
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Deep Learning Driven Arabic Text to Speech Synthesizer for Visually Challenged People
1 King Salman Center for Disability Research, Riyadh, 13369, Saudi Arabia
2 Department of Information Technology, College of Computers and Information Technology, Taif University, P.O. Box 11099, Taif, 21944, Saudi Arabia
3 Department of Special Education, College of Education, King Saud University, Riyadh, 12372, Saudi Arabia
4 Department of Computer Science, College of Science & Arts at Muhayel, King Khaled University, Abha, 62217, Saudi Arabia
5 Department of Computer Science, College of Sciences and Humanities-Aflaj, Prince Sattam bin Abdulaziz University, Al-Aflaj, 16733, Saudi Arabia
6 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, 16242, Saudi Arabia
* Corresponding Author: Fahd N. Al-Wesabi. Email:
Intelligent Automation & Soft Computing 2023, 36(3), 2639-2652. https://doi.org/10.32604/iasc.2023.034069
Received 05 July 2022; Accepted 14 October 2022; Issue published 15 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Text-To-Speech (TTS) is a speech processing tool that is highly helpful for visually-challenged people. The TTS tool is applied to transform the texts into human-like sounds. However, it is highly challenging to accomplish the TTS outcomes for the non-diacritized text of the Arabic language since it has multiple unique features and rules. Some special characters like gemination and diacritic signs that correspondingly indicate consonant doubling and short vowels greatly impact the precise pronunciation of the Arabic language. But, such signs are not frequently used in the texts written in the Arabic language since its speakers and readers can guess them from the context itself. In this background, the current research article introduces an Optimal Deep Learning-driven Arab Text-to-Speech Synthesizer (ODLD-ATSS) model to help the visually-challenged people in the Kingdom of Saudi Arabia. The prime aim of the presented ODLD-ATSS model is to convert the text into speech signals for visually-challenged people. To attain this, the presented ODLD-ATSS model initially designs a Gated Recurrent Unit (GRU)-based prediction model for diacritic and gemination signs. Besides, the Buckwalter code is utilized to capture, store and display the Arabic texts. To improve the TSS performance of the GRU method, the Aquila Optimization Algorithm (AOA) is used, which shows the novelty of the work. To illustrate the enhanced performance of the proposed ODLD-ATSS model, further experimental analyses were conducted. The proposed model achieved a maximum accuracy of 96.35%, and the experimental outcomes infer the improved performance of the proposed ODLD-ATSS model over other DL-based TSS models.Keywords
The term ‘Visually Impaired (VI)’ denotes individuals with non-recoverable low vision or no vision [1]. Per a survey conducted earlier, 89% of visually-impaired persons live in less-developed nations, whereas nearly half are women. Braille is a language that was particularly developed for those who lost their vision. It has numerous compilations of six-dot patterns [2]. In the Braille language, the natural language symbols about the sounds are indicated by the activation or deactivation of the dots. Primarily, the Braille language is written and read on slates or paper with raised dots. It was introduced by Perkin Brailler, a Braille typewriter, who specifically created this writing pattern for visually-impaired people. With the arrival of technology, multiple mechanisms and touchscreen gadgets have been developed. Their applications have expanded in terms of smart magnifiers, talkback services, navigators, screen readers and obstacle detection & avoidance mechanisms for visually-impaired people [3]. The Braille language helps them to interact with their counterparts and others globally. It helps enhance natural language communication and conversational technology for educational objectives [4]. Most vision-impaired people hesitate to leverage their smartphones due to usability and accessibility problems. For instance, they find it challenging to identify the location of a place on smartphones. Whenever vision-impaired persons execute a task, a feedback mechanism should be made available to them to provide the result [5,6].
Conventional Machine Learning (ML) techniques are broadly utilized in several research fields. But, such methodologies necessitate profound knowledge in the specific field and utilize the pre-defined characteristics for assessment [7,8]. So, it becomes essential to manually execute an extensive range of feature extraction works in the existing techniques. Deep Learning (DL), one of the ML techniques, is a sub-set of Artificial Intelligence (AI) techniques. It is characterized by a scenario in which computers start learning to think based on the structures found in the human brain [9]. The DL techniques can examine the unstructured data, videos and images in several ways, whereas ML techniques cannot easily perform these tasks [10]. The ML and the DL techniques are applied in multiple industrial domains, whereas language plays a significant role in the day-to-day life of human beings. Language is of prime importance, whether it may be a passion, speech, a coding system or sign language, i.e., to convey meaning via touch. It expresses one’s experiences, thoughts, reactions, emotions and intentions. The Text-To-Speech (TTS) synthesizer converts the language data, stored in the form of text, to a speech format. Recently, it has been primarily utilized in audio-reading gadgets for vision-impaired persons [11].
TTS has become one of the major applications of the Natural Language Processing (NLP) technique. Various researchers have worked on speech synthesis processes in literature since the significance of novel applications has increased, such as the information retrieval services over the telephone like banking services, announcements at public locations such as train stations and reading manuscripts to collect the data [12]. Many research works have been conducted earlier in two languages, English and French, in the domain of TTS. However, other languages like Arabic are yet to be explored in detail. Sufficient space exists for the growth and development of research works in this arena. So, the development of an Arabic Text-To-Speech system is still in the nascent stage. Hence, this project’s scope is limited in terms of providing the guidelines for developing an Arabic speech synthesis technique and changing the methodology to overcome the difficulties experienced by the authors in this domain. This is done to help the researchers build highly-promising Voice-to-Text applications for the Arabic language [13].
In the study conducted earlier [14], a new structure was devised for signer-independent sign language detection with the help of multiple DL architectures. This method had hand-shaped feature representations, Deep Recurrent Neural Network (RNN) and semantic segmentation. An advanced semantic segmentation technique, i.e., DeepLabv3+, was trained to utilize pixel-labelled hand images to extract hand regions from every frame of the input video. Then, the extracted hand regions were scaled and cropped to a fixed size to alleviate the hand-scale variations. The hand-shaped features were attained with the help of a single-layer Convolutional Self-Organizing Map (CSOM) instead of a pre-trained Deep Convolutional Neural Network (CNN). In literature [15], a prototype was developed for a text-to-speech synthesizer for Tigrigna Language.
In literature [16], the Arabic version of the data was constructed as a part of MS COCO and Flickr caption data sets. In addition, a generative merger method was introduced to caption the images in the Arabic language based on CNN and deep RNN methods. The experimental results inferred that when using a large corpus, the merged methods can attain outstanding outcomes in the case of Arabic image captioning. The researchers [17] investigated and reviewed different DL structures and modelling choices for recognising Arabic handwritten texts. Moreover, the imbalanced dataset issue was overcome by offering the model to the DL mechanism. To face this problem, a new adaptive data-augmentation method was presented to promote class diversity. Every word was allocated weight in the database lexicon. The authors [18] aim to automatically detect the Arabic Sign Language (ArSL) alphabet using an image-related method. To be specific, several visual descriptors were analyzed to construct an accurate ArSL alphabet recognizer. The derived visual descriptors were conveyed to the One-vs.-All Support Vector Machine (SVM) method.
The current study introduces an Optimal Deep Learning-driven Arab Text-to-Speech Synthesizer (ODLD-ATSS) model to help the visually-challenged people in the Kingdom of Saudi Arabia. The prime objective of the presented ODLD-ATSS model is to convert the text into speech signals for the visually-challenged people. To attain this, the presented ODLD-ATSS model initially designs a Gated Recurrent Unit (GRU)-based prediction model for diacritic and gemination signs. Besides, the Buckwalter code is also utilized to capture, store and display the Arabic text. In order to enhance the TSS performance of the GRU model, the Aquila Optimization Algorithm (AOA) is used. Numerous experimental analyses were conducted to establish the enhanced performance of the proposed ODLD-ATSS model.
In this study, a novel ODLD-ATSS technique has been proposed for the TSS process so that it can be used by the visually-challenged people in the Kingdom of Saudi Arabia. The presented ODLD-ATSS model aims to convert text into speech signals for visually-impaired people. The overall working process of the proposed model is shown in Fig. 1.
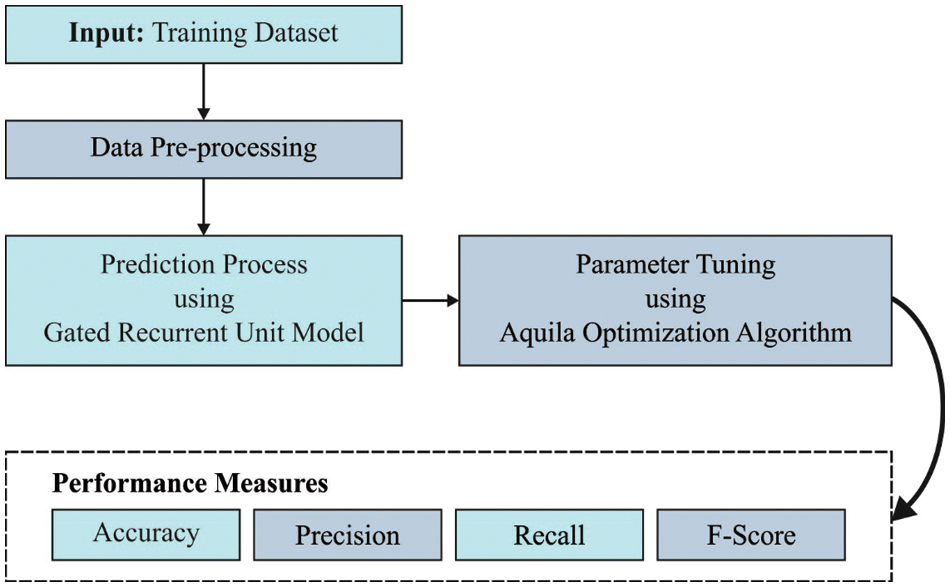
Figure 1: Overall process of the ODLD-ATSS model
2.1 GRU-Based Diacritic and Gemination Sign Prediction
The presented ODLD-ATSS model initially designs a GRU-based prediction model for diacritic and gemination signs. The RNN characterizes the Neural Network (NN) through multiple recurrent layers in the form of hidden layers. It diverges from others in the reception of an input dataset. The RNN method is mainly applied in sequence datasets that are closely connected with time series datasets, for instance, stock prices, language, weather and so on. So, the previous dataset creates an impact on the outcomes of the model [19]. The RNN model is a well-developed model that can process the time series datasets easily; it employs the recurrent bias as well as the weights by passing the dataset via a cyclic vector. It attains the
The GRU model is a variant of the LSTM model whereas the latter contains three gate functions with respect to RNN such as the output gate, input gate and the forget gate to the output value, control input and the memory respectively. There are two gates present in the GRU mechanism such as the upgrade gate and the reset gate. Fig. 2 shows a specific architecture in which
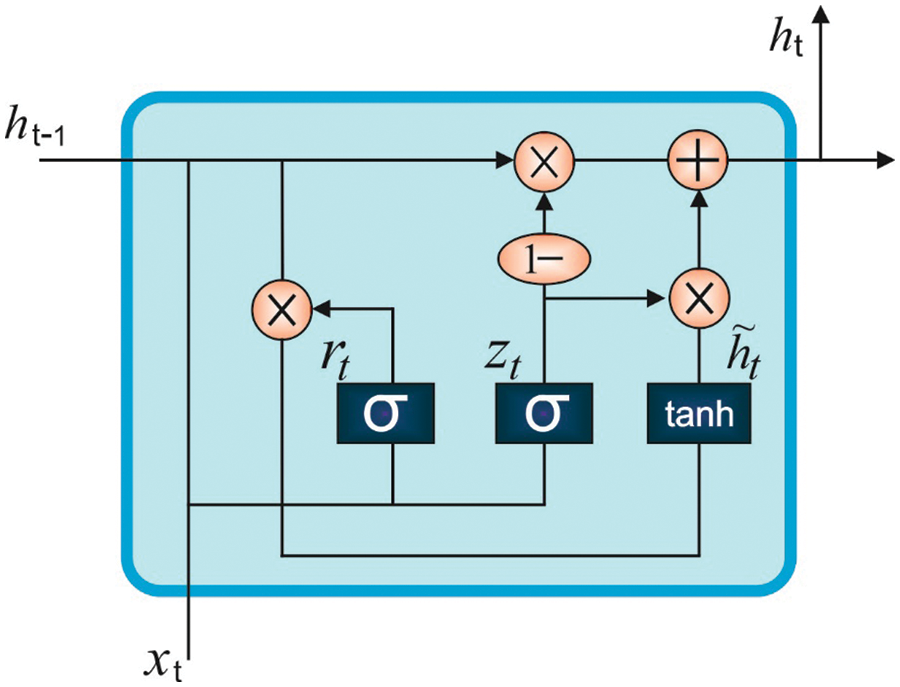
Figure 2: Structure of the GRU model
In this expression,
Now,
The Backpropagation (BP) methodology is exploited to learn the network. Therefore, the partial derivatives of the loss function must be evaluated for the variable. After the evaluation of the partial derivatives, the loss convergence is iteratively defined and the variable is upgraded.
2.2 AOA Based Hyperparameter Optimization
In order to improve the TSS performance of the GRU model, the AOA technique is used as a hyperparameter optimizer [21]. Like other birds, Aquila has a dark brown colour complexion. The back of its head has an additional golden brown colour. These birds have agility and speed. Furthermore, it has sharp claws and strong legs that assist in capturing the target. Aquila is famous for attacking the adult deer. It constructs large nests in mountains or in high altitudes. Aquila is a skilled hunter and its intelligence is equal to that of the human beings’ intelligence. Similar to the population-based algorithms, the AOA methodology starts with a population of the candidate solutions. The technique stochastically initiates with an upper limit and a lower limit [21]. Every iteration almost defines the optimal solution as given below.
In Eq. (7),
- Step 1: Increased exploration
In step 1, the Aquila explores from the sky to define a searching region and identifies the location of the prey. Then, it recognizes the areas of the prey and selects the finest area for hunting.
Here, the solution for iteration
- Step 2: Limited exploration
Next, the target is established at a high altitude. Here, the Aquila encircles in the cloud, reaches the location and gets ready to attack the target. This process is arithmetically expressed through the following equations.
In these expressions, the conclusion of iteration
- Step 3: Increased exploitation
In this step, the Aquila is present at the location of exploitation, viz., gets closer to the prey and makes a pre-emptive attack as shown below.
In this exploitation tuning parameter set, the small values
- Step 4: Limited exploitation
Now, the Aquila approaches the nearby prey. Then, the Aquila attacks the target on the ground i.e., its final position, by walking on the ground to catch the prey. The behaviour of the Aquila is modelled as given herewith.
In Eq. (24), the iteration solution that is produced by the last searching technique
2.3 Buckwalter Code Based Transcription Model
At last, the Buckwalter code is utilized to capture, store and display the Arabic text. It is predominantly applied in the Arabic transcription process to capture, store and display Arabic text. Being a stringent transcription method, it adheres to the spelling agreements of the language. Further, it substitutes one-to-one mapping and is completely reversible to contain every data that is required for good pronunciation.
The current section presents the overall analytical results of the proposed ODLD-ATSS model under distinct aspects. The parameter settings are given herewith; learning rate: 0.01, dropout: 0.5, batch size: 5, epoch count: 50 and activation: ReLU. The proposed model was simulated in Python.
Table 1 and Fig. 3 provide the detailed
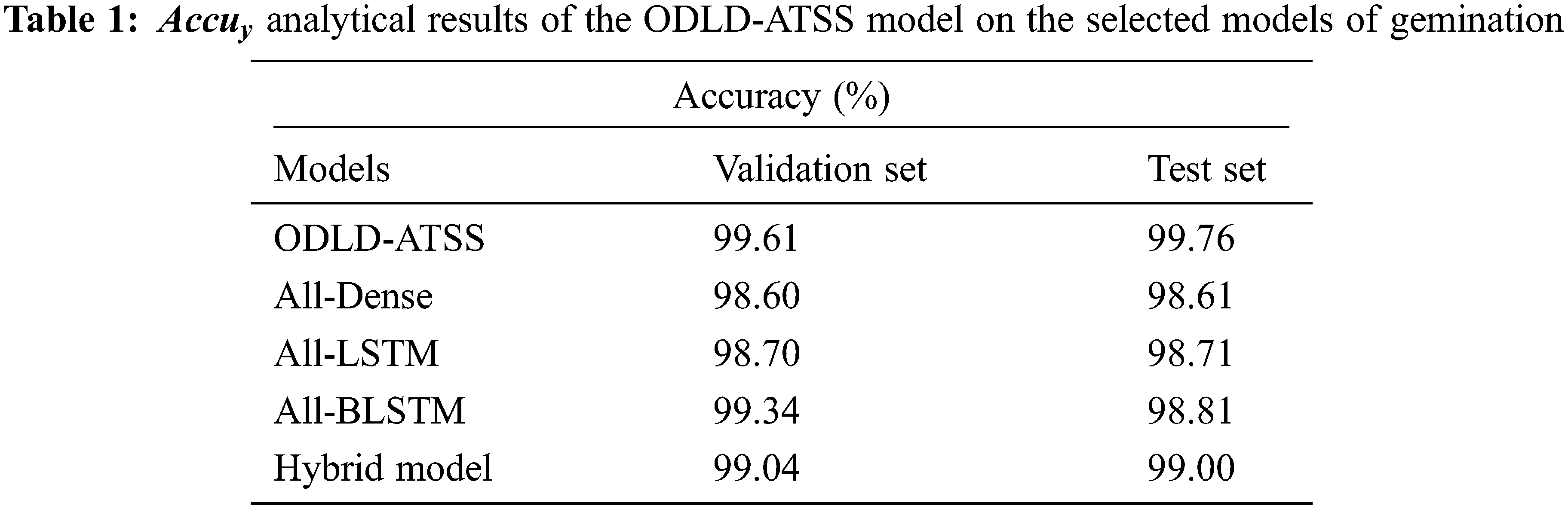
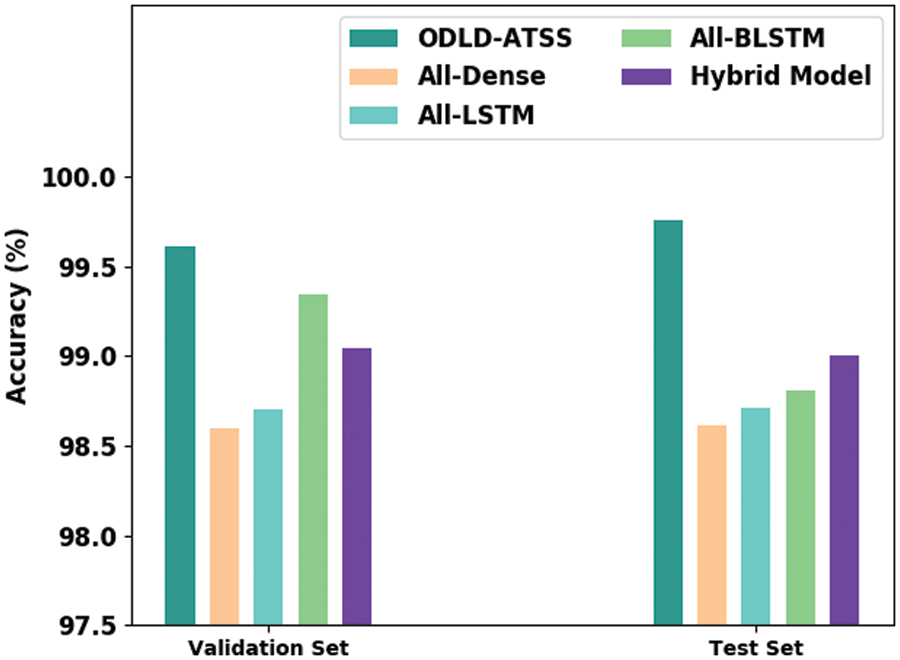
Figure 3: Comparative
Table 2 provides the overall results achieved by the proposed ODLD-ATSS model on germination signs with the DNN model. The results imply that the proposed ODLD-ATSS model produced enhanced outcomes for both non-geminated and geminated classes. For instance, the presented ODLD-ATSS model categorized the non-geminated classes with a
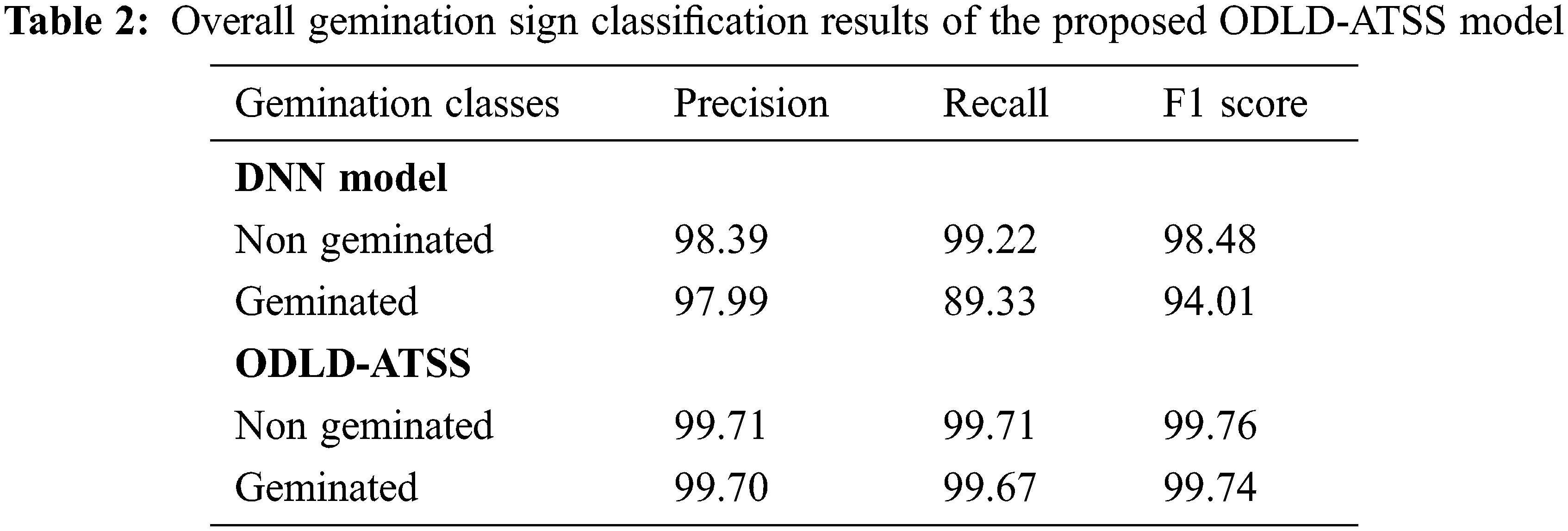
Table 3 reports the overall gemination prediction outcomes accomplished by the proposed ODLD-ATSS model. The results imply that the proposed ODLD-ATSS model attained the effectual prediction outcomes for gemination on the validation dataset and the testing dataset. For instance, on the validation dataset, the proposed ODLD-ATSS model offered an increased
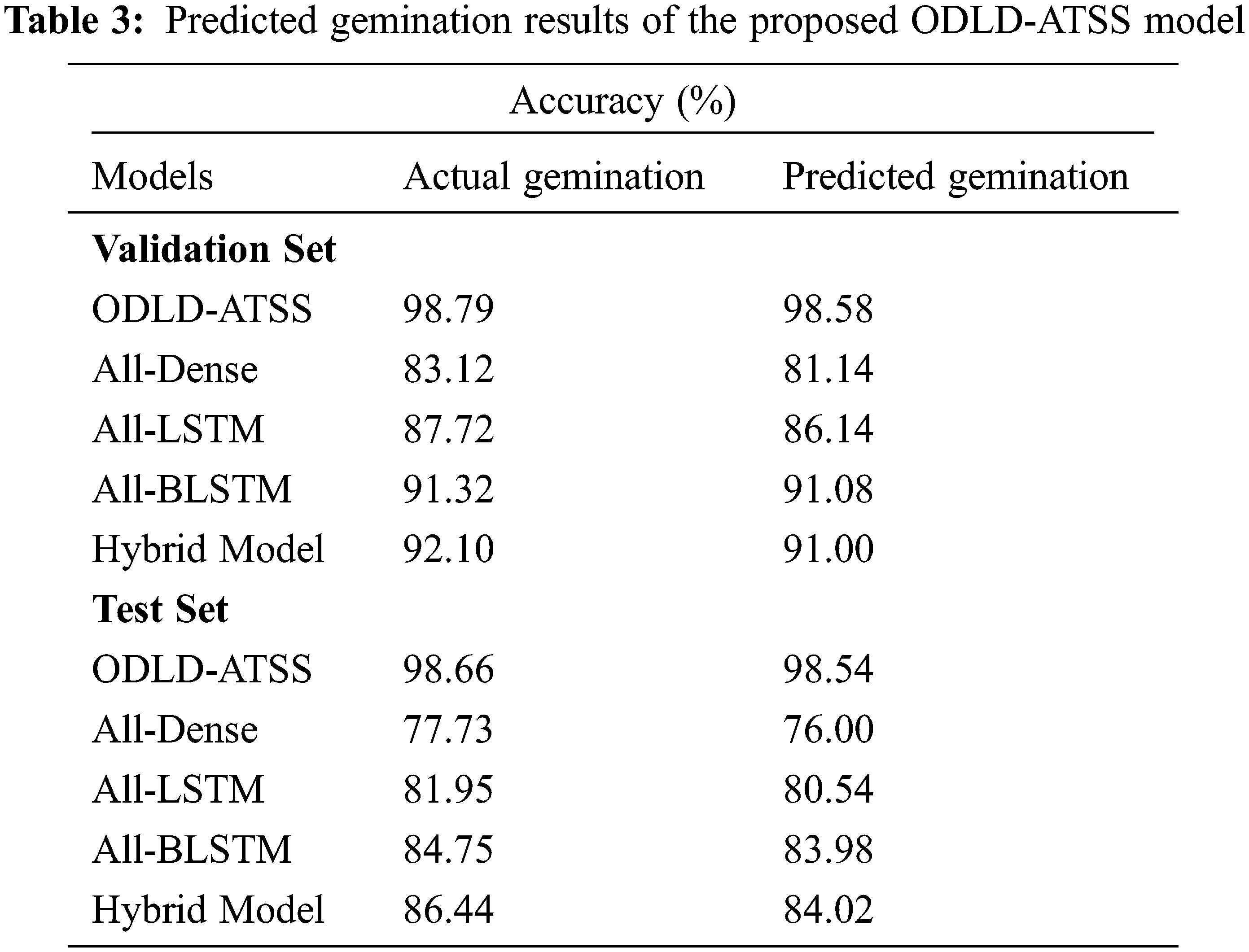
Table 4 and Fig. 4 provide the detailed final diacritization
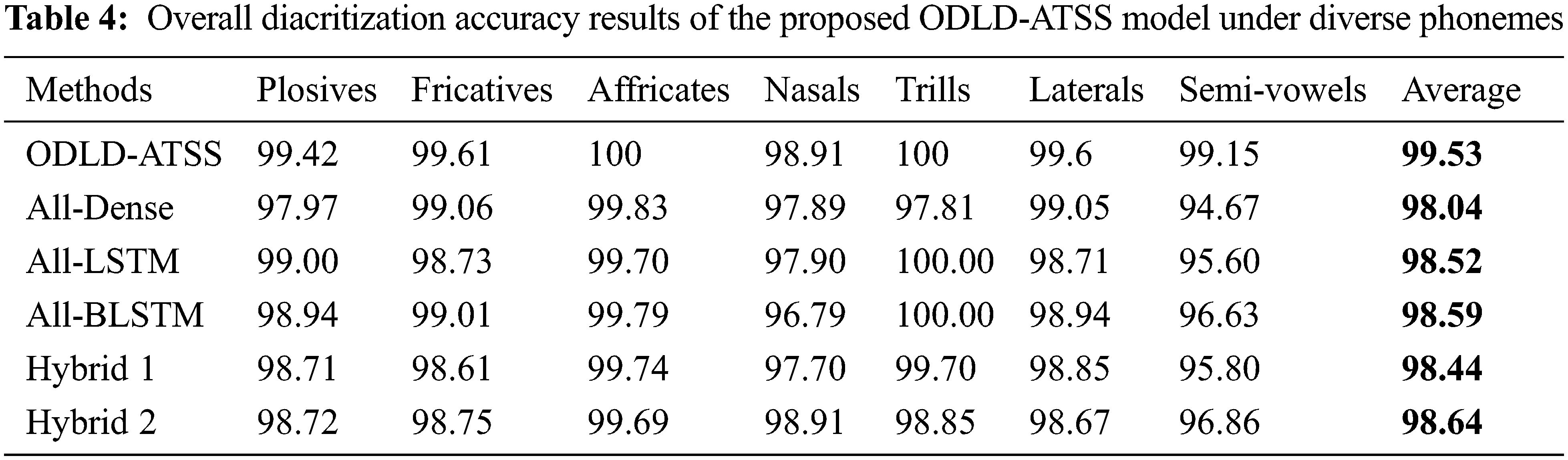
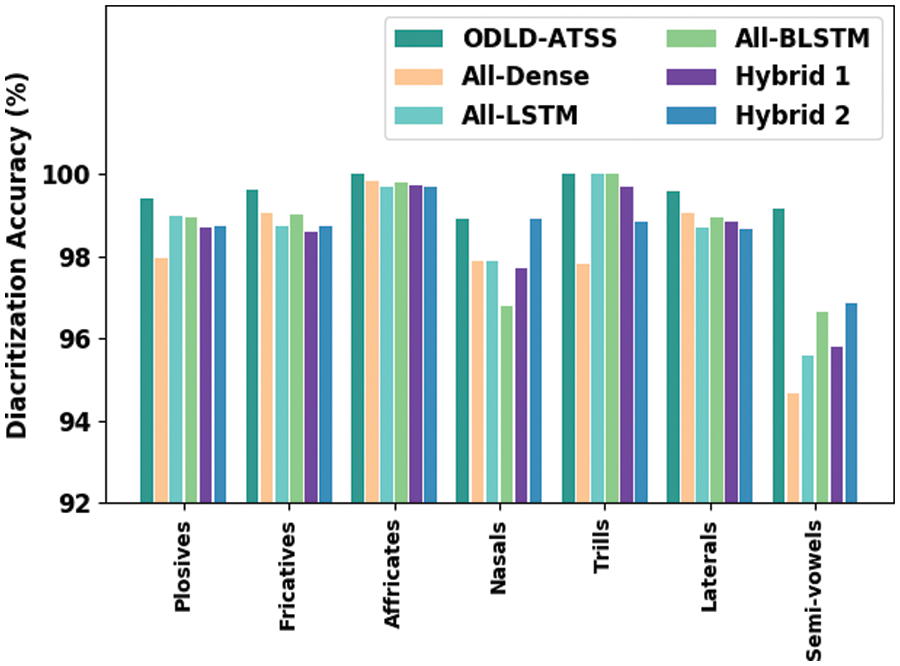
Figure 4: Comparative diacritization accuracy results of the proposed ODLD-ATSS model under diverse phonemes
Table 5 provides the overall classification results accomplished by the proposed ODLD-ATSS model under distinct diacritic classes. Fig. 5 shows the brief results of the proposed ODLD-ATSS model under distinct diacritic sign classes in terms of
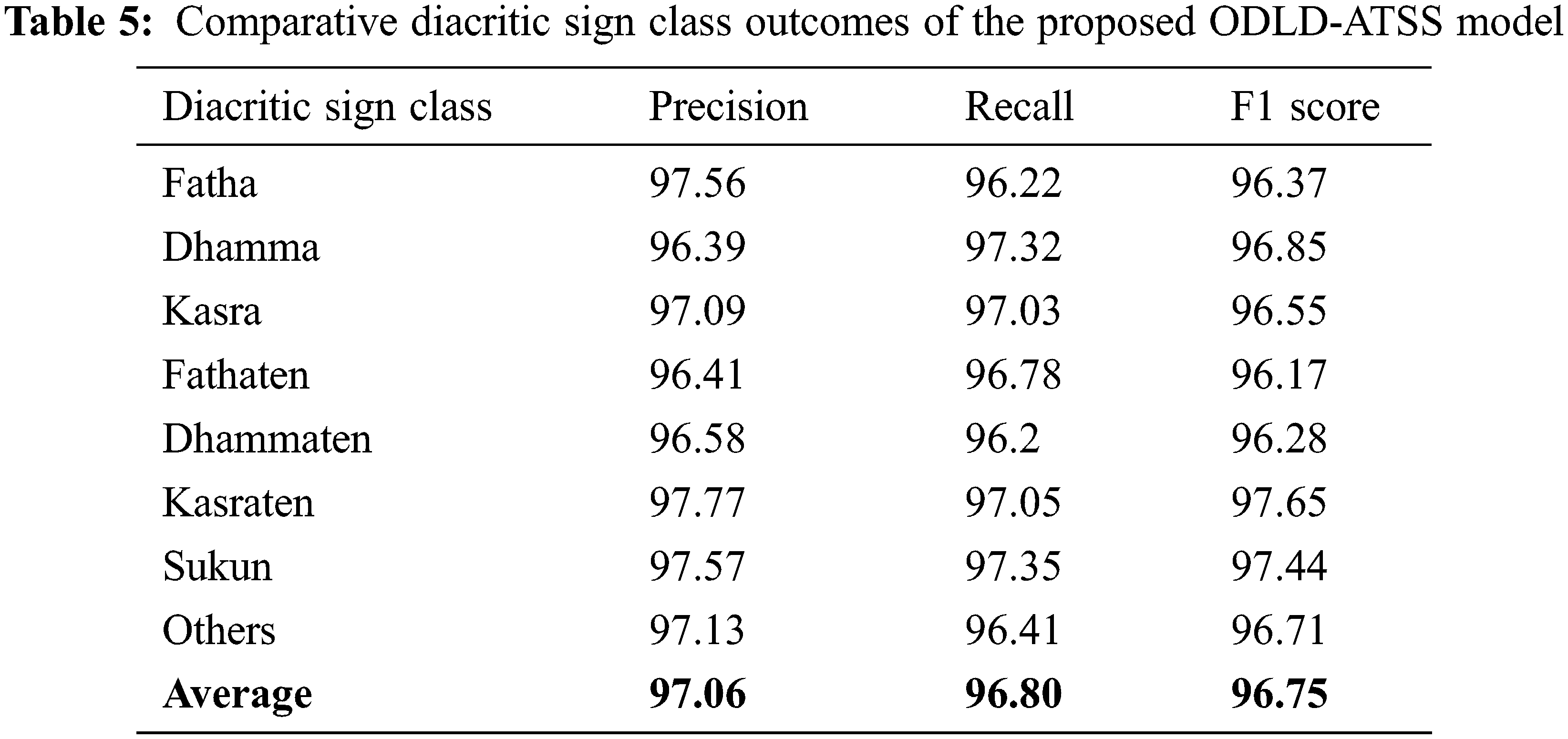
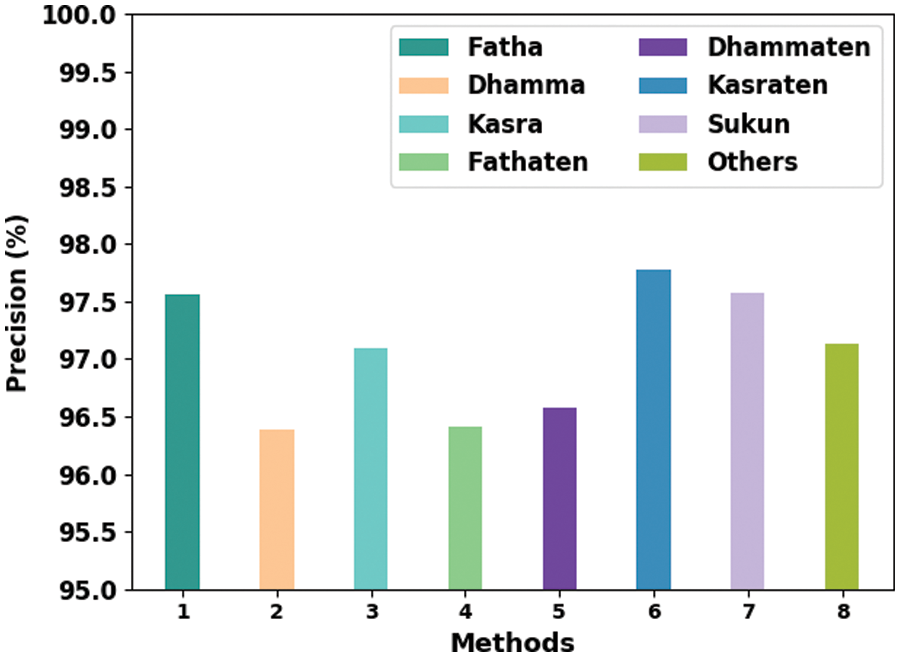
Figure 5: Comparative
Fig. 6 portrays the comprehensive analytical results attained by the proposed ODLD-ATSS algorithm under different diacritic sign classes in terms of
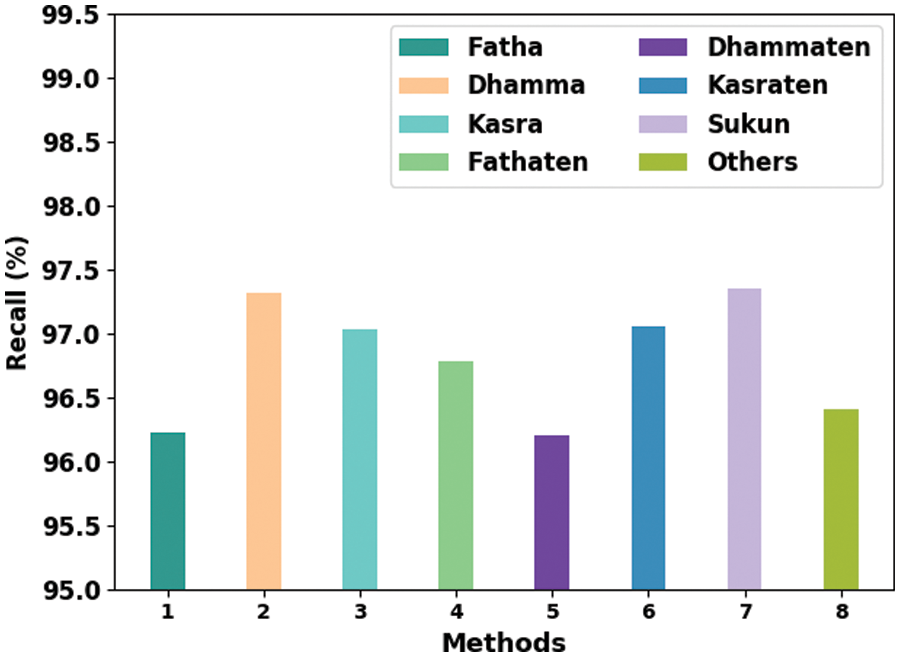
Figure 6: Comparative
Fig. 7 provides the detailed illustration of the results achieved by the proposed ODLD-ATSS model under different diacritic sign classes in terms of
Figure 7: Comparative
Table 6 and Fig. 8 exhibit the comparative
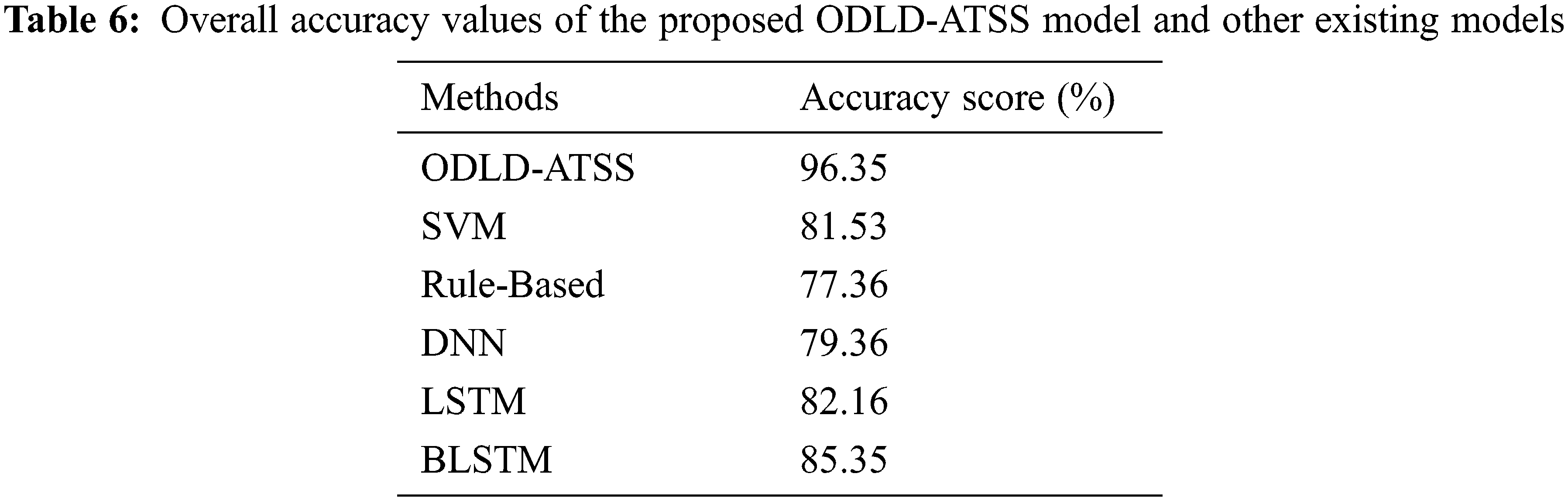
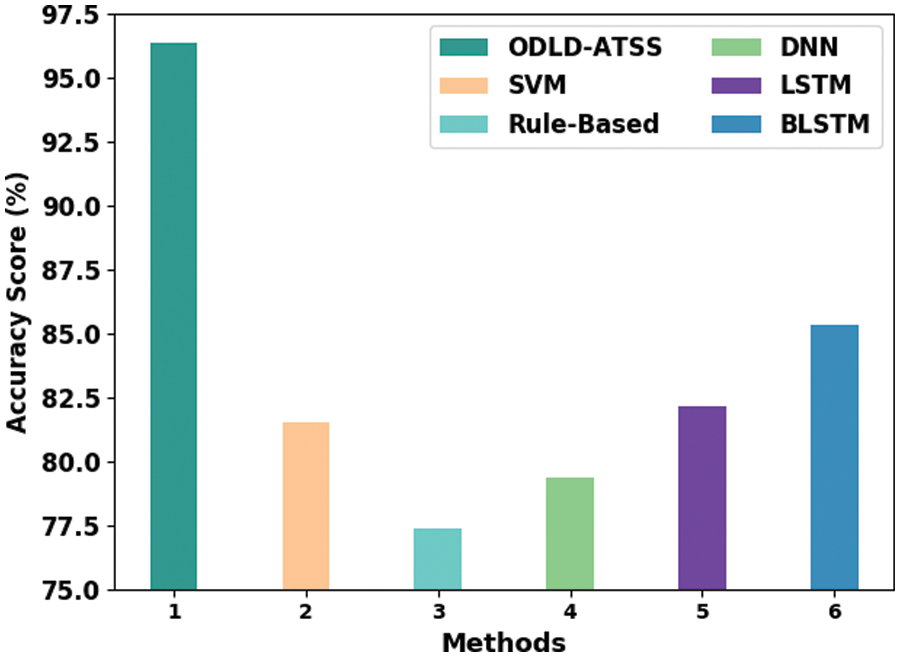
Figure 8: Comparative
In the current study, the proposed ODLD-ATSS technique has been developed for the TSS process to be used by the visually-challenged people in the Kingdom of Saudi Arabia. The prime objective of the presented ODLD-ATSS model is to convert the text into speech signals for the visually-challenged people. To attain this, the presented ODLD-ATSS model initially designs a GRU-based prediction model for diacritic and gemination signs. Besides, the Buckwalter code is also utilized to capture, store and display the Arabic text. In order to enhance the TSS performance of the GRU method, the AOA technique is used. To establish the enhanced performance of the proposed ODLD-ATSS algorithm, various experimental analyses were conducted. The experimental outcomes confirmed the improved performance of the ODLD-ATSS model over other DL-based TSS models. The proposed ODLD-ATSS model achieved a maximum accuracy of 96.35%. In the future, the performance of the proposed ODLD-ATSS model can be enhanced using hybrid metaheuristic algorithms. Besides, the presented model can also be extended for the object detection process in real-time navigation techniques.
Funding Statement: The authors extend their appreciation to the King Salman center for Disability Research for funding this work through Research Group no KSRG-2022-030.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. R. Olwan, “The ratification and implementation of the Marrakesh Treaty for visually impaired persons in the Arab Gulf States,” The Journal of World Intellectual Property, vol. 20, no. 5–6, pp. 178–205, 2017. [Google Scholar]
2. R. Sarkar and S. Das, “Analysis of different braille devices for implementing a cost-effective and portable braille system for the visually impaired people,” International Journal of Computer Applications, vol. 60, no. 9, pp. 1–5, 2012. [Google Scholar]
3. M. Awad, J. El Haddad, E. Khneisser, T. Mahmoud, E. Yaacoub et al., “Intelligent eye: A mobile application for assisting blind people,” in IEEE Middle East and North Africa Communications Conf. (MENACOMM), Jounieh, pp. 1–6, 2018. [Google Scholar]
4. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
5. N. B. Ibrahim, M. M. Selim and H. H. Zayed, “An automatic arabic sign language recognition system (ArSLRS),” Journal of King Saud University-Computer and Information Sciences, vol. 30, no. 4, pp. 470–477, 2018. [Google Scholar]
6. M. Al Duhayyim, H. M. Alshahrani, F. N. Al-Wesabi, M. A. Al-Hagery, A. M. Hilal et al., “Intelligent machine learning based EEG signal classification model,” Computers, Materials & Continua, vol. 71, no. 1, pp. 1821–1835, 2022. [Google Scholar]
7. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
8. A. L. Valvo, D. Croce, D. Garlisi, F. Giuliano, L. Giarré et al., “A navigation and augmented reality system for visually impaired people,” Sensors, vol. 21, no. 9, pp. 3061, 2021. [Google Scholar] [PubMed]
9. H. Luqman and S. A. Mahmoud, “Automatic translation of Arabic text-to-Arabic sign language,” Universal Access in the Information Society, vol. 18, no. 4, pp. 939–951, 2019. [Google Scholar]
10. R. Jafri and M. Khan, “User-centered design of a depth data based obstacle detection and avoidance system for the visually impaired,” Human-Centric Computing and Information Sciences, vol. 8, no. 1, pp. 1–30, 2018. [Google Scholar]
11. Y. S. Su, C. H. Chou, Y. L. Chu and Z. Y. Yang, “A finger-worn device for exploring chinese printed text with using cnn algorithm on a micro IoT processor,” IEEE Access, vol. 7, pp. 116529–116541, 2019. [Google Scholar]
12. M. Brour and A. Benabbou, “ATLASLang MTS 1: Arabic text language into arabic sign language machine translation system,” Procedia Computer Science, vol. 148, no. 6, pp. 236–245, 2019. [Google Scholar]
13. T. Kanan, O. Sadaqa, A. Aldajeh, H. Alshwabka, S. AlZu’bi et al., “A review of natural language processing and machine learning tools used to analyze arabic social media,” in IEEE Jordan Int. Joint Conf. on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, pp. 622–628, 2019. [Google Scholar]
14. S. Aly and W. Aly, “DeepArSLR: A novel signer-independent deep learning framework for isolated Arabic sign language gestures recognition,” IEEE Access, vol. 8, pp. 83199–83212, 2020. [Google Scholar]
15. M. Araya and M. Alehegn, “Text to speech synthesizer for tigrigna linguistic using concatenative based approach with LSTM model,” Indian Journal of Science and Technology, vol. 15, no. 1, pp. 19–27, 2022. [Google Scholar]
16. O. A. Berkhemer, P. S. Fransen, D. Beumer, L. A. V. D. Berg, H. F. Lingsma et al., “A randomized trial of intraarterial treatment for acute ischemic stroke,” The New England Journal of Medicine, vol. 372, no. 1, pp. 11–20, 2015. [Google Scholar] [PubMed]
17. M. Eltay, A. Zidouri and I. Ahmad, “Exploring deep learning approaches to recognize handwritten arabic texts,” IEEE Access, vol. 8, pp. 89882–89889, 2020. [Google Scholar]
18. R. Alzohairi, R. Alghonaim, W. Alshehri and S. Aloqeely, “Image based arabic sign language recognition system,” International Journal of Advanced Computer Science and Applications, vol. 9, no. 3, pp. 185–194, 2018. [Google Scholar]
19. J. X. Chen, D. M. Jiang and Y. N. Zhang, “A hierarchical bidirectional GRU model with attention for EEG-based emotion classification,” IEEE Access, vol. 7, pp. 118530–118540, 2019. [Google Scholar]
20. H. M. Lynn, S. B. Pan and P. Kim, “A deep bidirectional GRU network model for biometric electrocardiogram classification based on recurrent neural networks,” IEEE Access, vol. 7, pp. 145395–145405, 2019. [Google Scholar]
21. I. H. Ali, Z. Mnasri and Z. Lachiri, “DNN-based grapheme-to-phoneme conversion for Arabic text-to-speech synthesis,” International Journal of Speech Technology, vol. 23, no. 3, pp. 569–584, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools