DOI:10.32604/iasc.2021.017652
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2021.017652 | |
| Article |
A New Four-Parameter Moment Exponential Model with Applications to Lifetime Data
1Department of Mathematics, Faculty of Science, Jazan University, Jazan, Saudi Arabia
2Faculty of Graduate Studies for Statistical Research, Department of Mathematical Statistics, Cairo University, Egypt
3Sadat Academy for Management Sciences, Department of Mathematics, Statistics and Insurance, Cairo, Egypt
4Department of Mathematics, Faculty of Science, Jazan University, Jazan, Saudi Arabia
5Faculty of Graduate Studies for Statistical Research, Department of Mathematical Statistics, Cairo University, Egypt
*Corresponding Author: Rokaya E. Mohamed. Email: rokayaelmorsy@gmail.com
Received: 01 February 2021; Accepted: 06 March 2021
Abstract: In this research article, we propose and study a new model the so-called Marshal-Olkin Kumaraswamy moment exponential distribution. The new distribution contains the moment exponential distribution, exponentiated moment exponential distribution, Marshal Olkin moment exponential distribution and generalized exponentiated moment exponential distribution as special sub-models. Some significant properties are acquired such as expansion for the density function and explicit expressions for the moments, generating function, Bonferroni and Lorenz curves. The probabilistic definition of entropy as a measure of uncertainty called Shannon entropy is computed. Some of the numerical values of entropy for different parameters are given. The method of maximum likelihood is adopted for estimating the model parameters. We study the behavior of the maximum likelihood estimates for the model parameters using simulation study. A numerical study is performed to evaluate the behavior of the estimates with respect to their absolute biases, standard errors and mean square errors for different sample sizes and for different parameter values. Further, we conclude that the maximum likelihood estimates of the Marshal-Olkin Kumaraswamy moment exponential distribution perform well as the sample size increases. We take advantage of applied studies and offer two applications to real data sets that prove empirically the power of adjustment of the new model when compared to other lifetime distributions.
Keywords: Marshal-Olkin Kumaraswamy family; moment exponential distribution; quantile function; maximum likelihood estimation
The modeling and analysis of lifetimes are important aspects of statistical work in a wide variety of technological fields. The procedure of adding one or two shape parameters to a class of distributions to obtain more flexibility, especially for studying tail behavior, is a well-known technique in the statistical literatures. Marshall et al. [1] proposed a method of adding a shape parameter to a family of distributions and many authors used their method to extend several well-known distributions.
The cumulative distribution function (cdf) and the probability density function (pdf) of the Marshall- Olkin (MO) family are defined as follows:
and,
where,
Tahir et al. [4] presented another generalization by exponentiating the cdf of the MO family; as follows:
[For more on MO distributions see [5–13]]. Cordeiro et al. [14] defined the Kumaraswamy-G (Kw-G) class with the cdf and pdf given by
and,
where a > 0 and b > 0 are shape parameters, in addition to those in the baseline distribution which partly govern skewness and variation in tail weights. Handique et al. [15] proposed a new extension of the MO family by considering the cdf and pdf of Kw-G distribution in (5) and (6) and call it MO Kumaraswamy-G (MOKw-G) distribution with cdf and pdf given by:
and,
where
The exponential distribution is a very popular statistical model and, probably, is one of the parametric models that most extensively applied in several fields [16]. Due to its importance, several studies introducing and/or studying extensions of the exponential distribution are available in the literatures. Some forms of exponential distribution are; the exponentiated exponential [17,18], beta exponential [19], beta generalized exponential [20], moment exponential [21], exponentiated moment exponential [22], generalized exponentiated moment exponential [23], extended exponentiated exponential [24], MO exponential Weibull [25], MO generalized exponential (MOGE) [26], MO length-biased exponential (MOLBE) [27], alpha power transformed extended exponential [28] and MO Kumaraswamy exponential (MOKwE) [29] distributions.
Moment distributions have a vital role in mathematics and statistics, in particular in probability theory, in the perspective research related to ecology, reliability, biomedical field, econometrics, survey sampling and in life-testing. Dara et al. [21] proposed the moment exponential (ME) distribution through assigning weight to the exponential distribution. They showed that their proposed model is more flexible model than the exponential distribution. The pdf of the ME distribution is specified by:
where,
In this paper, we introduce and study the MO Kumaraswamy ME (MOKwME) distribution. The MOKwME model includes as special cases the generalized exponentiated ME (GEME), exponentiated ME (EME), MOLBE, Kumaraswamy ME (KwME) and ME distributions, which are very important statistical models, especially for applied works. It is interesting to observe that its hazard rate function can be, increasing, decreasing, and upside-down bathtub. Accordingly, it can be used effectively to analyze lifetime data sets. Some statistical properties of the proposed model are provided. Maximum likelihood (ML) estimators of the model parameters are presented. A simulation study and an application of the suggested model on real life data set are given.
The cdf and pdf of the MOKwME distribution are obtained by substituting (9) and (10) in (7) and (8) as follows:
and,
where,
• For
• For
• For
• For
• For
Next, we provide a simple motivation for the MOKwME distribution in the medical context as follows (see [15]): Consider a random sample X1, X2,…, XN, where the Xi’s, i =1,2,…,N, be a sequence of identically independent distributed random variables with survival function
• If N has a geometric distribution with parameter
• If N has a geometric distribution with parameter
This setup is usually common in oncology, where N represents the amount of cells with metastasis potential and Xi denotes the time for the ith cell to metastasis. So, X represents the recurrence time of the cancer.
The survival and hazard rate functions of X are given, respectively, as follows:
and
Plots of the pdf and hrf of the MOKwME distribution are displayed in Figs. 1 and 2, respectively, for different values of parameters. As seen from Fig. 1, the shapes of the pdf take different forms. Also, it is clear from Fig. 2 that the shapes of the hrf are reversed J-shaped, decreasing, increasing and upside-down bathtub at some selected values of parameters.
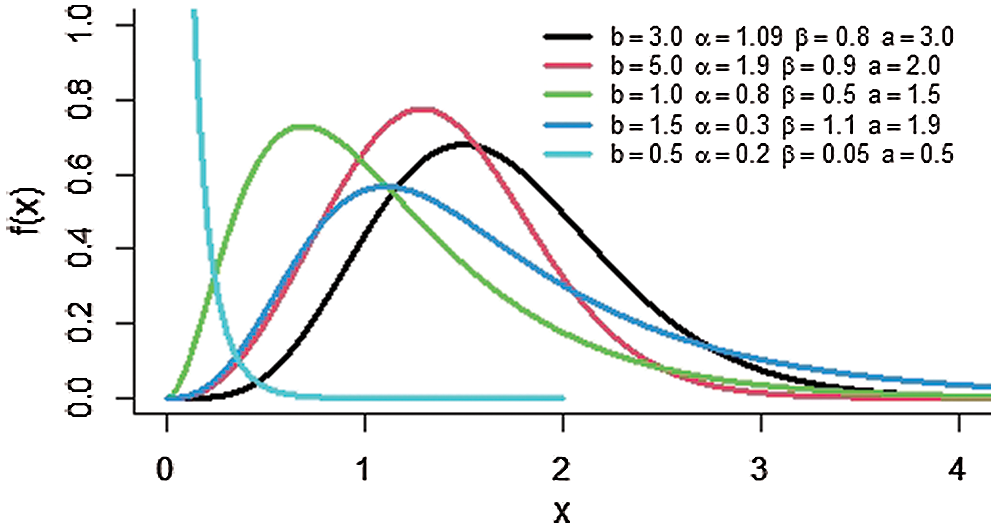
Figure 1: The pdf of the MOKwME distribution for some values of parameters
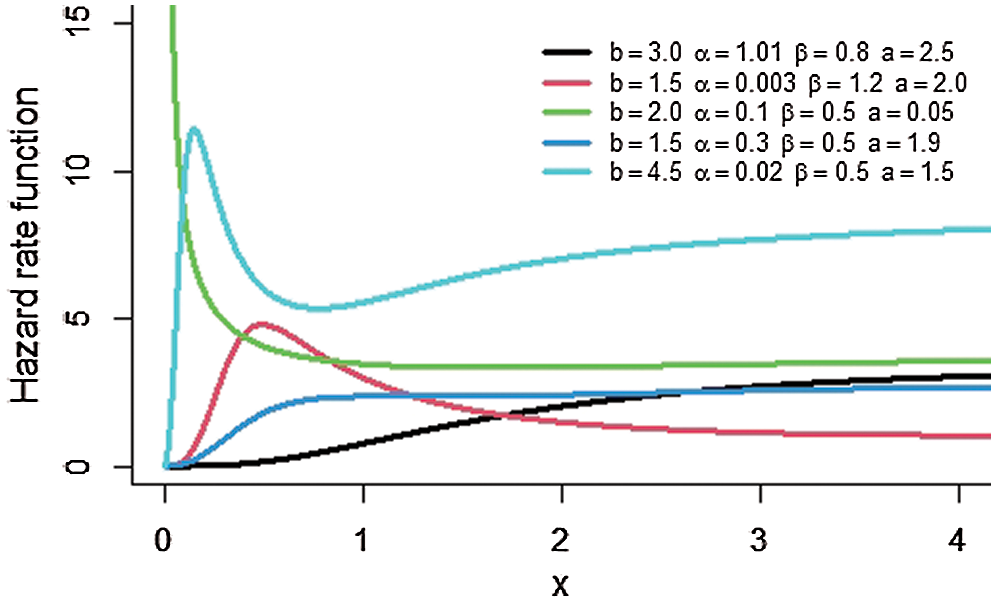
Figure 2: The hrf of the MOKwME distribution for some values of parameters
Here, explicit expression for the MOKwME density function is provided. Since, the binomial expansion, for real non-integer value of k, is given by:
Using (15) in pdf (12), we obtain
Again applying the binomial expansion in "previous equation", we obtain
Hence the pdf of MOKwME distribution can be written as follows:
where,
Eq. (18) reveals that the MOKwME density function is a linear mixture of EME density functions with power parameter
Here, we discuss the sth moment for the MOKwME distribution. The sth moment for the MOKwME distribution about zero is derived by using pdf (18) as follows:
Suppose
Using binomial expansion, then
where
The mean of the MOKwME distribution is obtained by putting s =1 in (21). The sth central moment (
The sth incomplete moment, say
Hence, the sth moment of MOKwME is derived by substituting (18) in (23) as follows:
where
The Bonferroni curve of MOKwME distribution is obtained as
3.4 Moments of Residual Life Function
The residual life plays an important role in life testing situations and reliability theory. The nth moment of the residual life is defined by:
Using the binomial expansion and pdf (18), then
So, after simplification the nth moment of the residual life of MOKwME distribution is obtained as follows:
where
The P-th quantile function (also called the percentile of order p) of the MOKwME distribution is of the form:
In particular, the median, denoted by M, can be obtained from (30) by substituting P = 0.5 and solving the following:
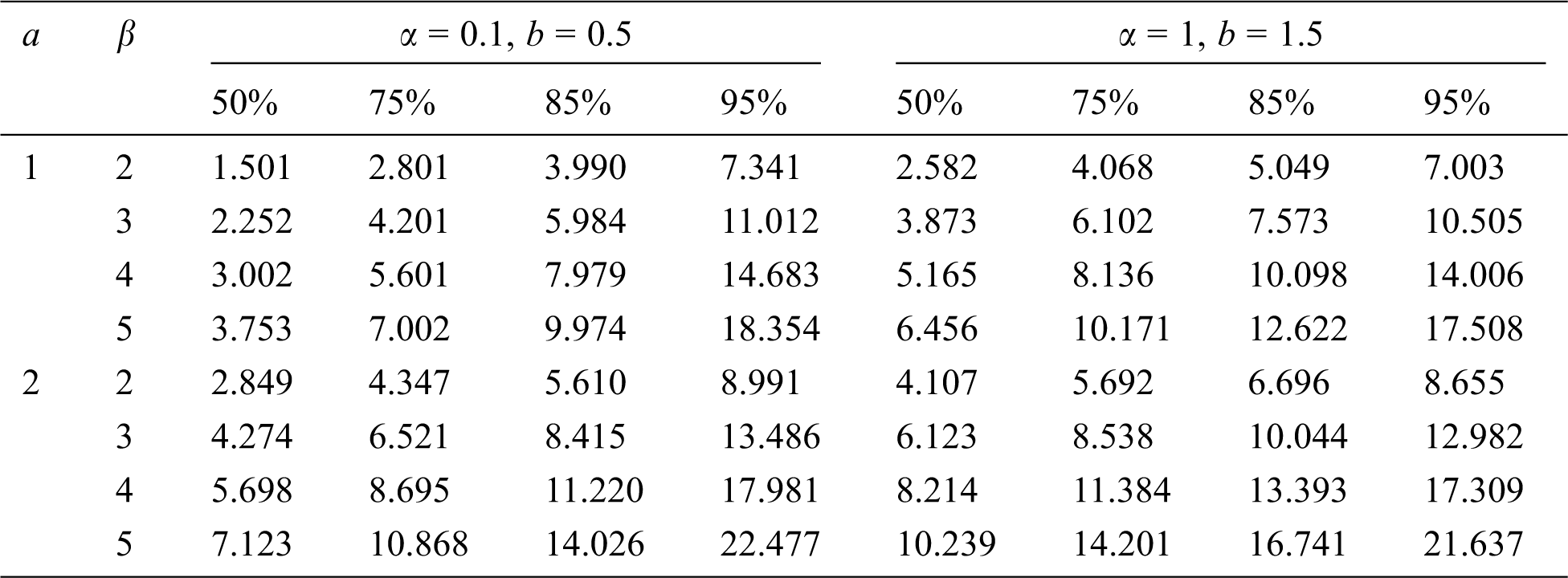
Solving the Eq. (30) numerically, the percentage points are computed for some selected values of the parameters. These values are provided in Tab. 1.
Table 1: Percentage points for
Shannon [31] introduced the probabilistic definition of entropy as a measure of uncertainty. It is also a useful instrument for comparing two or more distributions. The Shannon entropy of a random variable X is defined by:
The Shannon entropy for the MOKwME distribution with pdf (12) is as follows:
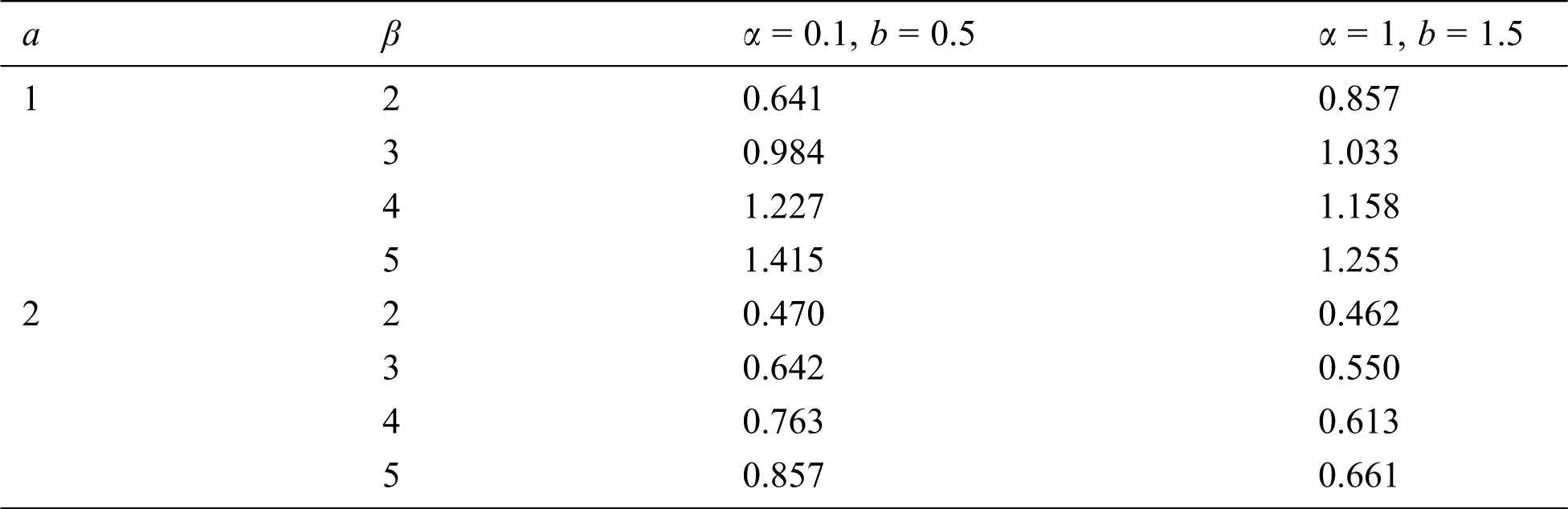
Since the theoretical result of entropy is not in a closed form, some of the numerical values of entropy for different parameters are given in Tab. 2.
Table 2: Shannon Entropy for some values of
5 Maximum Likelihood Estimators
We consider the estimation of the unknown parameters of the MOKwME distribution using the ML method. Let X1, X2, …, Xn be the observed values from the MOKwME distribution with set of parameters
The partial derivatives of the log-likelihood function with respect to
and,
The ML estimators of the model parameters are determined by solving the non-linear equations
A numerical study is performed to evaluate the performance of the estimates with respect to their absolute biases (ABs), standard errors (SEs) and mean square errors (MSEs) for different sample sizes and for different parameter values. The numerical procedures are described through the following steps:
Step 1: A random sample X1,…,Xn of sizes n =10, 20, 30, 50 and 100 are selected, these random samples are generated from the MOKwME distribution.
Step 2: Four different set values of the parameters are selected as,
Step 3: For each sample size, the ML estimates (MLEs) of α, β, a and b are computed.
Step 4: Steps from 1 to 3 are repeated 1000 times, then, the ABs, SEs and MSEs of the estimates are computed.
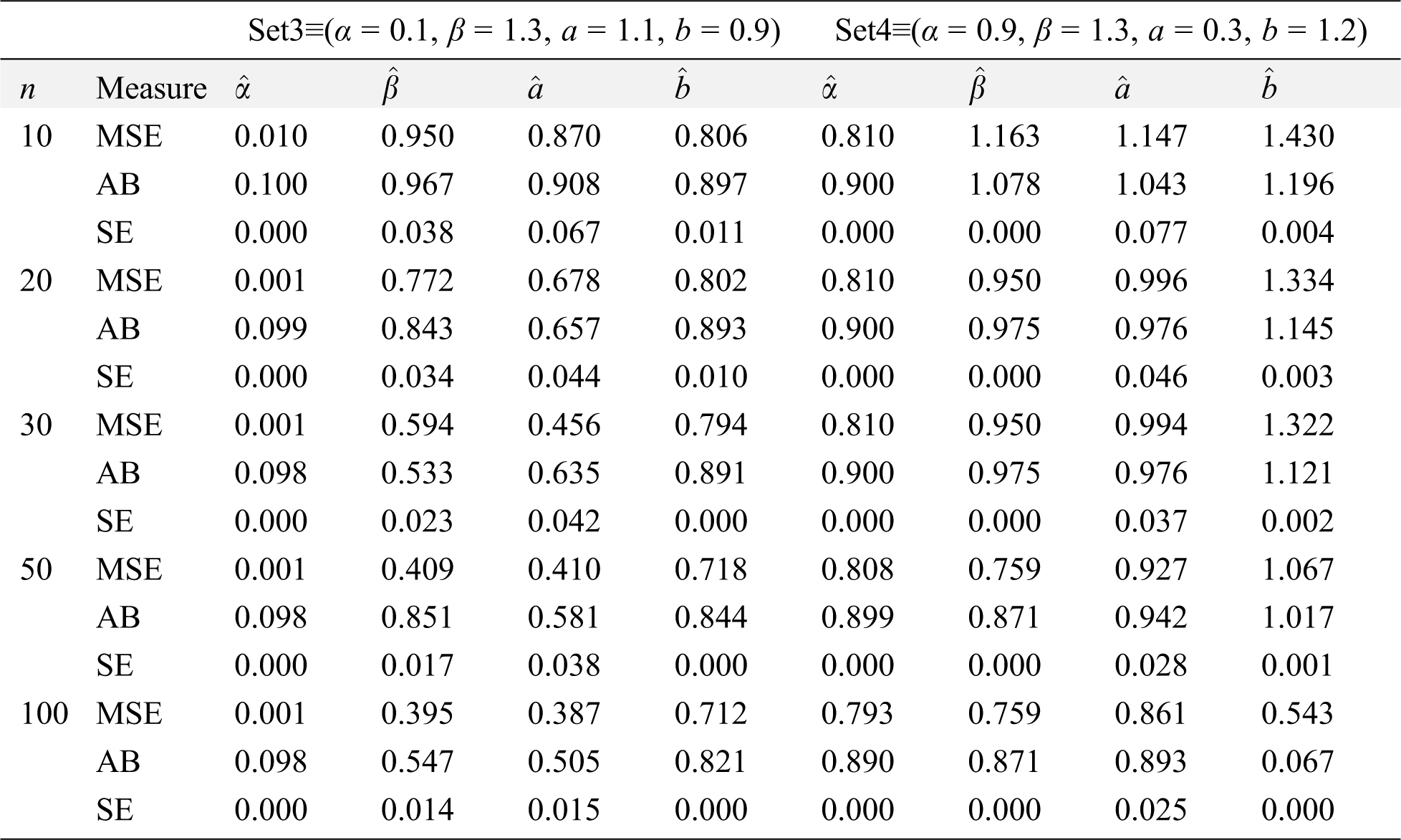
Numerical results are reported in Tabs. 3 and 4, from these tables, the following observations can be detected on the behavior of estimated parameters from the MOKwME distribution.
• The ABs, SEs and MSEs decrease as sample sizes increase (see Tabs. 3 and 4).
• The ABs of
• For fixed values of
Table 3: ABs, SEs and MSEs of MOKwME parameter estimates for Set 1and Set 2
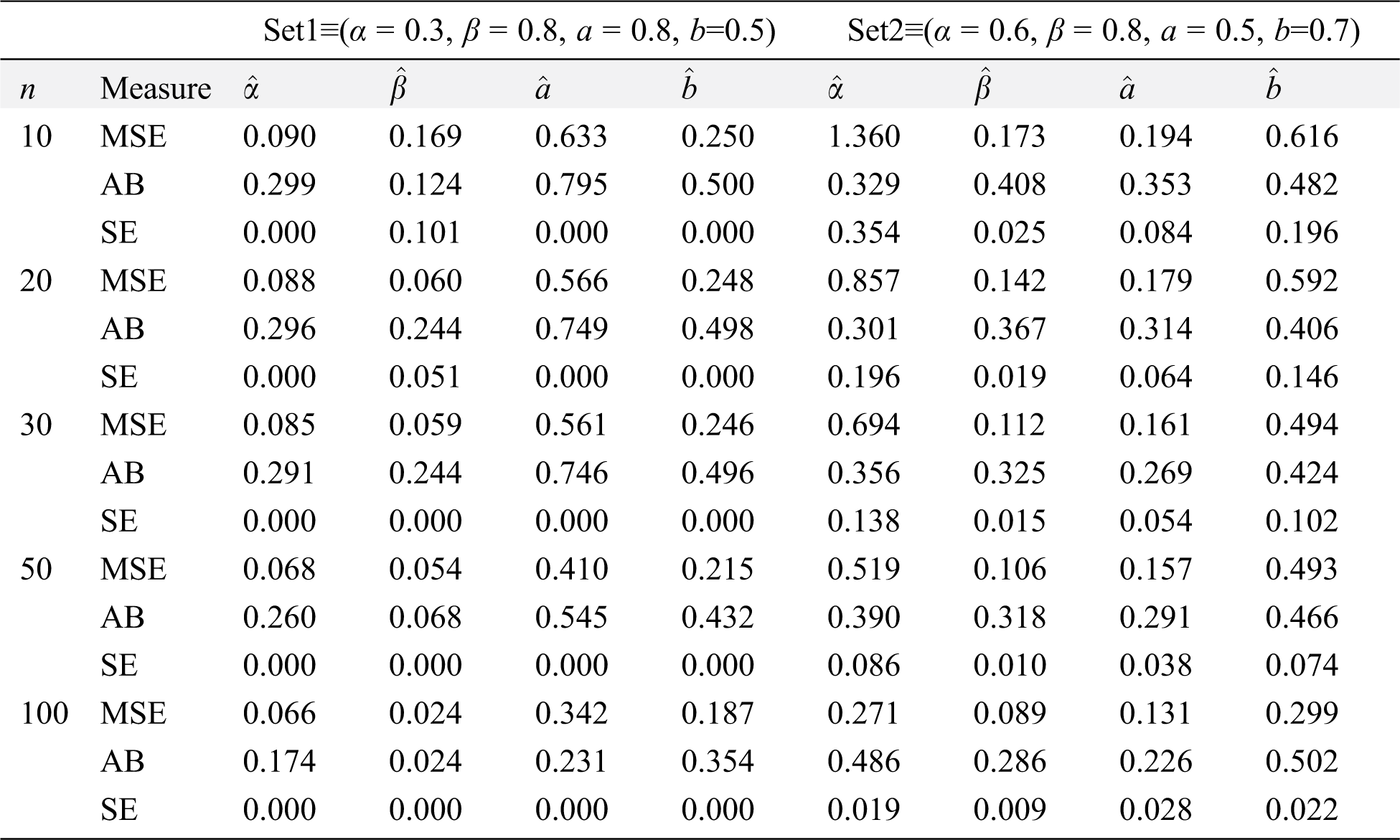
Table 4: ABs, SEs and MSEs of MOKwME parameter estimates for Set 3and Set 4
In this section, we fit the MOKwME distribution into two distinct real data sets and we compare the performance with those of MOLBE, GEME, MOGE, EME, ME and MOKwE distributions. In each real data set, the MLEs and their corresponding SEs (in parentheses) of the model parameters are obtained. -2 log-likelihood (-2LnL), Akaike information criterion (AIC), the correct Akaike information criterion (CAIC), Bayesian information criterion (BIC), Hannan-Quinn information criterion (HQIC), Anderson-Darling (A*) statistic, Cramér- von Mises (W*) statistic and Kolmogorov-Smirnov (K-S) statistic are used to assess the effectiveness of the models. The model with the smallest value of these measures gives a better representation of the data set than the others.
First Real Data Set: The first data refer to Smith et al. [32] which represent the strengths of 1.5 cm glass fibers, measured at the National Physical Laboratory, England. The data are:
0.55, 0.93, 1.25, 1.36, 1.49, 1.52, 1.58, 1.61, 1.64, 1.68, 1.73, 1.81, 2.0, 0.74, 1.04, 1.27, 1.39, 1.49, 1.53, 1.59, 1.61, 1.66, 1.68, 1.76, 1.82, 2.01, 0.77, 1.11, 1.28, 1.42, 1.50, 1.54, 1.60, 1.62, 1.66, 1.69, 1.76, 1.84, 2.24, 0.81, 1.13, 1.29, 1.48, 1.5, 1.55, 1.61, 1.62, 1.66, 1.70, 1.77, 1.84, 0.84, 1.24, 1.30, 1.48, 1.51, 1.55, 1.61, 1.63, 1.67, 1.70, 1.78, 1.89.
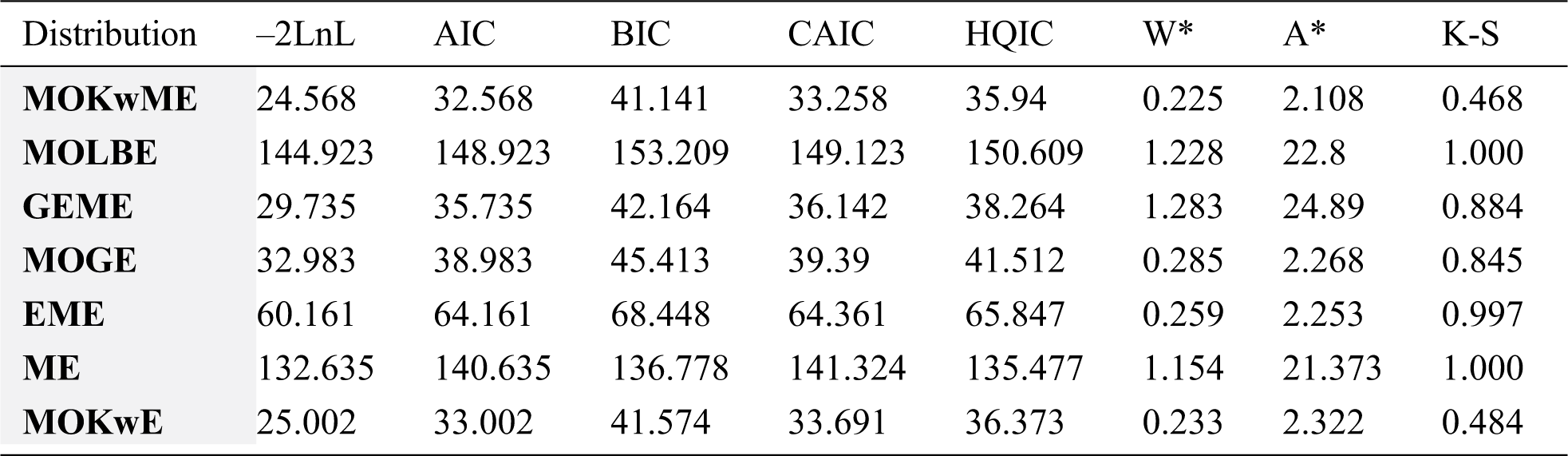
The MLEs and their corresponding SEs (in parentheses) of the model parameters are listed in Tab. 5. Also, the above suggested statistical measures of all models are listed in Tab. 6. It is observed, from Tab. 6, that the MOKwME distribution gives a better fit than other fitted models.
Table 5: MLEs of all models and the corresponding SEs (in parentheses) for the first data
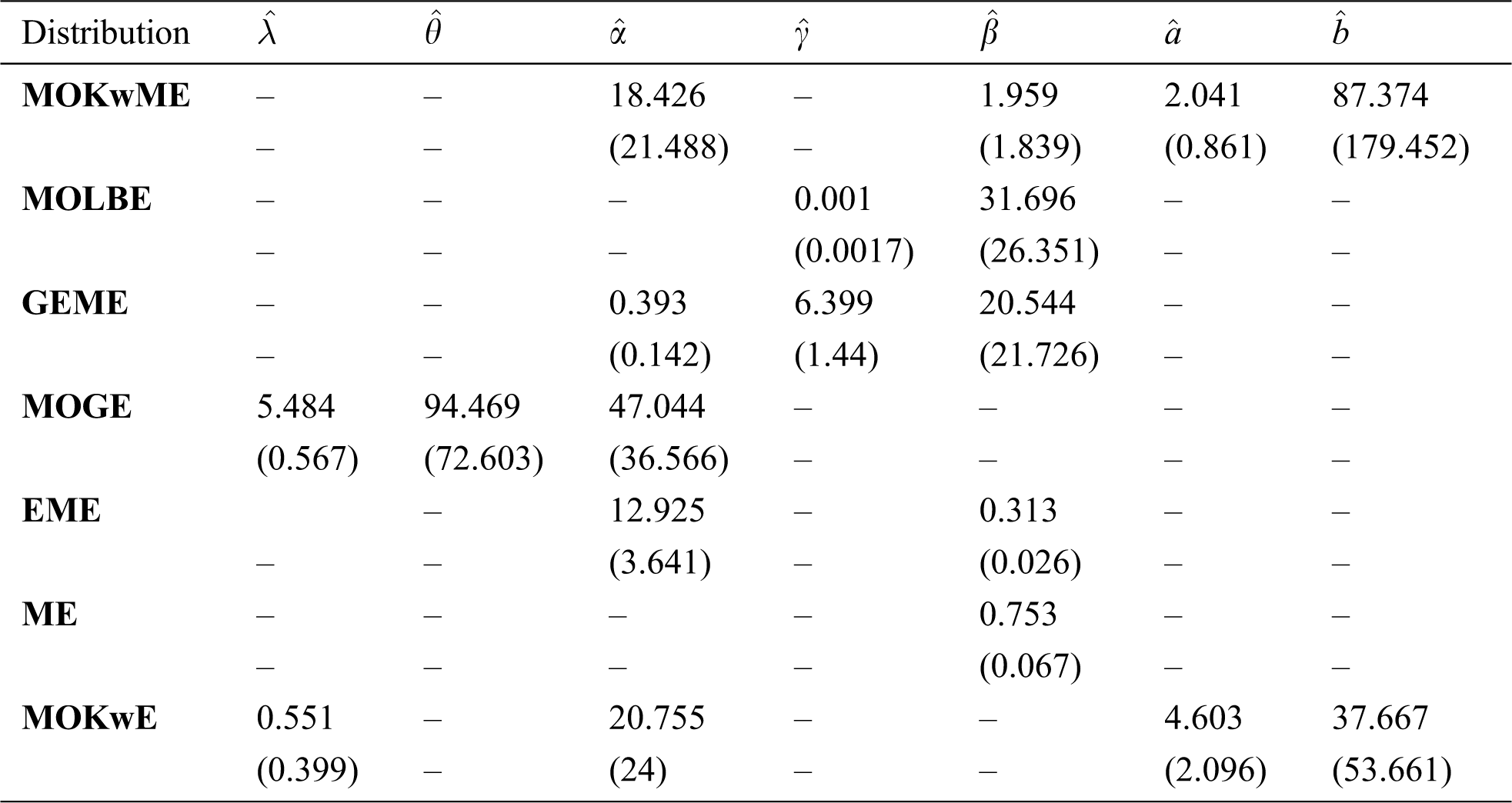
Table 6: Statistics measures for the first data
The empirical pdf and estimated cdf for the first data set are provided in Figs. 3 and 4.
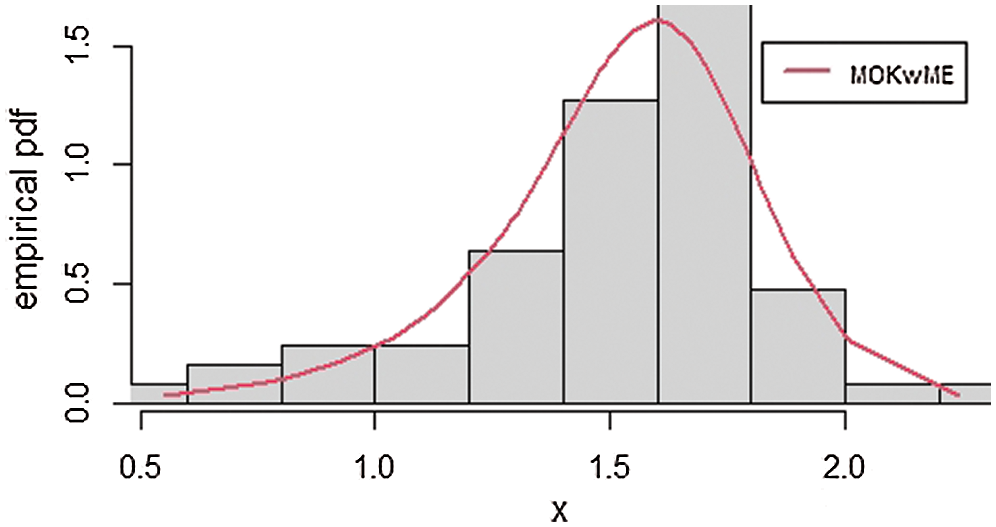
Figure 3: The empirical pdf of the MOKwME distribution for the first real data
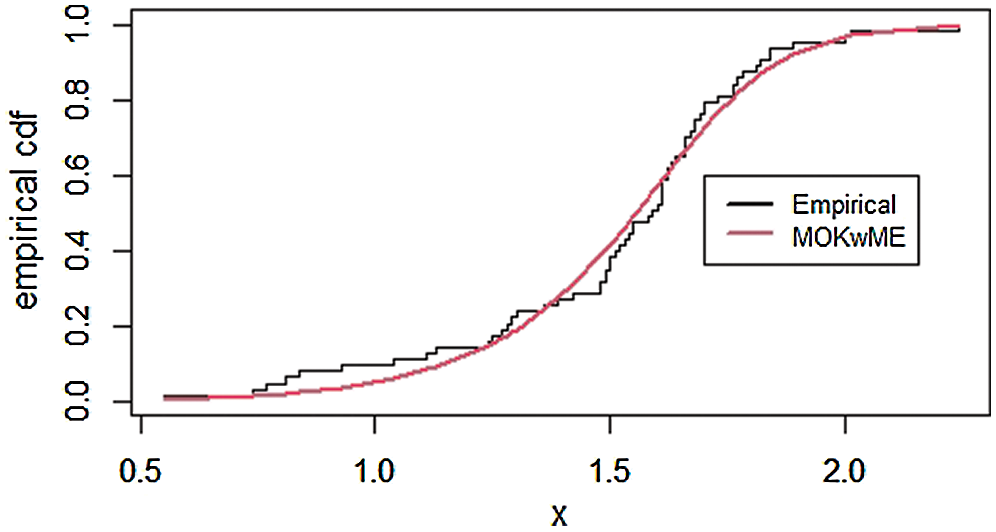
Figure 4: The empirical cdf of the MOKwME distribution for the first real data
Second Real Data: The second data were discussed in Ristić et al. [26], which represent the strength data measured in GPA, the single carbon fibers, and impregnated 1000-carbon fiber tows. Single fibers were tested under tension at gauge length 1 mm. The data are:
2.247, 2.64, 2.908, 3.099, 3.126, 3.245, 3.328, 3.355, 3.383, 3.572, 3.581, 3.681, 3.726, 3.727, 3.728, 3.783, 3.785, 3.786, 3.896, 3.912, 3.964, 4.05, 4.063, 4.082, 4.111, 4.118, 4.141, 4.246, 4.251, 4.262, 4.326, 4.402, 4.457, 4.466, 4.519, 4.542, 4.555, 4.614, 4.632, 4.634, 4.636, 4.678, 4.698, 4.738, 4.832, 4.924, 5.043, 5.099, 5.134, 5.359, 5.473, 5.571, 5.684, 5.721, 5.998, 6.06.
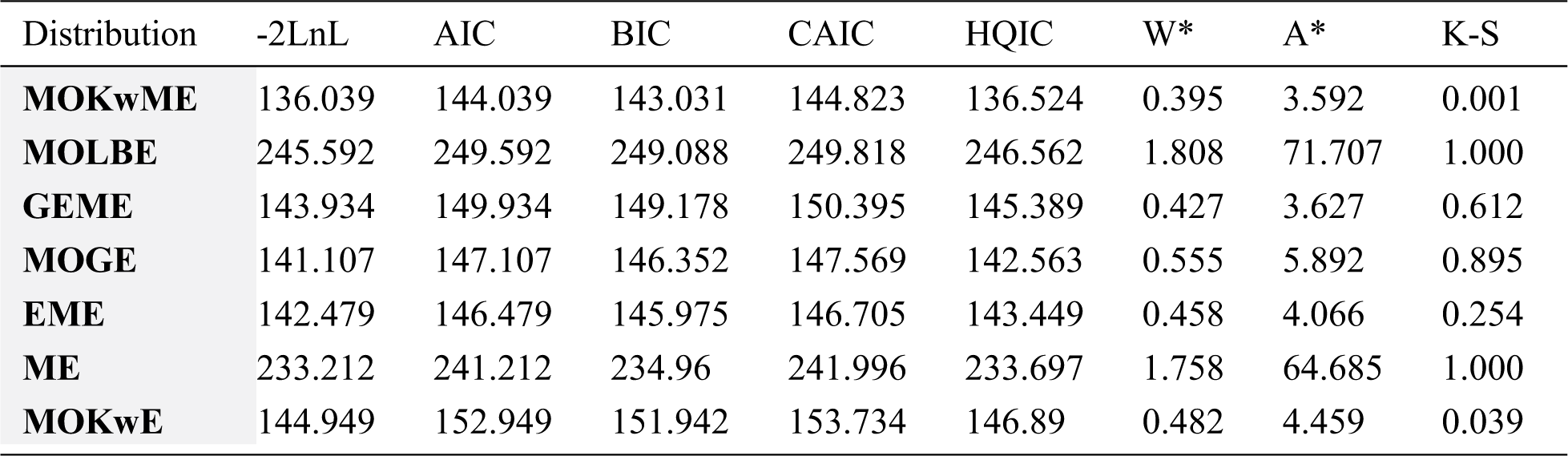
The MLEs and the SEs of the model parameters are listed in Tab. 7 whereas Tab. 8 gives the statistics measures of all models. It is observed, from Tab. 8, that the MOKwME distribution gives a better fit than other fitted models.
Table 7: MLEs of all models and the corresponding SEs (in parentheses) for the second data
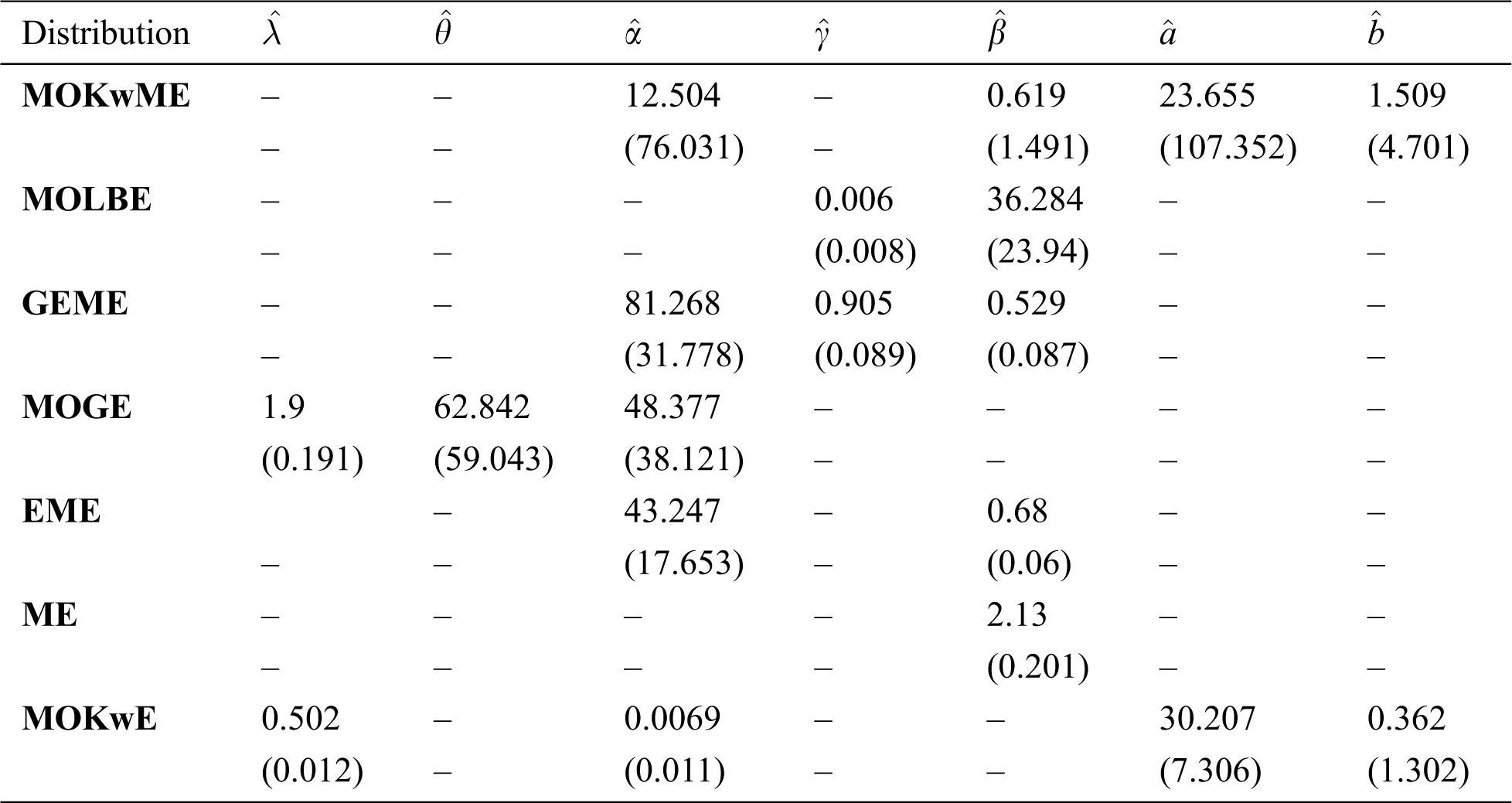
Table 8: Statistics measures for the second data
The empirical pdf and cdf for the second data set are provided in Figs. 5 and 6.
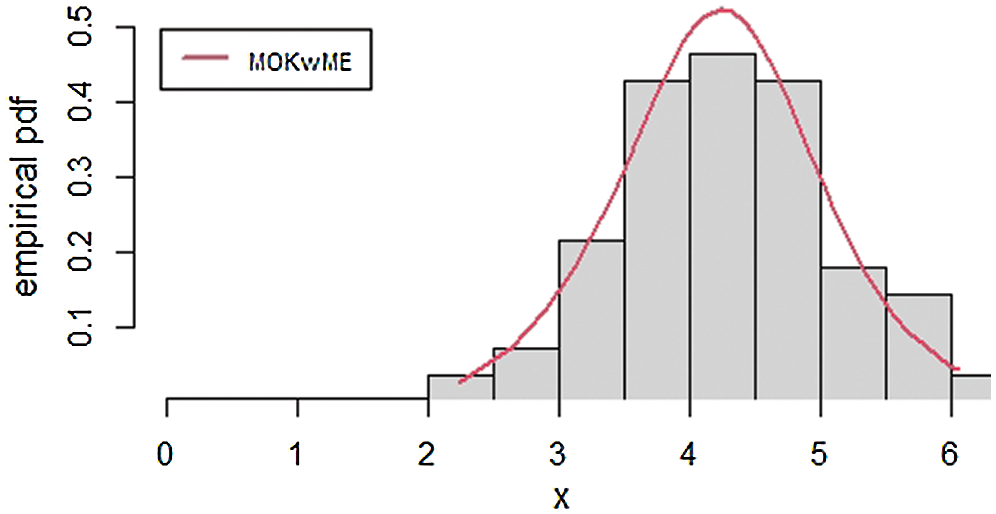
Figure 5: The empirical pdf of the MOKwME distribution for the second real data
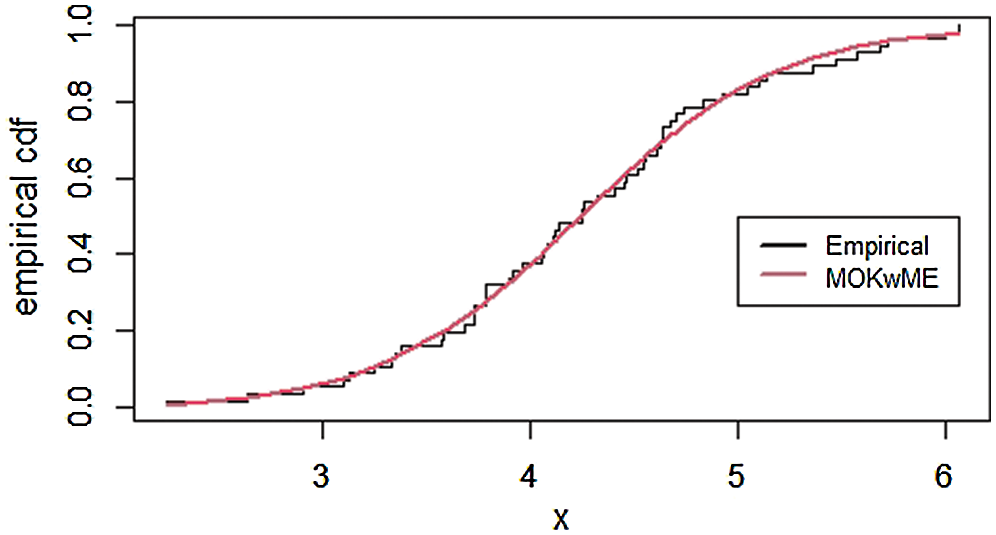
Figure 6: The empirical cdf of the MOKwME distribution for the second real data
In this paper, we introduce a new probability model called the Marshal-Olkin Kumaraswamy moment exponential. The new model includes; exponentiated moment exponential, generalized exponentiated moment exponential, Marshall-Olkin length-biased exponential and moment exponential distributions. At the same time, it contains the Kumaraswamy moment exponential distribution as a new model. We study some of its structural properties including an expansion for the density function and explicit expressions for the moments, generating function, Bonferroni and Lorenz curves. The maximum likelihood method is employed for estimating the model parameters. The usefulness of the new model is illustrated by means of an application to real data set.
Acknowledgement: The authors would like to thank the editor and the anonymous referees for their valuable and very constructive comments, which have greatly improved the contents of the paper
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare no conflict of interest.
1. A. W. Marshall and I. Olkin, “A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families,” Biometrika, vol. 84, no. 3, pp. 641–652, 1997. [Google Scholar]
2. A. K. Nanda and S. Das, “Stochastic orders of the Marshall-Olkin extended distribution,” Statistics & Probability Letters, vol. 82, no. 2, pp. 295–302, 2012. [Google Scholar]
3. K. Jayakumar and T. Mathew, “On a generalization to Marshall-Olkin scheme and its application to Burr type XII distribution,” Statistical Papers, vol. 49, no. 3, pp. 421–439, 2008. [Google Scholar]
4. M. H. Tahir and S. Nadarajah, “Parameter induction in continuous univariate distributions: Well-established G families,” Anais da Academia Brasileira de Ciências, vol. 87, no. 2, pp. 539–568, 2015. [Google Scholar]
5. H. Barakat, M. Ghitany and E. Al-Hussaini, “Asymptotic distributions of order statistics and record values under the Marshall-Olkin parametrization operation,” Communications in Statistics-Theory and Methods, vol. 38, no. 13, pp. 2267–2273, 2009. [Google Scholar]
6. M. Alizadeh, M. Tahir, G. M. Cordeiro, M. Mansoor, M. Zubair et al., “The Kumaraswamy Marshal-Olkin family of distributions,” Journal of the Egyptian Mathematical Society, vol. 23, no. 3, pp. 546–557, 2015. [Google Scholar]
7. R. Bantan, A. S. Hassan and M. Elsehetry, “Generalized Marshall Olkin inverse Lindley distribution with applications,” CMC-Computers, Materials & Continua, vol. 64, no. 3, pp. 1505–1526, 2020. [Google Scholar]
8. W. Barreto-Souza, A. J. Lemonte and G. M. Cordeiro, “General results for the Marshall and Olkin's family of distributions,” Anais da Academia Brasileira de Ciências, vol. 85, no. 1, pp. 3–21, 2013. [Google Scholar]
9. G. M. Cordeiro, A. J. Lemonte and E. M. Ortega, “The Marshall-Olkin family of distributions: Mathematical properties and new models,” Journal of Statistical Theory and Practice, vol. 8, no. 2, pp. 343–366, 2014. [Google Scholar]
10. C. R. Dias, G. M. Cordeiro, M. Alizadeh, P. R. D. Marinho and H. F. C. Coêlho, “Exponentiated Marshall-Olkin family of distributions,” Journal of Statistical Distributions and Applications, vol. 3, no. 1, pp. 106, 2016. [Google Scholar]
11. K. K. Jose and E. Krishna, “Marshall-Olkin extended uniform distribution,” ProbStat Forum, vol. 4, no. October, pp. 78–88, 2011. [Google Scholar]
12. I. Elbatal and M. Elgarhy, “Extended Marshall-Olkin length-Biased exponential distribution: Properties and applications,” Advances and Applications in Statistics, vol. 64, no. 1, pp. 113–125, 2020. [Google Scholar]
13. M. Haq, G. G. Hamedani, M. Elgarhy and P. L. Ramos, “Marshall-Olkin power Lomax distribution: Properties and estimation based on complete and censored samples,” International Journal of Statistics and Probability, vol. 9, no. 1, pp. 48–62, 2020. [Google Scholar]
14. G. M. Cordeiro and M. de Castro, “A new family of generalized distributions,” Journal of Statistical Computation and Simulation, vol. 81, no. 7, pp. 883–898, 2011. [Google Scholar]
15. L. Handique, S. Chakraborty and G. G. Hamedani, “The Marshall-Olkin-Kumaraswamy-G family of distributions,” Journal of Statistical Theory and Applications, vol. 16, no. 4, pp. 427–447, 2017. [Google Scholar]
16. A. J. Lemonte, “A new exponential-type distribution with constant, decreasing, increasing, upside-down bathtub and bathtub-shaped failure rate function,” Computational Statistics & Data Analysis, vol. 62, pp. 149–170, 2013. [Google Scholar]
17. R. D. Gupta and D. Kundu, “Generalized exponential distributions: Theory & methods,” Australian & New Zealand Journal of Statistics, vol. 41, no. 2, pp. 173–188, 1999. [Google Scholar]
18. R. D. Gupta and D. Kundu, “Exponentiated exponential family: An alternative to gamma and Weibull distributions,” Biometrical Journal: Journal of Mathematical Methods in Biosciences, vol. 43, no. 1, pp. 117–130, 2001. [Google Scholar]
19. S. Nadarajah and S. Kotz, “The beta exponential distribution,” Reliability Engineering & System Safety, vol. 91, no. 6, pp. 689–697, 2006. [Google Scholar]
20. W. Barreto-Souza, A. H. Santos and G. M. Cordeiro, “The beta generalized exponential distribution,” Journal of Statistical Computation and Simulation, vol. 80, no. 2, pp. 159–172, 2010. [Google Scholar]
21. S. T. Dara and M. Ahmad, in Recent Advances in Moment Distribution and Their Hazard Rates. Germany: LAP LAMBERT Academic Publishing, 2012. [Google Scholar]
22. S. A. Hasnain, “Exponentiated moment exponential distributions,” Ph.D. dissertation. National College of Business Administration & Economics, Lahore, Pakistan, 2013. [Google Scholar]
23. Z. Iqbal, S. A. Hasnain, M. Salman, M. Ahmad and G. Hamedani, “Generalized exponentiated moment exponential distribution,” Pakistan Journal of Statistics, vol. 30, no. 4, pp. 537–554, 2014. [Google Scholar]
24. S. Abu-Youssef, B. Mohammed and M. Sief, “An extended exponentiated exponential distribution and its properties,” International Journal of Computer Applications, vol. 121, no. 5, pp. 1–6, 2015. [Google Scholar]
25. T. K. Pogány, A. Saboor and S. Provost, “The Marshall-Olkin exponential Weibull distribution,” Hacettepe Journal of Mathematics and Statistics, vol. 44, no. 6, pp. 1579, 2015. [Google Scholar]
26. M. M. Ristić and D. Kundu, “Marshall-Olkin generalized exponential distribution,” METRON, vol. 73, no. 3, pp. 317–333, 2015. [Google Scholar]
27. M. A. Haq, R. M. Usman, S. Hashmi and A. I. Al-Omeri, “The Marshall-Olkin length-biased exponential distribution and its applications,” Journal of King Saud University - Science, vol. 31, no. 2, pp. 246–251, 2019. [Google Scholar]
28. A. S. Hassan, R. E. Mohamed, M. Elgarhy and A. Fayomi, “Alpha power transformed extended exponential distribution: properties and applications,” Journal of Nonlinear Sciences & Applications, vol. 12, no. 04, pp. 239– 251, 2018. [Google Scholar]
29. S. Chakraborty and L. Handique, “The generalized Marshall-Olkin-Kumaraswamy-G family of distributions,” Journal of Data Science, vol. 15, no. 3, pp. 391–422, 2017. [Google Scholar]
30. C. Kleiber and S. Kotz, in Statistical Size Distributions in Economics and Actuarial Sciences, Vol. 470, Hoboken, New Jersey: John Wiley & Sons, Inc., 2003. [Online] https://onlinelibrary.wiley.com/doi/pdf/10.1002/0471457175. [Google Scholar]
31. C. E. Shannon, “A mathematical theory of communication,” Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948. [Google Scholar]
32. R. L. Smith and J. C. Naylor, “A comparison of maximum likelihood and Bayesian estimators for the three-parameter Weibull distribution,” Journal of the Royal Statistical Society: Series C (Applied Statistics), vol. 36, no. 3, pp. 358–369, 1987. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |