
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Fireworks Optimization with Deep Learning-Based Arabic Handwritten Characters Recognition Model
1 Department of Computer and Self Development, Prince Sattam bin Abdulaziz University, AlKharj, 16278, Saudi Arabia
2 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Makkah, 24211, Saudi Arabia
4 Department of Information Systems, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
5 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
* Corresponding Author: Abdelwahed Motwakel. Email:
Computer Systems Science and Engineering 2024, 48(5), 1387-1403. https://doi.org/10.32604/csse.2023.033902
Received 01 July 2022; Accepted 07 November 2022; Issue published 13 September 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Handwritten character recognition becomes one of the challenging research matters. More studies were presented for recognizing letters of various languages. The availability of Arabic handwritten characters databases was confined. Almost a quarter of a billion people worldwide write and speak Arabic. More historical books and files indicate a vital data set for many Arab nations written in Arabic. Recently, Arabic handwritten character recognition (AHCR) has grabbed the attention and has become a difficult topic for pattern recognition and computer vision (CV). Therefore, this study develops fireworks optimization with the deep learning-based AHCR (FWODL-AHCR) technique. The major intention of the FWODL-AHCR technique is to recognize the distinct handwritten characters in the Arabic language. It initially pre-processes the handwritten images to improve their quality of them. Then, the RetinaNet-based deep convolutional neural network is applied as a feature extractor to produce feature vectors. Next, the deep echo state network (DESN) model is utilized to classify handwritten characters. Finally, the FWO algorithm is exploited as a hyperparameter tuning strategy to boost recognition performance. Various simulations in series were performed to exhibit the enhanced performance of the FWODL-AHCR technique. The comparison study portrayed the supremacy of the FWODL-AHCR technique over other approaches, with 99.91% and 98.94% on Hijja and AHCD datasets, respectively.Keywords
Arabic remains the official language for major nations in the Middle East region. It was the original language of the Hadith and the Quran; therefore, it has become extensively learned by Muslims across the globe. There were three major methods of the Arabic language. Firstly, traditional Arabic was utilized in Islamic manuscripts like the Quran [1]. The Arabic dialect is classified into seven categories: Maltese, Egyptian, North African, Levantine, Yemeni, and Gulf, Iraqi [2]. Arabic has become part of the Semitic linguistic family. Writings in Arabic were written and read from left to right in contrast to English linguistics. The Arabic alphabet has twenty-eight letters [3]. It has just 2 vowels: (أ/alif and ي/yaa’). Every letter in Arabic is printed in many shapes based on the word’s position. For instance, the letter “ف/faa”’ is printed as  based on the position that is placed in the middle, in the beginning, or the word end [4].
based on the position that is placed in the middle, in the beginning, or the word end [4].
The utility of diacritics has become common in Arabic. Diacritics were named Harakāt or Tashkīl in Arabic, and it is employed as a phonetic guide. In certain cases, diacritics help reduce ambiguity, as multiple words in Arabic could share the same spelling but contains various meaning and pronunciations [5,6]. For instance, the Arabic word  denotes hair,
denotes hair,  represents feel, and “شِعْر” indicates poetry. In a few decades, numerous studies have focused on researching Arabic handwriting due to its distinct properties compared to other languages [7]. It was a cursive script which has twenty-eight basic letters in which, the majority of which changed their shape following their position across the globe
represents feel, and “شِعْر” indicates poetry. In a few decades, numerous studies have focused on researching Arabic handwriting due to its distinct properties compared to other languages [7]. It was a cursive script which has twenty-eight basic letters in which, the majority of which changed their shape following their position across the globe  . Handwriting analysis is done to recognize the script, detect the writer, and recognise the expressive state of the writer [8,9]. There were 2 branches of handwriting detection. Initially, offline in which, the handwriting can be attained from a digital input source. In this case, it attains a binary image in which the pixel values are either 0 or 1 [10]. Another one, termed online handwriting script, was captured by touch-sensitive gadgets. After dynamic data was obtainable, like pen pressure, (x, y) coordinates, the temporal order of trajectory, and velocity profile, with the advancement of deep learning (DL), convolutional neural networks (CNNs) have shown an important ability to recognize handwritten characters of various languages [11]: Malayalam, Latin, Devanagari, Chine, etc. Many studies enhanced the CNN structure for achieving good handwritten character recognition performances. But neural network (NN) with excellent performance generally needs a moral tune of CNN hyperparameter and the finest choice of implied optimizing techniques [12]. Additionally, many trained datasets were needed to achieve outstanding performances [13].
. Handwriting analysis is done to recognize the script, detect the writer, and recognise the expressive state of the writer [8,9]. There were 2 branches of handwriting detection. Initially, offline in which, the handwriting can be attained from a digital input source. In this case, it attains a binary image in which the pixel values are either 0 or 1 [10]. Another one, termed online handwriting script, was captured by touch-sensitive gadgets. After dynamic data was obtainable, like pen pressure, (x, y) coordinates, the temporal order of trajectory, and velocity profile, with the advancement of deep learning (DL), convolutional neural networks (CNNs) have shown an important ability to recognize handwritten characters of various languages [11]: Malayalam, Latin, Devanagari, Chine, etc. Many studies enhanced the CNN structure for achieving good handwritten character recognition performances. But neural network (NN) with excellent performance generally needs a moral tune of CNN hyperparameter and the finest choice of implied optimizing techniques [12]. Additionally, many trained datasets were needed to achieve outstanding performances [13].
In [14], the authors devised and advanced a deep ensemble architecture in which ResNet-18 architecture can be exploited for modelling and classifying character images. To be specific, it implemented ResNet-18 by accumulating a dropout layer after all convolutional layers and compiled it in multiple ensembling methods to detect isolated handwritten Arabic characters mechanically. Alkhateeb [15] presented an efficient technique for devising a mechanism to recognize an isolated handwritten Arabic character depending on a DL method. The DL methods depended on the CNNs. It plays a significant part in any computer vision (CV) application. The CNN technique can be trained and developed with handwritten Arabic characters offline, utilizing 3 Arabic handwritten character recognition data sets. Saleem et al. [16] modelled an innovative, effective segmenting algorithm by modifying an ANN technique and making it suitable for the binarizing phase related to blocks. Our modified approach can be integrated into a novel actual rotation method for achieving precise segmenting via scrutinising the histogram of binary images. Additionally, project an innovative structure for correct text rotation that would help us establish a segmentation approach that could facilitate text abstraction from its background. The radon transforms and Image projections were utilized and enhanced by machine learning (ML) depending on a co-occurrence matrix for producing binary images.
Elleuch et al. [17] implied Convolutional Deep Belief Networks (CDBN) to textual image data has Arabic handwritten script (AHS) and assessed it on 2 distinct databases classified by the high or low-dimensional properties. Along with the advantages of deep networks, the mechanism can be protected against overfitting. In [18], the recognition and segmentation stages will be addressed. The text segmentation difficulties and a solution set for every challenge were presented. The CNN DL approach was utilized in the recognition stage. The use of CNN results in important enhancements over distinct ML classifier methods. It enables the automated feature extraction of images. Fourteen native CNN structures were suggested once a set of try-and-error trials.
This study develops fireworks optimization with a deep learning-based AHCR (FWODL-AHCR) technique. The major intention of the FWODL-AHCR technique is to recognize the distinct handwritten characters in the Arabic language. It initially pre-processes the handwritten images to improve their quality of them. Then, the RetinaNet-based deep convolutional neural network is applied as a feature extractor to produce feature vectors. Next, the deep echo state network (DESN) model is utilized to classify handwritten characters. Finally, the FWO algorithm is exploited as a hyperparameter tuning strategy to boost recognition performance. A series of simulations have been performed to exhibit the enhanced performance of the FWODL-AHCR technique.
In this study, a new FWODL-AHCR technique has been developed to recognize the distinct handwritten characters in the Arabic language. It initially pre-processes the handwritten images to improve their quality of them. Then, the RetinaNet-based deep convolutional neural network is applied as a feature extractor to produce feature vectors. Next, the FWO with DESN model is utilized to classify handwritten characters. Fig. 1 portrays the overall block diagram of the FWODL-AHCR approach.
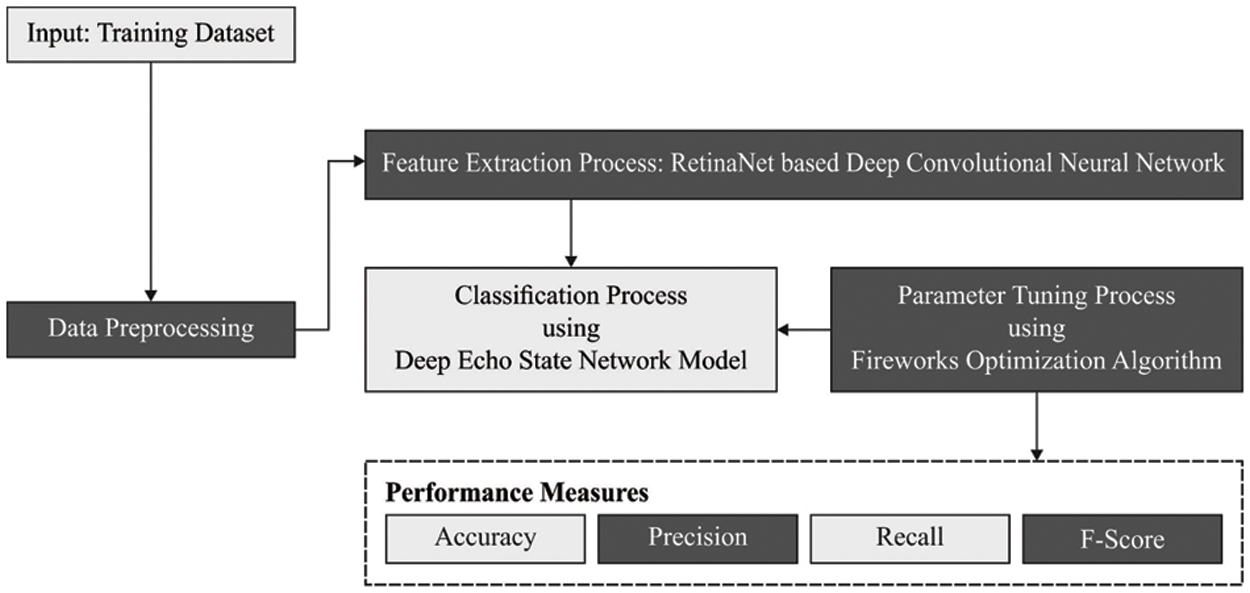
Figure 1: Overall block diagram of FWODL-AHCR approach
Initially, a new Wienmed filter (WIMF) is employed to remove the undesirable portions and inappropriate noise in the background of an image, thus confining the higher or lower frequency that perceives or improves the image boundary. The WIMF is the cooperative form of two filters, namely median and Wiener filters [19]. Both filters are integrated to reduce errors and noise distribution in an image efficiently. The filter aims to replace the neighbourhood and noisy image pixels, which were previously arranged based on the image intensity. Now, the
In Eq. (1), (
The Wiener formula for the novel image pixel is as follows, w indicates the wiener parameter. Now, the traced noise feature has been eliminated from the data.
Thus, the WIMF eliminates undesirable noise in an image, and the attained image is moved to the classification process.
2.2 RetinaNet Feature Extraction
The RetinaNet-based deep convolutional neural network is applied as a feature extractor to produce feature vectors. The RetinaNet-based transfer learning (TL) mechanism is employed in the study to derive feature vectors [20]. An input map based on the individual layer still accomplishes the resultant map. Assume
Then, the max-pooling layer is applied to decrease the parameter and computation with the size of imputing shapes. It estimates the maximal response of each image channel from the
At last, the fully connected (FC) layer is a group of layers which incorporates the data extracted from the preceding layer. This layer gets an X input, processes them, and the final FC layer produces
Focal loss: it is an adapted form of the cross entropy (
In Eq. (6),
The previous equation is rewritten by:
To overcome the issue of data imbalance amongst the negative and positive instances is formulated:
Amongst them,
In Eq. (10),
2.3 Handwritten Character Recognition Using DESN Model
At this stage, the DESN model is utilized to classify handwritten characters. DESN is a straight stack of reservoirs. In the t time step, the primary layer of DESN is fed through the external input
In Eq. (12),
Especially,
This study exploits the FWO algorithm as a hyperparameter tuning strategy to boost recognition performance. Recently, the study presented an FWO algorithm that is a swarm intelligence (SI) optimization technique based on the explosion of fireworks (FW) [22]. Once the FW detonates, the sparks are in all places. The detonation procedure of the FW is considered the search behaviour in the local space. It is highlighted that FW of different qualities produces dissimilar sparks once they explode. Higher-quality FW produces numerous sparks once they explode. The explosion of FW forms a circle, and the spark is focused in the explosion centre.
On the other hand, the worst FW produces fewer sparks once it explodes, and the sparks expand to a peculiar form. In the context of the SI approach, an FW is considered a solution candidate. A better FW implies that a solution candidate is positioned closer to the global optimum solution in a promising region. As a result, additional sparks are produced nearby better FWs to discover the optimal global solution, and the search radius is smaller. The worst FW implies that the location of the solution candidate is not perfect. Hence, the search radius must be large, decreasing the spark produced. Fig. 2 demonstrates the flowchart of the FWO technique.
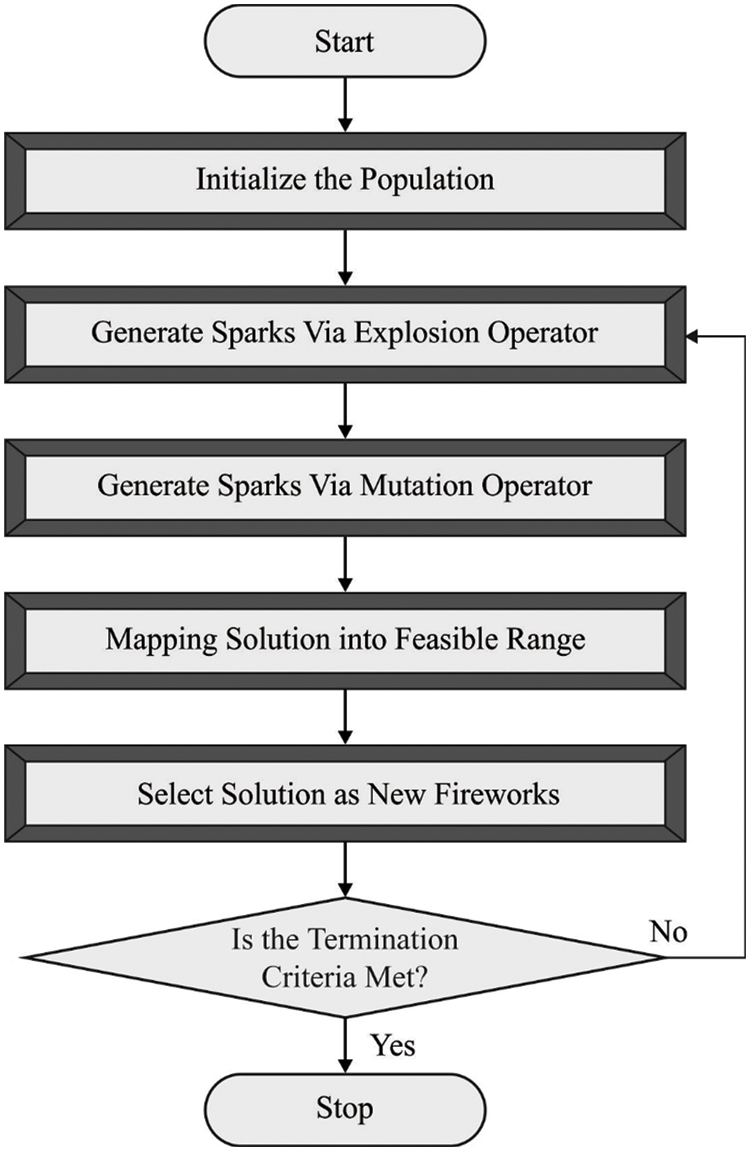
Figure 2: Flowchart of FWO technique
From the above mentioned, better FW must generate additional sparks, whereas worst FW produces fewer sparks. The approximation of the number of sparks produced by each FW is shown in Eq. (16). Good FWs are closer to the global optimum, so the explosion amplitude is small, whereas the worst FW is the opposite. The amplitude of explosion for every FW can be determined by:
From the expression,
Notably, FW design two ways of producing sparks; one is an explosion spark for a standard search, and its approach is demonstrated in Algorithm 1. Another is the Gaussian spark, a mutation model, and the algorithm is demonstrated in Algorithm 2.


The proposed model is simulated using Python 3.6.5 tool. The proposed model experiments on PC i5-8600k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1 TB HDD. The parameter settings are learning rate: 0.01, dropout: 0.5, batch size: 5, epoch count: 50, and activation: ReLU. In this section, the performance validation of the FWODL-AHCR model is tested using 28 Arabic characters, as given in Table 1.
Table 2 and Fig. 3 report the overall recognition outcomes of the FWODL-AHCR model on the test AHCD dataset. The results implied that the FWODL-AHCR model improved performance under all characters. For instance, on Chr-1, the FWODL-AHCR model has offered
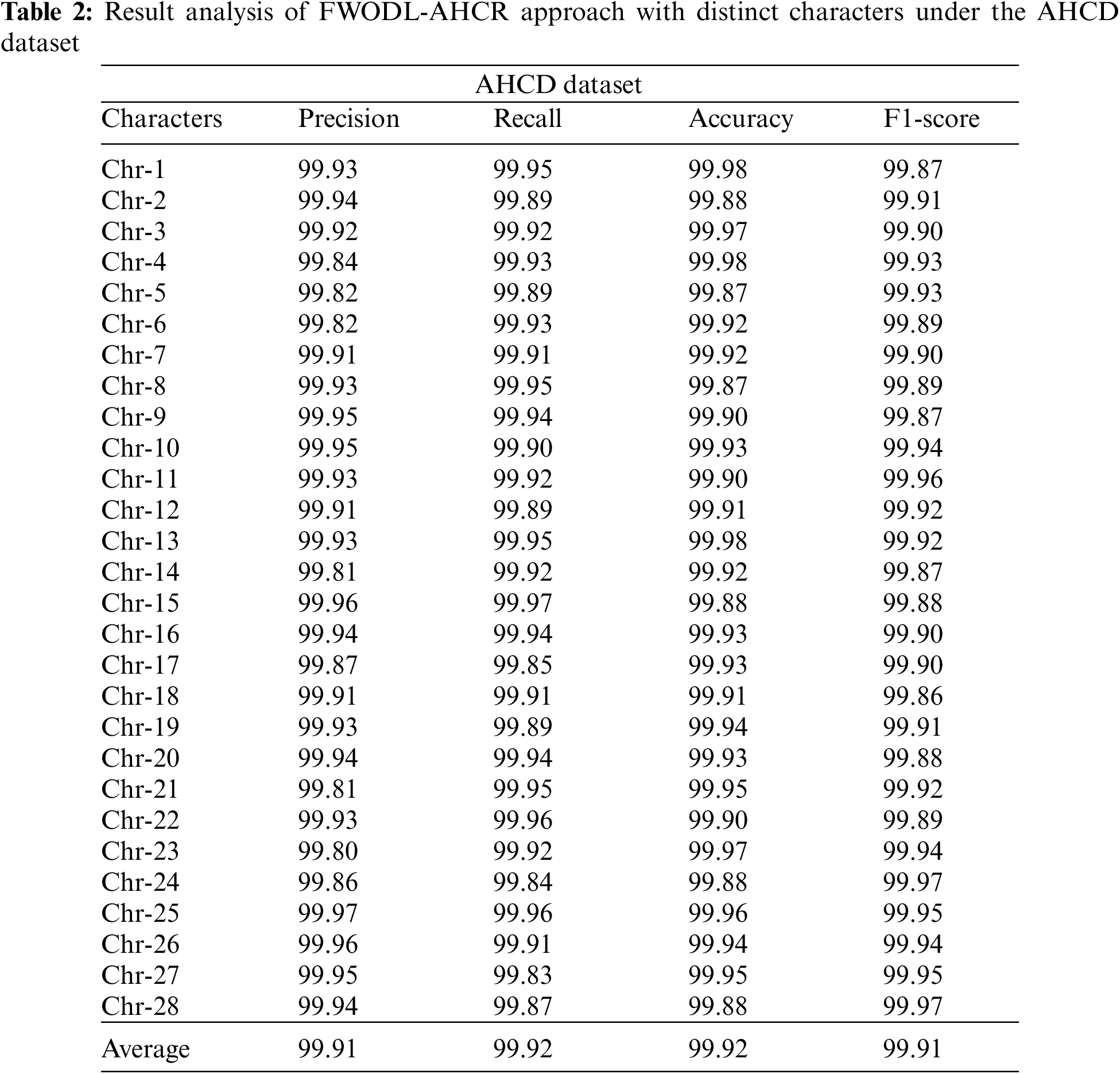

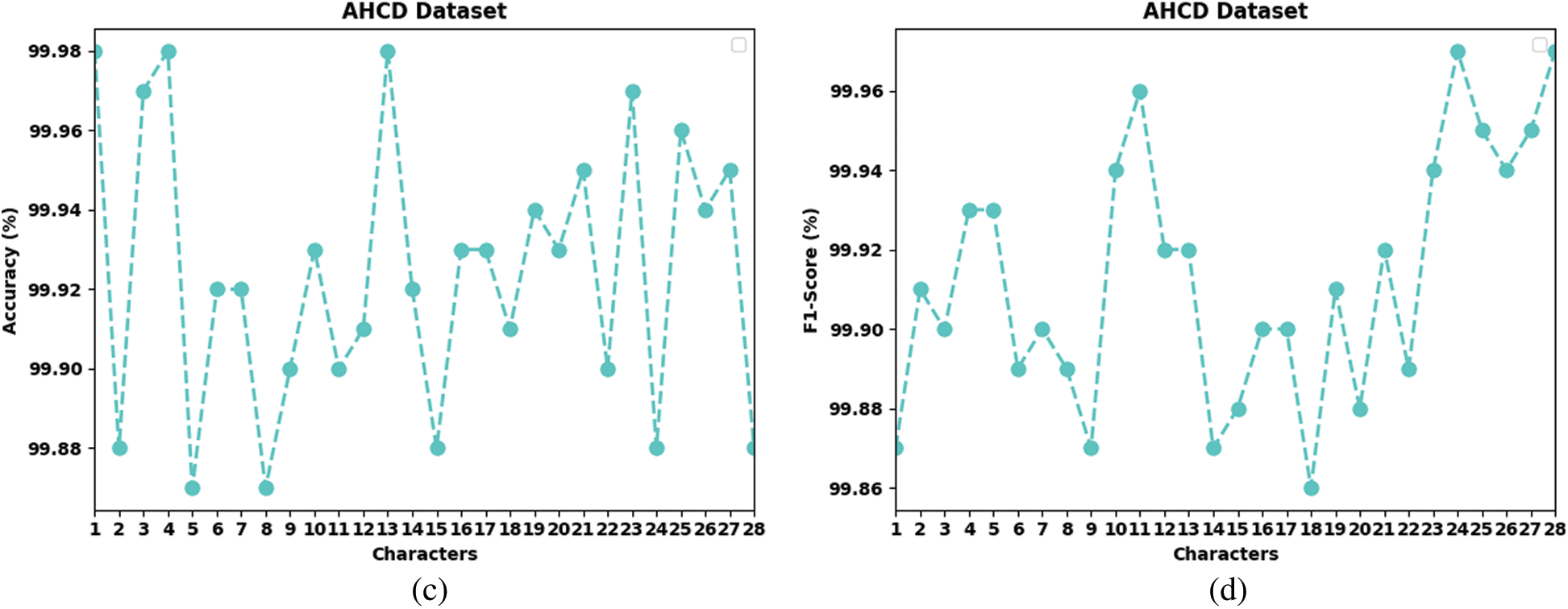
Figure 3: Result analysis of FWODL-AHCR approach under AHCD dataset (a)
The training accuracy (TA) and validation accuracy (VA) attained by the FWODL-AHCR method on the AHCD dataset is shown in Fig. 4. The experimental outcome implicit in the FWODL-AHCR technique has reached maximal values of TA and VA. In Particular, the VA is greater than TA.
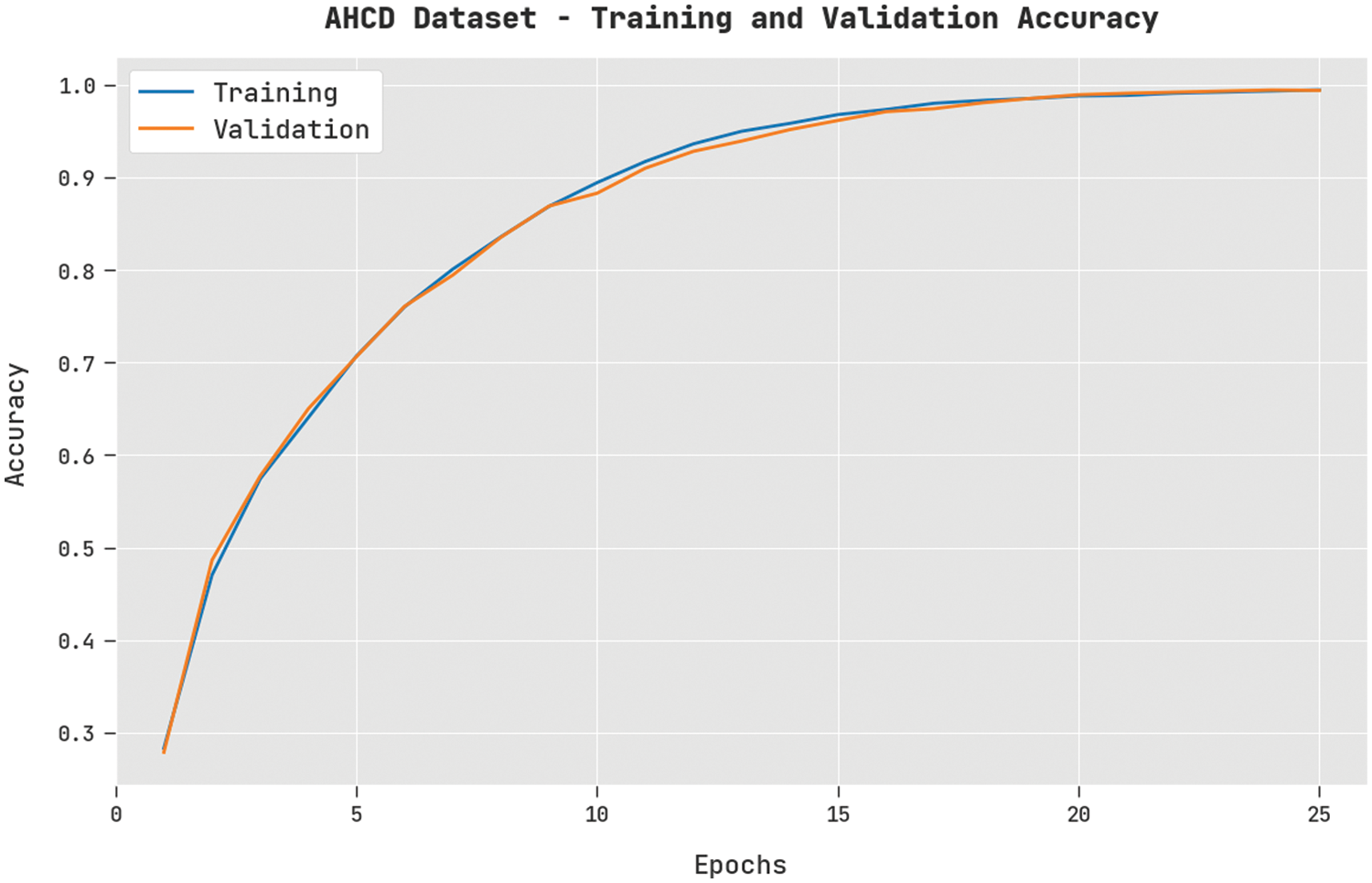
Figure 4: TA and VA analysis of FWODL-AHCR approach under the AHCD dataset
The training loss (TL) and validation loss (VL) reached by the FWODL-AHCR approach on the AHCD dataset are exhibited in Fig. 5. The experimental outcome implied that the FWODL-AHCR algorithm had accomplished the least values of TL and VL. Specifically, the VL is lesser than TL.
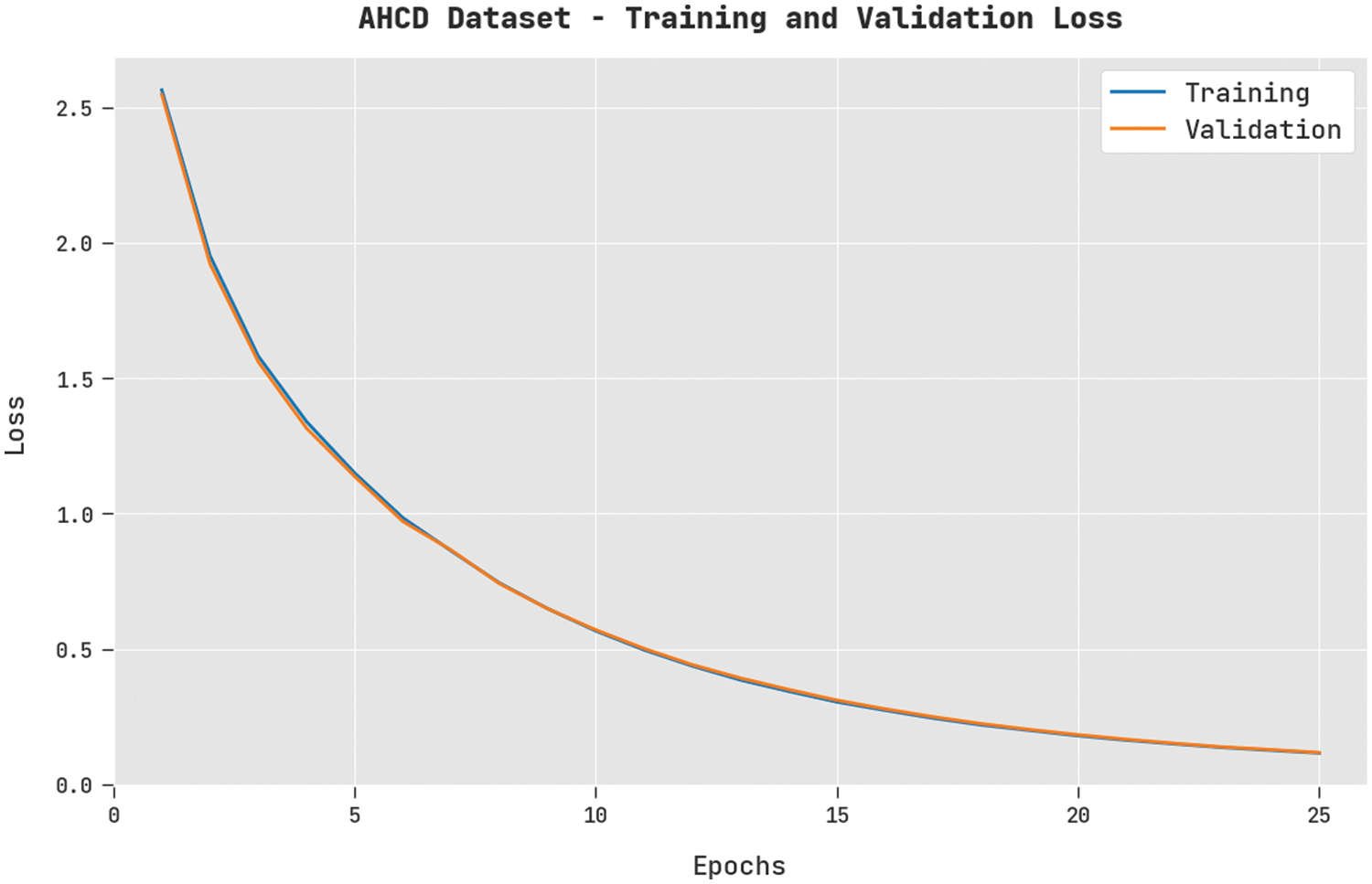
Figure 5: TL and VL analysis of FWODL-AHCR approach under the AHCD dataset
Table 3 and Fig. 6 report the overall recognition outcomes of the FWODL-AHCR model on the test Hijja dataset. The results implied that the FWODL-AHCR model improved performance under all characters. For example, on Chr-1, the FWODL-AHCR model has offered
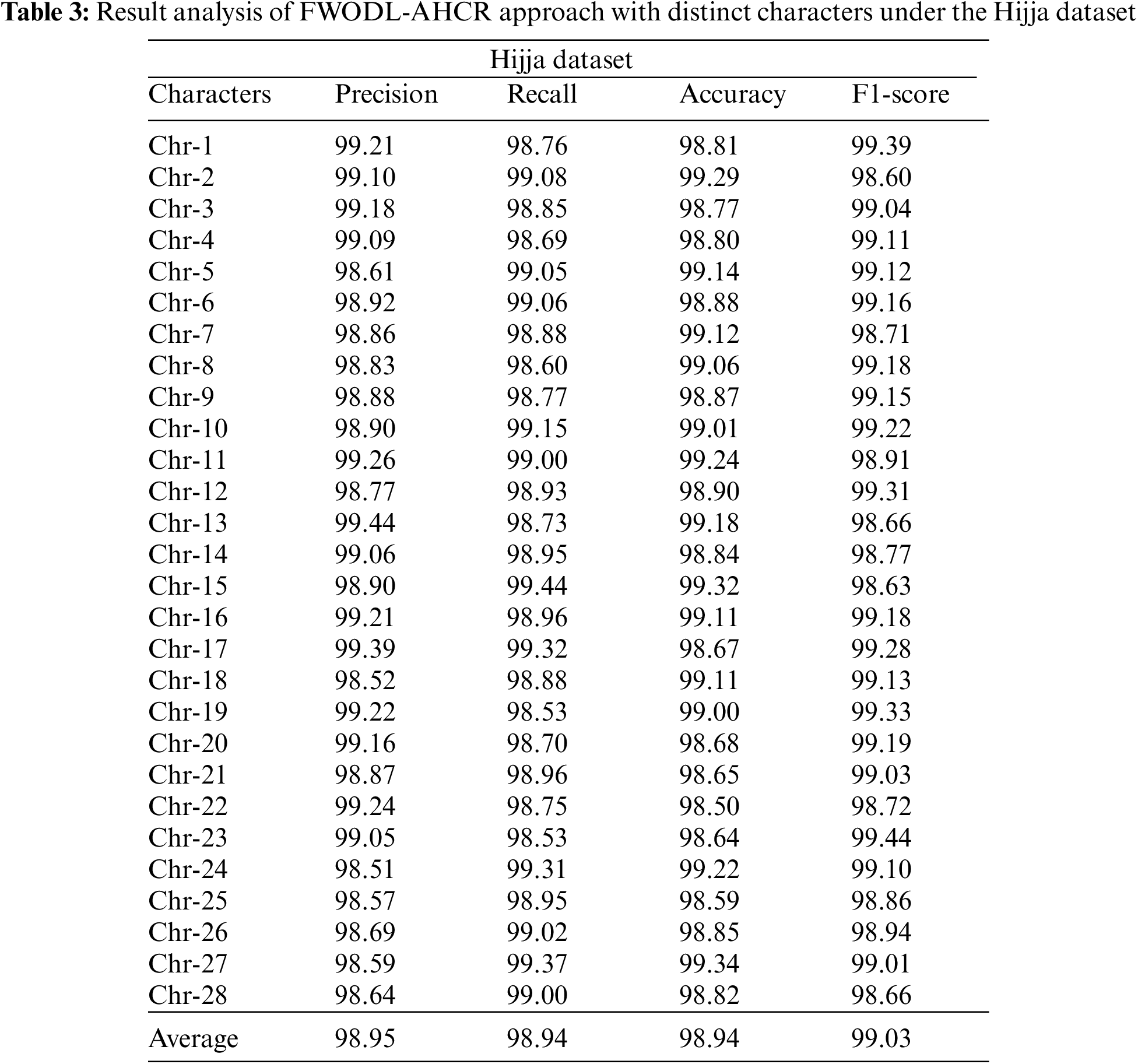

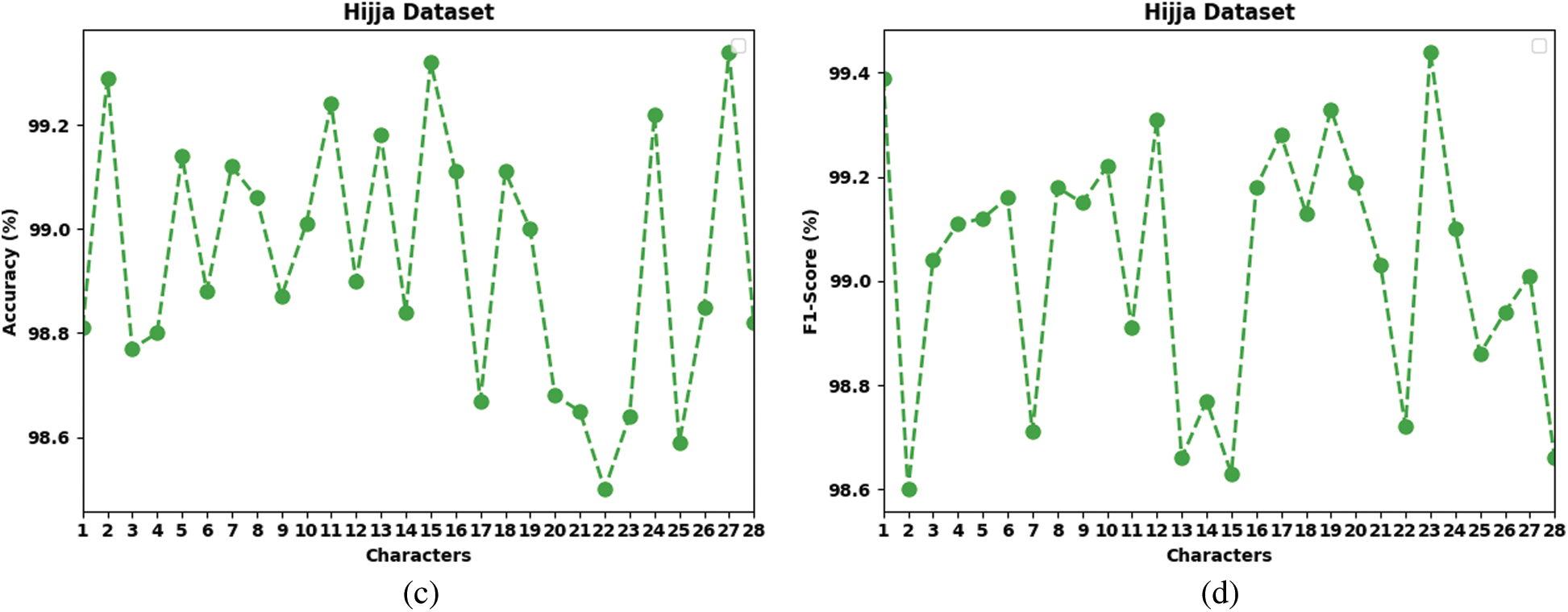
Figure 6: Result analysis of FWODL-AHCR approach under Hijja dataset (a)
The TA and VA obtained by the FWODL-AHCR method on the Hijja dataset are shown in Fig. 7. The experimental outcome implicit in the FWODL-AHCR technique has obtained maximal values of TA and VA. In specific, the VA is greater than TA.
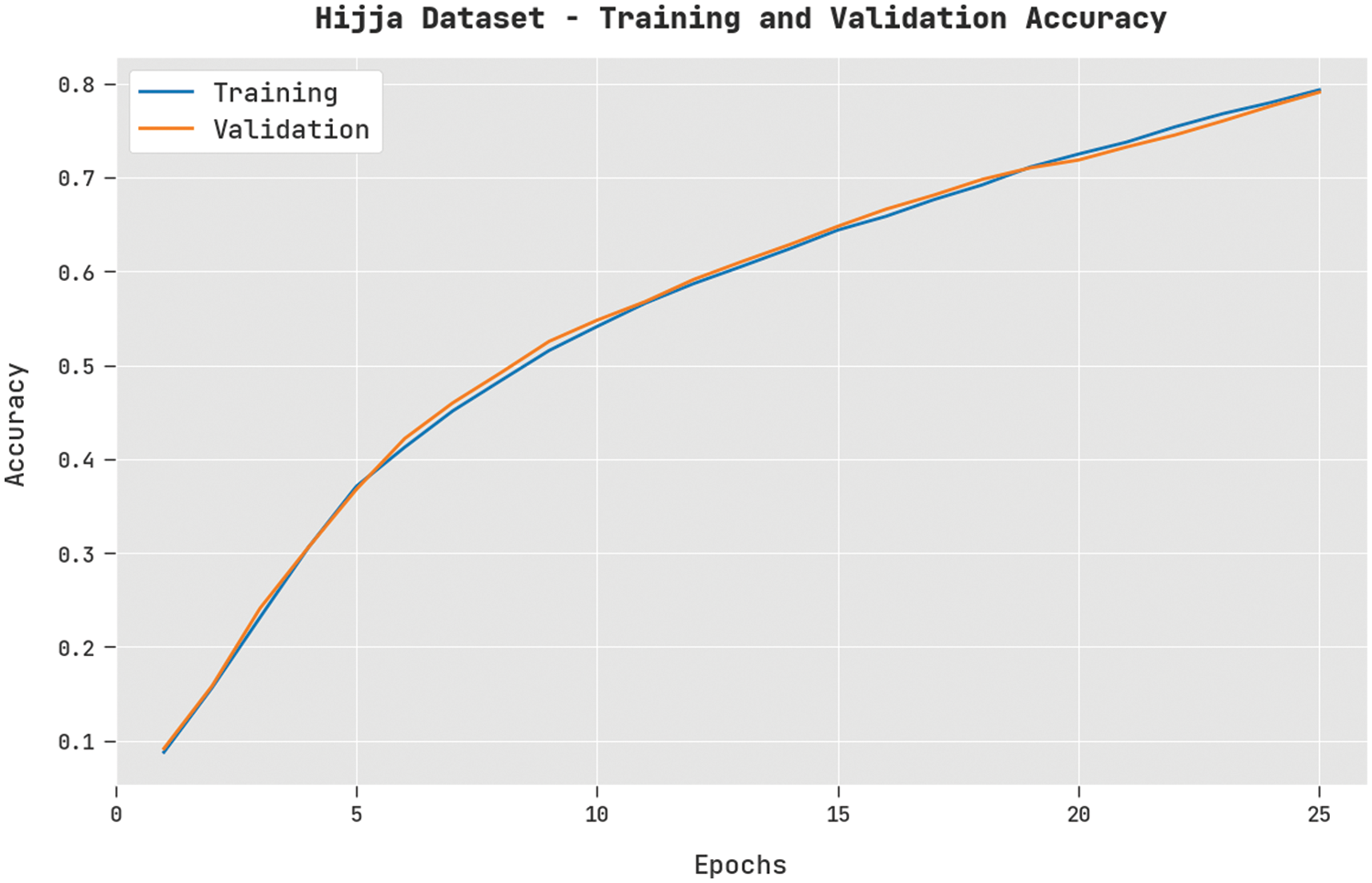
Figure 7: TA and VA analysis of FWODL-AHCR approach under the Hijja dataset
The TL and VL achieved by the FWODL-AHCR approach on the Hijja dataset are established in Fig. 8. The experimental outcome implied that the FWODL-AHCR method had accomplished the least values of TL and VL. Particularly, the VL is lesser than TL.
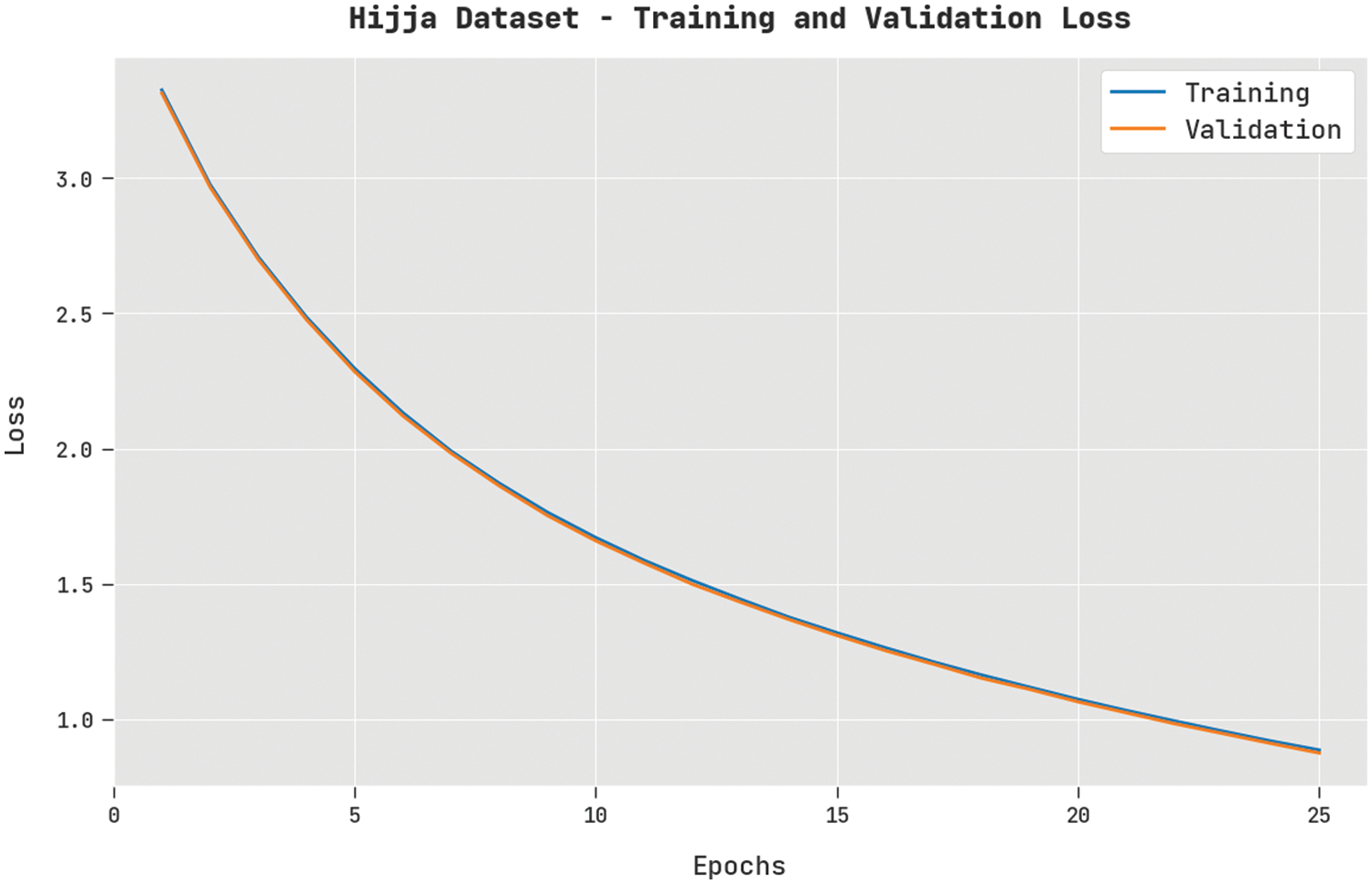
Figure 8: TL and VL analysis of FWODL-AHCR approach under the Hijja dataset
Table 4 exhibits the outcomes of the FWODL-AHCR model with other models on the AHCD dataset [23]. The experimental outcomes indicated that the FWODL-AHCR model had enhanced performance over other models. Based on
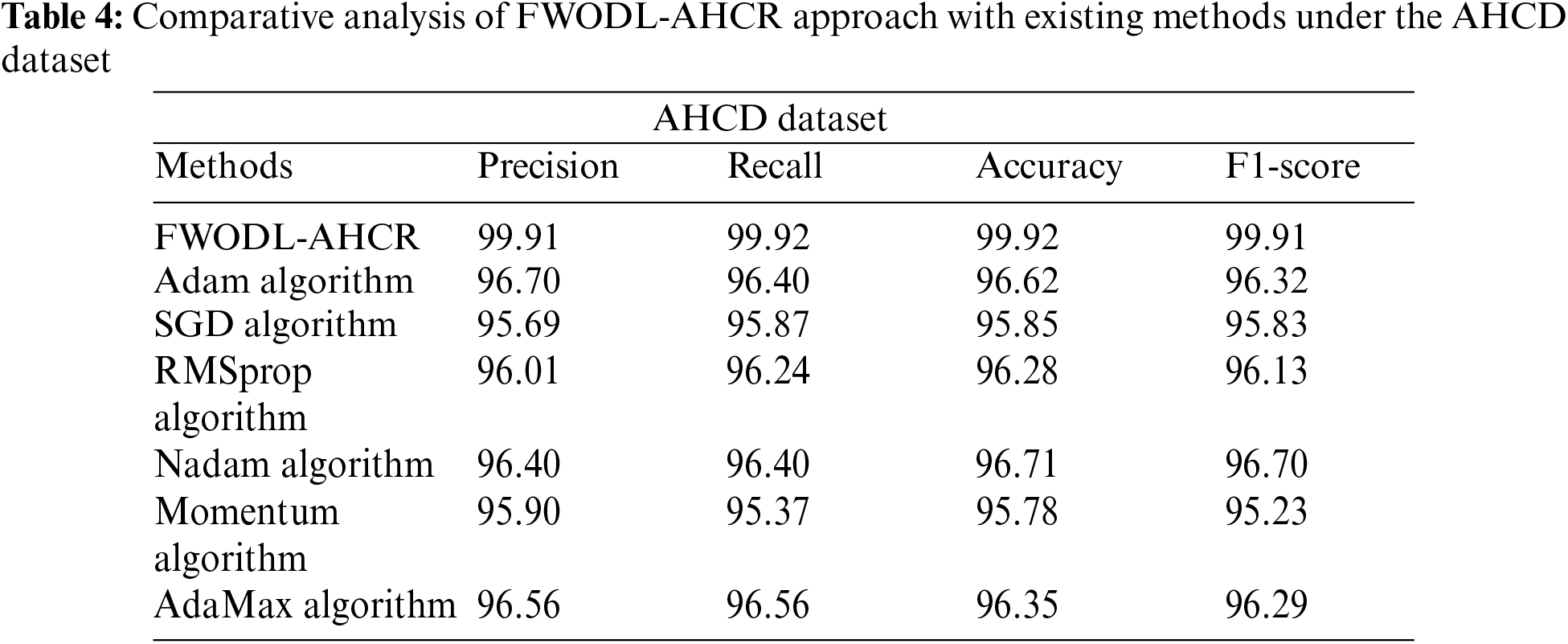
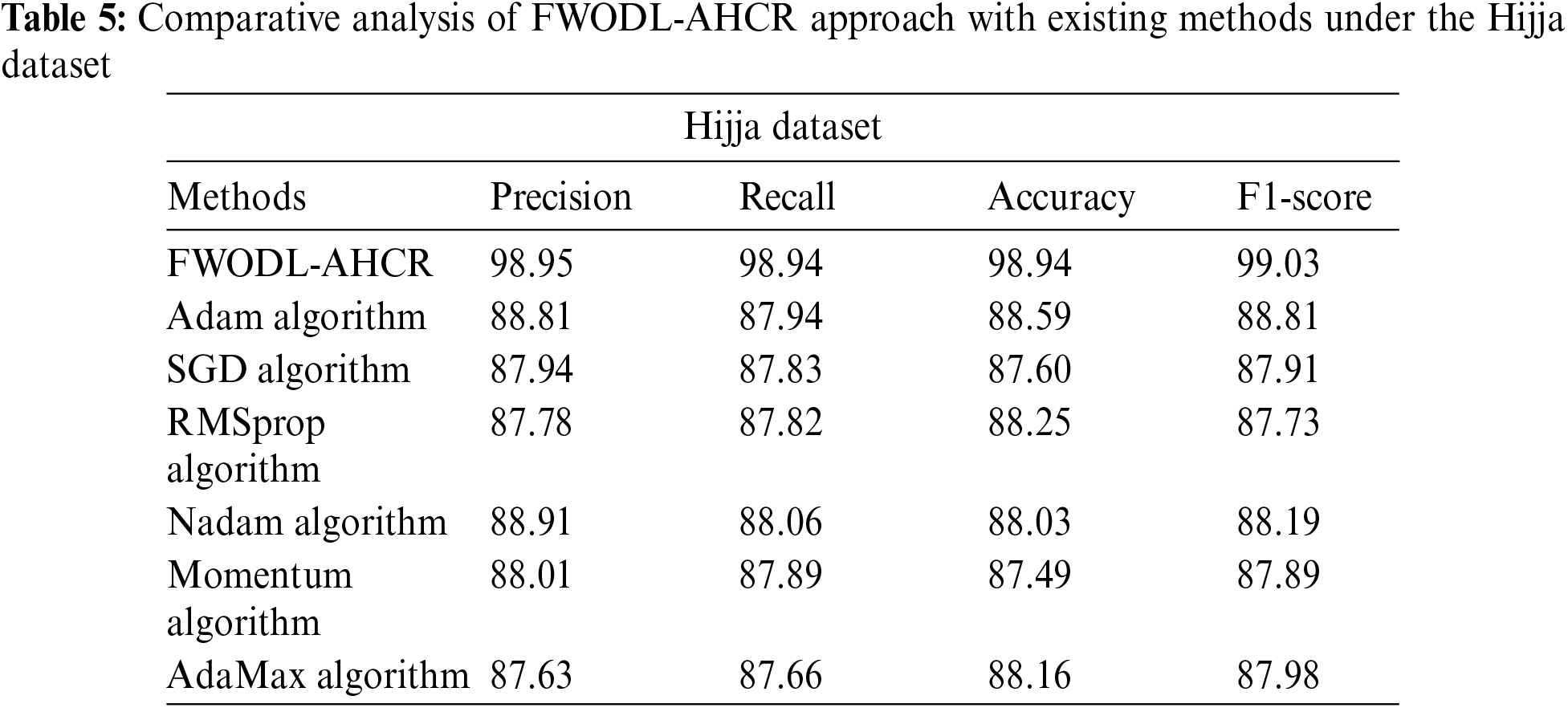
Table 5 exhibits the outcomes of the FWODL-AHCR model with other models on the Hijja dataset. The experimental outcomes indicated that the FWODL-AHCR model had enhanced performance over other models. Based on
In this study, a new FWODL-AHCR technique has been developed to recognize the distinct handwritten characters in the Arabic language. It initially pre-processes the handwritten images to improve their quality of them. Then, the RetinaNet-based deep convolutional neural network is applied as a feature extractor to produce feature vectors. Next, the DESN model is utilized for the classification of handwritten characters. Finally, the FWO algorithm is exploited as a hyperparameter tuning strategy to boost recognition performance. A series of simulations have been performed to exhibit the enhanced performance of the FWODL-AHCR technique, and the comparison study portrayed the supremacy of the FWODL-AHCR technique over other approaches. In the future, the FWODL-AHCR technique’s performance can be boosted using the fusion models.
Acknowledgement: None.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4340237DSR39.
Author Contributions: The manuscript was written through contributions of all authors. All authors have given approval to the final version of the manuscript. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data sharing not applicable to this article as no datasets were generated during the current study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. H. M. Balaha, H. A. Ali, M. Saraya, and M. Badawy, “A new Arabic handwritten character recognition deep learning system (AHCR-DLS),” Neural Comput. Appl., vol. 33, no. 11, pp. 6325–6367, 2021. doi: 10.1007/s00521-020-05397-2. [Google Scholar] [CrossRef]
2. R. Ahmed et al., “Novel deep convolutional neural network-based contextual recognition of Arabic handwritten scripts,” Entropy, vol. 23, no. 3, 2021, Art. no. 340. doi: 10.3390/e23030340. [Google Scholar] [PubMed] [CrossRef]
3. Y. S. Can and M. E. Kabadayı, “Automatic cnn-based Arabic numeral spotting and handwritten digit recognition by using deep transfer learning in ottoman population registers,” Appl. Sci., vol. 10, no. 16, 2020, Art no. 5430. doi: 10.3390/app10165430. [Google Scholar] [CrossRef]
4. A. A. A. Ali, M. Suresha, and H. A. M. Ahmed, “A survey onArabichandwrittencharacterrecognition, SN Computer Science,” SN Comput. Sci., vol. 1, no. 3, p. 152, 2020. doi: 10.1007/s42979-020-00168-1. [Google Scholar] [CrossRef]
5. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Comput. Mater. Contin., vol. 67, no. 3, pp. 3635–3648, 2021. doi: 10.32604/cmc.2021.015865. [Google Scholar] [CrossRef]
6. B. H. Nayef, S. N. H. S. Abdullah, R. Sulaiman, and Z. A. A. Alyasseri, “Optimized leaky ReLU for handwritten Arabic character recognition using convolution neural networks,” Multimed. Tools Appl., vol. 81, no. 2, pp. 2065–2094, 2022. doi: 10.1007/s11042-021-11593-6. [Google Scholar] [CrossRef]
7. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted viainternet,” Comput. Mater. Contin., vol. 66, no. 1, pp. 195–211, 2021. doi: 10.32604/cmc.2020.012088. [Google Scholar] [CrossRef]
8. M. Elkhayati and Y. Elkettani, “UnCNN: A new directed CNN model for isolated Arabic handwritten characters recognition,” Arab. J. Sci. Eng., vol. 47, no. 8, pp. 10667–10688, 2022. doi: 10.1007/s13369-022-06652-5. [Google Scholar] [CrossRef]
9. M. Haddad, D. Gaceb, and S. Faouci, “Offline Arabic handwritten character recognition: From conventional machine learning system to deep learning approaches,” Int. J. Comput. Sci. Eng., vol. 25, no. 4, pp. 385–398, 2022. doi: 10.1504/IJCSE.2022.124562. [Google Scholar] [CrossRef]
10. S. Benbakreti, M. Benouis, A. Roumaneand, and S. Benbakreti, “Stacked autoencoderforArabichandwriting word recognition,” Int. J. Comput. Sci. Eng., vol. 24, no. 6, pp. 629–638, 2021. doi: 10.1504/IJCSE.2021.119988. [Google Scholar] [CrossRef]
11. A. Khémiri, A. K. Echi, and M. Elloumi, “Bayesianversusconvolutional networksforArabichandwriting recognition,” Arab. J. Sci. Eng., vol. 44, no. 11, pp. 9301–9319, 2019. doi: 10.1007/s13369-019-03939-y. [Google Scholar] [CrossRef]
12. M. Salam and A. A. Hassan, “OfflineisolatedArabichandwriting characterrecognitionsystembased on SVM,” Int. Arab J. Inf. Technol., vol. 16, no. 3, pp. 467–472, 2019. [Google Scholar]
13. N. Altwaijry and I. Al-Turaiki, “Arabic handwriting recognition system using convolutional neural network,” Neural Comput. Appl., vol. 33, no. 7, pp. 2249–2261, 2021. doi: 10.1007/s00521-020-05070-8. [Google Scholar] [CrossRef]
14. H. Alyahya, M. M. B. Ismail, and A. Al-Salman, “Deep ensembleneural networksforrecognizingisolated Arabic handwritten characters,” ACCENTS Trans. Image Process. Comput. Vis., vol. 6, no. 21, pp. 68–79, 2020. doi: 10.19101/TIPCV.2020.618051. [Google Scholar] [CrossRef]
15. J. H. Alkhateeb, “Aneffectivedeeplearning approachforimproving off-lineArabichandwrittencharacter recognition,” Int. J. Softw. Eng. Comput. Syst., vol. 6, pp. 53–61, 2020. doi: 10.15282/ijsecs.6.2.2020.7.0076. [Google Scholar] [CrossRef]
16. S. I. Saleem, A. M. Abdulazeez, and Z. Orman, “A new segmentation framework for Arabic handwritten text using machine learning techniques,” Comput. Mater. Contin., vol. 68, no. 2, pp. 2727–2754, 2021. doi: 10.32604/cmc.2021.016447. [Google Scholar] [CrossRef]
17. M. Elleuch and M. Kherallah, “Boosting of deep convolutional architectures for Arabic handwriting recognition,” Int. J. Multimed. Data Eng. Manag., vol. 10, no. 4, pp. 26–45, 2019. doi: 10.4018/IJMDEM. [Google Scholar] [CrossRef]
18. H. M. Balaha et al., “RecognizingArabichandwritten characters usingdeeplearning andgenetic algorithms,Multimedia Tools and Applications,” Multimed. Tools Appl., vol. 80, no. 21– 23, pp. 32473–32509, 2021. doi: 10.1007/s11042-021-11185-4. [Google Scholar] [CrossRef]
19. K. M. Chang and S. H. Liu, “GaussiannoisefilteringfromECGby wienerfilterand ensembleempirical mode decomposition,” J. Signal Process. Syst., vol. 64, no. 2, pp. 249–264, 2011. doi: 10.1007/s11265-009-0447-z. [Google Scholar] [CrossRef]
20. Y. Wang, C. Wang, H. Zhang, Y. Dong, and S. Wei, “Automatic ship detection based on retinanet using multi-resolution Gaofen-3 imagery,” Remote Sens., vol. 11, no. 5, 2019, Art. no. 531. doi: 10.3390/rs11050531. [Google Scholar] [CrossRef]
21. J. Long, S. Zhang, and C. Li, “Evolving deep echo state networks for intelligent fault diagnosis,” IEEE Trans. Ind. Inform., vol. 16, no. 7, pp. 4928–4937, 2020. doi: 10.1109/TII.2019.2938884. [Google Scholar] [CrossRef]
22. Y. J. Zheng, Q. Song, and S. Y. Chen, “Multiobjective fireworks optimization for variable-rate fertilization in oil crop production,” Appl. Soft Comput., vol. 13, no. 11, pp. 4253–4263, 2013. doi: 10.1016/j.asoc.2013.07.004. [Google Scholar] [CrossRef]
23. N. Wagaa, H. Kallel, and N. Mellouli, “Improved Arabic alphabet characters classification using convolutional neural networks (CNN),” Comput. Intell. Neurosci., vol. 2022, pp. 1–16, 2022. doi: 10.1155/2022/9965426. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools