
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Multiple Perspective of Multipredictor Mechanism and Multihistogram Modification for High-Fidelity Reversible Data Hiding
1 Department of Information Engineering and Computer Science, Feng Chia University, Taichung, 407, Taiwan
2 Department of Computer Science and Information Engineering, National Chin-Yin University of Technology, Taichung, 411, Taiwan
* Corresponding Authors: Chin-Chen Chang. Email: ; Chia-Chen Lin. Email:
Computer Systems Science and Engineering 2024, 48(3), 813-833. https://doi.org/10.32604/csse.2024.038308
Received 07 December 2022; Accepted 24 February 2023; Issue published 20 May 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Reversible data hiding is a confidential communication technique that takes advantage of image file characteristics, which allows us to hide sensitive data in image files. In this paper, we propose a novel high-fidelity reversible data hiding scheme. Based on the advantage of the multipredictor mechanism, we combine two effective prediction schemes to improve prediction accuracy. In addition, the multihistogram technique is utilized to further improve the image quality of the stego image. Moreover, a model of the grouped knapsack problem is used to speed up the search for the suitable embedding bin in each sub-histogram. Experimental results show that the quality of the stego image of our scheme outperforms state-of-the-art schemes in most cases.Keywords
With the rapid development of big data and Internet technologies, information security has become an important issue. Information security is a broad topic that includes protecting digital information from unauthorized access or disclosure. One technique used in information security is watermarking, which allows for the embedding of specific information to identify copyright or for auditing purposes in digital media such as images and text files. Complementary to watermarking methods are watermarking attack methods [1,2], which are used to attempt to remove or alter the embedded information in order to make it difficult or impossible to trace the usage of the media. The study of these attack methods can help to inform the development of a more robust watermarking technology. Image encryption [3] is another useful tool for information security as it involves encrypting image files so that they can only be decrypted and viewed with the correct key. In addition, image description is the process of processing an image so that lost information can be recovered or reconstructed or the quality of the image can be improved [4–6]. All of these techniques can be used in information security and can help protect the integrity and security of digital information. Data hiding, an important branch of information security, can achieve the goals of copyright protection, secret communication, etc., via embedding secret data into cover media such as images, videos, and audio in a perceptible way. Nevertheless, data hiding can also cause irreversible damage to the cover media while embedding the secret data. Reversible data hiding (RDH) [7–10], as a derivative technique of data hiding, is characterized by the ability to recover the cover media losslessly after the correct extraction of the secret data. Currently, RDH is widely used in medical, military, and e-commerce fields, which do not allow reversible damage to the cover media.
After decades of research, many effective RDH algorithms have been proposed [11–14]. Currently, RDH schemes can be classified into four categories: (1) RDH based on the spatial domain [15–19]; (2) RDH based on the encrypted domain [20–24]; (3) RDH based on the transform domain [25–27]; and (4) RDH based on the compressed domain [28,29]. Further, the proposed scheme is focused on the first category of RDH. Thus far, many excellent spatial domain-based RDH schemes have been proposed, such as histogram shifting (HS) [7], difference expansion (DE) [30,31], prediction error expansion (PEE) [15–19], etc. The concept of HS, which refers to histogram manipulation in which the peak bins are used to carry the secret data, while the remaining bins are shifted, was first introduced by Ni et al. [7]; while Tian et al. [30] first proposed the DE-based scheme, which expands the difference between adjacent pixels; then, a vacant least-significant-bit (LSB) is created for the data embedding. As an extension of DE, PEE was first proposed by Thodi and Rodriguez [32]. Unlike DE, which embeds the secret data by expanding the difference between neighboring pixels, PEE exploits the difference between a pixel’s intensity and its predicted value for embedding. Since the accuracy of prediction directly corresponds to the distortion of the cover image, research has focused on how to improve the accuracy of prediction [33–35]. PEE is an effective and extensively exploited scheme, as it exploits the redundancy of the cover image and constructs a sharper prediction error histogram (PEH). Note that the performance of PEE has been continuously enhanced by many works, such as through precise prediction mechanisms [11,13,17,36], adaptive 1D PEH modifications [37], 2D PEH modifications [16,18], and so on.
According to the principle of PEE, the prediction scheme involves the predicted pixel and predicted value, which determines the distribution of prediction errors. In 2009, Sachnev et al. [38] proposed a prediction mechanism, which predicts a central pixel by averaging its four neighboring pixels. Thus far, many PEE schemes have used the rhombus prediction mechanism. To further improve PEE performance, Li et al. [39] proposed a novel PEE scheme called “pixel value ordering” (PVO), which aims to predict the maximum and minimum values using the second-largest and second-smallest values in each image block, respectively. PVO has been verified to achieve low distortion under low payload. Afterward, a large number of PVO-based schemes were proposed. In [40], PVO was extended to PVO-k by modifying the k largest/smallest pixels of each image block. In [41], Peng et al. added the concept of the relative position of pixels to PVO and proposed improved PVO (IPVO) with better performance. After that, Wang et al. [42] used a strategy to determine the block size adaptively, which increased the embedding performance. In addition, Qu et al. [43] proposed a pixel-based PVO scheme that abandons the use of the image block, where each pixel is predicted by its sorted context.
The aforementioned PVO-based schemes are well established, but such schemes only perform well in a smooth image area. There should be a more efficient solution in the complex image areas to reduce distortion. In [44], Ma et al. proposed a multipredictor scheme to predict a pixel in different methods and select the most appropriate predicted value. This scheme is good at reducing the distortion of the complex regions; however, the conditions of data embedding are too harsh, which leads to the low hiding capacity of the algorithm as well. To ensure the embedding volume and image quality, we propose a novel RDH, which combines the advantages of the multipredictor mechanism and multihistogram technique. First, we improve the prediction accuracy by combining IPVO and the median edge detector (MED) prediction mechanism [45]. To further enhance the performance of the proposed scheme, a new complexity metric is proposed to skip the complex regions in the cover image. Finally, we use the multihistogram technique to select the optimal embedding bin in each subhistogram. Experimental results show that the proposed scheme achieves an advantage in fidelity over a series of state-of-the-art schemes with moderate capacity. The main contributions of this paper are summarized as follows:
1. Novel multipredictor mechanism. In combining IPVO and MED, a novel multipredictor mechanism is proposed to better improve prediction accuracy.
2. Adaptive local complexity metric. The proposed complexity metric can help filter the appropriate regions in the cover image and the generation of multiple histograms.
3. Incorporation of multihistogram and optimal embedding bin selection. How the grouping backpack model is applied to the selection of optimal embedding bins is studied.
The rest of this paper is organized as follows. Section 2 introduces the preliminary works. In Section 3, we describe the proposed scheme step by step. In Section 4, the experimental results of the proposed scheme are provided. Finally, conclusions and prospects are presented in Section 5.
In this section, the basic principle of the PVO-based schemes is first reviewed in Subsections 2.1 and 2.2. Then, the technique of MED prediction is introduced in detail, which is an important part of the proposed scheme. Next, because the concept of the multipredictor mechanism (MPM) is applied in the proposed scheme, we also give a brief introduction to the MPM in Subsection 2.4.
Li et al. [39] first designed a PVO scheme by using the conventional PEE. In their scheme, the original image is first divided into mutually exclusive blocks. Assume that each block contains
Then, the prediction errors are modified to
where
Although PVO-based PEE is effective, it has an obvious drawback. According to Eqs. (2) and (3), prediction-error valued 0 is excluded for data embedding, which wastes the embedding capacity of a large number of the smooth block. To solve this problem, the concept of relative location is utilized in [36] by renewing the prediction-errors as
where
Then, the maximum and minimum pixels
2.3 Median-Edge Detector Prediction
Generally speaking, IPVO-based schemes can be regarded as a prediction method that uses the second-largest and second-smallest values within a block to predict the largest and smallest values. However, this prediction method only performs well on smooth blocks.
Weinberger et al. [45] first proposed the median-edge detector prediction (MED), which can offer more accurate predictions even in normal image blocks. As shown in Fig. 1, MED applies the edge rule to predict the current pixel

Figure 1: Data structure of median-edge detector prediction (MED)
where
The prediction error
Using only one prediction rule does not apply to all blocks in the image. To obtain higher prediction accuracy, Ma et al. [44] proposed a multiprediction mechanism, which used
where
Similarly, the prediction error
For Type 1, new prediction error
For Type 2 and Type 3, new prediction error
Finally, the new embedded pixel
This section presents an adaptive RDH algorithm using a multipredictor mechanism combined with the multihistogram technique. First, we describe and analyze the novel multipredictor mechanism combining IPVO and MED. Then, we propose an adaptive local complexity metric. After that, we incorporate the multihistogram technique. Finally, we present implementation details for the proposed scheme.
3.1 Multipredictor Mechanism Combining IPVO and MED
Assuming the original gray-scale image is divided into

If
If
Finally, the maximum pixel
As shown in Fig. 2, there are three types of relationship among
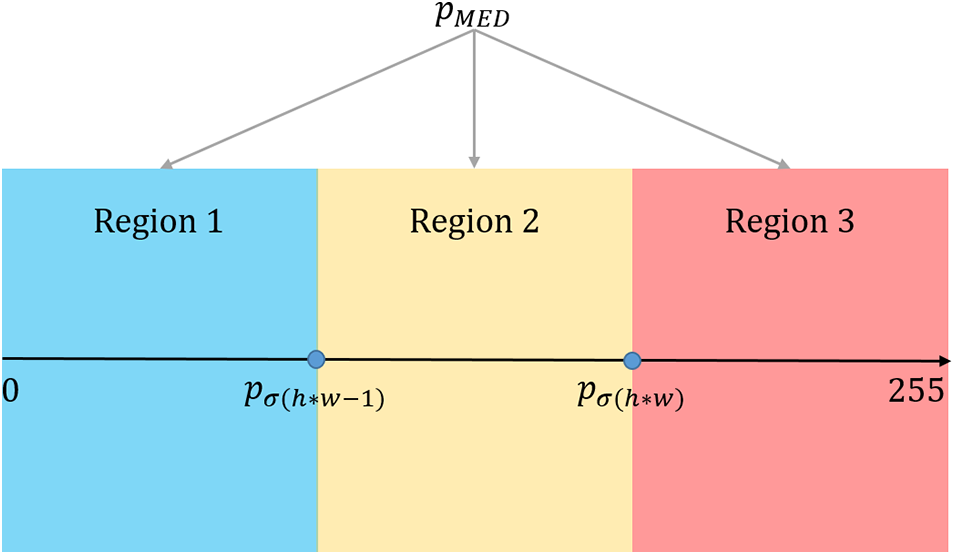
Figure 2: Three types of relationships among
When performing the embedding process, the secret data are first embedded in the largest pixel of each block in index order. When the largest pixel is used up, the secret data are then embedded in the smallest pixel of each block according to the same index order. The previous schemes [11,13,40,41] used the maximum and minimum pixels of each block simultaneously, leading to two problems: (1) when the value of the largest pixel changes, it may affect the prediction value of the smallest pixel, making the smallest pixel unavailable; (2) when the largest pixel within a block is shifted, then the texture around the current block is complex. At this time, it is highly probable that the smallest pixel will be shifted in the embedding process. Provided we divide the maximum and minimum pixels in the block into two layers to embed the secret data, when the amount of data to be embedded is small, we can protect the partial smallest pixels from being shifted, which can improve image quality.
3.2 Adaptive Local Complexity Metric
Obviously, the above multipredictor mechanism is not suitable for all types of image blocks. A more accurate prediction depends not only on the texture feature of the current image block but also on the complexity of the three neighboring pixels around the predicted pixel. Thus, the block-based complexity measure proposed by Peng et al. [41], i.e.,
When embedding a small payload, the image block size is relatively large, for example,
where
3.3 Adaptive Multiple Histograms Generation and Optimal Embedding Bins Selections
It is well known that the objective of the RDH scheme is to achieve a certain payload while minimizing cover image distortion. A feasible way to accomplish this is to divide the predicted pixels into multiple classes according to our complexity metric and design different embedding mechanisms for each class of predicted pixels to minimize image distortion. First, we set a threshold
For the one histogram shifting algorithm, brute force search is one of the most frequently used search algorithms, which searches for the best embedding bins by traversing all possible combinations thereof. However, for multiple histograms, many possible combinations of embedding bins can achieve a certain payload. Therefore, it is time-consuming to iterate through all possible combinations one by one.
Searching for the optimal embedding bins of multiple histograms can be considered a combinatorial optimization problem. Thus, we transform the above search problem into a typical grouped knapsack problem.
To simplify the grouped knapsack problem, we count only the prediction errors using IPVO. First, we divide a cover image into two layers and calculate all the bins suitable for
where
where
Next, we transform Eq. (16) into a grouped knapsack problem. We replace the embedding capacity and embedding distortion with the weight and value of the commodity, respectively. This establishes a one-to-one relationship between the parameters in Eq. (16) and the grouped knapsack problem. For example,
where
For example, provided the threshold of the complexity metric is set to 5.9, then all the
3.4 Implementation of the Proposed Scheme
To better demonstrate the process of data embedding, two types of examples are given in Fig. 3. Here, suppose that the block size is
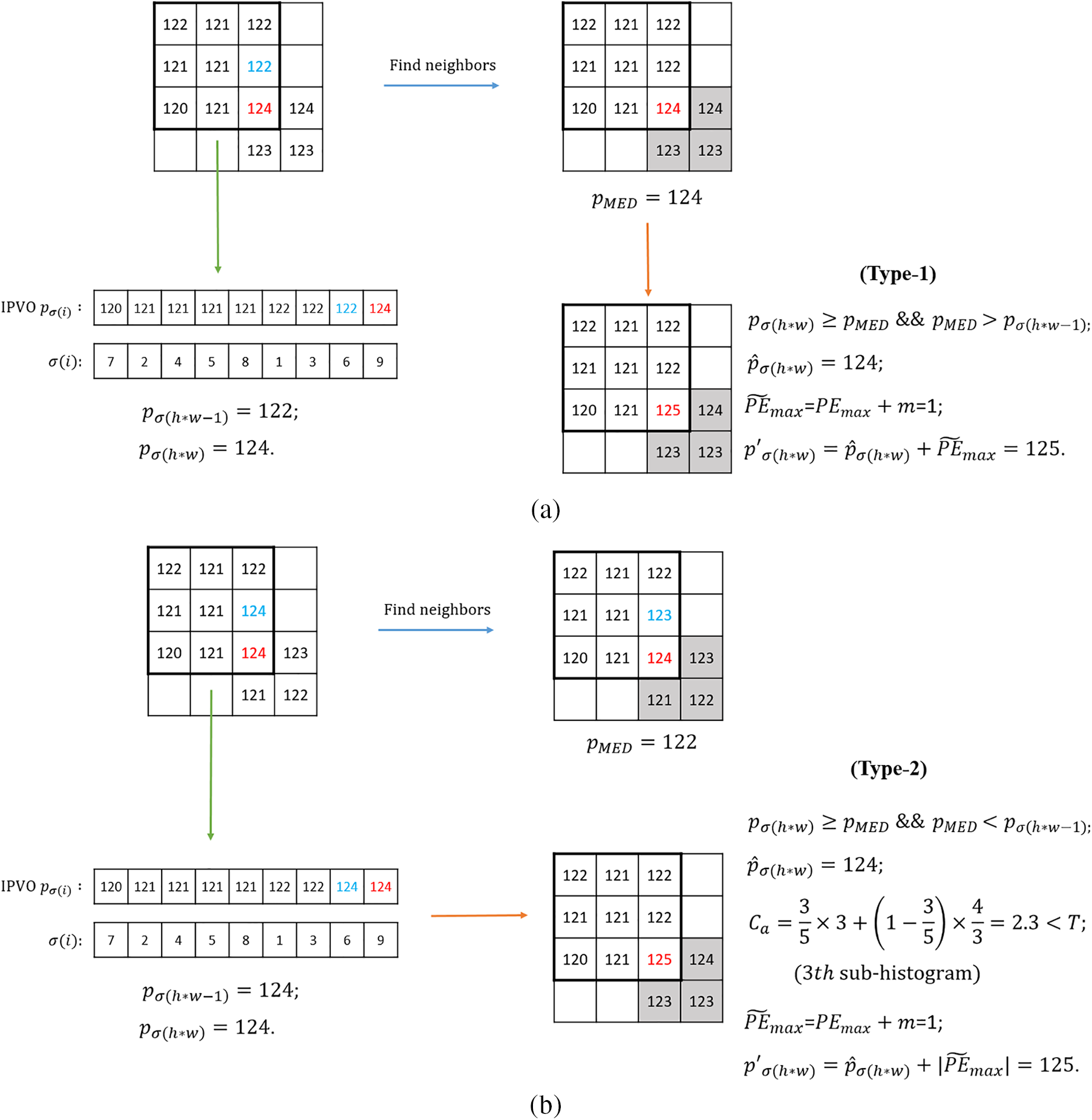
Figure 3: Examples of embedding process
Now, we will elaborate on the processes of data embedding and data extraction. To solve the pixel overflow/underflow problem, we utilize a location map to ensure that pixels in the stego image do not exceed the range [0,255]. The value 255 is modified to 254, and the value 0 is modified to 1. Meanwhile, the location of each modified pixel is recorded as 1 on the location map, while those that are not modified are recorded as 0. Then, we losslessly compress the location map using arithmetic compression to reduce its length.
Besides the location map, some auxiliary information also needs to be recorded:
The auxiliary information is embedded in the last two rows of the cover image through LSB replacement so that the extractor can access this information and thus extract the secret data correctly and recover the cover image losslessly. Next, the complete process of data embedding occurs as follows.
Data Embedding Process
Step 1. Construct the location map to prevent the pixel overflow/underflow problem. Empty the LSBs of pixels in the first two rows. Add the replaced LSBs to the head of the payload.
Step 2. Divide the cover image into mutually exclusive blocks of size
Step 3. Select the appropriate bins for each sub-histogram of the first layer.
Step 4. Embed the secret data in the first layer using the proposed multipredictor mechanism and the selected bins.
Step 5. Embed the secret data for the second layer as in Steps 3 and 4.
Step 6. Record the auxiliary information into the LSBs of the pixels of the first two rows. Finally, generate the stego image.
For data extraction and image recovery, all operations are inversions of the embedding process, i.e., we process the second layer and then the first layer; the blocks are processed in the inverse scanning order of data embedding. The detailed data extraction process is as follows.
Data Extracting Process
Step 1. Extract and decode the auxiliary information from the LSBs of the pixels in the first two rows.
Step 2. Divide the stego image into mutually exclusive blocks of size
Step 3. Recover the pixels of the first two rows using the header of the extracted secret data.
Step 4. Decompress the map and use it to losslessly restore the original cover image.
In this section, we perform some experiments to verify the performance of the proposed scheme. Six standard gray-scale images are used as test images, i.e., Lena, Barbara, Boat, Elaine, Lake, and Airplane. In addition, we also use images from two databases, i.e., BOSS [46] and BOWS-2 [47], to test the proposed scheme. All programs are implemented with MATLAB R2017a. It is worth mentioning that the embedding procedure is carried out for different block sizes taking
4.1 Effectiveness Verification
In the first experiment, the performance of the proposed scheme is demonstrated. As shown in Fig. 4b, a binary image sized

Figure 4: Results of an example experiment: (a) cover image; (b) secret image; (c) stego image (PSNR = 61.43 dB; payload = 10,000 bits); (d) recovered cover image; (e) extracted secret image
where
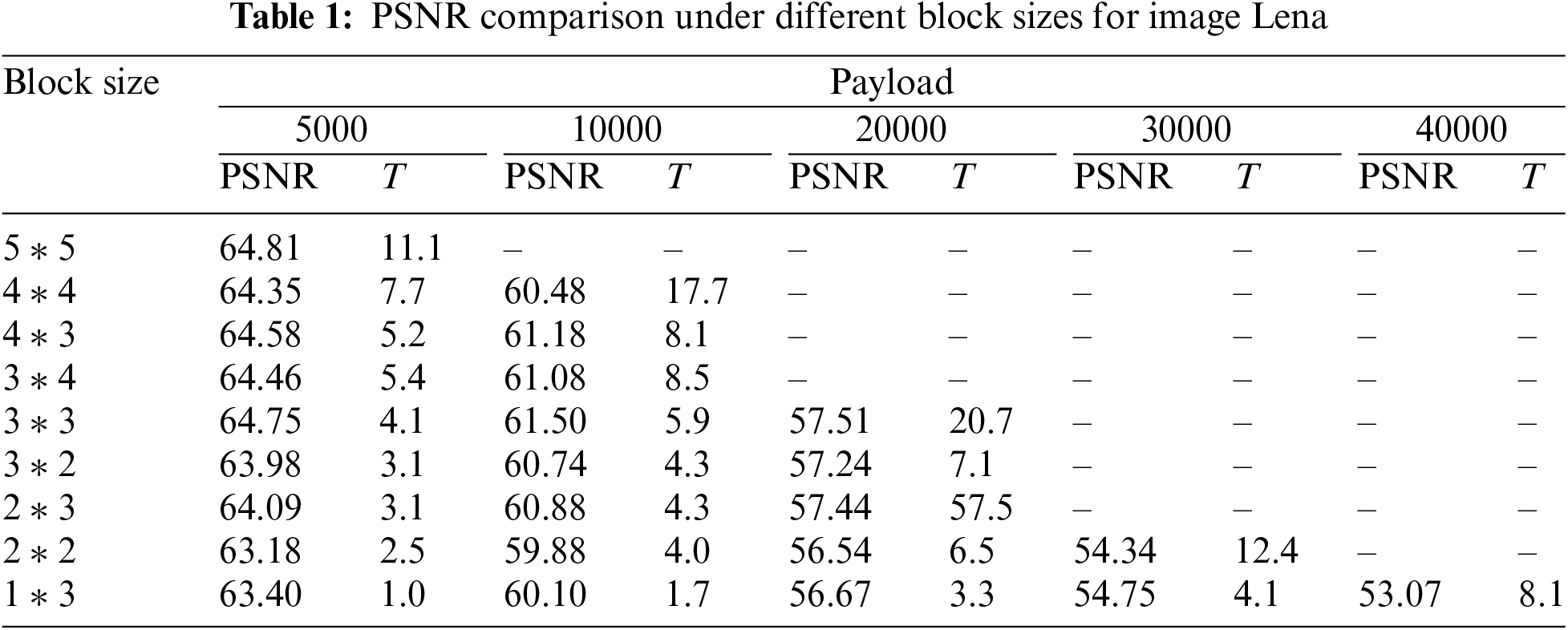
Fig. 5 and Table 1 show the performance comparison of the proposed scheme for different block sizes. It is worth mentioning that there are many other choices of block sizes, and only nine of them are taken as examples. As we can see, as the block size becomes smaller, the embedding capacity (EC) of the proposed scheme becomes larger, but the PSNR decreases sharply. Among them, the 5 * 5 size block has the best performance when the payload is 5000 bits, reaching 64.81. Since this size of the block is only suitable for smooth areas, it can only be used with a small payload. The 3 * 3 block performs best when the payload is increased to 10,000 and 20,000 bits, reaching 61.50 and 57.51, respectively. This result shows that the 3 * 3 block is more suitable for smooth and normal areas and can maintain good image quality even with moderate embedding capacity. When the embedding requirement increases, we can use smaller size blocks, such as 2 * 2, 1 * 3, etc., to sacrifice image quality for more embedding space.
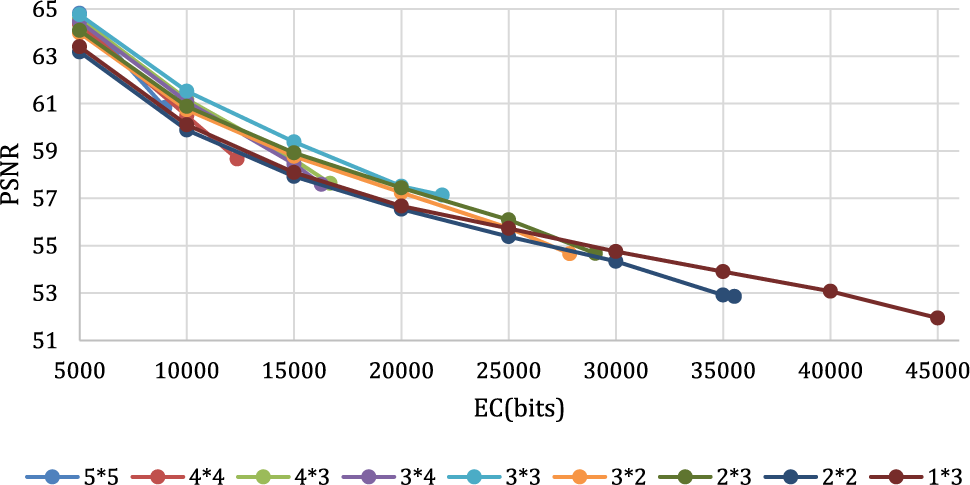
Figure 5: PSNR comparison under different block sizes for image Lena
4.2 Comparison with Other Schemes
Then, we compare the proposed scheme with nine state-of-the-art schemes of He et al. [11], Abolfazl et al. [12], Kong et al. [13], He et al. [14], He et al. [15], Yu et al. [16], Fan et al. [17], Zhang et al. [18], and Chang et al. [19]. Tables 2–4 show the comparison results of PSNR for embedding capacities with 5000 bits, 10,000 bits, and 20,000 bits. Also, the performance comparison between the proposed scheme and nine compared schemes is shown in Fig. 6. It noted that the block size and thresholds for different images are adaptively chosen. According to the tables and figures, it is easy to see that the proposed scheme has the best performance in most cases under moderate capacity.
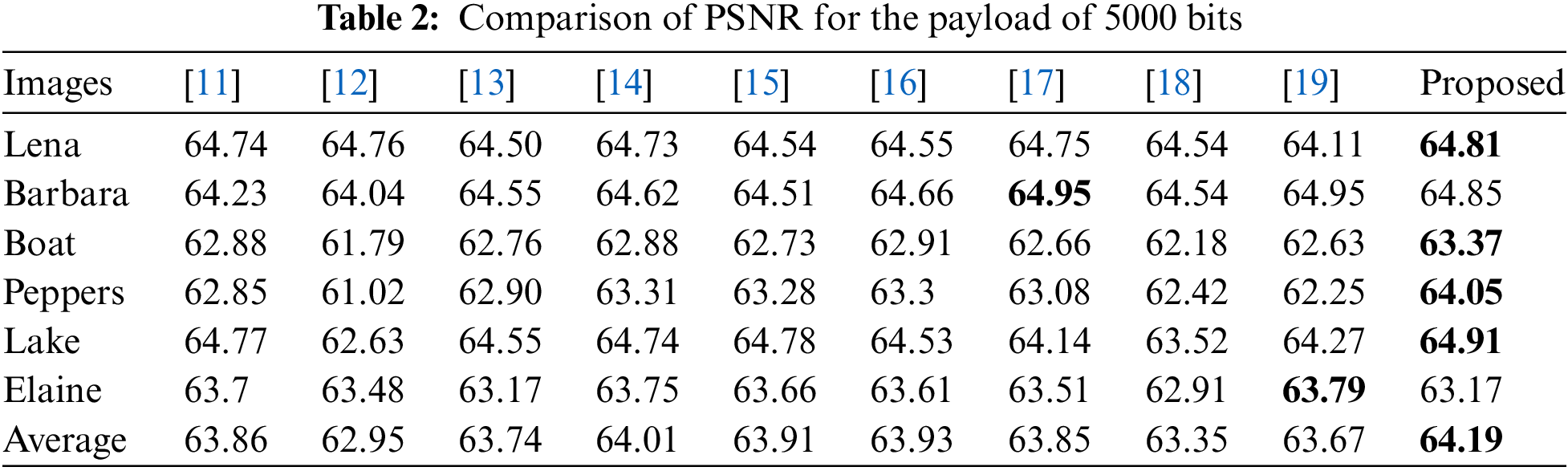
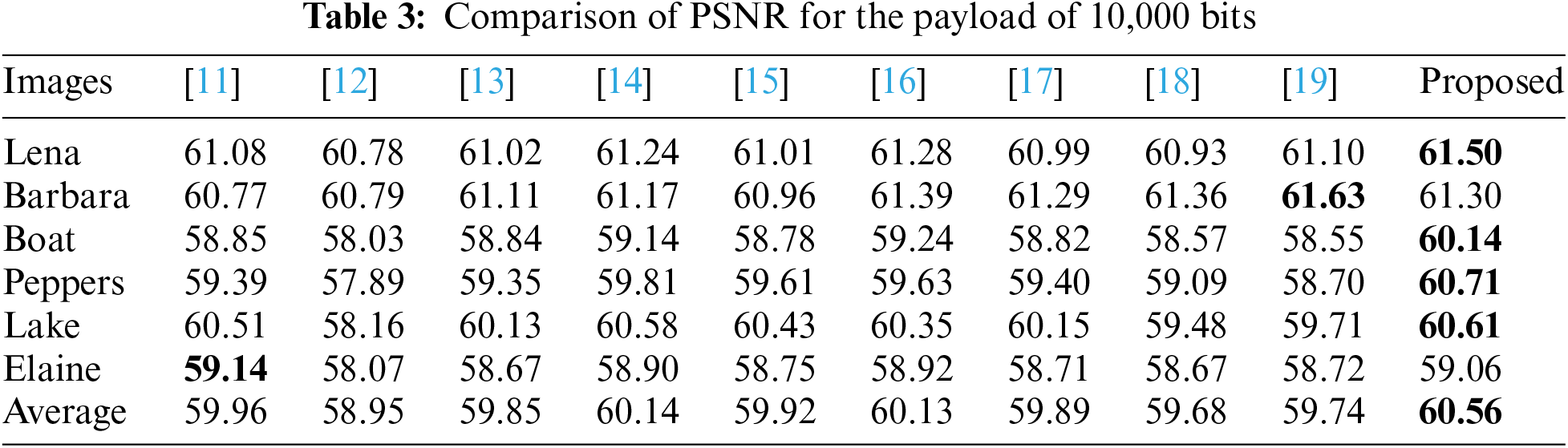
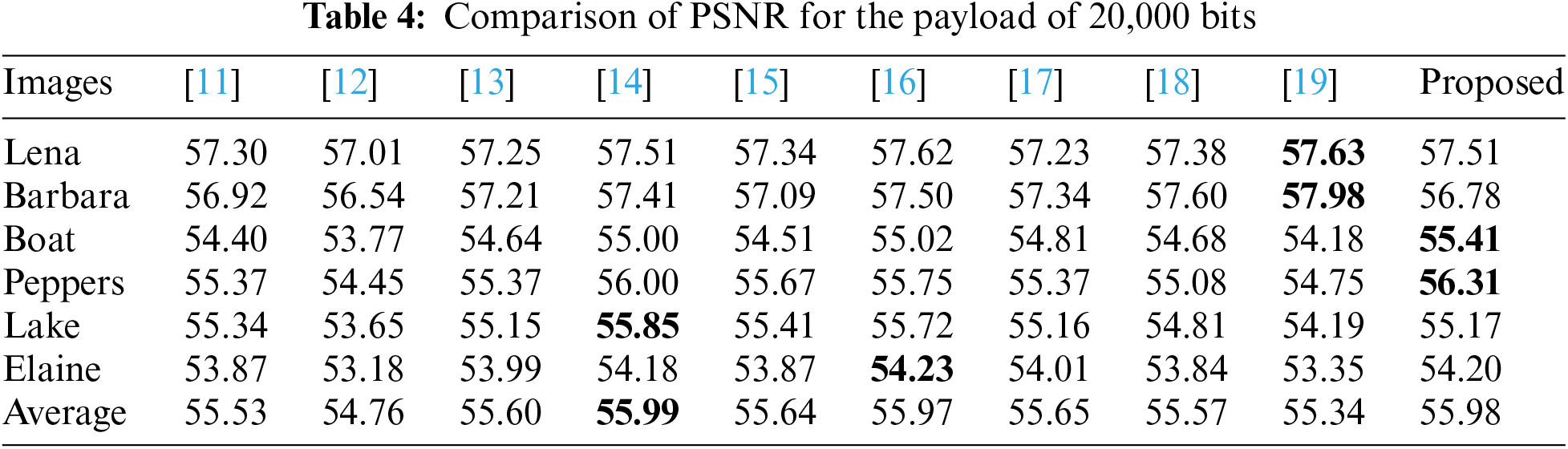
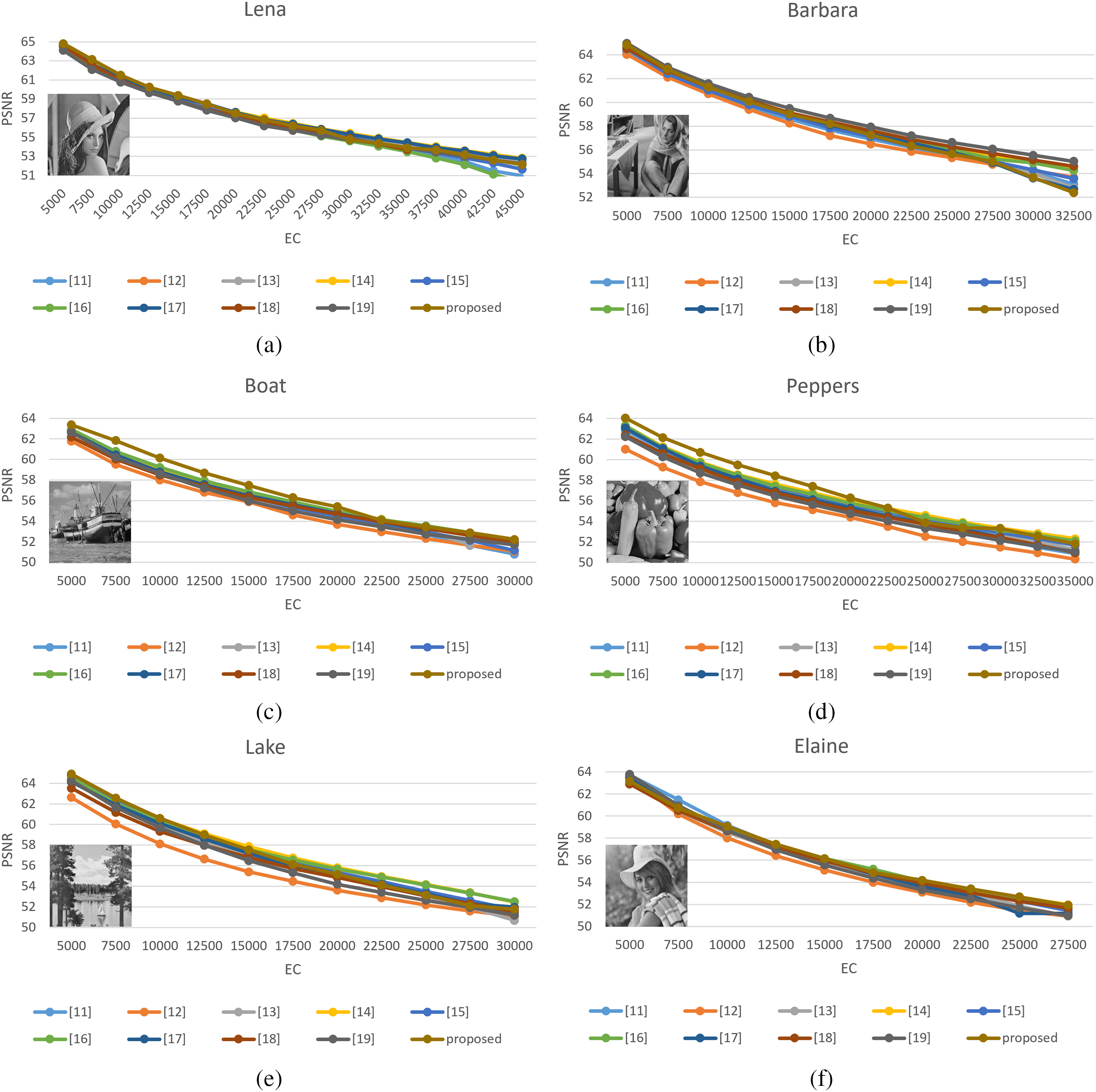
Figure 6: The performance comparison between the proposed scheme and nine compared schemes
Based on the above experimental results, it is obvious that our schemes and the existing nine are quite competitive. To further explore the advantage of our proposed scheme, the relationship between the embedding capacity (EC) and corresponding image quality (PSNR) is summarized in Table 5 with the test image “Lena.” Here, we can see that our proposed scheme offers the highest image quality with 64.81 dB when secret bits are only 5000 bits. Although the largest hiding capacity of our proposed scheme is 45,000 bits, which is higher than in [17], the same as that of [13] and similar to those of [11] and [15] but less than those of the remaining schemes. Considering the largest hiding capacity among nine existing schemes and ours listed in Table 5, it can be found that schemes in [18] and [19] offer the largest hiding capacity, i.e., around 64,000∼65,000 bits. The computation complexity of the schemes in [18] and [19] and ours is O(K * b * m), O(K * b * m), and O(K * S), respectively, where K indicates the number of histograms, b indicates the number of pairs, m indicates the number of mappings, and S is the amount of bin for each histogram set. The computation complexity of our proposed scheme is relatively lower than the schemes in [18] and [19] and maintains a good balance between storage capacity and image quality. In other words, the proposed RDH scheme is suitable for real-time applications, i.e., IIoT or IoT, etc.
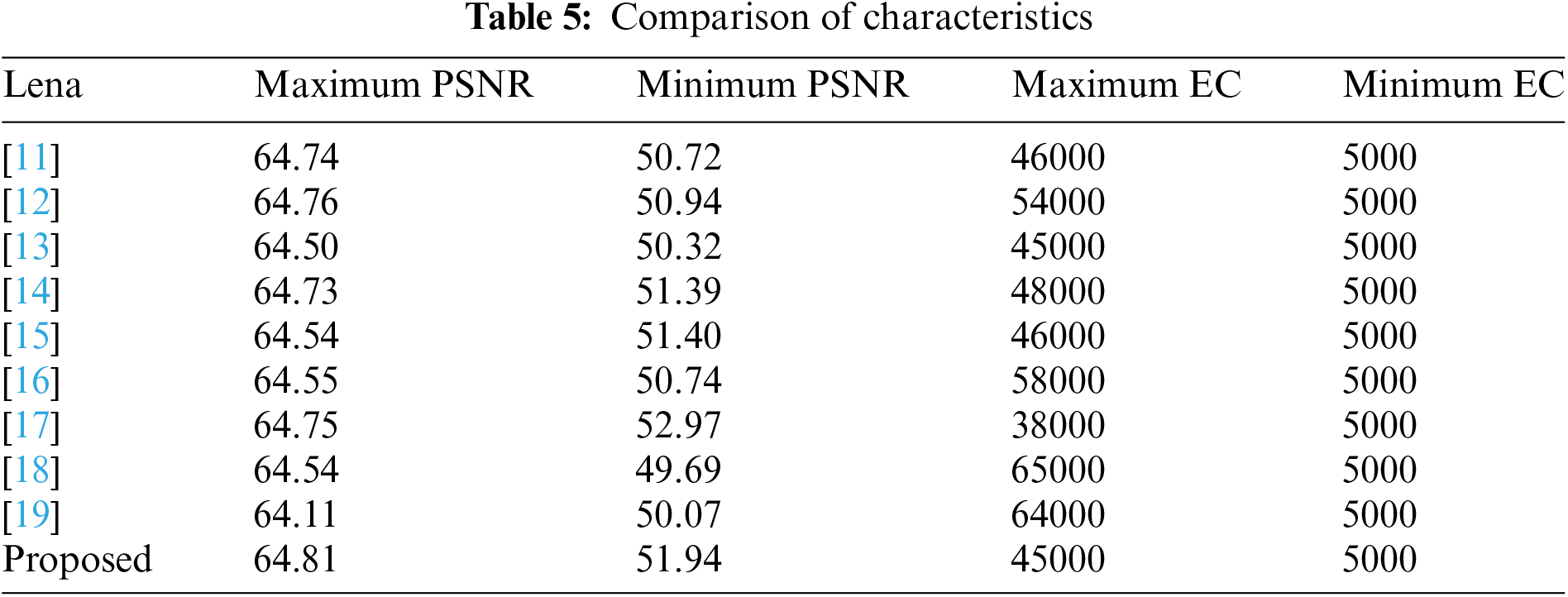
4.3 Applicability to Image Databases
In order to further evaluate the performance of the proposed scheme for various types of images, 100 images sized 512 × 512 are randomly selected from two databases (BOSS [46] and BOW-2 [47]) with a payload of 10,000 bits. As shown in Figs. 7a and 7b, the PSNR of selected images mainly ranges from 56 to 67 dB. Only three of the 200 test images have PSNR less than 58 dB. Therefore, our proposed scheme has universality and is applicable to most images. The indicators reflecting the trend of the data are shown in Fig. 7c. As illustrated in Fig. 8, it is obvious that the stego images with a high PSNR value are low-contrast images and vice versa. However, the superiority of the proposed scheme in terms of the image quality of the stego image can be demonstrated by the data in Table 6, including the maximum, minimum, and average values.
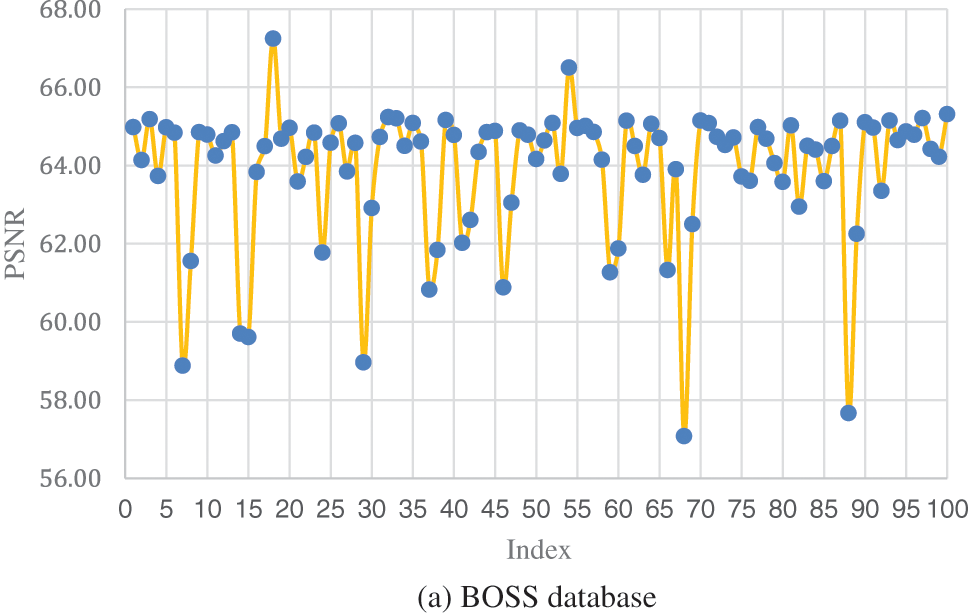
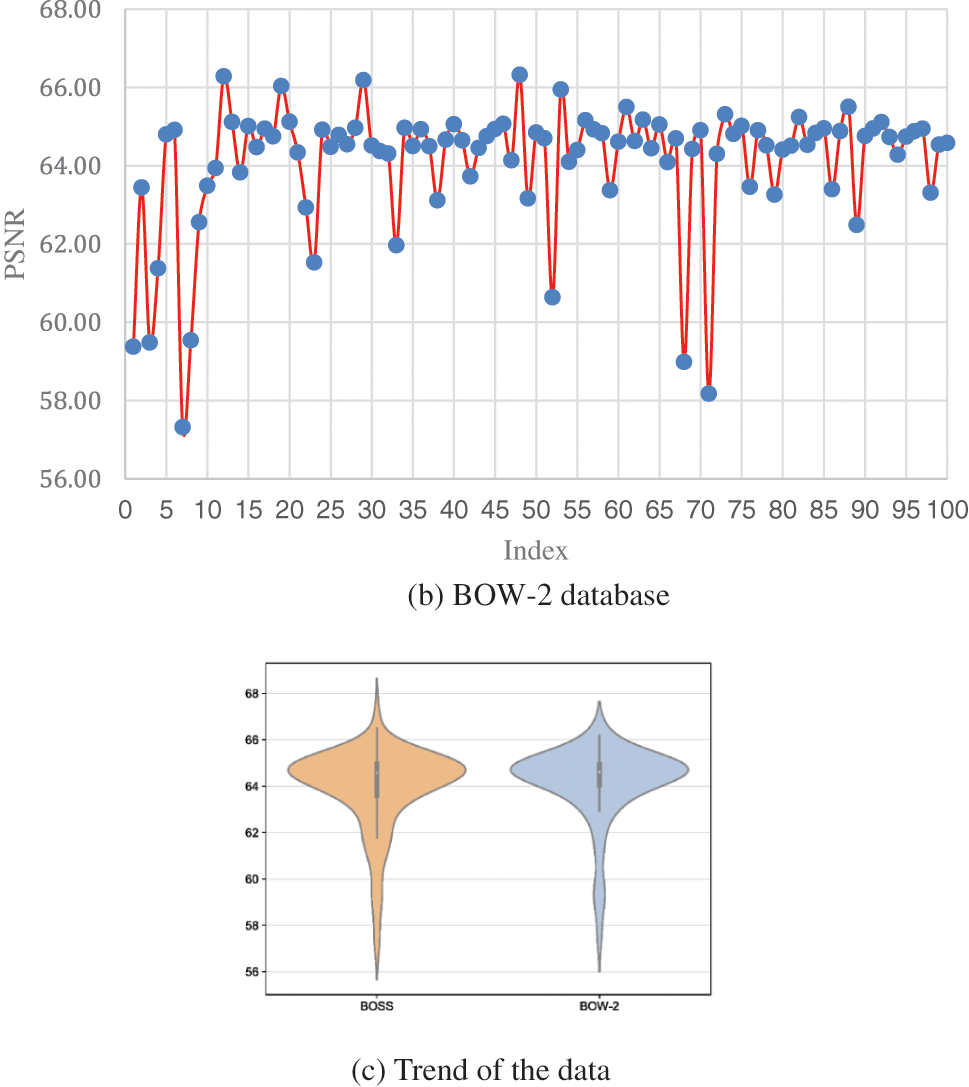
Figure 7: PSNR for 100 randomly selected images from BOSS [46] and BOW-2 [47]

Figure 8: Images correspond to the highest and lowest PSNR values
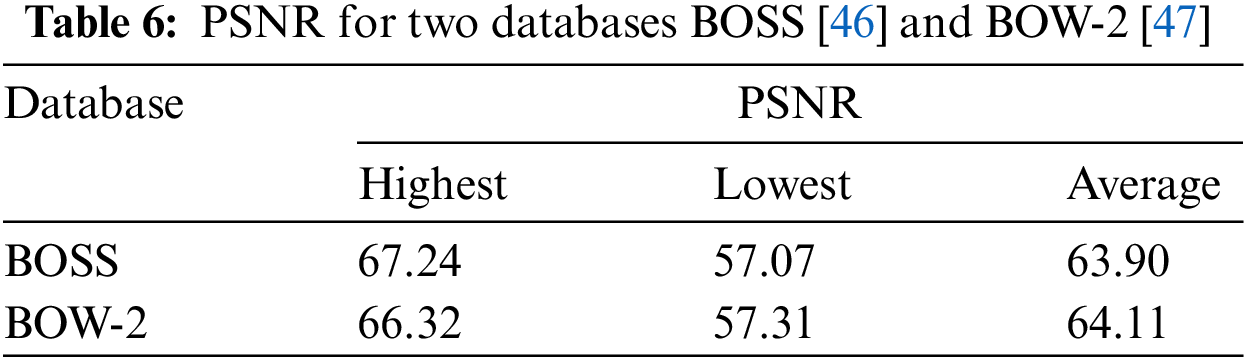
4.4 Security Analysis and Steganalysis
To estimate the security of the proposed scheme, we apply the number of pixels change rate (NPCR), the unified average changing intensity (UACI) and structural similarity (SSIM) to evaluate the performance of six stego images under 10000 and 20000 payloads. The definitions of NPCR, UACI and SSIM are
where
As shown in Tables 7 and 8, the NPCR and UACI values of the stego images are both low, indicating that the modification of the original image by the stego images is not easily detectable. The values of SSIM are very close to 1, representing that the stego image is very similar to the original image. The results of Tables 7 and 8 indicate that the stego image generated by the proposed scheme is not easily suspected by the attacker during transmission.


To verify whether the proposed scheme can guarantee the high-fidelity of the stego image, pixel value differencing (PVD) steganalysis [48] is used to test the stego images. The histograms of PVD are shown in Fig. 9. An analysis of two test images (“Lena” and “Boat”) is presented. To better compare the differences between the stego image and the cover image, we also draw the details of the histograms in the peak range. As shown in the figures, the histograms of embedded stego images under 10,000 and 20,000 bits are close to the histograms of the cover images. The analysis shows that the proposed scheme greatly preserves the characteristics of the cover image and achieves high-fidelity reversible data hiding.
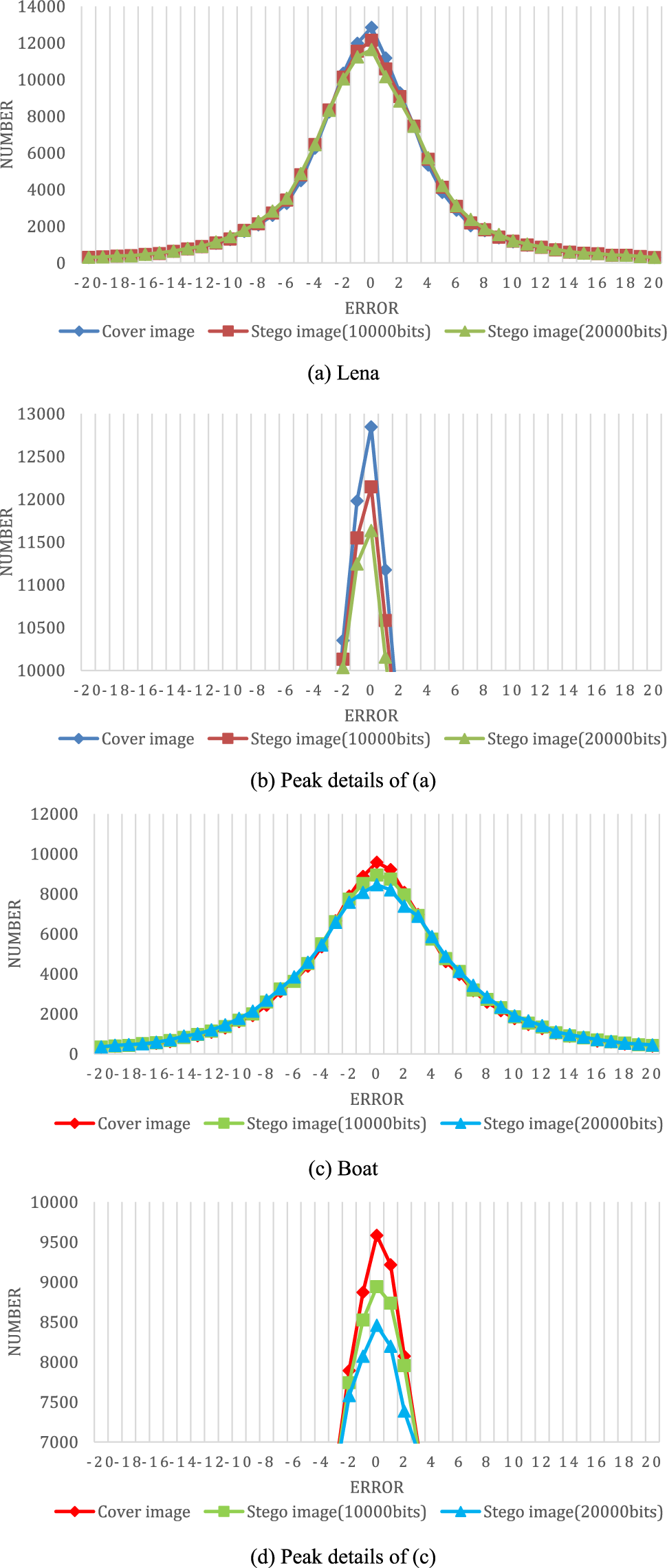
Figure 9: PVD analysis of the stego images and cover images
In this paper, a novel high-fidelity RDH scheme is proposed. Based on the multiprediction mechanism and multihistogram technique, the proposed scheme effectively improves the prediction accuracy as well as reduces the distortion of the cover image. Experimental results show that the quality of the stego image of our scheme outperforms the state-of-the-art schemes in most cases, especially for high-contrast cover images. In addition, we also confirm the high fidelity of the stego image by steganalysis. In the future, we will investigate how to further improve the quality of the stego image with more effective algorithms.
Acknowledgement: This paper is supported by Feng Chia University, Taichung, Taiwan and National of Chin-Yi University of Technology, Taichung, Taiwan.
Funding Statement: This paper is funded by National Science Council, Taiwan, the Grant Number is NSC 111-2410-H-167-005-MY2.
Author Contributions: The authors confirm the contribution to the paper as follows: Conceptualization: Kai Gao; Methodology: Kai Gao; Formal analysis and investigation: Chia-Chen Lin; Writing-original draft preparation: Kai Gao; Writing-review and editing: Chia-Chen Lin and Chin-Chen Chang; Resources: Chia-Chen Lin and Chin-Chen Chang; Supervision: Chin-Chen Chang.
Availability of Data and Materials: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. H. Jiang et al., “FAWA: Fast adversarial watermark attack,” IEEE Trans. Comput., vol. 73, no. 2, pp. 301–313, 2024. [Google Scholar]
2. C. P. Wang et al., “CWAN: Covert watermarking attack network,” Electronics, vol. 12, no. 2, pp. 1–12, 2023. [Google Scholar]
3. M. Kaur, S. Singh, and M. Kaur, “Computational image encryption techniques: A comprehensive review,” Math. Probl. Eng., vol. 2021, pp. 1–17, 2021. [Google Scholar]
4. G. Kulkarni et al., “BabyTalk: Understanding and generating simple image descriptions,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 12, pp. 2891–2903, 2013 [Google Scholar] [PubMed]
5. P. Kinghorn, L. Zhang, and L. Shao, “A region-based image caption generator with refined descriptions,” Neurocomputing, vol. 272, pp. 416–424, 2018. [Google Scholar]
6. Y. J. Xian and X. Y. Wang, “Fractal sorting matrix and its application on chaotic image encryption,” Inf. Sci., vol. 547, no. 8, pp. 1154–1169, 2021. [Google Scholar]
7. Z. C. Ni, Y. Q. Shi, N. Ansari, and W. Su, “Reversible data hiding,” IEEE Trans. Circuits Syst. Video Technol., vol. 16, no. 3, pp. 345–362, 2006. [Google Scholar]
8. S. Kumar, A. Gupta, and G. S. Walia, “Reversible data hiding: A contemporary survey of state-of-the-art, opportunities and challenges,” Appl. Intell., vol. 52, pp. 7373–7406, 2022. [Google Scholar]
9. C. C. Chang, C. T. Li, and K. M. Chen, “Privacy-preserving reversible information hiding based on arithmetic of quadratic residues,” IEEE Access, vol. 7, pp. 54117–54132, 2019. [Google Scholar]
10. Y. Q. Chen, W. J. Sun, L. Y. Li, C. C. Chang, and X. Wang, “An efficient general data hiding scheme based on image interpolation,” J. Inf. Secur. Appl., vol. 54, pp. 102854, 2020. [Google Scholar]
11. W. G. He and Z. C. Cai, “An insight into pixel value ordering prediction-based prediction-error expansion,” IEEE Trans. Inf. Forensics Secur., vol. 15, pp. 3859–3871, 2020. [Google Scholar]
12. K. Abolfazl and M. H. Sedaaghi, “Reversible data hiding based on high fidelity prediction scheme for reducing the number of invalid modifications,” Inf. Sci., vol. 589, pp. 46–61, 2022. [Google Scholar]
13. X. X. Kong and Z. C. Cai, “An information security method based on optimized high-fidelity reversible data hiding,” IEEE Trans. Ind. Inform., vol. 18, no. 22, pp. 8529–8539, 2022. [Google Scholar]
14. W. G. He and Z. C. Cai, “Reversible data hiding based on dual pairwise prediction-error expansion,” IEEE Trans. Image Process., vol. 30, pp. 5045–5055, 2021 [Google Scholar] [PubMed]
15. W. G. He, Z. C. Cai, and Y. M. Wang, “High-fidelity reversible image watermarking based on effective prediction error-pairs modification,” IEEE Trans. Multimed., vol. 23, pp. 52–63, 2020. [Google Scholar]
16. C. Q. Yu, X. Q. Zhang, D. W. Wang, and Z. J. Tang, “Reversible data hiding with pairwise PEE and 2D-PEH decomposition,” Signal Process., vol. 196, pp. 108527, 2022. [Google Scholar]
17. G. J. Fan, Z. B. Pan, E. D. Gao, X. Y. Gao, and X. R. Zhang, “Reversible data hiding method based on combining IPVO with bias-added rhombus predictor by multi-predictor mechanism,” Signal Process., vol. 180, pp. 107888, 2021. [Google Scholar]
18. C. Zhang and B. Ou, “Reversible data hiding based on multiple adaptive two-dimensional prediction-error histograms modification,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 7, pp. 4174–4187, 2021. [Google Scholar]
19. Q. Chang, X. L. Li, Y. Zhao, and R. R. Ni, “Adaptive pairwise prediction-error expansion and multiple histograms modification for reversible data hiding,” IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 12, pp. 4850–4863, 2021. [Google Scholar]
20. A. Malik, H. X. Wang, Y. L. Chen, and A. N. Khan, “A reversible data hiding in encrypted image based on prediction-error estimation and location map,” Multimed. Tools Appl., vol. 79, pp. 11591–11614, 2020. [Google Scholar]
21. X. C. Cao, L. Du, X. X. Wei, D. Meng, and X. J. Guo, “High capacity reversible data hiding in encrypted images by patch-level sparse representation,” IEEE Trans. Cybern., vol. 46, no. 5, pp. 1132–1143, 2015 [Google Scholar] [PubMed]
22. B. Chen, W. Lu, J. W. Huang, J. Weng, and Y. C. Zhou, “Secret sharing based reversible data hiding in encrypted images with multiple data-hiders,” IEEE Trans. Dependable Secure Comput., vol. 19, no. 2, pp. 978–991, 2015. [Google Scholar]
23. C. H. Yang, C. Y. Weng, and Y. J. Chen, “High-fidelity reversible data hiding in encrypted image based on difference-preserving encryption,” Soft Comput., vol. 26, pp. 1727–1742, 2022. [Google Scholar]
24. F. Huang, J. Huang, and Y. Q. Shi, “New framework for reversible data hiding in encrypted domain,” IEEE Trans. Inf. Forensics Secur., vol. 11, no. 12, pp. 2777–2789, 2016. [Google Scholar]
25. F. Li, Q. Mao, and C. C. Chang, “A reversible data hiding scheme based on IWT and the sudoku method,” Int. J. Netw. Secur., vol. 18, pp. 410–419, 2014. [Google Scholar]
26. H. Zhang and L. T. Hu, “A data hiding scheme based on multidirectional line encoding and integer wavelet transform,” Signal Process. Image Commun., vol. 78, pp. 331–334, 2019. [Google Scholar]
27. C. Y. Yang and W. C. Hu, “Reversible data hiding in the spatial and frequency domains,” Int. J. Image Process., vol. 3, no. 6, pp. 373–384, 2010. [Google Scholar]
28. M. Y. Xiao, X. L. Li, and Y. Zhao, “Reversible data hiding for JPEG images based on multiple two-dimensional histograms,” IEEE Signal Process. Lett., vol. 28, pp. 1620–1624, 2021. [Google Scholar]
29. Z. Qian, X. Zhang, and S. Wang, “Reversible data hiding in encrypted JPEG bitstream,” IEEE Trans. Multimed., vol. 16, no. 5, pp. 1486–1491, 2014. [Google Scholar]
30. J. Tian, “Reversible data embedding using a difference expansion,” IEEE Trans. Circuits Syst. Video Technol., vol. 13, no. 8, pp. 890–896, 2003. [Google Scholar]
31. Y. J. Hu, H. K. Lee, K. Y. Chen, and J. W. Li, “Difference expansion based reversible data hiding using two embedding directions,” IEEE Trans. Multimed., vol. 10, no. 8, pp. 1500–1512, 2008. [Google Scholar]
32. D. M. Thodi and J. J. Rodriguez, “Expansion embedding techniques for reversible watermarking,” IEEE Trans. Image Process., vol. 16, no. 3, pp. 721–730, 2007 [Google Scholar] [PubMed]
33. R. Kumar, D. Sharma, A. Dua, and K. H. Jung, “A review of different prediction methods for reversible data hiding,” J. Inf. Secur. Appl., vol. 78, pp. 103572, 2023. [Google Scholar]
34. L. Luo, Z. Chen, M. Chen, X. Zeng, and Z. Xiong, “Reversible image watermarking using interpolation technique,” IEEE Trans. Inf. Forensics Secur., vol. 5, no. 1, pp. 187–193, 2009. [Google Scholar]
35. I. C. Dragoi and D. Coltuc, “Local-prediction-based difference expansion reversible watermarking,” IEEE Trans. Image Process., vol. 23, no. 4, pp. 1779–1790, 2014 [Google Scholar] [PubMed]
36. R. W. Hu and S. J. Xiang, “CNN prediction based reversible data hiding,” IEEE Signal Process. Lett., vol. 28, pp. 464–468, 2021. [Google Scholar]
37. X. L. Li, W. M. Zhang, X. L. Gui, and B. Yang, “Efficient reversible data hiding based on multiple histograms modification,” IEEE Trans. Inf. Forensics Secur., vol. 10, no. 9, pp. 2016–2027, 2015. [Google Scholar]
38. V. Sachnev, H. J. Kim, J. Nam, S. Suresh, and Y. Q. Shi, “Reversible watermarking algorithm using sorting and prediction,” IEEE Trans. Circuits Syst. Video Technol., vol. 19, no. 7, pp. 989–999, 2009. [Google Scholar]
39. X. L. Li, J. Li, B. Li, and B. Yang, “High-fidelity reversible data hiding scheme based on pixel-value-ordering and prediction-error expansion,” Signal Process., vol. 93, pp. 198–205, 2013. [Google Scholar]
40. O. Bo, X. L. Li, Y. Zhao, and R. R. Ni, “Reversible data hiding using invariant pixel-value-ordering and prediction-error expansion,” Signal Process., vol. 29, pp. 760–772, 2014. [Google Scholar]
41. F. Peng, X. L. Li, and B. Yang, “Improved PVO-based reversible data hiding,” Digit. Signal Process., vol. 25, pp. 255–265, 2014. [Google Scholar]
42. X. Wang, L. Ding, and Q. Q. Pei, “A novel reversible image data hiding scheme based on pixel value ordering and dynamic pixel block partition,” Inf. Sci., vol. 310, pp. 16–35, 2015. [Google Scholar]
43. X. C. Qu and H. J. Kim, “Pixel-based pixel value ordering predictor for high-fidelity reversible data hiding,” Signal Process., vol. 111, pp. 249–260, 2015. [Google Scholar]
44. X. Ma, Z. Pan, S. Hu, and L. Wang, “High-fidelity reversible data hiding scheme based on multi-predictor sorting and selecting mechanism,” J. Vis. Commun. Image Represent., vol. 28, pp. 71–82, 2015. [Google Scholar]
45. M. J. Weinberger, G. Seroussi, and G. Sapiro, “The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG-LS,” IEEE Trans. Image Process., vol. 9, no. 8, pp. 1309–1324, 2000 [Google Scholar] [PubMed]
46. P. Bas, T. Filler, and T. Pevný, “Break our steganographic system—the ins and outs of organizing BOSS,” in Int. Workshop Inform. Hiding, Berlin, Heidelberg, Springer, 2011, pp. 59–70. [Google Scholar]
47. A. Gupta, “BOWS2,” 2017. Mendeley Data, Vl. NCU, 2023. doi: 10.17632/kb3ngxfmjw.l. [Google Scholar] [CrossRef]
48. X. Zhang and S. Wang, “Vulnerability of pixel-value differencing steganography to histogram analysis and modification for enhanced security,” Pattern Recognit. Lett., vol. 25, no. 3, pp. 331–339, 2004. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools