DOI:10.32604/iasc.2021.017232
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2021.017232 | |
| Article |
Identification of Abnormal Patterns in AR (1) Process Using CS-SVM
1College of Mechanical and Electrical Engineering, Kunming University of Science & Technology, Kunming, 650500, China
2School of Engineering, Cardiff University, Cardiff, CF24 3AA, UK
*Corresponding Author: Bo Zhu. Email: zhubo20110720@163.com
Received: 24 January 2021; Accepted: 01 March 2021
Abstract: Using machine learning method to recognize abnormal patterns covers the shortage of traditional control charts for autocorrelation processes, which violate the applicable conditions of the control chart, i.e., the independent identically distributed (IID) assumption. In this study, we propose a recognition model based on support vector machine (SVM) for the AR (1) type of autocorrelation process. For achieving a higher recognition performance, the cuckoo search algorithm (CS) is used to optimize the two hyper-parameters of SVM, namely the penalty parameter
Keywords: Control chart pattern; support vector machine; cuckoo search algorithm; autocorrelation process; Monte Carlo simulation
Nowadays, the integration concept of informatization and industrialization is gradually being proposed. Many new technologies emerge continuously, such as Virtual Manufacturing (VM), Computer Integrated Manufacturing (CIM), and Radio-frequency Identification (RFID), Concurrent Engineering (CE), [1–5]. Under such a background, manufacturing companies have begun to shift from incremental competition to stock competition. Subsequently, product quality has become one of the core competitiveness of enterprises for success. In the quality engineering field, statistical process control (SPC) is an essential means for ensuring quality in the manufacturing process, which takes the control chart as the basic tool. The use of traditional control charts must follow the premise that the observed data is independent identically distributed (IID). However, Shiau [6], Montgomery [7] pointed out that process data generally cannot approximately satisfy this premise in actual production process. When there are obvious autocorrelation phenomena presented in the observed data, the control chart often subjects to serious false alarm so that cannot detect true process abnormities effectively. Studies have shown that the autocorrelation phenomena significantly reduce the performance of control chart [8,9].
Academia has carried out much studies on process quality control with autocorrelation phenomena and proposed some approaches. The main category is to use statistical methods to eliminate the influence of autocorrelation on process data. The most representative one is the residual control chart. Montgomery and Woodall [10], Runger [11] proposed to use a fitted time series model to monitor the autocorrelation process. Because the controlled statistics’ residuals are independent identically distributed theoretically, the conventional Shewhart control chart can be used to monitor the residuals effectively. Sun [12] and Zhang [13] carried out much research on the residual control chart of the autocorrelation process and validated its effectiveness. With the development of artificial intelligence technology, pattern recognition methods based on machine learning are proposed and introduced into the process quality control field. There are also some machine learning based methods applied to the autocorrelation process that have been reported. For example, Cook and Chiu [14] used the BP neural network to recognize the autocorrelation process’ abnormal pattern. Experiments results show that it gets an advantage over the traditional statistical methods. Lin and Guh [15] applied a support vector machine (SVM) based model to abnormal pattern identification of autocorrelation process, which achieved better performance in both recognition accuracy and recognition speed. Zhu and Liu [16] proposed to use random forest for control chart pattern recognition in autocorrelation process, and verified that the performance of their model is better than that of the BP neural networks through simulation experiments.
SVM is a major machine learning method for classification, which has been also used frequently in control chart pattern recognition [17]. SVM first appeared in the 1990s. In contrast with the BP neural network’s pursuit of minimizing experience risk, SVM takes minimum of the structural risk as optimizing goal. In that, SVM can better deal with the over-fitting problem, and then often achieve better generalization performance, especially under small sample conditions. Simultaneously, it has much fewer parameters need to be adjusted and accommodate to high-dimensional features. The use of SVM involves selecting an appropriate kernel function and tuning of the related hyper-parameters, which is essential for its generalization performance. Currently, there are some algorithms, such as artificial fish swarm algorithm (AFSA), genetic algorithm (GA), artificial bee colony (ABC), grid search (GS) and particle swarm optimization (PSO) [18–22], have been applied in the optimization of the hyper-parameters of SVM. The cuckoo search algorithm (CS) is a type of combination optimization algorithm appeared in recent years. Compared with other algorithms, it has many advantages, for instance, simpler structure, easy to jump out of local optimal values, and fewer control parameters.
Due to the superiorities of the SVM and the CS, we proposed an autocorrelation process pattern recognition model based on SVM optimized by CS (CS-SVM), which is used as the pattern classifier. In this model, the hyper-parameters of the SVM are optimized by the CS to get higher generalization performance. To verify this model’s effectiveness, the data sets of basic patterns in AR (1) type of autocorrelation process, including normal pattern and seven types of abnormal pattern, are generated by Monte Carlo simulation method. Based on the data sets, some verification experiments are conducted. The experiment results show that the proposed model has apparent advantages over some other methods, both in recognition accuracy and training efficiency. At the same time, it has an acceptable on-line detecting performance.
The paper is structured as follows. In Section 2, some related theories and methods are reviewed. In Section 3, the model is established, and its structure graph is presented. In Section 4, the environment and data of the simulation experiments are given and results are discussed. Section 5 concludes the paper with a summary and remarks. Description of the Monte Carlo simulation functions of the eight patterns is displayed in the Appendix A.
2 Related Theories and Methods
2.1 AR (1) Autocorrelation Process
In the modern manufacturing process, the production tempo is getting faster and faster, and the automatic data acquisition technology is used more and more widely. As a result, the observed values of a specific variable get at different moment frequently present certain type of dependence with each other. That is called the autocorrelation phenomenon [23]. The autocorrelation in actual process is usually modeled with certain time series model in researches. Different time series model can be used to fit autocorrelation process, such as AR(p), MA(q), ARMA (p, q), etc. The literature research indicates that the AR (1) model appears most commonly. Its mathematic expression is as follows:
In Eq. (1):
In actual production process, affected by certain assignable cause, process variable may takes on certain type of fluctuation, which can be seen from the control chart. Academia has defined these fluctuations as control chart patterns (CCP). There are eight major types of CCP, namely the Normal (NOR), the Upward Shift (US), the Downward Shift (DS), the Increasing Trend (IT), the Decreasing Trend (DT), the Cycle (CYC), the Systematic (SYS), and the Mixture (MIX). These CCPs can still take place in the process as there is autocorrelation exists. The Fig. 1 shows eight CCPs in autocorrelation process.
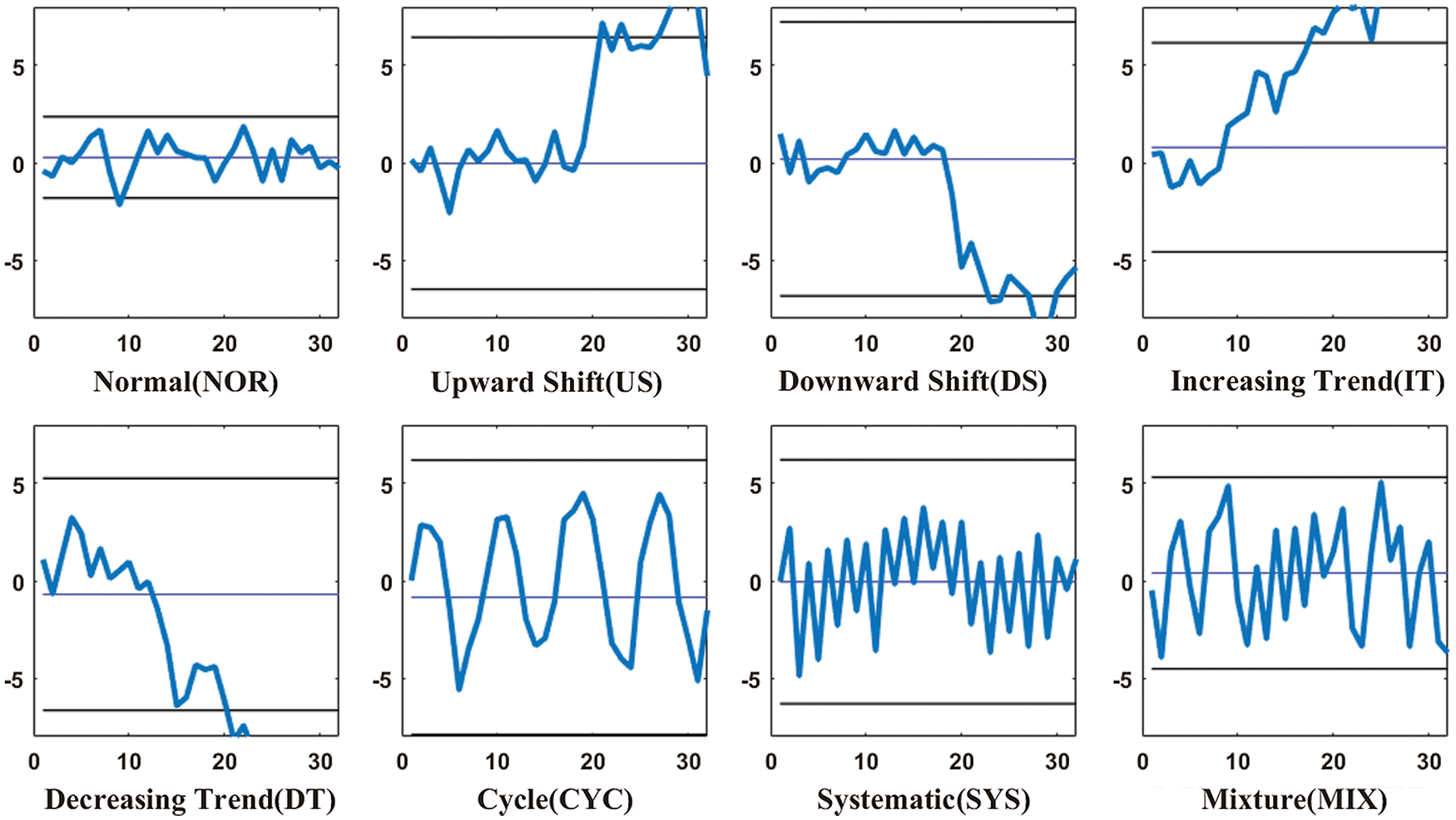
Figure 1: Control chart patterns in autocorrelation process
The classification problem using support vector machines can be described as follows. Given a sample set
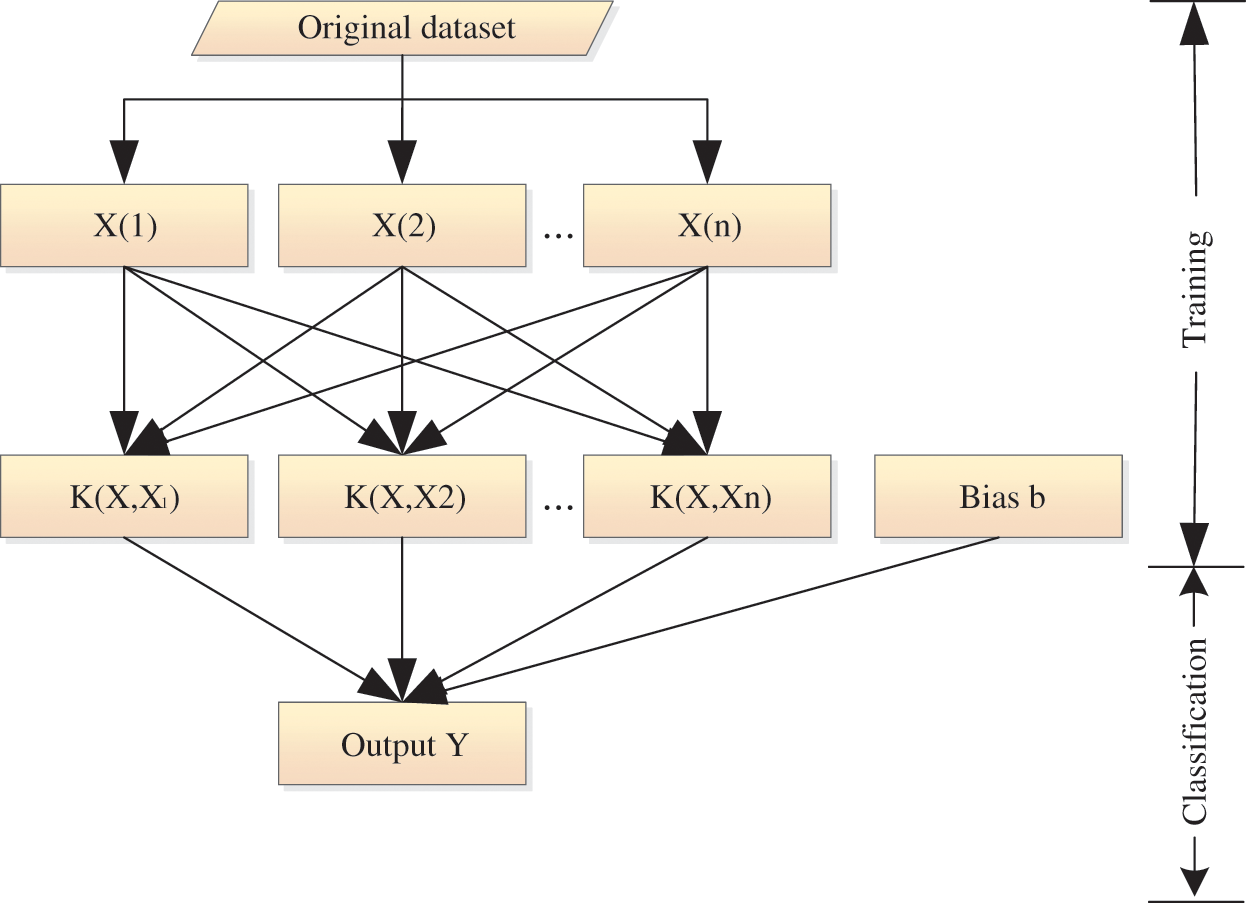
Figure 2: The basic structure of SVM
SVM is essentially a hyper-plane
In Eq. (2):
The most crucial characteristic of SVM is that it can transfer nonlinear separable samples in lower dimensional space to linear separable samples in higher dimensional space through using kernel function. The kernel function
There are many types of kernel function, including the radial basis function (RBF), the sigmoid kernel, the linear kernel and the polynomial kernel, etc. Literature reviews show that the SVM with RBF has good performance in control chart pattern recognition. Therefore, the SVM with RBF is used as the pattern classifier in this study. The formula of RBF is as follows:
The parameter
CS is a new meta-heuristic search optimization algorithm illuminated by the biological characteristics in nature [24]. It combines the simulation of cuckoo birds’ parasitic reproduction process with the Levy flight search principle. In nature, the cuckoo finds its nest position randomly. There are three ideal hypotheses for the cuckoo’s search for the optimal nest: (1) The number of host nests
among them
In Eq. (6):
After updating the position by Eq. (6), a random number
The recognition model based on CS-SVM is shown in Fig. 3. It is composed of three modules, namely the data generation module, the CS optimization module and the pattern recognition module. The implementation process of the CS to optimize the hyper-parameters
Step 1: Initialize the basic parameters. When the probability that the host bird finds a non-self bird egg is 0.25, it is sufficient for most optimization problems, so
Step 2: The position and state of the non-optimal nest are updated by using Eq. (6). The updated nest position is used to recalculate the fitness function value, which is compared with that of the best nest position reserved by the previous generation. When the current value is better, the new nest position is reserved to replace the old best nest.
Step 3: After the nest position is updated, the random number
Step 4: If the maximum number of iterations or required accuracy is reached, the obtained optimal bird nest position is accepted as the global optimal solution; otherwise, turn back to step 2 and continue to iterate and update.
Step 5: Output the position of the global optimal nest, namely the best hyper-parameters
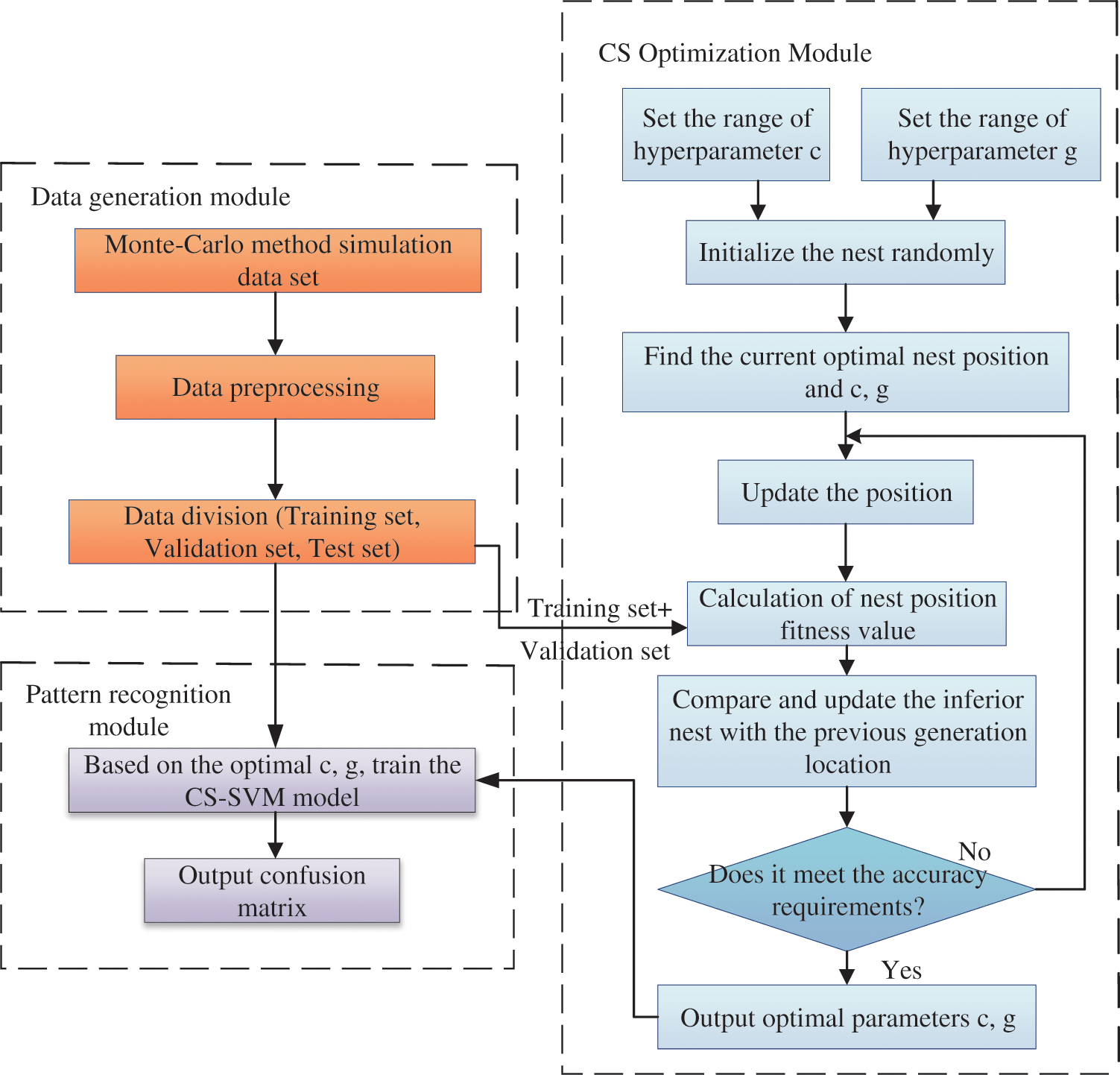
Figure 3: Recognition model based on CS-SVM
4.1 Experimental Environment and Data
In order to verify the performance of the proposed model, which is established through programming in the MATLAB2018, and hereinto, the SVM is realized by the Libsvm toolbox. Then, some simulation experiments with this model are carried out in the MATLAB2018. The performance indicators of the computer used are CPU2.4GHZ, RAM12.0G. Following the conventional research methods in this field, eight types of basic CCP sample (as described in 2.1) of AR (1) process are generated by Monte carol simulation method. These samples are divided into three mutually exclusive sets, including the training set, the validation set and the test set. The number of samples for each pattern in each set is shown in Tab. 1. To reflect the diversity of abnormal amplitudes in actual processes, exception parameters of the abnormal patterns take values within certain specific range. The parameter choices of all patterns are shown in Tab. 2. With reference to other literatures, the dimension of the pattern sample vector (that is, the width of the online recognition window) is set equal to 32.
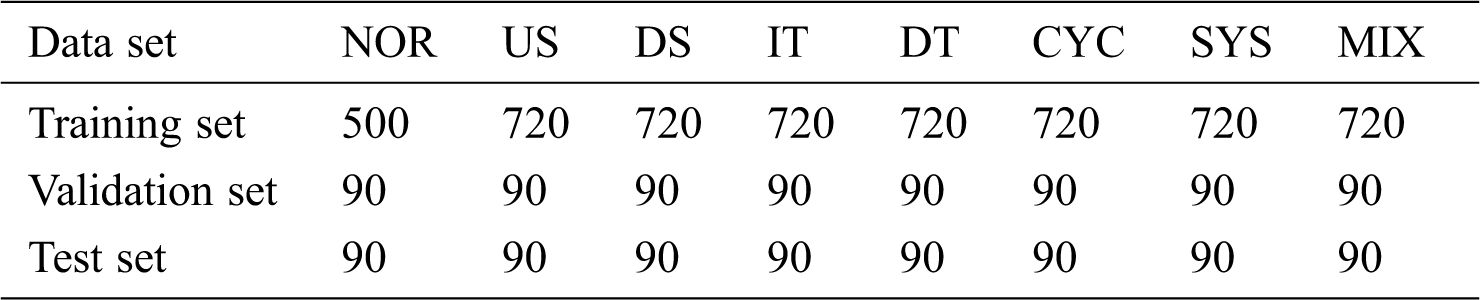
Table 2: Parameter settings of the eight patterns
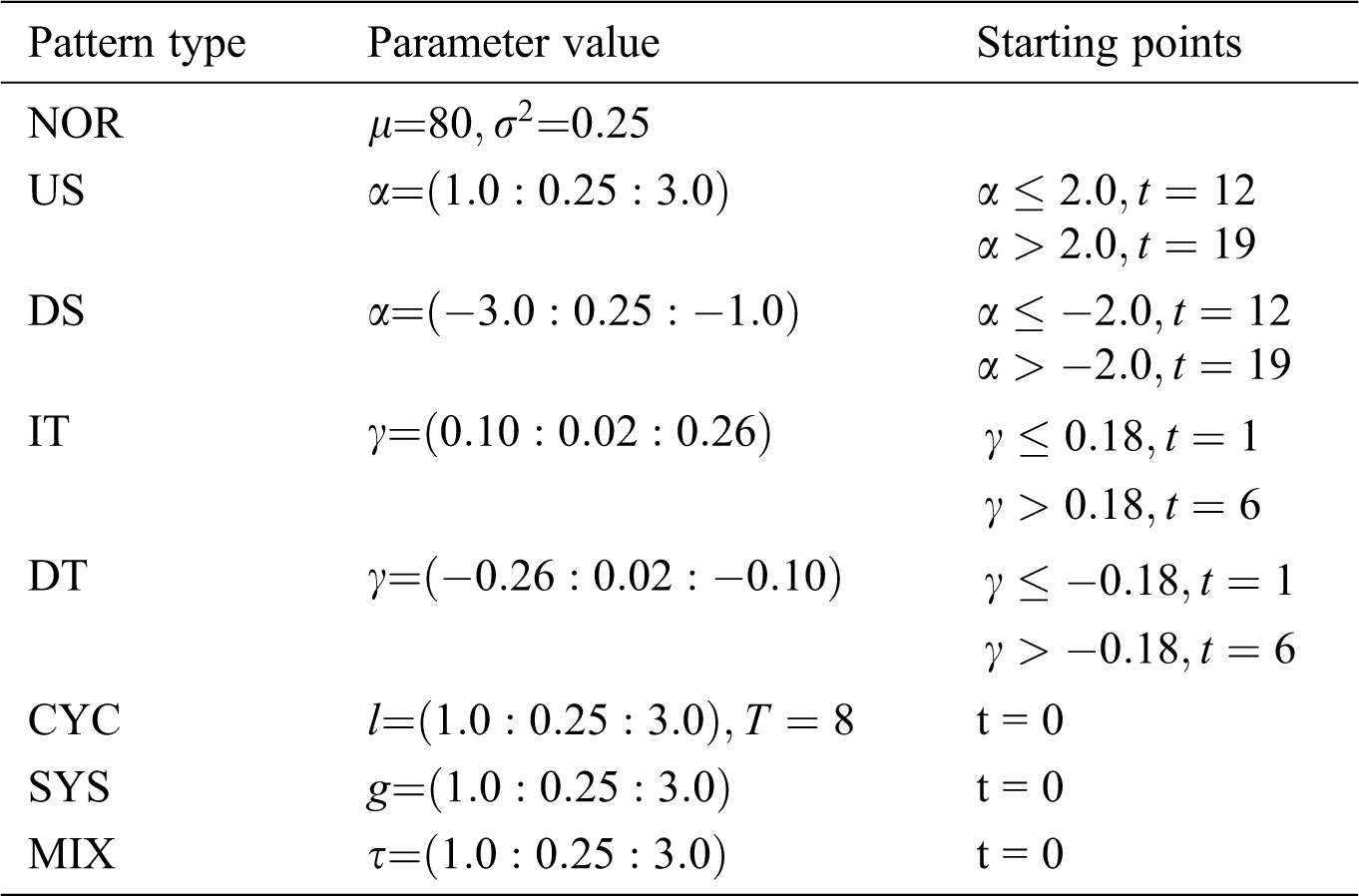
For the patterns of US, DS, IT, and DT, different starting points of exception are set for different abnormity amplitudes. Small amplitudes have smaller abnormal starting points, for example, in US,
4.2 Optimization Process of CS-SVM
In each iteration of the CS, the CS-SVM model is trained after being given the hyper-parameters, and calculated recognition accuracy with the verification set. The result is taken as the fitness value. Without loss of generality, the hyper-parameters are optimized when the autocorrelation coefficient
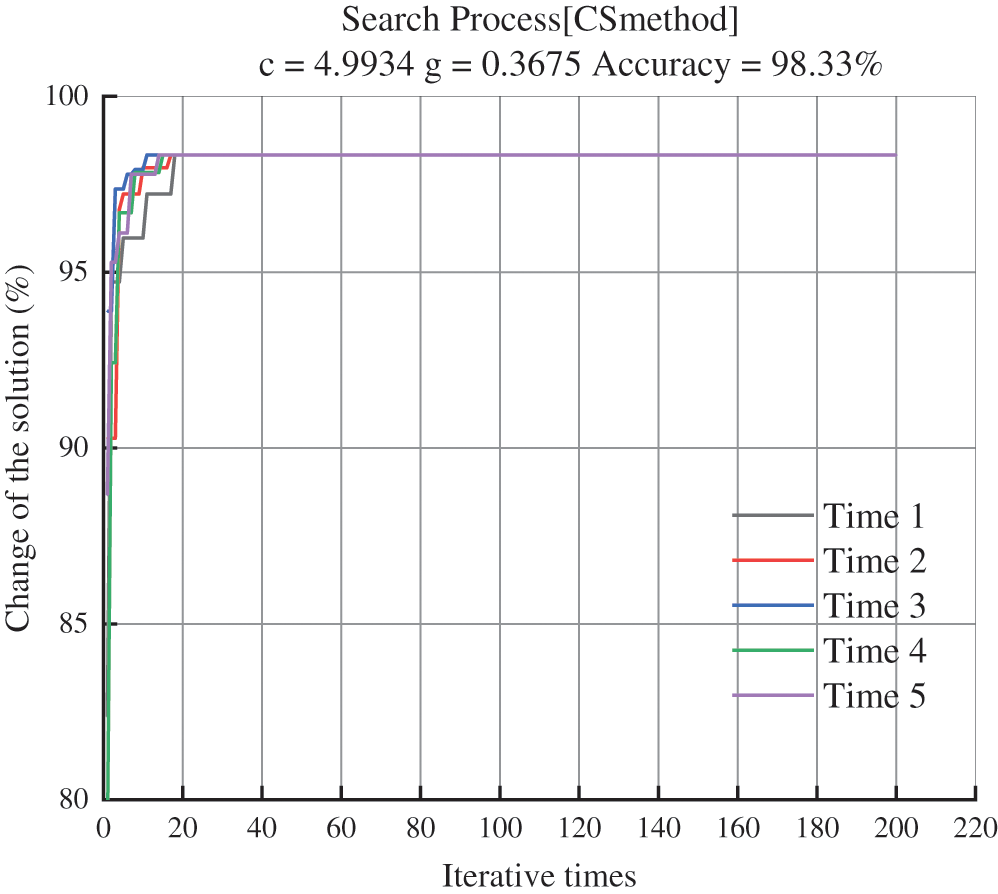
Figure 4: Iteration of CS-SVM model
Recognition accuracy test of this model is carried out on the test set. For the case of
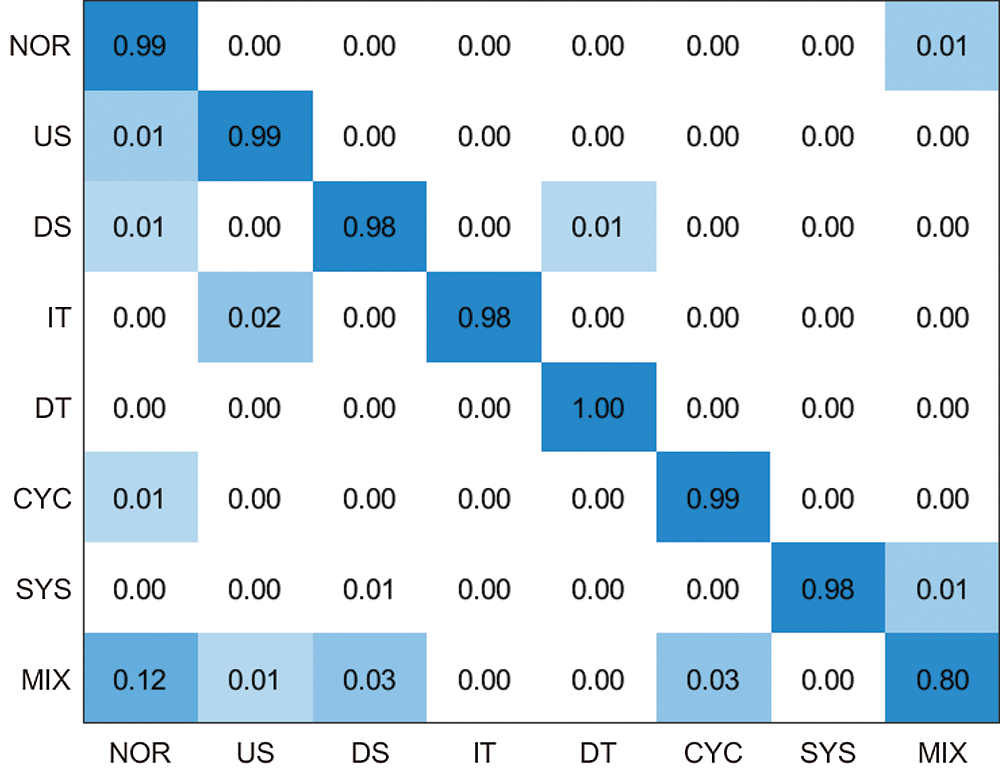
Figure 5: Confusion matrix for the case of
The average accuracy of processes with some other different level of autocorrelation coefficients (
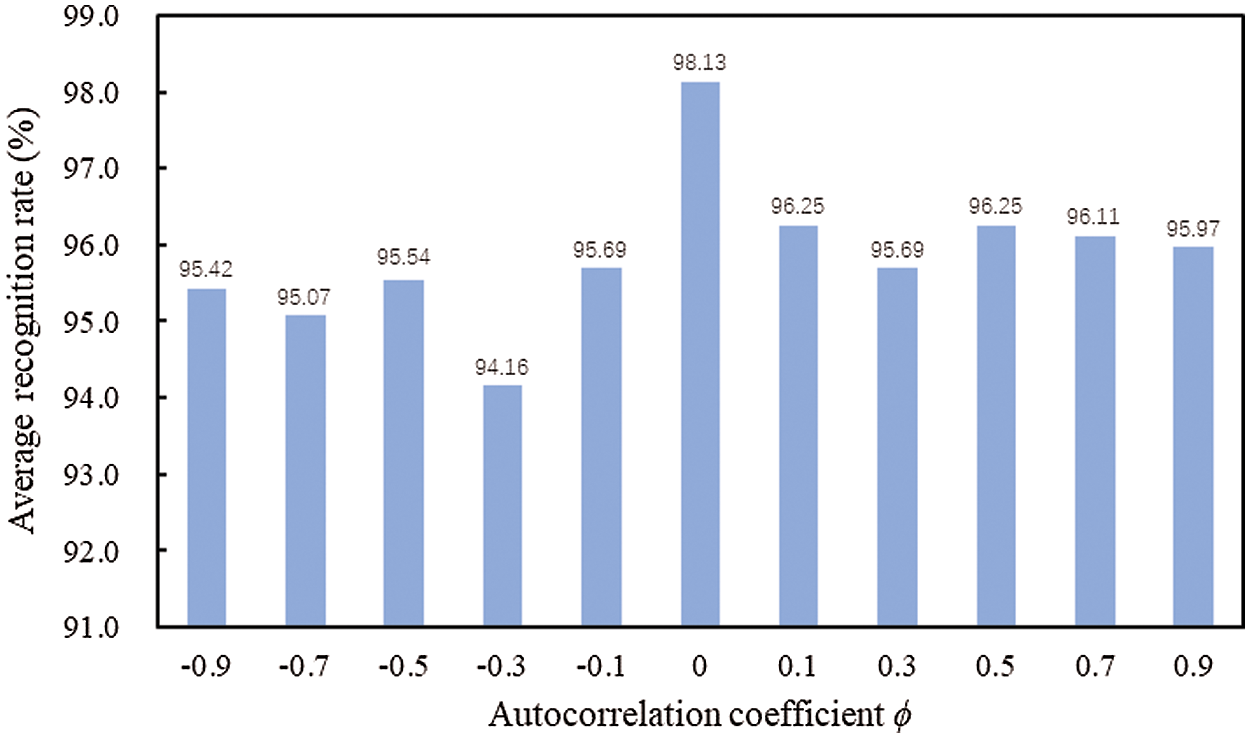
Figure 6: Recognition accuracy in different level of autocorrelation
In order to further verify the superiority of this model, a comparative experiment was carried out based on the same data sets. The chosen comparative objects are the model based on SVM optimized by particle swarm optimization (PSO-SVM) and the model based on SVM optimized by genetic algorithm (GA-SVM). The reason is that both PSO and GA are intelligent optimization algorithms, which are often used to optimize the hyper-parameters of SVM. Five times of optimization are conducted for the case of autocorrelation coefficients
Table 3: The setting of main parameters
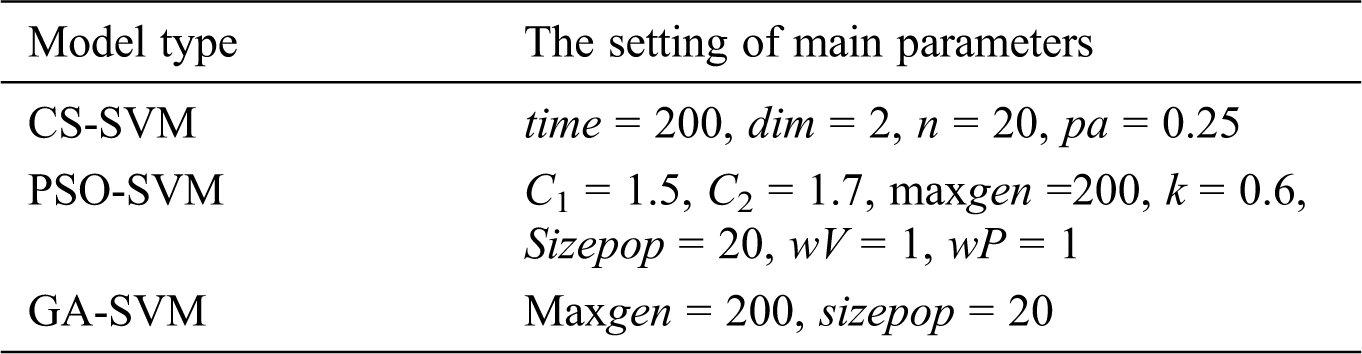
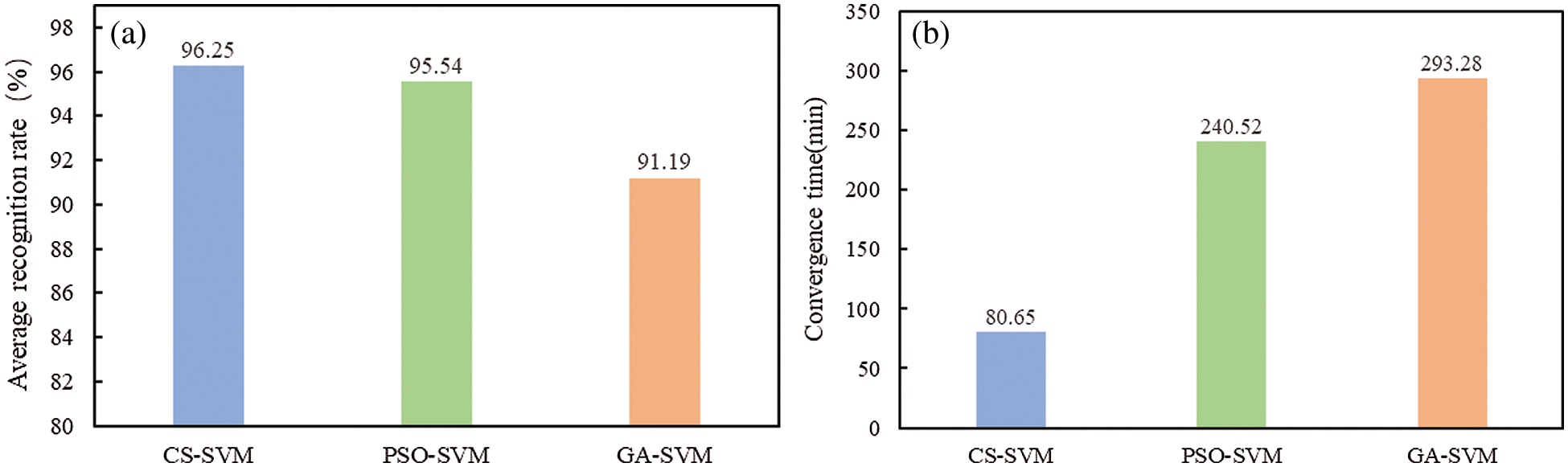
Figure 7: Performance comparison of model optimized by three algorithms. (a) Comparison of recognition accuracy and (b) Comparison of convergence time
It can be seen from Fig. 7a that the proposed model obtains the highest average recognition accuracy with
Average run length (ARL) is a key indicator of the online performance of control chart or other process anomaly detectors. ARL can be measured through simulation method. The usual practice is to simulate lots of data streams first, and then fetch data from each data stream with a sliding window, till a normal pattern sample is misrecognized as abnormal (ARL0) or an abnormal pattern is identified (ARL). In this study, 3000 in-control data streams and 3000 × 9 × 7 out-of-control data streams are separately generated for each autocorrelation level. The ARL0 reflexes the probability of occurrence of the type I error in the model, and should be controlled as close as possible to the theoretical value (370 for the univariate process) before measuring ARL. For that reason, the try and error method is applied, i.e., the number of the NOR sample in the train data set is adjusted according to the achieved ARL0 value till it reaches slightly higher than 370. In addition, the SRL (standard deviation of ARL) is also calculated to measure the stability of ARL performance.
In order to verify the online performance of the proposed CS-SVM based model, an SVM based model in reference [15] is chosen as a comparative object, and the comparative data are obtained from its Tab. 3. The Tab. 4 shows the comparison of the average ARL values and the average SRL values of the proposed model and those of the comparative object, which are calculated for different abnormity magnitudes of each abnormal pattern under different level of autocorrelation. For comparative purpose, the ARL value of the proposed model which is not lower than that of the comparative object is highlighted in bold in the Tab. 4.
Table 4: Comparison of ARL and SRL values between the CS-SVM based model and the referenced SVM based model

It can be seen that the proposed model performs better for the US, DS, IT and DT pattern as
This study uses CS to optimize the two hyper-parameters of SVM (CS-SVM), and then based on which to establish a recognition model for abnormal patterns in autocorrelation process. A series of simulation experiments have been conducted to test the performances of this model. The experiment results show that the established model can achieve higher recognition accuracy in comparison with the model based on SVM optimized by the PSO or the GA. In the meantime, it takes much less time to optimize the hyper-parameters for this model. That means this model has higher training efficiency, considering that the parameter optimization procedure is involved in the training process. Furthermore, the model shows good recognition accuracy for each tested autocorrelation level (whether positive or negative autocorrelation), indicating its broad applicability. At last, the ARL values of the model at different autocorrelation levels are measured, which are generally better than those of the comparative model from the reference. That indicates the model also possesses an acceptable online performance. Identification of abnormal patterns in autocorrelation process is still in the exploratory stage, and the proposed model provides a new way for it. Currently, we have verified the model’s effectiveness through simulation experiments. Testing the model’s effectiveness for other types of autocorrelation processes except AR (1) and studying how to use it in the actual manufacturing process will be our next work.
Acknowledgement: I want to take this chance to thanks my tutor----Bo Zhu. In composing this paper, he gives me much academic and constructive advice and helps me correct my essay. Besides these, he also allowed me to do my teaching practice. At the same time, I want to thank my friends Chunmei Chen, Kaimin Pang and Yuwei Wan. They participated much in this research. Finally, I’d like to thank all my friends, especially my three lovely roommates, for their encouragement and support.
Funding Statement: This research was financially supported by the National Key R&D Program of China (2017YFB1400301).
Conflicts of Interest: The authors declare that they have no interest in reporting regarding the present study.
1. Y. Li, J. Li, P. Shi and X. Qin, “Building an open cloud virtual dataspace model for materials scientific data,” Intelligent Automation and Soft Computing, vol. 25, no. 3, pp. 615–624, 2019. [Google Scholar]
2. X. Zhang, J. Duan, W. Sun and N. I. Badler, “An integrated suture simulation system with deformation constraint under a suture control strategy,” Computers, Materials & Continua, vol. 60, no. 3, pp. 1055–1071, 2019. [Google Scholar]
3. J. Su, Z. Sheng, A. X. Liu and Y. Chen, “A partitioning approach to RFID identification,” IEEE/ACM Transactions on Networking, vol. 28, no. 5, pp. 2160–2173, 2020. [Google Scholar]
4. J. Su, Z. Sheng, A. X. Liu, Y. Han and Y. Chen, “Capture-aware identification of mobile RFID tags with unreliable channels,” IEEE Transactions on Mobile Computing, vol. 14, no. 8, pp. 1–14, 2020. [Google Scholar]
5. S. Wang, T. Yue and M. A. Wahab, “Multiscale analysis of the effect of debris on fretting wear process using a semi-concurrent method,” Computers, Materials & Continua, vol. 62, no. 1, pp. 17–36, 2020. [Google Scholar]
6. Y. R. Shiau, “Inspection allocation planning for a multiple quality characteristic advanced manufacturing system,” International Journal of Advanced Manufacturing Technology, vol. 21, no. 7, pp. 494–500, 2003. [Google Scholar]
7. D. C. Montgomery and C. M. Mastrangelo, “Some statistical process control methods for autocorrelated data,” Journal of Quality Technology, vol. 23, no. 3, pp. 179–204, 1991. [Google Scholar]
8. L. C. Alwan and H. V. Roberts, “Time-series modeling for statistical process control,” Journal of Business & Economic Statistics, vol. 6, no. 1, pp. 87–95, 1988. [Google Scholar]
9. H. D. Maragah and W. H. Woodall, “The effect of autocorrelation on the retrospective X-chart,” Journal of Statistical Computation and Simulation, vol. 40, no. 1–2, pp. 29–42, 1992. [Google Scholar]
10. D. C. Montgomery and W. H. Woodall, “A discussion on statistically-based process monitoring and control,” Journal of Quality Technology, vol. 29, no. 2, pp. 121, 1997. [Google Scholar]
11. G. C. Runger, F. B. Alt and D. C. Montgomery, “Contributors to a multivariate statistical process control chart signal,” Communications in Statistics, vol. 25, no. 10, pp. 2203–2213, 1996. [Google Scholar]
12. J. Sun, “Residual error control chart of autocorrelation process,” Journal of Tsinghua University (Natural Science Edition), vol. 42, no. 6, pp. 735–738, 2002. [Google Scholar]
13. M. Zhang and W. M. Cheng, “Control chart pattern recognition based on adaptive particle swarm algorithm and support vector machine,” Industrial Engineering, vol. 15, no. 5, pp. 128–132, 2012. [Google Scholar]
14. D. F. Cook and C. U. Chiu, “Using radial basis function neural networks to recognize shifts in correlated manufacturing process parameters,” IIE Transactions, vol. 30, no. 3, pp. 227–234, 1998. [Google Scholar]
15. S. Y. Lin, R. S. Guh and Y. R. Shiue, “Effective recognition of control chart patterns in autocorrelated data using a support vector machine based approach,” Computers & Industrial Engineering, vol. 61, no. 4, pp. 1123–1134, 2011. [Google Scholar]
16. B. Zhu, B. B. Liu, Y. Wan and S. R. Zhao, “Recognition of control chart patterns in auto-correlated process based on random forest,” 2018 IEEE International Conference on Smart Manufacturing, Industrial & Logistics Engineering, vol. 1, pp. 53–57, 2018. [Google Scholar]
17. Y. M. Liu and Z. Y. Zhao, “Recognition of abnormal quality patterns based on feature selection and SVM,” Statistics and Decision, vol. 10, no. 502, pp. 47–50, 2018. [Google Scholar]
18. Q. Wang and X. Wang, “Parameters optimization of the heating furnace control systems based on BP neural network improved by genetic algorithm,” Journal on Internet of Things, vol. 2, no. 2, pp. 75–80, 2020. [Google Scholar]
19. T. Huang, Y. Q. Wang and X. G. Zhang, “Color image segmentation algorithm based on GS-SVM,” Electronic Measurement Technology, vol. 40, no. 7, pp. 105–108, 2017. [Google Scholar]
20. C. Z. Wang, Y. L. Du and Z. W. Ye, “P2P traffic recognition based on the optimal ABC-SVM algorithm,” Computer Application Research, vol. 35, no. 2, pp. 582–585, 2018. [Google Scholar]
21. Y. Xue, T. Tang, W. Pang and A. X. Liu, “Self-adaptive parameter and strategy based particle swarm optimization for large-scale feature selection problems with multiple classifiers,” Applied Soft Computing, vol. 88, no. 4, pp. 106031, 2020. [Google Scholar]
22. C. Y. Liu, A. Y. Wang and R. Li, “Mine multi-mode wireless signal modulation recognition based on GA-SVM algorithm,” Science Technology and Engineering, vol. 20, no. 6, pp. 2186–2191, 2020. [Google Scholar]
23. B. B. Liu, B. Zhu, Y. W. Wan and Y. Y. Song, “Using optimized probabilistic neural networks to identify autocorrelation process abnormalities,” Manufacturing Automation, vol. 40, no. 2, pp. 70–73, 2018. [Google Scholar]
24. H. R. Xue, K. H. Zhang, B. Li and C. H. Peng, “Transformer fault diagnosis based on cuckoo algorithm and support vector machine,” Power System Protection and Control, vol. 43, no. 8, pp. 15–20, 2018. [Google Scholar]
Appendix A. Mathematical Expressions of Eight CCPs
In this research, the Monte Carlo simulation approach was used to generate the required sets of CCPs for training, test, and validation data set. The CCP herein is expressed in a general form that consists of the process mean, the common-cause variation, and a special disturbance from specific causes.
Process Simulator
where
Normal (NOR):
Shift (US/DS):
where
Trend (IT/DT):
where
Cycle (CYC):
where
T = cycle period (T = 8 in this research)
Systematic (SYS):
where
Mixture (MIX):
where
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |