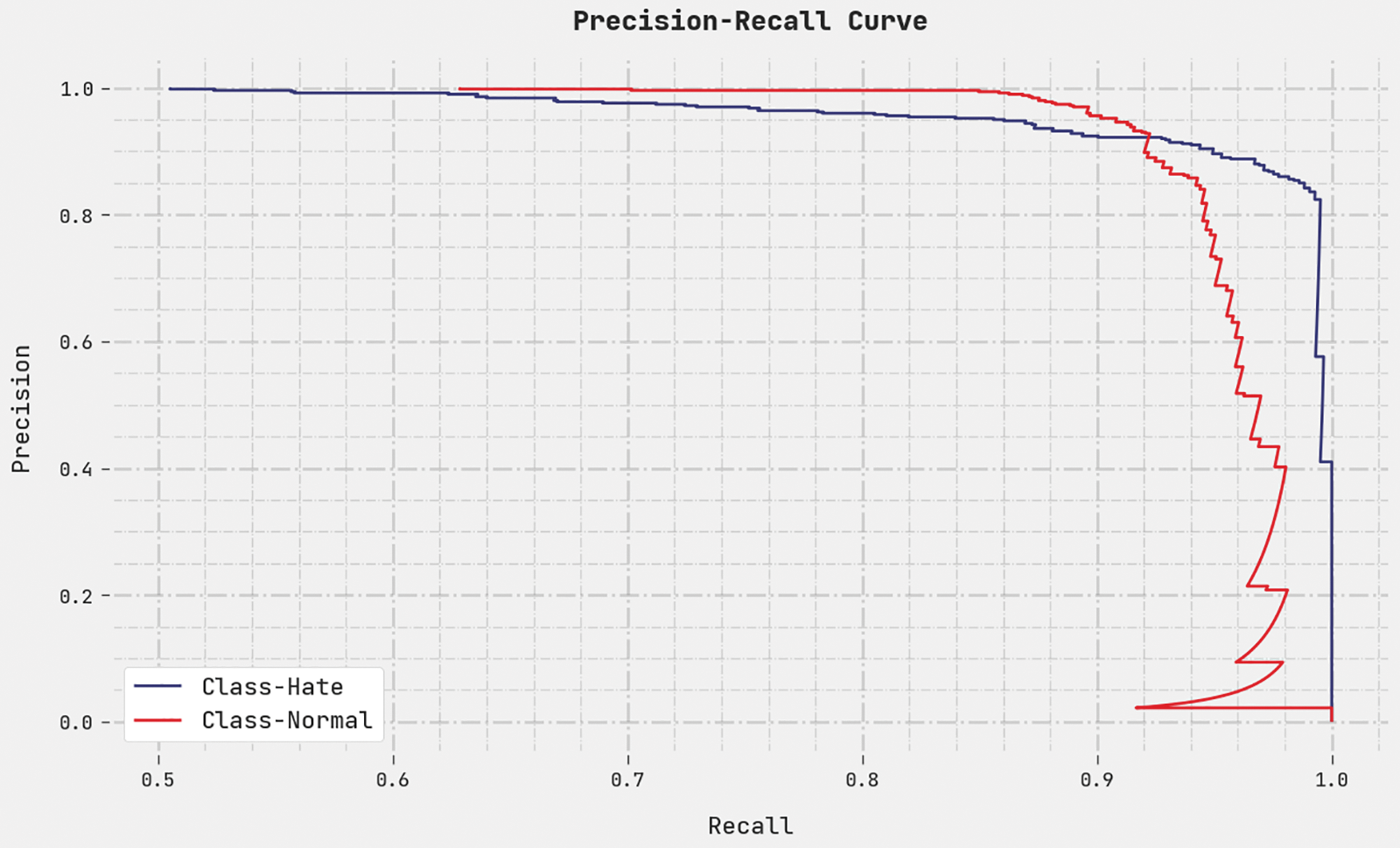
Figure 9: Precision-recall curve analysis results of CEHOML-HSD methodology
A brief ROC analysis was conducted upon CEHOML-HSD system using the test dataset and the results are demonstrated in Fig. 10. The outcomes reveal that the proposed CEHOML-HSD approach established its ability in categorizing the test dataset under distinct classes.
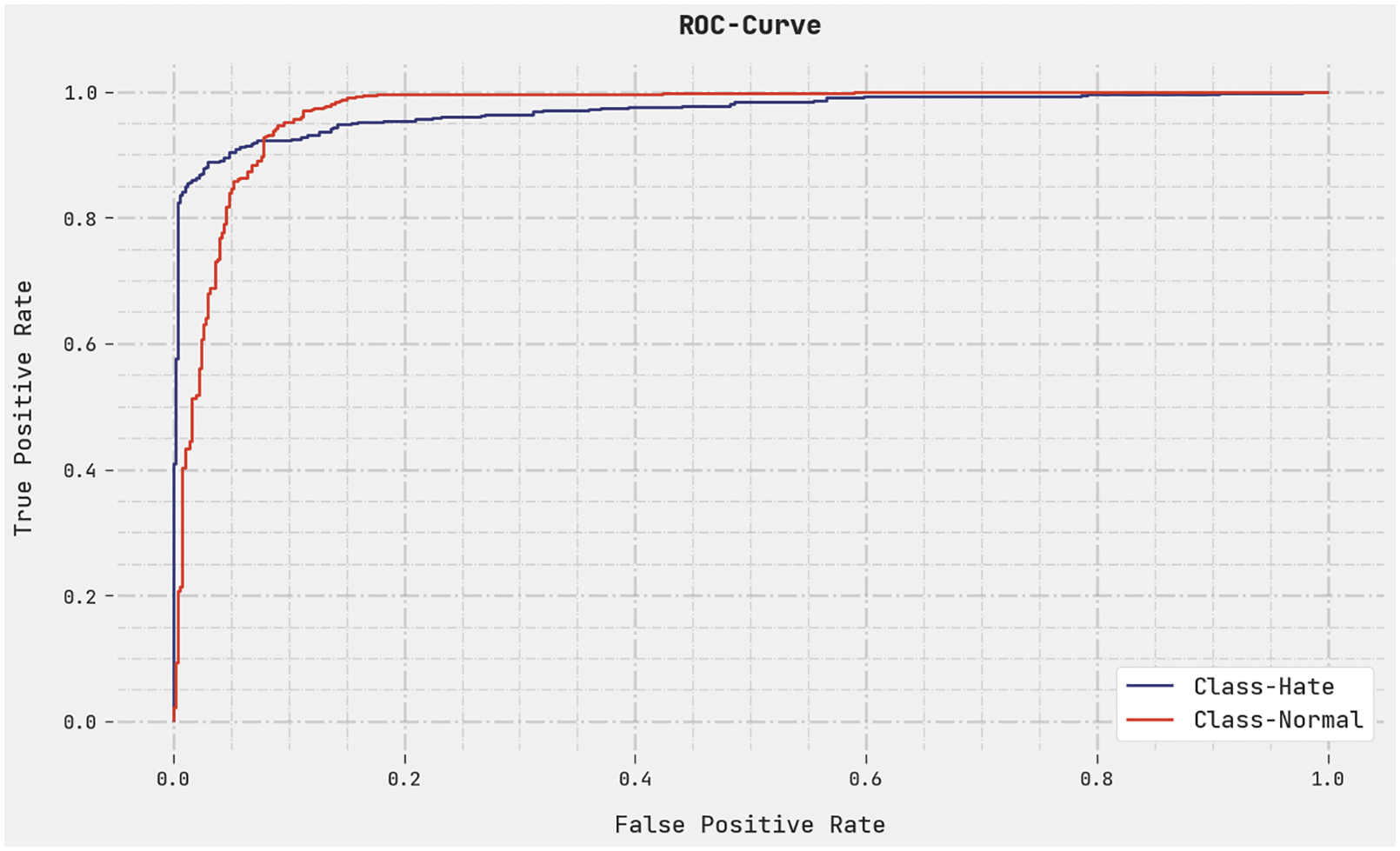
Figure 10: ROC curve analysis results of CEHOML-HSD methodology
Table 5 offers the hate speech detection outcomes yielded by the proposed CEHOML-HSD model and other existing models [23]. Fig. 11 portrays the comparative study results achieved by the proposed CEHOML-HSD model and other recent models in terms of
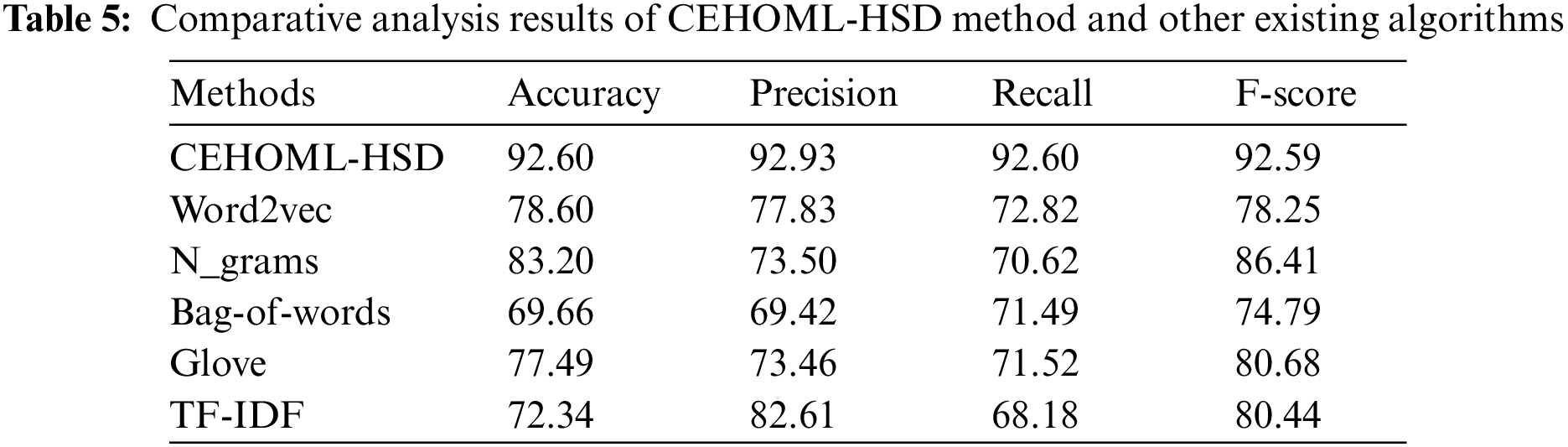
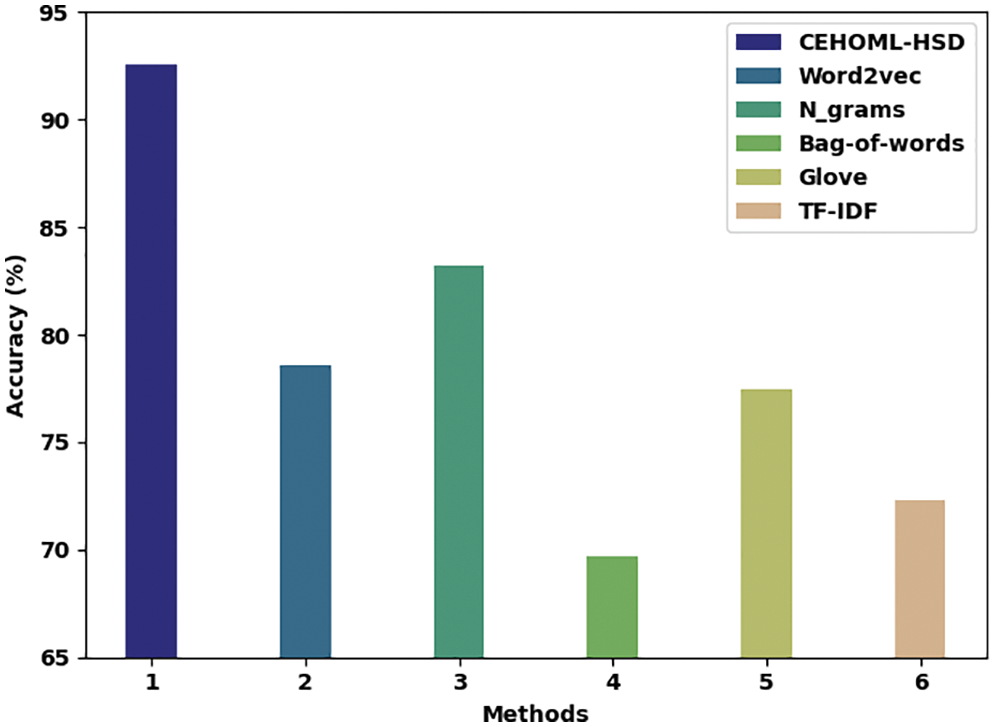
Figure 11:
Fig. 12 reports the comparative analysis results achieved by the proposed CEHOML-HSD model and other recent models with respect to
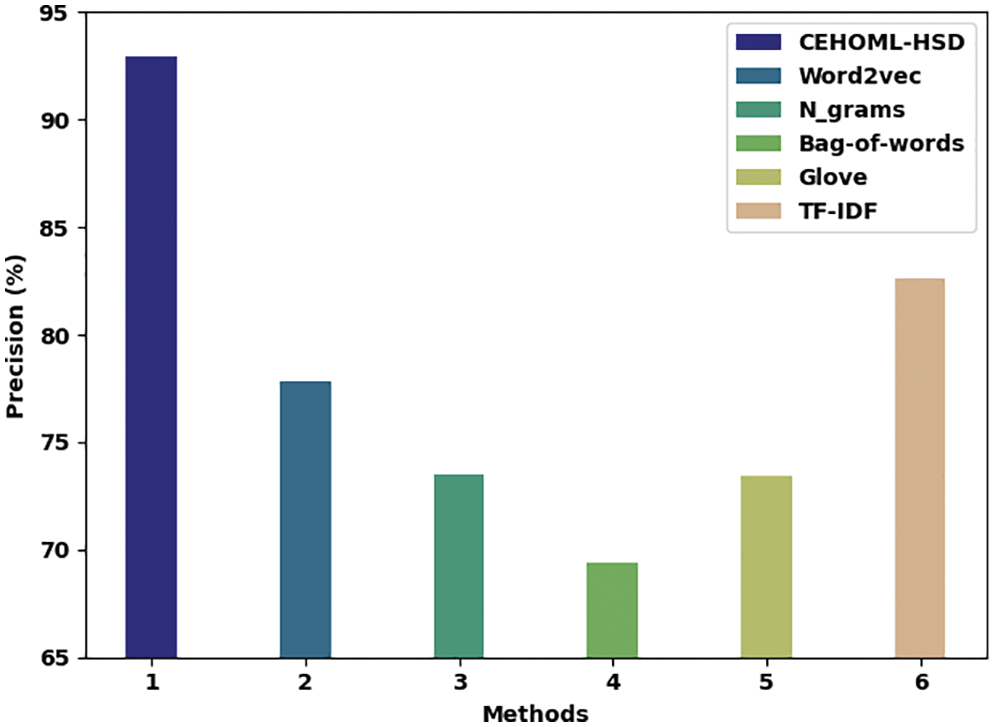
Figure 12:
Fig. 13 portrays the comparative investigation outcomes of the proposed CEHOML-HSD system and other recent models in terms of

Figure 13:

Figure 14:
In this study, a novel CEHOML-HSD approach has been developed for the identification and categorization of the Arabic text into hate speech and normal. The proposed CEHOML-HSD model uses the TF-IDF vectorizer at the initial stage to pre-process the data. Next, the SVM method is used to detect and classify the hate speeches made in the Arabic language. Lastly, the CEHO technique is employed for optimal fine-tuning SVM parameters. The CEHO algorithm is introduced by combining the chaotic functions with the classical EHO algorithm. A widespread experimental analysis was executed to validate the enhanced performance of the proposed CEHOML-HSD model. The comparative study outcomes established the supremacy of the proposed CEHOML-HSD model over other approaches. In the future, the performance of the proposed CEHOML-HSD model can be improved with the help of advanced feature selection and feature reduction approaches.
Acknowledgement: None.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2024R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. This study is supported via funding from Prince Sattam bin Abdulaziz University Project Number (PSAU/2024/R/1445).
Author Contributions: Conceptualization, Badriyya B. Al-onazi; Methodology, Jaber S. Alzahrani; Software, Najm Alotaibi; Validation, Hussain Alshahrani and Jaber S. Alzahrani; Investigation, Badriyya B. Al-onazi; Data curation, Jaber S. Alzahrani; Writing–original draft, BadriyyaB. Al-onazi, Jaber S. Alzahrani, Najm Alotaibi, Mohamed Ahmed Elfaki, Radwa Marzouk and Heba Mohsen; Writing–review & editing, Abdelwahed Motwakel, Jaber S. Alzahrani, Radwa Marzouk and Heba Mohsen; Visualization, Abdelwahed Motwakel; Project administration, Abdelwahed Motwakel; Funding acquisition, Badriyya B. Al-onazi and Jaber S. Alzahrani. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data sharing not applicable to this article as no datasets were generated during the current study.
Conflicts of Interest: The authors declare they have no conflicts of interest to report regarding the present study.
References
1. R. Alshalan and H. A. Khalifa, “A deep learning approach for automatic hate speech detection in the Saudi twittersphere,” Applied Sciences, vol. 10, no. 23, pp. 8614, 2020. doi: 10.3390/app10238614. [Google Scholar] [CrossRef]
2. N. Defersha and K. Tune, “Detection of hate speech text in Afan Oromo social media using machine learning approach,” Indian Journal of Science and Technology, vol. 14, no. 31, pp. 2567–2578, 2021. doi: 10.17485/IJST. [Google Scholar] [CrossRef]
3. Z. Mossie and J. H. Wang, “Vulnerable community identification using hate speech detection on social media,” Information Processing & Management, vol. 57, no. 3, pp. 102087, 2020. doi: 10.1016/j.ipm.2019.102087. [Google Scholar] [CrossRef]
4. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. doi: 10.1587/transinf.2020EDP7011. [Google Scholar] [CrossRef]
5. F. Poletto, V. Basile, M. Sanguinetti, C. Bosco and V. Patti, “Resources and benchmark corpora for hate speech detection: A systematic review,” Language Resources and Evaluation, vol. 55, no. 2, pp. 477–523, 2021. doi: 10.1007/s10579-020-09502-8. [Google Scholar] [CrossRef]
6. F. N. Al-Wesabi, “A smart english text zero-watermarking approach based on third-level order and word mechanism of Markov model,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1137–1156, 2020. doi: 10.32604/cmc.2020.011151. [Google Scholar] [CrossRef]
7. E. Pronoza, P. Panicheva, O. Koltsova and P. Rosso, “Detecting ethnicity-targeted hate speech in Russian social media texts,” Information Processing & Management, vol. 58, no. 6, pp. 102674, 2021. doi: 10.1016/j.ipm.2021.102674. [Google Scholar] [CrossRef]
8. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. doi: 10.32604/cmc.2020.012088. [Google Scholar] [CrossRef]
9. O. Araque and C. A. Iglesias, “An ensemble method for radicalization and hate speech detection online empowered by sentic computing,” Cognitive Computation, vol. 14, no. 1, pp. 48–61, 2022. doi: 10.1007/s12559-021-09845-6. [Google Scholar] [CrossRef]
10. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. doi: 10.32604/cmc.2021.015865. [Google Scholar] [CrossRef]
11. A. Y. Muaad, H. J. Davanagere, M. A. Al-antari, J. V. B. Benifa and C. Chola, “AI-based misogyny detection from Arabic Levantine twitter tweets,” in Proc. of the 1st Int. Electronic Conf. on Algorithms, Computer Sciences & Mathematics Forum, Switzerland, vol. 2, pp. 15, 2021. [Google Scholar]
12. N. Albadi, M. Kurdi and S. Mishra, “Investigating the effect of combining gru neural networks with handcrafted features for religious hatred detection on Arabic twitter space,” Social Network Analysis and Mining, vol. 9, no. 1, pp. 1–19, 2019. [Google Scholar]
13. M. K. A. Aljero and N. Dimililer, “A novel stacked ensemble for hate speech recognition,” Applied Sciences, vol. 11, no. 24, pp. 11684, 2021. doi: 10.3390/app112411684. [Google Scholar] [CrossRef]
14. A. Y. Muaad, H. Jayappa, M. A. Al-antari and S. Lee, “ArCAR: A novel deep learning computer-aided recognition for character-level Arabic text representation and recognition,” Algorithms, vol. 14, no. 7, pp. 216, 2021. doi: 10.3390/a14070216. [Google Scholar] [CrossRef]
15. I. Aljarah, M. Habib, N. Hijazi, H. Faris, R. Qaddoura et al., “Intelligent detection of hate speech in Arabic social network: A machine learning approach,” Journal of Information Science, vol. 47, no. 4, pp. 483–501, 2021. doi: 10.1177/0165551520917651. [Google Scholar] [CrossRef]
16. A. Elouali, Z. Elberrichi and N. Elouali, “Hate speech detection on multilingual twitter using convolutional neural networks,” Revue d’Intelligence Artificielle, vol. 34, no. 1, pp. 81–88, 2020. doi: 10.18280/ria. [Google Scholar] [CrossRef]
17. R. Duwairi, A. Hayajneh and M. Quwaider, “A deep learning framework for automatic detection of hate speech embedded in Arabic tweets,” Arabian Journal for Science and Engineering, vol. 46, no. 4, pp. 4001–4014, 2021. doi: 10.1007/s13369-021-05383-3. [Google Scholar] [CrossRef]
18. W. Aldjanabi, A. Dahou, M. A. A. Al-qaness, M. A. Elaziz, A. M. Helmi et al., “Arabic offensive and hate speech detection using a cross-corpora multi-task learning model,” Informatics, vol. 8, no. 4, pp. 69, 2021. doi: 10.3390/informatics8040069. [Google Scholar] [CrossRef]
19. F. Y. A. Anezi, “Arabic hate speech detection using deep recurrent neural networks,” Applied Sciences, vol. 12, no. 12, pp. 6010, 2022. doi: 10.3390/app12126010. [Google Scholar] [CrossRef]
20. H. Wang, B. Zheng, S. W. Yoon and H. S. Ko, “A support vector machine-based ensemble algorithm for breast cancer diagnosis,” European Journal of Operational Research, vol. 267, no. 2, pp. 687–699, 2018. doi: 10.1016/j.ejor.2017.12.001. [Google Scholar] [CrossRef]
21. S. D. Correia, M. Beko, L. A. D. S. Cruz and S. Tomic, “Elephant herding optimization for energy-based localization,” Sensors, vol. 18, no. 9, pp. 2849, 2018. doi: 10.3390/s18092849. [Google Scholar] [PubMed] [CrossRef]
22. D. Oliva, A. A. Ewees, M. A. E. Aziz, A. E. Hassanien and M. Peréz-Cisneros, “A chaotic improved artificial bee colony for parameter estimation of photovoltaic cells,” Energies, vol. 10, no. 7, pp. 865, 2017. doi: 10.3390/en10070865. [Google Scholar] [CrossRef]
23. H. Faris, I. Aljarah, M. Habib and P. A. Castillo, “Hate speech detection using word embedding and deep learning in the Arabic language context,” in Proc. of the 9th Int. Conf. on Pattern Recognition Applications and Methods (ICPRAM 2020), Valleta, Matta, pp. 453–460, 2020. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools