
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Recognition of Handwritten Words from Digital Writing Pad Using MMU-SNet
Department of Computer Science and Engineering, SRM Institute of Science and Technology, Kattankulathur, Tamilnadu, India
* Corresponding Author: V. Jayanthi. Email:
Intelligent Automation & Soft Computing 2023, 36(3), 3551-3564. https://doi.org/10.32604/iasc.2023.036599
Received 06 October 2022; Accepted 23 November 2022; Issue published 15 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In this paper, Modified Multi-scale Segmentation Network (MMU-SNet) method is proposed for Tamil text recognition. Handwritten texts from digital writing pad notes are used for text recognition. Handwritten words recognition for texts written from digital writing pad through text file conversion are challenging due to stylus pressure, writing on glass frictionless surfaces, and being less skilled in short writing, alphabet size, style, carved symbols, and orientation angle variations. Stylus pressure on the pad changes the words in the Tamil language alphabet because the Tamil alphabets have a smaller number of lines, angles, curves, and bends. The small change in dots, curves, and bends in the Tamil alphabet leads to error in recognition and changes the meaning of the words because of wrong alphabet conversion. However, handwritten English word recognition and conversion of text files from a digital writing pad are performed through various algorithms such as Support Vector Machine (SVM), Kohonen Neural Network (KNN), and Convolutional Neural Network (CNN) for offline and online alphabet recognition. The proposed algorithms are compared with above algorithms for Tamil word recognition. The proposed MMU-SNet method has achieved good accuracy in predicting text, about 96.8% compared to other traditional CNN algorithms.Keywords
According to Ethnologue statics, Tamil Language (TL) is a 5000-year-old language. TL is spoken in the state of Tamil Nadu, India and other countries such as Srilanka, Malaysia and Singapore. The Tamil Language is the oldest language of the Dravidian people. Tamil language alphabets have 12 vowels called Uyirezhuthu, 18 consonants called Meyyezhuthu, and one unique character called Aythaezhuthu. The combinations of 12 vowels and 18 consonants lead to the uyirmeyyezhuthu alphabet of 216 alphabets. The total TL alphabets are 247. TL has five consonants from the Sanskrit language, combined with Tamil vowels, and produces 60 alphabets; in total, TL has 307 alphabets [1]. Based on the centuries, TL alphabets are categorized into karosti ezhuthukal, Brahmi ezhuthukal, Vattu ezhuthukal, Grantha ezhuthukal and Tamil ezhuthukkal. The karosti ezhuthukal are written from right to left, which was first read by General Ventura in 1830. Brahmi ezhuthukal was used in India except in Tamil Nadu till the 6th century. Vattu ezhuthukal scripts are called disks because they are written in a circular pattern during Circa BC 500 to BC. Granth is a type of writing, referred to as Grantha Scripts, developed from the oldest form of Tamil script in Tamil Nadu after the 3rd century. Modern literary Tamil has continued since 1600. From the Brahmi script, the Tamil writing system developed. When printing was invented in the 16th century, the letter shapes underwent significant modification until finally settling. Although several letters with asymmetrical shapes were standardized throughout the modern era, the main change to the alphabet was the introduction of Grantha letters to express unassimilated Sanskrit words.
TL’s writing style, alphabet, and slang vary from country to country, state to state, and region to region in India. Spoken TL is recognizable to all Tamil-speaking people, whereas recognizing the Tamil handwritten text from a digital writing pad is a complex and challenging task for computers and humans. A slight change in size and shape of the alphabet will change the meaning [2]. Visual interpretation of the TL alphabet is a challenging task and still a significant problem for computers to recognize the handwritten text of TL due to complex structures such as curves and loops in the alphabet. Especially when we write on a digital writing pad, the font and shape of the alphabet change for various reasons, and the meaning of the words is changed during OCR to test conversion using the software. The change in the alphabet is due to glass surfaces in the digital writing pads; writing on a frictionless surface glass shows a different alphabet after conversion from OCR to a text file, as shown in Fig. 1.
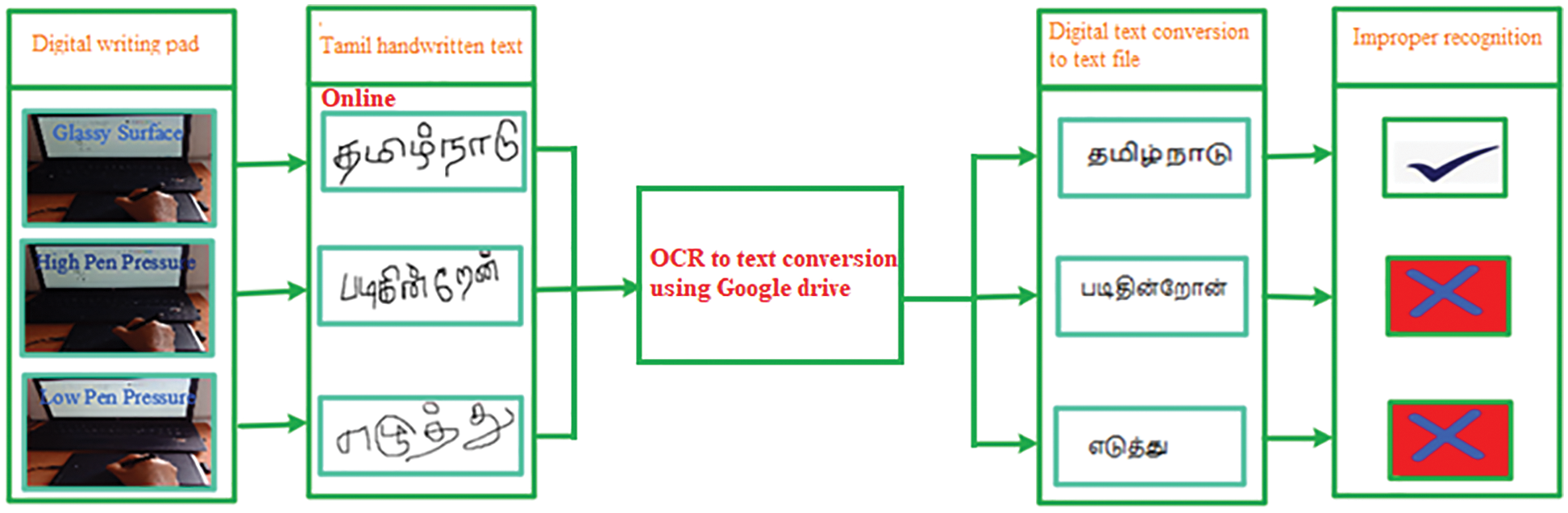
Figure 1: Tamil handwritten text from digital writing pad recognition through OCR google.doc
Moreover, the stylus has pressure sensitivity on the screen and within the stylus itself, which leads to changes in the curves in the alphabet. The handwritten notes into digital text conversion increased after COVID-19 pandemic during any conversion such as OCR to text or text to OCR. OCR is a technology that transforms text into a machine-readable form from handwritten, typed, scanned, or text contained inside images. Any image file containing text, a PDF file, a scanned document, a printed document, or a readable handwritten document can all be used with OCR to extract text. OCR can use OCR to eliminate manual data entry with digitized documents. OCR is also used for book scanning, where it turns raw images into a digital text format. The quality of OCR depends on the quality of the input image that is provided to it, and if there are any imperfections in an image, OCR will have a harder time extracting text from it.
Fig. 2 shows the Tamil handwritten text from digital writing pad recognition. The Tamil handwritten text from digital writing pad sentence in Fig. 2  can be mispredicted as become meaningless. The real-time Tamil handwritten text from digital writing pad recognition problem can be overcome using the proposed MMU-SNet method.
can be mispredicted as become meaningless. The real-time Tamil handwritten text from digital writing pad recognition problem can be overcome using the proposed MMU-SNet method.
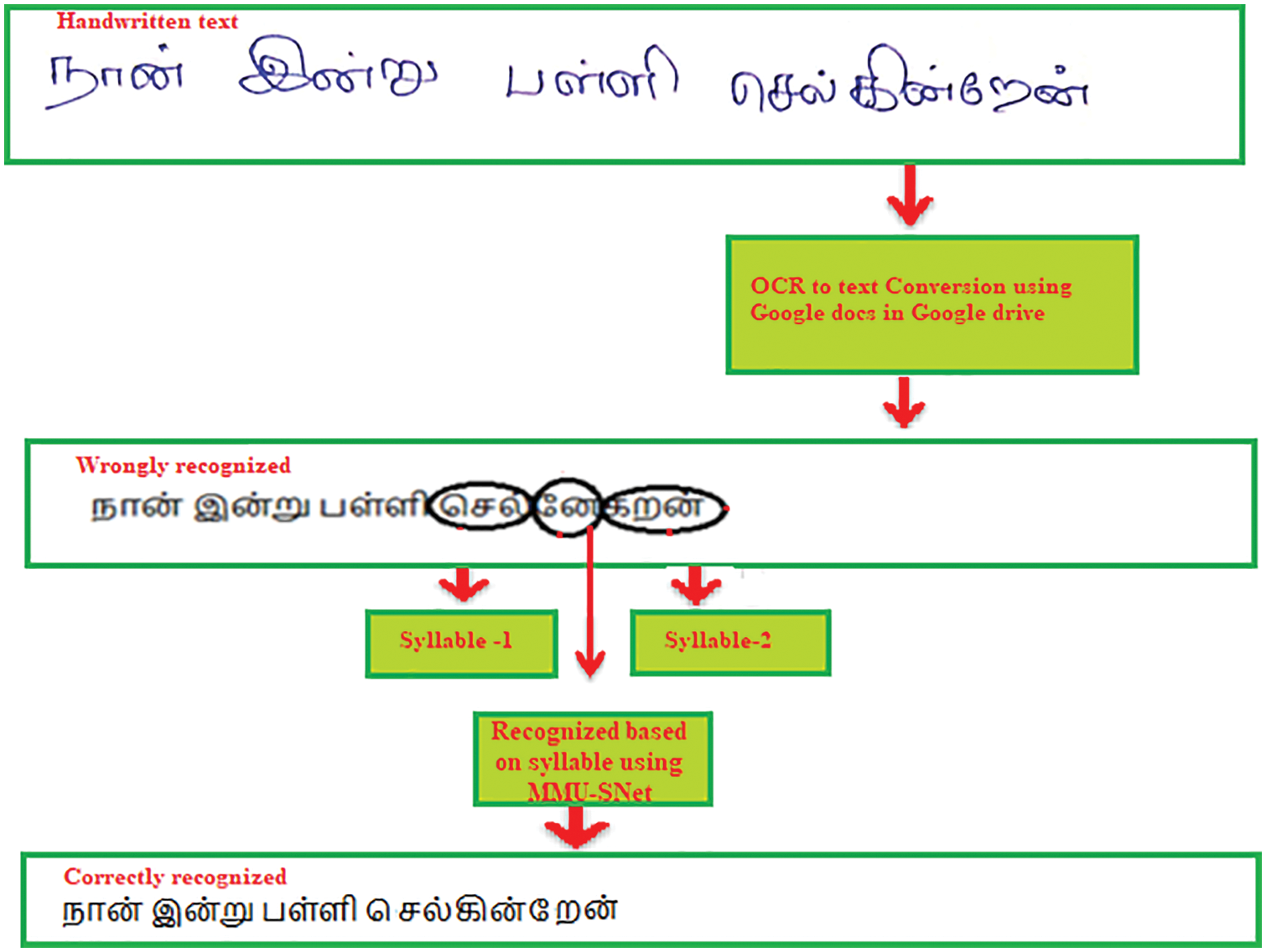
Figure 2: Tamil handwritten text from digital writing pad recognized using MMU-SNet
Automatic Recognition of Handwritten words from a digital writing pad and converting them into a text file is more challenging due to curvature and loops in text. The offline handwritten recognition is done on a skimmed image that contains the handwritten text for identification, which means the skimmed image’s handwritten alphabet is translated to digital form and preserved in the computer. To solve the above problem, MMU-SNet is proposed, consisting of a Residual Module (RM) for constructing a backbone network (BN). The BN is separated into five stages and two times down sampling at each stage.
Contributions
• To recognize handwritten text using MMU-SNet algorithm based on semantic segmentation and upgraded Residual Module for better accuracy.
• To recognize digitized writings in Tamil language using dialect-based alphabet classification using MMU-SNet algorithm for regions such as Madurai, Tirunelveli, Coimbatore, and Thanjavur in Tamilnadu/India.
• To recognize digitized writings in Tamil language using syllable-based alphabet classification using MMU-SNet algorithm, CNN+SALA, AlexNet, and VGG19Net.
• To compare handwriting in the Tamil alphabet based on accuracy, precision, recall, and F1 score for dialect-based alphabet classification, syllable-based alphabet classification, and traditional alphabet classification.
The recognition of handwritten Chinese text by segmentation is developed with the [3] integration of contextual data by guiding the network’s feature extraction. A Recurrent Neural Network (RNN) is proposed for recognizing online handwritten Chinese text through different architectures such as weight vector and variance constraint [4]. Gurmukhi language in India has been recognized Gurmukhi language in India from an online handwritten alphabet based on preserved and marked stroke levels in the alphabet. RNN classifier achieved better accuracy in [5].
A Glyph Semanteme Fusion Embedding (GSFE) for Chinese text recognition is proposed. It consists of an encoder CNN-BiLSTM for extracting sequential features, and a Long Short Term Memory (LSTM) network is used as a decoder. The character level Glyph Semanteme Fusion Embedding (GSFE) and word level GSFE are used in the LSTM decoder for better prediction accuracy than the standard LSTM decoder [6]. Modified Artificial Neural Network (ANN) is used in Tamil handwritten character recognition, which consists of Elephant Herding Optimization (EHO) for the optimization of weights in ANN [7].
Handwritten English text recognition on historical documents using CRNN improves recognition accuracy. The Fully Convolutional network (FCN) is proposed for unconstrained English Text recognition [8]. The performance in classifying depth-wise separable convolutions is a key computational component. PUNet is an efficient deep learning architecture for English hand-handwritten word spotting. In PUnet is developed with U-Net and pyramidal histogram [9].
Multi-Dimensional Long Short Term Memory (MDLSTM) is used in Arabic offline handwriting recognition. The MDLSTM is used for many recurring connections. There are spatiotemporal dimensions in the data. These connections are used to create flexible internal context representation [10]. A CNN-based model is proposed for Tamil offline handwritten recognition; the individual characters are segregated from the text then the segregated character is given to the trained CNN model and predict the character. Hyperparameter tuning is used in the model and achieves reasonable accuracy [11]. Fast writer adaption with the Style Extractor Network (SEN) is proposed for Chinese handwritten text recognition. SEN extracts personalized writer information [12].
Besides this, Table 1 tabulates the dataset, methods, and writing devices used for handwritten recognition in various languages.
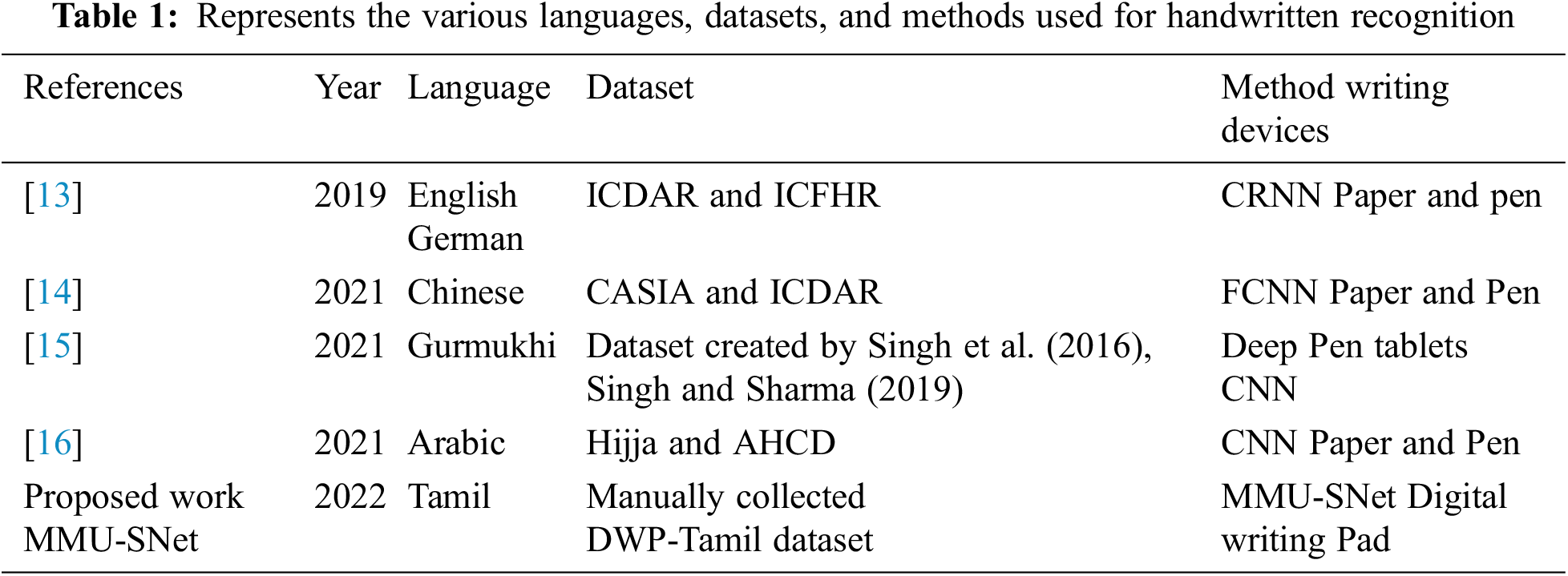
Fig. 3 shows the block diagram of Tamil handwritten text recognition and classification from digital writing pad recognition using MMU-SNet. The text images are obtained from offline, such as text written on paper and pen, online, and note-taking for recognition of Tamil text. DWP-Handwriting (DWP-H) database contains handwritten Tamil characters. DWP-H dataset was collected using Wacom CTL-672/K0-CX Graphic Tablet used for online and offline writer identification and verification experiments. Text datasets were collected from ambient lighting conditions and pressure base stylus writing on the digital pad. A total of 151 writers’ contributions are in tiff format, obtained from different age groups such as children, adults, old males, and females. Samples per class 5, a few contributed as many as ten, and the number of samples per class is 150 samples with the character of size 92 × 133. The writers are from different demographics of regions such as Chennai, Madurai, and trichy in Tamilnadu. The writing style of different writers from different demographics shows variation in stylus pressure and character. The DWP-H Database is available in the following Google drive link. https://drive.google.com/drive/folders/1nzJL4puQ4Ly9fpi2jHxteDgPjwCUupqx?usp=sharing. Fig. 4 shows the model built-in backbone network (BN) in an encoder with the upgraded residual basic module. There are five stages in the backbone network, and two times downsampling can be performed in each stage. A basic Residual Module (RM) in each stage is 2. The added non-local attention module after the backbone network’s last module captures spatial features and long-term context information and avoids increasing parameters and calculations.
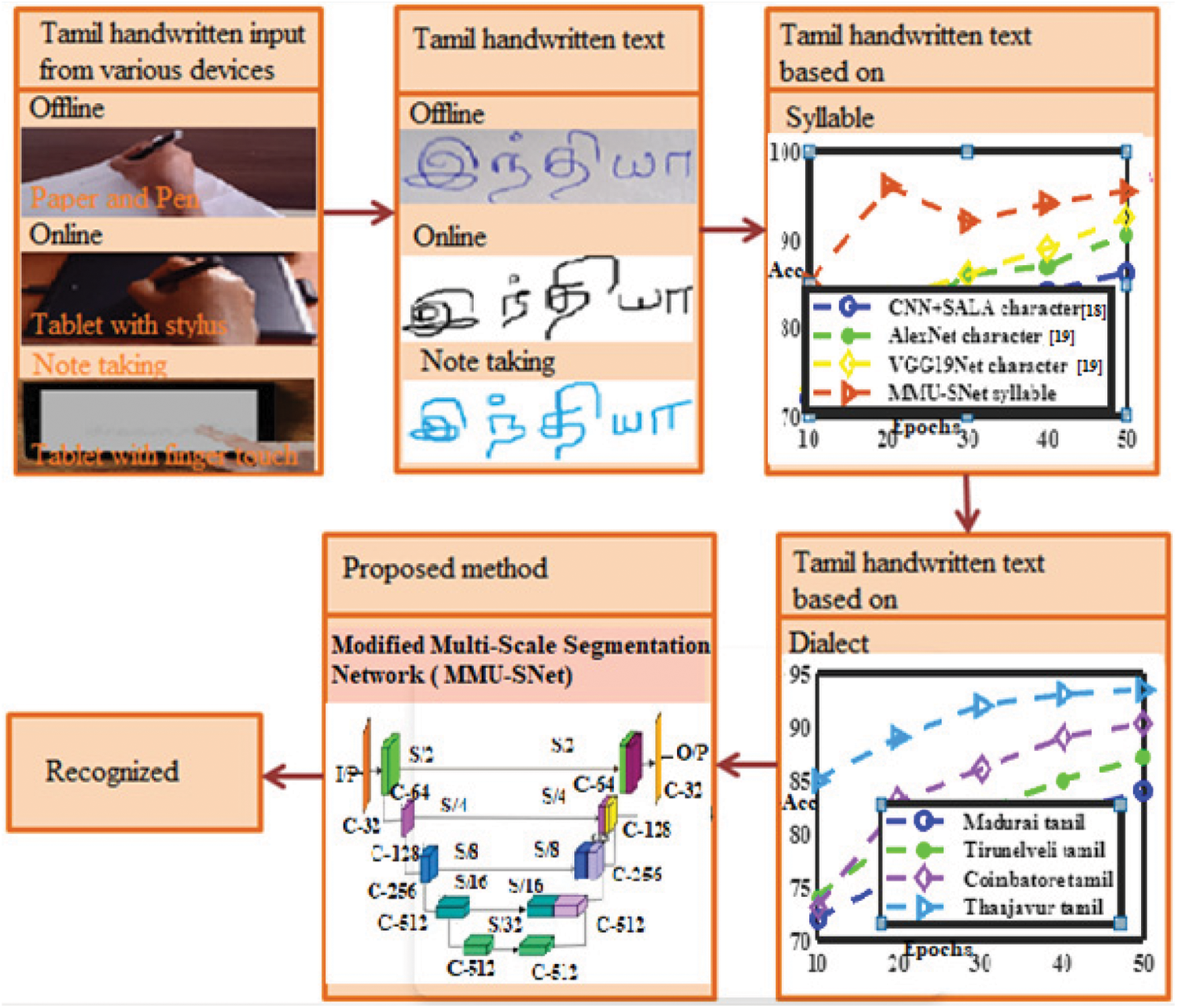
Figure 3: Tamil handwritten text from digital writing pad recognition using MMU-SNet
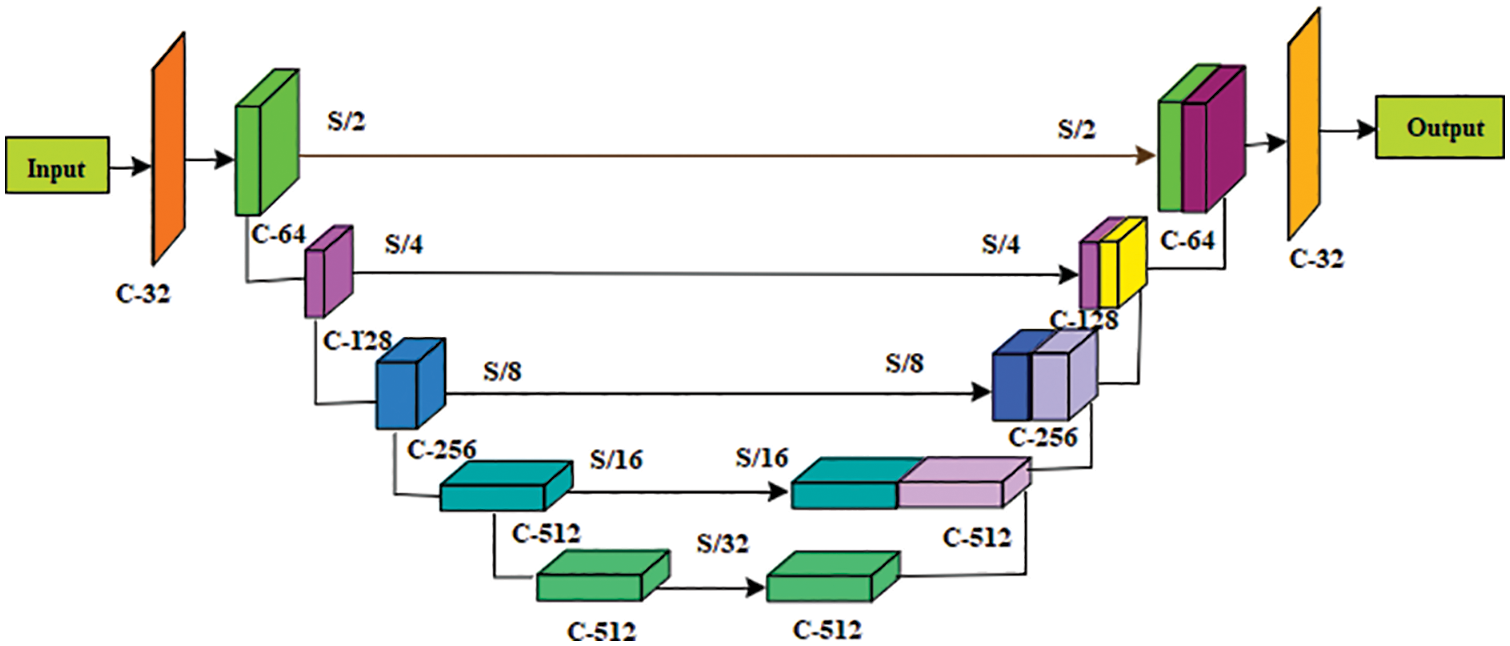
Figure 4: Modified multi-scale segmentation network (MMU-SNet) architecture
A U-shaped skip connection structure similar to U-network is used to recover more detailed information. Finally, the Up-sampling and classification module restore the activation map to the size of the input image. The upgraded RM is used in Multi-Scale (MS). The RM is shown in Fig. 5; the two modules with slight variation are designed to carry out down sampling.
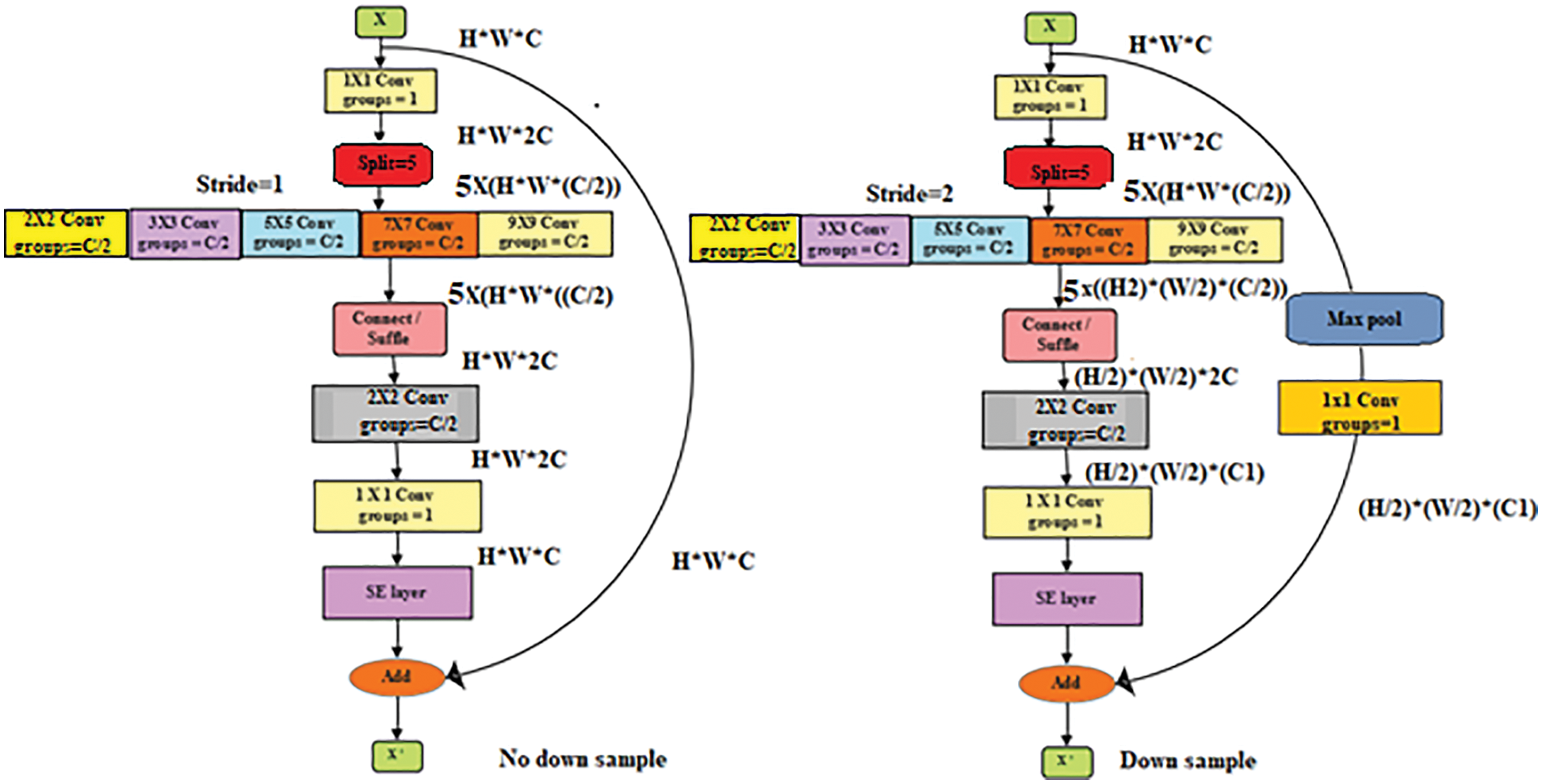
Figure 5: Multi-scale residual module
The various initial residual networks carry out the procedure of reducing the dimensionality first and then expanding the channel in our proposed MMU-SNet system, first expanding and after reducing the dimensionality of the channel in [17]. Precisely, to raise the channel dimension of the input feature two times, use 1 × 1 convolutions, and based on the channel dimension, the activation map is divided into five small activation maps. Then the depth-wise separable convolution with the convolution filter size of [2 × 2, 3 × 3, 5 × 5, 7 × 7, 9 × 9] is used to achieve the convolution operation on the five activation maps and then attach the five activation maps into a new large activation map in the channel dimension. Subsequently, apply 2 × 2 group convolutions to merge multi-scale features and then utilize 1 × 1 convolutions to decrease the channel dimension. In the meantime, a channel attention module of the Squeeze Excitation (SE) layer is added after this step. The SE layer is used for feature recalibration. The core of SE is compression, squeeze, and excitation. After the convolution operation has obtained the features with the multi-channels and then recalibrates the weight of each feature channel using an SE layer.
At last, adding the residual connection of input features is carried out. It is essential to observe that the max pool and 1 × 1 convolution operations are achieved by downsampling the input features previous residual connection. Simultaneously, the BN layer is added later to each convolution layer. Moreover, to the five convolution layer, which extracts multi-scale features, the RELU activation layer is added to each convolution layer.
The PyTorch-1.5 framework is used to build our network. The models are trained o with a memory capacity of 24 GB, mini-batch practice with Stochastic Gradient Descent (SGD) as the optimizer to train the network, with batch size set to 64 and the learning rate is 0.0001. The cross-entropy loss function is used in training. The image was resized to 50 * 50. Finally, arbitrarily shamble the training samples with 50 epochs of training.
This part begins with a brief overview of the test bases and a summary of the performance metrics employed for the assessment. Then, mathematical results and a helpful comparison are delivered. We conclude by giving a brief analysis of our approach.
Four statistical measures are used to evaluate the MMU-SNet classifier’s effectiveness: Accuracy, precision, recall, and F1 score. The metrics are calculated mathematically in Eqs. (1)–(4), where the True positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN). Table 2 show the performance analysis of classifiers with accuracy, precision, recall, and F1 score.
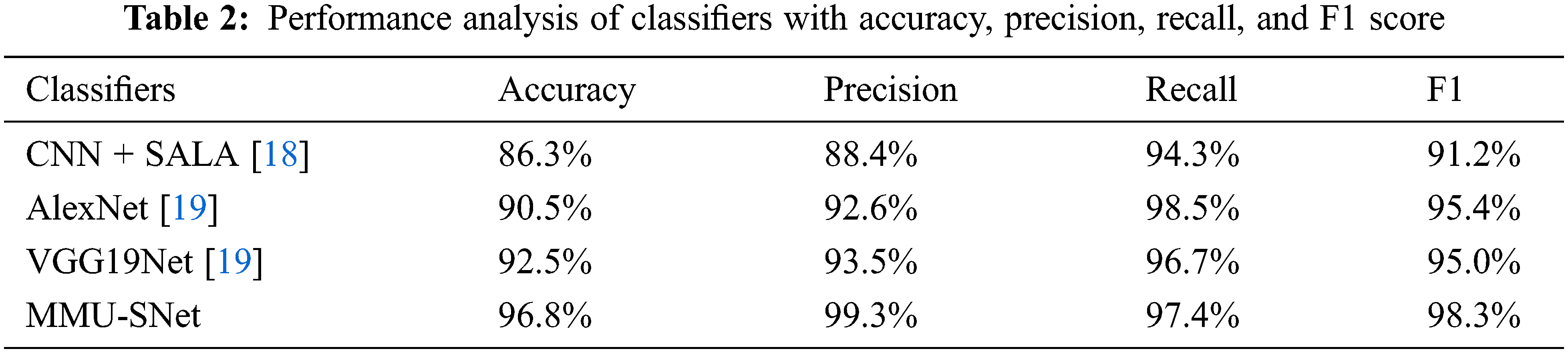
The accuracy metric commonly defines how the model completes across all classes. Accuracy is calculated as the ratio of correct predictions to the total number of predictions.
The P is calculated as the ratio between the numbers of positive samples correctly classified to the total number of samples classified as positive. The P measures the model’s accuracy in classifying a sample as positive.
The R is calculated by dividing the total number of positive samples by the proportion of positive samples correctly identified as positive. The R evaluates a model’s capacity to identify positive samples. More positive samples are found when R is higher.
The F1 score is the weighted average of P and R. This F1 score takes both false positives and false negatives into account.
Figs. 6 to 9 shows the accuracy, precision, recall, and F1 score of the proposed MMU-SNet with the existing classifier, the Convolutional Neural Network, and Self Adaptive Lion algorithm (CNN+SALA) never encoding the position and orientation of the alphabet into their predictions. CNN makes predictions of an image by determining whether there are edges, endpoints, and corners, then the image is classified appropriately. The AlexNet model comprises five consecutively connected Conv layers of reducing filter size tailed by three fully linked layers. The main characteristic of AlexNet is the fast downsampling of the in-between representations using stridden conv and max pooling layers. The final convolutional map is reshaped into a vector and treated as an input to a sequence of two fully linked layers of 4096 units in size. The depth of the AlexNet model is significantly less; it performs less in learning features from image sets and consumes more time with fewer accuracy results. The VGG19Net model uses a sequence of conv layers with small filter sizes, such as 3 × 3 and has more profound conv architecture than AlexNet. Except for the final conv layer, which is followed by two fully linked layers, each series of conv layers is followed by a max pooling layer. The VGG19Net is slower and experiences a vanishing gradient problem. A proposed semantic segmentation network for handwritten words with less computation and memory. The first modifies the U-type skip-connection structure of the U-Net network to recover more comprehensive information in the decoder. The second step is to boost the residual network’s RM and expands the network’s receptive field size and multi-scale features. Moreover, it utilizes the attention mechanism, gathers long-term context information, and strengthens the network’s capacity for representation.
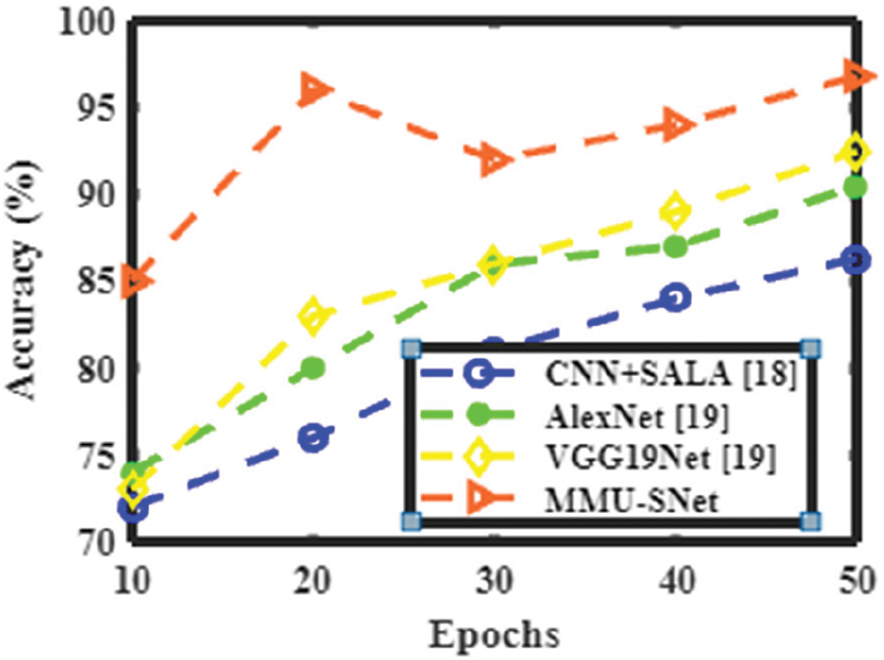
Figure 6: Performance analysis of various methods in terms of accuracy
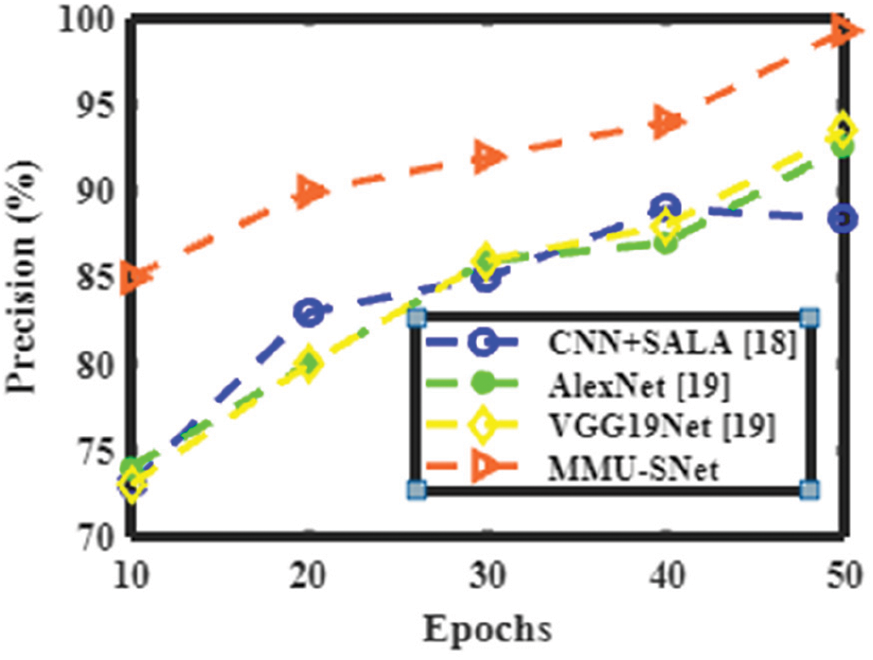
Figure 7: Performance analysis of various methods in terms of precision
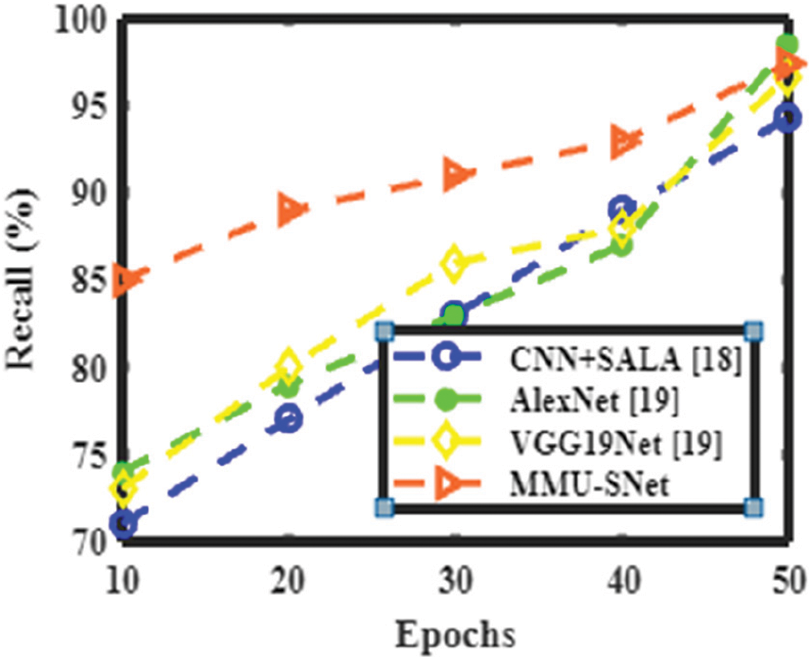
Figure 8: Performance analysis of various methods in terms of recall
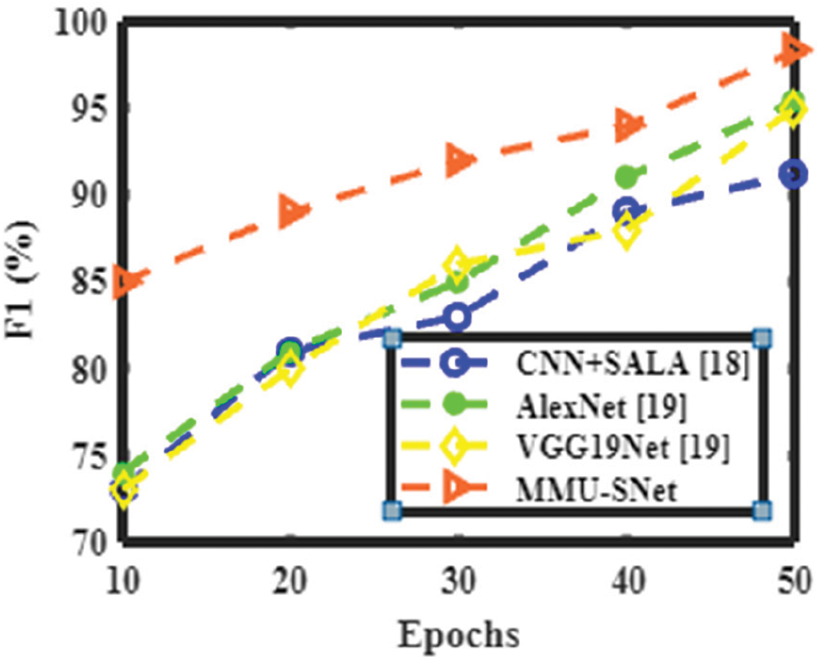
Figure 9: Performance analysis of various methods in terms of F1
A similar word that can speak differently in various languages according to the user is called dialect. The speaker’s social and geographic background determines the dialect. The language may vary from one region to another. In Tamilnadu, there are numerous dialects according to the area where there are spoken. Tamil languages as dialects in Tamil Nadu are in various cities such as Madurai Tamil, Tirunelveli Tamil, Coimbatore, and Thanjavur. Tamil dialects are distinguished from each other by different phonological changes and sound shifts in developing from old Tamil. For example, the word for “here,” inku ( ) in the dialect of Coimbatore, inga (இங்க) in the dialect of Thanjavur and old Tamil’s inkan (இங்கன்) is the source of inkane (இங்கேன) in the dialect of Tirunelveli, old Tamil inkittu is the source of inkuttu (
) in the dialect of Coimbatore, inga (இங்க) in the dialect of Thanjavur and old Tamil’s inkan (இங்கன்) is the source of inkane (இங்கேன) in the dialect of Tirunelveli, old Tamil inkittu is the source of inkuttu ( ) in the dialect of Madurai. Table 3 shows the performance analysis of the classifier with accuracy, precision, recall, and F1 score based on the dialect.
) in the dialect of Madurai. Table 3 shows the performance analysis of the classifier with accuracy, precision, recall, and F1 score based on the dialect.
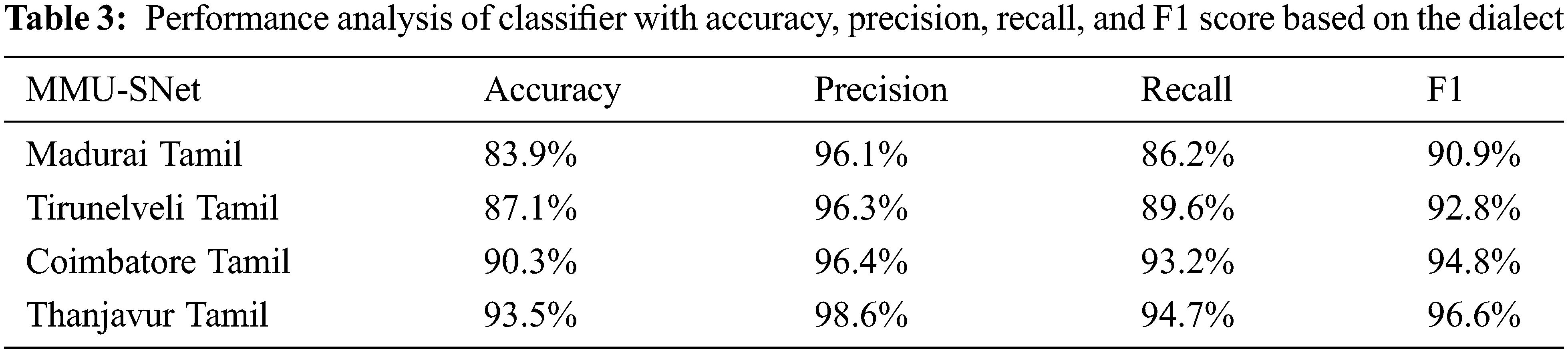
Figs. 10 to 13 shows the accuracy, precision, recall, and F1 score of dialects spoken in Madurai Tamil, Tirunelveli Tamil, Coimbatore Tamil, and Thanjavur Tamil.
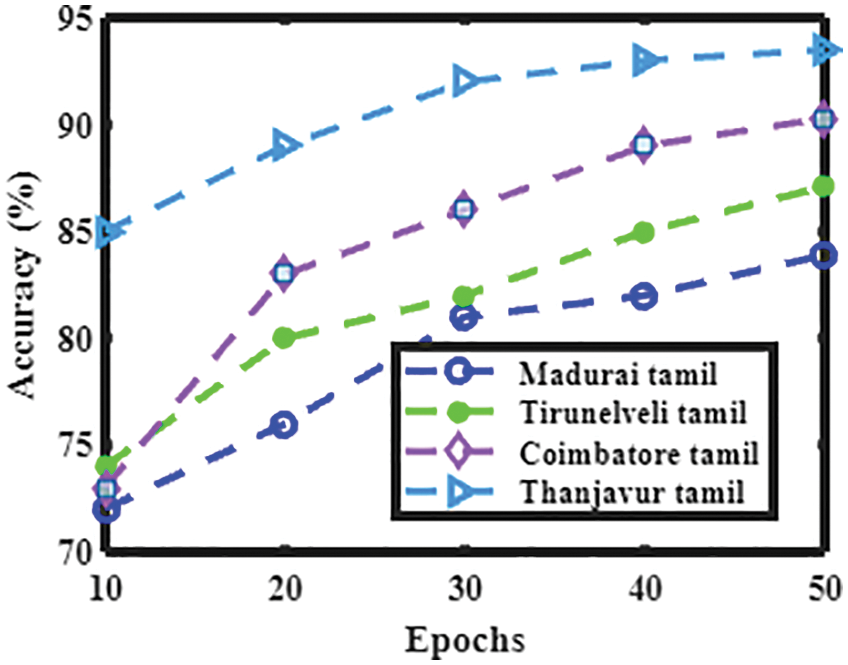
Figure 10: Performance analysis of the present method with various Tamil dialects in terms of accuracy
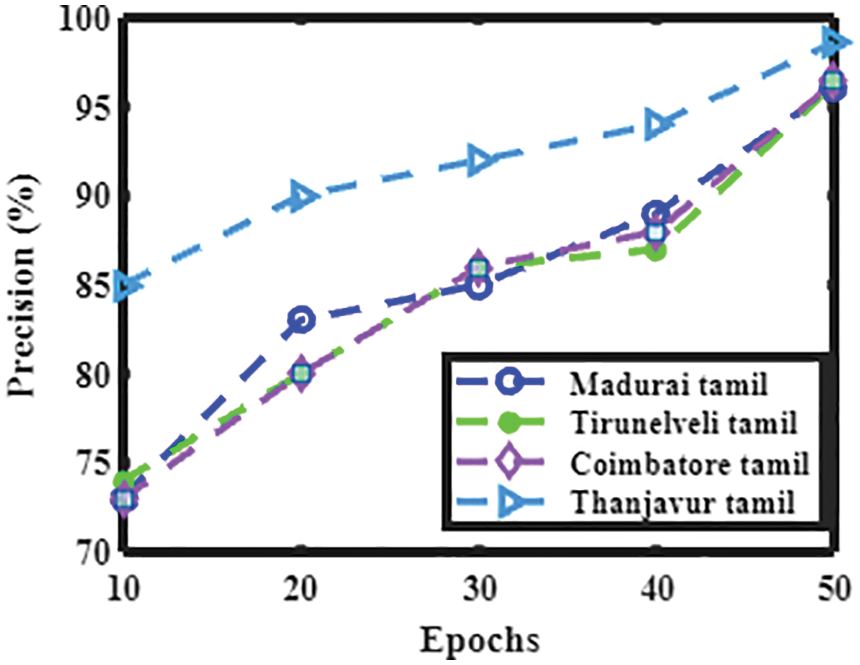
Figure 11: Performance analysis of the present method with various Tamil dialects in terms of precision
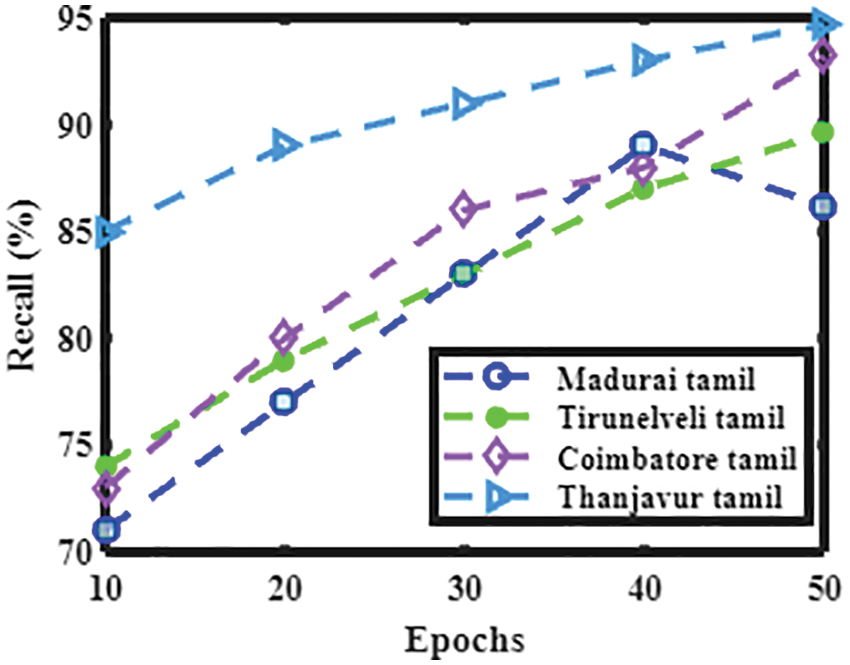
Figure 12: Performance analysis of the present method with various Tamil dialects in terms of recall
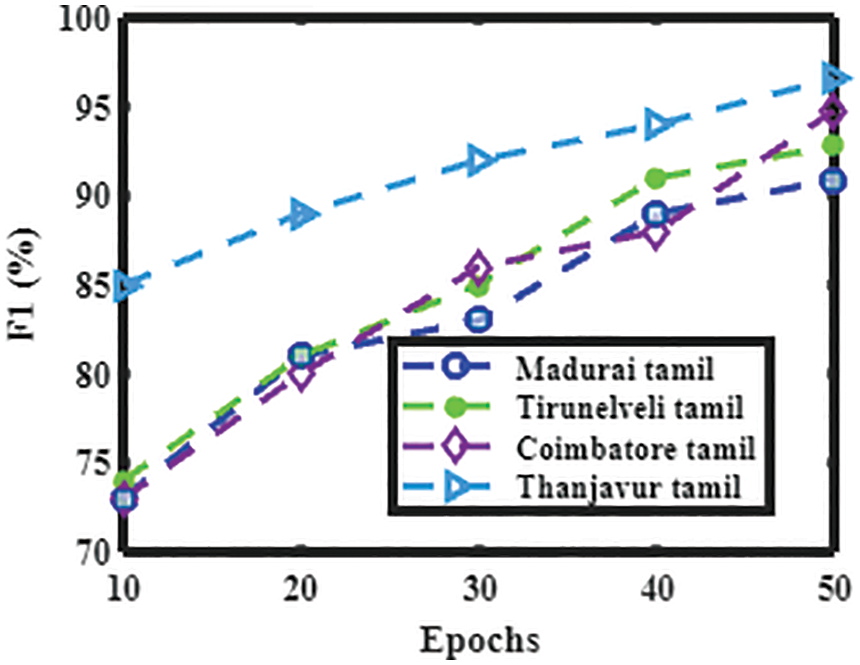
Figure 13: Performance analysis of the present method with various Tamil dialects in terms of F1
Syllabication is dividing a word into smaller parts known as syllables, a single unbroken sound of a spoken or a written word. A word or a part of a word contains a vowel sound, the first step in syllables to identify the vowels in a word. The number of vowel sounds in a word equals the number of syllables. Identify the vowels and break the word according to the vowel sounds. Table 4 shows the Performance analysis of classifiers with accuracy, precision, recall, and F1 score based on a syllable.
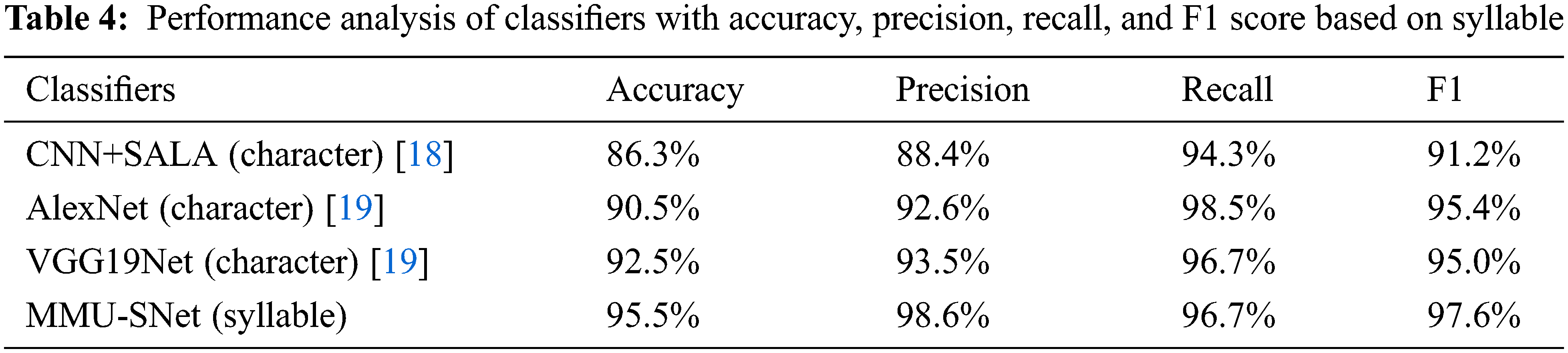
Figs. 14 to 17 shows the accuracy, precision, recall, and F1 score of the proposed MMU-SNet with classifiers CNN+SALA, AlexNet, and VGG19Net. The proposed MMU-SNet system achieved high accuracy, precision, recall, and F1 score based on a syllable.
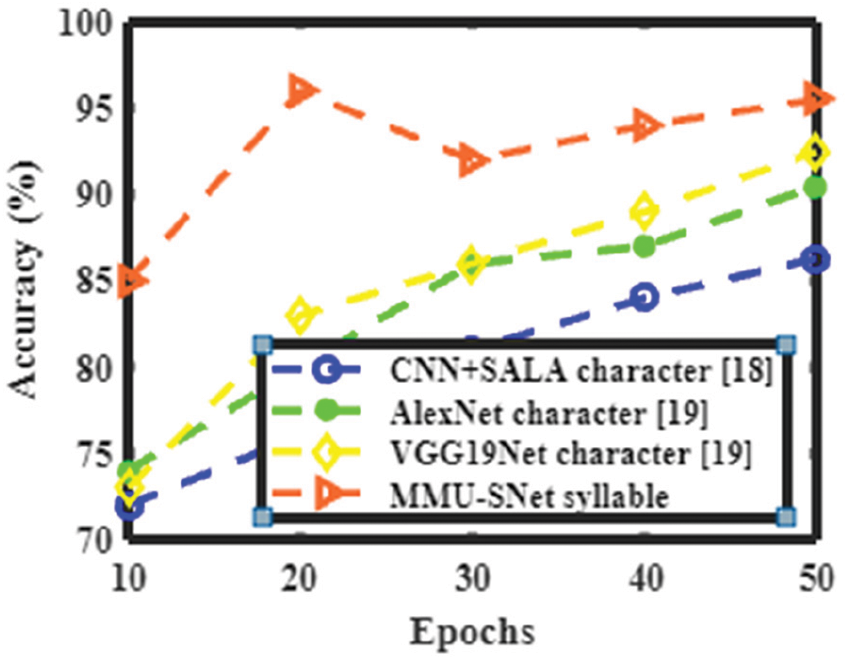
Figure 14: Performance analysis of the present method with the various method in terms of accuracy
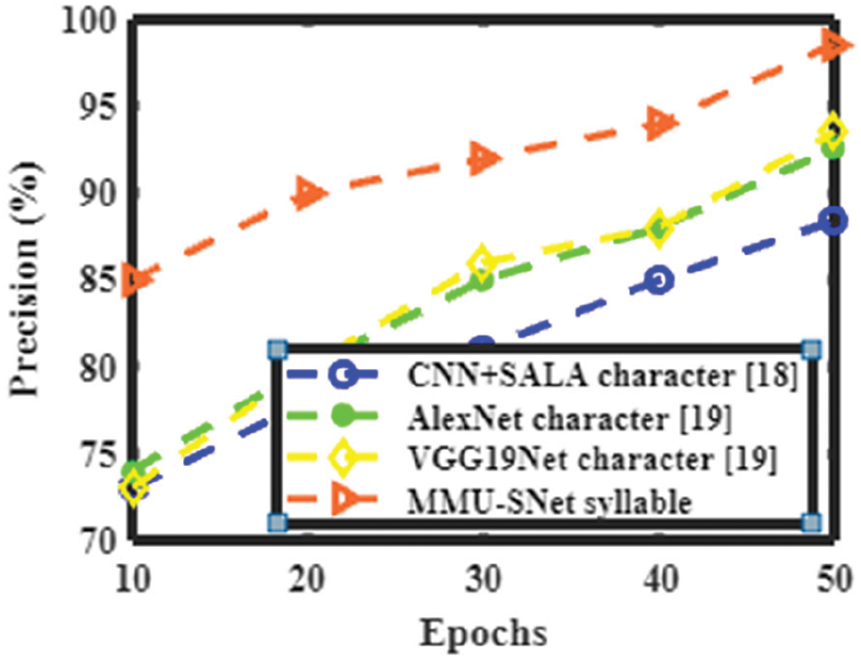
Figure 15: Performance analysis of the present method with the various method in terms of precision
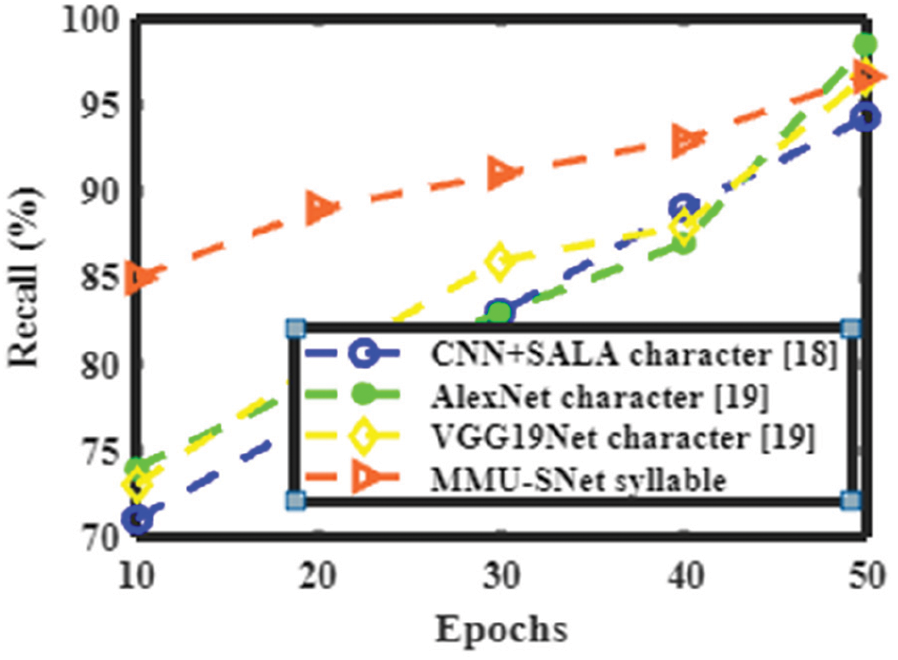
Figure 16: Performance analysis of the present method with the various method in terms of recall
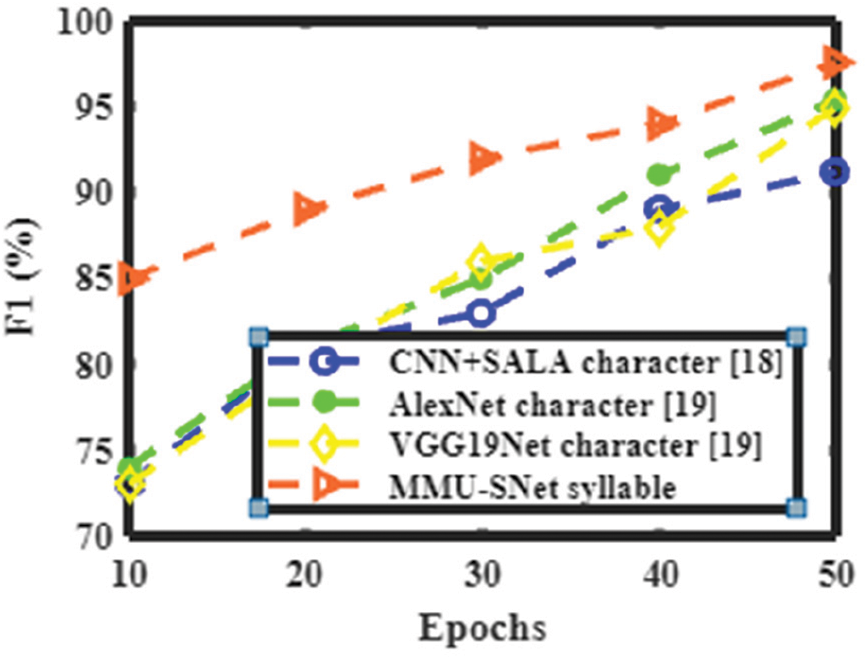
Figure 17: Performance analysis of the present method with the various method in terms of F1
The Modified Multi-scale Segmentation Network (MMU-SNet) is proposed for digital writing pad-based handwritten text detection and classification. Handwritten character changes Tamil words due to stylus pressure, writing on a frictionless glass surface, and less skilled in short writing, alphabet size, style, carved symbols, and orientation angle variations solved through the proposed MMU-SNet. The proposed MMU-SNet method compared with various neural network architectures such as CNN+SALA, AlexNet, and VGG19Net. The proposed MMU-SNet method has achieved good accuracy in predicting text, about 96.8% compared to other traditional CNN algorithms. The proposed MMU-SNet applies to Tamil handwritten text from digital writing pad recognition. The semantic segmentation provides pixelwise recognition, which is convenient for handling complex Tamil handwritten text from a digital writing pad. For example, the alphabet overlaps with other alphabets and spaces in between alphabets. Generally, semantic segmentation is used to label each pixel of an image with a corresponding class to which it belongs. The proposed MMU-SNet performs better than traditional architecture.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. B. R. Kavitha and C. Srimathi, “Benchmarking on offline handwritten Tamil character recognition using convolutional neural networks,” Journal of King Saud University-Computer and Information Sciences, vol. 34, no. 4, pp. 1183–1190, 2022. [Google Scholar]
2. B. Liu, X. Xu and Y. Zhang, “Offline handwritten Chinese text recognition with convolutional neural networks,” arXiv:2006.15619, 2020. [Google Scholar]
3. P. Dezhi, J. Lianwen, M. Weihong, X. Canyu, Z. Hesuo et al., “Recognition of handwritten Chinese text by segmentation: A segment-annotation-free approach,” IEEE Transactions on Multimedia, vol. 67, pp. 1520–9210, 2022. [Google Scholar]
4. R. Haiqing, W. Weiqiang and L. Chenglin, “Recognizing online handwritten Chinese characters using RNNs with new computing architectures,” Pattern Recognition, vol. 93, no. 5786, pp. 179–192, 2019. [Google Scholar]
5. S. Harjeet, S. Rajendra Kumar, V. P. Singh and K. Munish, “Recognition of online handwritten Gurmukhi characters using recurrent neural network classifier,” Soft Computing, vol. 25, no. 8, pp. 6329–6338, 2021. [Google Scholar]
6. Z. Hongjian, L. Shujing and L. Yue, “Improving offline handwritten Chinese text recognition with glyph-semanteme fusion embedding,” International Journal of Machine Learning and Cybernetics, vol. 13, no. 2, pp. 485–496, 2022. [Google Scholar]
7. S. Kowsalya and P. S. Periasamy, “Recognition of Tamil handwritten text from digital writing pad character using modified neural network with aid of elephant herding optimization,” Multimedia Tools and Applications, vol. 78, no. 17, pp. 25043–25061, 2019. [Google Scholar]
8. Y. Mohamed, F. Khaled Hussain and S. Usama Mohammed, “Accurate, data-efficient, unconstrained text recognition with convolutional neural networks,” Pattern Recognition, vol. 108, no. 11, pp. 107482, 2020. [Google Scholar]
9. B. Omar, M. Dominique and H. Walid Khaled, “PUNet: Novel and efficient deep neural network architecture for handwritten documents word spotting,” Pattern Recognition Letters, vol. 155, no. 3, pp. 19–26, 2022. [Google Scholar]
10. M. Rania and K. Monji, “New MDLSTM-based designs with data augmentation for offline Arabic handwriting recognition,” Multimedia Tools and Application, vol. 81, no. 7, pp. 10243–10260, 2022. [Google Scholar]
11. R. C. Suganthe, K. Pavithra, N. Shanthi and R. S. Latha, “A CNN model-based approach for offline handwritten Tamil text recognition system,” Natural Volatiles & Essential Oils Journal, vol. 8, no. 5, pp. 164–175, 2021. [Google Scholar]
12. W. ZiRui and D. Jun, “Fast writer adaptation with style extractor network for handwritten text recognition,” Neural Networks, vol. 147, no. 8, pp. 42–52, 2022. [Google Scholar]
13. A. Joan, R. Veronica, H. Alejandro Toselli, V. Mauricio and V. Enrique, “A set of benchmarks for handwritten text recognition on historical documents,” Pattern Recognition, vol. 94, no. 9, pp. 122–134, 2019. [Google Scholar]
14. Y. Wang, Y. Yang, W. Ding and S. Li, “A residual-attention offline handwritten Chinese text recognition based on fully convolutional neural networks,” IEEE Access, vol. 9, pp. 132301–132310, 2021. [Google Scholar]
15. S. Singh, A. Sharma and V. K. Chauhan, “Online handwritten Gurmukhi word recognition using fine-tuned deep convolutional neural network on offline features,” Machine Learning with Applications, vol. 5, pp. 100037, 2021. [Google Scholar]
16. N. Altwaijry and I. Al-Turaiki, “Arabic handwriting recognition system using convolutional neural network,” Neural Computing and Applications, vol. 33, no. 7, pp. 2249–2261, 2021. [Google Scholar]
17. B. Wang, J. Zhou and B. Zhang, “MSNet: A multi-scale segmentation network for documents layout analysis,” Learning Technologies and Systems, vol. 117, no. 9, pp. 225–235, 2020. [Google Scholar]
18. R. BabithaLincy and R. Gayathri, “Optimally configured convolutional neural network for Tamil handwritten character recognition by improved lion optimization model,” Multimedia Tools and Applications, vol. 80, no. 4, pp. 5917–5943, 2021. [Google Scholar]
19. A. Vijay, M. Deepak, P. Kavin, K. Ramar and B. Shajith, “Transfer learning based offline handwritten recognition system using Tamil characters,” in Proc. ICSCD, Erode, India, pp. 214–220, 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools