
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
An Enhanced Task Migration Technique Based on Convolutional Neural Network in Machine Learning Framework
1 Department of Computer Science, Faculty of Computer Science & IT, Superior University, Lahore, 54000, Pakistan
2 School of Electrical, Computer and Telecommunications Engineering, University of Wollongong, Wollongong, NSW 2522, Australia
3 School of Mathematics and Applied Statistics, University of Wollongong, Wollongong, NSW 2522, Australia
4 School of Information Technology, King’s Own Institute, Sydney, NSW 2000, Australia
5 Faculty of Computer and Information Systems, Islamic University of Madinah, Al Madinah Al Munawarah, 42351, Saudi Arabia
6 Department of Information Technology, Wentworth Institute of Higher Education, Sydney, NSW 2000, Australia
7 Faculty of Electrical Engineering and Technology, Superior University, Lahore, 54000, Pakistan
* Corresponding Author: Hamayun Khan. Email:
Computer Systems Science and Engineering 2025, 49, 317-331. https://doi.org/10.32604/csse.2025.061118
Received 18 November 2024; Accepted 17 January 2025; Issue published 19 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The migration of tasks aided by machine learning (ML) predictions IN (DPM) is a system-level design technique that is used to reduce energy by enhancing the overall performance of the processor. In this paper, we address the issue of system-level higher task dissipation during the execution of parallel workloads with common deadlines by introducing a machine learning-based framework that includes task migration using energy-efficient earliest deadline first scheduling (EA-EDF). ML-based EA-EDF enhances the overall throughput and optimizes the energy to avoid delay and performance degradation in a multiprocessor system. The proposed system model allocates processors to the ready task set in such a way that their deadlines are guaranteed. A full task migration policy is also integrated to ensure proper task mapping that ensures inter-process linkage among the arrived tasks with the same deadlines. The execution of a task can halt on one CPU and reschedule the execution on a different processor to avoid delay and ensure meeting the deadline. Our approach shows promising potential for machine-learning-based schedulability analysis enables a comparison between different ML models and shows a promising reduction in energy as compared with other ML-aware task migration techniques for SoC like Multi-Layer Feed-Forward Neural Networks (MLFNN) based on convolutional neural network (CNN), Random Forest (RF) and Deep learning (DL) algorithm. The Simulations are conducted using super pipelined microarchitecture of advanced micro devices (AMD) XScale PXA270 using instruction and data cache per core 32 Kbyte I-cache and 32 Kbyte D-cache on various utilization factors 12%, 31% and 50%. The proposed approach consumes 5.3% less energy when almost half of the CPU is running and on a lower workload consumes 1.04% less energy. The proposed design accumulatively gives significant improvements by reducing the energy dissipation on three clock rates by 4.41%, on 624 MHz by 5.4% and 5.9% on applications operating on 416 and 312 MHz standard operating frequencies.Keywords
Energy-aware multiprocessor systems-on-chips (MPSoCs) are widely used for multimedia and gaming embedded systems. Multi-core processors are rapidly turning into the norm for embedded real-time systems because of the demand for multimedia and gaming systems. These processors take into consideration greater adaptability while making undertakings, giving a substantially more productive environment for task assignments [1]. Task dispatching is a significant part of multiprocessors this article presents a dividing technique for reducing the energy of CPU in multi-core frameworks that reduces the worst-case execution time (WCET) and the absolute energy utilization of the framework. Our calculation is contrasted with others and we exhibit its prevalence [2].
MPSoC consists of multiple processors and all the components on the same chip consume low energy and require less power because of the tightly integrated architecture [3]. The consumption of MPSoC occurs in many abstractions from the logic level to the circuit. It’s an integrated circuit and is designed for application with specific special software and hardware [4]. Proposed a scheduling technique for execution and assessment of CPU energy and memory of the central framework that is associated with multimedia applications. The proposed scheduler is dependent on a constant bandwidth server (CBS) [5]. Introduce an energy-efficient CPU scheduler that maps data using the earliest deadline first-based window constraint migration (EDF-WM) for multiprocessors in which memory reservation instrument uses paging calculations called shared anonymous private pages (PSAP) [6]. Introduce an energy-aware technique for the smooth allocation of the task. Task allocation expands the addition recurrence (usefulness) of its appointed tasks, which brings about expanded CPU clock recurrence [7]. Introduced an efficient processor with chip-packaged-based multi-core processing units, in which at least two processors are utilized to complete execution in equal intervals. This advancement in CPUs gives fast response and quicker execution times [8]. Introduce a Tasks scheduling based on logical link control (LLC) using Convolutional Neural Network (CNN) as shown in Fig. 1 based on the m processor scheduling algorithm (MPSA), L1-D, LLC and NOC Route showing multi-task mapping that creates an ideal schedule that expands the throughput of programs while fulfilling the processor’s mapping requirements [9].
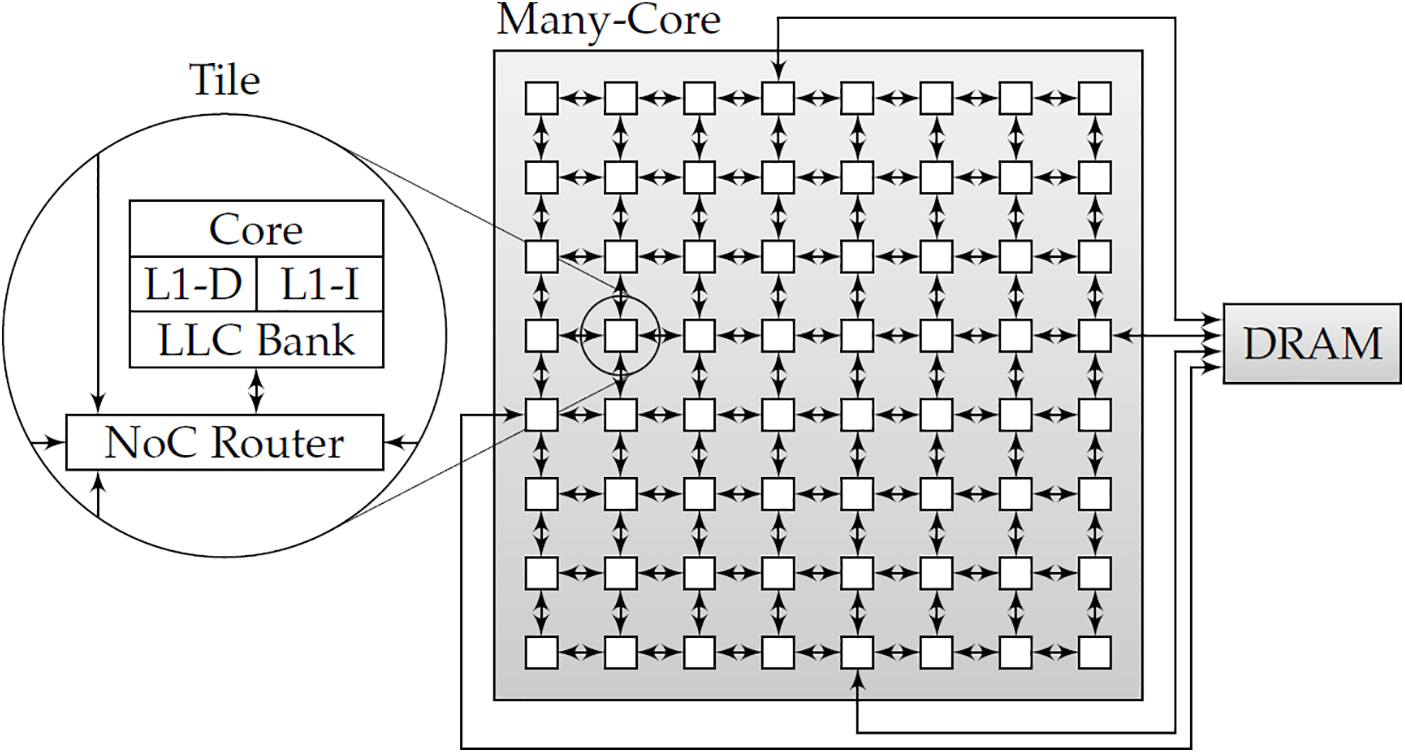
Figure 1: Tasks scheduling based on LLC using CNN
Energy dissipation and Energy-Efficient Scheduling play a vital role in the Migration of tasks while using a Homogeneous platform to meet deadlines of tasks during execution [10]. An energy-efficient dissipation method is proposed to enhance the task migration abilities of MPSoC. Introduce an efficient energy dissipation strategy. Shrinkage of the chip and certainly increasing the electronic element transistor on a chip the frequency and power densities are gradually increasing causing many problems like power consumption and thermal issues as well as higher dissipation of energy [11]. Efficient multi-core systems are introduced but due to the increase in energy thermal issues arise that are the major problems [12].
Introduces a mechanism that energy consumption (
In CMOS chips, the consumption of dynamic power due to the transistor’s switching can be calculated using Eq. (2):
Slave and Master thread Migration ratio in AI-based MPSoC that shows core performance using AMD hops in Fig. 2. The load capacitance is denoted as
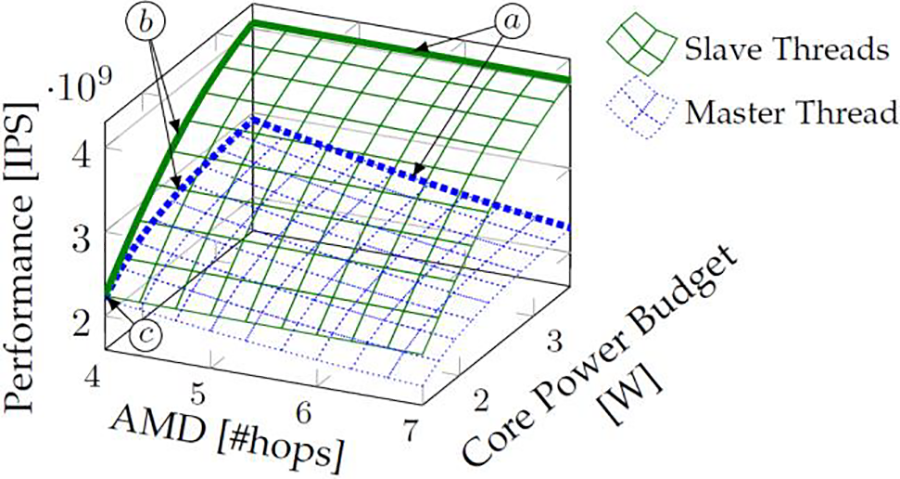
Figure 2: Slave and master thread migration ratio in AI-based MPSoC
Task migration based on GPU memory for power efficient MPSoC is a mechanism that is used to move an executing task from one host CPU in a distributed architecture to another CPU. DVFS based selection of a task and movement to the host CPU for a new time can task and the creation of the task on that host increase the performance, reliability and processing speed. The lack of task migration on affect the overall system performance [14]. Most of the current techniques improve energy and power management-related problems. The mapping of ready task allocation to CPU is another approach to scheduling, there are three main classes of task scheduling multiprocessor partitioned scheduling, restricted-migration scheduling, and full-migration scheduling.
1.3 Partitioned Migration Scheduling
Introduced an energy aware partitioned migration scheduling technique that is used for the optimization of energy-aware distributed multiprocessor. The system mapped each ready task to a single processor π at the system-design time [15]. Statically assignment of the task to the CPU is preferable for the uniprocessor schedule as illustrated in Fig. 3.
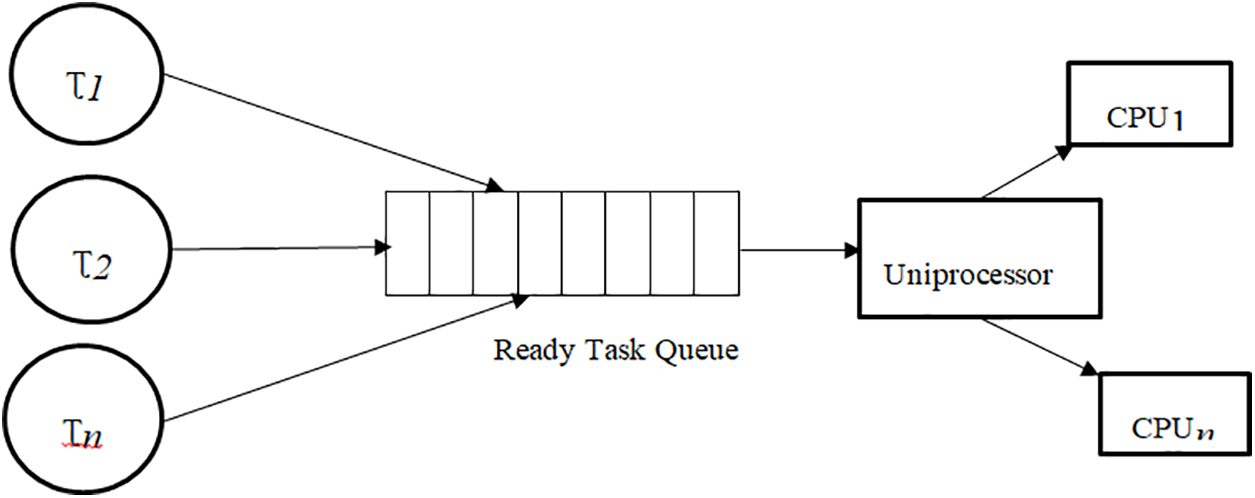
Figure 3: Tasks scheduling using partitioned migration
Introduced full migration task scheduling technique based on dynamic voltage and frequency scaling DVFS that is widely used as the least restrictive method widely used in scheduling. An energy and performance efficient DVFS scheme can handle task that halt on one CPU and reschedule the execution on a different processor to avoid delay and meet the deadline. Job-level parallelism is restricted because tasks cannot execute parallel on two or more different CPU cores [16]. Each arrived task is placed into a priority queue. The scheduler can have the option to decide what task requires execution on each CPU at the current time interval as shown in Fig. 4.
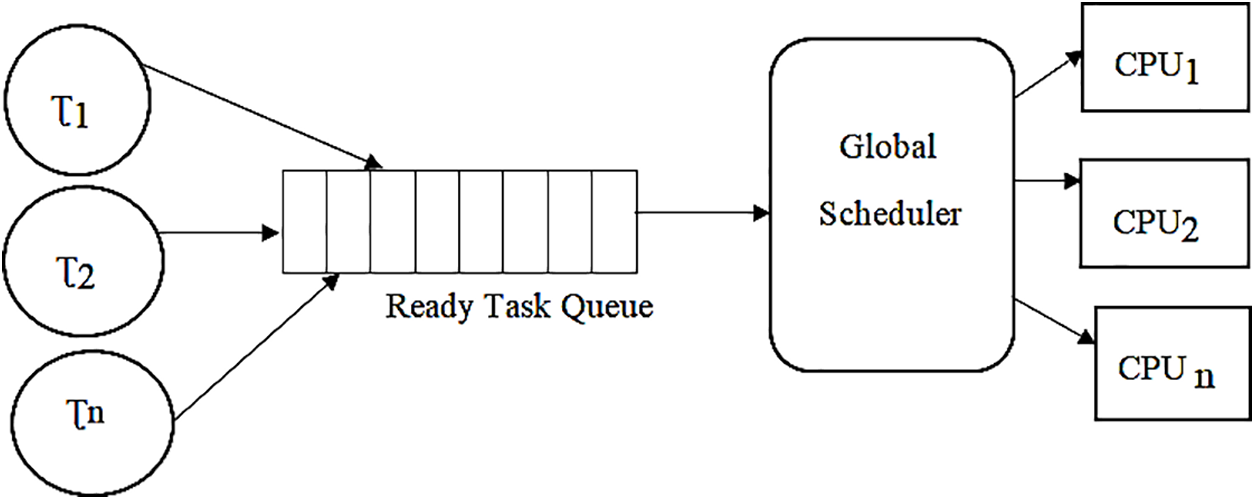
Figure 4: Tasks scheduling of tasks using partitioned migration
1.5 Restricted Migration Scheduling
Introduce a restricted migration scheduling based on a Resource-aware load balancing model for a batch of tasks (BoT) considering the deadline and best-fit migration policy for homogenious and heterogeneous distributed computing systems that migrate tasks between CPUs, each arrived task can execute on only one CPU core at a time [17]. Proposed a Dynamic scheduling technique for real-time tasks in heterogeneous multicore systems in which the arrivals of the task are not prioritized. In restricted migration, a scheduler can adapt to two levels. Generated tasks are placed on the global priority queue [18]. Reference [19] introduced an energy optimization for real-time multiprocessor that runs only periodic tasks with uncertain execution time by considering the migration policy to reduce the effects of the increase in temperature on the chip that can smoothly perform and achieve a normal working condition. A uniprocessor scheduling algorithm is used to schedule each processor’s assigned task as shown in Fig. 5.
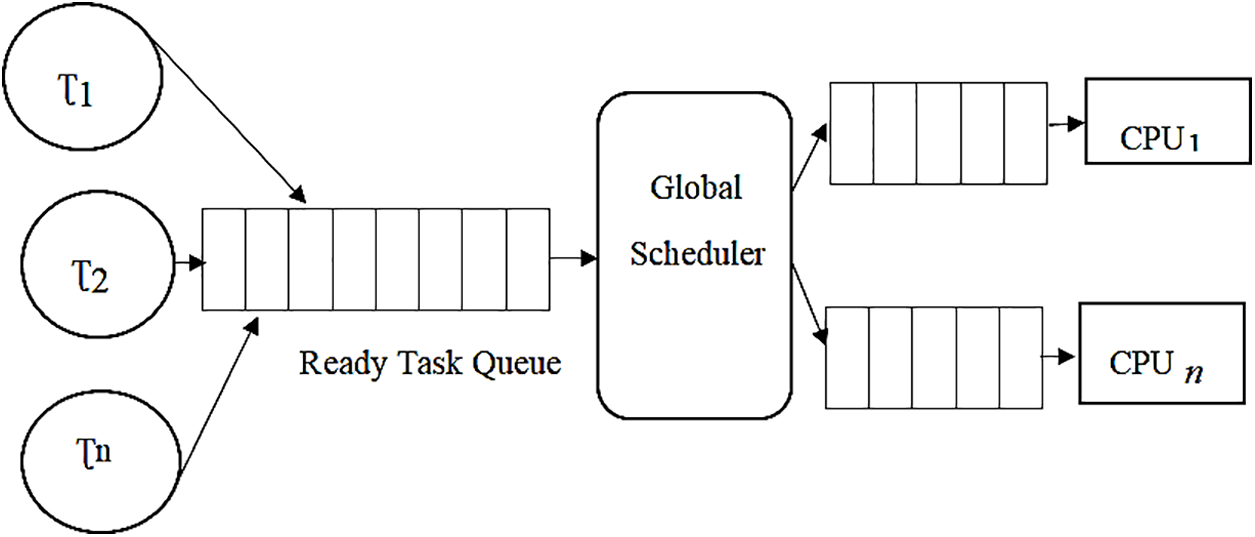
Figure 5: Tasks scheduling using partitioned migration
System-level application-aware dynamic power management (DPM) in adaptive pipelined MPSoCs for software-based energy and power reduction schemes are implemented at the consumer level and the consumption of energy is reduced using the software. Instruction reordering and energy-efficient code are widely used software-based energy optimization techniques. Energy optimization using software-based methods includes instruction level, operating system (OS) level and compiler level implementation [20]. Introduce an Online dynamic power management (DPM) for efficient execution of interactive workloads AND instruction-level energy optimization technique. The instruction level analysis is used to assign a defined energy budget to any ready task. Proposed a compiler-level mechanism that plays an important role in the behavior of an application during execution and determines the no of instructions being executed, order as well as type and has a significant impact on the reduction of energy consumption [21]. Dynamic power management (DPM) for multidomain system-on-chip is introduced with an optimal control approach to reduce the consumption of energy and power. Introduces a memory latency optimization technique that is used for the latency optimizations at the compiler level That modifies the memory layout and program access pattern operating system (OS) level [22]. The implementation of Optimal Dynamic power management for multidomain is used for the optimization of software-level approach and also used in hardware as pointer synthesis [23].
Proposed a real-time model that is based on finite elements and used for the optimization and reduction of memory by considering dynamic memory and dynamic power approach as high-speed on-chip memory is widely used to reduce the consumption of energy during the run time. Introduce an instruction rescheduling technique that is highly used compiler-level energy and power reduction technique that is used to enhance the performance as well as also remove the pipeline stalls that cause a delay in processing [24]. Proposed an analysis and optimization of MPSoCs reliability test that utilize the operating system according to the requirement and demand of tasks related to OS processes. The OS level optimization technique is implemented on dynamic power management (DPM), CPU clock, scheduling algorithms, Input-output (I/O) and speed management software-based DPM technique using an operating system level is implemented to reduce energy for performance enhancement as shown in Eq. (5).
The energy consumed during the transmission is represented as
Whereas
While another task
The utilization bound
Introduce a P-EDF-based utilization bound for identical MPSoC first fit decreasing (FFD), best fit (BF) and random fit (RF) are widely used for assigning tasks to CPU and it’s observed that all these variations have the same utilization bound. Introduce a mechanism to find the utilization bound that determines the least number of processors that are required to schedule
Marvel X-Scale AMD PXA-270 is widely used for symmetric multiprocessing when a real-time task load arrives and all the processors in a multi-core embedded system are of the same type. Simulation tools for real-time multiprocessors (STORM) implement various scheduling techniques on MPSoC-based architecture using both homogeneous and heterogeneous CPUs. STORM generates the energy profiles and evaluates performance and task scheduling on the MPSoC [26].
3 An Improved Machine Learning-Based EA-EDF Scheduling Model
The scheduling algorithm applies migration of task
Using the proposed full task migration strategy in which all the task
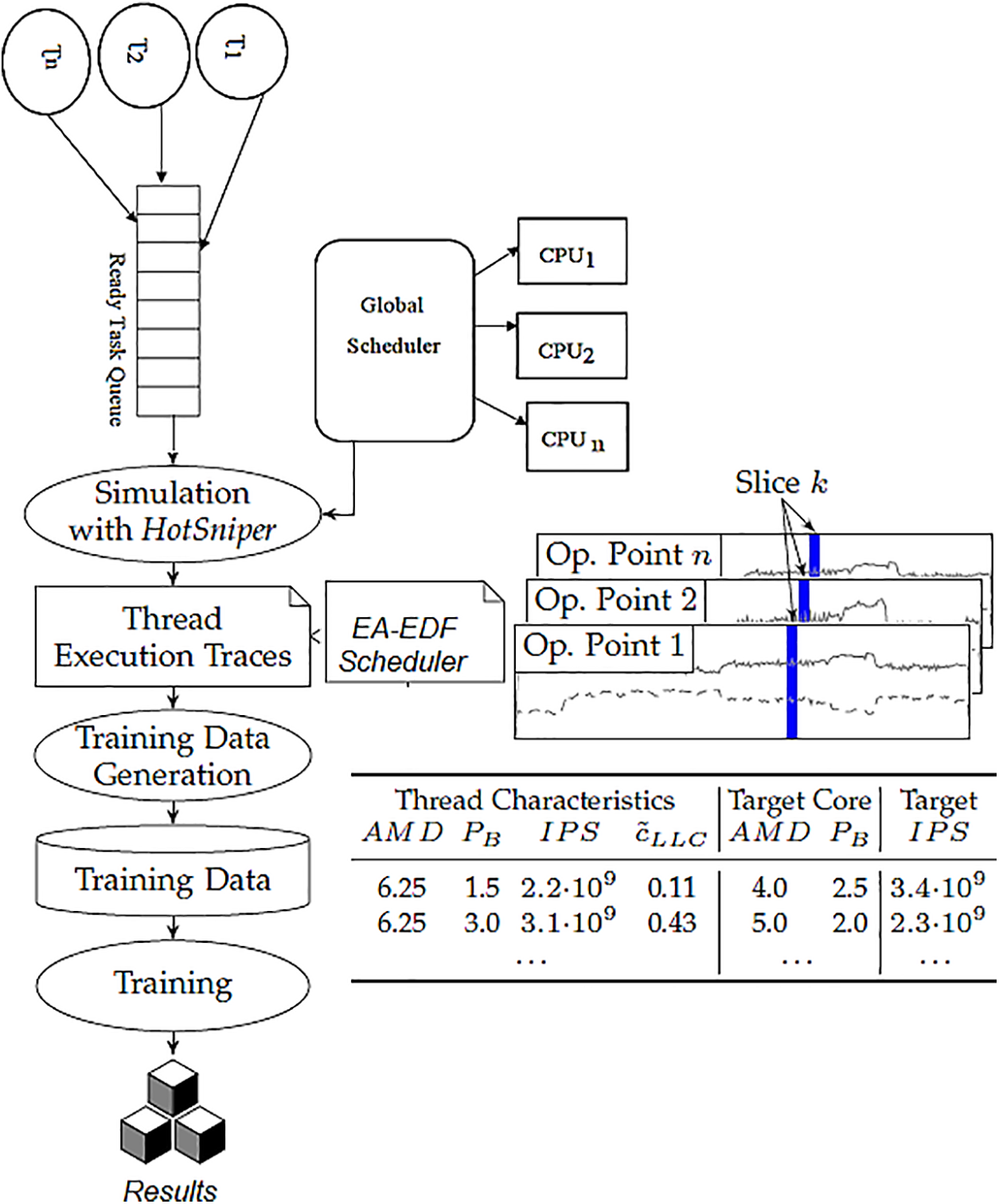
Figure 6: Machine learning-based task migration model using integrating CNN into EA-EDF
Considering the concurrent arrival of tasks having the same deadlines and priority and the task required the CPU cycle for mapping and allocation of resources access to CPU. Improper task scheduling consumes more energy and causes a delay in the CMOS chip. High task utilization without proper allocation of CPU degrades the reliability and performance of MPSoC, missing task
Dataset Description and Preprocessing
The PTB Suggestive ECG Data set, which comes from Physionet, is the dataset that was used in this research for processing over the CPU as a ready task the dataset is publically open and available for use as referred to in [27]. The 14,552 ECG accounts in this dataset are isolated into two packs are used during the testing and training process because using more than 14,552 samples can cause a very high upsurge and requires to make atlest three packs for the ML system in our upcoming research with more advanced ML system we will be able to use 21,837 ECG samples together. Considering two uniform multiprocessors denoted by
Let’s assume the parameters (
Eq. (11) states that initial.
Eq. (13) illustrates if
Therefore, the completion of
If
Task
Moreover in the
CPU core at the speed of
The proposed framework migrates tasks to the core when
Eq. (17) represents the integration of a full task migration model for various utilization factors (
Eq. (18) represents the integration of a full task migration model for various utilization factors (
Eq. (19) represents the integration of a full task migration model for various utilization factors (
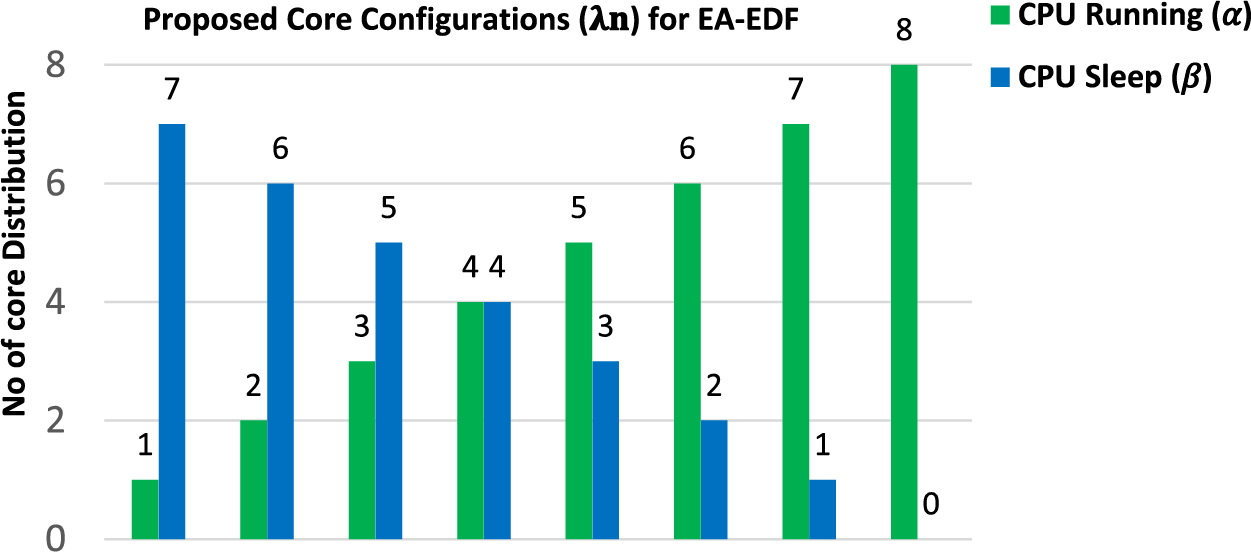
Figure 7: Various proposed stages for the core distribution mode
The experimental evaluation of uniform multiprocessor is considered using STORM for the multithreaded application that executes an XML file containing the task (
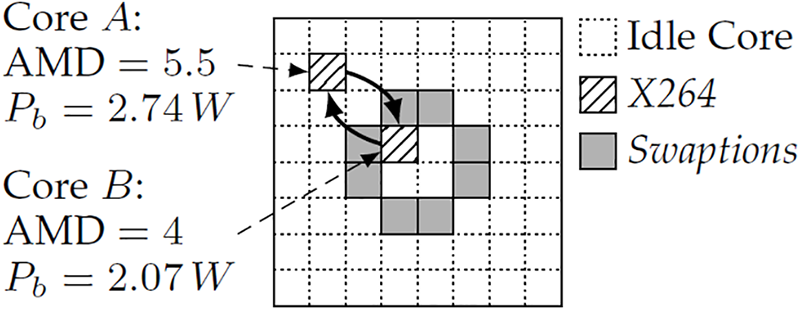
Figure 8: Core distribution model for X264 CPU Core

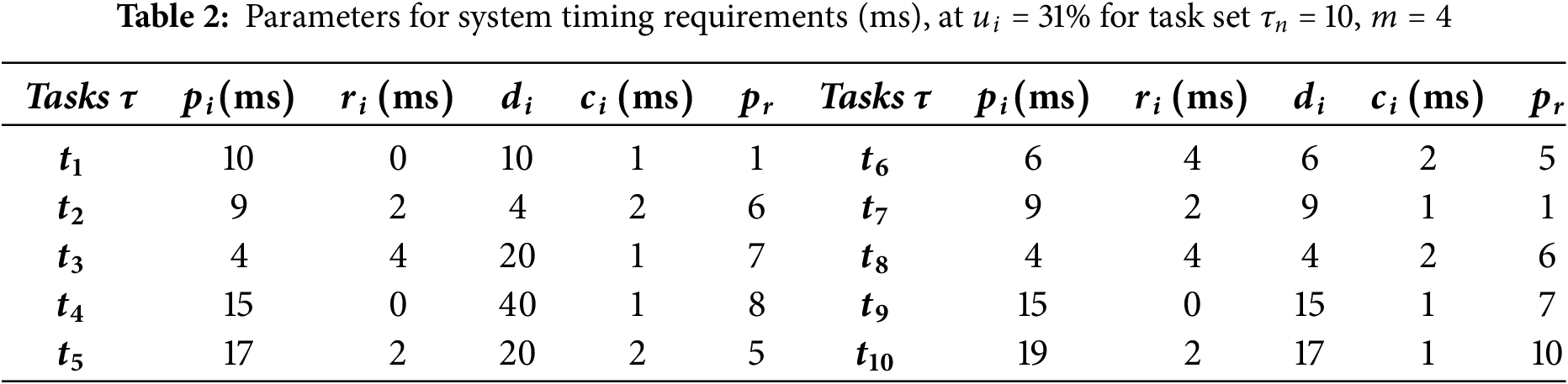
All the tasks are periodic and denoted as
Table 2 represents the parameters of system timing requirements at 31% utilization factor considering 4 core CPU.
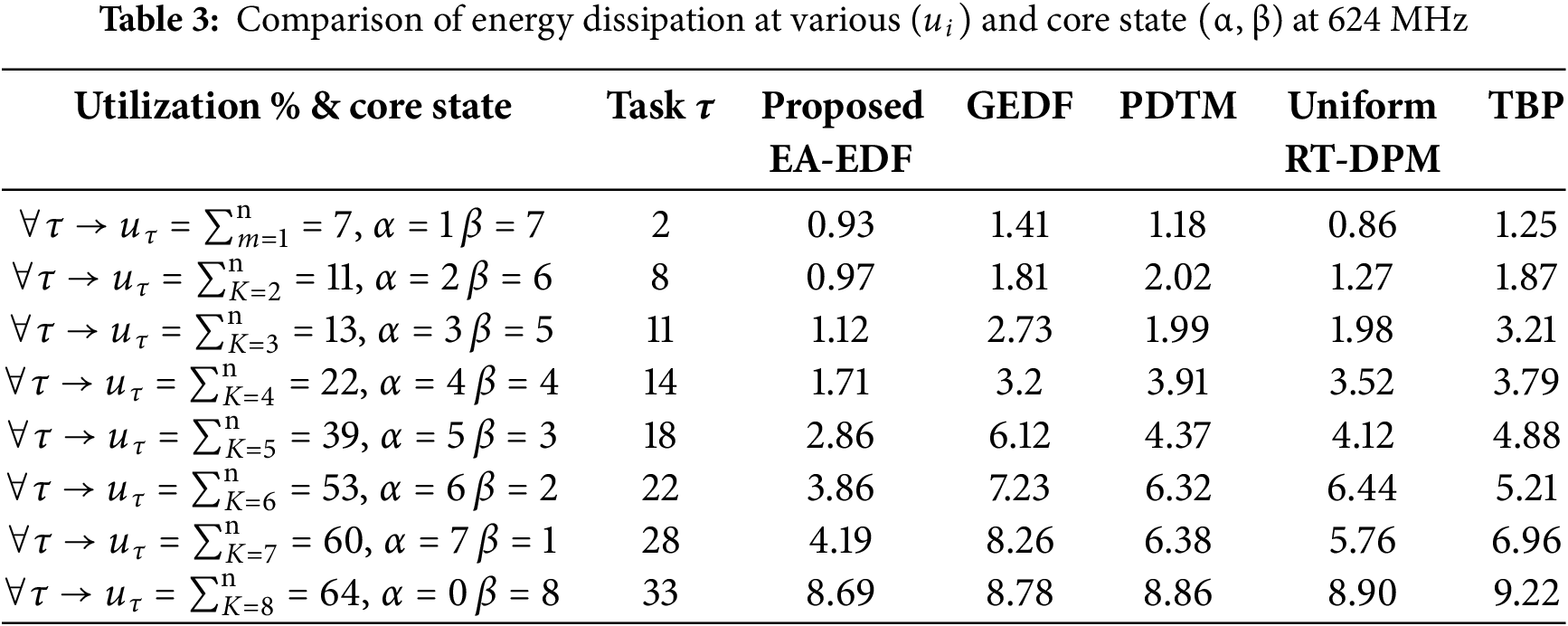
Fig. 9 represents the analysis that compares the energy dissipation of the proposed approach on numerous frequencies using AMD PXA-270. Table 3 represents the comparison of energy dissipation on various clock frequencies underutilization.
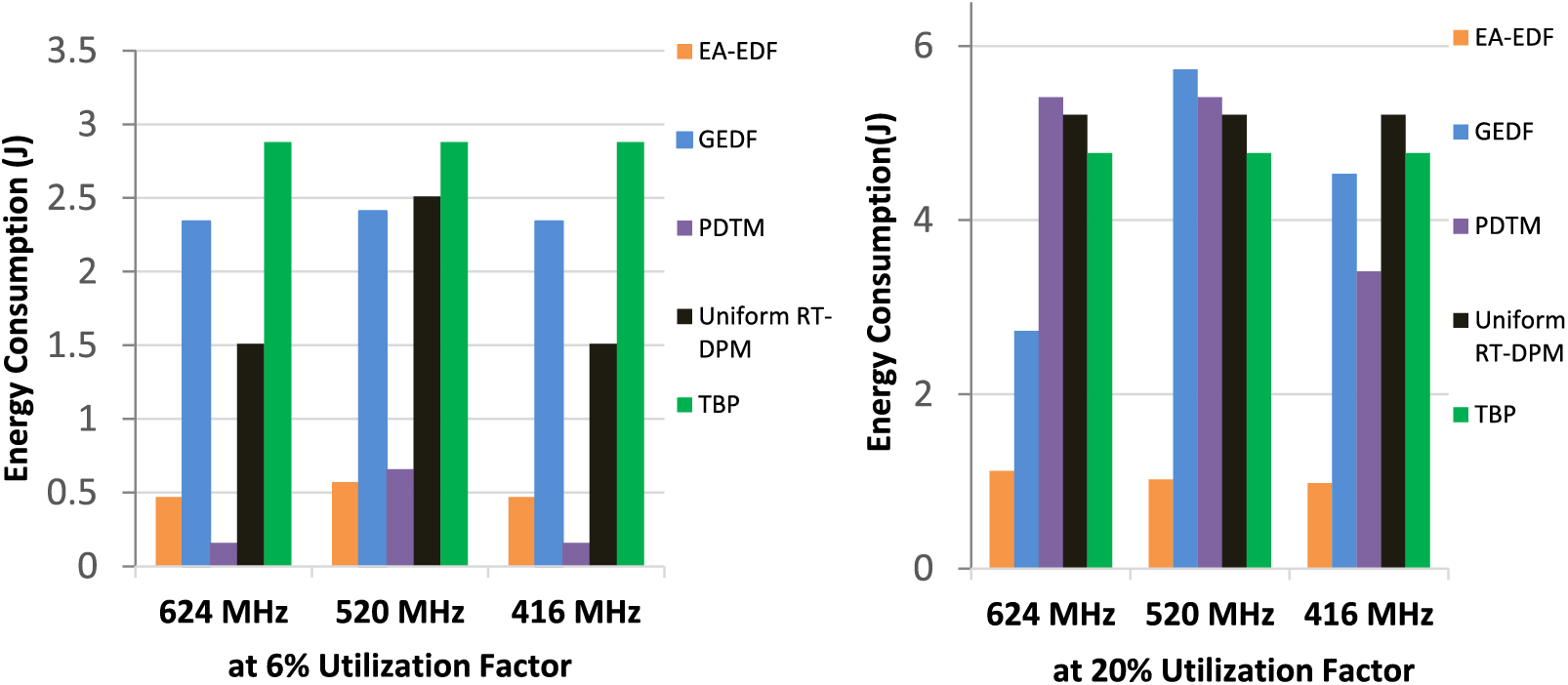
Figure 9: Comparison of energy consumption at
Figs. 10 and 11 represent the analysis that compares the performance of our proposed approach EA-EDF using AMD PXA-270 MPSoC in terms of dynamic energy dissipation for a different ready task set at various
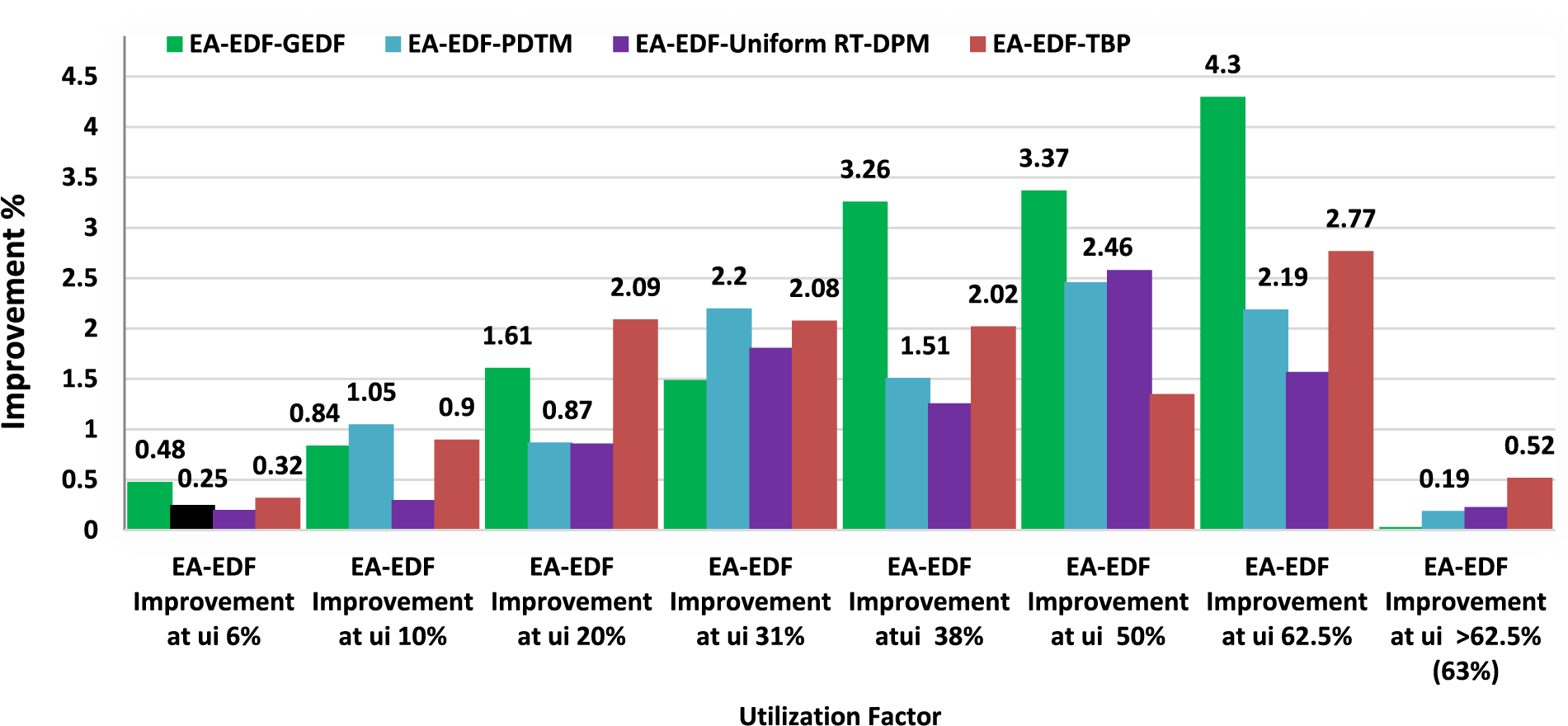
Figure 10: Proposed EA-EDF energy consumption comparison with G-EDF, PDTM U-RT-DPM, TBP at 624 MHz
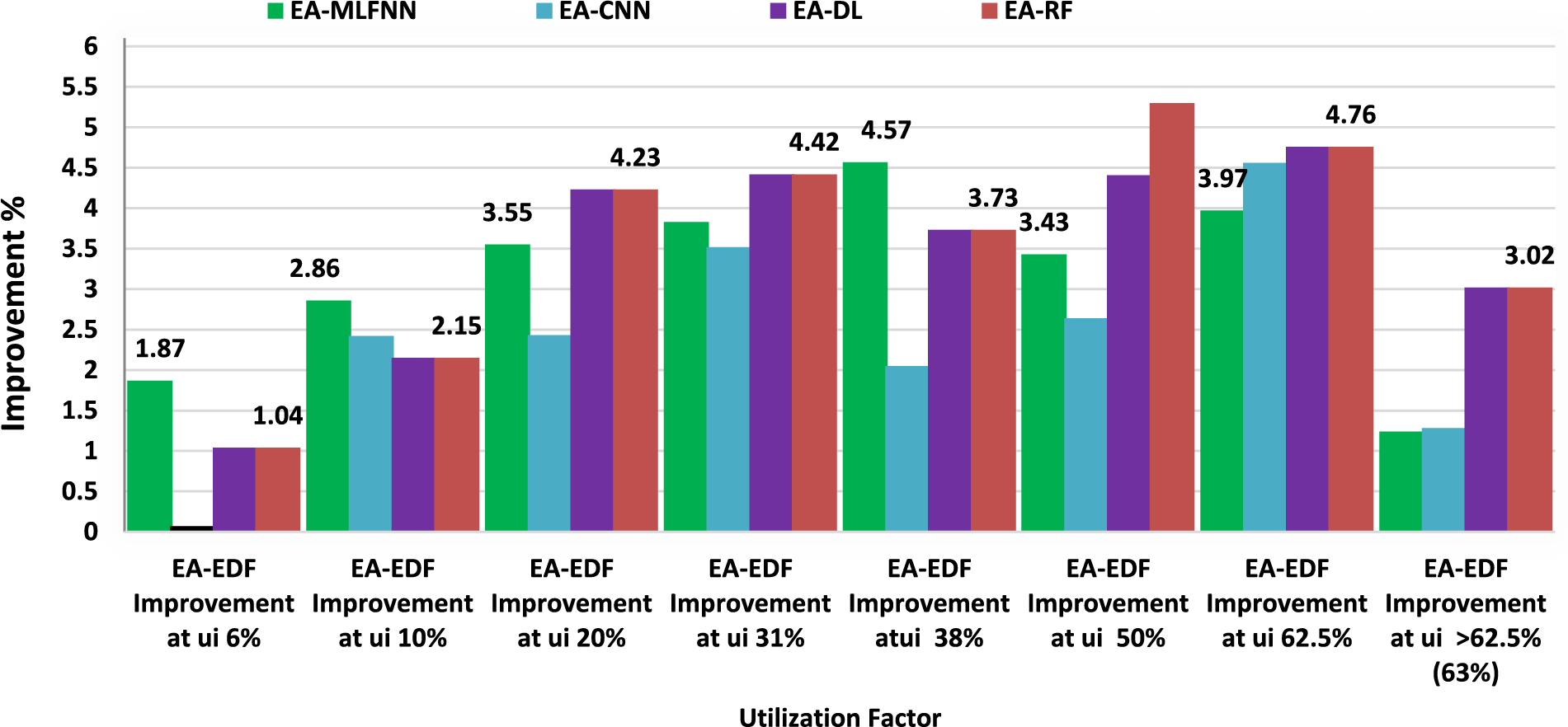
Figure 11: Proposed EA-EDF energy consumption comparison with EA-MLFNN, EA-CNN, EA-DL-EA-RF at 416 MHz
DPM is more convenient when tasks
This article effectively demonstrates the viability of utilizing Convolutional Neural Network (CNN) based Multiprocessing architectures that are used for high-dimensional datasets, especially with available electrocardiography datasets to evaluate the task scheduling and migration that play a vital role in energy reduction, particularly in multiprocessor design. The rapid increase in the demand for multithreaded applications enhances the thermal heat dissipation in MPSoC. A full task migration policy based on Dynamic power management techniques (DPM) for efficient task allocation and scheduling is the finest integration used for decreasing the consumption of energy. MARVEL AMD PXA-270, PXA-271 and PXA-250, are using system-level DPM for switching CPU modes as per the need of the energy-power model. Various parameters like WCET, BCET, deadline, period and priority are the main characteristics of multithreaded real-time (R-T) applications. In this article, we have designed a system-level task migration policy used to tackle improper task allocation to the CPU core and inefficient task scheduling for real-time applications with deadline and priority constraints that ultimately reduce energy dissipation and improve overall performance.
Acknowledgement: The authors sincerely thank Prof. Son Lam Phung from the University of Wollongong, Australia for important suggestions and feedback on this paper.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Hamayun Khan is the corresponding author of this article, he worked on data analysis, the introduction and methodology of research paper by explaining the scope, context, research from write-up to analysis contributed critically to the research paper. Muhammad Atif Imtiaz worked on the development of the algorithm and results analysis in depth. Hira Siddique worked on the development of mathematical analysis of the research work and aligned the algorithm and flow chart analysis from implementation to results initiation. Arshad Ali worked on the proofreading and implemenation of the dataset, testing, and validation of the proposed model. Muhammad Zeeshan Baig worked on literature and data collection processes that helped in the implementation of the proposed model and migration policy using three-stage migration techniques in the research. Muhammad Tausif Afzal Rana validated the methodology and mathematical analysis by evaluating the model on STORM tool and generated high-resolution results for migration policies. Saif ur Rehman developed all the tables and calculated the utilization factor at various frequencies, especially implementation at 512 higher frequencies. Yazed Alsaawy’s role is to enhance the overall structure of the research paper by removing the typo mistakes supported in proofreading and English grammar enhancing the overall quality of work. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: All data are available from the corresponding author on reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Irwin MJ, Benini L, Vijaykrishnan N, Kandemir M. Techniques for designing energy-aware MPSoCs. Multiprocess Syst-on-Chips. 2005;13(5):21–47. doi:10.1016/B978-012385251-9/50016-5. [Google Scholar] [CrossRef]
2. Burns A, Andy W. Dispatching domains for multiprocessor platforms and their representation in ada. In: International Conference on Reliable Software Technologies; 2010; Berlin/Heidelberg, Germany: Springer. p. 41–53. [Google Scholar]
3. Gonzalez-Martinez G, Sandoval-Arechiga R, Solis-Sanchez LO, Garcia-Luciano L, Ibarra-Delgado S, Solis-Escobedo JR, et al. A survey of MPSoC management toward self-awareness. Micromachines. 2024;15(5):577. doi:10.3390/mi15050577. [Google Scholar] [PubMed] [CrossRef]
4. Liu J, Mao M, Gao J, Bai J, Sun D. Hardware-accelerated YOLOv5 based on MPSoC. J Phys: Conf Ser. 2024;2732(1):012013. doi:10.1088/1742-6596/2732/1/012013. [Google Scholar] [CrossRef]
5. Verma P, Maurya AK, Yadav RS. A survey on energy-efficient workflow scheduling algorithms in cloud computing. Softw Pract Exp. 2024;54(5):637–82. doi:10.1002/spe.3292. [Google Scholar] [CrossRef]
6. Yu T, Zhong R, Janjic V, Petoumenos P, Zhai J, Leather H, et al. Collaborative heterogeneity-aware OS scheduler for asymmetric multicore processors. IEEE Trans Parallel Distrib Syst. 2021;32(5):1224–37. doi:10.1109/TPDS.2020.3045279. [Google Scholar] [CrossRef]
7. Rao W, Li H. Energy-aware scheduling algorithm for microservices in Kubernetes clouds. J Grid Comput. 2024;23(1):2. doi:10.1007/s10723-024-09788-w. [Google Scholar] [CrossRef]
8. Gaffour K, Benhaoua MK, Benyamina AEH, Singh AK. A new efficient multi-task applications mapping for three-dimensional network-on-chip based MPSoC. Concurr Comput Pract Exp. 2021;33(10):1–20. doi:10.1002/cpe.6194. [Google Scholar] [CrossRef]
9. Hu Y, Liu Y, Liu Z. A survey on convolutional neural network accelerators: GPU, FPGA and ASIC. In: 2022 14th International Conference on Computer Research and Development (ICCRD); 2022 Jan 7–9; Shenzhen, China: IEEE; 2022. p. 100–7. doi:10.1109/ICCRD54409.2022.9730377 [Google Scholar] [CrossRef]
10. Gonzalez R, Horowitz M. Energy dissipation in general purpose microprocessors. IEEE J Solid State Circuits. 1996;31(9):1277–84. doi:10.1109/4.535411. [Google Scholar] [CrossRef]
11. Choi S, Prasanna VK, Jang JW. Minimizing energy dissipation of matrix multiplication kernel on Virtex-II. In: Reconfigurable technology: FPGAs and reconfigurable processors for computing and communications IV. Boston, MA, USA: SPIE; 2002. doi:10.1117/12.455487. [Google Scholar] [CrossRef]
12. Ali H, Tariq U, Hardy J, Zhai X. A survey on system level energy optimisation for MPSoCs in IoT and consumer electronics. Comput Sci Rev. 2021;41(1):100–16. doi:10.1016/j.cosrev.2021.100416. [Google Scholar] [CrossRef]
13. Feliu J, Sahuquillo J, Petit S, Eeckhout L. Thread isolation to improve symbiotic scheduling on SMT multicore processors. IEEE Trans Parallel Distrib Syst. 2020;31(2):359–73. doi:10.1109/TPDS.2019.2934955. [Google Scholar] [CrossRef]
14. Somdip D, Isuwa S, Saha S, Singh AK, Maier KM. CPU-GPU-memory DVFS for power-efficient MPSoC in mobile cyber physical systems. Future Internet. 2022;14(3):91–103. doi:10.3390/fi14030091. [Google Scholar] [CrossRef]
15. Jiang E, Wang L, Wang J. Decomposition-based multi-objective optimization for energy-aware distributed hybrid flow shop scheduling with multiprocessor tasks. Tsinghua Sci Technol. 2021;26(5):646–63. doi:10.26599/TST.2021.9010007. [Google Scholar] [CrossRef]
16. Liang CY, Liu S, Chung EY, Gaudiot JL. An energy and performance efficient dvfs scheme for irregular parallel divide-and-conquer algorithms on the AMD scc. IEEE Comput Archit Lett. 2013;13(1):13–6. [Google Scholar]
17. Alam M, Haidri RA, Shahid M. Resource-aware load balancing model for batch of tasks (BoT) with best fit migration policy on heterogeneous distributed computing systems. Int J Pervasive Comput Commun. 2020;16(2):113–41. doi:10.1108/IJPCC-10-2019-0081. [Google Scholar] [CrossRef]
18. Baital K, Chakrabarti A. Dynamic scheduling of real-time tasks in heterogeneous multicore systems. IEEE Embedd Syst Lett. 2018;11(1):29–32. doi:10.1109/LES.2018.2846666. [Google Scholar] [CrossRef]
19. Huang K, Wang K, Zheng D, Jiang X, Zhang X, Yan R, et al. Expected energy optimization for real-time multiprocessor socs running periodic tasks with uncertain execution time. IEEE Trans Sustain Comput. 2018;6(3):398–411. doi:10.1109/TSUSC.2018.2853621. [Google Scholar] [CrossRef]
20. Haris J, Shafique M, Henkel J, Parameswaran S. System-level application-aware dynamic power management in adaptive pipelined MPSoCs for multimedia. In: IEEE/ACM International Conference on Computer-Aided Design (ICCAD); 2011; Washington, DC, USA. p. 616–23. [Google Scholar]
21. James B, Tenentes V, AlHashimi BM, Merrett GV. Online tuning of dynamic power management for efficient execution of interactive workloads. In: IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED); 2017; Boston, MA, USA. p. 1–6. [Google Scholar]
22. Bogdan P, Marculescu R, Jain S. Dynamic power management for multidomain system-on-chip platforms: an optimal control approach. ACM Trans Design Autom Electron Syst. 2013;18:1–20. doi:10.1145/2504904. [Google Scholar] [CrossRef]
23. Khan H, Din IU, Ali A, Husain M. An optimal DPM based energy-aware task scheduling for performance enhancement in embedded MPSoC. Comput Mater Contin. 2023;74(1):2097–113. doi:10.32604/cmc.2023.032999. [Google Scholar] [CrossRef]
24. Zhang X, Zhang W, Sun W, Wu H, Song A, Jha SK. A real-time cutting model based on finite element and order reduction. Comput Syst Sci Eng. 2022;43(1):1–15. doi:10.32604/csse.2022.024950. [Google Scholar] [CrossRef]
25. Kivilcim CA, Rosing TS, Mihic K, Leblebici Y. Analysis and optimization of MPSoC reliability. J Low Power Electron. 2006;2(1):56–69. doi:10.1166/jolpe.2006.007. [Google Scholar] [CrossRef]
26. Richard U, Deplanche AM, Trinquet Y. Storm a simulation tool for real-time multiprocessor scheduling evaluation. In: IEEE 15th Conference on Emerging Technologies & Factory Automation (ETFA); 2010; Bilbao, Spain. p. 1–8. [Google Scholar]
27. Wagner P, Strodthoff N. PTB-XL, a large publicly available electrocardiography dataset. Sci Data. 2020;7(1):1–15. doi:10.1038/s41597-020-0495-6. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools