
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Evaluating Public Sentiments during Uttarakhand Flood: An Artificial Intelligence Techniques
1 School of Electrical and Information Engineering, Tianjin University, Tianjin, 300072, China
2 Department of Information Technology and Decision Sciences, University of Energy and Natural Resources, Sunyani, 00233, Ghana
3 International Divisions, Ajeenkya D.Y. Patil University, Pune, 412105, India
4 Business School, La Trobe University, Melbourne, Victoria, 3086, Australia
5 Research Division, Swiss School of Business and Management, Geneva, 1213, Switzerland
6 Department of Social Science and Geography, Aprade Senior High Technical School, Koforidua, 03225, Ghana
* Corresponding Authors: Stephen Afrifa. Email: ; Vijayakumar Varadarajan. Email:
Computer Systems Science and Engineering 2024, 48(6), 1625-1639. https://doi.org/10.32604/csse.2024.055084
Received 16 June 2024; Accepted 05 September 2024; Issue published 22 November 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Users of social networks can readily express their thoughts on websites like Twitter (now X), Facebook, and Instagram. The volume of textual data flowing from users has greatly increased with the advent of social media in comparison to traditional media. For instance, using natural language processing (NLP) methods, social media can be leveraged to obtain crucial information on the present situation during disasters. In this work, tweets on the Uttarakhand flash flood are analyzed using a hybrid NLP model. This investigation employed sentiment analysis (SA) to determine the people’s expressed negative attitudes regarding the disaster. We apply a machine learning algorithm and evaluate the performance using the standard metrics, namely root mean square error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE). Our random forest (RF) classifier outperforms comparable works with an accuracy of 98.10%. In order to gain a competitive edge, the study shows how Twitter (now X) data and machine learning (ML) techniques can analyze public discourse and sentiments regarding disasters. It does this by comparing positive and negative comments in order to develop strategies to deal with public sentiments on disasters.Keywords
Natural hazards are undesirable occurrences brought on by Earth’s natural forces, such as earthquakes, cyclones, hurricanes, storms, floods, volcanic eruptions, and tsunamis, which inflict significant destruction and the loss of life. A natural disaster invariably results in casualties and property destruction, and it frequently leaves behind economic harm, the severity of which varies on how severe the disaster was [1]. Poorer countries experience more of the damaging effects of natural disasters than more prosperous ones [2]. Today, information on events, such as disasters, is disseminated through the traditional media and social media [3]. Social media is a new form of communication that leverages the Internet to create online or virtual communities [4]. Social media have been extensively used to find and compile pertinent information on opinions and actions [5]. Social media platforms like Twitter (now X), TikTok and Facebook are being utilized to share information and disseminate it during emergencies and disasters [6]. These social media platforms let users exchange content in the form of text, graphics/drawings, and images as well as audio, video, and animated graphical interchange formats (GIFs) [7]. Numerous firms are paying a lot of attention to sentiment analysis (SA) using online evaluations as a result of the exponential growth of social media information and messaging data (e.g., private, government, and academia) [8]. Sentiment analysis is a technique in natural language processing (NLP) used for detecting the sentiments underlying any text [9]. SA analyzes the input texts and identifies the sentiments within the text. NLP uses machine learning to uncover the structure and meaning of text.
The state of Uttarakhand in northern India had significant rains in June 2013, which led to disastrous floods and landslides, making it the nation’s greatest natural disaster since the 2004 tsunami [10]. On 16–17 June 2013, 12 out of Uttarakhand’s 13 districts were devastated by flash floods brought on by exceptionally high rainfall and cloudburst [11]. The four districts that were most severely impacted were Pithoragarh, Uttarkashi, Chamoli, and Rudraprayag. The microblogging platform Twitter (now X) is a popular social media choice and is essential for spreading information. People expressed their feelings on the forum on the flash floods in Uttarakhand. This calls for an improved analysis of the sentiments shared by the people to ascertain the impact and provide guidelines for improved government decision-making. By examining tweets gathered between 17 June 2013, and 31 August 2013, this study employs NLP and machine learning (ML) approaches to interpret sentimental tendencies related to the 2013 Uttarakhand flash floods. The study also employs appropriate evaluation criteria to assess how well the supervised ML classifier performed on tweets about the Uttarakhand flash floods. Additionally, to the best of our knowledge, this study is the first to consider both SA and ML models to analyze the flash flood in Uttarakhand. The results will come in handy for helping governments, organizations, and other policymakers analyze trends in social media data related to disasters and make prompt adjustments to disaster education to increase public confidence in emergency response.
The remainder of the paper is structured as follows: The related works are summarized in Section 2. The methodology is also presented in Section 3. Additionally, Section 4 presents the results and findings from the paper. Section 5 gives an in-depth analysis of the study and themed “Discussion.” Finally, Sections 6 and 7 summarize the study in conclusion and future works.
Sentiment analysis (also known as opinion mining) is a natural language processing method used to assess the positivity, negativity, and neutrality of data. Textual data is frequently subjected to sentiment analysis. To begin with, Mendon et al. [12] created a system to assess Twitter users’ sentiments regarding natural disasters using data pre-processing techniques and a blend of machine learning, statistical modeling, and a lexicon-based approach. Sufi et al. [13] proposed a new fully automated approach based on artificial intelligence (AI) and natural language processing (NLP) for extracting location-oriented public sentiments on the state of the worldwide crisis. Additionally, sentiment analysis was done by Parimala et al. [14] on tweets about a specific disaster setting for a specific area at various points in time. In another study, Folgado et al. [15] used a Fully-Connected Neural Network (FCNN) to assess complex human communication and used tweets from political party leaders as a dynamic proxy for political agendas and ideas. They conducted a study to identify a tweet’s political affiliations.
Additionally, Behl et al. [16] used supervised learning approaches to compare the multi-class classification of Twitter data. In their investigation, they used openly available data from the 2015 Nepal earthquake and the 2016 earthquake in Italy. In order to explore the major concerns that have drawn public attention, as well as the obstacles and enablers to effective COVID-19 immunization, Liew et al. [6] employed social media data to record nearly real-time public opinions and attitudes regarding COVID-19 vaccines. Ragini et al. [17] suggested a big data-driven approach for disaster response through sentiment analysis in a related piece of work. Their suggested model gathered information on disasters from social networks and organized it in accordance with the needs of those who were affected. Machine learning algorithms were used to classify the disaster data in order to analyze public mood.
In another similar work, Bello et al. [18] developed a technique for identifying a writer’s perspective and attitude in a tweet based on context. Their experimental findings revealed that the combination of BERT with other models performed well when compared to using Word2vec and using it without any modification in terms of accuracy, precision, recall, and F1-score. Furthermore, Wadud et al. [19] developed a detection method to identify offensive social media postings used to harass others. The system used deep convolutional neural networks with bidirectional encoder representations from transformers (Deep-BERT) to recognize offensive texts in both monolingual and multilingual languages. Their research looked into a range of techniques to address multilingualism, sentiment analysis based on translation and cooperative multilingualism.
Rahaman et al. [7] proposed a deep learning-enabled SA (DLNLP-SA) approach for sarcasm categorization. Their suggested DLNLP-SA approach was designed to identify and categorize the presence of sarcasm in input data. A full set of simulations were carried out using the benchmark dataset, and the results demonstrated superiority over previous methodologies. In a related study, Bimantara et al. [20] gathered reviews of the BRImo application from the Google Play store, examining favorable reviews to bolster the app’s benefits and negative reviews to pinpoint the app’s shortcomings that might undermine its competitiveness. The study’s experimental outcomes demonstrated the significance of sentiment analysis in decision-making. Finally, by using both machine learning and deep learning techniques for the catastrophic moments, Demirci et al. [21] generated sentiment analysis, also known as opinion mining, using the information on the coup attempt that occurred on 15 July 2016, in Turkey.
Many people today use multimedia tools like Twitter (now X), Facebook, Instagram, and many others to express their ideas on social media. The concept of natural communication [22], which includes multimedia and Natural Language Processing (NLP) [22,23], has emerged as a result of technological innovation. As shown in Fig. 1, social media feeds, such as Tweets, are gathered based on particular search criteria. The dataset is received as input and will be annotated and pre-processed. Multiple features are extracted in the preprocessing stage. This study takes into account how people felt and expressed themselves in relation to the flash flood in the Indian city of Uttarakhand. On 16 June, a flood flash occurred in Uttarakhand. Fig. 1 shows the framework for the sentiment analysis (SA) and machine learning (ML) methods. The search terms on Twitter’s microblogging platform were the hashtags “Uttarakhand flash flood,” along with “flooding,” “Uttarakhand,” and “landslides.” The hashtags were used to collect the tweets using the Python snscrape module.
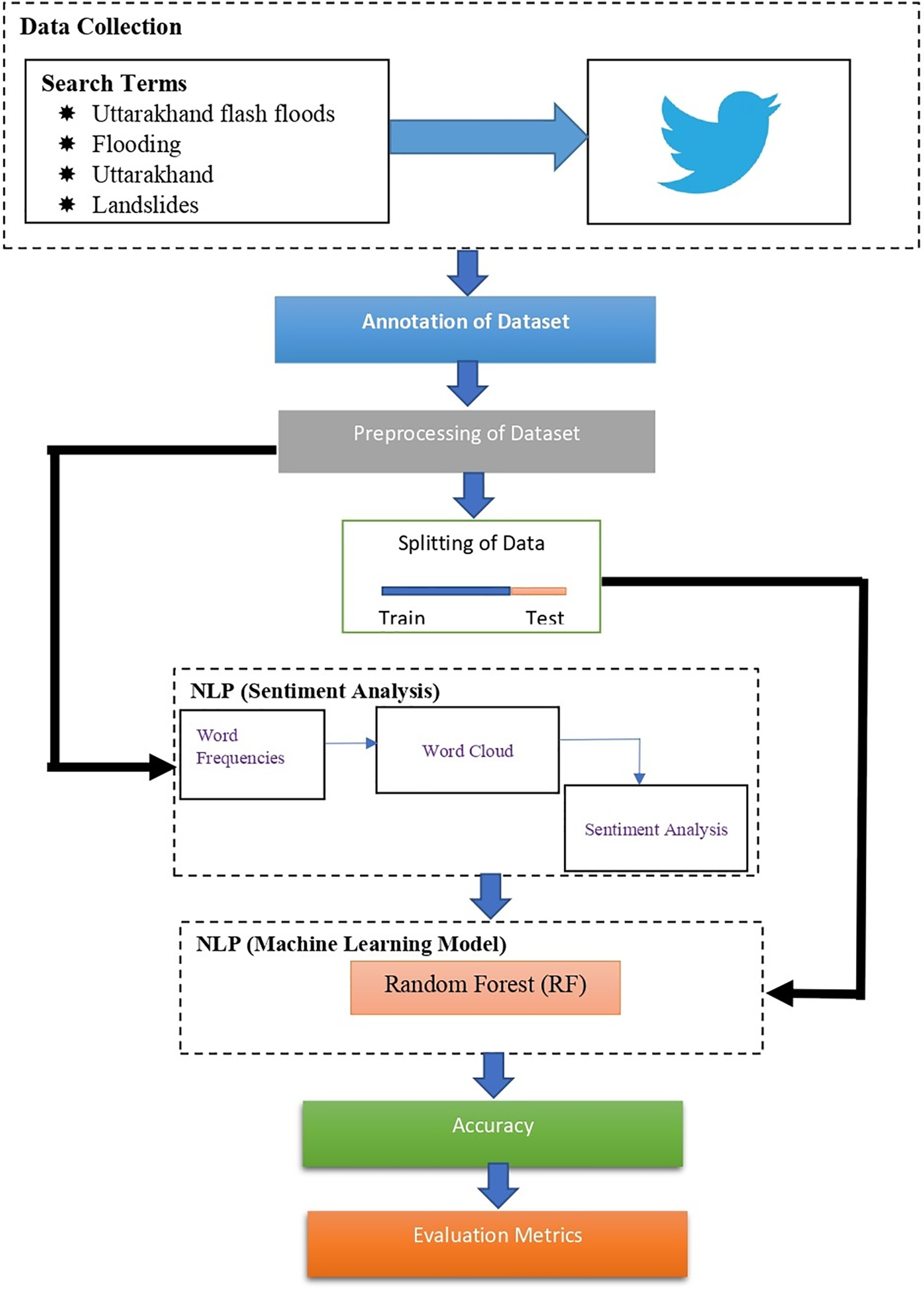
Figure 1: Framework of the study
The acquired data was then annotated to include target labels for the machine learning model’s training. Preprocessing the data is the next phase, which converts raw data into a format that computers and ML can comprehend and analyze. The text cleaning, stemming and lemmatization, tokenizing, stopword removal, and feature selection were carried out during the preprocessing using the RStudio software. We did text feature representation and selection, choosing the most reliable characteristics that accurately describe a text and can be used to effectively and accurately predict the sentiment class of the text. The bag of words technique, which gathers words or attributes from a sentence, document, website, or other sources, and then categorizes them based on how frequently they are used, has been used by us. To assess the sentiment in each data sample, the polarity of each tweet is computed. To create the predictive machine learning algorithm, the data was divided into training and testing sets. Using various evaluation indicators, the random forest (RF) algorithm’s accuracy was assessed. The findings of machine learning and the data’s user sentiment were then compared.
To acquire Twitter data, the snscrape Python package was utilized. The hashtags #uttarakhand, #flooding, #landslides, and #flood were used to filter all of the tweets available between 17 June 2013, and 31 August 2013. Since the flash flood only affected the city of Uttarakhand in India, our attention was heavily concentrated there. Tweets related to the Uttarakhand flash flood were collected using the Twitter (now X) API, focusing on a specific time frame around the disaster event. Keywords and hashtags such as “#UttarakhandFlood” and “#UttarakhandDisaster” were employed to filter related tweets. The search criteria were able to accumulate a total of 1106 tweets. Before preprocessing, sample tweets that were gathered from Twitter are shown in Table 1 below.

Data annotation is the process of adding classifications, labels, and other contextual features to a raw data gathering so that the information may be interpreted and utilized by computers. In order to help our ML system understand and identify the meaning-based organization of common phrases and other textual data, we focused on sentiment annotation in this study, adding labels and instructions to the tweets. Sentiment annotation allows ML to discern texts’ deeper meanings beyond their literal meaning [24]. By calculating polarity, the labeling process seeks to categorize tweets as positive, negative, or neutral. The dataset contains two columns (tweets and analysis). Coarse-grained sentiment (positive and negative) is used in dataset annotation to offer a comprehensive overview of sentiment patterns, making it easier to identify and evaluate general attitudes [25]. Eq. (1) below shows the polarity calculation of the tweets.
where the absolute maximum of the two scores is calculated by

3.3 Preprocessing of the Dataset
In order to improve the classifier’s performance and hasten the classification process, we reduced the text noise. Tweets were filtered to exclude retweets, non-English tweets, and those without relevant keywords through filtering. The text was tokenized into individual words. This enabled real-time sentiment analysis and machine learning. Online writings frequently include distracting and uninformative elements like Hypertext Markup Language (HTML) tags, scripts, uniform resource locator (URL) links, and advertisements [26].
The RStudio software was used to preprocess the data. RStudio is an open-source, free software package. In our preprocessing methods, the following processes are performed to extract features that stand for positive, negative, or neutral opinions. Some ways for cleaning online texts (tweets) are turning all letters lowercase, eliminating punctuation, digits, stop words, links (HTML and URL), stemming, decreasing white space, and feature selection. The pre-processing is defined in Eq. (2).
such that: (i)
Words were reduced to their base or root form (e.g., “flooding” to “flood”). The cleaned and processed text data was converted into a numerical format using the Term Frequency − Inverse Document Frequency (TF – IDF) technique. Eq. (3) below presents the feature selection:
where N is the number of documents, and DF is the number of documents containing the feature. FP assigns a value of 0 or 1 depending on whether the feature is absent or present in the document. Sample tweets after data preprocessing are summarized in Table 3.

3.4 The Random Forest Algorithm
The polarity (analysis) of the tweets was determined using the machine learning method random forest (RF). The RF is a collection of decision trees, each with its variable space broken into a smaller subspace, providing data that is as uniform as possible throughout each zone [27]. In order to boost the accuracy of the regression, the RF fits a variety of decision trees using subsamples from the entire data set. It is predicated on the idea that distinct independent predictors forecast inadequately in various contexts, and that total prediction accuracy may be increased by integrating the independent predictors’ prediction outcomes. RF was chosen for its ability to handle high-dimensional data and prevent overfitting via ensemble learning. RF successfully manages missing values, provides insights on feature relevance, and regularly achieves high classification accuracy [28], making it perfect for the complex, real-world datasets in our study. The RF classifier is a component of this model, and its performance is enhanced by other sophisticated NLP approaches used in the study. The major goal of the study is to give practical insights into public mood during the Uttarakhand disaster. The RF classifier’s demonstrated efficiency and accuracy assure consistent results [29], making it an appropriate solution for real-world disaster management and response applications. RF strikes a compromise between performance and computing economy [30], making it ideal for the study’s goal of accurately evaluating public opinions during the Uttarakhand disaster. Eq. (4) represents the RF algorithm.
To forecast the outcome for x′, we may take the average of all the trees fi that correspond to x′.
3.4.1 Evaluation Metrics for the Machine Learning Classifier
Evaluation metrics are vital for ML models to evaluate and monitor the performance and accuracy of their predictions [31]. The random forest (RF) algorithm accuracy was evaluated against three different evaluation metrics namely, root mean square error (RMSE), mean square error (MSE), and mean absolute percentage error (MAPE). The mathematical equation of the metrics is represented in Eqs. (5)–(7) below.
where the total number of observations are n,
This section presents the results and findings from sentiment analysis (SA) and machine learning (ML) classifiers, as proposed in the framework (Fig. 1). In-depth analysis of the various NLP models, thus, sentiment analysis and machine learning are presented in the following subsections.
4.1 The Sentiment Analysis Classification
The flood in Uttarakhand happened on 16 June 2013. Data on the floods in Uttarakhand were gathered between 17 June and 31 August 2013. A total of 1106 tweets were gathered. After preprocessing, sentiment analysis was performed on the text data (tweets). To determine word frequency in our text data (tweets), we created a term document matrix (TDM). Fig. 2 shows the word frequency from our Twitter data.
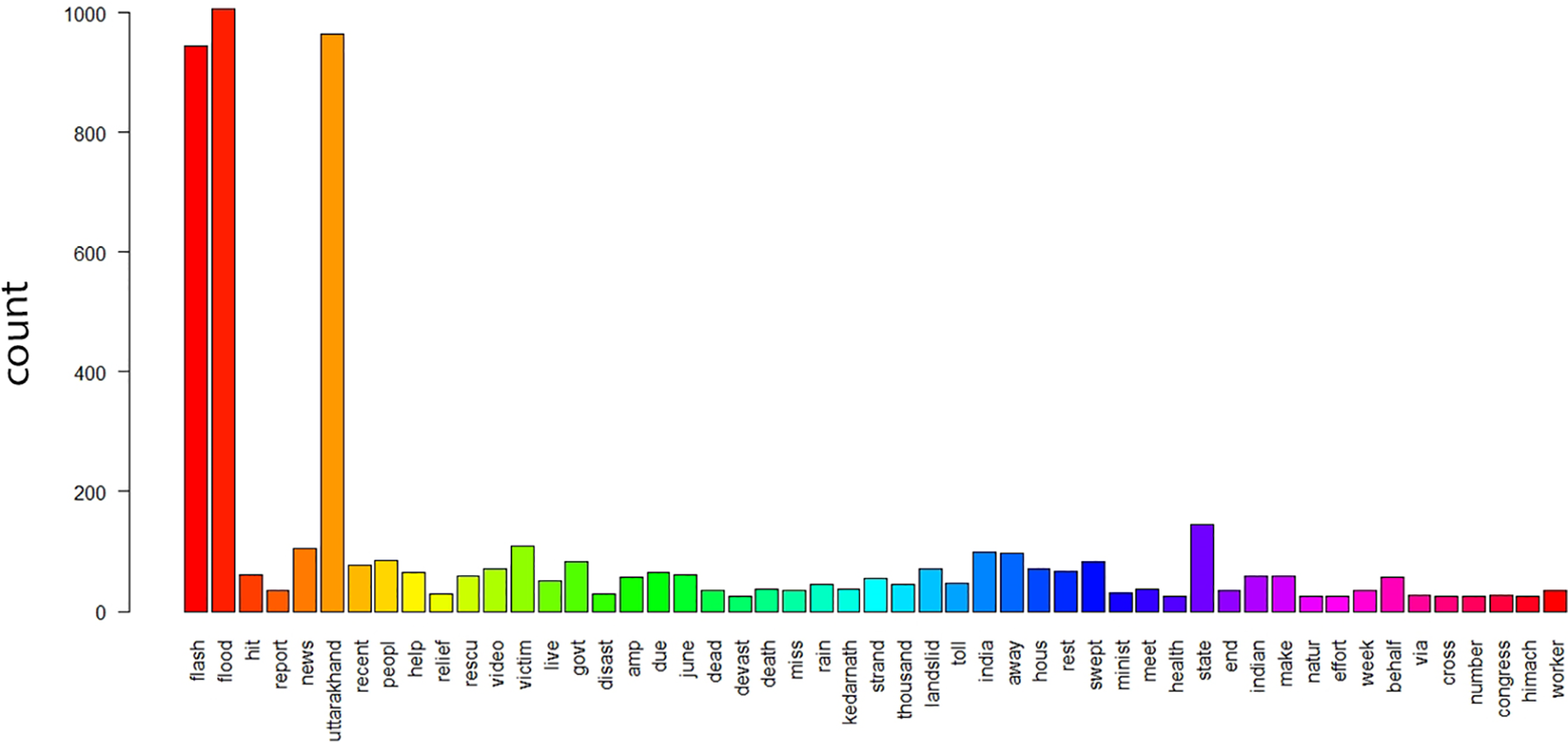
Figure 2: Word frequency of the text tweets
Fig. 2 shows that the words “flood,” “Uttarakhand,” and “flash” were the words that were most often used in our text data (tweets), with 1000, 990, and 980 mentions, respectively. Additionally, the word cloud was used to visualize how words are distributed across the dataset. The most used terms reveal how user opinions regarding the flood changed on Twitter over the research period (Fig. 3). The primary goal is to analyze any trends that may be detected from the frequency of terms in our Twitter data. The word cloud picture demonstrates that numerous instances of the words “flood” and “flash” were found alongside the search term “Uttarakhand.” These words highlight how the calamity affected people.

Figure 3: Word cloud of the text data (tweets)
As “government,” “state,” and “people” were among the most frequently used words on Twitter, some individuals once more emphasized the vital responsibilities that these three entities performed during the crisis. On the other hand, it should be highlighted that the word “people” might also refer to the afflicted individuals that Twitter users were discussing. The sentiment scores are summarized in Fig. 4.
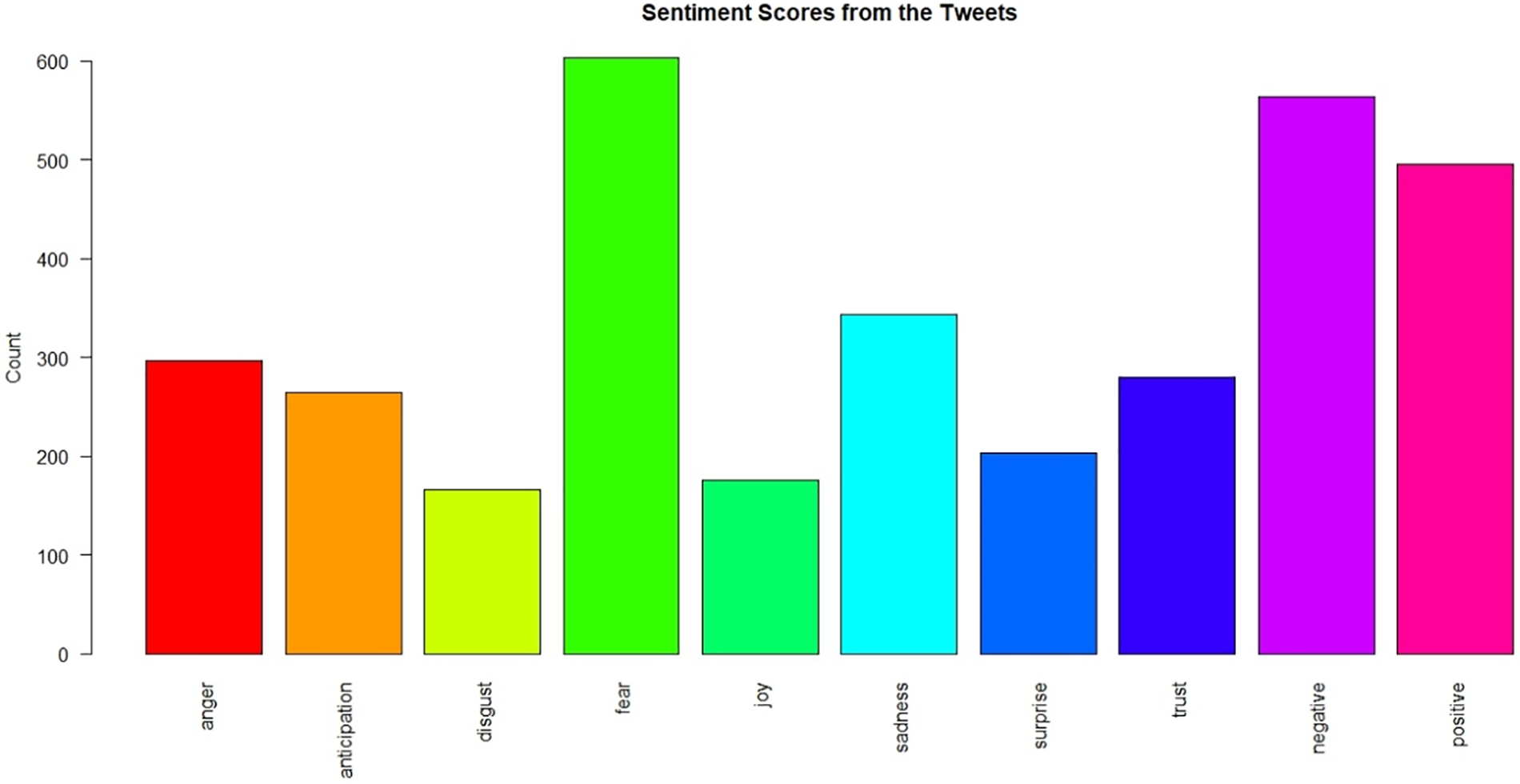
Figure 4: Sentiment ratings from tweets
The sentiment ratings in our text data (tweets) were determined using the following phrases: anger, disgust, fear, sadness, joy, surprise, trust, negative and positive. Sentiment counts more on fear followed by negative, positive, sadness, anger, trust, and anticipation. People were unhappy about the incident, which is a reflection of how people feel when a calamity hits, as evidenced by the fear and negativity rates. It was clear from the tweets that individuals expressed their sympathy. The magnitude of the “anger” and “sadness” sentiment scores also reveals the peoples’ emotional states. It must be emphasized that, fine-grained emotion labels provide a more precise comprehension of the individual emotions portrayed, increasing the depth and richness of the study. The sentiment analysis is evaluated using the identification of sentiment scores, and the time complexity for doing the analysis was 31 s.
4.2 Performance of the ML Classifier
The preprocessed data was divides into training (70%) and testing (30%) sets. The random forest (RF) algorithm was used to build a predictive model. The RF uses subsamples of the data set to fit a collection of decision trees and then combines the results to increase regression accuracy. We set a baseline accuracy to check proportion of the labels in the target variable to evaluate the RF model accuracy. Based on our dataset, our target variables are neutrality, positivity, and negativity. The obtained baseline accuracy was 84.56 percent. When compared to the baseline accuracy, the RF predictive model had an accuracy of 98.10 percent. The RMSE, MSE, and MAPE metrics were used to evaluate the random forest model. The accuracy and other evaluation metrics are summarized in Table 4.
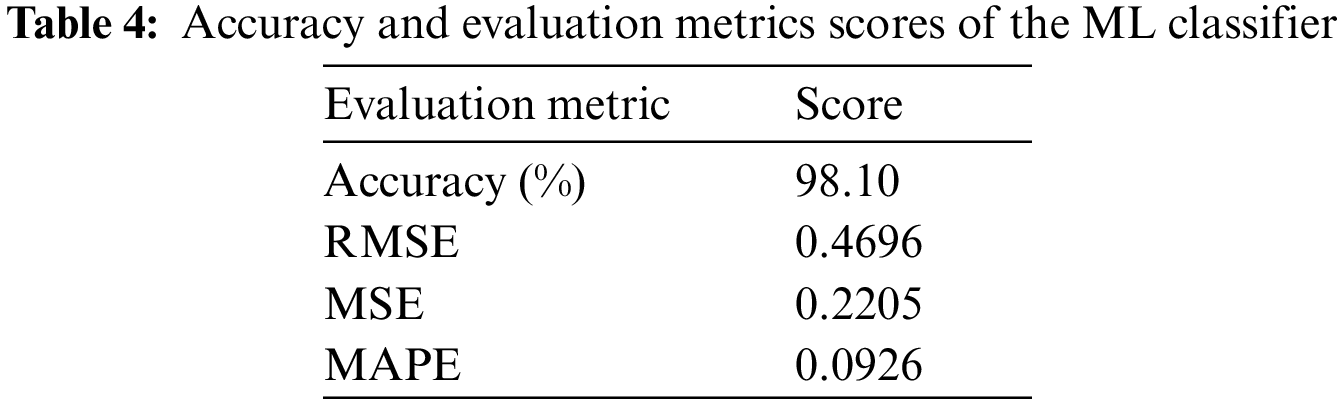
The outcome reveals that the accuracy score for the RF classifier is 98.10 percent. When compared to the works of Demirci et al. [21] and Behl et al. [16], which similarly used a random forest model classifier on text (tweets) data, our model had a greater accuracy.
The goal of this study was to investigate trends that may be inferred from the collected Twitter (now X) dataset. The study shows that the majority of the tweets were unfavorable, which reflects the general dissatisfaction of the population with the Uttarakhand flash flood. The sentiment scores also reflect the level of dread among the populace and the contributions made by the government, state, and general public during the crisis. According to our study, social media sentiment analysis during times of natural or human calamity may aid in boosting the number of human rescues. Additionally, the training dataset and test dataset of the paper’s sentiment analysis of Indians are analyzed. Python package, snscrape, is used to extract the dataset. Using particular search terms, the tweets were extracted. The extracted data underwent data annotation and preprocessing in natural language processing (NLP). After preprocessing, we ran sentiment analysis on our dataset. Based on the word cloud and word frequency, our findings revealed that terms like “Uttarakhand,” “flood,” and “flash” were most frequently used. To emphasize the individual efforts made during the tragedy, other words like “government,” “state,” and “people” were also used. Furthermore, the study employed machine learning techniques on the data. A predictive model was created using the random forest classifier and compared to related works that employed text (tweets) data. On the dataset, the random forest classifier did reasonably well. The study is the first of its type to consider this approach on the Uttarakhand dataset using a hybrid framework. Only English-language tweets were taken into account in this study. The findings of the study were compared with other state-of-the-art in terms of evaluations and it outperformed in all evaluations as summarized in Table 5 below.
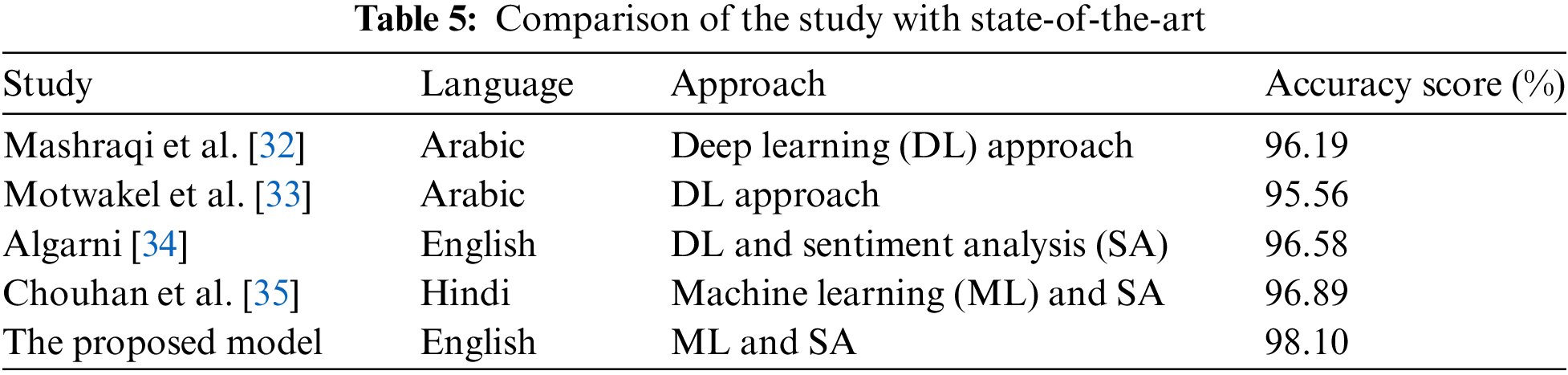
It can be emphasized that, our study presents a novel approach of both machine learning and sentiment analysis which are artificial intelligence models in evaluating tweets. The findings surpassed state-of-the-art in terms of accuracies and approaches (Table 5). As compared to the study that employed both DL/ML and SA, our study performed better in terms of accuracies with substantial scores and significant error scores.
Sentiment analysis enables constant monitoring of public emotions and worries, identifying early signs of discomfort or panic. This real-time data can assist emergency responders in more efficiently allocating resources, prioritizing locations with high negative sentiment or urgent requirements. Furthermore, the study allows disaster management organizations to customize their communication tactics. Positive reinforcement may be applied toward regions of fear or negativity, increasing public compliance with safety measures and instilling a sense of confidence among impacted groups. The study also aids in policy creation, since reoccurring unfavorable views regarding certain disaster response features might suggest opportunities for policy reform. The sentiment data also aids in detecting possible regions of disturbance or noncompliance, allowing for proactive intervention to improve public safety. For example, if a study reveals that evacuation processes are becoming increasingly frustrating, authorities might act with greater help and clearer information to reduce hazards. The use of sentiment analysis in catastrophe management facilitates data-driven decision-making. By connecting emergency response methods with the public’s real-time demands and emotions, authorities can improve disaster management initiatives’ overall efficacy and responsiveness. The use of sentiment analysis and machine learning in social media data not only provides a great tool for rapid disaster response but also adds to the continuous development of disaster management practices and policies.
Only English-language tweets were taken into account in this study. Due to the possibility of omitting crucial information from tweets written in other languages, there may be some bias in our analysis. One significant drawback is the emphasis on English-language tweets. Social media is a worldwide platform, with people talking in a variety of languages. Excluding non-English tweets may result in the loss of a wealth of essential information and various views. This language bias might slant the study toward attitudes and opinions shared by English-speaking users, who may not reflect the entire impacted community.
The data collecting technique included utilizing certain keywords and hashtags linked to the Uttarakhand flash flood. This strategy may add sampling bias because it relies on users using these terms in their tweets. Users who do not utilize these exact phrases, even when discussing the tragedy, will be removed from the study, potentially missing vital attitudes and information. Additionally, the study is limited to a single time period, which may not reflect the changing nature of public mood prior to, during, and following the event. This temporal bias may impair the accuracy and usefulness of sentiment analysis. Recognizing and overcoming these constraints would considerably improve the robustness and credibility of social media-based sentiment analysis in disaster management.
This study provided a framework for analyzing public debate and responses on Twitter (now X) regarding the 2013 flash flood in India’s Uttarakhand region. To forecast opinions/sentiments from the gathered tweets, sentiment analysis (SA) and machine learning (ML) approaches for natural language processing (NLP) were used. The majority of Twitter (now X) users expressed fear and negativity in response to the disaster in Uttarakhand. A few decision-generation systems were also produced by our machine learning classifier by attributing the unfavorable sentiments in the provided dataset. Our random forest method surpassed other similar efforts that took into account text (Twitter) data with a prediction accuracy of 98.10 percent. These findings can be a useful tool for assisting relevant authorities, organizations, and policymakers in anticipating the best course of action to take in order to mitigate any potential tragedy. In order to increase public trust and confidence in authorities, institutions, and legislators, disaster management involves quick responses to public concerns.
Future studies might look at analyzing vast amounts of data using the proposed framework to train models and comparing the models with machine learning and other deep learning techniques such as the artificial neural network (ANN), support vector machine (SVM), and convolutional neural network (CNN). In order to produce sufficient decision-generation systems, these models would conduct sentiment analysis. It must be emphasized that the proposed framework is not just for disasters, however, can be utilized in evaluating and adjusting the suggested methodology to forecast several other real-world occurrences, including pandemics, policies, market events, cyberattacks, and fraud detection.
Acknowledgement: The authors are grateful to Adwoa Afriyie, known as Amanpene; and Malcolm Afrifa for their encouragement and support throughout the study.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm their contribution to the paper as follows: study conception and design: Stephen Afrifa, Vijayakumar Varadarajan, Tao Zhang and Peter Appiahene; data collection: Stephen Afrifa and Richmond Afrifa; analysis and interpretation of results: Stephen Afrifa, Peter Appiahene and Richmond Afrifa; draft manuscript preparation: Richmond Afrifa and Stephen Afrifa; supervision: Vijayakumar Varadarajan, Tao Zhang and Peter Appiahene. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are publicly available in the Figshare repository via Stephen Afrifa (2024). Uttarakhand Flood Flash Data. Figshare. Dataset. https://doi.org/10.6084/m9.figshare.26341615.v1 (accessed on 4 September 2024).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. Bozkurt and S. Duran, “Effects of natural disaster trends: A case study for expanding the pre-positioning network of CARE International,” Int. J. Environ. Res. Public Health, vol. 9, no. 8, pp. 2863–2874, 2012. doi: 10.3390/ijerph9082863. [Google Scholar] [PubMed] [CrossRef]
2. UN.org, “Economic recovery after natural disasters | United Nations,” 2016. Accessed: Aug. 08, 2022. [Online]. Available: https://www.un.org/en/chronicle/article/economic-recovery-after-natural-disasters [Google Scholar]
3. P. Appiahene, V. Varadarajan, T. Zhang, and S. Afrifa, “Experiences of sexual minorities on social media: A study of sentiment analysis and machine learning approaches,” J. Auton. Intell., vol. 6, no. 2, pp. 1–15, 2023. doi: 10.32629/jai.v6i2.623. [Google Scholar] [CrossRef]
4. S. Vinerean, “Importance of strategic social media marketing,” Expert. J. Mark., vol. 5, no. 1, pp. 28–35, 2017. doi: 10.1515/mt-1999-417-807. [Google Scholar] [CrossRef]
5. S. Afrifa and V. Varadarajan, “Cyberbullying detection on twitter using natural language processing and machine learning techniques,” Int. J. Innov. Technol. Interdiscip. Sci., vol. 5, no. 4, pp. 1069–1080, 2022. doi: 10.15157/IJITIS.2022.5.4.1069-1080. [Google Scholar] [CrossRef]
6. T. M. Liew and C. S. Lee, “Examining the utility of social media in COVID-19 vaccination: Unsupervised learning of 672,133 Twitter posts,” JMIR Public Heal. Surveill., vol. 7, no. 11, pp. 1–19, 2021. doi: 10.2196/29789. [Google Scholar] [PubMed] [CrossRef]
7. A. Rahaman, W. Sait, and M. K. Ishak, “Deep learning with natural language processing enabled sentimental analysis on sarcasm classification,” Comput. Syst. Sci. Eng., vol. 44, no. 3, pp. 2553–2567, 2023. doi: 10.32604/csse.2023.029603. [Google Scholar] [CrossRef]
8. P. K. Jain, V. Saravanan, and R. Pamula, “A hybrid CNN-LSTM: A deep learning approach for consumer sentiment analysis using qualitative user-generated contents,” ACM Trans. Asian Low-Resour. Lang. Inf. Process., vol. 20, no. 5, 2021. doi: 10.1145/3457206. [Google Scholar] [CrossRef]
9. K. H. Manguri, R. N. Ramadhan, and P. R. Mohammed Amin, “Twitter sentiment analysis on worldwide COVID-19 outbreaks,” Kurdistan J. Appl. Res., pp. 54–65, 2020. doi: 10.24017/covid.8. [Google Scholar] [CrossRef]
10. NDTV.com, “Uttarakhand 2013 floods: Latest news, photos, videos on Uttarakhand 2013 Floods,” 2013. Accessed: Aug. 08, 2022. [Online]. Available: https://www.ndtv.com/topic/uttarakhand-2013-floods [Google Scholar]
11. Reliefweb.int, “Uttarakhand flash floods–A report—India | ReliefWeb,” 2013. Accessed: Aug. 08, 2022. [Online]. Available: https://reliefweb.int/report/india/uttarakhand-flash-floods- [Google Scholar]
12. S. Mendon and P. Dutta, “A hybrid approach of machine learning and lexicons to sentiment analysis: Enhanced insights from twitter data of natural disasters,” Inf. Syst. Front., vol. 23, no. 5, pp. 1145–1168, 2021. doi: 10.1007/s10796-021-10107-x. [Google Scholar] [CrossRef]
13. F. K. Sufi and I. Khalil, “Posts using AI-based location intelligence and sentiment analysis,” IEEE Trans. Comput. Soc. Syst., pp. 1–11, 2022. doi: 10.1109/TCSS.2022.3157142. [Google Scholar] [CrossRef]
14. M. Parimala, R. M. Swarna Priya, M. Praveen Kumar Reddy, C. Lal Chowdhary, R. Kumar Poluru and S. Khan, “Spatiotemporal-based sentiment analysis on tweets for risk assessment of event using deep learning approach,” Softw-Pract. Exp., vol. 51, no. 3, pp. 550–570, 2021. doi: 10.1002/spe.2851. [Google Scholar] [CrossRef]
15. M. G. Folgado and V. Sanz, “Exploring the political pulse of a country using data science tools,” J. Comput. Soc. Sci., vol. 5, no. 1, pp. 987–1000, 2022. doi: 10.1007/s42001-021-00157-1. [Google Scholar] [CrossRef]
16. S. Behl, A. Rao, S. Aggarwal, S. Chadha, and H. S. Pannu, “Twitter for disaster relief through sentiment analysis for COVID-19 and natural hazard crises,” Int. J. Disaster Risk Reduct., vol. 55, 2021, Art. no. 102101. doi: 10.1016/j.ijdrr.2021.102101. [Google Scholar] [CrossRef]
17. J. R. Ragini, P. M. R. Anand, and V. Bhaskar, “Big data analytics for disaster response and recovery through sentiment analysis,” Int. J. Inf. Manage., vol. 42, pp. 13–24, 2018. doi: 10.1016/j.ijinfomgt.2018.05.004. [Google Scholar] [CrossRef]
18. A. Bello, S. C. Ng, and M. F. Leung, “A BERT framework to sentiment analysis of tweets,” Sensors, vol. 23, no. 1, 2023, Art. no. 506. doi: 10.3390/s23010506. [Google Scholar] [PubMed] [CrossRef]
19. M. A. H. Wadud, M. F. Mridha, J. Shin, K. Nur, and A. K. Saha, “Deep-BERT: Transfer learning for classifying multilingual offensive texts on social media,” Comput. Syst. Sci. Eng., vol. 44, no. 2, pp. 1775–1791, 2023. doi: 10.32604/csse.2023.027841. [Google Scholar] [CrossRef]
20. M. D. Bimantara and I. Zufria, “Text mining sentiment analysis on mobile banking application reviews using TF-IDF method with natural language processing approach,” J. Inf. Vis., vol. 5, no. 1, 2024. doi: 10.35877/454RI.jinav2772. [Google Scholar] [CrossRef]
21. G. M. Demirci, S. R. Keskin, and G. Dogan, “Sentiment analysis in Turkish with deep learning,” in Proc. 2019 IEEE Int. Conf. Big Data (Big Data), 2019, pp. 2215–2221. doi: 10.1109/BigData47090.2019.9006066. [Google Scholar] [CrossRef]
22. I. Marstc, A. Medl, and J. Flanagan, “Natural communication with information systems,” Proc. IEEE, vol. 88, no. 8, pp. 1354–1365, 2000. doi: 10.1109/5.880088. [Google Scholar] [CrossRef]
23. C. Friedman, T. C. Rindflesch, and M. Corn, “Natural language processing: State of the art and prospects for significant progress, a workshop sponsored by the National Library of Medicine,” J. Biomed. Inform., vol. 46, no. 5, pp. 765–773, 2013. doi: 10.1016/j.jbi.2013.06.004. [Google Scholar] [PubMed] [CrossRef]
24. A. Montoyo, P. Martínez-Barco, and A. Balahur, “Subjectivity and sentiment analysis: An overview of the current state of the area and envisaged developments,” Decis. Support Syst., vol. 53, no. 4, pp. 675–679, 2012. doi: 10.1016/j.dss.2012.05.022. [Google Scholar] [CrossRef]
25. F. Wunderlich and D. Memmert, “A big data analysis of Twitter data during premier league matches: Do tweets contain information valuable for in-play forecasting of goals in football?” Soc. Netw. Anal. Min., vol. 12, no. 1, pp. 1–15, 2022. doi: 10.1007/s13278-021-00842-z. [Google Scholar] [PubMed] [CrossRef]
26. E. Deepak Chowdary, S. Venkatramaphanikumar, and K. Venkata Krishna Kishore, “Aspect-level sentiment analysis on goods and services tax tweets with dropout DNN,” Int. J. Bus. Inf. Syst., vol. 35, no. 2, pp. 239–264, 2020. doi: 10.1504/IJBIS.2020.110173. [Google Scholar] [CrossRef]
27. Y. Ren, N. Xu, M. Ling, and X. Geng, “Label distribution for multimodal machine learning,” Front Comput. Sci., vol. 16, no. 1, 2022, Art. no. 161306. doi: 10.1007/s11704-021-0611-6. [Google Scholar] [CrossRef]
28. G. Chandrasekaran, N. Antoanela, G. Andrei, C. Monica, and J. Hemanth, “Visual sentiment analysis using deep learning models with social media data,” Appl. Sci., vol. 12, no. 3, 2022. doi: 10.3390/app12031030. [Google Scholar] [CrossRef]
29. D. Ren and G. Srivastava, “A novel natural language processing model in mobile communication networks,” Mob. Netw. Appl., no. 2022, pp. 2575–2584, 2023. doi: 10.1007/s11036-022-02072-9. [Google Scholar] [CrossRef]
30. P. Appiahene et al., “Analyzing sentiments towards E-Levy policy implementation in Ghana using twitter data,” Int. J. Inf. Technol., vol. 16, no. 4, pp. 2199–2214, 2024. doi: 10.1007/s41870-024-01784-3. [Google Scholar] [CrossRef]
31. S. Afrifa, V. Varadarajan, P. Appiahene, T. Zhang, and E. A. Domfeh, “Ensemble machine learning techniques for accurate and efficient detection of botnet attacks in connected computers,” Eng, vol. 4, no. 1, pp. 650–664, 2023. doi: 10.3390/eng4010039. [Google Scholar] [CrossRef]
32. A. M. Mashraqi and H. T. Halawani, “Dragon fly optimization with deep learning enabled sentiment analysis for arabic tweets,” Comput. Syst. Sci. Eng., vol. 46, no. 2, pp. 2555–2570, 2023. doi: 10.32604/csse.2023.031246. [Google Scholar] [CrossRef]
33. A. Motwakel, B. B. Al-onazi, J. S. Alzahrani, and S. Alazwari, “Improved ant lion optimizer with deep learning driven arabic hate,” Comput. Syst. Sci. Eng., vol. 46, no. 3, pp. 3993–4006, 2023. doi: 10.32604/csse.2023.033901. [Google Scholar] [CrossRef]
34. A. D. Algarni, “Web intelligence with enhanced sunflower optimization algorithm for sentiment analysis,” Comput. Syst. Sci. Eng., vol. 47, no. 1, pp. 1233–1247, 2023. doi: 10.32604/csse.2022.026915. [Google Scholar] [CrossRef]
35. K. Chouhan, M. Yadav, R. K. Rout, K. S. Sahoo, and N. Z. Jhanjhi, “Sentiment analysis with tweets behaviour in twitter streaming API,” Comput. Syst. Sci. Eng., vol. 45, no. 2, pp. 1113–1128, 2023. doi: 10.32604/csse.2023.030842. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools