
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Optimizing Power Allocation for D2D Communication with URLLC under Rician Fading Channel: A Learning-to-Optimize Approach
1 School of Information Engineering, Southwest University of Science and Technology, Mianyang, 621010, China
2 School of Software Engineering, Northeastern University, Shenyang, 110167, China
3 School of Information and Software Engineering, University of Electronic Sciences and Technology, Chengdu, 610000, China
* Corresponding Author: Hong Jiang. Email:
Intelligent Automation & Soft Computing 2023, 37(3), 3193-3212. https://doi.org/10.32604/iasc.2023.041232
Received 15 April 2023; Accepted 21 June 2023; Issue published 11 September 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
To meet the high-performance requirements of fifth-generation (5G) and sixth-generation (6G) wireless networks, in particular, ultra-reliable and low-latency communication (URLLC) is considered to be one of the most important communication scenarios in a wireless network. In this paper, we consider the effects of the Rician fading channel on the performance of cooperative device-to-device (D2D) communication with URLLC. For better performance, we maximize and examine the system’s minimal rate of D2D communication. Due to the interference in D2D communication, the problem of maximizing the minimum rate becomes non-convex and difficult to solve. To solve this problem, a learning-to-optimize-based algorithm is proposed to find the optimal power allocation. The conventional branch and bound (BB) algorithm are used to learn the optimal pruning policy with supervised learning. Ensemble learning is used to train the multiple classifiers. To address the imbalanced problem, we used the supervised undersampling technique. Comparisons are made with the conventional BB algorithm and the heuristic algorithm. The outcome of the simulation demonstrates a notable performance improvement in power consumption. The proposed algorithm has significantly low computational complexity and runs faster as compared to the conventional BB algorithm and a heuristic algorithm.Keywords
URLLC is one of the most important scenarios in 5G, whose goal is to make it possible for new services and applications to have high reliability, availability, and minimal latency [1]. D2D communication is a promising solution with URLLC, adopted as a vital communication scenario in 5G mobile communication networks, and it is becoming increasingly important to offer end-to- end services with low latency and high reliability [2]. URLLC has very stricter requirements, such as
To enhance power allocation, traditional wireless networks have been developed with long-packet transmission scenarios, where ensuring high reliability and low latency at the same time is generally difficult [3]. D2D communication is utilized in various scenarios to enhance the Quality of Service (QoS) of the network by reducing power consumption, lowering latency, and improving reliability, resulting in a significant improvement in performance [5,6]. Moreover, resource allocation and power allocation are major issues for D2D communication underlying cellular networks. D2D communication can decrease latency and enhance network capacity, thereby optimizing resource allocation. D2D communications reduce overall power usage due to users’ proximity, which is impossible in conventional cellular communications [7]. D2D communications are emerging as a potential technique for meeting the URLLC’s strict standards [8,9].
In wireless communication, resource allocation management affects the performance of the optimization. Machine learning has demonstrated a high degree of efficacy in resolving non-convex optimization issues related to D2D communication, such as power allocation [10] and interference management [11], that affect communication performance. Global optimization algorithms, such as the BB algorithm, have exponential complexity, and the majority of recent studies have concentrated on heuristic or suboptimal algorithms. Machine learning is a relatively new technique for balancing performance gaps and computational complexity that has proven effective in addressing difficult optimization problems, particularly those that are non-convex and NP-hard [12,13]. This field of research is referred to as learning-to-optimize for resource allocation in wireless communication in order to address wireless network optimization problems [14]. Learning-to-optimization aims to minimize the computational complexity and resources needed to obtain solutions that are nearly optimal [12].
Some studies examine the D2D architecture with URLLC, where they attempt to preserve URLLC’s strict QoS requirements. Chang et al. [15] propose an autonomous probability-based D2D transmission method under the Rayleigh fading channel in URLLC to minimize the transmission power. A frequency-division duplex system is used in the uplink and downlink spectrums of D2D communication under cellular networks with URLLC requirements for optimized resource allocation. An unbalanced distribution of data traffic between both frequency bands could lead to less effective use of network resources [8]. For improving the transmission power for a finite block-length rate with the discrete-time block-fading channel, a resource allocation algorithm is proposed to maximize the achievable rate and optimize the power allocation for D2D communication with URLLC requirements [3]. Similarly, in [16], the proposed real-time wireless control systems for D2D communication were primarily focused on transmission power optimization within the confines of URLLC, and a Rayleigh fading channel is used, which decreases power consumption but is not as effective as Rician fading. The authors in [17] formulated an optimal power allocation problem in an uplink D2D communication scenario under a cellular network with Rayleigh fading, maximized the overall system throughput of the communication system, and ensured the URLLC requirements.
Numerous studies have been done on optimization-based algorithms for wireless resource allocation problems [18]. The majority of wireless resource allocation problems are non-convex or NP-hard problems, and optimization algorithms are known for being either excessively time-consuming or exhibiting significant performance gaps [19]. In order to achieve efficient and nearly optimal resource allocation, learning-to-optimize is a disruptive technique for solving resource allocation problems. Learning-to-optimize combines knowledge and techniques from wireless communications, mathematical optimization, and machine learning. It aims to develop algorithms that can dynamically and efficiently solve optimization problems while effectively balancing the computational complexity and the optimality gap in optimization problems. Policy learning is one of the major subcategory of learning-to-optimization; training an agent to discover the best solution to a problem within a specified algorithm is known as policy learning [20]. In order to solve the mixed integer nonlinear programming (MINLP) problem for resource allocation in D2D communication, the authors in [21] propose a policy learning method for node pruning in the BB algorithm.
This paper investigates uplink D2D communication underlying the cellular system in a single-cell environment with a Rician fading channel. URLLC is utilized in D2D communication to deal with the extremely high QoS requirements for D2D communication. In order to maintain satisfactory performance for all users, we focus on maximizing and analyzing the minimum rate of D2D users. However, the theoretical analysis that corresponds to this idea is complex because of the complicated interference patterns of the system under consideration. Finding a solution to the problem of maximizing the minimal rate and analyzing the interference effects on the maximized minimal rate is challenging. In this paper, we use a policy learning approach to solve the power allocation problem with low computational complexity in D2D communication. The following are the contributions of this research:
• A framework has been developed to analyze D2D communication in a cellular network. This framework utilizes the Rician fading channel to enable D2D communication that meets URLLC QoS requirements. We maximize the minimal rate of D2D users. The formulated problem is a non-convex problem with a complex expression of the achievable rate, which is solved by using the proposed scheme.
• We propose a fast iterative learning-to-optimize-based algorithm to maximize the minimal achievable rate
• The conventional BB algorithm is used to generate the training sample sets and learn the optimal pruning policy for power allocation in D2D communication. To address the imbalanced problem, we used an undersampling technique, and ensemble learning is used with supervised learning, which involves training multiple classifiers and combining their outputs to enhance overall performance. The computational complexity of the proposed algorithm is significantly less than that of the BB algorithm and heuristic algorithm.
The rest of the paper is structured in the following manner: Section 3 provides a brief introduction to the system model. Section 4 formulates the problem, and Section 5 presents the learning-to-optimize-based algorithm to solve the problem. Section 6 of the paper contains the simulation and numerical results, while the conclusion can be found in Section 7.
Notation: The following notations will be used throughout the paper:
In this section, we consider uplink D2D communication within a cellular system in a single-cell network, as depicted in Fig. 1. We consider N cellular users (CUs) and M D2D pairs where
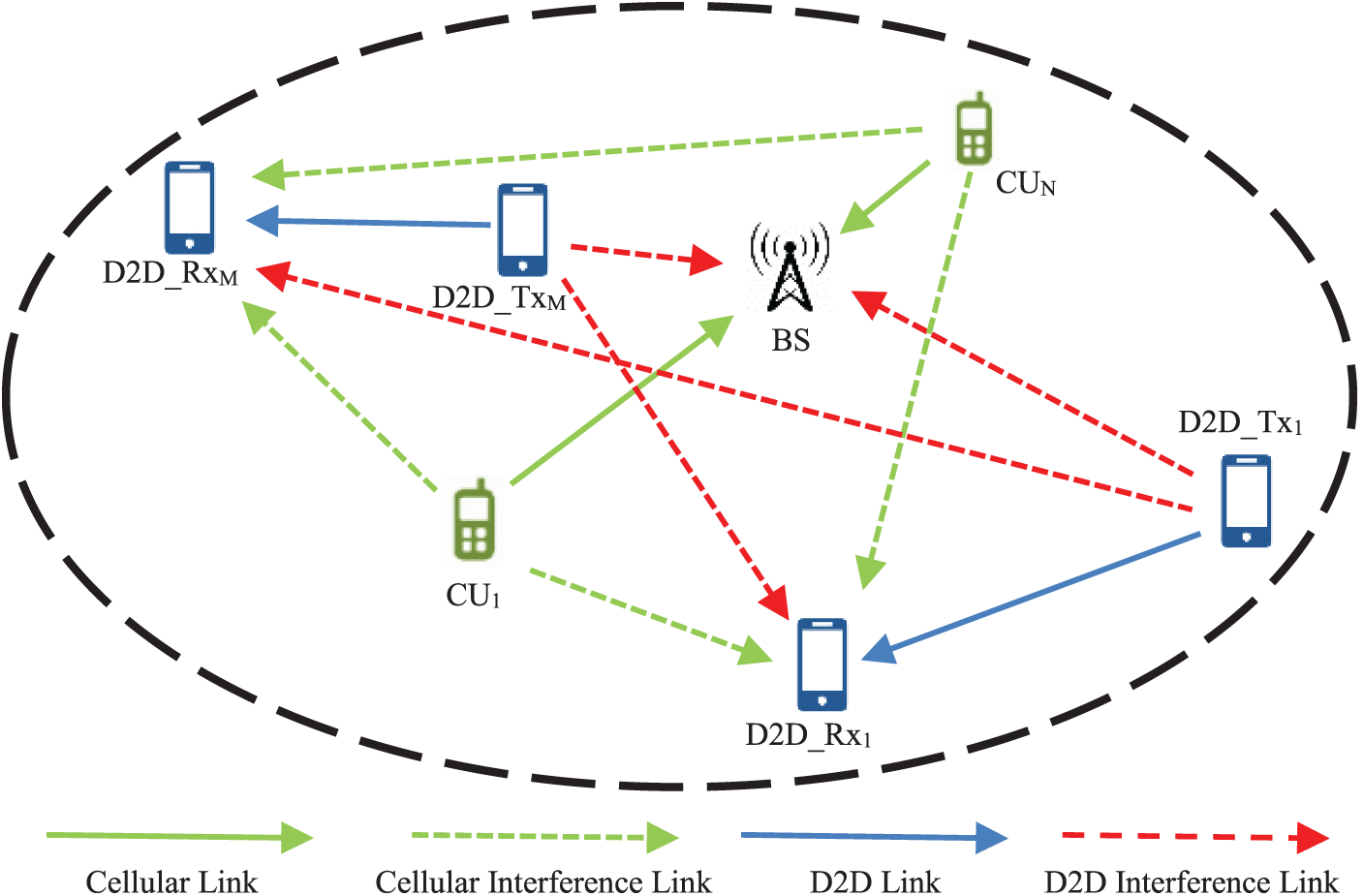
Figure 1: System model
We can suppose that the slow fading is comprised of known constants and the fast fading is comprised of random variables where
where
Outage Probability
The outage probability of D2D links is analytically expressed as
where
From the CUE to the D2D receiver, the interference power is usually substantially greater than the noise power [25]. We make the assumption that D2D links are limited by interference and that the impact of noise power on the outage probability can be ignored [7]. Eq. (3) can be expressed in the probability density function (PDF) as
The instantaneous signal power PDF is
where K is the Rician fading parameter,
Solving the inner integral of Eq. (7) and getting the outage probability as
Proof: See Appendix A.
In URLLC scenarios, we anticipate users to send short packets to achieve low latency, and the successful packet error probability is used as a measure of high reliability. The uplink channel capacity expression for D2D communication is as follows:
where
The capacity loss resulting from transmission errors is represented by channel dispersion
When SINR is higher than
where the expectation
Theorem 1: In D2D communication, the ergodic capacity is given by
where
Proof: See Appendix B.
Then Eq. (9) can be rewritten as
The probability of a packet error during the transmission of
where
In this section, we formulate the optimization problem to maximize the minimal achievable rate among the D2D users where the power allocation is optimized, which is described as:
The objective of this optimization problem is to maximize the minimal achievable rate
The aforementioned problem
To solve the problem
According to this significant finding, by solving the following set of equations, the optimal solution of
Proof: See Appendix C.
Conventional Branch and Bound Algorithm
The traditional BB algorithm often addresses non-convex optimization problems by repeatedly exploring a tree with high computational complexity [21]. The BB algorithm is a binary tree search problem where the original problem is represented at the root node and each leaf node represents a subproblem within its corresponding subregion [32]. All of the tree’s branches have been explored to estimate the objective function’s upper bound and optimal power allocation [33]. If the optimal transmit power exceeds the maximum transmit power, that particular branch is eliminated and removed from the area being searched. Once all the branches have been investigated, the solution that possesses the minimum value is regarded as the ultimate optimal solution [12,34]. All unexplored branches are pruned, if the solution is found on the last branch, the majority of the branches will not be pruned; in this situation, the computational complexity will increase. Because of the BB algorithm’s limited performance and high computational complexity, we proposed a learning-to-optimize-based algorithm with low computational complexity that outperforms the conventional BB algorithm.
5 Learning-to-Optimize Approach
The learning-to-optimize approach is used to find a near-optimal solution for the power allocation problem in D2D communication with URLLC QoS constraints and provide low computational complexity. The conventional BB algorithm is used to learn the optimal pruning policy, which is the process of learning a complicated step in a particular algorithm and using that policy to produce optimal results with low computational complexity.
5.1 Proposed Learning-to-Optimize-Based Algorithm
The search process of the BB algorithm can be seen as a problem of making sequential decisions in a binary tree. We generate the unbalanced training sample sets from the BB algorithm because the number of preserve nodes is fewer than the number of prune nodes. An undersampling technique is utilized to address the unbalanced problem. We sample multiple disjoint subsets of the majority set with the same size as the minority set and then train a separate classifier for each dataset. Along with the minority set, a balanced training set can be achieved for each classifier. Several classifiers are being trained via ensemble learning, and their performance is subsequently improved by combining them. A node in the tree is either pruned or not in each decision based on the pruning policy. We are considering using supervised learning to develop a pruning policy that acts like a binary classifier. The feature node serves as the input, and the decision to either preserve or prune is the output. A learning-to-optimize-based algorithm learns the pruning policy from the BB algorithm search process and uses the features and labels to optimize the solution and ensure that it effectively identifies nodes to determine whether a node should be pruned or preserved with low computational complexity. Pruning policy explores every branch of the tree to determine the upper bound, lower bound, and optimal transmit power for the objective function. The related branch is deleted if the optimal transmit power is greater than the maximum transmit power. The ultimate optimal solution is the one that among all explored branches, has the lowest value. Fig. 2 shows the complete process of the training and testing phases. The major components of the learning-to-optimize-based algorithm are the classifier, feature design, flow of the algorithm, and computation complexity, which are defined in the following steps:
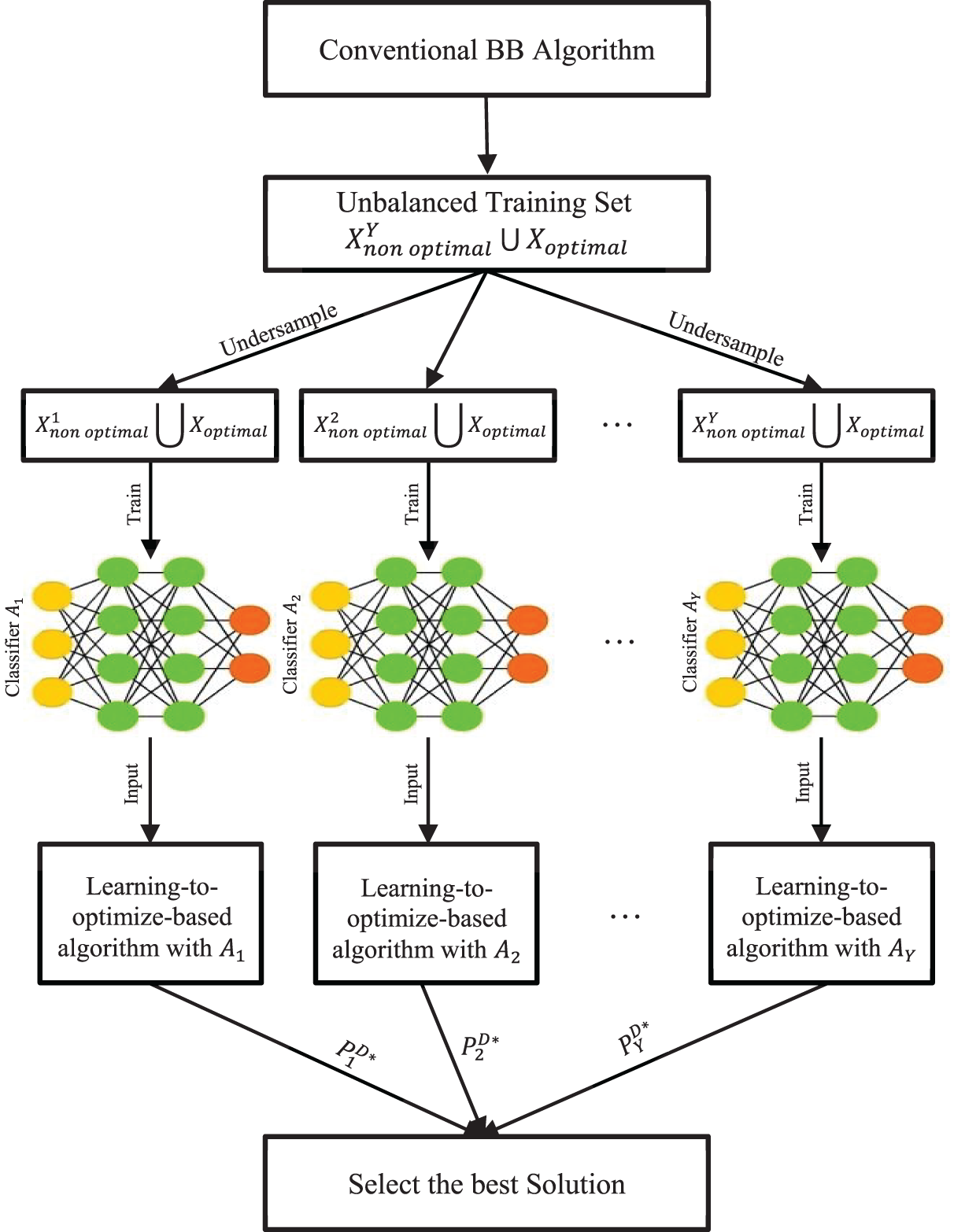
Figure 2: The complete process of the training and testing phases
Ensemble learning is used in conjunction with supervised learning to train multiple classifiers and combine their outputs for improved performance [35]. Using neural networks as a classifier in pruning policy involves training an
where
To effectively train classifiers, feature design is very important. An optimal solution to the problem
Independent features contain information about the conventional BB algorithm search processes, such as node features, branching features, and tree features; they contain the upper bound, lower bound, optimal value, and argument set
The dependent features are strongly associated with specific problems such as URLLC QoS constraints, channel state information (CSI), SINR, and power allocation constraints for D2D communication.
The proposed algorithm consists of a training dataset generated by the BB algorithm. An undersampling method is utilized for an imbalanced training dataset that integrates ensemble learning to train multiple classifiers and combine them to improve performance. The proposed learning-to-optimize-based algorithm explains in the following key steps:
In steps 1-2, the conventional BB algorithm is used to produce the training dataset. The features of every node that was explored are recorded by the algorithm. Nodes that have a feasible region that includes the best possible solution are identified as “preserve,” whereas the other nodes are designated as “prune” and store all the features and optimal solution into
In steps 3-4, the training set generated by the BB algorithm is unbalanced because there are fewer nodes that are preserved compared to the nodes that are pruned. Using this training set with traditional supervised learning, the classifier may not obtain the optimal solution for optimal nodes and bias for non-optimal nodes. We used the undersampling supervised learning technique to avoid the unbalanced training set problem. Undersampling creates multiple training sets that include both the minority class and a random subset of the majority class and then trains a classifier on each of these sets [36]. We divide the training set X into two subsets as
In step 5, we used an ensemble-based test that is similar to ensemble learning to test the multiple classifiers. Specifically, the proposed learning-to-optimize-based algorithm is run for Y times, each time for the different classifiers.
In steps 6−7, the upper bound is set to
In step 8, instead of using a counter, we establish a tolerance threshold
In step 9, set the auxiliary variable
In steps 10–16, ensemble learning is used for better performance,
In step 20, we get the most optimal solution among all classifiers. The proposed learning-to-optimize-based algorithm is shown in Algorithm 1.

The complexity of the learning-to-optimize-based algorithm can be evaluated by measuring the expected number of nodes explored. The anticipated number of examined nodes and the number of relaxed problems solved is
6 Simulation and Numerical Results
The performance of the proposed method is illustrated in this section through simulation results. We evaluate the performance achieved by the learning-to-optimize-based algorithm and compare it with the BB algorithm and heuristic algorithm. The optimization problem is to maximize the minimal achievable rate where the power allocation is optimized under the Rician fading channel. It is further obtained that the proposed learning-to-optimize-based algorithm minimizes the power consumption under the URLLC requirements. The dataset encompasses various data elements, including node features, branching features, tree features, upper bound, lower bound, optimal value, the argument set
The outage probability of D2D communication is demonstrated in Fig. 3 with different Rician
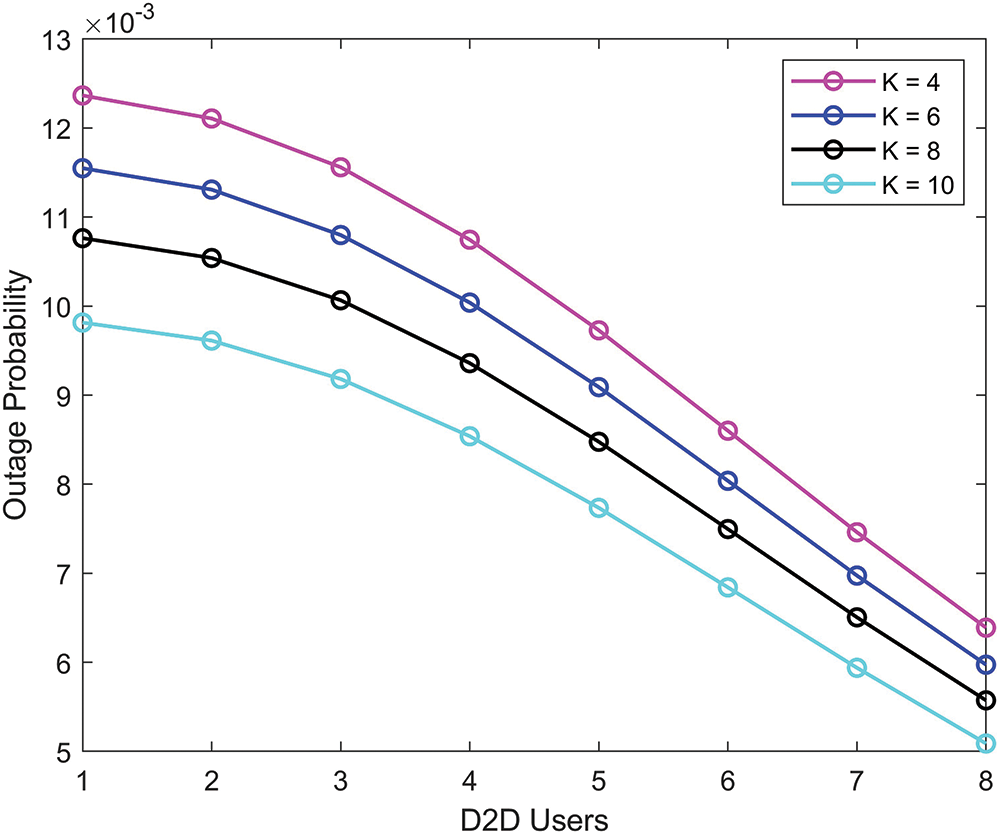
Figure 3: Outage probability of D2D communication with different Rician
Fig. 4 illustrates the transmit power performance of the learning-to-optimize-based algorithm compared with the BB algorithm and heuristic algorithm. We used different Rician K-factors, and we can see that the learning-to-optimize-based algorithm provides the optimal solution and minimum power consumption in D2D communication.
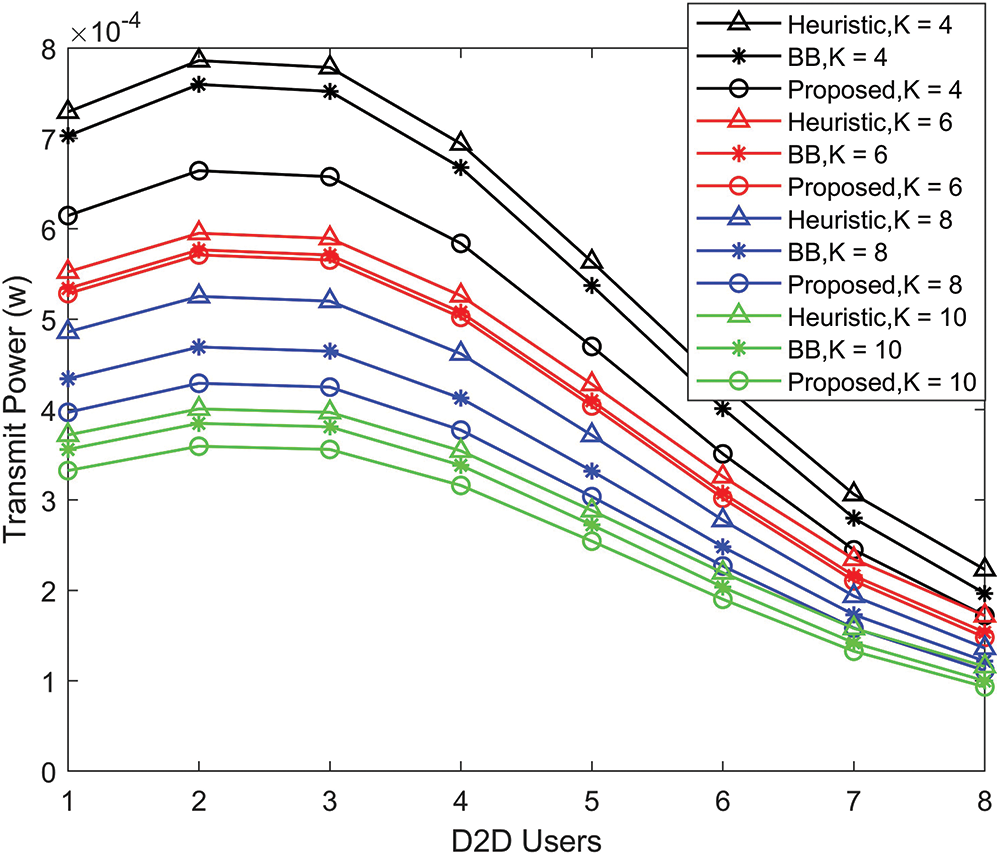
Figure 4: Optimal transmit power of D2D communication under URLLC with different Rician
At the same time, there is a considerable performance gap between the heuristic algorithm, BB algorithm, and the learning-to-optimize-based algorithm, which shows the optimality of our proposed algorithm. When the Rician
Table 2 presents the computation time and average transmit power for different Rician
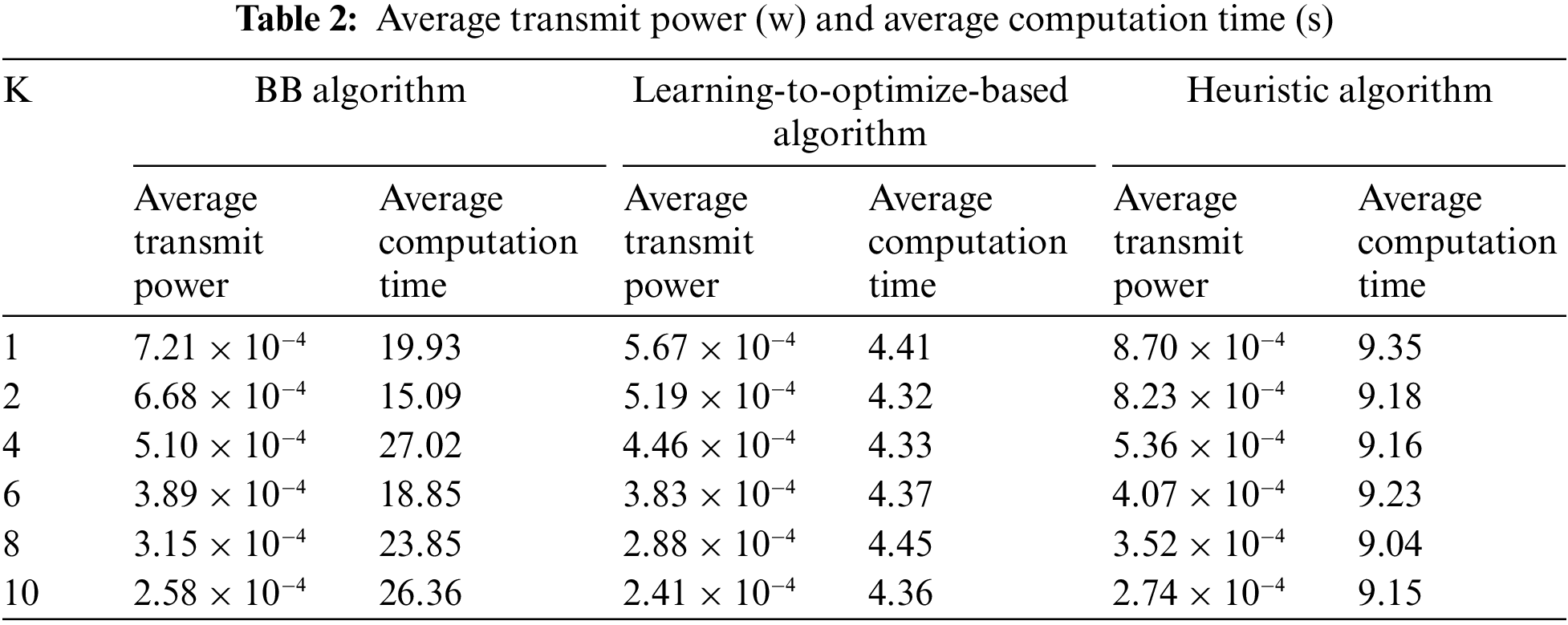
Fig. 5 plots the gap between the upper bound
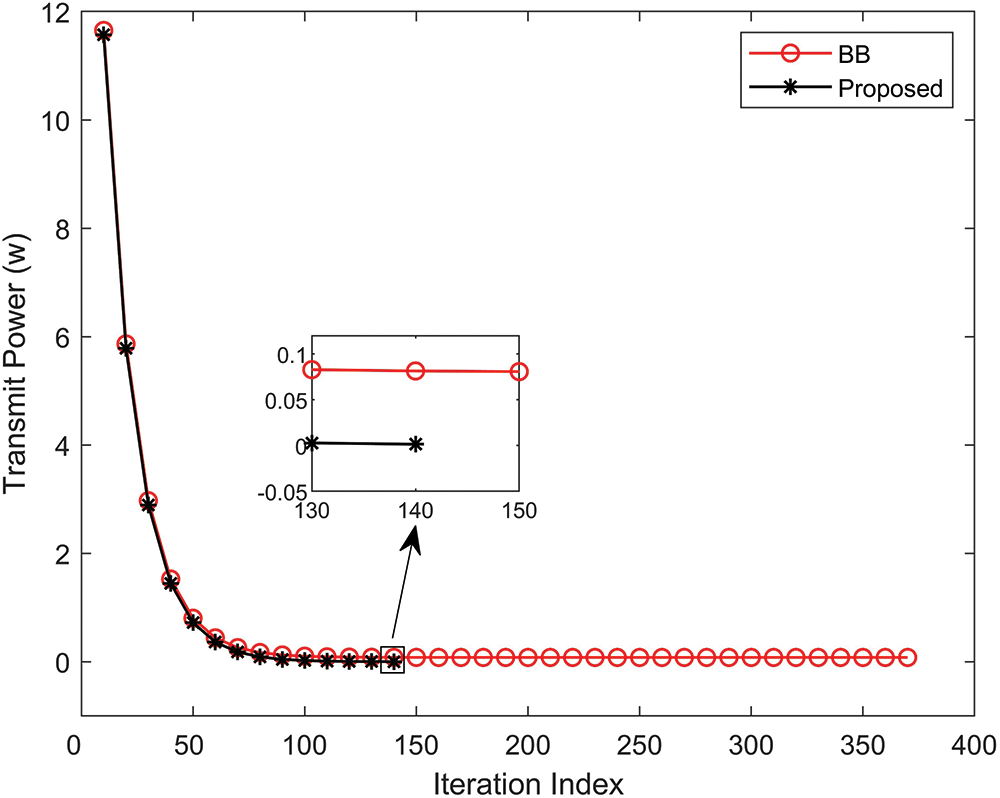
Figure 5: Convergence behavior of learning-to-optimize-based algorithm and BB algorithm with
In Fig. 6, by comparing the achievable capacity of D2D communication, we can notice that the Rician
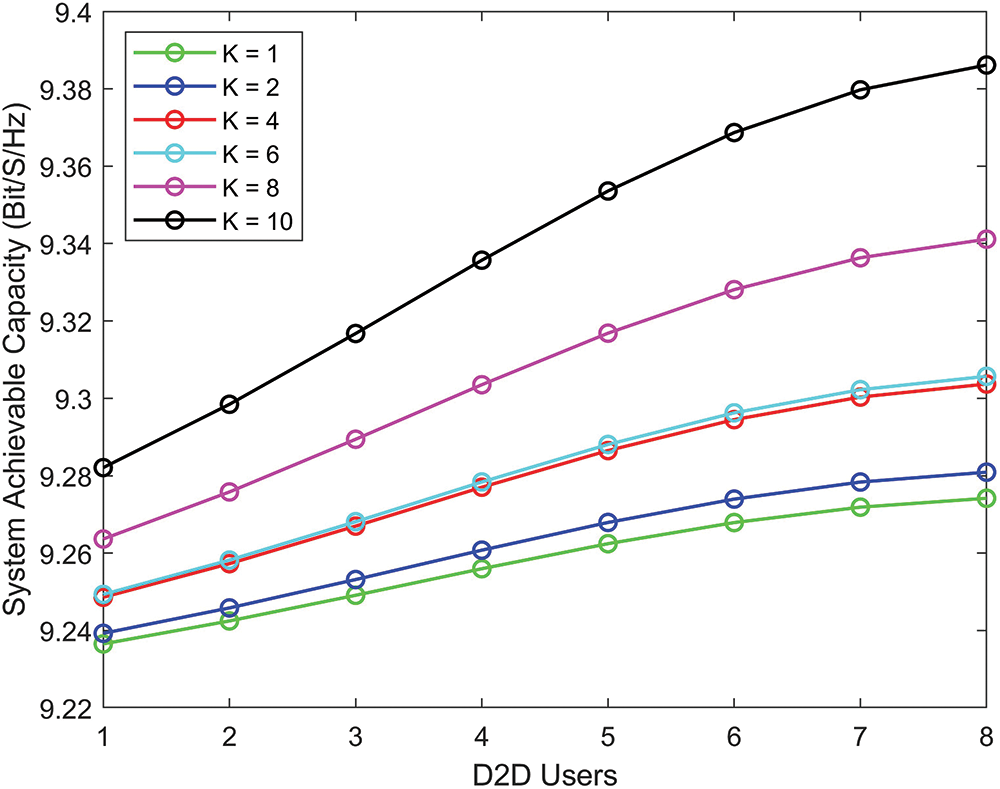
Figure 6: Achievable capacity of D2D communication with different
This paper focused on finding the optimal power allocation in D2D communication. We considered an uplink D2D communication underlying the cellular system in a single-cell environment, and the Rician fading channel was investigated. The impact of the Rician K-factor was examined in the simulation and numerical results. We formulated the optimization problem of power allocation and maximized the minimal rate of D2D communication. The learning-to-optimize-based algorithm is proposed for optimizing the power allocation under the constraints of URLLC with Rician fading in D2D communication. The pruning policy learns from the BB algorithm, and the unbalanced dataset problem is handled by the undersampling method. Ensemble learning is used with supervised learning to train and combine multiple classifiers for better performance. The learning-to-optimize-based algorithm iteratively achieves an optimal solution and is compared with the BB algorithm and heuristic algorithm. The study has found that the learning-to-optimize-based algorithm has considerably lower computational complexity than the BB algorithm and heuristic algorithm and achieves better performance than the conventional BB algorithm.
Funding Statement: This work was supported in part by the National Natural Science Foundation of China under Grant 61771410, in part by the Sichuan Science and Technology Program 2023NSFSC1373, and in part by Postgraduate Innovation Fund Project of SWUST 23zx7101.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. D. Zhai, R. Zhang, Y. Wang, H. Sun, L. Cai et al., “Joint user pairing, mode selection, and power control for D2D-capable cellular networks enhanced by nonorthogonal multiple access,” IEEE Internet of Things Journal, vol. 6, no. 5, pp. 8919–8932, 2019. [Google Scholar]
2. C. She and C. Yang, “Available range of different transmission modes for ultra-reliable and low-latency communications,” in Proc. IEEE 85th Vehicular Technology Conf. (VTC Spring), Sydney, NSW, Australia, pp. 1–5, 2017. [Google Scholar]
3. Z. Chu, W. Yu, P. Xiao, F. Zhou, N. Al-Dhahir et al., “Opportunistic spectrum sharing for D2D-based URLLC,” IEEE Transactions on Vehicular Technology, vol. 68, no. 9, pp. 8995–9006, 2019. [Google Scholar]
4. P. Gandotra and R. K. Jha, “Device-to-device communication in cellular networks: A survey,” Journal of Network and Computer Applications, vol. 71, pp. 99–117, 2016. [Google Scholar]
5. R. I. Ansari, C. Chrysostomou, S. A. Hassan, M. Guizani, S. Mumtaz et al., “5G D2D networks: Techniques, challenges, and future prospects,” IEEE Systems Journal, vol. 12, no. 4, pp. 3970–3984, 2017. [Google Scholar]
6. F. Jameel, Z. Hamid, F. Jabeen, S. Zeadally and M. A. Javed, “A survey of device-to-device communications: Research issues and challenges,” IEEE Communications Surveys & Tutorials, vol. 20, no. 3, pp. 2133–2168, 2018. [Google Scholar]
7. R. Yin, C. Zhong, G. Yu, Z. Zhang, K. K. Wong et al., “Joint spectrum and power allocation for D2D communications underlaying cellular networks,” IEEE Transactions on Vehicular Technology, vol. 65, no. 4, pp. 2182–2195, 2015. [Google Scholar]
8. B. Singh, Z. Li and M. A. Uusitalo, “Flexible resource allocation for device-to-device communication in FDD system for ultra-reliable and low latency communications,” in Proc. of Advances in Wireless and Optical Communications (RTUWO), Riga, Latvia, pp. 186–191, 2017. [Google Scholar]
9. Y. Wu, D. Wu, L. Ao, L. Yang and Q. Fu, “Contention-based radio resource management for URLLC-oriented D2D communications,” IEEE Transactions on Vehicular Technology, vol. 69, no. 9, pp. 9960–9971, 2020. [Google Scholar]
10. H. Sun, X. Chen, Q. Shi, M. Hong, X. Fu et al., “Learning to optimize: Training deep neural networks for interference management,” IEEE Transactions on Signal Processing, vol. 66, no. 20, pp. 5438–5453, 2018. [Google Scholar]
11. W. Cui, K. Shen and W. Yu, “Spatial deep learning for wireless scheduling,” IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1248–1261, 2019. [Google Scholar]
12. Y. Shen, Y. Shi, J. Zhang and K. B. Letaief, “LORM: Learning to optimize for resource management in wireless networks with few training samples,” IEEE Transactions on Wireless Communications, vol. 19, no. 1, pp. 665–679, 2019. [Google Scholar]
13. Z. Zhang and M. Tao, “A learning based branch-and-bound algorithm for single-group multicast beamforming,” in Proc. of IEEE Global Communications Conf. (GLOBECOM), Madrid, Spain, pp. 1–6, 2021. [Google Scholar]
14. A. Zappone, M. Di Renzo, M. Debbah, T. T. Lam and X. Qian, “Model-aided wireless artificial intelligence: Embedding expert knowledge in deep neural networks for wireless system optimization,” IEEE Vehicular Technology Magazine, vol. 14, no. 3, pp. 60–69, 2019. [Google Scholar]
15. B. Chang, G. Zhao, Z. Chen, P. Li and L. Li, “D2D transmission scheme in URLLC enabled real-time wireless control systems for tactile internet,” in Proc. of 2019 IEEE Global Communications Conf. (GLOBECOM), Waikoloa, HI, USA, pp. 1–6, 2019. [Google Scholar]
16. B. Chang, L. Li, G. Zhao, Z. Chen and M. A. Imran, “Autonomous D2D transmission scheme in URLLC for real-time wireless control systems,” IEEE Transactions on Communications, vol. 69, no. 8, pp. 5546–5558, 2021. [Google Scholar]
17. I. O. Sanusi, K. M. Nasr and K. Moessner, “Resource allocation for a reliable D2D enabled cellular network in factories of the future,” in Proc. of European Conf. on Networks and Communications (EuCNC), Dubrovnik, Croatia, pp. 89–93, 2020. [Google Scholar]
18. M. Hong and Z. Q. Luo, “Signal processing and optimal resource allocation for the interference channel,” Academic Press Library in Signal Processing, vol. 2, pp. 409–469, 2014. [Google Scholar]
19. Z. Zhang and M. Tao, “Learning-based branch-and-bound for non-convex complex modulus constrained problems with applications in wireless communications,” IEEE Transactions on Wireless Communications, vol. 21, no. 6, pp. 3752–3763, 2021. [Google Scholar]
20. Y. Bengio, A. Lodi and A. Prouvost, “Machine learning for combinatorial optimization: A methodological tour d’horizon,” European Journal of Operational Research, vol. 290, no. 2, pp. 405–421, 2021. [Google Scholar]
21. M. Lee, G. Yu and G. Y. Li, “Learning to branch: Accelerating resource allocation in wireless networks,” IEEE Transactions on Vehicular Technology, vol. 69, no. 1, pp. 958–970, 2019. [Google Scholar]
22. D. Feng, L. Lu, Y. Yuan-Wu, G. Y. Li, G. Feng et al., “Device-to-device communications underlaying cellular networks,” IEEE Transactions on Communications, vol. 61, no. 8, pp. 3541–3551, 2013. [Google Scholar]
23. L. Liang, G. Y. Li and W. Xu, “Resource allocation for D2D-enabled vehicular communications,” IEEE Transactions on Communications, vol. 65, no. 7, pp. 3186–3197, 2017. [Google Scholar]
24. A. Goldsmith, Wireless Communications. UK: Cambridge University Press, 2005. [Google Scholar]
25. M. Peng, Y. Li, T. Q. Quek and C. Wang, “Device-to-device underlaid cellular networks under Rician fading channels,” IEEE Transactions on Wireless Communications, vol. 13, no. 8, pp. 4247–4259, 2014. [Google Scholar]
26. Y. Wang, M. Chen, N. Huang, Z. Yang and Y. Pan, “Joint power and channel allocation for D2D underlaying cellular networks with Rician fading,” IEEE Communications Letters, vol. 22, no. 12, pp. 2615–2618, 2018. [Google Scholar]
27. K. M. S. Huq, S. Mumtaz and J. Rodriguez, “Outage probability analysis for device-to-device system,” in Proc. of IEEE Int. Conf. on Communications (ICC), Kuala Lumpur, Malaysia, pp. 1–5, 2016. [Google Scholar]
28. H. C. Yang and M. S. Alouini, “Closed-form formulas for the outage probability of wireless communication systems with a minimum signal power constraint,” IEEE Transactions on Vehicular Technology, vol. 51, no. 6, pp. 1689–1698, 2002. [Google Scholar]
29. H. He, H. Daume III and J. M. Eisner, “Learning to search in branch and bound algorithms,” Advances in Neural Information Processing Systems, vol. 27, no. 1, pp. 1–11, 2014. [Google Scholar]
30. G. Durisi, T. Koch and P. Popovski, “Toward massive, ultrareliable, and low-latency wireless communication with short packets,” in Proc. of the IEEE, vol. 104, no. 9, pp. 1711–1726, 2016. [Google Scholar]
31. C. Sun, C. She, C. Yang, T. Q. Quek, Y. Li et al., “Optimizing resource allocation in the short blocklength regime for ultra-reliable and low-latency communications,” IEEE Transactions on Wireless Communications, vol. 18, no. 1, pp. 402–415, 2018. [Google Scholar]
32. C. Lu and Y. F. Liu, “An efficient global algorithm for single-group multicast beamforming,” IEEE Transactions on Signal Processing, vol. 65, no. 14, pp. 3761–3774, 2017. [Google Scholar]
33. Y. Zhang, Y. Yang and L. Dai, “Energy efficiency maximization for device-to-device communication underlaying cellular networks on multiple bands,” IEEE Access, vol. 4, no. 1, pp. 7682–7691, 2016. [Google Scholar]
34. T. H. Cormen, C. E. Leiserson, R. L. Rivest and C. Stein, Introduction to Algorithms. USA: MIT press, 2022. [Google Scholar]
35. M. A. Arbib, The Handbook of Brain Theory and Neural Networks. USA: MIT Press, 2002. [Google Scholar]
36. X. Y. Liu, J. Wu and Z. H. Zhou, “Exploratory undersampling for class-imbalance learning,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 39, no. 2, pp. 539–550, 2008. [Google Scholar]
37. A. Nuttall, “Some integrals involving the Q_M function (Corresp.),” IEEE Transactions on Information Theory, vol. 21, no. 1, pp. 95–96, 1975. [Google Scholar]
38. Y. D. Yao and A. Sheikh, “Outage probability analysis for microcell mobile radio systems with cochannel interferers in Rician/Rayleigh fading environment,” Electronics Letters, vol. 13, no. 26, pp. 864–866, 1990. [Google Scholar]
Appendix A
Regarding the outage probability of the D2D link, we have
The outage probability of D2D can be rewritten by using Eqs. (5) and (6) in Eq. (24)
Solving the inner integral of Eq. (25) and getting the outage probability as
where
where
where
The interference-limited
Appendix B.Proof of Theorem 1
Applying integration-by-parts
The Eq. (33) is derived by substituting
Appendix C
The minimum transmit power can be derived from Eq. (9) with an auxiliary variable
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools