DOI:10.32604/iasc.2022.022493
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.022493 | |
| Article |
A Novel Method of User Identity Recognition Based on Finger Trajectory
1School of Mechanical and Electrical Engineering, Jinling Institute of Technology, Nanjing, 211169, China
2School of Computer and Software, Nanjing University of Information Science and Technology, Nanjing, 210044, China
3College of Engineering, Mathematics and Physical Sciences, University of Exeter, Cornwall, TR10 9FE, UK
*Corresponding Author: Jin Han. Email: hjhaohj@126.com
Received: 09 August 2021; Accepted: 25 October 2021
Abstract: User identity recognition is the key shield to protect users’ privacy data from disclosure and embezzlement. The user identity of mobile devices such as mobile phones mainly includes fingerprint recognition, nine-grid password, face recognition, digital password, etc. Due to the requirements of computing resources and convenience of mobile devices, these verification methods have their own shortcomings. In this paper, a user identity recognition technology based on finger trajectory is proposed. Based on the analysis of the users’ finger trajectory data, the feature of the user's finger movement trajectory is extracted to realize the identification of the user. Also, in this paper, we design and implement an android app, through which we collect the real finger trajectory data of 34 people and use K-means clustering combined with Bayesian classification to recognize and distinguish the user identity. The experimental results show that the finger trajectory has a good performance on identifying the users, which can be constructed as a new low-cost scheme for mobile device user identity recognition.
Keywords: Finger trajectory; user identity recognition; K-mean clustering; Bayesian classification
With the development of computer software and hardware technology, the functions of mobile devices are more and more powerful. Because of its portability, mobile devices tend to collect a large number of user privacy and sensitive information. Therefore, to protect the important information stored in mobile devices, user identity recognition has become a key security shield. At present, the user identity recognition schemes of most mobile devices can be divided into two categories: one is based on knowledge, such as PIN code, nine-gird pattern, power on password authentication scheme [1]. This kind of identification is completed by the users’ memory and reproduction of the authentication request data. The other is based on biometrics, which realizes the authentication process according to the biometrics of human body, mainly including fingerprint recognition, voiceprint recognition [2], face recognition [3], etc. It is not easy to be embezzled or copied because biometrics are in the users’ own, so the scheme has high identification effect and security.
These two kinds of schemes have their own advantages and disadvantages. Knowledge-based schemes have the characteristics of low demand for computing resources and low cost of implementation. They are especially suitable for mobile devices, but they are easy to forget and embezzle. On the contrary, the biometric-based scheme has high demand for computing resources and high cost of implementation, but it is not easy to be embezzled or copied. In view of the shortcomings of the above two kinds of schemes, this paper proposes a scheme based on the users’ finger trajectory to realize the user identity recognition.
From the current research, the feature analysis of users’ finger trajectory belongs to the recognition of behavior and posture. According to various gestures and behaviors, gesture recognition can be divided into static gesture and dynamic gesture [4,5]. Static gestures only consider the relative position of the fingers when they slide on the screen. Dynamic gesture is an ordered set of static gestures executed by users in a period of time, including the spatial motion information of fingers [6,7]. Static gestures obtain information according to the relative position and shape, which does not include time variables, while dynamic gestures consider the motion information and temporal information. Therefore, the information conveyed by dynamic gestures are more accurate.
In this paper, the users’ finger trajectory data refers to the directions, speed and interval data of the fingers collected through the touch screen of mobile devices such as mobile phones. A total of 34 users’ finger trajectory is collected. According to the collected data, the improved K-means clustering algorithm is used to realize the feature extraction and recognition of users’ finger trajectory. In addition, while we design the experiment, a novel system that combines the recognition of user's iris and user's device was considered [8]. Simultaneously, the experimental results show that the finger trajectory has a statistical effect on user identity recognition.
The method of user identity recognition proposed in this paper makes use of the touch screen of current mobile devices, so it does not need any new hardware. At the same time, because the characteristics of finger movement do not need user memory, it has the advantages of the two kinds of user identity recognition methods mentioned above, which owns good application prospect.
2 Restrictions and Feature Definition of Finger Trajectory
2.1 The Restrictions of Finger Trajectory
In order to facilitate the collection of users’ finger trajectory, this paper uses a standardized definition of it, which divides the finger trajectory into multiple segments, each segment has a finger motion (i.e., the whole trajectory is composed of each different finger trajectory segment). In this scheme, each trajectory segment is limited to the trajectory that can only slide left or right, as shown in Fig. 1.

Figure 1: The initial slider state and a complete user finger trajectory
Fig. 1 is an APP UI implemented by Android programming, in which five tracks are displayed, with a slider in the center of each track. Users can use their fingers to slide the slider from top to bottom and slide left or right along the track. In this paper, the users’ finger trajectory should be formed according to the following restrictions:
■ Use your fingers to operate the slider on each track from top to bottom
■ Only one operation is allowed for each slide
■ Operate the track sliders in order from top to bottom. It is not allowed to skip or reverse the order
It is worth noting that although the finger trajectory in this paper defines the order of operating the slider from top to bottom, it does not limit the sliding direction of the user operating the slider on the track.
2.2 Feature Data Definition of Finger Trajectory
In this paper, the finger trajectory data is collected by the user using the finger to operate the slider in the above UI. Combined with the above operation restrictions, the finger trajectory data extracted includes three aspects: temporal feature, motion feature and spatial feature. The temporal feature is divided into sliding time and time interval between two sliding operations. The motion feature refers to sliding speed and acceleration, and the spatial feature refers to sliding direction and the position of sliders. Therefore, through the above UI, this paper can use the following data structure to define the finger trajectory:
Among them, each Si represents a slider operation, and each Ti represents the time interval between two slider operations.
While each Si is composed of
■ ti: The time from the beginning of sliding to the stop of sliding by finger touch
■ di: The distance of slider from the center of track
■ is Left: The sliding direction of the slider is true when it slides to the left and false when it slides to the right
■ vi: The average speed of the slider operated by the user
■ ai: The maximum acceleration of the slider
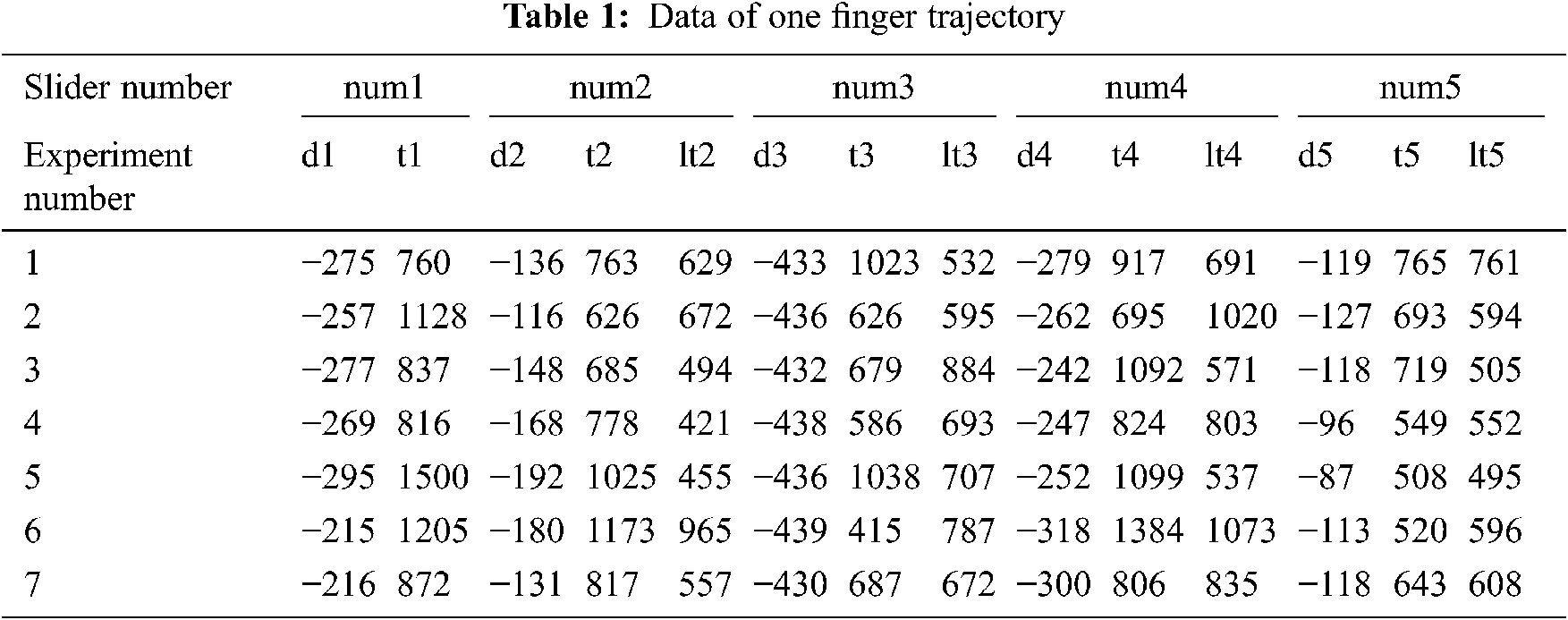
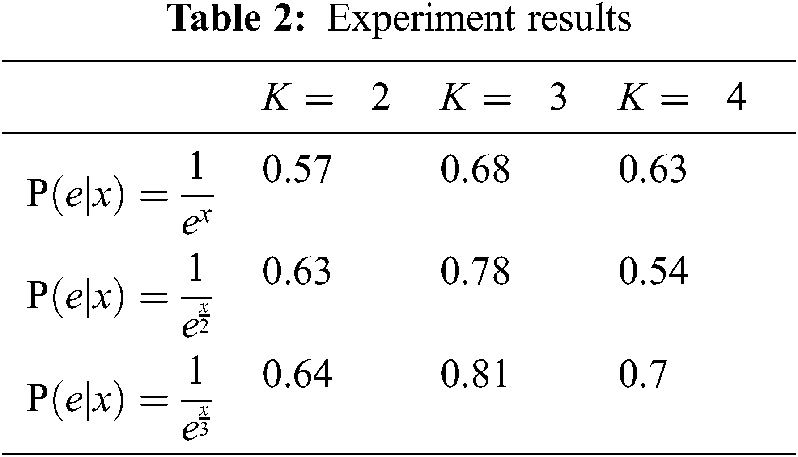
In this paper, the APP implemented by Android program operates the real users’ finger trajectory. A total of 34 users’ finger trajectory data is collected, of which each user has carried out 50 finger trajectory operations. After the data is formed, it is collected by the app and uploaded to the servers. The data of one finger trajectory is shown in Tab. 1, and the experimental results is shown in Tab. 2.
3 User Identity Recognition Algorithm Based on Finger Trajectory
3.1 K-means and Bayesian Classification
K-means clustering algorithm is a classical unsupervised clustering algorithm [9], which is more suitable for the application scenarios in this paper. The steps of the algorithm are relatively simple, the algorithm needs to give a group of data points to be classified and the number of subclasses K to be divided. The general steps are shown in Algorithm 1:

Among them, the termination condition of K-means can be set to two conditions: one is when no sample is redistributed to other subclasses that do not belong to its current subclass, and the other is when no change is found in the current cluster center after iteration [11].
The K-means clustering method is used in this paper, which is based on the observation of experimental data. The coordinates of the first slider data of 50 finger trajectory of some experimental users collected are shown in Fig. 2.

Figure 2: The first sliding distance and time coordinate of the 50 finger trajectories of 11 users
In Fig. 2, the diagram displays evidently that there is a clustering distribution on data of user's finger trajectory. According to that feature, this paper adopts the K-means clustering algorithm, and the center points of subclass obtained through the clustering algorithm are used as the preliminary extraction of the features of each user's finger trajectory.
As mentioned above, the user's finger trajectory has data of five slider operations and interval between four slider operations, whereas the interval between five feature data of each slider operation data has only one data item. Therefore, this paper uses Euclidean distance to calculate the distance between the sample and the center point of the subclass, the formula is shown below:
By using K-means clustering, user classification corresponding to single sliding trajectory can be extracted. However, the outcome of classification judgement is clearly not accurate, which is also indicated above in Fig. 2 that there are multiple user classifications overlapping each other. Therefore, to identify a user, it is necessary to combine all these data in a finger trajectory to form a judgment [12]. This paper adopts Bayesian classification to realize the judgement process.
Bayesian classification [13,14], which is also a classic classification algorithm, is based on the Bayesian formula to classify data samples. It requires training samples in the first place to obtain the probability of sample classification and the probability of each sample appears in different classifications, and then achieving the classification of samples through Bayesian classification algorithm. The basic process is as follows.
Assuming that there exist m classes named C1, C2, …, Cm. Given tuple X, the classifier will predict that X belongs to classification with best posterior probability. That is to say, naive Bayes classifier predict X belongs to class Ci, if and only if:
In this way,
Because P(X), which is the probability of sample appearance, is the same for each classification. Therefore, using Bayes to calculate classification is only based on the size of the molecules of the above formula generally, and put the sample into the C classification with the maximum numerator evaluated in the formula.
However, Bayesian classification requires the probability model obtained by training to realize judgment. Therefore, this paper proposes a method of using the distance mapping between the sample and the center point of the subclass to obtain the sample appearance probability P(X |
3.2 Implementation of User Identity Recognition Algorithm
In this paper, the starting point of using the user's finger trajectory data to identify the user's identity is that each user is different because of the length of the finger, habits when using mobile device, and the hand-held posture of the mobile device, causing the difference in features of the above-mentioned data such as the acceleration and time interval of the finger sliding the slider on the touch screen of the mobile device [15]. As a result, usage of finger trajectory to identify the user's identity is a problem of data classification and judgment.
Combining the above-mentioned K-means clustering and Bayesian classification algorithm, this paper proposes a identity recognition algorithm based on the user's finger trajectory, which is mainly divided into two steps: training and recognition testing. In addition, the combined algorithm can also employ the attentive time-aware user similarity modeling to identify the same user, which is compared with the model for user-generated contents (UGCs) [16].
The algorithm used in the training phase is the K-means algorithm, performing K-means clustering for each component of the finger trajectory data of each user, which is to form the following data model by training the trajectory data of user's finger:
Among them: Ci represents the data classification center point of each slider sliding, Ti represents the classification center point of the time interval. Every feature data has K center points because K-means algorithm is used to realize self-clustering.
After completing the K-means algorithm training, the process moves on to the identity recognition and testing phase. In this paper, the Bayesian classification algorithm is used to realize the identity recognition of users, which is given new test samples 〈S1, T1, S2, T2, S3, T3, S4, T4, S5〉 How to determine that the sample belongs to a specific user. According to the Bayesian classification formula, the following formula can be obtained:
Above formula represents the probability that under current circumstance of sample 〈S1, T1, S2, T2, S3, T3, S4, T4, S5〉 it belongs to a specific user. Further conversion of the above formula can be obtained:
About the probability of certain sample 〈S1, T1, S2, T2, S3, T3, S4, T4, S5〉 appearing, this paper consider
And since P(x) is the probability of a certain user's appearance, in the implementation of this paper, the finger trajectory data submitted by each user is 50 times, so the probability of P(x) is also the same, and Bayesian classification algorithm can be used. This paper only needs to compare the probability of
Also, because the nine feature data of each data sample 〈S1, T1, S2, T2, S3, T3, S4, T4, S5〉 is not well linked, this paper treats each feature data as probabilistic independent events, and have:
Therefore, the identity recognition process in this paper is transformed into solving the cumulative probability of the nine finger operation data S1, T1, S2, T2, S3, T3, S4, T4, S5 for a specific user x. The user with the largest cumulative probability is the outcome of the identity recognition algorithm.
For the above data sample, this paper uses mapping function to obtain the probability
Obviously, the mapping result of the above formula is between
In this paper, 34 people's real finger trajectory data were collected, and each person submitted their finger trajectories 50 times, and 49 finger trajectory data of each user are extracted randomly to form a training set, using the remaining one trajectory data as a test sample set. The above-mentioned user data training and experiment algorithm in this paper was realized through programming, and 100 repeated experiments were carried out. For the results of the experiment, this paper only evaluates the classification accuracy (CLA), that is, the proportion of the times that users are correctly identified in N test samples.
Because there are some singular values, which is data that deviates from the normal value relatively large, in the collection process of the user's finger trajectory. Therefore, this kind of data is filtered in the experiment of this paper, and a small amount of singular value data is removed. Furthermore, the number of clustering subclass K needs to be specified in advance to use K-means clustering and combined with the experimental effect. At the same time, when calculating the value of
From the experimental results, it is feasible for user identity recognition based on the user's finger trajectory. The results of the algorithm in this paper show that this method has statistical meaning for user identity recognition.
Simultaneously, it is evident that the number of clustering subclass K results in different values of P(e|x), among which the highest is when K = 3. Simultaneously, the results show the trend of ascending when the denominator changed from x to x/2 and to x/3. Therefore it can be concluded that it is feasible for user identity recognition based on the user's finger trajectory and the results of the algorithm in this paper show that this method has statistical meaning for user identity recognition.
This paper proposes a method to identify users based on the trajectory of their fingers. This method is different from the traditional knowledge-based and biometric-based identity recognition. This method uses the user's finger trajectory to realize user identity recognition, and no user memory and additional physical parts of the mobile device are required. Comparing to facial recognition, the demand for the computing power of the device is lower likewise. Therefore, it is a promising user identity recognition scheme.
This paper also gives the realization principle and algorithm of this scheme and verifies it through experiments. The experimental verification results show the feasibility of this method. The experimental results of this paper show that the accuracy of recognition requires further improvement to practically use this scheme in real scenes. It is noticeable that the Bayesian model used in the recognition algorithm in this paper does not introduce the sequence characteristic of finger operations. Therefore, this paper will further improve the recognition rate of the recognition algorithm through the design of the user's finger trajectory and the introduction of time series.
Funding Statement: This work is supported by the National Natural Science Foundation of China (No. 51905242).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. G. Nandhini and S. Jayanthy, “Mobile communication based security for atm pin entry,” in Proc. Int. Conf. on Computer Networks and Communication Technologies, Singapore, pp. 453–467, 2019. [Google Scholar]
2. R. Kosono, T. Nishio, M. Morikura, K. Yamamoto, Y. Maki et al., “Mobile user identification by camera-based motion capture and mobile device acceleration sensors,” in Proc. of the 13th Workshop on Challenged Networks, New York, NY, USA, pp. 25–31, 2018. [Google Scholar]
3. Q. Wang, X. Lin, M. Zhou, Y. Chen, C. Wang et al., “Voicepop: A pop noise based anti-spoofing system for voice authentication on smartphones,” in Proc. IEEE INFOCOM 2019-IEEE Conf. on Computer Communications, Paris, France, pp. 2062–2070, 2019. [Google Scholar]
4. Z. Syed, J. Helmick, S. Banerjee and B. Cukic, “Touch gesture-based authentication on mobile devices: The effects of user posture, device size, configuration, and inter-session variability,” Journal of Systems and Software, vol. 149, pp. 158–173, 2019. [Google Scholar]
5. K. Cheng, N. Ye, R. Malekian and R. Wang, “In-air gesture interaction: Real time hand posture recognition using passive RFID tags,” IEEE Access, vol. 7, pp. 94460–94472, 2019. [Google Scholar]
6. F. Liu, J. Yan, W. Wang, J. Liu, J. Li et al., “Scalable skin lesion multi-classification recognition system,” Computers, Materials & Continua, vol. 62, no. 2, pp. 801–816, 2020. [Google Scholar]
7. G. D. Penna D and S. Orefice, “Using spatial relations for qualitative specification of gestures,” Computer Systems Science and Engineering, vol. 34, no. 6, pp. 325–338, 2019. [Google Scholar]
8. C. Galdi, M. Nappi and J. L. Dugelay, “Multimodal authentication on smartphones: Combining iris and sensor recognition for a double check of user identity,” Pattern Recognition Letters, vol. 82, no. 2, pp. 144–153, 2016. [Google Scholar]
9. S. S. Yu, S. W. Chu, C. M. Wang, Y. K. Chan and T. C. Chang, “Two improved k-means algorithms,” Applied Soft Computing, vol. 68, pp. 747–755, 2018. [Google Scholar]
10. P. Nerurkar, A. Shirke, M. Chandane and S. Bhirud, “Empirical analysis of data clustering algorithms,” Procedia Computer Science, vol. 125, pp. 770–779, 2018. [Google Scholar]
11. Y. Wang, X. Luo, J. Zhang, Z. Zhao and J. Zhang, “An improved algorithm of k-means based on evolutionary computation,” Intelligent Automation & Soft Computing, vol. 26, no. 5, pp. 961–971, 2020. [Google Scholar]
12. F. Xiao, W. Liu, Z. Li, L. Chen and R. Wang, “Noise-tolerant wireless sensor networks localization via multi-norms regularized matrix completion,” IEEE Transactions on Vehicular Technology, vol. 67, no. 3, pp. 2409–2419, 2018. [Google Scholar]
13. Y. Ko, “How to use negative class information for naive Bayes classification,” Information Processing & Management, vol. 53, no. 6, pp. 1255–1268, 2017. [Google Scholar]
14. M. M. Saritas and A. Yasar, “Performance analysis of ANN and Naive Bayes classification algorithm for data classification,” International Journal of Intelligent Systems and Applications in Engineering, vol. 7, no. 2, pp. 88–91, 2019. [Google Scholar]
15. Z. Li, J. Xie, G. Zhu, X. Peng, Y. Choi et al., “Block-based projection matrix design for compressed sensing,” Chinese Journal of Electronics, vol. 25, no. 3, pp. 551–555, 2016. [Google Scholar]
16. X. Chen, X. Song, S. Cui, T. Gan, Z. Cheng et al., “User identity linkage across social media via attentive time-aware user modeling,” IEEE Transactions on Multimedia, no. 99, pp. 1–1, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |