
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Efficient Intelligent E-Learning Behavior-Based Analytics of Student’s Performance Using Deep Forest Model
1 Applied College, Shaqra University, P.O. Box 33, Shaqra, 11961, Saudi Arabia
2 College of Computing and Information Technology, Shaqra University, P.O. Box 33, Shaqra, 11961, Saudi Arabia
3 Faculty of Computers and Artificial Intelligence, Sohag University, Sohag, 82524, Egypt
4 Faculty of Electronic Engineering, Menoufia University, Menouf, 32952, Egypt
* Corresponding Author: Mohamed Esmail Karar. Email:
Computer Systems Science and Engineering 2024, 48(5), 1133-1147. https://doi.org/10.32604/csse.2024.053358
Received 29 April 2024; Accepted 11 July 2024; Issue published 13 September 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
E-learning behavior data indicates several students’ activities on the e-learning platform such as the number of accesses to a set of resources and number of participants in lectures. This article proposes a new analytics system to support academic evaluation for students via e-learning activities to overcome the challenges faced by traditional learning environments. The proposed e-learning analytics system includes a new deep forest model. It consists of multistage cascade random forests with minimal hyperparameters compared to traditional deep neural networks. The developed forest model can analyze each student’s activities during the use of an e-learning platform to give accurate expectations of the student’s performance before ending the semester and/or the final exam. Experiments have been conducted on the Open University Learning Analytics Dataset (OULAD) of 32,593 students. Our proposed deep model showed a competitive accuracy score of 98.0% compared to artificial intelligence-based models, such as Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) in previous studies. That allows academic advisors to support expected failed students significantly and improve their academic level at the right time. Consequently, the proposed analytics system can enhance the quality of educational services for students in an innovative e-learning framework.Keywords
E-learning platforms have become more important for all educational institutions because they provide their educational activities via e-learning. According to [1], after the pandemic of COVID-19, e-learning systems have been globally utilized in educational activities due to it having advantages such as high flexibility in location and time, availability of education for all people and rich resources. It has been claimed that studying students’ learning performance and predicting their performance in future exams helps instructors improve and change their teaching methods to reduce the percentage of failure in the courses and ensure the quality of learning is achieved. In other words, students’ learning performance is influenced by students’ e-learning behavior [1]. Along the same line, using data on the learning process, learning performance prediction has become more interesting these days because these data can enhance the teaching methods and provide a clear picture of students learning and avoid future problems that may happen [2,3]. The aim of e-learning behavior data is to understand the e-learning process, and it indicates the data that became from students’ activities on an e-learning platform and other e-learning activities such as the number of accesses to a collection of resources and number of participants in lectures [4].
E-learning is defined as using modern technologies such as Web 4.0, the Internet, extranets, and intranets in educational activities to transfer skills and knowledge between students and lecturers [5]. In other words, e-learning indicates using students’ and instructors’ information and communications technology (ICT) in the educational process [6]. Four essential perspectives of e-learning are Cognitive perspective (CoP), Emotional perspective (EmP), Behavioral perspective (BeP), and Contextual perspective (CtP), as shown in Fig. 1. Universities use them, and they correlated together and are equally crucial to e-learning success [7]. According to [8], now many universities use e-learning platforms because most students have experience using these technologies, which attracts them to educational activities. E-learning is used to increase the quality of the education system, provide online learning to students anytime and anywhere, and enhance the level of competition between institutes [9]. It has been noted that e-learning offers effective learning between students and tutors easily and quickly, and it becomes more critical and essential for education entities to survive [10]. E-learning may help students succeed because it supports them to be independent and responsible for their knowledge [11]. E-learning allows students to enhance and develop their study skills by engaging them effectively in educational activities.
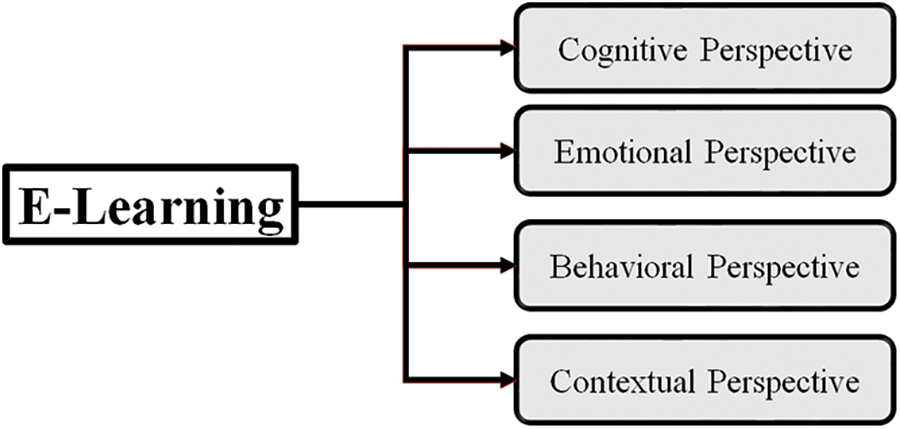
Figure 1: Fundamental perspectives of e-learning
Any information that results from students’ behaviors on e-learning systems, such as the number of forum participants, platforms used for registering in, and resource accesses, is referred to as e-learning behavior data [12]. The performance of online learning is found to be heavily influenced by e-learning behavior. It has been claimed that learner performance can be calculated by measuring their achievements in some academic tasks such as assignments, quizzes, tests and attendance in e-learning systems [13]. It has been claimed that it takes more work for instructors to get students’ performance directly in e-learning and immediately get feedback. It’s usually called this information at the end of the semester, negatively affecting learning and students because they may decide to postpone and drop their education [12]. Therefore, early prediction of students ‘grades is one way to detect their course performance [14]. The prediction of learning performance aims to understand and predict the student’s performance in classes during the semester, help instructors understand students’ academic condition and execute the plans to enhance students’ experience based on expected results [15]. There are many difficulties related to the data to run this method, such as how to get data and its process, and how to build models for learning behavior data. According to [16], modern technologies such as artificial intelligence (AI) changed traditional learning methods. Large amounts of data from e-learning platforms, such as user interactions, quiz results, assignment submissions, and discussion forum participation, can be processed by AI algorithms. AI technology can be used for educational activities in e-learning systems by providing personalized content to students [17]. For more accurate predictions, sophisticated methods such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs) are able to handle complicated and high-dimensional data.
Various frameworks of smart learning are technologically sophisticated teaching strategies that expose students to interactive services in the real world. Several research works of computer science and education studies have focused on making learning systems intelligent [18]. Additionally, many learning systems have been incorporated as web-based learning systems due to the rise in the use of computer networks and Internet technology. Computer-based learning systems, adaptive learning systems, web-based learning, smart tutoring systems, context-aware ubiquitous learning, and mobile learning deploying sensor-based technologies are examples of intelligent learning landscapes [19]. Open sources, collaborative, and long-term learning represent primary benefits from many incorporating artificial intelligence technology into the classroom environments [20]. The incorporation of AI in education might improve the delivery of individual and customized teaching. By evaluating the needs of specific learners, including learning behaviors and particular support, as well as their location in the real world or on the Internet, a smart learning design could offer learners both direct and proactive assistance from different perspectives [21]. Furthermore, these smart environments can provide students with intelligent, tailored support, such as learning monitoring and resources adapted to their requirements. Students are given access to digital resources, and they are able to interact with learning systems at any time, despite their location. These systems support them with the necessary resources, learning advice, hints, or suggestions at the appropriate time, location, and suitable approach [22].
This article proposes a new analytics system to support academic evaluation for students via e-learning activities. This study presents the following contributions:
• Establishing advanced analytics systems of academic performance evaluation for e-learning students.
• Proposing a new multistage random forest model to accurately predict failed students before the end of the academic year.
• Conducting a comparative study to validate the superior performance of our proposed AI-based predictor against machine learning and deep learning models in previous studies.
Machine Learning (ML) is a subfield of AI which enables a computer to learn from data in order to perform specific tasks accurately. They are recognized as the basis of AI techniques used to provide predictions that improve achievement. Models of machine learning are important for both feature selection methods and educational activity. The training and evaluation of numerous ML classification models has recently aided in the estimation of learning effectiveness. For instance, authors in [23] developed a classifier based on regression analysis that considered how students performed on their first week of homework assignments as well as how they interacted with others to forecast their performance activities in the course. Abdul Aziz et al. [24] utilized the naive Bayes classifier for the average grade point prediction after considering five main parameters: college enrollment form, gender, race category, family income, and average score mark. The K-nearest neighbor (KNN) method is used in [25] to forecast the results of students’ academic progress upon considering earlier academic achievements and non-academic factors. To predict student performance, the authors in [26] suggested a hybrid machine learning approach. The best-performing predictive model is chosen by this system using 8-classification models and employing 3-ensemble approaches (Bagging, Boosting, and Voting). The study results showed that, as compared to single classifiers, ensemble approaches exhibited greater predictive accuracy. In order to improve the e-learning process in the educational perimeter and anticipate pass or fail outcomes, a useful and acceptable technique for multiagent-based ML algorithms and feature selection methods is proposed in [26]. The outcomes demonstrated that, based on the evaluation of cross validation and testing, the learning method that has been estimated using the Extra Trees approach has attained the maximum performance value. Undergraduate students’ final exam scores are predicted using a novel approach based on ML algorithms using the grades of midterm exam as the input data in [27]. According to the findings, the offered support vector machine (SVM) model has a classification accuracy of between 70 to 75 percent.
The authors in [28] used two cutting-edge structured methods, that is CNN-LSTM and Conv-LSTM for the enhancement of the performance ratio and explain-ability of the predictive models for predicting student performance. The two suggested prediction models provide multiple improvements, including a smaller misclassification rate, a greater sensitivity rate, and explain-ability characteristics for instructors to strengthen VLE activities. A model using artificial neural networks based on data from student records regarding their use of the LMS created in [29]. The findings evidenced that student performance was significantly impacted by demographics and clickstream behavior. It is noted that students who completed courses successfully performed better. It concluded that the deep learning model would be a useful tool for producing too early predictions about student performance. Researchers in [30] employed the multitask cascaded convolution network (MTCNN) method for locating cartoon character faces, carry out face recognition and visual feature spot identification, and determine the cartoon-style graphic expression. This study in [30] examines the necessity, value, and applications of the IoT with a specific emphasis on how to improve the standard of online instruction for students. The proposed study integrates IoT and electroencephalography (EEG) with BiLSTM networks used to accurately predict the preferred learning styles of pupils by anticipating their recollection. Academic performance is improved via an IoT-enabled e-learning system with accuracy of 97.16%. A systematic comparison of some recent research using different data sets for performance of e-learning methods is provided in Table 1. Overall, a number of research works in literature [31,32] make use of ML, DL, and IoT approaches to project student performance using several indicators of student academic achievement.

One of the most extensive open datasets in terms of e-learning activities datum related to demographic information of students is the Open University Learning Analytics Dataset which is known as (OULAD) [33]. The ultimate goal of OULAD is to assist both academic and studies in the area of distance learning investigation by providing a public dataset that includes student data for academic guidance. The OULAD is composed of seven course modules, 22 courses. Moreover, it includes e-learning behavioral data and the learning effectiveness rates of 32,593 students during academic year 2013–2014. Table 2 illustrates the description of the main 12 e-learning activities of students in the DDD course to be used as features for our proposed predictor in this study.

Deep forest (DF) is a well-known decision-tree ensemble mechanism, which uses less hyper-parameters than similar deep networks [34]. It is designed as a cascading structure, as shown on Fig. 2. Each current level of this structure receives feature information manipulated by the preceding level. Based on the input data that has been analyzed, deep forest levels are automatically calculated. A collection of random forest stages is displayed on one level of the deep forest. For example, two fully random forests as well as two extra random forests [35] are added to increase divergence as illustrated in Fig. 2. Wholly one random forest is made up of 500 entirely decision trees [36], which were constructed via the random feature definition for splitting at each tree node. Whenever each of the leaf nodes has one class of all instances, or the Gini value (which gauges defects of leaf nodes) is equal to zero, a growing tree is then ended. In a similar vein, 500 decision trees make up each random forest with the number of trees representing a hyper_parameter for every decision forest. Supreme feature candidate from the d input features that earned Gini best values for splitting is chosen at random as described in [34]. By estimating the proportion of various training sample classes at the leaf node on the same location of the instance, also by scaling over fully decision trees in the same RF, the class distribution for a specific instance can be determined based on every RF. Based on the estimated class distribution, each class vector is created. It is then joined to the primary feature vector to serve as the input for the deep forest’s subsequent level. A three-dimension class vector for three classes will be produced by each of four RFs, for instance. As a result, the input of the following level receives 12 (= 3 × 4) augmented characteristics, as shown in Fig. 1. K-fold cross validation [37] was used to create the resulting class vector for each random forest in order to prevent the overall deep forest model from becoming overfit. Accordingly, each instance will be used k − 1 times in the dataset training phase, producing k − 1 times as many class vectors. These vectors will then be estimated to produce the latest class vector, which will serve as enhanced features for the subsequent phase of the cascade forest stages. After adding a new level, the decision forest model’s overall performance may be evaluated on the validation set. In addition, the learning process will finish if no significant performance is found. As a result, the quantity of decision forest levels can be automatically determined. Instead of using cross-validation error to limit the growth of forest levels, training error can be used when training phase computation costs are high and/or there are few computing resources available. This enables the deep forest’s adaptive model complexity to be built at various training data scales [38].
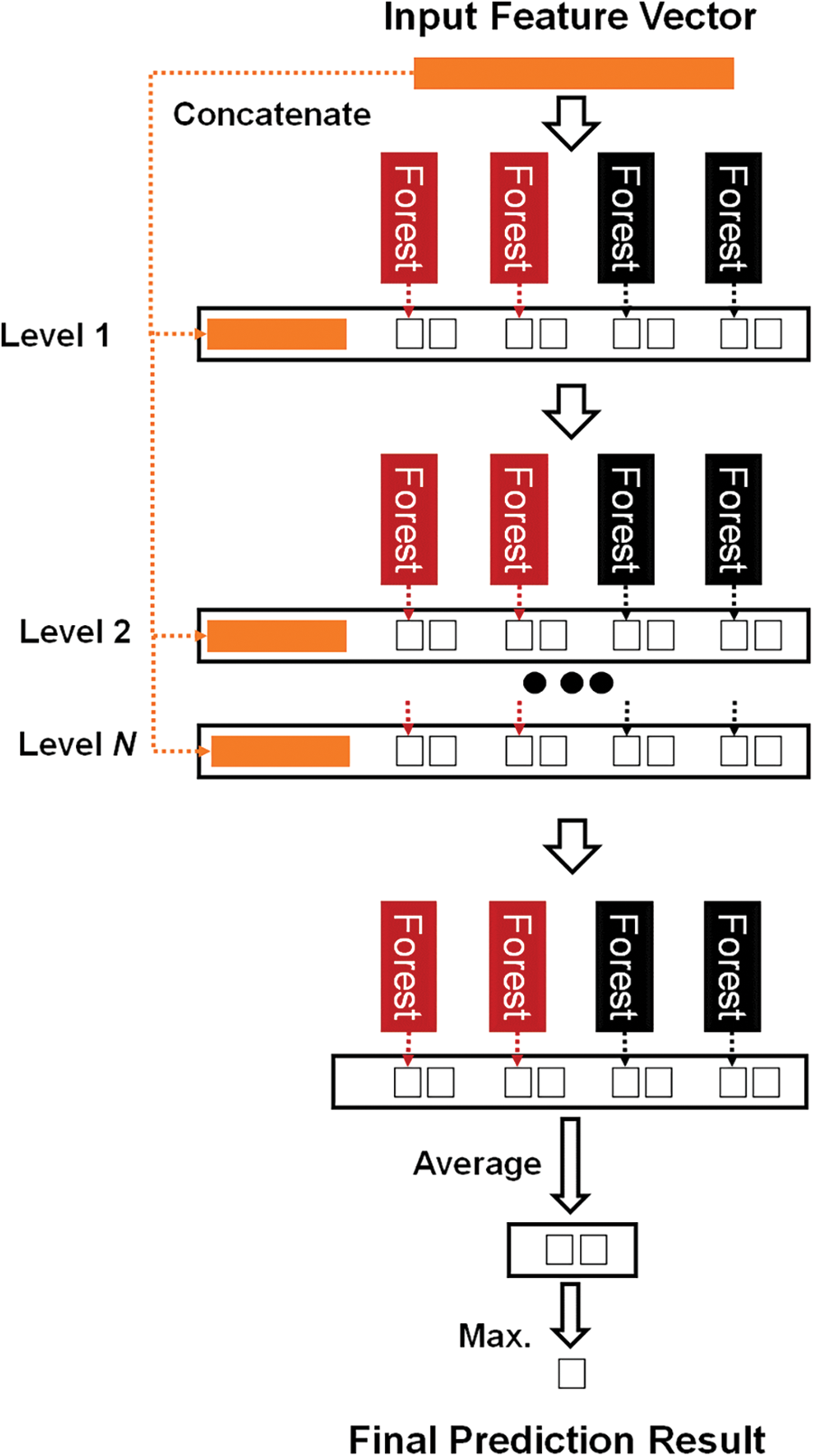
Figure 2: Basic architecture of deep forest algorithm. Two predicted classes with two decision forests (in black), and two absolutely random forests (in red) for each level. Each decision forest produces an integrated class vector to feed the next forest phases
3.3 Proposed Student Performance Analytics
Fig. 3 shows our proposed smart prediction system for evaluating student performance based on the suggested deep forest algorithm. The workflow of smart performance prediction system includes three main stages as follows. In stage 1, the e-learning platform is used to provide courses and all resources for students during the academic year. In parallel, it has records of each student activity for data collection. Stage 2 presents feature engineering and selection of student activity data. As illustrated in Table 2, 12 key e-learning activities of students have been exploited to identify the expected result of each student before ending the semester. In the final stage, our proposed machine learning method is applied to predict the result of students if they can pass or fail, as depicted in Fig. 3.
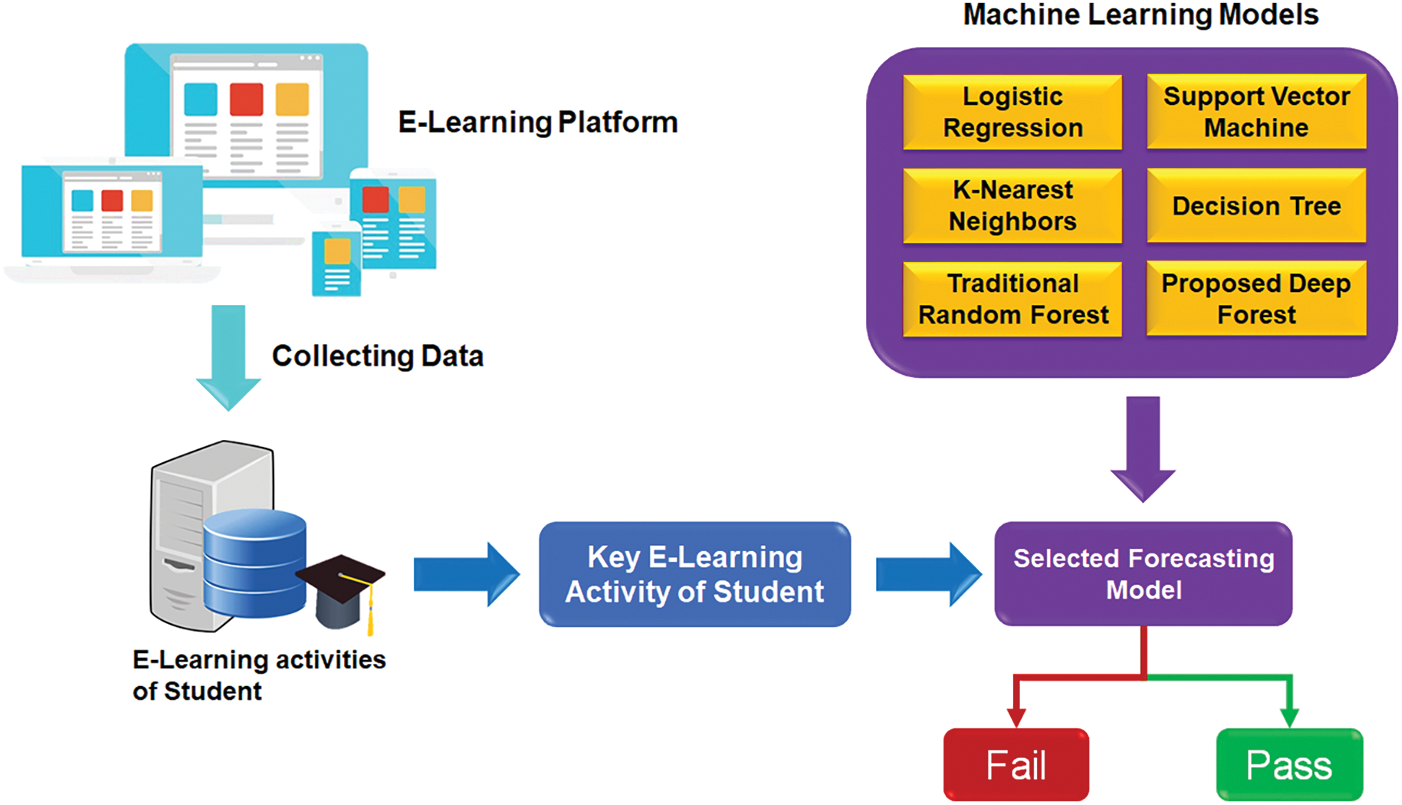
Figure 3: The workflow of our proposed analytics framework to evaluate student performance based on e-learning activities data
The forthcoming evaluation measures have been applied to estimate our suggested deep forest classifier for analytics academic performance of students. The cross-validation estimation in [39] was used to construct a 2 × 2 confusion matrix. True_Positive (TP), True_Negative (TN), False_Positive (FP), and False_Negative (FN) rates are 4-outcomes for fail and pass cases prediction. Additionally, accuracy, precision, recall (sensitivity), and F1-measures have also been computed, as in Fig. 4 diagram.
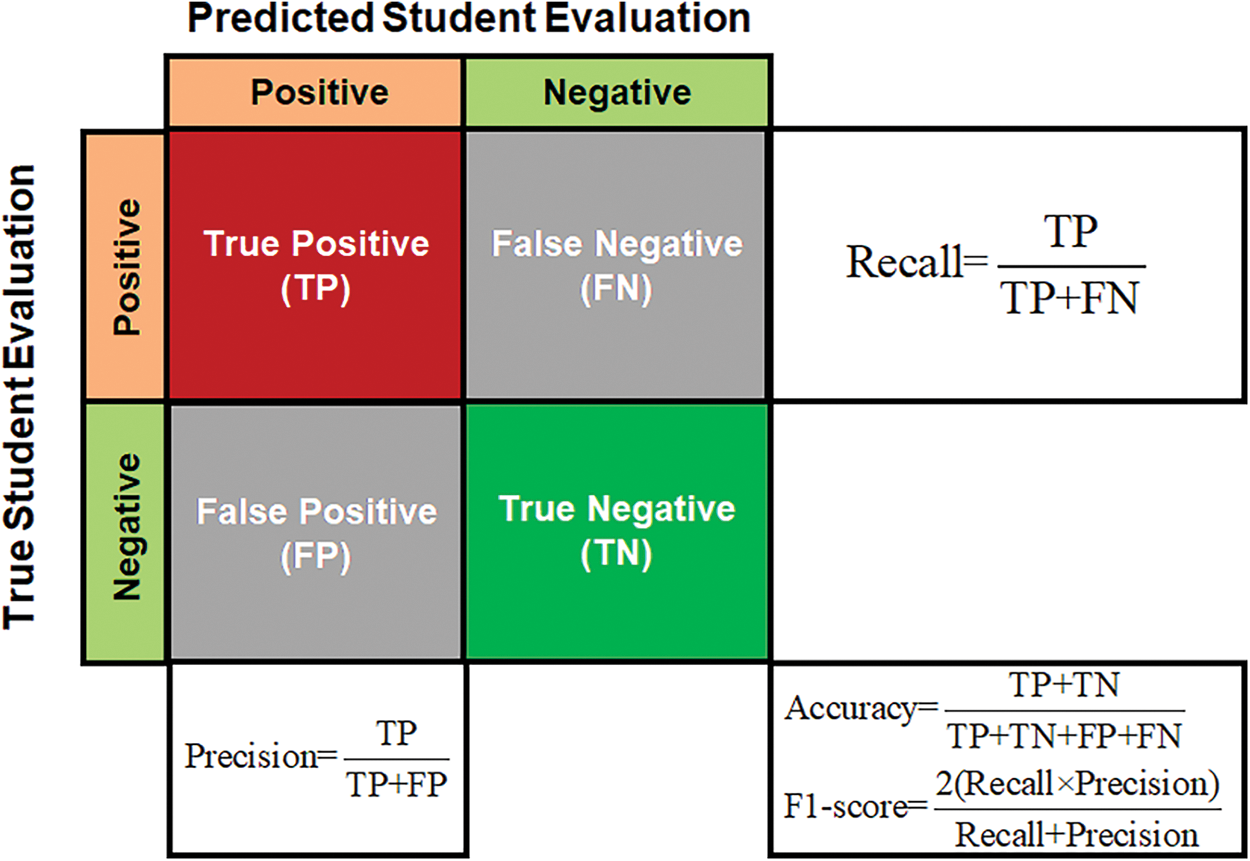
Figure 4: Schematic diagram of a 2 × 2 confusion matrix to quantitively analyze results of student performance evaluation
The suggested deep forest classifier and other ML models were implemented using the Tensorflow 2 and Keras packages. A laptop equipped with an Intel(R) Core (TM) i7-2.2 GHz processor and 16 GB of RAM was used to conduct various classification tests. Each experiment additionally makes use of a 4 GB NVIDIA graphics processing unit (GPU). In addition to the suggested deep forest classifier, three ML models—decision trees, SVM, and KNN—have been carried out and examined to identify fail cases. Thus, we are able to confirm the deep forest model’s beneficial performance. In both deep forest and traditional RF, the number of trees is precisely fixed at ten. Early paradigm training termination is triggered on the basis of an automated assessment of the validation fidelity for every created layer in order to prevent overfitting circumstances. As presented in Table 3, the final ideal number is 2 layers of our suggested deep forest classifier.,
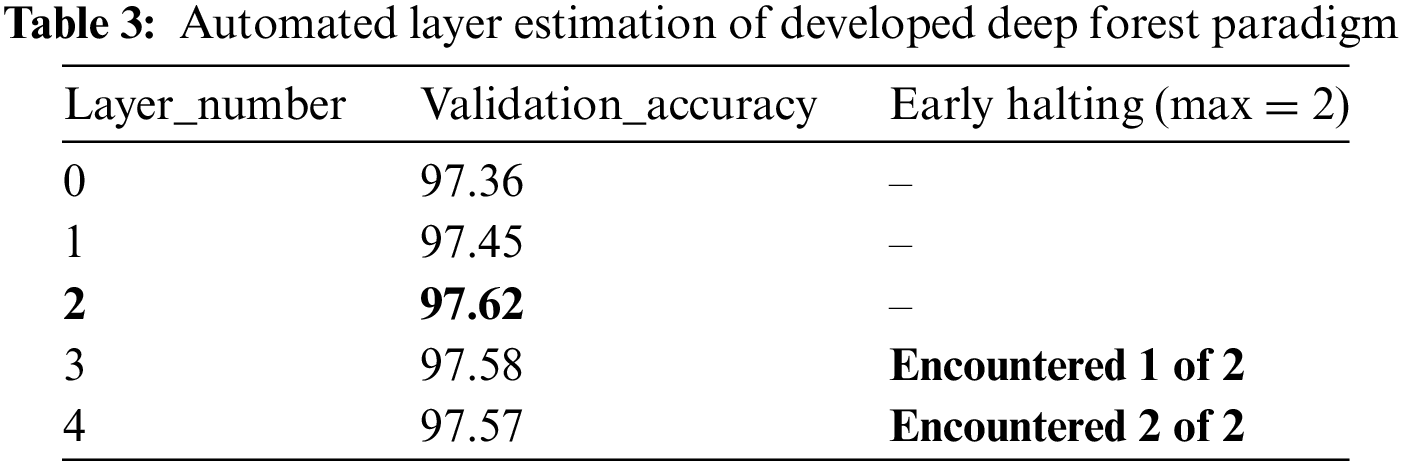
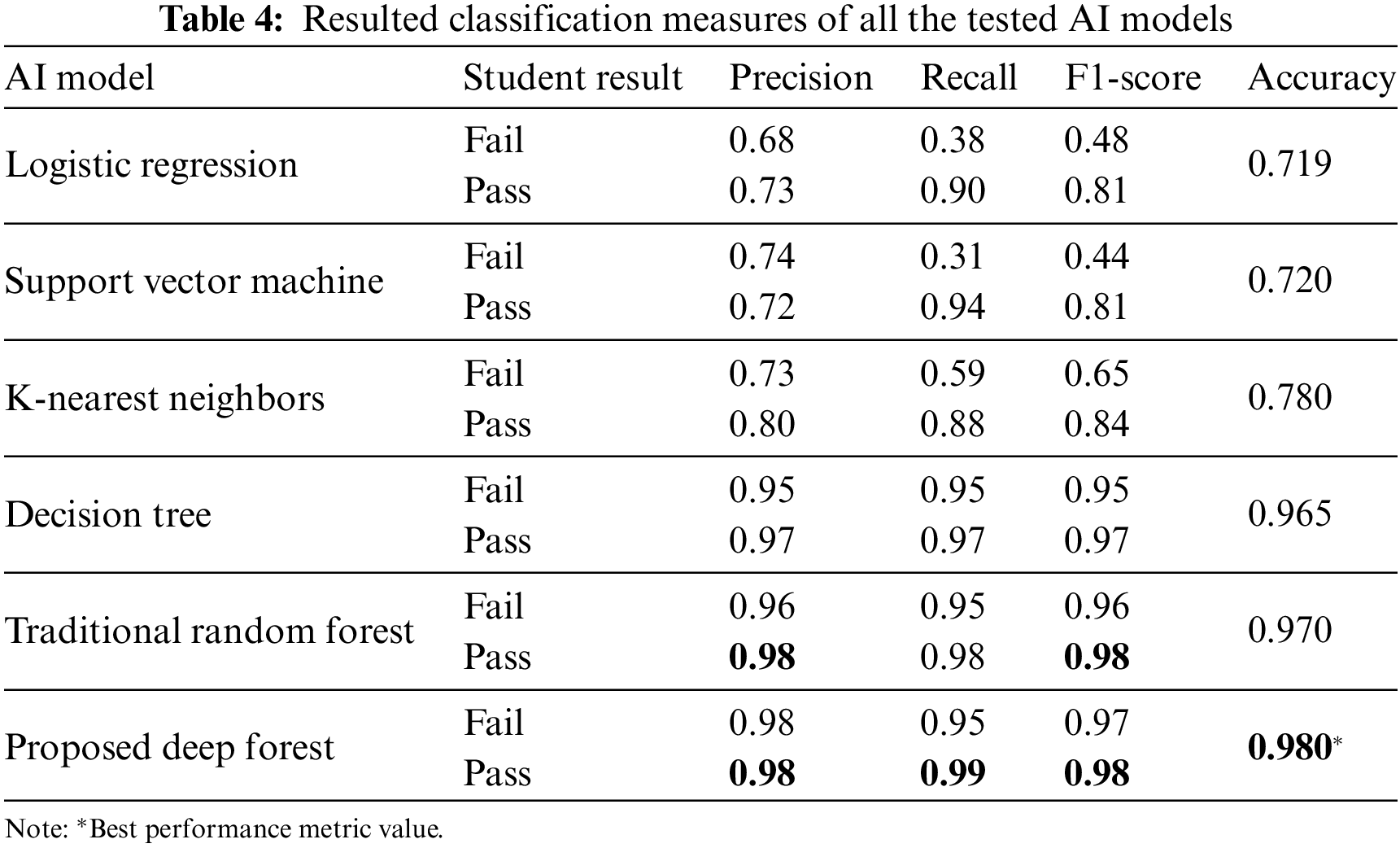
Resulted confusion matrices for the whole of the tested predictors are depicted in Fig. 5. Additionally, Table 4 illustrates quantitative values of 4-classification measures, specifically accuracy, precision, sensitivity or recall, and F1-score for each tested predictor. The superior classification metrics by our proposed deep forest model resulting in topmost accuracy score of 0.98. The logistic regression and SVM models showed approximately the same worst accuracy value of 0.72. The accuracy of KNN is 0.87 and also not efficient to predict the student performance. However, the decision tree and traditional random forest showed significant accuracy values of 0.965 and 0.970, respectively, but their performance is still lower than the proposed deep forest, as listed in Table 4.
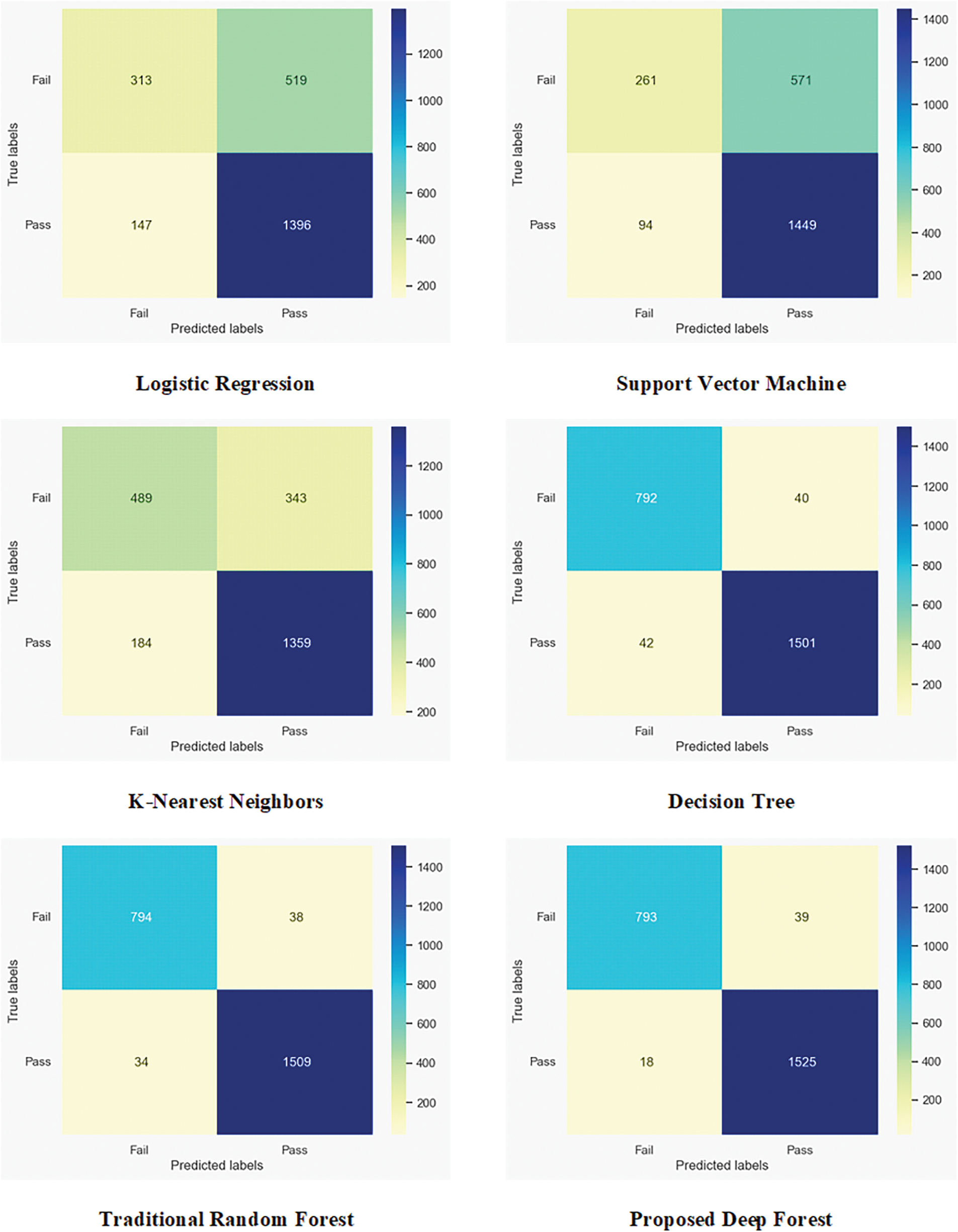
Figure 5: Confusion matrices of predicted fail and pass status of students using all tested models
Using the same publicly available dataset [35], Table 5 compares the results of our proposed deep forest model with those of other machine and deep learning models from earlier studies. The multi-layer perceptron [40], LSTM [41], decision tree [42], and hybrid CNN [43] achieved accuracy scores less than 0.90. The behavior classification-based e-learning performance (BCEP) [1] presents the second-best predictor with accuracy of 0.97. However, our proposed deep forest predictor showed the best performance by achieving the highest accuracy score of 0.98.

The above evaluations of this work demonstrated that the proposed deep forest predictor is effective and accurate in identifying the expected failed and succeeded students when compared to traditional ML and/or deep learning classifiers, as presented in Tables 4 and 5. Using the public OULAD dataset, the proposed analytics model achieved the highest accuracy of 0.98 for all tested student cases using 12 key features of e-learning student activities, as depicted in Figs. 3 and 5.
The accurate and successful performance of our proposed model can be explained as follows. The basic operation of random forest is based on ensemble technique, which gives the best prediction result. Also, the automated estimation of deep forest levels enables a good fit to the big data of e-learning student activities, as given in Table 2. In addition, the number of proposed deep forest hyperparameters is significantly smaller than the hyperparameters of deep learning models, such as CNN and LSTM networks. That allows easy manual tuning of the proposed deep forest at low-cost computing resources. Although the early stopping constraint is applied to avoid the trained model overfitting, the processing time of proposed deep forest model is relatively long because of the optimal model level estimation. Generally, the improvement process is time-consuming to obtain excellent hyperparameter value. Therefore, exploiting cloud and/or edge computing services can solve this timing problem [30,44]. Nevertheless, our proposed deep forest model is still valid to achieve the targeted performance of predicted evaluation of students within academic e-learning framework.
Moreover, privacy and security of the student data and analytics results are one of the most important aspects in the e-learning platform system [44]. Collecting e-learning activities of each student and analytic procedures should be conducted using our proposed machine learning algorithm on a secure University server. Cryptography is one of the most techniques for securing data transfer over open Internet networks and communications in the presence of suspicious behavior [45]. Therefore, the future version of our proposed analytics model will include end-to-end encryption for achieving high protection of student data.
This paper proposed an effective new AI-based e-learning architecture. The proposed multistage random forest model was used to accurately predict the failed students before ending the academic year. To improve learning, it was crucial to integrate wireless devices and the Internet for every student in the class. They conducted studies and worked together using wireless resources. Interactive monitors and smart screens are the main objectives for classroom pupils as they promote collaboration and ensure the sharing of learning outcomes. A good smart-teaching platform should overcome current and future challenges, including social and cultural structures, the development of educational technology, and various issues within contemporary society. The results demonstrate that the new suggested strategy improves the overall prediction and performance ratio of the students’ online learning interactions with a high accuracy rate of 98%. So, it is comparable to other widely used e-learning approaches.
In future and upcoming works, polar sentiment classification can be exploited to include numerous behaviors and optimize the current approaches to boost productivity [46]. To assess the importance and impact of all the actions included in the used dataset, a thorough investigation is needed. Textual data relevant to student feedback and advanced deep learning models will also be used to examine activity-wise importance in the future to identify activities that have a significant impact on the students’ performance.
Acknowledgement: The authors thank to the deanship of scientific research at Shaqra University for funding this research work through the Project Number (SU-ANN-2023017).
Funding Statement: The authors thank to the deanship of scientific research at Shaqra University for funding this research work through the Project Number (SU-ANN-2023017).
Author Contributions: Mohamed Esmail Karar, conceptualization, idea proposal, editing, and software; Raed Alotaibi, data curation, writing, and supervision; Omar Reyad, preparation, editing, visualization, and review. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that supports the findings of this research is publicly available as indicated in the references.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. F. Qiu et al., “Predicting students’ performance in e-learning using learning process and behaviour data,” Sci. Rep., vol. 12, no. 453, pp. 125, Jan. 2022. doi: 10.1038/s41598-021-03867-8. [Google Scholar] [PubMed] [CrossRef]
2. D. Gašević, G. Siemens, and C. P. Rosé, “Guest editorial: Special section on learning analytics,” IEEE Trans. Learn. Technol., vol. 10, no. 1, pp. 3–5, Jan. 1–Mar. 2017. doi: 10.1109/TLT.2017.2670999. [Google Scholar] [CrossRef]
3. L. Mishra, T. Gupta, and A. Shree, “Online teaching-learning in higher education during lockdown period of COVID-19 pandemic,” Int. J. Edu. Res. Open, vol. 1, pp. 100012, Sep. 2020. doi: 10.1016/j.ijedro.2020.100012. [Google Scholar] [PubMed] [CrossRef]
4. Y. Zhao, “Analysis of learner’s behavior characteristics based on open university online teaching,” in Data Science, Communications in Computer and Information Science, Singapore: Springer, 2020, vol. 1258, pp. 561–573. [Google Scholar]
5. S. Choudhury and S. Pattnaik, “Emerging themes in e-learning: A review from the stakeholders’ perspective,” Comput. Edu., vol. 144, pp. 103657, Jan. 2020. doi: 10.1016/j.compedu.2019.103657. [Google Scholar] [CrossRef]
6. M. D. Shieh and H. Y. Hsieh, “Study of influence of different models of e-learning content product design on students’ learning motivation and effectiveness,” Front. Psychol., vol. 12, pp. 753458, Sep. 2021. doi: 10.3389/fpsyg.2021.753458. [Google Scholar] [PubMed] [CrossRef]
7. S. K. Basak, M. Wotto, and P. Bélanger, “E-learning, M-learning and D-learning: Conceptual definition and comparative analysis,” E-Learn. Digit. Med., vol. 15, no. 4, pp. 191–216, 2018. doi: 10.1177/2042753018785180. [Google Scholar] [CrossRef]
8. E. H. K. Wu, C. H. Lin, Y. Y. Ou, C. Z. Liu, W. K. Wang and C. Y. Chao, “Advantages and constraints of a hybrid model K-12 E-learning assistant chatbot,” IEEE Access, vol. 8, pp. 77788–77801, 2020. doi: 10.1109/ACCESS.2020.2988252. [Google Scholar] [CrossRef]
9. A. Z. Rawashdeh, E. Y. Mohammed, A. R. Arab, M. Alara, and B. Rawashdeh, “Advantages and disadvantages of using e-learning in university education: Analyzing students’ perspectives,” Electron. J. E-Learn., vol. 19, no. 3, pp. 107–117, 2021. doi: 10.34190/ejel.19.3.2168. [Google Scholar] [CrossRef]
10. A. Garad, A. M. Al-Ansi, and I. N. Qamari, “The role of e-learning infrastructure and cognitive competence in distance learning effectiveness during the COVID-19 pandemic,” Jurnal Cakrawala Pendidikan, vol. 40, pp. 81–91, Feb. 2021. doi: 10.21831/cp.v40i1.33474. [Google Scholar] [CrossRef]
11. S. Maqbool et al., “Student’s perception of E-learning during COVID-19 pandemic and its positive and negative learning outcomes among medical students: A country-wise study conducted in Pakistan and Iran,” Ann. Med. Surg., vol. 82, Oct. 2022. doi: 10.1016/j.amsu.2022.104713. [Google Scholar] [PubMed] [CrossRef]
12. F. Qiu et al., “E-learning performance prediction: Mining the feature space of effective learning behavior,” Entropy, vol. 24, no. 5, pp. 722, May 2022. doi: 10.3390/e24050722. [Google Scholar] [PubMed] [CrossRef]
13. N. Elfaki, I. Abdulraheem, and R. Abdulrahim, “Impact of e-learning vs traditional learning on student’s performance and attitude,” Int. J. Med. Res. Health Sci., vol. 8, no. 10, pp. 76–82, 2019. [Google Scholar]
14. L. Huang, C. D. Wang, H. Y. Chao, J. H. Lai, and P. S. Yu, “A score prediction approach for optional course recommendation via cross-user-domain collaborative filtering,” IEEE Access, vol. 7, pp. 19550–19563, 2019. doi: 10.1109/ACCESS.2019.2897979. [Google Scholar] [CrossRef]
15. M. F. Musso, C. F. R. Hernández, and E. C. Cascallar, “Predicting key educational outcomes in academic trajectories: A machine-learning approach,” High. Educ., vol. 80, no. 5, pp. 875–894, 2020. doi: 10.1007/s10734-020-00520-7. [Google Scholar] [CrossRef]
16. A. Shahzad, R. Hassan, A. Y. Aremu, A. Hussain, and R. N. Lodhi, “Effects of COVID-19 in E-learning on higher education institution students: The group comparison between male and female,” Qual. Quant., vol. 55, pp. 805–826, 2021. doi: 10.1007/s11135-020-01028-z. [Google Scholar] [PubMed] [CrossRef]
17. M. Murtaza, Y. Ahmed, J. A. Shamsi, F. Sherwani, and M. Usman, “AI-based personalized E-learning systems: Issues, challenges, and solutions,” IEEE Access, vol. 10, pp. 81323–81342, 2022. doi: 10.1109/ACCESS.2022.3193938. [Google Scholar] [CrossRef]
18. G. J. Hwang, “Definition, framework and research issues of smart learning environments—A context-aware ubiquitous learning perspective,” Smart Learn. Environ., vol. 1, no. 4, pp. 492, 2014. doi: 10.1186/s40561-014-0004-5. [Google Scholar] [CrossRef]
19. P. Karampiperis and D. G. Sampson, “Adaptive learning resources sequencing in educational hypermedia systems,” J. Educ. Technol. Soc., vol. 8, no. 4, pp. 128–147, Oct. 2005. [Google Scholar]
20. S. A. Gamalel-Din, “Smart e-learning: A greater perspective; from the fourth to the fifth generation e-learning,” Egypt. Inform. J., vol. 11, no. 1, pp. 39–48, 2010. doi: 10.1016/j.eij.2010.06.006. [Google Scholar] [CrossRef]
21. D. Keržič et al., “Academic student satisfaction and perceived performance in the e-learning environment during the COVID-19 pandemic: Evidence across ten countries,” PLoS One, vol. 16, no. 10, pp. e0258807, 2021. doi: 10.1371/journal.pone.0258807. [Google Scholar] [PubMed] [CrossRef]
22. K. C. Li and B. T. -M. Wong, “Review of smart learning: Patterns and trends in research and practice,” Australas. J. Educ. Technol., vol. 37, no. 2, pp. 189–204, 2021. doi: 10.14742/ajet.6617. [Google Scholar] [CrossRef]
23. S. Jiang, A. E. Williams, K. Schenke, M. Warschauer, and D. O’Dowd, “Predicting MOOC performance with Week 1 behavior,” in Proc. 7th Int. Conf. Educ. Data Min., 2014, pp. 273–275. [Google Scholar]
24. A. Abdul Aziz, N. H. Ismail, F. Ahmad, and H. Hassan, “A framework for students’ academic performance analysis using Naïve Bayes classifier,” J. Teknol., vol. 75, no. 3, pp. 13–19, 2015. doi: 10.11113/jt.v75.5037. [Google Scholar] [CrossRef]
25. S. H. Hessen, H. M. Abdul-kader, A. E. Khedr, and R. K. Salem, “Developing multiagent e-learning system-based machine learning and feature selection techniques,” Comput. Intell. Neurosci., vol. 2022, pp. 1–8, Jan. 2022. doi: 10.1155/2022/2941840. [Google Scholar] [PubMed] [CrossRef]
26. E. Evangelista, “A hybrid machine learning framework for predicting students’ performance in virtual learning environment,” Int. J. Emerg. Technol. Learn. (iJET), vol. 16, no. 24, pp. 255–272, 2021. doi: 10.3991/ijet.v16i24.26151. [Google Scholar] [CrossRef]
27. M. Yağcı, “Educational data mining: Prediction of students’ academic performance using machine learning algorithms,” Smart Learn. Environ., vol. 9, no. 11, pp. 157, 2022. doi: 10.1186/s40561-022-00192-z. [Google Scholar] [CrossRef]
28. H. C. Chen et al., “Week-wise student performance early prediction in virtual learning environment using a deep explainable artificial intelligence,” Appl. Sci., vol. 12, no. 4, pp. 1885, 2022. doi: 10.3390/app12041885. [Google Scholar] [CrossRef]
29. H. Waheed, S. U. Hassan, N. R. Aljohani, J. Hardman, S. Alelyani and R. Nawaz, “Predicting academic performance of students from VLE big data using deep learning models,” Comput. Human Behav., vol. 104, pp. 106189, 2020. doi: 10.1016/j.chb.2019.106189. [Google Scholar] [CrossRef]
30. K. Kumar and A. Al-Besher, “IoT enabled e-learning system for higher education,” Meas.: Sens., vol. 24, pp. 100480, 2022. doi: 10.1016/j.measen.2022.100480. [Google Scholar] [CrossRef]
31. R. Ahuja and Y. Kankane, “Predicting the probability of student’s degree completion by using different data mining techniques,” in Fourth Int. Conf. Image Inform. Process. (ICIIP), Shimla, India, 2017, pp. 1–4. doi: 10.1109/ICIIP.2017.8313763. [Google Scholar] [CrossRef]
32. Q. Cao, W. Zhang, and Y. Zhu, “Deep learning-based classification of the polar emotions of “Moe”-style cartoon pictures,” Tsinghua Sci. Technol., vol. 26, no. 3, pp. 275–286, 2021. doi: 10.26599/TST.2019.9010035. [Google Scholar] [CrossRef]
33. J. Kuzilek, M. Hlosta, and Z. Zdrahal, “Open University learning analytics dataset,” Sci. Data, vol. 4, pp. 49, 2017. doi: 10.1038/sdata.2017.171. [Google Scholar] [PubMed] [CrossRef]
34. Z. H. Zhou and J. Feng, “Deep forest,” Natl. Sci. Rev., vol. 6, no. 1, pp. 74–86, 2019. doi: 10.1093/nsr/nwy108. [Google Scholar] [PubMed] [CrossRef]
35. L. Breiman, “Random forests,” Mach. Learn., vol. 45, pp. 5–32, 2001. doi: 10.1023/A:1010933404324. [Google Scholar] [CrossRef]
36. F. T. Liu, K. M. Ting, Y. Yu, and Z. H. Zhou, “Spectrum of variable-random trees,” J. Artif. Intell. Res., vol. 32, pp. 355–384, 2008. doi: 10.1613/jair.2470. [Google Scholar] [CrossRef]
37. T. T. Wong, “Performance evaluation of classification algorithms by k-fold and leave-one-out cross validation,” Pattern Recognit., vol. 48, no. 9, pp. 2839–2846, 2015. doi: 10.1016/j.patcog.2015.03.009. [Google Scholar] [CrossRef]
38. M. E. Karar, O. Reyad, and H. I. Shehata, “Deep forest-based fall detection in internet of medical things environment,” Comput. Syst. Sci. Eng., vol. 45, no. 3, pp. 2377–2389, 2023. doi: 10.32604/csse.2023.032931. [Google Scholar] [CrossRef]
39. M. Sokolova and G. Lapalme, “A systematic analysis of performance measures for classification tasks,” Inform. Process. Manage., vol. 45, no. 4, pp. 427–437, 2019. doi: 10.1016/j.ipm.2009.03.002. [Google Scholar] [CrossRef]
40. A. Rivas, A. González-Briones, G. Hernández, J. Prieto, and P. Chamoso, “Artificial neural network analysis of the academic performance of students in virtual learning environments,” Neurocomputing, vol. 423, pp. 713–720, 2021. doi: 10.1016/j.neucom.2020.02.125. [Google Scholar] [CrossRef]
41. L. Zhao et al., “Academic performance prediction based on multisource, multifeature behavioral data,” IEEE Access, vol. 9, pp. 5453–5465, 2021. doi: 10.1109/ACCESS.2020.3002791. [Google Scholar] [CrossRef]
42. S. Rizvi, B. Rienties, and S. A. Khoja, “The role of demographics in online learning; A decision tree based approach,” Comput. Educ., vol. 137, pp. 32–47, 2019. doi: 10.1016/j.compedu.2019.04.001. [Google Scholar] [CrossRef]
43. S. Poudyal, M. J. Mohammadi-Aragh, and J. E. Ball, “Prediction of student academic performance using a hybrid 2D CNN model,” Electronics, vol. 11, no. 7, pp. 1005, 2022. doi: 10.3390/electronics11071005. [Google Scholar] [CrossRef]
44. M. Korir, S. Slade, W. Holmes, Y. Héliot, and B. Rienties, “Investigating the dimensions of students’ privacy concern in the collection, use and sharing of data for learning analytics,” Comput. Human Behav. Rep., vol. 9, pp. 100262, 2023. doi: 10.1016/j.chbr.2022.100262. [Google Scholar] [CrossRef]
45. J. G. Sahaya Stalin and C. C. Seldev, “Secure cloud data storage approach in e-learning systems,” Cluster Comput., vol. 22, no. 5, pp. 12857–12862, 2019. doi: 10.1007/s10586-018-1785-z. [Google Scholar] [CrossRef]
46. A. Baqach and A. Battou, “A new sentiment analysis model to classify students’ reviews on MOOCs,” Educ. Inform. Technol., vol. 150, pp. 1–28, 2024. doi: 10.1007/s10639-024-12526-0. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools