DOI:10.32604/iasc.2023.025762
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2023.025762 | |
| Article |
An Optimal Cluster Head and Gateway Node Selection with Fault Tolerance
Coimbatore Institute of Engineering and Technology, Coimbatore, Thondamuthur, 641109, Tamil Nadu, India
*Corresponding Author: P. Rahul. Email: rahulpphd@gmail.com
Received: 03 December 2021; Accepted: 28 February 2022
Abstract: In Mobile Ad Hoc Networks (MANET), Quality of Service (QoS) is an important factor that must be analysed for the showing the better performance. The Node Quality-based Clustering Algorithm using Fuzzy-Fruit Fly Optimization for Cluster Head and Gateway Selection (NQCAFFFOCHGS) has the best network performance because it uses the Improved Weighted Clustering Algorithm (IWCA) to cluster the network and the FFO algorithm, which uses fuzzy-based network metrics to select the best CH and entryway. However, the major drawback of the fuzzy system was to appropriately select the membership functions. Also, the network metrics related to the path or link connectivity were not considered to effectively choose the CH and gateway. When learning fuzzy sets, this algorithm employs a new Continuous Action-set Learning Automata (CALA) approach that correctly modifies and chooses the fuzzy membership functions. Despite the fact that it extends the network’s lifespan, it does not assist in the detection of defective nodes in the routing route. Because of this, a new Fault Tolerance (NQCAEFFFOCHGS-FT) mechanism based on the Distributed Connectivity Restoration (DCR) mechanism is proposed, which allows the network to self-heal as a consequence of the algorithm’s self-healing capacity. Because of the way this method is designed, node failures may be utilised to rebuild the network topology via the use of cascaded node moves. Founded on the fractional network information and topologic overhead related with each node, the DCR is suggested as an alternative to the DCR. When compared to the NQCAFFFOCHGS algorithm, the recreation results display that the proposed NQCAEFFFOCHGS-FT algorithm improves network performance in terms of end-to-end delay, energy consumption, Packet Loss Ratio (PLR), Normalized Routing Overhead (NRO), and Balanced Load Index (BLI).
Keywords: Hybrid-manet; cluster head; gateway; node failure; fault tolerance; distributed connectivity restoration
MANET has a many self-configuring mobile nodes which are connected with each other wirelessly for data transmission. Each mobile node can move in any direction without using any backbone infrastructures that causes the network topology frequently. Each node may act as a router by transmitting a unique traffic to each other nodes through the routing paths Typically, such networks are more robust than the centralized networks because of its ability to relay the data packets based on the multihop approach. The duty for dynamically determining a routing route falls on the shoulders of each node [1].
In MANET, clustering and routing are the most challenging processes due to node mobility that causes a high packet loss and energy consumption. To tackle this issue, clustering techniques have been proposed that divided the entire system into small quantity of clusters to reduce the packet loss, bandwidth and energy consumption Mostly, those clustering algorithms split the network into clusters and built a network backbone to support the control functions. In each cluster, nodes are considered as any one of the category, namely Cluster Head (CH), cluster member and gateway. For each cluster, any node can select as CH and act as a local controller to perform routing, scheduling and transmission of inter-cluster traffic between each cluster members. The nodes other than CH are known as the cluster members that are act as normal node and not concerned in the routing or inter-cluster transmission. Cluster gateway is a boundary node that has a minimum one neighbor belonging to the various clusters and used for transmitting the data from one cluster to another.
On the one hand, the packet loss and mobility rate is higher in the previous works. On the other hand, the node failures in the routing path may degrade the network lifetime rapidly. The major contributions of this paper is follows,
• As a consequence, the NQCAEFFFOCHGS-FT technique, which is based on the DCR, is given, in which node failures may be utilised to reconstruct the network topology via the use of cascaded node movements to restore the original network topology.
• Based on this technique, the process of optimum CH selection and also the gateway selection is implemented by using the fuzzy set approach.
• By extending the network’s life span while concurrently decreasing routing overhead, the proposed approach is both efficient and cost-effective in its implementation.
The following is how the balance of the article is organised: Section II provides the results of a survey on the selection of CHs and gateways, as well as fault tolerance methods, in MANET networks. Using the improved CH and gateway selection algorithms, Section III describes the idea of the proposed method for increasing network performance based on the suggested algorithm. Section IV compares and contrasts the recreation results of the projected method with those of the current algorithm. Finally, Section V brings the study project to a close.
Using an energy-balanced QoS-based CH selection approach for WSN, Mahajan et al. [2] proposed a solution that was successfully applied in practise. This approach was implemented using a mechanism known as Clustered Chain Weight Metrics (CCWM), that was selected in line with the system’s requirements. When the CH selection process was completed, the outcome was a set of nodes with a computed value of Position metrics that was greater than that of the other nodes (POS). However, it does not take into consideration the selection of the gateway in order to enhance network performance even more in this case.
The Efficient Fault Detection and Routing (EFDR) system developed by Banerjee et al. [3] was designed to handle a large-scale wireless sensor network. This system has the capability of identifying and managing defective nodes in a timely and effective way. According to this method, the defective nodes were identified based on the sequential and geographical association of sensing material between neighbouring nodes and the heart beat message sent by the cluster head. In order to manage transmitter circuit/battery condition or microcontroller fault representation, three linear Cellular Automata (CA) methods were used: receiver circuit fault representation, sensor circuit fault representation, and receiver circuit fault representation. In addition, a data routing method based on L-system principles was suggested for finding the optimum routing route between the cluster head and the base station. On the other hand, the software failure detection and recovery was not taken into consideration.
In their paper [4], Senturk et al. suggested two distributed relay node placement methods for guaranteeing network recovery for partitioned WSNs by reducing the movement cost of the relay nodes. It was decided to use the first method because it was based on virtual force-based relay motions, whereas the second way was based on a game theory approach among the leaders of the divisions. The force-based method was utilised to progressively expand the network with the addition of more relays, which resulted in a more stable network. As a result of the game-theoretic method, the leader relay nodes determined which partitions should be linked with based on the probability distribution function (pdf) of the partitions in question. The partitions with a bigger pdf are thus given precedence over other partitions when it comes to recovery. Until the network was completely recovered by achieving a system-wide unique Nash equilibrium, recovery was preceded by the partition receiving the next greatest priority until the network was fully restored. The remaining energy of the nodes, on the other hand, was not taken into account while making movement choices.
In order to improve the security of MANET, Paramasivan et al. [5] suggested a Secure and Fair CH selection Protocol (SFCP) to be used. By requiring nodes that are completely surrounded by hostile neighbours to dynamically alter their trust and mistrust levels, this protocol was able to solve the issue of attacker detection and classification. In this protocol, the security considerations were incorporated into the clustering method in order to enable attacker identification and classification, which was accomplished via clustering. For this procedure, a cooperative method based on Byzantine agreement was employed, which makes the network more attack resistant as a result. In addition, the secure and energy-efficient CH, which acts as a local detector without adding any overhead to the clustering performance, was chosen for this use case. The routing latency associated with this protocol, on the other hand, was very long.
Ponnan et al. [6] presented a Detection and Replacement of Failing Node (DRFN) method for the preservation of connection by performing a replacement chain in accordance with a distributed algorithm for the purpose of maintaining connectivity. When it comes to optimising the variables that are used to calculate the weight of a node, an optimization technique must be used in order to achieve success. Known as CLC DGS (Cross Layer Control with Dynamic Gateway Selection), Duan et al. [7] presented a new joint traffic splitting, rate control, routing, and scheduling algorithm that incorporates several layers of control. It distributes traffic flow into multiple gateways in an optimal manner in order to ensure the maximum network utility while ensuring the minimum network overhead. A new improved CLC DGS DD (CLC DGS and Delay Differentiation) algorithm, which takes into account the latency needs of network flows, has also been presented in this paper. It has a flexible architecture that allows it to alter the delays between various flows while still achieving minimal delays for prospective flows. The broadcasts under a realistic interference-free schedule, on the other hand, fail owing to the dynamic nature of wireless channels.
Aljeri and Abrougui [8] developed a fault tolerant gateway discovery protocol that is dependable, QoS-aware, and fault tolerant, and that enables the connecting to heterogeneous wireless networks. This protocol was developed in order to guarantee the identification of gateway routers in the event of particular system faults in the gateway routers. It does so by using a fault tolerant method. Also included was the ability for gateway requesters to choose and connect to a less crowded gateway through the least jammed routing route while still maintaining the required quality of service. The total average bandwidth consumption of this protocol, on the other hand, was very high.
Obstacle-avoidance Connection Restoration Strategy (OCRS) was developed by Mi and Yang [9] in order to recover the connectivity of mobile sensor networks while providing assured inter-sensor collision avoidance as well as guaranteed sensor-to-obstacle collision avoidance. In order to reinstate connectivity and avoid received obstacles and neighbouring sensors, an actual backup sensor selection algorithm was developed and implemented, followed by the integration of a gyroscopic forces-based motion controller to drive the backup sensor to its designated geographical position. It should also be noted that this approach only needed 2-hop adjacent information. Nonetheless, the residual energy and network lifespan of the nodes were not taken into account.
Reference [10] presented a CH selection approach for wireless MANETs based on the spectral graph theory methodology, which was implemented. In this research, the primary goal was to investigate a technique based on spectral graph theory that might be used to identify CHs and uncover the communities that were connected with them. The network topology and wireless environment may be used to calculate how many CHs are required, as well as which nodes are assigned to each CH, using this technique. It is necessary, however, to determine the amount of computing power needed to run these clusters.
Reference [11] established a security fault-tolerant routing for multi-layer non-uniform clustered WSNs in order to progress the security dependability of network operation and data transmission while maintaining network performance. Originally, the multi-layer non-uniform clustered network architecture was implemented in order to reduce network energy consumption while simultaneously improving network stability and scalability. During the CH selection process, the trust model and fuzzy logic were utilised to evaluate the quality of sensors to be considered for the position of CH. After determining the security CH as the next hop, the routing algorithm use the precedence level and the trust value to create a routing route between the various layers that passes via the security CH and the other hops. Following that, a fault-tolerant method based on the rollback approach was developed. The major disadvantage of this protocol, on the other hand, is the inability to correctly choose the membership functions of the fuzzy logic system.
Reference [12] proposed a Soft Computing-Based Approach for CH Selection (SCBCH) in MANET with the use of a Fuzzy Inference Control System, which they called the Fuzzy Inference Control System (FICS) (FICS). A model for fuzzy-based CH selection in MANET was presented in this method, and it was recommended that it be adopted. A total of three variables were considered in the FICS for selecting the CH: outstanding energy, trip count, and significance. In order to identify which parameter had the highest likelihood of being chosen, an IF-THEN rule was used [13]. The AND operation was carried out by using the computed all possible combinations among all the parameters in order to execute the AND operation. It was then decided which node had the highest chance of being chosen as CH. Mobility, on the other hand, was required as a measure that would assist in the continued development of network performance in order to achieve the desired results.
In a heterogeneous cluster WSN, Song et al. [14] proposed a CH selection technique based on the Minimum Connected Dominating Set with Multi-hop Information (MCDS-MI) and Bi-Partite Graph (BG) techniques, as well as the Minimum Connected Dominating Set with Multi-hop Information (MCDS-MI) technique. In this method, the outstanding energy of each sensor node was calculated in order to establish a load balancing network on the network. To choose the best CH dominator, the sensor node with the greatest remaining energy was nominated. It was also developed a fault-tolerant and transmission-reliable steiner tree that was much enhanced over previous versions. The steiner tree may result in the creation of a virtual dominator, which will serve as the network’s backbone in its entirety [15]. The data latency during data transfer was decreased as a result of this technique, which increased the dependability of the data transmission. However, this approach does not take into account the security elements and problems that may exist in the network.
In this section, the projected algorithm is described in brief. The network is represented by an undirected graph G = (V, E), where V = vi refers the set of nodes and E = ei signifies the set of links. Initially, network is clustered by NQCA that uses IWCA to split the network according to the node priority and range zone aggregation. After that, the characteristics for each cluster member and QoS metrics are computed and converted as fuzzy sets using fuzzy logic system.
3.1 Fine-Tuning of Fuzzy Membership Function
In this process, the following link connectivity metrics are considered:
The QoS of a path or link i is measured based on the link availability time, residual load capacity of a link and link latency which are given below:
3.1.2 Link Expiration Time (LET) or Path Duration
The period of time path availability between two nodes is known as path duration/path availability time. The path availability time (Li) of a path i between any MANET node and gateway indicate the entire time that a gateway is available by the MANET node via that path. The minimum path accessibility time is estimated as follows:
In (1), LETu denotes the path availability time between two neighbour ing intermediate nodes in a path i from a source node (S) to the gateway and u denotes each connection amongst transitional nodes on path i. Consider two nodes vi and vj be within the transmission range (R) of each other including (xi, yi) and (xj, yj) are the coordinates of vi and vj, respectively. Also, Si and Sj are the speed and θi and θj are the direction of movement of nodes vi and vj, respectively. Then, LETu of node vi and vj is estimated as follows:
where a = Si cos θi − Sj cos θj; b = xi − xj; c = Si sin θi − Sj sin θj; d = yi − yj
• Residual Load Capacity (RLC) of a path
The RLC of a path is defined as the least existing load capacity at any node including the gateway and the intermediate mobile nodes in that path. Consider the maximum load capacity of a node vi is μ and the present traffic flow load handled by vi is
In (3), aj and kj are the average packet arrival rate and the average packet size of the traffic from source j, correspondingly. The overall RLC of a path i is computed as:
In (4), RLCj is the RLC of in-between nodes in the path plus gateway node.
• Path latency
Latency of path i(Yi) is defined as the stabilizer quantity of latency at each connection on the path between the gateway and movable node. The global QoS value of a path i(QoSi) is computed as follows:
In (5), Lmax, RLCmax and Ymin are the maximum path duration, maximum RLC and smallest path potential from all the current paths among a normal node and entry node, correspondingly.
In networking, the hop count is defined as the number of hops made between each node and the CH and the gateway. In most cases, it is a measure of the distance between two nodes in a network. A hop count of n indicates that the source node was separated from the destination node by an n-number of nodes. When a MANET node or source node (s) is connected to a gateway or CH or destination node (d), the hop count H(s, d) is calculated as shown below:
The mobility is defined as the movement of any node which is computed as an average speed (S) of node in time period T.
where
where the distance (DΔt(vi, vj)) covered by node vi and vj in time interval Δt from position Pt−1(xi, yi) to Pt(xi, yi) and Pt−1(xj, yj) to Pt(xj, yj) is given by,
3.1.5 Residual Path Lifetime (RPL)
It is defined as the time during which the path exists between the nodes. The RPL of path i is computed as:
where the relative speed,
For a transmission range R, link stability (Q) between two nodes vi and vj over time T is computed as follows:
Similarly, the path stability
where N denotes the number of links along the path.
The selection of both CH and gateway is done based on the weight value (w) associated with each node. In this proposed algorithm, the metrics given in [8] also considered with the link connectivity metrics are converted into fuzzy sets to calculate the combined weight value by using FIS which uses triangular membership function to define these parameters and five linguistic terms such as Very Low (L), Low (L), Medium (M), High (H) and Very High (VH). The combined weight value of node vi on the path i is computed as:
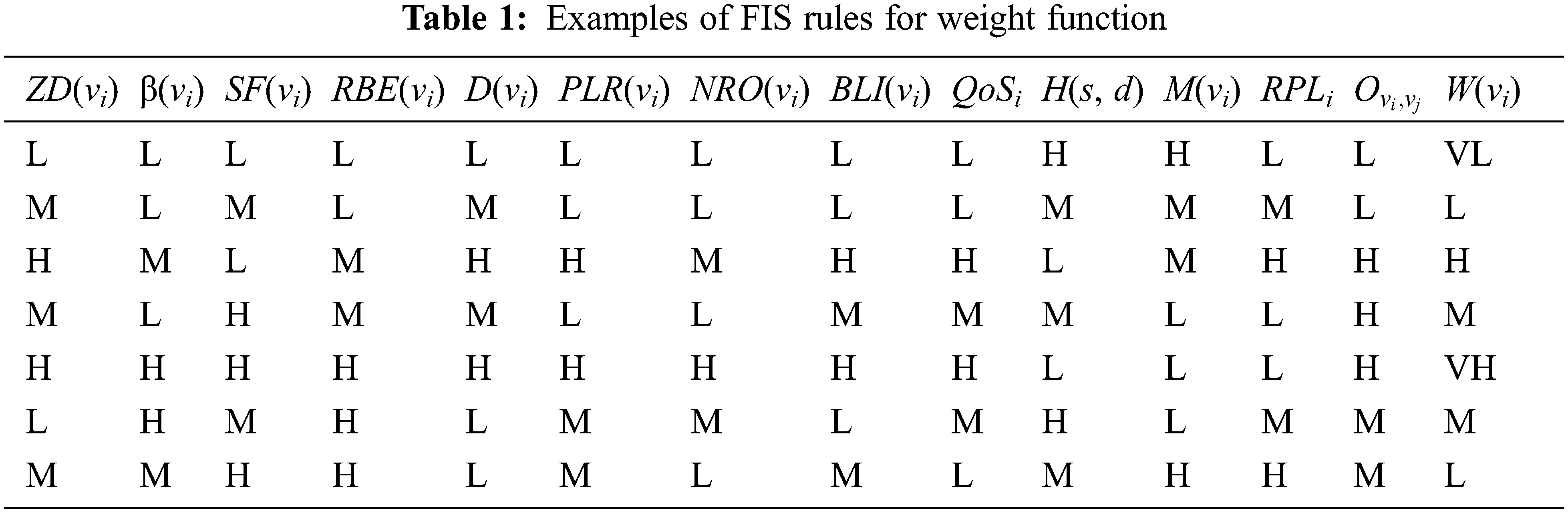
where ZD is the total environmental distance from a parent node vi, β is the relative dissemination degree of node vi, SF is the stability factor of node vi, RBE is the enduring battery energy of node vi, D is the average distance of node vi with its neighbors, PLR is the packet loss ratio of node vi, NRO is the normalized routing overhead of node vi and BLI is the balanced load index of node vi. The fuzzy system generates the number of rules based on these computed parameters. Some of rules are given in Tab. 1.
The CALA method is used in this proposed algorithm to optimise the number and placement of membership functions used in the FIS in this recommended algorithm, which is discussed in more detail later in this document. Automated systems make use of a real line that acts as an action-set, and the probability distribution of actions is assumed to be standard, with a mean (t) and a normal deviation (s) both of which are t. (t). N(t), t). It is the actions t and t that are utilised as the involvements to the random environments, with t denoting the time of day in each case, which are represented by the t-values, and the CALA uses these signals to learn. The variables t and t are then updated in the following manner:
n the preceding equations, λ (0 < λ < 1) is the knowledge parameter, G > 0 is a big positive constant that controls the shrinkage of t, and _L is a suitably tiny lower limit on the value of σ(t). So the lower limit _L > 0 is utilised, and the learning goal is kept as (t) converging to _L and (t) converging to _L and (t) converging to _L and *. If you choose L and sufficiently small, as well as G sufficiently big, the CALA algorithm’s t(t) will be close to a smallest of E[ (t) ] with a possibility close to unity, as shown in Fig. 1.

Figure 1: Assessment of delay
Consider a set of x linguistic words indicated by L = f 1, f 2,…, f n, and the membership functions (=a 1, a 2,…, a n) in triangular form for these linguistic terms, where each triangular membership function a i is signified as a triple (_i, i, i ). Assume that the value of each metric falls within the range [_min, max]. The initialization of the action probability distributions for all CALAs is accomplished by assigning a CALA i to the centre parameter I of each of the remaining n-2 membership functions in order to learn the optimal value for that parameter. The parameters (0) and (0) of the action possibility distributions for all CALAs are also initialised. It is then necessary to iteratively adjust the fuzzy membership functions in accordance with the travels selected by CALAs, and to update the action prospect supplies of CALAs in accordance with the presentation of CH and gateway selection, in order to discover the most suitable relationship functions. The following describes the recapitulation process for the projected CALA: Fine-tuning of the Membership Function: The action chosen by each CALA i, indicated by the letter I. Consider that the result of this phase is a collection of membership functions that has been fine-tuned to a high degree of precision. Initially, a 1 of consists of the initial membership function of a 1, which is a 1=(a 1, a 1, a1, a1, a1, a 1 ). The following condition is checked for each additional association function a i (1in) fit in to the group a i (1in):
where k denotes the size of
Wherever the symbol
• Recital Evaluation: In this phase, the set
Termination Condition: The membership function fine-tuning or modification process and the performance analysis of FIS-FFOA are continued until for all CALAs, μ(t) does not transformation obviously and σ(t) touches near to the lesser bound σL. Thus, the new fuzzy membership function set
However, since the defective nodes in the routing route are not identified and recovered, the network performance suffers as a result. It is suggested to use the DCR method to identify and recover defective nodes.
As an example, if extra than one swelling is eligible as FC at the same period for the position of a node v x in a repossession route, and each of those nodes may be relocated to the location of v x while satisfying both criteria (18) and (19), then the node that is the closest to v x is selected as FC(v x).
a) Topological Overhead (also known as “topological overhead”) (TO)
It is not necessary to move any node to its position if the movement of the FC node does not result in any connection loss with any of its neighbours during the cascaded node movements; thus, there is no need for any additional cascaded node moves. An example of this node is a candidate for a foliage node in the repossession path. If each node in the network has access to information about such leaf nodes, it may be possible to recover from a failure with the fewest number of node moves possible. This means that when a node v x is dislocated and in the process of recovering, a node that has any leaf node at the smallest distance from it may be a suitable option for FC(v x ) among all neighbours of v x while attempting to find the shortest recovery path. The TO for a node is the shortest distance in terms of the number of hops required to reach the bordering leaf node from that swelling in the grid. The following is the procedure that is followed in order to locate and maintain TO for each node:
The TO for v i is determined by taking the lowest number in the TO column and denoting it as TO i. Each node v i first sets its TO i = and TO k = values to the values corresponding to all of its neighbours in the table of v i. Then, for each node v i, the following criteria are used to govern whether or not the node is a leaf node: A leaf node is any node that contains just one adjacent node and is not connected to any other nodes. It is possible for a node to function as a leaf node if it has more than one adjacent node and all of the nearby nodes are unswervingly associated to one other.
Assuming that node v i is a foliage node, it sets TO i = 1 and transmissions its TO i to all of its neighbouring nodes in the form of a message MsgL(ID i,TOi ), which covers both the ID and TO of the node in question. Aside from that, it just waits for a message to arrive from any of its neighbours v k. Each node v i perform the following actions in response to a message received from any adjacent node v k: If v i finds that TO i > TO k + 1, it updates the value of TO k in its table and sets v i = TO k + 1, as well as broadcasting v i to its neighbours. If v i finds that TO i > TO k + 1, it updates the value of v i into its table and sets v i = TO k + 1, it broadcasts v i to its neighbours. Alternately, if TO i = TO k + 1, then v i checks the most recently reorganized value of TO k in its table, and if TO k is less than the most recently updated value corresponding to the newly established value, then it bring up-to-date the table with the novel value.
4.1 Prediction of Failure Controller (FC) Failure
The TO value of a nearby node v k, the distance between v k and node v I and the ID of node v k are the decision criteria that determine whether a nearby node v k is deemed an FC for a specific node v i. Following the calculation of the TO for each of their 1-hop neighbours, all nodes conversation emails with their 1-hop neighbours in order to gather information on the distance and time of arrival (TO) of their 1-hop neighbours. Once this information has been shared with their neighbours once more, the nodes continue to exchange information about their neighbours with all of their neighbours, resulting in all nodes collecting information on their two-hop neighbours. In order to maintain information about each neighbour v k, each node v I stores information in tables corresponding to each neighbour v k. This allows each node v I to retain information about each neighbour v k. A node ID, distance from v k, distance to v, and status are all included in each table, with the initial status column being empty. The following fields are included inside each table: If v k has more than one neighbour, each table that corresponds to that neighbour contains rows that correspond to each of those neighbours. If v jNeigh(v k ), each table that belongs to that neighbour has more than one neighbour. Each node keeps track of the information about its two-hop neighbours, and it makes use of this information to choose the most appropriate FCs for a particular scenario as quickly and efficiently as possible.
When a node is verified to have failed, the nodes in its immediate vicinity search for similar tables in the database to investigate. The information included in the table applies to all of the nodes that are neighbours of the failed node. As a consequence, all nodes that are close to a failed node have tables that are identical to the tables of the failed node. As a consequence, each neighbour may independently select the most appropriate node to act as an FC between them by consulting their own tables. When it comes to choosing the most suitable FC, the TO is given the highest level of consideration. To decide which node wins a race when additional than one bulge has equal lowest TOs, the reserve amongaun successful node and each of its surrounding nodes is measured and utilised to determine which node wins. The node ID is also used for the final settlement procedure if both the TO and distance are equal. This results in the creation of a new function FCindex, which takes these parameters as inputs and returns a value that is used to calculate the final FC. In the case that a node v f failure is verified, the following actions must be taken: As a result, each of the node v i’s neighbouring nodes v I must locate and compute the FCindex I that corresponds to the node v f failure in the following manner:
In (18), D(v i, v f ) implies that node v i is at the same position as node v f and that no other nodes need to be moved in order to achieve this. In the same way, v i finds FCindex for each commotion of the table that corresponds to each adjacent node of v f by traversing the graph. Then, each node v i determines whether it is an acceptable FC among all of v f’s neighbours or not by comparing the rate of FCindex with the morals of other adjacent nodes. A nearby node v i that finds that it has the lowest FCindex among all of its siblings demonstrates that it is FC(v f); otherwise, it is not FC(v f). NFC stands for not a football club, i.e.,
4.2 Failure Recovery and to-Update Information
As soon as it has been determined that node v f has failed, the following recovery procedure is followed:
Every node v iNeigh(v f ) searches for a counter agreeing to node v f that it keeps and determines if it is FC(v f ) or not by checking the innards of the table.
As soon as node v i establishes that it is FC(v f), it sends out a message M mov to all of its neighbours and transfers to the situation of node v f.
Following receipt of the message M mov from node v i, each adjacent node of v i performs the two procedures outlined above to determine if it is FC(v i) or not with regard to v i.
Similar to this, all intermediate nodes go on with these processes until they do not come across a leaf node.
The cascaded movements of nodes in the direction of the failing node are causing very minor changes in the network architecture. These modifications should be reflected in the 2-hop information tables in order to cope with the occurrence of consecutive node failures.
Whenever a node v i gets a message M mov from a nearby node, it validates both its own TO and the adjacent node that sent the message. The TO of a moving neighbour is set if it is a node that is distinct from this v i and has its own TO. Each adjacent node v k conducts the following actions in response to receiving a search message from node v i: If v k has a valid TO, it will begin the TO calculation procedure by broadcasting the message MsgL(ID k, TO k ) to the whole network.
Once the TOs have been updated, nodes that detect any changes in their immediate vicinity will update the 2-hop information table. The routing route is therefore optimised by detecting and recovering the defective or failed nodes as soon as possible in order to improve network performance overall.
The proposed NQCAEFFFOCHGS-FT and NQCAEFFFOCHGS is evaluated as well as related with the present NQCAFFFOCHGS algorithm by via Network Simulator (NS2.34). The assessment is ended in terms of unlike network metrics, namely PLR, NRO, BLI and energy consumption. They are described as follows:
• PLR: It is distinct as the measure of packet loss to the total number of transmitted packets.
• NRO: Specifically, it is described as a connection among the quantity of properly customary packages and the total quantity of control packets sent across a network.
• BLI: It shows the degree to which each node v i has been overloaded in terms of resources. It is computed in the following way:
In (12), Li refers the load supported for each node and N denotes the entire number of bumps in the net.
• Energy consumption: It is demarcated as the amount of energy consumed during transmission. It is computed by using the average of distances D(vi) with its neighbors vj as follows:
The simulation parameters are shown in Tab. 2.
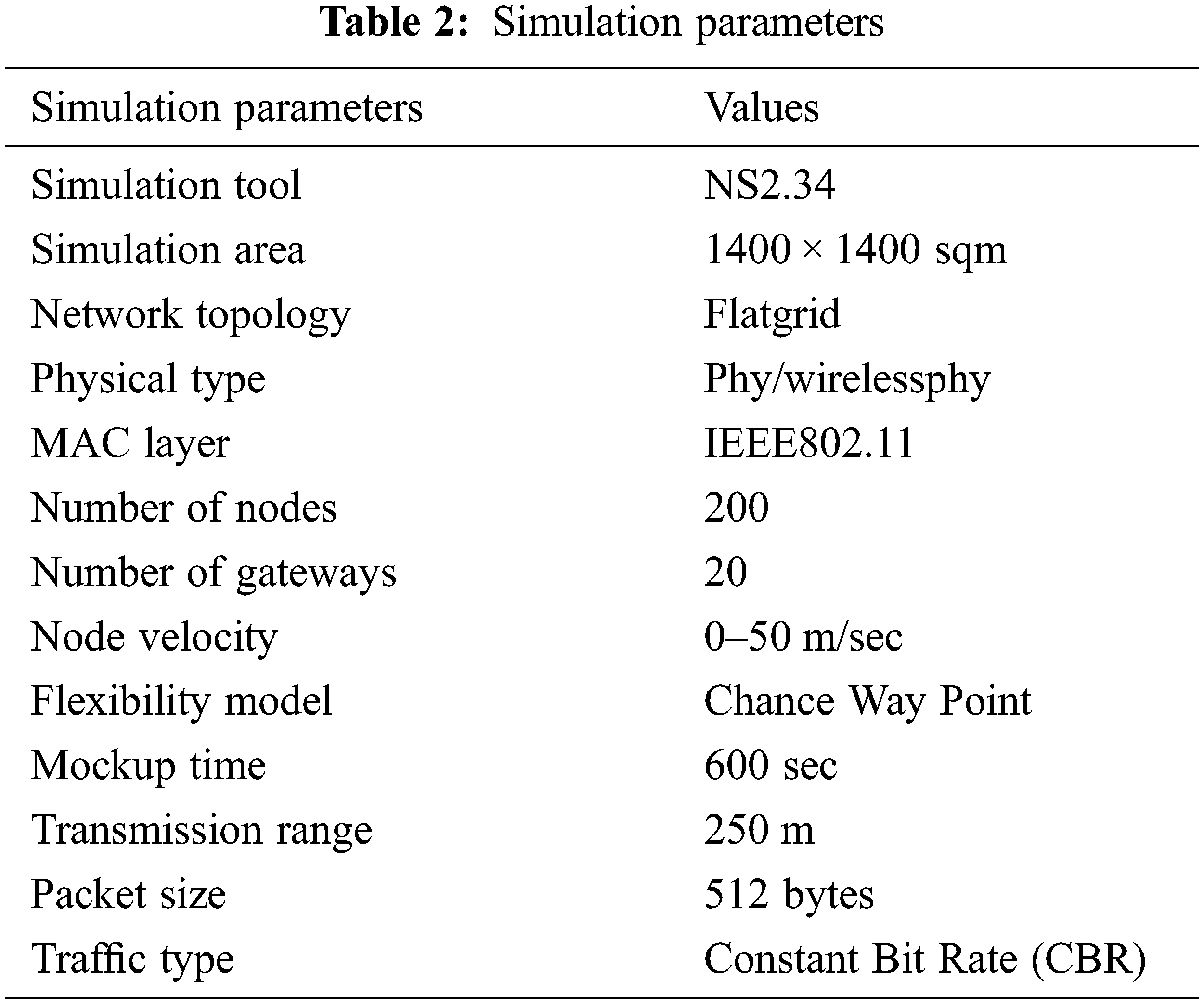
Fig. 1 shows that the assessment of delay for NQCAEFFFOCHGS-FT, NQCAEFFFOCHGS and NQCAFFFOCHGS algorithms. When the node speed is considered as 10 m/s, the delay of NQCAEFFFOCHGS-FT is 11% less than NQCAEFFFOCHGS and 24.7% less than NQCAFFFOCHGS. From this, it is obviously noticed that there is a considerable reduction in delay in NQCAEFFFOCHGS-FT by recovering the faulty nodes and selecting the most optimal CH and gateway rapidly. Therefore, NQCAEFFFOCHGS-FT achieves least amount of delay than the other algorithms.
Fig. 2 shows that the evaluation of PLR for NQCAEFFFOCHGS-FT, NQCAEFFFOCHGS and NQCAFFFOCHGS algorithms. When the node speed is considered as 10 m/s, the PLR of NQCAEFFFOCHGS-FT is 20.74% reduced than NQCAEFFFOCHGS and 29.22% less than NQCAFFFOCHGS. From this, it is obviously noticed that NQCAEFFFOCHGS-FT achieves reduced PLR by transmitting the packets via the chosen CH and gateway without any node failures in the particular route.

Figure 2: Assessment of PLR
The comparison of NQCAEFFFOCHGS-FT, NQCAEFFFOCHGS and NQCAFFFOCHGS algorithms in terms of NRO is shown in Fig. 3. When the node speed is taken as 10 m/s, the NRO of NQCAEFFFOCHGS-FT is 0.53% less than NQCAEFFFOCHGS and 1.01% less than NQCAFFFOCHGS. From this, it is observed that NQCAEFFFOCHGS-FT achieves reduced NRO than the other algorithms.

Figure 3: Evaluation of NRO
Fig. 4 expressions that the judgment of BLI for NQCAEFFFOCHGS-FT, NQCAEFFFOCHGS and NQCAFFFOCHGS algorithms. When the node speed is considered as 10 m/s, the BLI of NQCAEFFFOCHGS-FT is 3.84% reduced than NQCAEFFFOCHGS and 5.65% less than NQCAFFFOCHGS. From this, it is clearly observed that NQCAEFFFOCHGS-FT achieves reduced BLI compared to other algorithms.

Figure 4: Comparison of BLI
The comparison of energy consumption for NQCAEFFFOCHGS-FT, NQCAEFFFOCHGS and NQCAFFFOCHGS algorithms is shown in Fig. 5. When the node speed is taken as 10 m/s, the energy consumption of NQCAEFFFOCHGS-FT is 5.19% less than NQCAEFFFOCHGS and 9.69% less than NQCAFFFOCHGS.

Figure 5: Comparison of Energy Consumption
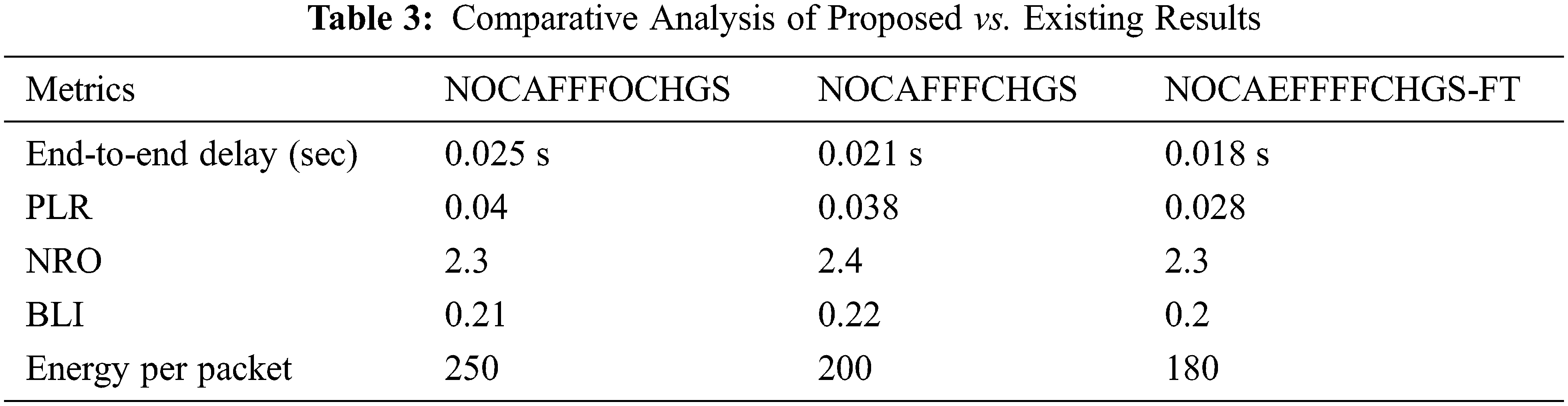
On this, it is determined that the projected NQCAEFFFOCHGS-FT achieves reduced energy consumption than the other algorithms. Tab. 3 summarized the proposed vs. existing results.
In this article, a CALA-based fuzzy learning method is proposed with NQCAFFFOCHGS algorithm to fine-tune the fuzzy membership functions. While optimizing the combined weight values of all network and link connectivity parameters that chooses both optimum CH and gateway in MANETs. Moreover, the DCR-based fault tolerance scheme is also combined to detect and recover the faulty nodes in the network during transmission. Based on this algorithm, the network topology can be changed to construct the recovery route while faulty nodes are identified. In conclusion, the simulation results prove that the projected algorithm outpaces than the prevailing algorithm in terms of reduced delay, energy consumption, BLI, NRO and PLR. In future, 5G/IoT based environment is integrated together to perform the cluster based routing in MANETs.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. Kumar and R. Mishra, “An overview of MANET: History, challenges and applications,” Indian Journal of Computer Science and Engineering (IJCSE), vol. 1, pp. 121–125, 2012. [Google Scholar]
2. S. Mahajan, J. Malhotra and S. Sharma, “An energy balanced QoS based cluster head selection strategy for WSN,” Egyptian Informatics Journal, vol. 15, pp. 9, 2014. [Google Scholar]
3. P. Banerjee, H. Chanak, H. Rahaman and T. Samanta, “Effective fault detection and routing scheme for wireless sensor networks,” Computers & Electrical Engineering, vol. 40, pp. 291–306, 2014. [Google Scholar]
4. I. F. Senturk, K. Akkaya and S. Yilmaz, “Relay placement for restoring connectivity in partitioned wireless sensor networks under limited information,” Ad Hoc Networks, vol. 13, pp. 487–503, 2014. [Google Scholar]
5. B. Paramasivan, M. J. V. Prakash and M. Kaliappan, “Secure and fair cluster head selection protocol for enhancing security in mobile ad hoc networks,” The Scientific World Journal, vol. 14, pp. 1–6, 2014. [Google Scholar]
6. S. Ponnan, A. K. Saravanan, C. Iwendi, E. Ibeke and G. Srivastava, “An artificial intelligence-based quorum system for the improvement of the lifespan of sensor networks,” IEEE Sensors Journal, vol. 21, no. 15, pp. 17373–17385. 2021. [Google Scholar]
7. N. Duan, W. Xu, S. Wang, J. Zhu and Y. Guo, “A new preisach type hysteresis … for wireless mesh networks,” Computer Communications, vol. 55, pp. 69–79, 2015. [Google Scholar]
8. N. Aljeri and K. Abrougui, “A reliable quality of service aware fault tolerant gateway discovery protocol for vehicular networks,” Wireless Communication. Mobile. Computing, vol. 15, pp. 1485–1495, 2015. [Google Scholar]
9. Z. Mi and J. Y. Yang, “Obstacle-avoidance connectivity restoration for mobile sensor systems with local information,” in IEEE Int. Conf. on Communications, ICC 2015, pp. 6395–6399, 2015. [Google Scholar]
10. T. Parker and J. McEachen, “Cluster head selection in wireless mobile ad hoc networks using spectral graph theory techniques,” in IEEE Hawaii Int. Conf. on System Sciences, 2016, pp. 5851–5857, 2016. [Google Scholar]
11. Z. Ye, T. Wen, Z. Liu, X. Song and C. Fu, “A security fault-tolerant routing for multi-layer non-uniform clustered WSNs,” EURASIP Journal. Wireless. Communication. Network, vol. 1, pp. 1–2, 2016. [Google Scholar]
12. J. Prakash, D. K. Gupta and R. Kumar, “Soft computing based cluster-head selection in mobile ad-hoc network,” Journal of Artifical. Intelligence, vol. 10, pp. 98–111, 2014. [Google Scholar]
13. R. R. Priyadarshini and N. Sivakumar, “Cluster head selection based on minimum connected dominating set and bi-partite inspired methodology for energy conservation in WSNs,” Journal of King Saud University-Computer and Information Sciences, vol. 33, pp. 1132–1144, 2021. [Google Scholar]
14. Y. Song, H. Luo, S. Pi, C. Gui and B. Sun, “Graph kernel based clustering algorithm in MANETs,” IEEE Access, vol. 8, pp. 107650–107660, 2021. [Google Scholar]
15. H. Luo, W. Feng, B. Sun and Y. Song, “Graph kernel based clusterhead selection algorithm in internet of things,” in Int. Conf. on Computer, Control and Robotics (ICCCR), pp. 288–291, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |