
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Power Information System Database Cache Model Based on Deep Machine Learning
Kyonggi University, Suwon, 449-701, Korea
* Corresponding Author: Manjiang Xing. Email:
Intelligent Automation & Soft Computing 2023, 37(1), 1081-1090. https://doi.org/10.32604/iasc.2023.034750
Received 26 July 2022; Accepted 13 December 2022; Issue published 29 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
At present, the database cache model of power information system has problems such as slow running speed and low database hit rate. To this end, this paper proposes a database cache model for power information systems based on deep machine learning. The caching model includes program caching, Structured Query Language (SQL) preprocessing, and core caching modules. Among them, the method to improve the efficiency of the statement is to adjust operations such as multi-table joins and replacement keywords in the SQL optimizer. Build predictive models using boosted regression trees in the core caching module. Generate a series of regression tree models using machine learning algorithms. Analyze the resource occupancy rate in the power information system to dynamically adjust the voting selection of the regression tree. At the same time, the voting threshold of the prediction model is dynamically adjusted. By analogy, the cache model is re-initialized. The experimental results show that the model has a good cache hit rate and cache efficiency, and can improve the data cache performance of the power information system. It has a high hit rate and short delay time, and always maintains a good hit rate even under different computer memory; at the same time, it only occupies less space and less CPU during actual operation, which is beneficial to power The information system operates efficiently and quickly.Keywords
With the advent of the era of big data, the informatization level of electric power enterprises has maintained an upward trend, and various business systems have emerged as the times require. Power information systems are facing huge system access pressure and massive data storage pressure [1,2]. Only a database with powerful data storage and read and write capabilities can improve the efficiency of power information systems [3]. Not only does the infrastructure need to remain the same, but the database needs to be accessed more efficiently. Data caching can reduce the application program’s access to physical data sources, improve the efficiency of database access, and even the entire power information system.
The current analysis of database cache mainly focuses on data blocks or data sets [4–6]. Literature [7] proposed a database cache model based on multiple storage environments. This model uses data compression techniques to optimize caching. However, this method takes up a lot of memory and is not suitable for TB-level data caches. Literature [8] proposes an information database cache model based on the Rsdis tool. The model uses the Rsdis tool to build the cache framework and optimize the cache. However, the certainty of the results returned by this method is poor. If the query result set is large, memory blockage will occur, and the hit rate will drop rapidly.
Aiming at the above-mentioned problems of slow running speed and low database hit rate, this paper studies the database cache model of electric power information system based on deep machine learning. The cache model includes program cache, SQL preprocessing and core cache modules. Build predictive models using boosted regression trees in the core cache module. A series of regression tree models are generated using machine learning algorithms for analyzing resource occupancy in power information systems. According to the dynamic adjustment of the voting threshold of the prediction model, the re-initialization of the cache model is realized.
2 Database Caching Model of Power Information System Based on Deep Machine Learning
First, the database cache model structure of the overall power information system is constructed based on deep machine learning. The cache model includes program cache, SQL preprocessing and core cache modules. Build predictive models using boosted regression trees in the core cache module. Generate a series of regression tree models using machine learning algorithms. At the same time, according to the dynamic adjustment of the voting threshold of the prediction model, the re-initialization of the cache model is realized.
The buffer module, buffer core module and SQL preprocessing module in power information system make up the buffer model of power information system database based on deep machine learning. The overall model structure is shown in Fig. 1.
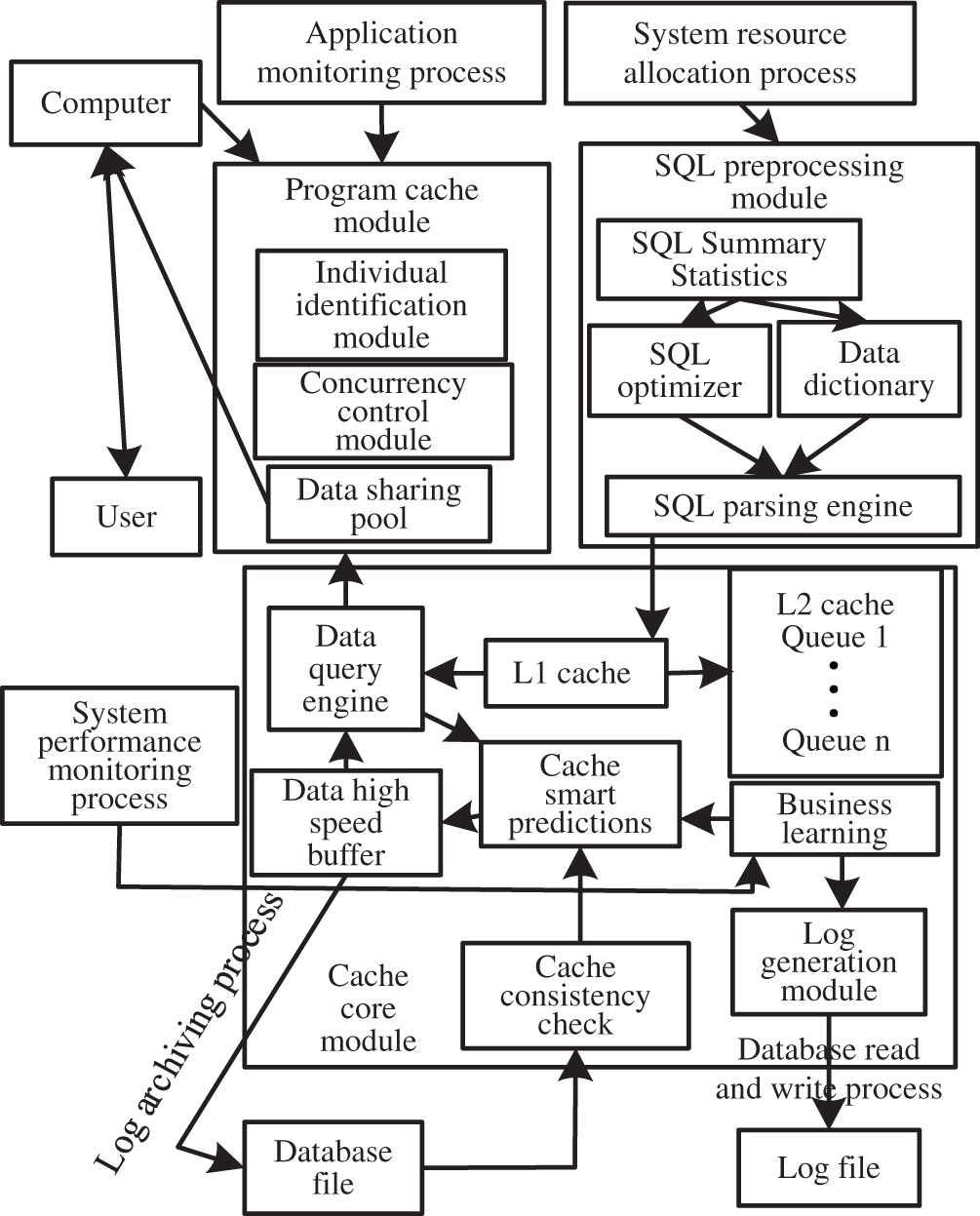
Figure 1: Overall model structure
(1) Program Cache Module
The program cache module is embedded in the relevant background programs of the power information system. This module is mainly composed of data sharing pool, concurrency control sub-module and individual identification sub-module. The idea of module editing is aspect-oriented, and it does not modify the original business system logic while monitoring the module persistence layer. Paste the time sequence number and individual identification in the corresponding query command submitted by each user. Appropriate concurrent access strategies are required to ensure a specific level of transaction isolation. Shared query result set uses data sharing pool [9–11].
(2) SQL Preprocessing Module
SQL preprocessing module is used when parsing and optimizing query statements. The way to improve the efficiency of statements is to adjust the operation of multi-table joins and keywords replacement in SQL optimizer. SQL parsing using the parsing engine module reference data dictionary reference information, ensure that suitable for intelligent forecasting module and business learning to complete processing work [12].
(3) Cache Core Module
The SQL statements introduced in the first-level cache are called by the data query engine. When dividing different queues in the secondary cache, we need the individual identity document (ID) of the previous model. Based on the regression tree, the lifting regression tree is used to construct the original prediction model to calculate the residual of training set. Machine learning algorithm is used to learn the residual of training set. In the Business Learning Module, the Caching Intelligent Prediction Submodule searches the same operation node to cache possible queries [13]. The data cache reads the result set. The cache consistency checking submodule is responsible for synchronizing the database and cache using fixed algorithms.
(4) Business Process
In the process of system resource allocation, the cache core module is allocated to several terminals for simultaneous execution using Hadoop technology. The system performance monitoring process is mainly responsible for the dynamic adjustment of the relevant indicators. Power information system database cache principle flowchart is shown in Fig. 2.
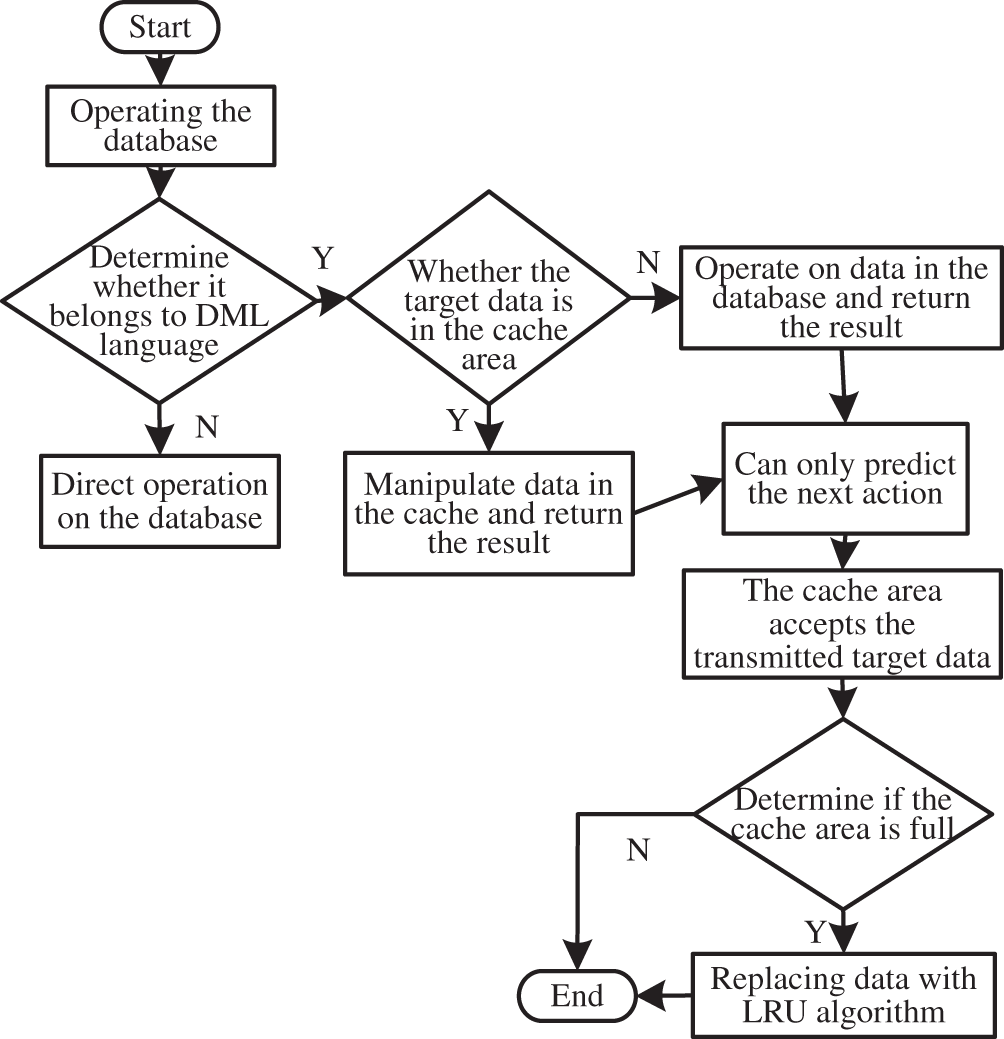
Figure 2: Database cache principle flowchart
After the implementation of the database to determine whether the database language belongs to the DML language. If the result is negative, the database is operated directly. If the result is affirmative, the next step will be taken. Is the target data in the cache or, if not, in the database and return the result. If it belongs to the buffer area, the operation is performed in the buffer area and the result is returned. After completing the above operations and after the results are returned, use intelligence to predict the next action. The target data item is transmitted to the cache to determine whether the cache is full or not. If not, end the cache. If full, end the cache after replacing the data with the LRU algorithm.
2.2 Database Cache Model Based on Boosting Regression Tree
Regression tree is a tree-structured algorithm that describes the basis and belongs to a nonparametric model. A set of training data specified by the electric power information system is continuously divided into a subset without repetition by using a divide and conquer, top-down learning strategy. After the division is completed, the output is set as the mean value of the sample responses in each subset to construct a prediction model. The mathematical model of the regression tree is as follows:
In Eq. (1),
Identify a training dataset in a power information system. The training data set
Because the single recursion tree model of power information system has limited prediction accuracy. Boosting algorithm is proposed to improve the prediction accuracy of regression tree model. The addition model is used to combine the final model and the forward distribution algorithm is used to fit a series of regression trees [14]. That is to say, each regression tree model needs a previous model as its basis. Eq. (3) is the boosted regression tree model:
The prediction model of regression tree was constructed based on regression tree and ascending regression tree. The machine learning algorithm generates a series of regression tree models and combines the output averagely.
There is an independent relationship among the regression tree models obtained by machine learning algorithm. Use Eq. (4) to express regression tree prediction model:
The number of regression tree models is represented by
The stochastic attributes are introduced into the stochastic sampling feature space and sample space when constructing the belonging models. Therefore, the relativity between recursive tree models is reduced, and the generalization of the model is reduced, which improves the robustness, efficiency and accuracy of the model.
The most important model parameter when building a model is the number of regression tree models
Based on the regression tree prediction model, through the performance detector, the regression tree prediction model can obtain the operation status of power information system and analyze the resource occupancy rate. Dynamic adjustment of voting options for regression trees [15].
Assuming you have hit the SQL statement, set it
If the power information system can maintain normal operation and all resources are available, then the cache set predicted by regression tree prediction model is represented as
3 Experimental Analysis and Results
A certain electric power company is taken as the research object and its information system is called after negotiation. The company is located in a city in central China, mainly responsible for more than half of the city’s commercial areas, residential areas of power supply and power consumption management. The actual work includes charging, managing the regional power supply system, power supply equipment maintenance and some regional line laying. Since its inception in 2009, the annual increase in turnover has become an important economic support enterprises in the region. The data required for the experiment is the data with user identification automatically recorded in the background of the company’s power information system. About 8,000 access records were selected for 2 days.
The model is applied to the system to verify the performance of the model. The three comparison models are the database cache model based on multiple storage environments, the information database cache model based on rsdis tools and a novel adaptive database cache optimization algorithm based on predictive working sets in cloud environment. Two methods of comparison were derived from references [7–9].
The main metrics to analyze cache performance include latency, metric hit ratio, and byte hit ratio. The latency time represents the total amount of time the server downloaded the object until the client implemented the cache. Metric hit ratio represents the number of objects the user gets from the cache and the total number of objects obtained. The byte hit ratio represents the number of objects obtained from the buffered user and the total number of objects obtained.
Comparison of three models in the case of different cache file size, the results are shown in Table 1.
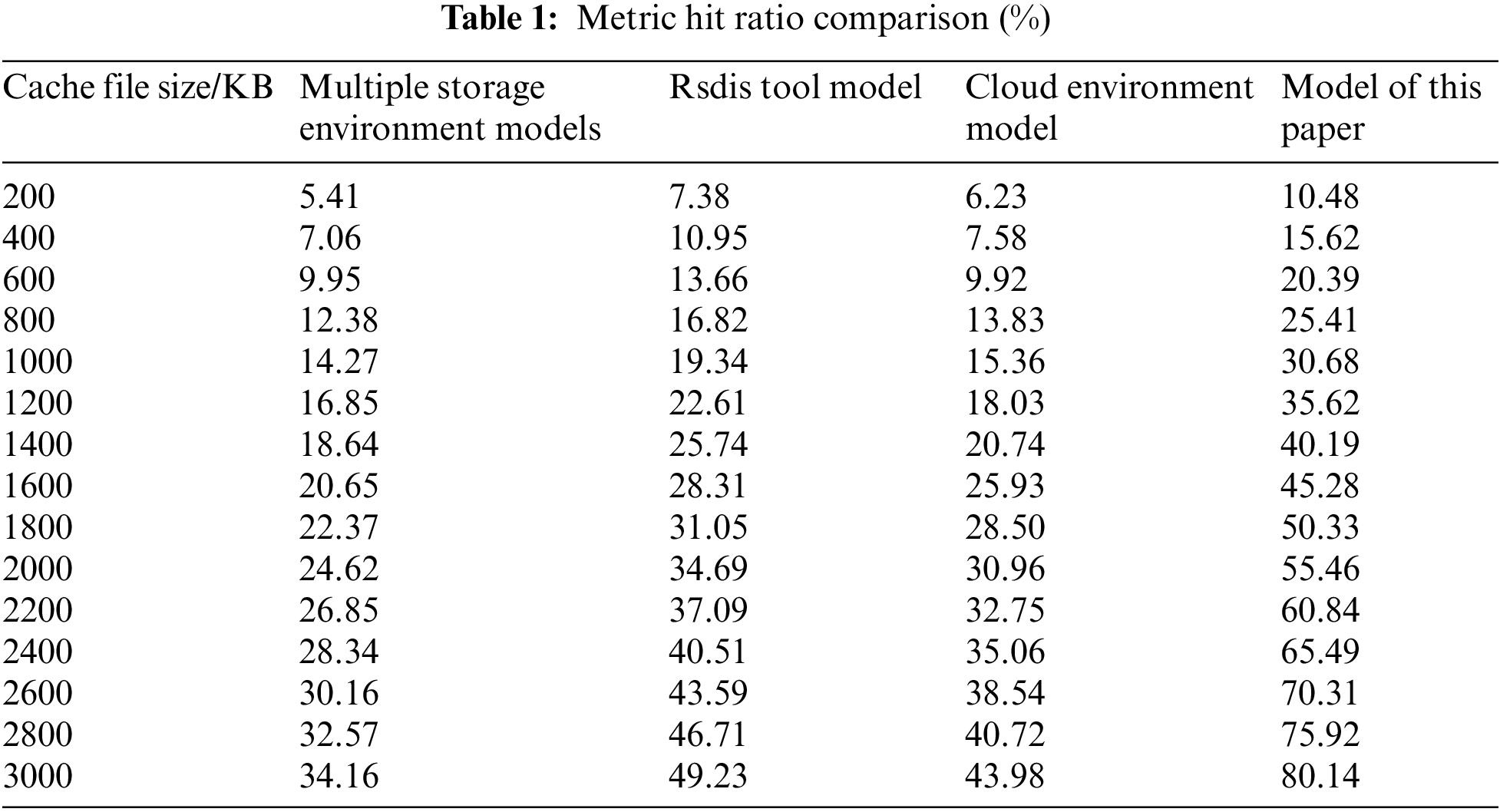
As you can see from Table 1, as the cache file size increases, the hit ratio of each model tends to increase. But the upward trend of the two comparison models was slower, when the cache file reached 3000KB. The hit ratios of various storage environment models , rsdis tool models and cloud environment models reached 34.16% ,49.23% and 43.98% respectively, while the model in this paper reached 80.14%. It can be seen that using this model can greatly reduce the redundancy of the database cache files, improve the hit rate and improve the overall performance of the power information data caching system.
The byte hit ratios of the three models are compared and the results are shown in Table 2.
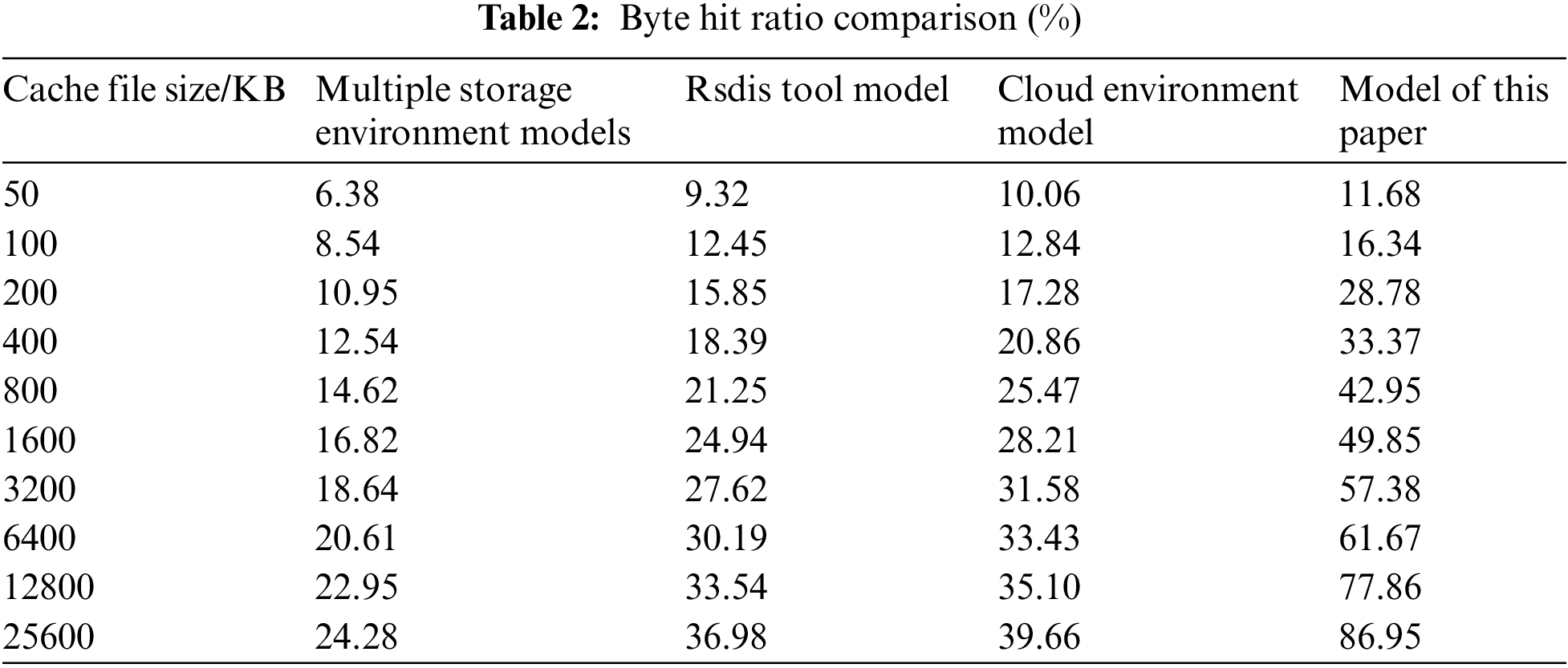
As you can see from Table 2, similar to metric hit ratio, all four models increase byte hit ratio as the cache file size increases. This model has a higher byte hit ratio than the comparison model. So it can be proved that this model has better effect of eliminating redundancy.
Comparing the latency times of the three models with different cache file sizes, the results are shown in Fig. 3.
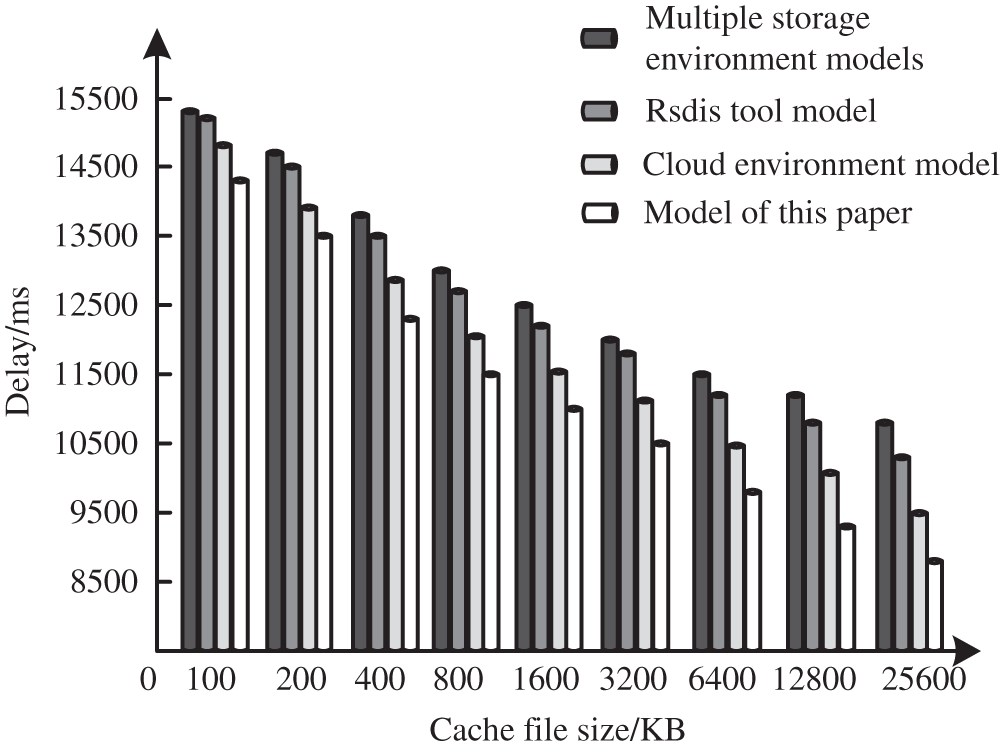
Figure 3: Latency comparison results
As you can see from Fig. 3, the latency of each model decreases as the cache file grows. In contrast, this model has the shortest latency, which shows that this model has a faster cache efficiency in caching database files.
The byte hit ratio and index hit ratio of each model are compared under different computer memory sizes. The experimental results are shown in Table 3.
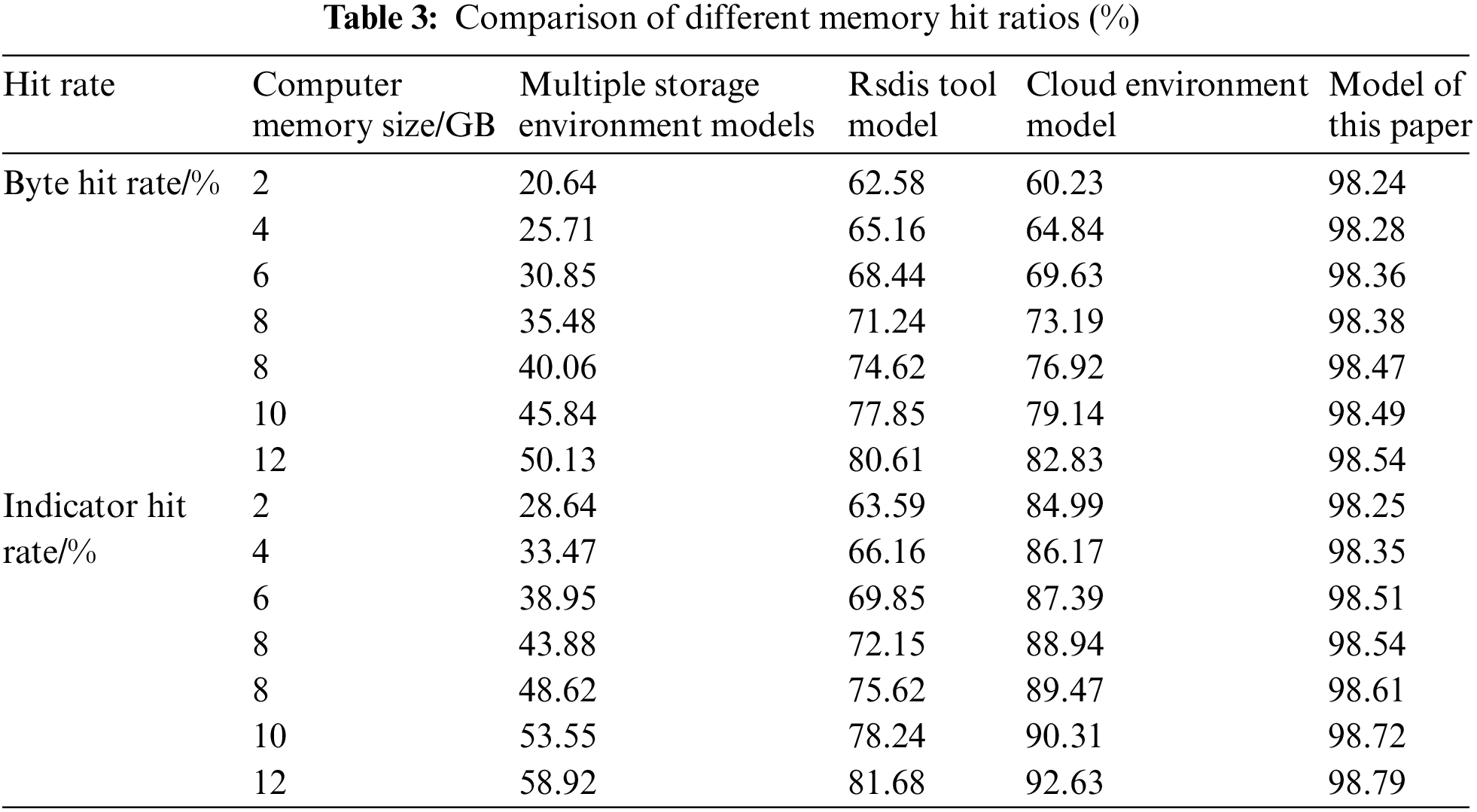
Analysis of Table 3 shows that with the increase of computer memory, the hit rate of the three comparison models gradually increases. The computer memory size directly affects the model cache hit rate. Only computers with large enough memory can achieve a high cache hit rate; The byte hit rate and index hit rate of the method in this paper are both high. At the same time, the stability of the hit rate of the model in this paper is relatively high, and the size of the computer memory will not have a serious impact on the cache hit rate. It can ensure the smooth operation of the data cache of the power information system.
Compare the memory usage and CPU usage of the three models with different cache file sizes. The experimental results are shown in Table 4.
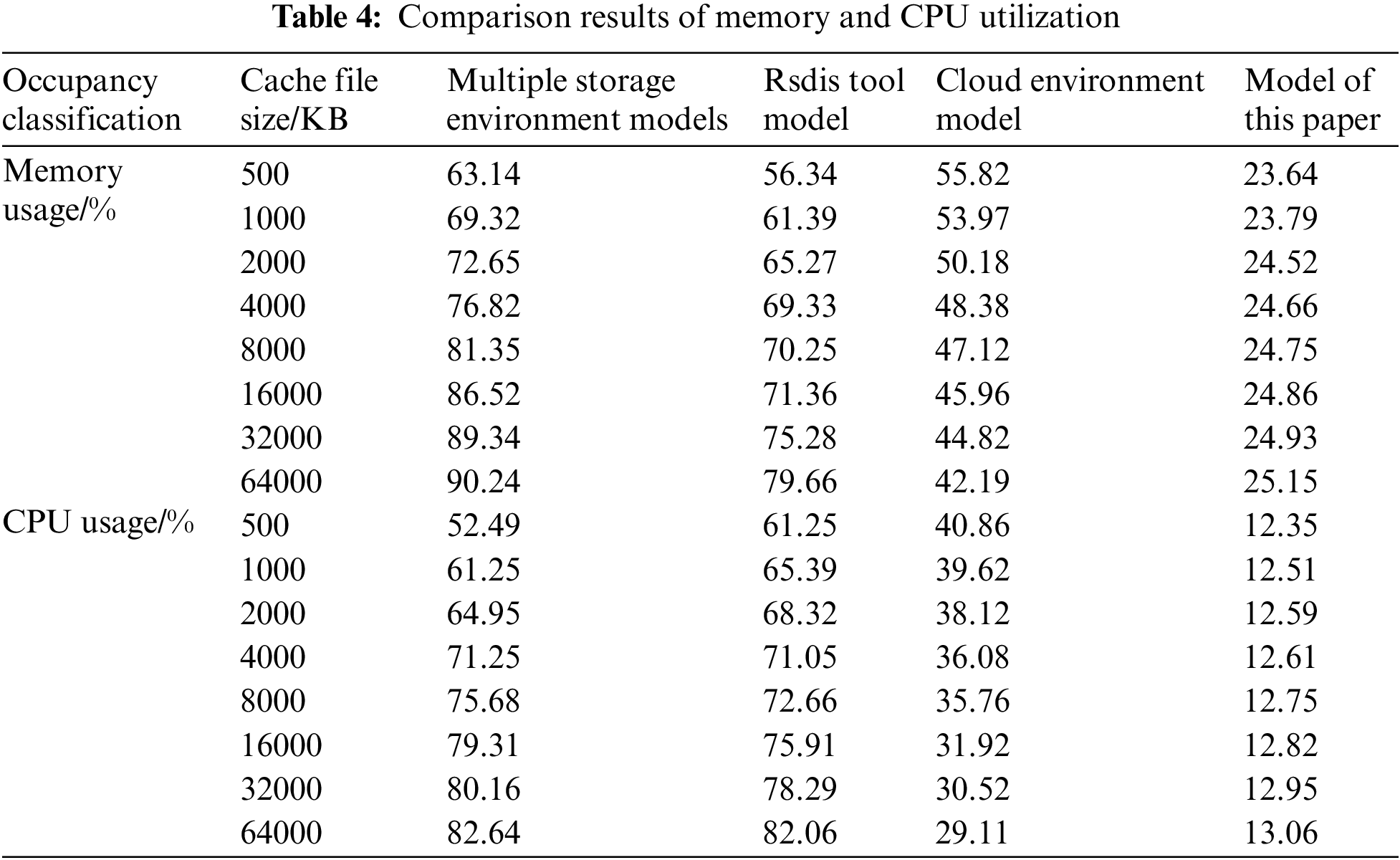
From the analysis of Table 4, it can be seen that compared with the three comparison models, the memory occupancy rate and CPU occupancy rate of the model in this paper are lower. It shows that the use of the model in this paper will not affect the operation state of the power information system, and even improve the operation effect of the system. It has a positive impact on the system and has broad application prospects.
At present, the power information system often has a huge amount of data, and the concurrent access volume is high. A database caching model must be explored. It can greatly reduce the cache occupancy rate and also has a high de-redundancy and hit rate. Aiming at the above problems, this paper proposes a database caching model for power information systems based on deep learning. This paper uses the regression tree as the basis for the cache model of the power information system, and learns the residuals on the training set through machine learning. The actual use of the power information system as the research object to carry out practical verification, the method in this paper has a high hit rate and a short delay time. This method can always maintain a good hit rate even under different computer memory. At the same time, the method in this paper only takes up less space occupancy and less CPU occupancy during actual operation. It is conducive to the efficient and fast operation of the power information system.
Funding Statement: The author received no specific funding for this study.
Conflicts of Interest: The authors declare they have no conflicts of interest to report regarding the present study.
References
1. N. C. Zhou, J. Q. Liao, Q. G. Wang, C. Y. Li and J. Li, “Analysis and prospect of deep learning application in smart grid,” Automation of Electric Power Systems, vol. 43, no. 4, pp. 180–191, 2019. [Google Scholar]
2. X. Gao, G. F. Chen and H. L. Zhao, “Network security situation assessment of power information system based on data mining,” Electrical Measurement & Instrumentation, vol. 56, no. 19, pp. 102–106, 2019. [Google Scholar]
3. T. N. Ma, C. Wang, L. L. Peng, X. F. Guo and M. Ming, “Short-term load forecasting of power system considering demand response and multi-task learning based on deep structure,” Electrical Measurement & Instrumentation, vol. 56, no. 16, pp. 50–60, 2019. [Google Scholar]
4. Z. C. Qu, L. Gao, B. L. Kang and G. Y. Shi, “A power system fault full information diagnosis model based on multi-source data,” Power System Protection and Control, vol. 47, no. 22, pp. 59–66, 2019. [Google Scholar]
5. L. Xi, L. Yu, X. Zhang and W. Hu, “Automatic generation control of ubiquitous power Internet of Things integrated energy system based on deep reinforcement learning,” Scientia Sinica Technologica, vol. 50, no. 2, pp. 221–234, 2020. [Google Scholar]
6. L. P. Chen, L. F. Yin, T. Yu and K. Y. Wang, “Short-term power load forecasting based on deep forest algorithm,” Electric Power Construction, vol. 39, no. 11, pp. 42–50, 2018. [Google Scholar]
7. J. C. Zhang, X. G. Liu and G. Wang, “Cache optimization for compressed databases in various storage environments,” Journal of Computer Applications, vol. 38, no. 5, pp. 1404–1409, 2018. [Google Scholar]
8. Z. Y. Sun, “Optimizing method of large-scale electronic information cache in compressed database,” Electronic Design Engineering, vol. 28, no. 7, pp. 95–98+103, 2020. [Google Scholar]
9. A. O. Thakare and P. S. Deshpande, “A novel adaptive database cache optimization algorithm based on predictive working sets in cloud environment,” IEEE Access, vol. 7, no. 7, pp. 54343–54359, 2019. [Google Scholar]
10. L. T. Tan, J. L. Li, B. Ren, Y. He, X. Gao et al., “Health evaluation model of smart grid dispatch and control system based on RB-XG Boost algorithm,” Electric Power Automation Equipment, vol. 40, no. 2, pp. 189–198, 2020. [Google Scholar]
11. Y. Deng, M. F. Peng and J. W. Liu, “Power cyber-physical system modeling and information attack mechanism analysis,” Acta Power System and Its Automation, vol. 33, no. 10, pp. 10–17, 2021. [Google Scholar]
12. Z. Ruan, L. Lv, Y. B. Liu, J. Liu, D. G. Wang et al., “Coordinated attack model of cyber-physical power system considering false load data injection,” Electric Power Automation Equipment, vol. 39, no. 2, pp. 181–187, 2019. [Google Scholar]
13. C. B. Sun, M. Cheng, K. Yuan, J. Sun, Y. Song et al., “Real time simulation platform of power cyber-physical system based on node mapping model,” Power System Technology, vol. 43, no. 7, pp. 2368–2377, 2019. [Google Scholar]
14. S. Z. Chen, J. L. Liang, D. Y. Lu, Z. X. Zeng and X. R. Deng, “Multi-source fault data comprehensive analysis method for power system based on COMTRADE model,” Journal of Electric Power Science and Technology, vol. 126, no. 3, pp. 94–102, 2019. [Google Scholar]
15. X. L. Feng, H. Wei, H. B. Wei and Y. Zhang, “Distributed real-time database for dispatching automation system with micro-services,” Power System Protection and Control, vol. 46, no. 21, pp. 138–144, 2018. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools