
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Deep Learning-Based Sign Language Recognition for Hearing and Speaking Impaired People
Department of Information Technology, College of Computers and Information Technology, Taif University, P.O. Box 11099, Taif, 21944, Saudi Arabia
* Corresponding Author: Mrim M. Alnfiai. Email:
Intelligent Automation & Soft Computing 2023, 36(2), 1653-1669. https://doi.org/10.32604/iasc.2023.033577
Received 21 June 2022; Accepted 04 August 2022; Issue published 05 January 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Sign language is mainly utilized in communication with people who have hearing disabilities. Sign language is used to communicate with people having developmental impairments who have some or no interaction skills. The interaction via Sign language becomes a fruitful means of communication for hearing and speech impaired persons. A Hand gesture recognition system finds helpful for deaf and dumb people by making use of human computer interface (HCI) and convolutional neural networks (CNN) for identifying the static indications of Indian Sign Language (ISL). This study introduces a shark smell optimization with deep learning based automated sign language recognition (SSODL-ASLR) model for hearing and speaking impaired people. The presented SSODL-ASLR technique majorly concentrates on the recognition and classification of sign language provided by deaf and dumb people. The presented SSODL-ASLR model encompasses a two stage process namely sign language detection and sign language classification. In the first stage, the Mask Region based Convolution Neural Network (Mask RCNN) model is exploited for sign language recognition. Secondly, SSO algorithm with soft margin support vector machine (SM-SVM) model can be utilized for sign language classification. To assure the enhanced classification performance of the SSODL-ASLR model, a brief set of simulations was carried out. The extensive results portrayed the supremacy of the SSODL-ASLR model over other techniques.Keywords
Recently, the population of deaf-dumb victims has raised due to birth defects and other problems. A deaf and mute individual may not able to interact with ordinary people by relying certain kinds of transmission mechanisms [1]. The gesture displays certain physical actions of the hand which conveys a part of information. Gesture recognition was the analytical clarification of movement of a person via information processing mechanisms. Verbal communication offers the most effectual conversation platform for mute person for speaking with ordinary people [2]. Only some individual realizes the meaning of sign. Usually, deaf person was deprived of usual contact with other typical individuals in the society. Human computer interface (HCI) was an exciting system amongst devices and individuals. This was an exciting research area which aims at the usage and formation of computer technology and particularly, combined communications amongst devices and humans. HCI structure was amazingly protracted and enhanced by the technical transition [3]. On the basis of fruitful usability, evolving technologies apply modern user lines like Speech recognition, Non-Touch, and Gesture. It is a complex and expensive technology to reach [4,5]. This newly applied technology was after combined as implying particular applications on the basis of cost-effectiveness and demand. For addressing the complexities, numerous authors were attempting for developing such interferences with regard to robustness, performance, and accessibility [6]. The optimum model could have several standard features like scalability, simplicity, flexibility, and precision. Nowadays, the human gesture turns to be an extensive HCI application, and the usage of human gestures, that fulfils all such standards, was rising quickly [7,8].
Sign language (SL) always considered the main way of verbal interaction amongst individuals who were both dumb and deaf [9]. Whereas interacting such people is very helpless and therefore were only depends on hand gestures. Visual signs and gestures were an energetic part of automated sign language (ASL) which offers deaf individuals reliable and easy communication [10]. It has well-defined code gestures in which every sign carries a specific meaning relating to communication. There were several methods to seek gestural data. But limiting to only major kinds there were 2 significant familiar kinds they are Vision-related and Sensor-related techniques [11]. The sensor-related technique gathers data from the glove produced by hand movement. In the vision-related technique, the image was considered by using cameras [12]. This technique indulges the image qualities like texture part and coloring which was necessary to the specific hand gesture.
In [13], a comparative analysis of different gesture recognition methods including convolutional neural network (CNN) and machine learning (ML) procedures has been deliberated and verified for realistic performance. A hierarchical neural network, pre-trained VGG16 with fine-tuning, and VGG16 with transfer learning were analyzed according to a trained parameter count. The model was trained on a self-developed datasets comprising images of Indian Sign Language (ISL) representation of each twenty-six English alphabet. In [14], the authors shows that a later fusion technique to multi-modality in sign language detection increases the entire capacity of algorithm when compared to singular approach of Leap Motion data and image classification. Using a larger synchronous dataset of eighteen BSL gestures gathered from different subjects, two deep neural networks (DNNs) were compared and benchmarked for deriving an optimal topology. The Vision model was carried out by a CNN and optimized artificial neural network (ANN), and the Leap Motion mechanism is carried out using an evolutionary search of ANN model.
Kumar et al. [15] developed the usage of graph matching (GM) to allow three dimensional motion capture for Indian sign language detection. The sign recognition and classification problems to interpret three dimensional motion signs are taken into account an adoptive GM (AGM) problems. But, the existing model to solve an AGM issue have two most important disadvantages. Firstly, spatial matching is implemented on a number of frames with a definite set of nodes. Then, temporal matching splits the whole three dimensional datasets into a definite set of pyramids. In [16], the authors conducted a complete systematic mapping of translation-assisting techniques to the provided sign language. The mapping has regarded the primary guideline for systematic review that is, pertains software engineering because it is necessary to take responsible for multidisciplinary fields of education, accessibility, human computer communication, and natural language processing. A continuous improvement of software tools named SYstematic Mapping and Parallel Loading Engine (SYMPLE) enabled the construction and querying of a base set of candidate studies. Parvez et al. [17] related the gap among conventional teaching and the technology-based methods that are employed to teach arithmetical concepts. The participant was separated into developed mobile applications and conventional approaches (board and flash cards). The variance in the performance these groups is assessed by accompanying quizzes.
This study introduces a shark smell optimization with deep learning based automated sign language recognition (SSODL-ASLR) model for hearing and speaking impaired people. The presented SSODL-ASLR technique majorly concentrates on the recognition and classification of sign language provided by deaf and dumb people. The presented SSODL-ASLR model encompasses a two stage process namely sign language detection and sign language classification. At the first stage, the Mask Region based Convolution Neural Netwokr (Mask RCNN) model is exploited for sign language recognition. Secondly, SSO algorithm with soft margin support vector machine (SM-SVM) model was utilized for sign language classification. To assure the enhanced classification performance of the SSODL-ASLR model, a brief set of simulations was carried out.
In this study, a new SSODL-ASLR technique was introduced for the recognition of SL for hearing and speaking impaired people. The presented SSODL-ASLR technique majorly concentrates on the recognition and classification of sign language provided by deaf and dumb people. The presented SSODL-ASLR model encompasses a two stage process namely sign language detection and sign language classification.
2.1 Sign Language Detection: Mask RCNN Model
In the first stage, the Mask RCNN model is exploited for sign language recognition. Mask RCNN was a DNN mainly focused on solving instance segmentation issues in computer vision or ML [18]. In other words, it can separate different objects in an image or a video. The feature pyramid network (FPN) to object detection, a 1st block structure of Mask RCNN is accountable for extracting features. The regional proposal network (RPN), the 2nd part of Mask RCNN, and shares whole image convolutional features with detection network thus approximately assisting cost-free RPN. Once the extended Fast RCNN processes the Mask RCNN with added a branch to forecast an object mask from equivalent with the suggested branch to bound box recognition. The RPN is carried out from Mask RCNN instead of selective search and thus RPN shares the convolution features of entire map with detection network. It forecasts fused boundary location and objects score at each place, and it is fully convolution network (FCN). Based on the Mask RCNN, it presented an algorithm to improve the speed using side fusion feature pyramid network (SF-FPN) with Resnet-86 and enlighten the performance. In such cases, the dataset, FPN architecture, and RPN variable setting were improved. The improved method developed in such cases is appreciating the segmentation, recognition, and detection of target at the same time. Fig. 1 illustrates the infrastructure of Mask RCNN method.

Figure 1: Structure of mask RCNN
During the multitasking, loss function is carried out by trainable Mask
From the expression,
2.2 Sign Language Classification: SM-SVM Model
In this study, the SM-SVM model is utilized for sign language classification. SM-SVM aim is to expand the Maximal Separating Margin SVM (hard margin SVM), such that the hyperplane enables a noisy dataset to exist. In the event, a variable
That is,
The Primal Problem is defined by
The Dual Problem Function of soft margin was equated by
KKT complementary conditions in inseparable instance are represented as follows
From the expression,
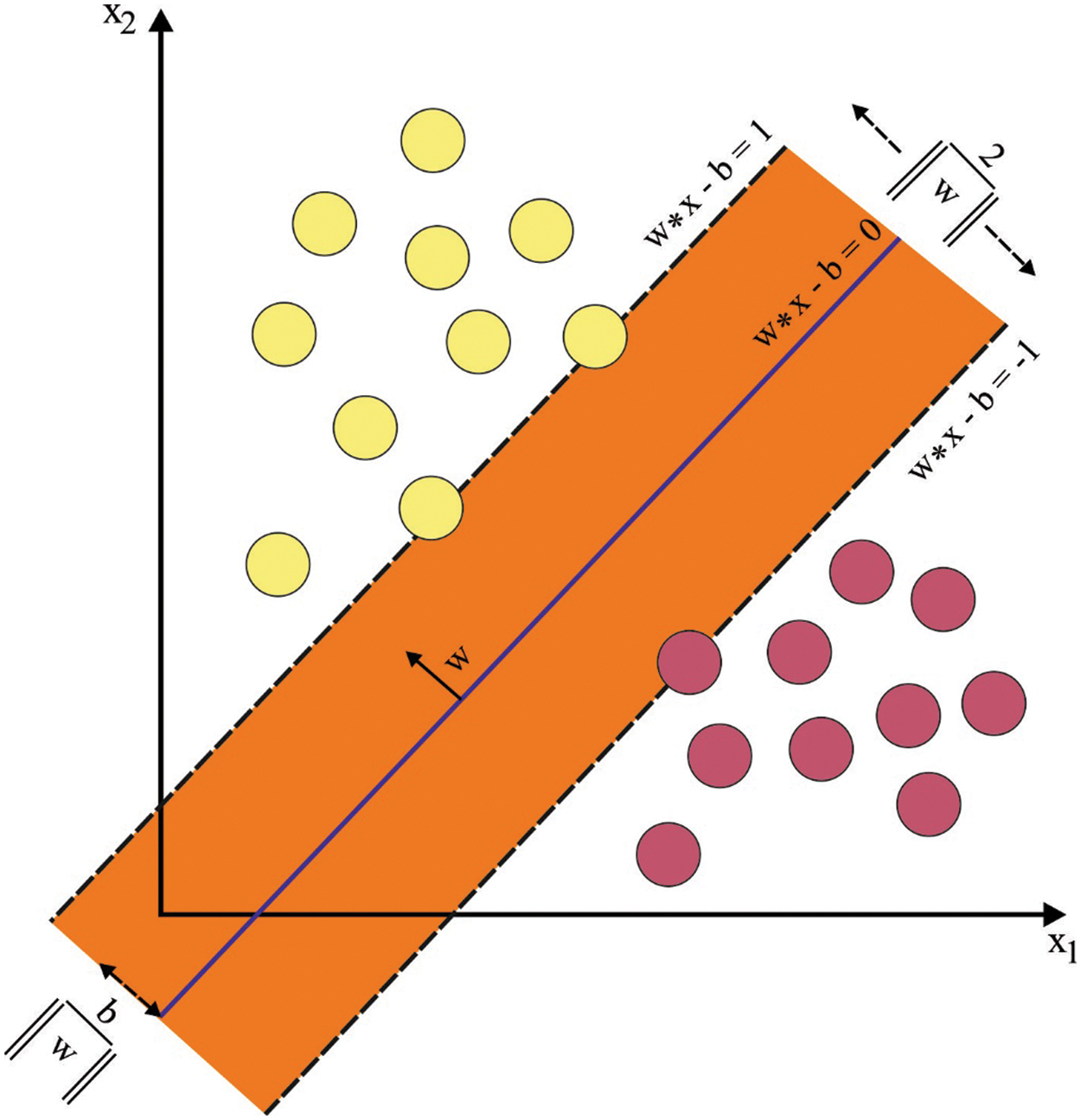
Figure 2: SVM hyperplane
At the same time considered (10) and (11), we obtain;
As a result, the optimum weight
The optimum bias
2.3 Parameter Tuning: SSO Algorithm
To optimally modify the SM-SVM parameter values, the SSO algorithm has been exploited in this study. As the optimum hunter by their nature, the sharks are foraging nature that rotate and drives frontward which is very effectual from determining prey [20]. An optimized approach for simulating shark foraging is most effectual optimized approach. To certain places, the shark transfers at speed to particles that take intensive scent, so initial velocity vector is formulated as:
The sharks take inertia once it swims, so velocity equation of every dimensional is provided under,
In which
whereas
In which
The rotating shark moves from the closed range which could not fundamentally a circle. During the view of optimized, the shark executes local searching at all the phases to determine optimum candidate solutions. The searching equation to this place was provided under as:
whereas
As aforementioned,
The aforementioned formula endures normalized if it obtains executed to search region with many dimensional. For normalizing it, the search agent and the respective opposite solution is demonstrated as:
The value of every component from
At this point, the fitness function can be
3 Simulation Results and Discussion
The proposed model is simulated using Python 3.6.5 tool. The proposed model is experimented on PC i5-8600k, GeForce 1050Ti 4GB, 16GB RAM, 250GB SSD, and 1TB HDD. In this section, the sign language recognition performance of the SSODL-ASLR model is tested using a dataset comprising 3600 samples with 36 classes as illustrated in Tab. 1. A few sample American Sign Language Code images are displayed in Fig. 3.


Figure 3: Sample American sign language code images
Fig. 4 implies the confusion matrix formed by the SSODL-ASLR model on the applied 70% of training (TR) data. The figure indicated that the SSODL-ASLR model has proficiently recognized all the 36 class labels on 70% of TR data.

Figure 4: Confusion matrix of SSODL-ASLR approach under 70% of TR data
The classifier output of the SSODL-ASLR model is derived on 70% of TR data in Tab. 2. The experimental outcomes demonstrated the SSODL-ASLR method has resulted in effectual outcomes over other models. For instance, on class label 1, the SSODL-ASLR model has provided

Fig. 5 exhibits average classifier outcomes of the SSODL-ASLR model on 70% of TR data. The figure reported that the SSODL-ASLR model has reached effectual classification outcomes with average

Figure 5: Average analysis of SSODL-ASLR approach under 70% of TR data
Fig. 6 portrays the confusion matrix formed by the SSODL-ASLR method on the applied 30% of testing (TS) data. The figure signifies the SSODL-ASLR technique has proficiently recognized all the 36 class labels on 30% of TS data.

Figure 6: Confusion matrix of SSODL-ASLR approach under 30% of TS data
The classifier output of the SSODL-ASLR approach is derived on 30% of TS data in Tab. 3. The experimental outcomes established the SSODL-ASLR technique has resulted in effectual outcomes over other models. For example, on class label 1, the SSODL-ASLR approach has offered

Fig. 7 displays an average classifier outcome of the SSODL-ASLR model on 30% of TS data. The figure reported that the SSODL-ASLR model has reached effectual classification outcomes with average

Figure 7: Average analysis of SSODL-ASLR approach under 30% of TS data
The training accuracy (TA) and validation accuracy (VA) acquired by the SSODL-ASLR method on test dataset is established in Fig. 8. The experimental outcome inferred the SSODL-ASLR technique has achieved maximal values of TA and VA. Predominantly the VA is greater than TA.

Figure 8: TA and VA analysis of SSODL-ASLR approach
The training loss (TL) and validation loss (VL) attained by the SSODL-ASLR approach on test dataset are established in Fig. 9. The experimental outcome implied the SSODL-ASLR algorithm has exhibited least values of TL and VL. In specific, the VL is lesser than TL.
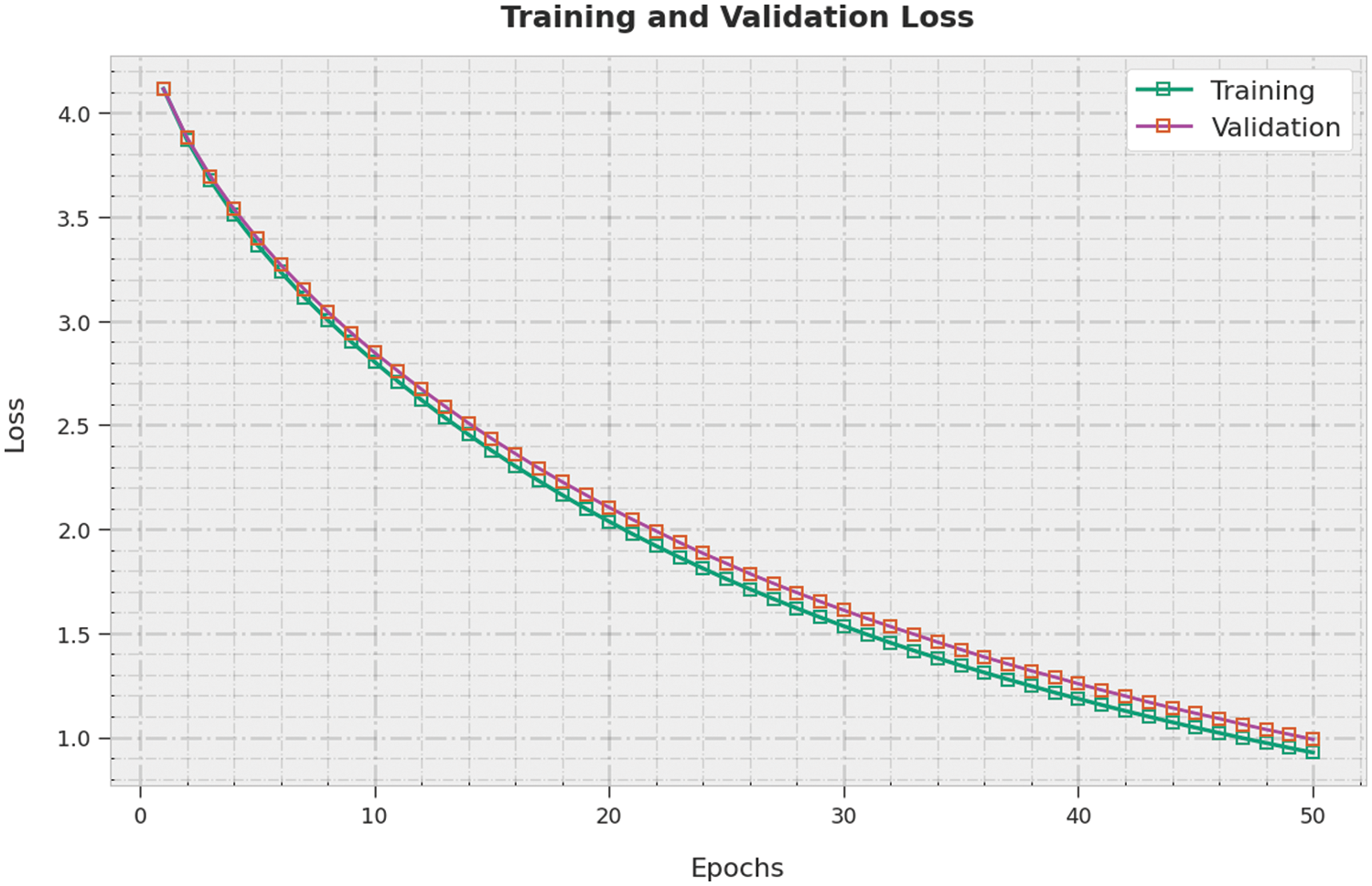
Figure 9: TL and VL analysis of SSODL-ASLR approach
Tab. 4 exemplifies a comparative assessment of the SSODL-ASLR model with recent models [21]. Fig. 10 reports a brief comparison study of the SSODL-ASLR model with latest methods interms of


Figure 10:
The results highlight the SSODL-ASLR model has granted higher
In this study, a new SSODL-ASLR technique was introduced for the recognition of sign language for hearing and speaking impaired people. The presented SSODL-ASLR technique majorly concentrates on the recognition and classification of sign language provided by deaf and dumb people. The presented SSODL-ASLR model encompasses a two stage process namely sign language detection and sign language classification. Primarily, the Mask RCNN model is exploited for sign language recognition. In the next stage, the SSO algorithm with SM-SVM model is utilized for sign language classification. To assure the enhanced classification performance of the SSODL-ASLR model, a brief set of simulations was carried out. The extensive results portrayed the supremacy of the SSODL-ASLR model over other techniques.
Funding Statement: The author received no specific funding for this study.
Conflicts of Interest: The author declares that he has no conflicts of interest to report regarding the present study.
References
1. M. A. Ahmed, B. B. Zaidan, A. A. Zaidan, M. M. Salih and M. M. bin Lakulu, “A review on systems-based sensory gloves for sign language recognition state of the art between 2007 and 2017,” Sensors, vol. 18, no. 7, pp. 2208, 2018. [Google Scholar]
2. M. Friedner, “Sign language as virus: Stigma and relationality in urban India,” Medical Anthropology, vol. 37, no. 5, pp. 359–372, 2018. [Google Scholar]
3. X. Jiang, S. C. Satapathy, L. Yang, S. -H. Wang and Y. -D. Zhang, “A survey on artificial intelligence in Chinese sign language recognition,” Arabian Journal for Science and Engineering, vol. 45, no. 12, pp. 9859–9894, 2020. [Google Scholar]
4. V. S. Pineda and J. Corburn, “Correction to: Disability, urban health equity, and the coronavirus pandemic: Promoting cities for all,” Journal of Urban Health, vol. 98, no. 2, pp. 308–308, 2021. [Google Scholar]
5. M. Al Duhayyim, H. Mesfer Alshahrani, F. N. Al-Wesabi, M. Abdullah Al-Hagery, A. Mustafa Hilal et al., “Intelligent machine learning based EEG signal classification model,” Computers, Materials & Continua, vol. 71, no. 1, pp. 1821–1835, 2022. [Google Scholar]
6. P. Kumar, R. Saini, P. P. Roy and D. P. Dogra, “A position and rotation invariant framework for sign language recognition (SLR) using Kinect,” Multimedia Tools and Applications, vol. 77, no. 7, pp. 8823–8846, 2018. [Google Scholar]
7. S. A. Qureshi, S. E. Raza, L. Hussain, A. A. Malibari, M. K. Nour et al., “Intelligent ultra-light deep learning model for multi-class brain tumor detection,” Applied Sciences, 2022. https://doi.org/10.3390/app12083715. [Google Scholar]
8. N. S. Khan, A. Abid and K. Abid, “A novel natural language processing (nlp)–based machine translation model for English to Pakistan sign language translation,” Cognitive Computation, vol. 12, no. 4, pp. 748–765, 2020. [Google Scholar]
9. M. Khari, A. K. Garg, R. G. Crespo and E. Verdú, “Gesture recognition of rgb and rgb-d static images using convolutional neural networks,” International Journal of Interactive Multimedia and Artificial Intelligence, vol. 5, no. 7, pp. 22, 2019. [Google Scholar]
10. S. Shivashankara and S. Srinath, “American sign language recognition system: An optimal approach,” International Journal of Image, Graphics and Signal Processing, vol. 11, no. 8, pp. 18, 2018. [Google Scholar]
11. J. G. Ruiz, C. M. T. González, A. T. Fettmilch, A. P. Roescher, L. E. Hernández et al., “Perspective and evolution of gesture recognition for sign language: A review,” Sensors, vol. 20, no. 12, pp. 3571, 2020. [Google Scholar]
12. N. B. Ibrahim, H. H. Zayed and M. M. Selim, “Advances, challenges and opportunities in continuous sign language recognition,” Journal of Engineering and Applied Science, vol. 15, no. 5, pp. 1205–1227, 2019. [Google Scholar]
13. A. Sharma, N. Sharma, Y. Saxena, A. Singh and D. Sadhya, “Benchmarking deep neural network approaches for Indian sign language recognition,” Neural Computing and Applications, vol. 33, no. 12, pp. 6685–6696, 2021. [Google Scholar]
14. J. J. Bird, A. Ekárt and D. R. Faria, “British sign language recognition via late fusion of computer vision and leap motion with transfer learning to American sign language,” Sensors, vol. 20, no. 18, pp. 5151, 2020. [Google Scholar]
15. D. A. Kumar, A. S. C. S. Sastry, P. V. V. Kishore and E. K. Kumar, “Indian sign language recognition using graph matching on 3D motion captured signs,” Multimedia Tools and Applications, vol. 77, no. 24, pp. 32063–32091, 2018. [Google Scholar]
16. L. N. Zeledón, J. Peral, A. Ferrández and M. C. Rivas, “A systematic mapping of translation-enabling technologies for sign languages,” Electronics, vol. 8, no. 9, pp. 1047, 2019. [Google Scholar]
17. K. Parvez, M. Khan, J. Iqbal, M. Tahir, A. Alghamdi et al., “Measuring effectiveness of mobile application in learning basic mathematical concepts using sign language,” Sustainability, vol. 11, no. 11, pp. 3064, 2019. [Google Scholar]
18. I. P. Borrero, D. M. Santos, M. J. V. Vazquez and M. E. G. Arias, “A new deep-learning strawberry instance segmentation methodology based on a fully convolutional neural network,” Neural Computing & Applications, vol. 33, no. 22, pp. 15059–15071, 2021. [Google Scholar]
19. H. Liang, H. Bai, N. Liu and X. Sui, “Polarized skylight compass based on a soft-margin support vector machine working in cloudy conditions,” Applied Optics, vol. 59, no. 5, pp. 1271, 2020. [Google Scholar]
20. L. Wang, X. Wang, Z. Sheng and S. Lu, “Multi-objective shark smell optimization algorithm using incorporated composite angle cosine for automatic train operation,” Energies, vol. 13, no. 3, pp. 714, 2020. [Google Scholar]
21. T. Chong and B. Lee, “American sign language recognition using leap motion controller with machine learning approach,” Sensors, vol. 18, no. 10, pp. 3554, 2018. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools