
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Multimodal Machine Learning Based Crop Recommendation and Yield Prediction Model
Department of Computer and Information Science, Faculty of Science, Annamalai University, Chidambaram, 608002, India
* Corresponding Author: P. S. S. Gopi. Email:
Intelligent Automation & Soft Computing 2023, 36(1), 313-326. https://doi.org/10.32604/iasc.2023.029756
Received 10 March 2022; Accepted 19 April 2022; Issue published 29 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Agriculture plays a vital role in the Indian economy. Crop recommendation for a specific region is a tedious process as it can be affected by various variables such as soil type and climatic parameters. At the same time, crop yield prediction was based on several features like area, irrigation type, temperature, etc. The recent advancements of artificial intelligence (AI) and machine learning (ML) models pave the way to design effective crop recommendation and crop prediction models. In this view, this paper presents a novel Multimodal Machine Learning Based Crop Recommendation and Yield Prediction (MMML-CRYP) technique. The proposed MMML-CRYP model mainly focuses on two processes namely crop recommendation and crop prediction. At the initial stage, equilibrium optimizer (EO) with kernel extreme learning machine (KELM) technique is employed for effectual recommendation of crops. Next, random forest (RF) technique was executed for predicting the crop yield accurately. For reporting the improved performance of the MMML-CRYP system, a wide range of simulations were carried out and the results are investigated using benchmark dataset. Experimentation outcomes highlighted the significant performance of the MMML-CRYP approach on the compared approaches with maximum accuracy of 97.91%.Keywords
Precision Agriculture allows precise utilization of inputs such as water, seed, fertilizers, and pesticides to maximize quality, yields, and productivity of the crop. By installing sensors for mapping and data collection field, farmers might understand the field in a better way reduce adverse effects on the environment and conserve the resource being used [1]. Mostly, farmer practices traditional farming patterns for deciding crop to be cultivated in a field. But the farmer doesn’t recognize crop production is interdependent on climatic conditions and soil characteristics [2]. Predicting the crop types for a specific region is a challenging task and very complex because it is affected by various parameters dependent upon the climatic parameters and type of soil. Further, the crop is based on the variety of techniques utilized by the farmer from field to field, so forecasting the Crop type performance in parametric viewpoint is a challenging task [3]. With the increase in population, there is a significant demand for crop worldwide; therefore, farmer needs that aware of crop type that is treatable for soil type and geographical location. Hence, it can be necessary to offer timely-based, accurate data according to the soil type and climatic parameters to the farmer, helping them create the better decision for the soil, resulting in great productivity and profitability [4].
Crop yield prediction (CYP) depends on input features like temperature, area, irrigation methods, and so on [5]. The precision of CYP is accomplished by adapting suitable input and model without affecting the agriculture production system and nature [6].
Agriculture researcher explores the best CYP, according to the collection of agriculture information, and develops CYP method to enhance rural and agricultural data. However, there is no standard dataset presented for agriculture study and it differs for distinct positions, irrigation method, climatic condition, and type of crop [7,8]. Researchers use data driven models for getting precise predictions. In data driven method, the Machine Learning (ML) algorithm plays significant role in accomplishing better performance [9]. The accuracy of the prediction and the reservation established by the ML algorithm depends on the model representativeness, data quality, and the reliance among the target and input variables in the gathered data sets [10]. Various studies employed regression model for CYP to analyze its applicability with other methods.
This paper presents a novel Multimodal Machine Learning Based Crop Recommendation and Yield Prediction (MMML-CRYP) technique. The proposed MMML-CRYP model mainly focuses on two processes namely crop recommendation and crop prediction. Firstly, equilibrium optimizer (EO) with kernel extreme learning machine (KELM) method was employed for effectual recommendation of crops. Besides, the EO algorithm is applied to optimally adjust the KELM parameters. Secondly, random forest (RF) technique was applied for predicting the crop yield accurately. In order to report the enhanced performance of the MMML-CRYP model, a wide range of simulations were carried out and the outcomes are investigated using benchmark dataset.
The rest of the paper is organized as follows. Section 2 offers a detailed literature review and Section 3 provides the proposed model. Next, Section 4 gives performance validation and Section 5 concludes the work.
Doshi et al. [11] proposed a smart technology named AgroConsultant that aim is to help the Indian farmer in making an informed decision where crop grows dependent on geographical position, soil characteristics, the sowing season, and environmental factors like rainfall and temperature. Pande et al. [12] presented a user-friendly and yield viable prediction technique for the farmer. The presented method offers connectivity to farmers through mobile applications. Global positioning system (GPS) assists in identifying the client’s position. The client offers the area and soil type as input. The ML algorithm allows selecting the more efficient yield list or prediction the crop yield for user-selected crops. For forecasting crop production, selected ML approaches are employed.
Paudel et al. [13] integrate agronomic principle of crop modelling with ML to construct an ML basis for forecasting large-scale crop production. It is modularity, reusability, and workflow emphasizing correctness. For correctness, it can be focus on developing understandable predictors or features (regarding crop development and growth) and apply ML without data leakage. The authors in [14] designed an approach by employing deep learning (DL) technique and crop prediction, accurate data can be accomplished by the amount of soil ingredient required with the expense. It offers better performance when compared to the present method. It analyses the data and assists the farmer in forecasting a crop that assists in gaining profit. Kolli et al. [15] employed artificial neural network (ANN) with Elman backpropagation and cascade-forward backpropagation (BP) for predicting crops. To define input parameters that increase the neuron activation, the positive gradient backpropagate by Cascade-Forward back propagation technique.
In [16], a hybrid regression-based method, Reinforcement learning (RL) is presented that shows considerably improved performance over conventional ML approaches. The approach implements RL at each selection of splitting attributes. The authors in [17] developed a hybrid DL technique with deep belief network (DBN) and feed-forward neural network (FNN). DBN is an integration of probability and statistics with NN. Although DBN performs well for non-linear systems, the approach could not offer good outcomes interms of learning speed, robustness, and model accuracy, i.e., predominant because of gradient diffusion. Gong et al. [18] proposed a greenhouse technique, by integrating two advanced methods for temporal sequence processing—recurrent neural network (RNN) and temporal convolutional network (TCN).
In this study, a new MMML-CRYP technique has been developed for effective crop recommendation and crop yield prediction. At the initial stage, the crop recommendation process is carried out by the use of EO algorithm with KELM model. Secondly, at the crop yield prediction stage, the RF model is utilized. The application of EO algorithm to tune the KELM parameters helps to considerably boost the performance of the KELM model. Fig. 1 depicts the overall block diagram of MMML-CRYP technique.
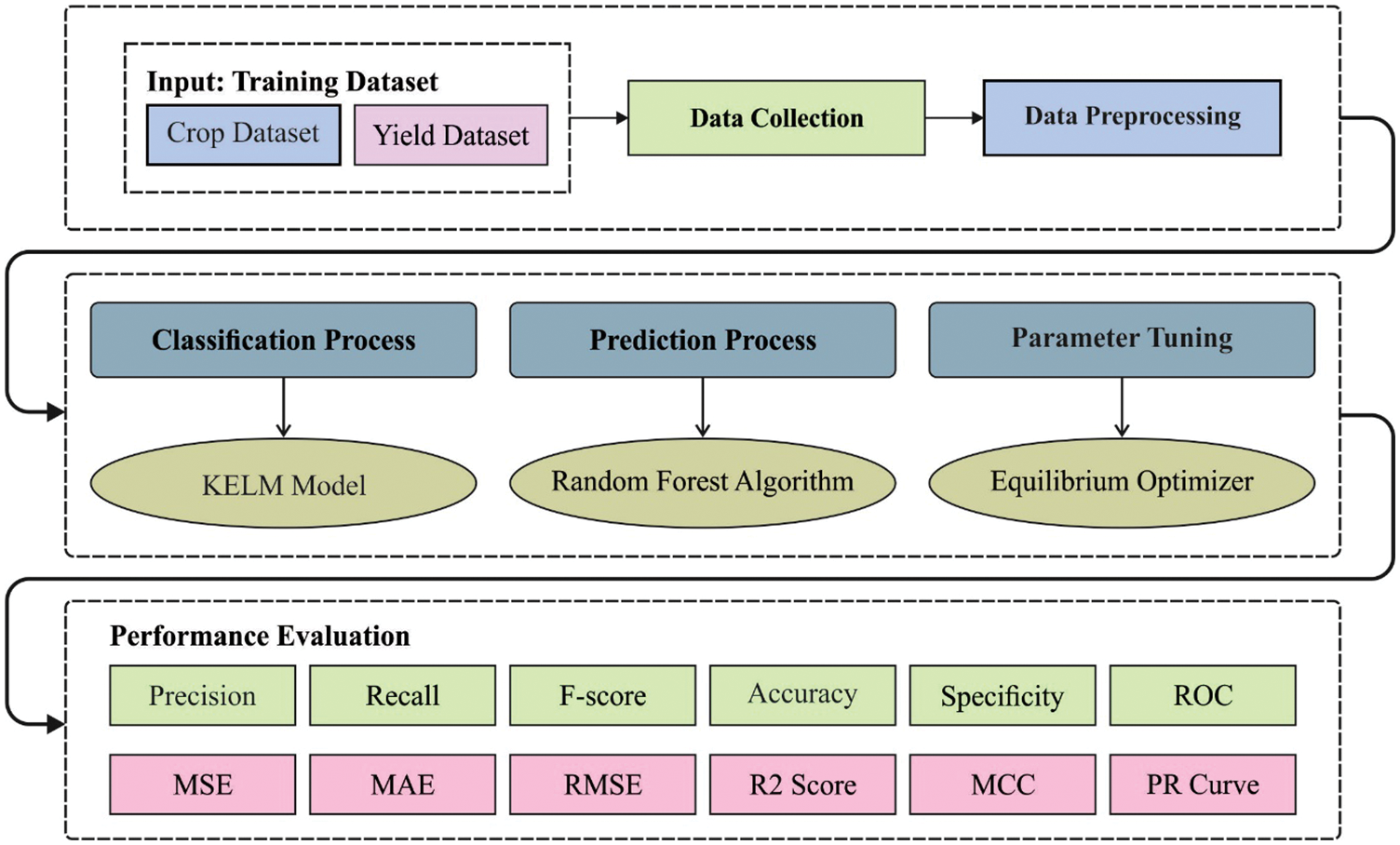
Figure 1: Overall block diagram of MMML-CRYP technique
3.1 Crop Recommendation Module
In order to identify the crop suitable for cultivation in the target region, in this study, the KELM model is used. The KELM model receives input parameters such as nutrients (Nitrogen, Phosphorous, and Potassium), temperature, humidity, and pH values for crop recommendation. For enhancing the efficiency of the KELM model, the EO algorithm is used as hyperparameter optimizer. Extreme learning machine (ELM) was presented as a faster-learning technique where the hidden state could be any form of piecewise continuous computation function. In ELM, the amount of hidden node possesses as a structural parameter that should be predetermined, whereas parametric setting of the hidden node (e.g., the influencing factor of the radial basis function (RBF) node, input weight, or the bias of additive node) are assigned arbitrarily. Assumed training instances
In the equation,
While
Several effective approaches are utilized for calculating the output weight
When
Next, substitute (5)–(4) into (1), we could attain the kernel form of output function in the following. Fig. 2 demonstrates the framework of KELM.
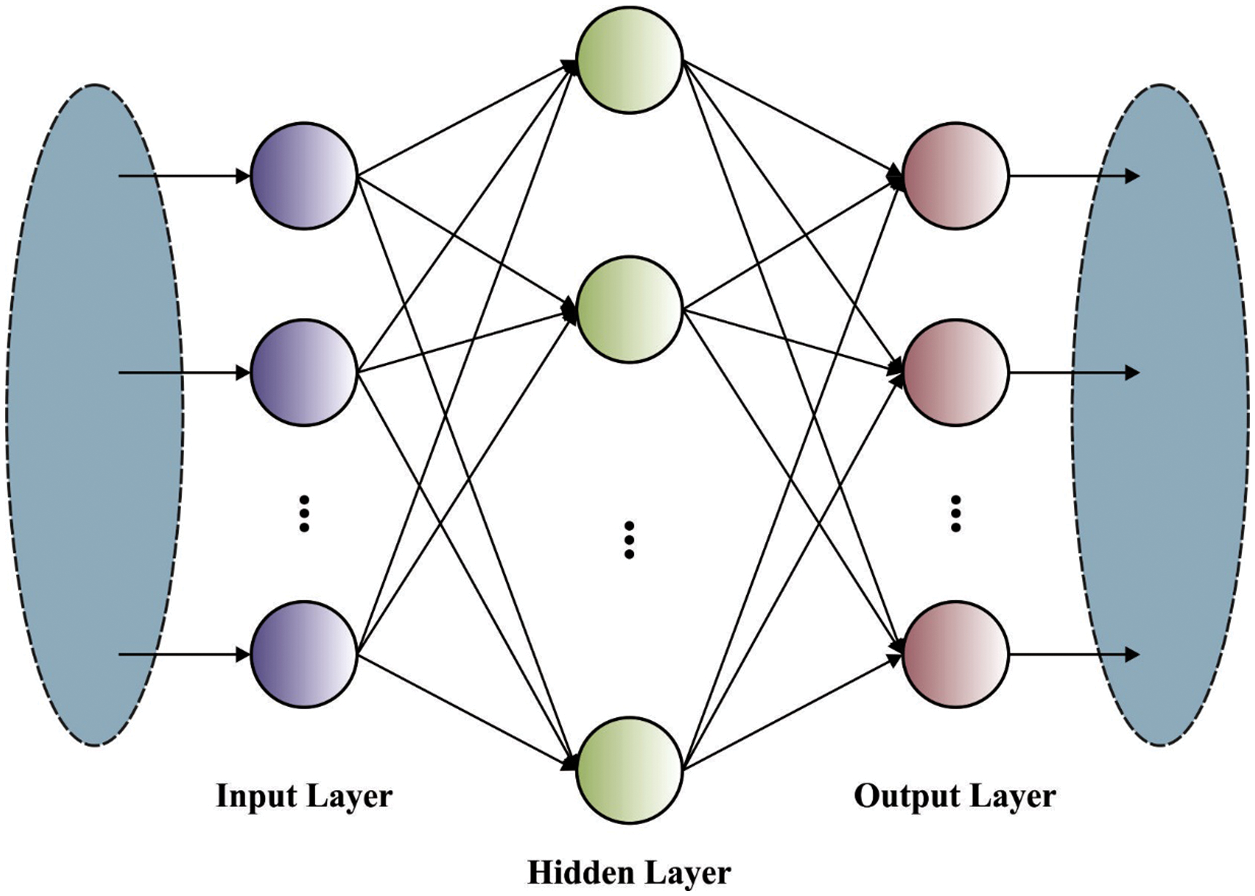
Figure 2: Structure of KELM
The EO is established in 2019 by Faramaezi et al. [20]. An important stimulus of this technique is the dynamic mass balance in physics. Related to other techniques, EO also begins the searching by initialized the population of candidate solutions as:
whereas,
In which
The vectors
In which time
The term
The value of variable
The generation rate
whereas
3.2 Crop Yield Prediction Module
During the crop yield prediction process, the proposed MMML-CRYP technique primarily pre-processes the input data by the use of one hot encoding. Besides, RF model was executed for predicting the crop yield proficiently. The RF classification is a supervised technique where multiple decision trees (DTs) are utilized for creating a forest. The forest is very effective while high amount of trees is utilized in making decisions. In general, a leaf is taken into account for increasing the construction of trees. The margin function can be formulated by
whereas
In
The margin function for RF is shown below:
and the strength of classification
The RF is an effective method which creates multiple DTs and merges them with a single tree to have maximum predictive performance. The RF approach is defined below:
Step 1: Dataset
Step 2: The model is trained for generating the novel data set from the reduced sample and estimating the unbiased error.
Step 3: At every node point in the dataset,
Step 4: In our model, various trees grow at the same time and the last prediction can be performed by the set of individual decisions to attain the optimal classifier performance.
In this section, the performance validation of the MMML-CRYP model is performed using two datasets. Firstly, the Crop Recommendation Dataset (available at https://www.kaggle.com/atharvaingle/crop-recommendation-dataset) from Kaggle repository is used, which comprises rainfall, climate, and fertilizer data. It holds 2000 samples with distinct classes such as apple, kidney beans, rice, chickpea, moth beans, orange, mungbean, jute, lentil, blackgram, pomegranate, banana, mango, pigeon peas, grapes, watermelon, maize, muskmelon, papaya, cotton, coffee, and coconut. Next, the crop yield prediction dataset (https://www.kaggle.com/prasadkevin/crops-prediction-indian-dataset/data) holds instances under different classes such as Groundnut, Maize, Moong (Green Gram), Rice, and Urad. The features involved in the dataset are State_Name, District_Name, Crop_Year, Season, Crop Area, and Production. Fig. 3 demonstrates the confusion matrix generated by the MMML-CRYP model. The figure reported that the MMML-CRYP model has effectively identified the samples under 21 class labels.
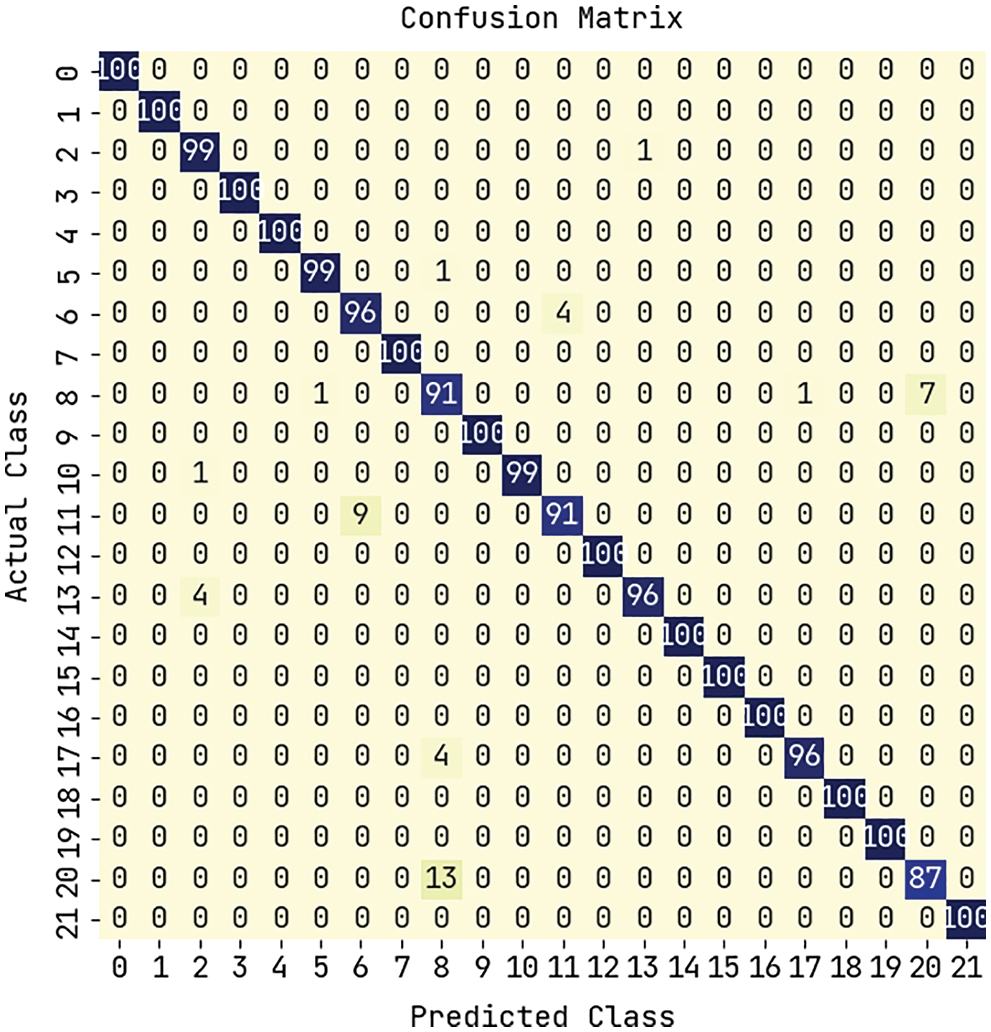
Figure 3: Confusion matrix of MMML-CRYP technique
Tab. 1 and Fig. 4 indicate an overall crop recommendation performance of the MMML-CRYP model on the test dataset. The experimental values indicated that the MMML-CRYP model has gained effective recommendation outcome with
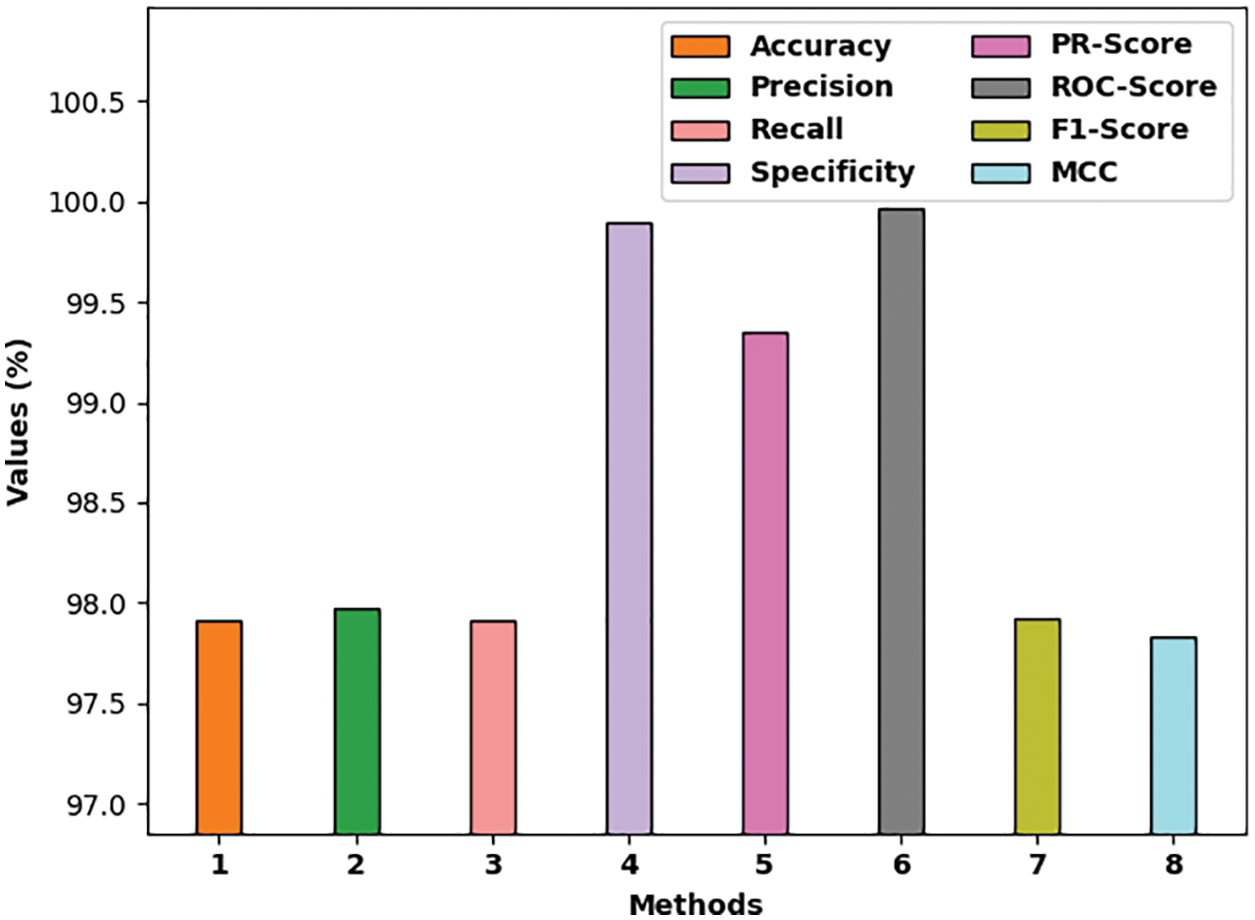
Figure 4: Overall result analysis of MMML-CRYP technique with distinct measures
Fig. 5 showcases the precision-recall analysis of the MMML-CRYP approach on the test dataset. The figure revealed that the MMML-CRYP system has the capability of accomplishing maximum outcomes under all class labels.
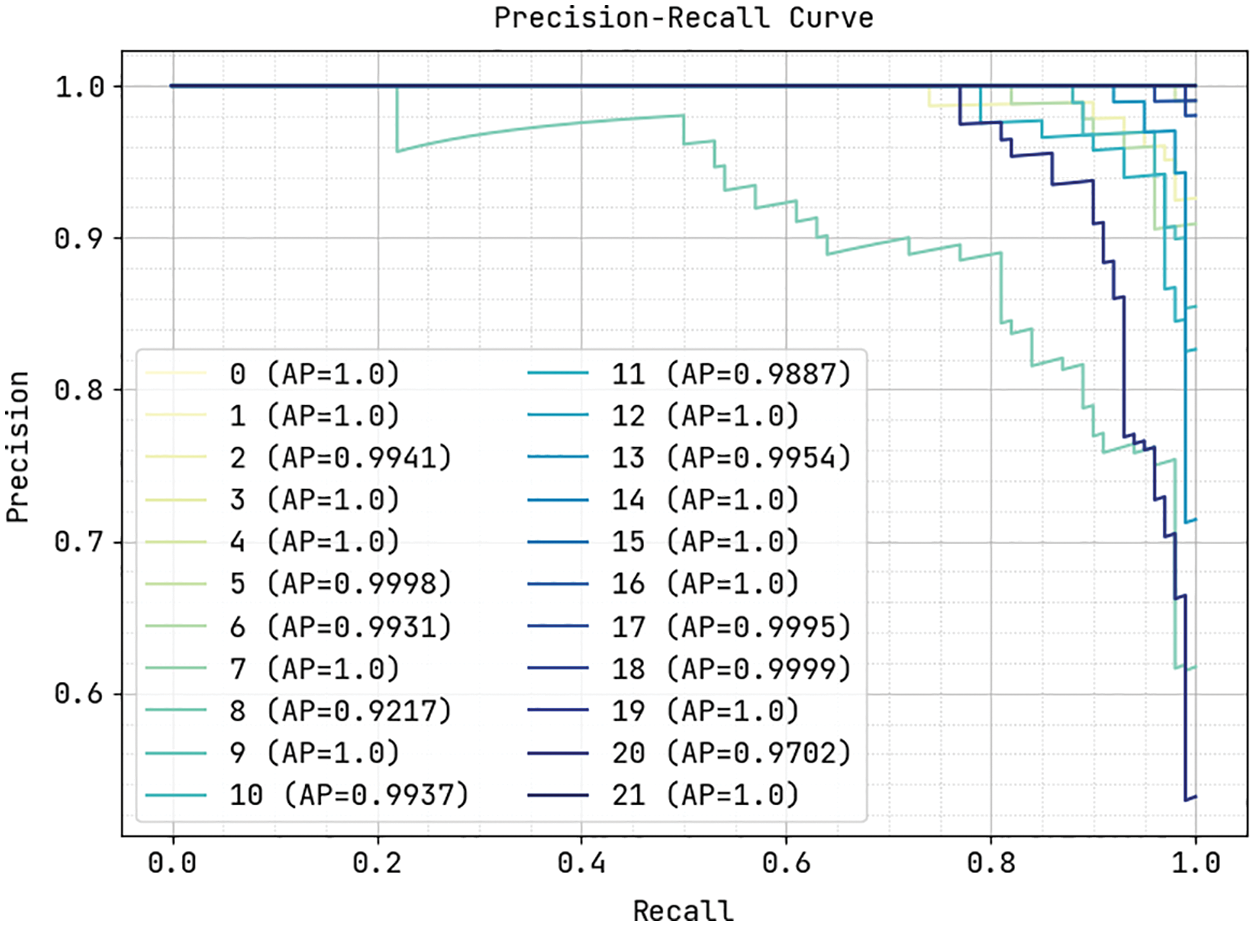
Figure 5: Precision-recall analysis of MMML-CRYP technique
Fig. 6 illustrates the ROC inspection of the MMML-CRYP model on the test dataset. The figure reported that the MMML-CRYP model has the ability to accomplish maximum outcomes under all class labels.
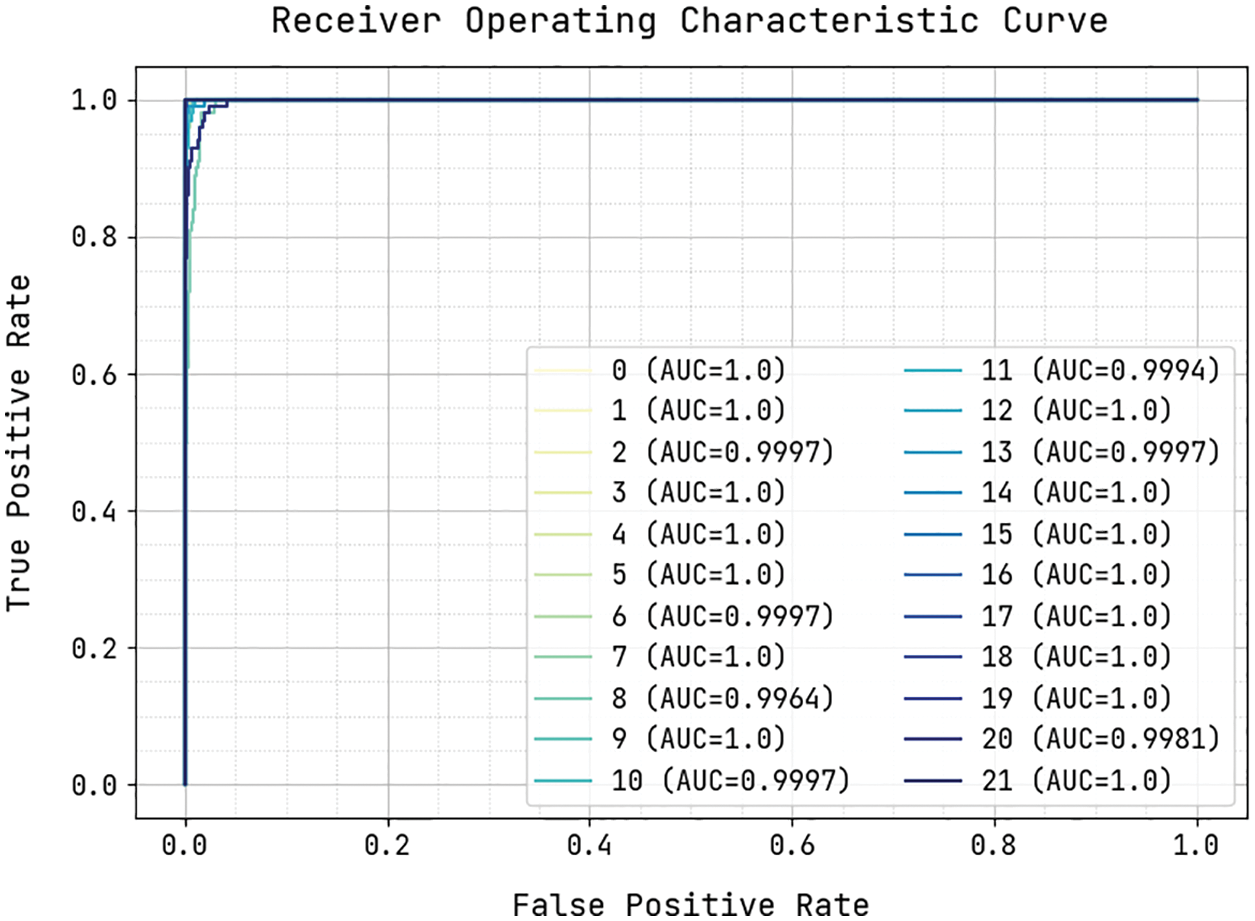
Figure 6: ROC analysis of MMML-CRYP technique on crop recommendation
A comparative investigation of the MMML-CRYP model with recent methods such as non-negativity constraint with sparse auto-encoder (NC-SAE), support vector machine (SVM)-Kernel, SVM, stacked sparse autoencoder with convolution neural network (SSAE-CNN), principal component analysis with CNN (PCA-CNN), and DT models is provided in Tab. 2 [21]. The experimental values indicated that the proposed MMML-CRYP model resulted in better results.
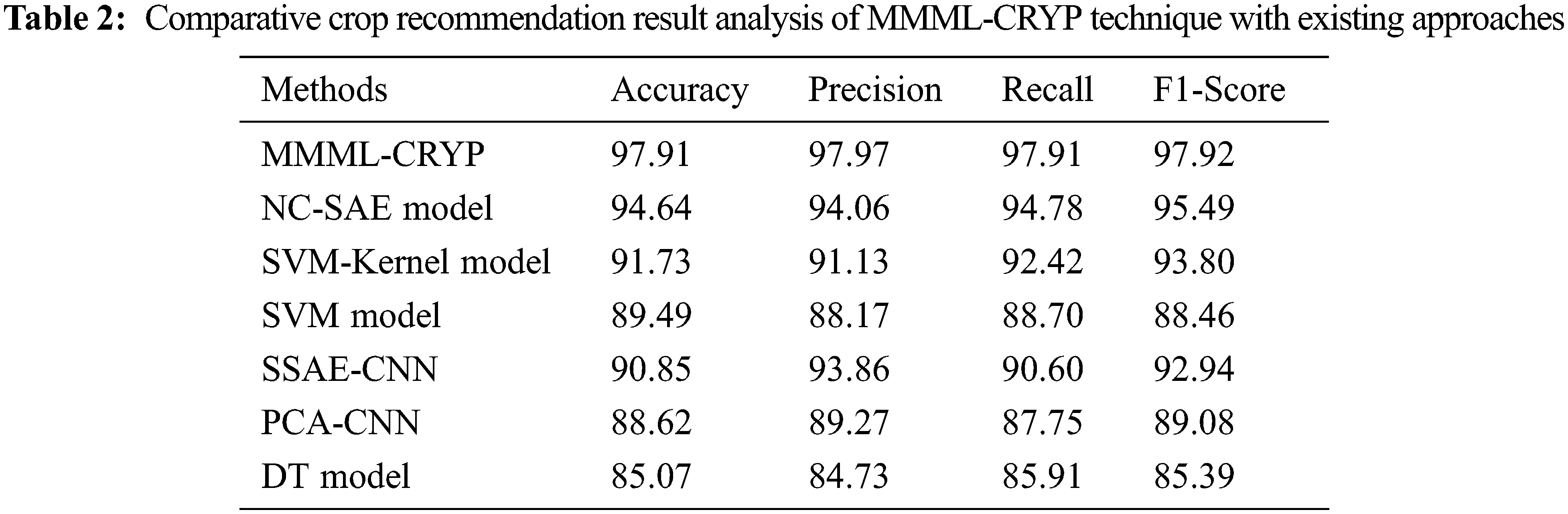
Fig. 7 inspects a comparison study of the MMML-CRYP model with other methods interms of
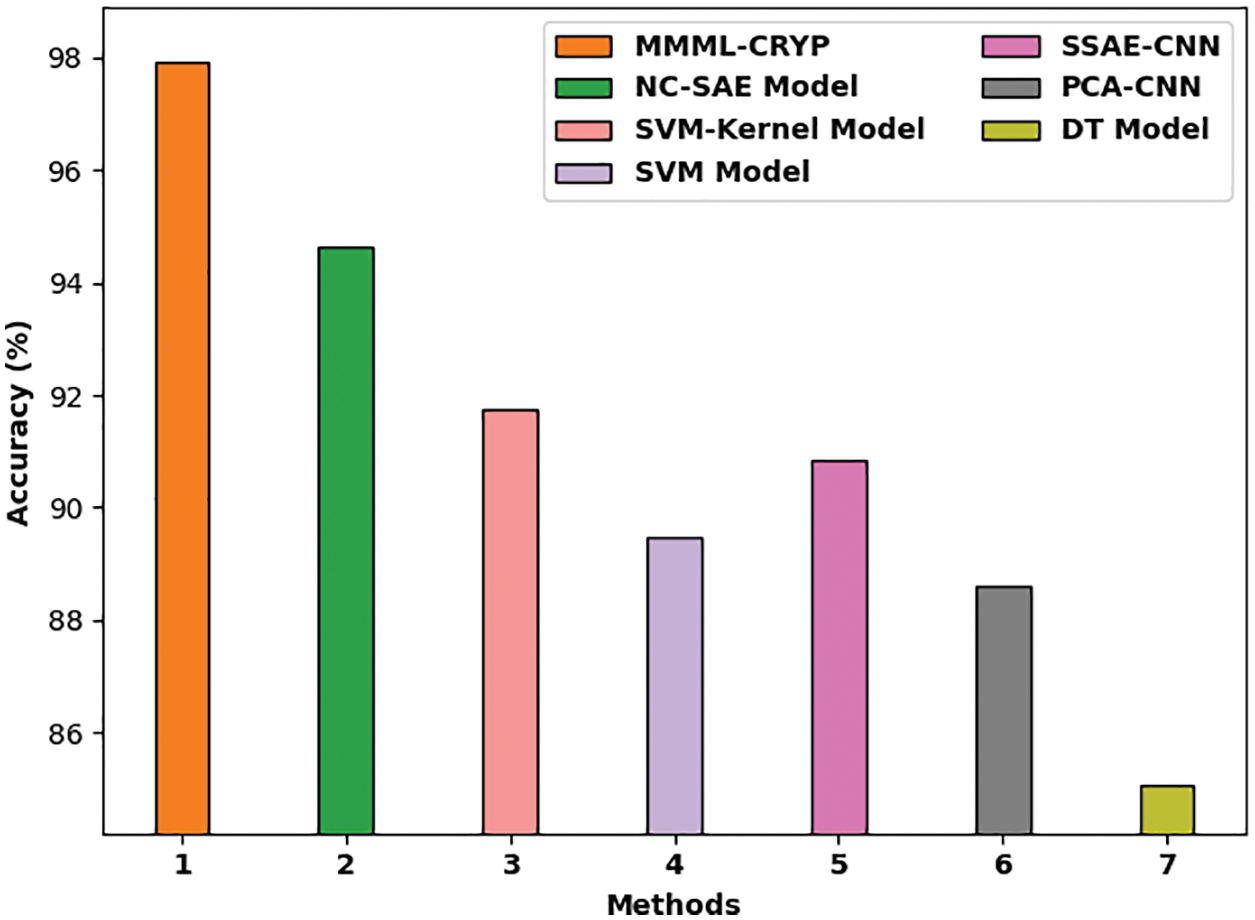
Figure 7:
Fig. 8 showcases a comparison study of the MMML-CRYP approach with other methods in terms of
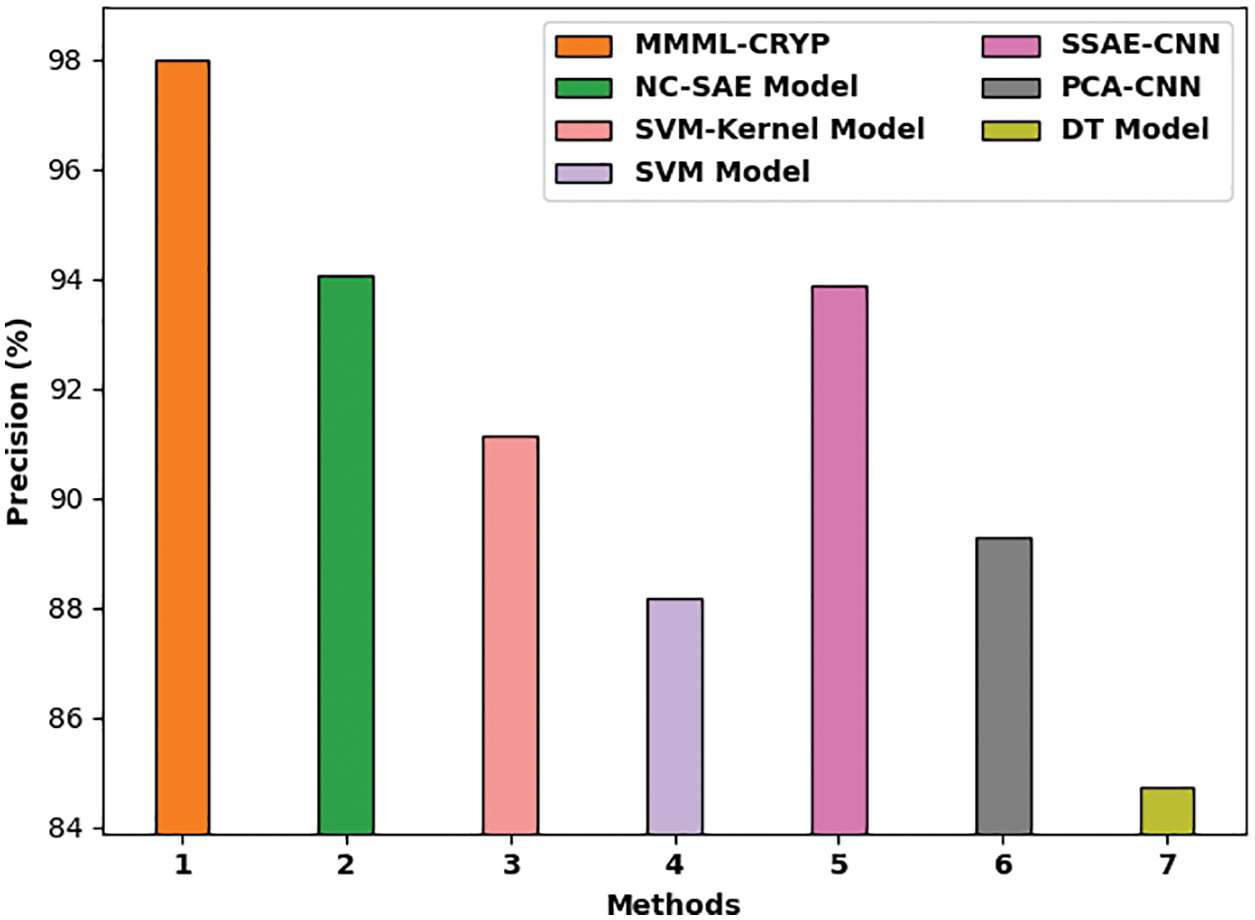
Figure 8:
Fig. 9 examines a comparison study of the MMML-CRYP algorithm with other methods with respect to
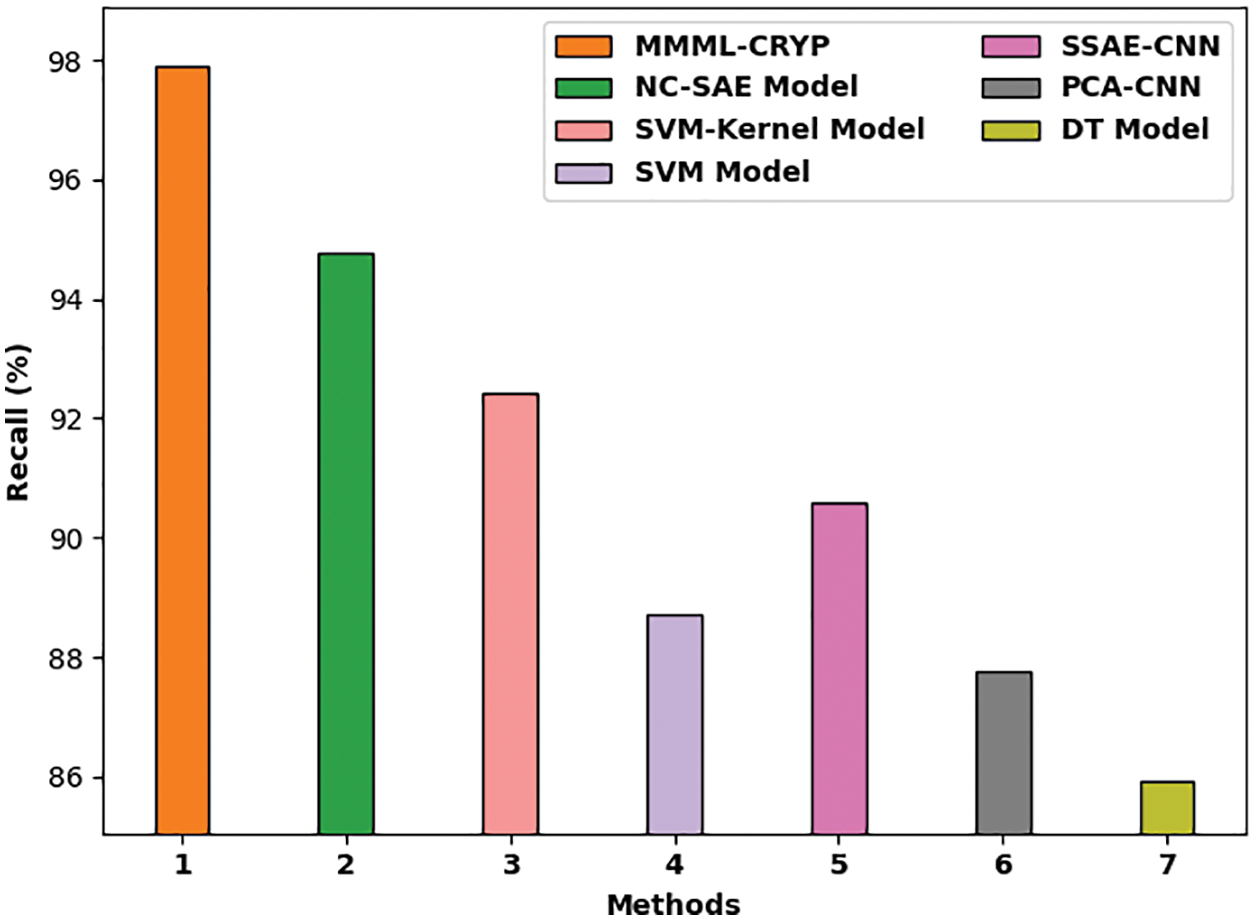
Figure 9:
Fig. 10 demonstrates a comparison study of the MMML-CRYP model with other methods in terms of
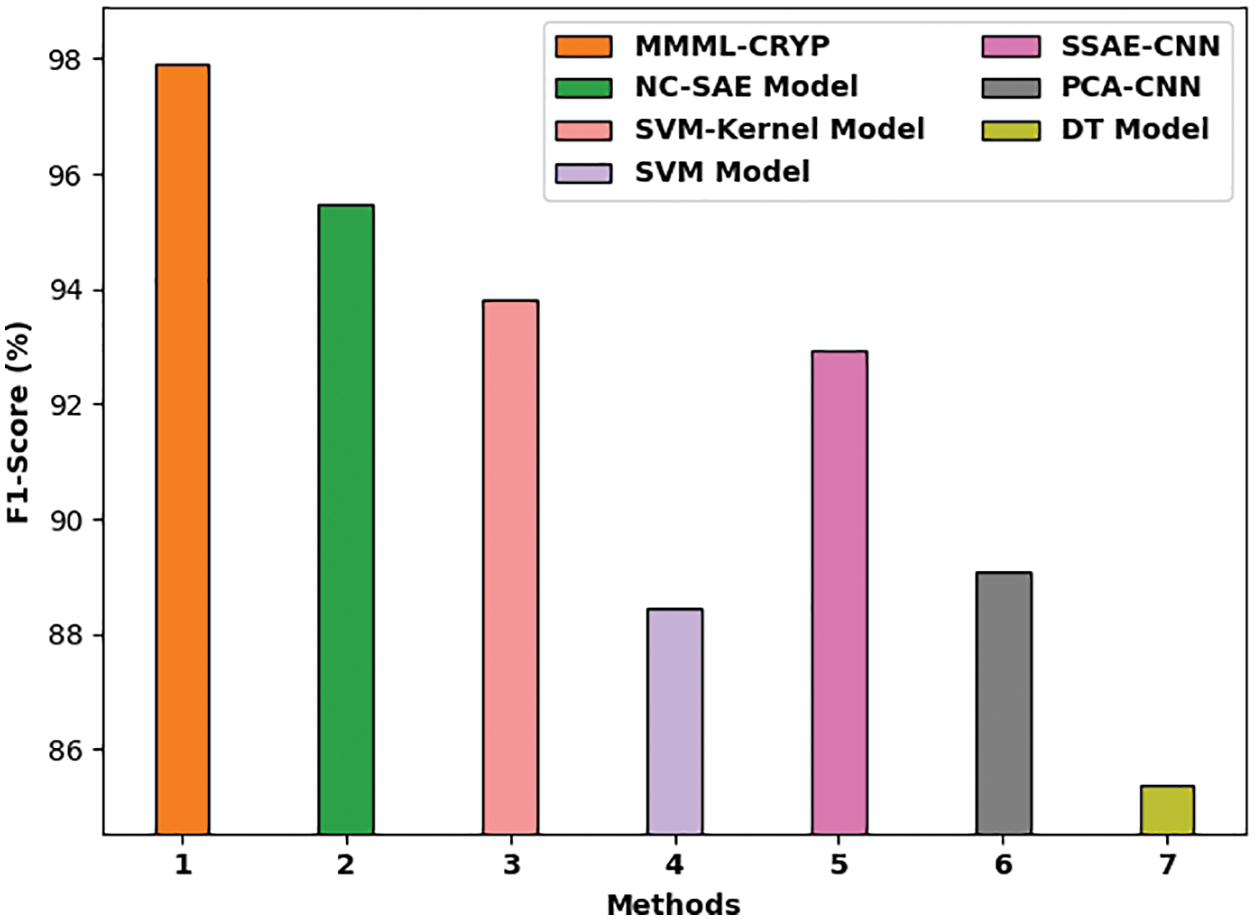
Figure 10:
Fig. 11 shows the predictive outcome of the MMML-CRYP model on the crop yield dataset. The figure indicated that the MMML-CRYP model has gained effective predictive outcomes. The difference amongst the actual and predicted outcomes is almost closer to one another.
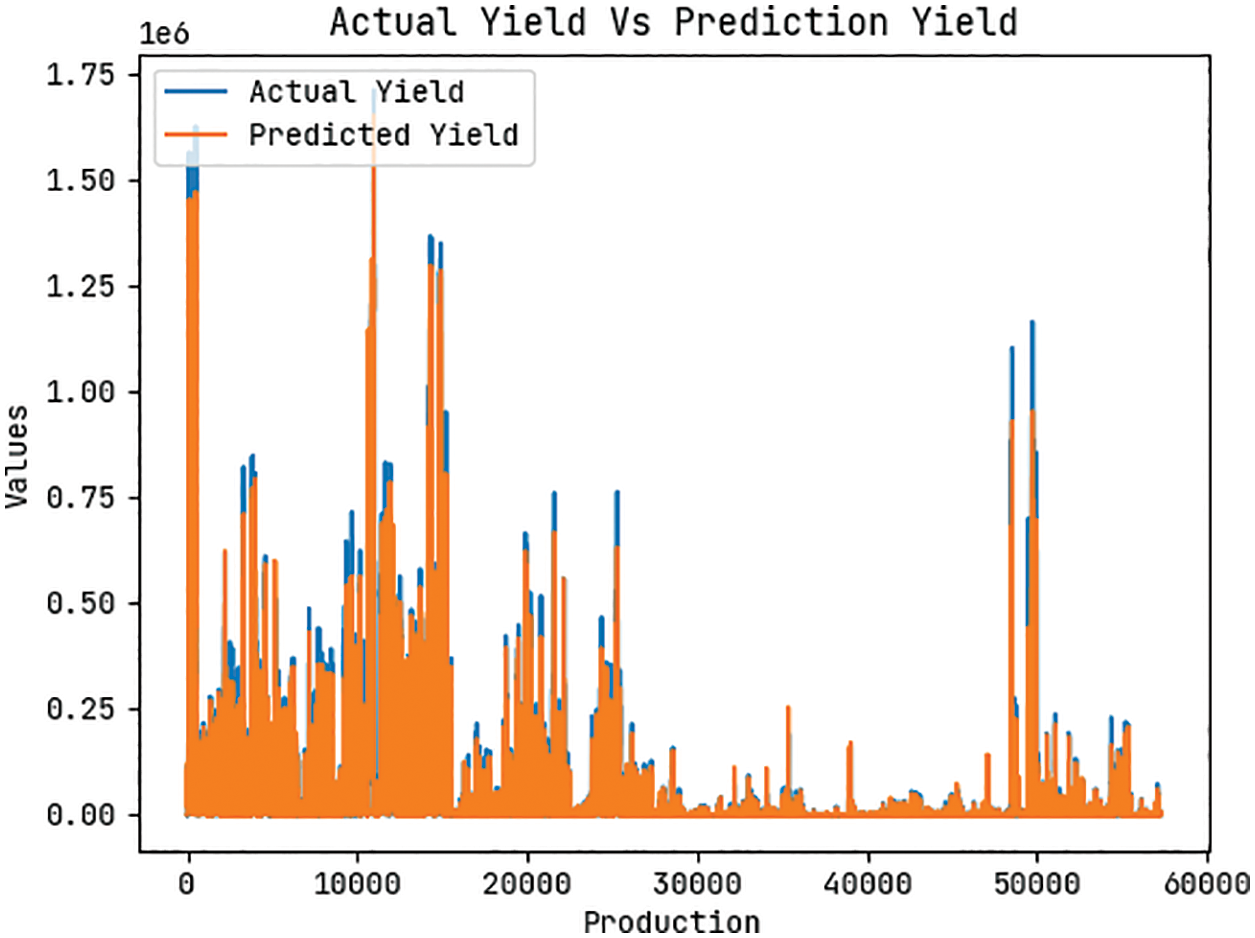
Figure 11: Predictive analysis of MMML-CRYP model on crop yield dataset
Tab. 3 provides a brief crop yield prediction performance of the MMML-CRYP technique. The outcomes indicated that the MMML-CRYP technique has shown effectual outcomes with the R2score, RMSE, and MAE of 0.9854, 12618.2059, and 3469.3239 respectively.
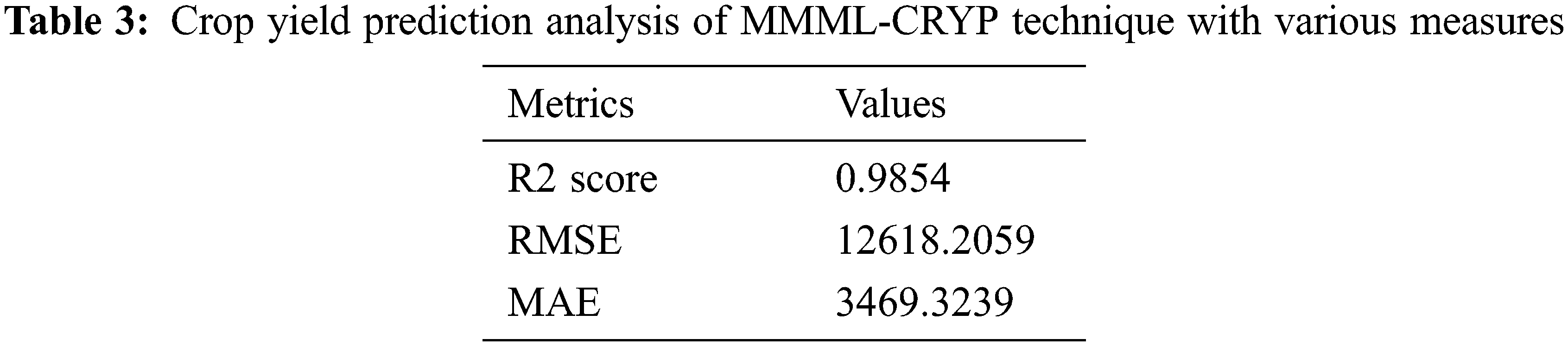
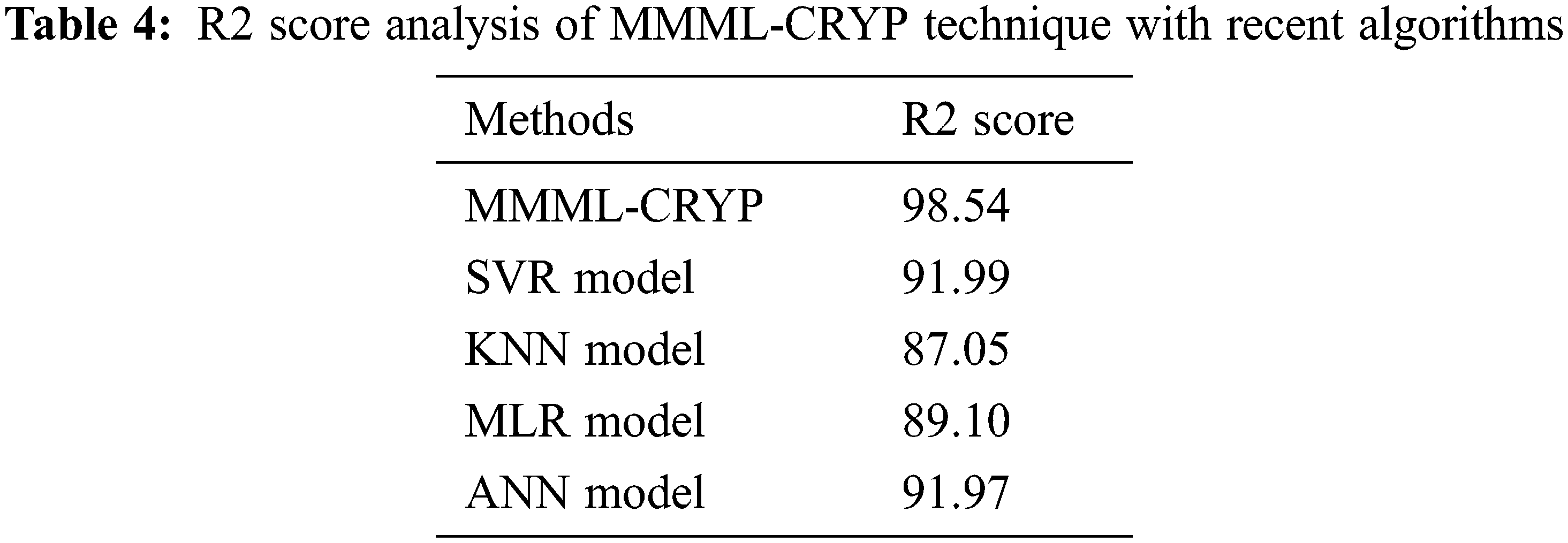
Tab. 4 examines an R2 score analysis of the MMML-CRYP methodology with other methodologies. The figure indicated that the KNN system has resulted in the least performance with R2 score of 87.05%. Next, the MLR approach has achieved moderate result R2 score of 89.10%. Afterward, the ANN and SVM models have accomplished reasonable R2 scores of 91.97% and 91.99% correspondingly. At last, the MMML-CRYP model has resulted in maximal R2 score of 98.54%. After examining the above mentioned tables and figures, it is evident that the MMML-CRYP model has accomplished effectual outcome over the other methods.
In this study, a new MMML-CRYP approach has been developed for effective crop recommendation and crop yield prediction. At the initial stage, the crop recommendation process is carried out by the use of EO algorithm with KELM model. Secondly, at the crop yield prediction stage, the RF method is utilized. The application of EO technique for tuning the KELM parameters supports to significantly boost the performance of the KELM model. For reporting the improved performance of the MMML-CRYP model, a wide range of simulations were carried out and the outcomes are investigated using benchmark dataset. Experimentation outcomes highlighted the significant performance of the MMML-CRYP technique on the compared approaches. Thus, the MMML-CRYP model was employed as a proficient tool for crop recommendation and yield prediction. In future, the DL models are utilized for effective classification of crops.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. Khaki and L. Wang, “Crop yield prediction using deep neural networks,” Frontiers in Plant Science, vol. 10, pp. 621, 2019. [Google Scholar]
2. X. R. Zhang, X. Chen, W. Sun and X. Z. He, “Vehicle re-identification model based on optimized DenseNet121 with joint loss,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3933–3948, 2021. [Google Scholar]
3. T. van Klompenburg, A. Kassahun and C. Catal, “Crop yield prediction using machine learning: A systematic literature review,” Computers and Electronics in Agriculture, vol. 177, pp. 105709, 2020. [Google Scholar]
4. R. Dash, D. K. Dash and G. C. Biswal, “Classification of crop based on macronutrients and weather data using machine learning techniques,” Results in Engineering, vol. 9, pp. 100203, 2021. [Google Scholar]
5. T. van Klompenburg, A. Kassahun and C. Catal, “Crop yield prediction using machine learning: A systematic literature review,” Computers and Electronics in Agriculture, vol. 177, pp. 105709, 2020. [Google Scholar]
6. W. Sun, L. Dai, X. R. Zhang, P. S. Chang and X. Z. He, “RSOD: Real-time small object detection algorithm in UAV-based traffic monitoring,” Applied Intelligence, pp. 1–16, 2021. https://doi.org/10.1007/s10489-021-02893-3. [Google Scholar]
7. P. S. Maya Gopal and R. Bhargavi, “A novel approach for efficient crop yield prediction,” Computers and Electronics in Agriculture, vol. 165, pp. 104968, 2019. [Google Scholar]
8. M. Rashid, B. S. Bari, Y. Yusup, M. A. Kamaruddin and N. Khan, “A comprehensive review of crop yield prediction using machine learning approaches with special emphasis on palm oil yield prediction,” IEEE Access, vol. 9, pp. 63406–63439, 2021. [Google Scholar]
9. M. Shahhosseini, G. Hu, I. Huber and S. V. Archontoulis, “Coupling machine learning and crop modeling improves crop yield prediction in the US Corn Belt,” Scientific Reports, vol. 11, no. 1, pp. 1606, 2021. https://doi.org/10.1038/s41598-020-80820-1. [Google Scholar]
10. P. Malik, S. Sengupta and J. S. Jadon, “Comparative analysis of soil properties to predict fertility and crop yield using machine learning algorithms,” in 2021 11th Int. Conf. on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, pp. 1004–1007, 2021. [Google Scholar]
11. Z. Doshi, S. Nadkarni, R. Agrawal and N. Shah, “AgroConsultant: Intelligent crop recommendation system using machine learning algorithms,” in 2018 Fourth Int. Conf. on Computing Communication Control and Automation (ICCUBEA), Pune, India, IEEE, pp. 1–6, 2018. [Google Scholar]
12. S. M. Pande, P. K. Ramesh, A. Anmol, B. R. Aishwarya, K. Rohilla et al., “Crop recommender system using machine learning approach,” in 2021 5th Int. Conf. on Computing Methodologies and Communication (ICCMC), Erode, India, pp. 1066–1071, 2021. https://doi.org/10.1109/ICCMC51019.2021.9418351. [Google Scholar]
13. D. Paudel, H. Boogaard, A. de Wit, S. Janssen, S. Osinga et al., “Machine learning for large-scale crop yield forecasting,” Agricultural Systems, vol. 187, pp. 103016, 2021. https://doi.org/10.1016/j.agsy.2020.103016. [Google Scholar]
14. S. Agarwal and S. Tarar, “A hybrid approach for crop yield prediction using machine learning and deep learning algorithms,” Journal of Physics: Conference Series, vol. 1714, no. 1, pp. 12012, 2021. [Google Scholar]
15. K. Kolli, B. Neeraja and V. S. N. Reddy, “A data mining approach to crop yield prediction using machine learning,” PalArch’s Journal of Archaeology of Egypt/Egyptology, vol. 18, no. 4, pp. 1608–1626, 2021. [Google Scholar]
16. D. Elavarasan and P. M. Durai Raj Vincent, “A reinforced random forest model for enhanced crop yield prediction by integrating agrarian parameters,” Journal of Ambient Intelligence and Humanized Computing, vol. 12, no. 11, pp. 10009–10022, 2021. [Google Scholar]
17. D. Elavarasan and P. M. Durai Raj Vincent, “Fuzzy deep learning-based crop yield prediction model for sustainable agronomical frameworks,” Neural Computing and Applications, vol. 33, no. 20, pp. 13205–13224, 2021. [Google Scholar]
18. L. Gong, M. Yu, S. Jiang, V. Cutsuridis and S. Pearson, “Deep learning based prediction on greenhouse crop yield combined TCN and RNN,” Sensors, vol. 21, no. 13, pp. 4537, 2021. [Google Scholar]
19. A. Subudhi, M. Dash and S. Sabut, “Automated segmentation and classification of brain stroke using expectation-maximization and random forest classifier,” Biocybernetics and Biomedical Engineering, vol. 40, no. 1, pp. 277–289, 2020. [Google Scholar]
20. A. Faramarzi, M. Heidarinejad, B. Stephens and S. Mirjalili, “Equilibrium optimizer: A novel optimization algorithm,” Knowledge-Based Systems, vol. 191, pp. 105190, 2020. [Google Scholar]
21. W.-T. Zhang, M. Wang, J. Guo and S.-T. Lou, “Crop classification using MSCDN classifier and sparse auto-encoders with non-negativity constraints for multi-temporal, Quad-Pol SAR data,” Remote Sensing, vol. 13, no. 14, pp. 2749, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools