DOI:10.32604/iasc.2023.028041
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2023.028041 | |
| Article |
Enhanced Sentiment Analysis Algorithms for Multi-Weight Polarity Selection on Twitter Dataset
College of Computer and Information Sciences, Jouf University, Sakaka, 72314, Saudi Arabia
*Corresponding Author: Ayman Mohamed Mostafa. Email: amhassane@ju.edu.sa
Received: 31 January 2022; Accepted: 20 March 2022
Abstract: Sentiment analysis is based on the orientation of user attitudes and satisfaction towards services and subjects. Different methods and techniques have been introduced to analyze sentiments for obtaining high accuracy. The sentiment analysis accuracy depends mainly on supervised and unsupervised mechanisms. Supervised mechanisms are based on machine learning algorithms that achieve moderate or high accuracy but the manual annotation of data is considered a time-consuming process. In unsupervised mechanisms, a lexicon is constructed for storing polarity terms. The accuracy of analyzing data is considered moderate or low if the lexicon contains small terms. In addition, most research methodologies analyze datasets using only 3-weight polarity that can mainly affect the performance of the analysis process. Applying both methods for obtaining high accuracy and efficiency with low user intervention during the analysis process is considered a challenging process. This paper provides a comprehensive evaluation of polarity weights and mechanisms for recent sentiment analysis research. A semi-supervised framework is applied for processing data using both lexicon and machine learning algorithms. An interactive sentiment analysis algorithm is proposed for distributing multi-weight polarities on Arabic lexicons that contain high morphological and linguistic terms. An enhanced scaling algorithm is embedded in the multi-weight algorithm to assign recommended weight polarities automatically. The experimental results are conducted on two datasets to measure the overall accuracy of proposed algorithms that achieved high results when compared to machine learning algorithms.
Keywords: Sentiment analysis; semi-supervised framework; multi-weight polarity algorithm; Arabic lexicons and automated scaling algorithm
Sentiment analysis is the mechanism and methodology for analyzing user attitudes and opinions toward services, products, and events. The role of sentiment analysis is to explore the user opinions and directions and then classify the polarity for each sentiment whether it is negative, positive or neutral [1]. Different types of sentiment analysis are used to efficiently resolve and classify the user polarities based on the aspect, sentence, or document levels [1,2]. Sentiment analysis can be applied in a wide range of domains such as business intelligence, recommender systems, healthcare sectors, and provided services in cloud computing [3]. The extracted data of sentiment analysis can contain different formats such as TXT, CSV, XML, HTML, JSON, or other media files [3]. These formats should be preprocessed in order to generate feature extraction for each sentiment. Different feature extraction techniques can be applied to the selected data to analyze the polarity of sentiments such as polarity weight score and classification of orientation [4]. Regarding the polarity weight score, each detected polarity is given a predefined weight score to identify the sentiment orientation. Different feature selection methods can be applied during the analysis of sentiment terms. These methods can be a unigram where only one term is used at a time, a bigram where pair of terms can be analyzed, and N-gram where a sequence of more than two terms is analyzed for verifying the orientation of each sentence [5]. After applying the data extraction and feature extraction, the analysis process of sentiments is based on two main approaches: supervised and unsupervised methods [6]. The supervised sentiment analysis uses machine learning algorithms are applied on training and testing datasets while the unsupervised sentiment analysis is based on generating a lexicon for obtaining the polarity terms along with their weights. The contribution of this paper is as follows:
• Building enhanced sentiment analysis lexicons for storing polarity terms with different orientations.
• Applying the created lexicons to the Arabic language as it contains high morphological and linguistic terms that are highly difficult to detect and analyze.
• Applying machine-learning algorithms on two labeled datasets from Twitter with different polarities.
• Provide a hybrid framework for merging supervised and unsupervised mechanisms for increasing the performance of the analyzed data.
• Developing a multi-weight polarity algorithm for analyzing polarity sentiments with different weights.
• Providing a scaling mechanism for distributing the overall polarity of the sentiment according to the provided algorithm.
• Enhancing an automated recommender algorithm for tracing the scaling of each polarity and distributing the recommended polarity weight according to the detected word terms and polarity terms.
Sentiment analysis models and applications have increased in an accelerated way due to the spread of social networks and online shopping websites. In this section, a comprehensive review of recent sentiment analysis research is provided. Recent sentiment analysis researches that are conducted using supervised and unsupervised approaches are proposed with major models, frameworks and mechanisms.
2.1 Supervised Sentiment Analysis
Supervised sentiment analysis is based on creating a corpus for sentiments and terms along with their polarity. The collected dataset is split into training and testing datasets where the training dataset must be labeled to train the classifier. As presented in [7], a sentiment analysis approach is applied on Arabic social media datasets where a corpus is manually built. A set of machine learning algorithms are applied to the training and testing datasets to identify the accuracy of the proposed approach. As presented in [8], a sentiment analysis mechanism is proposed for processing sentiments from learning and teaching datasets. A feature selection is applied to the processed data by creating four models and a sentiment classification using a support vector machine (SVM) algorithm is implemented to provide the accuracy of the models. As shown in [9], a Naïve Bayes (NB) classifier is applied to Arabic tweets by performing term frequency techniques. The polarity of the tweets is classified by dividing the testing datasets into five partitions. Another sentiment analysis mechanism is applied using SVM for classifying text datasets [10]. The results are tested on five rounds and the average performance is measured. As presented in [11], a sentiment classification is applied using different machine learning algorithms and the performance of the machine learning algorithms is measured.
An automatic classifier is presented in [12] that merges both lexicon-based and machine learning algorithms. In this research, the dataset is collected and preprocessed and a lexicon is created using Senti-Word-Net. The authors of [13] applied term frequency to classify the sentiment polarity of the dataset. The dataset is divided into training and testing labels to measure the performance of machine learning techniques. Feature extraction methods are defined with sentiment analysis methods as proposed in [14]. An evaluation of the methods of feature extraction is provided with different dataset domains. As presented in [15], SVM and NB techniques are applied to the E-commerce dataset for classifying customer preferences. The accuracy of the machine learning techniques is measured where NB achieved higher accuracy than SVM.
One of the recent research methods for analyzing sentiments is presented in [16] where a large-scale dataset of text and images is provided for classifying the orientation of sentiments. The polarity prediction for text, image and multimodal is applied on different dataset domains and the average accuracy for each aspect is determined. A recent sentiment analysis research is proposed in [17] where the LSTM is applied as a deep learning algorithm on a large dataset from Twitter. The LSTM is used to measure the performance of the dataset and the validation of data is processed using different machine learning algorithms. As presented in [18], a deep learning mechanism using LSTM is applied to explore sentiments automatically based on a predefined dictionary. Another deep learning mechanism is applied to social media dataset for analyzing sentiments automatically [19]. This research provided a framework that performs a preprocessing for data using different deep learning models. The authors of [20] perform a classification process based on both deep learning and machine learning algorithms. Both methods are applied to the preprocessed dataset and the efficiency is measured to explain the best results. As presented in [21], a hybrid model based on Bi-LSTM and Convolutional Neural Network (CNN) is applied on short sentiments. This model aims to classify sentiments by extracting features from training datasets. Although a deep learning algorithm is merged with CNN to analyze sentiments more effectively. The same algorithms of LSTM and CNN are compared in [22] to measure the performance and accuracy of analyzing sentiments retrieved from movie ranking evaluations. The dataset is formalized according to the mechanism of each algorithm.
An aspect-based sentiment analysis model is presented in [23]. In this model, the aspect is applied based on the category of the term of the sentiment where the sentiment polarity can contain different orientations according to the aspect of the dataset. Genetic algorithm is also a new applied methodology on sentiment analysis as proposed in [24] where the sentiments are classified and labeled into 5-weight orientations. A lexicon is created to rank sentiments that are near to the target word and the results of this model are considered relatively average. One of the recent researches in sentiment analysis is presented in [25] where Hidden Markov Models (HMMs) are used to predict hidden sentiments in the text. The authors aimed to provide different architectures of HMM for training and testing sentiments.
2.2 Unsupervised Sentiment Analysis
In unsupervised sentiment analysis, the dataset is not assigned to any labels for training and testing like supervised sentiment analysis. On the contrary, a lexicon is created automatically or manually for obtaining datasets with different n-grams and weights. As presented in [26], an Arabic sentiment analysis lexicon is created by assigning a score for each Arabic term with its corresponding term in the English language. Each term is classified according to its polarity and the polarity score is added to each term to define the orientation of the sentence. A framework for sentiment lexicon is created for determining the polarity of each term by assigning a score for each polarity term [27]. The difference in this research from the previous one is that the lexicon is created using Hadoop for storing the sentences. A model is created to define the label for each sentiment based on a recursive neural tensor network (RNTN) to compare its accuracy with the applied lexicon. Another sentiment analysis framework using Hadoop is presented in [28] where the dataset is collected from Twitter social media. The data is cleaned, preprocessed and finally labeled for classifying sentiments. As explained in the research papers [29–32] different lexicons are created to provide a dictionary for sentiments along with their polarities. The authors of [29] constructed a lexicon for topics and sentiments where each word in the sentiment can obtain different polarities according to its meaning in the topic. The authors of [30] created a sentiment lexicon dictionary for the Malay language that stores each term and its polarity in English with its corresponding meaning in Malay. The results of the research provided a challenging accuracy. As presented in [31], a lexicon dictionary is created for enlarging the size of terms and their polarities. The dataset is collected from user reviews of movies and each term is classified to positive or negative polarity only. As shown in [32], a traditional method for creating a dictionary is proposed for storing polarity sentiments after performing the preprocessing step for removing stop words and slang terms.
As shown in [33], a sentiment dictionary is created based on two lexicons. The first lexicon is used to store and detect negative polarities while the second lexicon is used to classify the remaining sentiments. Other sentiment analysis dictionaries are proposed in [34] but based on Chinese text. Different weights are given based on the degree of polarity in order to increase the accuracy of the lexicon. The experimental results are conducted using supervised machine learning techniques to validate the accuracy of the sentiments. Another Chinese lexicon is proposed in [35] based on E-commerce customer reviews but the analysis process was conducted using deep learning techniques. As presented in [36], an augmented lexicon is created based on specific terms and words for classifying the orientation of polarities. The authors started their framework by building a lexicon and performing preprocessing on the data collected from different reviews. Another sentiment lexicon but for the Arabic language was presented in [37]. The lexicon is created by inserting each term in the lexicon and embedding letters to the term such that the term still obtains the same meaning. A 4-weight is applied to the created lexicon to explore the polarity for each term.
Enhanced methodologies in sentiment analysis are proposed in [38–40]. These research papers explore state-of-the-art methodologies and models in sentiment analysis. As presented in [38], a sentiment analysis model is generated by collecting reviews from different songs and lyrics from YouTube. The degree of agreement is determined based on the classification of data that are related to the same aspect. As shown in [39], a sentiment analysis model is created for classifying topics and sentiments based on their polarity. Each sentiment is assigned with a score and the overall results are compared to traditional supervised methods. The authors of [40] applied sentiment analysis but on the reviews related to the COVID-19 pandemic. The accuracy is measured in each social media platform and is compared with other platforms.
2.3 Automated Sentiment Analysis Models
As proposed in our papers [41,42], automated sentiment analysis is applied for analyzing sentiments based on a predefined lexicon. The main objective is to create a lexicon that obtains Arabic linguistic terms from different domains and then analyze these sentiments to measure the accuracy. As presented in [41], a multi-weight lexicon is created for analyzing Arabic sentiments. The lexicon is created using different classical and slang Arabic terms and the data cleaning is applied for removing stop words and objective terms that do not have polarity. Our paper is extended in [42] for performing exceptional negation methodology on Arabic terms. Most research papers applied negation terms as a traditional method where the negation term must precede the polarity term to inverse the orientation weight value.
As shown in [43], a sentiment analysis method for analyzing terms is applied. The proposed mechanism is based on a sentiment graph for categorizing the polarity of each term. Another sentiment analysis method based on topic modeling is presented in [44] where each sentiment is classified based on its topic. Each topic is manually labeled using a dictionary that measures the false positive rate for each topic. Another automated method for analyzing user comments is presented in [45] where user reviews are classified into four dimensions. The sentiment polarity is analyzed based on the dimensions to determine the accuracy percentage for each dimension. In supervised mechanisms, the labeled data is considered a time-consuming method due to the manual annotation of data. The authors of [46] created a lexicon for storing polarities and their orientations. Different algorithms are proposed for scoring terms and polarities.
2.4 Sentiment Analysis Mechanisms and Frameworks
The developed mechanisms and frameworks in sentiment analysis provide a comprehensive view of sentiment architectures and the methods of processing datasets. In addition, the analysis mechanisms that classify data are also identified. As presented in [47], a hierarchical framework for analyzing sentiments about COVID19 is developed. The dataset is collected from users’ opinions about the virus and a hierarchical tree is proposed for extracting features of data. As proposed in [48], a fast LSTM model is applied for analyzing text sentiments. The proposed model is inherited from the LSTM model where the data is divided into five parts. Four parts are used for training while the last part is used for testing. The accuracy is conducted between different machine learning techniques and the fast LSTM that achieved high accuracy. Another framework is proposed in [49] that acquires datasets, extracts sentiments, and classifies sentiments. Different machine learning techniques are used for measuring the accuracy of sentiment polarities. As shown in [50], a survey is established for measuring the attitude about a specific domain and then the score is given to this attitude.
One of the promising ideas for extending sentiment analysis mechanisms is to review the orientation of polarities on security models on medical datasets. This can increase the robustness of proposed algorithms and provide a clear vision of the capabilities of the enhanced methods. As presented in [51], a watermarking algorithm is applied for embedding and extracting watermarks. The proposed algorithm is conducted on MRI image datasets that achieved high performance. The authors of [52] maintain the protection of privacy by applying a reversible watermarking scheme on medial audio datasets.
3 Comparative Analysis of Sentiment Analysis Mechanisms
Based on the previous evaluation of sentiment analysis methods and research methodologies, most of the presented mechanisms and applications fall within the scope of supervised, unsupervised and deep learning mechanisms where the dataset is classified and analyzed based on the detected polarity weight. Each detected term must have a polarity that expresses the orientation of user preferences to evaluate the overall polarity of the sentence or the document. As presented in Tab. 1, some research methodologies used only positive and negative polarities while most of the presented research papers used a 3-weight polarity that contains positive, negative and neutral orientations. The proposed table summarizes the objective, dataset language, polarity weight and applied mechanisms.
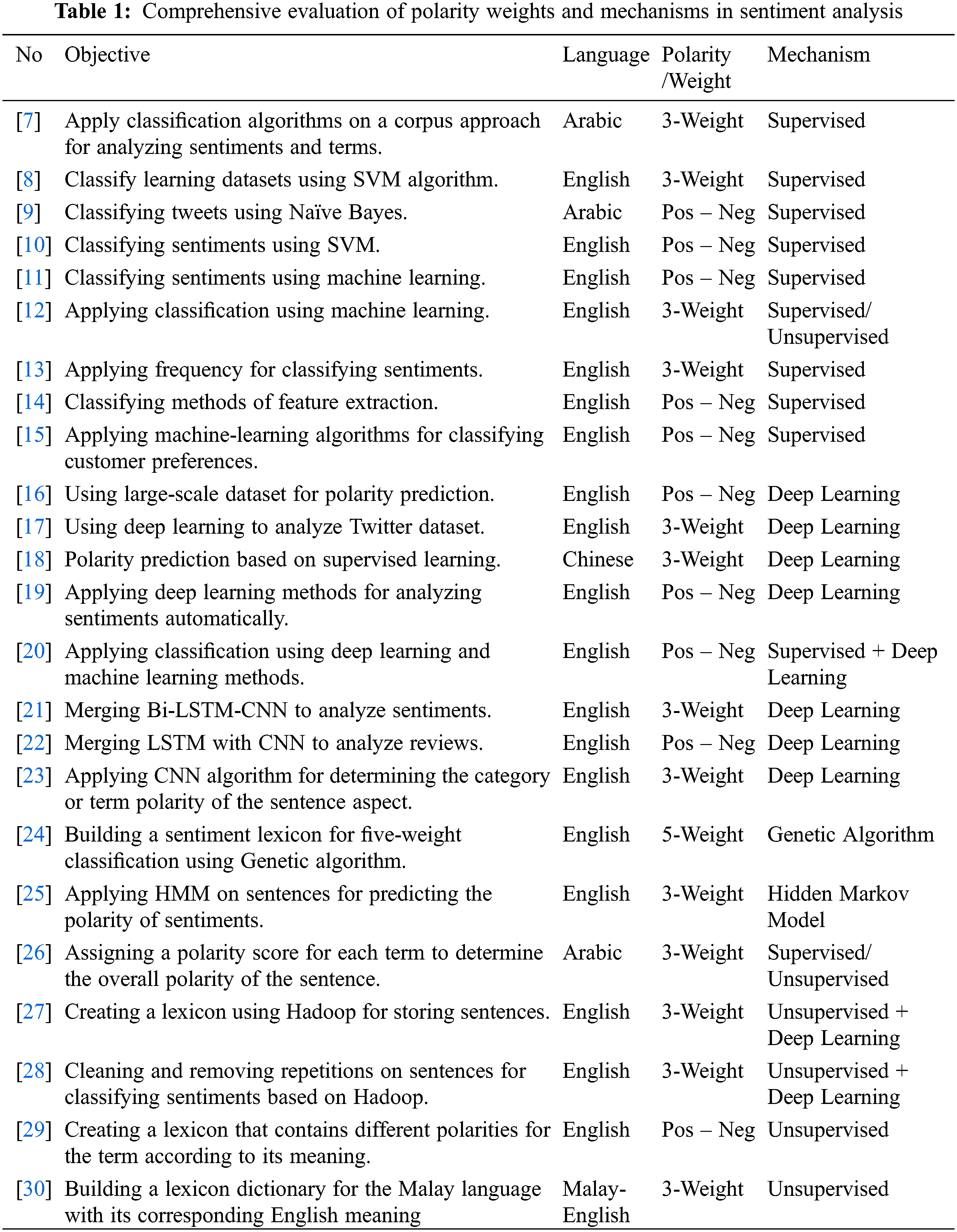
As presented in Fig. 1, a summary for multi-weights distribution is provided to explain the relationship between supervised and unsupervised mechanisms with different weights of terms and polarities. As explained, the supervised mechanisms are concentrated on both 2-weight and 3-weight. Using unsupervised mechanisms, most conducted experiments are used on 3-weight with 64.7% while 23.5% of experiments are applied on 2-weight. Semi-supervised mechanisms that apply both supervised and unsupervised are distributed on 3-weight, 4-weight and multi-weight with 57.14%, 14.28% and 28.58% respectively. Finally, deep learning algorithms are applied on only 2-weight and 3-weight with 41.67% and 58.33% respectively.
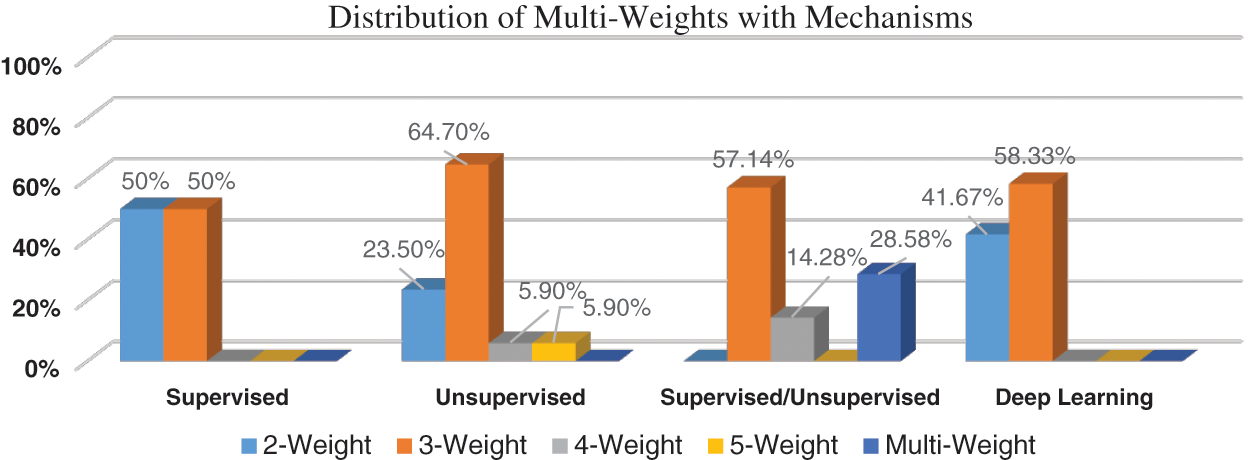
Figure 1: Distribution of multi-weights with mechanisms
The improvements of services in many sites and platforms depend mainly on the opinions of user reviews. These reviews are distributed in several languages where the dataset is collected and extracted to perform the analysis process. The Arabic language is one of the most widely used languages that contains high morphological and linguistic terms that are difficult to extract and analyze. Data preprocessing is used as a first step for cleaning data and removing unnecessary terms. The classification of subjective-objective sentences is the first step in data preprocessing. The subjective sentences contain polarity terms that express the attitudes and orientations of users. These polarity terms will be extracted and analyzed. The objective sentences are based on real facts and do not have any polarity terms to be analyzed. After performing the discrimination process, the following steps are executed:
In this step, insignificant terms that do not affect the analysis process are eliminated. The pronouns “and – or” that mean “أو – و” are eliminated. The most widely used preposition terms such as “above – under –across – after – before – into – on – of” that mean “من – على – في – قبل – بعد – خلال – تحت - فوق” respectively are also eliminated. The adverb terms such as “always – sometimes – never – generally – often” that mean “غالبا – عموما – أبدا – أحيانا – دائما” respectively are also eliminated. The elongation terms are also preprocessed by removing recurring letters in the word such as “أهلاااااا” will be converted to “أهلا” that means “Hello”.
The irony detection process is used to remove terms that may obtain different polarities whether positive or negative. Irony detection is considered critical for sentiment analysis processes as the terms can obtain confusion meaning that may affect the accuracy of the sentiment orientation. This paper provides automated multi-weight polarity algorithms that contain separate lexicons for storing positive, negative, neutral, negation and irony terms. These terms can affect the sentiment analysis of the sentence and the overall document. For example, the terms “!يا سلام! – يا راجل” that mean “Hey. Man! – Oh. Yeah!” with exclamation mark may obtain negative or positive orientation.
As presented in our paper [42], the negation terms and exceptional index are applied to the dataset. During the lexicon construction, negation terms are added to the lexicon. Once the polarity term is detected with a negation term precedes it, the orientation of the term will be inversed. In addition, the exceptional negation index is applied to trace the negation terms even if they do not precede the polarity term immediately. By applying both negation methods, the accuracy of polarity detection will be improved.
5 Sentiment Analysis Mechanism for Multi-Weight Polarity Selection
Based on the presented comparative analysis, it is clear that sentiment analysis is considered a challenging analysis method, especially in Arabic sentiments due to the high morphological linguistics. In addition, the mechanisms of analyzing data contain some difficulties. Supervised mechanisms apply machine-learning algorithms that achieve moderate or high accuracy but the manual annotation of data is considered a time-consuming process. In unsupervised mechanisms, a lexicon is constructed for storing polarity terms where the accuracy of analyzing data varies based on the size of the dataset. This paper applied a semi-supervised mechanism where a lexicon is constructed for storing large polarity terms and the dataset is labeled for analyzing the sentiments using machine-learning algorithms.
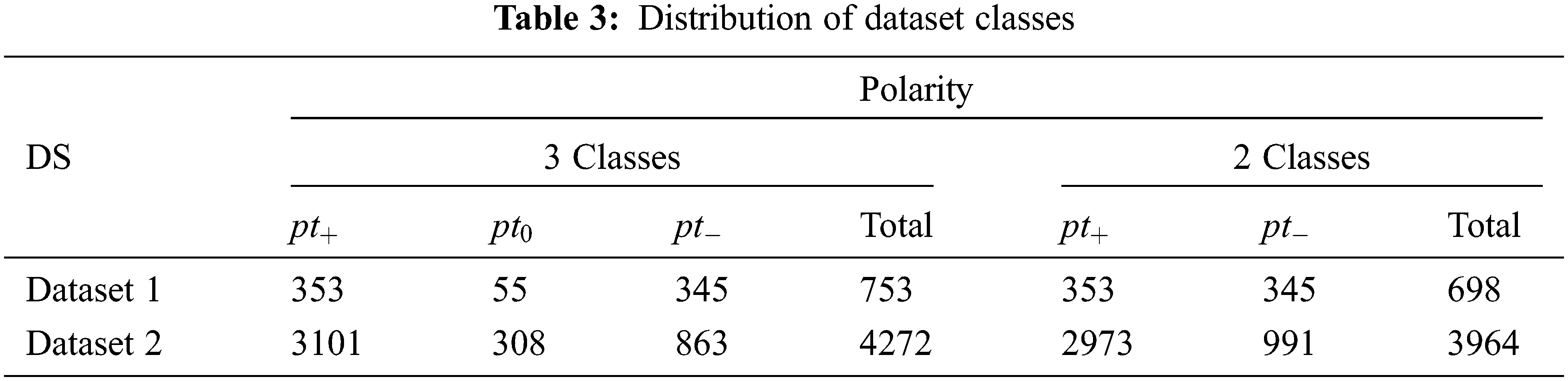
The dataset in this paper is collected from two sources. As presented in Tab. 2, the first dataset is manually collected from different platforms of Twitter. The second dataset is collected from GitHub [53] contains a labeled dataset. Both datasets are labeled based on a 3-weight polarity that contains positive, negative, and neutral sentiments. The datasets are analyzed based on 3-weight polarity then the multi-weight polarity algorithms will be adapted to the datasets to analyze the performance.
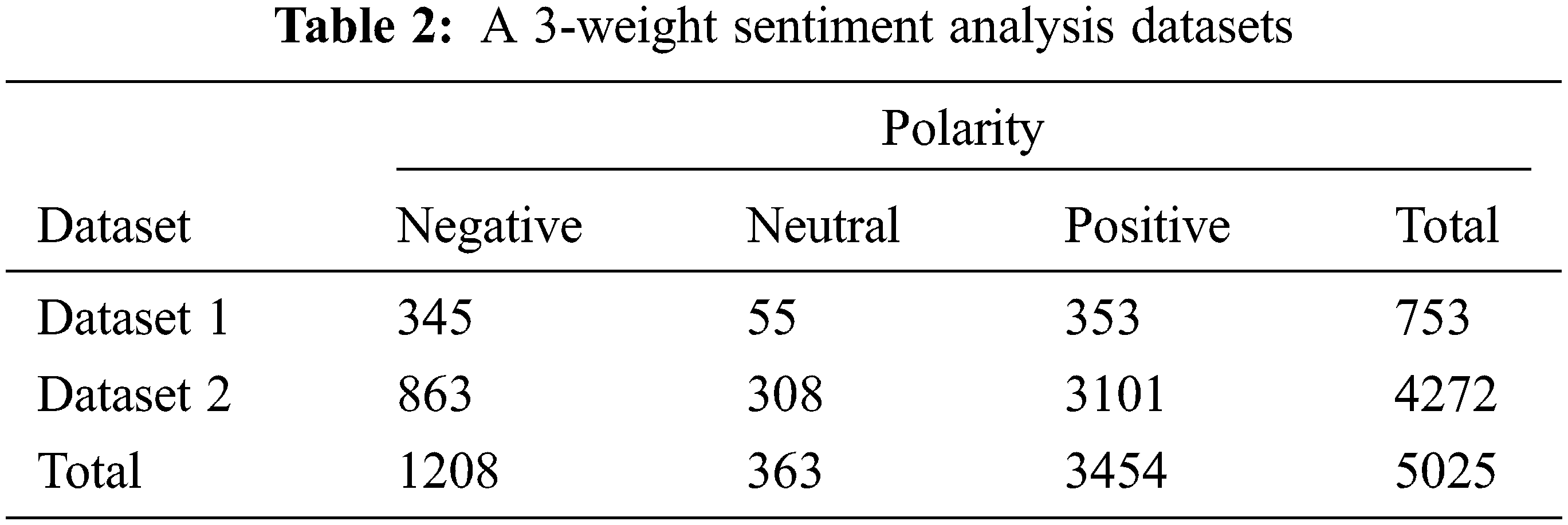
Based on the collected datasets, four lexicons are constructed for storing negative, positive, neutral and irony terms while the fifth lexicon is used to store negation terms. During the sentiment analysis, if a negation term is detected, the polarity term will be converted to its inverse meaning. Each sentence in the dataset is traced using the constructed lexicons and the datasets are analyzed based on two methods:
• Lexicon programming method: in this method, the word terms and polarity terms are identified and detected. The positive terms and negative terms are counted then the percentage of both positive and negative terms are calculated. The percentage of each polarity is then measured to verify the overall orientation of each sentence.
• Machine learning method: different machine learning algorithms are applied to the labeled datasets to measure the accuracy of training and testing datasets. In this paper, the machine learning algorithms for 3-classes with positive, negative and neutral terms. The experiments are executed again for 2-classes with only positive and negative to measure the effect of neutral terms on the overall accuracy. Both methods will be discussed in detail in Sections 6 and 7.
5.3 Proposed Polarity Selection Framework
The proposed sentiment analysis framework is based on two parallel methodologies for measuring the accuracy and recommending the appropriate polarity weight based on the labeled dataset. The two datasets that are selected in Section 5.1 are applied on two paths. As presented in Fig. 2, the first path uses a lexicon-based method where a dictionary or lexicon is generated for storing polarity terms. A tracing mechanism is applied after data preprocessing for counting word terms
The binary approach traces each polarity term and verifies whether it is present in the sentiment or not. The counting approach is used to count the polarity terms for identifying sentiment terms that contain more polarity terms. The term frequency-inverse document frequency (TFIDF) scores each detected polarity based on its frequency in the sentiment terms
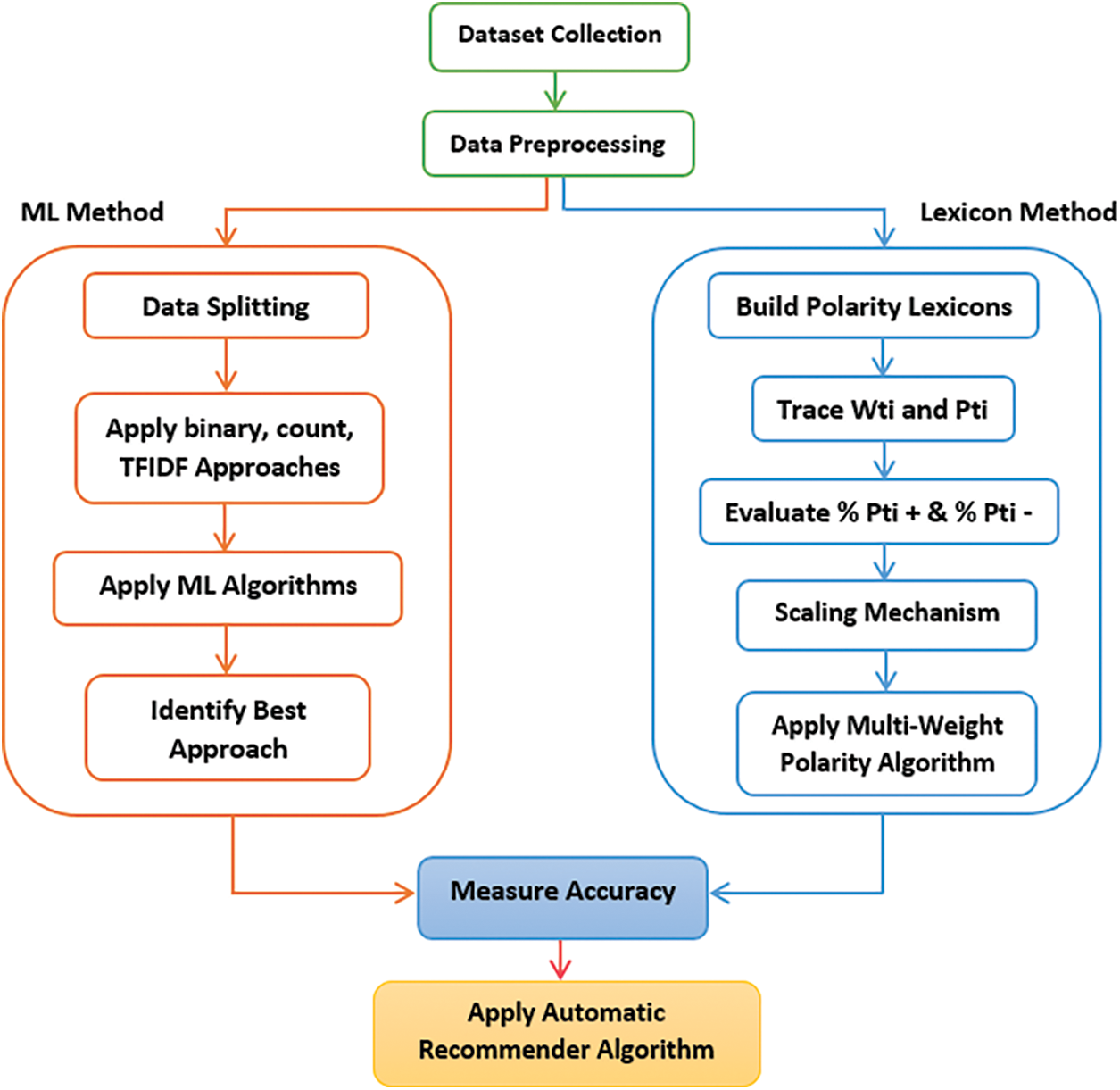
Figure 2: Proposed framework for polarity identification and distribution
6 Proposed Algorithms for Multi-Weight Polarity Sentiments
Based on our presented comparative analysis of sentiment analysis mechanisms, most of the conducted research methodologies use only 2-weight scaling for positive and negative sentiments or 3-weight scaling for positive, neutral and negative sentiments. Applying multi-weight polarity selection on sentiments, especially in the Arabic language is considered a challenging methodology due to the high difficulty in analyzing morphological terms that may obtain different polarity orientations. In addition, using multi-weight polarities on Arabic sentiments can increase the accuracy of polarity prediction on new sentiments. The process of applying multi-weight polarity is based on two major algorithms. Algorithm 1 is based on distributing the multi-weight polarity manually based on the percentage of detected positive and negative polarities while Algorithm 2 is based on an automatic distribution of multi-weights for recommending the appropriate weight based on the sentiment
As presented in Algorithm 1, the identification of multi-weight polarity is verified by adding the datasets
where

The scaling process for a 3-weight polarity is presented in Fig. 3. In each sentiment
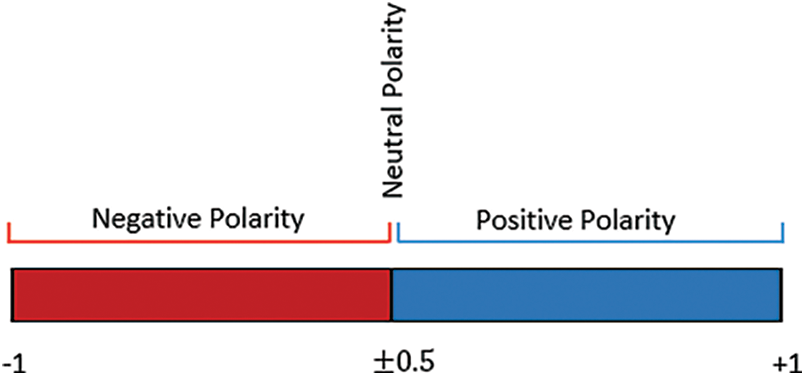
Figure 3: A 3-weight polarity scaling
As presented in Fig. 4, the scaling process for a 5-weight polarity is divided into 5 parts and the percentage of both
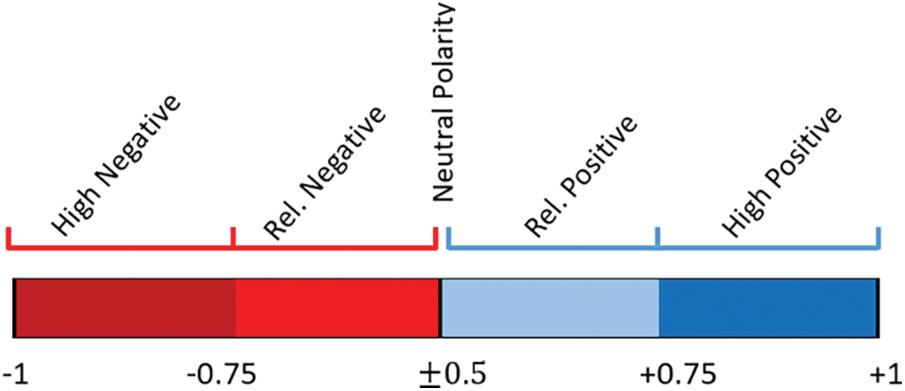
Figure 4: A 5-weight polarity scaling
The 7-weight polarity scaling is applied for any sentiment
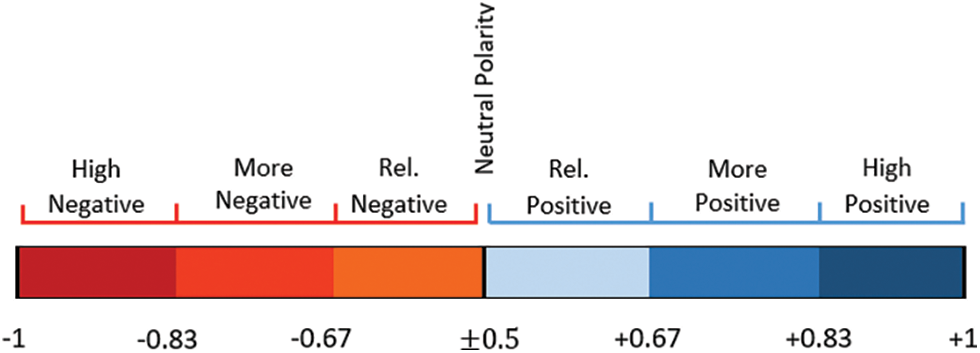
Figure 5: A 7-weight polarity scaling
Given a sentiment term
Algorithm 2 provides an alternative and advanced method for distributing polarity weights automatically. The core objective of this algorithm is to store the datasets
where:

The experimental results of the proposed multi-weight polarity algorithm are conducted on both datasets for measuring the performance and accuracy of the algorithm as explained in Tab. 3. The proposed algorithm is compared with logistic regression (LR) [54], support vector classifier (SVC) [54], random forest (RF) classifier [55], Ada boost classifier [55], K-nearest neighbor (KNN) [56], extreme gradient boosting (XGB) [57], extra trees classifier [58], gradient boosting classifier [59], and Gaussian NB [60]. These classifiers are conducted based on two and three classes for measuring the performance in each one. The datasets are split into 75% for training and 25% for testing.
Firstly, the proposed multi-weight polarity algorithm is adapted to 3-classes to be compatible with the labeled datasets of the machine learning classifiers. The experiments are conducted again with only 2-classes: positive and negative without neutral sentiments. In neutral sentiments, the number of positive and negative polarities are equal in the sentiments that cause overhead on measuring the accuracy in the same sentiment. Fig. 6 presents the accuracy of the first dataset on both classes. The LR classifier algorithm achieved the highest accuracy of machine learning classifiers with 63% and 70% on 3-classes and 2-classes respectively while the proposed multi-weight distribution algorithm achieved 98.53% and 98.82% on 3-classes and 2-classes respectively. As presented in Fig. 7, the accuracy of the second dataset is measured in both classes. The second dataset is considered a large dataset when compared with the first dataset. As a result, the performance of the classifiers is increased. The XGB classifier algorithm achieved the highest accuracy of machine learning classifiers with 79% and 85% on 3-classes and 2-classes respectively while the proposed multi-weight distribution algorithm achieved 98.61% and 98.89% on 3-classes and 2-classes respectively. As presented in Fig. 8, the average performance of the multi-weight polarity distribution algorithm explained the performance on the 3-classes for positive, negative and neutral polarities and the 2-classes for only positive and negative polarities.
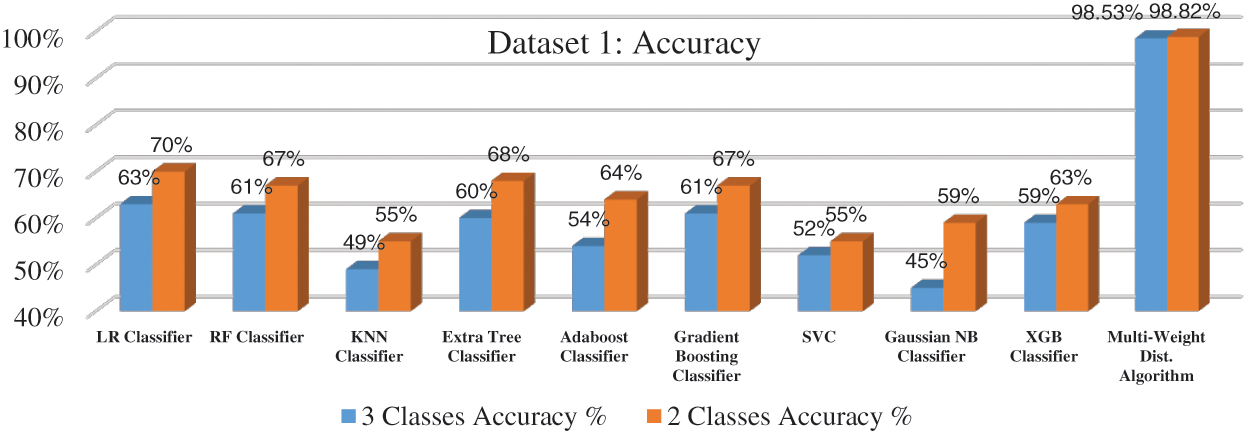
Figure 6: Accuracy of proposed algorithm on the first dataset
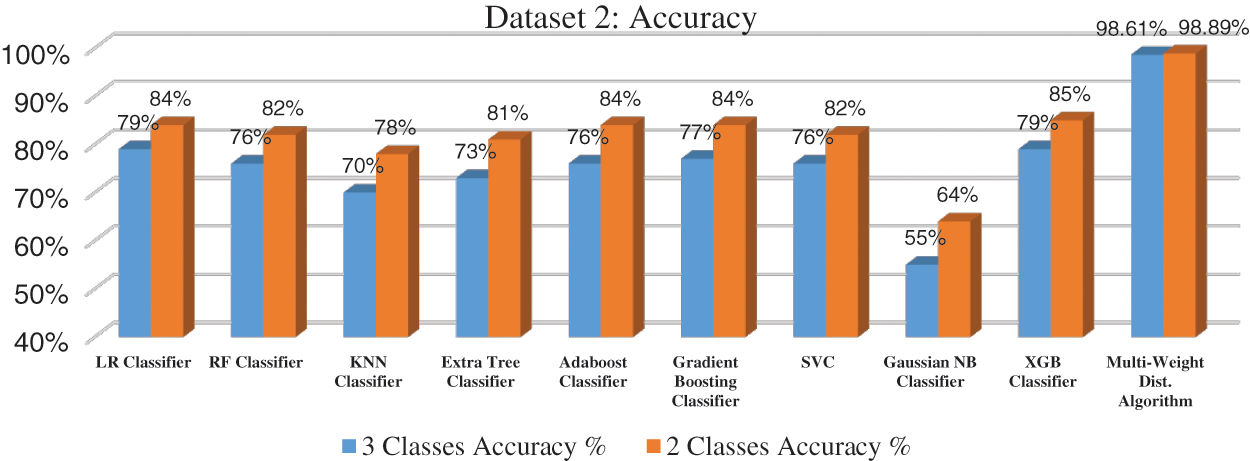
Figure 7: Accuracy of proposed algorithm on the second dataset
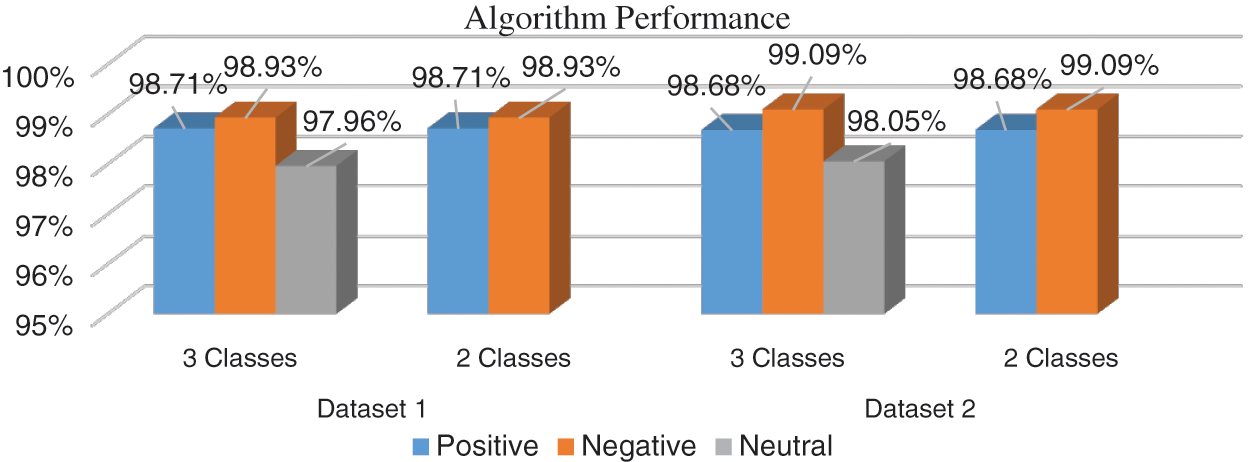
Figure 8: Algorithm performance for 3-classes and 2-classes
The results are conducted using the binary, count, and TFIDF machine learning approaches. Each approach achieved different accuracy according to the machine-learning algorithm. The average performance of the approaches is compared with the average performance of the proposed multi-weight distribution algorithm on the two and three classes. As presented in Fig. 9, the machine learning algorithms on 3-classes achieved the lowest performance on both datasets with 55.96% and 73.26% respectively. Using only 2-classes the performance is increased to 62.3% and 80.15% on the first and second datasets respectively. The performance of the proposed algorithm in both classes achieved high accuracy especially on the 2-classes due to the elimination of neutral polarities that may affect the orientation of the sentiment. In the first dataset, the achieved accuracy recorded 98.53% and 98.82% using 3-classes and 2-classes respectively. In the second dataset, the achieved accuracy recorded 98.61% and 98.89% respectively.
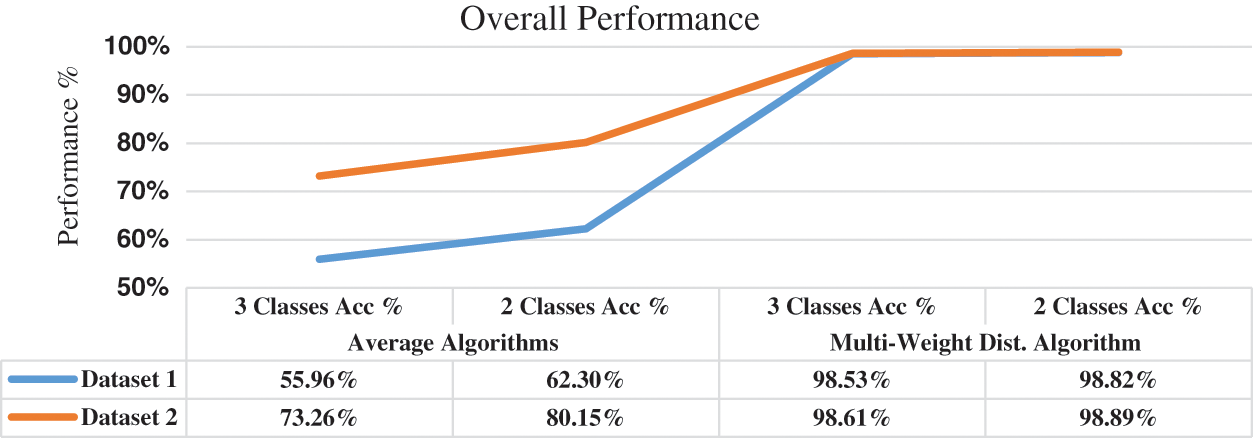
Figure 9: Overall performance of datasets
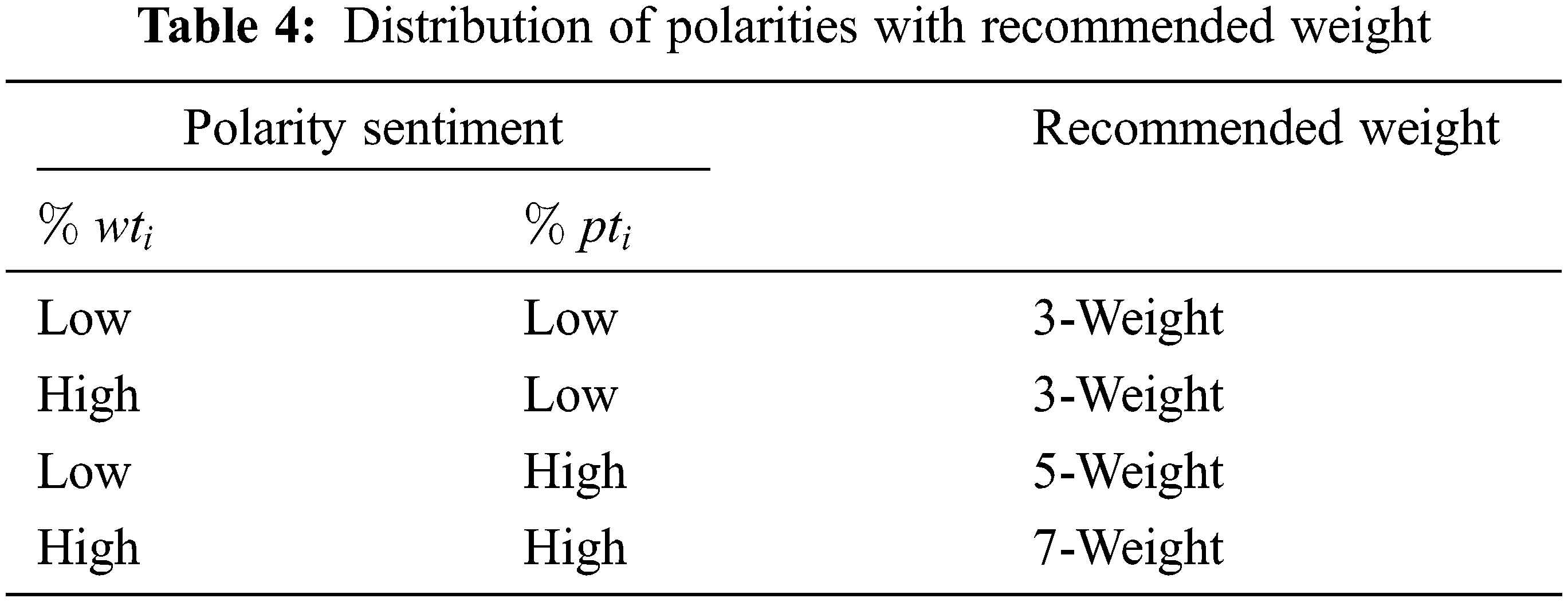
The created lexicon in this paper is optimized for applying Algorithm 2 to automatically recommending the appropriate weight based on the word term
•
•
•
•
Based on the distribution of polarities and the recommended weights in both datasets, Fig. 10 summarizes the percentage of weight distribution where the 3-weight recorded 65.34% and 54.19% on the first and second datasets respectively. The 5-weight recorded 18.19% and 24.88% on both datasets while the 7-weight recorded 16.47% and 20.93%. From the results of Fig. 8, we conclude that the larger the dataset as in the second dataset, the distribution of multi-weight polarities becomes clearer.
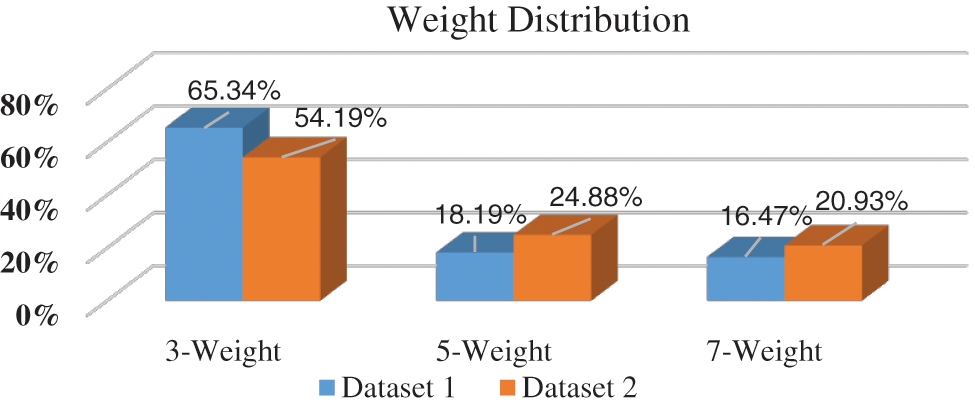
Figure 10: Weight distribution of polarities
Sentiment analysis is considered a challenging direction due to the difficulty in obtaining and analyzing sentiments, especially in the Arabic language that contains complex linguistics. This paper provides a comprehensive evaluation of recent research to explore the applied mechanisms and polarities. A framework is applied using lexicon-based and machine learning algorithms by using count, binary and TFIDF approaches that are applied on two and three classes to measure the accuracy on two Arabic datasets that contain different lengthy sentiments and linguistic terms. The results showed high performance on the proposed algorithm for detecting polarities and distributing multi-weights effectively. An improved algorithm for recommending and assigning multi-weights automatically is added to the distribution algorithm for speeding up the analysis process without user intervention. Future directions on this research will be directed on measuring the accuracy of the distributed multi-weight polarities on Arabic datasets with slang or colloquial terms that are widely used in social media platforms. This can obtain a wide vision of the major characteristics of the proposed algorithms.
Funding Statement: This work was funded by the Deanship of Scientific Research at Jouf University under Grant No. (DSR-2021-02-0102).
Conflicts of Interest: The author declares that there are no conflicts of interest to report regarding the present study.
1. A. Mostafa, “An evaluation of sentiment analysis and classification algorithms for Arabic textual data,” International Journal of Computer Applications, vol. 158, no. 3, pp. 29–36, 2017. [Google Scholar]
2. P. Sudhir and V. Suresh, “Comparative study of various approaches, applications and classifiers for sentiment analysis,” Global Transitions Proceedings, Elsevier, vol. 2, no. 2, pp. 205–211, 2021. [Google Scholar]
3. M. Birjali, M. Kasri and A. Beni-Hssane, “A comprehensive survey on sentiment analysis: Approaches, challenges and trends,” Knowledge-Based Systems, Elsevier, vol. 226, pp. 107–134, 2021. [Google Scholar]
4. S. Pasarate and R. Shedge, “Comparative study of feature extraction techniques used in sentiment analysis,” in IEEE Int. Conf. on Innovation and Challenges in Cyber Security, India, pp. 182–186, 2016. [Google Scholar]
5. S. Zirpe and B. Joglekar, “Polarity shift detection approaches in sentiment analysis: A survey,” in IEEE Int. Conf. on Inventive Systems and Control, India, pp. 1–5, 2017. [Google Scholar]
6. H. Kaur, V. Mangat and N. Nidhi, “A survey of sentiment analysis techniques,” in IEEE Int. Conf. on I-SMAC, India, pp. 921–925, 2017. [Google Scholar]
7. A. Hnaif, E. Kanan and T. Kanan, “Sentiment analysis for Arabic social media news polarity,” Intelligent Automation and Soft Computing (IASC), vol. 28, no. 1, pp. 107–119, 2021. [Google Scholar]
8. A. Muhammad, S. Abdullah and N. Sani, “Optimization of sentiment analysis using teaching-learning based algorithm,” Computers, Materials & Continua (CMC), vol. 69, no. 2, pp. 1783–1799, 2021. [Google Scholar]
9. H. AlSalman, “An improved approach for sentiment analysis of Arabic tweets in twitter social media,” in IEEE Int. Conf. on Computer Applications & Information Security, Saudi Arabia, pp. 1–4, 2020. [Google Scholar]
10. K. Han, C. Chiu and W. Chien, “The application of support vector machine (SVM) on the sentiment analysis of internet posts,” in IEEE Eurasia Conf. on IOT, Communication and Engineering, Taiwan, pp. 154–155, 2019. [Google Scholar]
11. M. Wongkar and A. Angdresey, “Sentiment analysis using Naive Bayes algorithm of the data crawler: Twitter,” in IEEE Fourth Int. Conf. on Informatics and Computing (ICIC), Indonesia, pp. 1–5, 2019. [Google Scholar]
12. R. Jose and V. Chooralil, “Prediction of election result by enhanced sentiment analysis on twitter data using classifier ensemble approach,” in IEEE Int. Conf. on Data Mining and Advanced Computing, India, pp. 64–67, 2016. [Google Scholar]
13. A. Poornima and K. Priya, “A comparative sentiment analysis of sentence embedding using machine learning techniques,” in IEEE Int. Conf. on Advanced Computing and Communication Systems, India, pp. 493–496, 2020. [Google Scholar]
14. M. Haberzettl and B. Markscheffel, “A literature analysis for the identification of machine learning and feature extraction methods for sentiment analysis,” in IEEE Int. Conf. on Digital Information Management, Germany, pp. 6–11, 2018. [Google Scholar]
15. S. Vanaja and M. Belwal, “Aspect-level sentiment analysis on e-commerce data,” in IEEE Int. Conf. on Inventive Research in Computing Applications, India, pp. 1275–1279, 2018. [Google Scholar]
16. J. Zhou, J. Zhao, J. Huang, Q. Hu and L. He, “MASAD: A large-scale dataset for multimodal aspect-based sentiment analysis,” Journal of Neurocomputing, Elsevier, vol. 455, pp. 47–58, 2021. [Google Scholar]
17. A. El-Demerdash, S. Hussein and J. Zaki, “Course evaluation based on deep learning and SSA hyper parameters optimization,” Computers, Materials & Continua (CMC), vol. 71, no. 1, pp. 941–959, 2022. [Google Scholar]
18. G. Li, Q. Zheng, L. Zhang, S. Guo and L. Niu, “Sentiment information based model for Chinese text sentiment analysis,” in IEEE Int. Conf. on Automation, Electronics and Electrical Engineering, China, pp. 366–371, 2021. [Google Scholar]
19. L. Cheng and S. Tsai, “Deep learning for automated sentiment analysis of social media,” in IEEE/ACM Int. Conf. on Advances in Social Networks Analysis and Mining, Canada, pp. 1001–1004, 2019. [Google Scholar]
20. A. Goel and K. Batra, “A deep learning classification approach for short messages sentiment analysis,” in IEEE Int. Conf. on System, Computation, Automation and Networking, India, pp. 1–3, 2020. [Google Scholar]
21. W. Yue and L. Li, “Sentiment analysis using word2vec-cnn-bilstm classification,” in IEEE Int. Conf. on Social Networks Analysis, Management and Security (SNAMS), France, pp. 1–5, 2021. [Google Scholar]
22. M. Haque, S. Lima and S. Mishu, “Performance analysis of different neural networks for sentiment analysis on IMDb movie reviews,” in IEEE Int. Conf. on Electrical, Computer & Telecommunication Engineering, Bangladesh, pp. 161–164, 2021. [Google Scholar]
23. J. I. Yang and J. U. Yang, “Aspect based sentiment analysis with self-attention and gated convolutional networks,” in IEEE Int. Conf. on Software Engineering and Service Science, China, pp. 146–149, 2020. [Google Scholar]
24. J. Li and Y. Liang, “Refining word embedding based on improved genetic algorithm for sentiment analysis,” in IEEE Int. Information Technology and Artificial Intelligence Conf., China, pp. 213–216, 2021. [Google Scholar]
25. I. Perikos, S. Kardakis and I. Hatzilygeroudis, “Sentiment analysis using novel and interpretable architectures of Hidden Markov Models,” Journal of Knowledge-Based Systems, Elsevier, vol. 229, pp. 1–18, 2021. [Google Scholar]
26. K. Sabra, R. Zantout, M. El Abed and L. Hamandi, “Sentiment analysis: Arabic sentiment lexicons,” in IEEE Int. Conf. on Sensors Networks Smart and Emerging, Lebanon, pp. 1–4, 2017. [Google Scholar]
27. Y. Woldemariam, “Sentiment analysis in a cross-media analysis framework,” in IEEE Int. Conf. on Big Data Analysis (ICBDA), China, pp. 1–5, 2016. [Google Scholar]
28. W. Chan and T. Thein, “Sentiment analysis system in big data environment,” Computer System Science and Engineering (CSSE), vol. 33, no. 3, pp. 187–202, 2018. [Google Scholar]
29. D. Deng, L. Jing, J. Yu and M. Ng, “Topic-adaptive sentiment lexicon construction,” in IEEE Conf. on Affective Computing and Intelligent Interaction, China, pp. 1–6, 2018. [Google Scholar]
30. N. Mahadzir, M. Omar, M. Nawi, A. Salameh, K. Hussin et al., “MELex: The construction of Malay-English sentiment lexicon,” Computers, Materials & Continua (CMC), vol. 71, no. 1, pp. 1789–1805, 2022. [Google Scholar]
31. E. Alshari, A. Azman and S. Doraisamy, “Effective method for sentiment lexical dictionary enrichment based on word2vec for sentiment analysis,” in IEEE Int. Conf. on Information Retrieval and Knowledge Management (CAMP), Malaysia, pp. 177–181, 2018. [Google Scholar]
32. A. Kusrini and M. Mashuri, “Sentiment analysis in twitter using lexicon based and polarity multiplication,” in IEEE Int. Conf. of Artificial Intelligence and Information Technology, Indonesia, pp. 365–368, 2019. [Google Scholar]
33. V. Ikoro, M. Sharmina, K. Malik and R. Navarro, “Analyzing sentiments expressed on twitter by UK energy company consumers,” in IEEE Int. Conf. on Social Networks Analysis, Management and Security (SNAMS), Spain, pp. 95–98, 2018. [Google Scholar]
34. G. Xu, Z. Yu, H. Yao, F. Li, Y. Meng et al., “Chinese text sentiment analysis based on extended sentiment dictionary,” IEEE Access, vol. 7, pp. 43749–43762, 2019. [Google Scholar]
35. L. Yang, Y. Li and R. Sherratt, “Sentiment analysis for e-commerce product reviews in Chinese based on sentiment lexicon and deep learning,” IEEE Access, vol. 8, pp. 23522–23530, 2020. [Google Scholar]
36. S. Yadav and N. Saleena, “Sentiment analysis of reviews using an augmented dictionary approach,” in IEEE Int. Conf. on Computing, Communication and Security, India, pp. 1–5, 2020. [Google Scholar]
37. M. Youssef and S. El-Beltagy, “MoArLex: An Arabic sentiment lexicon built through automatic lexicon expansion,” in Int. Conf. on Arabic Computational Linguistics, Procedia Computer Science, United Arab Emirates, vol. 142, pp. 94–103, 2018. [Google Scholar]
38. M. Qureshi, M. Asif, M. Hassan, G. Mustafa, M. Ehsan et al., “A novel auto-annotation technique for aspect level sentiment analysis,” Computers, Materials & Continua (CMC), vol. 70, no. 3, pp. 4987–5004, 2022. [Google Scholar]
39. M. Baniata and S. Asghar, “Sentiment analytics: Extraction of challenging influencing factors from COVID-19 pandemics,” Intelligent Automation and Soft Computing (IASC), vol. 30, no. 3, pp. 821–836, 2021. [Google Scholar]
40. P. Kalaivaani and R. Thangarajan, “Enhancing the classification accuracy in sentiment analysis with computational intelligence using joint sentiment topic detection with MEDLDA,” Intelligent Automation and Soft Computing (IASC), vol. 26, no. 1, pp. 71–79, 2020. [Google Scholar]
41. A. Mostafa, “Advanced automatic lexicon with sentiment analysis algorithms for Arabic reviews,” American Journal of Applied Sciences, vol. 14, no. 8, pp. 754–765, 2017. [Google Scholar]
42. A. Mostafa, “An automatic lexicon with exceptional-negation algorithm for Arabic sentiments using supervised classification,” Journal of Theoretical and Applied Information Technology, vol. 95, no. 15, pp. 3662–3671, 2017. [Google Scholar]
43. R. Abinaya and S. Abinaya, “Automatic sentiment analysis of user reviews,” in IEEE Int. Conf. on Technological Innovations in ICT For Agriculture and Rural Development, India, pp. 158–162, 2016. [Google Scholar]
44. T. Sokhin and N. Butakov, “Semi-automatic sentiment analysis based on topic modeling,” Procedia Computer Science, Elsevier, vol. 136, pp. 284–292, 2018. [Google Scholar]
45. H. Lin, T. Wang, G. Lin, S. Cheng, H. Chen et al., “Applying sentiment analysis to automatically classify consumer comments concerning marketing 4Cs aspects,” Applied Soft Computing, vol. 97, pp. 1–20, 2020. [Google Scholar]
46. M. AL-Sharuee, F. Liu and M. Pratama, “Sentiment analysis: An automatic contextual analysis and ensemble clustering approach and comparison,” Data and Knowledge Engineering, Elsevier, vol. 115, no. 10, pp. 194–213, 2018. [Google Scholar]
47. A. Ibrahim, M. Hassaballah, A. Ali, Y. Nam and I. Ibrahim, “COVID19 outbreak: A hierarchical framework for user sentiment analysis,” Computers, Materials & Continua (CMC), vol. 70, no. 2, pp. 2507–2524, 2022. [Google Scholar]
48. Z. Lin, L. Wang, X. Cui and Y. Gu, “Fast sentiment analysis algorithm based on double model fusion,” Computer System Science and Engineering (CSSE), vol. 36, no. 1, pp. 175–188, 2021. [Google Scholar]
49. K. Zvarevashe and O. Olugbara, “A framework for sentiment analysis with opinion mining of hotel reviews,” in IEEE Conf. on Information Communications Technology and Society, South Africa, pp. 1–4, 2018. [Google Scholar]
50. J. Featherstone and G. Barnett, “Validating sentiment analysis on opinion mining using self-reported attitude scores,” in IEEE Int. Conf. on Social Networks Analysis, Management and Security (SNAMS), France, pp. 1–4, 2020. [Google Scholar]
51. X. R. Zhang, W. F. Zhang, W. Sun, X. M. Sun and S. Jha, “A robust 3-D medical watermarking based on wavelet transform for data protection,” Computer Systems Science & Engineering, vol. 41, no. 3, pp. 1043–1056, 2022. [Google Scholar]
52. X. R. Zhang, X. Sun, X. M. Sun, W. Sun and S. K. Jha, “Robust reversible audio watermarking scheme for telemedicine and privacy protection,” Computers, Materials & Continua, vol. 71, no. 2, pp. 3035–3050, 2022. [Google Scholar]
53. https://github.com/hadyelsahar/large-arabic-sentiment-analysis-resouces. [Google Scholar]
54. A. AlFutamani and H. Al-Baity, “Emotional analysis of Arabic Saudi dialect tweets using a supervised learning approach,” Intelligent Automation and Soft Computing (IASC), vol. 29, no. 1, pp. 89–109, 2021. [Google Scholar]
55. R. Sujatha, B. Krishna, J. Chatterjee, P. Naidu, N. Jhanjhi et al., “Prediction of suitable candidates for COVID-19 vaccination,” Intelligent Automation and Soft Computing (IASC), vol. 32, no. 1, pp. 525–541, 2022. [Google Scholar]
56. M. Huq, A. Ali and A. Rahman, “Sentiment analysis on Twitter data using KNN and SVM,” International Journal of Advanced Computer Science and Applications, vol. 8, no. 6, pp. 19–25, 2017. [Google Scholar]
57. D. Chatterjee, S. Mukhopadhyay, S. Goswami and P. Panigrahi, “Efficacy of oversampling over machine learning algorithms in case of sentiment analysis, Data Management, Analytics and Innovation,” Advances in Intelligent Systems and Computing, vol. 1175, pp. 247–260, 2020. [Google Scholar]
58. Y. Al-Sariera, V. Adeyemo, A. Balogun and A. Alazzawi, “AI meta-learners and extra-trees algorithm for the detection of phishing websites,” IEEE Access, vol. 8, pp. 142532–142542, 2020. [Google Scholar]
59. J. Dutta, Y. Kim and D. Dominic, “Comparison of gradient boosting and extreme boosting ensemble methods for webpage classification,” in IEEE Int. Conf. on Research in Computational Intelligence and Communication Networks, India, pp. 77–82, 2021. [Google Scholar]
60. I. Kaibi, E. Nfaoui and H. Satori, “A comparative evaluation of word embedding techniques for Twitter sentiment analysis,” in IEEE Int. Conf. on Wireless Technologies, Embedded and Intelligent Systems, Morocco, pp. 1–4, 2019. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |