DOI:10.32604/iasc.2022.020287
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.020287 | |
| Article |
Recommendation Learning System Model for Children with Autism
Easwari Engineering College, Chennai, 600089, India
*Corresponding Author: V. Balaji. Email: balajiv.iniyan@gmail.com
Received: 18 May 2021; Accepted: 01 July 2021
Abstract: Autism spectrum disorder (ASD), is a neurological developmental disorder. It affects how people communicate and interact with others, as well as how they behave and learn. The symptoms and signs appear when a child is very young. Derived with increased usage of machine learning procedure in the medicinal analysis investigations. In this paper, our objective is to find out the most significant attributes and automate the process using classification techniques and pattern clustering using K-means clustering. We have analyzed ASD datasets of children towards determining the best performance of classifier for these binary datasets considering recall, precision, accuracy and classification errors. For this purpose only we use classifier along with a training model with the deep learning technique. In this deep neural network the different types of patterns have been obtained, and then the entire autism dataset has been trained using this classification technique. After that, the group of patterns has been formed using K- means clustering technique. Then these grouped patterns have been sent to the stochastic gradient descent (SGD) for obtaining the classification with enhanced accuracy, and after this, the regression process is done, then by this classified output, the recommendation learning system model is given for autism affected children. The need for recommendation for ASD is due to slow functioning of the brain and change in personal characteristic of the affected children, so it is necessary for recommendation learning model in ASD.
Keywords: ASD; classification; confusion matrix; DNN; K-means Clustering; SGD; Recommendation Learning Model
Autism Spectrum Disorder (ASD) is a neuro disorder, one will have lifetime consequence on synergy and communication with others. Autism will be identified at anyone of the stages in any individual life and known as “behavioral disease” due to the primary of two years of life symptom regularly emerge [1]. In agreement with ASD crisis, begins with babyhood and keep on growing on into teens and maturity. It is a lifelong condition and cannot be cured. There is 33% of children with some other problems apart from ASD are having symptoms of ASD will not met with the entire criteria of classification is studied by Wiggin et al. [2]. ASD have major monetary crash because of the increased ASD numerical cases across the globe, and the duration and expenses concerned in patient diagnosis.
Very first discovery of ASD will assist both patient and medical management by recommended suitable medication and/or therapy required and thus decreasing the long-term expense linked with belated analysis. Diversely the conventional medical techniques like Autism Diagnostic Interview Revised (ADI-R) and Autism Diagnostic Observation Schedule Revised (ADOS-R), are time consuming and cumbersome [3,4]. The children who are too young and have delayed speech issue roughly score 25% of the total ADI-R items because the verbal sections can’t be answered accurately for the patient. Besides, performing consultation with a custodian by a skilled inspector will take around 90-150 min. Consequently, this will consume lot of time and cause non-random missing data in score of summary. Diversely the ASD detection by ADOS-R is based on scoring measurements with the results given. Furthermore, main disadvantages of this are the propensity to in excess of categorizing children who have other clinical confusion [5]. So, the screening models of ASD which are efficient in time and accessed easily are needed urgently by the clinical practitioners. The ASD characteristics present in the patients are accurately detected and notify the patient whether for pursuing a proper medical diagnosis.
Currently, the diseases like depression, ASD, etc. are detected by machine learning. For the improvement of accuracy and time reduction in diagnosis are the chief reasons for using machine learning order to offer earlier admission to medical management. As the case’s diagnosis process will involve with the right class (ASD, No-ASD) will depends upon the characteristics of input case, this method will be credited as a prognostic mission in machine learning. Improved precision, recall and predictive accuracy on the feature selection method consequences is obtained by concerning classification techniques [6]. Moreover, a evaluation of the state-of-the-art classifiers has been performed considering learning errors values. In this work, we simply set out to assess the predictive power of PCD (personal characteristic data) for ASD diagnosis and evaluate which machine learning model is most robust for this task. Specifically, we employed and validated nine machine learning models by using PCD, such as age, sex, handedness, and IQ, for ASD classification of individual subjects. Taking advantage of such a large PCD dataset from ABIDE (Autism Brain Imaging Data Exchange), we systematically evaluated the predictive power of PCD features on ASD classification and compared the performance of those nine machine learning models. By classifying the ASD datasets and performing feature and predictive analyses, the below contributions have been achieved:
1. We analyze the features of Child ASD datasets, and present a correlation between the demographic feature and ASD cases.
2. We explore benchmark feature selection methods and identify the most significant ones to classify ASD cases. Our analysis shows to predict the feature selection of ASD.
3. Appropriate feature selection can significantly improve the ASD classification performance.
4. We compare the state-of-the-art classification methods and identify the best performing classifier that is suitable for all four ASD datasets.
The contents of this paper are organized as follows: Section 2 describes the analysis of several current literatures, where few methods of ASD recommendation learning model are expanded. Section 3 explains the datasets involved in the paper, afterwards explanation of methodology every constituent is utilized in this work. The consequences acquired after several experiments are presented and conversed in Section 4 afterwards this paper is concluded in Section 5.
The techniques for prediction ASD are explained in brief in this section. ML (machine learning) effectiveness is fairly admirable in the prediction of different types of infections depends upon syndrome. Cruz et al. [7] attempted to make a diagnosis of cancer by ML at the same time Khan et al. [8] utilized ML for predicting a diabetes of an individual. Wall et al. [9] utilized Alternating Decision Tree (AD Tree) to reduce the screening period and quick ASD qualities discovery. Autism Diagnostic Interview is utilized by them, Revised (ADI-R) process and achieves increased accuracy level having information about 891 persons. Other than the test were restricted in 5 to 17 ages and botched for predicting ASD among various groups of ages (kids, teens and matured person). Bone et al. [10] put in ML for similar reason and utilized support vector machine (SVM) to get 89.2% sensitivity and 59% specificity. Their investigation incorporated 1264 individuals having ASD and 462 persons having NON-ASD behavior. Though because of the extensive ranges (4-55 years), their study wasn’t established for the entire group of ages, people as screening methodology. Allison et al. [11] utilized ‘Red Flags’ screening ASD tool by means of Autism Spectrum Quotient for kids and matured persons, and short-list the persons AQ-10 having exceeding accuracy 90%. Thabtah [12] collated, earlier tasks on prediction autism ML algorithms behavior, while Hauck and Kliewer [13] attempted for recognizing comparatively additional significant screening queries for ADOS (Autism Diagnostic Observation Schedule) and ADI-R (Autism Diagnostic Interview Revised) screening process and established that ADI-R and ADOS screening examination will improve work while they were joined in concert. Bekerom [14] utilized many techniques of ML as well as naive Bayes, SVM and random forest algorithm are used for determining the traits of ASD among kids such as evolutional set back, obesity, decreased physical action and evaluated these outcomes. Wall et al. [15] employed on autism classification with small screening examination, justification and established that AD and the functional tree are carried out fine having increased sensitivity, specificity and accuracy. Heinsfeld [16] put in deep learning algorithm and neural network for identifying ASD suffering persons by great dataset for brain imaging from the Autism Imaging Data Exchange (ABIDE I) and attained a 70% mean classification accuracy having range of 66% to 71% accuracy. SVM classifier attained 65% accuracy mean; as the Random Forest classifier attained 63% of accuracy mean. Liu [17] Using various machine learning algorithms such as ADTree to classify individuals with autism from controls, sensitivite and specificity in the nd 93% fewer than the full ADI-R, and performed with greater than 99% in this paper. Bone et al. [18] resulted the earlier tasks of Wall et al. [9] and Kosmicki et al. [19] to recognize the problems in theoretical crisis configuration, practical execution and clarification and replicated its outcomes utilizing their ML methodologies. As a result of literature study it is obvious that, numerous examinations are undergone in this are abut there is no crucial results to overcome the difficulties on utilizing ML methodologies for simplifying autism screening test tool as to the group of ages. Various methods and tools were suited previously the autism screening tests, but there is no app based results for various age groups.
Dekhil et al. [20] stated a new autism diagnostic CAD method with synthesis of anatomical and functional data from sMRI and fMRI. The CAD method can be put in 47 cases and presented increased accuracy of 94.74% on the whole dissimilarities among autism and brains that are normally developed. Local brain region assessment are also incorporated, are able to categorize the cases to the autism spectrum and assist doctors to offer precise concern autism people. Osman et al. [21] explained autism classification utilizing many cortical features obtained from SBM and contrasting the classification outcomes among the features of mixture. The curvature provides simply restricted data on the ASD’s predictive model thickness and the answers indicate that ASD suffering person will contain high uneven cortical thickness than cortical curvature. Anibal Sólon Heinsfeld et al. [22] considered useful patterns of communication which classifies suffering persons of ASD impartially from functional brain imaging information and effort to depict its neural arrangements which is created from the classification. Analysts also stated the areas in brain are mainly donated to separate ASD from characteristically budding functions with respect to thought of deep learning. Algorithm performs good than the present algorithm, adaptable and increased reliability. Outcomes of ADI-R and SRS ML-based union are accounted and dispensed by means of a algorithm of screening under (over) age 10 attained 89.2% sensitivity (86.7%) and 59.0% specificity (53.4%) only having conduct 5 codes. Yan Jin et al. [23] revealed the machine learning method viability for classifying the increased-risk ASD on new born soon after six months of birth. It depends on white matter (WM) tract and integration of entire brain ASD is persuaded with faults are started previously and will happen within 2 years. New multi-kernel support vector machine classification system was introduced utilizing the features of connectivity acquired from WM communication networks and achieved 76% accuracy and 0.80 area beneath the Curve for operating feature for receiver (AUC) was contrasted to accuracy 70% and AUC 70% provided through most excellent single-scale parameter network. The author in [24] attempt to explore the possibility to use Naïve Bayes, Support Vector Machine, Logistic Regression, KNN, Neural Network and Convolutional Neural Network for predicting and analysis of ASD problems in a child, adolescents, and adults. The proposed techniques are evaluated on publicly available three different non-clinically ASD datasets. First dataset related to ASD screening in children has 292 instances and 21 attributes. Second dataset related to ASD screening Adult subjects contains a total of 704 instances and 21 attributes. Third dataset related to ASD screening in Adolescent subjects comprises of 104 instances and 21 attributes. After applying various machine learning techniques and handling missing values, results strongly suggest that CNN based prediction models work better on all these datasets with higher accuracy of 99.53%, 98.30%, 96.88% for Autistic Spectrum Disorder Screening in Data for Adult, Children, and Adolescents respectively. Another researcher in [25] aims to classify ASD data to provide a quick, accessible and easy way to support early diagnosis of ASD. Three ASD datasets are used for children, adolescences and adults. To classify the ASD data, we used the k-Nearest Neighbours method (kNN), the Support Vector Machine method (SVM) and the Random Forests method (RF). In our experiments, the data was randomly split into training and test sets. The parts of the data were randomly selected 100 times to test the classification methods. In [26] the author focused to find out the most significant traits and automate the diagnosis process using available classification techniques for improved diagnosis purpose. We have analyzed ASD datasets of Toddler, Child, Adolescent and Adult. They determine the best performing classifier for these binary datasets using the evaluation metrics recall, precision, F-measures and classification errors. These finding shows that Sequential minimal optimization (SMO) based Support Vector Machines (SVM) classifier outperforms all other benchmark machine learning algorithms in terms of accuracy during the detection of ASD cases and produces less classification errors compared to other algorithms.
3 Architectural Process of Research Methodology
Usage of techniques for classification is explored as an attempt. Here the input dataset has been classified using a Deep neural network and obtain the trained output. Then by this classified output, the recommendation is given on the educational system for autism affected children. We pre-process our dataset by removing the attributes that have missing values and also those that do not offer any benefit during the analyses. Fig. 1, shows an overview of our methodology for detecting ASD cases.

Figure 1: Proposed architecture
In this framework, the output label will be recommended for ASD by the proposed deep learning technique for the individual ASD screaming process. Besides, we also determine the attribute counts and the corresponding accuracy values to identify the most significant attributes.
The process of data pre-processing is used to alter the unprocessed data into a significant and comprehensible arrangement. Actual data is usually of an imperfect and conflicting nature as it encloses enormous faults and unacceptable ideals. A perfect outcome will be obtained from perfect pre-processed data. Several data pre-processing technologies are utilized for handling imperfect and conflicting data such as treating values missed, aberration proposal learning methods, discretization and reduction of data (dimension and numerosity reduction), etc. By the technique of dimensionality reduction. The issue of searching for the missed value in these datasets is switched by the process of imputation.
3.2 Classification of Data Using Deep Neural Networks
Deep neural networks were auspiciously appealed for classification collectively based on voxel and functional connectivity. The ABIDE repository is used for obtaining sufficient samples for study of DNN, Multilayer Perceptron (MLP) having four dissimilar arrangements. In general, techniques like MRI and fMRI give various stages of the brain images provided as the machine learning input. The voxels which are known as small cubic divisions of the brain are carried out in fMRI data and each voxel’s activity over time is taken out as a time series. The arithmetical organization among two voxels is called its functional connectivity which is distinct as the connection between its time series values.
Autism Brain Imaging Data Exchange (ABIDE) proposal had given a dataset that contains fMRI and MRI data produced from 1112 health control and ASD cases. From the 17 dissimilar brain imaging centres the data is obtained. Analysts undergo new ASD techniques for diagnosis through MRI and fMRI data given by the ABIDE repository. Other arrangements are configured having two or more hidden layers (e.g., hidden layer of 3 and 4) with reduced outcomes in experiments because of training sample shortages. Extra layers are also made to boost the experimental cycle owing to the drawbacks in the present equipment. Nevertheless, the outcomes of the experiment are superior to the branded non-DNN techniques. The proposed technique is possible to be applied for further layering to our DNNs on gaining the admission to a well-built dataset and/or stages of experiment through extra vigorous equipment in further analysis. The MLP with 77028-1024-512-2 is demonstrated in Fig. 2. It believes an 77028 feature input space (pair wise autonomous connectedness characteristics intended for all subjects is obtained in Section II-D), 2 number space output. Both the hidden layers with 1024 and 512 parts are present in the network in between input and output layers in that order. From Fig. 2, it is observed that MLP encloses a momentous weighted number. The main goal of administered training is to regulate the output weights to the classes anticipated, then reduces its prediction error. The loss function in (1) is utilized for measuring the obtained prediction error. The layer of output encloses a pair of output units where every unit presents the input probability obtained from an ASD or a TD subject. The probability of output is acquired through a softmax application.

Figure 2: DNN architecture
Binary classification technique is involved in this study and binary entropy is the loss function. Implementation of the entire training processes are carried out by the deep learning framework Tensor Flow altogether with the algorithm of optimization called Adam Optimizer. S as to achieve the reduced over fitting, a l2 regularization term is added as a loss function. In (1), number of samples as re represented by m(m = 1025), sum of number of labels as K(K = 2), sum of number of DNN hidden layer is L(L = 2), sum of number of the units in hidden layer 1 is Sl, and sum of number of the units in hidden layer 2 is Sl+1
3.3 Pattern Clustering by K-means Clustering Algorithm
Here the clustering is used for differentiating the pattern for each person with autism. When the abnormal pattern is detected then recommendation for an educational system is given. This process is carried out by a clustering technique. The pattern has been classified as 5 types. The input pattern has been obtained from clustering. K-means clustering algorithm is employed for this calculation for extracting general action outlines over the challenging behavior’s formerly distinct classes. Earlier to the outcomes presented, and elaborated arithmetical summary of K-means is presented in this paper. Cluster membership through cluster centroid identification is determined by the easy algorithm K-means. D data matrix is considered with m×n dimension, D = {X1, X2, …,Xm} is the vector representation of D. Every vector, Xi, symbolizes an exclusive data instance, and every element vector, Xi, j, and exact measurement (attributes) for that point. K-means clustering obtains D as input, also the number of clusters is fitted in data, k. The proceeded algorithm is given below:
1) Initializing k centroids C = {C1, C2, …,Ck} having random data points k.
2) For every point, Xi ∈ D, finding the nearest centroid, Cj , from C depends on some suitable distinct metric. Assign Xi to cluster j.
3) The whole Cj ∈ C appraise Cj = (X i Xi)/Pj for all Xi allocated for clustering j and Pj is the number of points to which the cluster j assigned.
4) Second Step is preceded then repeated till not changing cluster memberships.
On stabilizing the cluster membership, cluster structure was imagined having each cluster centroid helping as a data point representative explanation arrested through that group. For the identification of grouping as k-means gives a direct algorithm. The dare considered to determine their cluster number are processed. Without the information of the domain, it sets the accurate parameter; many methods survive for demographical calculation of most likely k, together with non-parametric statistics methodologies. The results depend on the determination of k through predicting the value which provides the large radical decrement in the intra-cluster sum of squared distance.
3.4 Stochastic Gradient Descent (SGD)
The SGD learning routine assisting different functions of loss and classification penalities are implemented by Stochastic Gradient Descent (SGD) classifier. Stochastic Gradient Descent (SGD) regressor fundamentally outfits a simple SGD learning routine assisting several loss functions and penalty for fitting the models of linear regression. Scikit-learn gives SGD Regressor module for implementing SGD regression.
The almost same parameters are utilized for both SGD Regressor and SGD Classifier. The ‘loss’ parameter is responsible for difference. The positive values of loss parameter for SGD Regressor are followed as below
The ordinary least squares fit is represented by Square_Los.
hubr: SGDReg − The outliers are corrected by switching from squared to linear loss past a epsilon distance. The duty of ‘hubr’ is modifying ‘Square_Los’ enabling the algorithm possess less concentration on outlier correction.
Square_
‘Pow_T’ with 0.25 as default value by contrast 0.5 in SGDClas. Moreover, it does not contain ‘clas_wei’ and ‘m_job’ parameter.
SGDRegressor Attributes almost similar to SGDClassifier module. Slightly extra three attributes are as follows −
aver_coeff_ − arr, shpe(m_feature,)
denotes that, it gives the normal weight allocated to the features.
aver_inter_ − arr, shpe(1,)
denotes, it gives the averaged intercept term.
T_- in
gives the weight update number carried out throughout the training phase.
Note − the attributes aver_coeff_ and aver_inter_ can do subsequent to enable parameter ‘aver’ to True
3.5 Training and Testing Model
The entire dataset was divided into a pair of parts, i.e., training and testing are the dataset having the ratio of 80:20 correspondingly. To cross-validate the reason once more, the training data was split into a pair of parts, i.e., a training and validation dataset having 80:20 ratio correspondingly. Fig. 3 represents the concluded sets for training, testing and validation through classification was executed. Based on the figure, it shows that dataset which has been splitted for training set and testing set. From training set of the data, training set and validation set has been classified. And finally the based on trained output, validated output and tested output of the dataset, the proposed design output has been obtained.

Figure 3: Training, testing and validation of dataset
The obtained output is deliberated by specificity, sensitivity, and accuracy by utilizing the confusion matrix and classification report. Its resultant output relies on the accuracy of the model.
Performance Evaluation metrics
The performance of the classification model is evolved to check its efficiency in achieving a target. The effectiveness and classification model performance is evaluated by performance evaluation in the test dataset. The model performances such as confusion matrix, accuracy, precision, recall are evaluated by choosing the correct metrics. The elements of confusion matrix has been given by Tab. 1 for actual ASD values based on predicted ASD values i.e., TP, FP, FN, TN.

Different machine learning algorithms methodologies results having the entire features selection are shown for ASD screening data for matured people, kids, and teens. The entire 21 features are chosen for finding the specificity, sensitivity, and accuracy in this paper. The ASD traits of ROC curve for true positive and false positive rate are provided in Fig. 4 below.

Figure 4: ROC curve for ASD
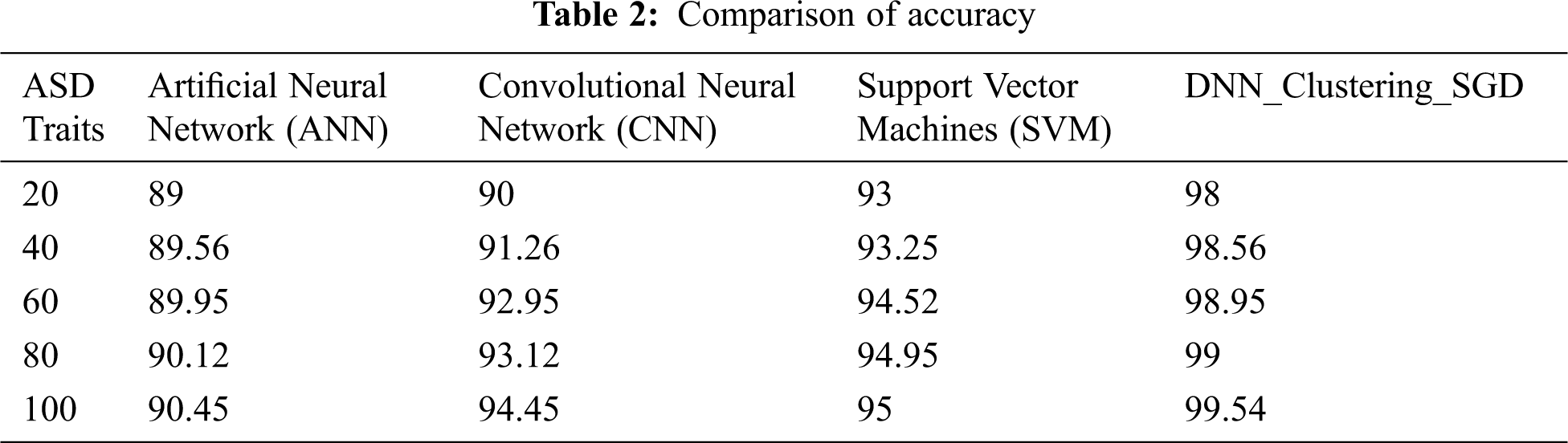

Figure 5: Accuracy comparison for ASD traits
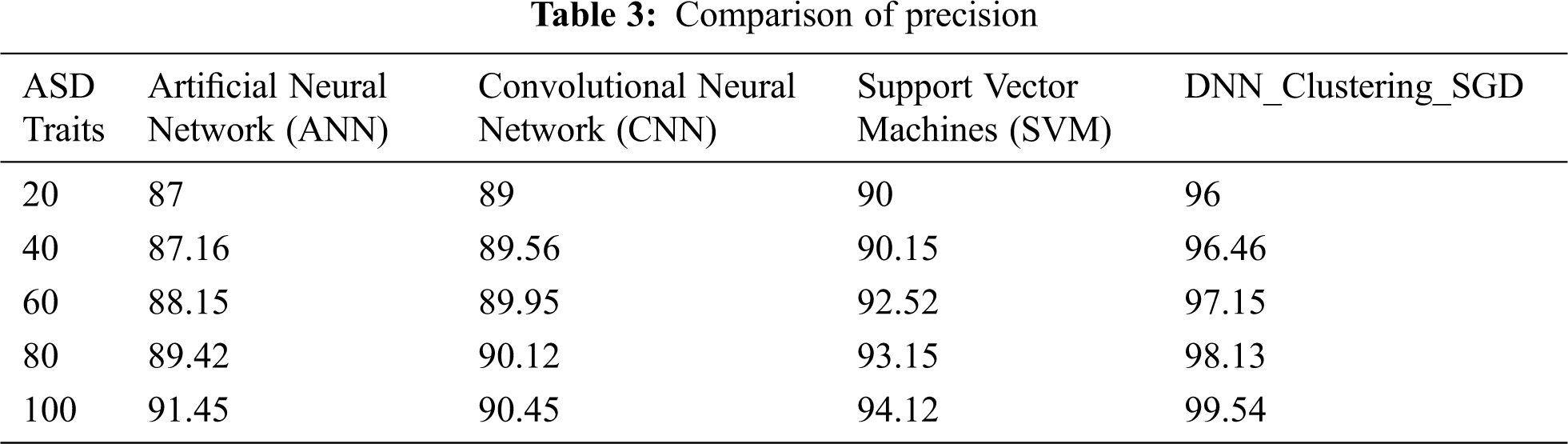

Figure 6: Precision comparison for ASD traits


Figure 7: Recall comparison for ASD traits
On the whole, performance computed for every machine learning classifiers with all 3 existing techniques has been compared with proposed DNN Clustering SGD. Tabs. 2–4. Figs. 5–7 shows the comparison of various existing techniques on the subject of Accuracy, Precision, Recall, and F1 score. Above all are comparisons for the input dataset between existing and proposed techniques. From the comparison, the experimental results show that the proposed DNN_ Clustering_ SGD achieves maximum percentage in Accuracy, Precision, Recall and F1 when compared to SVM, CNN and ANN.

The comparison graph for above Tab. 5 has been given in Fig. 8.
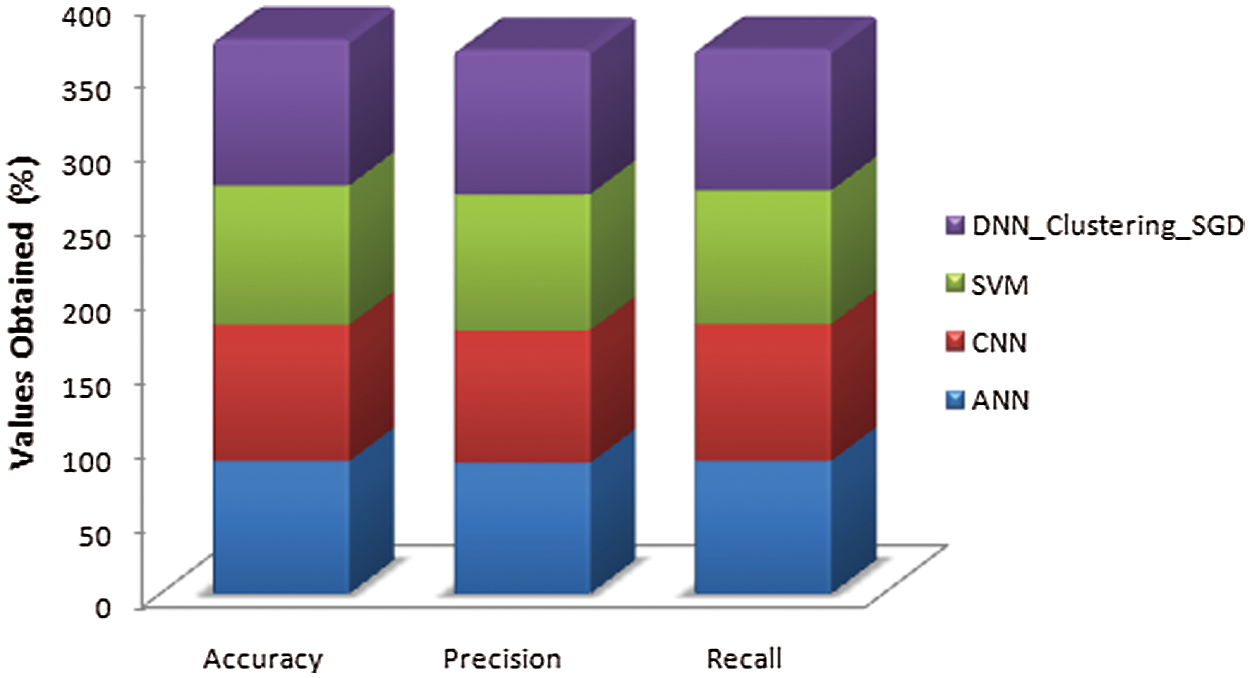
Figure 8: Parametric comparison of proposed with existing technique

Figure 9: Output for dataset classification and Autism Recommendation learning management system

Figure 10: Output for Autism Recommendation learning management system model
The above Figs. 9 and 10 shows the recommendation output for autism Recommendation learning system model. This output represents the clustered pattern differentiating for recommendation output.
The autism Spectrum Disorder recommended in this work was challenged by deep learning techniques and clustering model proposed. Different performance evaluation metrics was utilized for analyzing the model’s performance executed for recommendation of ASD non-medical dataset from 3 groups of age set viz. kids, teens and matured people. Furthermore, the model proposed will calculate autism behavior of various groups of age, as lots of existing methods failed to spot this feature. The resultant output demonstrated marginal performance on the subject of accuracy (77% to 85%) for the original dataset. The major motive at the back of this trivial result was inadequate in the real dataset number. In the second process, this analysis gives a relative observation amongst various ML approach methodologies on the subject of their performance. The propose technique uses DNN for classification of input data and the patterns of that classified data have been cluster using K-means clustering technique and, finally, the stochastic gradient descent regressor with classifier is used for obtaining higher accuracy than the existing technique. The obtained results powerfully recommend the proposed technique will be executed for recommendation learning model of Autism Spectrum Disorder alternatively and another traditional machine learning classifier recommended for previous works.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. D. Peebles and F. Thabtah, “A new machine learning model based on induction of rules for autism detection,” Health Informatics Journal, vol. 26, no. 1, pp. 264–286, 2019. [Google Scholar]
2. R. Anden, D. R. Dixon, K. K. Hyde, M. N. Novack and C. Parlett-Pelleriti, “Applications of supervised machine learning in autism spectrum disorder research: A review,” Review Journal of Autism and Developmental Disorders, vol. 6, no. 2, pp. 128–146, 2019. [Google Scholar]
3. L. Antezana, K. D. Cantin Garside, S. Kim, Z. Kong, M. A. Nussbaum et al., “Detecting and classifying self-injurious behavior in autism spectrum disorder using machine learning techniques,” Journal of Autism and Developmental Disorders, vol. 50, no. 11, pp. 4039–4052, 2020. [Google Scholar]
4. M. Duda, J. Daniels, N. Haber and D. P. Wall, “Crowd sourced validation of a machine-learning classification system for autism and ADHD,” Translational Psychiatry, vol. 7, no. 5, pp. 1133–1138, 2017. [Google Scholar]
5. I. Bilgen, G. Guvercin and I. Rekik, “Machine learning methods for brain network classification: Application to autism diagnosis using cortical morphological networks,” Journal of Neuroscience Methods, vol. 343, pp. e108799, 2020. [Google Scholar]
6. A. O. Bali, M. Bohlouli, M. Hosseinzadeh, J. Koohpayehzadeh Rad, A. Mazaherinezhad et al., “A review on diagnostic autism spectrum disorder approaches based on the Internet of Things and Machine Learning,” Journal of Supercomputing, vol. 7, no. 3, pp. 2590–2608, 2020. [Google Scholar]
7. J. A. Cruz and D. S. Wishart, “Applications of machine learning in cancer prediction and prognosis,” Cancer Informatics, vol. 2, no. 1, pp. 59–78, 2006. [Google Scholar]
8. M. N. Islam, A. Kabir, N. S. Khan and M. H. Muaz, “Diabetes predicting mhealth application using machine learning,” in Proc WIECON-ECE. Dehradun, India, pp. 237–240, 2017. [Google Scholar]
9. R. Dally, T. F. DeLuca, J. Y. Jung, R. Luyster and D. P. Wall, “Use of artificial intelligence to shorten the behavioral diagnosis of autism,” PLOS One, vol. 7, no. 8, pp. e43855, 2012. [Google Scholar]
10. S. L. Bishop, M. P. Black, D. Bone, M. S. Goodwin, C. Lord et al., “Use of machine learning to improve autism screening and diagnostic instruments: Effectiveness, efficiency, and multi-instrument fusion,” Journal of Child Psychology and Psychiatry, vol. 57, no. 8, pp. 927–937, 2016. [Google Scholar]
11. C. Allison, B. Auyeung and S. Baron-Cohen, “Toward brief red flags for autism screening: The short autism spectrum quotient and the short quantitative checklist in 1,000 cases and 3,000 controls,” Journal of the American Academy of Child & Adolescent Psychiatry, vol. 51, no. 2, pp. 202–212, 2012. [Google Scholar]
12. F. Thabtah, “Autism spectrum disorder screening: Machine learning adaptation and DSM-5 fulfillment,” in Proc. ICMHI, Taiwan, pp. 1–6, 2017. [Google Scholar]
13. F. Hauck and N. Kliewer, “Machine Learning for Autism Diagnostics: Applying Support Vector Classification,” in Proc. HIMS, USA, pp. 120–123, 2017. [Google Scholar]
14. Bram van den Bekerom, “Machine Learning for detection of Autism Spectrum Disorder,” in Proc. SCIT, Netherlands, pp. 99–110, 2017. [Google Scholar]
15. T. F. Deluca, V. A. Fusaro, E. Harstad, J. Kosmicki and D. P. Wall, “Use of machine learning to shorten observation-based screening and diagnosis of autism,” Translational psychiatry, vol. 2, no. 4, pp. e100, 2012. [Google Scholar]
16. A. Buchweitz, R. C. Craddock, A. R. Franco, A. S. Heinsfeld and F. Meneguzzi, “Identification of autism spectrum disorder using deep learning and the ABIDE dataset,” NeuroImage: Clinical, vol. 17, no. 1, pp. 16–23, 2018. [Google Scholar]
17. M. Li, W. Liu and L. Yi, “Identifying children with autism spectrum disorder based on their face processing abnormality: A machine learning framework,” Autism Research, vol. 9, no. 8, pp. 888–898, 2016. [Google Scholar]
18. K. Audhkhasi, D. Bone, M. P. Goodwin, C. C. Lee and S. Narayanan, “Applying machine learning to facilitate autism diagnostics: Pitfalls and promises,” Journal of Autism and Developmental Disorders, vol. 45, no. 5, pp. 1121–1136, 2015. [Google Scholar]
19. M. Duda, J. A. Kosmicki, V. Sochat and D. P. Wall, “Searching for a minimal set of behaviors for autism detection through feature selection-based machine learning,” Translational psychiatry, vol. 5, no. 2, pp. e514, 2015. [Google Scholar]
20. O. Dekhil, A. Elmaghraby, M. Ismail, R. Keynton, A. Shalaby et al., “A novel CAD system for autism diagnosis using structural and functional MRI,” in Proc. ISBI, Australia, pp. 995–998, 2017. [Google Scholar]
21. O. Altay and M. Ulas, “Prediction of the autism spectrum disorder diagnosis with linear discriminant analysis classifier and K-nearest neighbor in children,” in Proc ISDFS. Turkey, pp. 1–4, 2018. [Google Scholar]
22. Anibal Solon and Heinsfeld, “Identification of autism disorder through functional MRI and deep learning,” M.S. Thesis. Pontifical Catholic University, Brazil, 2017. [Google Scholar]
23. D. Ni, J. Yin, F. Shi, K. H. Thung, C. Y. Wee et al., “Identification of infants at high-risk for autism spectrum disorder using multi parameter multi scale white matter connectivity networks,” Journal of Human Brain Mapping, vol. 36, no. 12, pp. 4880–4896, 2015. [Google Scholar]
24. S. Raj and S. Masood, “Analysis and detection of autism spectrum disorder using machine learning techniques,” Procedia Computer Science, vol. 167, no. 12, pp. 994–1004, 2020. [Google Scholar]
25. U. Erkan and Dang N. H. Thanh, “Autism spectrum disorder detection with machine learning methods,” Current Psychiatry Research and Reviews Formerly: Current Psychiatry Reviews, vol. 15, no. 4, pp. 297–308, 2020. [Google Scholar]
26. M. D. Hossain, M. A. Kabir, A. Anwar and M. Z. Islam, “Detecting Autism Spectrum disorder using Machine Learning Techniques,” Health Information Science and Systems, vol. 9, no. 1, pp. 1–13, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |