
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
XGBoost Based Multiclass NLOS Channels Identification in UWB Indoor Positioning System
1 Faculty of Electrical Engineering, University of Technology Malaysia, Johor Bahru, 81310, Malaysia
2 Iraqi Ministry of Interior, Directorate of Training and Scientific Qualification, Baghdad, 10001, Iraq
3 Air Navigation Academy, General Company of Air Navigation Service, Baghdad, 10001, Iraq
* Corresponding Author: Ammar Fahem Majeed. Email:
Computer Systems Science and Engineering 2025, 49, 159-183. https://doi.org/10.32604/csse.2024.058741
Received 19 September 2024; Accepted 03 December 2024; Issue published 03 January 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Accurate non-line of sight (NLOS) identification technique in ultra-wideband (UWB) location-based services is critical for applications like drone communication and autonomous navigation. However, current methods using binary classification (LOS/NLOS) oversimplify real-world complexities, with limited generalisation and adaptability to varying indoor environments, thereby reducing the accuracy of positioning. This study proposes an extreme gradient boosting (XGBoost) model to identify multi-class NLOS conditions. We optimise the model using grid search and genetic algorithms. Initially, the grid search approach is used to identify the most favourable values for integer hyperparameters. In order to achieve an optimised model configuration, the genetic algorithm is employed to fine-tune the floating-point hyperparameters. The model evaluations utilise a wide-ranging dataset of real-world measurements obtained with a Qorvo DW1000 UWB device, covering various indoor scenarios. Experimental results show that our proposed XGBoost achieved the highest overall accuracy of 99.47%, precision of 99%, recall of 99%, and an F-score of 99% on an open-source dataset. Additionally, based on a local dataset, the model achieved the highest performance, with an accuracy of 96%, precision of 96%, recall of 97%, and an F-score of 97%. In contrast to current machine learning methods in the literature, the suggestion model enhances classification accuracy and effectively addresses the NLOS/LOS identification as a multiclass propagation channel. This approach provides a robust solution with generalisation and adaptability across various dataset types and environments for more reliable and accurate indoor positioning technologies.Keywords
Experts predict that global Internet of Things (IoT) device connectivity will surpass 22 billion by 2025. As a result, localisation has emerged as a critical component of the IoT. However, accurate location awareness is critical for optimising the vast majority of IoT services [1]. Consider navigating visitors through a large hospital, a labyrinthine shopping mall, a massive warehouse complex, or a convoluted industrial zone. The COVID-19 pandemic has significantly increased the interest in research in this field [2], particularly in the context of indoor positioning solutions that achieve sub-metre accuracy to enhance emergency response, security, and safety measures. Indoor positioning, or indoor localisation, is a technique employed to ascertain the precise location of individuals or objects within enclosed architectural spaces. It employs a variety of technological solutions, such as computer vision methodologies, infrared detection, acoustic signal processing, and wireless communication protocols, to enable precise localisation within buildings or similar confined environments [3–5]. However, the effectiveness of these systems is frequently limited by factors such as low positional accuracy, typically around 2.5 m, and substantial performance degradation in non-line-of-sight (NLOS) environments, during device movement, or under conditions of multipath propagation caused by signal reflections from walls or objects. The rising demand for precise indoor localization has spurred the advancement of diverse applications, utilized in environments like commercial buildings, department stores, airports, and museums. In indoor positioning systems, the primary objective is to establish efficient, accurate, and adaptable positioning methods that are both user-friendly and capable of adjusting to dynamic environmental conditions and expansive areas. While outdoor positioning techniques, including GPS, video tracking, and radio-wave combinations, have proven effective, their limitations in accuracy under indoor conditions underscore the need for highly specialized and precise indoor localization solutions. The impressive properties of ultra-wideband (UWB) technology have made it an increasingly critical component of precise indoor localisation systems. These consist of a high multipath immunity, low power consumption, short to medium ranges, large bandwidth, and fast data rate. The UWB technology’s exceptional time resolution facilitates centimeter-level localization accuracy for mobile or stationary objects in open environments [6]. UWB systems rely on precise distance measurements taken from a minimum of three anchor points. As a result, any errors caused by these difficult conditions can accumulate and have a significant impact on the overall positioning accuracy. Nonetheless, practical applications face significant obstacles, particularly the NLOS problem. This problem causes signal delays and biased distance estimates, leading to a decrease in positioning accuracy. In specific circumstances, NLOS situations arise when there is a barrier between the communication transmitter and receiver [7,8]. Moreover, the current literature frequently disregards the intricacies of real-world environments, particularly in difficult scenarios that involve hard-NLOS (multiple barriers, such as walls, obstruct the signal path) and multipath (MP) conditions (signals travel different routes to reach the receiver), and instead concentrates on binary LOS/NLOS classification in UWB ranging systems [9]. Accurate NLOS identification is essential for precise indoor positioning, particularly in autonomous navigation, search-and-rescue operations, and industrial tracking, where sub-metre accuracy is required [4,10,11]. Models with restricted generalisation are the consequence of the absence of dynamic adaptation to a variety of indoor environments in current methodologies.
Machine learning has emerged as a highly efficient method for data mining and has experienced significant advancements in recent years, leading to its widespread adoption across various domains. Among the many machine learning techniques, the XGBoost (extreme gradient boosting) algorithm, introduced by Chen and Guestrin in 2016 [12], is particularly noteworthy. XGBoost is an advanced ensemble learning algorithm, an enhancement of the gradient-boosting decision tree [13], and is distinguished by its ability to function without the need for extensive feature engineering. In contrast to the gradient boosting decision tree algorithm, XGBoost exhibits superior predictive accuracy and improved generalisation capabilities, which have contributed to its widespread popularity and application in a variety of fields. For instance, XGBoost has been employed as a predictive model for crude oil price forecasting, utilized for identifying key features to enhance the classification of urban road traffic accidents within big data frameworks, and integrated into hybrid gene selection methodologies for cancer classification [14–16]. Overall, XGBoost is acknowledged for its strong performance, efficient operation, and ability to use many threads for parallel data processing. Yet, if implemented without parameter optimisation, XGBoost may demonstrate suboptimal fit with particular datasets, leading to diminished generalisation performance and adaptability [17]. To overcome this constraint, the current work utilises a blend of grid search and genetic algorithms to enhance the hyperparameter setting of the XGBoost method. The grid search approach is initially used to evaluate the integer hyperparameters and establish the optimisation ranges for the floating-point hyperparameters. The genetic algorithm is employed to determine the most favourable values of the floating-point hyperparameters. Subsequently, the enhanced XGBoost algorithm forecasts and detects non-line-of-sight (NLOS) propagation channels in indoor UWB location sensor systems. The contributions we have made are as follows:
(a) We propose an enhanced XGBoost model with grid search and a genetic algorithm to address the existing difficulties in NLOS condition prediction. These challenges include the requirement for a model that can robustly generalise and adapt to different indoor settings with high precision, and achieve superior overall accuracy compared to other machine learning approaches.
(b) NLOS conditions prediction, in UWB communications, as a multiclass propagation channel (LOS, MP, both soft and hard NLOS) with the proposed model is performed, and the results are compared with other recent existing methods, i.e., the support vector machines (SVM), semi-supervised support vector machines (S3VM), random forest (RF), multi-layer perceptron (MLP), stochastic gradient descent (SGD), decision tree (DT), Naive Bayes (NB), AdaBoost, logistic regression (LR), K-Nearest Neighbors (KNN), gaussian process (GP), Generalized Linear Models (GLM), and CNN based the real measurement dataset obtained by Qorvo DW1000 UWB device from open source dataset in addition to local dataset created in this project. We demonstrate that our proposed method can achieve state-of-the-art results when compared to other methods.
(c) The Qorvo DW1000 device is used to collect an authentic dataset through various propagation channels in two distinct scenarios, with the goal of reducing the need for extensive laboratory work when changes to the working environment are required. A thorough analysis of the data was conducted to excel in distinguishing between NLOS conditions and determining the best parameters for achieving high prediction accuracy.
The rest of the article is structured in the following manner: Section 2 provides an overview of the works that are related to the topic. Section 3 outlines the system architecture, dataset creation and preparation, feature extraction and selection, genetic and grid search algorithms, and the proposed XGBoost model. Section 4 discusses the evaluation metrics. Section 5 provides a comprehensive overview of the experimental setup, including the results and discussions. Lastly, Section 6 presents the conclusion and explores potential future work.
Efforts to address ranging errors in UWB systems caused by NLOS effects are typically categorised into two main strategies in the current literature: NLOS identification and NLOS mitigation [18] Usually, the method includes finding signals that do not follow a direct path and then adjusting the location algorithm to reduce the biases caused by these signals.
To advance the identification of NLOS propagation channels in UWB indoor positioning systems, it is essential to thoroughly understand the existing research. The literature on this subject can be broadly classified into three primary approaches: empirical methods, machine learning (ML), and deep learning (DL). As demonstrated in [19,20], empirical methods rely on developing mathematical models or statistical relationships to predict NLOS conditions using measurable parameters, with an accuracy of less than 90%. Although empirical approaches can achieve accuracy close to 90%, they often require substantial upfront laboratory setup expenses for each additional testing area. The two primary categories of ML approaches for NLOS identification are as follows: hybrid techniques that integrate multiple algorithms and those that employ individual algorithms. A study [21] compared the effectiveness of K-Nearest Neighbours (KNN), support vector machines (SVM), Generalised Linear Models (GLM) gaussian process (GP), and Decision Trees (DT) for three classification types: LOS, MP, and NLOS. They discovered that the accuracy of KNN and GP was less than 90%. Also, this project is highly dependent on the specific environment where the measurement campaign was conducted with a limited measurement data range of less than 9.5 m. Wang et al. [22] proposed a semi-supervised SVM (S3VM) with self-training, initially trained on a small labelled dataset. It iteratively pseudo-labels and adds unlabeled data based on confidence measures. While providing a 94% improvement over supervised methods, the increased complexity and computational demand may be unjustified. Without retraining, the model is prone to initial data biases and performs poorly. Performance is also affected by parameter selection, such as the weights between labelled and pseudo-labeled data, as well as scale factors during training. The authors in [23] used machine learning to detect NLOS conditions in UWB indoor localisation. They tested SVM, random forest (RF), and multilayer perceptron (MLP) classifiers. Accuracy significantly dropped when these models were tested in environments different from their training setting, indicating poor generalization and possible overfitting due to insufficiently diverse training data. For instance, RF accuracy fell from 91.9% to 73.5% across different environments.
Yang et al. [24] proposed a method to enhance the accuracy of LOS/NLOS identification by extracting new parameters from channel impulse response data. Their two-step classification process integrates a fuzzy credibility-based support vector machine and dynamic threshold comparison. Although the experimental results demonstrate a significant 93% increase in accuracy, the system’s dependence on precise Characteristic Parameters (CCP) thresholds may hinder its ability to handle environmental variations effectively. Further testing in diverse settings is needed to assess its broader applicability. The authors of [25] suggested a system that integrates feature extraction from the CIR with machine learning algorithms, employing SVM optimised via a genetic algorithm (GA) for feature selection. SVM is used to classify signal propagation conditions as either LOS or NLOS. The GA is employed to identify the optimal combination of features that maximises classification accuracy while minimising computational complexity. The proposed system achieves an NLOS detection accuracy of 91.86% with the optimal feature combination. For example, the research conducted by [26] in a controlled environment (anechoic chamber and corridor) combined SVM with Fisher’s linear discriminant (LDA) and achieved a high level of accuracy (92% and 100%) for binary classification (LOS/NLOS). However, the method’s effectiveness in dynamic environments has not been evaluated, which is a significant drawback for its practical use. In addition, the method has certain limitations. It requires extensive training datasets and may not be applicable to different environments. It also focuses only on static conditions and binary classification. In 2022, Che et al. [27] presented a feature-based approach to improve the accuracy of NLOS detection. Their method primarily addressed the issue arising from imbalanced datasets. Within this system, the utilisation of Gaussian distribution (GD) and generalised Gaussian distribution (GGD) is prevalent. The GD algorithm relies on the mean and variance of the features extracted, whereas the GGD takes into account kurtosis, which provides a more suitable representation of the data distribution. It achieved 98% accuracy in binary classification, especially on imbalanced datasets. They did, however, evaluate the system’s performance using a small dataset in a specific environment with a range of no more than seven meters, utilising a dynamic threshold that adapts based on the training data. The system is still susceptible to variations in various real-world indoor environments. That is, generalisability and robustness require more tests on a larger and more diverse dataset.
Furthermore, deep learning techniques, particularly convolutional neural networks (CNNs), have proven to be valuable tools in differentiating between NLOS and line-of-sight (LOS) conditions in UWB-ranging applications. Wang et al. [28] used CNN to binary classify various types of CIR figures, thereby converting the identification problem into one of image recognition. Similarly, Reference [29] employed capsule networks (CapsNets) for the same task. The CIR is processed using a short-time Fourier transform (STFT) to generate an impulse response spectrum, which serves as input to the CNN, achieving an accuracy of 98.24%. The CapsNets architecture consists of a convolutional layer, a primary capsule layer, and a channel capsule layer. The input data is formatted as a 6 × 6 × 1 monochrome image. CapsNets utilise a dynamic routing-by-agreement mechanism to continuously improve the coupling coefficients between capsules, leading to an impressive accuracy rate of 94.63%. Nevertheless, the effectiveness of both models is greatly impacted by the quantity and quality of the training data and by the selection of hyperparameters. It is important to carefully fine-tune and thoroughly validate the system in various indoor environments. However, this process can make it difficult to apply the system to new datasets. Furthermore, these models are more computationally intensive compared to traditional machine learning models, requiring the preprocessing and structuring of input data into image format [30].
In 2020, the authors of [31] put forward a method that combines morlet wavelet transformer (MWT) with CNN, called MWT-CNN, which transforms the UWB CIR data into time-frequency spectrums through MWT and then processes them with a CNN to extract the features for determining the NLOS conditions. It also has an accuracy as high as 98.84% in scenarios quite close to the training environments. The performance on the other testing scenes has significantly declined, with an accuracy of 76.65% in the industrial scene and 69.23% in the residential scene. As a result, MWT-CNN necessitates a highly controlled and consistent environment. This method presents significant challenges for broader and real-world applications due to its limited generalisation capability, high computational complexity, and large requirements on training data [31]. The authors of [30] proposed a novel deep-learning architecture known as ININN. This hybrid model combines a CNN for extracting spatial features, a gated recurrent unit (GRU) for extracting temporal features, and squeeze-and-excitation (SE) blocks for enhancing channel-wise features. While the system achieves an accuracy of 88.45% on an open-source dataset and demonstrates a variable accuracy range (87.5% to 99.9%) under different Eb/N0 conditions, its performance is susceptible to environmental factors and signal quality. Notably, including CNN, GRU, and SE components increases computational complexity, potentially limiting real-time applicability on resource-constrained devices. Further investigation is warranted to address the observed performance variability and optimize the model for real-world deployment. Wei et al. [32] introduced a multiple-input learning neural network that processes both raw CIR signals and time-frequency diagram of CIR (TFDOCIR) images generated using continuous wavelet transform (CWT). This system demonstrates an identification accuracy of 91.74%. Nevertheless, the model’s complexity, which integrates GRU and CNN layers, necessitates considerable computational resources and extended training times, posing challenges for deployment in real-time or resource-constrained environments. Furthermore, the accuracy of NLOS identification is highly dependent on the precise generation of TFDOCIR images from CIR signals; any errors in this preprocessing stage can significantly degrade the overall system performance.
While most studies have focused on treating the problem as a binary classification task, distinguishing between LOS and NLOS or LOS and MP, there have been limited investigations into UWB-based ranging errors as a multi-class problem. A study that utilised SVM introduced a two-step identification process that initially differentiates between LOS and NLOS. If NLOS is detected, the process is further classified as MP vs. NLOS [33]. A separate study examined the distinction between two types of NLOS conditions (soft-NLOS vs. hard-NLOS) in addition to LOS, based on the material of obstacles that the UWB signal passed through [34]. Furthermore, the methodology outlined in [21] employs KNN and GP algorithms as ternary classifiers to distinguish between LOS, soft-NLOS, and hard-NLOS conditions. In [23], SVM, RF, and MLP classifiers were evaluated for their ability to predict the three propagation channels, including LOS, MP, and NLOS.
In conclusion, the current methods employed to identify NLOS channel states have a few disadvantages. Initially, the majority of individuals concentrate on the comparison of LOS and NLOS without taking into account the complexities of real-world environments, such as hard NLOS and MP. Furthermore, machine learning techniques may not be able to effectively adapt to new environments without retraining, as they are dependent on specific testing conditions. In the same vein, hybrid ML approaches exhibit exceptional accuracy (e.g., 98%); however, they frequently encounter limitations as a consequence of evaluation in controlled environments with relatively small, environment-specific datasets. Similarly, deep learning models show promise, but they require stable and specific environments, as well as significant computational resources for tasks such as data preprocessing, image representation formatting, and extended training time. Based on a thorough review of current state-of-the-art methodologies, it is clear that addressing all of the issues raised remains a daunting task. To the best of the authors’ knowledge, no machine-learning model has been developed that effectively enhances both accuracy and generality while considering the necessary trade-offs. This article introduces an optimized XGBoost with grid search and a genetic algorithm to overcome the current challenges in NLOS condition prediction, e.g., the need for a model that has strong generalization and adaptability to varying indoor environments for multiclass LOS/NLOS condition identification, and achieve higher overall accuracy in comparison to other machine learning methods.
3.1 Proposed System Architecture
Fig. 1 outlines a research methodology that is systematic and aims to minimise ranging errors in UWB indoor systems, especially under varying conditions. The main focus of the initial stage is to create the dataset. This investigation aims to comprehensively analyse the behaviour of UWB devices in different scenarios, such as LOS and NLOS situations, which include soft NLOS, hard NLOS, and MP. Data collection is designed to capture the intricacies of real-world conditions by incorporating a variety of realistic environments. The objective is to produce a dataset that is both inclusive and robust. Critical cleaning tasks are addressed during a meticulous data preparation phase that follows data collection. This includes managing missing values, removing outliers and duplicates, and combining data from different scenarios into a unified dataset suitable for further analysis (details provided in Sections 3.2 and 3.3).
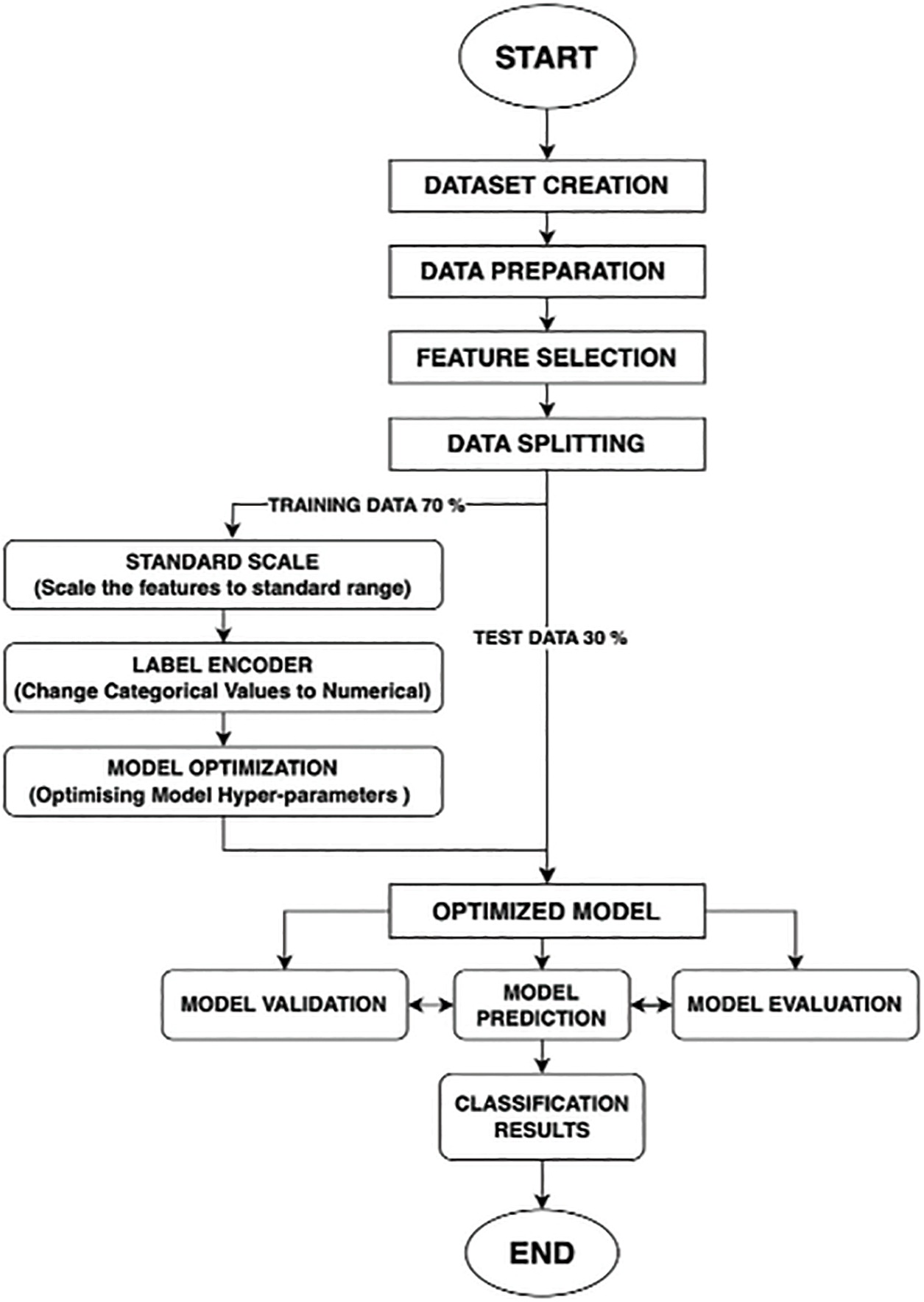
Figure 1: A proposed methodology for the indoor NLOS identification system of UWB
Afterwards, feature selection is used to identify the most relevant attributes that greatly improve the performance of the range-based Indoor Positioning System (IPS). As mentioned in Section 3.4, this step is crucial for improving the performance, interpretability, and efficiency of the model by focusing on the most informative features.
The dataset is then split into training and testing subsets, usually with a 70/30 split (training/testing). This guarantees that the model is trained on a significant portion of the data, while also setting aside an ample amount for thorough evaluation. Data preparation consists of two critical steps: standard scaling and label encoding. Standard scaling is used to normalise the features to a standard range, which helps maintain consistency across the dataset and enhances model performance. On the other hand, label encoding is a process that converts categorical variables into numerical values, which is often required for machine learning algorithms.
Next, model optimisation is performed by fine-tuning hyperparameters such as the learning rate, maximum tree depth, and the number of estimators. This process is designed to enhance the precision and overall effectiveness of the XGBoost model, as detailed in Section 3.5. The model with the optimised parameters goes through multiple validation and evaluation stages. The XGBoost model is initially used to predict and classify various NLOS conditions. This is important for reducing ranging errors in UWB systems. Furthermore, the efficacy of the model is evaluated by quantifying parameters such as accuracy, recall, precision, and F1-score. This provides a comprehensive assessment of how well the model handles UWB-ranging errors. Finally, model validation is carried out using a validation set to confirm the model’s efficacy on new data. Following this systematic workflow enables researchers to effectively address the challenges of UWB indoor NLOS identification, resulting in a robust model that improves indoor positioning accuracy. The use of this methodical approach ensures that each stage is completed carefully and precisely, which improves the overall success of the research.
Real-world data was collected [35] in two residential environments, which consisted of a range of rooms and corridors, to evaluate the propagation of UWB signals. Measurements were conducted in corridors of different widths, a hall and rooms of different sizes, all under different conditions including LOS, MP and NLOS. In order to simulate NLOS conditions and examine their influence on the transmission of UWB signals, obstructions, such as walls, were implemented. Fig. 2 illustrates the measurement scenarios and environments.
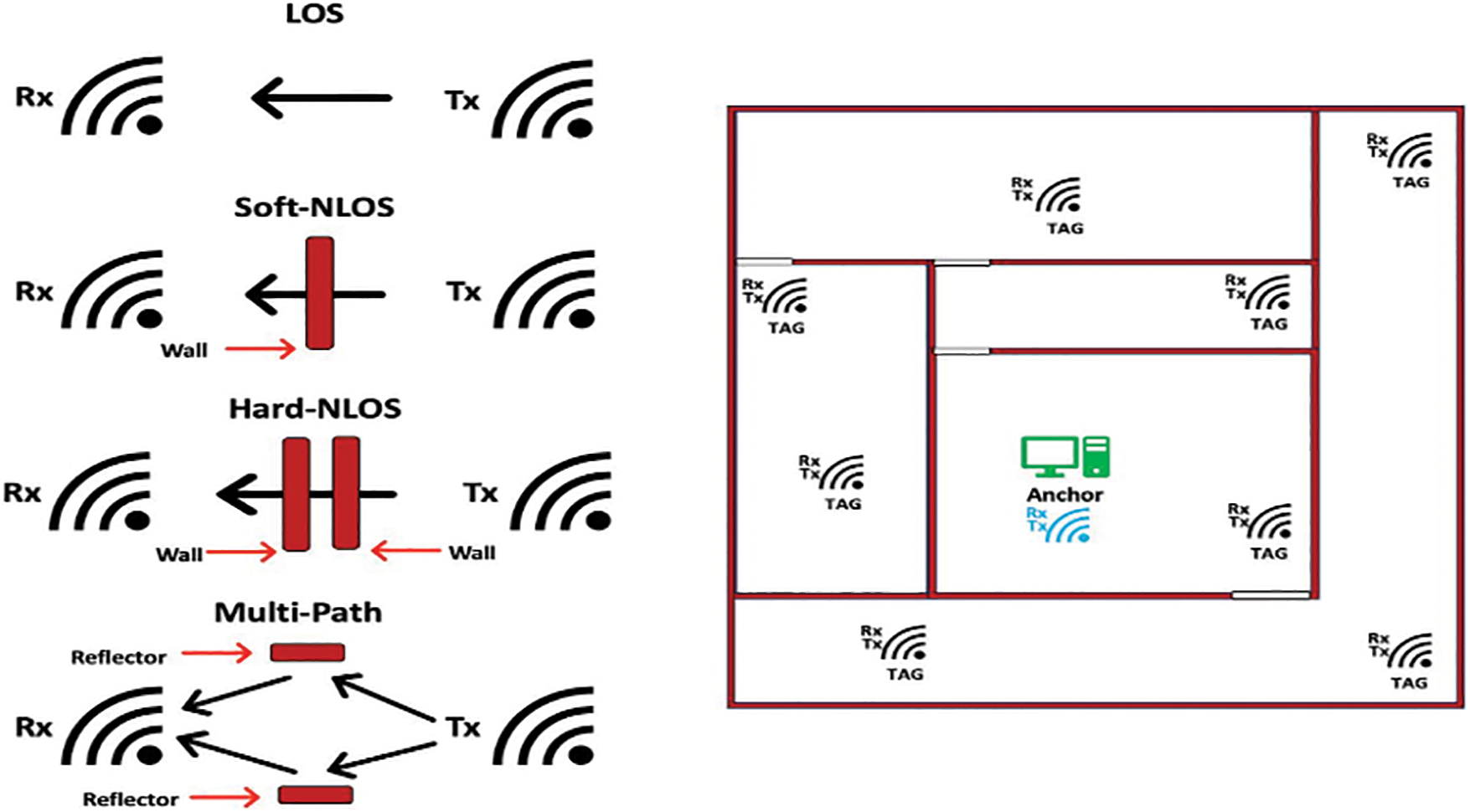
Figure 2: Indoor propagation channels
During the measurement phase, a basic network architecture was established to facilitate the data collection process in alignment with the study’s objectives. This network consisted of two nodes, each equipped with a DW1000 UWB transceiver. One transceiver functioned as an anchor, while the other served as a target. The anchor was connected to a computer via a serial port for data logging, allowing for precise capture and recording of UWB signal data during experiments. After data extraction, the resulting database, including the identified features for each measurement trial, was systematically stored in a file using MATLAB R2022a. This methodical approach ensured that the dataset was both comprehensive and well-organized, capturing a wide range of signal characteristics essential to the study. The antenna height of the static UWB device was consistently maintained at 2.00 m to minimize the effects of Fresnel zones on measurement accuracy, with data recorded directly on a connected PC.
The measurement data were collected across different propagation channels in various experimental scenarios. For the NLOS experiments, obstacles were introduced between the anchor and target transceivers to simulate NLOS conditions, utilizing two separate rooms. The focus was placed on analyzing both soft and hard NLOS propagation channels to better understand how different obstacles impact UWB signal transmission. Careful attention was given to designing the data collection methodology for both static and dynamic scenarios to allow for a thorough analysis of signal behaviour under diverse conditions.
In the dynamic scenarios, one transceiver was fixed and connected to a PC for data logging, while the other was mobile, carried by an individual performing random locomotion. This setup simulated real-life situations where the target device frequently changes position and orientation. In the static setup, both transceivers were positioned upright at a perpendicular angle to the ground and mounted on 2-m tripods, with the DW1000 antennas oriented vertically to ensure consistent device alignment for controlled UWB signal propagation measurements. During dynamic data collection, the mobile transceiver’s antenna was intermittently rotated at random intervals, introducing variability in orientation to assess its effect on signal strength and measurement quality, simulating more realistic usage conditions. The data collection process was designed to thoroughly evaluate the operational performance of the UWB system in indoor environments under various conditions. By incorporating movement and varying device orientations, the dataset became more comprehensive, leading to valuable insights regarding the system’s adaptability and effectiveness in real-world scenarios.
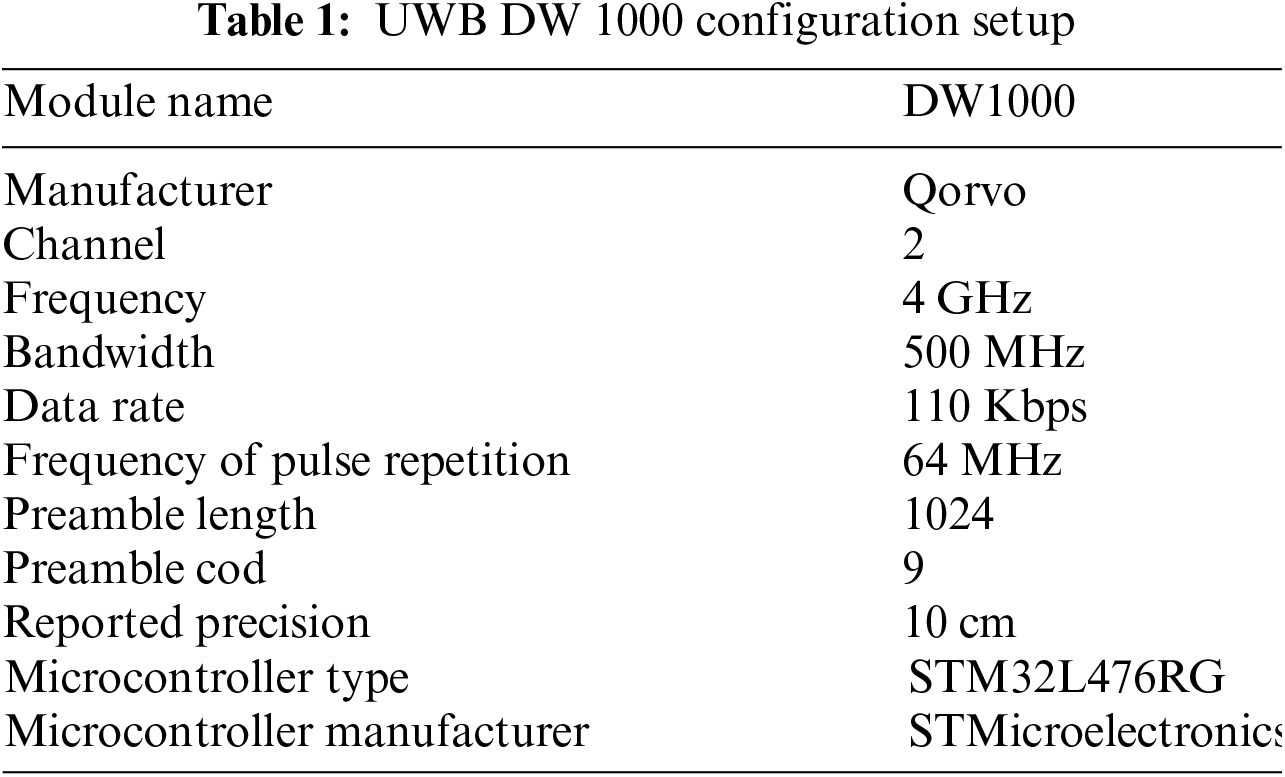
Fig. 3 depicts the experimental setup, which used the Qorvo DW1000 module to measure UWB data. This module is a low-power, multichannel, single-chip CMOS radio transceiver that meets the IEEE 802.15.4-2011 standard. The device uses time-of-flight (TOF) technology to achieve a range precision of ±10 cm. The DW1000 is intended to operate across six RF frequency bands (3.5–6.5 GHz), with a 500–900 MHz bandwidth. It supports data rates of up to 6.8 Mbps, making it extremely dependable even in difficult MP scenarios. The module was set up to utilise channel 2 at a frequency of 4 GHz, featuring a bandwidth of 500 MHz and a data rate of 110 Kbps. The frequency of pulse repetition employed was 64 MHz, accompanied by a preamble length of 1024 and a preamble code of 9. The reported precision for this setup was ±10 cm, which is essential for ensuring accurate UWB ranging measurements. For our experiments, we chose the STM32L476RG development board from STMicroelectronics as the main microcontroller unit (MCU) due to its ability to handle complex computations and data processing. The use of the STM32L476RG MCU resulted in strong performance and smooth communication between the UWB nodes and the data logging interfaces, improving the overall efficiency and dependability of our experimental setup.

Figure 3: The indoor environment of the real experimental setting
After collecting the data, we manually assigned class labels (LOS, MP soft-NLOS, and hard-NLOS). The data was then segregated and saved as separate files for each class. The data was rescaled during preprocessing using standardisation, which ensures that the mean is zero and the standard deviation is one (unit variance). The normalisation of input features generally leads to quicker training times and enhanced performance for numerous machine-learning models. We convert categorical labels into numerical values for machine learning algorithms.
3.4 Feature Extraction and Selection
The Qorvo DW1000 UWB modules were configured in accordance with the specifications outlined in Table 1, extracting twelve features. These include the following: raw timestamp, number of accumulated preamble symbols, received signal strength level (RSL), first passage signal strength (FSL), noise threshold values, a numerical representation of the signal’s leading edge, range correction values, timing difference between tag and anchors, measured distance, and the receiver’s internal re-sampler time delay.
Consequently, a feature selection procedure was implemented to ascertain the most pertinent attributes for NLOS identification. The wrapper technique was implemented in this process, which involved the utilisation of a machine learning model to evaluate the influence of individual features on the classification accuracy as a whole. The classification accuracy attained using each feature is illustrated in Fig. 4. The following characteristics were determined to be statistically significant based on this evaluation:
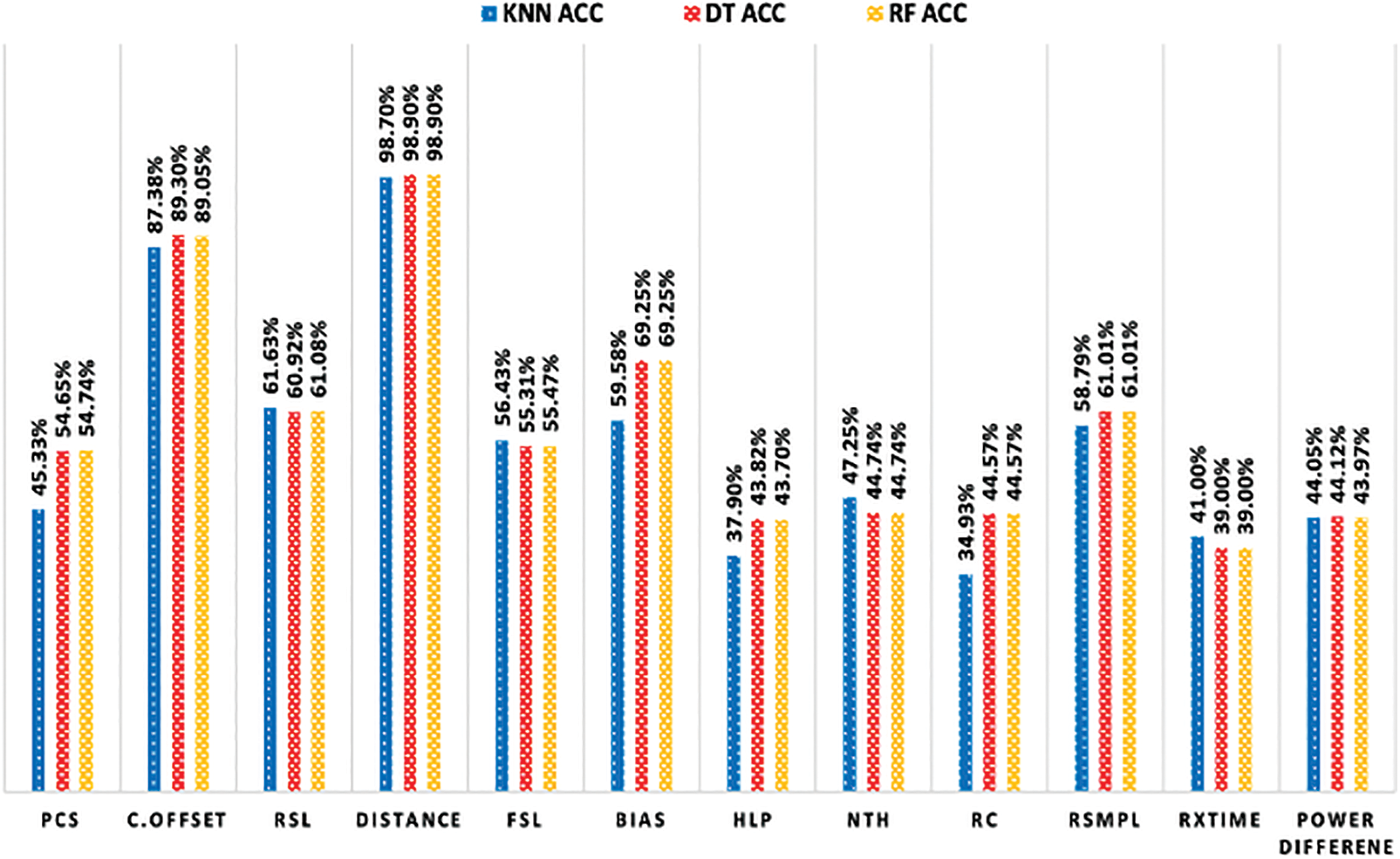
Figure 4: Classification performance of individual features
(a) Received Signal Level (RSL): Estimated by employing the formula that incorporates the Preamble Accumulation Count and Channel Impulse Response Power.
(b) First Passage Signal Level (FSL): Calculated by utilising the magnitudes of the First Path Amplitude points.
(c) Preamble Symbols Accumulated (PSC): Assists in accurately modelling the channel impulse response.
(d) Range Bias Error: The time-of-flight calculations are influenced by the fluctuation in the received signal level.
(e) RSMPDEL (RSMPL): Denotes the delay caused by the internal re-sampler.
(f) Clock Offset: Indicates the variation between the actual clock frequency and the nominal value in UWB transceivers.
3.5 Genetic and Grid Search Algorithms
The grid search method, a systematic approach to hyperparameter optimization, exhaustively evaluates all feasible combinations of parameter values within a predefined grid. By systematically testing each combination, this technique identifies the optimal hyperparameter configuration that maximizes the performance of a machine learning model. However, the grid search method is not ideal for optimizing floating-point hyperparameters due to its slow convergence speed [36]. Conversely, the genetic algorithm, a computational method that emulates the principles of natural selection and genetic processes, efficiently converges to optimal solutions through genetic operations like crossover and mutation [37]. The algorithm begins with a population of randomly generated potential solutions, referred to as chromosomes. Each chromosome’s fitness is assessed through a fitness function, with higher fitness values indicating a greater likelihood of being selected for reproduction. Iterative processes such as selection, crossover, and mutation generate successive populations that gradually converge on an optimal solution. This process is repeated until the best fit individual is identified or a predetermined number of iterations are completed. This paper presents an optimised XGBoost method that combines grid search for integer hyperparameter optimisation and a genetic algorithm for floating-point hyperparameter optimisation. The foundational methodology used in the Genetic and Grid Search framework for hyperparameter optimisation of the XGBoost Classifier is summarised as follows and illustrated in Fig. 5:
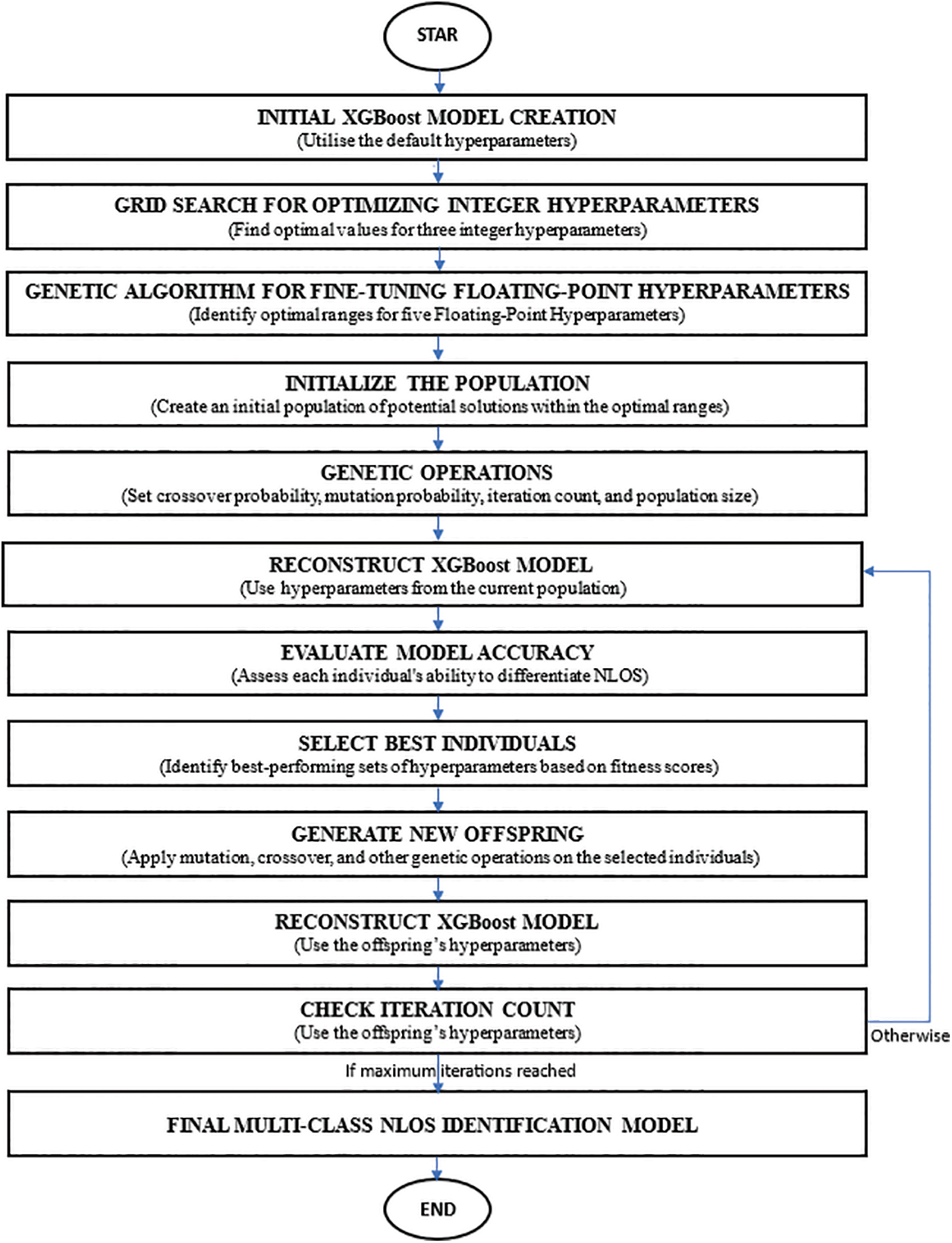
Figure 5: Description of genetic and grid search framework for XGBoost classifier hyperparameter optimisation
(a) Create an initial model for NLOS identification using the XGBoost algorithm with default hyperparameter values.
(b) Conduct a grid search to ascertain the optimal values for n_estimators, scale-pos weight, and max_depth.
(c) Determine the ideal ranges for the floating-point hyperparameters: gamma, subsample, colsample_bytree, reg-lambda, and learning rate reg-alpha.
(d) Start by initialising a population that falls within the optimal ranges of the floating-point hyperparameters.
(e) Configure the genetic algorithm parameters: crossover probability, mutation probability, iteration count, and population size.
(f) Reconstruct the XGBoost model for NLOS identification using the population.
(g) Assess the proficiency of each individual in the population by considering the model’s accuracy in differentiation.
(h) Choose the best individuals from the population.
(i) Generate offspring individuals by performing mutation, crossover, and other genetic operations.
(j) Reconstruct the NLOS identification model using the hyperparameters of the offspring individuals, which are based on XGBoost.
(k) Output the optimal individuals if the maximum number of iterations is reached.
(l) Otherwise, return to Step (f) and continue iterating.
(m) The final multi-class NLOS identification prediction model should be constructed by utilising the recently acquired optimal values for the six floating-point hyperparameters and the three integer hyperparameters.
Friedman introduced the gradient-boosting decision tree algorithm in 2001 [13]. It works by sequentially building decision trees, each aiming to correct the errors of its predecessors. This process is known as boosting. XGBoost, or Extreme Gradient Boosting, is a tree ensemble model that uses gradient descent to minimize the loss function. Unlike traditional gradient boosting, XGBoost leverages second-order derivatives to more efficiently determine the optimal direction for updates. It combines multiple CARTs (Classification and Regression Trees) to make predictions. XGBoost is an advanced version of the gradient-boosting decision tree algorithm. Unlike traditional GBDT, which iteratively adds residual trees, XGBoost incorporates a regularization term into its objective function to prevent overfitting and improve convergence [38–40]. This regularization is similar to but not identical to Lasso or Ridge regression. XGBoost has demonstrated exceptional computational efficiency and prediction accuracy, making it a popular choice for many machine-learning tasks. It offers several key advantages: it can automatically identify the most informative features, efficient handling of large-scale datasets. Training and testing times are generally fast, and the ability to learn from its mistakes. Additionally, XGBoost allows for fine-tuning of a wide range of hyperparameters, enhancing generalization and reducing the risk of overfitting [41]. It excels in identifying the best tree model, managing missing values, providing parallelism, and optimizing cache usage by allocating internal buffers for storing statistical information. The algorithm uses a depth-first search strategy for tree pruning and improves performance. XGBoost also includes built-in features such as weighted quantile sketching for finding optimal split points and cross-validation for model evaluation. The decision trees are constructed sequentially, with each tree assigning weights to the features based on their contribution to the prediction. Incorrectly predicted features are given higher weights in subsequent trees, leading to a more robust ensemble model [12,42].
This paper utilises the XGBoost method to construct a classifier and train datasets for the purpose of predicting the NLOS propagation channel in the UWB indoor positioning system. The dataset consists of {
The predicted value
XGBoost is a collection of weak learners that work together. The training process involves utilising a collection of K trees to generate predictions.
where
Expanding on the Gradient Boosted Decision Trees (GBDT) framework, XGBoost introduces a regularisation term to the objective function in order to reduce the complexity of the model and mitigate overfitting. This is outlined in Eqs. (4) and (5):
where
Here
For the t-th iteration, the object function to train the t-th weak learner is given by Eq. (6):
Eq. (7) provides the Taylor series expansion of the objective function. The second-order Taylor process accelerates the convergence speed of the model and allows for the attainment of the global optimal solution.
where
The algorithm aims to further divide the existing leaf nodes in each step to create the most efficient tree structure. According to Eq. (8), the splitting gain can be determined.
Once the splitting gain falls below the predefined threshold or the tree reaches its maximum depth, the splitting process comes to a halt, resulting in the final classification model. The classifier constructed in this paper utilises all the features to their fullest potential, ensuring that no information is lost. Additionally, the structure of the loss function is optimised through serial iteration to eliminate any non-orthogonal influence of the samples.
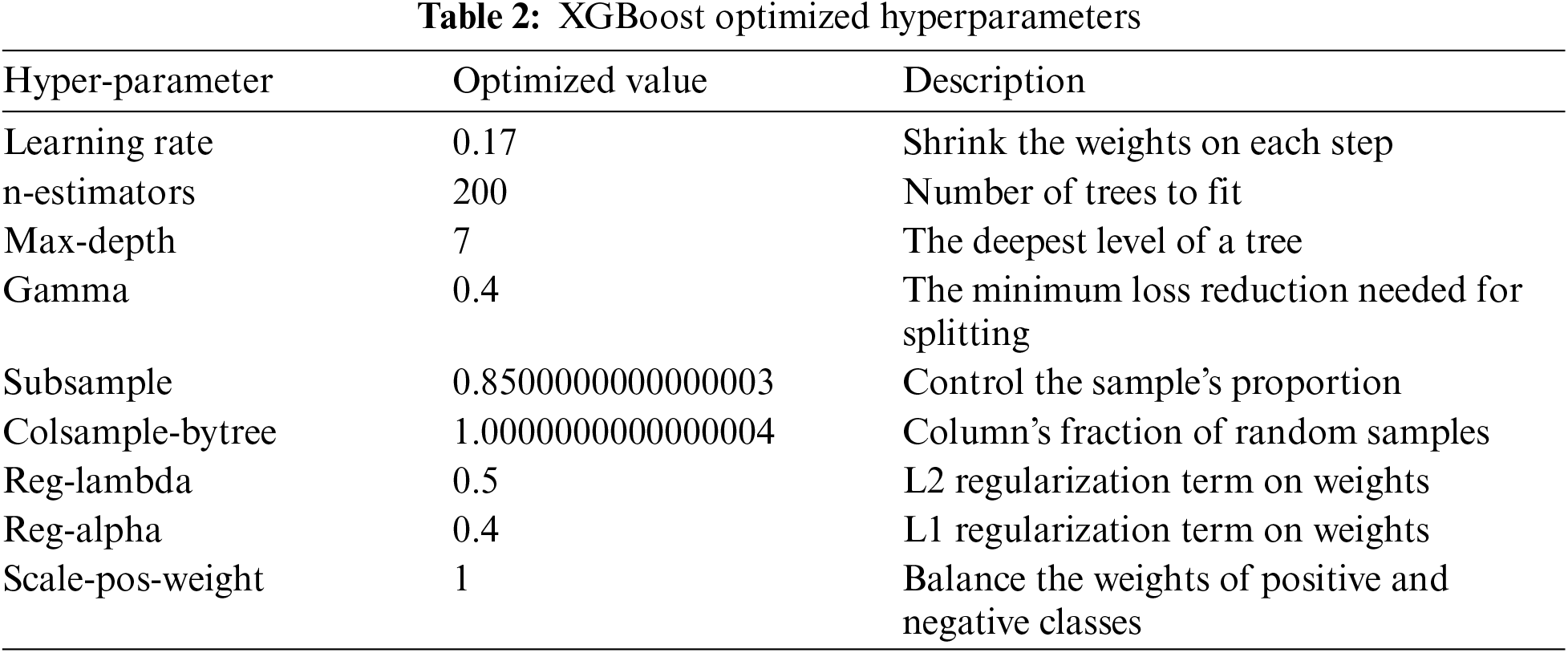
In this paper, we have chosen nine parameters for tuning. These parameters are listed in Table 2 and include learning rate, n-estimator, scale-pos-weight, max-depth, subsample, cosample-bytree, gamma, reg-alpha, and reg-lambda. The learning rate enhances the model’s stability and robustness, while the scale-pos-weight, max-depth, subsample, colsample-bytree, and gamma parameters are employed to regulate overfitting. Moreover, the regularisation parameters reg_lambda and reg_alpha impose penalties on models as their complexity grows, finally leading to their simplification. A range of evaluation metrics are employed to evaluate the performance of the selected optimised XGBoost model on the hold-out test data.
The proposed model has undergone quantitative analysis using performance metrics such as recall, precision, accuracy, and F1-score. Accuracy refers to the percentage of subjects that are correctly classified. The F1-score is a well-rounded metric that takes into account both precision and recall, offering valuable insights into the performance of a model. Precision, a crucial measure in classification tasks, calculates the percentage of positive instances that are accurately classified. It is defined according to Eq. (9):
Instances that are accurately categorised as positive are called true positives (TP), while erroneous positive classifications are referred to as false positives (FP). Accurate precision demonstrates a model’s capacity to reduce the occurrence of false positives. In situations where reducing false alarms is of utmost importance, precision is a highly valuable measure. Recall, also known as sensitivity, evaluates a model’s effectiveness to correctly detecting positive instances. It is computed as in Eq. (10):
A model’s capacity to reduce false negatives is indicated by a high recall. Recall is particularly critical in applications where the cost of missing positives is high, such as medical diagnosis or fraud detection. The F1-score provides a combined assessment of a model’s precision and recall. The calculation is as follows in Eq. (11):
The F1-score is useful when there is a need to achieve a balance between precision and recall. It emphasises the classifier’s overall efficacy in accurately identifying positive instances while minimising errors. The subsequent sections provide a performance comparison of the three classifiers. Metrics used include precision, F1-score, and recall.
The formula for calculating accuracy is defined as follows in Eq. (12):
The following section provides the findings of our experimental assessment, which examined the effectiveness of several machine learning classifiers on a range of data balancing techniques. A selection of classifiers used in this study comprised DT, RF, XGBoost, SVM, NB, ADA, SGD, LR, and KNN. We utilised four datasets to evaluate the operational effectiveness of these classifiers. The first dataset is based on the Bielefeld University 2020 research program [23] and contains three indoor scenarios classified as LOS, MP, and NLOS with different levels of data balance and sampling: DS1-1, unbalanced; DS1-2, under-sampled; and DS1-3, up-sampled. The other dataset, DS2, is collected from our experimental processes, containing four propagation channels: LOS, MP, and both soft and hard NLOS. On this front, an exhaustive set of performance metrics is used to evaluate and further validate this new multiclass NLOS identification model for achieving high accuracy. These measures include classification accuracy, precision, recall, and F-measure. The implemented model was run on a high-performance Lenovo laptop equipped with an Intel Core i7, 12th generation, 12700HQ processor, having a clock speed of 2.7 GHz and an 8 MB cache, besides 16 GB of RAM, with an NVIDIA GeForce RTX 3050 Ti as the graphics processor. The implementation utilized both Python and MATLAB R2022a programming languages.
5.1 Proposed Model Evaluation and Validation
In order to ensure a fair comparison and achieve realistic accuracy, we selected features that are similar to those mentioned in the open-source dataset [23]. Our focus was on the four most significant features. This approach ensures the precision of the proposed model and makes it easier to apply to various environments with similar data. The first three experiments were conducted using an open-source UWB CIR dataset from Bielefeld University (2020). This dataset includes three distinct types of collected data (DS1-1, DS1-2, and DS1-3), with UWB CIR data obtained using the DW1000 UWB module. Data collection occurred in three scenarios: two small rooms, a hall, and four corridors, spanning seven different indoor locations. The two rooms were a 6 m × 6 m laboratory environment and an approximately 8 m × 6 m communication room, both furnished with various items. The data collected in narrow corridors were to simulate MP conditions when the direct (LOS) was indistinguishable because of numerous signal reflections from the narrow walls. Data were gathered and analysed in both static and dynamic settings across all scenarios. The first dataset (DS1-1) comprises 61,930 samples for LOS, MP, and NLOS conditions, resulting in a total undersampled dataset of 188,791 samples. The second dataset (DS1-2) includes 111,468 samples for LOS, MP, and NLOS conditions, for a total of 335,539 samples. The third dataset (DS1-3) contains 273,041 samples, including 99,264 samples for LOS, 111,846 samples for MP, and 61,930 samples for NLOS. Likewise, for DS2, the experiments were conducted using UWB CIR data obtained based on the DW1000 UWB module. This dataset consisted of 585,744 LOS, 436,380 MP, 529,248 soft-NLOS, and 221,448 hard-NLOS measurements. The DS2 measurement data were collected in two residential settings, each including several rooms that were specifically chosen for the measurement campaign to comprehensively assess the diverse impact of indoor environments on the propagation of RF signals. The data necessary for our experimental evaluations were collected in four rooms of varying dimensions (5 m × 4 m, 10 m × 4 m, 20 m × 6 m, and 4 m × 2 m) within a building environment, a hall measuring 8 m × 48 m that featured a variety of furniture, and two corridors with widths of 3 and 1.5 m, respectively. Measurement data were acquired in these diverse scenarios using a variety of propagation channels.
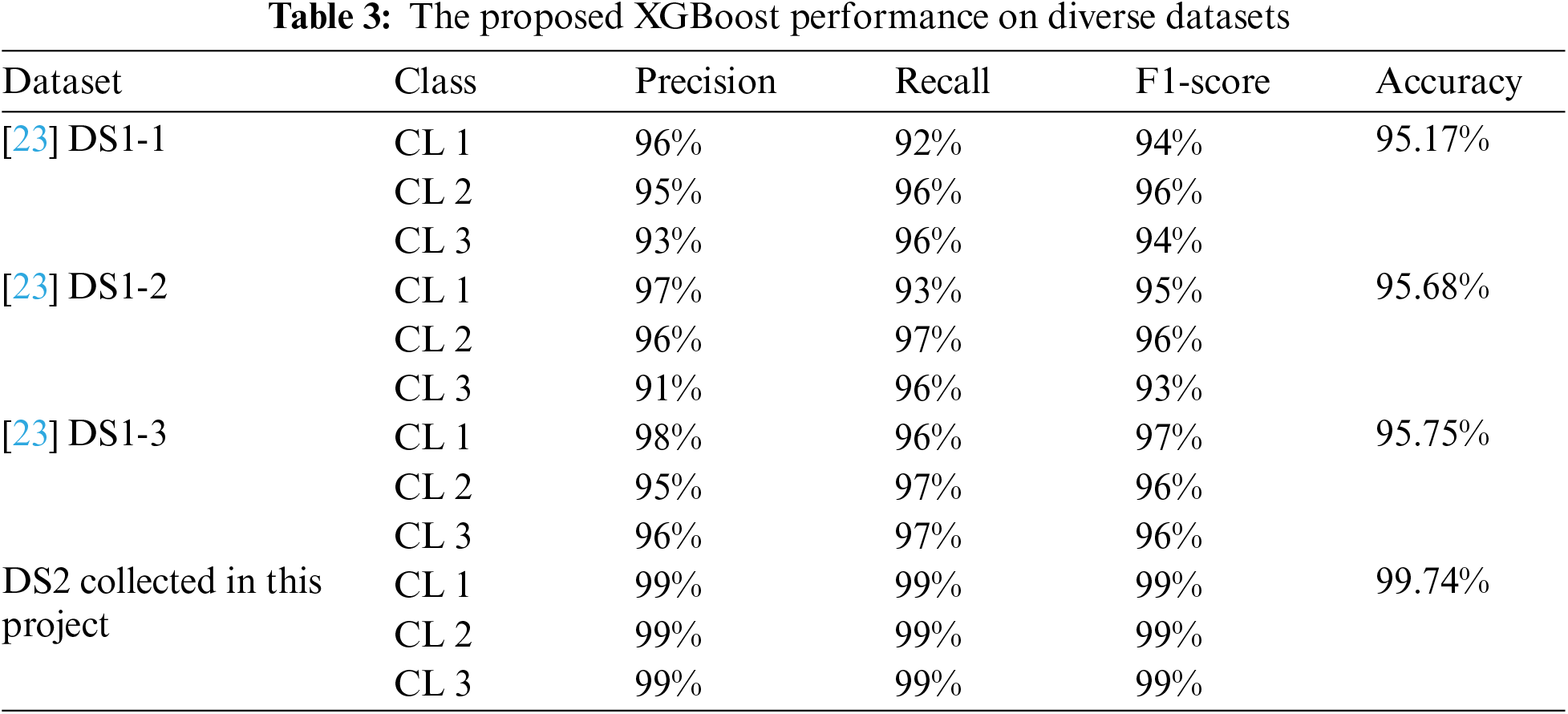
A thorough examination of the implemented XGBoost algorithm showed a notable enhancement in accuracy when identifying different classes within the dataset created for the project. The model’s strong ability to accurately predict positive instances is further supported by consistent gains in both precision and recall metrics across all classes. In addition, the F1-score, which takes into account both precision and recall, showed consistent improvement across different types of propagation channels, including LOS, MP, soft, and hard-NLOS, with an impressive 99%. Experimental results show that our proposed XGBoost achieved the highest overall accuracy of 99.47%, precision of 99%, recall of 99%, and an F-score of 99% on an open-source dataset. Additionally, based on a local dataset, the model achieved the highest performance, with an accuracy of 96%, precision of 96%, recall of 97%, and an F-score of 97%. The slight disparity in performance between the local dataset (99.47%) and the open-source dataset (96%) may indicate that the model is somewhat tailored to the specific characteristics of the local dataset. However, this variation in accuracy can be attributed to the inherent differences between the datasets, particularly in terms of environmental conditions and measurement setups as discussed in Section 5.3. To mitigate potential overfitting, we applied regularisation techniques within the XGBoost framework as outlined in Section 3.6. Moreover, our feature importance analysis (Section 5.2) demonstrates that the model relies on meaningful features, suggesting that overfitting is not a significant concern. This discovery suggests a well-rounded improvement in accuracy and recall, highlighting the effectiveness of the XGBoost algorithm in this classification assignment. Table 3 presents a comparison of the accuracy performance of the proposed XGBoost model on five datasets [23].
5.2 Comparison with Other ML Models
For classification and comparison, a total of eight supervised ML algorithms were used. These algorithms include DT, RF, XGBoost, SVM, NB, ADA, SGD, LR, and KNN. The performance metrics consisted of precision, recall, F1-score, and the overall classification accuracy. Table 4 and Fig. 6 provide a summary of the classification accuracies for each classifier across the four datasets. XGBoost, RF, and DT consistently achieve the highest level of accuracy, with XGBoost being the most effective. The significance of AdaBoost and SGD is highlighted by the considerable variation in sampling methods. The performance of SVM, NB, and LR is average to inconsistent, while KNN shows improvement with sampling, reaching an accuracy of up to 94.99%.
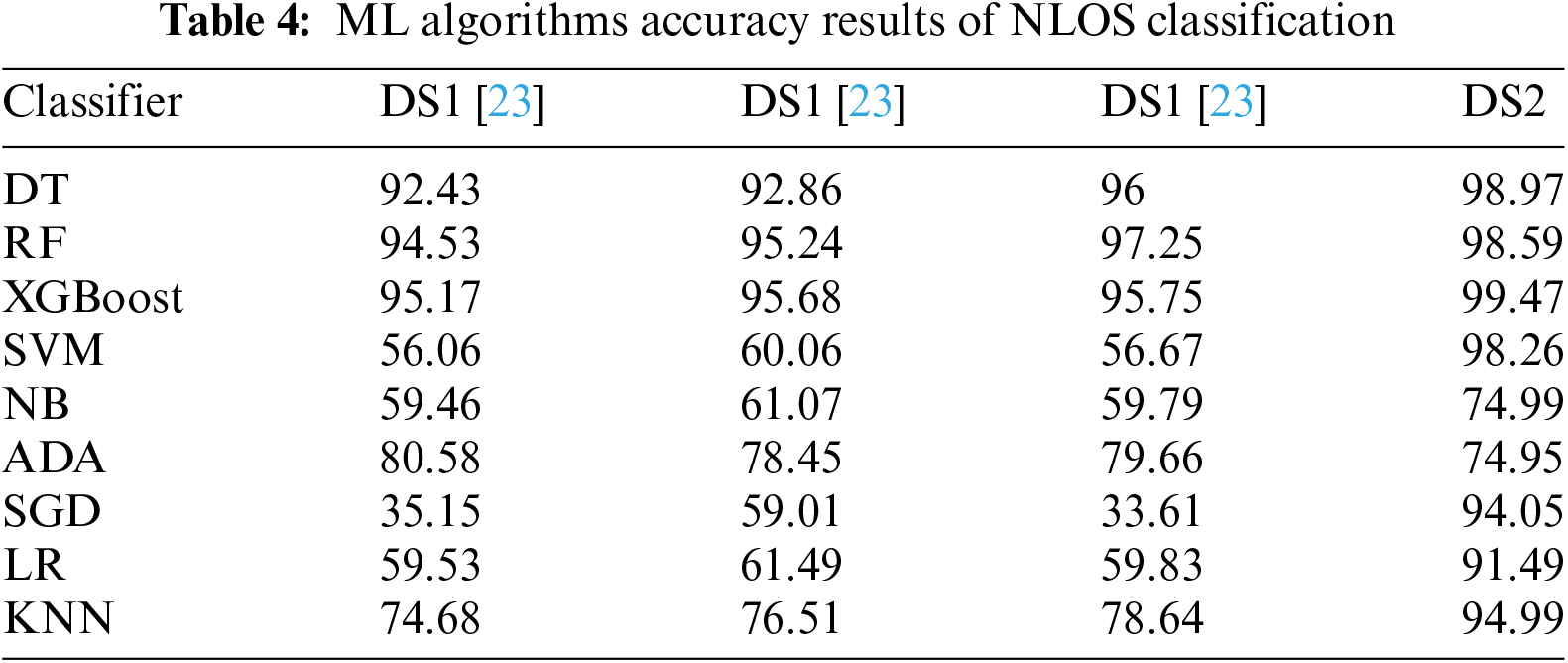
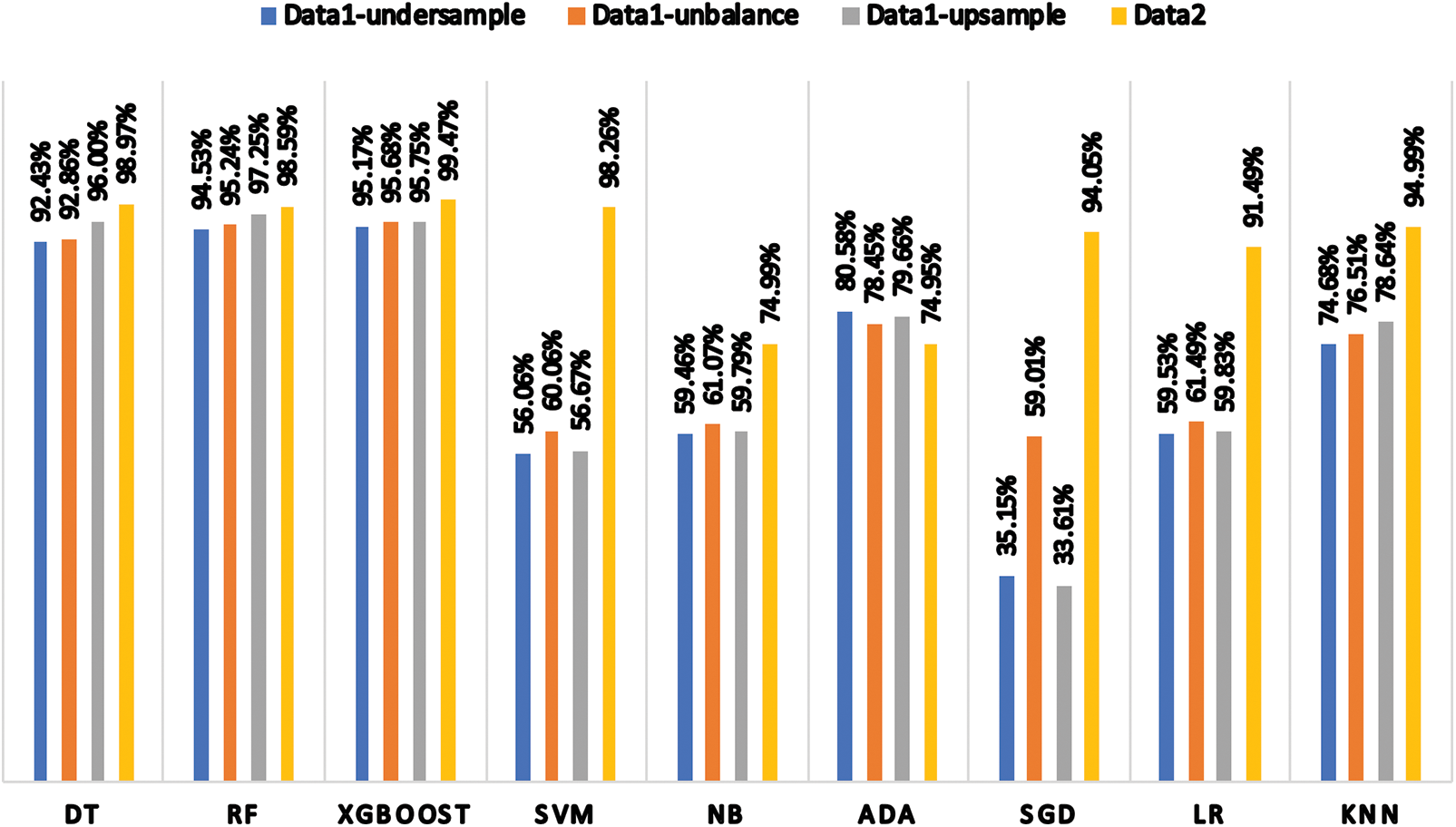
Figure 6: ML classifier’s accuracies results
The performance of the proposed XGBoost-based method was rigorously validated through a comprehensive comparative analysis with state-of-the-art models used on similar UWB DW1000 devices. This comparison utilized both publicly available and locally sourced datasets, encompassing a diverse range of propagation channels and indoor environments, providing a robust platform for performance evaluation. The datasets varied significantly with some being unbalanced, showcasing an unequal distribution of observations among LOS, NLOS conditions, and MP, while others were balanced through under-sampling and up-sampling techniques. Nevertheless, a thorough examination of various ML/DL algorithms in the relevant literature has been carried out to assess their accuracy in identification.
Despite these adjustments, a comprehensive survey of the relevant literature indicated a dearth of XGBoost applications for NLOS channel detection in UWB systems. This scarcity can be attributed to various factors, including the widespread adoption of neural networks (such as CNNs) due to their perceived ability to model complex data relationships. Furthermore, the researchers’ familiarity with traditional algorithms such as SVM, RF, and DT, as well as their demonstrated effectiveness in related fields. However, our proposed XGBoost-based approach has performed admirably, achieving high levels of accuracy, precision, recall, and F1-score. These findings emphasise XGBoost’s resilience and competitiveness in identifying NLOS propagation channels.
Comparative analysis with other machine learning classifiers revealed that the XGBoost classifier, across various datasets, consistently outperformed SVM, RF, DT, and other considered models. It showcased strong performance with high accuracy rates achieved as 99.47% on DS2, 95.68% on DS1-1, 95.17% on DS1-2, and 95.75% on DS1-3. Similarly, other models like RF, DT, SVM, and others showed improvements, but none could consistently outperform XGBoost across all datasets. However, in the case of the upsampled dataset (DS1-3), the RF algorithm attained the highest accuracy (97.25%), followed by the DT algorithm (96%), and the XGBoost algorithm (95.75%).
Based on the results, it is evident that the RF algorithm shows a marginally better performance than XGBoost and significantly better than DT when handling the upsampled dataset (DS1-3). The observed accuracy with the DS1-3 dataset can be attributed to the nature of the upsampling process, which involves duplicating observations from the minority class and may increase the risk of overfitting. In addition, the Support Vector Machine classifier demonstrated significant enhancement, achieving an accuracy of 0.9826. The Naive Bayes classifier demonstrated moderate enhancements, whereas AdaBoost maintained consistent performance across all datasets. The SGD showed a significant improvement in accuracy, reaching a value of 0.94045. Linear classifiers rely heavily on well-balanced and prepared data. LR also improved, reaching an accuracy of 0.9149. The KNN algorithm achieved its peak accuracy of 0.9499, showcasing the advantages of utilising a thorough and well-balanced dataset.
It is crucial to emphasise that even marginal improvements in accuracy can be highly significant in real-world applications where precise classification is essential, particularly in complex environments such as NLOS indoor positioning systems. In fields such as autonomous navigation and drone communication, slight increases in accuracy can substantially mitigate the risk of collisions or system failures. These improvements can prevent numerous misclassifications during critical operations, thereby enhancing both safety and reliability. Furthermore, UWB systems rely on accurate distance measurements from a minimum of three anchor points, and in challenging conditions, even small errors in these measurements can accumulate and adversely affect overall positioning accuracy. As a result, minor enhancements in measurement accuracy can significantly impact the system’s overall performance [6–8].
In addition to improvements in accuracy, XGBoost offers several other advantages, including faster convergence, superior handling of imbalanced datasets, better scalability for larger datasets, and a reduced risk of overfitting due to its regularisation features. These characteristics make XGBoost more robust and scalable compared to other machine learning algorithms in the literature, particularly in real-time systems where environmental conditions can fluctuate rapidly. Moreover, the use of grid search and genetic algorithms for hyperparameter tuning allows for more precise optimisation, increasing the model’s adaptability to different types of datasets and potentially reducing the need for extensive retraining. This leads to improved stability and robustness, particularly in real-world applications where dynamic and unpredictable environmental conditions are prevalent.
Similarly, the performance analysis of the deep learning models, as discussed in Section 2 and shown in Table 5, is significantly influenced by the quality and the volume of the training data and is sensitive to hyperparameter selection. This necessitates meticulous tuning and additional validation across diverse indoor environments, which can hinder generalisation to new datasets. Furthermore, these models are more computationally intensive compared to traditional machine learning models, requiring the preprocessing and structuring of input data into image format.
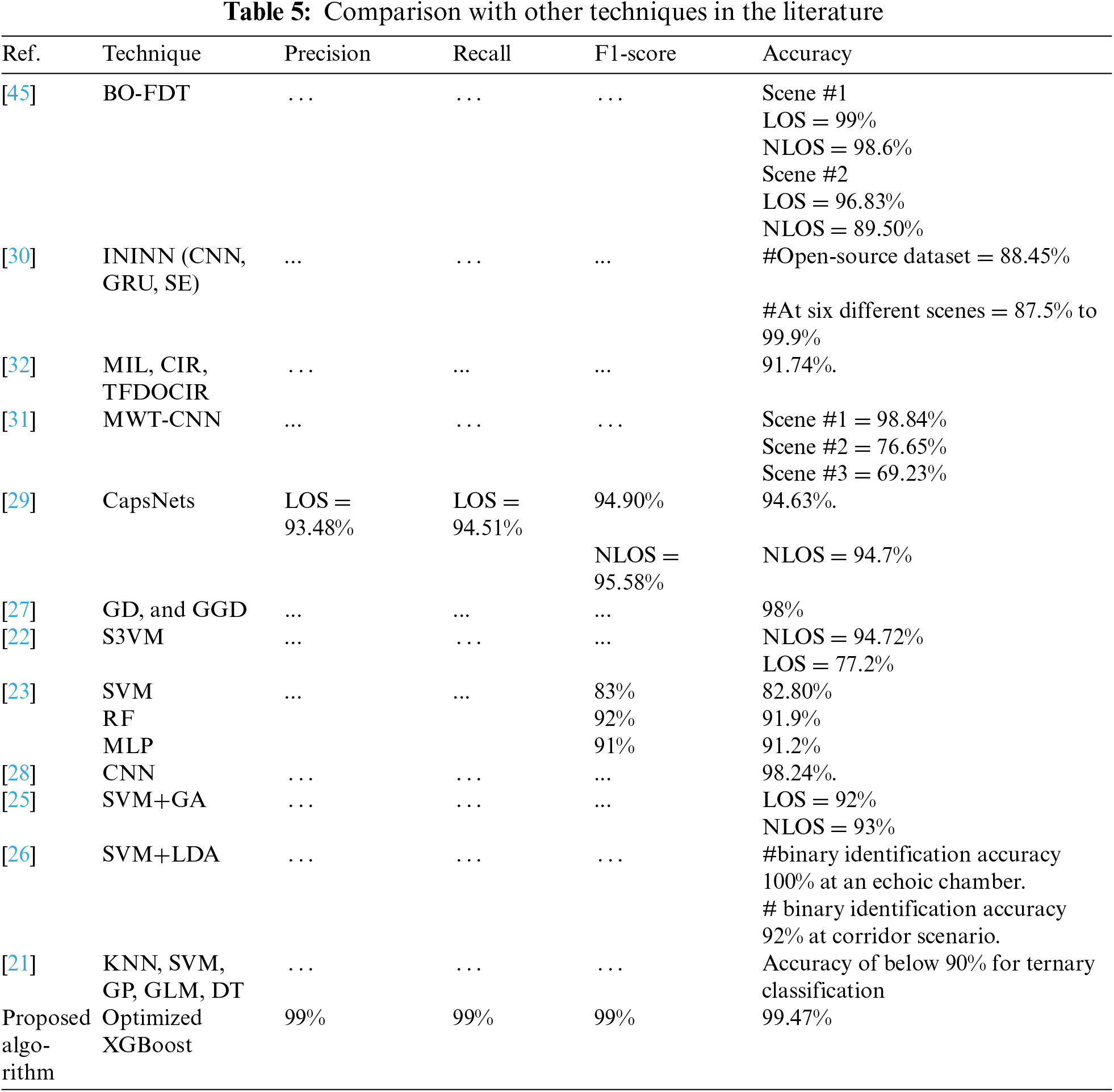
The proposed XGBoost provides a more efficient and practical solution for detecting NLOS channels in UWB systems. It outperforms traditional machine learning models like RF and DT and provides a useful, more efficient alternative to deep learning models. The stability and effectiveness of XGBoost were apparent in its robustness, accurate performance, adaptability, and resilience when handling different datasets. The findings highlight the significance of meticulous data preparation, feature selection, and balancing methods in enhancing the accuracy of machine learning models in intricate classification tasks. This approach provides a robust solution with generalization performance and adaptability across various dataset types and environments paving the way for more reliable and accurate indoor positioning technologies. Since the accurate non-line of sight (NLOS) identification technique in UWB location-based services is critical for applications like drone communication and autonomous navigation. Nonetheless, while our study demonstrates robust performance in identifying NLOS conditions across two diverse datasets representing various environments and propagation channels, it is important to acknowledge certain limitations. One key constraint is that, despite the diversity of the datasets used, real-world scenarios can exhibit far greater variation, particularly with respect to obstacle materials and dynamic conditions, including outdoor or mixed indoor-outdoor environments. Furthermore, while the hyperparameter optimization process was conducted rigorously using grid search and genetic algorithms, these techniques may not represent the most cutting-edge tuning methods currently available. More sophisticated approaches could potentially yield superior results, and further fine-tuning may be necessary for real-time, large-scale applications. Table 5 provides a summary of recent works that are relevant to the topic, highlighting performance trends and relative improvements. These studies were selected based on common criteria to ensure fair and meaningful comparisons, including the use of the DW1000 UWB device and similar dataset features within comparable indoor environments.
The investigation examines the efficacy of machine learning classifiers in addressing non-line-of-sight conditions in UWB ranging systems, as a multiclass propagation channel (LOS, MP, soft-NLOS, and hard-NLOS). The process entailed the meticulous collection of data, the extraction of features, and the rigorous evaluation of a variety of classifiers. The proposed optimized XGBoost demonstrated the most accurate, robust, and stable behaviour across various dataset types, showing reduced sensitivity to imbalanced data and achieving an overall accuracy of 99.47%. This approach offers a strong solution that can be applied to different types of datasets and environments, leading to more dependable and precise indoor positioning technologies. The results showed that the classifier’s performance improved significantly when using a well-prepared and balanced dataset. Furthermore, the research highlights the importance of data preparation and feature extraction in enhancing the performance of machine learning models. Further investigation should give priority to improving feature selection techniques and hyperparameter tuning, while also expanding the range to include real-world deployment experiences, particularly with regard to variations in obstacle materials and dynamic conditions in outdoor or mixed indoor-outdoor scenarios. It is advisable to use deep learning classifiers such as long short-term memory (LSTM), recurrent neural networks (RNN), and convolutional neural networks (CNNs) for additional data analysis.
Acknowledgement: The authors would like to thank all anonymous reviewers.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm their contribution to the paper as follows: study administration, formal analysis, and writing—review & editing: Ammar Fahem Majeed, Rashidah Arsat, Muhammad Ariff Baharudin, Nurul Mu’azzah Abdul Latiff, Abbas Albaidhani; conceptualization, and validation: Ammar Fahem Majeed, Rashidah Arsat, Muhammad Ariff Baharudin, Nurul Mu’azzah Abdul Latiff; funding acquisition, resources, software, and visualization: Ammar Fahem Majeed, Rashidah Arsat; data curation, investigation, methodology, and writing—original draft: Ammar Fahem Majeed; supervision: Rashidah Arsat, Muhammad Ariff Baharudin, Nurul Mu’azzah Abdul Latiff, Abbas Albaidhani. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The datasets generated during the current study are available in the IEEE Dataport repository (https://dx.doi.org/10.21227/nxvh-m657, accessed on 30 August 2024). Additionally, the data and materials that are derived from publicly accessible databases and previously published studies are cited throughout the text. References to these sources are provided in the bibliography.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. P. S. Farahsari, A. Farahzadi, J. Rezazadeh, and A. Bagheri, “A survey on indoor positioning systems for IoT-based applications,” IEEE Internet Things J., vol. 9, no. 10, pp. 7680–7699, 2022. doi: 10.1109/JIOT.2022.3149048. [Google Scholar] [CrossRef]
2. N. Min-Allah et al., “A survey of COVID-19 contact-tracing apps,” Comput. Biol. Med., vol. 137, 2021, Art. no. 104787. [Google Scholar]
3. M. K. Almutairi and S. Bhattacharjee, “A survey in localization techniques used in location-based access control,” in 2021 IEEE World AI IoT Congr. (AIIoT), Seattle, WA, USA, 2021, pp. 0427–0432. doi: 10.1109/AIIoT52608.2021.9454195. [Google Scholar] [CrossRef]
4. H. Chen, G. Shan, B. -H. Roh, S. Kim, J. Lim and G. Choi, “Visual landmark map-based spatial recognition using a monocular camera,” in 2024 IEEE Int. Conf. Consum. Electron. (ICCE), Las Vegas, NV, USA, 2024, pp. 1–4. doi: 10.1109/ICCE59016.2024.10444228. [Google Scholar] [CrossRef]
5. G. Shan, B. Park, S. Nam, B. Kim, B. Roh and Y. -B. Ko, “A 3-dimensional triangulation scheme to improve the accuracy of indoor localization for IoT services,” in 2015 IEEE Pacific Rim Conf. Commun., Comput. Signal Process. (PACRIM), Victoria, BC, Canada, 2015, pp. 359–363. doi: 10.1109/PACRIM.2015.7334862. [Google Scholar] [CrossRef]
6. L. Cheng, Z. Wu, B. Lai, Q. Yang, A. Zhao and Y. Wang, “Ultra wideband indoor positioning system based on artificial intelligence techniques,” in 2020 IEEE 21st Int. Conf. Inf. Reuse Integr. Data Sci. (IRI), Las Vegas, NV, USA, 2020, pp. 438–444. doi: 10.1109/IRI49571.2020.00073. [Google Scholar] [CrossRef]
7. J. Y. Lee and R. A. Scholtz, “Ranging in a dense multipath environment using an UWB radio link,” IEEE J. Sel. Areas Commun., vol. 20, no. 9, pp. 1677–1683, Dec. 2002. doi: 10.1109/JSAC.2002.805060. [Google Scholar] [CrossRef]
8. D. B. Jourdan, D. Dardari, and M. Z. Win, “Position error bound for UWB localization in dense cluttered environments,” IEEE Trans. Aerosp. Electron. Syst., vol. 44, no. 2, pp. 613–628, Apr. 2008. doi: 10.1109/TAES.2008.4560210. [Google Scholar] [CrossRef]
9. Y. Wang, P. P. Chen, X. W. Zhi, Q. Y. Zhang, and N. T. Zhang, “Characterization of indoor ultra-wide band NLOS channel,” in 2006 IEEE Annu. Wirel. Microw. Technol. Conf., Clearwater Beach, FL, USA, 2006, pp. 1–5. doi: 10.1109/WAMICON.2006.351904. [Google Scholar] [CrossRef]
10. Md. S. Rahman, A. Chakraborty, K. Sunderasan, and S. Rangarajan, “DynoLoc: Infrastructure-free RF tracking in dynamic indoor environments,” 2021, arXiv:2110.07365. [Google Scholar]
11. C. K. M. Lee, C. M. Ip, T. Park, and S. Y. Chung, “A bluetooth location-based indoor positioning system for asset tracking in warehouse,” in 2019 IEEE Int. Conf. Ind. Eng. Eng. Manag. (IEEM), Macao, China, 2019, pp. 1408–1412. doi: 10.1109/IEEM44572.2019.8978639. [Google Scholar] [CrossRef]
12. T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” Assoc. Comput. Machinery, vol. 11, no. 34, pp. 785–794, Aug. 2016. doi: 10.1145/2939672.2939785. [Google Scholar] [CrossRef]
13. J. H. Friedman, “Greedy function approximation: A gradient boosting machine,” Ann. Stat., vol. 29, no. 5, pp. 1189–1232, Oct. 2001. doi: 10.1214/aos/1013203451. [Google Scholar] [CrossRef]
14. M. Gumus and M. S. Kiran, “Crude oil price forecasting using XGBoost,” in 2017 Int. Conf. Comput. Sci. Eng. (UBMK), Antalya, Turkey, 2017, pp. 1100–1103. doi: 10.1109/UBMK.2017.8093500. [Google Scholar] [CrossRef]
15. Y. Qu, Z. Lin, H. Li, and X. Zhang, “Feature recognition of urban road traffic accidents based on GA-XGBoost in the context of big data,” IEEE Access, vol. 7, pp. 170106–170115, 2019. doi: 10.1109/ACCESS.2019.2952655. [Google Scholar] [CrossRef]
16. X. Deng, M. Li, S. Deng, and L. Wang, “Hybrid gene selection approach using XGBoost and multi-objective genetic algorithm for cancer classification,” Med. Biol. Eng. Comput., vol. 60, no. 3, pp. 663–681, Jan. 2022. doi: 10.1007/s11517-021-02476-x. [Google Scholar] [PubMed] [CrossRef]
17. Z. Wu, M. Zhou, Z. Lin, X. Chen, and Y. Huang, “Improved genetic algorithm and XGBoost classifier for power transformer fault diagnosis,” Front. Energy Res., vol. 9, Oct. 2021, Art. no. 745744. doi: 10.3389/fenrg.2021.745744. [Google Scholar] [CrossRef]
18. S. Maranò, W. M. Gifford, H. Wymeersch, and M. Z. Win, “NLOS identification and mitigation for localization based on UWB experimental data,” IEEE J. Sel. Areas Commun., vol. 28, no. 7, pp. 1026–1035, Sep. 2010. doi: 10.1109/JSAC.2010.100907. [Google Scholar] [CrossRef]
19. A. Liu, S. Lin, J. Wang, and X. Kong, “A method for non-line of sight identification and delay correction for UWB indoor positioning,” in 2022 IEEE 17th Conf. Ind. Electron. Appl. (ICIEA), Chengdu, China, 2022, pp. 9–14. doi: 10.1109/ICIEA54703.2022.10006070. [Google Scholar] [CrossRef]
20. Z. Xiao, H. Wen, A. Markham, N. Trigoni, P. Blunsom and J. Frolik, “Non-line-of-sight identification and mitigation using received signal strength,” IEEE Trans. Wirel. Commun., vol. 14, no. 3, pp. 1689–1702, Mar. 2015. doi: 10.1109/TWC.2014.2372341. [Google Scholar] [CrossRef]
21. V. Barral, C. J. Escudero, J. A. García-Naya, and R. Maneiro-Catoira, “NLOS identification and mitigation using low-cost UWB devices,” Sensors, vol. 19, no. 16, Aug. 2019, Art. no. 3464. doi: 10.3390/s19163464. [Google Scholar] [PubMed] [CrossRef]
22. T. Wang, K. Hu, Z. Li, K. Lin, J. Wang and Y. Shen, “A semi-supervised learning approach for UWB ranging error mitigation,” IEEE Wirel. Commun. Lett., vol. 10, no. 3, pp. 688–691, Mar. 2021. doi: 10.1109/LWC.2020.3046531. [Google Scholar] [CrossRef]
23. C. L. Sang, B. Steinhagen, J. D. Homburg, M. Adams, M. Hesse and U. Rückert, “Identification of NLOS and multi-path conditions in UWB localization using machine learning methods,” Appl. Sci., vol. 10, no. 11, Jun. 2020, Art. no. 3980. doi: 10.3390/app10113980. [Google Scholar] [CrossRef]
24. H. Yang, Y. Wang, C. K. Seow, M. Sun, M. Si and L. Huang, “UWB sensor-based indoor LOS/NLOS localization with support vector machine learning,” IEEE Sens. J., vol. 23, no. 3, pp. 2988–3004, Feb. 1, 2023. doi: 10.1109/JSEN.2022.3232479. [Google Scholar] [CrossRef]
25. Z. Zeng, S. Liu, and L. Wang, “UWB NLOS identification with feature combination selection based on genetic algorithm,” in 2019 IEEE Int. Conf. Consum. Electron. (ICCE), Las Vegas, NV, USA, 2019, pp. 1–5. doi: 10.1109/ICCE.2019.8662065. [Google Scholar] [CrossRef]
26. J. B. Kristensen, M. Massanet Ginard, O. K. Jensen, and M. Shen, “Non-line-of-sight identification for UWB indoor positioning systems using support vector machines,” in 2019 IEEE MTT-S Int. Wirel. Symp. (IWS), Guangzhou, China, 2019, pp. 1–3. doi: 10.1109/IEEE-IWS.2019.8804072. [Google Scholar] [CrossRef]
27. F. Che et al., “Feature-based generalized gaussian distribution method for NLoS detection in ultra-wideband (UWB) indoor positioning system,” IEEE Sens. J., vol. 22, no. 19, pp. 18726–18739, 2022. doi: 10.1109/JSEN.2022.3198680. [Google Scholar] [CrossRef]
28. F. Wang, Z. Xu, R. Zhi, J. Chen, and P. Zhang, “LOS/NLOS channel identification technology based on CNN,” in 2019 6th NAFOSTED Conf. Inf. Comput. Sci. (NICS), Hanoi, Vietnam, 2019, pp. 200–203. doi: 10.1109/NICS48868.2019.9023805. [Google Scholar] [CrossRef]
29. Z. Cui, T. Liu, S. Tian, R. Xu, and J. Cheng, “Non-line-of-sight identification for UWB positioning using capsule networks,” IEEE Commun. Lett., vol. 24, no. 10, pp. 2187–2190, Oct. 2020. doi: 10.1109/LCOMM.2020.3003688. [Google Scholar] [CrossRef]
30. Q. Liu, Z. Yin, Y. Zhao, Z. Wu, and M. Wu, “UWB LOS/NLOS identification in multiple indoor environments using deep learning methods,” Phys. Commun., vol. 52, no. 4, Jun. 2022, Art. no. 101695. doi: 10.1016/j.phycom.2022.101695. [Google Scholar] [CrossRef]
31. Z. Cui, Y. Gao, J. Hu, S. Tian, and J. Cheng, “LOS/NLOS identification for indoor UWB positioning based on morlet wavelet transform and convolutional neural networks,” IEEE Commun. Lett., vol. 25, no. 3, pp. 879–882, Mar. 2021. doi: 10.1109/LCOMM.2020.3039251. [Google Scholar] [CrossRef]
32. J. Wei, H. Wang, S. Su, Y. Tang, X. Guo and X. Sun, “NLOS identification using parallel deep learning model and time-frequency information in UWB-based positioning system,” Measurement, vol. 195, Apr. 2022, Art. no. 111191. doi: 10.1016/j.measurement.2022.111191. [Google Scholar] [CrossRef]
33. M. Kolakowski and J. Modelski, “Detection of direct path component absence in NLOS UWB channel,” in 2018 22nd Int. Microw. Radar Conf. (MIKON), Poznan, Poland, 2018, pp. 247–250. doi: 10.23919/MIKON.2018.8405190. [Google Scholar] [CrossRef]
34. K. Gururaj, A. K. Rajendra, Y. Song, C. L. Law, and G. Cai, “Real-time identification of NLOS range measurements for enhanced UWB localization,” in 2017 Int. Conf. Indoor Positioning Indoor Navig. (IPIN), Sapporo, Japan, 2017, pp. 1–7. doi: 10.1109/IPIN.2017.8115877. [Google Scholar] [CrossRef]
35. A. F. Majeed, R. Arsat, M. A. Baharudin, N. M. Abdul Latiff, and A. Albaidhani, “UWB DW1000 dataset for indoor environments,” in IEEE Dataport, 2024. doi: 10.21227/nxvh-m657. [Google Scholar] [CrossRef]
36. A. A. Chowdhury, A. Das, K. K. Shahjalal Hoque, and D. Karmaker, “A comparative study of hyperparameter optimization techniques for deep learning,” in Proc. Int. Joint Conf. Adv. Comput. Intell.: IJCACI 2021, Singapore, Springer Nature Singapore, 2022, pp. 509–521. [Google Scholar]
37. S. Katoch, S. S. Chauhan, and V. Kumar, “A review on genetic algorithm: Past, present, and future,” Multimed. Tools Appl., vol. 80, no. 5, pp. 8091–8126, Oct. 2020. doi: 10.1007/s11042-020-10139-6. [Google Scholar] [PubMed] [CrossRef]
38. J. Chen, F. Zhao, Y. Sun, and Y. Yin, “Improved XGBoost model based on genetic algorithm,” Int. J. Comput. Appl. Technol., vol. 62, no. 3, pp. 240–245, 2020. doi: 10.1504/IJCAT.2020.106571. [Google Scholar] [CrossRef]
39. T. Chen et al., “xgboost: Extreme gradient boosting.” 2013. Accessed: Dec. 02, 2022. [Online]. Available: http://download.nust.na/pub3/cran/web/packages/xgboost/vignettes/xgboost.pdf [Google Scholar]
40. W. Li, Y. Yin, X. Quan, and H. Zhang, “Gene expression value prediction based on XGBoost algorithm,” Front. Genet., vol. 10, Nov. 2019, Art. no. 1077. doi: 10.3389/fgene.2019.01077. [Google Scholar] [PubMed] [CrossRef]
41. R. D. Abdu-Aljabar and O. A. Awad, “A comparative analysis study of lung cancer detection and relapse prediction using XGBoost classifier,” IOP Conf. Ser.: Mater. Sci. Eng., vol. 1076, no. 1, Feb. 2021, Art. no. 012048. doi: 10.1088/1757-899X/1076/1/012048. [Google Scholar] [CrossRef]
42. Z. J. Ye and B. W. Schuller, “Capturing dynamics of post-earnings-announcement drift using genetic algorithm-optimised supervised learning,” 2020, arXiv:2009.03094. [Google Scholar]
43. R. Punmiya and S. Choe, “Energy theft detection using gradient boosting theft detector with feature engineering-based preprocessing,” IEEE Trans. Smart Grid, vol. 10, no. 2, pp. 2326–2329, Jan. 2019. doi: 10.1109/tsg.2019.2892595. [Google Scholar] [CrossRef]
44. S. Hu, “XGBoost math intuition summary—The startup-medium,” Medium, Mar. 30, 2022. Accessed: Dec. 02, 2024. [Online]. Available: https://medium.com/swlh/xgboost-math-intuition-summary-8dc6a04ff472 [Google Scholar]
45. F. Zhu, K. Yu, Y. Lin, C. Wang, J. Wang and M. Chao, “Robust LOS/NLOS identification for UWB signals using improved fuzzy decision tree under volatile indoor conditions,” IEEE Trans. Instrum. Meas., vol. 72, 2023, Art. no. 2514911. doi: 10.1109/TIM.2023.3276521. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools