| Energy Engineering |
DOI: 10.32604/EE.2021.017795
ARTICLE
Electricity Demand Time Series Forecasting Based on Empirical Mode Decomposition and Long Short-Term Memory
1Department of Mechanical and Energy Engineering, Purdue University, Indianapolis, USA
2Department of Mechanical Engineering, School of Engineering, Aalto University, Espoo, Finland
*Corresponding~Author: Behnam Talebjedi. Email: Behnam.talebjedi@aalto.fi
Received: 08 June 2021; Accepted: 29 July 2021
Abstract: Load forecasting is critical for a variety of applications in modern energy systems. Nonetheless, forecasting is a difficult task because electricity load profiles are tied with uncertain, non-linear, and non-stationary signals. To address these issues, long short-term memory (LSTM), a machine learning algorithm capable of learning temporal dependencies, has been extensively integrated into load forecasting in recent years. To further increase the effectiveness of using LSTM for demand forecasting, this paper proposes a hybrid prediction model that incorporates LSTM with empirical mode decomposition (EMD). EMD algorithm breaks down a load time-series data into several sub-series called intrinsic mode functions (IMFs). For each of the derived IMFs, a different LSTM model is trained. Finally, the outputs of all the individual LSTM learners are fed to a meta-learner to provide an aggregated output for the energy demand prediction. The suggested methodology is applied to the California ISO dataset to demonstrate its applicability. Additionally, we compare the output of the proposed algorithm to a single LSTM and two state-of-the-art data-driven models, specifically XGBoost, and logistic regression (LR). The proposed hybrid model outperforms single LSTM, LR, and XGBoost by, 35.19%, 54%, and 49.25% for short-term, and 36.3%, 34.04%, 32% for long-term prediction in mean absolute percentage error, respectively.
Keywords: Load forecasting; machine learning; LSTM; empirical mode decomposition; XGBoost; logistic regression (LR)
Electric energy production and consumption have increased globally in recent years [1–3]; nevertheless, producing, transmitting, and delivering electrical energy are still complicated and expensive. To lower the cost of electricity generation and increase ability to satisfy the rising demand for electric energy, efficient grid management is critical [4–6]. Accordingly, effective grid management requires accurate demand forecasting [7–9]. Demand forecasting aids system operators in completing unit commitment and assessing power system stability. Given the fierce competition in the electricity market, load forecasting can provide valuable information for aggregators when participating in energy trading and dynamically managing electricity demand [10].
Many attempts have been made in the past to solve the challenges associated with load power forecasting (detailed reviews can be found in [11,12]). Inputs, outputs, time intervals, scale, data sample sizes, and error types have all been considered when classifying load forecasting approaches [13]. The accepted load forecasting approaches can be categorized as follows. Regression or/and multiple regression are still commonly used and effective for long-term (≥1 week to several years ahead) prediction, according to [14]. Machine-learning (ML) and time series (including the autoregressive moving average (ARMA) and autoregressive integrated moving average (ARIMA)) [15] are preferred for very short (≤1 h) and short-term (hours or days ahead) prediction. Meteorological data are the most commonly used independent variables, particularly incorporated in ML models [16]. In most instances, time series analysis and regressions depend solely on historical electricity results, with no exogenous variables introduced.
Although ARMA and ARIMA are versatile and simple models, they are linear in nature and therefore are restricted in performance when dealing with real-world data, which often exhibit non-linear and temporal patterns [17]. To deal with this uncertainty and variability problem, non-linear forecasting algorithms should be incorporated. In this regard, previous studies have highlighted ML models due to their high performance and accuracy [18]. Artificial neural networks (ANNs) [19,20], Regression-based models [21], support vector machine [22], extreme gradient boosting (XGBoost) [23], and deep learning are among the most popular ML algorithms used on the task of demand forecasting. A comprehensive review of learning-based models, their applications, and performance comparison can be found in [18].
Of all the ML algorithms in the field, deep neural network (DNN) algorithms provide better learning capability, mainly when dealing with data with non-linear behavior [24–26]. Compared to other ML algorithms, the better performance of DNN models is shown in several studies [27–29]. For example, Dedinec et al. [30] made up a deep neural network to anticipate the building electricity demand. Their results show an 8.6% improvement in mean absolute percentage error compared to shallow multilayered perceptron networks. Deep neural network networks, in essence, increase the strength of ANNs by deepening their layers through stacking several layers. Stacking different layers can be done differently by creating multiple classes of DNNs with different configurations and characteristics. Three major classes of DNNs are (I) autoencoders that are developed to learn features and reduce dimension of big datasets [31]; (II) convolutional neural networks, which are used for image recognition, classification, etc. [32]; and (III) long short-term memory (LSTM) units, which is capable of learning order dependence in sequence prediction problems [33].
LSTM has recently been the focus of increased attention for load forecasting problems as it can fit with highly complex and non-linear datasets. LSTM is tested against a publicly available dataset of residential meters in [34]. Results showed that LSTM outperforms rival ML algorithms in the challenge of short-term load forecasting for individual residential households. LSTM algorithm is used to train a dynamic model and generate predictions for impulsive loads in [35]. Marino et al. [36] explored two LSTM-based architectures: 1) regular LSTM and 2) LSTM-based Sequence to Sequence. Both approaches were tested on a benchmark data collection with one residential customer's electricity usage data. Multiple configurations of LSTM are discussed in [7], and the best architecture along with optimized hyperparameters are proposed for load forecasting. A hybrid load prediction model is built on LSTM and XGBoost algorithms in [37]. The learning procedure of LSTM in time series forecasting consists of extracting patterns from past observations to estimate the underlying temporal relationships. Nevertheless, in real-world situations, a single LSTM cannot guarantee accurate electricity load forecasts due to model under-fitting, misspecification, or overfitting, as discussed in [34].
Hybrid structures combining classical statistical methods and LSTMs have achieved important accuracy outcomes in a variety of fields [38]. These hybrid systems use error series modeling, ensembling, stacking, or signal processing to increase LSTM's performance. Khashei et al. [39,40], and Zhu et al. [41] suggested hybrid systems that produce the final prediction via joint modeling of time series and residuals. To improve the effectiveness of coping with instabilities, signal processing techniques such as empirical mode decomposition (EMD) is often used in combination with LSTM networks [42,43]. EMD may well be applied to non-linear and non-stationary processes since it is dependent on the local characteristic and temporal dependencies of the data. Zhang et al. [44] forecasted land surface temperature using LSTM coupled with signal empirical mode decomposition (EMD). Their findings indicated that when EMD and LSTM are combined, the hybrid combination outperforms a single LSTM configuration in terms of accuracy and robustness. EMD divides the original data into multiple stable sub-series, allowing it to be fed into an LSTM. Although the combination of EMD and deep learning methods for data series prediction has been widely studied in several fields, few studies have combined and used EMD and LSTM methods for demand forecasting. This study aims to improve LSTM architecture performance for electricity demand forecasting problems by proposing a hybrid system using EMD. Based on the above discussion, the major contributions of this paper can be summarized as follows:
• A step-by-step framework is developed based on EMD to extract the intrinsic signals of electricity demand profiles (Section 2).
• A hybrid demand forecasting model is proposed based on empirical mode decomposition and LSTM network in order to resolve the limitations of single LSTM, catch related uncertainties, and improve forecasting efficiency (Section 3).
• A systematic analysis of parameters affecting demand forecasting results has been performed in Section 3. Multiple forecasting horizons (short, medium, and long-term), as well as various error functions (root mean squared error, mean absolute error, coefficient of determination, and mean absolute percentage error), are considered to evaluate the model accuracy. The proposed model is also compared with other state-of-the-art ML models such as XGBoost and logistic regression. To the best of our understanding, this is the first comprehensive study that considers various forecasting horizons and multiple accuracy metrics simultaneously (Section 4).
2 Mode Decomposition of Electricity Demand Profiles
In this section, the dataset used in this study is discussed, along with its characteristics and attributes. Then, data decomposition into several sub-series using the empirical mode decomposition (EMD) technique is explained.
To help utilities quantify coincident peaks for demand forecasting purposes, the California Energy Commission provides four years of historical load data at a 1-hour resolution [45]. The dataset includes aggregated demand information for 2018, 2019, 2020, and 2021 (January−April), thereby containing 29,160 samples. Fig. 1 shows the demand profile between January and April of 2021. Fig. 2 illustrates the demand's probability density function, which provides additional context for the data's average and standard deviation. Tab. 1 summarizes the data characteristics and their associated attributes.
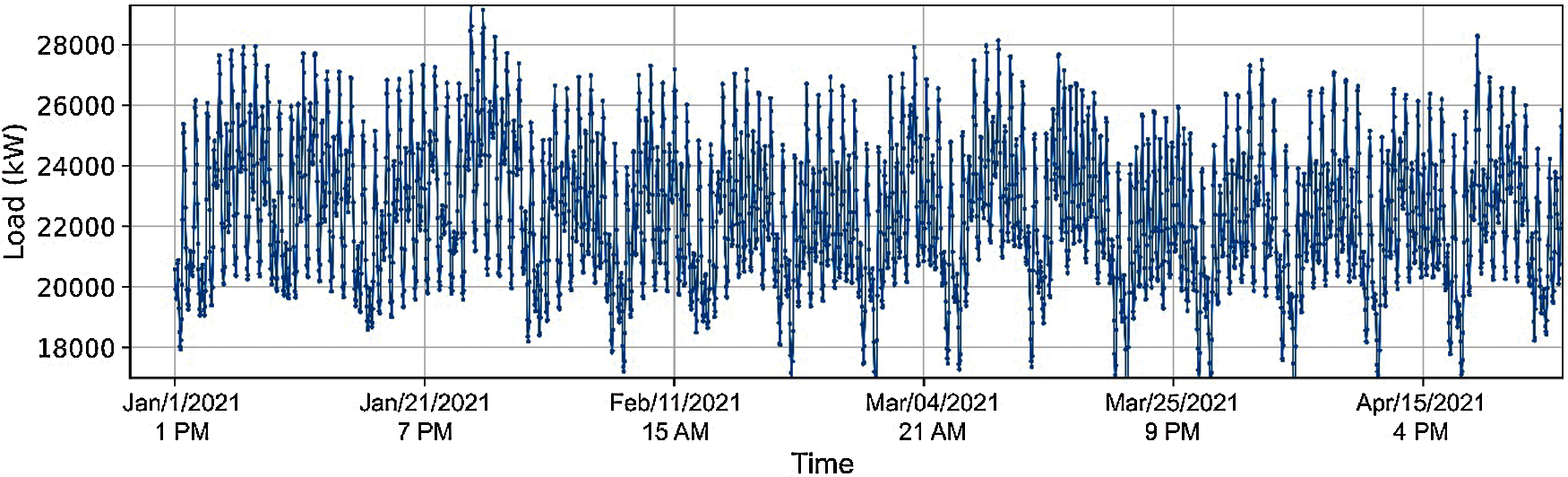
Figure 1: Demand profile between January and April of 2021
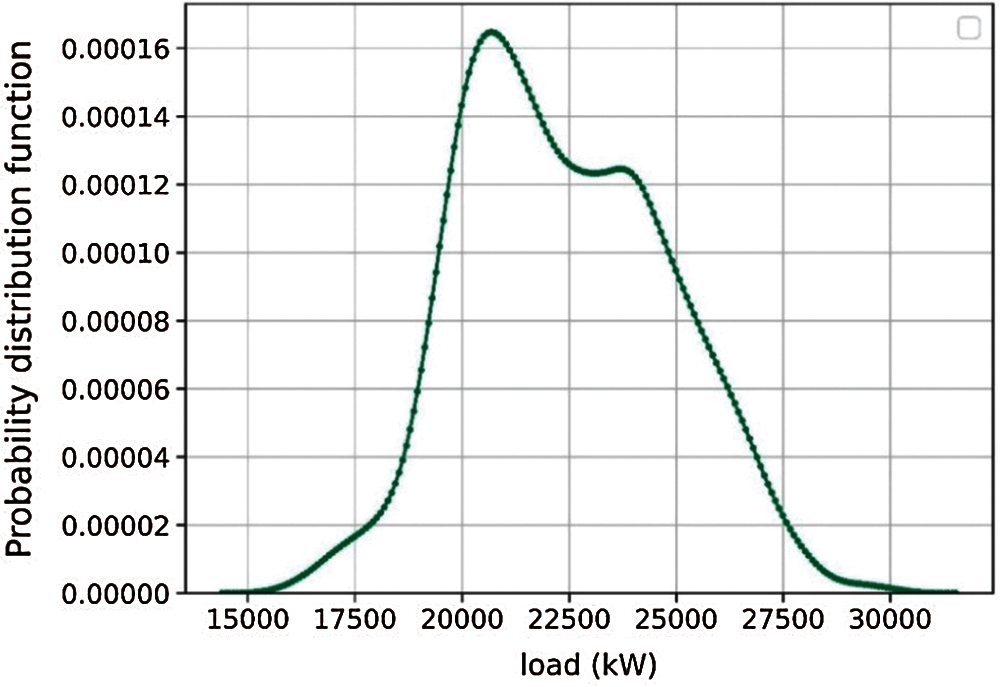
Figure 2: Demand's probability density function

2.2 Empirical Mode Decomposition
Empirical Mode Decomposition (EMD) is often desirable to decompose a signal, which is produced by multiple sources, in a way that approximates the contribution of each component. Fourier decomposition is a well-established mathematical technique for separating a signal into its components based on the frequency of fluctuations [46]. However, whenever a signal is nonstationary, such as when the signal mechanism varies with time, the right decomposition method to use is not obvious [47]. Empirical mode decomposition (EMD) is an alternative to Fourier decomposition in which the components of a signal are not constant in frequency over time, as would be the case if the signal generator is dynamic. EMD differs from theoretical decomposition, such as one relying on the Fourier Transform. As a result, it has several benefits when interacting with complex real-world signals, which are often nonstationary (i.e., not oscillating at the same frequency throughout time). EMD is mathematically expressed as follows:
where

The step criterion (SC) for the final step is the gap in normalized squares of two consecutive iterations, which can be expressed as:
SC is usually placed empirically in the range (0.2–0.3). It is taken to be 0.25 in this study. Step 1–Step 5 is conducted for the representative dataset. Per Step 1, the extreme positions are calculated and shown in Fig. 3.
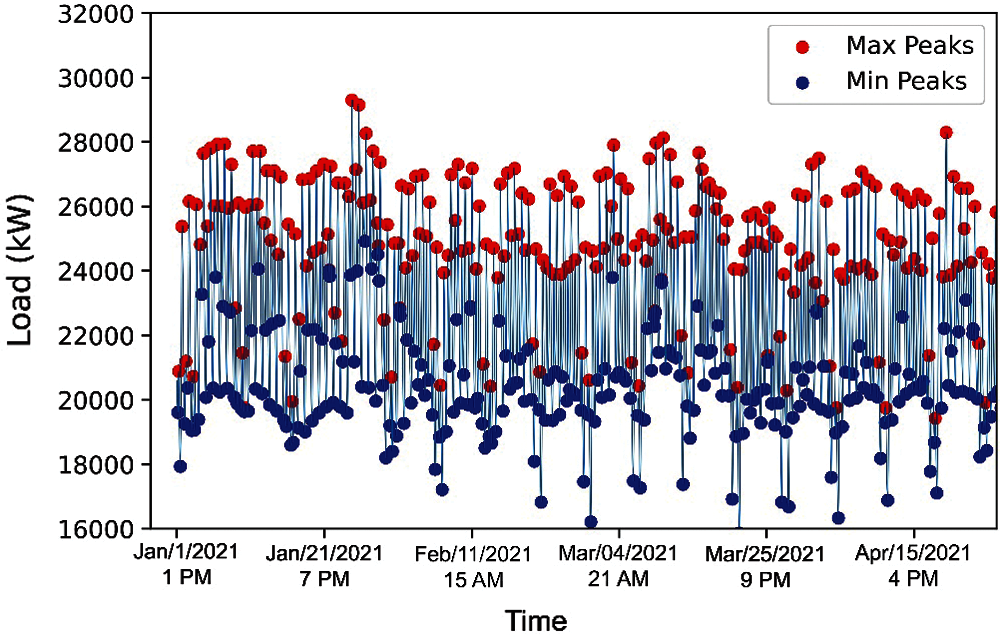
Figure 3: Positions of maximums and minimums associated with the representative dataset
For Step 2 and Step 3, the interpolation of maximum points, minimum points, and mean of those extrema envelopes are demonstrated in Fig. 4.
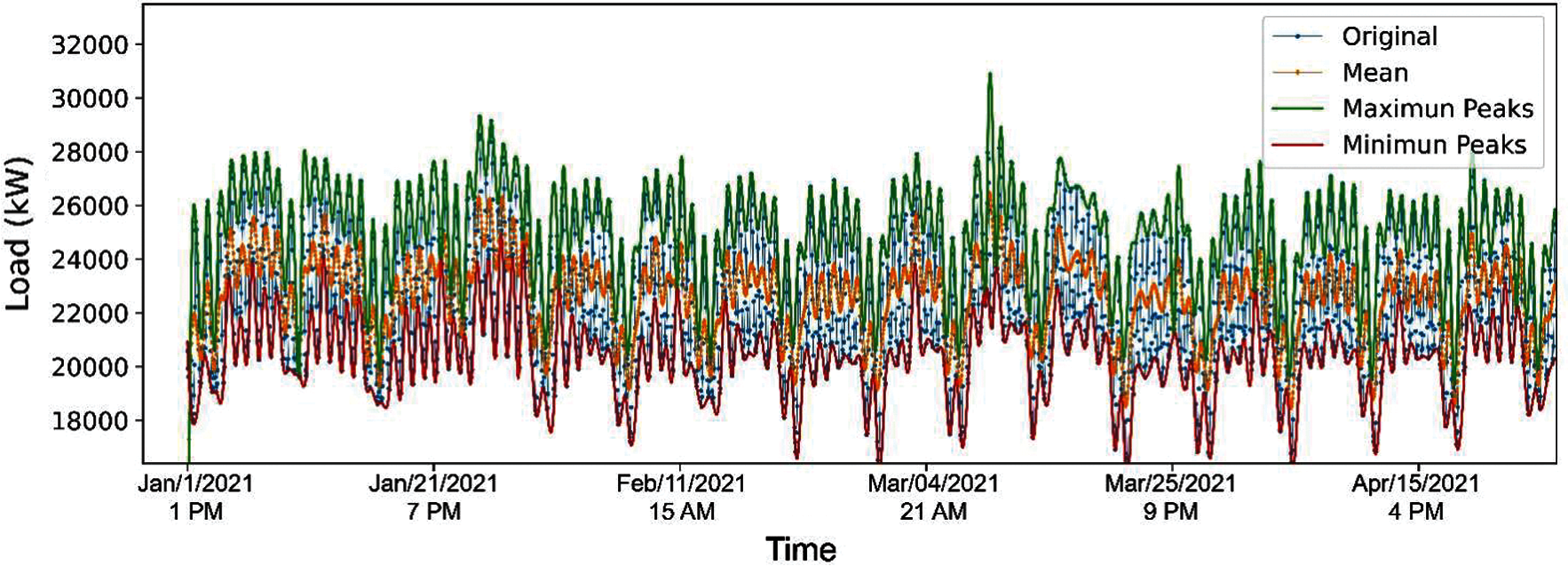
Figure 4: Minimum, maximum, and mean envelopes of the representative dataset
Next, oscillating signals are extracted based on the formula in Step 4 and then checked according to Step 5 to decide whether they have the potential to be regarded as IMFs. An IMF potential candidate oscillating signal is depicted in Fig. 5 to clarify the point.
The original dataset is decomposed into a variety of oscillatory modes or IMFs by repeating this method. Six IMFs are extracted from the original dataset, which is depicted in Fig. 6.
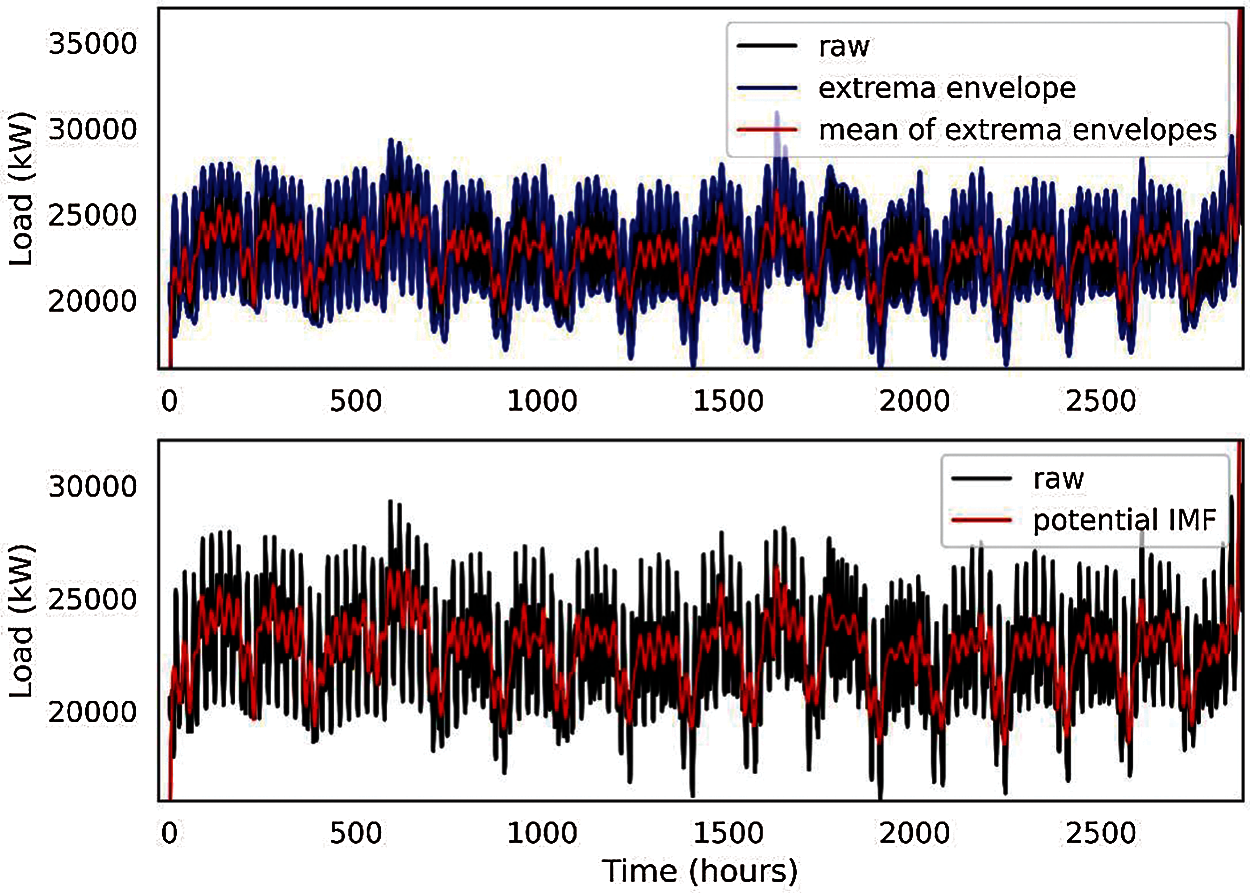
Figure 5: Potential IMF signal extracted from the original dataset
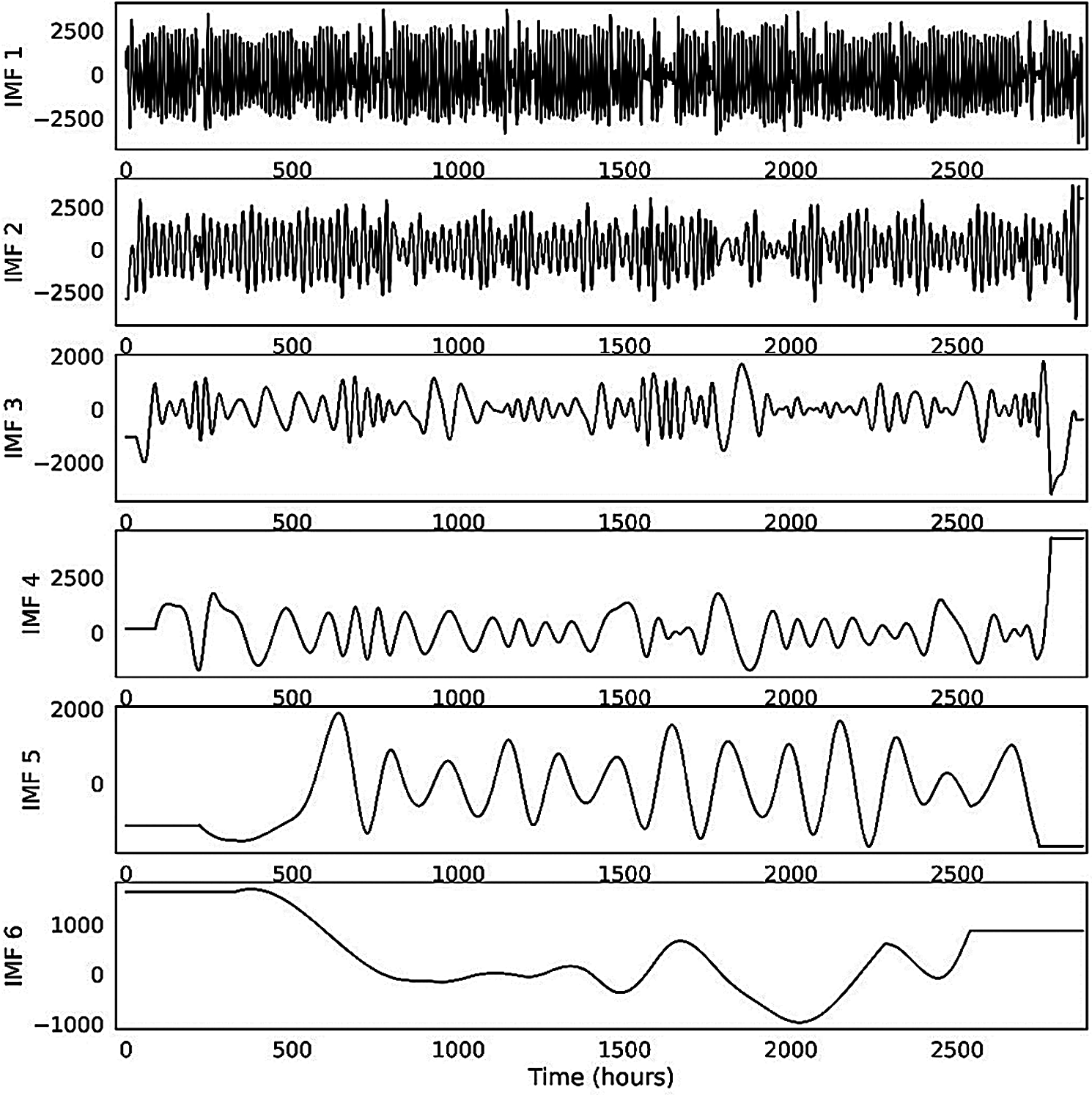
Figure 6: Intrinsic mode functions (IMFs) extracted from the historical load dataset
3 General Structure of the Proposed Method
In this section, the mathematical basis of the machine learning algorithms and the performance metrics used in the assessment process are presented. We then look at the general framework of the proposed method.
3.1 Long Short-Term Memory (LSTM)
A persistent limitation of classical neural networks is their inability to represent the temporal dependencies of operational datasets. To address this problem, recurrent neural networks (RNNs) are created. As shown in Fig. 7, a recursive framework enables RNNs to forecast a series of potential values using previously observable inputs while retaining knowledge over many time horizons.
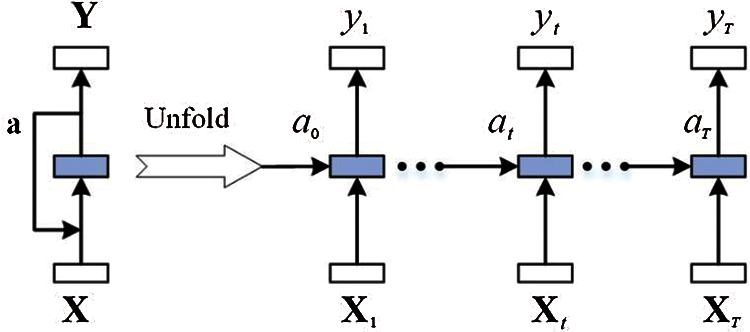
Figure 7: Schematic of a standard RNN structure (packed and unfolded in time)
RNNs are used to hope that utilizing historical data can help do more reliable load forecasting, even with a long-term time series. An activation function (a) determines the interaction between the output vector (Y) and the input vector (X). Typical RNNs, on the other hand, are unable to learn long-term temporal dependencies due to a phenomenon known as the vanishing gradients problem, which is discussed in detail in [48]. To address this problem, the LSTM unit is integrated into RNNs, converting them from normal to deep recurrent neural networks.
Hochreiter et al. presented LSTM as one of the deep learning strategies to increase the efficiency of standard RNNs in 1997 [49]. The training of LSTM is focused on the fact that it remembers previous states and can be prepared for tasks including state or memory recognition. Using this method, the LSTM network will solve problems related to gradient vanishing and bursting in standard RNN training phases. The LSTM, as seen in Fig. 8, is made up of memory cell mode blocks in which the flowed signal is controlled by an input gate, a forget gate, and an output gate. Each of these gates has its own set of computational relationships and functions, and the method of computing each vector at time t is shown below:
where
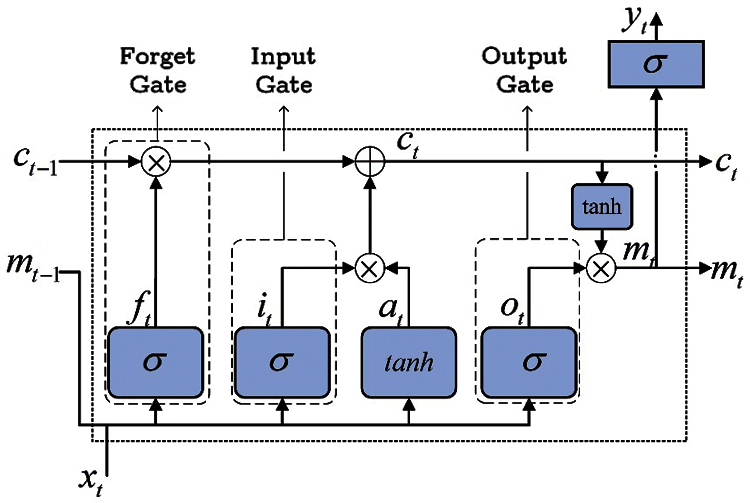
Figure 8: Principle architecture of the LSTM network
Evaluating the performance of models using different metrics is an integral part of any forecasting. While there are multiple metrics, accuracy is mostly adopted to assess the quality of a model, including mean absolute error (MAE), root mean square error (RMSE), mean absolute percentage error (MAPE), and coefficient of determination
In this research, the model dataset is separated into two sections by proportions of P percent as the training set and (1-P) percent as the cross-validation (CV). Random subsampling is used to split the dataset into training and test sets. Data points are expected to be chosen from the same probability distribution. We next choose the P percent of these samples at random for the training set and the remaining (1-P) percent for the assessment test. We utilize different P values to test the generalizability of the ML models over different forecasting time periods. For example, P = 95 implies that 5 percent of the data (1,458 samples out of 29,160) is linked with CV; consequently, the relevant forecasting horizon is about (1,458/8,760) = 2 months.
Root mean square error (RMSE)
Mean absolute percentage error (MAPE)
where N,
3.3 Decomposition-Based Long Short-Term Memory
Due to the uncertainty associated with load profiles, a single model is often insufficient to predict the electricity demand. Ensembling is a process of merging at least two ML algorithms to minimize bias/variance and maximize the learner's accuracy, precision, and robustness. Stacking is a heterogeneous ensembling that merges base learners in parallel, and then their predictions are fed as inputs to a meta-learner to form a new set of forecasts. Diversity of the base learners can be provided by using different learners, different hyper-parameter settings, different feature subsets, or different training sets. Herein, LSTM networks with the same hyper-parameters are adopted as base learners to exploit data deeply and learn order dependencies. However, the non-stationarity and stochasticity feature of meteorological variables still makes it challenging for LSTM networks to effectively recognize the pattern and provide high accuracy and robustness. To provide the requisite diversity and tackle the non-stationarity issue, two solutions are proposed in this paper based on mode decomposition and Dagging.
EMD decomposition technique is utilized to transform the non-stationary dataset into a series of relatively simple and stationary subsets. Therefore, a set of LSTM networks can be stacked in which each model only requires to focus on the frequency band components of a single subset, which can improve the overall performance of the stacked model. Moreover, Dagging technique is adapted to split the sizable non-stationary dataset into smaller equal-sized separate subsets and make it easier for the network to deal with the dataset's temporal dependencies. Therefore, a set of LSTM networks can be stacked in which each model only requires to focus on the corresponding subset, which can improve the overall performance of the stacked model. Fig. 9 illustrates the proposed stacking-based LSTM for accurate DLR forecasting based on mode decomposition and Dagging.
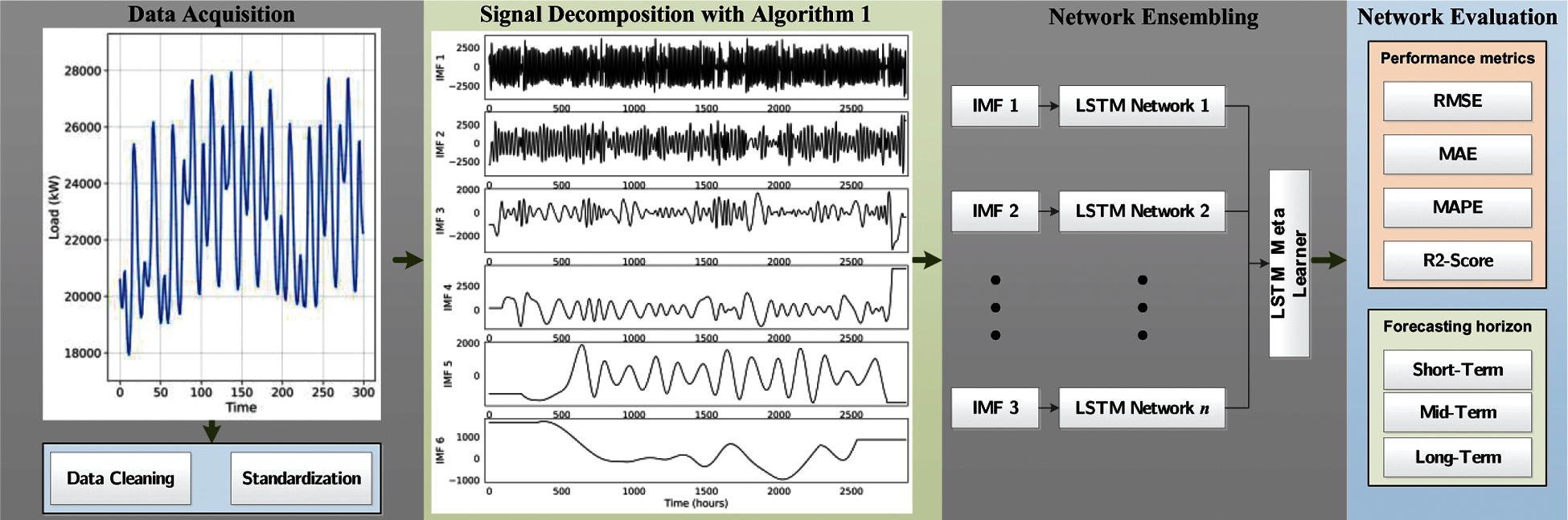
Figure 9: General structure of the proposed method
XGBoost stands for extreme Gradient Boosting. Gradient boosting is a division of ML algorithms that works based on sequential learning techniques. This technique adds new models to improve the errors made by existing models. Models are added sequentially till no more improvements can be obtained. When all of the models are tuned, a highly accurate generalization model is obtained on the task. The hallmark of GB is its ability to strike the optimal balance between model sophistication and generalization performance. There are multiple GB architectures developed in previous studies. Compared to the other implementations of gradient boosting, XGBoost is a well-established and fast algorithm [52]. A detailed description of the XGBoost algorithm is out of the scope of this work, and interested readers are referred to [53] for further details.
Logistic regression (LR) was originally developed as a modified version of linear regression for classification problems. As opposed to linear regression, a logistic model computes a weighted total of the input features; however, instead of outputting the raw data like regression, it outputs a logarithm of the logistic value between zero and one. This gives LR the ability to fit with non-linear data. Here, we used an LR inspired by the study of [35].
In this section, simulation results regarding the hybrid LSTM with Empirical Mode Decomposition (EMD), single LSTM, XGBoost algorithm, and logistic regression (LR) are provided. The studied data are the California ISO dataset which includes aggregated electricity demand from 2018 to 2020 and 2021 (January−April). Tab. 3 shows the model accuracy based on the model performance criterion discussed in chapter 2.4 for different time horizons. The studied time intervals for model evaluation are 24 h, 48 h, one week, and one month. The simulation results prove the superiority of the hybrid LSTM + EMD comparing to the single LSTM, LR, and XGBoost in terms of accuracy (model correlation coefficient and error). Results prove that in all prediction models, accuracy decreases from short-term to long-term prediction time horizons. For instance, in Hybrid LSTM + EMD, model root means squared increases from 278,76 to 423.22 and MAPE increases from 9.52 to 1,852, which correspond to 51% and 100% increase in RMSE and MAPE while the prediction time interval rises from 24 h to 1 month. On the other hand, the model determination coefficient also decreases 8.2% for Hybrid LSTM + EMD by increasing the prediction horizon from 24 h to 1 month. This fact is also true for other cases. For short term-load prediction (24 h) and long-term (1 month) electricity load prediction, the maximum determination coefficient
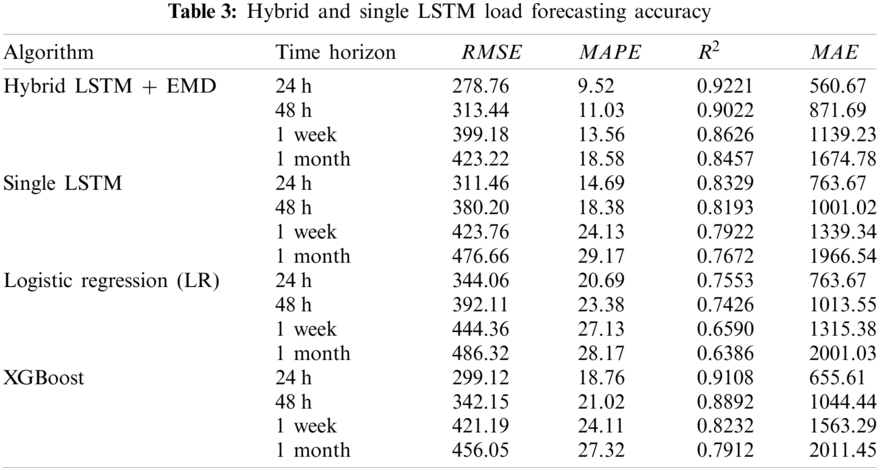
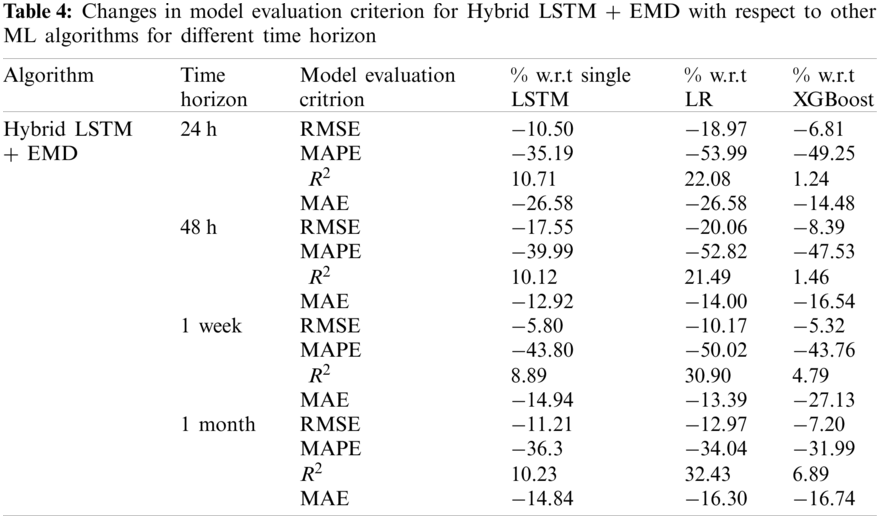
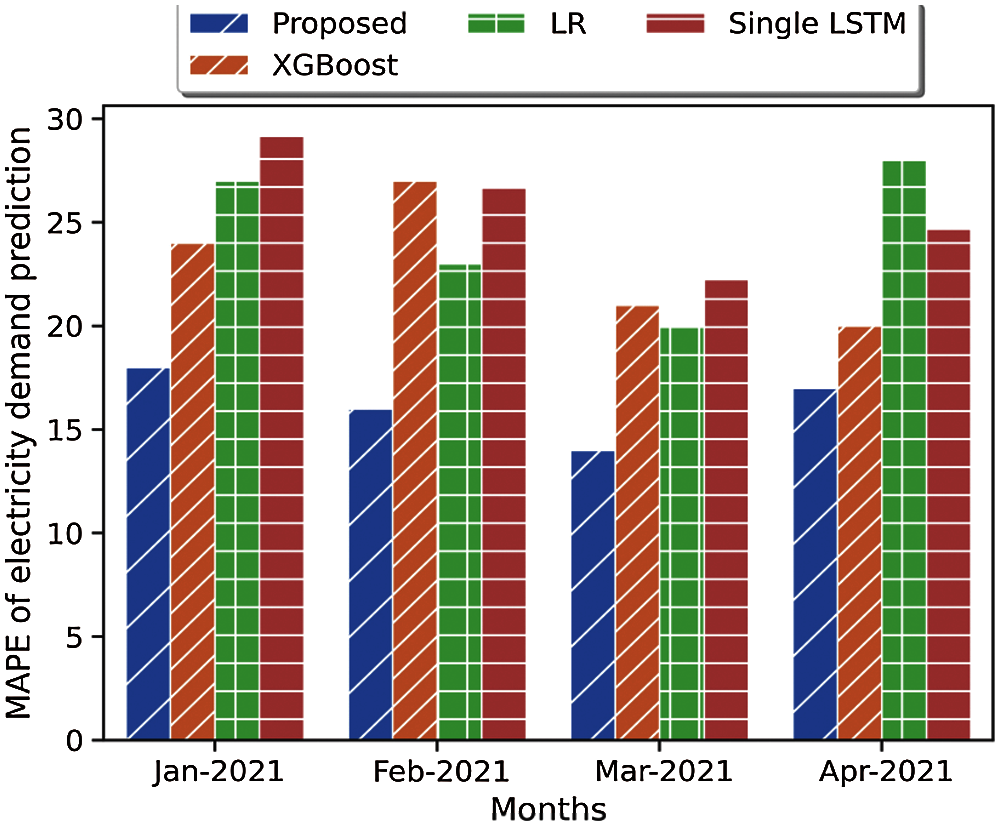
Figure 10: Mean absolute percentage error of different electricity load prediction methods (proposed method: Hybrid LSTM + EMD)
Fig. 11 illustrates the original (measured) electricity load data and predicted electricity load values for hybrid LSTM + EMD and single LSTM for different time intervals (40 to 700 h). The smaller the difference between the measured and predicted data, the higher the accuracy of the prediction and the model. As it is clear from the graphs, less simulation error can be found in hybrid LSTM since the target and predicted values are closer. Fig. 12 shows the original and predicted data for the proposed method and other state-of-the-art machine learning algorithms such as LR and XGBoost for 70 h time horizon. As it turns out, there is a greater correlation between the predicted data from the proposed method and the measured data, which indicates the higher accuracy of the proposed method than other machine learning algorithms.
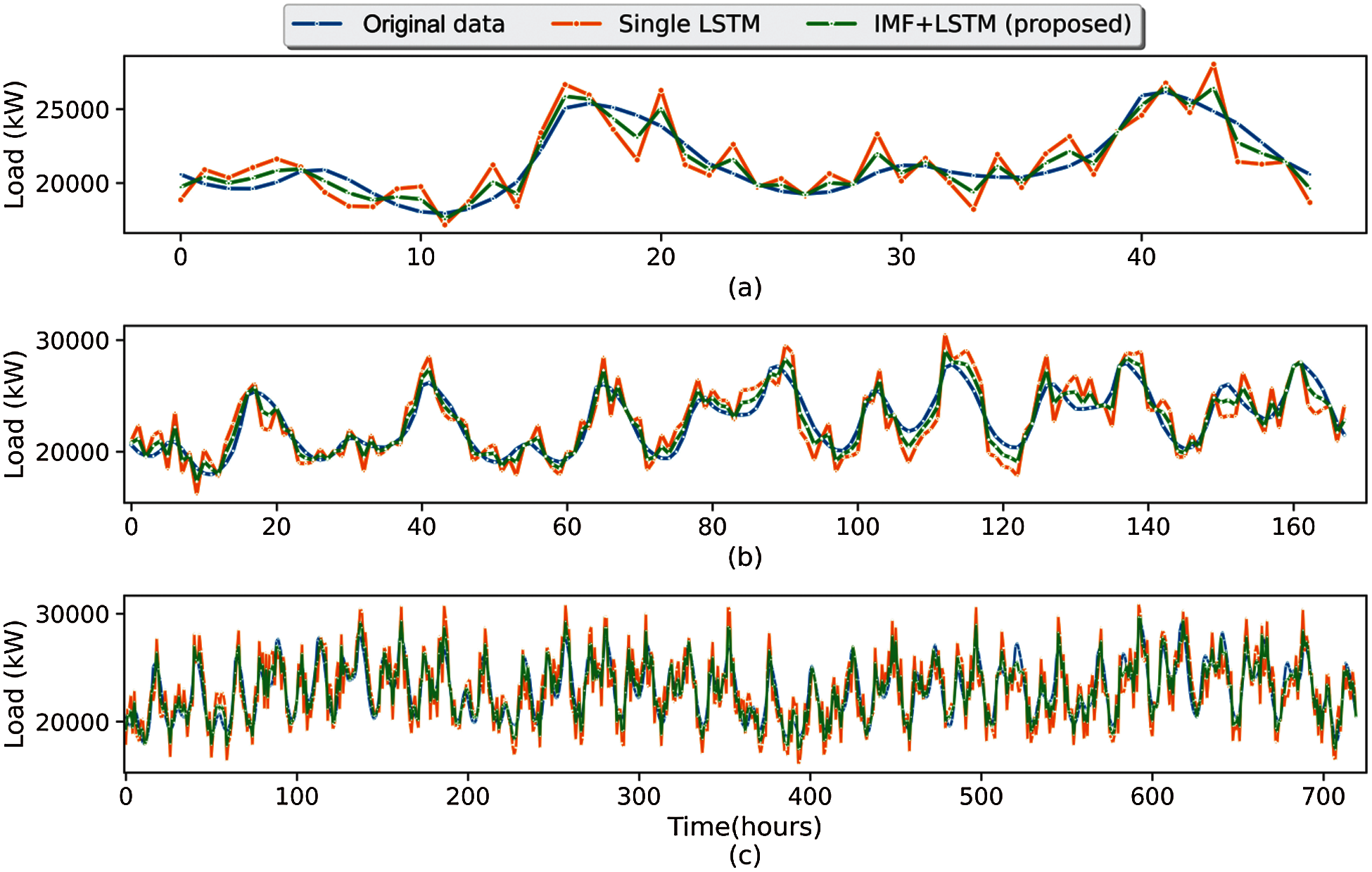
Figure 11: Original and predicted data of proposed LSTM + EMD and single LSTM algorithm for different time intervals: (a) 48 h; (b) 1 week; (c) 1 month
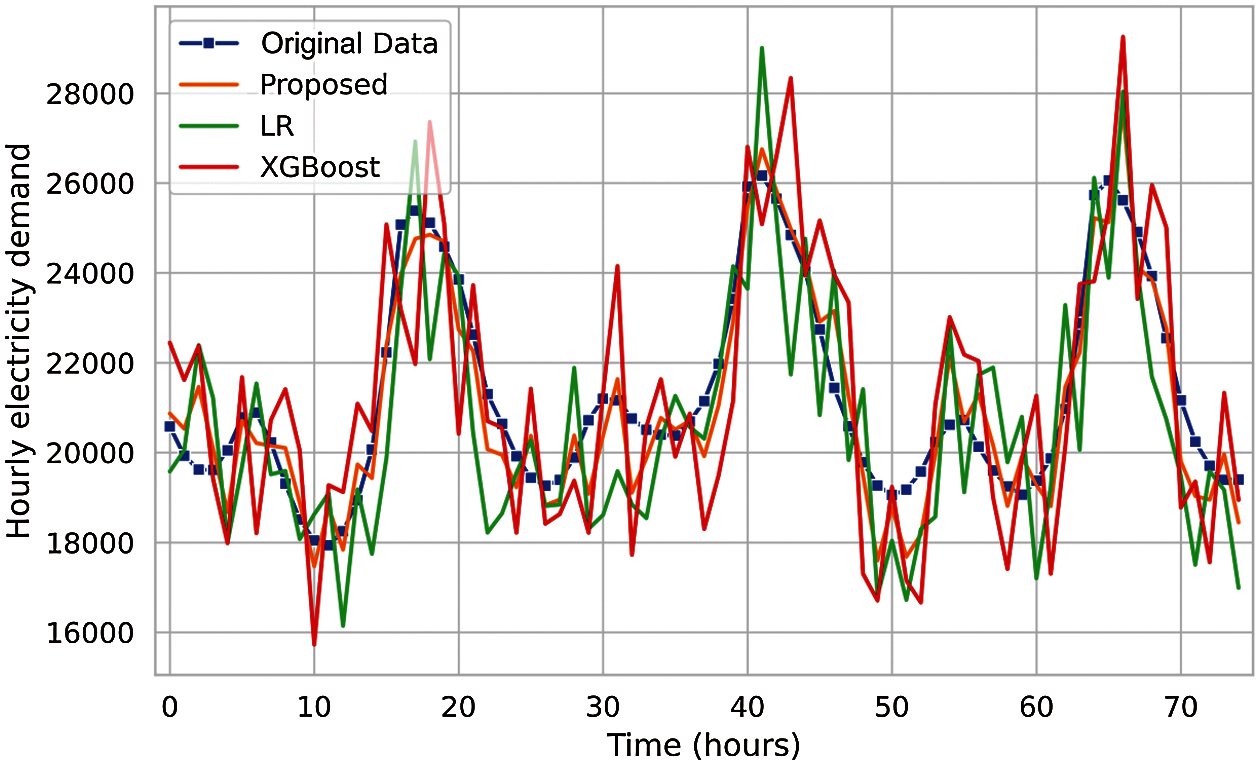
Figure 12: Original and predicted data of proposed LSTM + EMD and other state-of-the-art machine learning algorithms
Load forecasting is critical for a variety of applications in modern energy systems. Nonetheless, forecasting is a difficult task because electricity load profiles are tied with uncertain, non-linear, and non-stationary signals. To address these issues, long short-term memory (LSTM), a machine learning algorithm capable of learning temporal dependencies, has been extensively integrated into load forecasting in recent years. To overcome the shortcomings of single LSTM, capture relevant uncertainties, and increase forecasting performance, a hybrid demand forecasting model based on empirical mode decomposition and LSTM network (Hybrid LSTM + EMD) is proposed in this study. The model is intended to forecast California ISO aggregated electricity demand for the years 2018 to 2020, as well as 2021 (January to April). To assess the model's accuracy, multiple forecasting horizons (short, medium, and long-term) are regarded, as well as several error functions (root mean squared error, mean absolute error, coefficient of determination, and mean absolute percentage error). To test the efficiency of the proposed electricity load prediction techniques, the simulation findings are compared to other descent machine learning algorithms such as the XGBoost algorithm and Logistic regression (LR). Simulation findings show that the proposed Hybrid LSTM + EMD is superior to other machine learning methods for electricity load prediction, with correlation coefficients of 92% and 84% for short-term and long-term load prediction, respectively. In all cases (prediction approaches), the precision of the forecast model declines as the prediction horizon is extended. It can also be concluded that XGBoost outperforms single LSTM and LR in terms of overall performance and is more accurate for short-term prediction with the average determination coefficient of 91% for 24 h prediction horizon.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. Talebjedi, B., Behbahaninia, A. (2021). Availability analysis of an energy Hub with CCHP system for economical design in terms of energy Hub operator. Journal of Building Engineering, 33, 101564. DOI 10.1016/j.jobe.2020.101564. [Google Scholar] [CrossRef]
2. Khosravi, A., Sandoval Oscar Ricardo, R., Talebjedi, B., Laukkanen, T., Juan Jose Garcia, P. et al. (2020). New correlations for determination of optimum slope angle of solar collectors. Energy Engineering, 117(5), 249–265. DOI 10.32604/EE.2020.011024. [Google Scholar] [CrossRef]
3. Talebjedi, B., Laukkanen, T., Holmberg, H., Vakkilainen, E. (2021). Energy efficiency analysis of the refining unit in thermo-mechanical pulp mill. Energies, 14(6), 1664. DOI 10.3390/en14061664. [Google Scholar] [CrossRef]
4. Taheri, S., Ghoranee, R., Moeini, M., Safdarian, A. (2020). Stochastic framework for planning studies of energy systems: A case of EHs. IET Renewable Power Generation, 14(3), 435–444. DOI 10.1049/iet-rpg.2019.0642. [Google Scholar] [CrossRef]
5. Weron, R. (2007). Modeling and forecasting electricity loads and prices: A statistical approach, vol. 403. John Wiley & Sons. [Google Scholar]
6. Taheri, S. (2020). A multi-period water network planning for industrial parks; Impact of design periods on park's flexibility. arXiv preprint arXiv:2108.01047. [Google Scholar]
7. Taheri, S., Jooshaki, M., Moeini-Aghtaie, M. (2021). Long-term planning of integrated local energy systems using deep learning algorithms. International Journal of Electrical Power & Energy Systems, 129, 106855. DOI 10.1016/j.ijepes.2021.106855. [Google Scholar] [CrossRef]
8. Hong, T., Pinson, P., Fan, S., Zareipour, H., Troccoli, A. et al. (2016). Probabilistic energy forecasting : Global energy forecasting competition 2014 and beyond. International Journal of Forecasting, 32(3), 896–913. DOI 10.1016/j.ijforecast.2016.02.001. [Google Scholar] [CrossRef]
9. Hyndman, R., Athanasopoulos, G. (2013). Forecasting: Principles and practice. Melbourne, Australia, Otexts. http://otexts.org/fpp/. [Google Scholar]
10. Yildiz, B., Bilbao, J. I., Sproul, A. B. (2017). A review and analysis of regression and machine learning models on commercial building electricity load forecasting. Renewable and Sustainable Energy Reviews, 73, 1104–1122. DOI 10.1016/j.rser.2017.02.023. [Google Scholar] [CrossRef]
11. Kuster, C., Rezgui, Y., Mourshed, M. (2017). Electrical load forecasting models : A critical systematic review. Sustainable Cities and Society, 35, 257–270. DOI 10.1016/j.scs.2017.08.009. [Google Scholar] [CrossRef]
12. Hong, T., Fan, S. (2016). Probabilistic electric load forecasting : A tutorial review. International Journal of Forecasting, 32(3), 914–938. DOI 10.1016/j.ijforecast.2015.11.011. [Google Scholar] [CrossRef]
13. Alfares, H. K., Nazeeruddin, M. (2010). Electric load forecasting: Literature survey and classification of methods. International Journal of Systems Science, 33, 23–34. DOI 10.1080/00207720110067421. [Google Scholar] [CrossRef]
14. Kim, J., Cho, S., Ko, K., Rao, R. R. (2018). Short-term electric load prediction using multiple linear regression method. IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids, Aalborg, Denmark. [Google Scholar]
15. Niu, W., Feng, Z., Li, S., Wu, H., Wang, J. (2021). Short-term electricity load time series prediction by machine learning model via feature selection and parameter optimization using hybrid cooperation search algorithm. Environmental Research Letters, 16(5), 055032. DOI 10.1088/1748-9326/abeeb1. [Google Scholar] [CrossRef]
16. Apadula, F., Bassini, A., Elli, A., Scapin, S. (2012). Relationships between meteorological variables and monthly electricity demand. Applied Energy, 98, 346–356. DOI 10.1016/j.apenergy.2012.03.053. [Google Scholar] [CrossRef]
17. Chen, J., Wang, W., Huang, C. (1995). Analysis of an adaptive time-series autoregressive moving-average (ARMA) model for short-term load forecasting. Electric Power Systems Research, 34(3), 187–196. DOI 10.1016/0378-7796(95)00977-1. [Google Scholar] [CrossRef]
18. Hahn, H., Meyer-Nieberg, S., Pickl, S. (2009). Electric load forecasting methods : Tools for decision making. European Journal of Operational Research, 199(3), 902–907. DOI 10.1016/j.ejor.2009.01.062. [Google Scholar] [CrossRef]
19. Hippert, H. S., Pedreira, C. E., Souza, R. C. (2001). Neural networks for short-term load forecasting : A review and evaluation. IEEE Transactions on Power Systems, 16(1), 44–55. DOI 10.1109/59.910780. [Google Scholar] [CrossRef]
20. Tzafestas, S., Tzafestas, E. (2001). Computational intelligence techniques for short-term electric load forecasting. Journal of Intelligent and Robotic Systems, 31, 7–68. DOI 10.1023/A:1012402930055. [Google Scholar] [CrossRef]
21. Kyriakides, E., Polycarpou, M. (2007). Short term electric load forecasting: A tutorial. Trends in neural computation, studies in computational intelligence, pp. 391–418. Berlin, Heidelberg: Springer-Verlag. [Google Scholar]
22. Chen, B., Chang, M., Lin, C. (2004). Load forecasting using support vector machines : A study on EUNITE competition 2001. IEEE Transactions on Power Systems, 19(4), 1821–1830. DOI 10.1109/TPWRS.2004.835679. [Google Scholar] [CrossRef]
23. Zheng, H., Yuan, J., Chen, L. (2017). Short-term load forecasting using EMD-lSTM neural networks with a xgboost algorithm for feature importance evaluation. Energies, 10(8), 1168. DOI 10.3390/en10081168. [Google Scholar] [CrossRef]
24. Taheri, S., Ahmadi, A., Mohammadi-ivatloo, B., Asadi, S. (2021). Fault detection diagnostic for HVAC systems using deep learning algorithms. Energy and Buildings, 250, 111275. DOI 10.1016/j.enbuild.2021.111275. [Google Scholar] [CrossRef]
25. Taheri, S., Razban, A. (2021). Learning-based CO2 concentration prediction : Application to indoor air quality control using demand-controlled ventilation. Building and Environment, 205, 108164. DOI 10.1016/j.buildenv.2021.108164. [Google Scholar] [CrossRef]
26. Talebjedi, B., Ghazi, M., Tasnim, N., Janfaza, S., Hoorfar, M. (2021). Performance optimization of a novel passive T-shaped micromixer with deformable baffles. Chemical Engineering and Processing–Process Intensification, 163, 2021. DOI 10.1016/j.cep.2021.108369. [Google Scholar] [CrossRef]
27. He, W. (2017). Load forecasting via deep neural network. Procedia Computer Science, 122, 308–314. DOI 10.1016/j.procs.2017.11.374. [Google Scholar] [CrossRef]
28. Hosein, S., Hosein, P. (2017). Load forecasting using deep neural networks. IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Crystal Gateway, Washington DC. [Google Scholar]
29. Tian, C., Ma, J., Zhang, C., Zhan, P. (2018). A deep neural network model for short-term load forecast based on long short-term memory network and convolutional neural network. Energies, 11(12), 3493. DOI 10.3390/en11123493. [Google Scholar] [CrossRef]
30. Dedinec, A., Filiposka, S., Dedinec, A., Kocarev, L. (2016). Deep belief network based electricity load forecasting : An analysis of Macedonian case. Energy, 115(3), 1688–1700. DOI 10.1016/j.energy.2016.07.090. [Google Scholar] [CrossRef]
31. Guo, Y., Liu, Y., Oerlemans, A., Lao, S., Wu, S. et al. (2016). Deep learning for visual understanding : A review. Neurocomputing, 187, 27–48. DOI 10.1016/j.neucom.2015.09.116. [Google Scholar] [CrossRef]
32. Yoo, H. (2015). Deep convolution neural networks in computer vision : A review. IEIE Transactions on Smart Processing and Computing, 4(1), 35–43. DOI 10.5573/IEIESPC.2015.4.1.035. [Google Scholar] [CrossRef]
33. van Houdt, G., Mosquera, C., Nápoles, G. (2020). A review on the long short-term memory model. Artificial Intelligence Review, 53(8), 5929–5955. DOI 10.1007/s10462-020-09838-1. [Google Scholar] [CrossRef]
34. Bouktif, S., Fiaz, A., Ouni, A., Adel Serhani, M. (2018). Optimal deep learning LSTM model for electric load forecasting using feature selection and genetic algorithm : Comparison with machine learning approaches. Energies, 11(7), 1636. DOI 10.3390/en11071636. [Google Scholar] [CrossRef]
35. Jiao, R., Zhang, T., Jiang, Y., He, H. (2018). Short-term non-residential load forecasting based on multiple sequences LSTM recurrent neural network. IEEE Access, 6, 59438–59448. DOI 10.1109/ACCESS.2018.2873712. [Google Scholar] [CrossRef]
36. Marino, D., Amarasinghe, K., Manic, M. (2016). Building energy load forecasting using deep neural networks. 42nd Annual Conference of the IEEE Industrial Electronics Society, pp. 7046–7051. Florence, Italy. [Google Scholar]
37. Li, C., Chen, Z., Liu, J., Li, D., Gao, X. et al. ( 2019). Power load forecasting based on the combined model of LSTM and XGBoost. Proceedings of the 2019 the International Conference on Pattern Recognition and Artificial Intelligence, pp. 8–13. Wenzhou, China. [Google Scholar]
38. Syed, D., Abu-rub, H., Refaat, S. (2021). Household-level energy forecasting in smart buildings using a novel hybrid deep learning model. IEEE Access, 9, 33498–33511. DOI 10.1109/Access.6287639. [Google Scholar] [CrossRef]
39. Khashei, M., Bijari, M. (2011). A novel hybridization of artificial neural networks and ARIMA models for time series forecasting. Applied Soft Computing, 11(2), 2664–2675. DOI 10.1016/j.asoc.2010.10.015. [Google Scholar] [CrossRef]
40. Khashei, M., Bijari, M. (2010). Expert systems with applications an artificial neural network (p, d, q) model for timeseries forecasting. Expert Systems with Applications, 37(1), 479–489. DOI 10.1016/j.eswa.2009.05.044. [Google Scholar] [CrossRef]
41. Zhu, B., Wei, Y. (2013). Carbon price forecasting with a novel hybrid ARIMA and least squares support vector machines methodology. Omega, 41(3), 517–524. DOI 10.1016/j.omega.2012.06.005. [Google Scholar] [CrossRef]
42. Li, T., Wang, B., Zhou, M., Zhang, L., Zhao, X. (2018). Short-term load forecasting using optimized LSTM networks based on EMD. The 10th International Conference on Communications, Circuits and Systems Short-Term, pp. 84–88. Chengdu, China. [Google Scholar]
43. Lee, T. (2020). EMD and LSTM hybrid deep learning model for predicting sunspot number time series with a cyclic pattern. Solar Physics, 295(82), 1–23. DOI 10.1007/s11207-020-01653-9. [Google Scholar] [CrossRef]
44. Zhang, X., Zhang, Q., Zhang, G., Nie, Z., Gui, Z. et al. (2018). A novel hybrid data-driven model for daily land surface temperature forecasting using long short-term memory neural network based on ensemble empirical mode decomposition. International Journal of Environmental Research and Public Health, 15(5), 1032. DOI 10.3390/ijerph15051032. [Google Scholar] [CrossRef]
45. Farrokh, A., Alaywan, Z. (1999). California ISO formation andimplementation. https://www.caiso.com/Documents/HistoricalEMSHourly-LoadDataAvailable.html. [Google Scholar]
46. Rehman, N., Mandic, D. (2010). Multivariate empirical mode decomposition. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 466(2117), 1291–1302. [Google Scholar]
47. Rehman, N., Mandic, D. P. (2011). Filter bank property of multivariate empirical mode decomposition. IEEE Transactions on Signal Processing, 59(5), 2421–2426. DOI 10.1109/TSP.2011.2106779. [Google Scholar] [CrossRef]
48. Kingma, D. P., Ba, J. L. (2015). Adam: A method for stochastic optimization. 3rd International Conference for Learning Representations, pp. 1–15. San Diego, USA. [Google Scholar]
49. Wiesler, S., Richard, A., Schluter, R., Nye, H. (2014). Mean-normalized stochastic gradient for large-scale deep learning. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 180–184. Florence, Italy. [Google Scholar]
50. Wang, Y., Gan, D., Sun, M., Zhang, N., Lu, Z. et al. (2019). Probabilistic individual load forecasting using pinball loss guided LSTM. Applied Energy, 235, 10–20. DOI 10.1016/j.apenergy.2018.10.078. [Google Scholar] [CrossRef]
51. Klimberg, R. K., Sillup, G. P., Boyle, K. J., Tavva, V. (2010). Forecasting performance measures—What are their practical meaning ? Advances in Business and Management Forecasting, 7, 137–147. DOI 10.1108/abmf. [Google Scholar] [CrossRef]
52. Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29(5), 1189–1232. DOI 10.1214/aos/1013203451. [Google Scholar] [CrossRef]
53. Chen, T., Guestrin, C. (2016). XGBoost : A scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 785–794. San Francisco, California, USA. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |