
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

An Efficient Character-Level Adversarial Attack Inspired by Textual Variations in Online Social Media Platforms
1 Department of Artificial Intelligence, Ajou University, Suwon, Korea
2 Department of Computer Science, Munster Technological University, Cork, Ireland
3 Department of Software and Computer Engineering, Ajou University, Suwon, Korea
* Corresponding Author: Kyung-Ah Sohn. Email:
Computer Systems Science and Engineering 2023, 47(3), 2869-2894. https://doi.org/10.32604/csse.2023.040159
Received 07 March 2023; Accepted 17 May 2023; Issue published 09 November 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In recent years, the growing popularity of social media platforms has led to several interesting natural language processing (NLP) applications. However, these social media-based NLP applications are subject to different types of adversarial attacks due to the vulnerabilities of machine learning (ML) and NLP techniques. This work presents a new low-level adversarial attack recipe inspired by textual variations in online social media communication. These variations are generated to convey the message using out-of-vocabulary words based on visual and phonetic similarities of characters and words in the shortest possible form. The intuition of the proposed scheme is to generate adversarial examples influenced by human cognition in text generation on social media platforms while preserving human robustness in text understanding with the fewest possible perturbations. The intentional textual variations introduced by users in online communication motivate us to replicate such trends in attacking text to see the effects of such widely used textual variations on the deep learning classifiers. In this work, the four most commonly used textual variations are chosen to generate adversarial examples. Moreover, this article introduced a word importance ranking-based beam search algorithm as a searching method for the best possible perturbation selection. The effectiveness of the proposed adversarial attacks has been demonstrated on four benchmark datasets in an extensive experimental setup.Keywords
In the modern world, social media outlets, such as Twitter, Facebook, and Instagram, have become a major source of communication and information dissemination [1]. A wide audience and global accessibility are the key attributes that make such platforms a preferred choice for a diversified set of application domains. Thanks to natural language processing (NLP), computer vision (CV), and machine learning (ML) algorithms, meaningful information can be extracted for social media data. However, social media-based NLP applications are subject to various adversarial attacks. The key factors that influence the growing interest in attacking these applications include the dependency of these applications on automated decisions and the level of impact such attacks can have [2].
Adversarial attacks are designed to fool ML models while preserving human robustness. To this aim, attackers yield adversarial data samples by modifying instances of actual data samples from a dataset. Constructing an adversarial sample generally involves replacing 10%–30% of words in a sentence with synonyms or out-of-vocabulary (OOV) words that do not change their meaning. These adversarial examples are generated such that the model’s output over the perturbed input is incorrect with a high confidence score.
The typical characteristic of a quality adversarial attack is to cause maximal damage to the machine’s performance with minimal effect on the human understanding of the generated text [3–5]. In NLP, unlike CV, where pixel-level attacks may lead to catastrophic failure, producing a suitable and efficient adversarial attack is more challenging. In NLP, some existing word-level attacks are designed to delete words [6], substitute words by their synonyms and hyponyms [7], and paraphrase sentences [8]. However, these high-level attacks are not suitable in real-world social media based-NLP applications, such as spam generation, short-text generation, social media communication, and online conversations, due to the user’s ignorance of the training data, lack of vocabulary, and the classification model architecture. In contrast, low-level adversarial attacks result in OOV words by simple character-level perturbation, which is harder to detect and recognize. These perturbations include random character insertion, deletion, substitution, and transposition [9–13]. Although significant, these are not used in practice due to their limitations in generating simple editing modifications, effectiveness, replication of human cognition of text generation, and naturalness.
This work proposes a framework that effectively generates utility-preserving adversarial samples against state-of-the-art classification models under untargeted black-box settings. This article presents a set of perturbations inspired by text generation trends on online social networks, where intended messages are usually conveyed in a short text. Thus, to generate adversarial samples, social media text is perturbed by following the techniques used for minimizing the text. However, during the process, it is made sure that the perturbed text is either visually or phonetically similar to actual text so that the message is received without losing human robustness while fooling the filters. Moreover, a word importance ranking-based beam search mechanism is introduced to select the most suitable perturbations. This method first ranks the elements in the input string based on their importance and then chooses a beam of
The main contributions of this study are summarized as follows:
• To provide a hybrid perturbation method that mimics the social media textual variations to successfully attack social media-based NLP applications while preserving human and utility robustness.
• Introduce a word saliency-based beam search method for an efficient and effective adversarial attack in a black-box setting.
• Evaluate the effectiveness of the proposed adversarial attack on state-of-the-art text classification models and benchmark datasets in terms of attack success rate, perturbation rate, and preservation of semantic similarity.
• Discuss the potential defense strategies against the proposed attack with preliminary results.
The rest of the paper is organized as follows. Section 2 provides a detailed overview of related work. Section 3 describes the proposed adversarial attack. Section 4 details the experimental setup and the datasets used for the evaluation. Section 5 provides the experimental results. Section 6 discusses some potential defense mechanisms, and Section 7 concludes the paper.
The literature on adversarial ML is very rich. Most of the initial efforts in the domain are based on image-based solutions, and relatively less attention has been paid to adversarial text analysis. However, recently, adversarial text analysis has received increased attention due to the nature and dependency of NLP applications on automated decisions [2]. The literature already reports several attractive solutions exploring different aspects of adversarial text analysis. The generation of adversarial textual examples, which is one of the critical aspects of adversarial text analysis, is widely explored in the literature [14]. For instance, Papernot et al. [15] proposed a gradient-based perturbation method against recurrent neural network (RNN) classifiers. The authors applied the modification directly to the text iteratively until the successful generation of a misleading sequence. This method is named Fast Gradient Sign Method (FGSM) as it selects a random word from the input sample and generates gradient-based perturbations corresponding to the word vector. The perturbed word vector is then mapped into words with the least Euclidean distance in the word embedding space. On the other hand, Samanta et al. [10] used the embedding gradient to estimate the importance of the words using heuristic rules and manual synonyms and typos. Liang et al. [9] used word frequencies to select a class’s most important words. This method generates adversarial sequences by inserting, deleting, and modifying these critical words. These methods are applied in white-box settings as they access the model gradient and class labels for adversarial sample generations.
Adversarial attacks can be classified as high- or low-level attacks based on transformation types. High-level adversarial attacks involve insertion, deletion, replacement, and displacement of words, whereas low-level attacks involve modification at the character level. A vast majority of the literature is based on high-level adversarial attacks. For instance, Jia et al. [16] inserted semantically correct but irrelevant paragraphs into texts to fool neural reading comprehension models. Alzantot et al. [7] proposed an optimization-based method for adversarial text generation through the replacement of words in the input sequence with their nearest neighbors in the embedding space. The authors used the GloVe embedding space and a genetic algorithm for optimal solution selection. Checklist attack [17] is based on sentence contraction and extension, and name entities substitution. Similarly, TextFooler [18] which is a word-level adversarial attack, is generated through the replacement of words by their suitable synonyms and a word importance ranking-based greedy search. This method allows the generation of adversarial samples while preserving semantic similarity and syntactic correctness. Ren et al. [19] proposed another high-level attack, weighted word saliency, which replaces the most important words in the input sample with their nearest neighbors in WordNet. Zang et al. [20] used particle swarm optimization (PSO) and HowNet-based word swapping to fool the classification model.
Although effective, these rule-based adversarial attacks can generate out-of-context and complex replacements. BERT-based adversarial examples (BAE) were proposed to generate adversarial examples using the BERT-masked language model by context-aware modifications. BAE replaces and inserts tokens into the original text by masking a piece of the text and using the BERT-MLM to generate substitutes for the masked tokens. Li et al. [21] proposed BERT-Attack, attacking BERT using BERT. The authors used BERT to find the optimal solution in a huge space of possible transformation to preserve semantic consistency and fluency. The BERT-Attack uses BERT-masked token prediction with sub-word expansion. Li et al. [22] proposed Clare by using RoBERTa masked prediction to swap, insert, and merge tokens in the input samples. Wang et al. [23] proposed a fast gradient projection method (FGPM), a synonym replacement-based adversarial attack with higher time efficiency. Goa et al. [24] proposed an adversarially regularized auto-encoder (ARAE) that maps discrete text into a continuous space and generates the adversarial examples by adding the universal adversarial perturbations in the continuous space, selecting the natural adversarial samples. A rule-based method [25] is proposed to control the number of perturbations for the word-level adversarial attacks.
The word-level attacks performed well against the state-of-the-art deep learning (DL) models; however, they are more inclined to produce samples by inserting less frequent and complex words that are rarely used in online conversations. Such adversarial examples may fool the system but fail to convey the message efficiently. The low-level adversarial attacks suit well to real-life scenarios. There exist a variety of works that propose low-level orthographic attacks. For instance, Ebrahimi et al. [26] attacked the neural network-based text classification model in a white-box setting by flipping the characters with the most adverse effects. Ebrahimi et al. [27] also fooled machine translation systems with character-level modifications. Belinkov et al. [28] used a combination of keyboard-based character swapping to replicate synthetic keyboard typos and natural typing errors captured from different Wikipedia edit histories for perturbed text generation. Hosseini et al. [29] and Rodriquez et al. [30] attacked the toxicity system by generating multi-level adversarial samples using character-level modifications for the misspelling of the abusive words and polarity shifting by inserting the word “not” to fool the system. Eger et al. [5] utilized the visual similarity of characters for perturbation. They replaced some characters in the input samples with similar-looking characters to fool the model while preserving human robustness. Tan et al. [31] attacked words by replacing them with morphological variants, which mostly resulted in orthographic attacks (in English). Gao et al. [12], and Pruthi et al. [13] used composite transformations, including character insertion, deletion, substitution, and transposition, which replicate the most common typing mistakes, to attack text classification models. Similarly, TextBugger [11] also used a composite attack combining these four typos and synonym replacements to fool the classification models. Eger et al. [32] attacked RoBERTa using nine character-level perturbations based on visual and phonetic similarities. Bhalerao et al. [33] and Le et al. [34] proposed data-driven approaches to learn and generate adversarial samples from the human-written text on the Web. They collected data from online sources and learned text generation patterns in a specific domain.
Although the above approaches have achieved good results, there is still significant room for improvement in attack success rate, naturalness, perturbation rate, and semantic consistency. The success rate of the existing character-level attacks [11–13] against transformers-based models like BERT and RoBERTa is generally low, with a high perturbation rate. The perturbations generated by these approaches are usually basic and can only be considered as replicating typing mistakes such as a single character insertion, deletion, substitution, and transposition. Other methods, such as [32–34], to attack transformer-based models while preserving human robustness, however, have non-trivial and data-dependent substitution strategies, limiting their applicability to specific tasks. This work aims to introduce a set of perturbations learned from human text generation trends and a word saliency-based beam search mechanism for optimal adversarial example selection to enhance the attack success rate. The performance of the proposed method is evaluated and compared to the existing methods based on the evaluation metrics discussed in Section 4.4. Additionally, a basic defense system is applied to check the robustness of the proposed attack against the adversarial defense.
This work proposes a set of perturbations inspired by trends in text generation on online social networks. In online social networks, generally, the goal is to convey the intended message with the shortest possible text. To achieve this, considering the source and target, the message must be visually or phonetically similar. Inspired by social network trends, the perturbed text is generated by relying on four transformations to fool and generate human-understandable adversarial samples in this work. The proposed algorithm is presented as Algorithm 1. The problem is formulated in the following subsection.

Given a set of
The aim is to generate an adversarial example
Here,
From the literature, in the text classification, it is now a well-established fact that in a given instance
where
Moreover, the stop and short words are prohibited from perturbation by removing them from the list of candidates to preserve the fluency and grammar of the perturbed text. Short words are words that are considered too short to contribute significantly to the meaning of the text. Short words are not necessarily stop words, e.g., no, so, not, hot, etc. The length of the words to be filtered out varies depending on the user’s choice. In this work, words with less than three characters are considered short words. The words are then sorted in descending order based on the word’s saliency scores while leaving out the stop and short words.
The transformation for an input
Our approach uses composite transformation for the generation of adversarial examples. In the composite attack, a set of modifications is defined where each can modify the target words. This work uses a multi-stage perturbation method to generate hybrid samples for the target words. However, it is preferred to select the transformations that maximize the model loss with minimum possible perturbations. Fewer perturbations ensure the visual and semantic similarity of the original and adversarial samples. The transformations used in this work are discussed as follows.
In English, consonants are sound producers, whereas vowels are used to raise or lower the sounds of phonemes in the language. In informal communication on social networks, there is a trend of using consonants and excluding most vowels from words, except the starting vowels. This vowel removal can efficiently generate text samples with OOV tokens, which can easily fool the models, while a human can interpret them quickly with little cognitive effort [36]. The vowel removal can generate misspelled words with high phonetic similarity to the actual words, e.g., good (g
Vowel removal is a rule-based approach implemented with constraints such that the actual phonetic representation is modified the least. These constraints include not removing the first character and not removing vowels occurring between the same characters, which unlike the existing approaches preserve the human understanding while successfully modifying the target words, e.g., “adversarial attacks” is modified to “advrsrl attcks” instead of “dvrsrl ttcks” [32]. This transformation removes vowels from the candidate words to generate adversarial samples.
Additionally, instead of removing all vowels, a schwa removal method is utilized. In English, schwa (ə) is considered the most common vowel sound. Schwa is a concise neutral sound, and it is used as a reduced vowel in many unstressed syllables. The words are converted to their equivalent phonetic representations using IPA phonetic transcription, identified the schwa, and modified the word by deleting the vowel corresponding to schwa, e.g., “consistently (kən’sɪstəntli)” is modified to “cnsistntly (kən'sɪstəntli)” instead of “cnsstntly,” where only characters corresponding to shwa “ə” are removed despite all vowels.
An ideal phonetic perturbation modifies the spelling of the target word while leaving the pronunciation the same. The phonetic replacement of words, characters, and sub-words is commonly used on online platforms. It does not only occur mistakenly but also as a form of creative language use [37]. The phonetic replacement method includes two types of perturbations: a rule-based approach for substitution with similar sound characters/digits (atmosphere
LeetSpeak is a method of text modifications characterized by character replacement with a visually similar, non-alphabet character(s), which are referred to as homoglyphs. The most commonly used homoglyphs in LeetSpeak are numbers. This work generates adversarial samples by substituting a selected set of characters, including {a, b, e, g, l, i, o, s, t} with its similar looking homoglyphs like {4, 8, 3, 9, |, 1, 0, 5/$, 7}, respectively. For instance, the word “less,” “passionate,” and “stylish” are modified as “l3ss,” “passi0nate,” and “$tylish,” respectively. LeetSpeak-based substitution can be utilized to generate very complex adversarial examples by replacing a single character with multiple characters. However, keeping the motivation of human robustness, only the simplest one-with-one character mapping method is utilized.
Inserting unobstructive characters into words is frequently used in social media conversations, especially in the case of abusive and toxic language [38], to fool automatic harmful content detectors. The attack may minimally affect human understanding depending on the perturbation symbols used. In online social media spaces, dots, “–,” “*,” and “#” are the most commonly inserted symbols, where “*” is mostly inserted in slang, such as fuck
Moreover, in social media emotions are often textually expressed by character insertion which is referred to as word enlargement. The word enlargement results in the OOV words which are humanly understandable, e.g., goooooooood, baaaaaaaaddd, etc. Emotional expressions are generally found in adjectives, adverbs, or interjections. Such types of emotional expressions may fool the automatic text classification systems. In this work, random spaces, dots, “–,” “#,” and character repetition (based on POS) are inserted to generate candidate transformations.
The search method successively evaluates a model and selects the best possible perturbation out of all possible transformations based on the maximum model loss. It returns the perturbation that achieves the goal and satisfies all constraints.
This work proposes a word importance ranking-based beam search (WIR-BS). In this method, the words in a given sample
Constraints are rules used to determine the validity of a perturbation with respect to the input sample. These constraints include pre-transformation, overlap, grammatical, and semantic constraints. These constraints can be applied based on the type of perturbations.
This work imposes several constraints to keep the perturbation rate in the minimum possible range, including word length, stop words modification, the maximum number of words, edit distance, and modification repetition. The word length, stop words modification, and repeat modification are pre-transformation constraints performed before modifying the candidate samples. The word length constraint prevents the perturbation of words that are shorter than a user-defined length. The stop words modifications constraint disallows the modification of stop words. The repeat modification constraint disallows the modification of previously modified words. The maximum number of transformed words and edit distance are considered as overlap constraints. The overlap constraints determine the perturbation validity based on the difference between the input and modified samples, i.e., the maximum number of allowed editing operations, and the maximum number of transformed words. In this work, the values of these constraints are set as follows:
The overall procedure is presented in Algorithm 1, where the inputs are the set of original samples
The subroutine
This section discusses the target ML models, datasets, baseline algorithms, and evaluation measures used in our experiments. We selected four state-of-the-art text classification models, four benchmark datasets to attack, four baseline algorithms for comparison, and five evaluation measures. The general experimental process for generating adversarial attacks on text classification models involves the following steps: data collection, model selection, definition/selection of transformations, selection of constraints, goal function definition, and definition/selection of the search method. The TextAttack [40] framework provides a platform for defining customized attacks. In this work, we define the transformation methods and a new search method, while extracting the data and pre-trained models from Huggingface using the TextAttack1,2 framework. The following subsections provide details of each of the components of the experimental setup.
For our experiments, four state-of-the-art models for text classification are considered. These models include convolutional neural networks (CNN), RNNs, and transformers-based text classification algorithms. Each of the following models is pre-trained on their respective datasets, e.g., the BERT model trained by AGNews data set is used to evaluate the robustness of the BERT model to the adversarial attacks in multi-class (4 classes) classification.
WordCNN is one of the widely used models for text classification. It consists of an embedding layer that performs
4.1.2 Long Short-Term Memory (LSTM)
LSTM is also one of the most commonly used architectures for text analysis. This work used a pre-trained one-layer bi-directional LSTM with
Bidirectional Encoder Representations from Transformers (BERT) [41] is one of the state-of-the-art text analysis algorithms. In this work, we attacked the pre-trained BERT base uncased as one of the target classification models available on Huggingface for all target datasets. BERT is a SOTA model, pre-trained on a large English corpus and self-supervised. The strength of this model lies in its highly pragmatic approach and its training on large datasets like Wikipedia and BookCorpus. BERT is known for its high performance in numerous downstream NLP tasks. BERT is pre-trained with two main objectives, masked language modeling (MLM) and next sentence prediction (NSP). These two objectives enable the model to learn the internal representation of the language, which is utilized to extract salient features for downstream tasks. BERT utilizes transformer encoder architecture that tokenizes and processes each token in the context of its prior and later tokens. In this work, we used the pre-trained models provided in the Huggingface library4.
RoBERTa is a state-of-the-art model introduced by [42]. RoBERTa is pre-trained on English using masked language modeling (MLM) objective. RoBERTa is a robustly optimized replication of BERT pretraining. It is pre-trained on larger data with an increased number of iterations. This work used the pre-trained models provided in the Huggingface library5.
This work evaluated the proposed adversarial attack on four popular public benchmark datasets for text classification. This section provides the detail of the datasets. A summary of these datasets is provided in Table 1.
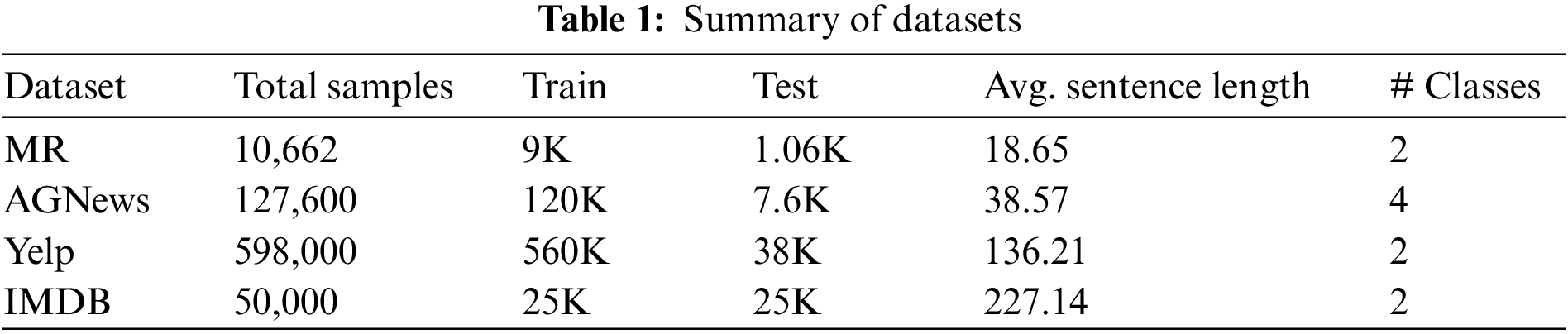
AGNews is a news categorization dataset constructed from the AG collection. AG is a collection of about one million news articles6. ComeToMyHead collected this dataset from more than 2,000 news sources in a period of over one year. The samples in AGNews are classified into four classes: business, world, sports, and science/technology. This dataset is split into training and test sets containing 120,000 and 7,600 samples, respectively. The dataset used in this work is available in Huggingface7.
4.2.2 Rotten Tomatoes Movie Reviews (MR)
The MR dataset contains a total of 10,662 movie reviews, including
4.2.3 Yelp Review Polarity Dataset
The Yelp review polarity dataset is extracted from data collected from the Yelp Dataset Challenge 2015. This dataset is constructed for binary sentiment classification. The reviews are labeled as positive or negative based on the rating scores provided by the reviewers. Scores of
The IMDB dataset consists of 50,000 labeled movie reviews collected from online sources. This dataset is divided into two halves, i.e., 25,000 training samples and 25,000 test samples. The average number of words per review sample is
Each dataset is split into training, validation, and test data. The training data is used to train the target models and the test data is used to evaluate the model performance when attacked by the adversarial models. The test data is exposed to adversarial attacks and then passed through a system trained on the training data. This work exposes pre-trained models to the proposed attack recipe to report its effectiveness. Moreover, the training data is utilized during adversarial training to retrain the model with the actual training data augmented with adversarial samples generated for randomly selected samples from training data. The number of augmented samples varies depending on the user’s choice.
Four well-known baseline algorithms are selected to compare the proposed model, including character-level, word-level, and multi-level perturbation. These recipes are briefly discussed as follows.
TextFooler [18] is a word-level, untargeted adversarial attack applied to both classification and entailment problems. TextFooler is a simple but strong baseline for generating utility-preserving adversarial examples in the black-box settings. This attack works on the principle of synonym substitution for the most important candidate words selected by the greedy-WIR method. In this attack, among all synonyms, only the ones with similar part-of-speech (POS) are considered as the initial candidates to avoid grammatical mistakes. Among these candidates, the ones with high universal sentence encoder (USE) scores are selected as the appropriate substitute to preserve the context of a sentence.
DeepWordBug [12] is a character-level adversarial attack that generates adversarial examples using four basic typographic editing operations: insertion, deletion, substitution, and transposition. In NLP, these operations may result in the most basic typographic spelling errors that may result in out-of-vocabulary words that are not recognized by the NLP algorithms without using spelling error correction techniques.
Pruthi et al. [13] is another character-level adversarial attack. It also uses composite transformation including insertion, deletion, transposition, and key-board-based transposition. Unlike DeepWordBug, which uses greedy-WIR, it uses a greedy algorithm for candidate selection.
TextBugger [11] is a multi-level adversarial attack that is reported to generate utility-preserving adversarial examples in both white-box and black-box environments. It introduces composite transformations to the most important words selected by the greedy-WIR method. These transformations include both word-level and character-level perturbations. The character-level perturbations used include insertion (space), deletion (random character), transposition (neighboring characters), and substitution (visually similar characters substitution), whereas word-level perturbation uses word substitution with the nearest neighbor selected from a set of top-
The performance of the proposed attack is compared with the existing attacks based on the model effectiveness, efficiency, naturalness, human robustness, and utility robustness, where effectiveness and efficiency are quantitative, and naturalness and robustness are qualitative measures.
Effectiveness is judged through the attack success rate and the model accuracy under attack.
• Success rate: The attack success rate is measured as the fraction of samples for which the attack is successful, i.e., that satisfies Eq. (2). It measures the effectiveness of the attack.
• Accuracy under attack: Accuracy under attack is the model accuracy over the adversarial samples. The accuracy under attack is also used to measure the effectiveness of the attack. Moreover, it can be used to measure the model’s robustness against adversarial attacks.
The efficiency of the model is reported via the perturbation rate. The perturbation rate is measured as the fraction of words modified for a successful attack. An attack with a high success rate and a low perturbation rate is considered efficient.
Naturalness measures the closeness of the generated samples to social media text. Closeness is defined as the average similarity score of the adversarial samples to the social media text provided by the participants to the given adversarial samples. It provides evidence of the generated samples replicating the trends and patterns used in real-life scenarios.
The human robustness metric is used to estimate the understanding and readability of the generated text by a human judge.
Utility robustness/preservation is the fraction of samples for which a human judge provides correct labels when provided with a mix of adversarial and legitimate samples.
This section discusses the performance and comparison of the proposed model with the four state-of-the-art adversarial attack methods discussed in Section 4.3 on the target models introduced in Section 4.1. Moreover, the results yielded from human evaluation and ablation study are also discussed in Sections 5.2 and 5.4, respectively.
This section discusses the proposed adversarial attack’s effectiveness and efficiency compared to the existing techniques. The effectiveness of the proposed adversarial attack is evaluated based on the attack success rate and model accuracy under attack. The simulation results prove the effectiveness of the proposed attack over the existing baseline attacks, as shown in Tables 2 and 3.


Table 2 shows the success rate of the proposed and existing attacks on the state-of-the-art text classification models using benchmark datasets in binary and multi-class classification. The success rate of the proposed attack is higher than the existing attacks with an improvement ranging from
Table 3 provides the evaluation and comparison of the models in terms of classification accuracy under attack. The proposed attack achieved high success in degrading the state-of-the-art model’s accuracy. The highest degradation caused by the proposed attack is against the BERT base uncased on the IMDB dataset, which is from
The proposed model achieved the highest (
Table 4 provides a comparison of the proposed attack with the existing attacks regarding the perturbation rate. An efficient adversarial attack is one that can achieve a high success rate with fewer perturbations. As shown in Tables 2 and 4, the simulation results demonstrate that the proposed model achieved a high success rate with relatively fewer perturbations.

Overall, the proposed attack and TextFooler performed better in degrading the model’s performances. However, TextFooler is a word-level adversarial attack that is reported to have the limitation of replacing words with less frequently used words that are not necessarily known to other users. Moreover, word-level adversarial text generation is rarely used in real-life scenarios like social media communication. Among the low-level adversarial attacks, the DeepWordBug and TextBugger performed well compared to Pruthi. The adversarial samples generated by DeepWordBug contain OOV words, likely to be corrected (defended) by using spell-checkers. The samples generated by these models are more similar to human-generated samples; however, it is not necessarily a close replication of the social media text. The human evaluation is discussed in the following Section 5.2.
This work conducted a study with human observers to estimate the quality of the adversarial samples in the context of naturalness, human robustness, and utility robustness. To measure naturalness, the participants were asked to score the generated adversarial samples from
The participants were provided with a shuffled mix of
After examining the results, the average similarity score provided by the participants to the samples provided was
About
The participants identified, on average,
Additionally, the participants were asked to provide suitable candidates for the samples, which they marked as adversarial examples. A total of
For comparison of the proposed model with existing approaches, the participants were provided with a mix of original and adversarial samples generated by the DeepWordBug, TextBugger, and Eger et al. [32]. Their task was to classify them into their respective classes, identify whether these samples are adversarial or original, and determine their similarity to human-generated text. The participants could correctly label up to 91% of the sentences, with DeepWordBug achieving the highest score of 96% and Eger et al. [32] having the lowest score of 80%. The participants, however, correctly identified all of the adversarial samples generated by Eger et al. [32] because out of nine transformation methods, the inner-shuffle, full-shuffle, intrude, and visual methods were used in this work. Unlike the other method, these methods have less similarity to human-generated text and hence can be easily identified as adversarial by human participants. The participants correctly identified 65% of the samples generated by the DeepWordBug, and 77% of the adversarial samples generated by the TextBugger method.
5.3 Examples of Generated Adversarial Sentences
Table 5 shows some examples of the adversarial samples generated by the existing and proposed methods. As seen in Table 5, the samples generated by the proposed method are consistent with the original input while successfully deceiving the classification model. By manually evaluating random samples, it is observed that although the word-level and multi-level adversarial perturbation performed better, they replaced simple words with complex and less frequently used words, i.e., “consistently

The proposed method uses composite transformation, where one or more types of perturbations are introduced to generate adversarial samples. Therefore, an ablation study is conducted to determine how the proposed method performs when these transformations are individually applied to attack the classification model. Moreover, the performance of the proposed attack with other search mechanisms like genetic algorithms and beam search methods is also examined.
The average perturbation ratio of different types of datasets (MR and AGNews) against BERT base uncased is shown in Fig. 1. The vowel removal is the most effective type of perturbation. In this experiment, the data was attacked by using the proposed composite transformation.
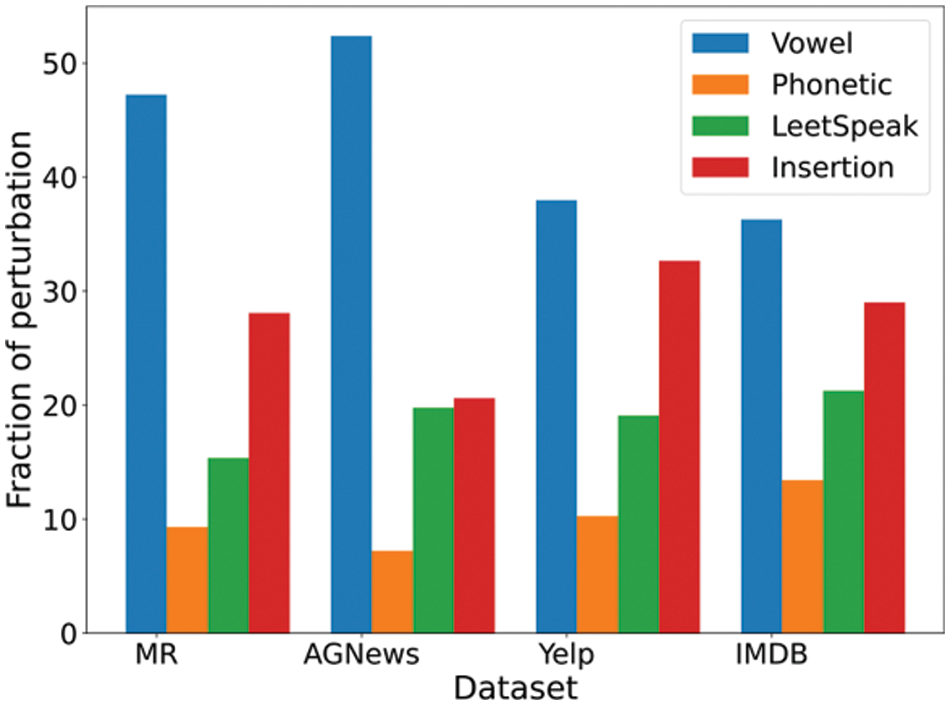
Figure 1: Fraction of perturbations against BERT base uncased model
Fig. 2 shows the performance of the individual transformations against the BERT base uncased model on the MR dataset. It is observed from simulations of individual transformations that vowel removal was the most effective attack, followed by character insertion and LeetSpeak. The vowel removal however consists of rule-based vowel removal and shwa removal. It is found that among the phonetic-based perturbations, the double meta-phone performed better than the rule-based mapping of words and sub-words to similar-sounding characters; however, the performance of such rule-based phonetic transformations was comparable.
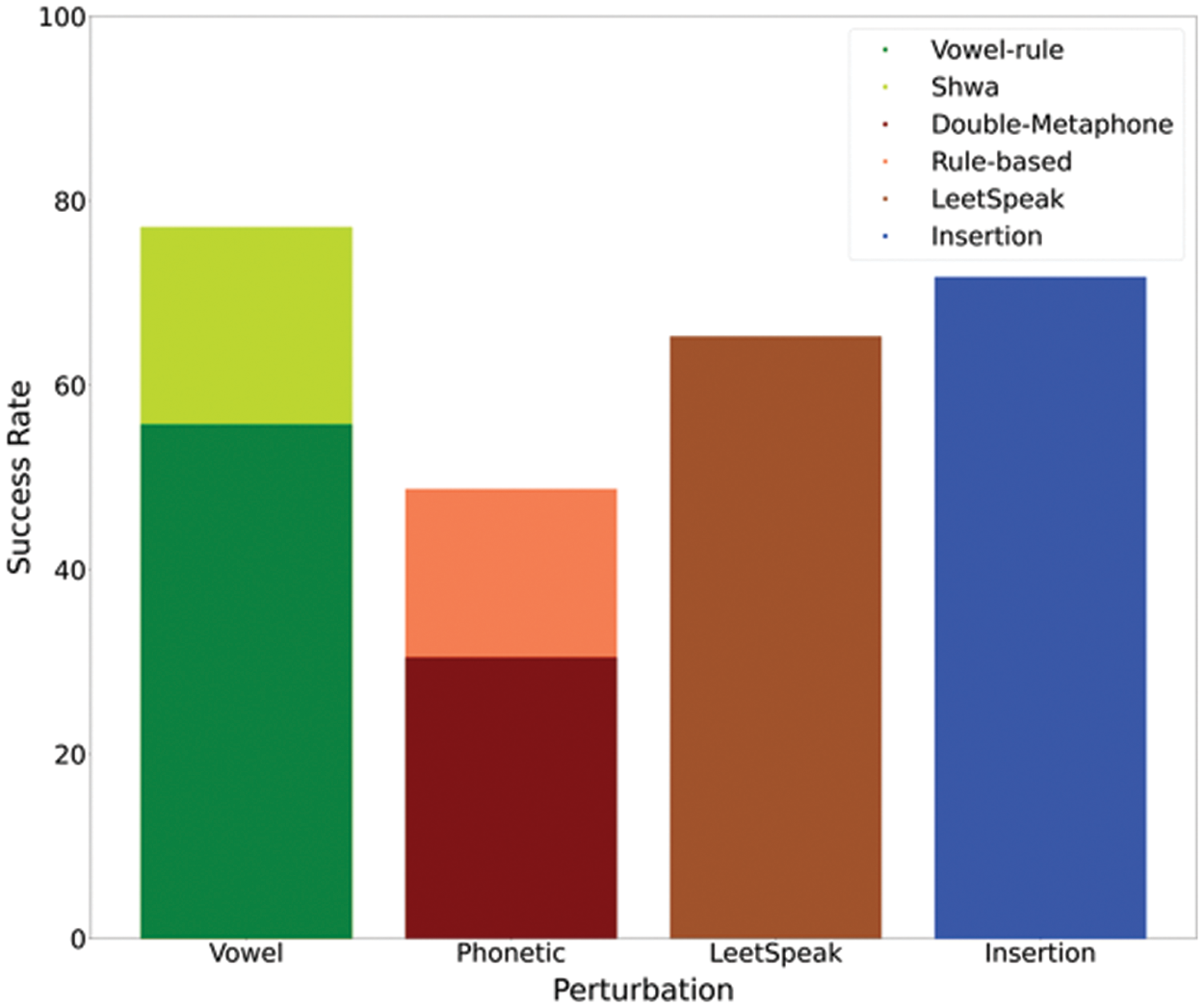
Figure 2: Performance of individual transformations against BERT base uncased on MR dataset
Table 6 shows the proposed method’s performance compared to the other search algorithms. The simulation results showed that the performance of the proposed word importance weight ranking-based beam search method was the best among the selected search methods, followed by the beam search algorithm. The beam search method with the proposed transformations performs well compared to the existing transformations, as evident in Table 6. The word importance ranking improved the performance of the beam search-based adversarial perturbations.

6 Defense Mechanisms against Adversarial Attacks
This section reports on experiments with two of the most commonly used defense techniques, text normalization, and adversarial training, to defend against the proposed adversarial attack.
To guard against adversarial attacks, one needs to train a classifier
Table 7 shows the performance of the AT with the proposed model. The actual accuracy is the accuracy of the model with legitimate training and test samples, the adversarial accuracy is the prediction accuracy of the new model trained with the augmented dataset over the legitimate test set, and the success rate (SR) is the success of the adversarial attack on the actual model, and the SR-with-AT is the proportion of misclassified samples by the new model trained with the augmented dataset. Table 7 shows that adversarial training increases the model’s robustness against adversarial attacks with a slight trade-off in the model’s performance. For instance, the attack success rate against BERT on the MR dataset is decreased by about

Despite its potential, the practical implementation of adversarial training is limited by its dependency on the type and number of adversarial samples. This requires sufficient knowledge about the attack strategy; however, an attacker does not announce the details of an attack.
The adversarial attack proposed in this work fools the target models by modifying certain words in the input samples at the character level. The adversarial samples generated by this recipe contain OOV words, which causes the target model to generate the wrong output because the model is unaware of the OOV text. One of the ways to defend against such an attack is adversarial training, as discussed in the previous Section 6.1, in which the model is trained on both legitimate and adversarial samples so that the model is familiar with both the legitimate and adversarial samples.
Text normalization is the process of translating noisy and non-standard OOV words into their standard lexical representation. The spelling error correction algorithm is one of the most basic and straightforward text normalization methods, where the OOV words are considered misspelled words. These algorithms normalize noisy misspelled OOV words to their standard lexical counterparts by using spell-checking algorithms to enhance the performance of the traditional text analysis methods [43,44]. Spell-checkers are reported in the literature [11,13] to perform well in defense against character-level adversarial attacks. Text normalization is not a “one size fits all” task of substituting OOV words with their valid replacements [45]. Besides the correction of the misspelled words, a normalization algorithm needs to handle a wide range of OOV words by sensing the error patterns, identifying the error types, and activating the appropriate correction methods.
In this work, a modified version of [46] is applied to detect and correct the OOV words in the input sequence that may be generated due to an adversarial attack before passing it through the classification model. The text normalization method is a stacked ensembled-based text normalization that utilizes a dictionary lookup method for OOV word detection and a hybrid method for OOV word correction. This method’s architectural and implementation details are discussed in [46].
Table 8 shows the effectiveness of the text normalization method in defense against character-level adversarial attacks. The simulation results showed that text normalization could be an effective and generalized defense against character-level adversarial attacks. The text normalization method is an extension of spell correction approaches suggested to defend against low-level attacks. The spell correction methods, however, fail to correct multiple perturbations and may not be very effective. The traditional spell correction method is a suitable defense against adversarial attacks, which may result in common typing mistakes, i.e., DeepWordBug [12], and Pruthi et al. [13]. We employed the text normalization as a defense to the character-level adversarial attacks to provide evidence of its effectiveness. The proposed text normalization method is very effective against the DeepWordBug method, due to its simple basic character-level editing operations. Similarly, in the case of TextBugger at the character level perturbations, the normalization was an effective defense, however, in case of word-level perturbations the text normalization failed to identify and defend the adversarial samples.

The text normalization was an effective defense against the proposed adversarial attack, which provide a way to utilize more advanced text normalization methods, that can handle multiple complex character level perturbations simultaneously, as a defense mechanism against the adversarial attacks.
This work focused on generating adversarial attacks inspired by the human cognition of text generation in online social media conversations. We selected four simple and most prominently used textual variations introduced intentionally in online communication. This paper introduced a word importance ranking-based beam search algorithm in the proposed attack to increase its effectiveness.
We studied adversarial attacks against state-of-the-art text classification models in untargeted black-box settings, including WordCNN, Bi-LSTM, BERT, and RoBERTa. Extensive simulations demonstrated the effectiveness and efficiency of the proposed adversarial attack over the most relevant existing attacks in all cases studied in this work. The adversarial samples generated by the proposed attack were more natural and similar to the text generated on social media platforms, as evaluated by human participants. The adversarial examples preserve human and utility robustness.
Moreover, this article presented the effectiveness of two potential defenses against such adversarial attacks, i.e., adversarial training and text normalization. It is observed that the attack success rate was reduced by about
Acknowledgement: None.
Funding Statement: This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT)(No. NRF-2022R1A2C1007434), and also by the BK21 FOUR Program of the NRF of Korea funded by the Ministry of Education (NRF5199991014091).
Author Contributions: All authors contributed equal to this work.
Availability of Data and Materials: The data used in this work is publicly available. All data that are not public are available from the corresponding author on request.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1https://github.com/QData/TextAttack
2https://textattack.readthedocs.io/en/latest/
3https://textattack.readthedocs.io/en/latest/3recipes/models.html
4https://huggingface.co/bert-base-uncased
5https://huggingface.co/roberta-base
6http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html
7https://huggingface.co/datasets/ag_news
8https://huggingface.co/datasets/rotten_tomatoes
9https://huggingface.co/datasets/yelp_polarity
10https://huggingface.co/datasets/imdb
References
1. N. Said, K. Ahmad, M. Riegler, K. Pogorelov, L. Hassan et al., “Natural disasters detection in social media and satellite imagery: A survey,” Multimedia Tools and Applications, vol. 78, no. 22, pp. 31267–31302, 2019. [Google Scholar]
2. I. Alsmadi, K. Ahmad, M. Nazzal, F. Alam, A. Al-Fuqaha et al., “Adversarial NLP for social network applications: Attacks, defenses, and research directions,” IEEE Transactions on Computational Social Systems, pp. 1–20, 2022. [Google Scholar]
3. I. J. Goodfellow, J. Shlens and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014. [Google Scholar]
4. C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan et al., “Intriguing properties of neural networks,” in 2nd Int. Conf. on Learning Representations (ICLR), Banff, AB, Canada, 2014. [Google Scholar]
5. S. Eger, G. G. Şahin, A. Rücklé, J. U. Lee, C. Schulz et al., “Text processing like humans do: Visually attacking and shielding NLP systems,” in Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, USA, vol. 1, pp. 1634–1647, 2019. [Google Scholar]
6. S. Feng, E. Wallace, A. Grissom II, P. Rodriguez, M. Iyyer et al., “Pathologies of neural models make interpretations difficult,” in Proc. of the 2018 Conf. on Empirical Methods in Natural Language Processing, Brussels, Belgium, pp. 3719–3728, 2018. [Google Scholar]
7. M. Alzantot, Y. S. Sharma, A. Elgohary, B. J. Ho, M. Srivastava et al., “Generating natural language adversarial examples,” in Proc. of the 2018 Conf. on Empirical Methods in Natural Language Processing, Brussels, Belgium, pp. 2890–2896, 2018. [Google Scholar]
8. M. T. Ribeiro, S. Singh and C. Guestrin, “Semantically equivalent adversarial rules for debugging NLP models,” in Proc. of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, vol. 1, pp. 856–865, 2018. [Google Scholar]
9. B. Liang, H. Li, M. Su, P. Bian, X. Li et al., “Deep text classification can be fooled,” in Proc. of the 27th Int. Joint Conf. on Artificial Intelligence, Stockholm, Sweden, pp. 4208–4215, 2017. [Google Scholar]
10. S. Samanta and S. Mehta, “Towards crafting text adversarial samples,” arXiv preprint arXiv:1707.02812, 2017. [Google Scholar]
11. J. Li, S. Ji, T. Du, B. Li and T. Wang, “Textbugger: Generating adversarial text against realworld applications,” in 26th Annual Network and Distributed System Security Symp., San Diego, CA, USA, 2019. [Google Scholar]
12. J. Gao, J. Lanchantin, M. L. Soffa and Y. Qi, “Black-box generation of adversarial text sequences to evade deep learning classifiers,” in IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, pp. 50–56, 2018. [Google Scholar]
13. D. Pruthi, B. Dhingra and Z. C. Lipton, “Combating adversarial misspellings with robust word recognition,” in Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, pp. 5582–5591, 2019. [Google Scholar]
14. W. E. Zhang, Q. Z. Sheng, A. Alhazmi and C. Li, “Adversarial attacks on deep-learning models in natural language processing: A survey,” ACM Transactions on Intelligent Systems and Technology, vol. 11, no. 3, pp. 1–41, 2020. [Google Scholar]
15. N. Papernot, P. McDaniel, A. Swami and R. Harang, “Crafting adversarial input sequences for recurrent neural networks,” in MILCOM 2016-2016 IEEE Military Communications Conf., Baltimore, MD, USA, pp. 49–54, 2016. [Google Scholar]
16. R. Jia and P. Liang, “Adversarial examples for evaluating reading comprehension systems,” in Proc. of the 2017 Conf. on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, pp. 2021–2031, 2017. [Google Scholar]
17. M. T. Ribeiro, T. Wu, C. Guestrin and S. Singh, “Beyond accuracy: Behavioral testing of NLP models with CheckList,” in Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4902–4912, 2020. [Google Scholar]
18. D. Jin, Z. Jin, J. T. Zhou and P. Szolovits, “Is bert really robust? A strong baseline for natural language attack on text classification and entailment,” in Proc. of the AAAI Conf. on Artificial Intelligence, New York, NY, USA, vol. 34, pp. 8018–8025, 2020. [Google Scholar]
19. S. Ren, Y. Deng, K. He and W. Che, “Generating natural language adversarial examples through probability weighted word saliency,” in Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, pp. 1085–1097, 2019. [Google Scholar]
20. Y. Zang, F. Qi, C. Yang, Z. Liu, M. Zhang et al., “Word-level textual adversarial attacking as combinatorial optimization,” in Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 6066–6080, 2020. [Google Scholar]
21. L. Li, R. Ma, Q. Guo, X. Xue and X. Qiu, “BERT-ATTACK: Adversarial attack against BERT using BERT,” in Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 6193–6202, 2020. [Google Scholar]
22. D. Li, Y. Zhang, H. Peng, L. Chen, C. Brockett et al., “Contextualized perturbation for textual adversarial attack,” in Proc. of the 2021 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5053–5069, 2021. [Google Scholar]
23. X. Wang, Y. Yang, Y. Deng and K. He, “Adversarial training with fast gradient projection method against synonym substitution based text attacks,” in Proc. of the AAAI Conf. on Artificial Intelligence, vol. 35, pp. 13997–14005, 2021. [Google Scholar]
24. H. Gao, H. Zhang, X. Yang, W. Li, F. Gao et al., “Generating natural adversarial examples with universal perturbations for text classification,” Neurocomputing, vol. 471, pp. 175–182, 2022. [Google Scholar]
25. N. Zhou, N. Yao, J. Zhao and Y. Zhang, “Rule-based adversarial sample generation for text classification,” Neural Computing and Applications, vol. 34, no. 13, pp. 10575–10586, 2022. [Google Scholar]
26. J. Ebrahimi, A. Rao, D. Lowd and D. Dou, “Hotflip: White-box adversarial examples for text classification,” in Proc. of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, vol. 2, pp. 31–36, 2018. [Google Scholar]
27. J. Ebrahimi, D. Lowd and D. Dou, “On adversarial examples for character-level neural machine translation,” in Proc. of the 27th Int. Conf. on Computational Linguistics, Santa Fe, New Mexico, USA, pp. 653–663, 2018. [Google Scholar]
28. Y. Belinkov and Y. Bisk, “Synthetic and natural noise both break neural machine translation,” in Int. Conf. on Learning Representations, Vancouver, BC, Canada, 2018. [Google Scholar]
29. H. Hosseini, S. Kannan, B. Zhang and R. Poovendran, “Deceiving Google’s perspective API built for detecting toxic comments,” arXiv preprint arXiv:1702. 08138, 2017. [Google Scholar]
30. N. Rodriguez and S. Rojas-Galeano, “Shielding Google’s language toxicity model against adversarial attacks,” arXiv preprint arXiv:1801.01828, 2018. [Google Scholar]
31. S. Tan, S. Joty, M. Y. Kan and R. Socher, “It’s morphin’time! combating linguistic discrimination with inflectional perturbations,” in Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 2920–2935, 2020. [Google Scholar]
32. S. Eger and Y. Benz, “From hero to zéroe: A benchmark of low-level adversarial attacks,” in Proc. of the 1st Conf. of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th Int. Joint Conf. on Natural Language Processing, Suzhou, China, pp. 786–803, 2020. [Google Scholar]
33. R. Bhalerao, M. Al-Rubaie, A. Bhaskar and I. Markov, “Data-driven mitigation of adversarial text perturbation,” arXiv preprint arXiv:2202.09483, 2022. [Google Scholar]
34. T. Le, J. Lee, K. Yen, Y. Hu and D. Lee, “Perturbations in the wild: Leveraging human-written text perturbations for realistic adversarial attack and defense,” in Findings of the Association for Computational Linguistics, Dublin, Ireland, pp. 2953–2965, 2022. [Google Scholar]
35. T. Niven and H. Y. Kao, “Probing neural network comprehension of natural language arguments,” in Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, pp. 4658–4664, 2019. [Google Scholar]
36. D. Boyd, S. Golder and G. Lotan, “Tweet, tweet, retweet: Conversational aspects of retweeting on Twitter,” in Proc. of the 2010 43rd Hawaii Int. Conf. on System Sciences, Honolulu, HI, USA, pp. 1–10, 2010. [Google Scholar]
37. C. Tagg, “Wot did he say or could u not c him 4 dust? Written and spoken creativity in text messaging,” Transforming Literacies and Language: Multimodality and Literacy in the New Media Age, vol. 223, pp. 223–236, 2011. [Google Scholar]
38. L. Philips, “The double metaphone search algorithm,” C/C++ Users Journal, vol. 18, no. 6, pp. 38–43, 2000. [Google Scholar]
39. J. Y. Yoo, J. Morris, E. Lifland and Y. Qi, “Searching for a search method: Benchmarking search algorithms for generating nlp adversarial examples,” in Proc. of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pp. 323–332, 2020. [Google Scholar]
40. J. X. Morris, E. Lifland, J. Y. Yoo, J. Grigsby, D. Jin et al., “TextAttack: A framework for adversarial attacks, data augmentation, and adversarial training in NLP,” in Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 119–126, 2020. [Google Scholar]
41. J. Devlin, M. W. Chang, K. Lee and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proc. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, USA, vol. 1, pp. 02, 2019. [Google Scholar]
42. Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi et al., “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv: 1907.11692, 2019. [Google Scholar]
43. J. Khan and S. Lee, “Enhancement of sentiment analysis by utilizing noisy social media texts,” The Journal of Korean Institute of Communication Sciences, vol. 45, no. 6, pp. 1027–1037, 2020. [Google Scholar]
44. A. Lertpiya, T. Chalothorn and E. Chuangsuwanich, “Thai spelling correction and word normalization on social text using a two-stage pipeline with neural contextual attention,” IEEE Access, vol. 8, pp. 133403–133419, 2020. [Google Scholar]
45. T. Baldwin and Y. Li, “An in-depth analysis of the effect of text normalization in social media,” in Proc. of the 2015 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, Colorado, USA, pp. 420–429, 2015. [Google Scholar]
46. J. Khan and S. Lee, “Enhancement of text analysis using context-aware normalization of social media informal text,” Applied Sciences, vol. 11, no. 17, pp. 8172, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools