
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
A Double-Interactively Recurrent Fuzzy Cerebellar Model Articulation Controller Model Combined with an Improved Particle Swarm Optimization Method for Fall Detection
The Department of Medical Informatics, Tzu Chi University, Hualien County, 97004, Taiwan
* Corresponding Author: Jyun-Guo Wang. Email:
Computer Systems Science and Engineering 2024, 48(5), 1149-1170. https://doi.org/10.32604/csse.2024.052931
Received 19 April 2024; Accepted 02 July 2024; Issue published 13 September 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In many Eastern and Western countries, falling birth rates have led to the gradual aging of society. Older adults are often left alone at home or live in a long-term care center, which results in them being susceptible to unsafe events (such as falls) that can have disastrous consequences. However, automatically detecting falls from video data is challenging, and automatic fall detection methods usually require large volumes of training data, which can be difficult to acquire. To address this problem, video kinematic data can be used as training data, thereby avoiding the requirement of creating a large fall data set. This study integrated an improved particle swarm optimization method into a double interactively recurrent fuzzy cerebellar model articulation controller model to develop a cost-effective and accurate fall detection system. First, it obtained an optical flow (OF) trajectory diagram from image sequences by using the OF method, and it solved problems related to focal length and object offset by employing the discrete Fourier transform (DFT) algorithm. Second, this study developed the D-IRFCMAC model, which combines spatial and temporal (recurrent) information. Third, it designed an IPSO (Improved Particle Swarm Optimization) algorithm that effectively strengthens the exploratory capabilities of the proposed D-IRFCMAC (Double-Interactively Recurrent Fuzzy Cerebellar Model Articulation Controller) model in the global search space. The proposed approach outperforms existing state-of-the-art methods in terms of action recognition accuracy on the UR-Fall, UP-Fall, and PRECIS HAR data sets. The UCF11 dataset had an average accuracy of 93.13%, whereas the UCF101 dataset had an average accuracy of 92.19%. The UR-Fall dataset had an accuracy of 100%, the UP-Fall dataset had an accuracy of 99.25%, and the PRECIS HAR dataset had an accuracy of 99.07%.Keywords
Declining birth rates have led to the gradual aging of society in many Eastern and Western countries. According to a World Health Organization report, the proportion of the population that is aged ≥65 and ≥70 years is increasing by 28%–35% and 32%–42% each year, respectively [1]. A survey from the US National Institutes of Health indicates that in the United States, approximately 1.6 million older adults experience a fall-related accident each year [2]. According to Carone et al. [3], the European Union’s elderly dependency ratio (the number of people aged ≥65 years divided by the number of people aged 15–64 years) is expected to double by 2050 to greater than 54%. China is also confronting a rapidly aging population. In 2020, older adults comprised approximately 17% of the Chinese population, and this percentage is predicted to increase to 35% by 2050 [2]. In Taiwan, which has been considered an aging society since 2018, individuals aged ≥65 years comprise 14% of the population. Families previously lived in multigenerational households, and at least one adult was available to care for older adult relatives. However, most adults now work outside the home; thus, the older adults in their families are often left alone at home. An accident experienced by an older adult when they are alone at home can have disastrous consequences. Falls are the main cause of injury-related death in older adults [4], and 87% of all fractures in older adults are caused by falls. Although many falls do not cause injury, 47% of older adults who are uninjured after a fall are nonetheless unable to move normally without assistance, which indirectly affects their health. In addition, in one study, 50% of older adults who fell and then remained on the floor for a certain period after their fall were found to die within 6 months, even if they had not been directly injured in the fall [5]. Therefore, a system that can automatically and immediately detect fall events and inform a caregiver or family member can substantially benefit older adults. Additionally, increasing economic stress has reduced the time available for young people to care for their older adult relatives. This crucial social problem can be addressed by using information collected through different systems, such as cameras.
Many methods have been proposed for posture recognition and fall detection. These methods can mainly be divided into two categories: non-computer-vision (NCV) and computer-vision (CV) methods. NCV methods involve automatically recognizing human actions by conducting mathematical modeling and using sensors. These methods can be divided into three subcategories: dynamic system methods [6–9], stochastic methods [10–12], sensor methods [13–16], and wearable-sensors [17–19]. Dynamic system methods involve encoding action data as differential equations, whereas stochastic methods involve encoding action data as state transitions and data representing the distribution of states. Finally, sensor methods involve using a set of model parameters, which are regarded as discrete points in a multidimensional parameter space. Thus, the obtained action data are compressed into a mathematical model through symbolic representations called action symbols. Action symbols facilitate not only the synthesis of human-like actions but also the recognition of human behavior from observations. However, such mathematical models are not intuitive representations. A model that classifies observations does not understand action categories such as “walking,” “running”, or “squatting”. In sensor methods, sound, vibration, and other data are captured using various sensors—fall detection can be achieved through the use of accelerometers, acoustic sensors, and floor vibration sensors. In [13], an activity detection method based on dynamic and static measurements made by a single-axis acceleration sensor was developed. Changes were observed by placing acceleration sensors on the chest and feet, and the measured signal is analyzed using a threshold-based algorithm for fall detection. In [14], a three-axis acceleration sensor was attached to different areas of the body, and the severity of the fall is determined by comparing the measured dynamic and static acceleration components to appropriate thresholds. Threshold-based algorithms can be used to detect certain falls, as shown by the experimental results of [14]. In [15], an acoustic fall detection system was designed that can automatically notify a guardian of a fall. The performance of this fall detection system was evaluated using simulated sounds corresponding to fall and nonfall events. A fall detection system based on ground vibration and sound induction was proposed in [16]. Suitable temporal and spectral characteristics were selected from signals generated by ground vibrations and sound induction, and fall and non-fall events were classified using a Bayesian classifier. The system above detects falls with a rate of 97.5% and detects errors with a rate of 1.4%. Although NCV methods can accurately detect falls, these methods have some limitations, such as the need for the individual under monitoring to wear an acceleration sensor. Moreover, environmental noise can affect the systems used in these methods. To overcome these problems, some scholars have proposed fall detection methods based on CV technology. However, the implementation of CV-based fall detection systems raises privacy concerns regarding the use of surveillance equipment. To alleviate these concerns, most such systems send an alarm to a caregiver or family member only when a fall is detected, and video of normal activities is neither stored nor transmitted.
In the past decade, substantial improvements have been achieved in CV systems using real-time object motion and video or image processing technologies, thus enabling the development of various fall detection methods. In [20–22], simple adaptive threshold or shape-based methods were used to distinguish falling from nonfalling actions. However, these methods had high false positive rates (e.g., the action of sitting down quickly was misclassified as a fall). The authors of [23] proposed a threshold-based method that involves using a calibrated camera to reconstruct the three-dimensional (3D) shape of a person. In the aforementioned study, fall events were detected by analyzing the volume distribution of the reconstructed 3D shape along the vertical axis. Experimental results demonstrated that the aforementioned method has excellent performance. Rapid developments have been made in pattern recognition technology, and many researchers have adopted this technology for fall detection [24–25]. In [24], a neurofuzzy network was used to classify postures and detect fall events. Similarly, in [25], the k-nearest neighbors’ classifier was used for posture classification, and statistical hypothesis testing was performed to determine the threshold time difference suitable for distinguishing falls from and lying-down events. This method was found to have a correct detection rate of 84.44%. In [26,27], fall and nonfall events were classified by extracting feature information (such as contour, bright, and flow features) to achieve a robust system that can be used in bright environments containing multiple objects. In [28], the fall detection performance of three models was compared. Among them, the neural network model was effective in detecting falls with a 92% fall detection rate and a 5% false positive rate, respectively. Short video clips have been used by researchers to categorize fall and non-fall events [29,30]. In [29], continuous contours are analyzed using bounding boxes and motion information and to extract features. These features were then used to train an HMM (hidden Markov model) for the classification of fall and nonfall events. In [30], the 3D position information of an object was extracted using multiple cameras, and an improved hierarchical hidden Markov model was developed for fall detection. In [31], a method was proposed for automatically extracting motion trajectories and thereby detecting abnormal human activities. In [32], a semantic video summarization system based on fuzzy logic for detecting falls was proposed. This system was tested using 14 and 32 data sets on fall and nonfall behaviors, respectively. The test results demonstrated that all fall behaviors were correctly detected by the system, whereas only two nonfall behaviors were incorrectly classified as fall behaviors. Additionally, some techniques [33–37] are designed to identify ADLs (activities of daily living) and create fall monitoring systems that detect falls and provide feedback to doctors or relatives of patients. In the same way, ADL monitoring can be utilized in rehabilitation-assisted living applications [38–40].
Substantial progress has been achieved in deep learning technology [41], which has resulted in natural language processing [42] and improved CV [43] methods. Convolutional neural networks (CNNs) have been particularly successful in image classification tasks [43,44], employed in a variety of tasks as specialized feature extractors [45–49] and related technologies [50–54]. In [55,56], scholars converted articulated coordinates into two-dimensional (2D) image information and then used a CNN model to classify actions on the basis of the 2D image information. In [57,58], the 3D joint trajectory shape of bones was converted into three types of images representing the front, top, and side views of the joint trajectory shape. Actions were then classified using a CNN model and the three types of images. In [59], a CNN model was demonstrated to be a powerful tool for feature extraction and classification. An overview of the latest progress in CNNs (e.g., in terms of aspects such as regularization, optimization, activation function, loss function, and weight initialization) was provided in [60]. In [61], action classification accuracy was improved using multiple types of information in deep CNNs for action recognition. Sharma et al. [62] developed a spatial attention model based on long short-term memory (LSTM) that combined temporal and spatial attention mechanisms into a single scheme. In their work, they employ the proposed model to caption images and recognize actions. The last convolutional layer of GoogleNet [63] generates a feature map tensor for each frame, which is later sent to an LSTM to forecast action labels and regions of interest. Lu et al. [64] developed a visual attention–guided 3D CNN, which incorporated a soft attention mechanism.
Although the aforementioned methods have acceptable performance, achieving highly accurate fall detection with them remains difficult. Simulating falls in a controlled environment is how training data for fall detection is typically generated; thus, obtaining a large number of training samples is difficult, and the performance of a trained classifier is limited. To create a method for detecting falls that is not dependent on simulated fall data, the present study integrated an improved particle swarm optimization (IPSO) method into a double interactively recurrent fuzzy cerebellar model articulation controller (D-IRFCMAC) model for fall detection. The D-IRFCMAC model is based on a modified fuzzy cerebellar model articulation controller (CMAC) model [65]. The CMAC is a feedforward neural network with a high learning speed. We extensively modified the fuzzy CMAC to enhance its precision, reduce its memory requirements, and enable differential computation. Kinematic data sets were employed instead of smaller fall data sets to train the D-IRFCMAC model efficiently. The proposed method can accurately detect human behavior and fall events in long-term care centers or in homes. This study makes three main contributions to the literature. First, it obtained an optical flow (OF) trajectory diagram from image sequences by using the OF method, and it solved problems related to focal length and object offset by employing the discrete Fourier transform (DFT) algorithm. Second, this study developed the D-IRFCMAC model, which combines spatial and temporal (recurrent) information. Third, it designed an IPSO algorithm that effectively strengthens the exploratory capabilities of the proposed D-IRFCMAC model in the global search space.
This paper is organized as follows. Section 1 introduces the background of the present study and describes related studies, Section 2 explains the proposed method, Section 3 details the experimental procedure and results, and Section 4 provides the conclusions of this study.
2 Feature Selection Using the Proposed Methods
Four algorithms are described in this section: an OF algorithm, the DFT, the proposed D-IRFCMAC, and an IPSO algorithm.
No line breaks between paragraphs belonging to the same section.
The goal of the OF method is to capture movement trajectories. To achieve this goal, the Lucas–Kanade (LK) OF algorithm [66] was employed in the present study for calculating the image flow vector (
where
Once the OF vector has been calculated, the OF method is used to analyze overlapping images of a continuous sequence (the trajectory image). Trajectory images are categorized as OF trajectory images (OFTIs) or foreground trajectory images (FTIs), as illustrated in Fig. 1a,b, respectively. An OFTI presents a representation of an action, which is defined as a motion over time.

Figure 1: Examples of an (a) OFTI and (b) FTI
The image
where OFI(x, y, t) represents the pixel values at positions x and y in an OF image at time t, defines the duration of a movement within a specific period, and U indicates the range of a set from one period to another. Although the LK OF algorithm can recognize most actions, it has difficulty in recognizing actions in some situations, such as when similar actions have different postures. Therefore, to distinguish different types of actions, a circle mark is added to the centroid of the action calculated using the OFTI. This circle mark facilitates calculation of the direction of motion to distinguish similar actions with different postures. However, the OFTI only approximately represents the movement of an object, and it does not enable the recognition of target types. Therefore, FTI features are also used because these features encode considerable foreground information. An FTI [denoted
where
First, the horizontal and vertical projections of the OFTI and FTI are calculated (Fig. 2). Subsequently, the DFT [67] is used to convert the projection images obtained from the OFTI and FTI. The advantages of the DFT are not limited to the focal distance of the camera and the location of the object; it can also reduce the number of feature dimensions by extracting low-frequency components. The conversion formula of the DFT is given as follows:
where H(y) and V(x) are the horizontal and vertical projections, respectively. The terms N and M denote the width and height of the trajectory image, respectively. Low-frequency features are selected using the DFT, and the 15 lowest-frequency values are used as features in the horizontal and vertical projections. Thus, a total of 60 features are selected from the horizontal and vertical projection images of the OFTI and FTI.

Figure 2: Horizontal and vertical projections of the OFTI and FTI
In this study, a D-IRFCMAC model that uses an interactive recurrent mechanism and a Takagi–Sugeno–Kang (TSK)-type linear function was developed for action recognition. The TSK-type linear function enables systematic extraction of fuzzy rules from data. From an input–output structure, this function systematically generates the antecedent and consequent of the relevant IF–THEN rule. The function adjusts the antecedent and consequent frameworks and variables in accordance with the adopted data. The structure of the proposed D-IRFCMAC model is displayed in Fig. 3. The model comprises the following six layers in sequence: an input layer, a membership function layer, a spatial firing layer, a temporal firing layer, a consequent layer, and an output layer. The function of each layer is detailed in the following paragraphs. The architecture implements similar fuzzy IF–THEN rules as described by using expression. The expression is computed as follows:

Figure 3: Architecture of the D-IRFCMAC model
Rule j:
IF x1 is A1j and x2 is A2j … and xi is Aij
where xi and yj represent the input variables and local output variables, respectively; Aij is the linguistic term of the antecedent part created using the Gaussian membership function; Oj is the output of the interactive feedback; and
Input layer (layer 1): This layer is used to input feature vectors into the D-IRFCMAC model; these input vectors consist of crisp values.
Membership function layer (layer 2): This layer is a fuzzy layer. The single linguistic label of the input variables in layer 1 corresponds to each node in layer 2. Input values are used to calculate membership values through layer 2 fuzzy sets. The Gaussian membership function implemented in layer 2 is expressed as follows:
where
where
Spatial firing layer (layer 3): The nodes in this layer are called rule nodes or hypercube cells. Each node in layer 3 determines the firing strength information for a hypercube cell in accordance with the information acquired from the nodes of a fuzzy set in layer 2; each of these nodes represents one fuzzy rule or hypercube cell rule. Therefore, the hypercube cell rule nodes perform a fuzzy product operation, and the output function is as follows:
Temporal firing layer (layer 4): Each node of this layer is a cyclic hypercube element node and comprises two parts: an internal feedback loop and external feedback loop interactively. Because the internal feedback of a hypercube element node alone is insufficient for representing all necessary information, the external feedback process is used obtain additional information from other nodes. In layer 4, each node has its own (self-loop) and other nodes (external loop) information reference. The temporal firing strength is expressed as follows:
where
Consequent layer (layer 5): In this layer, each node is a linear combination function associated with the input variables. The relevant equation is as follows:
Output layer (layer 6): This layer defuzzifies the fuzzy output of previous layers into a scalar output by using the center-of-gravity approach.
This section describes the particle swarm optimization (PSO) algorithm and the proposed IPSO algorithm.
The PSO algorithm was introduced by Kennedy and Eberhart [68] and was first used in the field of social and cognitive behavior. This algorithm is based on how birds and fish forage for food. The algorithm is simple to understand and implement and thus has been widely employed as a problem-solving method in engineering and computer science. The position and velocity vectors of the ith particle in an N-dimensional search space can be represented as
Among those,
The overall flowchart of the proposed IPSO algorithm is displayed in Fig. 4, and the steps of this algorithm are described in the following sections. The IPSO algorithm can be employed to analyze and optimize the internal parameters

Figure 4: Flowchart of the proposed IPSO algorithm
Step 1 Individual initialization
Random values are first generated in the range [−1, 1] for the individual initialization of each particle. These values represent the average, standard deviation, and weight of each variable in the D-IRFCMAC model. Subsequently, coding is performed. The coding step is related to the membership functions and fuzzy rules for particles suitable for IPSO. Fig. 5 shows how parameters are coded for a particle. The parameters i and j represent the input variables and rules in the D-IRFCMAC model.
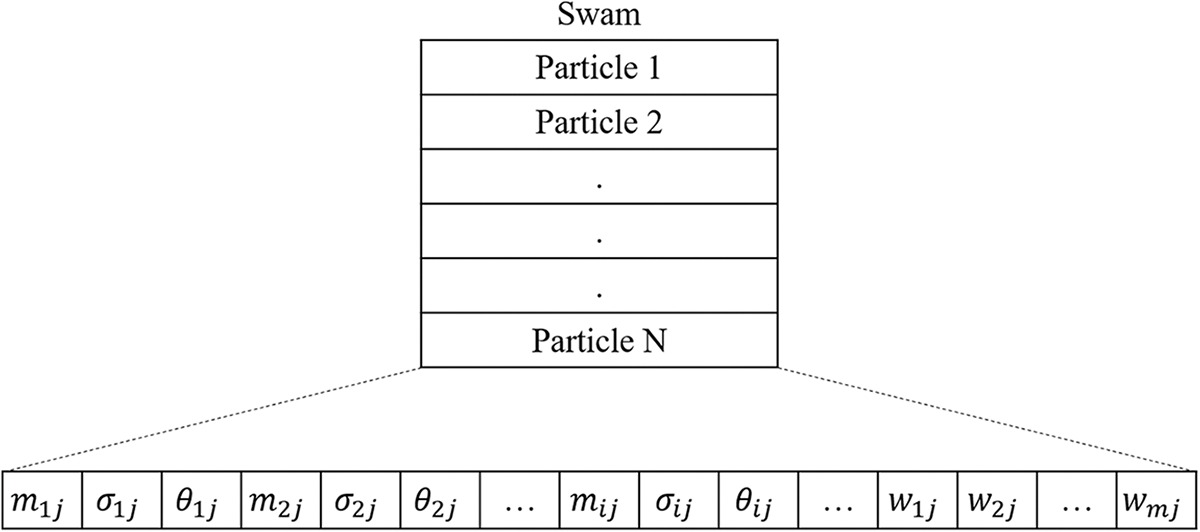
Figure 5: Coding of the fuzzy rule parameters of a particle in the IPSO algorithm
Step 2 Fitness evaluation
The fitness function for evaluating each particle in the swarm is defined as follows:
where N represents the number of input data points and yp and
Step 3 Updating the local best value
In case the fitness value of the evaluated particle surpasses the local optimal value, this fitness value takes the place of the local optimal value.
Step 4 Updating the global best value
In case the fitness value of the evaluated particle surpasses the global optimal value, this fitness value takes the place of the global optimal value.
Step 5 Modification operation for the evolutionary direction
Evolutionary optimization is performed by selecting the three most effective solutions from each generation. The goal of each new solution is to surpass the previous best solution. The three best particles are ordered in accordance with their fitness, and the particles with the highest, second-highest, and third-highest fitness values are called the first, second, and third particles, respectively (denoted Pf, Ps, and Pt, respectively). These particles are expressed as follows:
First particle:
Second particle:
Third particle:
The initial step is to update the third particle using a migration operation to create a new third particle. Subsequently, the second and first particles are used as references for the new third particle to move in the target direction; that is, the new third particle is updated again in accordance with the direction indicated by the second and first particles. The global search capacity is improved through this process. The modification operation for the evolutionary direction (MOED) is detailed as follows:
Step 5.1 The parameters of the two evolution directions and the initial index of the MOED are set as 1; that is, the initial number of iterations is set as 1. The number of MOED loops is set as NL. The three particles (Pf, Ps, and Pt) with the highest fitness values in the swarm are selected for evolutionary optimization.
Step 5.2 A migration operation is used to generate a new diverse population and to prevent particles from gradually clustering; thus, the migration operation considerably increases the size of the search space for small-swarm exploration. Migrating particles are generated through nonuniform random selection based on the three best particles. The objective is to prevent the MOED from becoming trapped in a local extremum. The second and third particles Ps and Pt, respectively) are updated using Eq. (17).
where r and th are random numbers in the interval [0, 1].
Step 5.3 The current evolutionary direction and current evolutionary step size of the parallelogram are used to generate particle Po, as expressed in Eq. (18). By using the two difference vectors
Step 5.4 The fitness Fo is evaluated using the newly generated output particle (Po).
Step 5.5 The third, second, and first particles (Pt, Ps, and Pf, respectively) are updated in sequence as follows:
(1) If Fo > Ff , then Pt = Ps , Ps = Pf , and Pf = Po.
(2) If Fo < Ff and Fo > Fs , then Pt = Ps , and Ps = Po.
(3) If Fo > Ft and Fo < Fs , then Pt = Po.
(4) If Fo = Ft = Fs , then
(5) If Fo < Ft , then
Under the first three aforementioned conditions, the first, second, and third particles are updated on the basis of the fitness value of Po. The fourth condition is considered if Po, Ps, and Pt have the same fitness values. In this case, a random disturbance factor is added to the fitness value of Po to prevent the MOED from becoming trapped at a local optimum. Finally, if the fitness value of Po is lower than those of Po, Ps, and Pt to obtain better fitness, the particle velocity is decreased with a constant penalty parameter (fifth condition).
Step 5.6 The global best value is updated. Replace the current global best particle with Po if the fitness value of Po is greater than the current global best value.
Step 6 Updating the particle velocity
By using the Eq. (13), the velocity of every particle dimension is updated.
Step 7 Updating the particle position
By using the Eq. (14), the position of every particle dimension is updated.
2.5 Proposed D-IRFCMAC-IPSO Method
A D-IRFCMAC model that combines spatial and temporal (recurrent) information is proposed. An IPSO algorithm that effectively strengthens the exploratory capabilities in the global search solution space is proposed. The IPSO is used to optimize the internal parameters of the D-IRFCMAC model and decrease the subjective influence of chosen parameters. The IPSO algorithm is employed to optimize the internal parameters of the D-IRFCMAC module, as depicted the overall process is shown in Fig. 6. The process area of the D-IRFCMAC model is depicted in the red block, while that of IPSO is depicted in the green block.

Figure 6: Flowchart of the D-IRFCMAC model and IPSO algorithm for fall detection
Two experiments were conducted to examine the fall detection performance of the proposed method, which involves integrating the proposed IPSO algorithm into the designed D-IRFCMAC model, and to also compare this performance with that of several existing state-of-art methods.
Three fall event data sets and two activity classification data sets were used to test the proposed model. The first fall event data set was collected using multiple cameras (eight cameras for each scene in each scenario) [69]; thus, this data set is called the multiple-camera fall data set. The aforementioned data set comprised 736 videos of different actions: 120 videos of falls, 192 videos of walking, 88 videos of pseudofalls, 80 videos of sitting, 32 videos of lying down, 16 videos of standing, 72 videos of crouching, 8 videos showing objects being dropped, 88 videos showing objects being carried (picked up or put down), 8 videos of taking off or hanging a coat on a coat rack, and 32 videos of sweeping. Each of the aforementioned videos had resolution of 720 × 480 pixels and a frame rate of 30 fps. A total of 80% and 20% of the aforementioned data set were used for training and testing, respectively. The second fall event data set, namely the fall detection data set (FDD) [70], comprised 192 videos of falls (forward falls, falls caused by an inappropriate sitting-down action, and falls caused by loss of balance) and 58 videos on several normal activities (walking in different directions, sitting down, standing up, crouching, housekeeping, and moving a chair). Each of these videos had resolution of 320 × 240 pixels and a frame rate of 25 fps. Each video was recorded from seven directions and positions in one of four locations: a home, a coffee room, an office, or a lecture room. Regarding the multiple-camera fall data set, 80% and 20% of the FDD were used for training and testing, respectively. The examined methods were also evaluated on the UR fall data set (URFD) [71], with 80% and 20% of the data set being used for training and testing, respectively. The URFD contains 70 videos: 30 videos on falls (e.g., forward falls and falls caused by loss of balance) and 40 videos on activities of daily living (e.g., walking, sitting down, crouching, and lying down) in various locations.
The second type tends to activity classification datasets, The UCF11 dataset [62] is an activity classification dataset that was also used to evaluate the performance of the proposed method and other methods. UCF11 is an action dataset composed of 1600 videos, including 11 action videos. The action videos included those of diving, cycling, basketball shooting and so on. Each action video only displayed one type of action. A similar dataset, UCF101 [72], was also used for evaluation. The UCF101 dataset contains 13,000 video clips from 101 activity categories. Both databases were divided into training, validation, and test sets at a 3:1:1 ratio.
All videos from the aforementioned five data sets were adjusted to resolution of 128 × 128 pixels before being processed. A total of 60 features obtained using the OF method and DFT for each video frame were used as the input in the training, validation, and testing of the D-IRFCMAC model integrated with the proposed IPSO algorithm.
Ablation studies were performed to determine the effectiveness of the added IPSO for improving FDD and FURD performance. The results are presented in Table 1. With the IPSO algorithm, the proposed D-IRFCMAC model has better accuracy.

3.3 Experimental Results for Fall Detection
For the three fall event data sets, the parameters of the proposed IPSO algorithm were set as follows: the initial coefficient w was set as 0.5, the cognitive and society coefficients were set as 1, the swarm size was set as 100, the number of iterations was set as 5000, and the number of fuzzy rules (hypercube cells) of the D-IRFCMAC model was set as 6 (six cells). The parameters

3.4 Experimental Results for Activity Recognition
The activity recognition performance of the proposed method was investigated on the UCF11 and UCF101 data sets. The parameters of the IPSO algorithm in the activity recognition experiment were the same as those in the fall detection experiment. Tables 3 and 4 present the average testing classification accuracy of the proposed method on the UCF11 and UCF101 data sets in five cross-validation trials (93.13% and 92.19%, respectively). Various existing state-of-the-art methods were also employed on the aforementioned data sets, and their performance was compared with that of the proposed method. The proposed method was discovered to outperform the state-of-the-art-methods in activity recognition on both the UCF11 and UCF101 data sets (Table 5). The proposed method had 1.12% and 1.73% higher accuracy than the method with the second-best performance, namely visual attention–guided 3D CNN, on the UCF11 and UCF101 data sets, respectively. The superior performance of the proposed method is reflected in the confusion matrix for the UCF11 data set, which is presented in Fig. 7. Most activities in this data set were correctly classified by the proposed method.




Figure 7: Confusion matrix for the proposed method when applied to the UCF11 data set
To verify the stability and effectiveness of the proposed method, this method and existing state-of-the-art methods [73–77] were tested on the UR-Fall, UP-Fall, and PRECIS HAR [78] data sets, which comprise data on activities of daily living, such as walking, standing, squatting, and sitting. For each data set, 90%, 5%, and 5% of the data were used for training, validation, and testing, respectively. Table 6 presents the results obtained on the aforementioned data sets; the proposed method outperformed the existing state-of-the-art methods.

The aforementioned experimental results indicate that the proposed method outperforms existing state-of-the-art methods in fall detection and activity recognition. The superior performance of the proposed method is attributable to the D-IRFCMAC model using both spatial and temporal (recurrent) information and the IPSO algorithm improving the exploration of the global search space by this model. The proposed method enables highly accurate fall detection to be achieved after training with a small fall event data set. However, this method can only detect a fall and not predict one. The prediction of fall events is a possible topic for future research.
This study developed a method that involves combining the proposed D-IRFCMAC model with an IPSO algorithm to achieve highly accurate fall detection and activity recognition. The designed D-IRFCMAC model processes spatial and temporal information in videos by using recurrent mechanisms. In addition, the proposed IPSO algorithm improves this model’s exploration of the global search space. The integration of the IPSO algorithm into the D-IRFCMAC model improves the model’s overall efficiency and effectiveness. Motion information features are crucial to fall detection and activity recognition. In the proposed method, OFTIs and FTIs are employed for feature selection and for efficiently encoding movement features. The selected features are then input to the D-IRFCMAC model integrated with the proposed IPSO algorithm to obtain accurate and robust fall detection or activity recognition results. The D-IRFCMAC model uses features obtained from OFTIs and FTIs to locate regions of interest in each video frame. The D-IRFCMAC model was discovered to exhibit excellent fall detection performance after being trained on different action-related data sets. Because simulated fall data sets are difficult to obtain, the aforementioned characteristic is a key advantage of this model. Experiments indicated that the proposed method outperforms existing state-of-the-art methods in terms of fall detection accuracy on the FDD and URFD and activity recognition accuracy on the UCF11 and UCF101 data sets. The proposed method also outperforms existing state-of-the-art methods in terms of action recognition accuracy on the UR-Fall, UP-Fall, and PRECIS HAR data sets. The UCF11 dataset had an average accuracy of 93.13%, whereas the UCF101 dataset had an average accuracy of 92.19%. The UR-Fall dataset had an accuracy of 100%, the UP-Fall dataset had an accuracy of 99.25%, and the PRECIS HAR dataset had an accuracy of 99.07%.
Acknowledgement: Not applicable.
Funding Statement: This research was supported by the National Science and Technology Council under grants NSTC 112-2221-E-320-002 and the Buddhist Tzu Chi Medical Foundation in Taiwan under Grant TCMMP 112-02-02.
Availability of Data and Materials: 1. The data that support the findings of this study are openly available in [Multiple Cameras fall dataset-MFD] at [https://www.iro.umontreal.ca/~labimage/Dataset/ (accessed on 07 Oct. 2010)]. 2. The data that support the findings of this study are openly available in [UCF101] at [https://www.crcv.ucf.edu/data/UCF101.php (accessed on 17 Oct. 2013)]. 3. The data that support the findings of this study are openly available in [UCF11] at [https://www.crcv.ucf.edu/data/UCF_YouTube_Action.php (accessed on 31 Oct. 2011)]. 4. The data that support the findings of this study are openly available in [UP-Fall] at [https://sites.google.com/up.edu.mx/har-up/ (accessed on 04 Aug. 2019)]. 5. The data that support the findings of this study are openly available in [UR-Fall] at [http://fenix.ur.edu.pl/~mkepski/ds/uf.html (accessed on 12 Jun. 2014)]. 6. The data that support the findings of this study are openly available in [PRECIS HAR] at [https://ieee-dataport.org/open-access/precis-har (accessed on 01 Feb. 2020)].
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that there are no conflicts of interest. The contents of the manuscript have been reviewed and approved by all co-authors, and there is no financial interest in reporting. We confirm that the submission is original work and is not currently under review at any other publication.
References
1. G. Sannino, I. De Falco, and G. De Pietro, “A supervised approach to automatically extract a set of rules to support fall detection in an mHealth system,” Appl. Soft Comput., vol. 34, pp. 205–216, 2015. doi: 10.1016/j.asoc.2015.04.060. [Google Scholar] [CrossRef]
2. L. Yang, Y. Ren, H. Hu, and B. Tian, “New fast fall detection method based on spatio-temporal context tracking of head by using depth images,” Sensors, vol. 15, no. 9, pp. 23004–23019, 2015. doi: 10.3390/s150923004. [Google Scholar] [PubMed] [CrossRef]
3. G. Carone and D. Costello, “Can Europe afford to grow old?” Int. Monet. Fund Finance Dev. Mag., vol. 43, no. 3, 2006. [Google Scholar]
4. J. Halter et al., “Hazzard’s Geriatric Medicine and Gerontology,” in JAMA Network, 8th ed., McGraw Hill/Medical, 2009, vol. 302. pp. 1813. [Google Scholar]
5. S. Lord, S. Smith, and J. Menant, “Vision and falls in older people: Risk factors and intervention strategies,” Clin. Geriatr. Med., vol. 26, no. 4, pp. 569–581, 2010. doi: 10.1016/j.cger.2010.06.002. [Google Scholar] [PubMed] [CrossRef]
6. M. Okada, K. Tatani, and Y. Nakamura, “Polynomial design of the nonlinear dynamics for the brain-like information processing of whole body motion,” in Proc. ICRA, Washington, DC, USA, 2002, pp. 1410–1415. [Google Scholar]
7. A. J. Ijspeert, J. Nakanishi, and S. Shaal, “Learning control policies for movement imitation and movement recognition,” Neural Inf. Process. Syst., vol. 15, pp. 1547–1554, 2003. [Google Scholar]
8. J. Tani and M. Ito, “Self-organization of behavioral primitives as multiple attractor dynamics: A robot experiment,” IEEE Trans. Syst., Man Cybern. A: Syst. Humans, vol. 33, no. 4, pp. 481–488, 2003. doi: 10.1109/TSMCA.2003.809171. [Google Scholar] [CrossRef]
9. H. Kadone and Y. Nakamura, “Symbolic memory for humanoid robots using hierarchical bifurcations of attractors in nonmonotonic neural networks,” in Proc. IROS, Edmonton, AB, Canada, 2005, pp. 2900–2905. [Google Scholar]
10. D. Kulic, H. Imagawa, and Y. Nakamura, “Online acquisition and visualization of motion primitives for humanoid robots,” in Proc. RO-MAN, Toyama, Japan, 2009, pp. 1210–1215. [Google Scholar]
11. K. Sugiura, N. Iwahashi, H. Kashioka, and S. Nakamura, “Active learning of confidence measure function in robot language acquisition framework,” in Proc. IROS, Taipei, Taiwan, 2010, pp. 1774–1779. [Google Scholar]
12. I. Mordatch, K. Lowrey, G. Andrew, Z. Popovic, and E. Todorov, “Interactive control of diverse complex characters with neural networks,” in Proc. NIPS, Montreal, QC, Canada, 2015, pp. 3132–3140. [Google Scholar]
13. P. Veltink, H. Bussmann, W. Vries, W. Martens, and R. Lummel, “Detection of static and dynamic activities using uniaxial accelerometers,” IEEE Trans. Rehab. Eng., vol. 4, no. 4, pp. 375–385, 1996. doi: 10.1109/86.547939. [Google Scholar] [PubMed] [CrossRef]
14. M. Kangas, A. Konttila, P. Lindgren, I. Winblad, and T. Jamsa, “Comparison of low-complexity fall detection algorithms for body attached accelerometers,” Gait Posture, vol. 28, no. 2, pp. 285–291, 2008. doi: 10.1016/j.gaitpost.2008.01.003. [Google Scholar] [PubMed] [CrossRef]
15. Y. Li, K. Ho, and M. Popescu, “A microphone array system for automatic fall detection,” IEEE Trans. Biomed. Eng., vol. 59, no. 2, pp. 1291–1301, 2012. doi: 10.1109/TBME.2012.2186449. [Google Scholar] [PubMed] [CrossRef]
16. Y. Zigel, D. Litvak, and I. Gannot, “A method for automatic fall detection of elderly people using floor vibrations and sound proof of concept on human mimicking doll falls,” IEEE Trans. Biomed. Eng., vol. 56, no. 12, pp. 2858–2867, 2009. doi: 10.1109/TBME.2009.2030171. [Google Scholar] [PubMed] [CrossRef]
17. L. Chen, R. Li, H. Zhang, L. Tian, and N. Chen, “Intelligent fall detection method based on accelerometer data from a wrist-worn smart watch,” Measurement, vol. 140, no. 2, pp. 215–226, 2019. doi: 10.1016/j.measurement.2019.03.079. [Google Scholar] [CrossRef]
18. M. M. Hassan, A. Gumaei, G. Aloi, G. Fortino, and M. Zhou, “A smartphone-enabled fall detection framework for elderly people in connected home healthcare,” IEEE Netw., vol. 33, no. 6, pp. 58–63, 2019. doi: 10.1109/MNET.001.1900100. [Google Scholar] [CrossRef]
19. J. S. Lee and H. H. Tseng, “Development of an enhanced threshold-based fall detection system using smartphones with built-in accelerometers,” IEEE Sens. J., vol. 19, no. 18, pp. 8293–8302, 2019. doi: 10.1109/JSEN.2019.2918690. [Google Scholar] [CrossRef]
20. C. Rougier, J. Meunier, A. St-Arnaud, and J. Rousseau, “Fall detection from human shape and motion history using video surveillance,” in Proc. AINAW, Niagara Falls, ON, Canada, 2007, pp. 875–880. [Google Scholar]
21. C. Rougier and J. Meunier, “3D head trajectory using a single camera,” Int. J. Future Gener. Commun. Netw., Invited Paper Special Issue Image Signal Process., vol. 3, no. 4, pp. 43–54, 2010. doi: 10.1007/978-3-642-13681-8. [Google Scholar] [CrossRef]
22. C. Rougier, J. Meunier, A. St-Arnaud, and J. Rousseau, “Robust video surveillance for fall detection based on human shape deformation,” IEEE Trans. Circuits Syst. Video Technol., vol. 21, no. 5, pp. 611–622, 2011. doi: 10.1109/TCSVT.2011.2129370. [Google Scholar] [CrossRef]
23. E. Auvinet, F. Multon, A. Saint-Arnaud, J. Rousseau, and J. Meunier, “Fall detection with multiple cameras: An occlusion-resistant method based on 3-D silhouette vertical distribution,” IEEE Trans. Inf. Technol. Biomed., vol. 15, no. 2, pp. 290–300, 2011. doi: 10.1109/TITB.2010.2087385. [Google Scholar] [PubMed] [CrossRef]
24. C. Juang and C. Chang, “Human body posture classification by a neural fuzzy network and home care system application,” IEEE Trans. Syst., Man, Cybern. A: Syst. Humans, vol. 37, no. 6, pp. 984–994, 2007. doi: 10.1109/TSMCA.2007.897609. [Google Scholar] [CrossRef]
25. C. Liu, C. Lee, and P. Lin, “A fall detection system using k-nearest neighbor classifier,” Expert. Syst. Appl., vol. 37, no. 10, pp. 7174–7181, 2010. doi: 10.1016/j.eswa.2010.04.014. [Google Scholar] [CrossRef]
26. T. Lee and A. Mihailidis, “An intelligent emergency response system: Preliminary development and testing of automated fall detection,” J. Telemed. Telecare, vol. 11, no. 4, pp. 194–198, 2005. doi: 10.1258/1357633054068946. [Google Scholar] [PubMed] [CrossRef]
27. M. Belshaw, B. Taati, J. Snoek, and A. Mihailidis, “Towards a single sensor passive solution for automated fall detection,” in Proc. 2011 Annu. Int. Conf. IEEE Eng. Med. Biol. Soc., 2011, pp. 1773–1776. [Google Scholar]
28. J. Jefn Gracewell and S. Pavalarajan, “Fall detection based on posture classification for smart home environment,” J. Ambient Intell. Humaniz. Comput., vol. 12, no. 3, pp. 3581–3588, 2019. doi: 10.1007/s12652-019-01600-y. [Google Scholar] [CrossRef]
29. D. Anderson, J. Keller, M. Skubic, X. Chen, and Z. He, “Recognizing falls from silhouettes,” in Proc. IEEE EMBS, New York, NY, USA, 2006, pp. 6388–6391. [Google Scholar]
30. N. Thome, S. Miguet, and S. Ambellouis, “A real-time, multiview fall detection system: A LHMM-based approach,” IEEE Trans. Circuits Syst. Video Technol., vol. 18, no. 11, pp. 1522–1532, 2008. doi: 10.1109/TCSVT.2008.2005606. [Google Scholar] [CrossRef]
31. S. McKenna and H. Nait-Charif, “Summarising contextual activity and detecting unusual inactivity in a supportive home environment,” J. Pattern Anal. Appl., vol. 7, no. 4, pp. 386–401, 2004. doi: 10.1007/s10044-004-0233-2. [Google Scholar] [CrossRef]
32. D. Anderson, R. Luke, J. Keller, M. Skubic, M. Rantz and M. Aud, “Linguistic summarization of video for fall detection using voxel person and fuzzy logic,” Comput. Vis. Image Underst., vol. 113, no. 1, pp. 80–89, 2009. doi: 10.1016/j.cviu.2008.07.006. [Google Scholar] [PubMed] [CrossRef]
33. R. Espinosa, H. Ponce, S. Gutierrez, L. Martinez-Villasenor, J. Brieva and E. Moya-Albor, “A vision-based approach for fall detection using multiple cameras and convolutional neural networks: A case study using the up-fall detection dataset,” Comput. Biol. Med., vol. 115, no. 11, pp. 103520, 2019. doi: 10.1016/j.compbiomed.2019.103520. [Google Scholar] [PubMed] [CrossRef]
34. S. Maldonado-Bascon, C. Iglesias-Iglesias, P. Martin-Martin, and S. Lafuente-Arroyo, “Fallen people detection capabilities using assistive robot,” Electronics, vol. 8, no. 9, pp. 1–20, 2019. doi: 10.3390/electronics8090915. [Google Scholar] [CrossRef]
35. A. Biswas and B. Dey, “A literature review of current vision based fall detection methods,” Adv. Commun., Devices Netw. Lecture Notes Electr. Eng., pp. 411–421, 2020. doi: 10.1007/978-981-15-4932-8_46. [Google Scholar] [CrossRef]
36. P. V. C. Souza, A. J. Guimaraes, V. S. Araujo, L. O. Batista, and T. S. Rezende, “An interpretable machine learning model for human fall detection systems using hybrid intelligent models,” in Challenges and Trends in Multimodal Fall Detection for Healthcare. Springer, 2020, vol. 273, pp. 181–205, doi:10.1007/978-3-030-38748-8_8. [Google Scholar] [CrossRef]
37. R. Espinosa, H. Ponce, S. Gutiérrez, L. Martínez-Villaseñor, J. Brieva and E. Moya-Albor, “Application of convolutional neural networks for fall detection using multiple cameras,” in Challenges and Trends in Multimodal Fall Detection for Healthcare. Springer, 2020, pp. 97–120, doi:10.1007/978-3-030-38748-8_5. [Google Scholar] [CrossRef]
38. M. Buzzelli, A. Albe, and G. Ciocca, “A vision-based system for monitoring elderly people at home,” Appl. Sci., vol. 10, no. 1, pp. 1–25, 2020. doi: 10.3390/app10010374. [Google Scholar] [CrossRef]
39. D. Liciotti, M. Bernardini, L. Romeo, and E. Frontoni, “A sequential deep learning application for recognising human activities in smart homes,” Neurocomputing, vol. 396, no. 6, pp. 501–513, 2020. doi: 10.1016/j.neucom.2018.10.104. [Google Scholar] [CrossRef]
40. H. Zhu, S. Samtani, H. Chen, and J. F. Nunamaker Jr, “Human identification for activities of daily living: A deep transfer learning approach,” J. Manag. Inf. Syst., vol. 37, no. 2, pp. 457–483, 2020. doi: 10.1080/07421222.2020.1759961. [Google Scholar] [CrossRef]
41. Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. doi: 10.1038/nature14539. [Google Scholar] [PubMed] [CrossRef]
42. I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proc. NIPS, 2014, pp. 3104–3112. [Google Scholar]
43. A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Commun. ACM, vol. 60, no. 6, pp. 84–90, 2017. doi: 10.1145/3065386. [Google Scholar] [CrossRef]
44. K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Proc. ICLR, 2015, pp. 1–14. [Google Scholar]
45. C. Doersch and A. Zisserman, “Sim2real transfer learning for 3D human pose estimation: Motion to the rescue,” in Proc. NeurIPS, Vancouver, BC, Canada, 2019. [Google Scholar]
46. Y. M. Galvão, J. Ferreira, V. A. Albuquerque, P. Barros, and B. J. T. Fernandes, “A multimodal approach using deep learning for fall detection,” Expert. Syst. Appl., vol. 168, no. 15, pp. 114226, 2021. doi: 10.1016/j.eswa.2020.114226. [Google Scholar] [CrossRef]
47. T. -H. Tsai and C. -W. Hsu, “Implementation of fall detection system based on 3D skeleton for deep learning technique,” IEEE Access, vol. 7, pp. 153049–153059, 2019. doi: 10.1109/ACCESS.2019.2947518. [Google Scholar] [CrossRef]
48. J. Wang, Y. Chen, S. Hao, X. Peng, and L. Hu, “Deep learning for sensor-based activity recognition: A survey,” Pattern Recognit. Lett., vol. 119, no. 1, pp. 3–11, 2019. doi: 10.1016/j.patrec.2018.02.010. [Google Scholar] [CrossRef]
49. A. Dhillon and G. K. Verma, “Convolutional neural network: A review of models, methodologies and applications to object detection,” Prog. Artif. Intell., vol. 9, no. 2, pp. 85–112, 2020. doi: 10.1007/s13748-019-00203-0. [Google Scholar] [CrossRef]
50. H. Sadreazami, M. Bolic, and S. Rajan, “Fall detection using standoff radar-based sensing and deep convolutional neural network,” IEEE Trans. Circuits Syst. II: Express Briefs, vol. 67, no. 1, pp. 197–201, 2019. doi: 10.1109/TCSII.2019.2904498. [Google Scholar] [CrossRef]
51. J. He, Z. Zhang, X. Wang, and S. Yang, “A low power fall sensing technology based on FD-CNN,” IEEE Sens. J., vol. 19, no. 13, pp. 5110–5118, 2019. doi: 10.1109/JSEN.2019.2903482. [Google Scholar] [CrossRef]
52. I. Kiprijanovska, H. Gjoreski, and M. Gams, “Detection of gait abnormalities for fall risk assessment using wrist-worn inertial sensors and deep learning,” Sensors, vol. 20, no. 18, pp. 5373, 2020. doi: 10.3390/s20185373. [Google Scholar] [PubMed] [CrossRef]
53. M. Musci, D. D. Martini, N. Blago, T. Facchinetti, and M. Piastra, “Online fall detection using recurrent neural networks on smart wearable devices,” IEEE Trans. Emerg. Top. Comput., vol. 9, no. 3, pp. 1276–1289, 2020. doi: 10.1109/TETC.2020.3027454. [Google Scholar] [CrossRef]
54. L. Yao, W. Yang, and W. Huang, “A fall detection method based on a joint motion map using double convolutional neural networks,” Multimed. Tools Appl., vol. 81, no. 4, pp. 1–18, 2020. doi: 10.1007/s11042-020-09181-1. [Google Scholar] [CrossRef]
55. Y. Du, Y. Fu, and L. Wang, “Skeleton based action recognition with convolutional neural network,” in Proc. ACPR, 2015, pp. 579–583. [Google Scholar]
56. Q. Ke, M. Bennamoun, S. An, F. Sohel, and F. Boussaid, “A new representation of skeleton sequences for 3D action recognition,” in Proc. CVPR, Honolulu, HI, USA, 2017, pp. 4570–4579. [Google Scholar]
57. Y. Hou, Z. Li, P. Wang, and W. Li, “Skeleton optical spectra-based action recognition using convolutional neural networks,” IEEE Trans. Circuits Syst. Video Technol., vol. 28, no. 3, pp. 807–811, 2018. doi: 10.1109/TCSVT.2016.2628339. [Google Scholar] [CrossRef]
58. P. Wang, W. Li, C. Li, and Y. Hou, “Action recognition based on joint trajectory maps with convolutional neural networks,” in Proc. ACM Multimedia, 2016. [Google Scholar]
59. J. Koushik, “Understanding convolutional neural networks,” in Proc. ICET, Antalya, Turkey, 2016. [Google Scholar]
60. J. Gu et al., “Recent advances in convolutional neural networks,” Pattern Recognit., vol. 77, no. 11, pp. 354–377, 2018. doi: 10.1016/j.patcog.2017.10.013. [Google Scholar] [CrossRef]
61. E. Park, X. Han, T. L. Berg, and A. C. Berg, “Combining multiple sources of knowledge in deep CNNs for action recognition,” in Proc. WACV, 2016, pp. 1–8. [Google Scholar]
62. S. Sharma, R. Kiros, and R. Salakhutdinov, “Action recognition using visual attention,” in Proc. ICLR, Canada, 2016, pp. 1–11. [Google Scholar]
63. C. Szegedy et al., “Going deeper with convolutions,” in Proc. CVPR, 2015, pp. 1–9. [Google Scholar]
64. N. Lu, Y. Wu, L. Feng, and J. Song, “Deep learning for fall detection: Three-dimensional CNN combined with LSTM on video kinematic data,” IEEE J. Biomed. Health Inform., vol. 23, no. 1, pp. 314–323, 2019. doi: 10.1109/JBHI.2018.2808281. [Google Scholar] [PubMed] [CrossRef]
65. K. Mohajeri, M. Zakizadeh, B. Moaveni, and M. Teshnehlab, “Fuzzy CMAC structures,” in Proc. FUZZ-IEEE, Jeju, Republic of Korea, 2009, pp. 2126–2131. [Google Scholar]
66. K. F. Sim and K. Sundaraj, “Human motion tracking of athlete using optical flow & artificial markers,” in Proc. ICIAS, Kuala Lumpur, Malaysia, 2010, pp. 1–4. [Google Scholar]
67. B. Sharma, K. S. Venkatesh, and A. Mukerjee, “Fourier shape-frequency words for actions,” in Proc. ICIIP, Shimla, India, 2011, pp. 1–6. [Google Scholar]
68. J. Kennedy and R. Eberhart, “Particle swarm optimization,” in Proc. ICNN, Perth, WA, Australia, 1995, pp. 1942–1948. [Google Scholar]
69. E. Auvinet, C. Rougier, J. Meunier, A. St-Arnaud, and J. Rousseau, “Multiple camera fall dataset,” Techn. Report, pp. 1–24, 2010. [Google Scholar]
70. I. ICharfi, J. Miteran, J. Dubois, M. Atri, and R. Tourki, “Definition and performance evaluation of a robust svm based fall detection solution,” in Proc. SITIS, Sorrento, Italy, 2012, pp. 218–224. [Google Scholar]
71. B. Kwolek and M. Kepski, “Human fall detection on embedded platform using depth maps and wireless accelerometer,” Comput. Methods Programs Biomed., vol. 117, no. 3, pp. 489–501, 2014. doi: 10.1016/j.cmpb.2014.09.005. [Google Scholar] [PubMed] [CrossRef]
72. S. Khurram, Z. Amir Roshan, and S. Mubarak, “UCF101: A dataset of 101 human actions classes from videos in the wild,” in Proc. CVPR, Orlando, FL, USA, 2012, pp. 1–7. [Google Scholar]
73. L. Martínez-Villaseñor, H. Ponce, J. Brieva, E. Moya-Albor, J. Núñez-Martínez and C. Peñafort-Asturiano, “UP-Fall detection dataset: A multimodal approach,” Sensors, vol. 19, no. 9, pp. 1988, 2019. doi: 10.3390/s19091988. [Google Scholar] [PubMed] [CrossRef]
74. S. K. Yadav, A. Luthra, K. Tiwari, H. M. Pandey, and S. A. Akbar, “ARFDNet: An efficient activity recognition & fall detection system using latent feature pooling,” Knowl.-Based Syst., vol. 239, no. 7, pp. 107948, 2022. doi: 10.1016/j.knosys.2021.107948. [Google Scholar] [CrossRef]
75. Y. M. Galvão, L. Portela, J. Ferreira, P. Barros, R. A. D. Fagundes and B. J. T. Fernandes, “A framework for anomaly identification applied on fall detection,” IEEE Access, vol. 9, pp. 77264–77274, 2021. doi: 10.1109/ACCESS.2021.3083064. [Google Scholar] [CrossRef]
76. F. Harrou, N. Zerrouki, Y. Sun, and A. Houacine, “An integrated vision based approach for efficient human fall detection in a home environment,” IEEE Access, vol. 7, pp. 114966–114974, 2019. doi: 10.1109/ACCESS.2019.2936320. [Google Scholar] [CrossRef]
77. A. C. Popescu, I. Mocanu, and B. Cramariuc, “Fusion mechanisms for human activity recognition using automated machine learning,” IEEE Access, vol. 8, pp. 143996–144014, 2020. doi: 10.1109/ACCESS.2020.3013406. [Google Scholar] [CrossRef]
78. A. Popescu, I. Mocanu, and B. Cramariuc, Precis har. Accessed: Feb. 01, 2020. [Online]. Available: https://ieee-dataport.org/open-access/precis-har [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools