
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Novel Incremental Attribute Reduction Algorithm Based on Intuitionistic Fuzzy Partition Distance
1 Graduate University of Science and Technology, Vietnam Academy of Science and Technology, Hanoi, 100000, Vietnam
2 Institute of Information Technology, Vietnam Academy of Science and Technology, Hanoi, 100000, Vietnam
3 HaUI Institute of Technology, Hanoi University of Industry, Hanoi, 100000, Vietnam
4 Faculty of Information Technology, University of Sciences, Hue University, Hue, 530000, Vietnam
5 AI Research Department, Neurond Technology JSC, Hanoi, 100000, Vietnam
6 Information and Communication Technology Center, Department of Information and Communications, Bacninh, 790000, Vietnam
* Corresponding Author: Nguyen The Thuy. Email:
Computer Systems Science and Engineering 2023, 47(3), 2971-2988. https://doi.org/10.32604/csse.2023.042068
Received 17 May 2023; Accepted 05 July 2023; Issue published 09 November 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Attribute reduction, also known as feature selection, for decision information systems is one of the most pivotal issues in machine learning and data mining. Approaches based on the rough set theory and some extensions were proved to be efficient for dealing with the problem of attribute reduction. Unfortunately, the intuitionistic fuzzy sets based methods have not received much interest, while these methods are well-known as a very powerful approach to noisy decision tables, i.e., data tables with the low initial classification accuracy. Therefore, this paper provides a novel incremental attribute reduction method to deal more effectively with noisy decision tables, especially for high-dimensional ones. In particular, we define a new reduct and then design an original attribute reduction method based on the distance measure between two intuitionistic fuzzy partitions. It should be noted that the intuitionistic fuzzy partition distance is well-known as an effective measure to determine important attributes. More interestingly, an incremental formula is also developed to quickly compute the intuitionistic fuzzy partition distance in case when the decision table increases in the number of objects. This formula is then applied to construct an incremental attribute reduction algorithm for handling such dynamic tables. Besides, some experiments are conducted on real datasets to show that our method is far superior to the fuzzy rough set based methods in terms of the size of reduct and the classification accuracy.Keywords
Attribute reduction has long been known as one of the pivotal problems in data preprocessing. The purpose of attribute reduction is to select important attributes and remove redundant or unnecessary ones from decision tables to enhance the efficiency of the classification models, especially for high dimension data. Dubois and Prade applied the fuzzy rough set (FRS) theory to the problem of attribute reduction for addressing directly with the original decision tables consisting of a numerical domain, instead of discretized data. According to this approach, some researches have been published based on fuzzy approximate space. Some typical methods comprise fuzzy membership function [1], fuzzy positive region [2–4], fuzzy information entropy [5–8] and fuzzy distance [9].
In big data trend, the decision tables have often the high dimension and may be updated regularly. The process of adding and removing objects is usually taking place. This problem has brought many difficulties to the traditional attribute reduction approaches. Firstly, the algorithms can meet an obstacle of processing speed and storage space on the high-dimensional decision tables. Secondly, for updated decision tables, the algorithms must also compute the reduct on the entire decision table again which makes to increase the computational time. To deal more effectively with these issues, many researchers proposed some incremental computational techniques for finding the reduct on the dynamic decision table. The incremental methods only update the subset of selected attributes on the altered part of data without re-computing it on the whole decision table. Hence, the processing time can be reduced significantly. Furthermore, with the high-dimensional decision table, it is possible to split data into many parts and apply incremental attribute reduction algorithms. Based on the FRS approach, the incremental algorithms are proposed for solving cases, including addition and removal of the object set [10–14] or the attribute set [15]. Additionally, some researchers extended the incremental algorithms to address incomplete dynamic decision tables. In particular, Giang et al. constructed the tolerance rough set to design hybrid incremental algorithms when supplementing and removing object sets [16]. Afterwards, Thang et al. also developed some formulas for their incremental algorithms for two cases of adding and removing attribute sets [17]. However, Hung et al. showed that the FRS based attribute reduction approach is less efficient in noisy data sets with the low classification accuracy [18].
Recently, some researchers proposed new models using intuitionistic fuzzy sets (IFSs) to solve the attribute selection problem. These models were designed to minimize the noisy information on the decision tables by using a further non-membership function which can adjust noisy objects to give a suitable classification [19]. For such noisy data sets, the IFS based attribute reduction algorithms have often the better processing ability than algorithms using other approaches, such as rough sets or fuzzy rough sets. From the IFSs approach, Tan et al. [20] constructed intuitionistic fuzzy conditional entropy measures and proposed a heuristic algorithm for finding a relative reduct. Then, Thang et al. [21] built a distance measure based on the IFS model. By using the constructed distance measure, they proposed the IFDBAR algorithm in the filter approach to select a subset of important attributes. The experimental results showed that IFDBAR achieved the superior classification ability to the FRS approach on the noisy data sets, especially in case of the low initial classification accuracy.
It can be said that the intuitionistic fuzzy set is a very efficient approach for attribute reduction on the noisy data sets. The subset of features selected from the IFS based algorithms can significantly improve the classification performance of the machine learning models. As mentioned, however, the IFS approach also exists a serious limitation that is the high computational time. Therefore, the attribute reduction algorithms using this approach are often ineffective in dealing with high-dimensional and large datasets. This motivated us to develop a novel incremental method for finding reducts more quickly and efficiently. Specifically, we present an original method to attribute reduction based on intuitionistic fuzzy partition distance. Then we propose an incremental algorithm to extract important attributes from the decision tables in case of the increase of the object number. In our method, an incremental formula is given to fast calculate the intuitionistic fuzzy partition distance on the decision tables when adding an object set. By theoretical and experimental results, we will demonstrate that the proposed method can enhance the performance of the attribute reduction process in comparing with some other state-of-the-art methods in terms of the computational time and classification accuracy.
The paper is organized as follows. The next section will recall several basic concepts of intuitionistic fuzzy sets and related properties. In Section 3, this paper shall define a new reduct based on the intuitionistic fuzzy partition distance and then propose an effective attribute reduction method. This paper will also provide an incremental algorithm for finding reducts on the dynamic decision tables. Section 4 will present experimental results as well as some related analyses. In the last section of this paper, we will draw several conclusions with future works.
This section will summarize some basic concepts of intuitionistic fuzzy sets which are an important foundation for proposing an attribute reduction algorithm in the third part of the paper. These basic concepts can be found in [21–23].
First, a decision table is a pair of
Without losing the comprehensive characteristics, hypothesis
Given a decision table
The hesitant degree of u in P is determined by
Consider two IFSs P and Q on U, we will define several set operations to compare them as follows:
1.
2.
3.
4.
To facilitate the deployment of definitions and calculation formulas later, an IFS P will sometimes be briefly represented by two components, membership and non-membership. Specifically,
Let U be the non-empty finite set of objects. An intuitionistic fuzzy binary relation R on
where
Then, R is called an intuitionistic fuzzy equivalence relation (IFER) if R satisfies:
1) Reflexive: iff
2) Symmetric: iff
3) Transitive: iff
Given an IFER R on U, an attribute subset
Consider
For
With
- If
- If
Suppose we are given two IFPs
3.1 Attribute Reduction Based on IFPD
This paper will present in this section a new method for finding a reduct set based on the IFP distance. The cardinal steps of the algorithm are structured as follows. Firstly, we introduce the distance between two IFPs. Then, we define the reduct and the significance of the attribute. Finally, we construct a heuristic algorithm based on the IFP measure.
Given
is an intuitionistic fuzzy partition distance (IFPD) between
It is easy to see that the minimum value of
Based on
Clearly, if
Definition 1. Let
1.
2.
This definition implies that for any
Definition 2. Let
It can be easily seen that
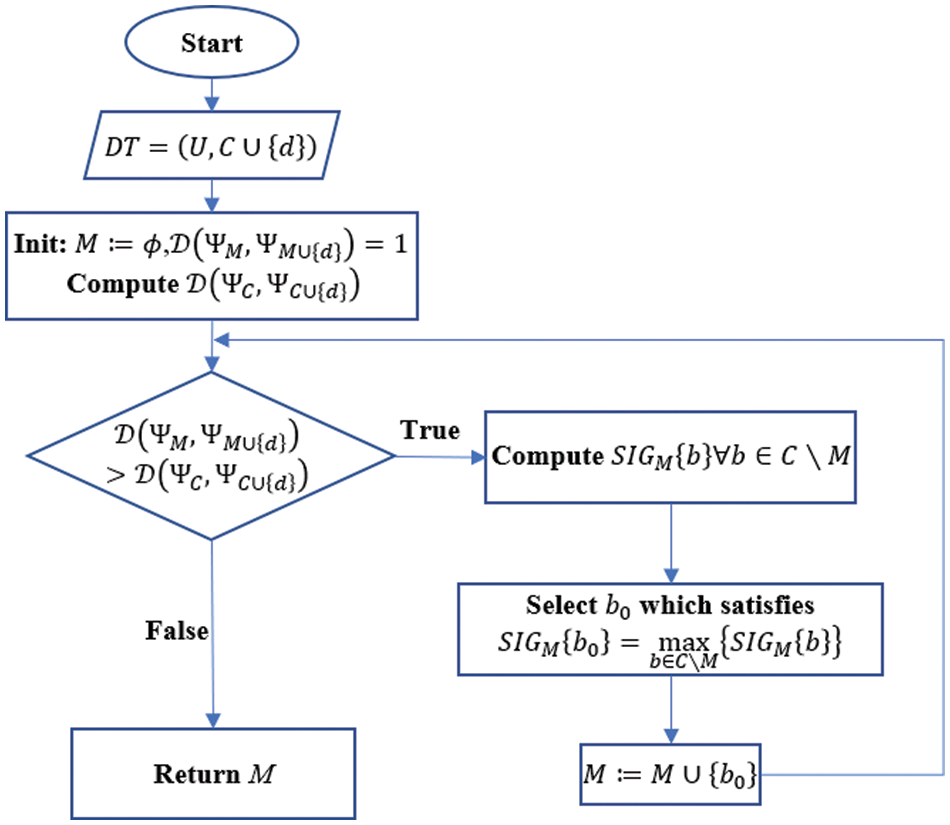
Figure 1: Flowchart of Algorithm 1

We now examine the computational complexity of ARIFPD. Suppose that
3.2 Incremental Attribute Reduction Algorithm
We will propose this section an incremental algorithm using IFPD when supplementing a new object set into a given decision table. We now begin with providing a formula to quickly calculate IFPD after supplementing an object set which is extended in [21].
Proposition 1. Given
where
Proof:
It is easy to see that if
To simplify for the proof of this proposition, we will set:
Since U is added s objects, the formula in (5) becomes:
We have
thus
Furthermore,
Hence,
The formula (6) consists of two main components. The first component computes the distance of two intuitionistic fuzzy partitions without adding the set of new objects. This component is already determined from the previous stages. Therefore, the incremental formula provided in Proposition 1 allows us to only executes on the second component consisting of the intuitionistic fuzzy equivalence classes generated by the additions of the new object set. From this formula, we will replace the formula (5) to conduct on the decision table when supplementing new objects. Accordingly, the algorithm will reduce the computational complexity and obtain a proximate reduct set.
Proposition 2. Let
1. If all objects in
2. If
Proof:
For any
1. If all objects in
2. If
Hence
Based on Proposition 1, we get:
Because M is a reduct of C, from the definition 1, we obtain
The result of Proposition 2 shown that the incremental algorithm for IFPD based Attribute Reduction when Adding Objects (ARIFPD_AO) comprises four main steps as in Algorithm 2 and its corresponding flowchart is visually represented in Fig. 2.
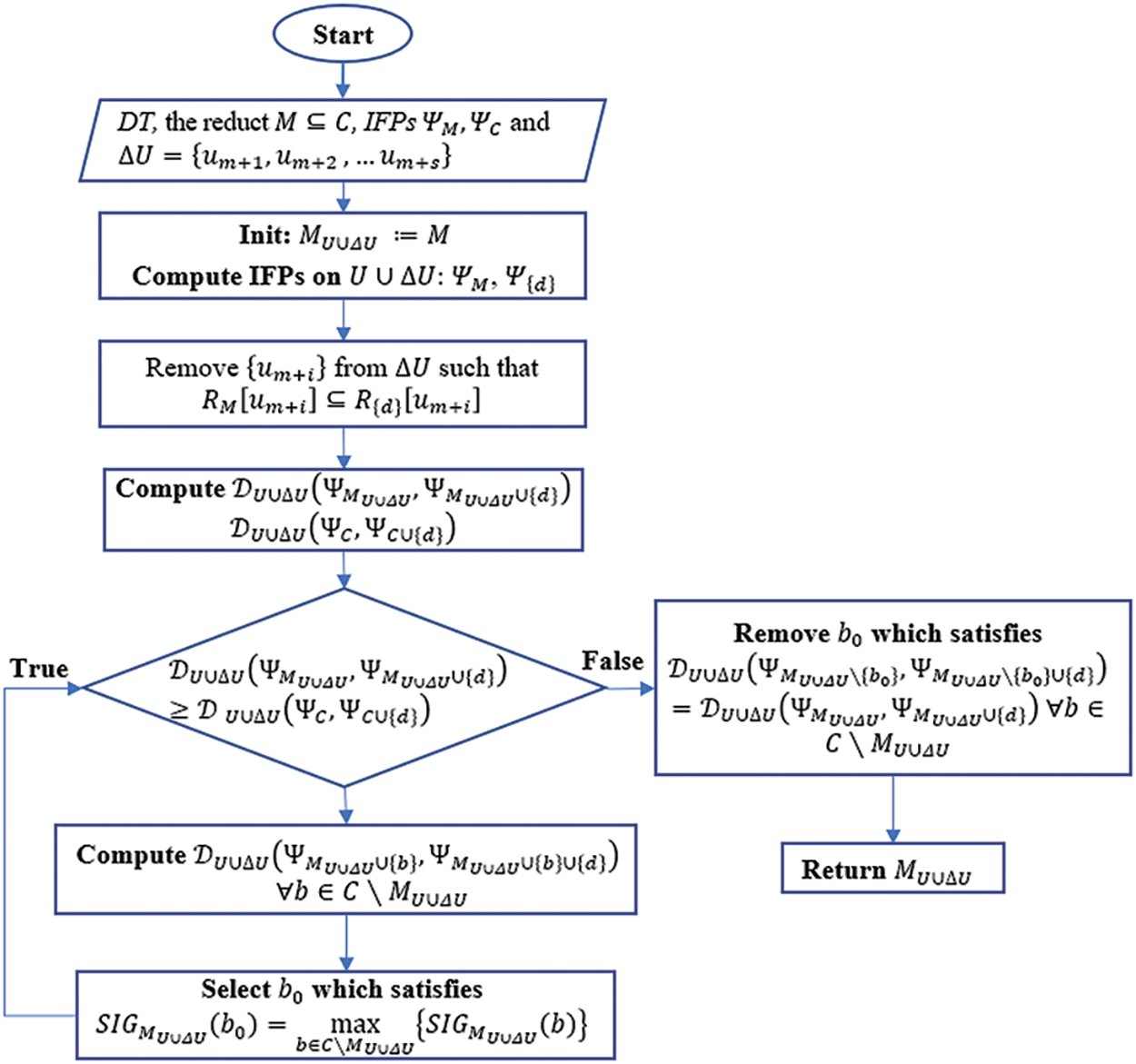
Figure 2: Flowchart of Algorithm 2

We continue to evaluate the computational complexity of the algorithm ARIFPD_AO. We use 3 symbols
In the previous sections, this paper presented an incremental approach based on IFPD to process the dynamic decision table. The paper will demonstrate this part with some experiments to prove the efficiency of our method (ARIFPD_AO). The paper compares the efficiency of the ARIFPD_AO, IFSA in [24] and FDAR_AO in [10] through three criteria: Classification accuracy performance based on classifier KNN (k =10) with tenfold cross-validation, size of reduct and computation time.
Experimental data: To prove the efficiency of the proposed method, we conduct experiments on some benchmark datasets from the UCI Machine learning repository [25]. The experimental data focuses mainly on sets with low initial classification accuracy and with a large number of instances. Data set is split up two subsets with the same number of objects. The first subset is denoted by Uori (Column 5 in Table 1) is used in the algorithm ARIFPD to find the reduct and Uinc (Column 6 in Table 1) is used in the incremental algorithm ARIFPD_AO. Next, the incremental set Uinc is separated into six equal parts U1, U2, U3, U4, U5, U6 respectively.
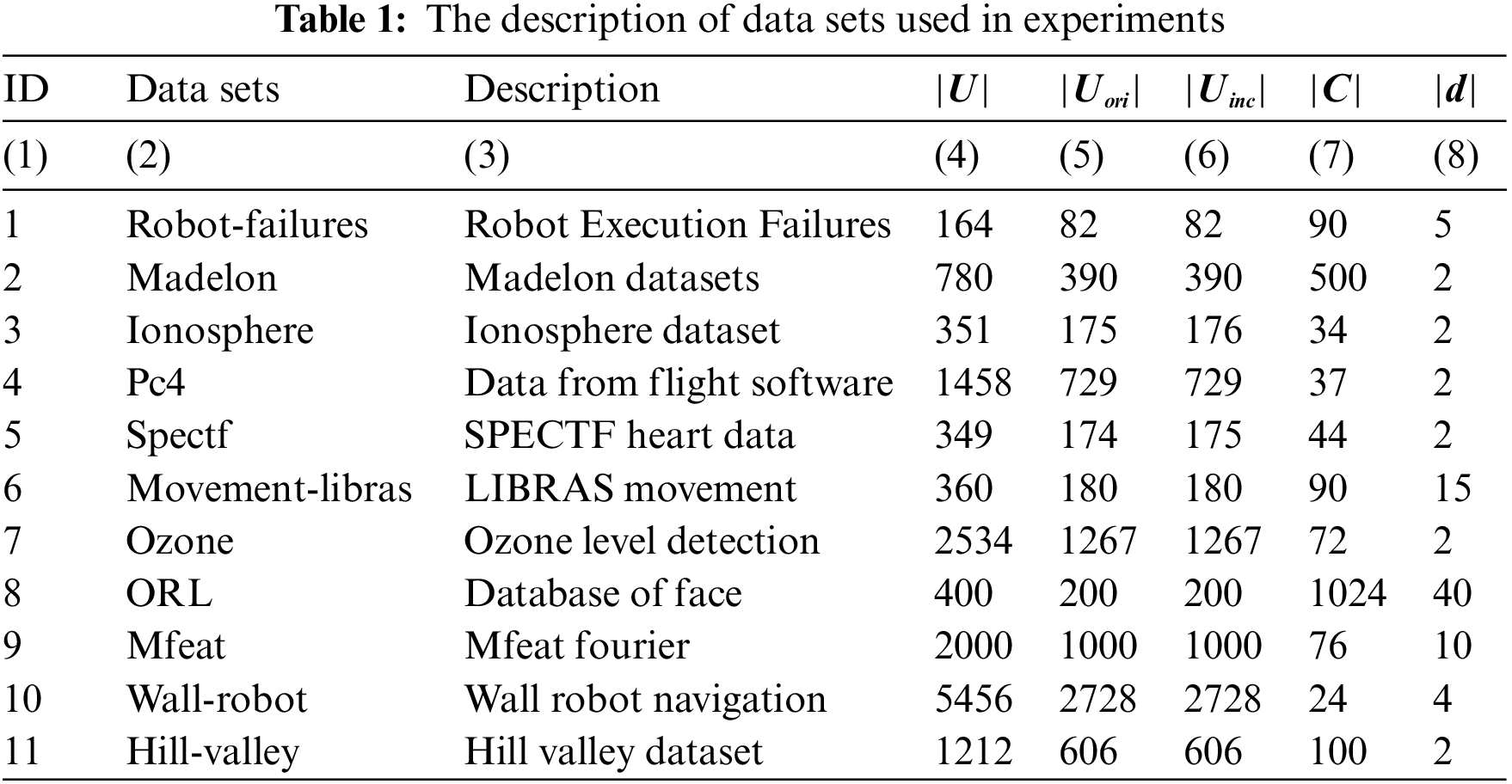
In Table 1, columns
Experimental scenario:
First, we use algorithms ARIFPD, GFS [25] and FDAR [10] to find the reduct on
Now, we construct IFERs including the IF similarity degree and IF diversity degree between two objects u and v with respect to the attribute a.
• If the value domain of a is a continuous value type, then:
The above formula determines the intuitionistic fuzzy similarity degree of the object u with the object v, in which min(a) and max(a) are minimal and maximal values corresponding to a. In essence, the denominator component of the formula above is the process of min-max data normalizing to ensure that the values in the decision table are in the range [0,1]. Finally, we compute the intuitionistic fuzzy diversity degree based on the below formula.
Clearly, if
in which
• If the value of a is a categorical value, then:
and
As mentioned above, the paper first compares the efficiency of the FDAR, GFS and ARIFPD algorithms. The size and the classification accuracy of reducts are shown in Table 2. Across all the data sets, it is clear that the reducts obtained from ARIFPD are often the smallest size, while the reducts obtained by FDAR still have large sizes on some datasets. The paper next compares the computational time between the three algorithms. The time of the algorithms is calculated after the step data preprocessing to when the reduct of the algorithms is determined. The results from Table 2 show shorter times when running the GFS algorithm on whole datasets. The reason for this is because the algorithms based on FRSs and IFSs must compute relational matrices with many elements. Besides, the FDAR algorithm only uses the similarity degree to calculate, while the ARIFPD algorithm has to calculate both the similarity and the diversity degree. Thus, the computational time of ARIFPD is the most complex. Next, this paper compares three algorithms through the KNN classifier to evaluate the classification capacity of reducts. Table 2 and Fig. 3 display the comparative results, in which the raw data column is the classification accuracy when we use the whole attributes of each data set to appreciate, and columns according to three methods provide the classification accuracies appreciated through the attribute subset chose by those algorithms. It can be emphasized that our method determines the important attributes very efficiently for different data sets. More especially, the comparison with raw data shows that the classification performance of the reduct from the proposed algorithm is superiority over the raw data in 9 cases. There is only one case where our reducts have lower classification accuracy than the raw data. In addition, the average classification accuracy of the method in this study reached 76.9% and the raw data reached 73.1%. Therefore, it indicated that the classification accuracy of the proposed algorithm is significantly higher than the original data. Even more intriguingly, ARIFPD’s reducts yield superior classification results compared to FDAR and GFS across nearly all datasets, despite ARIFPD selecting a smaller number of attributes, as evidenced in Figs. 3 and 4.
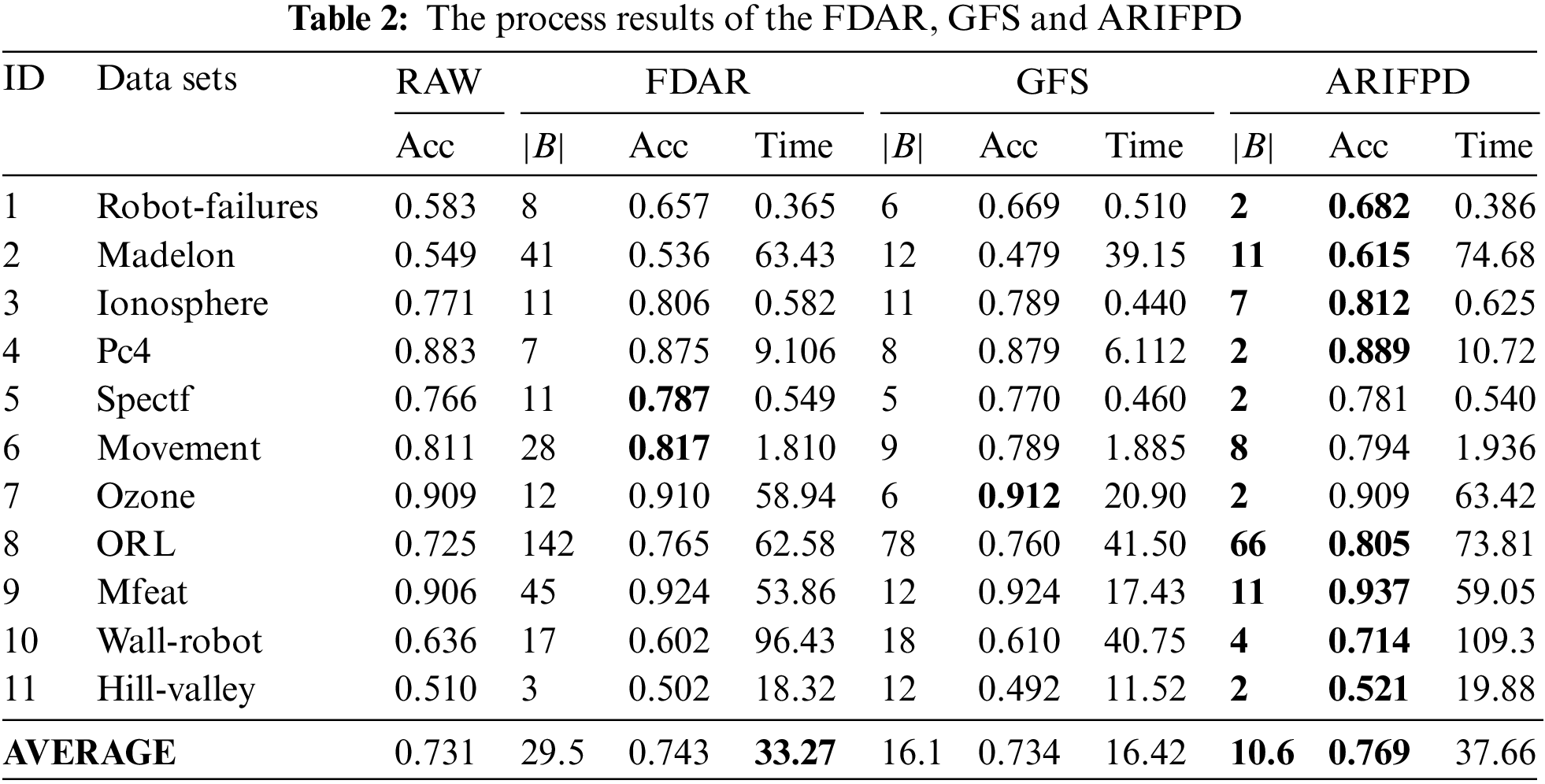
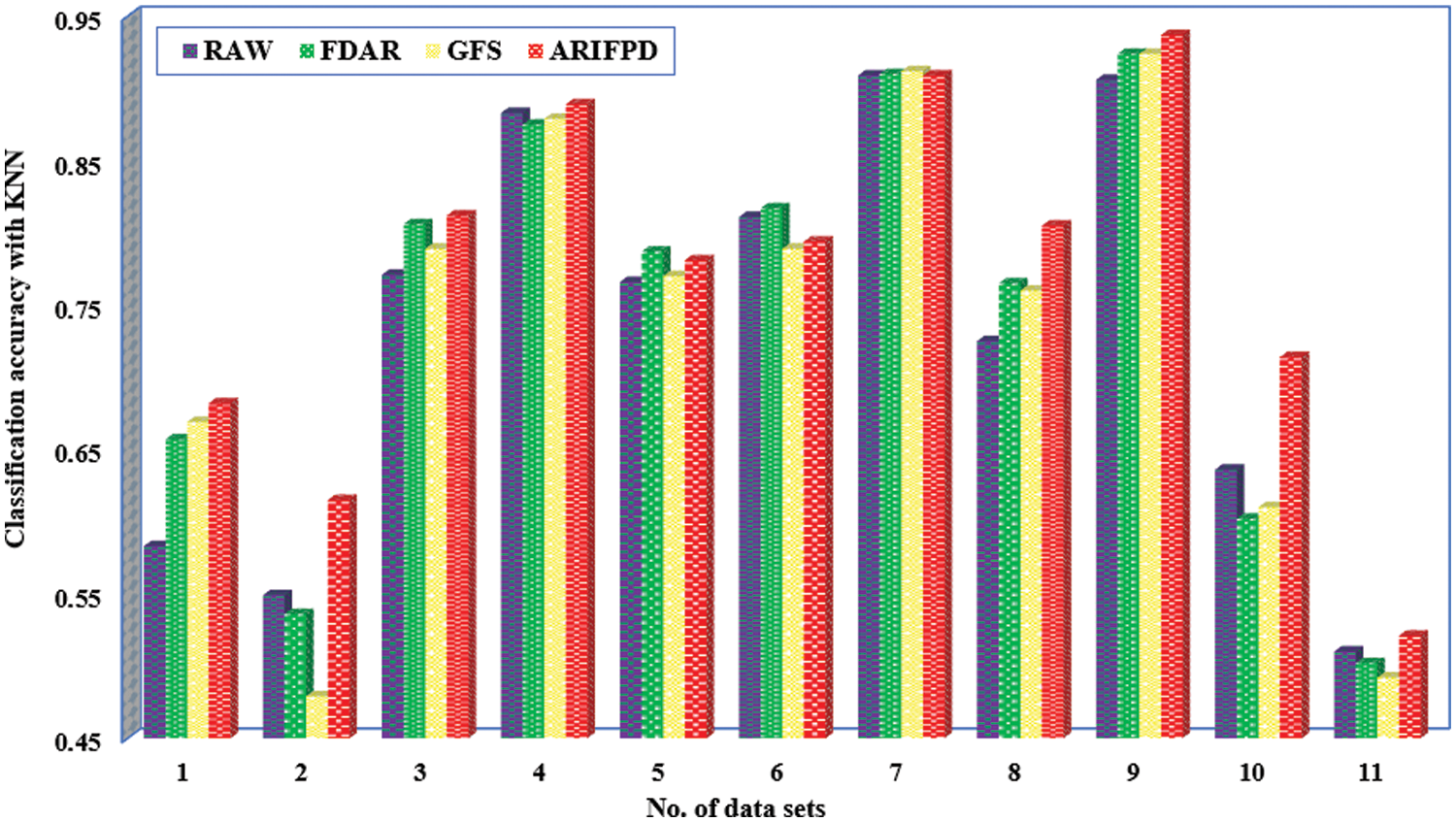
Figure 3: The classification accuracy of the FDAR, GFS and ARIFPD
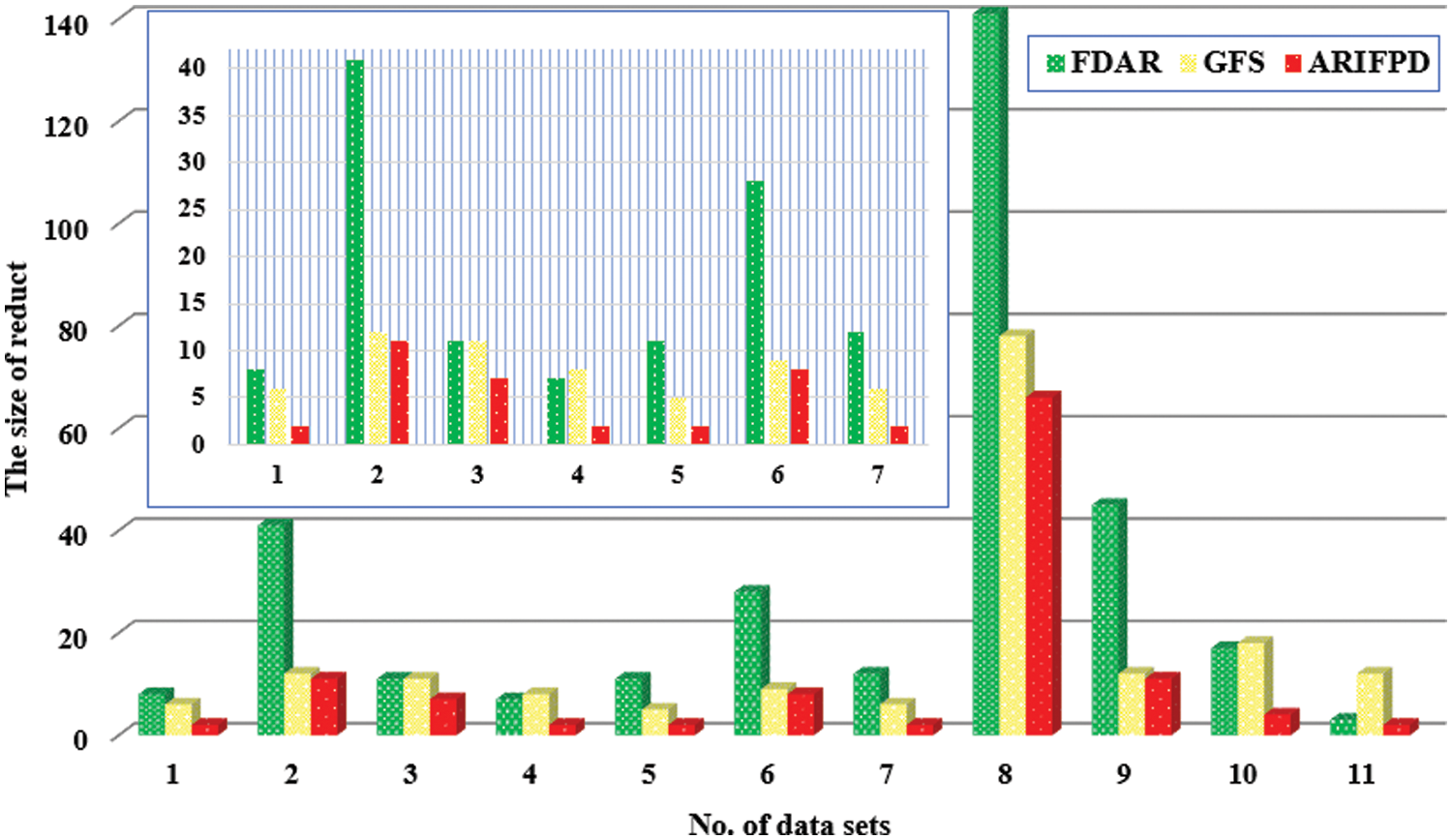
Figure 4: The size of reduct of the FDAR, GFS and ARIFPD
It can be observed more clearly from Table 2 and Fig. 3 that there is one case in the Movement dataset where our reduct has the lower accuracy. However, the average accuracy of our algorithm is also higher than the FDAR and GFS algorithms. It showed that the proposed algorithm has the capacity to select significant attributes for better improvement on the noisy data sets with low classification accuracy.
The performance of the proposed incremental method is appreciated by comparing the FDAR_AO, IFSA and ARIFPD_AO algorithms. First, it is obvious that the incremental algorithms have much faster processing time than the FDAR, IFSA and ARIFPD algorithms because the incremental algorithms compute on the additional parts of the data tables, instead of the whole data table.
Table 3 shows that for most datasets, the execution time of FDAR_AO and IFSA is faster when compared to ARIFPD_AO. It can be also explained similarly with comparing the execution times of the algorithms FDAR and ARIFPD. Furthermore, the proposed algorithm includes a processing step to remove redundant attributes. Hence the processing time of our algorithm will be slower. However, the execution time of ARIFPD_AO is better than FDAR_AO on some data sets, for example Robot-Failure and Ozone. This is because our obtained reduct is smaller than two remaining algorithms. Then the number of loops is conducted less. The accuracy and size of reducts extracted by our method are also investigated in Table 3. For the size of reduct at each incremental phase, ARIFD_AO is much smaller than FDAR_AO and IFSA, especially for several data sets with a large number of attributes, such as Robot-Failure, Libras-Movement.
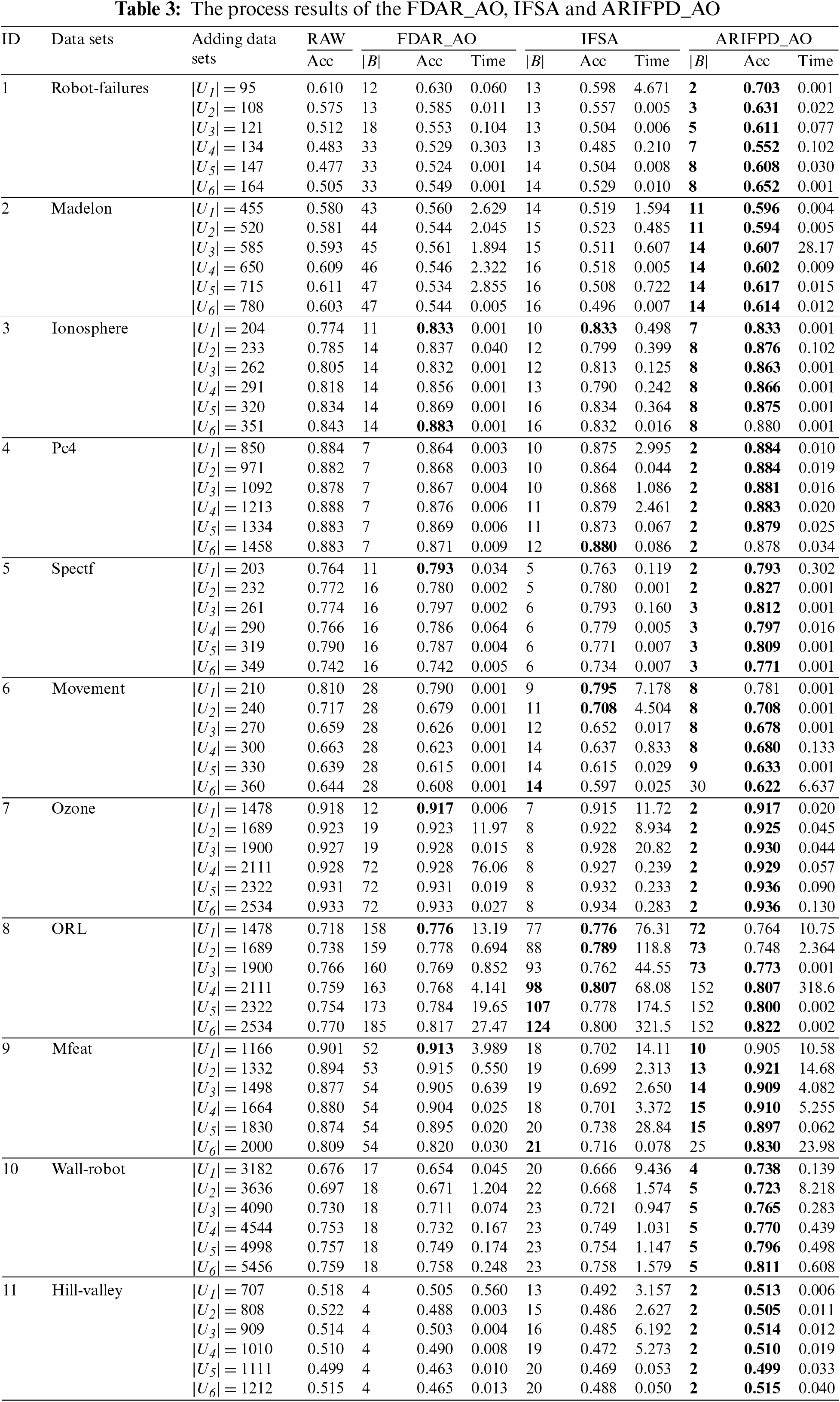
We consider 66 cases when adding the set of objects. There are 7 cases in which our reducts have no higher classification accuracy than the reducts of FDAR_AO. In the remaining 59 cases, the reducts of the proposed method show superiority in accuracy compared to FDBAR_AO and IFSA. Clearly, the proposed incremental method is also very effective on datasets with low initial classification accuracy. In other words, the attribute reduction methods based on the rough set approach and its extensions have many difficulties in improving the classification accuracy for the noisy data.
Based on the accuracy of algorithms in Table 3, paired two-tailed t-tests were also conducted with a confidence level of 0.95 to evaluate the differences between FDAR_AO, IFSA, and ARIFPD_AO. The corresponding p-values (two-tailed) were found at levels 1.17E-10 and 6.85E-10 for KNN. These results provide a sound basis to conclude that our algorithm outperforms the compared algorithms in statistical significance. From the above results, it can be confirmed that the incremental attribute reduction algorithm using the intuitionistic fuzzy set approach has outstanding advantages compared to algorithms based on the fuzzy rough set when processing noisy and inconsistent data.
With the primary purpose of reducing the number of features and improving the classification ability, attribute reduction is considered as a critical problem in the data preprocessing step. This paper recommends a measure for intuitionistic fuzzy partition distance and constructs an incremental formula to update the intuitionistic fuzzy partition distance when adding an object set. Thereby, this paper constructs two algorithms based on the intuitionistic fuzzy set approach. The first algorithm proposed to find the reduct on the decision table when there is no additional set of objects. The second algorithm is the incremental algorithm to find the approximate reduct when the decision table is increased in the object set. Compared to methods based on the rough set and fuzzy rough set approaches, the experimental results have shown that our methods can ameliorate the accuracy of inconsistent or low initial classification accuracy data sets.
It can be easily seen that the limitation of intuitionistic fuzzy set-based algorithms is the execution time due to the supplement of the diversity degree in intuitionistic fuzzy equivalence classes. For future researchers, we focus on developing the incremental formula to reduce the computational time and guarantee the classification accuracy. In addition, we also design incremental algorithms based on the intuitionistic fuzzy sets using granular structures. We will continue to study the incremental methods that find reducts from the decision tables in the case of supplementing and removing the set of attributes.
Acknowledgement: The authors thank you for the generous support of the Simulation and High-Performance Computing department (SHPC) of the HaUI Institute of Technology (HIT) for conducting experiments in this paper and sincerely thank you for the assistance of the research team VAST.
Funding Statement: This research is funded by Hanoi University of Industry under Grant Number 27-2022-RD/HĐ-ĐHCN (URL: https://www.haui.edu.vn/).
Author Contributions: Study conception and design: Pham Viet Anh, Nguyen The Thuy; data collection: Pham Dinh Khanh; analysis and interpretation of results: Nguyen Long Giang, Nguyen Ngoc Thuy; draft manuscript preparation: Pham Viet Anh, Nguyen The Thuy, Nguyen Long Giang, Nguyen Ngoc Thuy. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data presented in this study can be made available upon reasonable request from the corresponding author.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. X. Zhang, C. L. Mei, D. G. Chen and Y. Y. Yang, “A fuzzy rough set-based feature selection method using representative instances,” Knowledge Based Systems, vol. 151, pp. 216–229, 2018. https://doi.org/10.1016/j.knosys.2018.03.031 [Google Scholar] [CrossRef]
2. T. K. Sheeja and A. S. Kuriakose, “A novel feature selection method using fuzzy rough sets,” Computers in Industry, vol. 97, no. 3, pp. 111–116, 2018. https://doi.org/10.1016/j.compind.2018.01.014 [Google Scholar] [CrossRef]
3. X. Che, D. Chen and J. Mi, “Label correlation in multi-label classification using local attribute reductions with fuzzy rough sets,” Fuzzy Sets and Systems, vol. 426, pp. 121–144, 2022. https://doi.org/10.1016/j.fss.2021.03.016 [Google Scholar] [CrossRef]
4. Z. Huang and J. Li, “A fitting model for attribute reduction with fuzzy β-covering,” Fuzzy Sets and Systems, vol. 413, pp. 114–137, 2021. https://doi.org/10.1016/j.fss.2020.07.010 [Google Scholar] [CrossRef]
5. Q. H. Hu, D. R. Yu and Z. X. Xie, “Information-preserving hybrid data reduction based on fuzzy-rough techniques,” Pattern Recognition Letters, vol. 27, no. 5, pp. 414–423, 2016. [Google Scholar]
6. A. Meriello and R. Battiti, “Feature selection based on the neighborhood entropy,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 12, pp. 6313–6322, 2018. [Google Scholar]
7. B. Sang, H. Chen, L. Yang, T. Li and W. Xu, “Incremental feature selection using a conditional entropy based on fuzzy dominance neighborhood rough sets,” IEEE Transactions on Fuzzy Systems, vol. 30, no. 6, pp. 1683–1697, 2021. [Google Scholar]
8. Z. Yuan, H. Chen and T. Li, “Exploring interactive attribute reduction via fuzzy complementary entropy for unlabeled mixed data,” Pattern Recognition, vol. 127, pp. 108651, 2022. https://doi.org/10.1016/j.patcog.2022.108651 [Google Scholar] [CrossRef]
9. C. Z. Wang, Y. Huang, M. W. Shao and X. D. Fan, “Fuzzy rough set based attribute reduction using distance measures,” Knowledge-Based Systems, vol. 164, pp. 205–212, 2019. https://doi.org/10.1016/j.knosys.2018.10.038 [Google Scholar] [CrossRef]
10. N. L. Giang, L. H. Son, T. T. Ngan, T. M. Tuan, H. T. Phuong et al., “Novel incremental algorithms for attribute reduction from dynamic decision systems using hybrid filter-wrapper with fuzzy partition distance,” IEEE Transactions on Fuzzy Systems, vol. 28, no. 5, pp. 858–873, 2020. [Google Scholar]
11. Y. M. Liu, S. Y. Zhao, H. Chen, C. P. Li and Y. M. Lu, “Fuzzy rough incremental attribute reduction applying dependency measures,,” APWeb-WAIM 2017 Web and Big Data, vol. 10366, pp. 484–492, 2017. [Google Scholar]
12. Y. Y. Yang, D. G. Chen, H. Wang, E. C. C. Tsang and D. L. Zhang, “Fuzzy rough set based incremental attribute reduction from dynamic data with sample arriving,” Fuzzy Sets and Systems, vol. 312, pp. 66–86, 2017. https://doi.org/10.1016/j.fss.2016.08.001 [Google Scholar] [CrossRef]
13. Y. Y. Yang, D. G. Chen, H. Wang and X. H. Wang, “Incremental perspective for feature selection based on fuzzy rough sets,” IEEE Transactions on Fuzzy Systems, vol. 26, no. 3, pp. 1257–1273, 2017. [Google Scholar]
14. X. Zhang, C. L. Mei, D. G. Chen, Y. Y. Yang and J. H. Li, “Active incremental feature selection using a fuzzy-rough-set-based information entropy,” IEEE Transactions on Fuzzy Systems, vol. 28, no. 5, pp. 901– 915, 2020. [Google Scholar]
15. P. Ni, S. Y. Zhao, X. H. Wang, H. Chen, C. P. Li et al., “Incremental feature selection based on fuzzy rough sets,” Information Sciences, vol. 536, no. 5, pp. 185–204, 2020. https://doi.org/10.1016/j.ins.2020.04.038 [Google Scholar] [CrossRef]
16. N. L. Giang, L. H. Son, N. A. Tuan, T. T. Ngan, N. N. Son et al., “Filter-wrapper incremental algorithms for finding reduct in incomplete decision systems when adding and deleting an attribute set,” International Journal of Data Warehousing and Mining, vol. 17, no. 2, pp. 39–62, 2021. [Google Scholar]
17. N. T. Thang, N. L. Giang, H. V. Long, N. A. Tuan, T. M. Tuan et al., “Efficient algorithms for dynamic incomplete decision systems,” International Journal of Data Warehousing and Mining, vol. 17, no. 3, pp. 44–67, 2021. [Google Scholar]
18. W. L. Hung and M. S. Yang, “Similarity measures of intuitionistic fuzzy sets based on Lp metric,” International Journal of Approximate Reasoning, vol. 46, no. 1, pp. 120–136, 2007. [Google Scholar]
19. B. Huang, C. X. Guo, Y. L. Zhuang, H. X. Li and X. Z. Zhou, “Intuitionistic fuzzy multigranulation rough sets,” Information Sciences, vol. 277, pp. 299–320, 2014. https://doi.org/10.1016/j.ins.2014.02.064 [Google Scholar] [CrossRef]
20. A. Tan, S. Shi, W. Z. Wu, J. Li, W. Pedrycz et al., “Granularity and entropy of intuitionistic fuzzy information and their applications,” IEEE Transactions on Cybernetics, vol. 52, no. 1, pp. 192–204, 2022. [Google Scholar] [PubMed]
21. N. T. Thang, N. L. Giang, T. T. Dai, T. T. Tuan, N. Q. Huy et al., “A novel filter-wrapper algorithm on intuitionistic fuzzy set for attribute reduction from decision tables,” International Journal of Data Warehousing and Mining, vol. 17, no. 4, pp. 67–100, 2021. https://doi.org/10.4018/IJDWM [Google Scholar] [CrossRef]
22. K. T. Atanassov, “Intuitionistic fuzzy sets,” Fuzzy Sets and Systems, vol. 20, no. 1, pp. 87–96, 1986. [Google Scholar]
23. I. Iancu, “Intuitionistic fuzzy similarity measures based on Frank t-norms family,” Pattern Recognition Letters, vol. 42, pp. 128–136, 2014. https://doi.org/10.1016/j.patrec.2014.02.010 [Google Scholar] [CrossRef]
24. W. Shu, W. Qian and Y. Xie, “Incremental approaches for feature selection from dynamic data with the variation of multiple objects,” Knowledge-Based Systems, vol. 163, pp. 320–331, 2019. https://doi.org/10.1016/j.knosys.2018.08.028 [Google Scholar] [CrossRef]
25. UCI Machine Learning Repository, “Data,” 2021. [Online]. Available: https://archive.ics.uci.edu/ml/index.php [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools