
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

B-Spline-Based Curve Fitting to Cam Pitch Curve Using Reinforcement Learning
1 School of Physics and Information Engineering, Minnan Normal University, Zhang Zhou, Fujian, 363000, China
2 Department of Electrical and Computer Engineering, University of Nevada, Las Vegas, NV, 89154, USA
* Corresponding Author: Tianding Chen. Email:
Intelligent Automation & Soft Computing 2023, 36(2), 2145-2164. https://doi.org/10.32604/iasc.2023.035555
Received 25 August 2022; Accepted 01 November 2022; Issue published 05 January 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Directly applying the B-spline interpolation function to process plate cams in a computer numerical control (CNC) system may produce verbose tool-path codes and unsmooth trajectories. This paper is devoted to addressing the problem of B-spline fitting for cam pitch curves. Considering that the B-spline curve needs to meet the motion law of the follower to approximate the pitch curve, we use the radial error to quantify the effects of the fitting B-spline curve and the pitch curve. The problem thus boils down to solving a difficult global optimization problem to find the numbers and positions of the control points or data points of the B-spline curve such that the cumulative radial error between the fitting curve and the original curve is minimized, and this problem is attempted in this paper with a double deep Q-network (DDQN) reinforcement learning (RL) algorithm with data points traceability. Specifically, the RL environment, actions set and current states set are designed to facilitate the search of the data points, along with the design of the reward function and the initialization of the neural network. The experimental results show that when the angle division value of the actions set is fixed, the proposed algorithm can maximize the number of data points of the B-spline curve, and accurately place these data points to the right positions, with the minimum average of radial errors. Our work establishes the theoretical foundation for studying spline fitting using the RL method.Keywords
Plate cam is a significant part of mechanical design and manufacturing field [1]. It can not only help virtually specify any desirable output function, but also be used to ensure a curved surface to generate the output function of the follower in motion. The polynomial and simple harmonic motion (SHM) expressions with third-order or higher continuity are widely applied for the cam design [2]. As the computer numerical control (CNC) system does not come with a polynomial or SHM interpolation function, it is essential to adopt a computer-aided manufacturing (CAM) tool to discretize the cam profile into several linear segments presented as a sequence of G01 G-codes. Unfortunately, the tool-path code tends to be verbose and the G01 tool path does not go beyond G0 continuity, which may give rise to feed rate and acceleration fluctuation and produce machinery vibration and unexpected slowdowns during the process [3].
To smoothly match the CNC curves, and improve the quality of B-spline tool paths, Min et.al. [4] proposed a method that takes into account the arc-length-based parameter setting, G2 continuity, and the numerical measure. In another study, Jiang put forward a set of approaches for contour error prediction and compensation on the basis of deep learning and reinforcement learning (RL) [5]. Under the chord error constraint, Bi [6] presented a general, fast and robust B-spline fitting scheme for high-speed interpolation of a micro-line tool path. In [7], a progressive and iterative approximation for least squares (LSPIA) method is applied to avoid numerical instability, and lessen chord errors by applying stretching energy terms. All the above studies adopted online or offline optimization approaches to smooth the B-spline tool path locally or globally when the CNC is in operation. Actually, it is preferable to convert the polynomial or SHM expression of the cam into a B-spline expression before CNC machining so that one can directly use the spline interpolation function to operate the plate cam. To this end, this paper concentrates on the B-spline fitting of the plate cam pitch curve.
For a B-spline curve with a fixed degree, it is a complex nonlinear optimization problem to deal with the numbers and positions of knots or control points of the B-spline curve under the error constraints. While fitting the complex heat treatment curves or noise signal curves with multiple data points, the fitting performance is largely impacted by the appropriate numbers and positions of knots [8], and the methods suggested in [9–11], were thus focused on obtaining the numbers and positions of optimized knots, with little discussion on how to obtain these so-called appropriate number and position of data points.
Although one can create a B-spline curve that approximates the pitch curve by placing as many control points as possible, too many control points will lead to lengthy spline parameters, which is almost the same as using a large number of linear segments to approximate the curve. Instead, we intend to create a B-spline curve that meets the error requirements with the smallest possible number of the control points at the right positions. In practical terms, unless enough information about the shape of the original curve can be obtained a priori can one identify the high-quality feature points on the pitch curve [12]. In a nutshell, we can transform the problem of finding the number and position of control points into the problem of finding the number and position of data points on the pitch curve, and use these data points to determine the control points needed to construct the B-spline curve.
In light of the path planning of the unmanned surface vehicle (USV) [13], we shall be able to obtain the relevant data points for the construction of the B-spline curve. In this case, a pitch curve is treated as an ideal path, and an RL algorithm is applied to find an optimal policy that obtains the appropriate number and position of the data points on the ideal path (i.e. the pitch curve). When the actions set is discrete and the number of states set is limited, a Q-learning algorithm can be adopted to find the rough position of the probe point [14]. Similarly, it is possible to use the visualization table of Q-learning to obtain the optimum data points from the pitch curve. Note that accurately estimating the number and position of data points of an unknown curve that can fit a B-spline is mathematically infeasible. Correspondingly, the dimensions of the Q-table built from the numbers and positions of data points should be discrete in nature, and the searching process of the data points should be made model-free. As the framework of deep Q-network (DQN) is basically the same as that of Q-learning, and DQN adopts a neural network to replace the Q-table in Q-learning, DQN is suitable for model-free control problems with discrete variables. Furthermore, the double deep Q-network (DDQN) algorithm with model-free techniques is found to enhance the robustness of curve matching than supervised machine learning algorithms [15]. Compared with the advanced actor-critic (A2C) algorithm of on-policy, the proximal policy optimization (PPO) algorithm of off-policy and the deep deterministic policy gradient (DDPG) algorithm applicable to continuous and high dimensional action space, DDQN algorithm has a simple framework, fast convergence speed, and the ability to deal with the optimal solution of discrete variables under uncertain dimensions. In simple terms, the DDQN algorithm is more suitable for obtaining the optimal policy through the maximum Q-value, and it is thus adopted as the B-spline fitting algorithm of the pitch curve, as proposed in this paper.
In this paper, we propose a DDQN algorithm with data points traceability to cope with the B-spline fitting of the pitch curve. We take the pitch curve expression as the system environment of RL (see Section 2.1), and the agent applies the actions set
2 Modeling and Training Using RL
To find the data points on the pitch curve, the pitch curve expression is inputted to the RL environment. Let
The geometry of plate cam is shown in Fig. 1. Here,
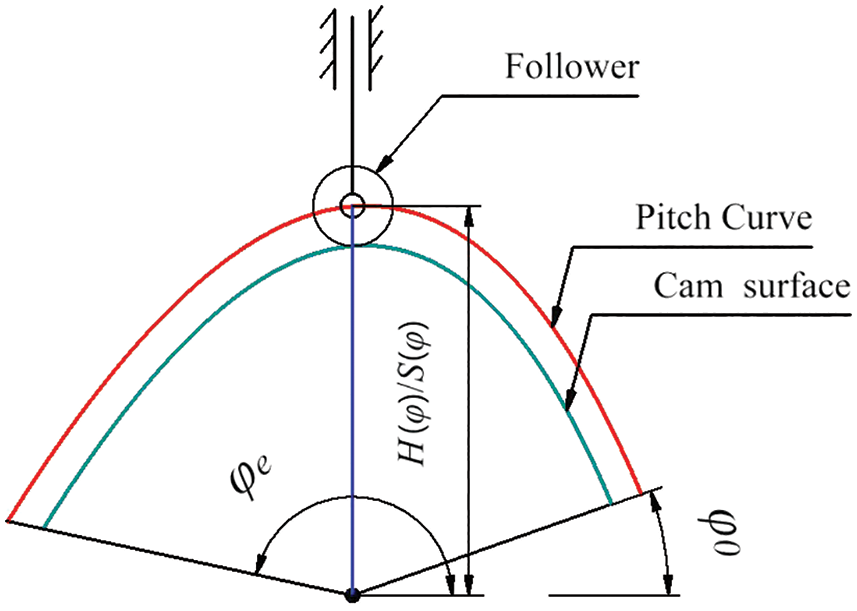
Figure 1: Geometry of plate cam
2.1.2 B-spline Curve Expression
The expression of the B-spline curve is simple and has a favorable local modification. The local shape of the curve can be modified by changing the position of the control points, which meets the fitting requirements of the pitch curve. B-spline curve expression
In Eqs. (3) and (4),
Number of knots:
Knot vector:
B-spline degree:
The number of basis functions
The number of data points
2.1.3 B-Spline Curve Expression as the Inverse of B-spline Knot Vector and Control Points
To ensure that the B-spline curve and the adjacent curve are G1 continuous at the joint points, the first and last data points on B-spline curve are included as the first and last points on the pitch curve. Next, the clamp property of B-spline is applied to make the positions of the first and last control points coincide with the positions of first and last data points. Correspondingly, the value of the first
The non-uniform interior knots
Here,
After the knot vector is determined, the control points of the B-spline can be solved by applying Eqs. (9) and (10) [16]:
Here,
In the next, we will show how to use the RL method to search for the data points with appropriate numbers and positions.
One iteration of RL is shown in Fig. 2. Here the agent starts from the initial point
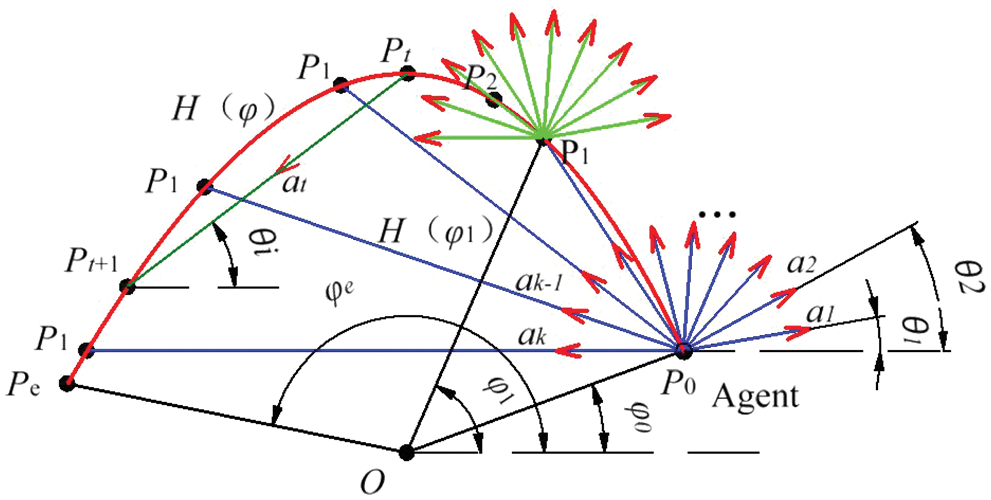
Figure 2: Actions of agent
In Fig. 2, We define the t-th action
Here,
2.2.2 Solving Data Points Using the Actions Set
We assume that in an iterative calculation, the agent selects an action
The two nonlinear equations, Eqs. (12) and (13), are solved with the agent applying action
(1) The cam shaft angle
(2) When the equations have no solution, set
(3) When the updated data point
(4) When the action
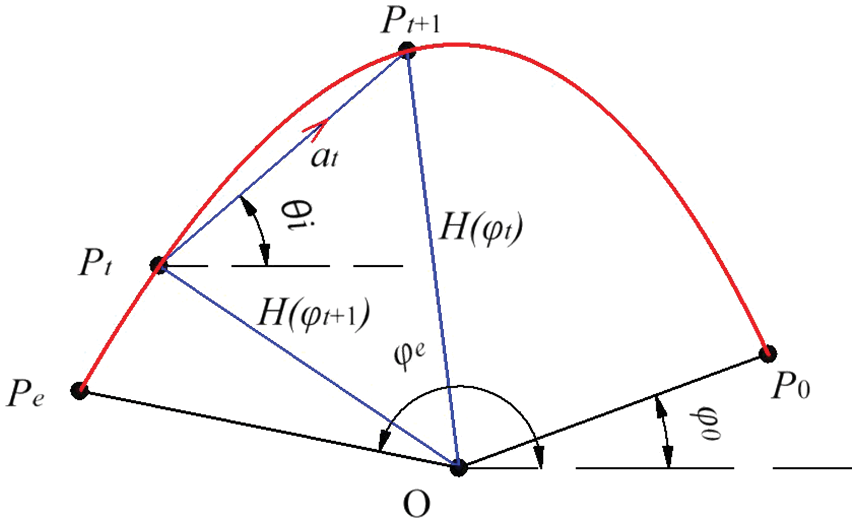
Figure 3: Intersection point that does not conform to counterclockwise direction
Agent adopts a greedy strategy to select the action
Here,
2.3 Current State Feature Model Build
When the agent adopts the actions defined in Section 2.2 to explore the environment defined in Section 2.1, it should obtain as much current information as possible. We define the set of all states
Here,
2.3.2 The Traceback of Data Points
Since the state vector
In Eq. (17),
Due to the mapping correlation between the state vector
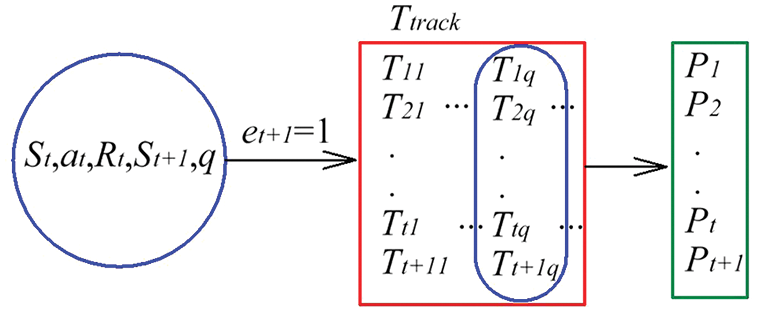
Figure 4: Traceback of the data points through memory
2.4.1 Reward Function for Obtaining the Maximum Number of Data Points
The reward function is of paramount importance to whether or not the agent can learn effective knowledge from the environment and evolve correctly. Regardless whether it is designed as single objective or multi-objective [17], a reward function must meet its control objectives to achieve an expected convergence effect [18]. The control objective in this paper is to construct a spline curve satisfying the fitting error with fewer data points. When the value of
The reward function defined by Eq. (18) indicates that:
(1) If the agent fails to find the first data point, it will be given a penalty −10 which is the same order of magnitude as the reward value. The larger penalty will encourage the agent to find the first data point in the exploration to speed up the RL algorithm assurance that the agent finds the data points effectively;
(2) If the agent finds the data point after the first action, but cannot find the data point in its current action, it will be rewarded with 0;
(3) When the agent finds the data point after the first action and also finds the new data point in current action, it will be given 10 rewards to encourage the agent to obtain as many data points as possible.
The DDQN algorithm using
where
2.4.2 Reward Function for Adjusting the Position of Data Points
Although the reward function
If the eccentricity
We replace the parameter
where
After several experiments, the value of
2.5 The Neural Network of Agent
Since the number of discrete actions of an agent is limited, it is appropriate to choose an artificial neural network (ANN) with a simple structure. Following the method to setting the number of hidden layers in [19] and testing several dissimilar types of network structures and layers, we select the backward propagation ANN that has an input layer, an output layer, and two hidden layers, as depicted in Fig. 5. The 5 inputs
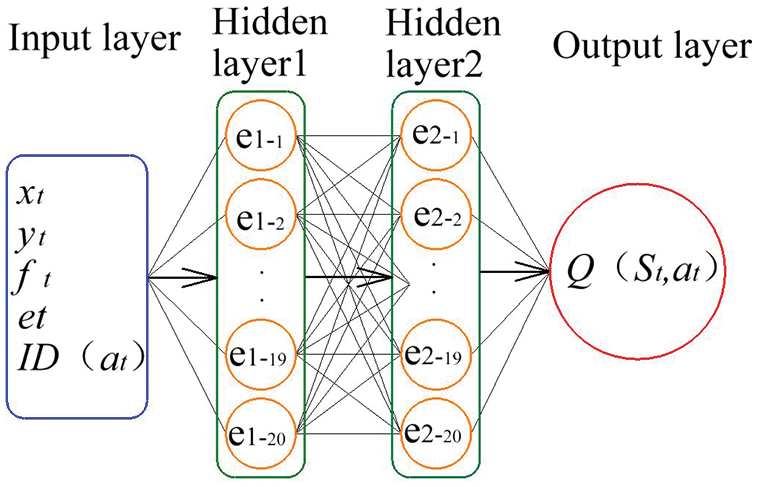
Figure 5: The artificial neural network model
2.5.2 Neural Network Initialization
The initial value of neural network remarkably affects the control performance and training convergence speed [20,21]. At the initial stage of agent searching the data points, if the Q-value estimated by the initial neural network is far from the ideal Q-value, the RL algorithm needs more samples and longer training time to converge.
After several experiments, we find that for constrained input and output variables of the initial neural network, there is no noticeable correlation between them, the convergence speed of the algorithm can be accelerated. Correspondingly, we apply only a small batch of training set to tune the initial parameters of the neural network. In reference to Fig. 5, we define the input and output value range of the training set as:
Here,
We replace
In summary, the DDQN algorithm with data points trajectory traceback function put forward in this paper is detailed in Algorithm 1.

We select the 5th degree polynomial rise function of a plate cam as the experiment curve of B-spline fitting. The basic parameters of the cam are: base circle radius
And the other boundary conditions of the cam are:
By substituting the basic parameters and boundary conditions of the cam into Eq. (1), the pitch curve
The rise segment of pitch curve is shown in Fig. 6.
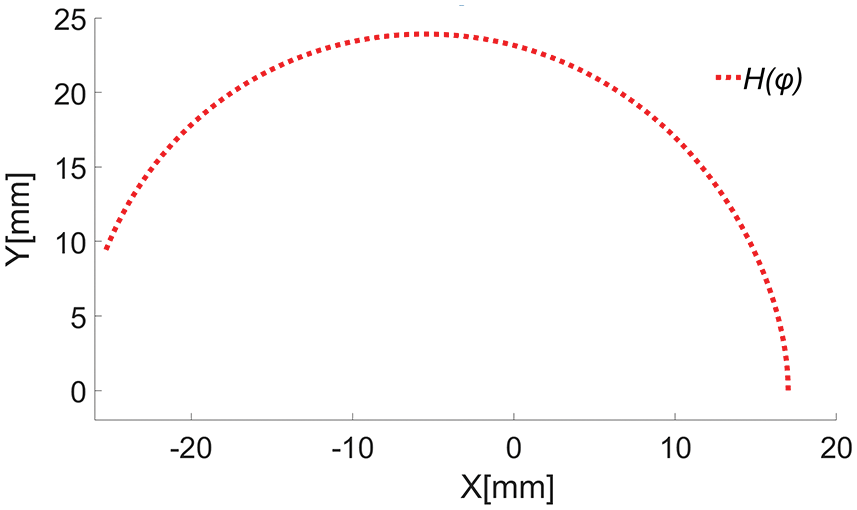
Figure 6: The pitch curve of the plate cam of the rise segment
The actions set
When
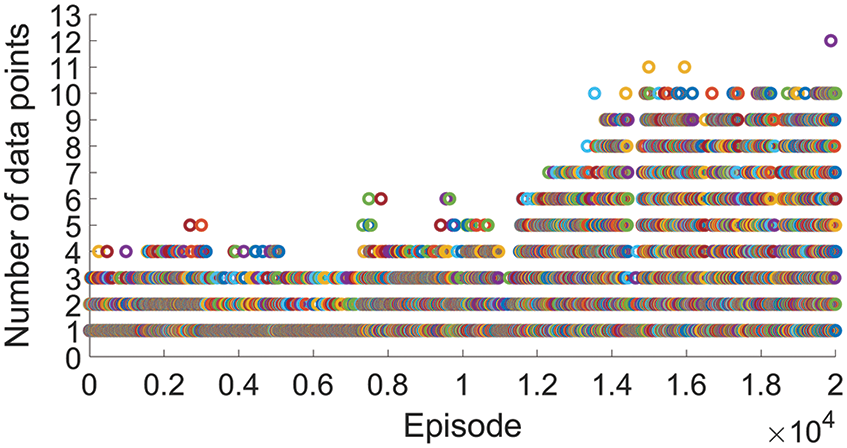
Figure 7: The number of data points obtained in each episode
The relationships between the sequence numbers of all actions and the predicted values
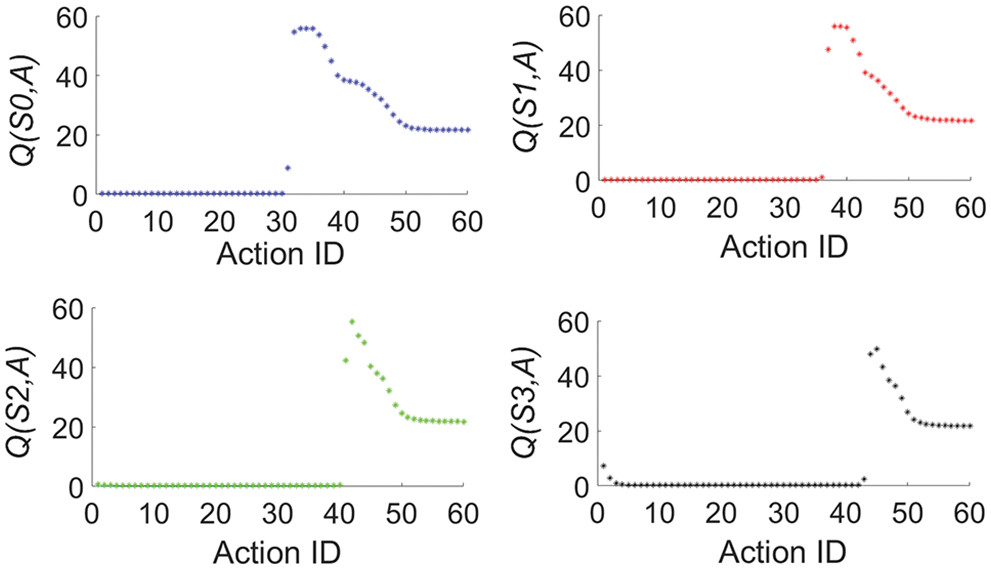
Figure 8: The predicted values
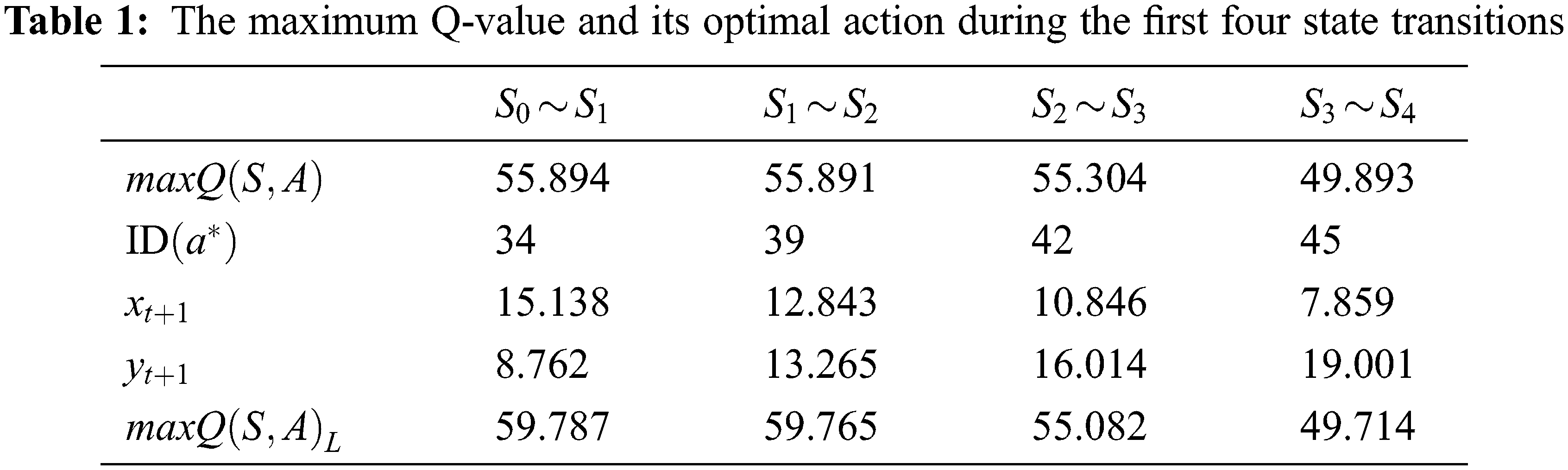
From Table 1, one can see that going from state
With all the data points
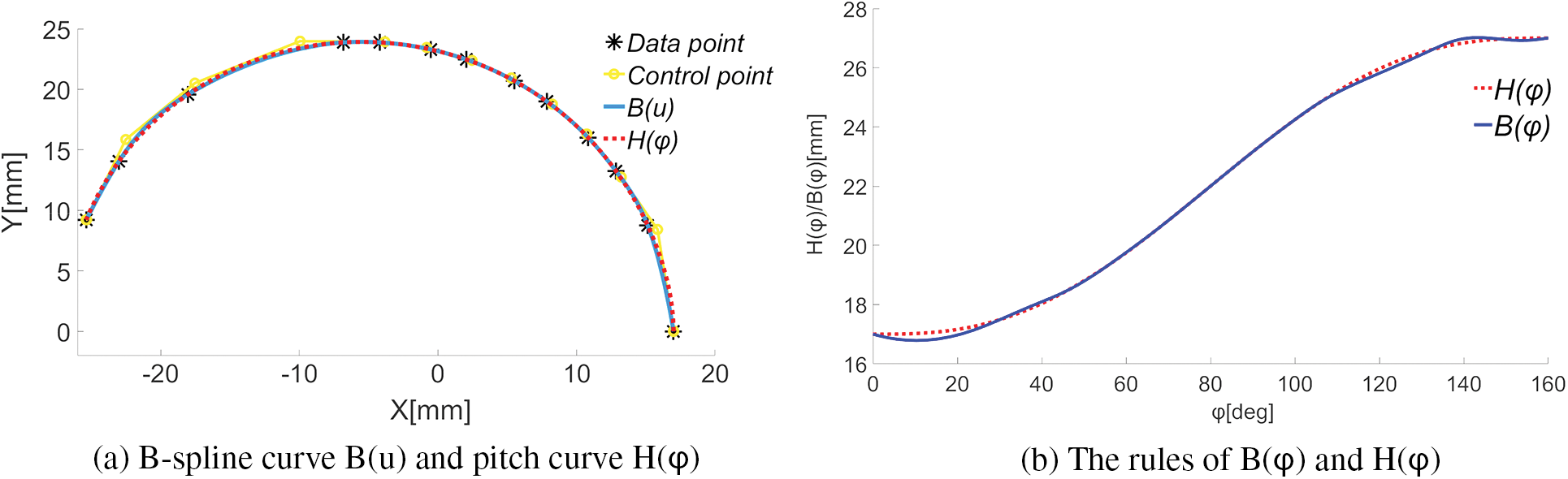
Figure 9: B-spline fitting effect of pitch curve
From Figs. 9a and 9b, one can see the followings.
When
When
When
Through sampling calculation, when only
To further lessen the fitting error, we take
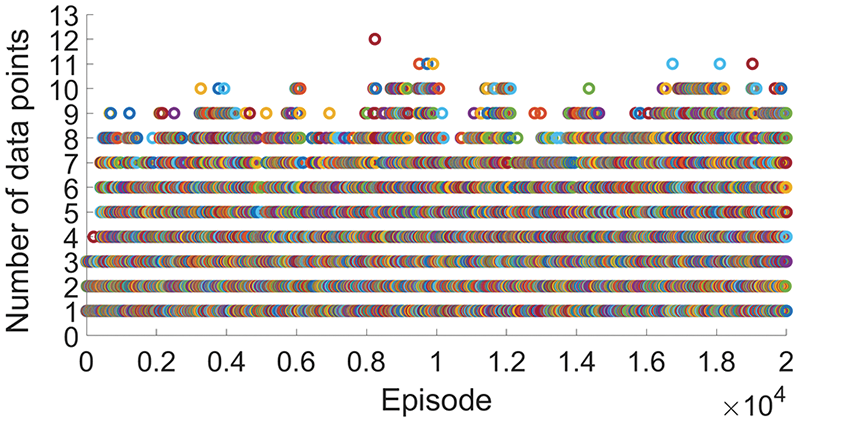
Figure 10: The number of data points obtained in each episode
As illustrated in Fig. 10, the agent can find 9 data points in the 1000-th episode. Starting from 4000th-episode, the agent can obtain 10 data points several times and find the most 12 data points in 8239th episode. After 10000 episodes, the agent can stably obtain more than 10 data points which indicates that the algorithm has converged. The convergence speed of RL learning in this section is faster than that in Section 3.1. This is because the neural network adopted in Section 3.1 only went though a basic training. At the beginning of iterative calculation, the agent clearly knows which action can obtain more data points, which contributes to the reduction of the number of blind exploration and invalid exploration. Since the reward
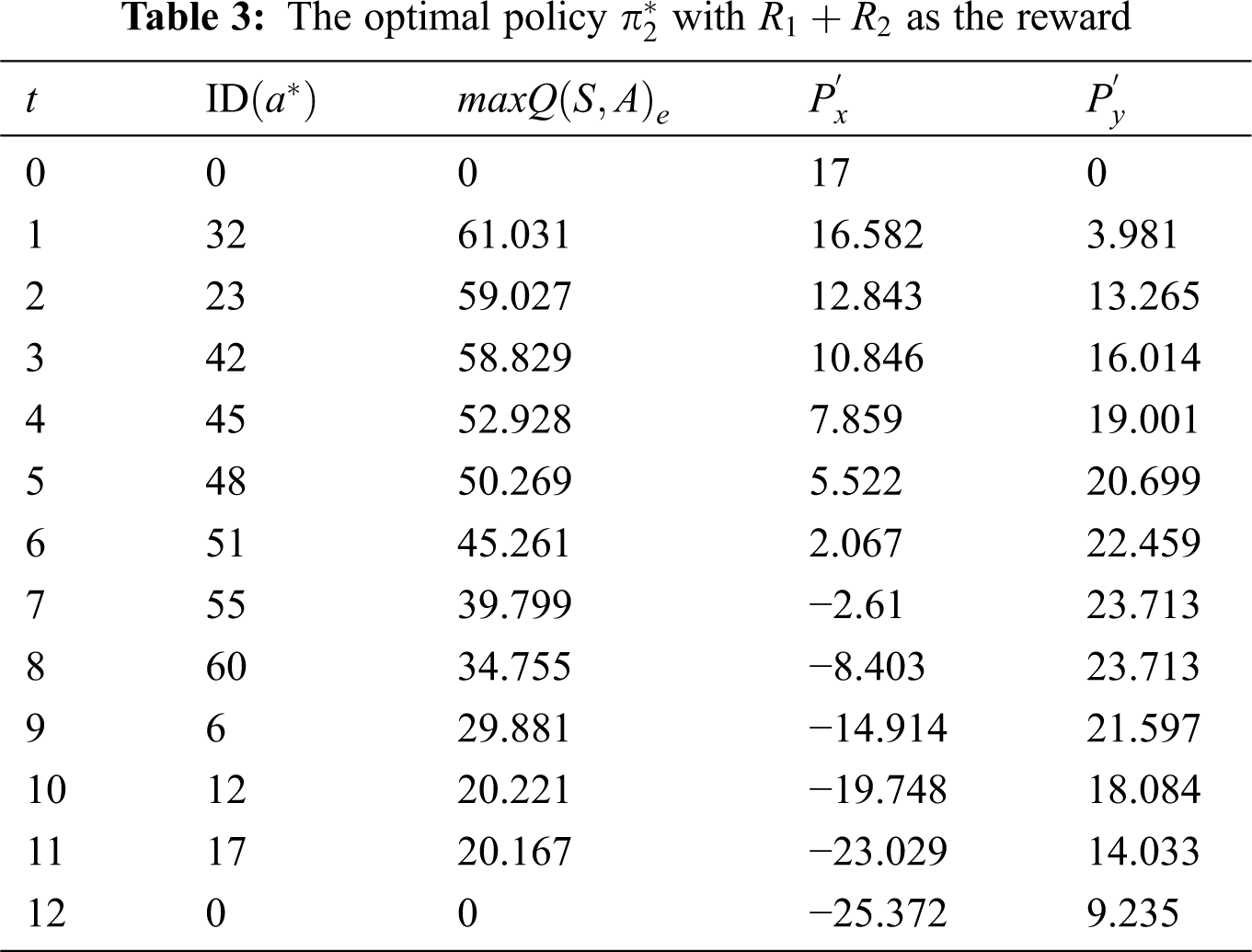
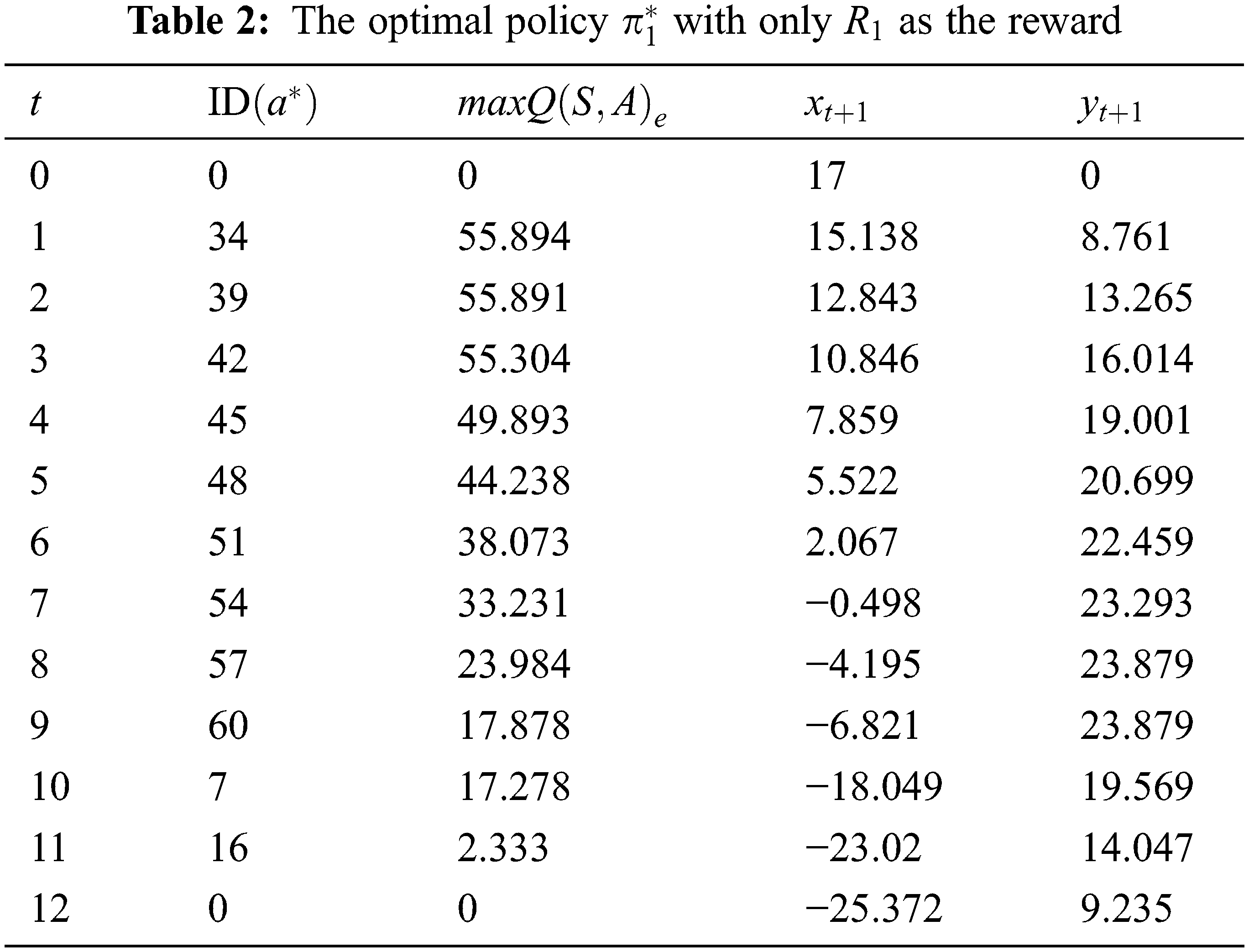
By comparing the optimal policies presented in Tables 3 and 2, one can see that the maximum number of data points obtained by
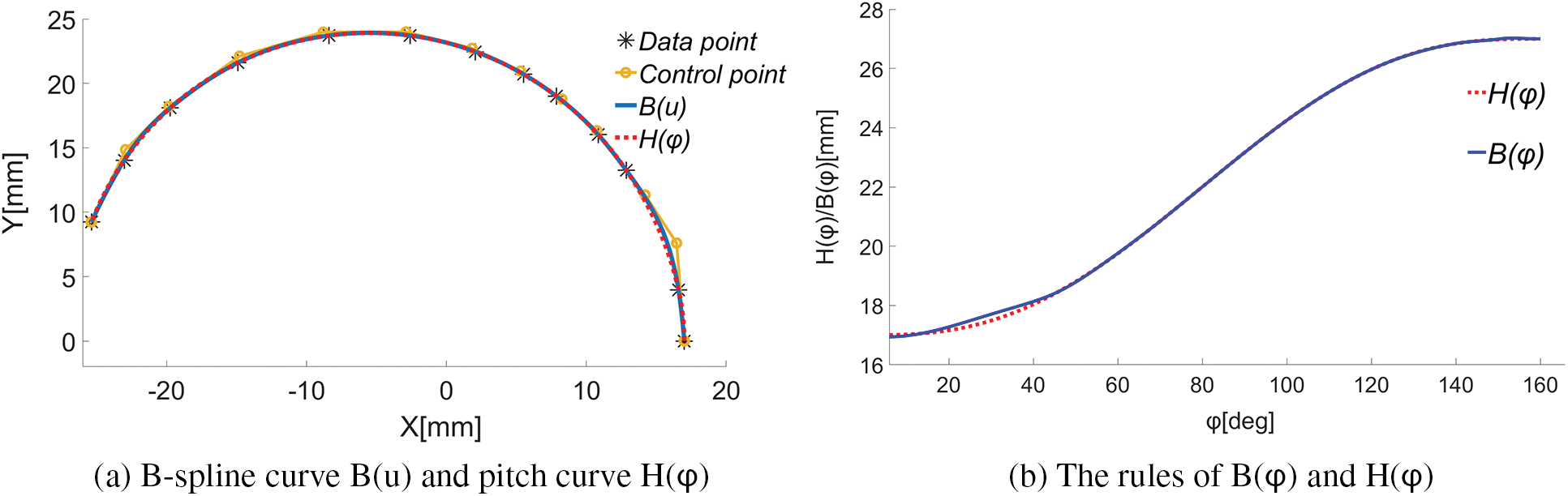
Figure 11: B-spline fitting effect of pitch curve
The data points in Fig. 11 are more evenly distributed than those in Fig. 9, and the radial error in Fig. 11 is further reduced. When
As experimentally constructed in Section 4.2, the B-spline curve satisfies the motion law of the cam follower. The average radial error between the B-spline curve and the pitch curve is 0.012 mm, which is the smallest fitting error obtained under the angular division of . This value conforms with the F tolerance level of ISO2786. To further suppress the fitting error, we can use a smaller angle division value in the search of data points. Tab. 4 lists the comparison of B-spline fitting results using Algorithm 1 under three angle division values.
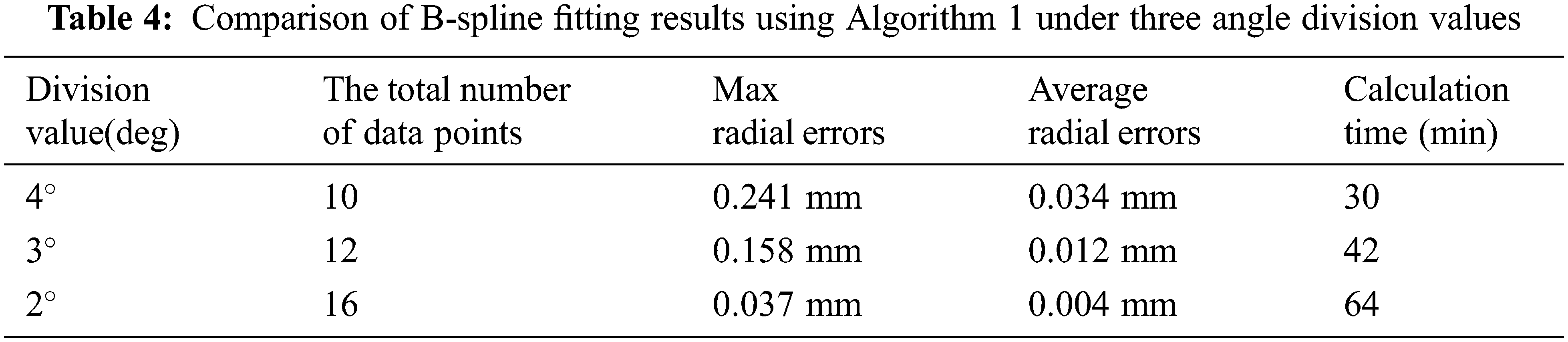
From Table 4, one can see that the smaller the angle division value is, the more data points obtained by the optimal policy. As a result, the fitting error of the B-spline curve gets even smaller a cost of longer computation time.
This paper presented an improved DDQN algorithm for fitting cam pitch curve with B-spline curve. In order to run and train the algorithm better, the environment modeling, actions set, states set, reward method and neural network were discussed in detail. This algorithm was found to automatically obtain the optimal numbers and positions of the data points on the pitch curve, and the fitting error of the B-spline curve constructed from these data points conform with the tolerance requirement. Specific contributions and discoveries were summarized below:
1. The theoretical basis of RL method for the B-spline fitting was established, and it was proved to be feasible to use RL algorithm to search for the optimal data points for curve fitting;
2. With reference to the path planning method in USV, the discrete actions set was designed to search for the optimal data points on the ideal path (the pitch curve in our case). The maximum number of data points can be controlled by scaling the angle division value of the actions set;
3. The DDQN algorithm with data point traceability was designed to accurately calculate the fitting error of the B-spline curve. The initial neural network of the proposed DDQN algorithm could be trained by a small batch of samples of which input values are randomized and output value is much smaller than the reward, to accelerate the convergence speed.
4. Two kinds of reward functions were designed in this paper. When the algorithm adopted the single objective reward function of obtaining data points, the optimal policy maximized nothing but the number of data points. When the algorithm adopted the double objective reward function of obtaining data points and calculating radial error, the optimal policy can maximize the number of data points and at the same time automatically adjust the position of data points to minimize the radial error.
Funding Statement: This research work is supported by Fujian Province Nature Science Foundation under Grant No. 2018J01553.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. P. H. Hoang and L. Q. Ngoc, “Development of the design and fabrication system for planar cam mechanisms,” Applied Mechanics and Materials, vol. 902, no. 5, pp. 114–125, 2020. [Google Scholar]
2. R. L. Norton, Cam design, in Design of machinery, 5th edition. vol. 8. Los Angeles, CA, USA: McGraw-Hill Education Press, pp. 401–431, 2014. [Google Scholar]
3. K. Min, C. H. Lee, C. Y. Yan, W. Fan and P. C. Hu, “Six-dimensional B-spline fitting method for five-axis tool paths,” The International Journal of Advanced Manufacturing Technology, vol. 107, no. 5, pp. 2041–2054, 2020. [Google Scholar]
4. K. Min, Y. Y. Sun, C. H. Lee, P. C. Hu and S. S. He, “An improved B-spline fitting method with arc-length parameterization, G2-continuous blending, and quality refinement,” International Journal of Precision Engineering and Manufacturing, vol. 20, no. 11, pp. 1939–1955, 2019. [Google Scholar]
5. Y. K. Jiang, J. H. Chen, H. C. Zhou, J. Z. Yang, P. C. Hu et al., “Contour error modeling and compensation of CNC machining based on deep learning and reinforcement learning,” The International Journal of Advanced Manufacturing Technology, vol. 118, no. 3, pp. 1–20, 2021. [Google Scholar]
6. Q. Z. Bi, J. Huang, Y. A. Lu, L. M. Zhu and H. Ding, “A general, fast and robust B-spline fitting scheme for micro-line tool path under chord error constraint,” Science China Technological Sciences, vol. 62, no. 2, pp. 321–332, 2019. [Google Scholar]
7. S. S. He, D. J. Ou, C. Y. Yan and C. H. Lee, “A chord error conforming tool path B-spline fitting method for NC machining based on energy minimization and LSPIA,” Journal of Computational Design and Engineering, vol. 2, no. 4, pp. 218–232, 2015. [Google Scholar]
8. F. Yoshimoto, T. Harada and Y. Yoshimoto, “Data fitting with a spline using a real-coded genetic algorithm,” Computer-Aided Design, vol. 35, no. 8, pp. 751–760, 2003. [Google Scholar]
9. H. M. Kang, F. L. Chen, Y. S. Li, J. S. Deng and Z. W. Yang, “Knot calculation for spline fitting via sparse optimization,” Computer-Aided Design, vol. 58, no. 1, pp. 179–188, 2015. [Google Scholar]
10. Z. G. Yong, H. M. Kang, Z. W. Yang and Y. Gu, “The unimodality of initial B-spline approximations in spline fitting,” Communications in Mathematics and Statistics, vol. 10, no. 2, pp. 331–352, 2022. [Google Scholar]
11. S. D. Mohanty and E. Fahnestock, “Adaptive spline fitting with particle swarm optimization,” Computational Statistics, vol. 36, no. 1, pp. 155–191, 2021. [Google Scholar]
12. L. Z. Lu and S. Q. Zhao, “High-quality point sampling for B-spline fitting of parametric curves with feature recognition,” Journal of Computational and Applied Mathematics, vol. 345, no. 1, pp. 286–294, 2019. [Google Scholar]
13. Y. J. Zhao, X. Qi, Y. Ma, Z. X. Li, R. Malekian et al., “Path following optimization for an underactuated USV using smoothly-convergent deep reinforcement learning,” IEEE Transactions on Intelligent Transportation Systems, vol. 99, no. 3, pp. 1–13, 2020. [Google Scholar]
14. Y. Z. Wei, K. F. Gu, X. J. Cui, C. Z. Hao, H. G. Wang et al., “Strategies for feet massage robot to position the pelma acupoints with model predictive and real-time optimization,” International Journal of Control, vol. 14, no. 2, pp. 628–636, 2016. [Google Scholar]
15. P. Dong, Z. M. Chen, X. W. Liao and W. Yu, “A deep reinforcement learning (DRL) based approach for well-testing interpretation to evaluate reservoir parameters,” Petroleum Science, vol. 19, no. 1, pp. 264–278, 2022. [Google Scholar]
16. C. D. Boor, The representation of PP functions by B-Splines, in A practical guide of splines, 1st ed., vol. 9. New York, NY, USA: Springer-Verlag New York Inc Press, pp. 87–106, 2001. [Google Scholar]
17. N. J. Zakaria, M. I. Shapiai and N. Wahid, “A study of multiple reward function performances for vehicle collision avoidance systems applying the DQN algorithm in reinforcement learning,” Materials Science and Engineering, vol. 1176, no. 1, pp. 1–13, 2021. [Google Scholar]
18. L. Zhang, Y. M. Xie, J. Ye, T. L. Xue, J. Z. Cheng et al., “Intelligent frequency control strategy based on reinforcement learning of multi-objective collaborative reward function,” Frontiers in Energy Research, vol. 9, no. 2, pp. 1–8, 2021. [Google Scholar]
19. M. Adil, R. Ullah, S. Noor and N. Gohar, “Effect of number of neurons and layers in an artificial neural network for generalized concrete mix design,” Neural Computing and Applications, vol. 34, no. 11, pp. 1–9, 2020. [Google Scholar]
20. W. Hu, G. S. Zhang and Y. Q. Zheng, “A novel optimal control design for unknown nonlinear systems based on adaptive dynamic programming and nonlinear model predictive control,” Asian Journal of Control, vol. 24, no. 4, pp. 1638–1649, 2022. [Google Scholar]
21. K. D. Humbird, J. L. Peterson and R. G. Mcclarren, “Deep neural network initialization with decision trees,” IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 5, pp. 1286–1295, 2018. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools