DOI:10.32604/iasc.2023.028604
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2023.028604 | |
| Article |
Minimizing Total Tardiness in a Two-Machine Flowshop Scheduling Problem with Availability Constraints
1Applied College, Taibah University, Saudi Arabia
2University of Tunis, Tunis, Tunisia
*Corresponding Author: Mohamed Ali Rakrouki. Email: mrakrouki@taibahu.edu.sa
Received: 13 February 2022; Accepted: 24 March 2022
Abstract: In this paper, we consider the problem of minimizing the total tardiness in a deterministic two-machine permutation flowshop scheduling problem subject to release dates of jobs and known unavailability periods of machines. The theoretical and practical importance of minimizing tardiness in flowshop scheduling environment has motivated us to investigate and solve this interested two-machine scheduling problem. Methods that solve this important optimality criterion in flowshop environment are mainly heuristics. In fact, despite the
Keywords: Optimization; machine scheduling; flowshop; evolutionary algorithms
Nomenclature
| Mi | machine |
| pij | processing time |
| rj | release date |
| dj | due date |
| hi | non-availability periods |
| Cj | completion time |
| Tj | tardiness |
| N | population size (number of solutions) |
| | population member |
| | velocity of particle |
| wt | inertia weight |
| σ | partial sequence of scheduled jobs |
| J | job set |
| πk | position of job |
| F | mutant factor |
| β | decrement factor |
| Ut | trial population |
| τ | matrix of the pheromone density |
| δ | matrix of the distance |
| κ | pheromone decay coefficient |
| Nimp | number of imperialists |
| Ncol | number of colonies Ψ normalized power |
| ϕ | cost of the imperialist |
| TCimp | total cost of the empire |
| f | due date slack factor |
| T | tardiness factor |
| R | dispersion factor |
Scheduling has been often considered in the literature and has many practical issues in domains like manufacturing, computer processing, transportation, production planning, etc., In these domains, scheduling involves a decision-making process. It is concerned with allocating resources (machines) to tasks (jobs) throughout certain time periods with the goal of optimizing one or more objectives [1]. The resources can be machinery resources, human resources, CPU, Web server, etc. and referred to as “machines”. The tasks to be scheduled can be production operations, CPU tasks, timetabling activities, etc., and referred to as “jobs”. Basic scheduling problems consider that machines are available during the scheduling, or in practice all machines may be unavailable during several periods of time due to machine breakdown (known as stochastic) or a preventive maintenance (known as deterministic). In real-world scheduling problems, the total tardiness criterion is highly crucial, especially in industry, since failure to meet deadlines can harm company’s reputation and lead to a loss of confidence, increased costs, and customer loss.
This paper deals with the two-machine flowshop scheduling problem where the machines are subject to non-availability constraints and the jobs are subject to release dates. More precisely, we are given
Moreover, the following assumptions are considered. Each machine
Let
The rest of this paper is organized as follows: A literature review is provided in Section 2. Section 3 discusses the five proposed metaheuristics. In Section 4, the experimental findings and the comparative analysis are discussed. Finally, conclusions are set out in Section 5.
This problem has been studied only once before, despite its theoretical and practical importance. Indeed, Berrais et al. [4] proposed a mixed-integer formulation as well as some constructive heuristics for the problem under consideration.
The
Sen et al. [16] considered the two-machine problem (
Schmidt [20] and Ma et al. [21] proposed good descriptions and details about availability constraints. Blazewicz et al. [22] proposed three heuristic methods as well as a simulated annealing algorithm for minimizing the makespan in the resumable case (
In this section, five evolutionary algorithms are described. These algorithms are combined with several local search procedures to take the advantages of rapid exploitation and global optimization.
3.1 Particle Swarm Optimization Algorithm
Particle Swarm Optimization (PSO) algorithm is an evolutionary meta-heuristic proposed by Kennedy et al. [26]. PSO is similar to genetic algorithms but it hasn’t neither crossover nor mutation operators. Instead, it uses randomness of real numbers and the global communication among the swarm particles. Since its introduction, PSO algorithm has been improved with different techniques and proposed for various problems [27–30].
A PSO algorithm consists of a population
The inertia weight
The velocity
where
The position of each particle
Since real numbers are used in the particle representation, real numbers are transformed to a feasible solution (permutation). Two approaches are used in our algorithm:
The Smallest Position Value (SPV): It consists of transforming the real values
The Biggest Position Value (BPV) have the same principle as SPV but the positions are sorted in descending order.
3.1.1 Particles Initialization
The population is initialized by generating randomly the initial position and velocity vectors for each particle. The initial position values
In order to obtain a heterogeneous population, most of the particles are randomly generated while some particles are generated using five constructive heuristics
3.1.2 Local Search Hybridization
In order to produce high-quality solutions, a local search (LS) procedure is integrated to the PSO algorithm. The proposed local search is based on the Nawaz et al. (NEH) algorithm [32].
Let

3.1.3 Pseudo-code of the proposed PSO algorithm
An outline of the proposed PSO is the following:

3.2 Differential Evolution Algorithm
Differential Evolution (DE) is an evolutionary algorithm firstly proposed by Storn et al. [33] for minimizing non differentiable continuous space functions. Like PSO, a DE algorithm is a population-based search meta-heuristic. It is one of the most powerful stochastic algorithms and it has been widely and successfully applied in many areas. DE algorithms were firstly designed to work with continuous variables. Then different strategies have been proposed to adapt the DE algorithm to optimize integer variables. Lampinen et al. [34] used a simple function to convert real numbers to integers. Onwubolu et al. [35] developed two strategies known as Forward Transformation (FT) and Backward Transformation (BT). Tasgetiren et al. [36] used the Smallest Position Value (SPV) rule inspired from random key representation encoding scheme of Beans [37].
In DE algorithm the first population is called target population. It consists of

Our DE starts with the initialization of the target population
To find the corresponding permutation,
3.2.2 Mutant Population Generation
A weighted difference between two randomly chosen members from the target population
3.2.3 Trial Population Generation
Let
Let
The SPV rule is used to obtain the permutation and then evaluate each member
To make selection and determine the members who will survive for the next generation, the fitness of the member
3.2.5 Local Search Hybridization
A hybridization of our DE algorithm is proposed by integrating some local search procedures, in order to enhance its performance. Ten local search schemes are proposed and, in each iteration, only one is used according to a probability
• Random_Exchange_LS: Generate two random positions
• Exchange_All_LS: Generate a random position
• Bloc_Exchange_LS: Decompose the sequence
• Symmetric_Exchange_LS: Exchange each job
• Intensive_Exchange_LS: Generate two random positions
• Insertion_LS: Remove a randomly chosen job
• Circular_Insertion_LS: Place the job in the first position
• Adjacent_Swap_LS: Starts from a randomly chosen position
• Bloc_Swap_LS: Decomposing the sequence in
• NEH_Based_LS.
3.3 Ant Colony Optimization Algorithm
Ant Colony Optimization (ACO) is an evolutionary algorithm based on the behavior of ants. In order to mark some shortest path between ant nest and food that should be followed by other colony ants, these ants deposit a chemical substance called pheromone.
ACO algorithm has been proposed in the early nineties by Dorigo et al. [38]. This meta-heuristic belongs to ant colony algorithm family introduced by Dorigo [39] to solve the Travel Salesman Problem. Several variants of ACO algorithms have since been proposed to solve various optimization problems.
The outline of our ACO algorithm is as follows:

All the steps of our ACO are described as follows.
3.3.1 Pheromone Trails Initialization
The ACO algorithm starts by initializing the pheromone trails. Let
After that, three matrices are initialized:
• The
• The
• The
3.3.2 The State Transition Rule
To move from job
Local updating rule favors the exploration of other solutions to avoid premature convergence. This rule is performed after each step by all the ants as follows:
where
3.3.4 The Global Updating Rule
At the end of each tour, a global updating rule is applied only by the ant finding the shortest way as follows:
where
3.4 Imperialist Competitive Algorithm
Imperialist Competitive Algorithm (ICA) is an evolutionary algorithm introduced by Atashpaz-Gargari et al. [40]. It’s a population-based algorithm inspired by the imperialistic competition. The imperialism consists of expanding the powerful of a country (known as imperialist) by dominating others countries (called colonies) to take control of their resources. So, several imperialists compete for taking possession of colonies of each other. Each individual in the population is called country and can be imperialist or colony. All these colonies are divided among the imperialists according to their power to form empires. Then each colony start moving toward their relevant imperialist country. The total power of an empire depends mainly on the power of the imperialist country and has a negligible effect by the power of the colonies. After that the imperialistic competition between these empires starts and some empires increase their power. However, the powerless ones can’t increase their power and will be eliminated from the competition.
Our proposed ICA algorithm follows these steps:

3.4.1 Initial Empires Generation
The ICA begins by generating the initial empires. Let
Then the
Therefore, the normalized power
Also, the initial number of colonies of an empire
For each imperialist, one of the three previously defined local search procedures are applied randomly: Insertion_Suppression_LS, Intensive_LS and NEH_Based_LS.
The aim of this step is to move the colonies of an empire toward the imperialist. A procedure of perturbation (NEH_Based_L_S) is applied to the job permutation of the colony. If the colony’s cost is less than the imperialist’s cost then we exchange the position of this colony with the relative imperialist.
After that the total cost of an empire is computed as follows. Let
So, the value of the total cost depends on the power of imperialist, and the power of the colony can weakly affect this value if
In this step, each empire tries to possess and control the colonies of other empires. As a result of this competition, the colonies of powerless empires will be divided among other imperialists and will not necessarily be possessed by the most powerful empires. To model this competition, first each empire’s ownership likelihood is calculated according to its total cost.
Let
Then the vector
Genetic Algorithm (GA) is an evolutionary algorithm that have been successfully applied to different complex combinatorial optimization problems such as scheduling problems, knapsack problems, traveling salesman problem, etc. The GAs were introduced by Holland [41] and are inspired from Darwin’s theory of evolution. So, GA approach is based on natural evolution techniques, such as selection, crossover and mutation.
GA is a population-based algorithm, so each member in the population is called chromosome or solution. Starting from an initial population, the goal is to create new populations with better solutions after some iterations (called generation). In each generation, the fitness of every chromosome in the population is computed by an evaluation function to select the most fitted individuals from the current population. Then some genetic operators such as crossover and mutation are applied to these selected chromosomes. This process is repeated until the satisfaction of a termination condition.
To solve our problem, a GA hybridized with local search procedures (known as genetic local search GLS) is used. This algorithm has been developed initially for the two-machine flowshop problem where the objective is to minimize the total completion time [42].
We recall here the pseudo-code of the GLS algorithm.

We The above procedure is adapted as follows. The initial population consists of
In order to evaluate the empirical performance of the proposed algorithms, a large set of computational tests have been undertaken. All these procedures were implemented in C and run on an Intel Core i5 PC (3.60 GHz) with 8 GB RAM.
Our proposed algorithms were tested on different problem sizes
After an experimental study of the different parameters of our proposed algorithms, the following settings have been used to achieve high-quality solutions:
- PSO:
- DE:
- ACO:
- GLS: The same parameters as in [42]
- ICA:
For all algorithms, the maximum number of iterations is fixed experimentally according to the size of the problem (
4.2 Performance of the Proposed Algorithms
To compare our algorithms’ performance, the average relative percentage deviation (ARPD) from the best-known solution is used. This percentage deviation is defined as
Tabs. 1 and 2 summarize the results of the computational experiments.
The analysis with respect to the problem size in Tab. 1 clearly reveals that the best results among all tested algorithms are found by the proposed ICA algorithm. In fact, in comparison to the remaining meta-heuristics this algorithm provides lower values of ARPD, for all problem sizes. Among the tested problems, ICA gives the best solutions for instances. It can solve very large instances with up to jobs within a moderate CPU time. The average time in all instances of jobs was
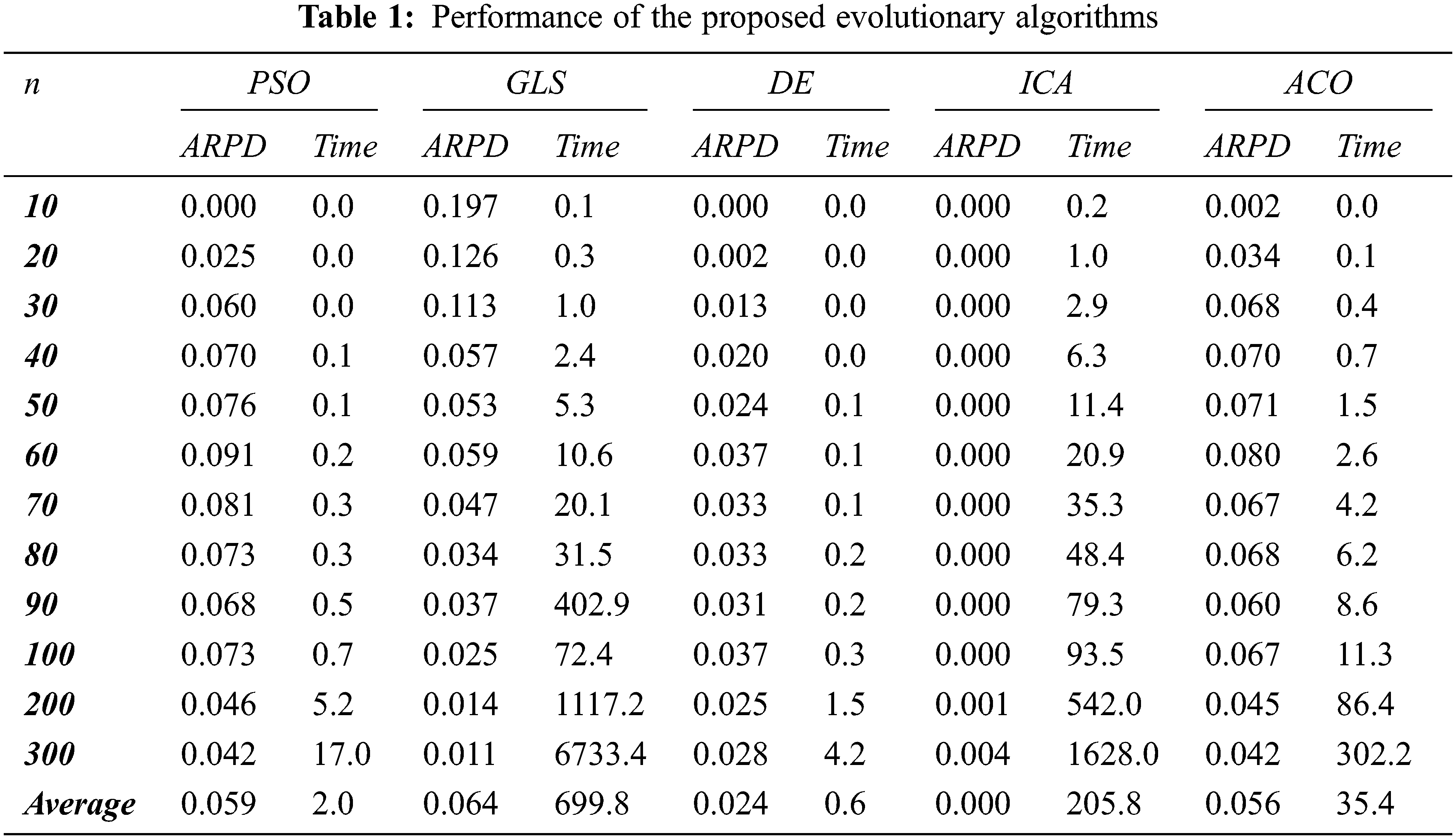
Regarding the computational results of the GLS algorithm, we observe that it gives very good results for large size problems (
Tab. 2 shows the ARPD of the proposed algorithms with respect to the combinations for the values of
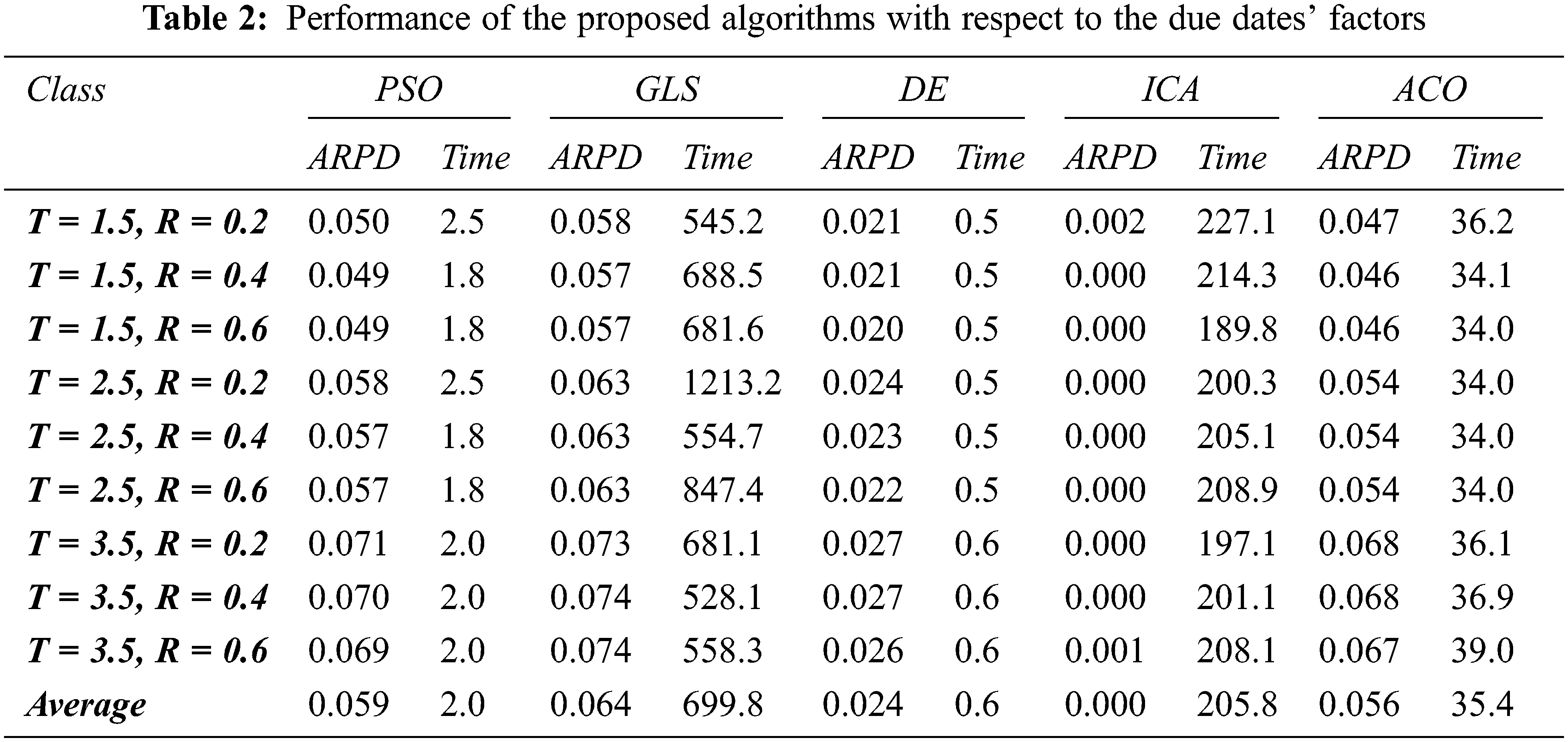
Regarding the due date range factor
In this paper, we have proposed five evolutionary algorithms developed to minimize the total tardiness in a two-machine flowshop scheduling problem where the machines and jobs are subject to non-availability constraints and unequal release dates, respectively. To avoid the rapid convergence of these algorithms and in order to derive high-quality solutions, we proposed a hybridization of our algorithms with several local search procedures. Computational tests provide strong evidence, on the tested instances, that the Imperialist Competitive Algorithm (ICA) outperforms all the proposed population-based approaches.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. L. Pinedo, Scheduling: theory, algorithms, and systems, 4th ed., New York, USA: Springer, 2012. [Google Scholar]
2. C. Y. Lee, “Minimizing the makespan in the two-machine flowshop scheduling problem with an availability constraint,” Operations Research Letters, vol. 20, no. 3, pp. 129–139, 1997. [Google Scholar]
3. J. K. Lenstra, A. H. Rinnooy Kan and P. Brucker, “Complexity of machine scheduling problems,” Annals of Discrete Mathematics, vol. 1, no. C, pp. 343–362, 1977. [Google Scholar]
4. Berrais, M. A. Rakrouki and T. Ladhari, “Minimizing total tardiness in two-machine machine permutation flowshop problem with availability constraints and subject to release dates,” in Proc. of the 14th Int. Workshop on Project Management and Scheduling, Munchen, Germany, pp. 32–35, 2014. [Google Scholar]
5. Y. D. Kim, “Minimizing total tardiness in permutation flowshops,” European Journal of Operational Research, vol. 85, no. 3, pp. 541–555, 1995. [Google Scholar]
6. V. A. Armentano and D. P. Ronconi, “Tabu search for total tardiness minimization in flowshop scheduling problems,” Computers and Operations Research, vol. 26, no. 3, pp. 219–235, 1999. [Google Scholar]
7. S. Hasija and C. Rajendran, “Scheduling in flowshops to minimize total tardiness of jobs,” International Journal of Production Research, vol. 42, no. 11, pp. 2289–2301, 2004. [Google Scholar]
8. C. S. Chung, J. Flynn and Ö. Kirca, “A branch and bound algorithm to minimize the total tardiness for m-machine permutation flowshop problems,” European Journal of Operational Research, vol. 174, no. 1, pp. 1–10, 2006. [Google Scholar]
9. F. Ghassemi Tari and L. Olfat, “COVERT based algorithms for solving the generalized tardiness flow shop problems,” Journal of Industrial and Systems Engineering, vol. 2, no. 3, pp. 197–213, 2008. [Google Scholar]
10. F. Ghassemi Tari and L. Olfat, “A set of algorithms for solving the generalized tardiness flowshop problems,” Journal of Industrial and Systems Engineering, vol. 4, no. 3, pp. 156–166, 2010. [Google Scholar]
11. C.-S. Chung, J. Flynn, W. Rom and P. Staliński, “A genetic algorithm to minimize the total tardiness for m-machine permutation flowshop problems,” Journal of Entrepreneurship, Management and Innovation, vol. 8, no. 2, pp. 26–43, 2012. [Google Scholar]
12. G. Liu, S. Song and C. Wu, “Some heuristics for no-wait flowshops with total tardiness criterion,” Computers and Operations Research, vol. 40, no. 2, pp. 521–525, 2013. [Google Scholar]
13. F. Ghassemi Tari and L. Olfat, “Heuristic rules for tardiness problem in flow shop with intermediate due dates,” International Journal of Advanced Manufacturing Technology, vol. 71, no. 1–4, pp. 381–393, 2014. [Google Scholar]
14. V. Fernandez-Viagas, J. M. Valente and J. M. Framinan, “Iterated-greedy-based algorithms with beam search initialization for the permutation flowshop to minimise total tardiness,” Expert Systems with Applications, vol. 94, no. 3, pp. 58–69, 2018. [Google Scholar]
15. K. Karabulut, “A hybrid iterated greedy algorithm for total tardiness minimization in permutation flowshops,” Computers and Industrial Engineering, vol. 98, no. 4, pp. 300–307, 2016. [Google Scholar]
16. T. Sen, P. Dileepan and J. N. Gupia, “The two-machine flowshop scheduling problem with total tardiness,” Computers and Operations Research, vol. 16, no. 4, pp. 333–340, 1989. [Google Scholar]
17. C. Koulamas, “A guaranteed accuracy shifting bottleneck algorithm for the two-machine flowshop total tardiness problem,” Computers and Operations Research, vol. 25, no. 2, pp. 83–89, 1998. [Google Scholar]
18. J. Schaller, “Note on minimizing total tardiness in a two-machine flowshop,” Computers and Operations Research, vol. 32, no. 12, pp. 3273–3281, 2005. [Google Scholar]
19. M. Kharbeche and M. Haouari, “MIP models for minimizing total tardiness in a two-machine flow shop,” Journal of the Operational Research Society, vol. 64, no. 5, pp. 690–707, 2013. [Google Scholar]
20. G. Schmidt, “Scheduling with limited machine availability,” European Journal of Operational Research, vol. 121, no. 1, pp. 1–15, 2000. [Google Scholar]
21. Y. Ma, C. Chu and C. Zuo, “A survey of scheduling with deterministic machine availability constraints,” Computers and Industrial Engineering, vol. 58, no. 2, pp. 199–211, 2010. [Google Scholar]
22. J. Blazewicz, J. Breit, P. Formanowicz, W. Kubiak and G. Schmidt, “Heuristic algorithms for the two-machine flowshop with limited machine availability,” Omega, vol. 29, no. 6, pp. 599–608, 2001. [Google Scholar]
23. F. Ben Chihaoui, I. Kacem, A. B. Hadj-Alouane, N. Dridi and N. Rezg, “No-wait scheduling of a two-machine flow-shop to minimise the makespan under non-availability constraints and different release dates,” International Journal of Production Research, vol. 49, no. 21, pp. 6273–6286, 2011. [Google Scholar]
24. J. Y. Lee and Y. D. Kim, “Minimizing total tardiness in a two-machine flowshop scheduling problem with availability constraint on the first machine,” Computers and Industrial Engineering, vol. 114, pp. 22–30, 2017. [Google Scholar]
25. J. Y. Lee, Y. D. Kim and T. E. Lee, “Minimizing total tardiness on parallel machines subject to flexible maintenance,” International Journal of Industrial Engineering: Theory Applications and Practice, vol. 25, no. 4, pp. 472–489, 2018. [Google Scholar]
26. J. Kennedy and R. C. Eberhart, “Discrete binary version of the particle swarm algorithm,” in Proc. of the IEEE Int. Conf. on Systems, Man and Cybernetics, Orlando, FL, USA, 5, pp. 4104–4108, 1997. [Google Scholar]
27. X. Zhang, W. Zhang, W. Sun, X. Sun and S. K. Jha, “A robust 3-D medical watermarking based on wavelet transform for data protection,” Computer Systems Science and Engineering, vol. 41, no. 3, pp. 1043–1056, 2022. [Google Scholar]
28. H. Moayedi, M. Mehrabi, M. Mosallanezhad, A. S. A. Rashid and B. Pradhan, “Modification of landslide susceptibility mapping using optimized PSO-ANN technique,” Engineering with Computers, vol. 35, no. 3, pp. 967–984, 2019. [Google Scholar]
29. H. Jiang, Z. He, G. Ye and H. Zhang, “Network intrusion detection based on PSO-Xgboost model,” IEEE Access, vol. 8, pp. 58392–58401, 2020. [Google Scholar]
30. M. A. Shaheen, H. M. Hasanien and A. Alkuhayli, “A novel hybrid GWO-PSO optimization technique for optimal reactive power dispatch problem solution,” Ain Shams Engineering Journal, vol. 12, no. 1, pp. 621–630, 2021. [Google Scholar]
31. J. C. Bansal, M. Arya and K. Deep, “A nature inspired adaptive inertia weight in particle swarm optimization,” International Journal of Artificial Intelligence and Soft Computing, vol. 4, no. 2–3, pp. 228, 2014. [Google Scholar]
32. M. Nawaz, E. E. Enscore and I. Ham, “A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem,” Omega, vol. 11, no. 1, pp. 91–95, 1983. [Google Scholar]
33. R. Storn and K. Price, “Differential evolution-a simple and efficient heuristic for global optimization over continuous spaces,” Journal of Global Optimization, vol. 11, no. 4, pp. 341–359, 1997. [Google Scholar]
34. J. Lampinen and I. Zelinka, “Mechanical engineering design optimization by differential evolution,” in New Ideas in Optimization, D. Corne, M. Dorigo, F. Glover (eds.UK: McGraw-Hill, pp. 127–146, 1999. [Google Scholar]
35. G. Onwubolu and D. Davendra, “Scheduling flow shops using differential evolution algorithm,” European Journal of Operational Research, vol. 171, no. 2, pp. 674–692, 2006. [Google Scholar]
36. M. F. Tasgetiren, Y. C. Liang, M. Sevkli and G. Gencyilmaz, “A particle swarm optimization algorithm for makespan and total flowtime minimization in the permutation flowshop sequencing problem,” European Journal of Operational Research, vol. 177, no. 3, pp. 1930–1947, 2007. [Google Scholar]
37. J. Beans, “Genetics and random keys for sequencing and optimization,” INFORMS Journal on Computing, vol. 6, no. 2, pp. 154–160, 1993. [Google Scholar]
38. M. Dorigo and L. M. Gambardella, “Ant colony system: a cooperative learning approach to the traveling salesman problem,” IEEE Transactions on Evolutionary Computation, vol. 1, no. 1, pp. 53–66, 1997. [Google Scholar]
39. M. Dorigo, “Optimization, learning and natural algorithms,” Ph.D. dissertation, Polytechnic University of Milan, Italy, 1992. [Google Scholar]
40. E. Atashpaz-Gargari and C. Lucas, “Imperialist competitive algorithm: An algorithm for optimization inspired by imperialistic competition,” in Proc. 2007 IEEE Congress on Evolutionary Computation, Singapore, pp. 4661–4667, 2007. [Google Scholar]
41. J. H. Holland, Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. USA: University of Michigan Press, 1992. [Google Scholar]
42. T. Ladhari and M. A. Rakrouki, “Heuristics and lower bounds for minimizing the total completion time in a two-machine flowshop,” International Journal of Production Economics, vol. 122, no. 2, pp. 678–691, 2009. [Google Scholar]
43. Y. D. Kim, “A new branch and bound algorithm for minimizing mean tardiness in two-machine flowshops,” Computers and Operations Research, vol. 20, no. 4, pp. 391–401, 1993. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |