
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Applied Linguistics with Mixed Leader Optimizer Based English Text Summarization Model
1 Department of Applied Linguistics, College of Languages, Princess Nourah Bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Saudi Arabia
3 Department of Information Systems, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
4 Research Centre, Future University in Egypt, New Cairo, 11845, Egypt
5 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
6 Department of English, College of Science & Humanities, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Manar Ahmed Hamza. Email:
Intelligent Automation & Soft Computing 2023, 36(3), 3203-3219. https://doi.org/10.32604/iasc.2023.034848
Received 29 July 2022; Accepted 23 November 2022; Issue published 15 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The term ‘executed linguistics’ corresponds to an interdisciplinary domain in which the solutions are identified and provided for real-time language-related problems. The exponential generation of text data on the Internet must be leveraged to gain knowledgeable insights. The extraction of meaningful insights from text data is crucial since it can provide value-added solutions for business organizations and end-users. The Automatic Text Summarization (ATS) process reduces the primary size of the text without losing any basic components of the data. The current study introduces an Applied Linguistics-based English Text Summarization using a Mixed Leader-Based Optimizer with Deep Learning (ALTS-MLODL) model. The presented ALTS-MLODL technique aims to summarize the text documents in the English language. To accomplish this objective, the proposed ALTS-MLODL technique pre-processes the input documents and primarily extracts a set of features. Next, the MLO algorithm is used for the effectual selection of the extracted features. For the text summarization process, the Cascaded Recurrent Neural Network (CRNN) model is exploited whereas the Whale Optimization Algorithm (WOA) is used as a hyperparameter optimizer. The exploitation of the MLO-based feature selection and the WOA-based hyperparameter tuning enhanced the summarization results. To validate the performance of the ALTS-MLODL technique, numerous simulation analyses were conducted. The experimental results signify the superiority of the proposed ALTS-MLODL technique over other approaches.Keywords
The web resources available on the Internet (for example, user reviews, websites, news, social networking sites, blogs, etc.) are gigantic sources of text datasets. Further, the text dataset is available in other forms, such as the archives of books, news articles, legal documents, journals, scientific papers, biomedical documents, etc. [1]. There is a dramatic increase experienced in the volume of text data available on the Internet and other archives. Consequently, a user consumes considerable time to find the required information [2]. As a result, it becomes crucial to summarize and condense the text resource to make it meaningful. However, manual summarization is highly challenging and consumes a lot of time and effort [3]. It is challenging for human beings to manually summarize huge volumes of textual datasets. The automated Text Summarization (ATS) process can be a major conclusion to this dilemma. The most important goal of the ATS system is to generate a low-volume summary that encompasses all the major ideas from the input document [4].
The automated Text Summarization (ATS) process is challenging in nature. When human beings try to summarize a text, the content is completely read and understood, and the key points are prepared. However, this is not the case in terms of the ATS process due to insufficient language processing and human knowledge capabilities in computers. So, automated text summarization is a difficult process [5]. ATS system is categorized into single- or multiple-document summarization schemes. Initially, the system generates a summary for a single document, producing the summaries for a cluster of documents. The ATS system aims to employ the text summarization methodologies such as hybrid, extractive and abstractive to achieve the outcomes [1]. Amongst these, the extractive method selects the main sentences from the input text and uses them to produce the summary. The hybrid method incorporates both extractive and abstractive methodologies [6]. The ATS system is primarily used in text analytics and mining applications like question answering, information retrieval, information extraction, etc. This system has been utilized with information retrieval techniques to improve the search engine’s abilities [7].
Due to the wide accessibility of the internet, a considerable number of study opportunities are available in the field of ATS with Natural Language Processing (NLP), especially based on statistical Machine Learning (ML) techniques. The primary aim of the ATS approach is to generate a summary similar to a human-generated summary [8]. Nonetheless, in many cases, both the readability and the soundness of the generated summary are unacceptable. This is because the summary doesn’t encompass each semantically-consistent feature of the data. Most of the recent TS approaches do not have an individual point-of-view over the semantics of the words [9]. To efficiently overcome the issues present in the existing TS methods, the current study presents a new architecture through the Deep Learning approach.
The current study introduces an Applied Linguistics-based English Text Summarization using a Mixed Leader-Based Optimizer with deep learning (ALTS-MLODL) model. The presented ALTS-MLODL technique aims to summarize the text documents in the English language. To accomplish the objective, the proposed ALTS-MLODL technique pre-processes the input documents and primarily extracts a set of features. Next, the MLO algorithm is used for the productive selection of the extracted features. The Cascaded Recurrent Neural Network (CRNN) model is exploited with Whale Optimization Algorithm (WOA) as a hyperparameter optimizer for the text summarization process. Exploiting the MLO-based feature selection and the WOA-based hyperparameter tuning enhanced the summarization results. Numerous simulation analyses were conducted to observe the better outcomes of the proposed ALTS-MLODL technique.
The rest of the paper is organized as follows. Section 2 provides a brief overview of text summarization approaches. Next, Section 3 introduces the proposed model and Section 4 offers performance validation. Finally, Section 5 draws the concluding remarks of the study.
2 Existing Text Summarization Approaches
Wan et al. [10] devised an innovative structure to address the tasks by extracting many summaries and ranking them in the targeted language. At first, the authors extracted many candidate summaries by presenting numerous methods to improve the quality of the upper-bound summary. Then, the author designed a novel ensembling ranking technique to rank the summaries of the candidates using the bilingual features. Song et al. [11] presented an LSTM-CNN-related ATS framework (ATSDL) that constructed innovative sentences by exploring the finely-grained fragments against the established sentences, like semantic phrases. Unlike the existing extraction methods, the ATSDL approach had two main phases: extracting phrases from source sentences and developing the text summaries using DL techniques. D’silva et al. [12] explored the summary extraction domain and proposed an automated text summarization method with the help of the DL technique. The authors implemented the method in the Konkani language since it is considered a language with fewer resources. Here, the resources correspond to the availability of inadequate resources, namely speakers, data, experts and tools in the Konkani language. The presented method used a fast-text pre-trained word embedding Facebook-based method to receive the vector representations for sentences. Afterwards, a deep multi-layer perceptron method was used as a supervised binary classifier task for auto-generating the summaries utilizing the feature vectors.
Maylawati et al. [13] introduced an ideology by combining the DL and SPM methods for a superior text summarization outcome. In the text summarization process, generating readable and understandable summaries is significant. SPM, as a text representation-extraction method, can maintain the meaning of the text by showing interest in the order of words’ appearance. DL is a famous and powerful ML approach broadly utilized in several data mining research works. It employs a descriptive research method that gathers every fact about the data based on DL and SPM techniques for text summarization. Here, the NLP technique is used as knowledge, whereas DL and the SPM techniques are applied for text summarization since it is the main issue that needs to be sorted. Khan et al. [14] focused on the extraction-based summarization process with the help of K-Means clustering and Term Frequency-Inverse Document Frequency (TFIDF). This study reflected the ideology of true K and utilized the value of K to split the sentences that belonged to the input document to arrive at the concluding summary.
Lin et al. [15] proposed a simple yet effective extraction technique in the name of the Light Gradient Boosting Machine regression method for Indonesian files. In this method, four features were derived such as the TitleScore, PositionScore, the semantic representation similarity between the title of the document and the sentence and the semantic representation similarity between a sentence’s cluster center and the sentence. The author described a formula to calculate the sentence score as its objective function. Zhao et al. [16] presented a Variational Neural Decoder text summarization approach (VND). This method presented a series of implicit variables by integrating the modified AE and the modified RNN to be utilized in capturing the complicated semantic representation at every decoding stage. It involved a variational RNN layer and a standard RNN layer. These two network layers produced a random hidden state and a deterministic hidden state. The author used two such RNN layers to establish the dependency between the implicit variables and the adjacent time steps.
3 The Proposed Text Summarization Model
In this article, a new ALTS-MLODL technique has been introduced as an effectual text summarization process. The presented ALTS-MLODL technique aims to summarize the text documents in the English language. Fig. 1 depicts the working process of the ALTS-MLODL approach.
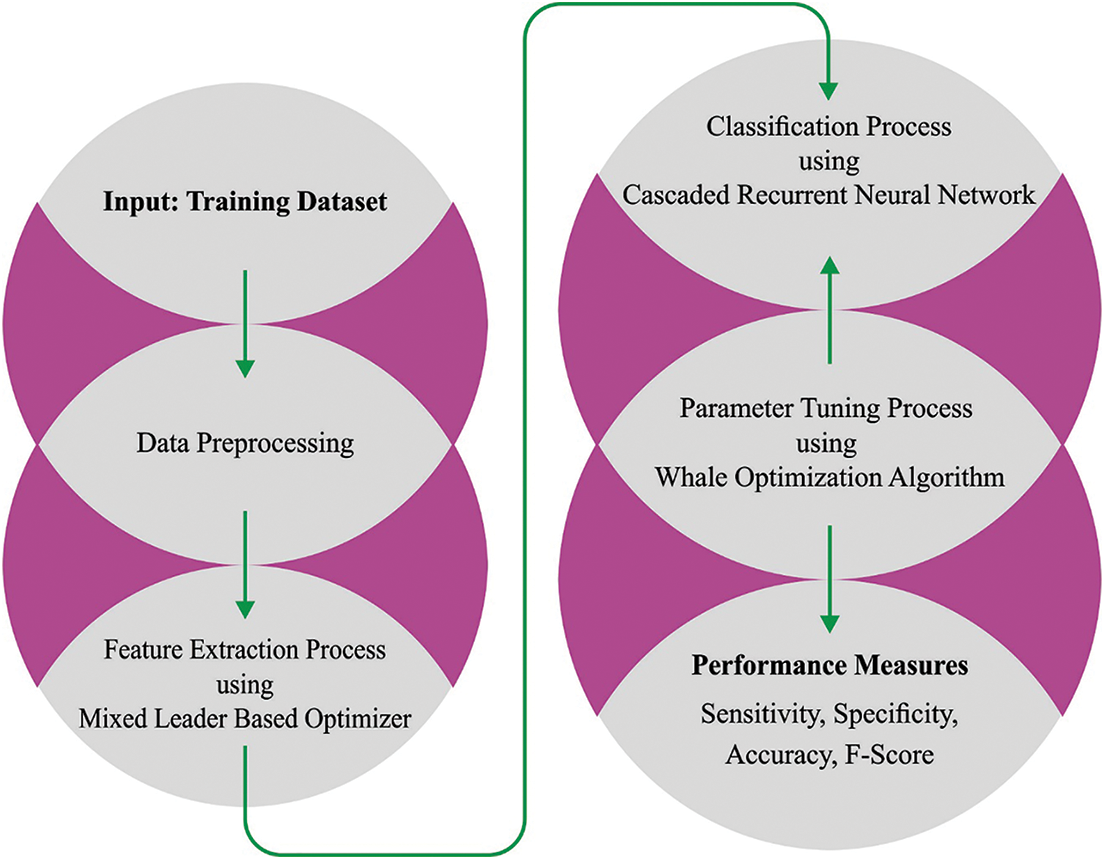
Figure 1: Working process of the ALTS-MLODL approach
3.1 Pre-Processing and Feature Extraction
At first, the proposed ALTS-MLODL technique pre-processes the input documents and primarily extracts a set of features. The basic concept of the proposed model is to create an input text document so it can be processed in multiple phases [17]. It transmits the input document since it contains important data. The presented method involves the following pre-processing sequencing functions: stemming process, letter normalization, tokenization and the removal of stop-words. During the feature extraction procedure, the sentences of special significance or importance are chosen in the group of features with a coherent summary to demonstrate the main issue of the offered documents. The pre-processed input document is represented as a vector of features. It contains elements that are employed to signify the summarized sentences. In this study, 15 features were extracted in total. All the features provide a disparate value. The maximum score values indicate a lesser occurrence of the features, whereas the minimal values correspond to a higher occurrence of the features from the sentence. To extract a summary, every sentence is ordered based on the score of words from all the sentences.
With the help of distinct features such as the term cue words, frequency and phrase, and the lexical measure, the words are identified by the scores. At this point, the pre-processed input document is represented as a vector of features. These elements are employed to signify the summary of the sentences described from F1 to F14.
3.2 Feature Selection Using MLO Algorithm
In this stage, the MLO algorithm is used to select the extracted features effectively. MLO is a population-based optimization technique that randomly produces a specific number of potential solutions for optimization problems [18]. Then, the MLO approach upgrades the presented solution through the iteration method. After the repetitions, the MLO method offers an appropriate quasi-optimum solution. The major concept used in guiding and updating the population is that a new member is utilized as the population leader and is generated by blending the optimal members of the population using an arbitrary member.
The population of the MLO approach is described as a matrix named ‘population matrix’ as given below.
In Eq. (1), X denotes the population,
All the members of the population matrix are considered viable solutions for the set value of the problem variable. Consequently, a value is attained for the objective function based on the values indicated by all the members of the problem parameter, which is shown below.
In Eq. (2), F refers to an objective function vector, and
During all the iterations, the population member that provides the optimal value for the objective function is regarded as the optimum population member. An arbitrary member is produced as given below as a possible solution.
In Eq. (3),
Now,
The population matrix, upgraded in the MLO, is inspired by the mixed leader of the population, as given below.
Now,
3.3 Text Summarization Using Optimal CRNN Model
For the text summarization process, the WOA approach is exploited in this study with the CRNN model. CRNN is a deep-cascaded network that contains a front-end network to extract the word mappings [19], a back-end network to exploit the deep semantic contexts and a CNN to extract the CNN features. Fig. 2 demonstrates the infrastructure of the CRNN method.
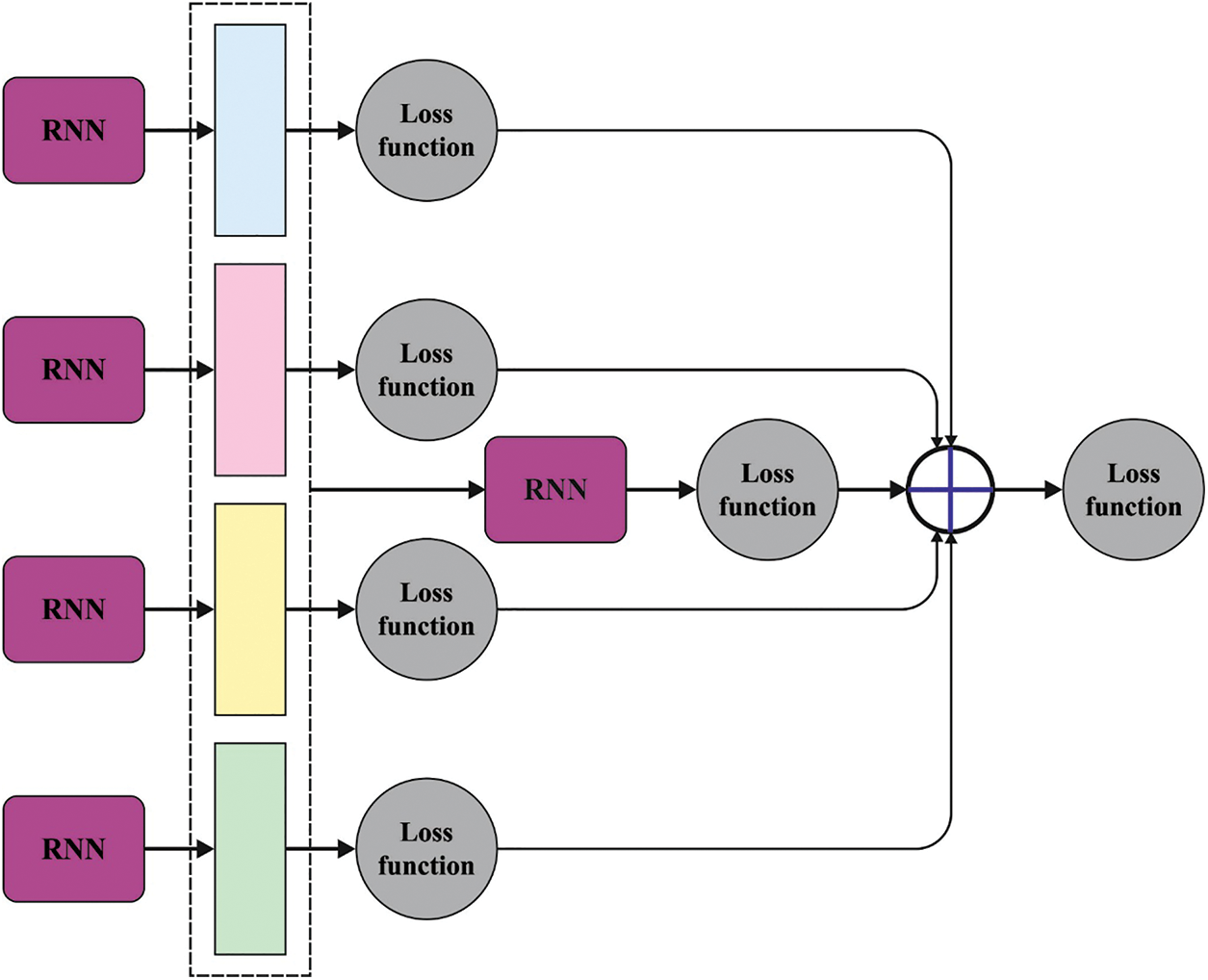
Figure 2: Structure of the CRNN approach
Like Google NIC, the front-end network adapts the encoder-decoder structure to extract the visual language interaction approach from the forward direction. The suggested method contains the output layers, the word input layers, the dense embedding layers and the recurrent layers. To learn the word mappings efficiently, the authors directly optimized the amount of probability for an accurate representation as determined in (9) through stochastic gradient descent.
In Eq. (9), I represent a CNN feature, and
In the case of a front-end network, two incorporated layers are employed to implement a one-hot vocabulary into a dense-word expression. This might enhance the semantic meaning of the words. Furthermore, an SGRU is also designed to map the deep words.
The SGRU approach generates all the recurrent units to capture the dependency of the distinct time scales adoptively. It contains two hidden states with a gating unit to modulate the data flow inside the unit instead of employing individual memory cells. The activation
In Eq. (10),
In Eq. (11),
In Eq. (13),
For optimal fine-tuning of the hyperparameter values, the WOA method is utilized. WOA is a recent metaheuristic approach that is stimulated by the social behaviours of humpback whales [20]. This approach starts with the arbitrary generation of a set of N solutions ‘TH’ that signifies the solution for the provided problem. Next, for all the solutions
In Eq. (14), g and
Here, D denotes the distance between
The solution
In Eq. (17),
Furthermore, the solution in the WOA gets upgraded based on the spiral-shaped path and shrinking path as follows.
In Eq. (18),
Also, the whales’ search on the
The procedure of upgrading the solution is executed based on
In this section, the text summarization results of the proposed ALTS-MLODL model are examined under two aspects such as single-document summarization and multi-document summarization. The proposed model is simulated using Python 3.6.5 tool on PC i5-8600 k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1 TB HDD. The parameter settings are given as follows: learning rate: 0.01, dropout: 0.5, batch size: 5, epoch count: 50, and activation: ReLU.
Table 1 provides the detailed summarization results of the proposed ALTS-MLODL model under varying file sizes on single-document summarization [17]. Fig. 3 portrays the comparative
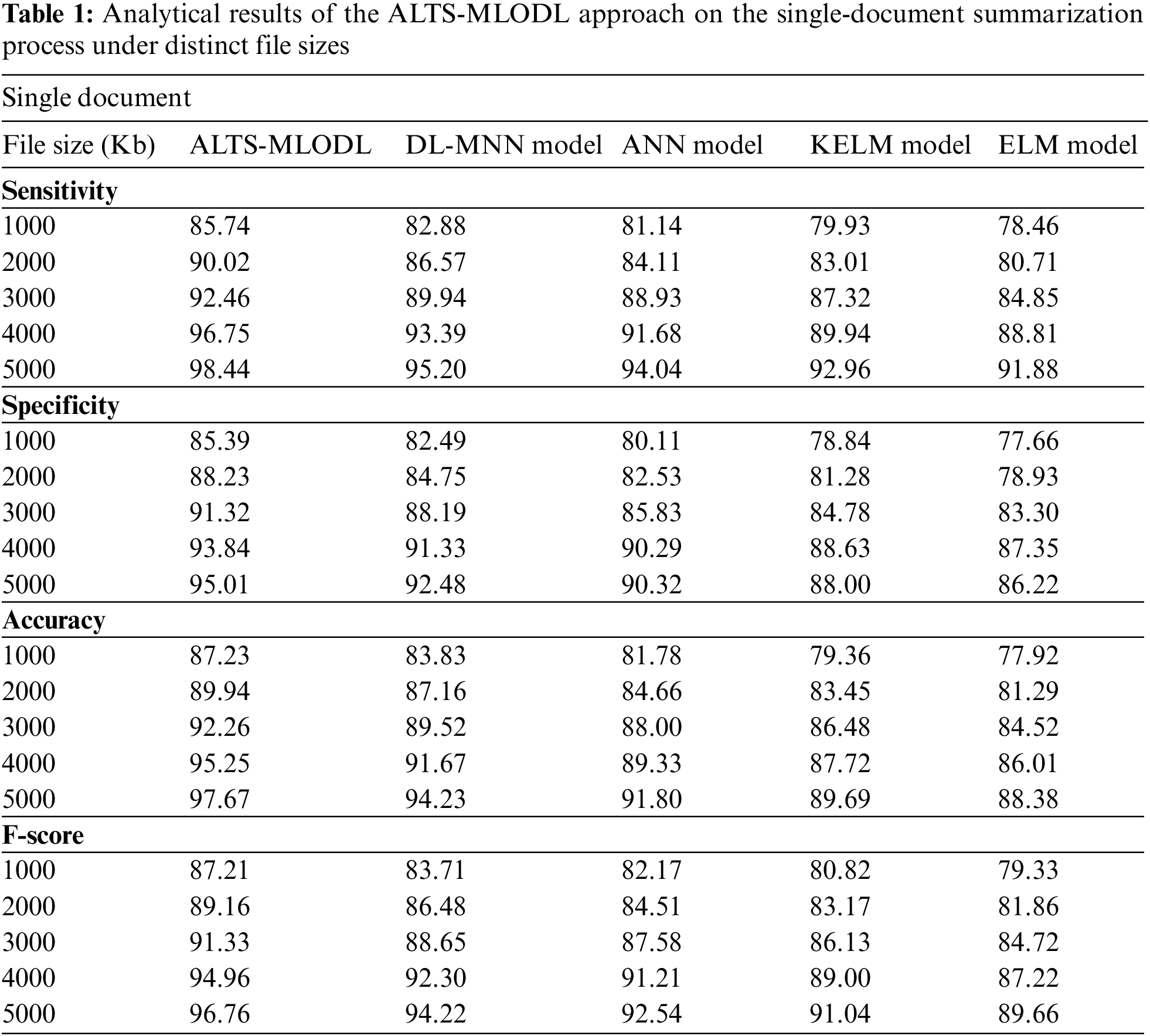
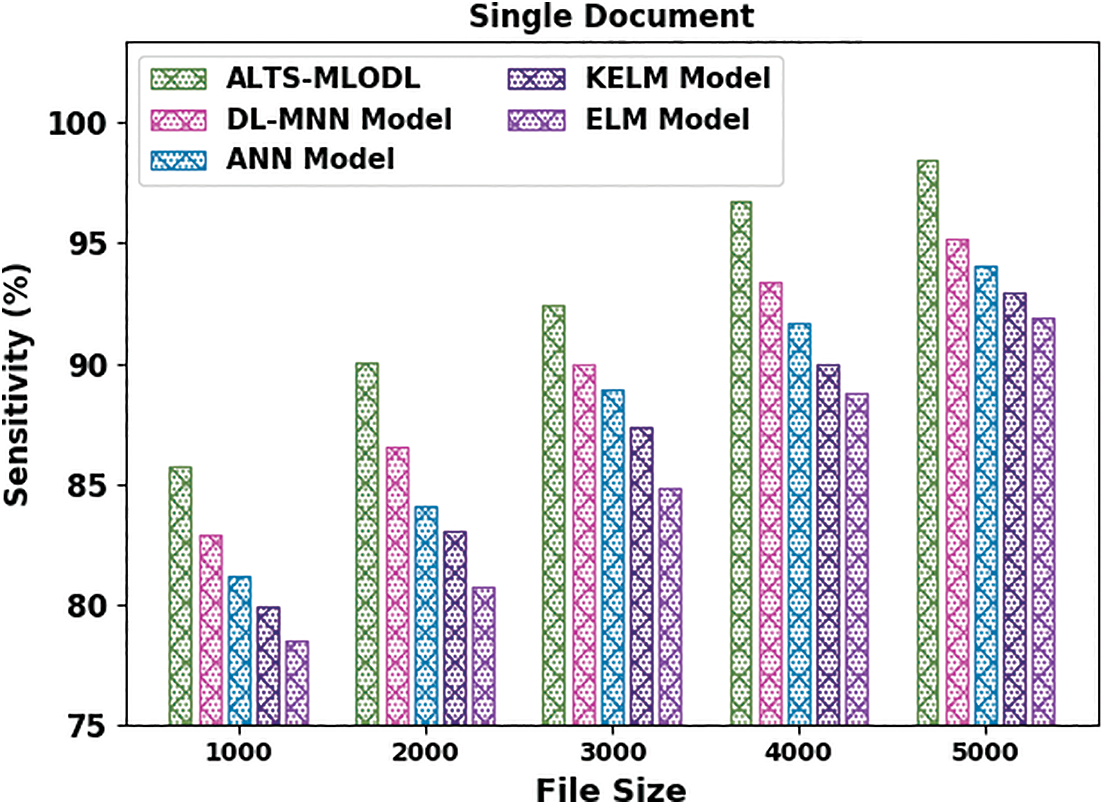
Figure 3:
Fig. 4 depicts the detailed
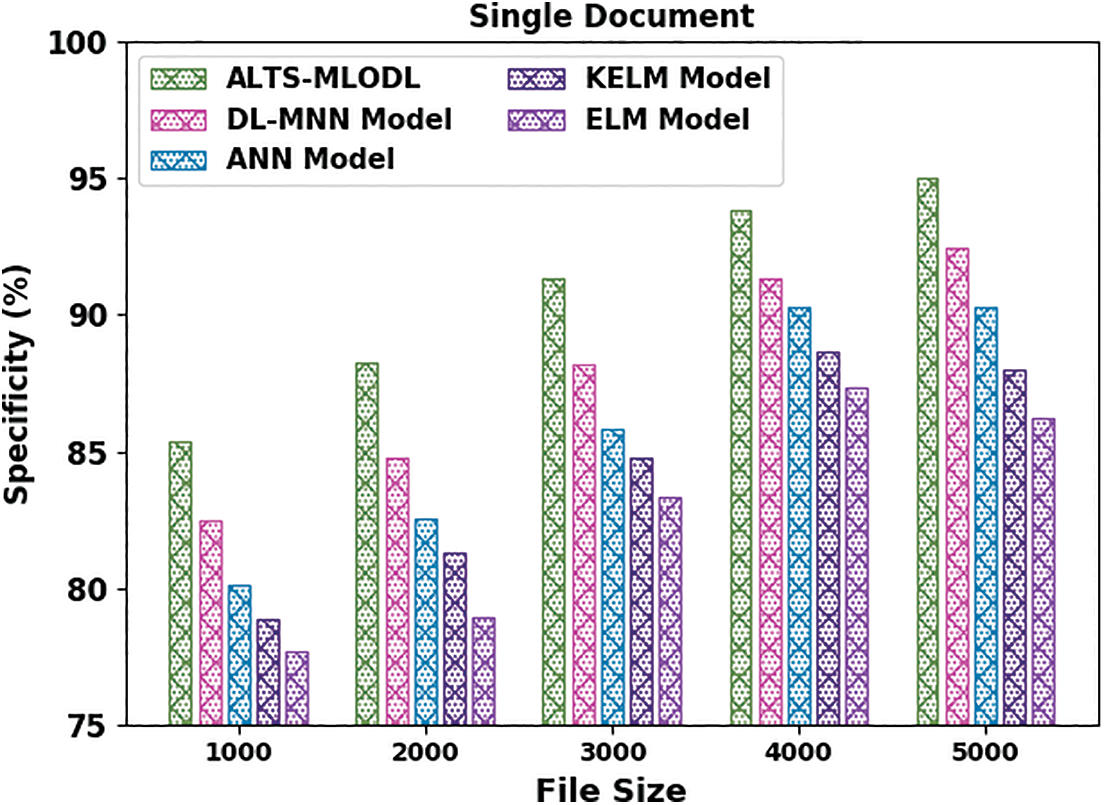
Figure 4:
Fig. 5 shows the comparative
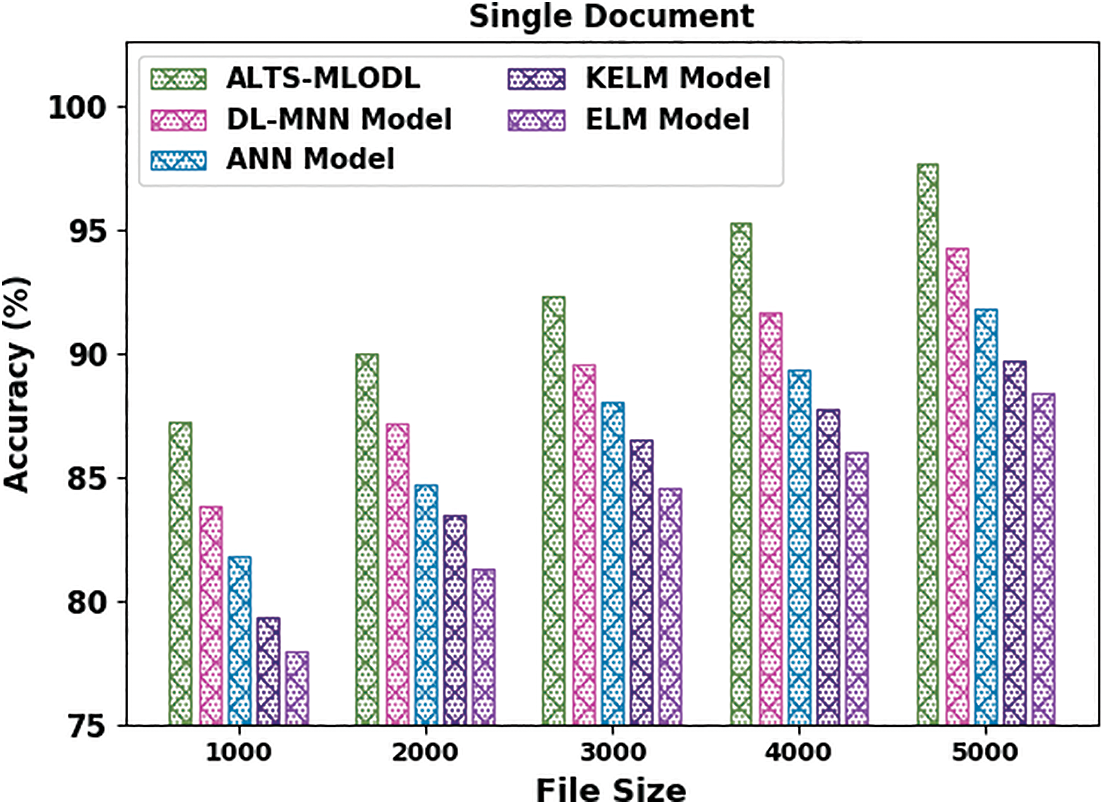
Figure 5:
Fig. 6 represents the comparative
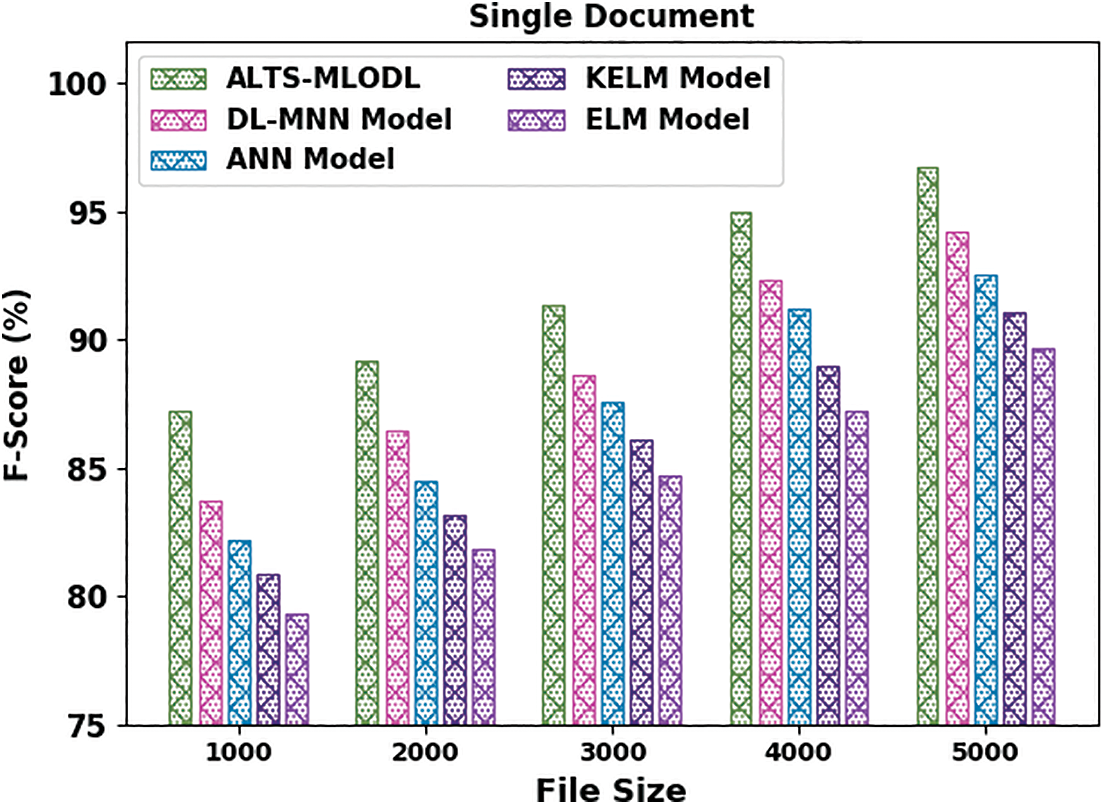
Figure 6:
Both Training Accuracy (TRA) and Validation Accuracy (VLA) values, acquired by the proposed ALTS-MLODL methodology under a single-document summarization process, are shown in Fig. 7. The experimental outcomes denote that the ALTS-MLODL approach attained the maximal TRA and VLA values whereas the VLA values were higher than the TRA values.
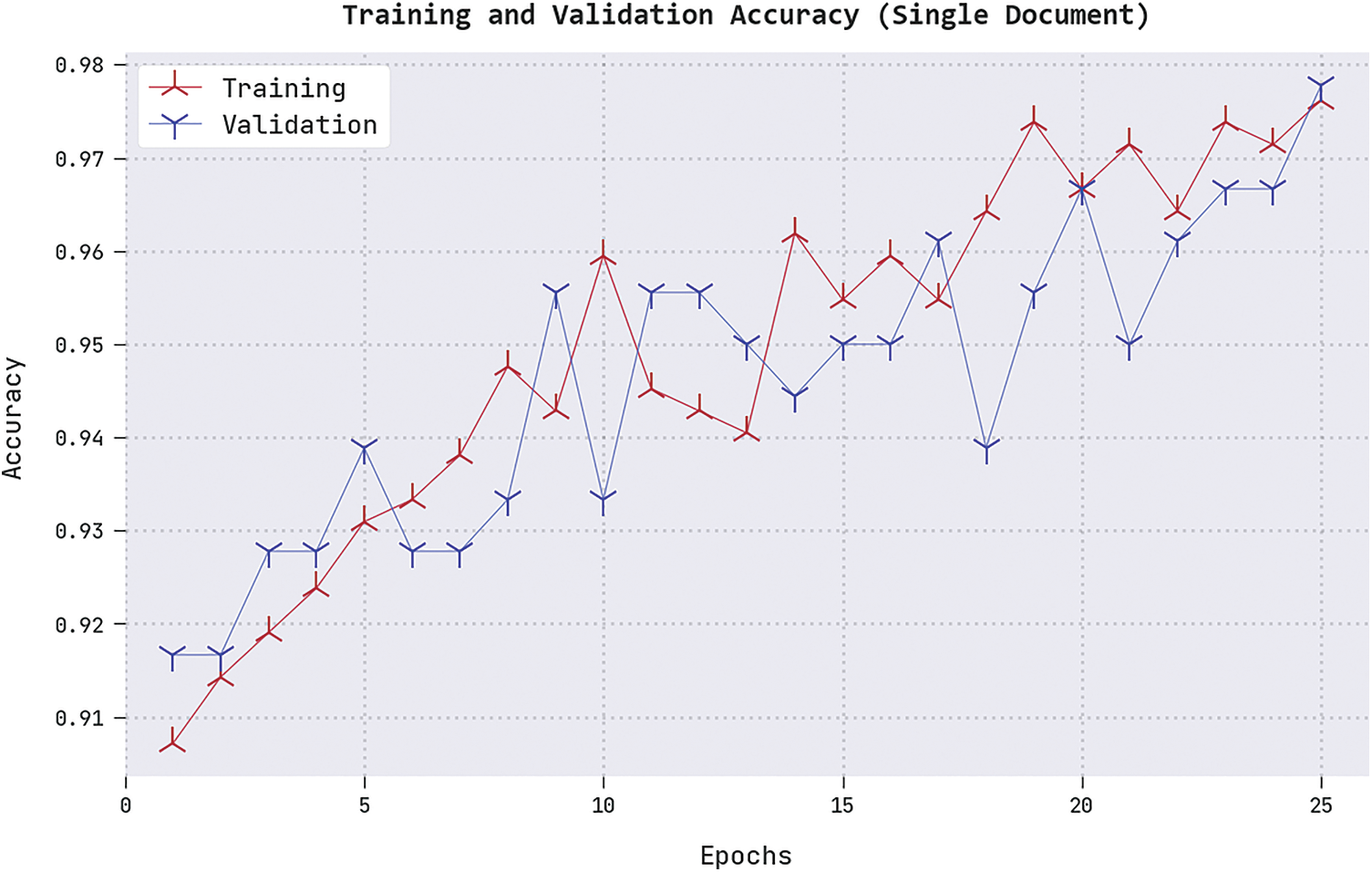
Figure 7: TRA and VLA analyses results of the ALTS-MLODL approach on the single document summarization process
Both Training Loss (TRL) and Validation Loss (VLL) values, gained by the proposed ALTS-MLODL technique under a single-document summarization process, are displayed in Fig. 8. The experimental outcomes infer that the ALTS-MLODL approach displayed the least TRL and VLL values whereas the VLL values were lesser than the TRL values.
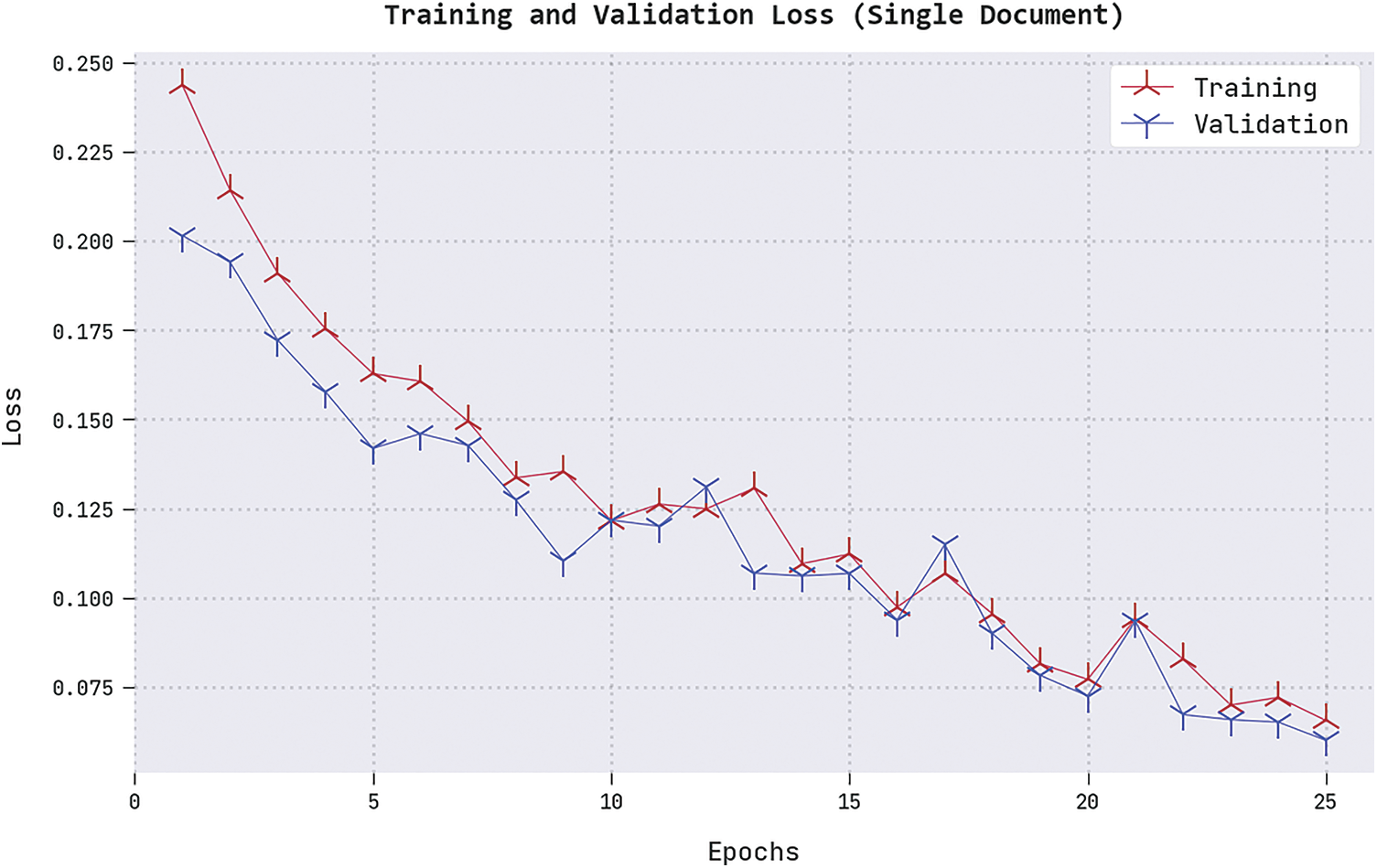
Figure 8: TRL and VLL analyses results of the ALTS-MLODL approach on the single-document summarization process
Table 2 offers the comprehensive summarization outcomes of the ALTS-MLODL algorithm under varying file sizes on the multi-document summarization process. Fig. 9 represents the detailed
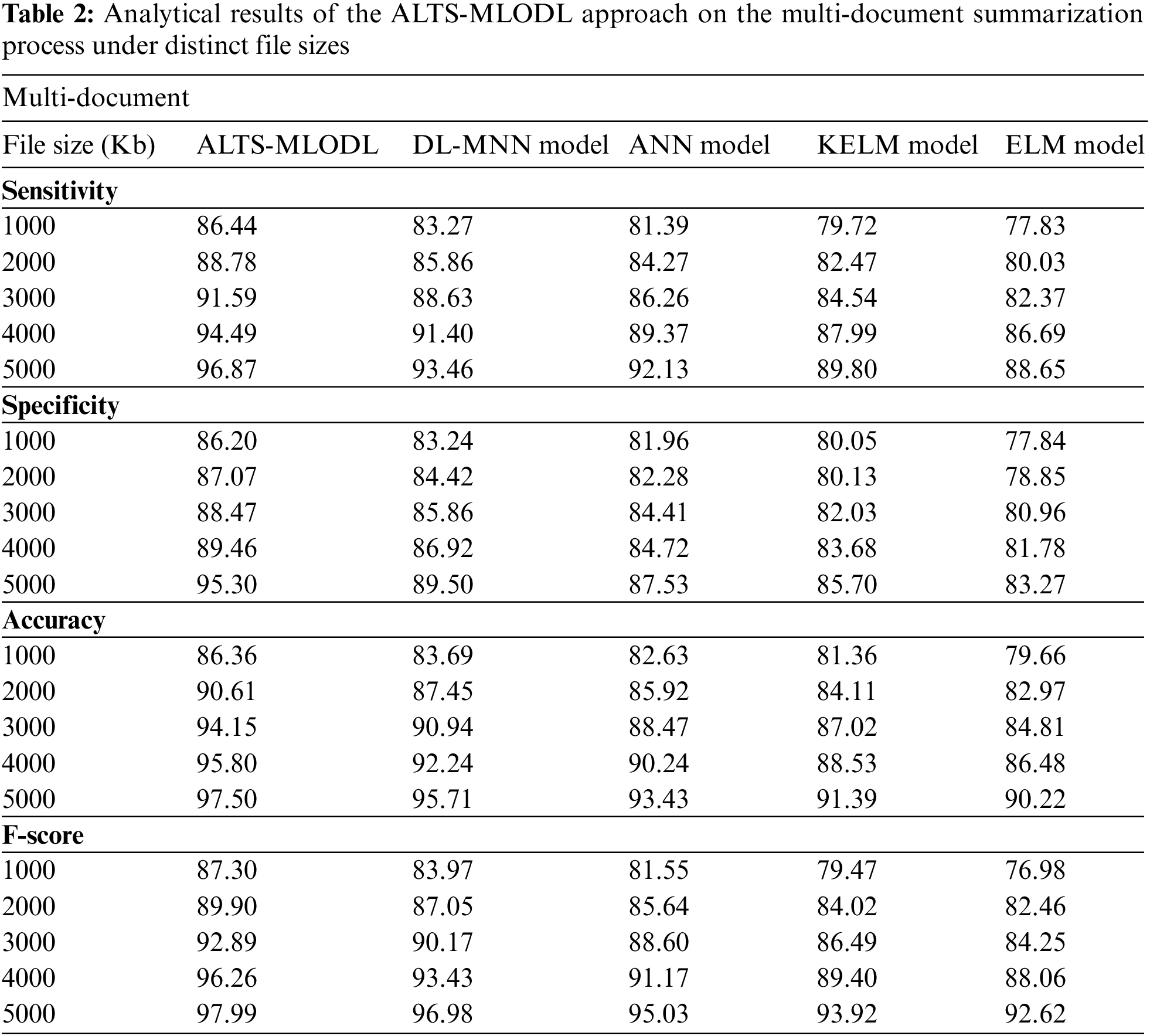
Figure 9:
Fig. 10 describes the comparative
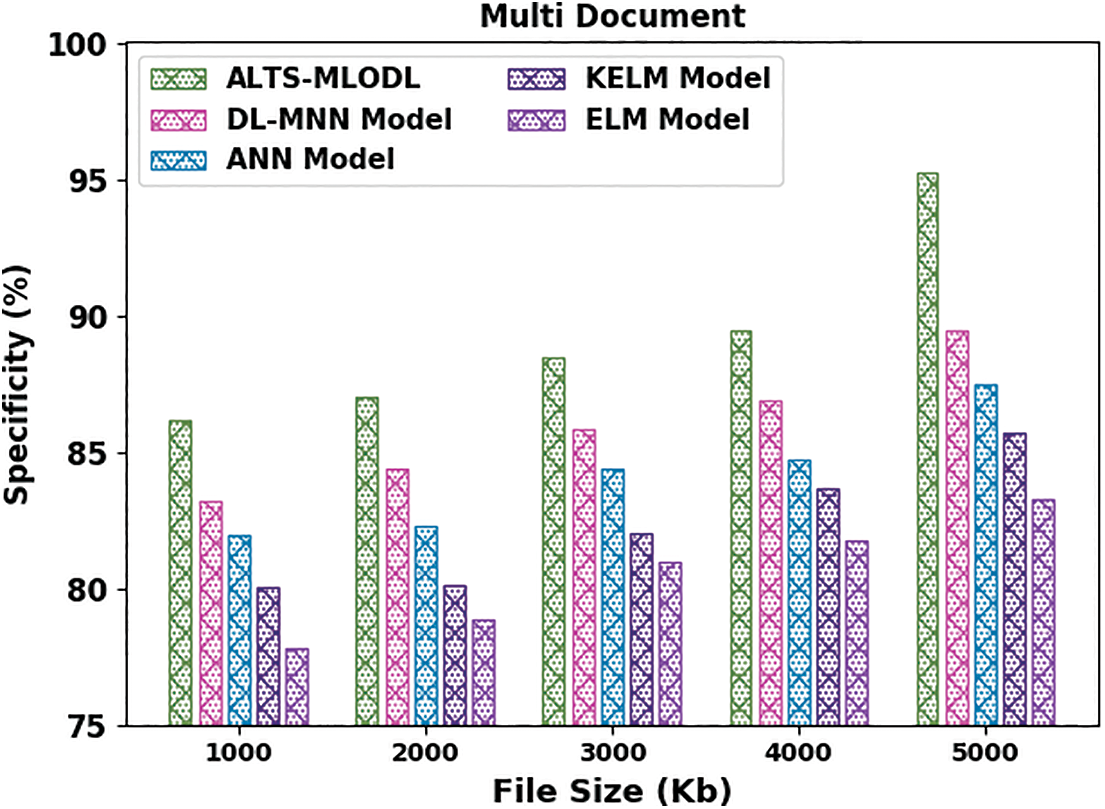
Figure 10:
Fig. 11 portrays the comprehensive
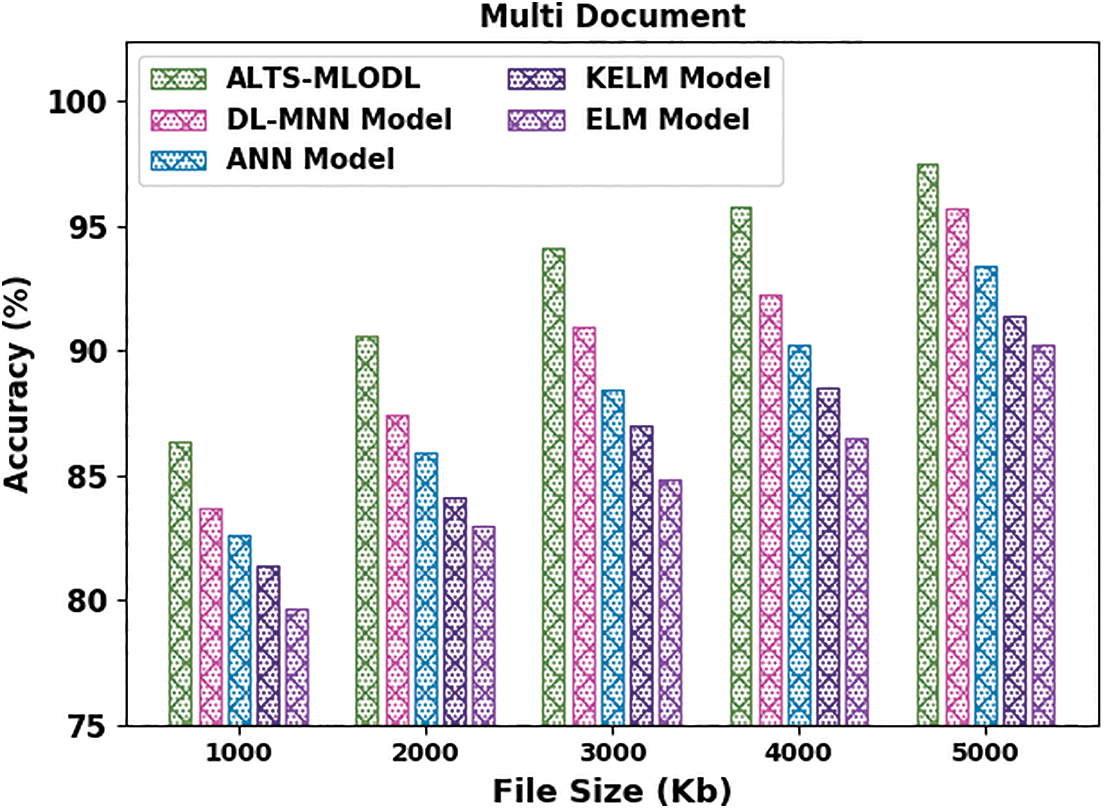
Figure 11:
Fig. 12 showcases the detailed
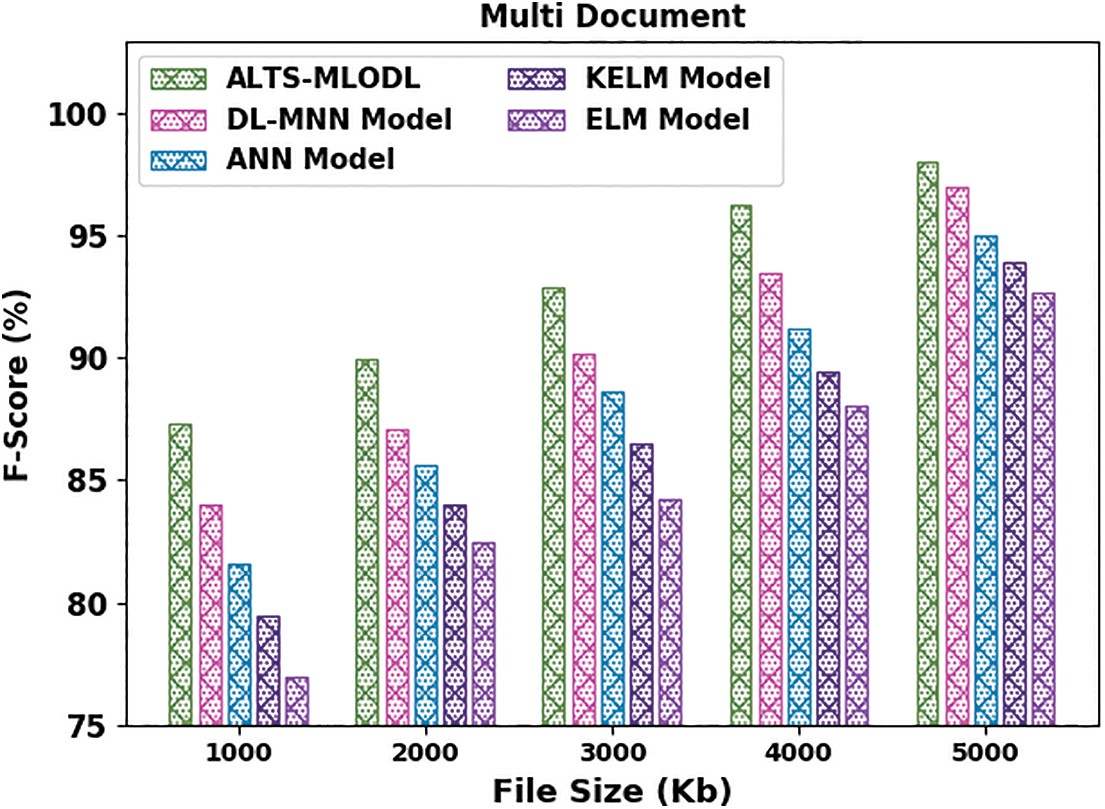
Figure 12:
In this article, a new ALTS-MLODL technique has been developed for an effectual text summarization outcome. The presented ALTS-MLODL technique aims to summarize the text documents in the English language. To accomplish the objective, the proposed ALTS-MLODL technique pre-processes the input documents and primarily extracts a set of features. Next, the MLO algorithm is used for the effectual selection of the extracted features. For the text summarization process, the CRNN model is exploited with WOA as a hyperparameter optimizer. The exploitation of the MLO-based feature selection and the WOA-based hyperparameter tuning enhanced the summarization results. To exhibit the superior performance of the proposed ALTS-MLODL technique, numerous simulation analyses were conducted. The experimental results signify the superiority of the proposed ALTS-MLODL technique over other approaches. In the future, hybrid DL models can be utilized for ATS and image captioning processes.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R281), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4331004DSR09).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. E. Vázquez, R. A. Hernández and Y. Ledeneva, “Sentence features relevance for extractive text summarization using genetic algorithms,” Journal of Intelligent & Fuzzy Systems, vol. 35, no. 1, pp. 353–365, 2018. [Google Scholar]
2. R. M. Alguliyev, R. M. Aliguliyev, N. R. Isazade, A. Abdi and N. Idris, “COSUM: Text summarization based on clustering and optimization,” Expert Systems, vol. 36, no. 1, pp. e12340, 2019. [Google Scholar]
3. A. Qaroush, I. A. Farha, W. Ghanem, M. Washaha and E. Maali, “An efficient single document arabic text summarization using a combination of statistical and semantic features,” Journal of King Saud University-Computer and Information Sciences, vol. 33, no. 6, pp. 677–692, 2021. [Google Scholar]
4. K. Yao, L. Zhang, D. Du, T. Luo, L. Tao et al., “Dual encoding for abstractive text summarization,” IEEE Transactions on Cybernetics, vol. 50, no. 3, pp. 985–996, 2018. [Google Scholar] [PubMed]
5. R. Elbarougy, G. Behery and A. El Khatib, “Extractive arabic text summarization using modified PageRank algorithm,” Egyptian Informatics Journal, vol. 21, no. 2, pp. 73–81, 2020. [Google Scholar]
6. N. Nazari and M. A. Mahdavi, “A survey on automatic text summarization,” Journal of AI and Data Mining, vol. 7, no. 1, pp. 121–135, 2019. [Google Scholar]
7. N. Landro, I. Gallo, R. L. Grassa and E. Federici, “Two new datasets for Italian-language abstractive text summarization,” Information, vol. 13, no. 5, pp. 228, 2022. [Google Scholar]
8. Y. Kumar, K. Kaur and S. Kaur, “Study of automatic text summarization approaches in different languages,” Artificial Intelligence Review, vol. 54, no. 8, pp. 5897–5929, 2021. [Google Scholar]
9. S. N. Turky, A. S. A. Al-Jumaili and R. K. Hasoun, “Deep learning based on different methods for text summary: A survey,” Journal of Al-Qadisiyah for Computer Science and Mathematics, vol. 13, no. 1, pp. 26, 2021. [Google Scholar]
10. X. Wan, F. Luo, X. Sun, S. Huang and J. G. Yao, “Cross-language document summarization via extraction and ranking of multiple summaries,” Knowledge and Information Systems, vol. 58, no. 2, pp. 481–499, 2019. [Google Scholar]
11. S. Song, H. Huang and T. Ruan, “Abstractive text summarization using LSTM-CNN based deep learning,” Multimedia Tools and Applications, vol. 78, no. 1, pp. 857–875, 2019. [Google Scholar]
12. J. D’silva and U. Sharma, “Automatic text summarization of konkani texts using pre-trained word embeddings and deep learning,” International Journal of Electrical and Computer Engineering, vol. 12, no. 2, pp. 1990, 2022. [Google Scholar]
13. D. S. Maylawati, Y. J. Kumar, F. B. Kasmin and M. A. Ramdhani, “An idea based on sequential pattern mining and deep learning for text summarization,” Journal of Physics: Conference Series, vol. 1402, no. 7, pp. 077013, 2019. [Google Scholar]
14. R. Khan, Y. Qian and S. Naeem, “Extractive based text summarization using k-means and tf-idf,” International Journal of Information Engineering and Electronic Business, vol. 11, no. 3, pp. 33, 2019. [Google Scholar]
15. N. Lin, J. Li and S. Jiang, “A simple but effective method for Indonesian automatic text summarisation,” Connection Science, vol. 34, no. 1, pp. 29–43, 2022. [Google Scholar]
16. H. Zhao, J. Cao, M. Xu and J. Lu, “Variational neural decoder for abstractive text summarization,” Computer Science and Information Systems, vol. 17, no. 2, pp. 537–552, 2020. [Google Scholar]
17. B. Muthu, S. Cb, P. M. Kumar, S. N. Kadry, C. H. Hsu et al., “A framework for extractive text summarization based on deep learning modified neural network classifier,” Transactions on Asian and Low-Resource Language Information Processing, vol. 20, no. 3, pp. 1–20, 2021. [Google Scholar]
18. F. A. Zeidabadi, S. A. Doumari, M. Dehghani and O. P. Malik, “MLBO: Mixed leader based optimizer for solving optimization problems,” International Journal of Intelligent Engineering and Systems, vol. 14, no. 4, pp. 472–479, 2021. [Google Scholar]
19. R. Hang, Q. Liu, D. Hong and P. Ghamisi, “Cascaded recurrent neural networks for hyperspectral image classification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 8, pp. 5384–5394, 2019. [Google Scholar]
20. Q. V. Pham, S. Mirjalili, N. Kumar, M. Alazab and W. J. Hwang, “Whale optimization algorithm with applications to resource allocation in wireless networks,” IEEE Transactions on Vehicular Technology, vol. 69, no. 4, pp. 4285–4297, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools