DOI:10.32604/iasc.2022.015685
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.015685 | |
| Article |
Personalized Information Retrieval from Friendship Strength of Social Media Comments
1Department of Software Engineering, University of Gujrat, Gujrat, 50700, Pakistan
2Department of Computer Science, University of Gujrat, Gujrat, 50700, Pakistan
3Department of Information and Communication Engineering, Yeungnam University, Gyeongsan, 38541, Korea
4Computer Science and Artificial Intelligence Department, College of Computer Science and Engineering, University of Jeddah, Saudi Arabia
5Faculty of CS & IT, Jazan University, Jazan, 45142, Saudi Arabia
6Department of Computer Science, COMSATS University Islamabad, Pakistan
7Department of Computer Science & IT, The Islamia University of Bahawalpur, Bahawalpur, Pakistan
*Corresponding Author: Muhammad Shafiq. Email: shafiq@ynu.ac.kr
Received: 02 December 2020; Accepted: 26 April 2021
Abstract: Social networks have become an important venue to express the feelings of their users on a large scale. People are intuitive to use social networks to express their feelings, discuss ideas, and invite folks to take suggestions. Every social media user has a circle of friends. The suggestions of these friends are considered important contributions. Users pay more attention to suggestions provided by their friends or close friends. However, as the content on the Internet increases day by day, user satisfaction decreases at the same rate due to unsatisfactory search results. In this regard, different recommender systems have been developed that recommend friends to add topics and many other things according to the seeker’s interests. The existing system provides a solution for personalized retrieval, but its accuracy is still a problem. In this work, we have proposed a personalized query recommendation system that utilizes Friendship Strength (FS) to recommend queries. For FS calculation, we have used the Facebook dataset comprising of more than 22k records taken from four different accounts. We have developed a ranking algorithm that provides ranking based on FS. Compared with existing systems, the proposed system can provide encouraging results. Key research groups and organizations can use this system for personalized information retrieval.
Keywords: Friendship strength; information retrieval; query recommendation
Most ordinary people use social media to express their views, opinions and share their feelings. Online social networks have become an important source of public opinion. A web-based social network is a place where a large amount of data is distributed by ordinary people of different ages, different groups, different countries and different areas of life. It enables them to connect with each other, discuss and share ideas, information, pictures, sounds and videos. They also express their emotions, feel and make friends. People firmly believe in news, assessments and information about all aspects of life that are shared through social networks. It helps them keep in touch with their peers or other people related to their studies, business, entertainment and other activities.
The level of friendship defines the level of trust in social media communications. This is how we evaluate friendship strength (FS) based on the Facebook data set. Facebook interactions (such as many photo tags and posts on the wall) are used to calculate FS [1]. These two attributes are still very effective for forecasting. Traditional technology uses user profile data to calculate the strength of the relationship between various users [2]. The user’s profile data provides detailed information about his hobbies, religious views, companions, work experience, etc. On the other hand, interactive activities such as commenting, sending messages, and tagging refer to the intimacy of friends.
In recent years, according to several studies, various types of advice-based work have been carried out based on the level of friendship. Various researchers are studying friend suggestions similar to Facebook mechanism [3]. Facebook recommends friends mainly based on mutual friends. User profiles are established based on historical records of performed activities, such as items explored and queries [3]. Then, provide different documents or queries as suggestions according to the configuration file.
Traditional information retrieval (IR) systems mainly return results based on keyword matching. If different users submit the same query, the system returns the same results to all users. The difference between the Personalized Information Retrieval (PIR) system and the traditional system is that it not only provides results related to the query, but also provides results related to the user who submitted the query. In order to provide better results, the PIR system will keep the user’s previous search history and provide result retrieval accordingly.
In this article, we propose a technique to perform PIR from the Facebook comments of close friends. First, the comment data is based on the FS ranking, and the FS is calculated based on the number of likes, comments and tags. FS is also used to rank the retrieved annotations based on user queries. These ranking comments are displayed as a pop-up menu for suggestions/expansion of the target query. When the user types in any keyword, suggestions will appear on the basis of FS and keyword matching. To evaluate the proposed method, we collected comments from friends’ Facebook accounts. After that, the data is preprocessed and FS is calculated. To conduct experiments, a search engine has been developed in which users can enter queries. The experiment was conducted on the query set and the results were compared with the parallel system. The main contributions of this paper can be summarized as follows:
• We made a query suggestion based on the FS metric used for ranking.
• We have developed a query suggestion algorithm based on social media comments
• We have also developed a recommendation system, which has been developed to provide FS-based recommendations.
The rest of this article is organized as follows. In Section 2, a summary of relevant literature is provided. The system model is introduced in Section 3, and the experimental evaluation is carried out in Section 4. Finally, conclusions are drawn in Section 5.
The literature review is divided into the following subsections.
2.1 Friendship Strength Calculation
Using social media data sets for financial statement calculations is still an effective method for different types of analysis. Previously, different attributes were used for FS calculations. A model has been established to calculate relationship strength based on user similarity and interactivity. The model was developed with the help of nodes and links. Nodes represent users, and links represent relationships between users [4]. Similarly, reference [1] suggests that transaction information can be used to measure relationship strength. This is a supervised learning method.
A lot of work has been done on personal similarity. These properties are good, but not the most effective for strength calculations. User profile information and communication tools (such as emails and messages) are used to calculate relationship strength [5]. In Xiang [4], latent variables have been used to calculate relationship strength. The user’s personal data and message history have been used for estimation in the latent variables. Some researchers have conducted research on “FS intensity” and the results have been ranked from closest friends to ordinary friends. Reference [6] proposed a model that uses social media data to show link strength. The link strength is divided into two types: strong relationship and weak relationship, which means that the model does not show the strength of the relationship, but only shows the relationship as strong or weak. Similarly, based on the proximity of nodes in social networks, a method for calculating relationship strength is proposed [7].
FS may also vary from friend to friend, and also depends on the situation/category. A person may have different groups of friends to work, and different groups of friends to play games or dine. FS increases through more interactions, and vice versa. In Singla [8], it was concluded that there is not only an association between users who use instant messaging to interact, but it also grows over time. In Pappalardo [9], another multidimensional importance of connection quality is recommended that abuses the presence of different associated shared associations among two people. They check the grouping on a multidimensional arrangement created upon clients in Facebook and Twitter, investigating the essential piece of strong and fragile associations, and associations with broadly perceived similarity strategies.
To show the strength of the relationship, an organized graphical model and independent learning are used. Therefore, customer intimacy, marking and correspondence are used [4]. In addition, four estimates of relationship strength are proposed in Granovetter [10]: joint effort, intimacy, energy, and duration of shared organization. Use FS to solve some special fascinating zones and the information between customers is integrated. Then, using the customer’s personal data and published information with the help of graphical models to evaluate the strength of the relationship [11]. Twitter’s enthusiast following relationship was used to create an association [12]. To evaluate the relationship strength, creators in De Choudhury [13] used email associations. More messages exchanged infer the closest relationship. Notwithstanding, in Liu [14] K-Means gathering and support vector computations are utilized to take a gander at the assessments in messages. In order to evaluate the emotions in blogs and texts, people are urged to establish a new framework that takes text documents and sentiment words as input, and generates sentiment classes as output [15].
The recommender system recommends items related to the user’s search. These suggestions are not only made based on matched keywords, but information is also collected from the user’s search history. A lot of work has been done on the different proposals. Some researchers are dedicated to topic suggestions, and few types of research will recommend “additional friends” based on mutual friends, the same geographic area, or the same study/work organization. In Liu [16], by proposing a new heuristic similarity model, the user’s own ratings and user behavior are used to calculate the similarity.
In previous studies, contour formation trends are still common. Researchers use activity or like/dislike history to create a profile of a specific user, and then provide recommendations based on the profile. This kind of work established a user electronic file using tags, and then used these files for query development [3]. Similarly, user-generated tags are used to calculate the common interests of a group of users on the Delicious website data [17]. In addition, a recommendation system for flashing tags has been proposed, which uses the user’s tag history and geographic information to provide tag recommendations [18].
In order to provide users with suggestions, clusters of related users are generated [19]. Use the similarity measure “usefulness” to provide suggestions. Experiments were conducted using flicker, movielens and Last.fm. Content-based filtering and collaborative filtering for recommendations are combined using user-generated content and relationships [20]. Calculate the link strength of users who use social circles and interactive information [21]. They also increase social services by proposing a link strength model. Use inspiring factors such as interests, social networking, and reputation to provide suggestions. Use the number of pictures shared between directly connected users to calculate inspiration [22].
The user’s interest is calculated through the interaction between them [23]. The system LAICOS provides a network search based on related tags and content tags to construct configuration files [24]. FS has been used to rearrange search results [25]. In order to illustrate the scores of users, user relationships based on location and mutual relationships in social networks are used [26], and user activities are used to calculate user interests. Activities are based on users’ social associations rather than documents [27]. In addition, the shortest path in social networks is proposed to establish a centrality measure [28].
Recommendations recommended by experts are called impact-based recommendations. These types of advice are mainly useful in the field of education. This system is proposed by a cooperative team (i.e., a group of expert knowledge personnel) to use their knowledge to make recommendations [29]. The ArnetMiner system is constructed by collecting data of researchers from the Internet. Using this system, related papers are recommended to users [30]. The PREMISE system uses expert information to provide recommendations. Experts are those who influence the press [31]. In Konstas [32], friendship information, tags, and play times are used to provide music recommendations through a random walk restart method.
Few researchers have dedicated themselves to query suggestions. Different techniques have been used for query suggestion and query ranking. Attributes such as gender, age, and location are used to build models based on personalized rankings. This data is extracted from the configuration file of a real Microsoft account. The query suggestion is different from the query expression, because in the query suggestion it is suggested to propose a better query for the search process, while in the query expression, a new query is developed [33]. “Query expansion” is a technique widely used for query suggestions. The basic purpose of query expansion is to improve query suggestions. Query suggestions can also be realized by reordering queries [34]. Query suggestions and term weight responses are used to rearrange suggestions [35]. Using query suggestion methods can enhance the performance of search engines. They divide query suggestion methods into two categories, one is based on search results, and the second is based on log files. Both categories have their own advantages and disadvantages, which make them suitable for different queries. Commonly used similarity calculation techniques for search queries are the cosine similarity method and the Jaccard similarity method [36]. The two techniques are distinguished by comparing Jaccard and cosine methods [37].
Clustering has also been used in previous methods to cluster related queries. Then according to the keyword matching, the whole clustering proposal is put forward. The query log is also used to collect the searched queries. The query log not only provides searched queries, but also provides clicked links for specific queries. In Zahera [38], query recommendations based on the query clustering process have been proposed, which are collected from the log files of search engines. They not only cluster related queries, but also rank them based on similarity measures.
Social media data is also used to construct query suggestions to build a circle of related people based on the suggested query. The social media attributes used for similarity measures are gender, city, and the same topic of discussion. Based on these attributes, a weight is provided for each user related to the search. The Jaccard similarity algorithm is further used to provide query ranking [39,40].
Query recommendations are also very important for children in the search process. In order to prevent children from finding irrelevant search results, it is important to only ask them reasonable and relevant queries. In this case, reference [41] proposed a query recommendation mechanism for children who use social media tags. This method can be used to improve search suggestions. They also proved that social media can play a very important role in advice and can replace traditional log-based advice methods.
The query used for search and the results selected from the search are also very effective for generating search suggestions. Based on the user’s previous research experience, a new query recommendation method is proposed. They suggested three utilities in the model. “Level utility” defines the user’s attractiveness to a specific query, “perceived utility” calculates the user’s actions on the search results, and the posterior utility calculates the user’s satisfaction with the selected results [42,43].
Query recommendations are provided from the query logs of search engines, similar to user queries. In addition, in order to personalize query suggestions, queries of users who have similar profiles to the current user can be suggested from the query log. It uses a similarity matrix to filter personalized results [39]. The bookmark data obtained from the social network is also used to generate query recommendations. According to the result retrieval based on the user’s query, the results are ranked using the user’s familiarity and similarity relationship [25]. On the label data, the top k queries are ranked based on the label/keyword input query. The algorithm uses the relationship strength and relevance of tags. Therefore, it incrementally provides the top k results including the most relevant queries [44]. In addition, query expansion is performed based on the similarity of the tags and the social similarity. Therefore, the relevant terms of the input query based on the above factors are sorted and appended to the query. It uses bookmark datasets for experimentation and comparison [45].
Fig. 1 shows the architecture of the proposed technology called “Personalized Retrieval from Social Media (PRISM)”. The flow of the architecture is as follows: Use Python scripts to extract datasets and annotations from Facebook. Then merge the two files to form a database. On the annotation file, perform preprocessing to remove irrelevant attributes. In the next step, FS will be calculated. The final database is further used in FS-based search engines. When the user types any word to be searched in the search box, the suggestion list will be displayed in a drop-down menu format. These suggestions change constantly as users type words or sentences. For the user’s query, a suggestion list containing the comments that the user’s friends have posted on his wall is retrieved.
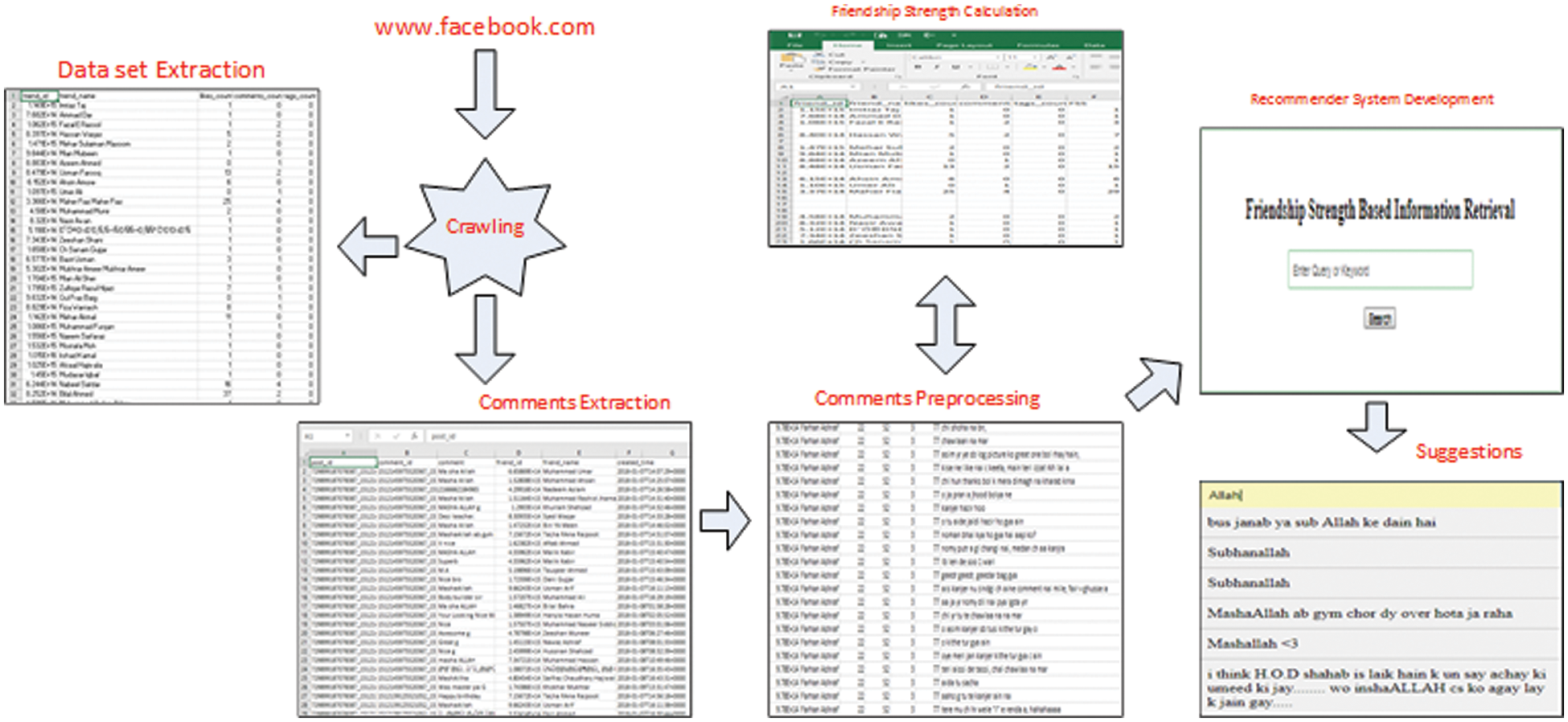
Figure 1: Architecture of the proposed methodology
A python script was developed to extract the dataset from Facebook. As output, a data set containing more than 22k records was generated. The two types of attributes that can be used in the structure of the data set are important. The first is personal similarity, for example, the same group likes to join the same page, or the same like/dislike. The second is interaction similarity, which uses transaction information to calculate similarity. In this work, we use interaction similarity to calculate FS. There have been many jobs on FS, and its work is based on personal similarity. The basic properties of FS calculation in this work are:
• Likes count
• Comments count
• Tags count
These attributes are very effective for FS calculations. The number of likes shows the total number of likes of a specific friend on the user’s wall. You can like on pictures, achievements, emotions or any type of post. The number of comments includes the number of comments made by a specific friend on the user’s wall. Comments can also be written on any post or status. The third attribute is the tag count, which shows the number of times the user has been tagged. It can be any post, status, picture, location, or any feature that a user is tagged by a specific friend. All these attributes are used to calculate FS for each individual friend. The specifications of the data set are given in Tab. 1.

We perform Crawling to extract data from Facebook. Therefore, the work of the data extraction process is shown in Fig. 2. When the script runs, the user is asked to enter Facebook’s unique ID/key. In the next step, the script will verify the Facebook key. If the input key is invalid, an error message will be displayed, otherwise the data extraction process will start. In the data extraction, the “friend’s ID”, “friend’s name”, “like count”, “comment count” and “tag count” attributes will be obtained, and a comma-separated value (CSV) file will be obtained as the file containing the required data Output.
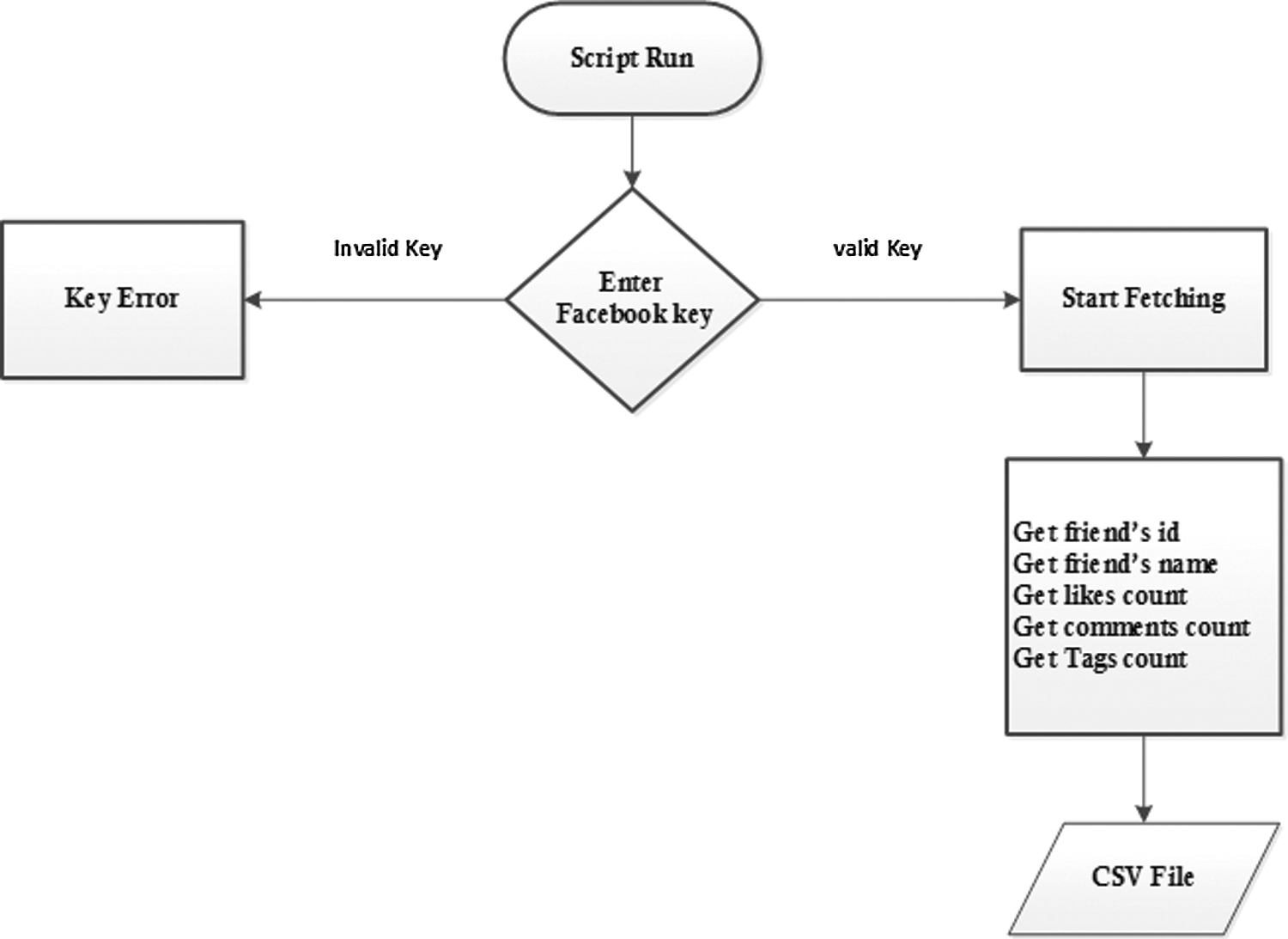
Figure 2: Crawling process for data extraction
3.3 Friendship Strength Calculation
The term “power of friendship” includes two parts: friendship and power. Friendship refers to the relationship between two people, and strength refers to the level of relationship between them. FS varies from friend to friend. As in real life, the level of our relationship with all our friends cannot be the same. Few of us are closer friends, and many are just formal friends. Similarly, we calculated the FS based on each friend of the user. The basic attributes calculated by FS are the number of likes, comments, and tags (photo tags, location tags, or any feature tags). Therefore, the sum of all these attributes can calculate the FS of the user and any of his friends, and the maximum degree of collaboration increases the level of the highest friendship. FS can be calculated as follows:
where
For example, the friend “Ali” has a total of 32 likes on the user’s wall, which means Ali likes his 32 posts, including pictures, videos, achievements or any other posts. Similarly, “Ali” posted a total of 42 comments on all posts, pictures or achievements on the user’s wall. In addition, the number of tags is between “Ali” and the user, including 22 locations. According to the three attribute values, the FS of the user with “Ali” is 96.
The process of annotation extraction is shown in Fig. 3. When the script runs, the user is asked to enter a Facebook unique ID/key. If the key is invalid, an error message will be displayed, otherwise the data acquisition process will begin. The extracted data attributes include the ID of the post, the ID of the comment, the comment, the ID of the friend, the name of the friend, and the creation time of the comment. Some less important attributes are removed during the preprocessing stage. The important attributes in the acquired attributes are the ID of the comment, the comment, the ID of the friend, and the name of the friend. These attributes are also used to provide recommendations through the FS portfolio.
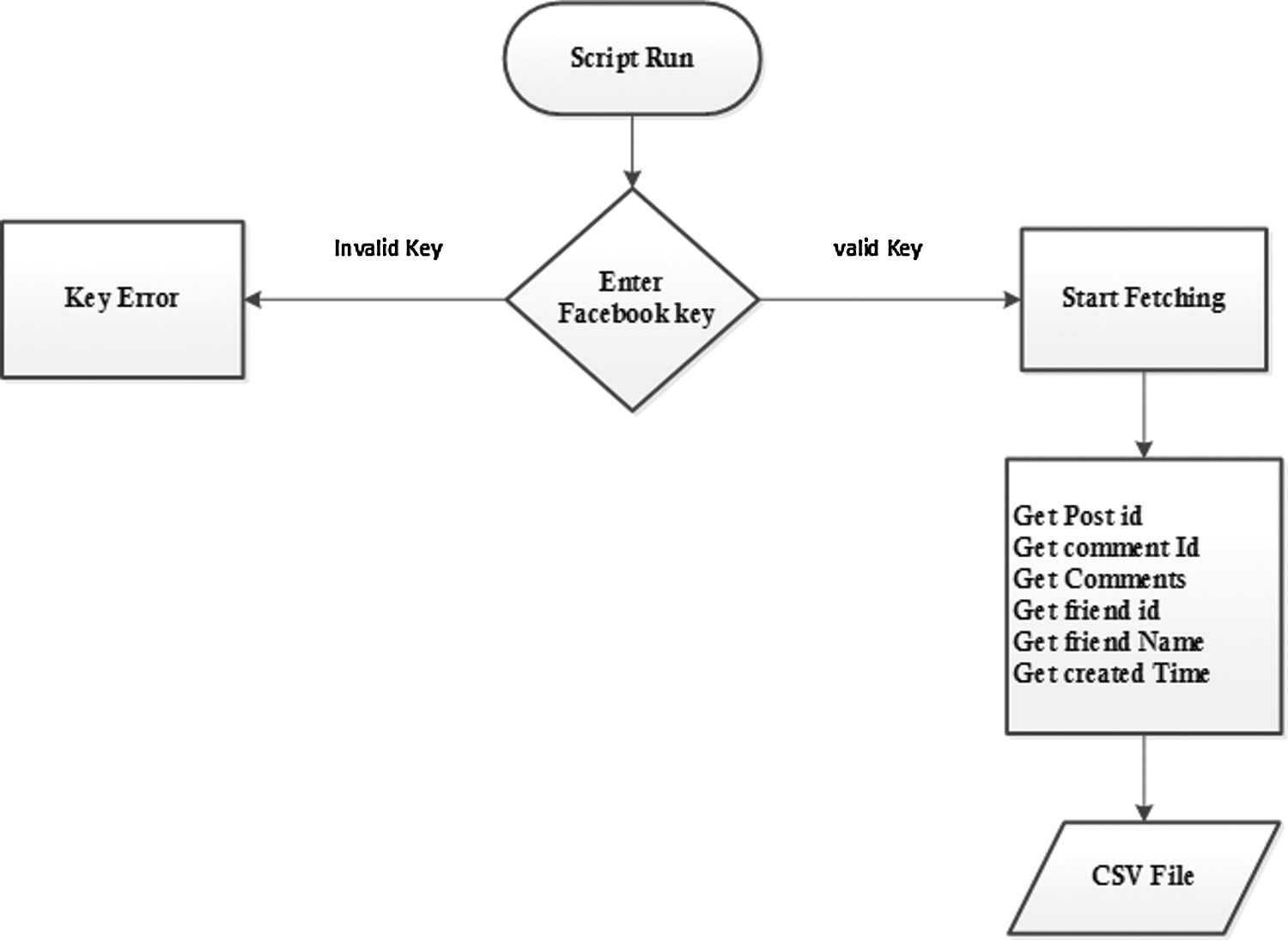
Figure 3: Comments extraction process
Preprocessing is the process of removing irrelevant attributes from the data set and retaining only the necessary attributes. Do this on both data set files to create the database used in the recommendation system. The data file contains the friend’s ID, friend name, like count, comment count, and tag count, while the comment file contains post ID, comment ID, comment, friend ID, friend’s name, and creation time. In the data file, the FS attribute is added. Later, the two files (i.e., the data file and the annotation file) were merged to form the final database.
The search engine has been developed on top of the database that is finalized by combining comments and FS attributes. The process of the search engine is given in Algorithm 1.

In Algorithm 1, the user enters a keyword query in the search engine (line 1). In the next step, divide the input query into words (line 2). In addition, every word in the query matches every word in the database (lines 3-4). It is recommended to print according to FS. Here, “DESC” is used to sort the suggestions in descending order relative to FS. The limit is 0.9 and is used to display a list of the top 10 suggestions in the output (line 5 and beyond). The information retrieval process is also shown in Fig. 4.
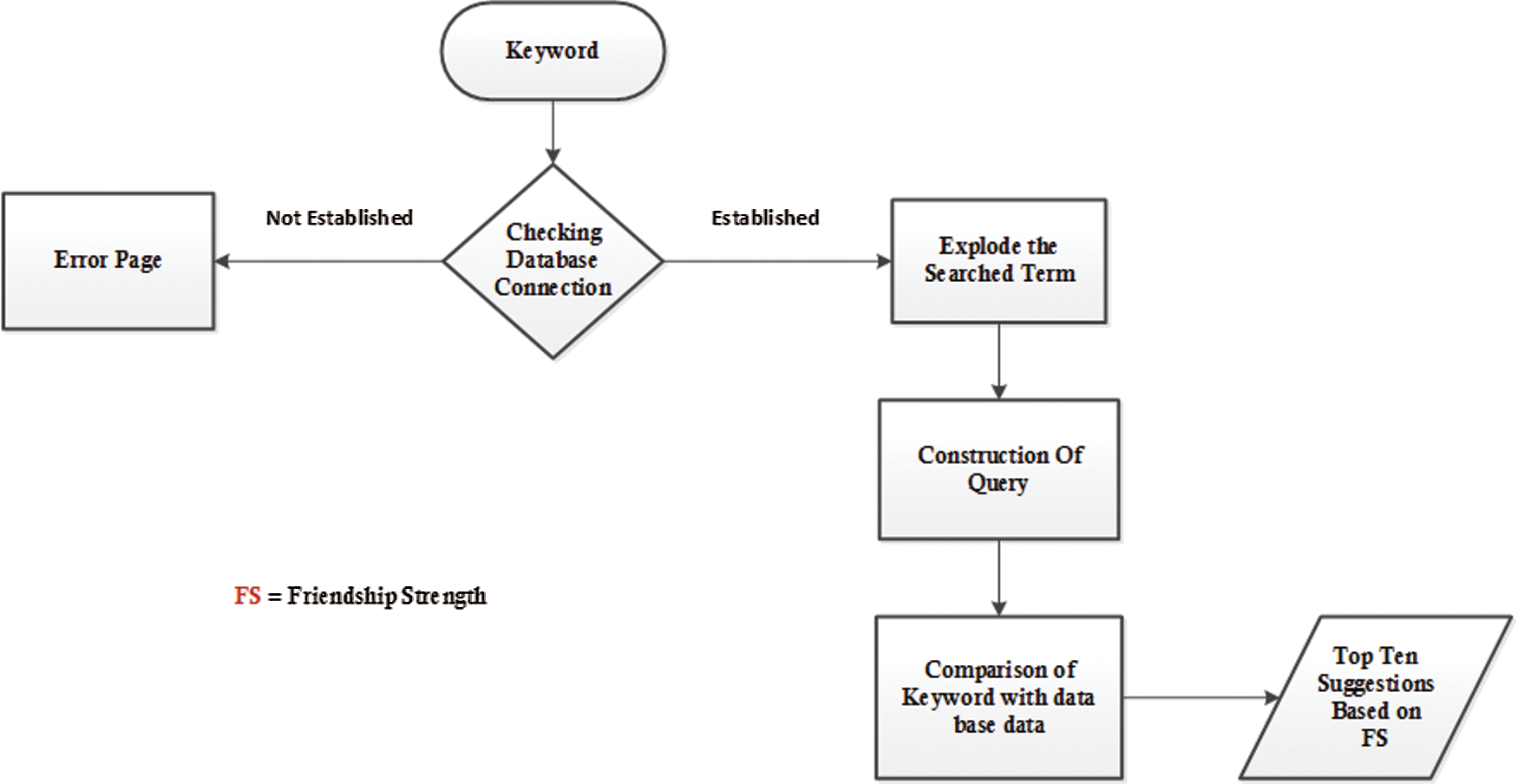
Figure 4: Information retrieval process
The output of the input query is a set of suggestions retrieved by the search engine. These are arranged according to FS. Therefore, the suggestions at the top of the list belong to the closest friends. In Fig. 5, the suggestions retrieved for the query “Allah” are described.
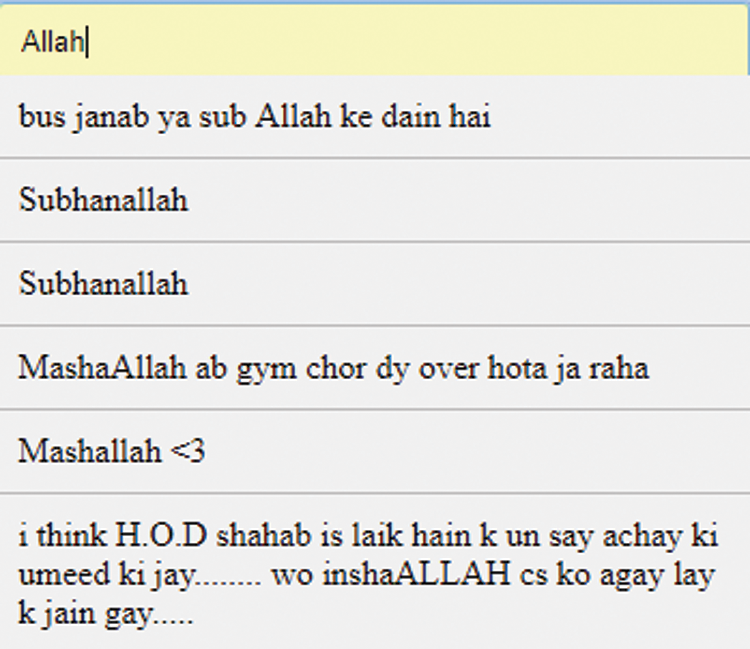
Figure 5: Suggested results
We have conducted experiments to evaluate the performance of the proposed technology PRISM. For experimentation, a search engine has been developed. In order to search for relevant data, the user types a query in the search box of a search engine. Therefore, suggestions are retrieved based on the input query. In order to describe the basic work of a search engine, Fig. 6 shows the suggestions of five friends for an input query. It only considers context-based retrieval without FS. The most relevant results were retrieved from the comments of “Saqib” and “Talha”, with a correlation of 100%. So, the relevance of “Kamar”‘s comments is 75%. The suggestions received from the comments of “Mudassar” are 60% relevant, while the comments of “Ali Naqvi” are 0% relevant.
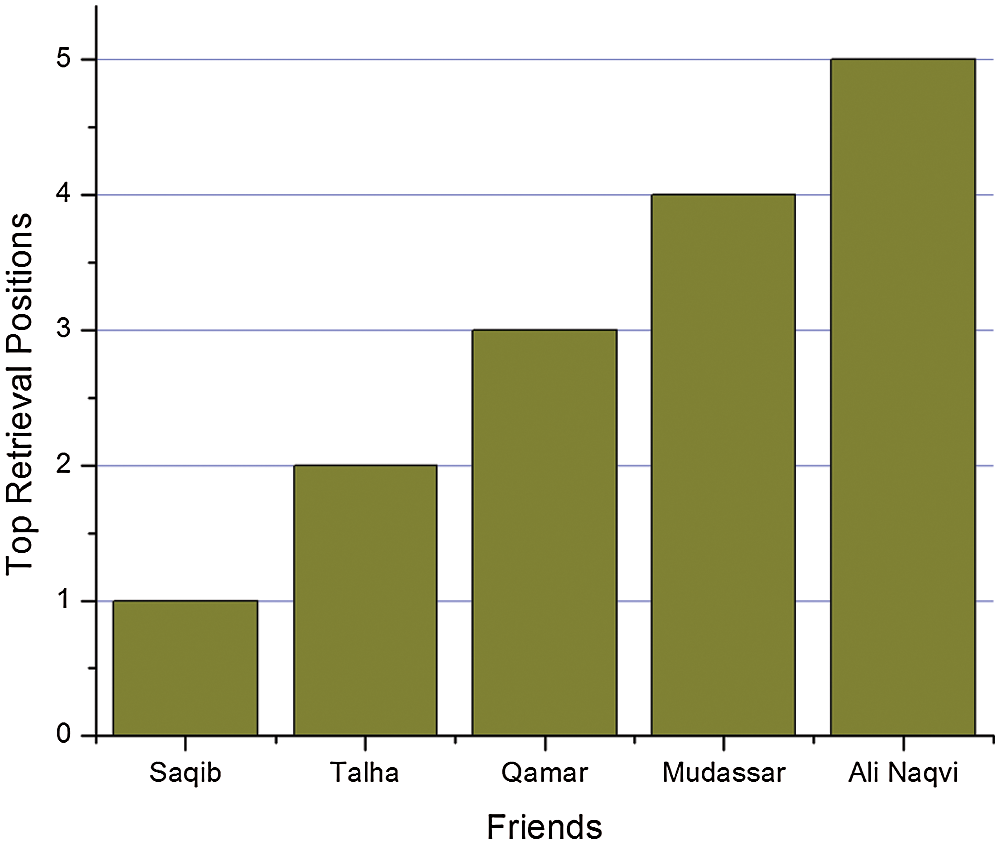
Figure 6: Context based retrieval
When it comes to FS, a different retrieval order will be obtained, as shown in Fig. 7. Using similar queries for context-based retrieval (Fig. 6), including FS will produce different results. Obviously, the comments of “Mudassar” occupy the first place because “Mudassar” is a close friend. Similarly, the comment of “Talha” is in the second position. Here, “Ali Naqvi” ranks third on the basis of FS, but since his keyword similarity is 0%, there are no suggestions in his comments. The “Qamar” proposal is in the 4th place, and the “Saqib” proposal is in the 5th place.
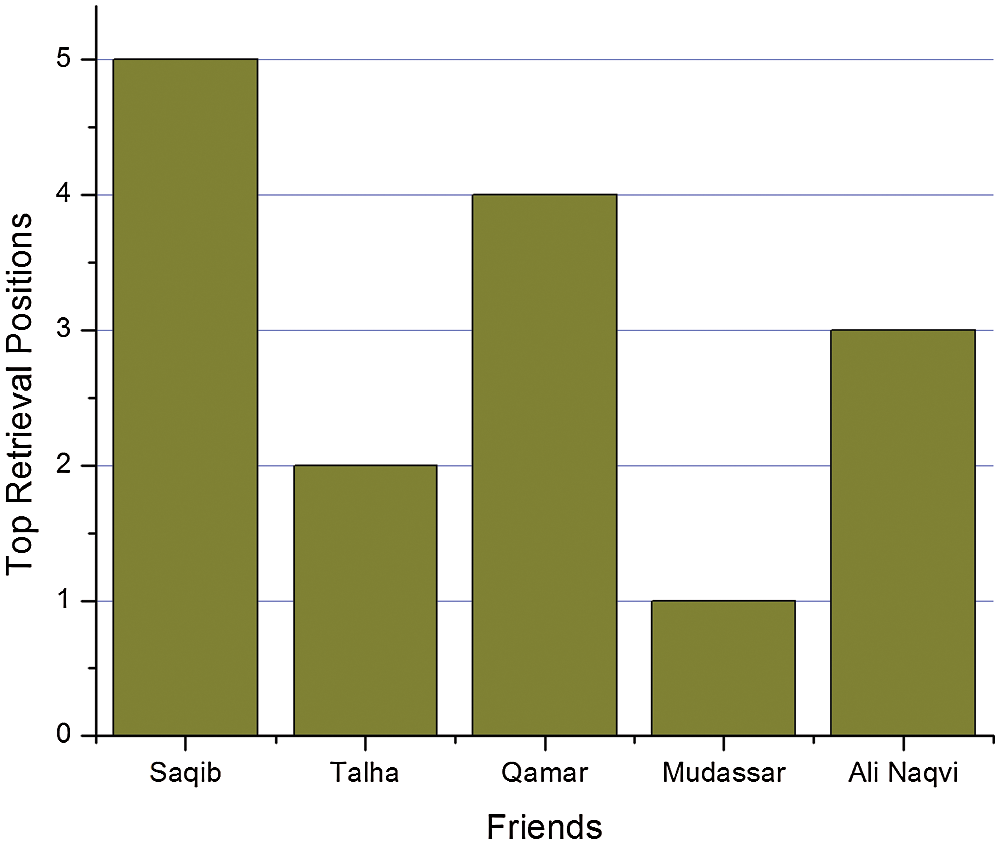
Figure 7: FS based retrieval
The comparison of the query results has been performed in Fig. 8. Here, the query “Noman Yousaf” is used to compare results based on FS and those without FS. It can be observed that when it comes to FS, the comment will change its position in the suggestion. One suggestion ranks first in the absence of FS, and when considering FS, it is recommended to occupy a position among the first 6 suggestions. The top 9 positions without FS are in the top 9 positions with FS.
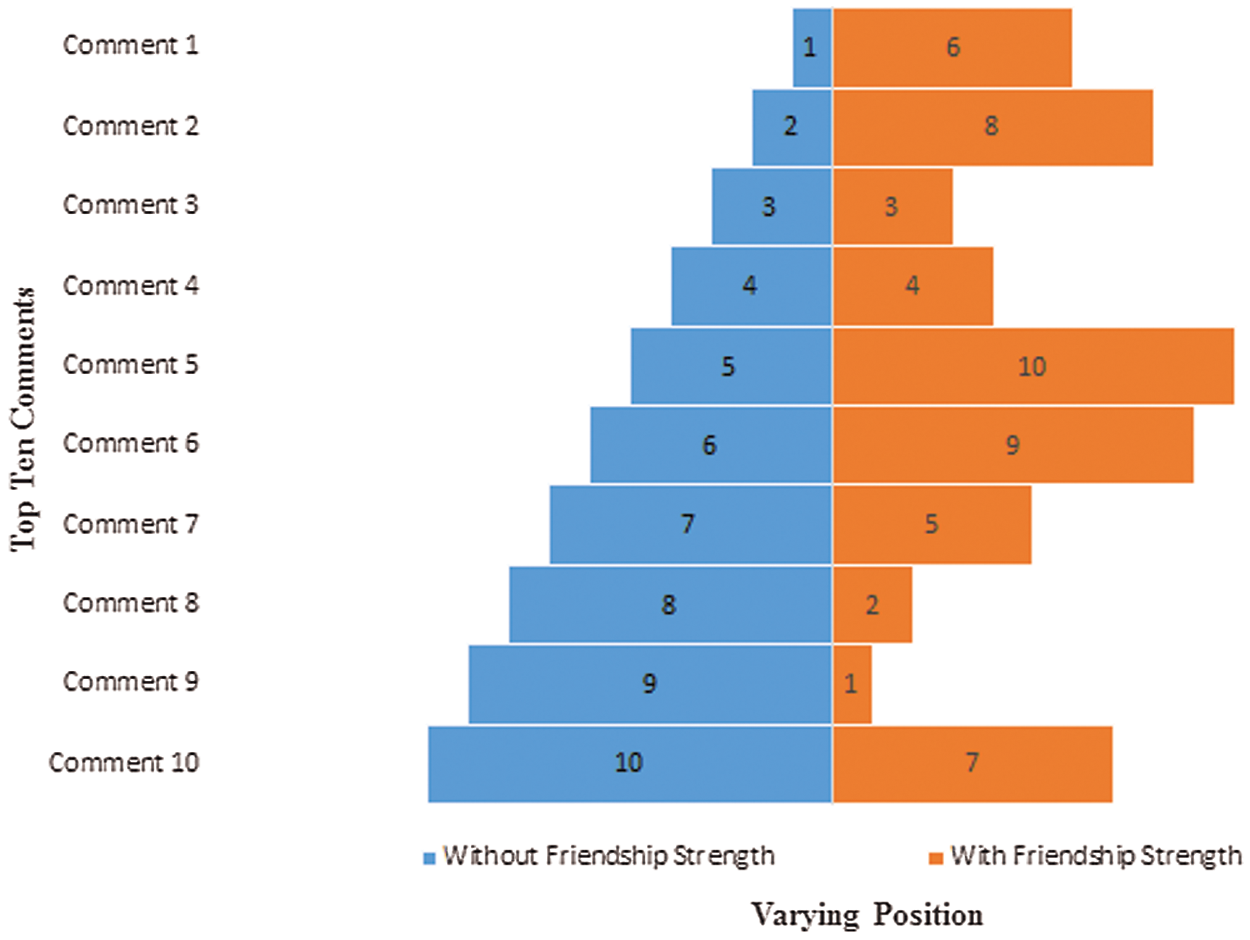
Figure 8: Comparison with and without FS
The comparison of the query results has been performed in Fig. 8. Here, the query “Noman Yousaf” is used to compare results based on FS and results without FS. It can be seen that for FS, the comment will change its position in the recommendation. In the absence of FS, a recommendation comes first. When considering FS, it is recommended to occupy a place among the first 6 recommendations. The first 9 positions without FS are located in the first 9 positions with FS.
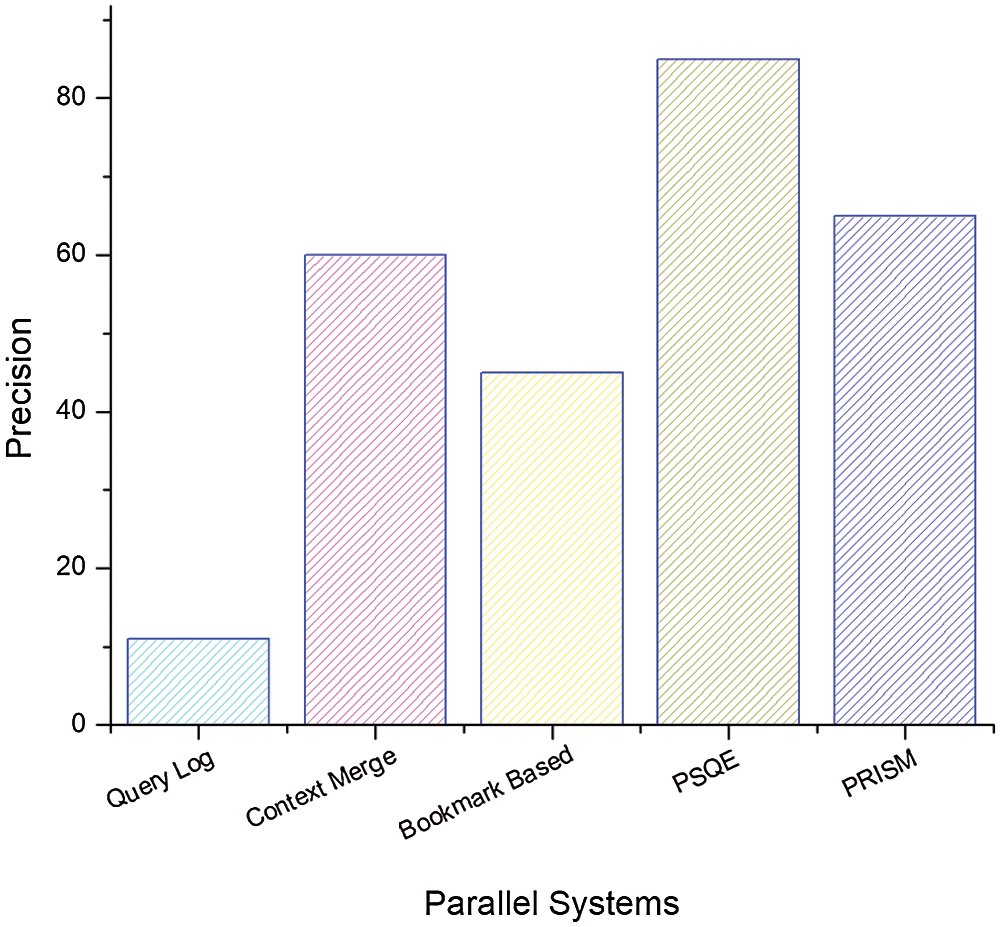
Figure 9: Context based comparison
Parallel systems related to our proposed PRISM include query log, context merging, bookmark-based and personalized social query expansion (PSQE). We show here the comparison between the proposed PRISM and the parallel system. Fig. 9 shows the retrieval of suggestions from matching reviews without considering social similarity (or FS measure). The average result of ten queries with the same number of terms has been proven. Using the weighted Borda Fuse (WBF) algorithm, PSQE achieves the greatest accuracy (without FS measure), while PRISM achieves the second best accuracy. However, when we consider the FS measure, our system outperforms existing solutions (see Figs. 10 and 11). In contrast to context-based retrieval, social similarity-based retrieval provides personalized results. As shown in Fig. 10, PRISM showed better results compared to other parallel systems, while previously it provided 61% correlation results without using a similarity measure.
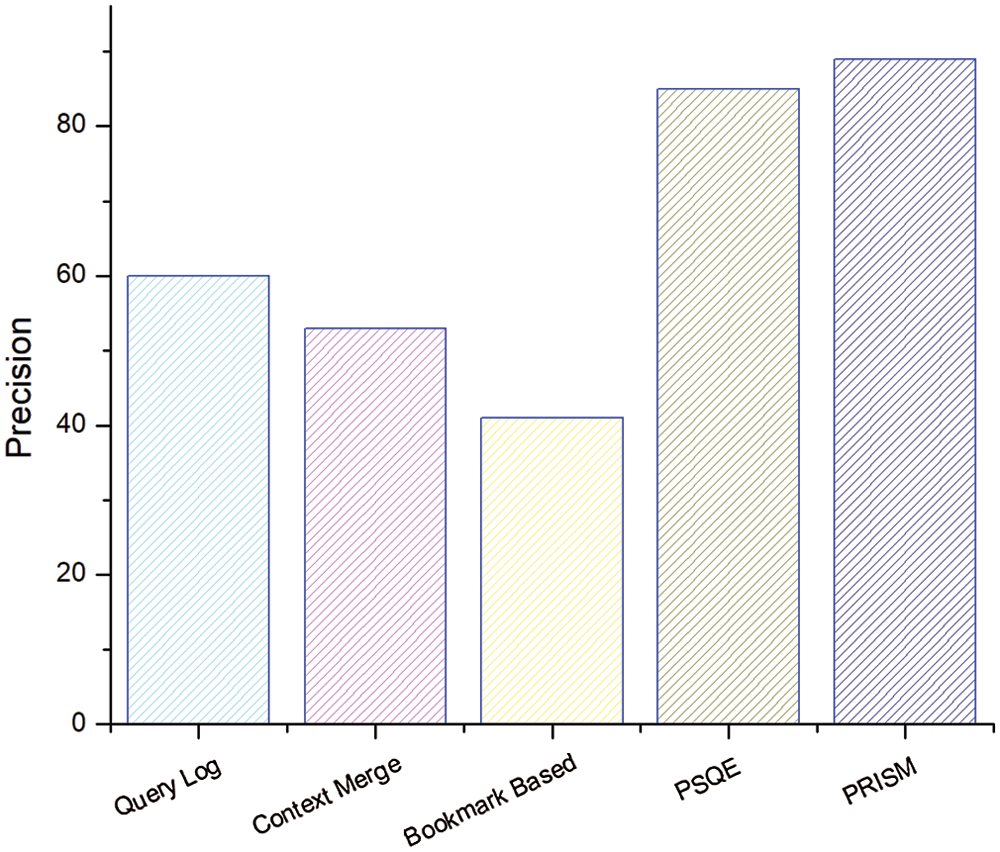
Figure 10: Social similarity based retrieval
In Fig. 11, we demonstrate the effect of different numbers of terms in the input query. We consider using 0 to 10 terms to track the results. It can be observed that when the number of items is the smallest, most systems provide better results. The accuracy decreases as the term increases. With existing systems, PSQE can produce good results. In contrast, PRISM can obtain the highest accuracy with FS.
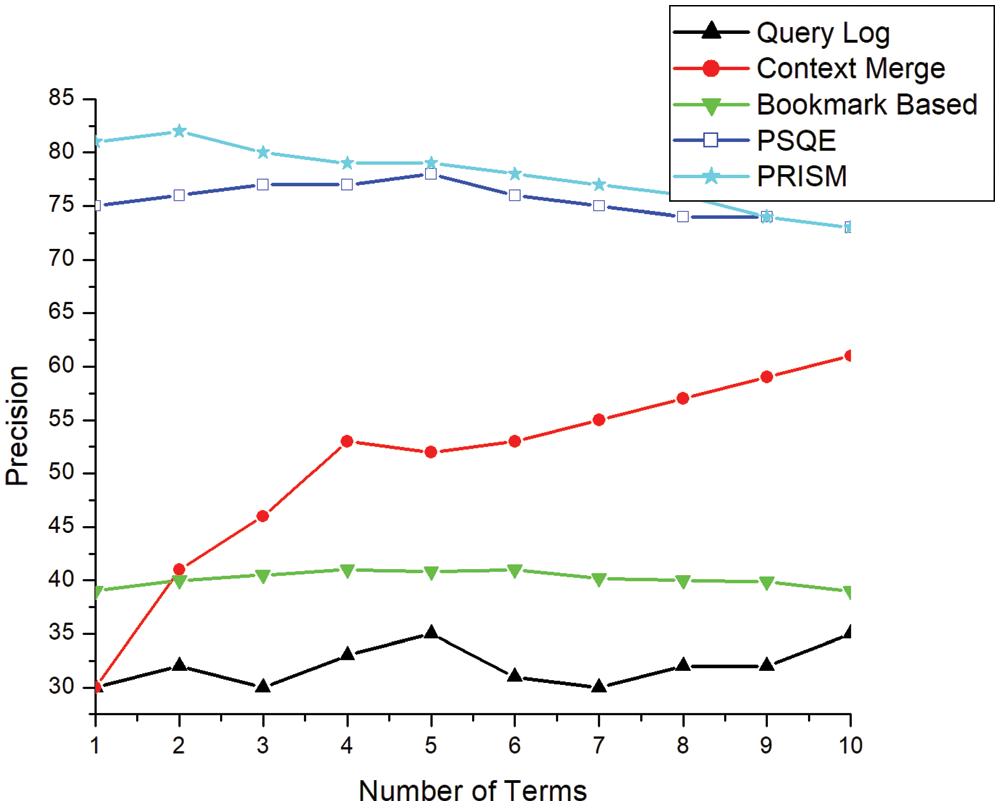
Figure 11: Number of terms
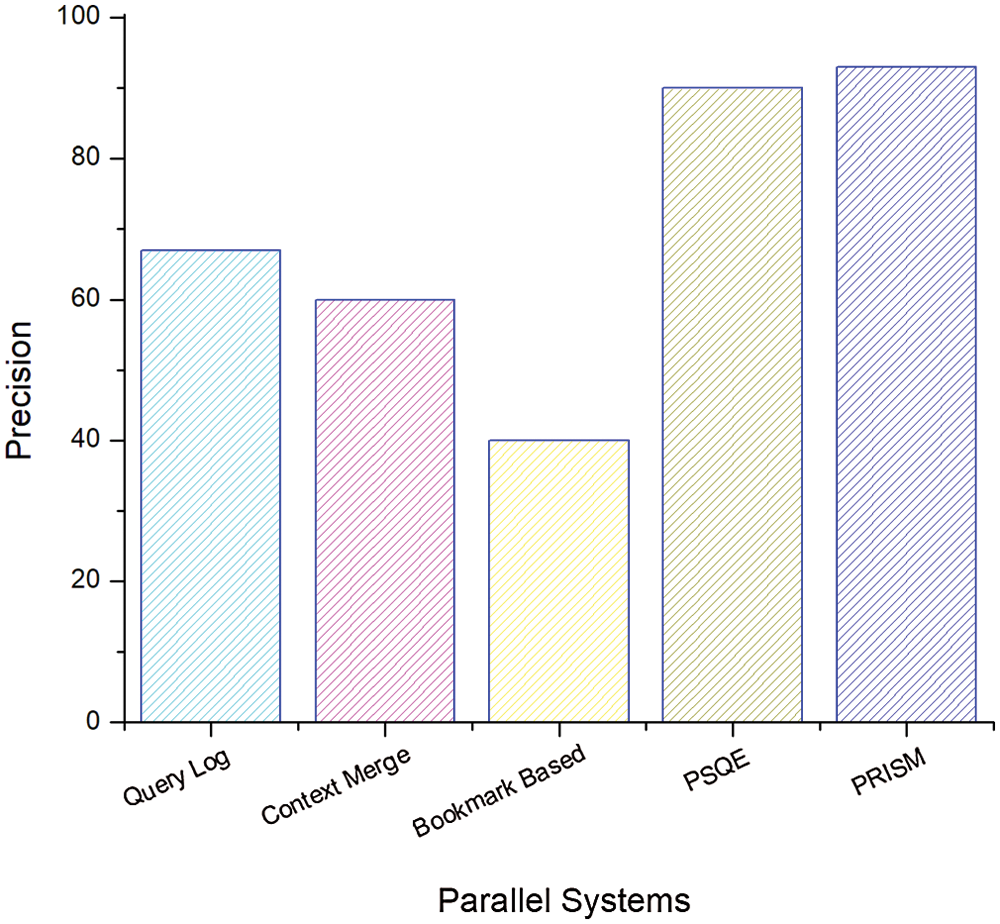
Figure 12: Comparison of social measures in retrieval
In Fig. 13, the results were produced without social measures. Compared with Fig. 12, when PSQE provides 70% accuracy and PRISM achieves 67% accuracy, the correlation of the results is reduced. It can be inferred that social measures increase the relevance of the search.
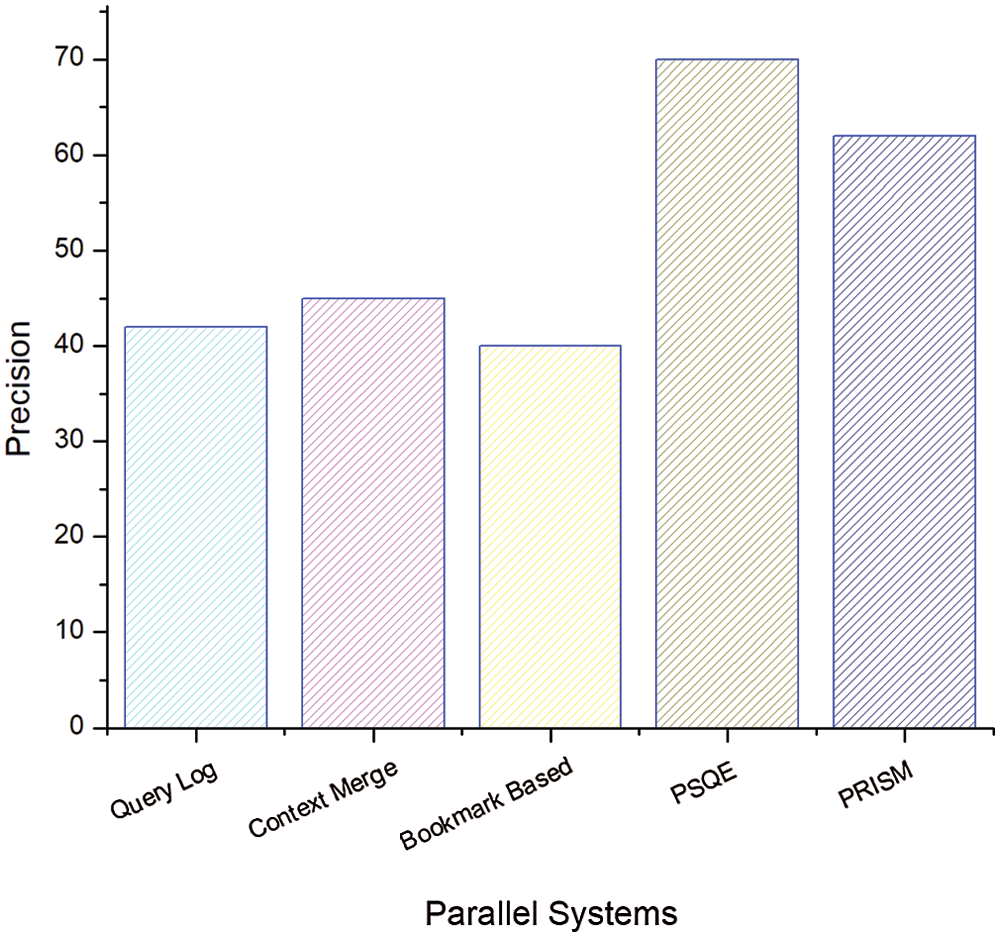
Figure 13: Relevance without social measures
This paper proposes a new query recommendation technology. It uses FS to rank queries. A query suggestion algorithm based on social media comments has been developed. Based on this algorithm, a recommender system is constructed to provide suggestions based on FS. The Facebook dataset has been constructed and used for experiments. By using the data set, a comparative analysis with the parallel system has been performed. The proposed system PRISM can provide about 85% accuracy. The accuracy of PSQE is about 80%, second only to the comparison system. Therefore, the accuracy of PRISM has been significantly improved. In the future, the FS-based recommendations can be improved by adopting the actual search queries of the research team. In addition, the query log can be used to collect queries, and surveys can be conducted from users to find the level of satisfaction regarding recommendations.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. I. Kahanda and J. Neville, “Using transactional information to predict link strength in online social networks,” in Proc. ICWSM, San Jose, California, pp. 74–81, 2009. [Google Scholar]
2. M. Burke, C. Marlow and T. Lento, “Social network activity and social well-being,” in Proc. CHI, Atlanta, GA, USA, pp. 1909–1912, 2010. [Google Scholar]
3. M. R. Bouadjenek, H. Hacid, M. Bouzeghoub and J. Daigremont, “Personalized social query expansion using social bookmarking systems,” in Proc. SIGIR, Beijing, China, pp. 1113–1114, 2011. [Google Scholar]
4. R. Xiang, J. Neville and M. Rogati, “Modeling relationship strength in online social networks,” in Proc. WWW, Raleigh, NC, USA, pp. 981–990, 2010. [Google Scholar]
5. D. Horowitz and S. D. Kamvar, “The anatomy of a large-scale social search engine,” in Proc. WWW, Raleigh, NC, USA, pp. 431–440, 2010. [Google Scholar]
6. E. Gilbert and K. Karahalios, “Predicting tie strength with social media,” in Proc. CHI, Boston, MA, USA, pp. 211–220, 2009. [Google Scholar]
7. E. S. Florentino, A. A. Cavalcante and R. R. Goldschmidt, “An edge creation history retrieval based method to predict links in social networks,” Knowledge-Based Systems, vol. 205, pp. 106268, 2020. [Google Scholar]
8. P. Singla and M. Richardson, “Yes, there is a correlation: from social networks to personal behavior on the web,” in Proc. WWW, Beijing, China, pp. 655–664, 2008. [Google Scholar]
9. L. Pappalardo, G. Rossetti and D. Pedreschi, “How well do we know each other?,” in Proc. ASONAM, Istanbul, Turkey, pp. 1040–1045, 2012. [Google Scholar]
10. M. Granovetter, “The strength of weak ties: A network theory revisited,” Sociological theory, vol. 1, pp. 201–233, 1983. [Google Scholar]
11. X. Zhao, J. Yuan, G. Li, X. Chen and Z. Li, “Relationship strength estimation for online social networks with the study on Facebook,” Neurocomputing, vol. 95, pp. 89–97, 2012. [Google Scholar]
12. H. Kwak, C. Lee, H. Park and S. Moon, “What is Twitter, a social network or a news media?,” in Proc. WWW, Raleigh, NC, USA, pp. 591–600, 2010. [Google Scholar]
13. M. De Choudhury, W. A. Mason, J. M. Hofman and D. J. Watts, “Inferring relevant social networks from interpersonal communication,” in Proc. WWW, Raleigh, NC, USA, pp. 301–310, 2010. [Google Scholar]
14. S. Liu and I. Lee, “A hybrid sentiment analysis framework for large email data,” in Proc. ISKE, Taipei, Taiwan, pp. 324–330, 2015. [Google Scholar]
15. S. N. Shivhare, S. Garg and A. Mishra, “EmotionFinder: detecting emotion from blogs and textual documents,” in Proc. Computing, Communication & Automation, Greater Noida, India, pp. 52–57, 2015. [Google Scholar]
16. H. Liu, Z. Hu, A. Mian, H. Tian and X. Zhu, “A new user similarity model to improve the accuracy of collaborative filtering,” Knowledge-Based Systems, vol. 56, pp. 156–166, 2014. [Google Scholar]
17. X. Li, L. Guo and Y. E. Zhao, “Tag-based social interest discovery,” in Proc. WWW, Beijing, China, pp. 675–684, 2008. [Google Scholar]
18. J. Liu, Z. Li, J. Tang, Y. Jiang and H. Lu, “Personalized geo-specific tag recommendation for photos on social websites,” IEEE Transactions on Multimedia, vol. 16, no. 3, pp. 588–600, 2014. [Google Scholar]
19. M. Servajean, E. Pacitti, M. Liroz-Gistau, S. Amer-Yahia and A. El Abbadi, “Exploiting diversification in gossip-based recommendation,” in Proc. Globe, Munich, Germany, pp. 25–36, 2014. [Google Scholar]
20. I. Guy, N. Zwerdling, I. Ronen, D. Carmel and E. Uziel, “Social media recommendation based on people and tags,” in Proc. SIGIR, Geneva, Switzerland, pp. 194–201, 2010. [Google Scholar]
21. S. Servia-Rodriguez, R. P. Diaz-Redondo, A. Fernandez-Vilas, Y. Blanco-Fernandez and J. J. Pazos-Arias, “A tie strength based model to socially-enhance applications and its enabling implementation: mySocialSphere,” Expert Systems with Applications, vol. 41, no. 5, pp. 2582–2594, 2014. [Google Scholar]
22. C. H. Lai, D. R. Liu and M. L. Liu, “Recommendations based on different aspects of influences in social media,” in Proc. EC-Web, Prague, Czech Republic, pp. 194–201, 2013. [Google Scholar]
23. J. Yu, Y. Shen and J. Xie, “Mining user interest and its evolution for recommendation on the micro-blogging system,” in Proc. WAIM, Beidaihe, China, pp. 679–690, 2013. [Google Scholar]
24. M. R. Bouadjenek, H. Hacid and M. Bouzeghoub, “Laicos: an open source platform for personalized social web search,” in Proc. KDD, Chicago, Illinois, USA, pp. 1446–1449, 2013. [Google Scholar]
25. D. Carmel, N. Zwerdling, I. Guy, S. Ofek-Koifman, N. Har’El et al., “Personalized social search based on the user’s social network,” in Proc. CIKM, New York, USA, pp. 1227–1236, 2009. [Google Scholar]
26. L. B. Jabeur, L. Tamine and M. Boughanem, “A social model for literature access: towards a weighted social network of authors,” in Proc. RIAO, Paris, France, pp. 32–39, 2010. [Google Scholar]
27. Q. Wang and H. Jin, “Exploring online social activities for adaptive search personalization,” in Proc. CIKM, Toronto, Canada, pp. 999–1008, 2010. [Google Scholar]
28. C. Bothorel, “Social network analysis and unpopular content recommendation,” Review of New Information Technologies (RNIT), vol. 5, no. 11, 2011. [Google Scholar]
29. L. Zhen, G. Q. Huang and Z. Jiang, “Recommender system based on workflow,” Decision Support Systems, vol. 48, no. 1, pp. 237–245, 2009. [Google Scholar]
30. J. Tang, S. Wu, J. Sun and H. Su, “Cross-domain collaboration recommendation,” in Proc. KDD, Beijing, China, pp. 1285–1293, 2012. [Google Scholar]
31. C. Lin, R. Xie, X. Guan, L. Li and T. Li, “Personalized news recommendation via implicit social experts,” Information Sciences, vol. 254, pp. 1–18, 2014. [Google Scholar]
32. I. Konstas, V. Stathopoulos and J. M. Jose, “On social networks and collaborative recommendation,” in Proc. SIGIR, Boston, MA, USA, pp. 195–202, 2009. [Google Scholar]
33. M. Shokouhi, “Learning to personalize query auto-completion,” in Proc. SIGIR, Dublin, Ireland, pp. 103–112, 2013. [Google Scholar]
34. S. Plansangket and J. Q. Gan, “A query suggestion method combining TF-IDF and jaccard coefficient for interactive web search,” Artificial Intelligence Research, vol. 4, no. 2, pp. 119–125, 2015. [Google Scholar]
35. D. Kelly, K. Gyllstrom and E. W. Bailey, “A comparison of query and term suggestion features for interactive searching,” in Proc. SIGIR, Boston, MA, USA, pp. 371–378, 2009. [Google Scholar]
36. J. M. Yang, R. Cai, F. Jing, S. Wang, L. Zhang et al., “Search-based query suggestion,” in Proc. CIKM, Napa Valley, California, pp. 1439–1440, 2008. [Google Scholar]
37. S. Sugiyamto, B. Surarso and A. Sugiharto, “Analisa performa metode cosine dan jacard pada pengujian kesamaan dokumen,” Jurnal Masyarakat Informatika, vol. 5, no. 10, pp. 1–8, 2014. [Google Scholar]
38. H. M. Zahera, G. F. El-Hady and W. F. Abd El-Wahed, “Query recommendation for improving search engine results,” in Information Retrieval Methods for Multidisciplinary Applications, IGI Global, pp. 46–53, 2013. [Google Scholar]
39. L. Ahmedi and D. Shabani, “Search engine query recommendation-using SNA over query logs with user profiles,” in Proc. WEBIST, Porto, Portugal, pp. 370–375, 2017. [Google Scholar]
40. M. Hosseini and H. Abolhassani, “Clustering search engine log for query recommendation,” in Proc. CSICC, Kish Island, Iran, pp. 380–387, 2008. [Google Scholar]
41. S. Duarte Torres, D. Hiemstra, I. Weber and P. Serdyukov, “Query recommendation for children,” in Proc. CIKM, Maui Hawaii, USA, pp. 2010–2014, 2012. [Google Scholar]
42. R. Khemiri and F. Bentayeb, “Interactive query recommendation assistant,” in Proc. DEXA, Vienna, pp. 93–97, 2012. [Google Scholar]
43. J. Wang, J. Z. Huang, J. Guo and Y. Lan, “Query ranking model for search engine query recommendation,” International Journal of Machine Learning and Cybernetics, vol. 8, no. 3, pp. 1019–1038, 2017. [Google Scholar]
44. R. Schenkel, T. Crecelius, M. Kacimi, S. Michel, T. Neumann et al., “Efficient top-k querying over social-tagging networks,” in Proc. SIGIR, Singapore, pp. 523–530, 2008. [Google Scholar]
45. M. R. Bouadjenek, H. Hacid and M. Bouzeghoub, “Personalized social query expansion using social annotations,” in Proc. TLDKS XL, Berlin, Heidelberg, pp. 1–25, 2019. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |