
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Deep Transfer Learning Approach for Robust Hand Detection
1 Faculty of Electronic Engineering, University of Nis, Nis, 18000, Serbia
2 Faculty of Mechanical Engineering, University of Nis, Nis, 18000, Serbia
* Corresponding Author: Stevica Cvetkovic. Email:
Intelligent Automation & Soft Computing 2023, 36(1), 967-979. https://doi.org/10.32604/iasc.2023.032526
Received 20 May 2022; Accepted 06 July 2022; Issue published 29 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Human hand detection in uncontrolled environments is a challenging visual recognition task due to numerous variations of hand poses and background image clutter. To achieve highly accurate results as well as provide real-time execution, we proposed a deep transfer learning approach over the state-of-the-art deep learning object detector. Our method, denoted as YOLOHANDS, is built on top of the You Only Look Once (YOLO) deep learning architecture, which is modified to adapt to the single class hand detection task. The model transfer is performed by modifying the higher convolutional layers including the last fully connected layer, while initializing lower non-modified layers with the generic pretrained weights. To address robustness issues, we introduced a comprehensive augmentation procedure over the training image dataset, specifically adapted for the hand detection problem. Experimental evaluation of the proposed method, which is performed on a challenging public dataset, has demonstrated highly accurate results, comparable to the state-of-the-art methods.Keywords
Accurate detection of human hands in images is of crucial importance for many high-level human behavior analysis tasks. A variety of applications in robotics and human-computer interaction, such as virtual reality [1], driver behavior monitoring [2] or sign language recognition [3,4]; heavily rely on accurate results from hand detection methods. It is still an extremely challenging task as hands can vary in shape and viewpoint, can be partially closed or occluded, can have different articulations of the fingers, etc.
Recent expansion of Deep Neural Networks (DNN) has led to adoption of this approach to the visual object detection task, which significantly improved the performance of conventional object detection methods. Beside significant detection accuracy improvements brought by modern DNN-based methods [5,6], there has been advances in terms of execution speed [7–9]. However, there is still a lack of research in terms of extension and adaptation of these methods to the specific domain problems, such as human hand detection in images. A powerful technique for adapting and reutilizing a generic pre-trained DNN on a specific domain task with a smaller target dataset, is denoted as Transfer Learning [10–13]. There are two main reasons for adapting a pre-trained DNN, instead of building and training a completely new network model from scratch. First, when the target dataset is significantly smaller than the original generic dataset, transfer learning enables additional training of large networks without overfitting. Also, it is an enormously faster approach than complete retraining, which is especially the case for large DNN models which took days or even months to be trained on large public datasets using advanced Graphics Processing Unit (GPU) architectures.
Therefore, in this paper, we investigated how to successfully apply a transfer learning approach over state-of-the-art DNN-based object detectors, in order to make them robust for a specific task of human hand detection. The main contributions of the paper are summarized as follows:
• We transferred and trained a Deep Neural Network based on a YOLO network architecture [9], by modifying it to adapt to the single class hand detection task.
• We proposed a comprehensive data augmentation procedure over the training image dataset, in order to address robustness issues.
• Training and evaluation of the proposed method, which is performed on a challenging public dataset, has demonstrated highly accurate results, comparable to the state-of-the-art methods.
In the rest of the paper we will first give an overview of related work, followed by a short description of the original YOLO object detection method. Then, we will present a detailed description of our approach for transferring the YOLO model to a robust hand detection method, denoted as YOLOHANDS. Description of the proposed data augmentation procedure is given before presenting the results of comprehensive evaluation on a publicly available dataset.
Many conventional computer vision methods have been proposed in the literature to detect human hands in color images. One of the first successful methods was proposed in [14]. It generates skin-based region proposals followed by a sliding window shape-based detector to increase detection recall. However, methods relying on skin detection have serious limitations in environments with poor illumination. Furthermore, they could be ambiguous if face regions are also present in the image. First applications of Deep Neural Networks (DNN) for object detection tasks started as extensions to the standard classification methods. They relied on external region proposal step to identify object region candidates which were afterwards classified using the DNN.
2.1 Region-Proposal Deep Learning Methods for Object Detection
One of the first successful DNN methods for object detection was introduced in [6]. It starts with a segmentation algorithm called “selective search”, to preselect large number of object region candidates (approx. 2000 candidates). Then, it applies a pretrained DNN to extract a fixed-length feature vector from each region proposal, which is followed by a Support Vector Machine (SVM) multi-class classifier. Slow execution times and limited accuracy were serious drawbacks of that method. Some improvements to the original method were presented in [5]. Instead of performing over 2000 forward passes for each object, it computes a convolutional feature map for the complete image in a single forward pass, making it significantly faster. Another improvement is that the neural network is trained end-to-end with a multi-task loss, resulting in a simpler training procedure. However, the speed of the method was still far from real-time performances. In [7], a significant improvement of the speed was presented, by abandoning the traditional region proposal method, and relying on a fully deep learning approach. The proposed network architecture consists of the two sub-networks which are merged into a single network and trained end-to-end. The method, denoted as Faster Region-based Convolutional Neural Network (Faster R-CNN) is still considered as one of the optimal object detectors in terms of accuracy [15].
2.2 Single-Stage Deep Learning Methods for Object Detection
While region-proposal methods might achieve higher accuracy, they still have significant drawbacks in terms of computation complexity. Single-stage object detectors use a single deep neural network to simultaneously predict object’s bounding box and class probabilities. This allows them to have significantly faster inference times, while still achieving the high accuracy of detections. The two most notable representatives of single-stage methods are Single Shot Detector (SSD) [16] and YOLO [8], where YOLO has demonstrated higher speed and accuracy of results. In this study we will rely on YOLOv3 Deep Neural Network architecture [9] for developing our robust hand detection method. We will first give a brief overview of a basic YOLO network architecture, followed by details of our modifications and adaptations to the specific problem of human hand detection in unconstrained environments.
2.3 Transformers for Object Detection
Transformer architecture [17], which has had a tremendous impact in the Natural Language Processing (NLP) domain, has recently been introduced into computer vision applications. One of the first successful methods to demonstrate how Transformers can replace standard convolutions in deep neural networks on large image datasets, was introduced in [18]. Vision Transformers (ViT) applied the original Transformer model on a sequence of image patches flattened as vectors. It has gained significant attention, and a number of recent methods have been proposed which build upon ViTs.
Object detection methods relying on Transformer modules, could be grouped into the following three categories. One group of methods use transformer backbones for feature extraction, combined with R-CNN head for detection [19]. Another group uses CNN backbone for visual feature extraction, followed by a Transformer based decoder for object detection [20]. Finally, an entirely transformer-based method for object detection is introduced in [21]. Since the transformer-based methods achieve state-of-the-art results, their potential to replace CNN networks for object detection tasks is very realistic.
3 Transferring a Generic Object Detection Model
We rely on a state-of-the-art deep neural network architecture for object detection–YOLOv3 [9], as a basis for developing our hand detection network. To adapt the network to the hand detection task, we applied a transfer learning approach [11,22–24].
3.1 Generic Object Detection Using YOLO Method
The YOLO object detection method was first introduced in 2016 [25]. The method is based on a single deep neural network trained to take an image as input and predict bounding boxes, class labels, and confidence scores for each detected bounding box. The initial version of YOLO neural network was operating very fast at 155 fps, while producing a relatively lower accuracy compared to the previously described region-proposal methods. Its algorithm starts by splitting the input image into
There have been many improvements of the initial YOLO detector over the years [8,9,27]. The improved YOLOv3 introduced a couple of significant improvements [9]. To create a network which is resilient to object size variations, the output vector is composed of three different output layers that take feature maps produced at different stages in the base architecture. This allows those layers to detect objects at three separate scales, inspired by work done in [16]. Since YOLOv3 considers three different scales, the main difference in outputs will be reflected in varying grid sizes. Instead of considering a single grid of
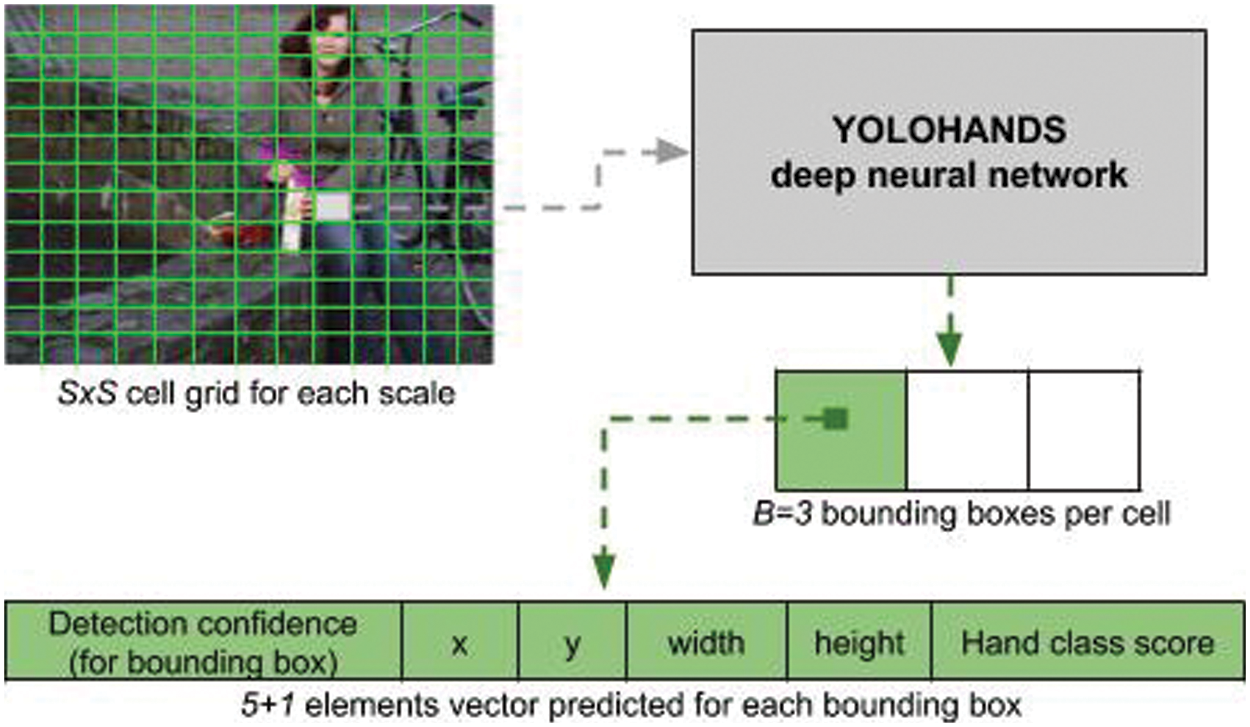
Figure 1: Illustration of the detection output for one image scale (3 scales are used)
3.2 A Deep Transfer Learning Approach for Robust Hand Detection
Our approach relies on the YOLOv3 network, which was originally created to detect
For initializing weights of the YOLOHANDS neural network, there are generally two options. Either to randomly initialize the weights in the network and start training from scratch, or to initialize the weights with previously learned values on some larger generic dataset. Since our YOLOHANDS model is built by modifying the higher convolutional layers including the last fully connected layer, we decided to initialize weights of lower non-modified convolutional layers with the existing pretrained weights, and to use random initialization for the introduced modified layers. There are several publicly available pretrained weight sets for YOLOv3 which are learned on several large public datasets, but two of them are the most commonly used: “yolov3.weights” and “darknet53.conv.74.weights” [9]. The first one, “yolov3.weights” contains weights for all the layers in the network that are learned on the COCO dataset [26], and the other one “darknet53.conv.74.weights” contains weights only for lower convolutional layers of the network that are learned on a larger ImageNet dataset [29]. Since the later one is trained on a larger dataset, we used that one for our model. The overall architecture of our approach is given in Fig. 2 below.
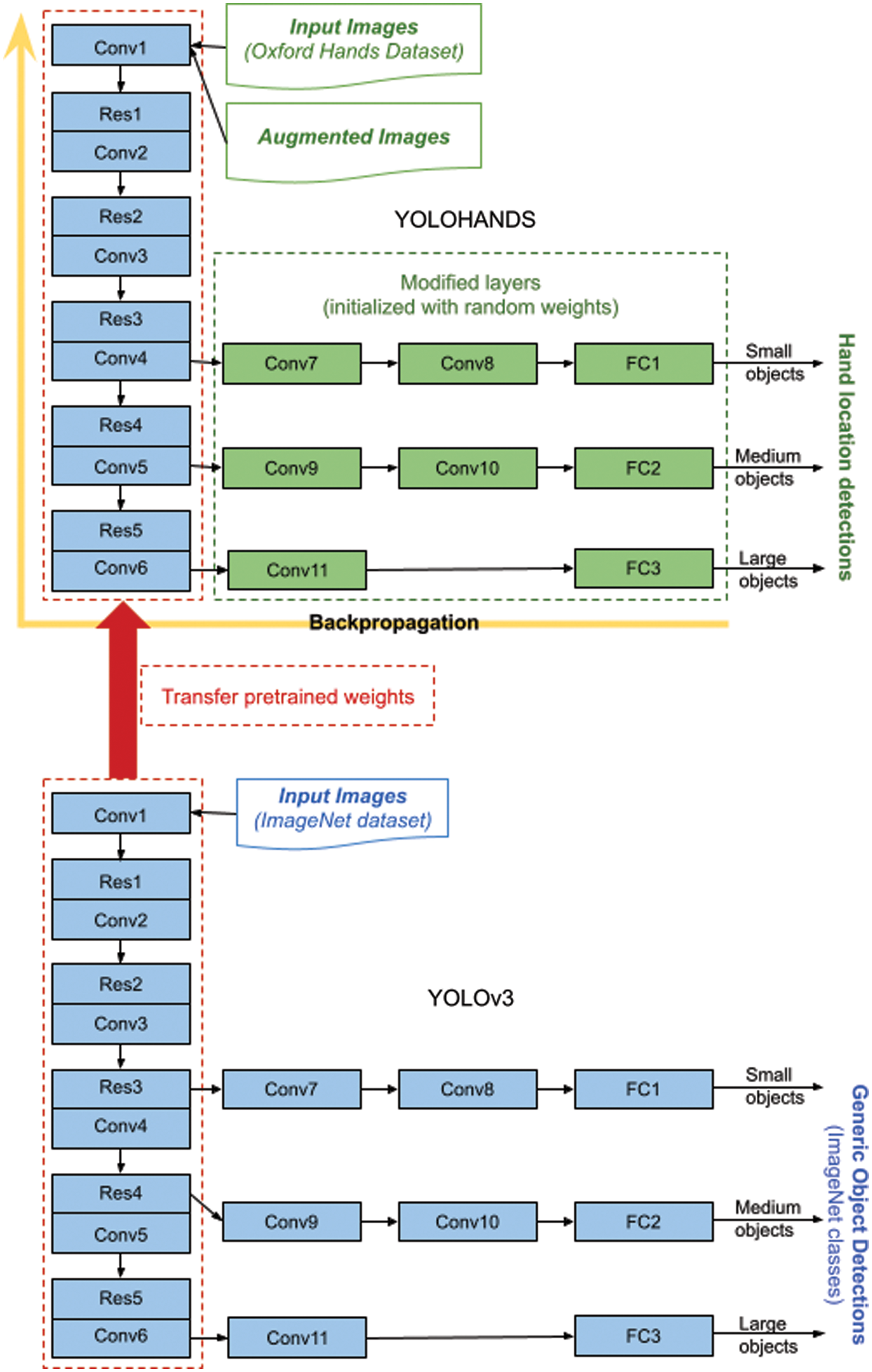
Figure 2: YOLOHANDS deep transfer learning approach based on pretrained YOLOv3 [9]
When choosing the training procedure for the network weights tuning, there are few options. One option is to lock the first several layers during training, meaning that the locked layers won’t be updated with gradients during backpropagation. In this case we would only update the weights of the last few layers. Although this can significantly reduce training speed and memory consumption, it is only applicable to detect objects with a similar appearance to the generic objects used for the original YOLO training. However, we are detecting a specific object class (i.e., human hands) which does not exist as a separate class in the training dataset of the original YOLO detector, so we decided to perform the training over all network layers. In this way we open all layers for adaptation during the backpropagation procedure.
Training of the YOLOHANDS model is performed in iterations, where each iteration consists of a single forward-backward pass over one batch of images. We used batches consisting of 64 images, due to GPU memory limitations. After every 1000 iterations, current weights of the network are stored to serve as checkpoints.
The original network outputs regressed bounding boxes around potential object locations, coupled with a detection confidence of the bounding boxes. By default, regressed bounding boxes whose confidence is below the value 0.5 are discarded. The option to change the confidence threshold values is exposed as a parameter of the network, and we take advantage of that for computing the Average Precision (AP) measure during the evaluation.
Choosing the appropriate dataset, as well as defining the corresponding preprocessing procedure, might be of crucial importance for Deep Learning applications. Therefore, we will first describe the dataset and give details of the proposed data augmentation algorithm.
The dataset used for evaluation is a publicly available Oxford Hand Dataset [14]. It has been created by aggregating several different image sources and annotated by a bounding box rotated with respect to the wrist orientation. All hand instances were split into two main groups: big and normal hand instances. Big hand instances are those that are larger than 1500 square pixels. For training and evaluation purposes in this study, two subsets of the Oxford Hand Dataset have been used–a training subset consisting of 9163 hand instances and a test subset of 2031 instances for evaluation. We were using the complete dataset, without making any distinction between ‘normal’ and ‘big’ hand instances. The original annotations for the Oxford Hand Dataset had to be slightly modified, since the architecture of the original YOLO detector is not designed for oriented object detection. Actually, YOLO network only accepts axis-aligned bounding boxes for training and produces axis-aligned bounding boxes during inference. Therefore, for every original ‘rotated’ annotation box we had to compute an axis-aligned bounding box that completely covers it.
Importance of data augmentation for visual recognition tasks has been verified through a number of studies [30,31]. We have experimented with different image augmentation techniques and finally formulated an extensive augmentation procedure over the training dataset by generating 38 augmented images for every single image in the training dataset. Before the augmentation, all images are resized to 416 by 416 pixel dimensions. The augmentation starts by rotating the image at an angle that was a random multiple of

For quality evaluation of the described YOLOHANDS detection method, we used the following three measures: Recall, Precision and F1 measure. Proper understanding of these measures in the context of object detection domain might be tricky, so we will give a brief description of the corresponding parameters, measures and computation procedures used in the paper. A true positive (TP) is a valid object detection, meaning an object is present in the scene and properly detected. False positive (FP) is an invalid object detection, meaning that an object which is not present in the scene is wrongly detected, or the object is present in the scene, but the detection is not overlapping it. False negative (FN) indicates that an object is present in the scene, but it is not correctly detected. Recall measure calculates the percentage of properly detected objects among all that are present in the dataset, and it can be computed in the following way

To measure if a single detected bounding box is correctly positioned relative to the annotation, an intersection over union (IoU) is computed between detected and annotated bounding boxes. IoU takes values from the interval [0,1], with value 0 meaning there is no intersection at all, and value 1 meaning that the detected and annotated boxes perfectly overlap. During testing, for every annotation we compute IoU with each of the detected bounding boxes and then take the maximum value. If, the value is above the threshold of 0.25, we will count that detection as valid and increment the TP score. To compute the FN score, we simply subtract the TP score from the number of annotations in an image. To compute the FP score, we subtract the TP score from the number of detected objects.
Training of the network is performed in batches of
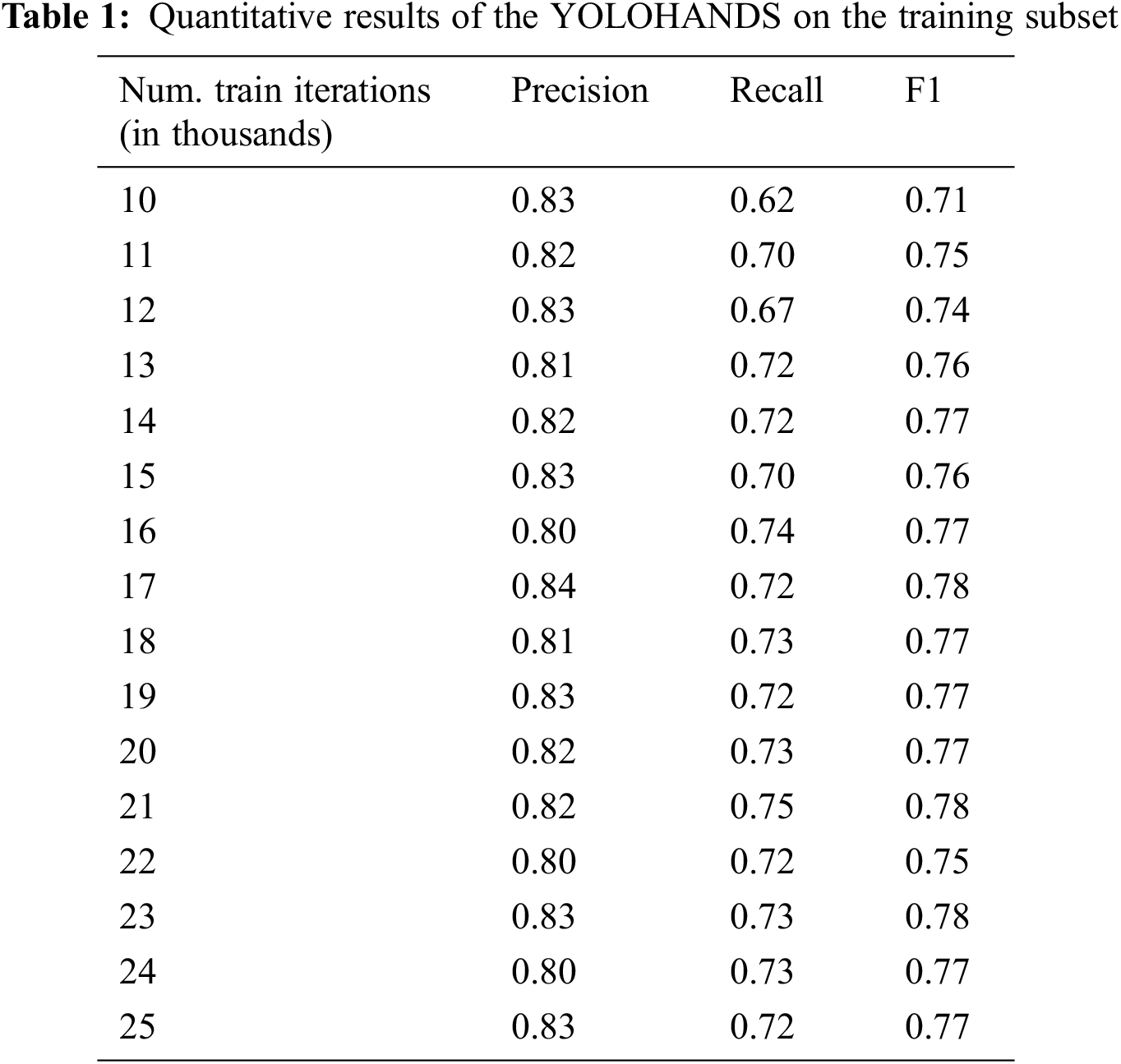
From the results given in Tab. 1, it can be noticed that Precision has a relatively stable value among all training checkpoints. On the other hand, the Recall and F1 measures show an increase in value until the 16000 training iterations (~3 training epochs), while stabilizing afterwards. If F1 score is assumed as a single measure of quality, it can be noticed that the optimal result of F1 = 0.78 is given after 21 k iterations (~4 training epochs). Therefore, for further experiments we will use the weights after 21 k iterations, where P = 0.82 and R = 0.75. Some qualitative results from the YOLOHANDS method can be seen in Fig. 4.
A commonly used single quality measure for evaluation of object detectors is Average Precision (AP), which is calculated as the area under the precision-recall curve. To generate the curve, we used the YOLOHANDS model weights with the optimal F1 score, and varied detection confidence thresholds (as described in 3.2). The computed precision and recall results are given in Tab. 2, with the corresponding curve presented in Fig. 3 below.

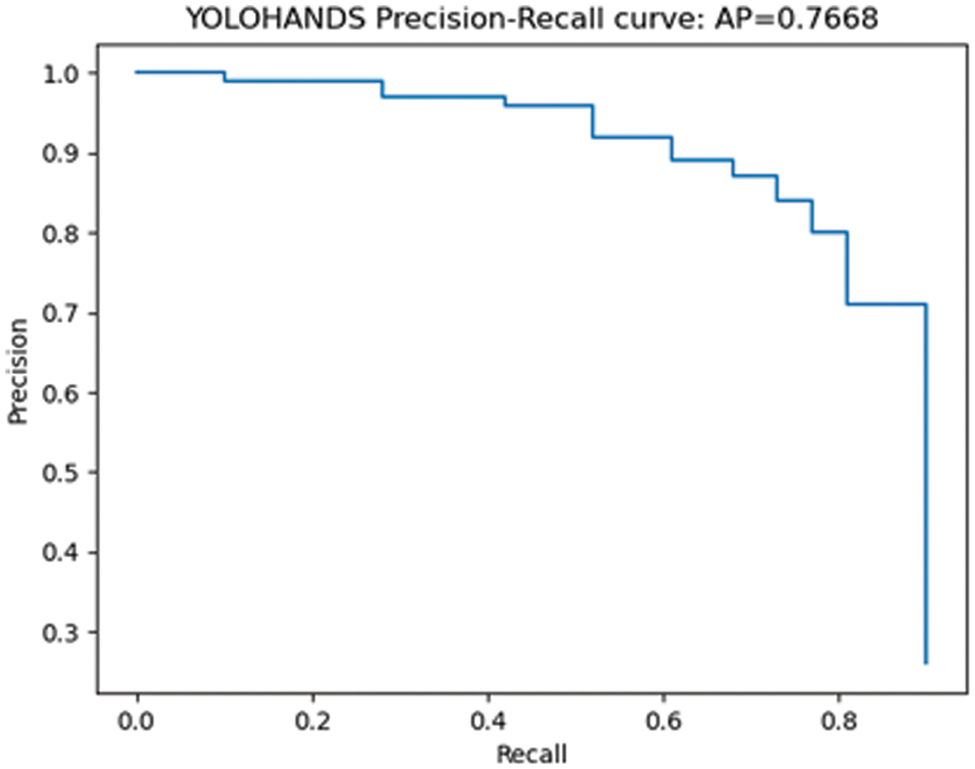
Figure 3: Precision-recall curve used to compute the final average precision AP = 76.68%
We further compared results of our approach with state-of-the-art results from the literature, evaluated on the same Oxford Hands Dataset (see Tab. 3).
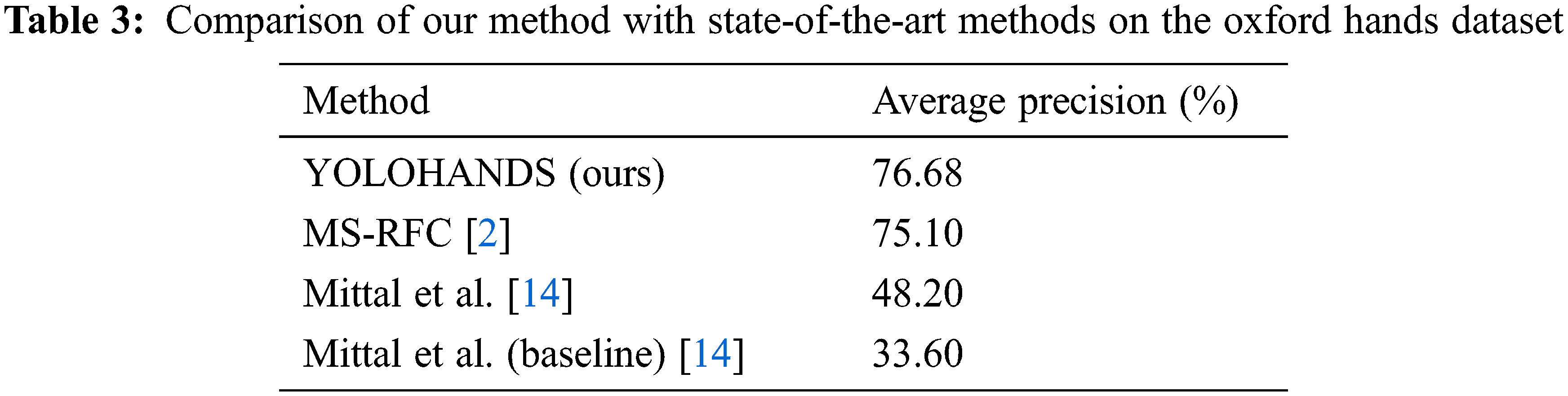
The obtained value of AP = 76.68% represents the top result on this dataset. This confirms the adaptation power of generic YOLO-based neural network architectures and its ability to successfully handle specific detection tasks, such as human hand detection. Some qualitative results of our YOLOHANDS detection approach in challenging environments, are given in Fig. 4.

Figure 4: Examples of detection results of the YOLOHANDS method (detected hands are marked with pink bounding boxes)
Robust and accurate detection of human hands in uncontrolled environments is a challenging visual recognition task, which is of crucial importance for many high-level human behavior analysis tasks. In this paper we proposed and evaluated a method for robust hand detection which is built by a deep transfer learning approach over YOLO neural network architecture. The initial model is adapted to the single class hand detection task, by modifying the higher convolutional layers including the last fully connected layer, while initializing lower non-modified layers with the generic pretrained weights. To address robustness issues of the overall method, we proposed a comprehensive data augmentation procedure over the training image dataset. The obtained experimental results on a challenging publicly available dataset show the highest level of accuracy of the proposed method, which is comparable to the state-of-the-art methods. It can be concluded that state-of-the-art generic object detection methods, such as YOLO, can be successfully adapted to the specific hand detection task by deep transfer learning approach and adequate data preprocessing procedure. The presented results encourage experimenting with other highly accurate object detection methods, such as Faster-RCNN [7] or YOLOS Transformer [21].
Funding Statement: The research presented in this paper is financed by the Ministry of Education, Science and Technological Development of the Republic of Serbia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. K. M. Sagayam and D. J. Hemanth, “Hand posture and gesture recognition techniques for virtual reality applications: A survey,” Virtual Reality, vol. 21, no. 2, pp. 91–107, 2017. [Google Scholar]
2. T. H. N. Le, K. G. Quach, C. Zhu, C. N. Duong, K. Luu et al., “Robust hand detection and classification in vehicles and in the wild,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, pp. 1203–1210, 2017. [Google Scholar]
3. D. Bragg, O. Koller, M. Bellard, L. Berke, P. Boudreault et al., “Sign language recognition, generation, and translation: An interdisciplinary perspective,” in Proc. of the 21st Int. ACM SIGACCESS Conf. on Computers and Accessibility, Pittsburg, USA, pp. 16–31, 2019. [Google Scholar]
4. J. Gangrade, J. Bharti and A. Mulye, “Recognition of Indian sign language using ORB with bag of visual words by kinect sensor,” IETE Journal of Research, vol. 69, no. 1, pp. 1–15, 2020. [Google Scholar]
5. R. Girshick, “Fast R-CNN,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Boston, USA, pp. 1440–1448, 2015. [Google Scholar]
6. R. Girshick, J. Donahue, T. Darrell and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Columbus, USA, pp. 580–587, 2014. [Google Scholar]
7. S. Ren, K. He, R. Girshick and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Proc. of the Advances in Neural Information Processing Systems, Montreal, Canada, pp. 91–99, 2015. [Google Scholar]
8. J. Redmon and A. Farhadi, “YOLO9000: Better, faster, stronger,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, USA, pp. 7263–7271, 2017. [Google Scholar]
9. J. Redmon and A. Farhadi, “YOLOv3: An incremental improvement,” arXiv preprint, arXiv:1804.02767, 2018. [Google Scholar]
10. J. Yosinski, J. Clune, Y. Bengio and H. Lipson, “How transferable are features in deep neural networks?,” in Proc. of the Advances in Neural Information Processing Systems, Montreal, Canada, pp. 3320–3328, 2014. [Google Scholar]
11. A. S. Razavian, H. Azizpour, J. Sullivan and S. Carlsson, “CNN features off-the-shelf: An astounding baseline for recognition,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition Workshops, Columbus, USA, pp. 806–813, 2014. [Google Scholar]
12. N. S. A. Hanan, A. Hosni Mahmoud and A. H. Alharbi, “Time-efficient fire detection convolutional neural network coupled with transfer learning,” Intelligent Automation & Soft Computing, vol. 31, no. 3, pp. 1393–1403, 2022. [Google Scholar]
13. R. J. K. R. P. Narmadha and N. Sengottaiyan, “Deep transfer learning based rice plant disease detection model,” Intelligent Automation & Soft Computing, vol. 31, no. 2, pp. 1257–1271, 2022. [Google Scholar]
14. A. Mittal, A. Zisserman and P. H. Torr, “Hand detection using multiple proposals,” in Proc. of the British Machine Vision Conf., Dundee, UK, pp. 1–11, 2011. [Google Scholar]
15. Z. G. Darehnaei, S. M. J. R. Fatemi, S. M. Mirhassani and M. Fouladian, “Ensemble deep learning using faster R-CNN and genetic algorithm for vehicle detection in UAV images,” IETE Journal of Research, vol. 70, no. 1, pp. 1–10, 2021. [Google Scholar]
16. W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed et al., “SSD: Single shot multibox detector,” in Proc. of the European Conf. on Computer Vision, Amsterdam, Netherlands, pp. 21–37, 2016. [Google Scholar]
17. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones et al., “Attention is all you need,” in Proc. of the Advances in Neural Information Processing Systems, Long Beach, USA, pp. 5998–6008, 2017. [Google Scholar]
18. A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai et al., “An image is worth 16 × 16 words: Transformers for image recognition at scale,” in Proc. of the Int. Conf. on Learning Representations, Vienna, Austria, pp. 1–21, 2021. [Google Scholar]
19. Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 10012–10022, 2021. [Google Scholar]
20. T. Chen, S. Saxena, L. Li, D. J. Fleet and G. Hinton, “Pix2seq: A language modeling framework for object detection,” in Proc. of the Int. Conf. on Learning Representations, pp. 1–17, 2022. [Google Scholar]
21. Y. Fang, B. Liao, X. Wang, J. Fang, J. Qi et al., “You only look at one sequence: Rethinking transformer in vision through object detection,” in Proc. of the Advances in Neural Information Processing Systems, New Orleans, USA, pp. 1–18, 2021. [Google Scholar]
22. M. Oquab, L. Bottou, I. Laptev and J. Sivic, “Learning and transferring mid-level image representations using convolutional neural networks,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition Workshops, Columbus, USA, pp. 1717–1724, 2014. [Google Scholar]
23. M. A. R. Khan and M. K. Jain, “Feature point detection for repacked android apps,” Intelligent Automation & Soft Computing, vol. 26, no. 6, pp. 1359–1373, 2020. [Google Scholar]
24. H. Sun and R. Grishman, “Lexicalized dependency paths based supervised learning for relation extraction,” Computer Systems Science and Engineering, vol. 43, no. 3, pp. 861–870, 2022. [Google Scholar]
25. J. Redmon, S. Divvala, R. Girshick and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition Workshops, Las Vegas, USA, pp. 779–788, 2016. [Google Scholar]
26. T. -Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona et al., “Microsoft COCO: Common objects in context,” in Proc. of the European Conf. on Computer Vision, Zurich, Switzerland, pp. 740–755, 2014. [Google Scholar]
27. A. Bochkovskiy, C. -Y. Wang and H. -Y. M. Liao, “YOLOv4: Optimal speed and accuracy of object detection,” arXiv preprint, arXiv:2004.10934, 2020. [Google Scholar]
28. K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition Workshops, Las Vegas, USA, pp. 770–778, 2016. [Google Scholar]
29. O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh et al., “ImageNet large scale visual recognition challenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015. [Google Scholar]
30. C. Shorten and T. M. Khoshgoftaar, “A survey on image data augmentation for deep learning,” Journal of Big Data, vol. 6, no. 1, pp. 60, 2019. [Google Scholar]
31. A. Robey, G. J. Pappas and H. Hassani, “Model-based domain generalization,” Advances in Neural Information Processing Systems, vol. 34, no. 1, pp. 20210–20229, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools