DOI:10.32604/iasc.2022.023145
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.023145 | |
| Article |
Person Re-Identification Using LBPH and K-Reciprocal Encoding
Department of Information Technology, National Engineering College, Kovilpatti, 628503, India
*Corresponding Author: V. Manimaran. Email: jeyamaran2002@gmail.com
Received: 29 August 2021; Accepted: 21 October 2021
Abstract: Individual re-identification proof (Re-ID) targets recovering an individual of interest across different non-covering cameras. With the recent development of technological algorithm and expanding request of intelligence video observation, it has acquired fundamentally expanded interest in the computer vision. Person re-identification is characterized as the issue of perceiving an individual caught in different occasions and additionally areas more than a few nonoverlapping camera sees, thinking about a huge arrangement of up-and-comers. This issue influences essentially the administration of disseminated, multiview observation frameworks, in which subjects should be followed across better places, either deduced or on-the-fly when they travel through various areas. Re-identification proof is a truly challenging issue, as more often than not individuals can be caught by a few low goal cameras, under impediment conditions, severely (and not quite the same as view to see) enlightened, and in differing presents. In this context an encoding technique K-reciprocal results using the LBPH (Local Binary Patterns Histogram) Algorithm has been proposed. This work aims to obtain a genuine image match more prone to the probe in the K-corresponding closest neighbour. When probe image is given, complementary is encoded with the k-equal nearest neighbours into a vector to rerank using the Jaccard matrix. The obtained result is a combination of a Mahalanobis metric, the Jaccard metric, and the LBPH algorithm. The reranking activity needs no Human interference in producing an appropriate enormous scale dataset. The performance of rank-1 metrics 77.27, 61.90, 76.34 &.55.11 percentage is achieved for large-scale Market-1501, CUHK03, MARS, and PRW datasets. The other metrics used for person re-id named mAP recorded 65.01%, 61.21%, 68.21% and 38.13% for the same dataset in that order.
Keywords: Image matching; image retrieval; person re-identification; graph theory
Initial ranking is the standard and effective reranking process for the ranking of similar images among pre-ranked images. An assumption with the ranked images within the K-nearest neighbours probe becomes the true match for the subsequent reranking process [1]. K-reciprocal encoding is forming a single vector from the K-reciprocal feature of the given image used for reranking. K-corresponding neighbours result in new queries that aid in producing the new ranking list. K-nearest neighbour [2] group includes both the true matches and the false matches. K-complementary finds false matches for the truly matched images.
The process begins with asymmetric feature mapping and discriminative dictionary learning in a unified scheme for heterogeneous person Re-ID. It alleviates databases across modalities in the projected subspace, and a shared discriminative dictionary can represent this heterogeneous data.
Fig. 1 shows a group of pictures for the subject below with varied conditions. These images are taken from two different surveillance cameras at various time intervals in a day. This picture depicts intrinsic subject variations and changes in viewpoint, pose and illumination conditions. One of the foremost tough challenges [3] is facing a person. Reidentification methods arise when the majority of clothing worn tends to be non-discriminative conditions. Attributes based strategies attempted to solve this drawback by incorporating attributes likely, ‘jeans,’ ‘male’ and ‘skirt’ area refers all sample of linguistics attributes. Linguistic attributes area unit mid-level options are learned from a larger dataset. They provide an advantage when a single image [4] describes the person present in the scene.

Figure 1: Person reidentification challenge scenes
In the present investigation, the related works are discussed in Section 2, the design of the system in Section 3 and the experimental results and discussion and concluding remarks are given in Section 4.
Person Re-identification will be matched with the captured image of a person through multiple cameras. However, persons across cameras with a pose, illumination, variation, and occlusion are rarely focused. These are caused mainly by environmental conditions like poor light due to bad weather and camera position. In this work, these challenges are worn off by the distance metric learning process. This proposed model eliminates the asymmetrical matches of the probe and provides an efficient outcome.
Ye et al. Stated that similar images are pulled, whereas images ranked dissimilar are pushed away [1].
The Multi-view [5] verification model proposed the ranking grouping algorithm with the view to improve the similarities and dissimilarities direction. In the ranking aggregation method, similarity and insulated dissimilarity are used. In the similarity ranking aggregation, an intersection set of top results with strongly similar images is treated as “new probes” to the query and named backward [6]. Re-query is enhanced by conducting cross-view based backward re-query. Graph-based weighted reranking helps in generating a refined ranking list. In Dissimilarities ranking aggregation, strongly dissimilar images are obtained from the union set of lowly ranked “k” results, and these results are treated as new probes to Re-query their frequency in the ranking order. New models will be developed for similar images to solve two problems based on the dataset size producing high computational cost and many not-so-similar items [7]. A small subset is to be filtered out for improving ranking strategy to reduce the computational cost.
Liao et al. Approach the Reranking method based on an expanded K-reciprocal neighbour approach [3]. The probe image was assumed to be an equivalent person in a gallery image by the expanded [8] K-reciprocal nearest neighbour. The probe image was replaced with the expanded reciprocal nearest neighbour. Therefore the final distance is decided by the mean of the corresponding neighbour set. This method was an automatic and unsupervised Re-ID problem. A simple direct rank list can be performed in a better way using this method. The nearest neighbour reduces the interference of mismatched pairs, and the similarity between the probe and the gallery is discovered to compare the distance in the reranking system [2]. Feature extraction, metric learning and Re-ranking are used to enhance Re-ID model learning. The expanded K-reciprocal nearest neighbour eliminates the false positives in the ranking list. Hence this fully automatic unsupervised model works with the known re-computation for any rank lists.
Wu proposed a retrieval system of the faced image being scalable to represent a face using both local and global features [9]. A new component with the special properties of faces [10] was designed as a local feature. These local features are quantized into visual works based on a quantization schema. The hamming signature was used in the process of encoding the discriminative feature for every face. The pedestrian image was refined by constructing a reference image set. From the inverted index of visual words, the person images are retrieved [11]. A multi reference distance by using a hamming distance was used to rerank the person images.
Pedronette proposed a new contextual-based method to consider the Re-ranking and the initial ranking list [12]. In this image retrieval method, more similar images are collected, which are appropriate to the query image. CBIR descriptors are used to compute the distance matrices by creating grayscale image representation for the contextual retrieval method [9]. For the query image, the K-nearest neighbour is constructed and is analyzed for the image processing technique. The ranking list and distance measurement are used in creating the contextual images [13].
Zhu proposed an aggregated algorithm for the reranking method [14]. To measure the dissimilarity between two images, rank order distances using the neighbouring information was used as the core of the algorithm. Similar neighbours are grouped using the faces of the same persons. A ranking order list was initially created for each face sorted from the datasets [15]. The rank order distance was calculated from the ranking order. Small groups are iterated from all the faces using the clustering algorithm on the new distance. This ranking method uses only the context distance ignoring content distance, which reduces the detection rate.
Gallery set with N images g = {gi | i = 1, 2… N} and probe p, the Mahalanobis distance measures the original distance between two persons p and gi where M is the positive semi-definite matrix, xgi and xp represent the appearance feature of the gallery gi and the probe p respectively.
To get more positive samples top-ranked in the list, Re-ranking is done for the initial rank list L (p, g). The ranking list L (p, g) = {
This reranking improves the performance of the person Re-identification. The pair wise distance between the gallery gi and the probe p is re-calculated by comparing the K-reciprocal nearest neighbour. The duplicate samples in the set are overlapped by the K-reciprocal nearest neighbour sets when two images are similar. The Jaccard distance of the K-reciprocal sets is calculated to find the new distance between the probe p and the gallery gi.
For a given query, the image is searched in multiple datasets for matching. The distance metrics like Mahalanobis and Jaccard distances [16] are calculated for the closely matched images as shown in Fig. 3.
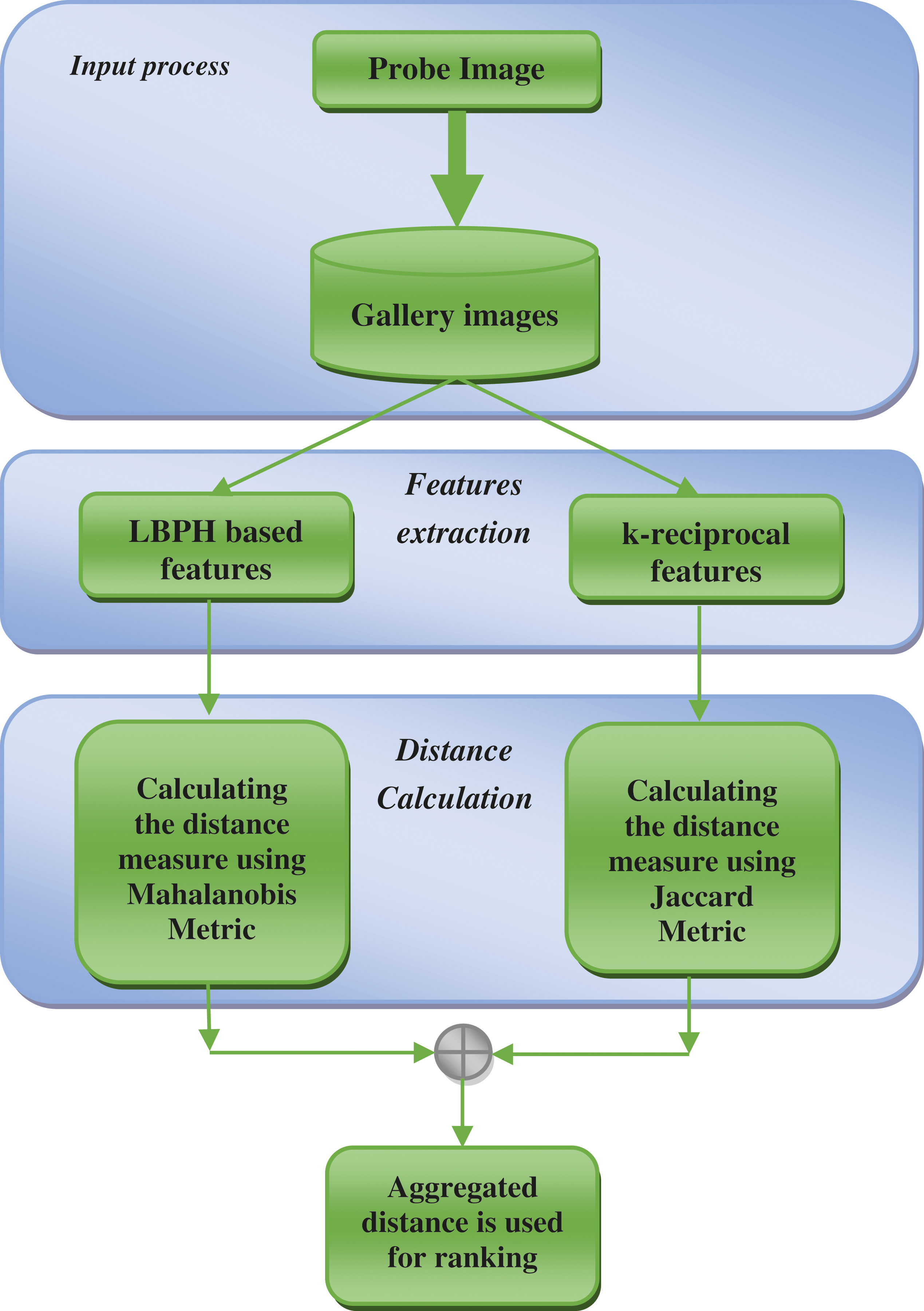
Figure 3: Proposed system architecture of LBPH
K-nearest neighbours may be identified by generating a top-n list of matched images (gn) with the probe “p” in the gallery set. In Fig. 2, exact 4 matches with the probe are p1, p2, p3, p4. But, all are not in the list of top-4 ranks. The top-ranked images may even possess false matched images. To solve this problem, K-reciprocal nearest neighbour is used. In the reranking process of a person, Re-identification is given to the probe and the gallery [12]. The features of appearance and K-reciprocal are abstracted for each person. Two similar images in the K-reciprocal nearest neighbours ranked in the top are chosen as the probe [17].

Figure 2: Probes for person reidentification
3.3 K-reciprocal Nearest Neighbor
Probe ‘p’ and one of the matched gallery image ‘gi’ is said to be K-reciprocal nearest neighbour. If it satisfies the following conditions
1. Image p is in the top-k list of image g.
2. Image g is in the top-k list of image p (image gi is treated as probe here).
In revising the initial ranking list with the newly formulated similarities, a bi-directional ranking method is considered a combination of both the content and contextual similarities [18]. New queries are obtained as the combination of local and global features of common nearest K-neighbors, and the initial ranking list is revised with the new ranking list [19]. Progress with the technique mentioned above ensures the feature contribution from K-nearest neighbour end to end re-ID.
The tendency to investigate the importance of K-reciprocal neighbours provides an effective reranking technique with head to head. However, due to the variation in the individual poses, illumination and exclusion of positive images are not excluded from the K-nearest neighbours.
The original distance with the LBPH feature is determined for each pair in the gallery and the probe. A ranking list is obtained with the final distance. This work is established with a single vector by encoding the k-reciprocal feature [14]. The LBPH metric and vector comparison provide ease in the reranking process. The face recognition algorithmic rule is answerable for finding characteristics that best describe the image with the facial pictures already extracted, cropped, resized and typically converted to grayscale.
Jaccard similarity coefficient is defined as the size of the union of the image set. It compares the set of predicated images for a sample to the corresponding set of images. At this point, the work is evaluating the proposed method on the re-ID dataset. The dataset is more challenging than the video and image-based datasets as it requires detecting probes from a raw dataset and identifying the correct probe from the chosen galleries [4].
Local Binary Pattern Histogram is a texture classification technique where the images are coded into a histogram [1]. Texture information along with the location is also coded. These texture descriptors provide a local feature of the person which will be combined into a global feature
Our Reranking approach is applied for four large-scale Reidentification datasets containing multiple samples as a match for each probe in the gallery based on the similar neighbour’s comparisons between two images.
The biggest image-based re-ID dataset consists of labelled bounding containers around 31,668 of 1,501 identities taken from 6 exceptional camera views [20]. A deformable part model is used in detecting bounding boxes. Training part with 12,936 images of 751 identities and 19,732 images with 750 identities are taken from the dataset. Ten batches with 1974 images are finally taken for the experiment.
A specific set-up for each person images with three different partitions for the gathered images in a well-known recent dataset was provided by the Chinese University of Hong Kong (CUHK). Cuhk03 [21] has 1,467 identities from 14,096 images. Each identification is captured from two different cameras in the CUHK campus and has a common of 4.8 images in every camera. Ten batches of 1410 images are finally taken for the experiment.
Motion Analysis and Re-Identification Set (MARS) is a new largest video re-id dataset, a video extension of the Market-1501 dataset [22]. The dataset contains 1,261 IDs, and around 20,000 tracks provide rich visual information compared to image-based datasets. Meanwhile, MARS reaches a step closer to practice. The tracks are automatically generated by the Deformable Part Model (DPM) as pedestrian detector and the GMMCP tracker.
PRW (Person Re-identification in the Wild) is the extension of Market 1501 using videos acquired through six synchronized cameras [23]. It contains 932 identities and 11,816 frames in which pedestrians are annotated with their bounding box positions and identities.
In general, person Re-identification models utilize two evaluation metrics to find out the effectiveness of the same. The first one considers re-ID as a ranking problem that reports the matching accuracy at rank-1, 5, and 10. Here, rank accuracy denotes the probability of appearing one or more correctly matched images in top - i. If no correctly matched image appears in the top – i of the retrieval list, the rank is −i = 0; otherwise, the rank is −i = 1.
The second metric considers the mean average precision (mAP) re-ID as an object retrieval problem [20]. Average Precision is the most frequently used metric in the person reidentification process. It computes the average precision value to recall over 0 to 1. Precision exposes the accuracy of the prediction. Recall identifies how effective in finding all the positives. Let us consider that a query image system will return top-10 matched images and out of which only 5 are exact matches and the remaining 5 are the same person in the following order as shown in Tab. 1.

Average Precision is estimated by finding the average of correct matched images to the probe. The value calculated for this system is (1 + 1 + 0.5 + 0.57 + 0.5)/5 = 0.714.
Similarly, mean average precision (mAP) is computed as the average of all average precisions across all classes using the following equation.
where, AP is Average precision of the class and n is the number of classes
ID-Discriminative Embedding (IDE) used in the classification produces a 1,024 vector for each image is useful in re-ID datasets. Contextual dissimilarity measure (CDM) takes into account the region of a point. This measure is iteratively acquired by regularizing the average distance of each factor to its neighbourhood. Cross view Discriminant Analysis (XQDA) applies discriminative subspace learning to maintain discriminative data in unique characteristics space, which commonly produces higher performance with a lower-dimensional subspace. The combination of CDM and XQDA with IDE results are compared with the proposed system with Market 1501 and CUHK03 dataset.
The Local Maximal Occurrence (LOMO) method proposed by Shengcai Liao et al. is helpful for an effective feature representation [3]. The LOMO feature analyzes the horizontal occurrence of local features, and the occurrence is maximized to make a stable representation against viewpoint changes, and it is compared with the proposed system of MARS and PRW dataset.
We evaluate our method with rank ‘i’ accuracy. Here, rank accuracy denotes the probability whether one or more correctly matched image appears in top - i. If no correctly matched images appear in the top – i of the retrieval list, rank-i = 0, otherwise rank-i = 1.
For Market 1501 dataset, the parameters are set as k1−19, k2−6, and λ=0.4 and the rank-1 result for each batch is tabulated in Tab. 2 and represented as a graph in Fig. 4 on various approaches viz., IDE+CDM, IDE+XQDA, LBPH.
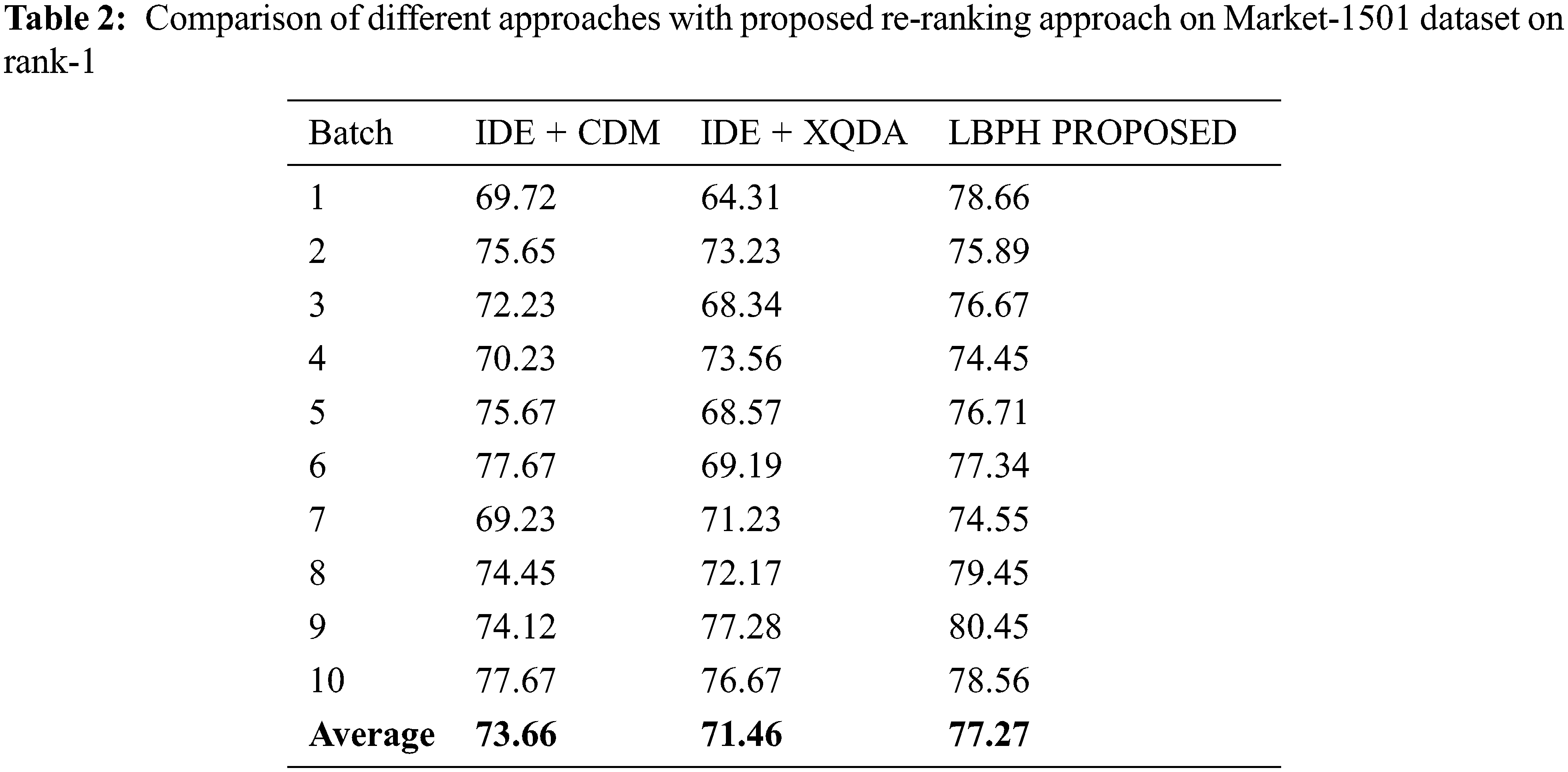
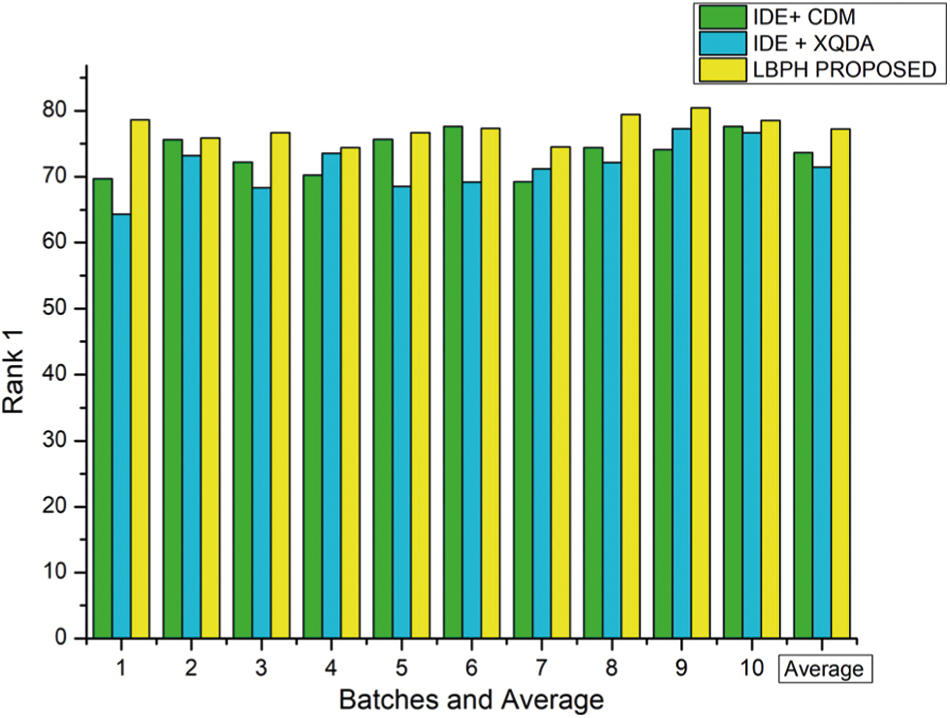
Figure 4: Comparison of different methods with proposed reranking approach using Market-1501 dataset on rank-1
For Cuhk03 dataset, the parameters are set as k1−8, k2−3, and λ = 0.95 and the rank-1 result is portrayed in Tab. 3 and depicted as a graph in Fig. 5 on various approaches viz., LOMO+CDM, IDE, LBPH.
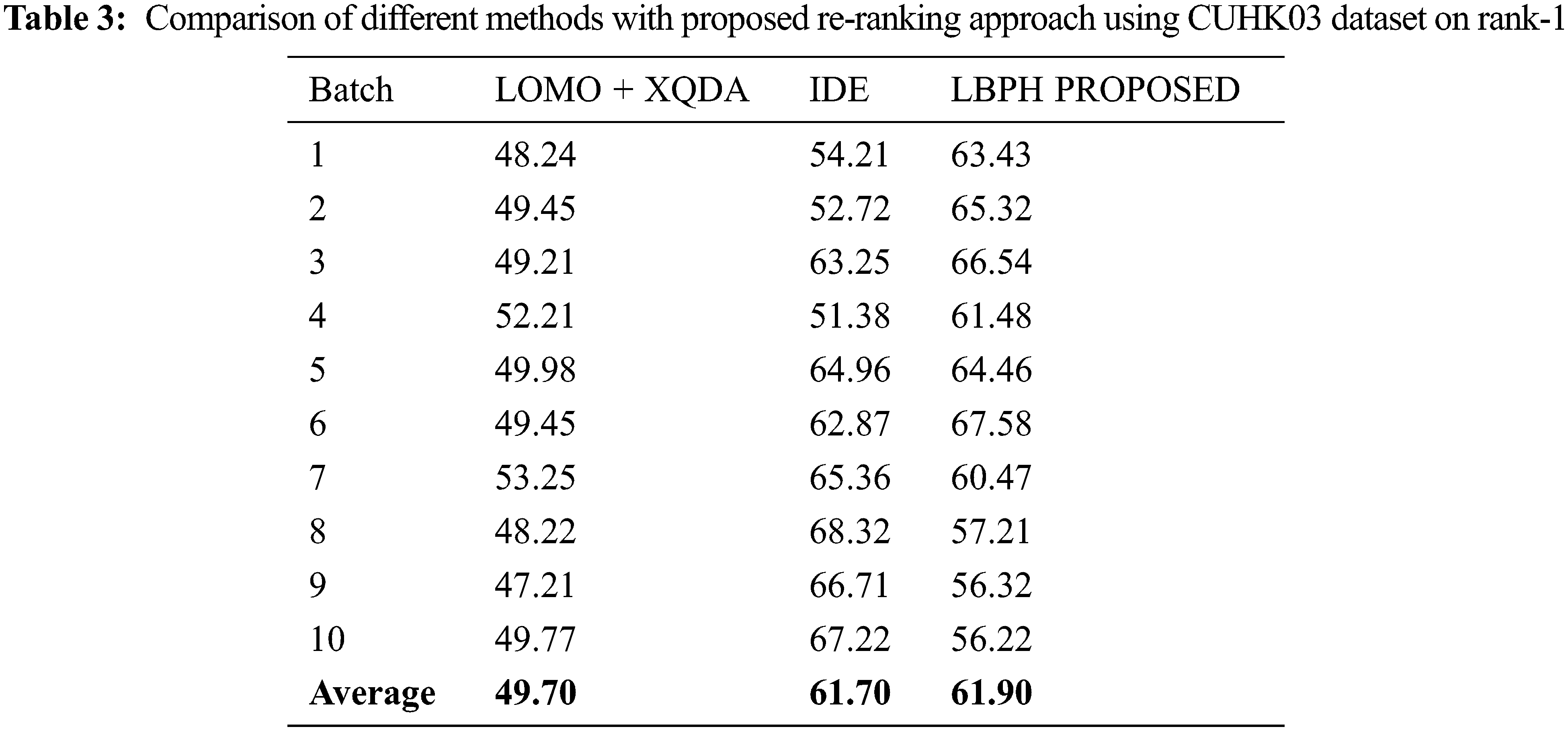
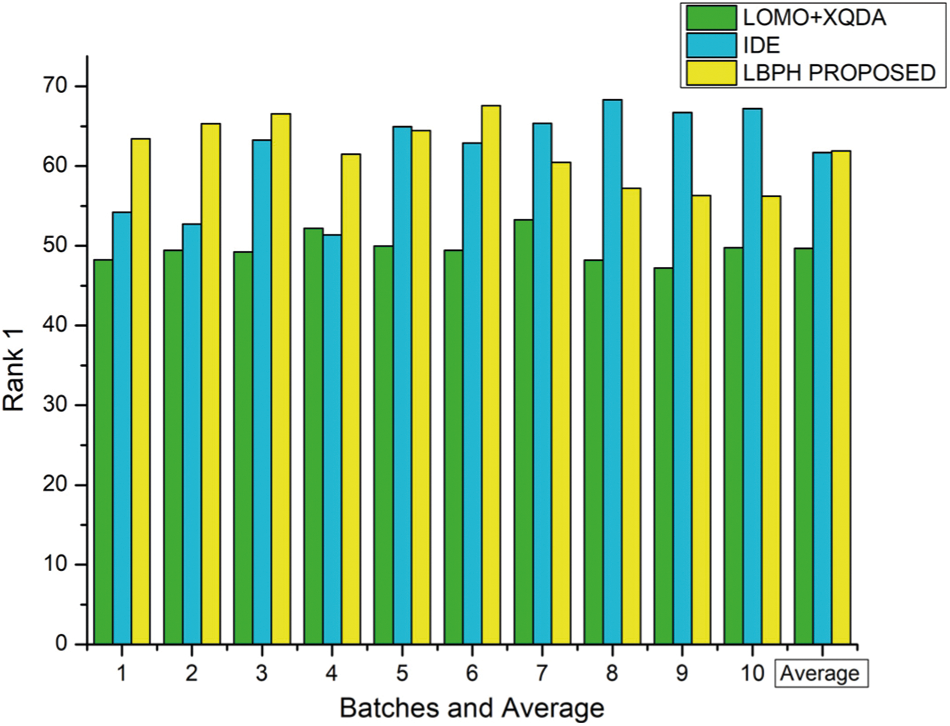
Figure 5: Comparison of different methods with proposed reranking approach using CUHK03 dataset on rank-1
The results showed that this proposed LBPH algorithm is better than the existing algorithms IDE+CDM and IDE+XQDA in terms of Rank-1 feature parameter for Person Re-identification using Market – 1501 dataset samples.
Our model gains 6.52% on the Market 1501 dataset and 2.31% on the CUHK03 dataset based on rank-1 accuracy. The results evidenced that this proposed LBPH algorithm is performed better than the existing algorithms LOMO+XQDA and IDE+XQDA in terms of Rank-1 feature parameter for Person Re-identification using CUHK03 dataset samples.
For the MARS dataset, the parameters are set as k1 − 20, k2 − 6 and λ = 0.3 and the rank-1 result for each batch is tabulated in Tab. 4 and represented as a graph in Fig. 6 on various approaches viz., IDE+CDM, IDE+XQDA, LBPH.
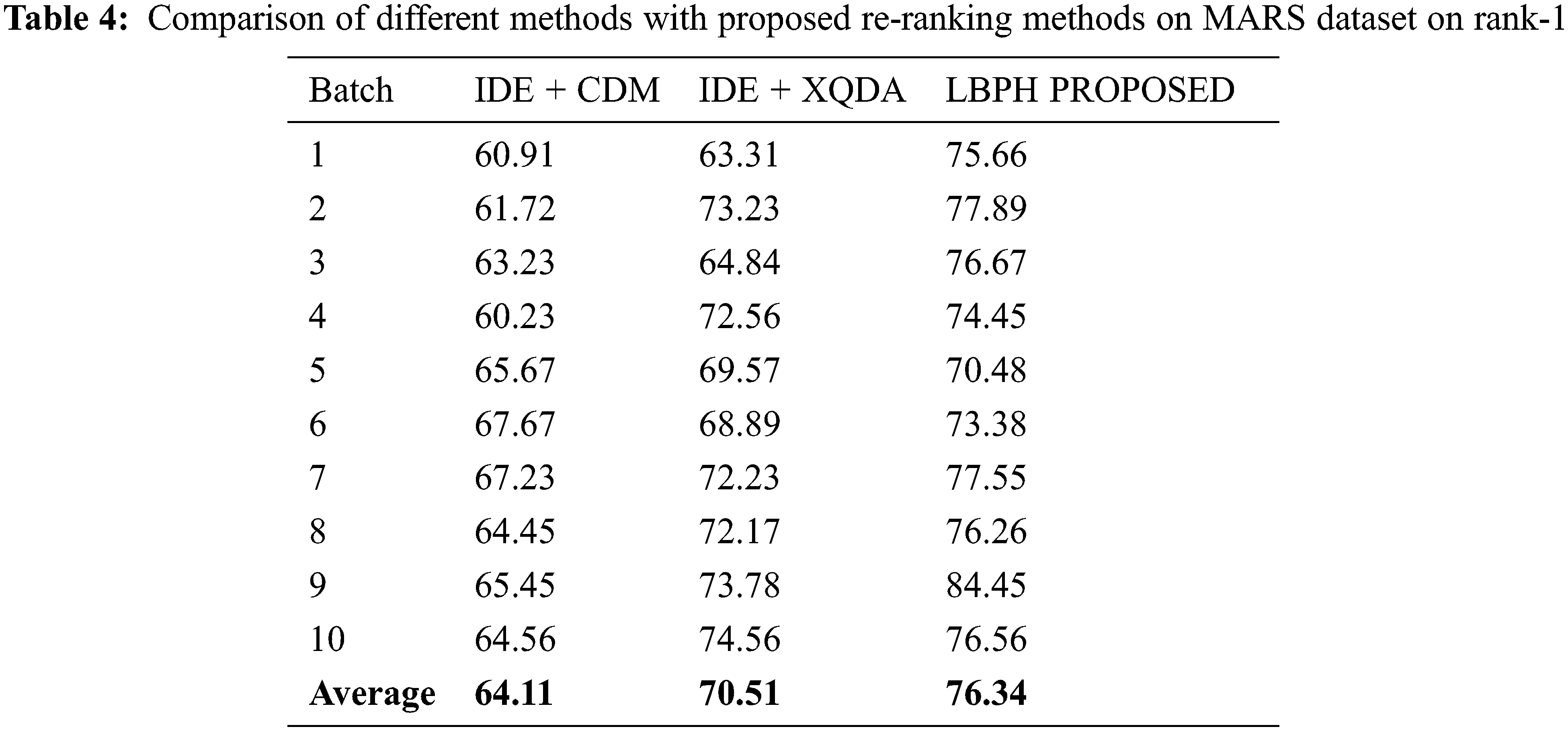
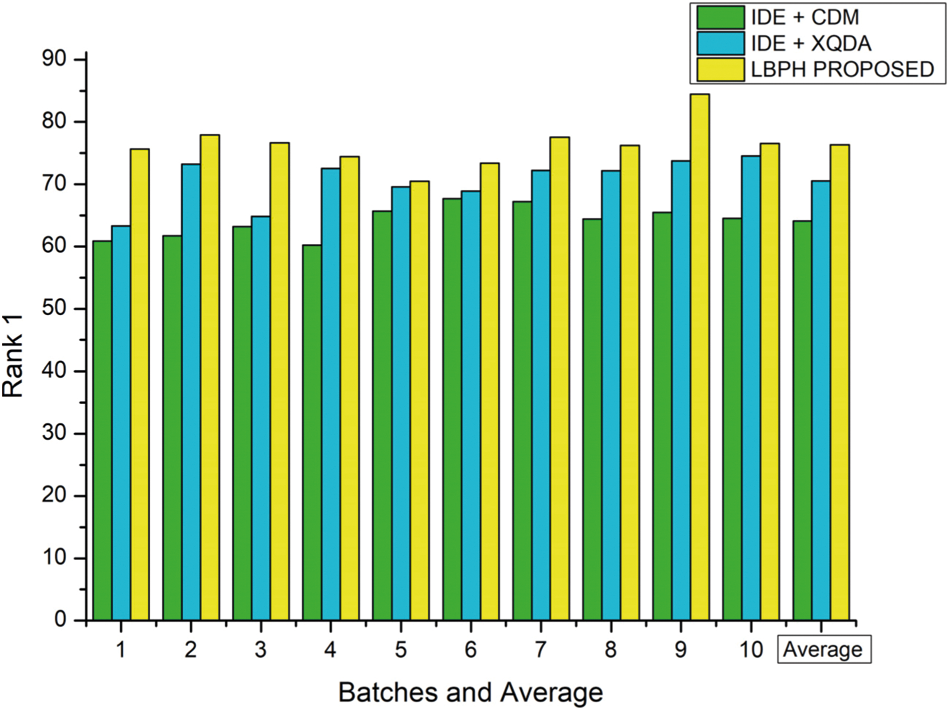
Figure 6: Comparison of different methods with proposed reranking approach using MARS dataset on rank-1
For the PRW dataset, the parameters are set as k1 − 20, k2 − 6, and λ = 0.3 and the rank-1 result is portrayed in Tab. 5 and depicted as a graph in Fig. 7 on various approaches viz., LOMO+CDM, IDE, LBPH.
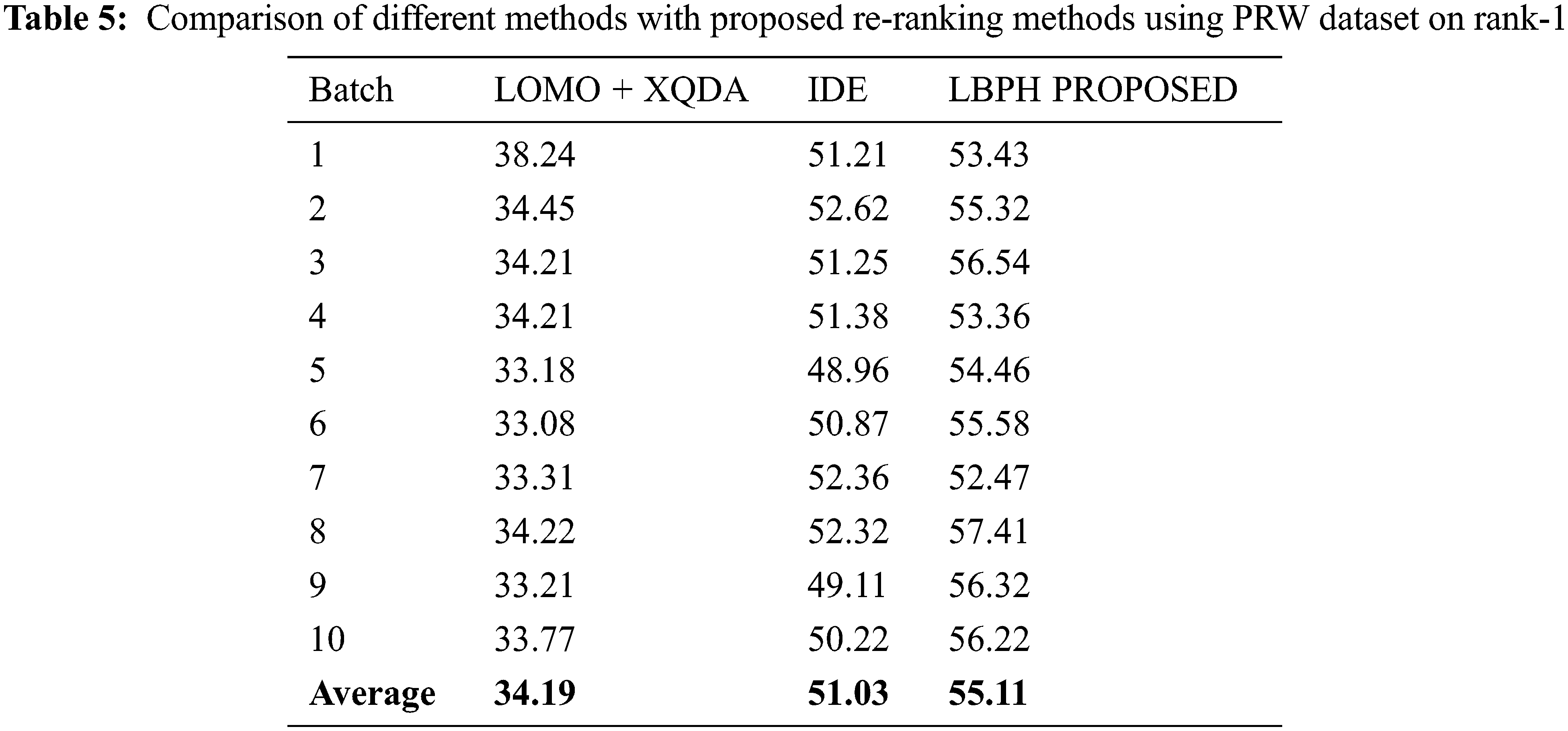
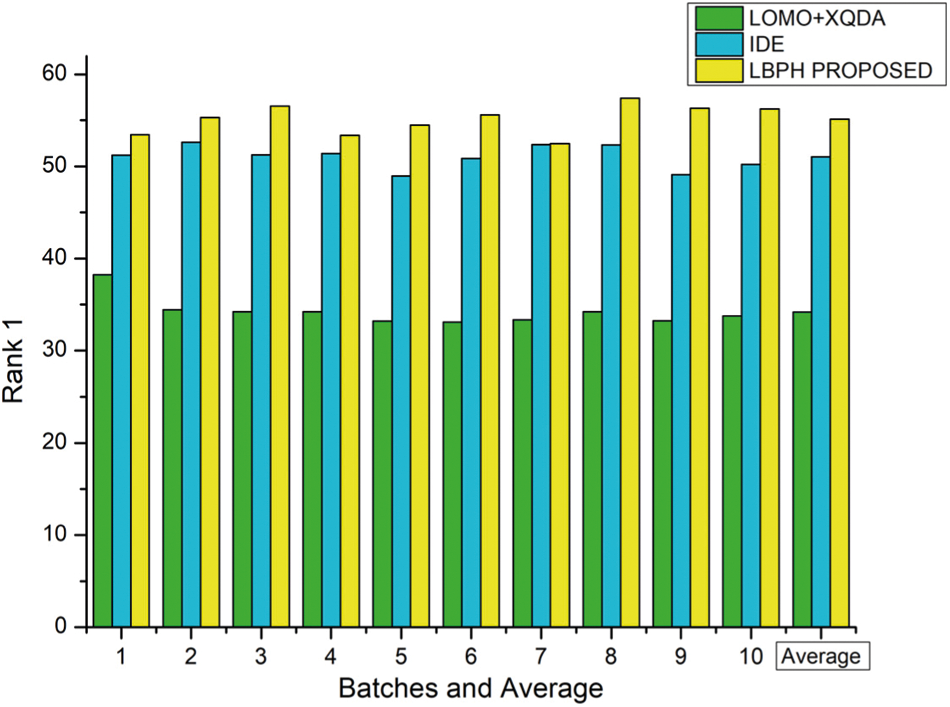
Figure 7: Comparison of different methods with proposed reranking approach using PRW dataset on rank-1
The results evidenced that this proposed LBPH algorithm is outperformed the existing algorithms IDM+CDM and IDE+XQDA in terms of Rank-1 feature parameter for Person Re-identification using MARS dataset samples.
The results indicated that the proposed LBPH algorithm achieved a better result than the existing algorithms LOMO+XQDA and IDE in terms of Rank-1 feature parameter for Person Re-identification using PRW dataset samples.
The identification process for a query is illustrated in Fig. 8. Images 1 to 10 are the observed output using the proposed method. Images within green boxes are correct matching images. The red box indicates incorrect matching images. Tab. 6 compared the mAP performance of IDE+CDM, I?DE+XQDA with the proposed system on Market 1501 and MARS dataset. LBPH system attained higher values than the other two methods, and the same is depicted in Fig. 9. The proposed system has an increasing percentage over the existing system of 32.97% and 11.04%.

Figure 8: Identified results by the proposed LBPH approach

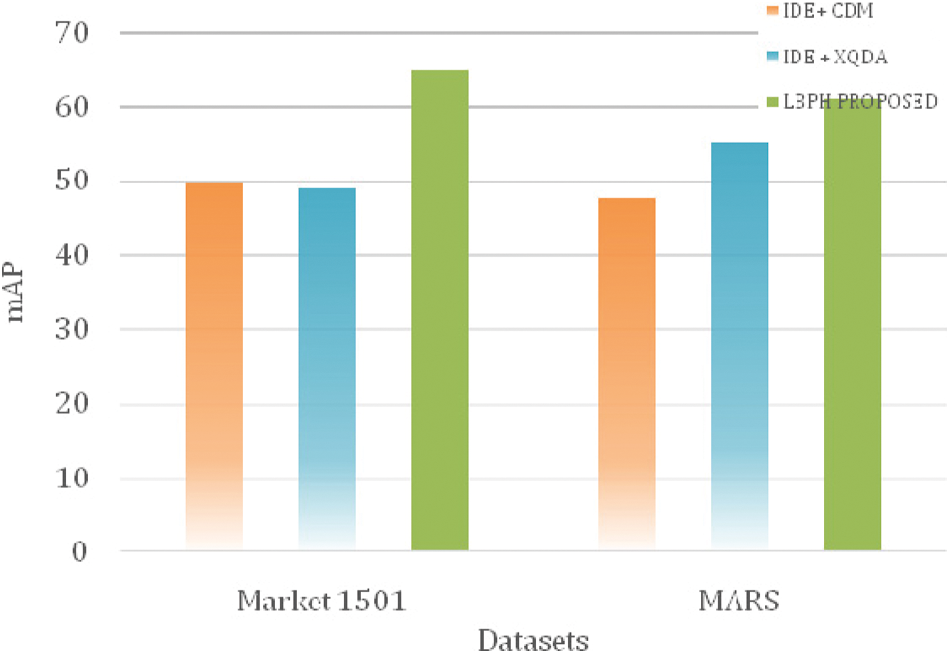
Figure 9: Comparison graph of mAP metric on different methods with the proposed system using Market-1501 and MARS dataset
The experimental results of mAP are recorded in Tab. 7 and Fig. 10 for CUHK03 and PRW datasets. Here, the state of art methods compared with the proposed system is LOMO+XQDA and IDE. The proposed system has a 0.77% and 20.08% increase over the existing higher value approaches tested for CUHK03 and PRW datasets.

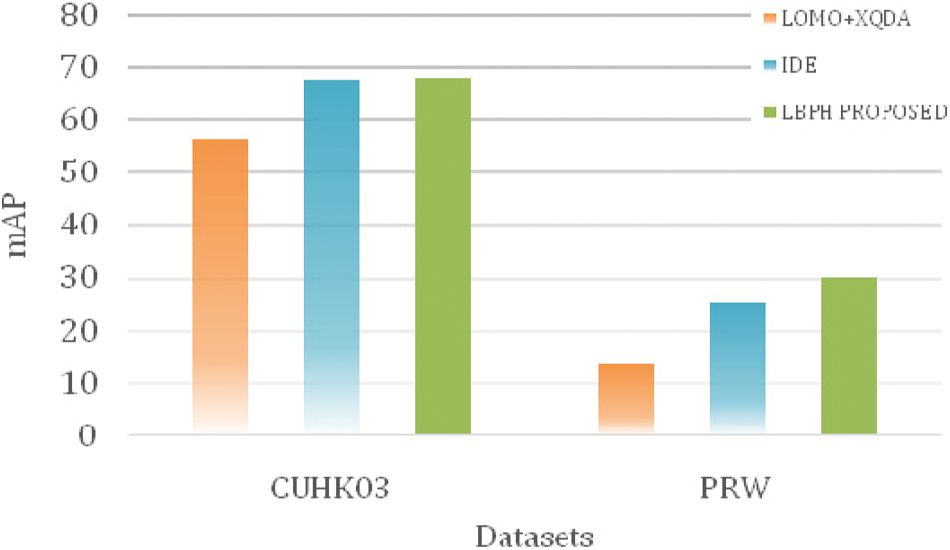
Figure 10: Comparison graph of mAP metric on different methods with proposed system using CUHK03 and PRW dataset
We have presented a novel methodology in the person re-identification using the reranking process metrics like Mahalanobis and Jaccard in determining the K-reciprocal nearest neighbour sets with four large datasets. The poposed work has features using LBPH and has enable multi directions for fture research work. In this work done, with the Market-1501, CUHK03, MARS and PRW dataset, the obtained result with respect to rank-1 are 77.27, 61.90, 76.34 and 55.11. Similarly the mAP performance metrics results for the Market-1501, CUHK03, MARS and PRW dataset are 65.01, 68.12, 61.21 and 30.13 respectively. The query was easily matched from the ranking list, where reranking was also done to improve the result. The similarity relationship captured from similar samples, proposed from the local expansion query, helped in obtaining a strong K-reciprocal feature. The easily obtained results are due to the aggregate of the original distance and the Jaccard distance in finding the final distance, which provided better performance in the person Re-identification. This work uses the local texture-based feature. The result may be further improved by considering chromatic-texture features in future research work.
Acknowledgement: The authors like to acknowledge and thank the management, director, principal and Head of IT department for providing facilities to carry out the research work.
Funding Statement: The authors received no specific funding for this research work
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present research work
1. M. Ye, C. Liang, Y. Yu, Z. Wang, Q. Leng et al., “Person reidentification via ranking aggregation of similarity pulling and dissimilarity pushing,” IEEE Transaction on Multimedia, vol. 18, no. 12, pp. 2553–2566, 2016. [Google Scholar]
2. C. Jose and F. Fleuret, “Scalable metric learning via weighted approximate rank component analysis,” in 14th European Conf. on Computer Vision, Amsterdam, The Netherland, pp. 875–890, 2016. [Google Scholar]
3. S. Liao, Y. Hu, X. Zhu and S. Z. Li, “Person reidentification by local maximal occurrence representation and metric learning,” in Proc. of the IEEE Conf. on Computer Vision Pattern Recognition, Boston, MA, USA, pp. 2197–2206, 2015. [Google Scholar]
4. J. You, A. Wu, X. Li and W. Zheng, “Top-push video-based person reidentification,” in Proc. of the IEEE Conf. on Computer Vision Pattern Recognition, Las Vegas, NV, USA, pp. 1345–1353, 2016. [Google Scholar]
5. I. B. Barbosa, M. Cristani, A. D. Bue, L. Bazzani and V. Murino, “Re-identification with RGB-D sensors,” in Proc. of the European Conf. on Computer Vision, Italy, pp. 433–442, 2012. [Google Scholar]
6. F. Xiong, M. Gou, O. Camps and M. Sznaier, “Person reidentification using kernel-based metric learning methods,” in Proc. of the European Conf. on Computer Vision, Zurich, Switzerland, pp. 1–16, 2014. [Google Scholar]
7. X. Ben, C. Gong, P. Zhang, R. Yan and Q. Wu, “Coupled bilinear discriminate projection for cross-view gait recognition,” IEEE Transactions on Circuits Systems for Video Technology, vol. 30, no. 3, pp. 734–747, 2020. [Google Scholar]
8. X. Ben, C. Gong, P. Zhang, X. Jia, Q. Wu et al., “Coupled patch alignment for matching cross-view gaits,” IEEE Transactions on Image Processing, vol. 28, no. 6, pp. 3142–3157, 2019. [Google Scholar]
9. Z. Wu, Q. Ke, J. Sun and H. Shum, “Scalable face image retrieval with identity-based quantization and multireference reranking,” in IEEE Computer Society Conf. on Computer Vision and Pattern Recognition, San Francisco, CA, USA, pp. 3469–3476, 2010. [Google Scholar]
10. B. Li, H. Chang and X. Chen, “Coupled metric learning for face recognition with degraded images,” Advances in Machine Learning, pp. 220–233, 2009. [Google Scholar]
11. A. Wu, W. Zheng and J. Lai, “Robust depth-based person reidentification,” IEEE Transactions on Image Processing, vol. 26, no. 6, pp. 2588–2603, 2017. [Google Scholar]
12. D. C. G. Pedronette, R. Da and S. Torres, “Exploiting contextual spaces for image reranking and rank aggregation,” in Proc. of the ACM Int. Conf. on Multimedia Retrieval, Trento, Italy, pp. 1–8, 2011. [Google Scholar]
13. Y. Wu, Y. Lin, X. Dong, Y. Yan, W. Bian et al., “Progreesive learning for person Re-identification with one example,” IEEE Transactions on Image Processing, vol. 28, no. 6, pp. 2872–2881, 2019. [Google Scholar]
14. C. Zhu, F. Wen and J. Sun, “A Rank-order distance based clustering algorithm for face tagging,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, pp. 481–488, 2011. [Google Scholar]
15. X. Ma, X. Zhu, S. Gong, X. Xie, J. Hu et al., “Person reidentification by unsupervised video matching,” Pattern Recognition, vol. 65, pp 197–210, 2017. [Google Scholar]
16. M. Baharani, S. Mohan and H. Tabkhi, “ “Real-time person Re-identification at the edge: A mixed precision approach,” in Proc. of the Int. Conf. on Image Analysis and Recognition, Waterloo, Canada, pp. 27–39, 2019. [Google Scholar]
17. T. Chen, S. Ding, J. Xie, Y. Yuan, W. Chen et al., “ABD-Net: Attentive but diverse person Re-identification,” in Proc. of the IEEE Int. Conf. on Computer Vision, Seoul, Korea (Southpp. 8350–8360, 2019. [Google Scholar]
18. H. Yu, A. Wu and W. Zheng, “Cross-view asymmetric metric learning for unsupervised person reidentification,” in Proc. of the IEEE Int. Conf. on Computer Vision, Venice, Italy, pp. 994–1002, 2017. [Google Scholar]
19. A. Fossati, A. Basso, E. Menegatti and L. V. Gool, “One-shot person Re-identification with a consumer depth camera,” Person Re-Identification, Advances in Computer Vision and Pattern Recognition, pp. 161–181, 2014. [Google Scholar]
20. L. Zheng, L. Shen, L. Tian, S. Wang, J. Wang et al., “Scalable person reidentification: A benchmark,” in Proc. of the IEEE Int. Conf. on Computer Vision, Santiago, Chile, pp. 1116–1124, 2015. [Google Scholar]
21. W. Li, R. Zhao, T. Xiao and X. Wang. “Deepreid: Deep filter pairing neural network for person reidentification,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Columbus, OH, USA, pp. 152–159, 2014. [Google Scholar]
22. L. Zheng, Z. Bie, Y. Sun, J. Wang, C. Su et al., “MARS: A video benchmark for large-scale person Re-identification,” in Proc. of the European Conf. on Computer Vision, Amsterdam, The Netherlands, pp. 868–884, 2016. [Google Scholar]
23. L. Zheng, H. Zhang, S. Sun, M. Chandraker and Q. Tian, “Person Re-identification in the wild,” Computer Vision and Pattern Recognition, pp. 1367–1376, 2017. https://arxiv.org/abs/1604.02531. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |