DOI:10.32604/iasc.2022.021939
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.021939 | |
| Article |
Classification of Elephant Sounds Using Parallel Convolutional Neural Network
1KCG college of Technology, Chennai, India
2Sri Sivasubramania Nadar College of Engineering, Chennai, India
*Corresponding Author: T. Thomas Leonid. Email: thomasleonid@gmail.com
Received: 21 July 2021; Accepted: 13 September 2021
Abstract: Human-elephant conflict is the most common problem across elephant habitat Zones across the world. Human elephant conflict (HEC) is due to the migration of elephants from their living habitat to the residential areas of humans in search of water and food. One of the important techniques used to track the movements of elephants is based on the detection of Elephant Voice. Our previous work [1] on Elephant Voice Detection to avoid HEC was based on Feature set Extraction using Support Vector Machine (SVM). This research article is an improved continuum of the previous method using Deep learning techniques. The current article proposes a competent approach to classify Elephant voice using Vocal set features based on Convolutional Neural Network (CNN). The proposed Methodology passes the voice feature sets to the Multi input layers that are connected to parallel convolution layers. Evaluation metrics like sensitivity, accuracy, precision, specificity, execution Time and F1 score are computed for evaluation of system performance along with the baseline features such as Shimmer and Jitter. A comparison of the proposed Deep learning methodology with that of a simple CNN-based method shows that the proposed methodology provides better performance, as the deep features are learnt from each feature set through parallel Convolution layers. The accuracy 0.962 obtained by the proposed method is observed to be better compared to Simple CNN with less computation time of 11.89 seconds.
Keywords: Elephant voice; CNN; vocal features; jitter; deep learning
The most challenging aspect in wildlife conservation is the Human-elephant conflict mitigation. The Asiatic elephant species (Elephas maximus) seems to be an endangered species as per the IUCN’s Red Data List [2]. Elephants need food and a vast ecosystem for their survival. There were many modern technologies developed for wildlife animal monitoring like Radio Tracking [3], WSN Tracking [4], GPS Tracking [5] and Camera traps. The popular tool which has been used in wildlife monitoring is the camera traps. The camera settings are flexible to track animals continuously. It can also consecutively snap thousands of images, providing a high data volume. For Ecologists who document wildlife, the information obtained with Camera traps makes it a powerful tool [6]. Elephants can produce sounds using their natural vocal cords. The low frequency sound of an elephant is unique among all the other wildlife sounds. Important aspects regarding vocalization are voice production that includes vocal pattern generation and the muscular control. Regarding muscular control, several factors make elephant vocalizations important namely the learning and the timing of the trunk movement [7].
For short and long-distance infrasonic range of communication with fundamental frequencies, vocalizations are used by the African elephants and Asian elephants [8]. Four types of classification of voice depending on structural characteristics are chirps, roars, trumpets, and rumbles [9]. To classify voice data effectively, relevant features need to be extracted from the samples of Elephant voice. In this study, various processing techniques for voice signal like MFCC, SSC, LPC and FBE are used to obtain the relevant features of Elephant voice and its classification. The common Machine learning techniques that could be used in the classification of elephant voice are Random forest, artificial neutral networks, Support vector machine and K-nearest neighbor method. These techniques relate to the selected data feature quality. It is difficult to choose relevant features manually from voice data. Through Deep Learning (DL), data latent properties could be learnt automatically. In recognition of speech, classification of image and video, deep learning [10] exhibits very good performance.
In the proposed method, CNN is used in extracting feature representations from different feature sets. The feature sets are combined using several convolution layers in parallel. Simultaneously, convolution is done in parallel layers and feature representation is obtained in concatenation from the layers. Different measures, which exhibit how well the elephant voice is distinguished by the classifier, are chosen for improved accuracy.
The paper is structured as follows. Section 2 summarizes the Elephant voice classification using ML and DL. Section 3 discusses the Elephant sounds, Feature extraction and Dataset. The existing method and proposed method are described in Section 4. Evaluation metrics is provided in Section 5. The simulation results and discussion are provided in Section 6. The conclusion is provided in Section 7.
Authors are required to adhere to this Microsoft Word template in preparing their manuscripts for submission. It will speed up the review and typesetting process.
This section summarizes the recent studies on voice classification that deploys machine learning and discusses the most recent methods of deep learning used in the classification of animal voice.
2.1 Elephant Voice Classification Using ML
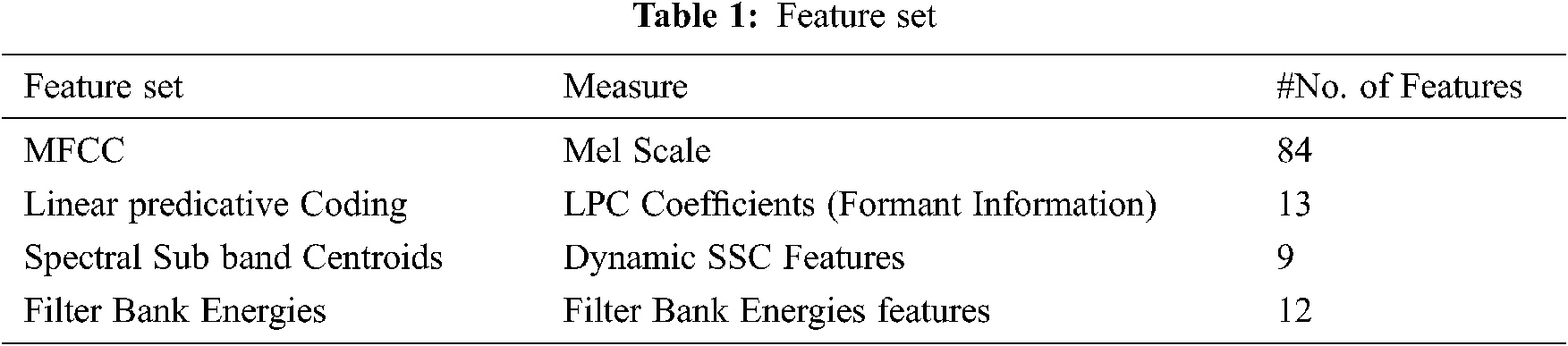
Classification of Voice relates to extraction of relevant feature selection using artificial learning methods. Animal Vocalization employs signal processing features apart from baseline features. In Voice classification, Mel-frequency Cepstral Coefficients (MFCC) [11], linear predicative Coding (LPC) [12], Spectral Sub band Centroids (SSCs) [13] and Filter Bank Energies [14] are the most important techniques in the extraction of relevant features.
Individual feature type combinations are used in the classification task rather than the feature types which are separate [15] in training the model.
The classifier performance metrics measured are error rate, accuracy, specificity, and sensitivity. All the methods mentioned use the features that are vocal based for Animal voice classification [16]. Recent studies extract the features from various sources of data like Spectrogram [17], and Acoustic signals improved performance can be obtained by using Machine learning classifiers.
2.2 Elephant Voice Classification Using DL
In Elephant voice studies, apart from common ML algorithms, deep learning which is a sub-division of ML is also successfully implemented. Recently, Convolutional Neural Networks (CNNs) [18] and Deep Neural Networks (DNNs) are used to automatically learn feature representations from complex data. The time-distributed spectrogram is used as the input to the CNN to train the model to distinguish local features at different time steps. Other researchers have used DNNs for cepstral feature extraction of Elephant voice sample. In ML and DL methods, preprocessed feature vectors and labeled vector features are given as inputs. When compared to traditional ML, the CNN classifier is found to be better in terms of accuracy.
Elephants can produce various sounds [19] ranging from exceptionally low frequency rumbles to high frequency snorts, trumpets, barks, grunts, roars, and cries.
Trumpets are conspicuous, loud, high-frequency voice calls. Their frequency range is 405–5879 Hz with mean duration about 1s. Roars are long noisy calls with frequency range of 305–6150 Hz and a mean duration of 2 s. Chirps have a frequency range of 313–3370 Hz. Rumbles are the only voice call type in repertoire with infrasonic components. Rumble’s frequency range is 10–173 Hz, with mean duration 5.2 s.
The voice classification algorithms can be generally divided into two parts: the feature extraction [20] part and the classification part. The feature extraction part is implemented mostly using CNNs as they can efficiently extract characteristics from raw data. The list of Feature sets is shown in Tab. 1.
Dataset preparation has a major part in determining the prediction accuracy. For experimental study, 4200 elephant vocal sounds and 2870 non-elephant vocal sounds, 7000 vocal sounds in total are obtained from the following sound Repositories.
1. www.Elephantvoices.Org,
2. www.AnimalSounds.Org,
3. www.Zapsplat.Com,
4. www.Freesound.Org,
5. www.Soundbible.Com,
6. www.Findsounds.Com.
From 4200 elephant Vocal sounds, 3000 elephant vocal sounds are used for training and 1200 vocal sounds are used for testing. From 2870 non-elephant vocal sounds, 1870 vocal sounds used for training and 1000 vocal sounds are used for testing. The dataset size is 1.1 MB. The microphone’s frequency response was tuned at 44.1 Mhz during data collection.
These elephant voice samples types were acoustically analyzed by using Praat1 to find objective voice measurements including the jitter, shimmer [21], and HNR.
Jitter:
The measure of fluctuating period-to-period in fundamental frequency is known as Jitter. The measure of voiced periods that are consecutive is computed by the formula:
where, Ti is the pitch period of the ith window and N is the total number of voices frames.
Shimmer:
The measure of amplitude variability within period-to-period is known as Shimmer and it is expressed as:
in which, Ai is the peak amplitude value of the ith window and N is the number of voiced frames.
In this study, Classification of Elephant voice is performed using CNN by combining the feature sets given to network input layer. In the following section, the elephant voice classification using a simple CNN and the proposed method are explained.
4.1 Convolutional Neural Networks (CNN)
CNN [22] exploits the knowledge of the domain about invariance features within their structure and is successfully applied for vocal analysis and tasks of recognition. For the processing of speech, CNN was proposed theoretically with convolution along the time axis to obtain features robust to small temporal shifts. Within the successive layers, the connection number is the difference between CNN and ANN.
On each CNN layer, convolution is performed by deploying inputs with different-sized filters. After performing the convolution, the convolution layer outputs are applied to the transfer function. From the activated outputs, the pooling layers are taken for performing sub-sampling. With pooling, input data dimensions are reduced automatically.
Compositionality and variance location resistance are the foremost attributes of CNN. As the trained filters of CNN pass input data, the patterns can be detected without knowing the location. The pooling process can reveal this, and it exhibits solution scaling and rotation in input data. It brings in the property of location invariance. The receptive field low-level features are converted to deeper layer high-level presentation features using CNN filters maintaining the property of compositionality.
Hyper-parameters of CNN are stride, pooling type, and filter size. Sliding window filter used in Convolution Filters are applied to every element in input data. Stride indicates the number of steps taken for each step-in window sliding.
Here, CNN is deployed as the approach for classification. This approach is completely an end-to-end NN where the Elephant vocal data is the input data to predict the elephant voice.
4.2 Proposed Methodology of CNN
To investigate every feature type effect on the process of classification, a set of features are linked as data input to the proposed classifiers. The CNN 10-layer includes single input layer, single output layer and single dense layer which are fully connected. It also has 6 convolution layers where each pair of convolution layers is chosen and followed by a max- pooling operation and the corresponding representation is shown in Fig. 1.
Feature sets of various types are concatenated in this approach, prior to serving the network layer of input. Hence, this approach is known as feature-level combination.
In the improved CNN approach, shown in Fig. 2, 10 layers in total are regarded as n feature sets in 1 input layer, n branches in 1 parallel layer, 1 fully connected dense layer, 1 merge layer, successive 4 layers of convolution and 1 output layer. n represents feature set number. Each pair of layers of convolution is followed by max-pooling operation. A simple CNN and the proposed improved method differ in feature set combination.
For each layers of input in this network, feature sets are given separately and are then sent to their corresponding parallel layer. Every parallel layer part has 2 convolution layer that can be applied for deep features extraction from individual feature pairs separately. Various feature sets of multiple feature set representations are formed by parallel layers which helped the researchers observe various feature type effects. All the extracted parallel layer features are concatenated in merge layer. To generate output, 4 more layers of Convolution of 2(5*1) & 2(3*1) are followed by a dense layer and Relu layer. The above approaches are implemented in python software and the performance metrics are evaluated.
The classification of Elephant voice is evaluated using Performance Evaluation metrics. Evaluation metrics are Accuracy, Specificity, Sensitivity, Precision, F1 Score, logarithmic loss, and Computation Time. Tab. 2 indicates absolute Boolean values variations that constitute Confusion Matrix in classification problem.

True Positives (A): The N samples in which elephant voice was predicted and the actual output was Elephant voice.
False Negatives (B): The N samples in which Non elephant voice was predicted, and the actual output was Elephant voice.
False Positives (C): The N samples in which elephant voice was predicted and the actual output was Non-Elephant voice.
True Negatives (D): The N samples in which Non elephant voice was predicted, and the actual output was Non-Elephant voice.
Accuracy is an evaluation performance metric for correct prediction. It can also be evaluated in terms of Positives and Negatives. To test the predictability of the classifiers, evaluation metrics are required.
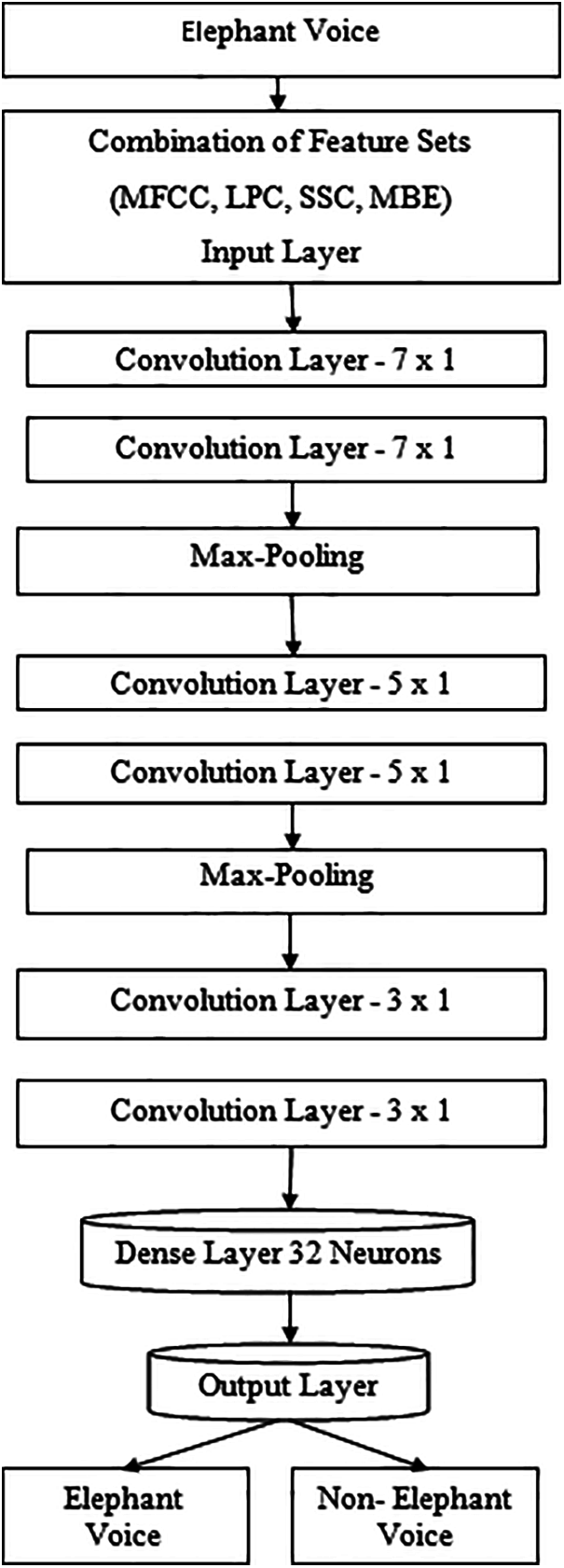
Figure 1: Combined feature set–simple CNN
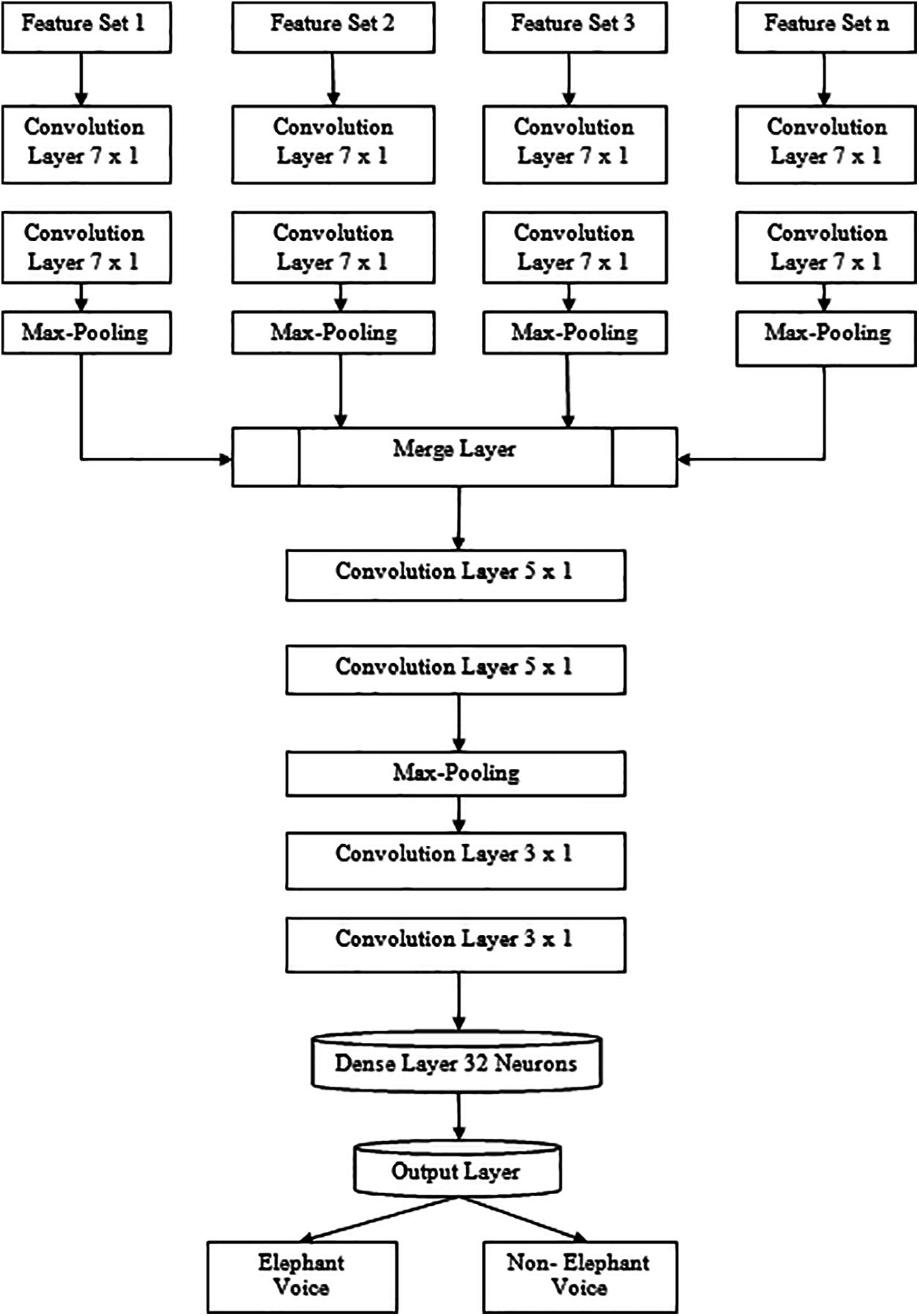
Figure 2: Model level combination – proposed CNN methodology
Although accuracy is a widely used metric, it might produce deceptive findings when data has an imbalanced class distribution. F1-Score, Recall, and Precision are examples of evaluation metrics that can be used to assess how successfully a classifier can discriminate between various classes, even when there is a class imbalance.
The confusion matrix in Tab. 2 can represent the counts of correctly and erroneously categorised occurrences per class for a binary classification. True positive (A), false positive (B), false negative (c), and true negative (D) numbers are represented by the letters A, B, C, and D in the confusion matrix, respectively.
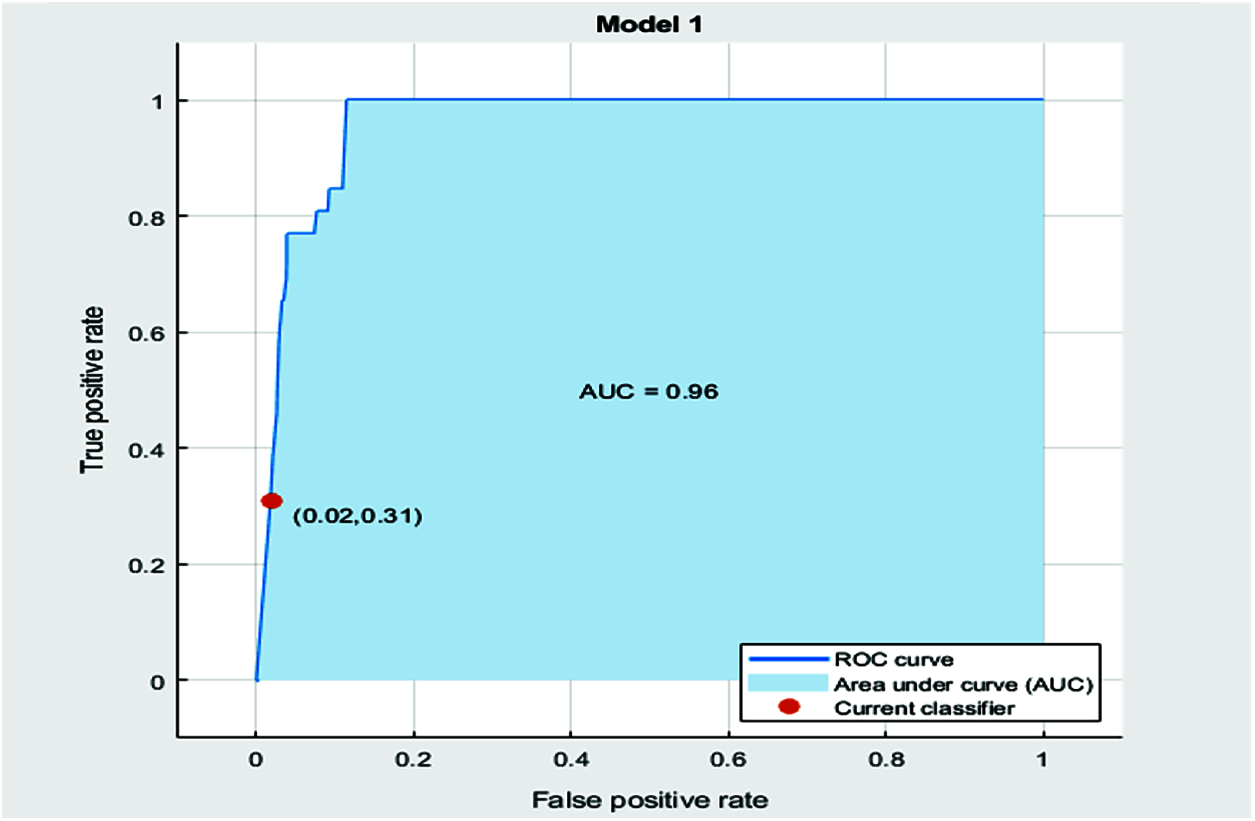
Figure 3: ROC curve (TP vs. FP)
Logarithmic loss works by correcting the inaccurate classification. The curve relating True positive rate vs. False Positive Rate for a sample is shown in Fig. 3. This represents the Receiver Operating Characteristic (ROC) curve and provides the measure of the collective amount (0.02,0.31) of performance across all possible classifications.
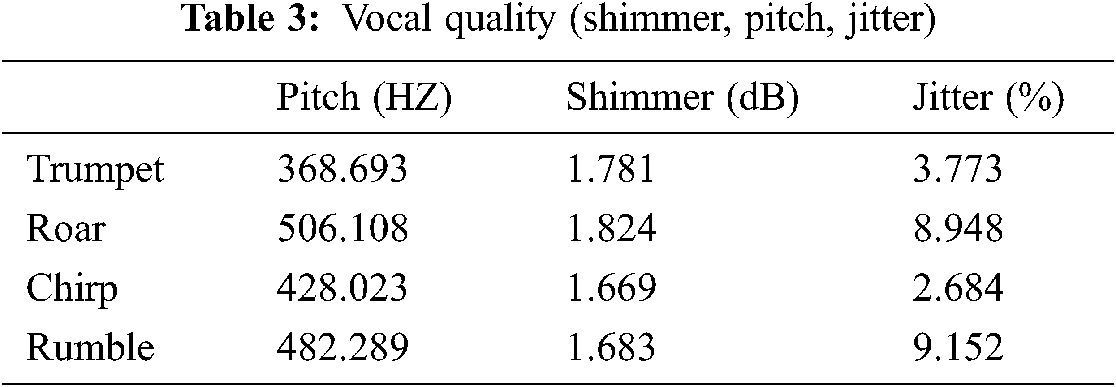
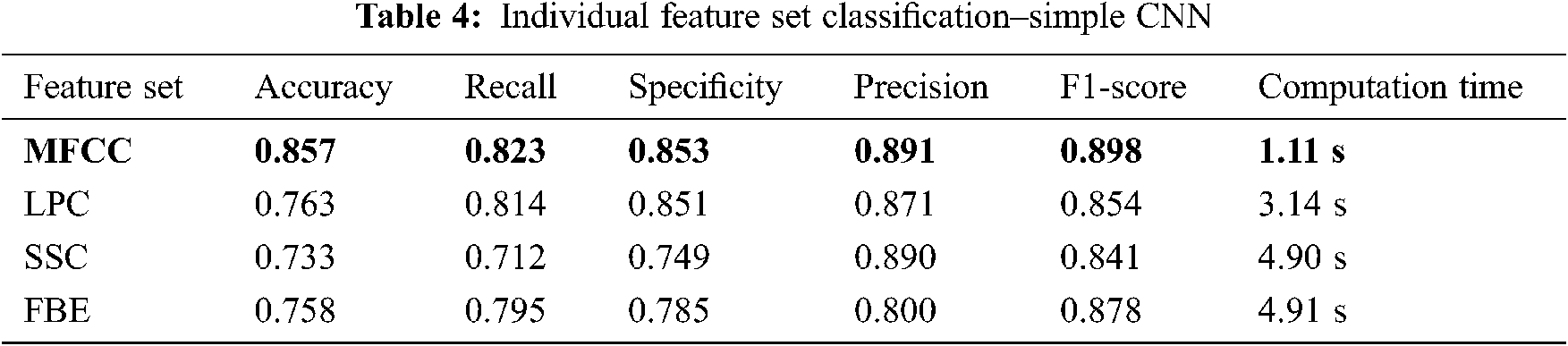
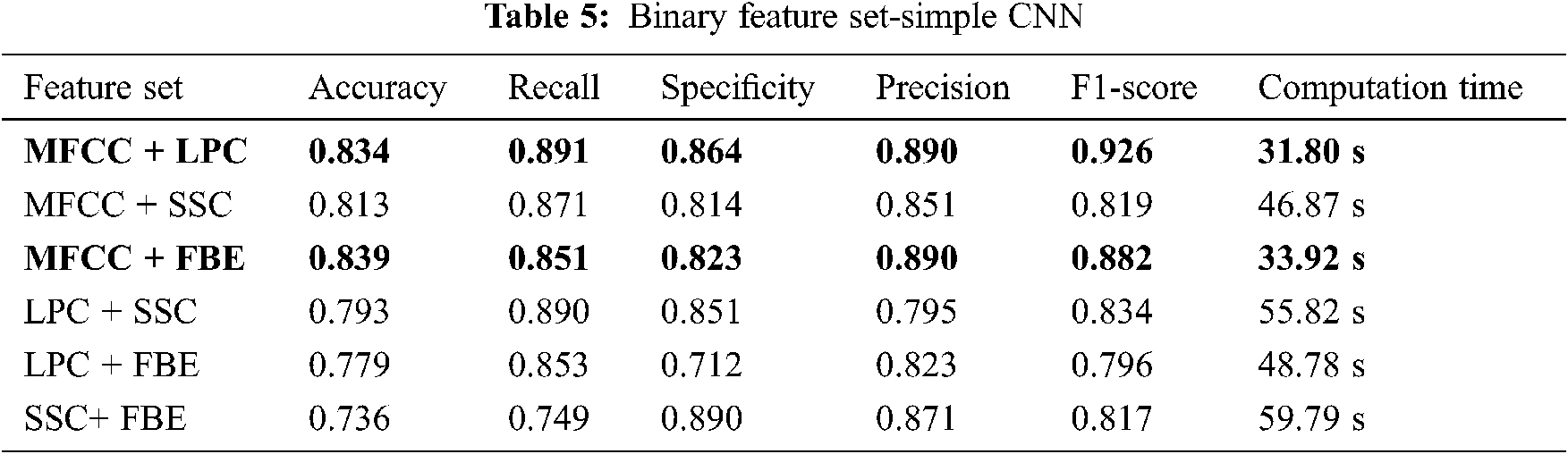
Some of these different vocalization types obtained using Praat Software tool are shown in Fig. 4. Shimmer, Pitch and Jitter are determined to specify the Elephant Voice Quality. The Pitch, Jitter and shimmer for various voice types are shown in Tab. 3.
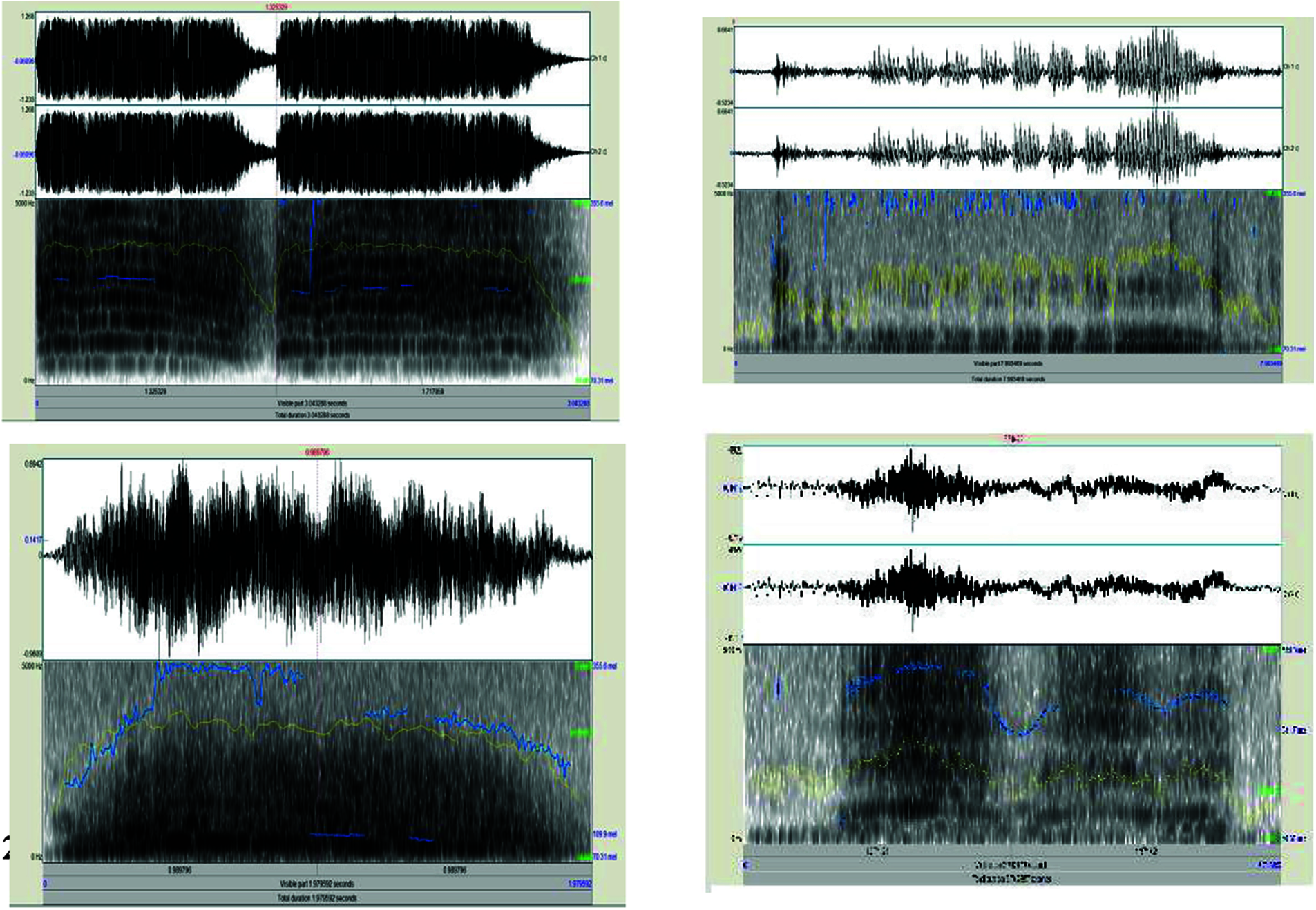
Figure 4: Various types of elephant vocalization
The results obtained using the proposed improved CNN architecture and that of simple CNN are described below.
Initially individual feature types are considered and concatenation of different types of feature is done at feature-level. Next, the combination of feature types two and three are considered. Accuracy, Precision, F1-Score, Computation times are the metrics used for accessing the performance of the classifiers. It is observed from Tab. 4 that in Evaluation metrics, MFCC features with accuracy value of 0.857 shows best performance over other classifiers.
Tab. 5 displays all possible binary feature sets. MFCC + LPC and MFCC + FBE Classifiers achieve above 0.83 accuracy with F1 score of above 0.88. The accuracy of other feature combinations (MFCC + SSC, LPC + SSC, LPC + FBE, SSC+ FBE) do not exceed 0.820, while their F1 scores are below than 0.83 with high computation times. The Triple combination of MFCC, LPC, FBE results in an accuracy of 0.848 as shown in Tab. 6. Combination without MFCC features (LPC + SSC + FBE) shows poor performance than the others in terms of the evaluation metrics considered.
In the proposed improved CNN, as per the Feature sets number that are designated to 2 parallel layers, the feature sets are given to parallel layer. If the feature set is triplet, parallel layers count will be 3.
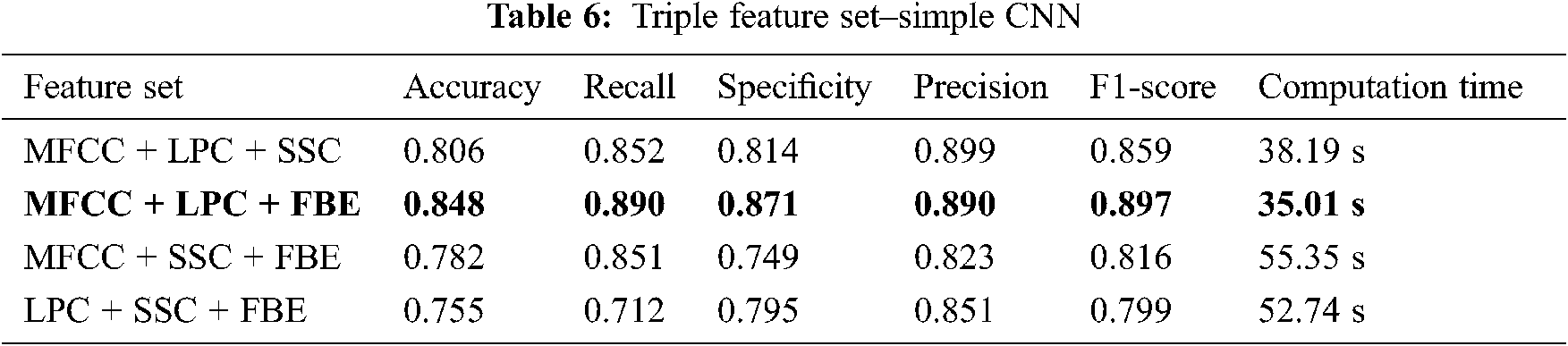
As per Tab. 7, the performance of proposed CNN classifier is improved by MFCC + LPC and MFCC + SSC with binary feature sets. In triple Feature sets that use combined model, the performance is improved. MFCC + LPC + FBE has the highest accuracy of 0.962 with less computation time of 13.89 s among all the combinations as shown in Fig. 5. Among all the models, LPC + SSC + FBE shows the lowest accuracy of 0.791 as represented in Tab. 8.
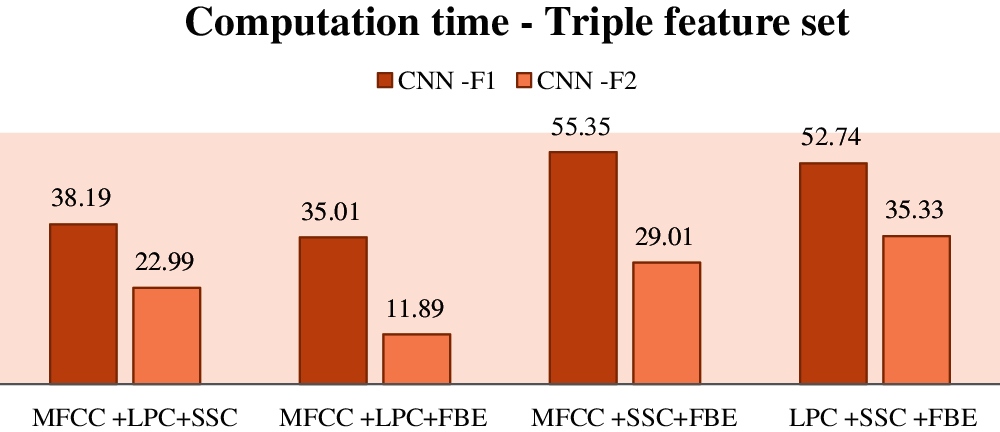
Figure 5: Computation time–triple feature set
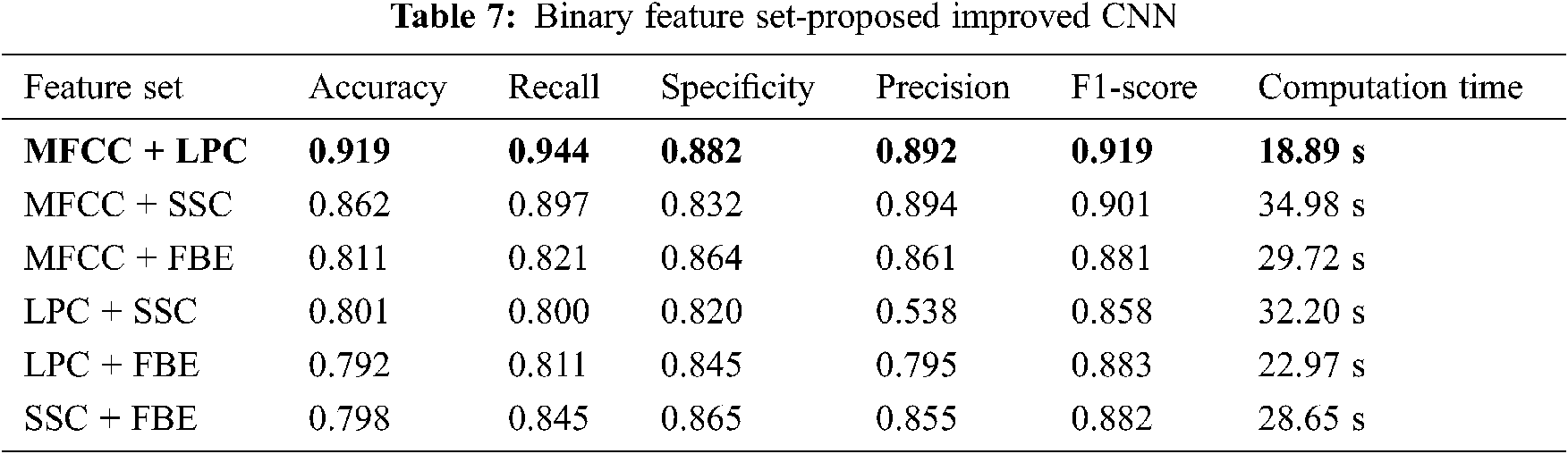
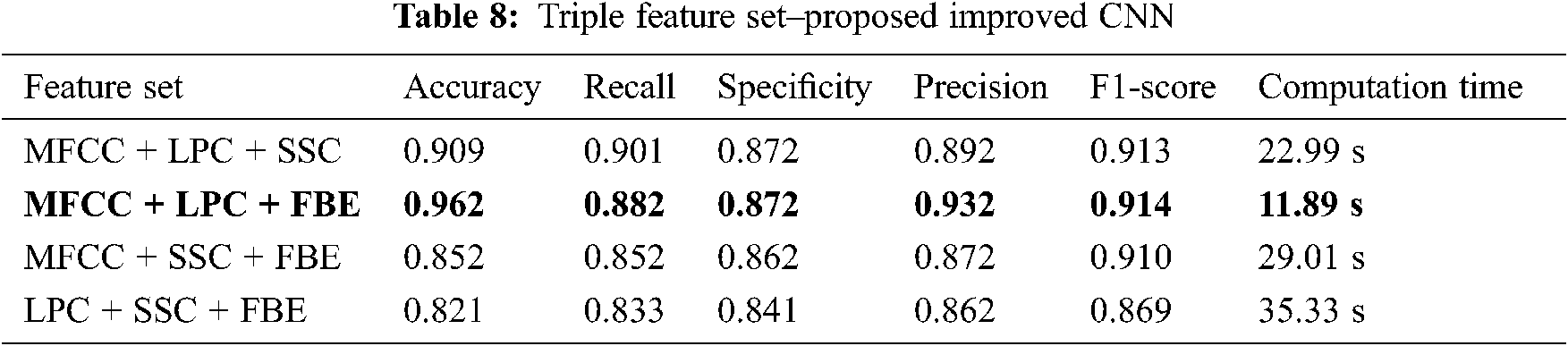
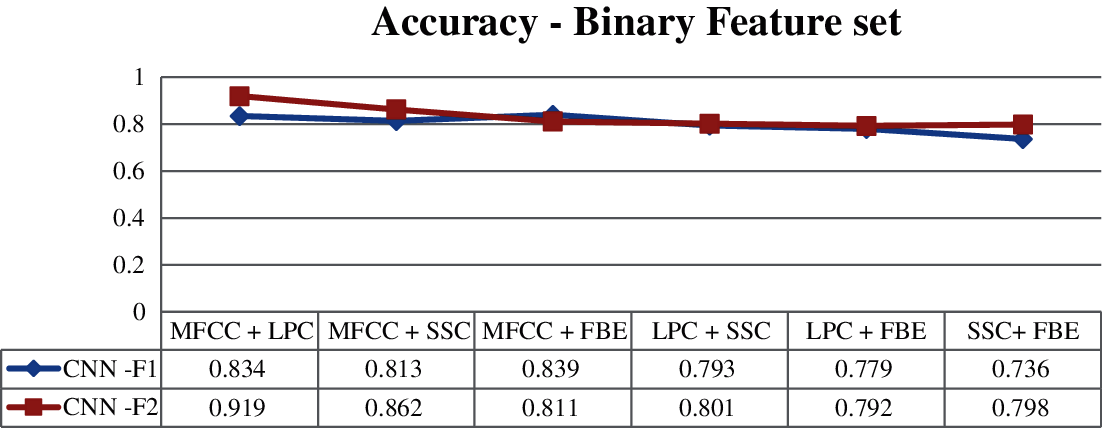
Figure 6: Binary feature set-accuracy
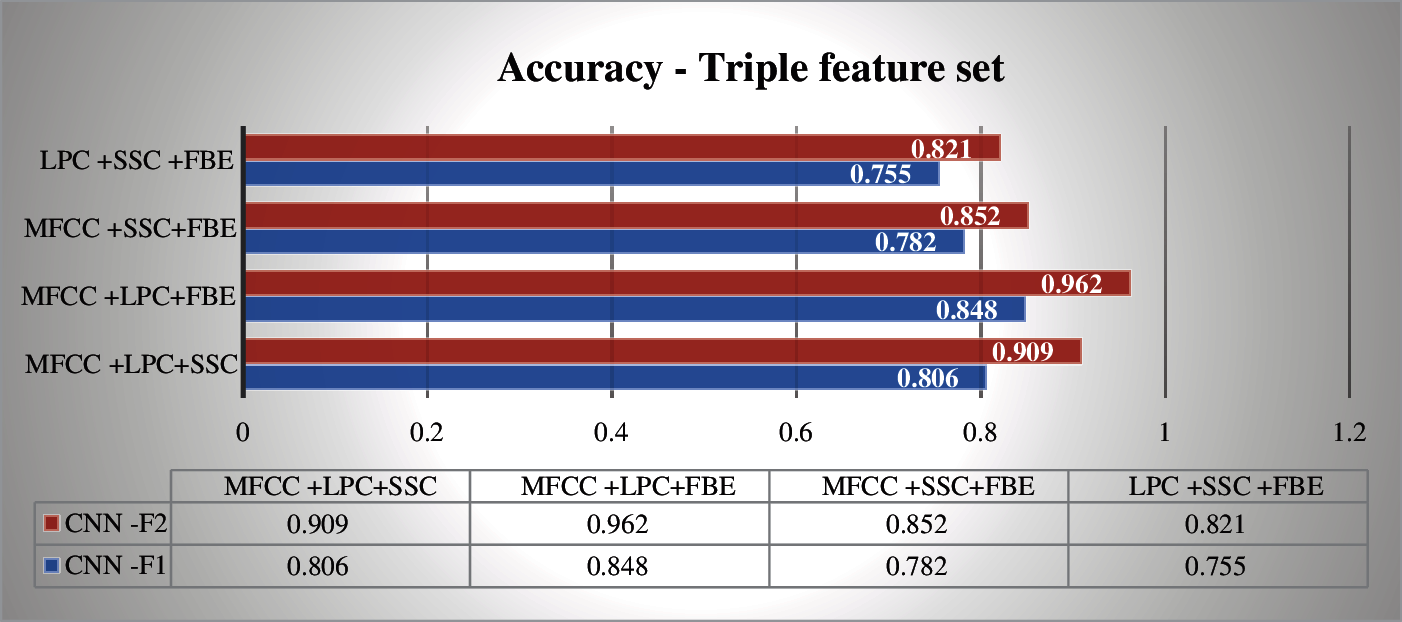
Figure 7: Triple feature sets-accuracy
We have proposed a deep CNN architecture to classify elephant voice using Vocal Feature sets This an improvement over a simple CNN architecture. Initially binary feature sets were used, and it is observed that MFCC + LPC show better performance than other possible combinations. When examination was performed with Triple set, it was observed that the improved CNN method has better accuracy for both (Binary + Triple) as shown in Figs. 6 and 7. Both approaches were trained with the dataset created with raw data. Due to the number of individuals, prediction of the two approaches is evaluated using F1 score and Computation time. The analysis of all trial tests show that the classification accuracy is improved when extreme features are extracted through convolution layers that are in parallel computing. The methodology of parallel computing offers scope for further research. In the proposed CNN, using convolution layers in parallel, inputs can be fed into the network as various data types. Different deep learning models are proposed to be used in the classification process in future extensions of this work.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. T. T. Leonid and R. Jayaparvathy, “Statistical-model based voice activity identification for human-elephant conflict mitigation,” Journal of Ambient Intelligence and Humanized Computing, vol. 12, no. 5, pp. 5269–5275, 2021. [Google Scholar]
2. T. N. C. Vidya, P. Fernando, D. J. Melnick and R. Sukumar, “Population genetic structure and conservation of Asian elephants (Elephas maximus) across India,” Animal Conservation Forum, vol. 8, no. 4, pp. 377–388, 2005. [Google Scholar]
3. P. Fernando, H. K. Janaka, T. Prasad and J. Pastorini, “Identifying elephant movement patterns by direct observation,” Gajah: Journal of the IUCN/SSC Asian Elephant Specialist Group, vol. 33, pp. 41–46, 2010. [Google Scholar]
4. M. S. Nakandala, S. S. Namasivayam, D. P. Chandima and L. Udawatta, “Detecting wild elephants via WSN for early warning system,” in 7th Int. Conf. on Information and Automation for Sustainability, IEEE, 2014. [Google Scholar]
5. A. Gamage and M. Wijesundara, “A solution for the elephant-human conflict,” in Texas Instruments India Educators’ Conf., IEEE, pp. 169–176, 2016. [Google Scholar]
6. H. Yousif, J. Yuan, R. Kays and Z. He, “Animal Scanner: Software for classifying humans, animals, and empty frames in camera trap images,” Ecology and Evolution, vol. 9, no. 4, pp. 1578–1589, 2019. [Google Scholar]
7. S. Stoeger and G. Heilmann, “Visualizing sound emission of elephant vocalizations: Evidence for two rumble production types,” PLoS One, vol. 7, no. 11, pp. e48907, 2012. [Google Scholar]
8. J. Soltis, “Vocal communication in African Elephants,” Zoo Biology, vol. 29, pp. 192–209, 2010. [Google Scholar]
9. S. Nair, R. Balakrishnan, C. S. Seelamantula and R. Sukumar, “Vocalizations of wild Asian elephants (Elephas maximusStructural classification and social context,” Journal of the Acoustical Society of America, vol. 126, no. 5, pp. 2768–2778, 2009. [Google Scholar]
10. Y. LeCun, Y. Bengio and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. [Google Scholar]
11. L. Muda, M. Begam and I. Elamvazuthi, “Voice recognition algorithms using Mel Frequency Cepstral Coefficient (MFCC) and Dynamic Time Warping (DTW) Techniques,” Journal of Computing, vol. 2, no. 3, pp. 2151, 2010. [Google Scholar]
12. F. Itakura, “Minimum prediction residual principle applied to speech recognition,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 23, no. 1, pp. 67–72, 1975. [Google Scholar]
13. K. P. Kuldip, “Spectral subband centroid features for speech recognition,” in Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 1998. [Google Scholar]
14. C. Nadeu, J. Hernando and M. Gorricho, “On the decorrelation of filter-bank energies in speech recognition,” Fourth European Conf. on Speech Communication and Technology, vol. 95, pp. 1381–1384, 1995. [Google Scholar]
15. C. Y. Yeo, S. A. R. Al-Haddad and C. K. Ng, “Animal voice recognition for identification (ID) detection system,” 2011 IEEE 7th Int. Colloquium on Signal Processing and its Applications, Penang, Malaysia, pp. 198–201, 2011. [Google Scholar]
16. U. Karthikeyan, K. Sridhar and R. K. Rao, “Audio signal feature extraction and classification using local discriminant bases,” IEEE Transactions on Audio, Speech, And Language Processing, vol. 15, no. 4, pp. 1236–1246, 2007. [Google Scholar]
17. Y. Li and Z. Wu, “Animal sound recognition based on double feature of spectrogram in real environment,” Int. Conf. on Wireless Communications & Signal Processing, IEEE, 2015. [Google Scholar]
18. T. Trnovszky, P. Kamencay, R. Orjesek, M. Benco and P. Sykora, “Animal recognition system based on convolutional neural network,” Advances in Electrical and Electronic Engineering, vol. 15, no. 3, pp. 517–525, 2017. [Google Scholar]
19. S. D. Silva, “Acoustic communication in the Asian elephant,” Behaviour, vol. 147, no. 7, pp. 825–852, 2010. [Google Scholar]
20. S. A. Al-agha, H. H. Saleh and R. F. Ghani, “Analyze features extraction for audio signal with six emotions expressions,” Int. Journal of Engineering and Advanced Technology (IJEAT), vol. 4, no. 6, pp. 333–341, 2015. [Google Scholar]
21. X. L. J. Tao, M. T. Johnson, J. Soltis and J. D. Newman, “Stress and emotion classification using jitter and shimmer features, acoustics, speech and signal processing,” 2007 IEEE Int. Conf. on Acoustics, Speech and Signal Processing, vol. 4, pp. 1081–1084, 2007. [Google Scholar]
22. S. Albawi, T. A. Mohammed and S. Al-Zawi, “Understanding of a convolutional neural network,” >Int. Conf. on Engineering and Technology, Antalya, Turkey, pp. 1–6, 2017. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |