
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Recognizing Ancient South Indian Language Using Opposition Based Grey Wolf Optimization
1 Department of CSE, Anna University, Chennai, 600025, Tamilnadu, India
2 Department of CSE, Agni College of Technology, Chennai, 600130, Tamilnadu, India
* Corresponding Author: A. Naresh Kumar. Email:
Intelligent Automation & Soft Computing 2023, 35(3), 2619-2637. https://doi.org/10.32604/iasc.2023.028349
Received 08 February 2022; Accepted 15 March 2022; Issue published 17 August 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Recognizing signs and fonts of prehistoric language is a fairly difficult job that requires special tools. This stipulation make the dispensation period overriding, difficult and tiresome to calculate. This paper present a technique for recognizing ancient south Indian languages by applying Artificial Neural Network (ANN) associated with Opposition based Grey Wolf Optimization Algorithm (OGWA). It identifies the prehistoric language, signs and fonts. It is an apparent from the ANN system that arbitrarily produced weights or neurons linking various layers play a significant role in its performance. For adaptively determining these weights, this paper applies various optimization algorithms such as Opposition based Grey Wolf Optimization, Particle Swarm Optimization and Grey Wolf Optimization to the ANN system. Performance results are illustrated that the proposed ANN-OGWO technique achieves superior accuracy over the other techniques. In test case 1, the accuracy value of OGWO is 94.89% and in test case 2, the accuracy value of OGWO is 92.34%, on average, the accuracy of OGWO achieves 5.8% greater accuracy than ANN-GWO, 10.1% greater accuracy than ANN-PSO and 22.1% greater accuracy over conventional ANN technique.Keywords
Several of the rock engravings that are found at various areas of the sphere expose the particulars of indulgence, regime, financial circumstance, principles, and managerial protocols trailed by numerous leaders and empires precise to those areas [1]. Recently, there has been a fast developing concern in the study on more varied languages and writings [2]. Tamil is one of the noteworthy languages in Dravidian Language Family. It has an opulent script basis start from 300BC [3]. Hence, it is essential to develop a new scheme which can identify the prehistoric Tamil fonts accurately and can alter them into contemporary Tamil fonts [4]. The prehistoric Tamil fonts i.e., the initial and primitive Tamil can be normally found in rock engravings and palm leaves. Only epigraphists can examine those rock engravings. To spread the readability and to defend the old realistic abilities, we require a decent appreciation scheme that can translate the prehistoric writing to contemporary writing [5].
There are several schemes available for printed script identification. When the plans formation is over, the test image is input into the scheme. The system splits the image into separate letters and each slice of the image is related with the preloaded patterns. A related technique is revised for every fragmented letter in the image [6]. Handwritten letter identification is a computer facilitated process that enables inferring and reading readable handwritten inputs provided on ancient scripts like palm leaves, rock engravings, etc. [7]. The development of imaging technology has swayed a few regions in the computer apparition community [8]. The process of prehistoric Tamil letter identification comprises removal of some categorized qualities named sorts to categorize an unidentified letter into one of the well-known classes. Pre-processing is fundamentally made use of to reduce ranges of handwritten letters. A feature extractor is rudimentary for creative data depiction and removing significant features for future dispensation. A classifier allocates the letters to one of the few classes [9].
A prehistoric Tamil letter identification procedure centred on fake resistant was suggested to advance the rate of letter identification [10]. ANN is an example of such an agenda that alters the masses of its networks from the training forms. These masses verifiably work as structures for cataloguing [11]. Sánchez et al. (Sánchez, Melin, & Castillo, 2017) have suggested GWO for training segmental neural network with a granulated method for human acknowledgment [12]. Despite the fact that the investigator changes the prehistoric letters up to 90% precision, the translation verses cannot be agreed with the appropriate connotation in the sentence [13].
Traditionally, recognizing the ancient language, symbols, and characters indeed required domain experts in that particular context. However, the availability of experts at the right place is not possible most of the time because of inadequate experts in this research field. In some complicated situations, the research experts themselves face complications and consume a long time for recognition. The research desperately required an efficient prediction model to resolve this issue. Hence, this research focuses on utilizing the ANN technique because of its ability to learn and model non-linear and complex relationships. The traditional ANN does not achieve remarkable performance since the randomly generated weight across the ANN layers does not yield appropriate results. Identifying appropriate weights through trial-and-error methods or manually varying all possibilities is monotonous and wastage of time to process.
The significant research objective is to develop a machine learning model to recognize ancient language, symbols, and characters. The research intends to reconfigure the randomly generated weights to enhance the performance of the conventional ANN model.
The main novelty of the work is to recognize the ancient Language, symbols and characters through ANN. OGWO is applied with ANN to identify the appropriate weights. OGWO is chosen for optimization since it includes opposition strategy to increase the chance of predicting appropriate weights over conventional GWO and other optimization techniques.
Kavitha et al. [14] have exploited the ultra-modern CNN for identifying handwritten Tamil letters in disconnected manner. CNNs differ from conservative procedure of Handwritten Tamil Character Recognition (HTCR) in removing the characteristics accordingly. That work was an effort to fix a yardstick for disconnected HTCR exploiting unfathomable learning methods. That work has generated a training accurateness of 95.16% which was very well compared with the orthodox methods.
Gao et al. [15] have premeditated an enhanced grey wolf optimization procedure with varied weights (VW-GWO). Outcomes validate that the suggested VW-GWO procedure performs higher than the normal GWO, Ant Lion optimization (ALO), PSO and Bat algorithm (BA). The VW-GWO procedure was furthermore tested in high-dimensional problems.
In Zhang et al. [16] work, the engraving images collected from Tamil Nadu Archaeological Department are pre-processed and fragmented. Letters are categorized and established reliant on Vectors mined; exploiting Support Vector Machine (SVM) classifier and the designs of the letter are synchronized with recognized letters and anticipated by means of Trigram method. Hence the suggested agenda can pay attention to the severe problems in reading the engraved images.
Zhang et al. [17] have proposed that identification of unrestrained (Handwritten) Devanagari letter was increasingly difficult because of the form of essential whacks. In that article, technique like PSO and SVM are applied and associated. An android phone was exploited for taking input letter for indicating the documented Devnagari letter. For linking the android device and MATLAB, they have used PHP language. The PSO technique provides exactness up to 90%.
Sridevi et al. [18] have provided a method to achieve grouping of handwritten prehistoric writings in Tamil. The approach utilises Extreme Learning Machine for grouping of handwritten prehistoric Tamil writings. The performance of Extreme Learning Machine is compared with Probabilistic Neural Networks. From the experiment outcomes it is collected that Extreme Learning Machine provides maximum precision rate of 95%.
The significant intention of this research is to develop a system for recognizing the ancient Language, symbols and characters through Artificial Intelligence (AI) techniques. This research includes ANN to recognize ancient Language, symbols, and characters. This research intends to identify appropriate weights to enhance the performance. The techniques involved in this process are PSO, GWO, and OGWO. Fig. 1 demonstrates the overall proposed process of ANN based recognition.
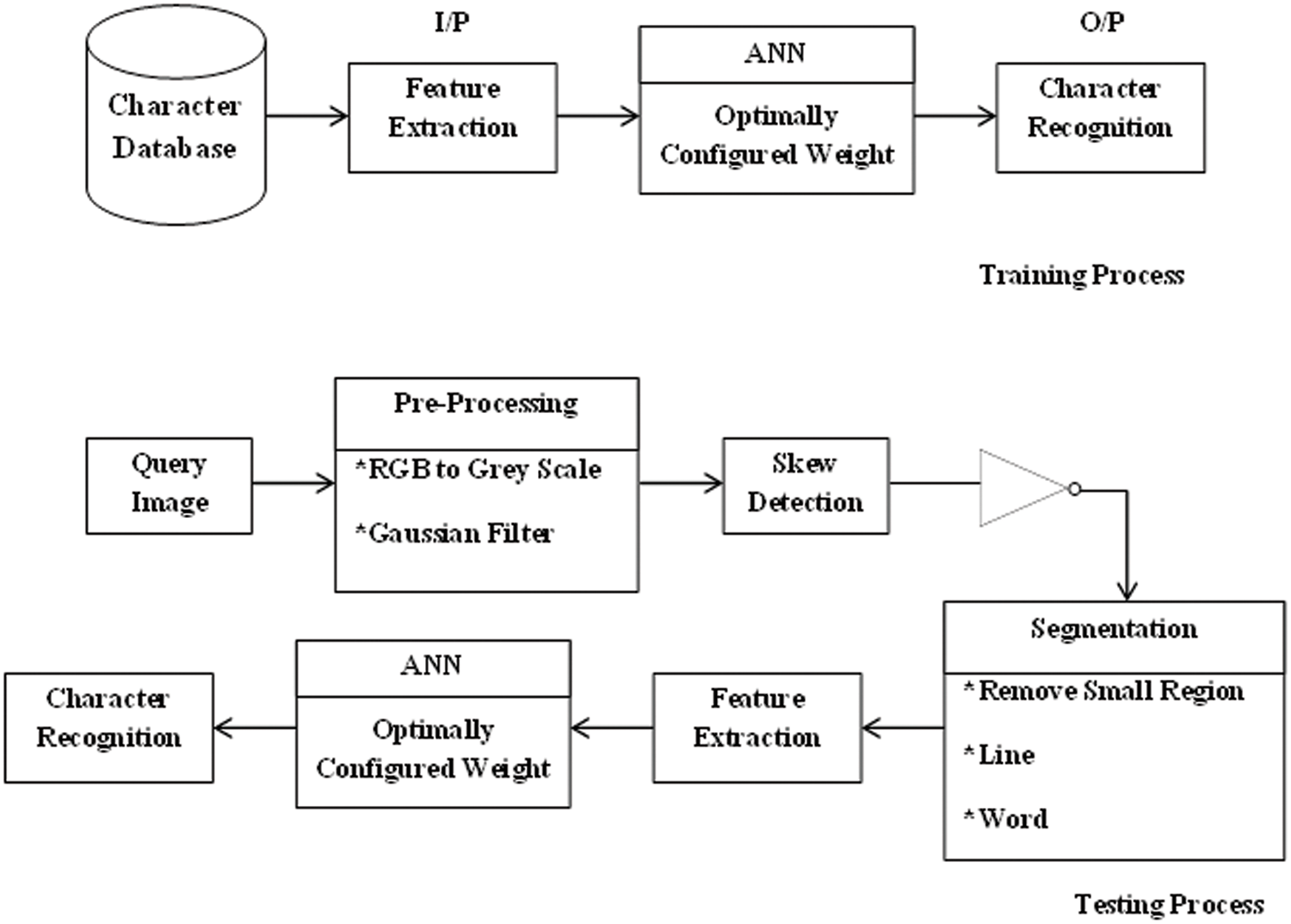
Figure 1: Block diagram of proposed framework
In training phase characteristics such as area, centroid (X-coordinates and Y-coordinates), bounding-box (corners and X-Y width), major axis distance, minor axis distance, eccentricity, orientation, perimeter, equiv diameter are initially removed from the manually fragmented 77-letters (listed in Tab. 3). These 13-characteristics are considered as an input factor and their equivalent letter images are considered as output class. Generally, the training procedure performs to conclude applicable masses for effective identification.
Pre-processing: The trained system receives the given query image (RGB) and it pre-processes the image by converting into a gray-scale, followed by applying a Gaussian filter to remove the noises.
Skew detection: A skew detection technique is used to straighten the image; which results in the image to binary form.
Segmentation based on Region growing: While reading the whole row of a pixel, if a white pixel is noticed and it is greater than 100, it is considered out of line and continues reading the succeeding pixel rows. If the white pixel not gets noticed up, it is considered as in line. A related procedure is made centred on column-wise for separating lyrics, and the above said 13-characteristics are removed for the fragmented word and those values are provided as input for the ANN prototype with organized masses. The presentation of every active method evaluates with exactness amount for two-query investigation case images.
Feature Extraction: Above mentioned 13-features are extracted for recognizing the given query character.
3.3 Artificial Neural Network (ANN)
ANN is a mathematical learning technique utilised in cognitive psychology and artificial intelligence. The ANN is an encoded computational prototype that aims to replicate the neural construction and working of the human brain. Fig. 2 shows the ANN architecture.
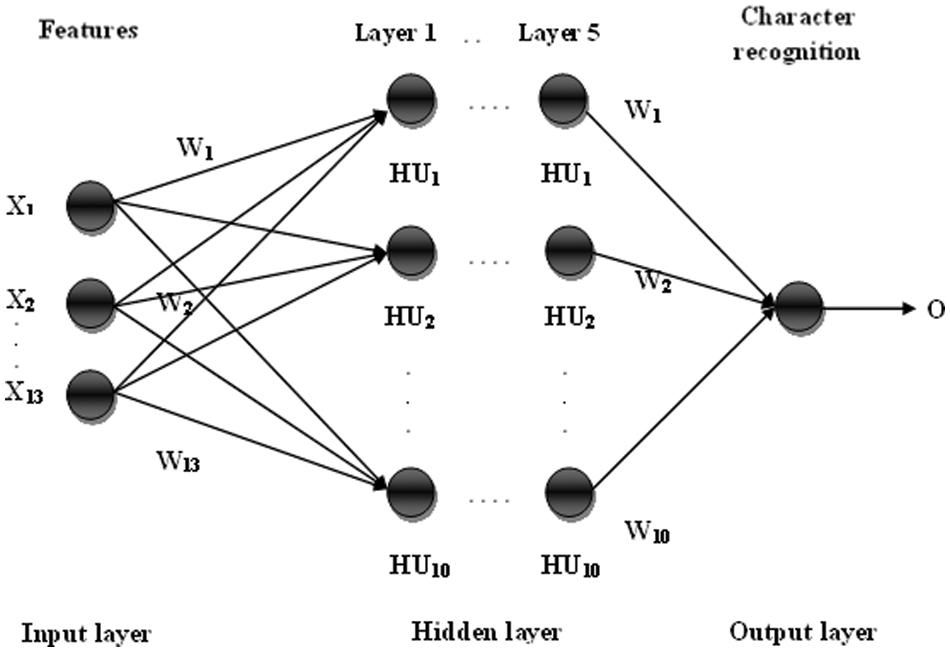
Figure 2: ANN structure
In Fig. 2, ANN contains three types of layers: input layer, hidden layer and output layer. Each layer of the ANN consists of several neurons. In this, every single neuron in the input layer is associated with the concealed layer neuron, and every concealed layer neuron associated with the output layer with an arbitrary weight. In our ANN model, 5 hidden layers are considered with 10 neurons. These arbitrary weights are allocated to every interrelated layer.
3.3.1 Structure Initialization
In the initialization process, 13 inputs based on the input layer weight wj and the hidden layer weights wij are initialized.
The input layer considers 13-input attributes as mentioned in the previous section. The input layer is the first layer of the neural network in which each input is connected with hidden layer neurons. The inputs I1, I2,…In are applied to the input neurons u1, u2,…un. Each neuron in the input layer is connected with the hidden layer neurons with random weight w11, w12,…wij. The basic function of hidden neurons is evaluated by
where Xf is a basics function, wij is an input layer weight and i is a number of input with this basic function the active function is combined.
The activation function of hidden neurons is evaluated in this sigmoidal function is exercised based on the equation shown below,
Multilayer perception is a sigmoidal activation function in the form of a hyperbolic tangent. The next layer of the ANN is hidden layer.
In this section, five numbers of hidden layers are revealed and in each hidden layer 10 neurons are performed. The number of neurons in the hidden layer is defined as Hu1, Hu2,…Hun, which are connected with the output layer neuron. Each neurons in the hidden layer is connected with the output layer neurons with random weight w11, w12,…wij
The hidden layer neurons are connected with the output layer and each connection has a weighted value such as w1, w2,…wn. The recognised character is the output of ANN. For optimizing the weight, OGWO is employed.
3.4 Opposition Based Grey Wolf Optimization Algorithm (OGWO)
When compared to traditional GWO, in OGWO, the opposition strategy utilizes to increase the probability of finding optimal weights to enhance the ANN predicting performance. The grey wolves sufficiently mount a Canidae's piece family and are respected as the top marauders presenting their place at the sustenance's food chain. They regularly display a disposition to make due as a set. The results produced by the alpha are distributed on to the set. The Beta says to the second rank in the striking sequence of the grey wolves. They are fundamentally and supplementary wolves that sufficiently provide certain aid to the alpha in the choice making or equivalent set purposes. The omega is the least bands of the grey wolf pack and it works as an ancillary proposing into the additional principle wolves very closely on every event and is allowed to have just the slight leftovers resembling a great doddle by the leader wolves. In our technique, the alpha (α) esteemed as the most suitable arrangement with a perspective to replicating the social pecking order of wolves logically while conceiving the OGWO. Thus, the second and the third-best arrangements are named as beta (β) and delta (δ) separately. The remaining applicant arrangements are regarded to be the omega (ω). In the OGWO method, the hunting (optimization) is guided by the α, β, δ, and ω.
Fig. 3 shows the flowchart for OGWO and the following sections explain the working procedures to identify of the appropriate weights for ANN
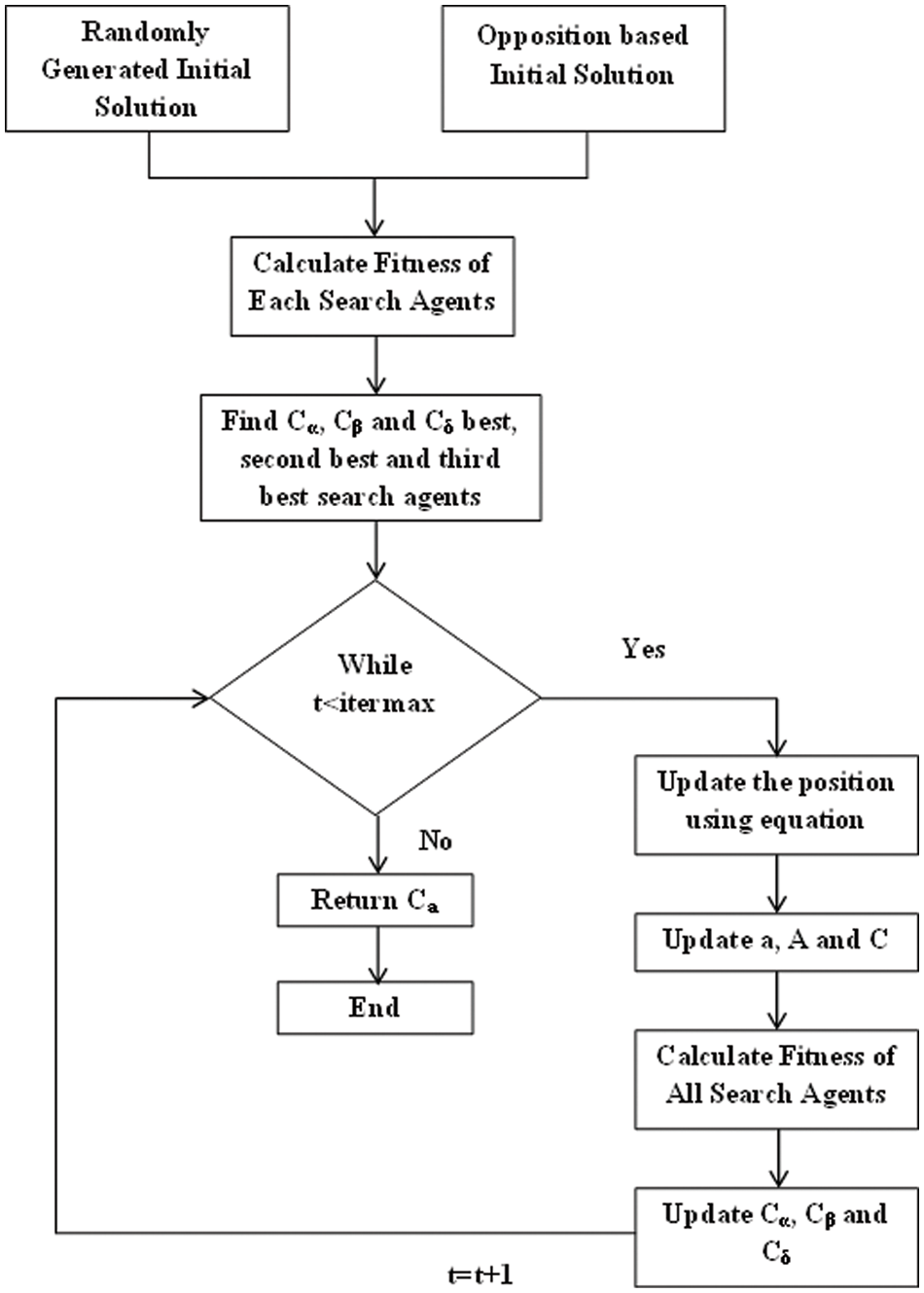
Figure 3: Flowchart of OGWO
3.4.1 Initial and Opposition Based Solution Generation
The preliminary step in the optimization process; here, the solutions is generated randomly based on constraints. The randomly generated solutions range from [−100 to 100] and length of a solution is 280. The length of the solution is mathematically expressed as follows,
where NI is the number of inputs (features: 13), NH is the number of hidden neurons; considered 20 (user-defined). Along with the preliminary random solution generation, this research includes opposition based solution generation, which would increase the probability of identifying an optimal weight as output solution. The mathematical expression of opposition-based solution generation is as follows.
Xi ɛ X1, X2, X3 … NP, are initial solution randomly generated suggest to generate opposition based solution where x and y are minimum and maximum values.
This process is utilized to evaluate the fitness of randomly and opposition based solution generation with the aid of following mathematical function.
where, Xi is known as input and α & β are called weights.
We assume that the alpha (best candidate solution), beta and delta have improved knowledge about the potential location of the prey to reproduce the hunting behavior of the grey wolves mathematically. As a result, we hoard the first three best solutions attained so far and require the other search agents (including the omegas) to revise their positions according to the location of the best search agent. For repetition, the new solution c (t + 1) estimated by using the formulae mentioned below.
To have hyper-spheres with different random radii, the arbitrary parameters A and C help the candidate solutions. Examination and usage are ensured by the adaptive estimations of A and a. With diminishing A, half of the iterations are committed to the investigation (/A/ < 1) and the other half are dedicated to the usage. Enclosing the conduct, the subsequent equations are utilized keeping in mind the end goal to give numerical model.
where t indicates the current iteration, A and C are coefficient vectors, Cp is the position vector of the prey c and indicates the position vector of a grey wolf. The components of a are linearly decreased from 2 to 0 over the course of iterations and r1, r2 are random vectors in [0, 1].
The OGWO has only two main parameters (A and C) to be adjusted. However, we have kept the OGWO algorithm as simple as possible, with the fewest operators to be adjusted. The process will be continued until the termination is obtained.
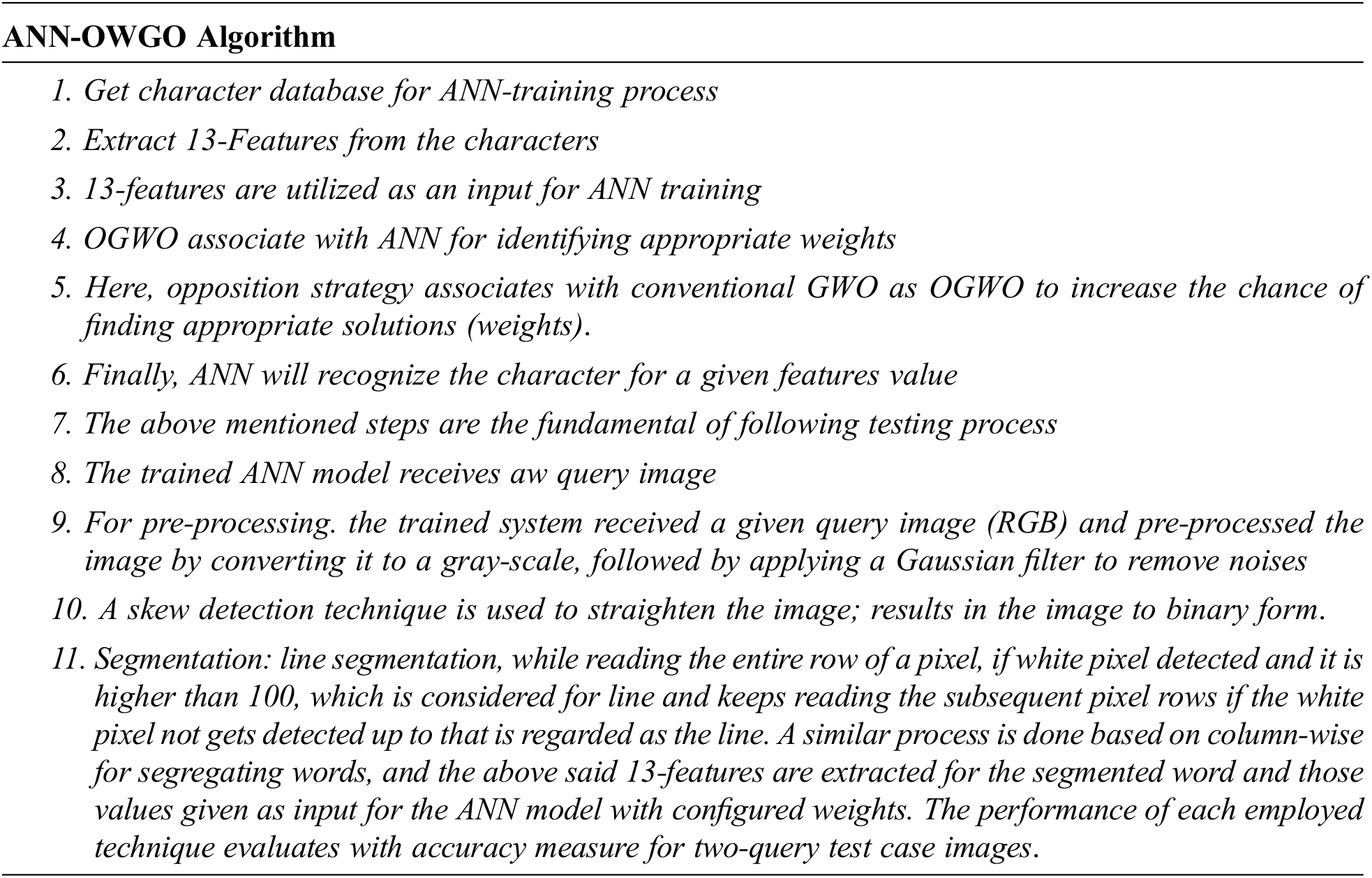
The entire steps involved in the process of ANN-OWGO based character recognition is given in the following algorithm.
This section discusses the different results are compared with existing techniques. Apart from OGWO, the other optimization techniques used in ANN weight determination are PSO and GWO. Accuracy and the convergence graphs are explained in the below sections. In Tab. 1, sample test case 1, Tab. 2 sample test case 2 and Tab. 3 input features extracted from concerned characters are presented. Tabs. 4 and 5 presents the performance results of the approaches.





From the Fig. 4 illustrated the proposed OGWO is having superior accuracy over other techniques. In case 1, the accuracy value for OGWO is 94.89%, for GWO having 89%, for PSO having 85%, and for default having 73%. In case 2, the accuracy value for OGWO in the validation above is 92.34%, for GWO having 86.7%, for PSO having 82% and for default having 70%. On average, the accuracy of OGWO achieves 5.8% greater accuracy than GWO, 10.1% greater accuracy than PSO, and 22.1% greater accuracy over conventional ANN technique (Randomly configured weights). In general, the incorporation of optimization techniques to configure ANN weights consequences the performance improvement. Employing optimization techniques to identify appropriate weights and integration of opposition strategy in GWO ensure the proficient performance of OGWO associate ANN.
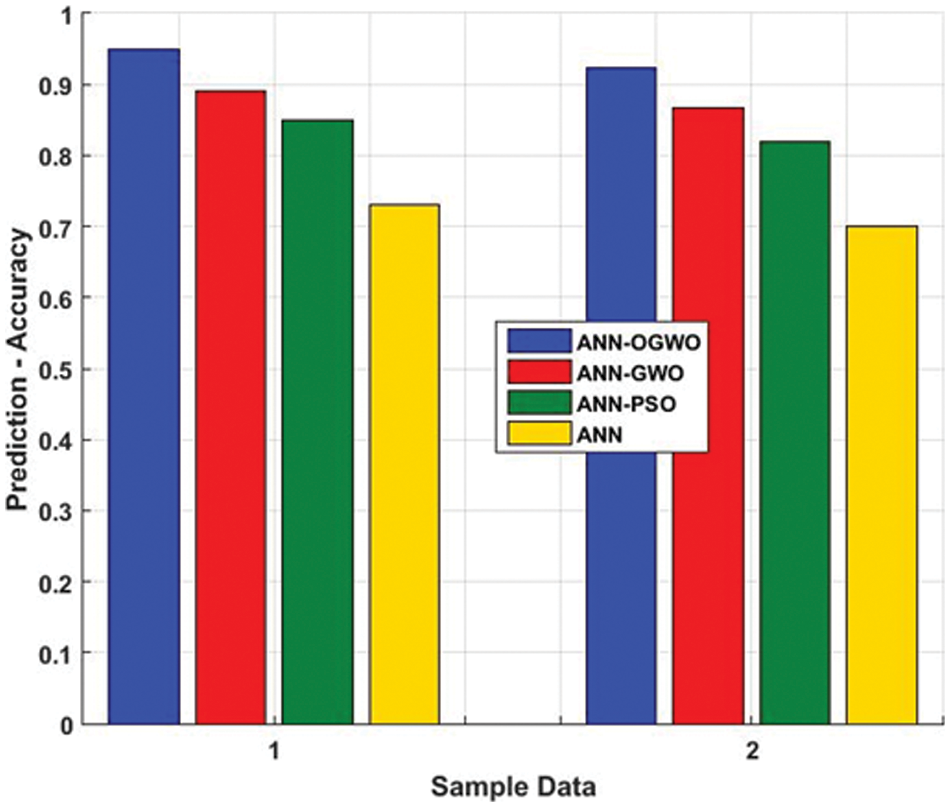
Figure 4: Comparison accuracy graph
This section Fig. 5, carryout different optimization technique involves in designing the ANN structure namely OGWO, GWO, and PSO amid OGWO converge faster than other at the same time fitness error reveal by the proposed OGWO also good compare with contest technique. The straight competition between PSO and GWO up to 100th iteration, then GWO varies low than PSO, and both saturate error value at 350th to 500th iteration. OGWO slightly saturate up to 400th iteration to 500th iteration, and the error value is lower than other two algorithms due to the optimization of ANN weights using OGWO. Employing optimization techniques to identify appropriate weights and integration of opposition strategy in GWO ensure the proficient performance of OGWO associate ANN
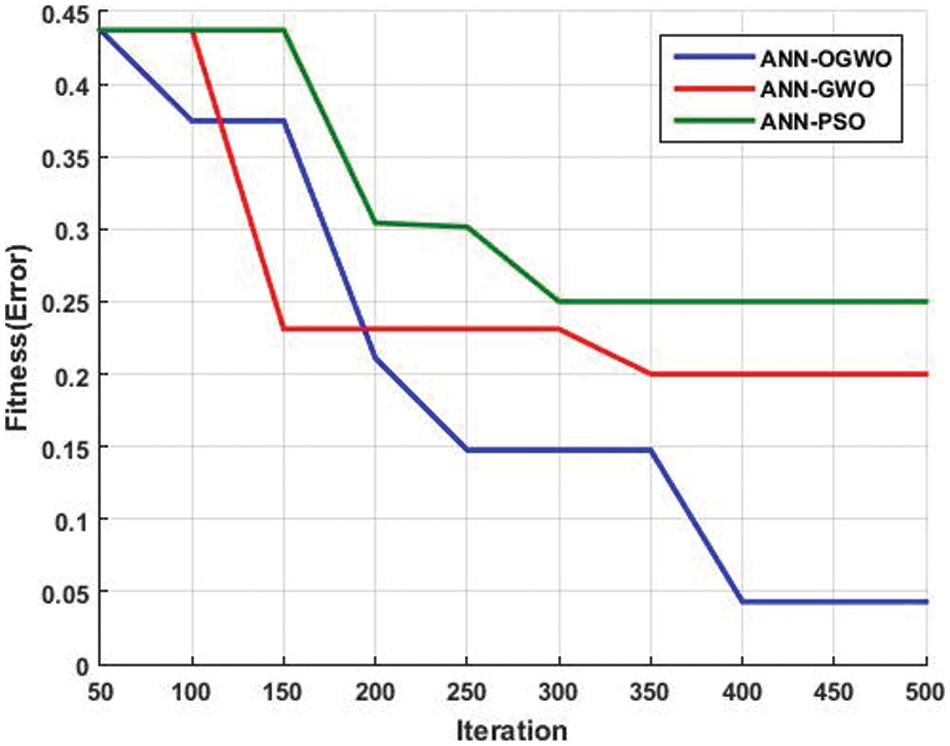
Figure 5: Convergence graph
Resolving the research problem through redesigned ANN associated with optimization techniques accomplished effectively. Incorporation of opposition strategy in conventional GWO literally enhances the performance even better over other techniques for recognizing the ancient language, symbols and characters. The results reveal that the proposed method attains accuracy as 93.6%, which is 5.8% greater than GWO, 10.1% greater than PSO, and 22.1% superior to conventional ANN model (Auto-configured weights). In the future, this research intends to reconfigure the structure of ANN to enhance predicting performance further.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. Aswatha, A. Talla, J. Mukhopadhyay and P. Bhowmick, “A method for extracting text from stone inscriptions using character spotting,” Indian Institute of Technology Kharagpur, vol. 5, no. 2, pp. 1–14, 2014. [Google Scholar]
2. H. Winskel, “Reading and writing in southeast asian languages,” Procedia-Social and Behavioural Sciences, vol. 97, pp. 437–442, 2019. [Google Scholar]
3. S. Franklin Thambi Jose and J. Samikkanu, “Criteria for the identification of adverbial phrases for tamil,” Procedia-Social and Behavioral Sciences, vol. 208, pp. 138–142, 2019. [Google Scholar]
4. E. Vellingiriraj and P. Balasubrmanie, “A novel hybrid neural learning based tamil handwritten character recognition system in palm manuscripts for siddha medicine,” Journal of Advance Research in Dynamical & Control Systems, vol. 9, no. 3, pp. 152–164, 2018. [Google Scholar]
5. G. Bhuvaneswari and V. Subbiah Bharathi, “Recognition of ancient stone inscription characters using normalized positional distance metric features,” Asian Journal of Research in Social Sciences and Humanities, vol. 6, no. 5, pp. 604–615, 2018. [Google Scholar]
6. D. Pugazhenthi and S. Arul Vallarasi, “Offline character recognition of printed tamil text using template matching method of bamini tamil font,” Indian Journal of Science and Technology, vol. 8, no. 35, pp. 1–4, 2015. [Google Scholar]
7. N. Panyam, T. Vijaya Lakshmi, R. Krishnan and N. Koteswara Rao, “Modelling of palm leaf character recognition system using transform based techniques,” Pattern Recognition Letters, vol. 84, pp. 29–34, 2018. [Google Scholar]
8. A. Barmpoutis, E. Bozia and S. Wagman, “A novel framework for 3D reconstruction and analysis of ancient inscriptions,” Machine Vision and Applications, vol. 21, pp. 989–998, 2017. [Google Scholar]
9. S. Rajakumar and V. Subbiah Bharathi, “Eighth century tamil consonants recognition from stone inscriptions,” in Int. Conf. on Recent Trends in Information Technology, China, pp. 40–43, 2019. [Google Scholar]
10. G. Bhuvaneswari and V. Subbiah Bharathi, “An efficient positional algorithm for recognition of ancient stone inscription characters,” in Seventh Int. Conf. on Advanced Computing, Bangkok, pp. 1–5, 2019. [Google Scholar]
11. N. Shanthi and K. Duraiswamy, “A novel SVM-based handwritten tamil character recognition system,” Pattern Anal Application, vol. 13, pp. 173–180, 2019. [Google Scholar]
12. S. Manikandan, A. Delphin Carolina Rani, C. Rajeswari, T. Suma and D. Sivabalaselvamani, “Recognition of font and tamil letter in images using deep learning,” Applied Computer Science, vol. 17, no. 2, pp. 90–99, 2021. [Google Scholar]
13. R. Giridharan, E. Vellingiriraj and P. Balasubramanie, “Identification of tamil ancient characters and information retrieval from temple epigraphy using image zoning,” in Int. Conf. on Recent Trends in Information Technology, Bangkok, pp. 1–7, 2019. [Google Scholar]
14. B. Kavitha and C. Srimathi, “Benchmarking on offline handwritten tamil character recognition using convolutional neural networks,” Journal of King Saud University–Computer and Information Sciences, vol. 5, no. 3, pp. 1–8, 2018. [Google Scholar]
15. Z. Gao and J. Zhao, “An improved grey wolf optimization algorithm with variable weights,” Computational Intelligence and Neuroscience, vol. 2019, pp. 1–13, 2020. [Google Scholar]
16. X. R. Zhang, W. F. Zhang, W. Sun, X. M. Sun and S. K. Jha, “A robust 3-D medical watermarking based on wavelet transform for data protection,” Computer Systems Science & Engineering, vol. 41, no. 3, pp. 1043–1056, 2022. [Google Scholar]
17. R. Zhang, X. Sun, X. M. Sun, W. Sun and S. K. Jha, “Robust reversible audio watermarking scheme for telemedicine and privacy protection,” Computers, Materials & Continua, vol. 71, no. 2, pp. 3035–3050, 2022. [Google Scholar]
18. N. Sridevi and P. Subashini, “Combining zernike moments with regional features for classification of handwritten ancient tamil scripts using extreme learning machine,” in IEEE Int. Conf. on Emerging Trends in Computing, Communication and Nanotechnology, Japan, vol. 14, no. 3, pp. 158–162, 2017. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools