| Energy Engineering |
DOI: 10.32604/EE.2021.014627
ARTICLE
Probabilistic Load Flow Calculation of Power System Integrated with Wind Farm Based on Kriging Model
1Faculty of Land Resource Engineering, Kunming University of Science and Technology, Kunming, 650500, China
2School of Control and Computer Engineering, North China Electric Power University, Beijing, 102206, China
*Corresponding Author: Xinglang Su. Email: ednali@126.com
Received: 13 October 2020; Accepted: 29 October 2020
Abstract: Because of the randomness and uncertainty, integration of large-scale wind farms in a power system will exert significant influences on the distribution of power flow. This paper uses polynomial normal transformation method to deal with non-normal random variable correlation, and solves probabilistic load flow based on Kriging method. This method is a kind of smallest unbiased variance estimation method which estimates unknown information via employing a point within the confidence scope of weighted linear combination. Compared with traditional approaches which need a greater number of calculation times, long simulation time, and large memory space, Kriging method can rapidly estimate node state variables and branch current power distribution situation. As one of the generator nodes in the western Yunnan power grid, a certain wind farm is chosen for empirical analysis. Results are used to compare with those by Monte Carlo-based accurate solution, which proves the validity and veracity of the model in wind farm power modeling as output of the actual turbine through PSD-BPA.
Keywords: Probabilistic load flow; Kriging model; wind turbine clusters; polynomial normal transformation; correlation
With the large-scale integration of renewable energy sources such as wind power and photovoltaics (PV) into the grid, there are more and more random factors in the operation of power system, which intensifies the uncertainty of system operation [1]. The calculation of probabilistic load flow (PLF) can take into account the influence of random disturbance or uncertain factors in the operation of power system on steady state operation of system, comprehensively evaluate the weak points and potential risks in the operation of system, and provide valuable information for planning and scheduling department to make decisions, which has always been a focus of research [2,3].
The common calculation methods of PLF include simulation methods and analytical methods. In simulation methods, Monte Carlo simulation (MCS) method [4] owns high accuracy when the sampling scale is large enough, but it takes a long time, so it is usually used as a standard method to evaluate the accuracy of other PLF methods. In analytical methods, convolution method performs convolution calculation according to the probability distribution function of input random variable and obtains the probability distribution characteristics of output random variable [5], which concept is clear but calculation burden is large. In order to solve the above problems, an approximate method is introduced, that is, on the premise of not reducing the accuracy, a mathematical model with a small amount of calculation and a calculation result similar to the actual simulation result is constructed to replace the actual simulation program. Moreover, common approximate models include polynomial response surface method (RSM) [6], artificial neural network (ANN) model [7], and support vector machine (SVM) function model [8], etc. However, polynomial response surface model has a lower fitting degree for nonlinear problems; the characteristics of SVM model varies with its used functions; ANN model is a “black box” model, which lacks strict statistical test and is easy to fall into local extremum. Kriging model is a kind of smallest unbiased variance estimation method estimating the unknown information, which can achieve global approximation in the design space and has high fitting accuracy [9,10].
Both analytical and approximate methods assume that random variables in probabilistic power flows are independent of each other. When it deals with random variables with correlation, new steps are needed to solve the correlation problem of random variables. Haesen et al. [11] used Nataf inverse transformation to predict wind speed to obtain a wind speed series with correlation. Liu et al. [12] transformed multidimensionally correlated non-normal random variables into independent normal random variables based on marginal probability distribution. Bin et al. [13] proposed a simulation method of correlated random variables based on Copula theory and rank correlation coefficient based on cumulative distribution function of random variables. The above correlation modeling methods all need to know the probability distribution function of random variables, but for non-normal multi-dimensional random variables, it is difficult to give a complete joint probability distribution [14].
Kriging is a regression algorithm for spatial modeling and prediction (interpolation) of stochastic process based on covariance function. This paper proposes a combined Kriging model and polynomial normal transformation (PNT) method to calculate PLF of wind farm access to system. Firstly, PNT is used for wind speed prediction to obtain wind speed sequences related to wind turbine clusters, while output model of wind turbine cluster is established. This method does not need to know the probability distribution function of input random variable, but only needs to use polynomial normal transformation according to its digital characteristics to quickly and accurately obtain relevant wind speed sequences. Then, taking the output of PNT as input, relationship between system response and random input is established by Kriging model, thus probability statistics of system response can be calculated. Finally, a wind farm in Yunnan power grid is taken as an example to verify the effectiveness, accuracy, and rapidity of the proposed method.
2 Polynomial Normal Transformation
In this paper, PNT is adopted to transform the non-normally correlated multi-dimensional random variables into the normal uncorrelated variable space, take sampling points in the normally uncorrelated variable space, and then inversely transform these sampling points to the original non-correlated variable space. This transformation-inverse transformation process enables the method to deal with the PLF problem with correlated random variables [15,16].
Common polynomial normal transformation methods mainly include third-order polynomial normal transformation (TPNT) [17], fifth-order polynomial normal transformation (FPNT) [18] and ninth-order polynomial normal transformation (NPNT) [19]. Considering the calculation accuracy and complexity of polynomial normal transformation, this paper employs the most widely applied third-order polynomial normal transformation (TPNT).
Assume a set of correlated multidimensional random variables, denoted
where
Besides,
where
The polynomial coefficient can be obtained from the probabilistic weighted moment (PWM) of random variable. Suppose PWM of random variable
The linear moment of
The coefficient of the polynomial can be obtained according to the linear moment of
The above transformation transforms non-normal random variables into normal random variables. In order to ensure that the correlated coefficient matrix of random variables remains unchanged in the transformation process, correlated coefficient matrix
The detailed relationship between
where
Solve the above unary cubic equation and select the root that satisfies
At this time,
where the lower triangular matrix
Substitute Eq. (8) into Eq. (2), the original space
Kriging model was proposed by Krige, a South African geologist, in 1951, which was first applied to geostatistics. Subsequently, Sack et al. [23] applied it to engineering design, and Remero et al. [24] applied it to structural reliability analysis in 2004. Since then, the application field of Kriging model has been explored and studied continuously.
As an approximate model, the essence of Kriging model instead of actual simulation program is to approximate the relationship between system response and design variables with Kriging model, which is composed of a parametric model and a non-parametric model. It is more flexible than the simple parametric model and simultaneously overcomes the limitation of non-parametric model in processing high-dimensional data [25]. Kriging model simulates a certain point with the help of known information around this point, so it establishes a model related to known information, which requires few parameters to be determined, small calculation amount, and simple model. In addition, the estimation model can be determined through a small number of sample tests.
Kriging model assumes that the actual relationship between system response and random variables can be expressed as
where
where
The commonly used regression models and related functions are listed in Appendices B and C respectively. Research shows that the type of regression model does not play a decisive role in the accuracy of simulation [26]. In order to simplify the calculation process, the regression value f(x) is set as 1. The existence of
where
After the regression model and correlation function are determined, the expression of approximate response
where
The maximum probability estimation factor is expressed as
The correlated model needs to solve the relevant parameter
The relevant parameter
At this point, Kriging model is established.
3.2 Case Studies of Kriging Models
The numerical example of Eq. (17) is used to verify the simulation effect of Kriging model. In the sampling space, four groups of training sample points with scales of 15, 25, 35, and 45 are respectively taken, which are substituted into Eq. (17) to obtain four sets of response values, and Kriging model is constructed. Zhu et al. [28] proposes a method to solve Kriging model, in which two main functions are dacefit and predictor. The function dacefit establishes Kriging model based on sample points, while the function Predictor calculates the response value of the measured points based on Kriging model.
When constructing Kriging model, it is necessary to give the initial value
Table 1: The parameter settings of Kriging model

After the model is established, the accuracy of the model should be tested. Randomly generate 100 sets of sample points to be tested in the sampling space, and substitute them into Kriging model and Eq. (17) to obtain the corresponding predicted and actual values. Their relative error is provided in Tab. 2, which shows that the established Kriging model owns good approximate accuracy.
Table 2: The relative error of Kriging model
Fig. 1 indicates the mean relative error between the predicted value and the actual value of Kriging model. It can be seen from that the accuracy of Kriging model is related to the size of training sample. The larger the training sample size is, the higher the accuracy of Kriging model will be.

Figure 1: The mean of relative error between predictive value of Kriging model and real value
In the deterministic power flow calculation, node injection power equation and branch power equation [29] of system can be expressed by
where
This paper defines output of wind turbine clusters in the node injected power as input variable and the amplitude of node voltage and the power of branch as output variable. When the input variable is a random variable, the output variable becomes a random variable. PLF problem is to obtain the probability distribution or digital characteristics of output variable when input variable is random.
During calculation, the sample value of output of
The calculation process is shown in Fig. 2 while the basic steps are as follows:
1. Input basic data: the number of wind turbine clusters
2. TPNT method is used to generate a series of wind speed sequences with a scale of
3. The node voltage and branch power corresponding to
4. TPNT method is used to generate a set of wind speed series with a scale of
5. The estimated values of node voltage and branch power corresponding to
6. The probability statistics of Kriging model results are calculated and compared with the exact solution based on Monte Carlo method.

Figure 2: Calculation flow chart
Based on historical wind speed data of an actual wind farm in Yunnan Power Grid, Kriging model is established, and the power flow calculation is performed on PSD-BPA through command line programming [31]. All case studies are undertaken by Matlab 2019a through a personal computer with IntelRcoreTMi7 CPU at 2.0 GHz and 32 GB of RAM. Monte Carlo method runs 5000 times to obtain near the wind farm node voltage and branch power of statistical information as accurate values, and 50 times in comparison with the results of Kriging model simulation input.
This wind farm has four wind turbine clusters, with installed capacity of 49.5 MW, 42 MW, 34.5 MW, and 42 MW respectively, and total installed capacity of 168 MW, operating with constant power factor of 0.95. Fig. 3 is a regional grid structure diagram of wind farm access system, which is connected to 220 kV main network in the 220 kV area by Node 2 through 110 kV line of two LGJ-300 conductors [32,33].

Figure 3: Structure diagram of regional grid after accessing wind farm
Fig. 4 shows the probability density curve of historical wind speed sequences and TPNT generated wind speed sequences (wind turbine cluster 1 and wind turbine cluster 2 are taken as examples). It can be seen from that wind speed sequences generated by TPNT are very close to the measured historical data, which indicates that TPNT method is effective.
Suppose historical wind speed and parameters of marginal probability distribution function of wind speed generated by TPNT are
where
In order to facilitate the calculation of Eq. (19), probability distribution model of wind speed adopts Weibull distribution that fits well with the actual statistical distribution of wind speed [34], and its probability distribution function can be expressed as
where
where
The accuracy of correlation model established by TPNT method can be evaluated through Eq. (19), and calculation results are shown in Tab. 3. It can be seen that the correlation samples generated by TPNT have high accuracy in fitting the parameters of marginal probability distribution function of input random variables, and the sample quality keeps improving with the increase of sampling scale.
Table 3: Relative error index of Weibull distribution parameters of wind speed

Figure 4: Probability density curves of wind speed. (a) Wind turbine cluster 1, (b) Wind turbine cluster 2
The voltage amplitude of two nodes near wind farm and power of three branches are selected as the observed values, which are numbered as Node 1, Node 2, Branch 1, Branch 2, and Branch 3, respectively, as shown in Fig. 3.
According to the historical wind speed data of 4 wind turbine clusters, a set of relevant wind speed sequences are generated from TPNT to establish wind turbine cluster output model, which is connected to the system for 50 basic power flow calculations to obtain the corresponding 50 voltage groups of Nodes 1 and 2, along with the response values of active power of Branch 1, Branch 2 and Branch 3. Kriging model is constructed according to 50 groups of response values, and 5000 groups of node voltage and branch power are generated by the constructed Kriging model, and the statistical results of 5000 Monte Carlo simulations are compared and analyzed to verify the validity, accuracy, and rapidity of Kriging model.
In Fig. 5, the probability density distribution curve of the voltage amplitude of Node 1 and Node 2 are obtained by Kriging model, and compared with the simulation result based on Monte Carlo method. As can be seen from Fig. 5, the results of 50 times Kriging model method have a high degree of fitting with 5000 times MCS, indicating that Kriging model can well simulate system output.
Figure 5: Probability density curves of the related bus voltages under Kriging and recorded history datum. (a) Node 1, (b) Node 2
Fig. 6 compares the probability density distribution of active power of three branches obtained by two methods. The probability density curve obtained by Kriging model fits the histogram obtained by MCS well.
Figure 6: Probability density distribution of the related branches’ power flow under Kriging and recorded history datum. (a) Branch 1, (b) Branch 2, (c) Branch 3
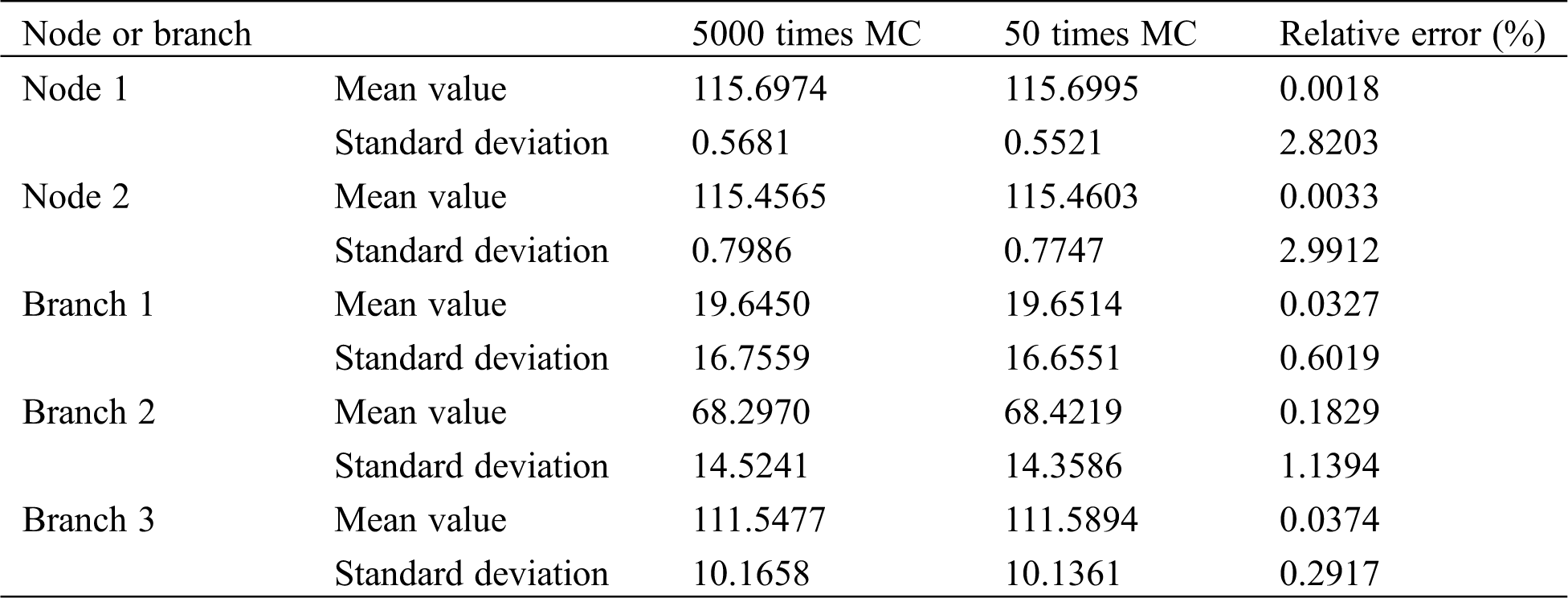
Table 4: Branch powers and bus voltage expectations and standard deviations
Let the simulation results of Kriging model and Monte Carlo method be
Tab. 4 compares mean value and standard deviation of the grid related node voltage and branch power. It can be seen from that the mean value and standard deviation of the Kriging model results and the relative error between the exact value are below “0.2%” and “3%”, respectively, which once again verifies the high accuracy of Kriging model.
Tab. 5 shows the simulation time of two methods. It shows that simulation time of Kriging model method is far less than that of Monte Carlo method, which proves the rapidity of the method proposed in this paper, and solves the problems of the traditional random analysis method with many simulation times and long simulation time.
Table 5: Simulation time of the two methods

Due to the proximity of geographical locations in the same wind farm, the wind speed between different wind power clusters has a strong correlation, so that the output of each wind turbine cluster has a strong correlation. In this paper, TPNT method is adopted to model wind turbine clusters with relevant wind speed, and Kriging model is applied to PLF analysis of system. An example of a real wind power farm in Yunnan power grid shows that Kriging model owns 100 times less than MC computation burden. Kriging also owns higher simulation accuracy, which verifies the effectiveness, accuracy, and rapidity of this method.
This paper provides an effective modeling and analysis method for studying PLF problem based on correlation. Compared with traditional random analysis method, it has fast calculation speed and less memory, and can quickly calculate system probability statistics with correlated random variables. Besides, based on calculation and analysis of PLF in this paper, Kriging model method could be applied to the Optimal power flow calculation and analysis of power system. The measured data will be used to verify feasibility of the proposed method.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. Li, L., Tan, Z. F., Zhang, E. Y. (2012). Simulation of the impact of environmental policies on long-term resource planning models. Electric Engineering, 6, 61–63. [Google Scholar]
2. Morales, J. M., Baringo, L., Conejo, A. J., Minguez, R. (2010). Probabilistic power flow with correlated wind sources. IET Generation Transmission and Distribution, 4(5), 641–651. DOI 10.1049/iet-gtd.2009.0639. [Google Scholar] [CrossRef]
3. Ei-Khattam, W., Hegazy, Y. G., Salama, M. M. A. (2006). Investigating distributed generation systems performance using Monte Carlo simulation. IEEE Transaction on Power Systems, 21(2), 524–532. DOI 10.1109/TPWRS.2006.873131. [Google Scholar] [CrossRef]
4. Hajian, M., Rosehart, W. D., Zareipour, H. (2013). Probabilistic power flow by Monte Carlo simulation with Latin supercube sampling. IEEE Transactions on Power Systems, 28(2), 1550–1559. DOI 10.1109/TPWRS.2012.2214447. [Google Scholar] [CrossRef]
5. Moszczyński, L., Bielski, T. (2013). Development of analytical method for calculation the expanded uncertainty in convolution of rectangular and Gaussian distribution. Measurement, 46(6), 1896–1903. DOI 10.1016/j.measurement.2013.02.013. [Google Scholar] [CrossRef]
6. Yu, H., Chung, C. Y., Wong, K. P., Lee, H. W., Zhang, J. H. (2009). Probabilistic load flow evaluation with hybrid Latin hypercube sampling and Cholesky decomposition. IEEE Transactions on Power Systems, 24(2), 661–667. DOI 10.1109/TPWRS.2009.2016589. [Google Scholar] [CrossRef]
7. Li, Z. C., Zhang, B. H., Ge, Y. B., Chen, Y., Miao, X. G. et al. (2013). Probabilistic available transfer capability calculation of wind farm incorporated power system. Advanced Materials Research, 724–725, 582–586. DOI 10.4028/www.scientific.net/AMR.724-725.582. [Google Scholar] [CrossRef]
8. Sui, B., Hou, K., Jia, H., Yunfei, M. U., Xiaodan, Y. U. (2018). Maximum entropy based probabilistic load flow calculation for power system integrated with wind power generation. Journal of Modern Power Systems and Clean Energy, 6(5), 202–210. DOI 10.1007/s40565-018-0384-6. [Google Scholar] [CrossRef]
9. Xu, X., Yan, Z. (2017). Probabilistic load flow calculation with Quasi-Monte Carlo and multiple linear regression. International Journal of Electrical Power & Energy Systems, 88, 1–12. DOI 10.1016/j.ijepes.2016.11.013. [Google Scholar] [CrossRef]
10. Gao, Y., Wang, C. (2015). Probabilistic load flow calculation of distribution system including wind farms based on total probability formula. Proceedings of the CSEE, 35(2), 327–334. [Google Scholar]
11. Haesen, E., Bastiaensen, C., Driesen, J., Belmans, R. (2009). A probabilistic formulation of load margins in power systems with stochastic generation. IEEE Transactions on Power Systems, 24(2), 951–958. DOI 10.1109/TPWRS.2009.2016525. [Google Scholar] [CrossRef]
12. Liu, P. L., Kiureghian, A. D. (1986). Multivariate distribution models with prescribed marginals and covariances. Probabilistic Engineering Mechanics, 1(2), 105–112. DOI 10.1016/0266-8920(86)90033-0. [Google Scholar] [CrossRef]
13. Bin, L., Shahzad, M., Bing, Q., Shoukat, M. U., Shakeel, M. et al. (2018). Probabilistic computational model for correlated wind farms using copula theory. IEEE Access, 6, 14179–14187. DOI 10.1109/ACCESS.2018.2812790. [Google Scholar] [CrossRef]
14. Sun, M., Wu, H., Qiu, Y., Gong, J., Song, Y. (2017). Probabilistic load flow for wind power integrated system based on generalized polynomial chaos methods. Automation of Electric Power Systems, 41(7), 54–60 and 100. [Google Scholar]
15. Defu, C., Dongyuan, S., Gaowang, L. I., Jinfu, C. (2013). A probabilistic load flow calculation method based on discrete data of input random variable. Power System Technology, 37(9), 2474–2479. [Google Scholar]
16. Dong, L., Cheng, W. D., Yang, Y. H. (2009). Probabilistic load flow calculation for power grid containing wind farms. Power System Technology, 33(16), 87–91. [Google Scholar]
17. Zhao, Y. G., Lu, Z. H. (2007). Fourth-moment standardization for structural reliability assessment. Journal of Structural Engineering, 133(7), 916–924. DOI 10.1061/(ASCE)0733-9445(2007)133:7(916). [Google Scholar] [CrossRef]
18. Headrick, T. C. (2002). Fast fifth-order polynomial transforms for generating univariate and multivariate nonnormal distributions. Computational Stats & Data Analysis, 40(4), 685–711. DOI 10.1016/S0167-9473(02)00072-5. [Google Scholar] [CrossRef]
19. Zou, B., Xiao, Q. (2013). Solving probabilistic optimal power flow problem using quasi Monte Carlo method and ninth-order polynomial normal transformation. IEEE Transactions on Power Systems, 29(1), 300–306. DOI 10.1109/TPWRS.2013.2278986. [Google Scholar] [CrossRef]
20. Chen, X., Tung, Y. K. (2003). Investigation of polynomial normal transform. Structural Safety, 25(4), 423–445. DOI 10.1016/S0167-4730(03)00019-5. [Google Scholar] [CrossRef]
21. Zhang, H., Xu, Y. (2018). Probabilistic load flow calculation by using probability density evolution method. International Journal of Electrical Power and Energy Systems, 99, 447–453. DOI 10.1016/j.ijepes.2018.01.043. [Google Scholar] [CrossRef]
22. Su, C. L. (2005). Probabilistic load-flow computation using point estimate method. IEEE Transactions on Power Systems, 20(4), 1843–1851. DOI 10.1109/TPWRS.2005.857921. [Google Scholar] [CrossRef]
23. Usaola, J. (2009). Probabilistic load flow with wind production uncertainty using cumulants and Cornish-Fisher expansion. International Journal of Electrical Power and Energy Systems, 31(9), 474–481. DOI 10.1016/j.ijepes.2009.02.003. [Google Scholar] [CrossRef]
24. Liu, Y., Gao, S., Cui, H., Yu, L. (2016). Probabilistic load flow considering correlations of input variables following arbitrary distributions. Electric Power Systems Research, 140, 354–362. DOI 10.1016/j.epsr.2016.06.005. [Google Scholar] [CrossRef]
25. Nikmehr, N., Najafi Ravadanegh, S. (2015). Solving probabilistic load flow in smart distribution grids using heuristic methods. Journal of Renewable & Sustainable Energy, 7(4), 752–759. [Google Scholar]
26. Usaola, J. (2010). Probabilistic load flow with correlated wind power injections. Electric Power Systems Research, 80(5), 528–536. DOI 10.1016/j.epsr.2009.10.023. [Google Scholar] [CrossRef]
27. Ye, L., Zhang, Y., Ju, Y., Song, X., Li, Q. (2017). Gaussian mixture model for probabilistic power flow calculation of system integrated wind farm. Proceedings of the CSEE, 37(15), 4379–4387. [Google Scholar]
28. Zhu, J. Z., Zhang, Y. (2019). Probabilistic load flow with correlated wind power sources using a frequency and duration method. IET Generation, Transmission and Distribution, 13(18), 4158–4170. DOI 10.1049/iet-gtd.2018.6530. [Google Scholar] [CrossRef]
29. Prusty, B. R., Jena, D. (2016). A critical review on probabilistic load flow studies in uncertainty constrained power systems with photovoltaic generation and a new approach. Renewable & Sustainable Energy Reviews, 69, 1286–1302. DOI 10.1016/j.rser.2016.12.044. [Google Scholar] [CrossRef]
30. Li, L., Tan, Z. F. (2013). Optimization design of wind/photovoltaic hybrid power systems based on genetic algorithms. Chinese Journal of Scientific Instrument, 278–280, 1692–1695. [Google Scholar]
31. Gupta, N., Daratha, N. (2017). Probabilistic three-phase load flow for unbalanced electrical systems with wind farms. International Journal of Electrical Power and Energy Systems, 87, 154–165. DOI 10.1016/j.ijepes.2016.11.002. [Google Scholar] [CrossRef]
32. Zhang, P., Lee, S. T. (2004). Probabilistic load flow computation using the method of combined cumulants and Gram-Charlier expansion. IEEE Transactions on Power Systems, 19(1), 676–682. DOI 10.1109/TPWRS.2003.818743. [Google Scholar] [CrossRef]
33. Prusty, B. R., Jena, D. (2016). Combined cumulant and gaussian mixture approximation for correlated probabilistic load flow studies: A new approach. CSEE Journal of Power and Energy Systems, 2(2), 71–78. DOI 10.17775/CSEEJPES.2016.00024. [Google Scholar] [CrossRef]
34. Liu, X. T., Zhao, J. Q., Luo, W. H., Zhao, J. (2013). A TPNT and cumulants based probabilistic load flow approach considering the correlation variables. Power System Protection and Control, 41(22), 13–18. [Google Scholar]
Appendix A. TPNT Generates Correlation Wind Speed Sequence
Using TPNT to generate a wind speed sequence with a specified correlation coefficient, which mainly includes three parts:
1. Sampling points are selected from the independent standard normal space
2. The transformation
3. Eq (2) is used to transform the sampling point from space
The flow chart of TPNT to predict relevant wind speed of wind farm group is depicted in Fig. A1:

Figure A1: Forecasting related wind speed of wind farm group by TPNT method
The regression part of Kriging model simulates the overall trend of the response, which provides global approximations within the design space, commonly employing zero-order, first-order and second-order polynomials, as follows
zero-order,
first-order,
second-order,
Researches indicate that regression part has little effect on the accuracy of the model, and usually just simply takes constant.
The existence of random function
where
The common correlation functions are shown in Tab. C1.
Table C1: Correlation function

Note:
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |