
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

SFSDA: Secure and Flexible Subset Data Aggregation with Fault Tolerance for Smart Grid
1 College of Cryptography Engineering, Engineering University of PAP, Xi’an, 710086, China
2 Key Laboratory of Network and Information Security under the PAP, Xi’an, 710086, China
3 Institute of Software Chinese Academy of Sciences, Beijing, 100080, China
* Corresponding Author: Tanping Zhou. Email:
Intelligent Automation & Soft Computing 2023, 37(2), 2477-2497. https://doi.org/10.32604/iasc.2023.039238
Received 17 January 2023; Accepted 11 April 2023; Issue published 21 June 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Smart grid (SG) brings convenience to users while facing great challenges in protecting personal private data. Data aggregation plays a key role in protecting personal privacy by aggregating all personal data into a single value, preventing the leakage of personal data while ensuring its availability. Recently, a flexible subset data aggregation (FSDA) scheme based on the Paillier homomorphic encryption was first proposed by Zhang et al. Their scheme can dynamically adjust the size of each subset and obtain the aggregated data in the corresponding subset. In this paper, firstly, an efficient attack with both theorems proving and experimentative verification is launched. We find that in a specific scenario where the encrypted data constructed by a smart meter (SM) exceeds the size of one Paillier ciphertext, the malicious fog node (FN) may use the received ciphertext to obtain the reading of the SM. Secondly, to avoid the possibility of privacy disclosure under certain circumstances, additional hash functions are added to the individual encryption process. In addition, fault tolerance is very important to aggregation schemes in practical scenarios. In most of the current schemes, once some SMs failed, then they will not work. As far as we know, there is no multi-subset aggregation scheme both supports flexible subset data aggregation and fault tolerance. Finally, we construct the first secure flexible subset data aggregation (SFSDA) scheme with fault tolerance by combining the fault tolerance method with the flexible multi-subset aggregation, where FN enables the control server (CS) to finally decrypt the aggregated ciphertext by recovering equivalent ciphertexts when some SMs fail to submit their ciphertexts. Experiments show that our SFSDA scheme keeps the efficiency in implementing a flexible multi-subset aggregation function, and only has a small delay in implementing fault-tolerant data aggregation.Keywords
As technologies such as artificial intelligence, 5G communications, big data, and more become widely available in various fields [1], the smart grid is gradually replacing traditional grids to provide efficient and reliable uninterrupted energy supply to households and businesses, with advantages such as dynamic electricity distribution, automatic pricing, and automatic troubleshooting [2].
In SG, device entities can interconnect and communicate with each other, which greatly increases productivity and automation [3–5]. However, many security issues in SGs pose a potential threat to personal privacy as well [6–8]. In smart grid, smart meters (SMs) installed in homes collect electricity consumption data from users in real-time and periodically submit this data to a control server (CS). CS collects and analyzes electricity consumption data from all users so that it can forecast electricity demand and adjust prices. While real-time individual electricity consumption can improve the quality of CS and user services, it is also capable of being used by malicious entities and inferring the user’s privacy. For example, analyzing many intimate details of users’ daily life through electricity consumption, such as the time of departure and return of the occupants, used appliances, and the use time of appliances [9], seriously threatens personal privacy. Therefore, it requires challenging efforts to balance the tradeoff between data sharing and data privacy to enable the convenience advantages brought by smart grid [10].
Privacy-Preserving Data Aggregation (PPDA) introduces the concept of edge computing to reduce data latency and communication bandwidth between edge devices [11]. To effectively protect personal privacy, it aggregates all the electricity consumption transmitted by SMs and then transmits the aggregated data to CS. As a result, CS no longer collects a single user’s electricity consumption, but the sum of all users’ consumption. This allows CS to analyze and process data without knowing individual data, taking full advantage of the convenience of smart grid. In recent years, the fog computing architecture is used in various data aggregation schemes to further improve aggregation efficiency while protecting personal privacy due to the powerful computing and storage capabilities of the Fog node (FN) [12]. Researchers use a variety of techniques for data aggregation that preserve privacy, such as homomorphic encryption, differential privacy, and blind factor. Although existing data aggregation schemes [13–15] are able to guarantee users’ privacy, most do not consider fine-grained requirements. In practical applications, CS needs not only to collect and analyze the total electricity consumption from all customers, but also to get more detailed and rich statistical characteristics through more detailed electricity consumption. To better determine generating capacity and pricing, for example, CS requires the total electricity consumption and the total number of customers within a given data range. As a result, the utility of the data will be greatly enhanced if the aggregation scheme meets the fine-grained requirements.
Various multi-subset data aggregation schemes [16–18] have been proposed for the past few years to achieve fine-grained requirements. Zhang et al. [19] found that proper subset adjustment allowed CS to gather data in a more focused way. For instance, during the day of the working day, the subset ought to be focused on a low-power interval range. Whereas, they found that existing multi-subset aggregation schemes cannot meet the requirement of dynamically adjusting the subset. If the subset is adjusted, the system parameters need to be updated again in their schemes. To address the shortcomings of the above multi-subset aggregation scheme, Zhang et al. [19] first proposed a novel flexible subset data aggregation (FSDA) scheme. In their scheme, The total interval
Contributions: The first flexible multi-subset aggregation scheme with both security and fault tolerance is proposed. The main contributions are summarized as follows:
(1) We find a potential security flaw in FSDA [19] scheme for personal privacy disclosure. Specifically, when the SM submits more than one Paillier ciphertext (for example, when
(2) A secure and flexible multi-subset aggregation improvement scheme is proposed. Based on FSDA scheme, different hash functions for different Paillier ciphertexts of a single SM are introduced to avoid the correlation between different ciphertexts of the SM, so even if the SM generates more than one Paillier ciphertext, revealing Paillier ciphertexts will not result in a single electricity consumption. Experiments show that the improved scheme enhances privacy while maintaining computational efficiency.
(3) A first flexible subset data aggregation scheme with fault tolerance was constructed. We combine the fault tolerance method proposed in [14] with the flexible multi-subset aggregation improvement scheme to improve application capability in real-world scenarios. Experimental results show that our scheme is computationally efficient for multi-subset aggregation with fault tolerance.
The rest of this paper is organized as follows. Section 2 discusses related works. Section 3 briefly reviews the FSDA scheme and introduces the extended Shamir’s threshold secret-sharing scheme (tSSS). Section 4 shows the security flaws of FSDA, and then presents an attack method and experimentative verification. Section 5 describes the improved SFSDA in detail, followed by security analysis and performance evaluation in Sections 6 and 7, respectively. Finally, a conclusion is drawn in Section 8.
Data aggregation in the smart grid not only protects data privacy, but also provides useful electricity consumption information for CS, which has become a research hotspot for privacy protection in smart grid in recent years. There are many techniques for achieving data aggregation to protect data privacy, such as homomorphic encryption [20,21] and differential privacy [22,23].
Homomorphic encryption allows data to be computed on the ciphertext, and the result of the additive operation on the ciphertext is equal to the result of adding plaintext and then encrypting it. Therefore, the aggregator can directly aggregate all the encrypted electricity consumption data submitted by SMs without knowing the raw electricity consumption data [24]. In recent years, Liu et al. [25], Ding et al. [26], Zhao et al. [27], Gope et al. [28], Li et al. [29], and Zhang et al. [30] have used homomorphic encryption for data aggregation to protect data privacy. In [29] and [30], aggregators use homomorphic encryption technology to achieve efficient privacy-preserving data aggregation, but the drawback of this scheme is that malicious aggregators have access to raw data. To prevent internal attacks, researchers typically combine homomorphic encryption technology with blind factors for data aggregation. Fan et al. [31] proposed the first data aggregation scheme for internal attackers by using homomorphic encryption and blind factor. However, the scheme only works in the case of short plaintext data, and Bao et al. [32] found that the scheme was not resistant to the public key replacement attack, because both public/private key pairs are generated by users themselves. In addition, differential privacy is often used for data aggregation. Liu et al. [33] protected the raw data by adding random noise, but the aggregation result obtained by this scheme is not accurate enough. Song et al. [34] propose a DMDA scheme. In their scheme, a set of known sum random numbers is used instead of random noise to obtain accurate aggregated data.
However, none of the above schemes is fault tolerant. To improve robustness and practicability, researchers have done in-depth research on fault-tolerant data aggregation. Xue et al. [15] proposed a fault-tolerant data aggregation scheme that does not rely on trusted authority (TA). However, once the failed SM returns to normal, its original secret key, including shares, must also be changed via the secure channel, which will lead to serious communication overload and high delay. Lyu et al. [35] proposed a data aggregation scheme with fault tolerance that requires the support of TA, which has low computational overhead. However, the fault tolerance of the scheme requires the protocol participants (FN, TA, and the cloud) to carry out an extra round of communication, resulting in a large communication cost. Saleem et al. [36] proposed a FESDA scheme with non-interactive fault-tolerant methods. In their scheme, CS prepares the equivalent ciphertext of all SMs in advance. If the SM fails, CS can decrypt aggregated data using the equivalent ciphertext of the failed SM. However, Wu et al. [14] found a security defect in FESDA scheme and demonstrated that CS can abuse equivalent ciphertexts of SMs to recover any SM’s reading. To remedy this defect, they introduced an extended Shamir’s threshold secret-sharing scheme (tSSS) and constructed FPDA, which is an improvement on FESDA scheme, and demonstrated its computational efficiency.
In addition to adding fault tolerance to improve the practicability of the scheme, the multi-subset aggregation has been extensively studied for the past few years as a means to enhance the functionality of aggregation schemes. In 2015, Lu et al. [17] realized two-subset aggregation for the first time based on Paillier homomorphic encryption. In the same year, Erikin [37] realized multi-subset data aggregation using Chinese remainder theorem and homomorphic encryption. To support users to join and quit dynamically, Liu et al. [38] constructed 3PDA scheme, in which, users can dynamically join the virtual aggregation domain of data aggregation. In [16] and [39], their proposed schemes are TA-independent that support users to join and exit dynamically without complicated initialization.
To obtain more detailed and targeted data with better statistical characteristics, Zhang et al. [19] recently proposed the first flexible subset aggregation scheme FSDA. In some situations, however, their scheme may reveal personal information.
The flexibility and fault tolerance described above are both important in multi-subset aggregation. To the best of our knowledge, there is no multi-subset aggregation both supports fault tolerance and flexible subset data aggregation. Our goal is to construct a secure flexible subset data aggregation with fault tolerance for smart grid.
Some preliminaries required for SFSDA scheme are introduced in this section including FSDA scheme and extended Shamir’s tSSS.
3.1 Brief Review of FSDA Scheme
As shown in Fig. 1, the system model consists four entity types: (1) TA: it is responsible for generating parameters for the system and sending private keys to CS and SMs respectively. TA will remain offline once the system is up and running. (2) SMs: each SM collects the multi-dimensional data, performs cryptographic operations, and then sends a report to FN. (3) FN: it uses the property of additive homomorphism to aggregate all reports submitted by SMs. (4) CS: it performs decryption using its private key. The dynamic subset adjustment aggregation reduces the computational consumption of encryption by adjusting subsets, and obtains better data acquisition results. Figs. 2a and 2b show the aggregation results of other subset aggregation schemes and the aggregation results of FSDA scheme after dynamically adjusting subsets, respectively. As can be seen from Fig. 2, FSDA scheme can optimize the distribution of electricity consumption according to real-time electricity consumption. The scheme consists of the following five main phases.
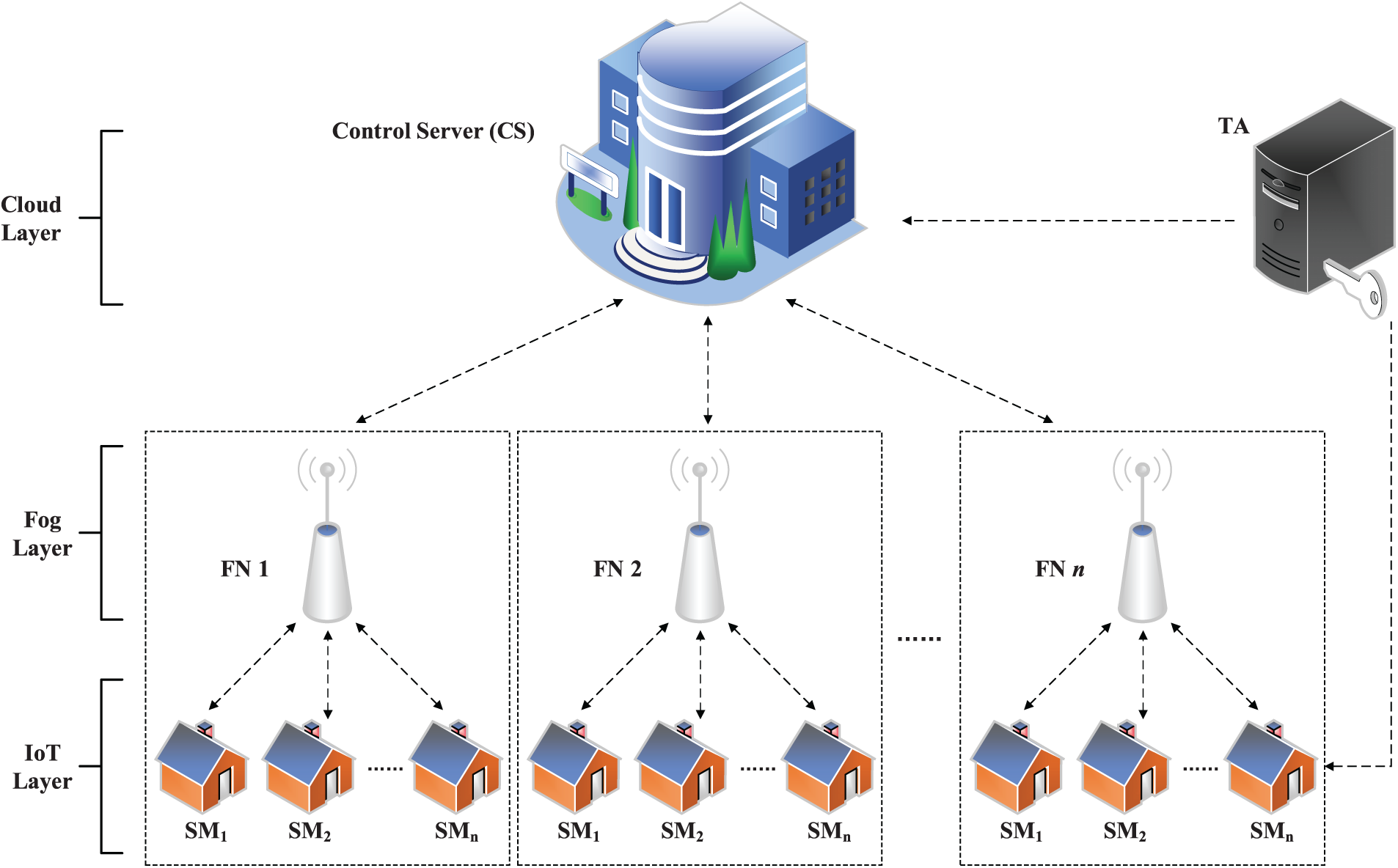
Figure 1: System model from FSDA scheme
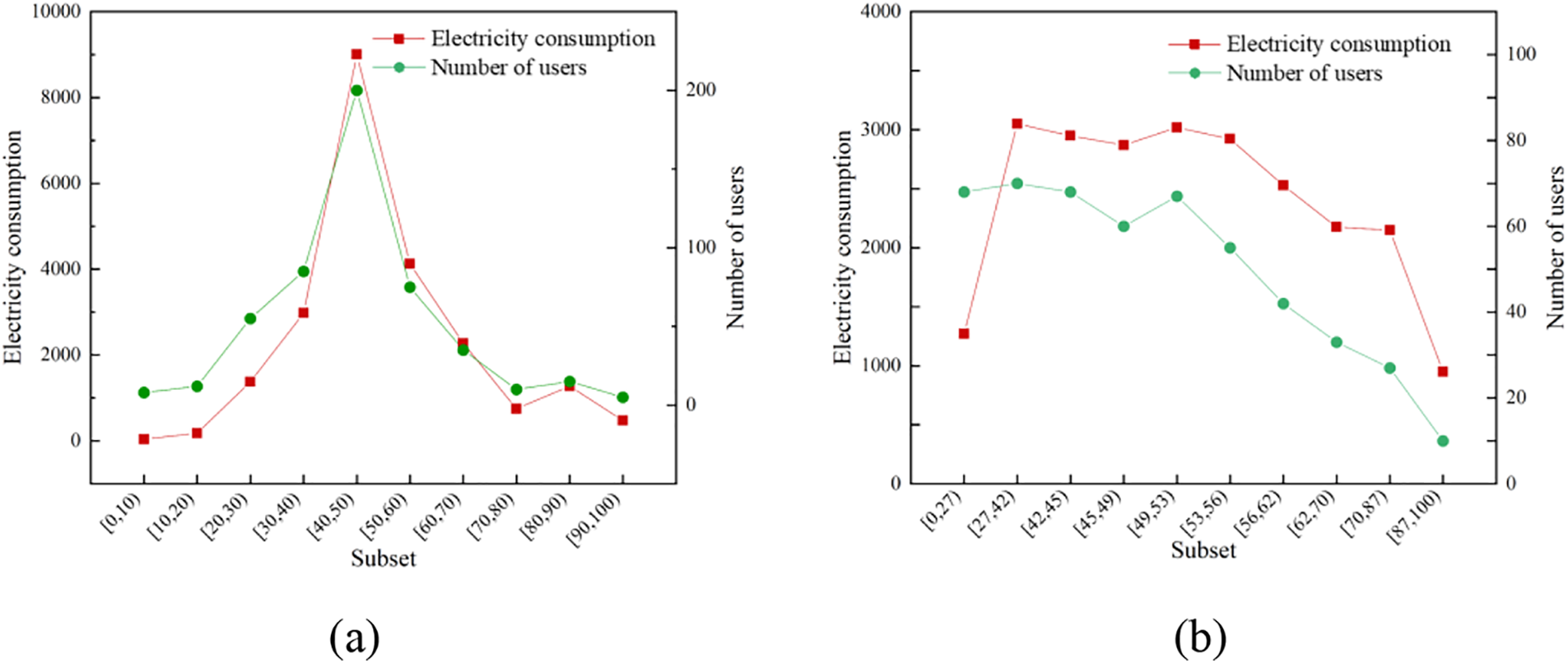
Figure 2: Examples of aggregation result. (a) Other schemes. (b) FSDA scheme
TA generates a public key
CS divides
FN calculates the size of each slot data
3.1.2 Individual Data Encryption
SMi constructs a data slot, where the size of a slot
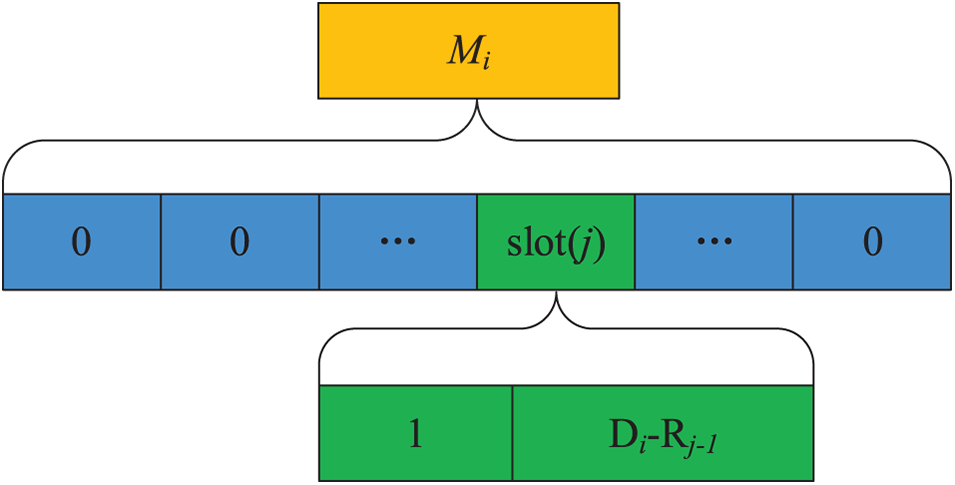
Figure 3: Data format of Mi
where
Remark: A ciphertext
After receiving all ciphertexts
Then, FN sends
CS calculates
And CS gets
CS resets the submission setting when a subset or interval time needs to be adjusted. First, CS redistributes
Shamir’s
Step 1: Share distribution. Given that
Given that
Step 2: Secret recovery. Take
where
To achieve fault tolerance for flexible subset data aggregation, we use extended Shamir’s
Step1: Setup. Choose a large prime number
Step2: Share distribution. The dealer calculates the share
Step 3: Secret recovery. Our goal is to recover
where
It is worth noting that the extended
4 Attack on FSDA Scheme in a Specific Scenario
In this section, the attack method in a specific scenario for FSDA is designed and verified by experiments.
In FSDA scheme, to realize flexible multi-subset aggregation, SMi constructs data
In the particular case described above, suppose that the goal of FN is to obtain a single electricity consumption
Step 1: Malicious FN receives the ciphertext
Step 2: FN extracts
Theorem 1: Assume
Proof: Given the ring
Since
Let
Step 3: Compute
Step 4: FN gets
Our attack on FSDA is shown in Fig. 4.
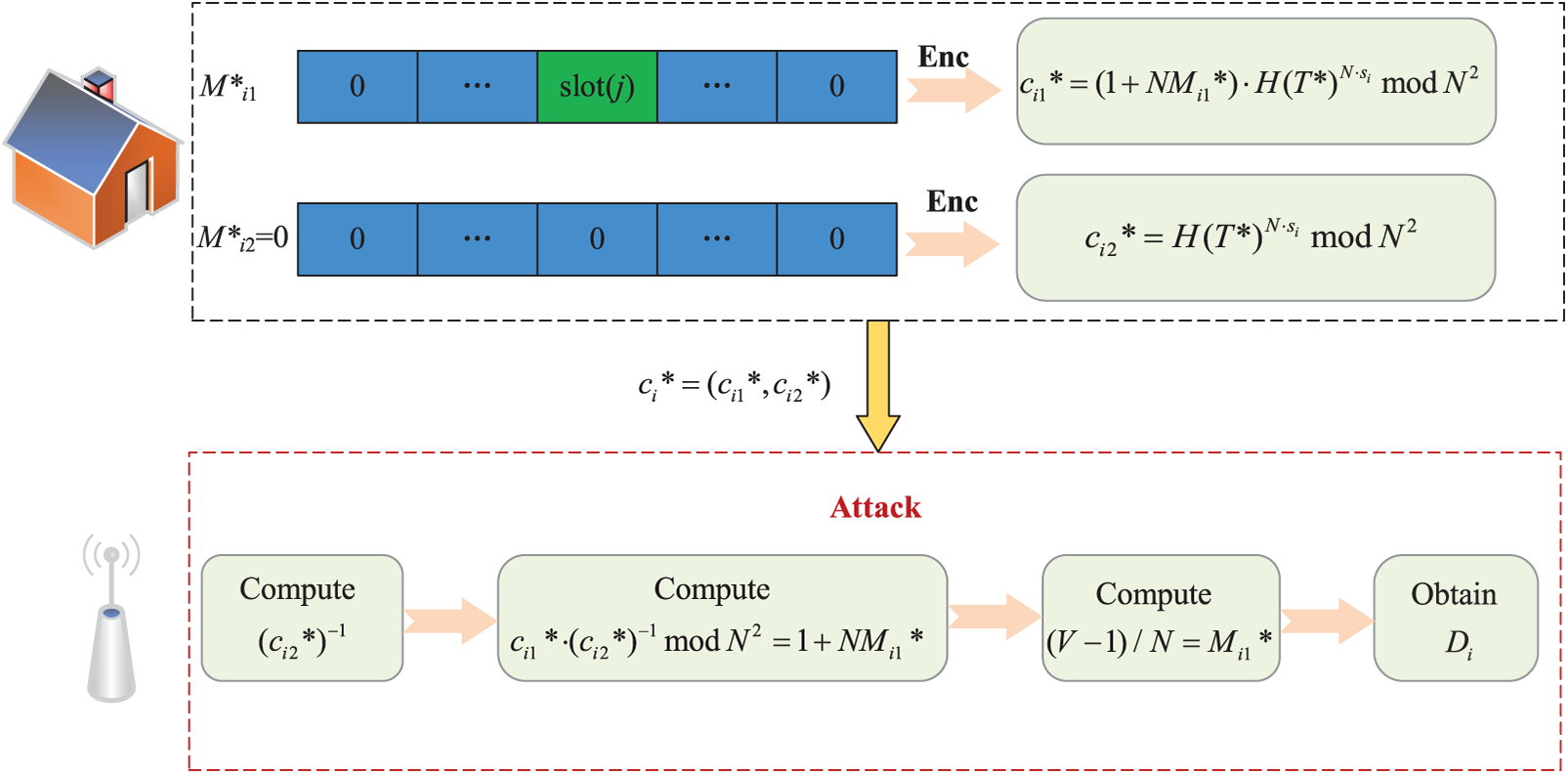
Figure 4: Flowchart of the attack method
4.2 Experimentative Verification
We implemented FSDA scheme in java and attacked it. The experimentation is performed on a computer with an Intel core i7 CPU (2.8 GHz) running Windows 10 and 16-GB RAM. In our experiment, the number of users is set to 10000, and SMs encrypts the data with their respective private keys and transmits it to FN. After FN gets the
An improved scheme SFSDA based on FSDA is proposed to improve the safety of the original scheme while adding fault tolerance features. The flow chart of the SFSDA scheme is shown in Fig. 5, where the additional fault-tolerant method is described in the red dotted line box.
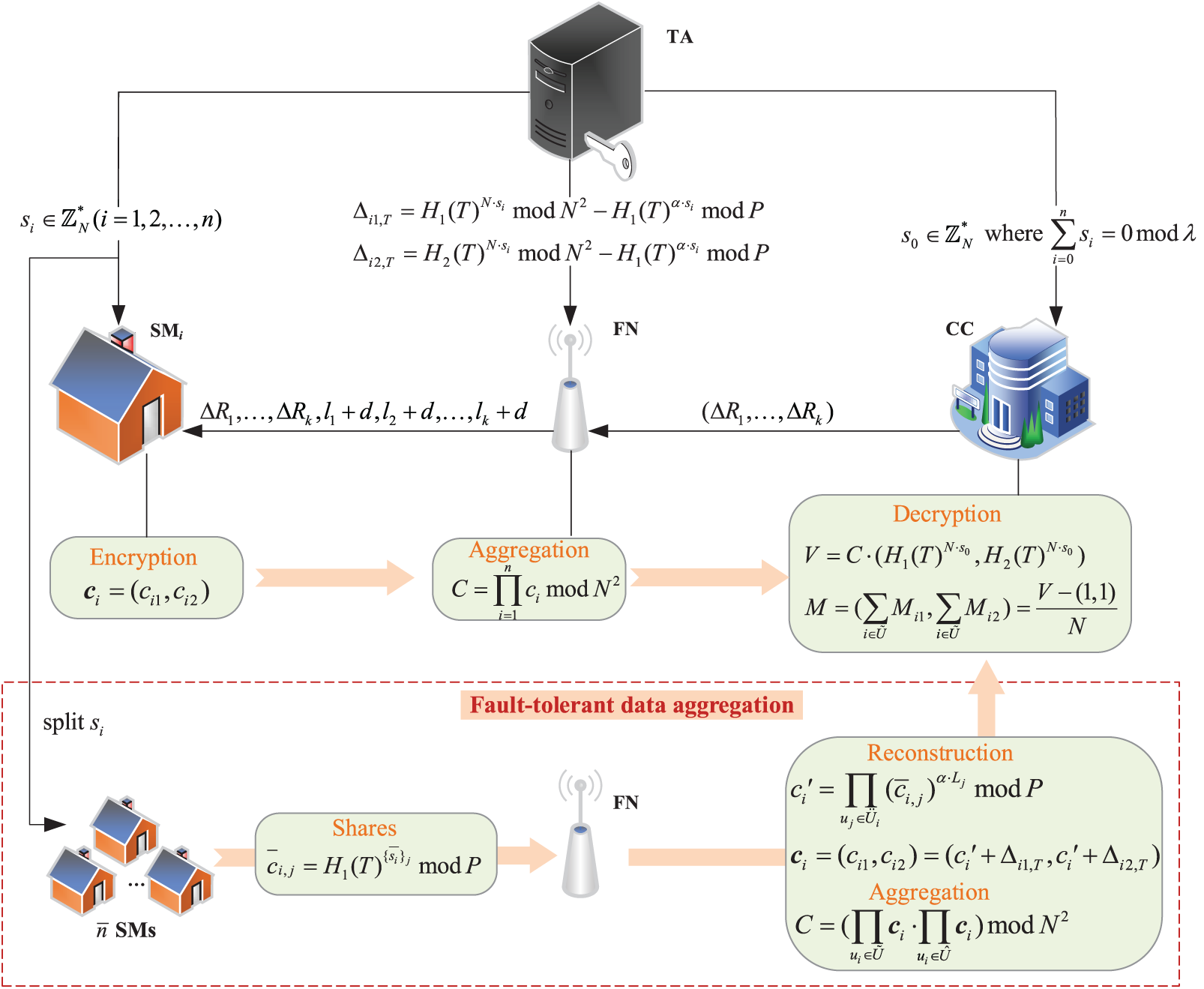
Figure 5: Schematic diagram of SFSDA scheme
5.1 System Model and Design Goal
The system model we consider is the same as FSDA scheme, as described in Section 3.1, which consists primarily of four entity types: Offline TA, CS, FNs, and SMs.
In the attacker model, FNs and CS are honest-but-curious. These entities will faithfully implement the protocol, but they are curious about the private information contained in the reports. Moreover, SMs are honest and tamper-resistant. However, there exists an external adversary
Our design goal of the improved scheme is mainly to provide privacy preservation, practicability, and the utility of data in smart grid. Specifically, it includes the following three aspects.
(1) Privacy: All electricity consumption information in smart grid should be protected. The adversary
(2) Flexible: Our scheme can achieve the same function of flexibly adjusting subsets as FSDA scheme. Compared with the traditional multi-subset aggregation scheme, our scheme can provide more targeted aggregation data for CS.
(3) Fault tolerance: Compared with FSDA scheme, our scheme can decrypt the data correctly when a user fails to submit the data. In practical applications, the user’s electric meter will often malfunction, and fault tolerance is the key to the application of the aggregation scheme in real life.
As mentioned above, FSDA scheme has the risk of disclosing personal privacy. Therefore, we add extra secure hash functions to the encryption phase of FSDA scheme, and introduce an extended Shamir’s
(1) Security enhancement. In the individual data encryption phase, SFSDA differs from the original scheme in that if the ciphertext
(2) Fault tolerance. When some faulty SMs cannot submit the ciphertext, In Eq. (3) of the decryption process in the FSDA scheme,
Without loss of generality, we describe SFSDA scheme in detail, taking the case where SMi needs to construct two pieces of data (i.e.,
In the initialization phase, TA is mainly responsible for generating system parameters, CS transfers data-related settings to FN, and FN assigns settings to SMs. It is divided into the following three steps.
Step 1: Given the system parameter
Step 2: Given the upper limit
Step 3: FN calculates the size
The registration of SMs and CS is completed by TA, which includes the following three steps.
Step 1: TA randomly selects
Step 2: TA randomly selects
Step 3: For each time
5.3.3 Individual Data Encryption
SMi needs to construct data
Step 1: SM constructs a data slot, where the size of slot
Step 2: SMi detects reading
Step 3: SMi encrypts data
and pass
FN checks all received
FN aggregates all equivalent ciphertexts and accepted ciphertexts
and pass
After obtaining the aggregated data, CS first decrypts the data, and then splits the decrypted data to obtain the aggregation results of each subset. It includes the following two steps.
Step 1: CS performs the following calculations with its private key
CS obtains
Step 2: CS splits
When CS wants to adjust the subset according to the specific situation, it only needs to reset the related settings of the subset.
Step 1: As in the initialization phase, CS divides
Step 2: FN recalculates the size
Step 3: SMi constructs new data
The correctness evaluation of SFSDA mainly includes the reconstruction of equivalent ciphertext and the decryption of aggregated ciphertext.
5.4.1 Reconstruction of Equivalent Ciphertext
After FN receives
where
5.4.2 Decryption of Aggregated Ciphertext
The last equation holds since
The security of the scheme is mainly analyzed through the following scenarios.
Scenario 1: The scenario described in Section 5 is semantically secure.
Proof: Both the single ciphertext submitted by SM and the aggregated ciphertext generated by FN calculation are valid ciphertexts of Paillier cryptosystem [42]. Because the security of the public key cryptosystem is based on solving Composite Residuosity Class Problem over
Scenario 2: Even if a malicious CS colludes with SMs and FN, it would not be computationally possible to gain privacy.
Proof: CS can decrypt aggregated data with its private key
For the first method, on the one hand,
For the second method, extended Shamir’s
Scenario 3: Malicious FN cannot obtain individual data and aggregate data results.
Proof: FN will receive all ciphertexts submitted from
In the case of user failure, the user
Scenario 4: Our scheme can effectively resist the attacks proposed in this paper.
Proof: Different from the FSDA scheme, our scheme uses different hash functions
In this section, we evaluate the performance of the proposed SFSDA scheme and compare it with FSDA [19], MSDA [39] and FPDA [14] in terms of computation overhead, communication overhead and storage overhead. It is worth noting that fault-tolerant data aggregation will incur additional overhead due to the addition of fault-tolerant functionality in our scheme. Therefore, the performance evaluation of the scheme will evaluate normal data aggregation and fault-tolerant data aggregation respectively.
Two evaluation environments are used. We evaluate computation costs for data aggregation and decryption on the first platform consisting of a computer with an Intel Core i7 CPU (2.8 GHz) and 16 GB of memory running on Ubuntu 18.04. Computation costs are evaluated for all encryption of SMs on the second platform with a Raspberry Pi (RasPi). The RasPi 3 Model B is installed Ubuntu MATE 21.04 operating system with 1.2-GHz quad-core 64-bit ARM Cortex-A53 CPU and 1 GB of memory. In our implementation, the basic security parameters are the same as described FSDA, where the size of
To facilitate the evaluation, some notations are defined. Exponentiation operation is denoted as
For normal data aggregation, our scheme and FSDA scheme work in the same way. Therefore, their computation overhead is the same. In SFSDA and FSDA, when SMi produces its report, it requires
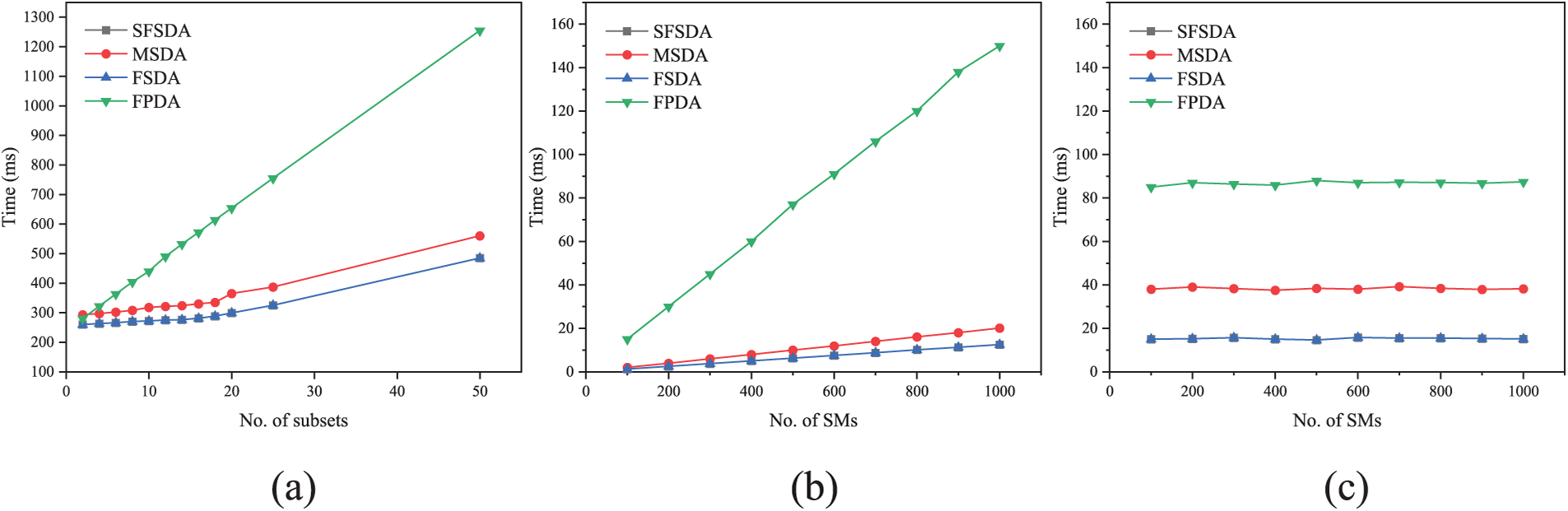
Figure 6: Normal data aggregation. (a) Computation overhead of SM (b) Computation overhead of FN with k = 15 (c) Computation overhead of CS with k = 15
For fault-tolerant data aggregation, our scheme generates extra computation overhead as shown in Fig. 7. Since CS is not involved in fault-tolerant data aggregation, Fig. 7 only gives the total time to generate shares for all SMs with different failure probabilities and different thresholds, and the time for FN to perform reconfiguration and aggregation. Figs. 7a and 7b show that under the same threshold, with the increase of failure probability, the total time for SMs to generate shares and the time for FN to perform reconstruction and aggregation increase approximately linearly with the increase of failure probabilities. As can be seen from Figs. 7a and 7b, the extra computation overhead incurred by SMs and FN would increase significantly if the thresholds were increased.
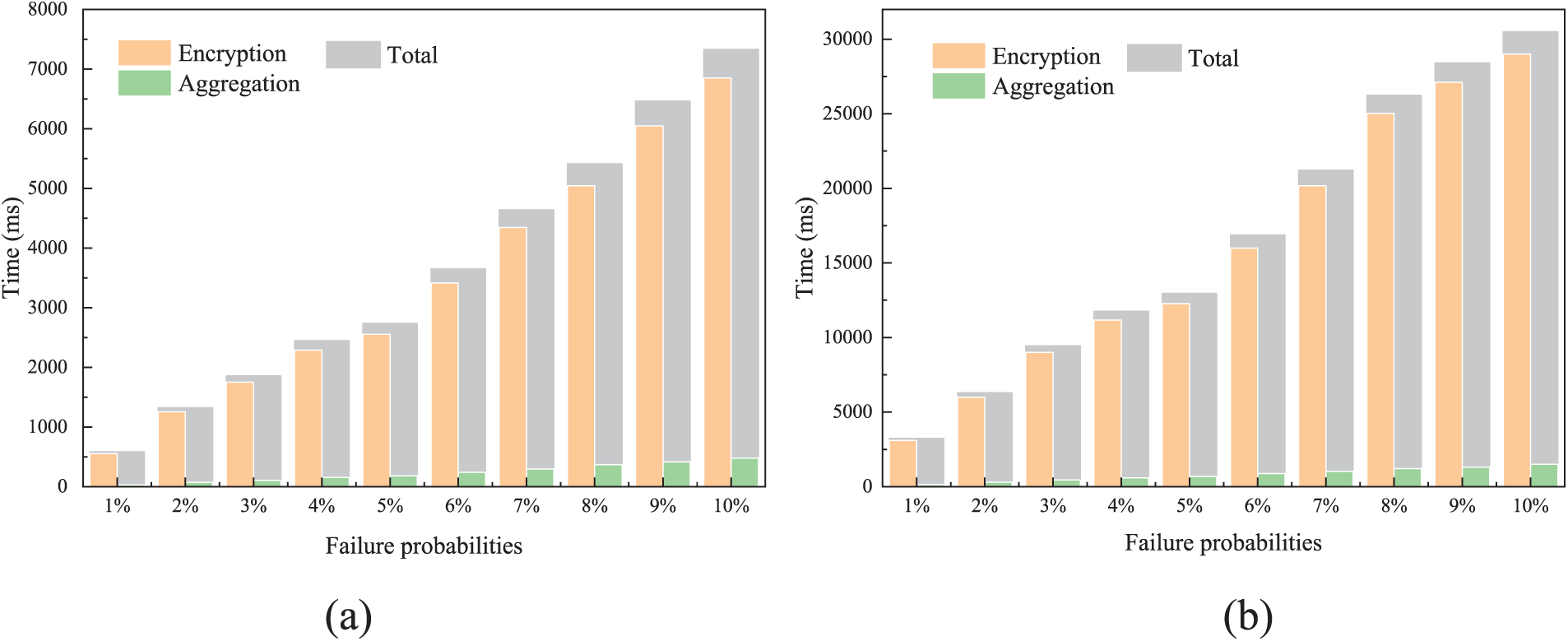
Figure 7: Fault-tolerant data aggregation. (a) Computation overhead under different failure probabilities with (3, 5),
In our scheme, the failure probability is defined as
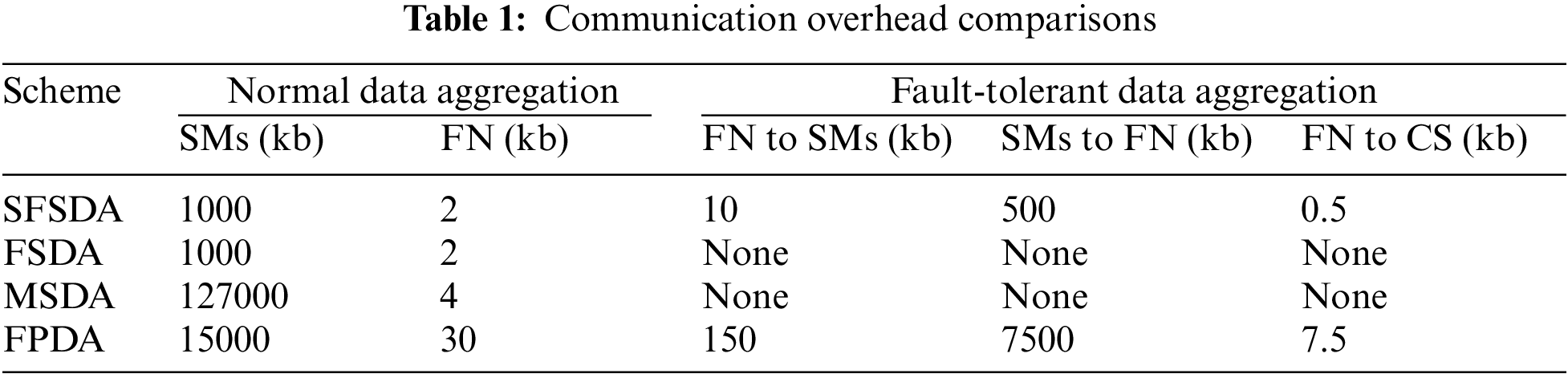
In SFSDA and FPDA schemes, to achieve fault tolerance, SM and FN need to store the original share

In this article, we identified the potential security flaw of personal privacy disclosure in the FSDA scheme. Once the ciphertext sent by SM to FN contains two or more Paillier ciphertexts, the ciphertext itself will reveal the encrypted personal electricity consumption, resulting in personal privacy infringement. In addition, the FSDA scheme lacks fault tolerance. Once SM cannot submit data, CS will not get the correct decryption results. To solve the above-mentioned security issues and hold the fault-tolerant property, a secure flexible subset data aggregation with fault tolerance SFSDA is proposed. On the one hand, our scheme allows for flexible subset aggregation, where the subset can be flexibly adjusted to the needs of CS without compromising user privacy. On the other hand, when the encrypted data of a faulty user cannot be obtained, the CS can still obtain the correct aggregation result by reconstructing the equivalent ciphertext in our scheme. The experimental results show that our scheme is efficient, flexible, and practical. For future work, as the existing data aggregation schemes for smart grids only perform sum operations on the data, some important operations, such as linear operations, are ignored. Therefore, maintaining linear homomorphism of data aggregation for smart grids is an important direction for our future research.
Funding Statement: This work was supported by National Natural Science Foundation of China (Grant Nos. 62102452, 62172436), Natural Science Foundation of Shaanxi Province (No. 2023-JC-YB-584), Innovative Research Team in Engineering University of PAP (KYTD201805), Engineering University of PAP’s Funding for Key Researcher (No. KYGG202011).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. H. Xu, M. Guo, N. Nedjah, J. Zhang and P. Li, “Vehicle and pedestrian detection algorithm based on lightweight YOLOv3-promote and semi-precision acceleration,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 10, pp. 19760–19771, 2022. [Google Scholar]
2. P. Kumar, Y. Lin, G. Bai, A. Paverd, J. S. Dong et al., “Smart grid metering networks: A survey on security, privacy and open research issues,” IEEE Communications Surveys & Tutorials, vol. 21, no. 3, pp. 2886–2927, 2019. [Google Scholar]
3. Y. Yang, X. Yang, M. Heidari, M. A. Khan, G. Srivastava et al., “Astream: Data-stream-driven scalable anomaly detection with accuracy guarantee in IIoT environment,” IEEE Transactions on Network Science and Engineering, 2022. [Google Scholar]
4. L. Qi, Y. Yang, X. Zhou, W. Rafique and J. Ma, “Fast anomaly identification based on multi-aspect data streams for intelligent intrusion detection toward secure industry 4.0,” IEEE Transactions on Industrial Informatics, vol. 18, no. 9, pp. 6503–6511, 2021. [Google Scholar]
5. Z. G. Al-Mekhlafi, M. A. Al-Shareeda, S. Manickam, B. A. Mohammed and A. Qtaish, “Lattice-based lightweight quantum resistant scheme in 5g-enabled vehicular networks,” Mathematics, vol. 11, no. 2, pp. 399, 2023. [Google Scholar]
6. M. A. Al-Shareeda, S. Manickam, S. A. Laghari and A. Jaisan, “Replay-attack detection and prevention mechanism in industry 4.0 landscape for secure secs/gem communications,” Sustainability, vol. 14, no. 23, pp. 15900, 2022. [Google Scholar]
7. M. A. Al-Shareeda and S. Manickam, “Msr-dos: Modular square root-based scheme to resist denial of service (dos) attacks in 5g-enabled vehicular networks,” IEEE Access, vol. 10, pp. 120606–120615, 2022. [Google Scholar]
8. M. A. Al-Shareeda, S. Manickam, B. A. Mohammed, Z. G. Al-Mekhlafi, A. Qtaish et al., “Provably secure with efficient data sharing scheme for fifth-generation (5G)-enabled vehicular networks without road-side unit (RSU),” Sustainability, vol. 14, no. 16, pp. 9961, 2022. [Google Scholar]
9. E. L. Quinn, “Privacy and the new energy infrastructure,” Available at SSRN 1370731, 2009. [Google Scholar]
10. F. Wang, G. Li, Y. Wang, W. Rafique, M. R. Khosravi et al., “Privacy-aware traffic flow prediction based on multi-party sensor data with zero trust in smart city,” ACM Transactions on Internet Technology (TOIT), 2022. [Google Scholar]
11. X. Zhou, X. Yang, J. Ma, I. Kevin and K. Wang, “Energy efficient smart routing based on link correlation mining for wireless edge computing in IoT,” IEEE Internet of Things Journal, vol. 9, no. 16, pp. 14988–14997, 2021. [Google Scholar]
12. M. A. Al-Shareeda and S. Manickam, “Covid-19 vehicle based on an efficient mutual authentication scheme for 5g-enabled vehicular fog computing,” International Journal of Environmental Research and Public Health, vol. 19, no. 23, pp. 15618, 2022. [Google Scholar] [PubMed]
13. H. Bao and R. Lu, “A new differentially private data aggregation with fault tolerance for smart grid communications,” IEEE Internet of Things Journal, vol. 2, no. 3, pp. 248–258, 2015. [Google Scholar]
14. L. Wu, M. Xu, S. Fu, Y. Luo and Y. Wei, “FPDA: Fault-tolerant and privacy-enhanced data aggregation scheme in fog-assisted smart grid,” IEEE Internet of Things Journal, vol. 9, no. 7, pp. 5254–5265, 2021. [Google Scholar]
15. K. Xue, B. Zhu, Q. Yang, D. S. Wei and M. Guizani, “An efficient and robust data aggregation scheme without a trusted authority for smart grid,” IEEE Internet of Things Journal, vol. 7, no. 3, pp. 1949–1959, 2019. [Google Scholar]
16. X. Wang, Y. Liu and K. K. R. Choo, “Fault-tolerant multisubset aggregation scheme for smart grid,” IEEE Transactions on Industrial Informatics, vol. 17, no. 6, pp. 4065–4072, 2020. [Google Scholar]
17. R. Lu, K. Alharbi, X. Lin and C. Huang, “A novel privacy-preserving set aggregation scheme for smart grid communications,” in 2015 IEEE Global Communications Conf. (GLOBECOM), San Diego, CA, USA, pp. 1–6, 2015. [Google Scholar]
18. S. Li, K. Xue, Q. Yang and P. Hong, “PPMA: Privacy-preserving multisubset data aggregation in smart grid,” IEEE Transactions on Industrial Informatics, vol. 14, no. 2, pp. 462–471, 2017. [Google Scholar]
19. L. Zhang and Y. Liu, “FSDA: Flexible subset data aggregation for smart grid,” IEEE Systems Journal, vol. 17, no. 1, pp. 569–578, 2023. [Google Scholar]
20. T. ElGamal, “A public key cryptosystem and a signature scheme based on discrete logarithms,” IEEE Transactions on Information Theory, vol. 31, no. 4, pp. 469–472, 1985. [Google Scholar]
21. P. Paillier, “Public-key cryptosystems based on composite degree residuosity classes,” in Int. Conf. on the Theory and Applications of Cryptographic Techniques, Berlin, Heidelberg, Springer, pp. 223–238, 1999. [Google Scholar]
22. C. Dwork, “Differential privacy: A survey of results,” in Int. Conf. on Theory and Applications of Models of Computation, Berlin, Heidelberg, Springer, pp. 1–19, 2008. [Google Scholar]
23. C. Dwork and A. Roth, “The algorithmic foundations of differential privacy,” Foundations and Trends® in Theoretical Computer Science, vol. 9, no. 3–4, pp. 211–407, 2014. [Google Scholar]
24. Z. Song, W. Zhong, T. Zhou, D. Chen, Y. Ding et al., “SEMDA: Secure and efficient multidimensional data aggregation in smart grid without a trusted third party,” Security and Communication Networks, 2023. [Google Scholar]
25. J. N. Liu, J. Weng, A. Yang, Y. Chen and X. Lin, “Enabling efficient and privacy-preserving aggregation communication and function query for fog computing-based smart grid,” IEEE Transactions on Smart Grid, vol. 11, no. 1, pp. 247–257, 2019. [Google Scholar]
26. Y. Ding, B. Wang, Y. Wang, K. Zhang and H. Wang, “Secure metering data aggregation with batch verification in industrial smart grid,” IEEE Transactions on Industrial Informatics, vol. 16, no. 10, pp. 6607–6616, 2020. [Google Scholar]
27. S. Zhao, F. Li, H. Li, R. Lu, S. Ren et al., “Smart and practical privacy-preserving data aggregation for fog-based smart grids,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 521–536, 2020. [Google Scholar]
28. P. Gope and B. Sikdar, “Lightweight and privacy-friendly spatial data aggregation for secure power supply and demand management in smart grids,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 6, pp. 1554–1566, 2018. [Google Scholar]
29. H. Li, X. Lin, H. Yang, X. Liang, R. Lu et al., “EPPDR: An efficient privacy-preserving demand response scheme with adaptive key evolution in smart grid,” IEEE Transactions on Parallel and Distributed Systems, vol. 25, no. 8, pp. 2053–2064, 2013. [Google Scholar]
30. K. Zhang, X. Liang, M. Baura, R. Lu and X. S. Shen, “PHDA: A priority based health data aggregation with privacy preservation for cloud assisted WBANs,” Information Sciences, vol. 284, pp. 130–141, 2014. [Google Scholar]
31. C. I. Fan, S. Y. Huang and Y. L. Lai, “Privacy-enhanced data aggregation scheme against internal attackers in smart grid,” IEEE Transactions on Industrial Informatics, vol. 10, no. 1, pp. 666–675, 2013. [Google Scholar]
32. H. Bao and R. Lu, “Comment on privacy-enhanced data aggregation scheme against internal attackers in smart grid,” IEEE Transactions on Industrial Informatics, vol. 12, no. 1, pp. 2–5, 2015. [Google Scholar]
33. Y. Liu, G. Liu, C. Cheng, Z. Xia and J. Shen, “A privacy-preserving health data aggregation scheme,” KSII Transactions on Internet and Information Systems (TIIS), vol. 10, no. 8, pp. 3852–3864, 2016. [Google Scholar]
34. J. Song, Y. Liu, J. Shao and C. Tang, “A dynamic membership data aggregation (DMDA) protocol for smart grid,” IEEE Systems Journal, vol. 14, no. 1, pp. 900–908, 2019. [Google Scholar]
35. L. Lyu, K. Nandakumar, B. Rubinstein, J. Jin, J. Bedo et al., “PPFA: Privacy preserving fog-enabled aggregation in smart grid,” IEEE Transactions on Industrial Informatics, vol. 14, no. 8, pp. 3733–3744, 2018. [Google Scholar]
36. A. Saleem, A. Khan, S. U. R. Malik, H. Pervaiz, H. Malik et al., “FESDA: Fog-enabled secure data aggregation in smart grid IoT network,” IEEE Internet of Things Journal, vol. 7, no. 7, pp. 6132–6142, 2019. [Google Scholar]
37. Z. Erkin, “Private data aggregation with groups for smart grids in a dynamic setting using CRT,” in 2015 IEEE Int. Workshop on Information Forensics and Security (WIFS), Rome, Italy, pp. 1–6, 2015. [Google Scholar]
38. Y. Liu, W. Guo, C. I. Fan, L. Chang and C. Cheng, “A practical privacy-preserving data aggregation (3PDA) scheme for smart grid,” IEEE Transactions on Industrial Informatics, vol. 15, no. 3, pp. 1767–1774, 2018. [Google Scholar]
39. Z. Zeng, X. Wang, Y. Liu and L. Chang, “MSDA: Multi-subset data aggregation scheme without trusted third party,” Frontiers of Computer Science, vol. 16, no. 1, pp. 1–7, 2022. [Google Scholar]
40. K. Xue, Q. Yang, S. Li, D. S. Wei, M. Peng et al., “PPSO: A privacy-preserving service outsourcing scheme for real-time pricing demand response in smart grid,” IEEE Internet of Things Journal, vol. 6, no. 2, pp. 2486–2496, 2018. [Google Scholar]
41. A. Shamir, “How to share a secret,” Communications of the ACM, vol. 22, no. 11, pp. 612–613, 1979. [Google Scholar]
42. D. Boneh, E. J. Goh and K. Nissim, “Evaluating 2-DNF formulas on ciphertexts,” TCC, vol. 3378, pp. 325–341, 2005. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools