
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Political Optimizer with Probabilistic Neural Network-Based Arabic Comparative Opinion Mining
1 Prince Saud AlFaisal Institute for Diplomatic Studies, Riyadh, 13369, Saudi Arabia
2 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Makkah, 24211, Saudi Arabia
4 Research Centre, Future University in Egypt, New Cairo, 11845, Egypt
5 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, 16242, Saudi Arabia
* Corresponding Author: Abdelwahed Motwakel. Email:
Intelligent Automation & Soft Computing 2023, 36(3), 3121-3137. https://doi.org/10.32604/iasc.2023.033915
Received 01 July 2022; Accepted 14 October 2022; Issue published 15 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Opinion Mining (OM) studies in Arabic are limited though it is one of the most extensively-spoken languages worldwide. Though the interest in OM studies in the Arabic language is growing among researchers, it needs a vast number of investigations due to the unique morphological principles of the language. Arabic OM studies experience multiple challenges owing to the poor existence of language sources and Arabic-specific linguistic features. The comparative OM studies in the English language are wide and novel. But, comparative OM studies in the Arabic language are yet to be established and are still in a nascent stage. The unique features of the Arabic language make it essential to expand the studies regarding the Arabic text. It contains unique features such as diacritics, elongation, inflection and word length. The current study proposes a Political Optimizer with Probabilistic Neural Network-based Comparative Opinion Mining (POPNN-COM) model for the Arabic text. The proposed POPNN-COM model aims to recognize comparative and non-comparative texts in Arabic in the context of social media. Initially, the POPNN-COM model involves different levels of data pre-processing to transform the input data into a useful format. Then, the pre-processed data is fed into the PNN model for classification and recognition of the data under different class labels. At last, the PO algorithm is employed for fine-tuning the parameters involved in this model to achieve enhanced results. The proposed POPNN-COM model was experimentally validated using two standard datasets, and the outcomes established the promising performance of the proposed POPNN-COM method over other recent approaches.Keywords
Social media has emerged as a powerful platform for obtaining different types of data from different fields. The advancement and the application of computerized techniques in the extraction of information and knowledge from Arabic text in mass media are still in a nascent stage due to the complex nature of the language [1]. Various techniques such as normalization, learning algorithms, text cleaning and the Natural Language Processing (NLP) method have recently evolved. Arabic is a Semitic language that closely relates to Islam and the Arabic culture. The Arabic language is used to write the verses in the holy book of Muslims [2]. It is an official language for 422 million people spread across the globe. Along with cultural uniqueness and rich history, the Arabic language has a distinct structure and nature compared to other languages, such as English. For instance, Arabic is written from right to left [3,4]. With a total of 28 letters, the language has three vowels and diacritics. The shapes of the letters in Arabic text vary under their position in a word and the absence of capitalization [5]. Arabic is a structured language with a large vocabulary. Its morphology serves a significant role. Further, the words are frequently built in a complicated manner [6,7] and might contain agglutinative words, drop features and affixes. The Arabic language’s characteristics and complexities make its opinion mining process a highly challenging one [8].
Businesses acquire insights about their customer purchase behaviour to gain an advantage over their competitors. These insights explain why customers are not purchasing a company’s products and prefer their competitors’ products [9]. Such crucial information gives the companies an overview of whether a new product or a new service is liked or not by the consumer. Public Facebook review pages, customer product review pages and blogs are filled with opinions of the end users instead of the entities that compare the outcomes against their competitors [10,11]. Mostly, the political reviews that compare a government’s performance are important for the decision-makers in order to ensure that the people find their government’s performance satisfactory and the country remains economically stable. This study examined different types of comparative sentences used in Arabic to extract and analyse the sentiments expressed in the public domain [12]. Comparative relations denote the extraction of the comparative opinion components. Many research works conducted in the comparative opinion mining domain are concerned with identifying comparative relationships and general classification of such relationships under pre-defined comparative classes [13]. Even though such efforts are highly significant in opinion mining, it becomes insufficient when the comparative opinions are recognized in relation to the argument [14]. Numerous research articles have been published on comparative opinions in the English language. However, the studies concerning the Arabic language focused only on the detection of comparative relations so far.
Aljedani et al. [15] proposed a hierarchical multi-label classification framework for the Arabic language. This study projected a Hierarchical Multi-label Arabic Text Classification (HMATC) technique with Machine Learning (ML). The study evaluated the impact of the feature set dimensions and the Feature Selection (FS) approaches on the classification performance. The outcomes of the Hierarchy of Multilabel ClassifiER (HOMER) approach were maximized by analysing different sets of multi-label classifiers, clustering methods and various clusters to enhance the performance of the hierarchical classification process. Boukil et al. [16] introduced a creative approach to Arabic text classification in which an Arabic stemming technique was used for extraction, selection and reducing the required features. Afterwards, the Term Frequency-Inverse Document Frequency (TF-IDF) method was leveraged as a feature weighting algorithm. At last, CNN, a Deep Learning technique, was used for classification. Though this technique is highly effective in other domains like pattern recognition and image processing, it is hardly utilized in text mining.
Bahassine et al. [17] modelled an enhanced algorithm for the classification of Arabic texts in which the Chi-square Feature Selection (FS) (referred to here as ImpCHI) method was used to enhance the classification performance. The study compared the outcomes of the enhanced chi-square method using three conventional FS metrics: the Chi-square method, mutual information and the information gain approach. Chantar et al. [18] projected an enhanced binary Grey Wolf Optimizer (GWO) wrapper FS method to handle the Arabic text classification process appropriately. The presented binary GWO was helpful as a wrapper-related FS method. The outcomes of the projected technique were compared with that of the established learning methods such as the Decision Tree (DT), k-Nearest Neighbour (KNN), Naïve Bayes (NB) and the Support Vector Machine (SVM) model. Muaad et al. [19] modelled a method to recognize and represent the Arabic text at the character level with the help of a Deep Convolutional Neural Network (CNN) method. In this study, the CNN method was authenticated through a 5-fold cross-validation test for classifying the Arabic text documents. In addition, the authors employed a mechanism to evaluate the Arabic texts. Finally, the ArCAR mechanism revealed the proposed method’s capability in character-level Arabic text classification.
The current study proposes a Political Optimizer with Probabilistic Neural Network-based Comparative Opinion Mining (POPNN-COM) model to classify the Arabic text. The goal of the proposed POPNN-COM model is to recognize comparative and non-comparative texts in Arabic social media content. Initially, the POPNN-COM model involves different levels of data pre-processing to transform the input data into a useful format. For classification, the pre-processed data is fed into the PNN model to recognize the class labels. At last, the PO algorithm is employed for fine-tuning the parameters involved in the model to achieve enhanced results. The proposed POPNN-COM model was experimentally validated using two datasets, and the results were discussed under different measures.
In the current study, a novel POPNN-COM model has been developed for opinion mining from the Arabic text. The goal of the proposed POPNN-COM model is to recognize comparative and non-comparative texts in the context of Arabic social media content.
In this stage, the POPNN-COM model involves different levels of data pre-processing to transform the input data into a useful format. The pre-processing stage aims to remove the noise from the text and reduce the number of features during text presentation. This process results in fewer storage requirements and high classification efficiency. The text pre-processing stage involves multiple sub-processes for the Arabic language. At first, the symbols such as ‘‘#” (hashtag), URLs, ‘‘@” (mention), EOL (End Of Line) and RT (retweet) are removed. Then, the Arabic stopwords are eliminated with the help of the Python NLTK (Natural Language Toolkit) library. The purpose of normalization is to convert every letter variant to a single form (viz., Ï !i). This process is applied to unify different letter formats, such as ya, alif and waw in Arabic. The speech effects and the single letters are repeatedly reiterated. For example, ‘Hellooo’ is one of the common features that appear in social media posts, which is mainly intended for emphasizing a conversation. Therefore, if such terms are removed, it produces a single form of the words, i.e., ‘Hellooo’ and ‘Helloooooo’ and so on, are mapped altogether against the word, ‘Hello’.
TF-IDF is a weighting factor that reflects the significance of a word in a corpus document. It measures a certain word’s overall number of occurrences in the provided document and is termed ‘Term Frequency’. Nonetheless, certain words, such as the stop-words, commonly emerge in every single document; such content should be discounted in a systematic manner. This procedure is named ‘Inverse Document Frequency’. The lesser the value is, as a sign of differentiating a specific document, the higher the amount of documents will be, in which the word appears. Then, the TF-IDF approach is applied as a part of the Scikit-learn library and is evaluated as given below [20].
Now, the number of times a word
2.2 Opining Mining Using PNN Model
For classification, the pre-processed data is fed into the PNN model to recognize the class labels. The PNN method is the most commonly-utilized data mining approach and is employed in several pattern recognition and classification problems [21]. In these kinds of Neural networks (NN), the operation is pre-arranged in a multi-layered network that contains four layers such as the output layer, input layer, pattern layer and summation layer. In the input layer, a dimension
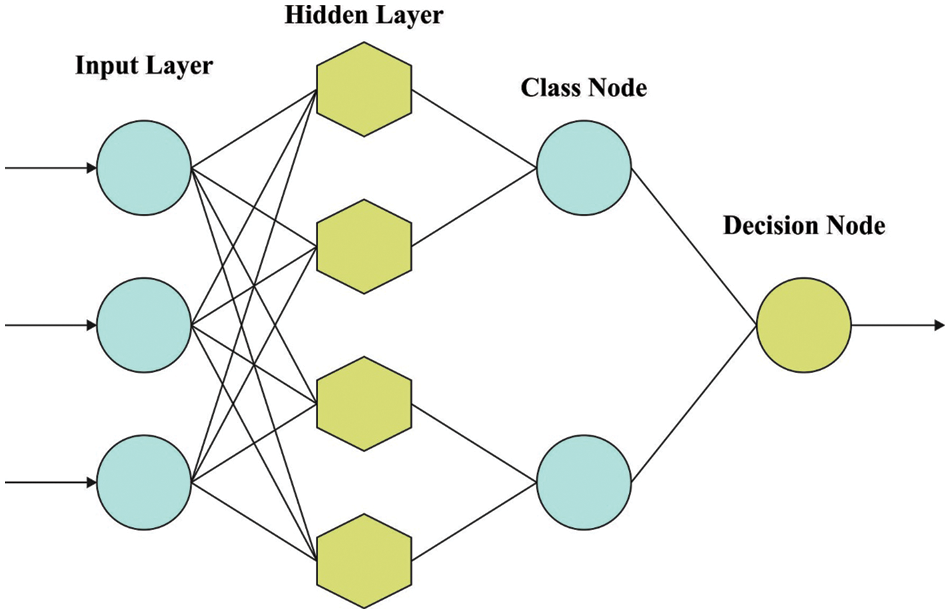
Figure 1: Architecture of the PNN approach
The operation formula of the PNN method includes all four important layers.
In the input layer, all the neurons have a prediction parameter. Its values are fed into every neuron in the hidden layer.
In the pattern layer, for all the training samples, a single layer formulates the product associated with an input vector
In Eq. (2),
The summation layer aggregates the enhanced values of all the input classes and produces the network output as a probability vector (Eq. (3)):
The output layer produces different classes that depend on the decision classes, such as
This node possesses a single weight
In Eq. (5),
2.3 Parameter Optimization Using PO
At last, the PO algorithm is employed for fine-tuning the parameters involved in the model to enhance the outcomes. The PO algorithm is an intelligent optimization technique developed based on political election procedures followed by human society [22]. In the PO algorithm, every party member is regarded as a solution candidate. The election performance of the party members is regarded as the assessment function. The PO algorithm searches for an optimum solution with the help of a multiple-phase iteration technique. Initially, the whole population encompassing
Here, every party member acts as an election candidate. As a result, the whole population is viewed as
Besides, the leader of the
Campaigning is a fundamental phase in the election process and is accountable for the updated position of the search agent. In this work, a particular presentation is that a party member changes their position based on their leader
In this expression,

Figure 2: Steps involved in the PO algorithm
The party-switching stage is executed to create a balance between the exploitation and the exploration phases. It presents an adaptive variable
Here, the fitness of every solution candidate is described, whereas the party leader and the constituency winner are upgraded.
The party-switching stage aims to alter a party’s perception, whereas the parliamentary affair stage is the modification of a constituency’s perspectives. A constituency winner interacts with others to enhance their fitness values. Every constituency winner uses the following formula to update their location based on the rest of the arbitrarily-designated constituencies. It is to be noted that the movement is employed when the fitness of

The current chapter assesses the proposed POPNN-COM model’s performance using two datasets, Corpus and Corpus+. The details of the datasets are given in Table 1. For experimental validation, ten-fold cross-validation was executed.
Fig. 3 demonstrates the confusion matrices generated by the POPNN-COM model on the Corpus dataset using distinct Training (TR) and Testing (TS) datasets. The figure indicates that the proposed POPNN-COM model properly recognized both CT and the NCT samples in all aspects. Table 2 and Fig. 4 portray the CT and the NCT classification outcomes achieved by the proposed POPNN-COM model on the Corpus dataset. Upon the entire dataset, the proposed POPNN-COM model produced average

Figure 3: Confusion matrices of the POPNN-COM approach on Corpus dataset (a) Entire dataset, (b) 70% of the TR data and (c) 30% of the TS data
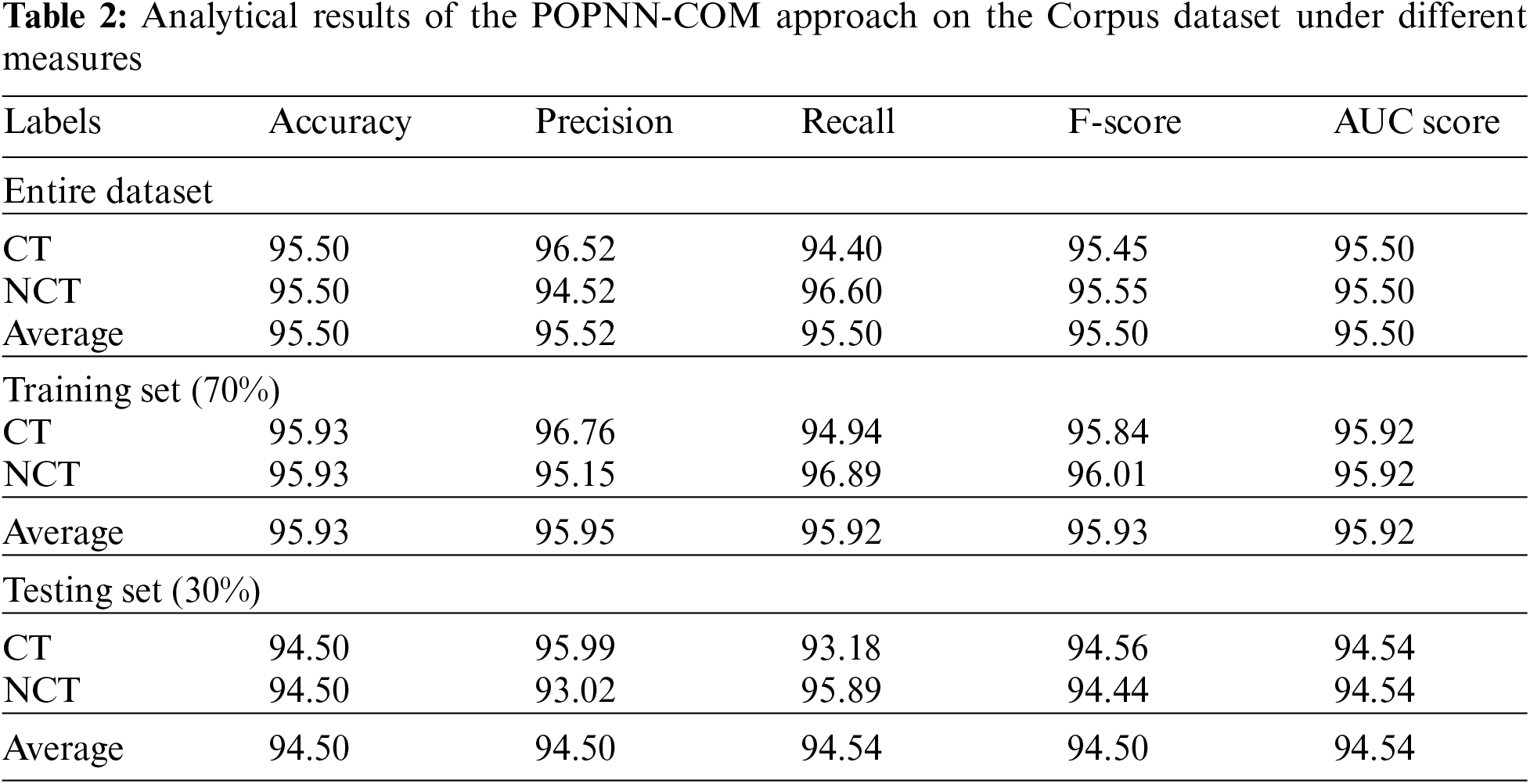

Figure 4: Analytical results of the POPNN-COM approach on the Corpus dataset
Both Training Accuracy (TA) and Validation Accuracy (VA) values attained by the proposed POPNN-COM method on Corpus dataset are illustrated in Fig. 5. The experimental outcomes denote that the proposed POPNN-COM technique achieved the maximal TA and VA values. In contrast, the VA values were higher than the TA values.

Figure 5: TA and VA analyses results of the POPNN-COM approach on the Corpus dataset
Both Training Loss (TL) and Validation Loss (VL) values, achieved by the proposed POPNN-COM approach on Corpus dataset, are shown in Fig. 6. The experimental outcomes imply that the presented POPNN-COM algorithm accomplished the least TL and VL values. In contrast, the VL values were lesser than the TL values.

Figure 6: TL and VL analyses results of the POPNN-COM approach on Corpus dataset
A clear precision-recall analysis was conducted on the proposed POPNN-COM method using the Corpus dataset, and the results are portrayed in Fig. 7. The figure indicates that the proposed POPNN-COM method produced the enhanced precision-recall values under all the classes.

Figure 7: Precision-recall analysis results of the POPNN-COM approach on the Corpus dataset
Fig. 8 establishes the confusion matrices created by the proposed POPNN-COM model on Corpus+ dataset. The figure represents that the proposed POPNN-COM model properly recognized both CT and the NCT samples in all aspects.
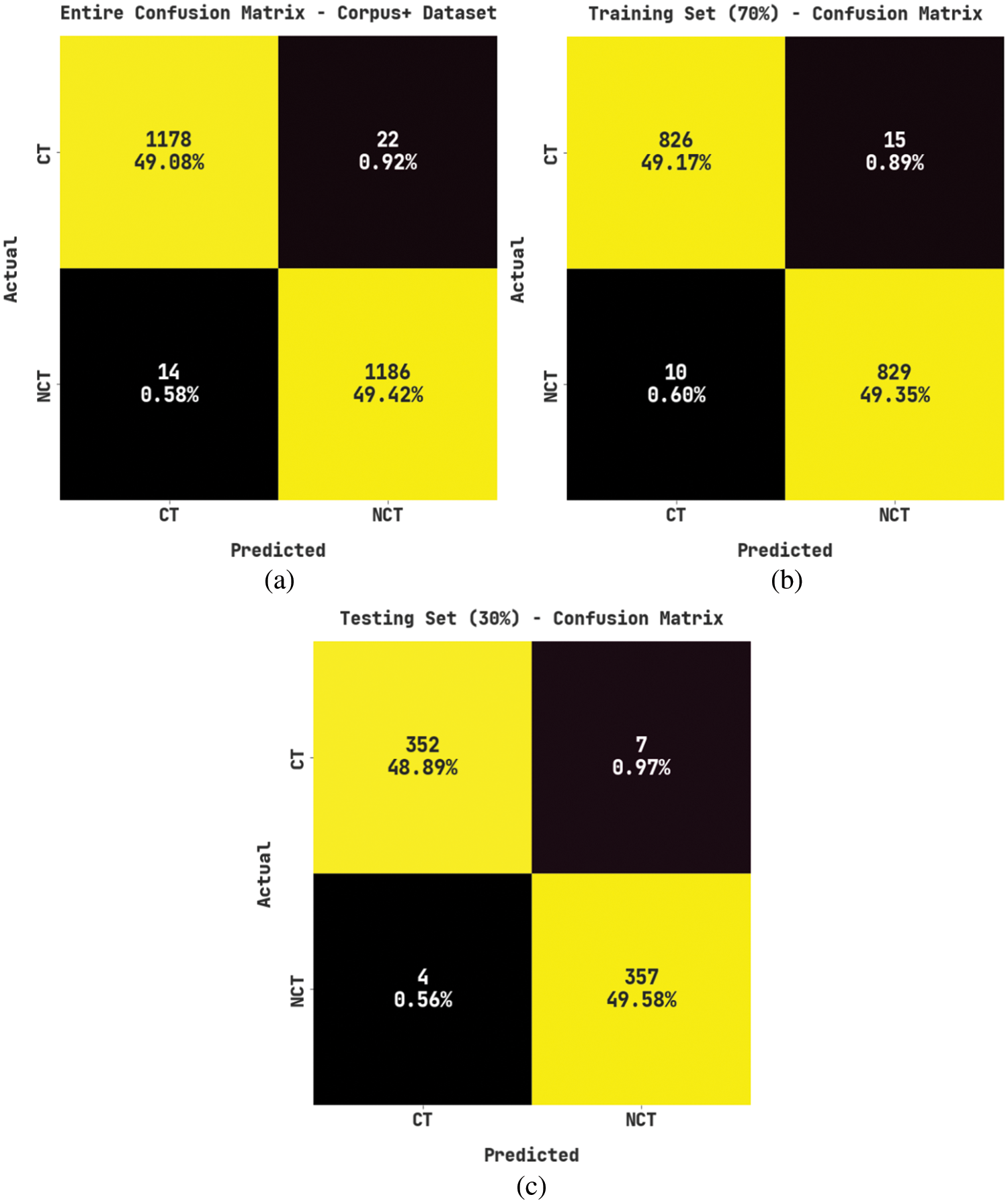
Figure 8: Confusion matrices of the POPNN-COM approach on Corpus+ dataset (a) Entire dataset, (b) 70% of the TR data and (c) 30% of the TS data
Table 3 and Fig. 9 signify the CT and the NCT classification outcomes achieved by the proposed POPNN-COM model on Corpus+ dataset. Upon the entire dataset, the proposed POPNN-COM model produced average
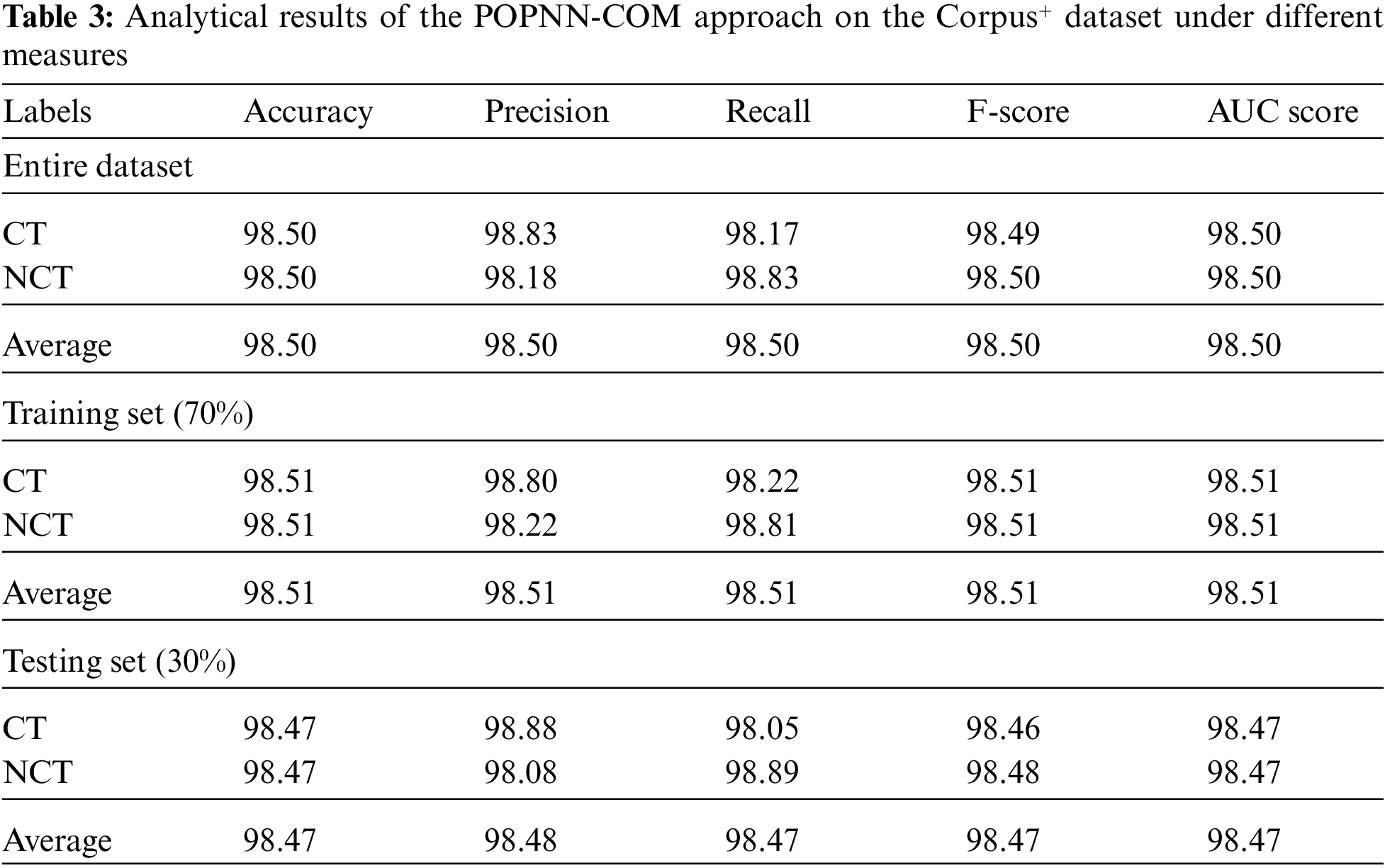

Figure 9: Analytical results of the POPNN-COM approach on the Corpus+ dataset
Both TA and VA values, obtained by the proposed POPNN-COM method on the Corpus+ dataset, are illustrated in Fig. 10. The experimental outcomes portray that the proposed POPNN-COM technique achieved the maximal TA and VA values. In contrast, the VA values were higher than the TA values.

Figure 10: TA and VA analyses results of the POPNN-COM approach on the Corpus+ dataset
Both TL and VL values, achieved by the presented POPNN-COM approach on the Corpus+ dataset, are established in Fig. 11. The experimental outcomes denote that the proposed POPNN-COM algorithm accomplished the least TL and VL values. In contrast, the VL values were lower than the TL values.

Figure 11: TL and VL analyses results of the POPNN-COM approach on the Corpus+ dataset
Table 4 showcases the comparative analytical results achieved by the proposed POPNN-COM technique and other existing techniques on the Corpus+ dataset. With respect to
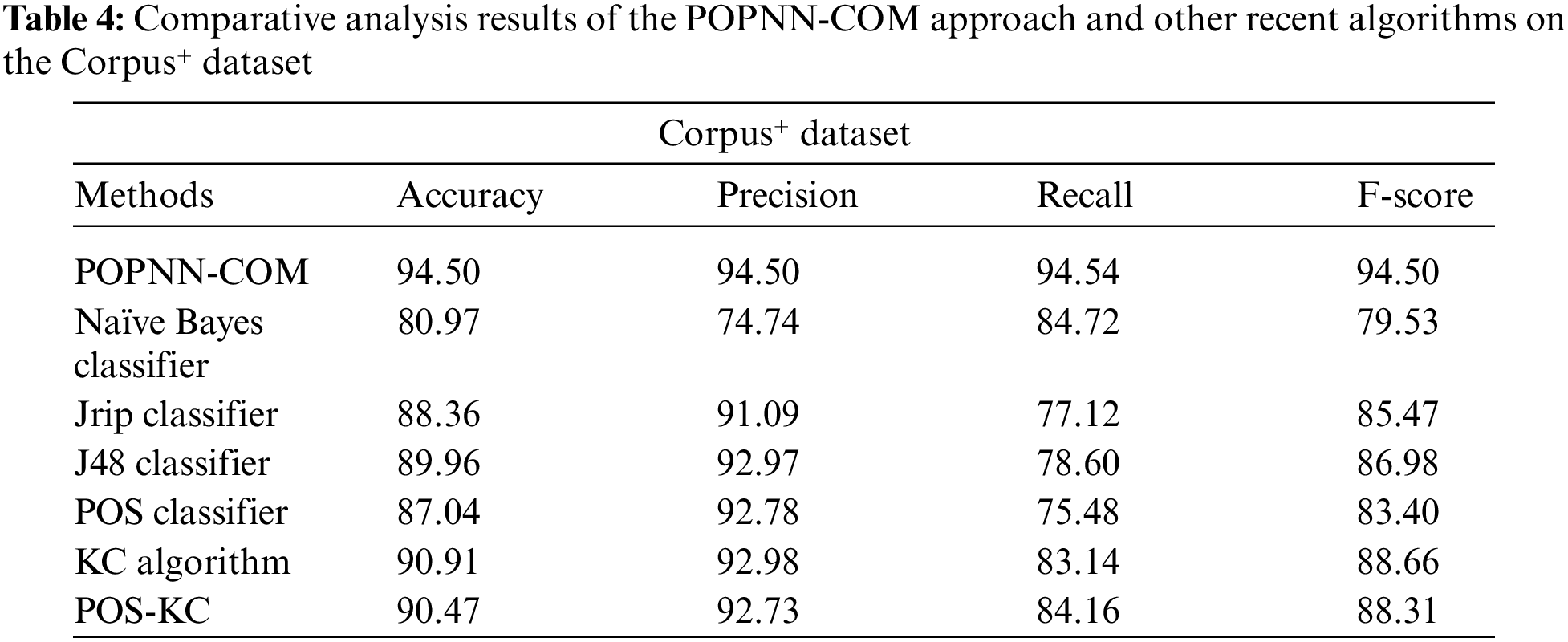
Table 5 portrays the comparison study outcomes of the proposed POPNN-COM technique and other existing techniques on the Corpus+ dataset. With respect to
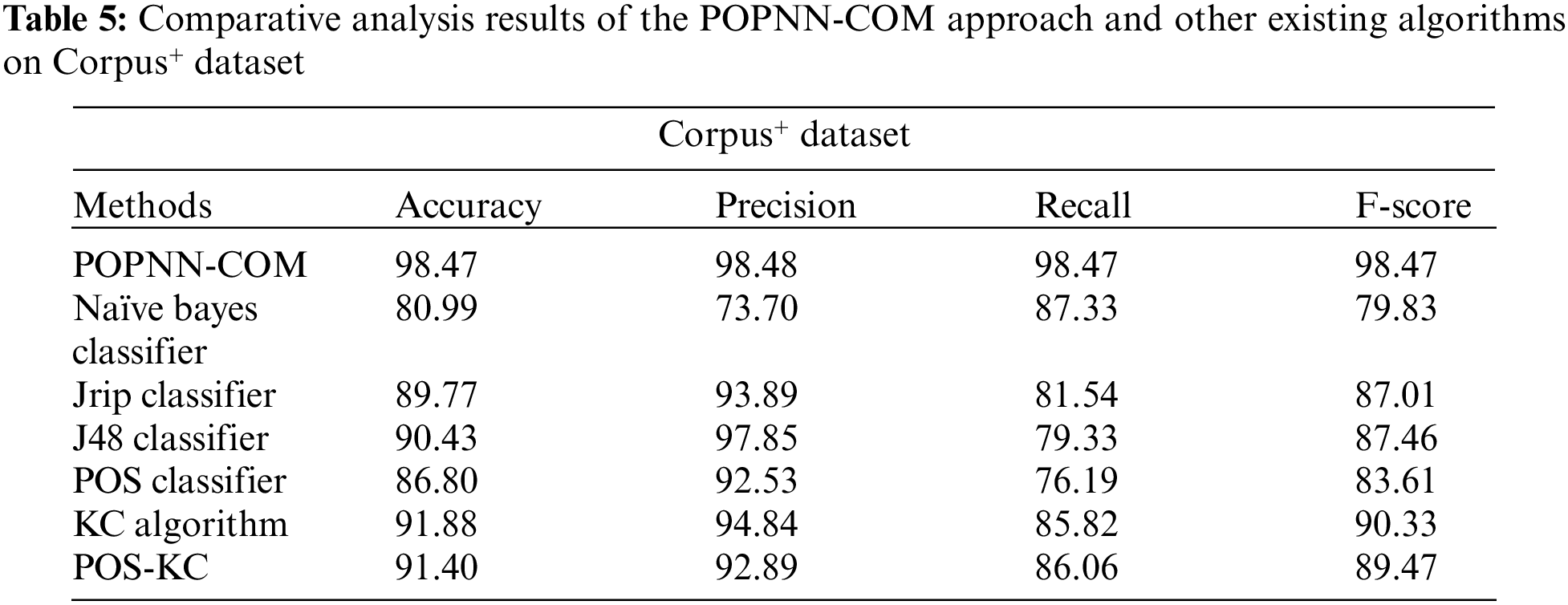
In the current study, a novel POPNN-COM model has been developed for opinion mining from the Arabic text. The proposed POPNN-COM model aims to recognize comparative and non-comparative texts in Arabic social media content. Initially, the POPNN-COM model involves different levels of data pre-processing to transform the input data into a useful format. For classification, the pre-processed data is fed into the PNN model to recognize the class labels. At last, the PO algorithm is employed for fine-tuning the parameters involved in the model to enhance the results. The proposed POPNN-COM model was experimentally validated using two datasets, and the outcomes establish the promising performance of the presented POPNN-COM algorithm over other recent approaches. Thus, the POPNN-COM model has been established as an effective tool for comparative opinion mining. It can be used in the future for real-time applications. Further, future studies can also extend the presented model for hate speech detection.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4310373DSR56.
Conflicts of Interest: The authors declare they have no conflicts of interest to report regarding the present study.
References
1. A. Elnagar, R. Al-Debsi and O. Einea, “Arabic text classification using deep learning models,” Information Processing & Management, vol. 57, no. 1, pp. 102121, 2020. [Google Scholar]
2. S. L. M. Sainte and N. Alalyani, “Firefly algorithm based feature selection for arabic text classification,” Journal of King Saud University-Computer and Information Sciences, vol. 32, no. 3, pp. 320–328, 2020. [Google Scholar]
3. A. M. F. Al-Sbou, “A survey of Arabic text classification models,” International Journal of Informatics and Communication Technology, vol. 8, no. 1, pp. 25–28, 2018. [Google Scholar]
4. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of arabic text,” Computers Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
5. A. Wahdan, S. A. L. Hantoobi, S. A. Salloum and K. Shaalan, “A systematic review of text classification research based on deep learning models in Arabic language,” International Journal of Electrical and Computer Engineering, vol. 10, no. 6, pp. 6629, 2020. [Google Scholar]
6. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of arabic text transmitted via internet,” Computers Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
7. M. A. Ahmed, R. A. Hasan, A. H. Ali and M. A. Mohammed, “The classification of the modern arabic poetry using machine learning,” TELKOMNIKA, vol. 17, no. 5, pp. 2667, 2019. [Google Scholar]
8. F. N. Al-Wesabi, “A smart english text zero-watermarking approach based on third-level order and word mechanism of Markov model,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1137–1156, 2020. [Google Scholar]
9. A. El Kah and I. Zeroual, “The effects of pre-processing techniques on Arabic text classification,” International Journal of Advanced Trends in Computer Science and Engineering, vol. 10, no. 1, pp. 41–48, 2021. [Google Scholar]
10. F. N. Al-Wesabi, A. Abdelmaboud, A. A. Zain, M. M. Almazah and A. Zahary, “Tampering detection approach of arabic-text based on contents interrelationship,” Intelligent Automation & Soft Computing, vol. 27, no. 2, pp. 483–498, 2021. [Google Scholar]
11. H. El Rifai, L. Al Qadi and A. Elnagar, “Arabic text classification: The need for multi-labeling systems,” Neural Computing and Applications, vol. 34, no. 2, pp. 1135–1159, 2022. [Google Scholar] [PubMed]
12. F. S. Al-Anzi and D. AbuZeina, “Beyond vector space model for hierarchical Arabic text classification: A Markov chain approach,” Information Processing & Management, vol. 54, no. 1, pp. 105–115, 2018. [Google Scholar]
13. A. Adel, N. Omar, M. Albared and A. Al-Shabi, “Feature selection method based on statistics of compound words for arabic text classification,” The International Arab Journal of Information Technology, vol. 16, no. 2, pp. 178–185, 2019. [Google Scholar]
14. F. A. Abdulghani and N. A. Z. Abdullah, “A survey on arabic text classification using deep and machine learning algorithms,” Iraqi Journal of Science, vol. 63, no. 1, pp. 409–419, 2022. [Google Scholar]
15. N. Aljedani, R. Alotaibi and M. Taileb, “HMATC: Hierarchical multi-label Arabic text classification model using machine learning,” Egyptian Informatics Journal, vol. 22, no. 3, pp. 225–237, 2021. [Google Scholar]
16. S. Boukil, M. Biniz, F. Adnani, L. Cherrat and A. Moutaouakkil, “Arabic text classification using deep learning technics,” International Journal of Grid and Distributed Computing, vol. 11, no. 9, pp. 103–114, 2018. [Google Scholar]
17. S. Bahassine, A. Madani, M. Al-Sarem and M. Kissi, “Feature selection using an improved Chi-square for Arabic text classification,” Journal of King Saud University-Computer and Information Sciences, vol. 32, no. 2, pp. 225–231, 2020. [Google Scholar]
18. H. Chantar, M. Mafarja, H. Alsawalqah, A. A. Heidari, I. Aljarah et al., “Feature selection using binary grey wolf optimizer with elite-based crossover for Arabic text classification,” Neural Computing and Applications, vol. 32, no. 16, pp. 12201–12220, 2020. [Google Scholar]
19. A. Y. Muaad, M. A. Al-antari, S. Lee and H. J. Davanagere, “A novel deep learning arcar system for arabic text recognition with character-level representation,” in Proc. of The 1st Int. Electronic Conf. on Algorithms, pp. 14, 2021. [Google Scholar]
20. M. C. Manning, D. K. Chou, B. M. Murphy, R. W. Payne and D. S. Katayama, “Stability of protein pharmaceuticals: An update,” Pharmaceutical Research, vol. 27, no. 4, pp. 544–575, 2010. [Google Scholar] [PubMed]
21. G. Capizzi, G. L. Sciuto, C. Napoli, D. Polap and M. Wozniak, “Small lung nodules detection based on fuzzy-logic and probabilistic neural network with bioinspired reinforcement learning,” IEEE Transactions on Fuzzy Systems, vol. 28, no. 6, pp. 1178–1189, 2020. [Google Scholar]
22. Q. Askari and I. Younas, “Political optimizer based feedforward neural network for classification and function approximation,” Neural Processing Letters, vol. 53, no. 1, pp. 429–458, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools