DOI:10.32604/iasc.2022.020164
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.020164 | |
| Article |
Machine Learning Privacy Aware Anonymization Using MapReduce Based Neural Network
Department of Computer Science and Engineering, St. Peter’s Institute of Higher Education and Research, Chennai, India
*Corresponding Author: U. Selvi. Email: slvunnikrishnan@gmail.com
Received: 12 May 2021; Accepted: 22 June 2021
Abstract: Due to the recent advancement in technologies, a huge amount of data is generated where individual private information needs to be preserved. A proper Anonymization algorithm with increased Data utility is required to protect individual privacy. However, preserving privacy of individuals whileprocessing huge amount of data is a challenging task, as the data contains certain sensitive information. Moreover, scalability issue in handling a large dataset is found in using existing framework. Many an Anonymization algorithm for Big Data have been developed and under research. We propose a method of applying Machine Learning techniques to protect and preserve the personal identities of Individuals in BigData framework, which is termed as BigData Privacy Aware Machine Learning. For addressing a large volume of data, MapReduce-based neural networks parallelism is taken into consideration with classification of data volume. Human contextual information as applied through collaborative Machine Learning is proposed. The result of our experiment shows that relating human knowledge to neural network and parallelism by MapReduce framework can yield a better and measurable classification results for large scale Applications.
Keywords: Privacy aware machine learning; anonymization; k-anonymity; bigdata; mapreduce; back-propagation neural network; machine learning
BigData as the name implies refers to massive amount of data, generated at high speed with different data types that cannot be processed by tools available for Database Management and are problematic to capture, collect, explore, share, examine and visualize data [1].
BigData and 4v’s characteristics:
i) Volume states the large quantity of Data Generation and Data Collection;
ii) Velocity states the timeliness of the data received at data pool for analysis;
iii) Variety states data forms like unstructured, structured and semi-structured data; and
iv) Value states information concealed from data.
MapReduce, the customary computation model is used for handling BigData applications [1,2]. It is a framework used for processing larger datasets and is consistent, fault-tolerant, accessible, and self-balancing when the size of dataset increases. MapReduce framework [3] handles the larger sets using Map and Reduce Functions. Basically, a map functions produces 〈key, value〉 pairs as intermediate results by processing data. A reduce function sorts and merges the 〈key, value〉 pairs collected from multiple mappers and applies the results for secondary processing. Finally the reducer generates the results, based on the input which is collected from the outputs of multiple mappers.
Data Anonymization is the technique of protecting sensitive information from disclosure and preserving the privacy of the users of the application. In our paper, the standard k-Anonymity algorithm is chosen to preserve privacy.
Artificial Neural Networks [4] (ANNs) is capable of modelling & processing non-linear relationships between input and output in parallel and have been widely used in various research scenario. One of the implementation of ANN is neural network which uses Back-Propagation (BPNN) approach, which is evidenced to be efficient in terms of approximation capability. An ‘n’ number of hidden inputs and outputs layers are found in BPNN, with each layer containing neurons. BPNN uses an error-back propagation mechanism for training data and employs feed forward network to produce the required output.
This paper tries to focus on MapReduce approach which implements Back-Propagation Neural Network (MRBPNN) by considering Classification of data Volume i.e., we aim to implement Machine Learning Algorithm in MapReduce for parallel processing.
Malle et al. [5] Aims to provide the report on information loss and Quasi-identifier distributions by defining a k-factor proposed by user. But the algorithm is found to be not interactive and doesn’t achieve the expected results during the learning phase. The user has to check whether the expected result is achieved or not and decide after completion of Anonymization run upon using Cornell Anonymization Toolkit (Cat) [6]. Our methodology adjusts algorithmic factors upon each (batch of) manual interruptions, to make the algorithm to be adapted in real-time.
Xu et al. [7] Proposes to construct generalization hierarchies by allowing human interventions to set constraints on attributes in the process of anonymization.
Our Contributions
We propose Hadoop MapReduce framework that implements Back-propagation Neural Network to achieve k-anonymity for large scale application.
Our contribution is summarized as follows:
i) Fast Correlation based on Feature Selection Algorithm using Map Reduce is used for pre- processing the dataset to select relevant feature.
ii) Then, the pre-processed data is fed to the MapReduce Framework. Each mapper has a Back Propagation Neural Network which maps the data to form equivalent groups which form clusters. The algorithm begins by selecting the next candidate for merging until the cluster reaches the size k. The k-anonymity criterion is satisfied by combining all data points to form clusters for a given dataset. The intermediate result from the mapper is fed as input to reducer function.
iii) BPNN uses the error propagation method to tune the network parameter until it satisfies the k-anonymity.
The paper organized as follows:
Section 2: Delivers contextual evidence around MapReduce-based Back Propagation Neural network and the architecture of BPNN. Section 3: Explains k-anonymity and Section 4: Deals with BigData MapReduce. Section 5: Describes the Iterative Machine learning to achieve Anonymity. Section 6: Deliberation and Analysis of the empirical studies. Section 7: Summarizes the conclusion of the paper.
This section explains the Paralleling Neural Networks with Back-Propagation.
2.1 Back-Propagation Neural Networks (BPNN)
Propagating errors in backward direction for training data is Back-Propagation Neural Network. It is a multi-layered structure and feeds forward network. Input-output mappings using BPNN can be performed with a large volume of data, without having adequate knowledge on mathematical equation involved. BPNN tunes the network parameter to achieve k-anonymity in the process of the error propagation. Fig. 1 depicts the BPNN which has a number of inputs and outputs with a multi-layered network structure. A BPNN has three explicit layers: (i) the input, (ii) the output and (iii) the hidden layers. It is the commonly accepted network structure to fit a mathematical equation and to map the relationships between inputs and outputs [8].
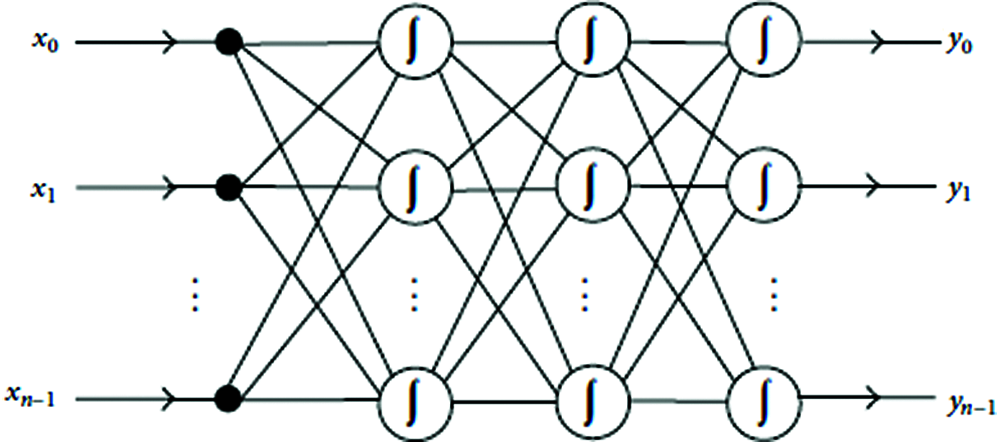
Figure 1: Neural network with back-propagation
2.2 The Design of MapReduce Back-Propagation Neural Network
Consider a testing instance j = {
i) Data instance is denoted by
ii) Dataset is denoted by Q;
iii) The dimension of
iv) The inputs are represented as 〈
v) Neural Network (NN) input
vi)
vii) Two values of field type includes: ‘trainset’ and ‘testset’, which are marked based on the category of
Initially, records covering instances are kept into HDFS. Each record has training and testing instances. Consequently, the record number η specifies the quantity of mappers used. The data chunk or the training data is fed as input to each mapper. Fig. 2 shows the architecture of MapReduce-based Back Propagation Neural Network (BPNN).
Initializing a neural network with each mapper function is the first step where the Algorithm begins. As a consequence, in a cluster, there are