
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Deer Hunting Optimization with Deep Learning Enabled Emotion Classification on English Twitter Data
1 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
2 Department of Applied Linguistics, College of Languages, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Makkah, Saudi Arabia
4 Department of Information Systems, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
5 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
6 Department of Information System, College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Abdelwahed Motwakel. Email:
Computer Systems Science and Engineering 2023, 47(3), 2741-2757. https://doi.org/10.32604/csse.2023.034721
Received 25 July 2022; Accepted 17 November 2022; Issue published 09 November 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Currently, individuals use online social media, namely Facebook or Twitter, for sharing their thoughts and emotions. Detection of emotions on social networking sites’ finds useful in several applications in social welfare, commerce, public health, and so on. Emotion is expressed in several means, like facial and speech expressions, gestures, and written text. Emotion recognition in a text document is a content-based classification problem that includes notions from deep learning (DL) and natural language processing (NLP) domains. This article proposes a Deer Hunting Optimization with Deep Belief Network Enabled Emotion Classification (DHODBN-EC) on English Twitter Data in this study. The presented DHODBN-EC model aims to examine the existence of distinct emotion classes in tweets. At the introductory level, the DHODBN-EC technique pre-processes the tweets at different levels. Besides, the word2vec feature extraction process is applied to generate the word embedding process. For emotion classification, the DHODBN-EC model utilizes the DBN model, which helps to determine distinct emotion class labels. Lastly, the DHO algorithm is leveraged for optimal hyperparameter adjustment of the DBN technique. An extensive range of experimental analyses can be executed to demonstrate the enhanced performance of the DHODBN-EC approach. A comprehensive comparison study exhibited the improvements of the DHODBN-EC model over other approaches with increased accuracy of 96.67%.Keywords
Emotions are the key to people’s thoughts and feelings. Online social networking platforms, like Facebook and Twitter, have transformed the language of communication. People can share opinions, emotions, facts, and emotion intensities on various topics in the shorter text [1]. Analyzing the emotion communicated in social network content has received considerable interest in natural language processing (NLP). For example, it is utilized in brand management, stock market monitoring, public health, and public opinion detection regarding political tendencies [2]. Emotion analysis is the process of defining the attitude towards a topic or target. The attitude could be polarity (negative or positive) or an emotional state like sadness, joy, or anger. Recently, the multi-label classification issue has gained significant attention because of its relevance to an extensive field involving bioinformatics, text classification, and scene and video classification [3]. Different from the conventional single-label classification problems (viz., binary or multi-class), whereby a sample is related to one label from a finite label set, in the multi-label classification of the impactful and fast-growing social networking platform is Twitter, where users could post, read, and upgrade shorter text message called as ‘tweets’ that allows user to share their sentiments, views, and opinions regarding a specific entity. Such sentimental bearing tweet plays a crucial part in several domains, for example, election campaign news, social media marketing, and academics [4].
Sentiment analysis (SA) aim is to categorize and determine the polarity of subjective texts at the sentence, phrase, or document level. It has applications in different areas involving politics, e-commerce, health care, entertainment, etc. For example, SA could assist businesses in tracking customer perception regarding the product and help customers select the optimal product according to their public opinions [5]. Though SA has a variety of applications and implementations in various domains, it comes with challenges and issues associated with NLP. The current study is based on SA yet suffers from technical complexities that limit its wide-ranging performance in detecting sentiment [6]. For SA, the major process is to categorize the divergence between opinion-bearing tweets as negative or positive. SA of tweets comes with its challenging problems. People typically use informal language in tweets that may intensify the possibility of not identifying the real sentiment of the text [7]. Few tweets are shorter text that might carry slight context data that offers a preliminary indication of sentiment. Also, Sentiment understanding of tweets comprising abbreviations and acronyms is an enormous problem for the computer [8]. Attributable to this problem, the increasing importance of researcher work is categorizing the sentiment of the tweets. Most preceding study on emotion and SA has concentrated only on single-label classification. Different machine learning (ML) methodologies were introduced for multi-label and conventional emotion classification. Many present techniques resolve the challenge of text classification [9]. The sentiment of tweets is examined by utilizing 3 techniques: (I) an ML methodology that makes use of a learning mechanism for sentiment classification; (II) a rule-based method that makes use of a linguistic dictionary for extraction of sentiments; corpus-based sentiment lexicon; and open source sentiment lexicon, (III) a hybrid mechanism that integrates the rule-based and ML approaches [10]. As a result, deep learning (DL) techniques have demonstrated the importance of speech recognition, SA, and computer vision (CV) as incorporated into numerous studies. As a result, the research workers illustrated that adding Convolutional Bidirectional Long Short-Term Memory (ConvBiLSTM), a DL method provided robust and more effective outcomes in the SA of Twitter.
This article proposes a Deer Hunting Optimization with Deep Belief Network Enabled Emotion Classification (DHODBN-EC) on English Twitter Data in this study. The presented DHODBN-EC model aims to examine the existence of distinct emotion classes in tweets. At the introductory level, the DHODBN-EC technique pre-processes the tweets at different levels. Besides, the word2vec feature extraction process is applied to generate the word embedding process. For emotion classification, the DHODBN-EC model utilizes the DBN model, which helps to determine distinct emotion class labels. Lastly, the DHO algorithm is employed for optimal hyperparameter adjustment of the DBN technique. An extensive range of experimental analyses can be executed to demonstrate the enhanced performance of the DHODBN-EC technique.
Hasan et al. [11] advanced and evaluated a supervised learning system to categorize emotion in text stream messages automatically. This technique has 2 main tasks: an online classification task and an offline training task. The initial task constitutes methods for classifying emotion in texts. For the second one, the author formulates a 2-stage structure named EmotexStream for classifying live streams of text messages for realistic emotion tracking. In [12], a work was introduced that decides human emotions at the time of COVID-19 utilizing several ML techniques. Hence, several methods namely decision tree (DT), support vector machine (SVM), Naïve Bayes (NB), Neural Networks (NN) and k-nearest neighbour (k-NN), techniques were utilized in determining human emotions. Jabreel et al. [13] defined the progression of a new DL-related mechanism that addresses the multiple emotion classifier issues in Twitter. The author develops a new technique for transforming it into a binary classifier issue and uses a DL technique to solve the transformed issue.
In [14], the authors accumulated 600 million public tweets utilizing URL-related security tools, and feature generation can be implemented for SA. The ternary classifier was processed related to pre-processing approach, and the outcomes of tweets transmitted by users were acquired. The author uses a hybridization approach utilizing 2 optimization approaches and one ML classifier, such as PSO and GA and DT, for classifier accuracy by SA. Suhasini et al. [15] modelled a technique that identifies the mood or emotion of the tweet and categorizes the Twitter message in suitable emotional categories. The initial technique was the Rule-Based Approach (RBA); the minor input in this method was feature selection, pre-processing, Knowledge base creation, and tagging. Selecting the Feature based on tags. This second method was ML Approach (MLA), which depends on a supervised ML technique named NB that needs labelled data. NB can be utilized for detecting and classifying the tweet’s emotion. The RBA output was presented to MLA as input since MLA needs labelled data previously constituted by RBA.
Tago et al. [16] examined the effect of emotional conduct on user relationships related to Twitter data utilizing 2 dictionaries of emotional words. The emotion score is computed through keyword matching. In addition, the author devised 3 experiments with different settings they are computing the user’s average emotion scores with random sampling, computing the abovementioned score utilizing all emotional tweets, and calculating the mentioned score with the help of emotional tweets, not including users of a few emotional tweets. Azim et al. [17] devised an ML-related technique of emotion extraction from the text that depends on annotated examples than emotion-intensity lexicons. The author inspected Multinomial NB (MNB) method, SVM, and artificial neural network (ANN) to mine emotion from text.
In this study, a new DHODBN-EC model has been developed for English Twitter Data. The presented DHODBN-EC model aims to examine the existence of distinct emotion classes in tweets. Fig. 1 depicts the block diagram of the DHODBN-EC technique.
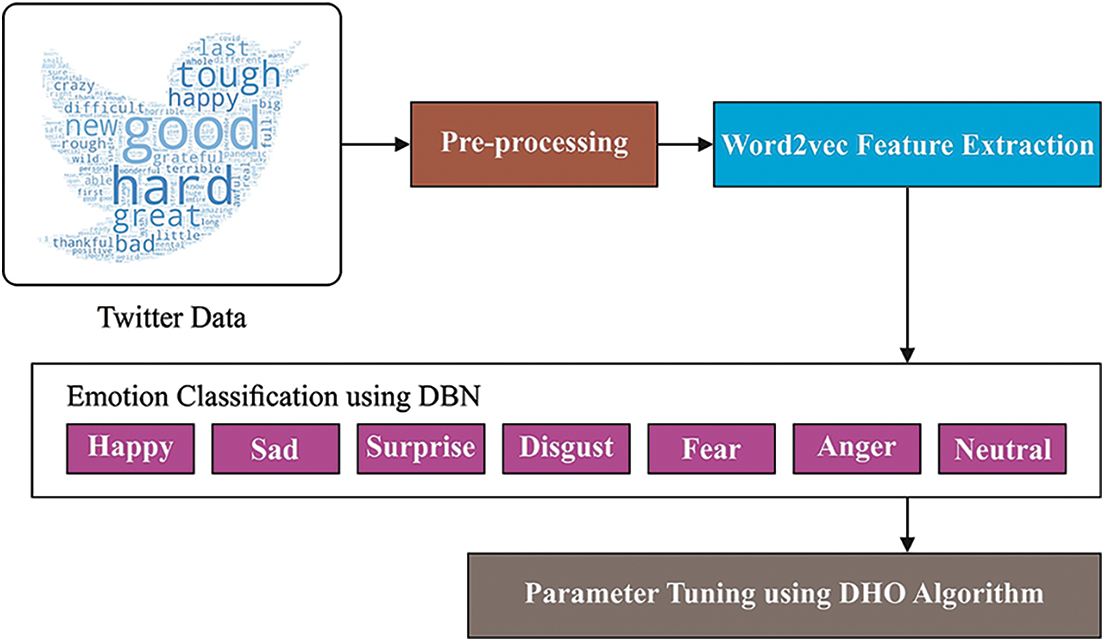
Figure 1: Block diagram of DHODBN-EC approach
The presented transformation technique XY-pair-set converts a multi-label classifier dataset D into a supervised binary dataset
It takes as input multi-label datasets D (Eq. (1)) and a subset of labels Y, as well as returns transformed binary datasets. Then, illustrate the following instance:
Consider
On the other hand, the output of the transformation technique is a single binary dataset
Different from the conventional supervised binary classification methods is to propose a learning method to learn an operation:
At the preliminary level, the DHODBN-EC technique pre-processes the tweets at different levels. Word2Vec is a neural network model that trains word embedding and distributed representation, including Skip-Gram and Continuous Bag-of-Word (CBOW) [18]. The last train s the current word is embedded through the context, while the last forecasts the context based on the present word. The word embedding trained using Word2Vec capture semantic similarities between words and the semantic data of words. This work uses a CBOW method based on negative sampling to train the word embedding.
A provided C corpus is regraded using its word series as
Now,
The arbitrary word u corresponds to = assistant vector
Now
Substitution of Eq. (6) into Eq. (4) leads to
Consequently, maximize G, viz., maximize
Especially as a positive sample increases, the probability of a negative sample reduces. As a result, this article resolves the problem of a present classification model.
3.2 DBN-Based Emotion Classification
For emotion classification, the DHODBN-EC model utilizes the DBN model, which helps to determine distinct emotion class labels. While backpropagation (BP) offers a properly productive process of learning several layers of non-linear features, it is complexity optimized the weight from the deep network, which has several layers of hidden neurons, and it needs a labelled trained dataset that is frequently costly for obtaining [19]. DBN overcome the restrictions of BP by utilizing unsupervised learning to create a layer of feature detector which models the statistical infrastructure of the input dataset without utilizing some data on the needed outcome. The higher-level feature detector, which captures difficult high-order statistical design from the input dataset, may later forecast the label. The DBN is an essential tool for DL structure in restricted Boltzmann machines (RBM). RBM contains an effective trained method that leads them to the appropriate key component for DBN.
RBM can use probabilistic graphical methods, which are taken as a stochastic neural network (SNN), which is a probability distribution about this group of inputs. The RBM is different from Boltzmann machines with a limit that its neurons have to make a bipartite graph whose vertices (V) are separated as to 2 independent sets,
The RBM is an energy-based method with n visible and m remote units; vectors v and h imply visible and hidden units correspondingly. To provide a group of states
In which
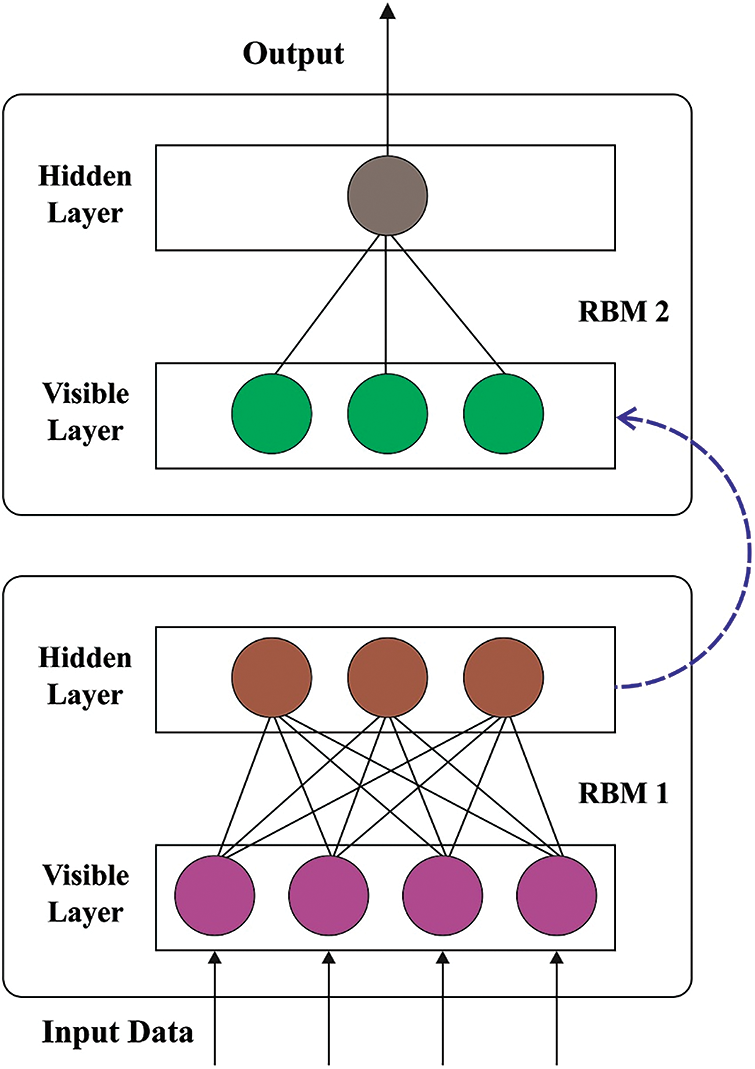
Figure 2: Framework of DBN
If the parameter is determined, it defines the joint likelihood distribution of
In which Z signifies the normalized constants. If the visible unit was provided, the activation state of all hidden layers was conditional independent. Consequently, the likelihood of activation of the
Whereas
Discriminating a
Whereas
In which
The DBN is a NN created in several layers of RBM, which procedure a stacked RBM. Stacking RBMs as follows, a high-level representation of input data is learned. DBN is introduced as the new ANN in the conventional form with network topology constructed from the layer of neuron model; however, with deeper architecture and advanced learning mechanics, without modelling the thorough biological phenomena constitutes human intelligence.
The DBN training frequently comprises (1) greedy layer-wise pretraining and (2) finetuning. Layer-wise pretraining includes model training the parameter layer-wise through CD algorithm and unsupervised training. In the primary stage, the training begins with the lower-level RBM that obtains the DBN input and slowly moves up until the RBM in the topmost layer, which contains the DBN output, is trained. As a result, the output of the preceding layer or learned features is applied as the input of succeeding RBM layers.
3.3 DHO-Based Parameter Optimization
Eventually, the DHO technique can be utilized for optimal hyperparameter adjustment of the DBN approach. To tune the internal modal factor of the NN classification in an optimum manner, this article used DHA [20]. It follows the characteristics of deer hunting to resolve the neural network parameter in the optimization problems. The DHOA is applied by its hunting behaviours; different variables are considered for the presented work. The hunting method is extremely useful because of its cooperation which is the core standard. It is capable of capturing ultra-frequency sound and well optical capacity. It is best suitable for resolving the classification performance by upgrading the position and adapting to engineering challenges.
The arithmetical modelling of the DHO is given in the following. At first, initializing the population of hunters, where the overall count of hunters is initialized. Next, significant variables like wind and the deer angle location are applied to describe the optimum location of the hunter is introduced.
The proliferation of location: Firstly, the optimum location is unknown and the procedure assumes that the candidate is closer to the optimum solution that is later defined based on the fitness function. Consider that two feasible solutions are leader and successor location; leader location defines the initial optimum location by the hunter and the successor location defines the following hunter location:
(a) Proliferation via a leader location: The updating process of the location starts afterwards the finest location is known and every individual tries to obtain the optimum location.
The mathematic model behindhand the proliferation stage is shown above.
(b) Proliferation via angle location: The searching space improved by considering the angle location in the update rule. The location of the hunter is defined through the computation in these cases the prey is unintentionally of the attack hence the hunting procedure could be extremely effective.
The variable presentation and mathematics for the proposal of the angle location in DHO are demonstrated in the above formula.
(c) Proliferation via the successor location: Firstly, the arbitrary search is considered and the vector D is assumed as lesser than one. Consequently, the primary best solution gained is regarded as more significant than the successor location. The location of the search agent is updated in iteration from the initial random solution. The finest solution is selected if
Termination: The location of agents or hunters is upgraded until it defines the best location.

This section examines the emotion classification outcomes of the DHODBN-EC method on a dataset comprising 1400 samples with 7 class labels. Each class holds a set of 200 samples, as depicted in Table 1.
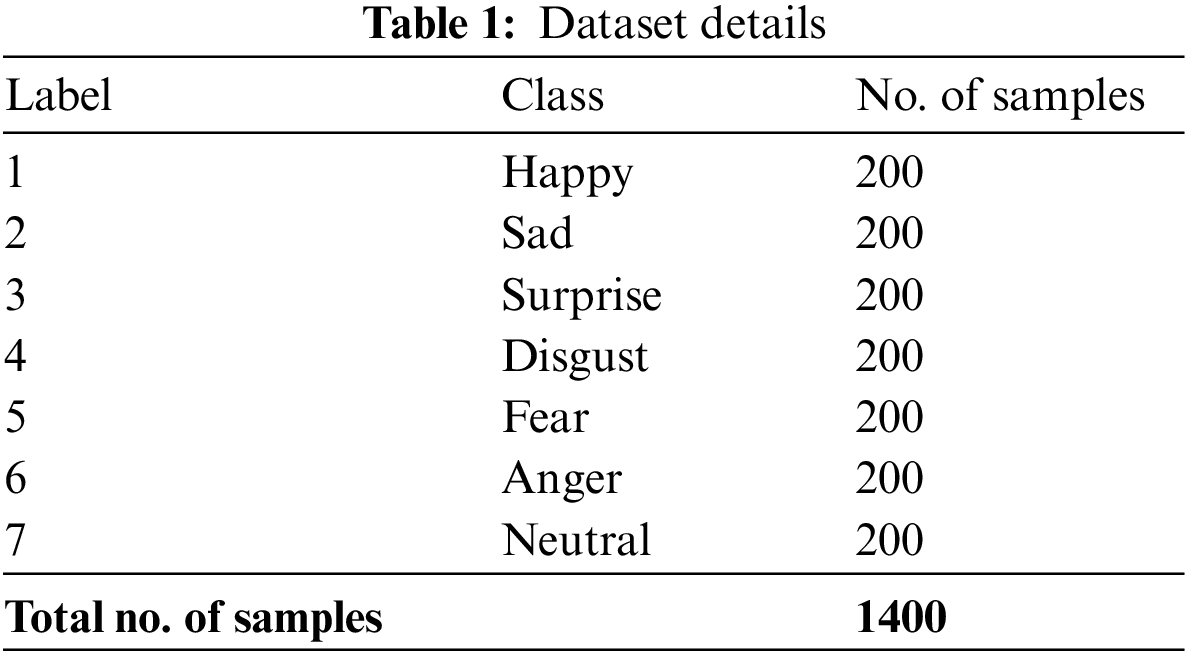
Fig. 3 shows the confusion matrices formed by the DHODBN-EC method. On the entire dataset, the DHODBN-EC model has recognized 173 samples into class 1, 189 samples into class 2, 175 samples into class 3, 183 samples into class 4, 182 samples into class 5, 174 samples into class 6, and 175 samples into class 7. Similarly, on 70% of training (TR) data, the DHODBN-EC technique has recognized 126 samples into class 1, 128 samples into class 2, 122 samples into class 3, 128 samples into class 4, 136 samples into class 5, 123 samples into class 6, and 117 samples into class 7. In addition, on 30% of testing (TS) data, the DHODBN-EC approach has recognized 47 samples into class 1, 61 samples into class 2, 53 samples into class 3, 55 samples into class 4, 46 samples into class 5, 51 samples into class 6, and 58 samples into class 7.
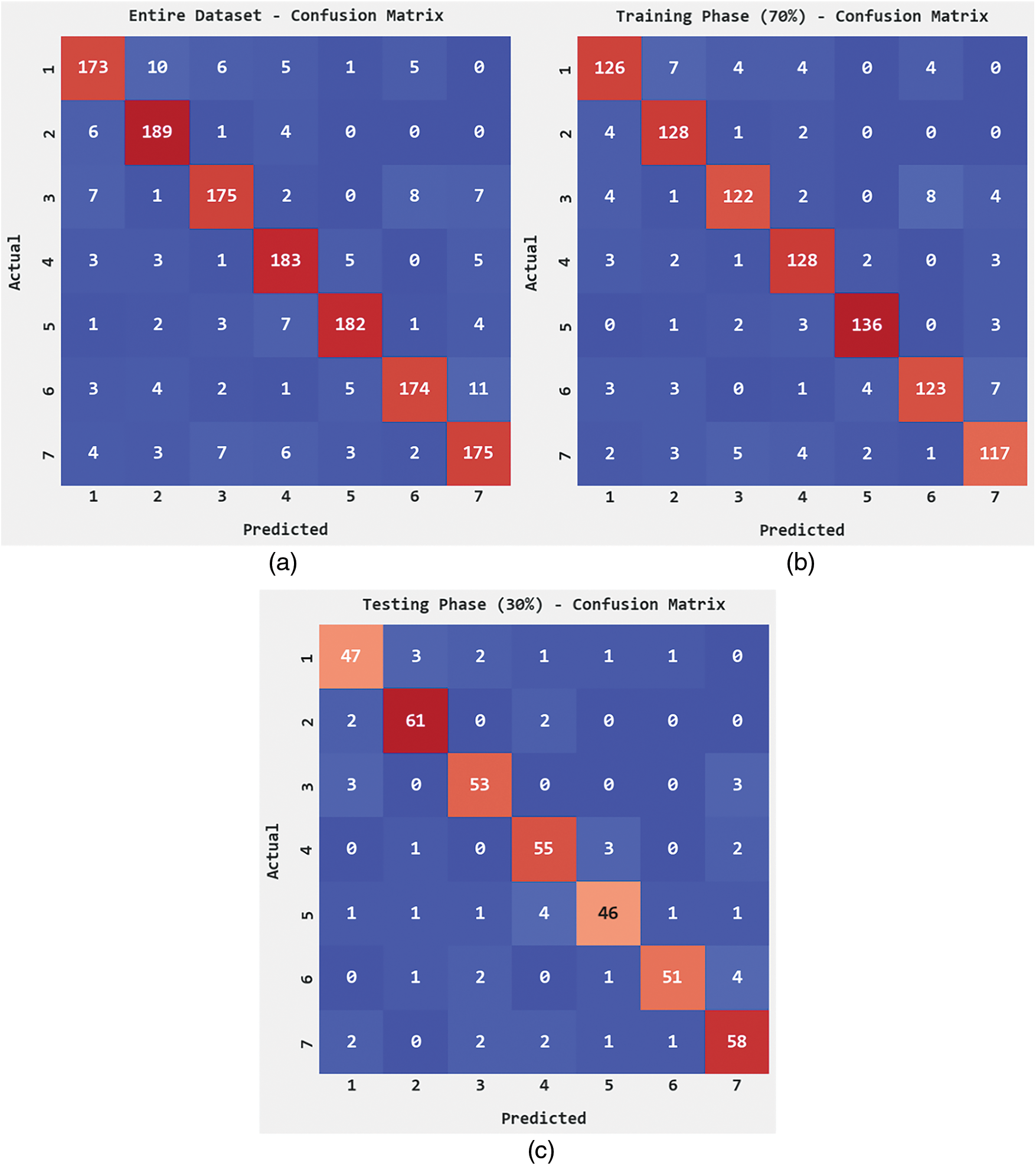
Figure 3: Confusion matrices of DHODBN-EC approach (a) Entire dataset, (b) 70% of TR data, and (c) 30% of TS data
Table 2 reports an overall emotion classification output of the DHODBN-EC model.
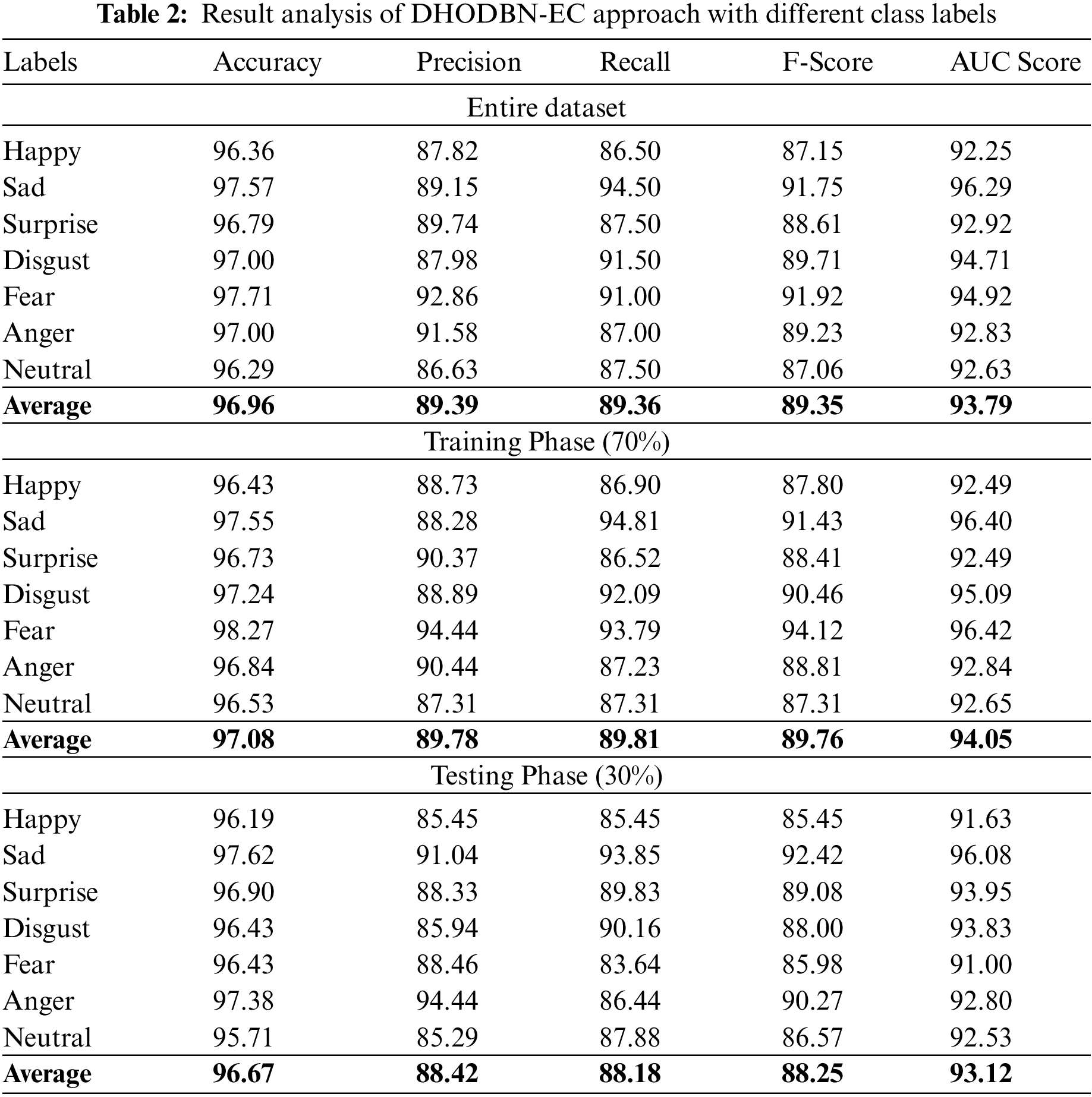
Fig. 4 portrays a brief emotion classification outcome of the DHODBN-EC model on the entire dataset. The DHODBN-EC approach has detected samples under happy class with
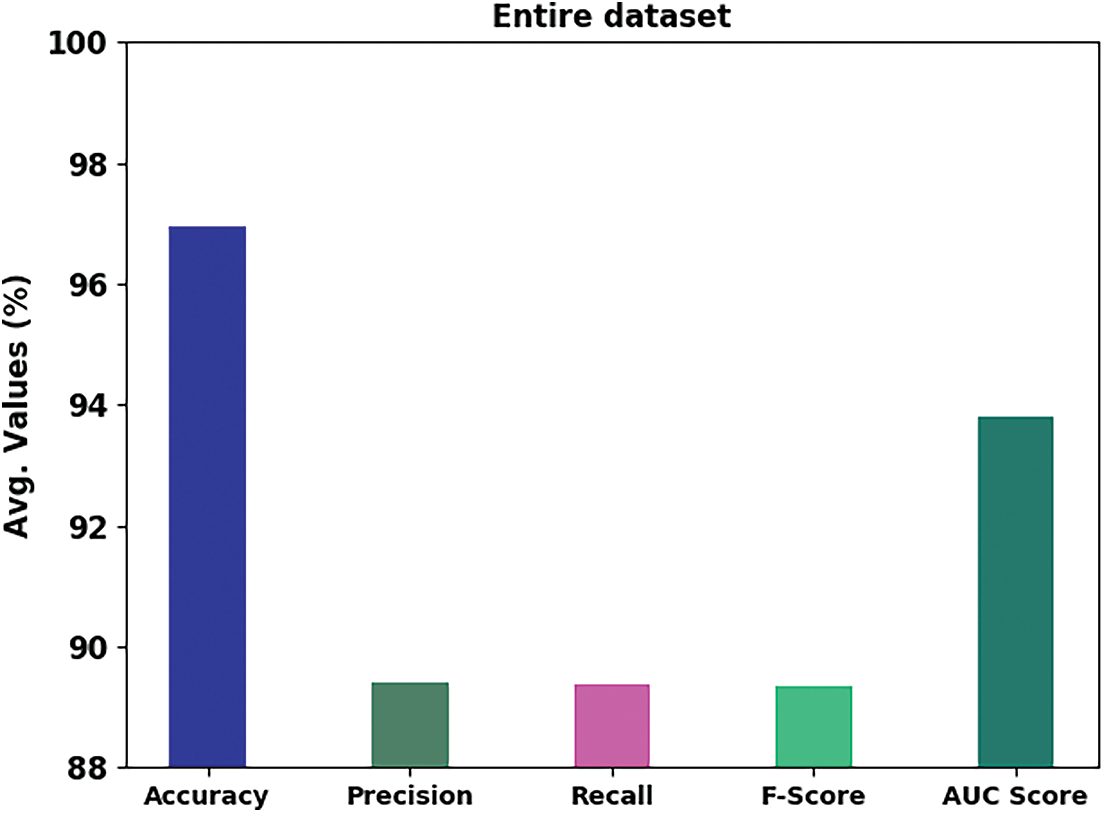
Figure 4: Result analysis of the DHODBN-EC approach under the entire dataset
Fig. 5 portrays detailed emotion classification outcomes of the DHODBN-EC technique on 70% of TR data. The DHODBN-EC algorithm has identified samples under happy class with
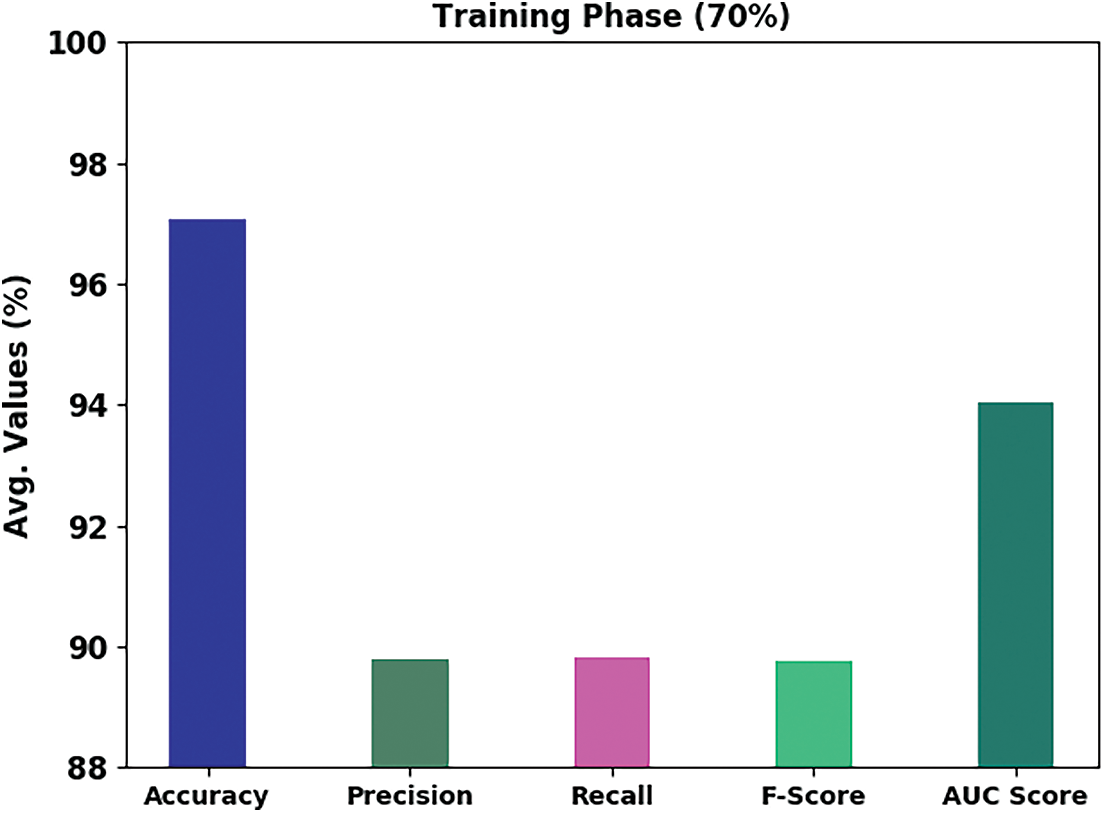
Figure 5: Result analysis of DHODBN-EC approach under 70% of TR data
Fig. 6 depicts a brief emotion classification outcome of the DHODBN-EC technique on 30% of TS data. The DHODBN-EC approach has identified samples under happy class with
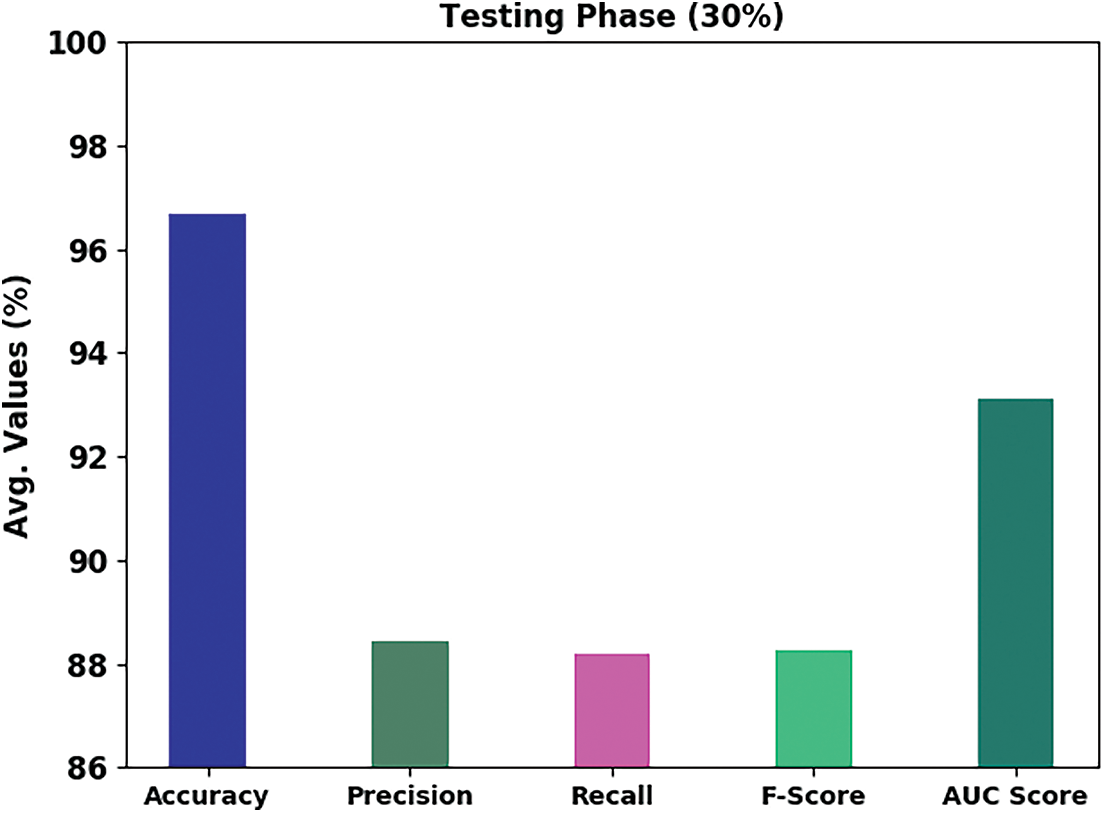
Figure 6: Result analysis of DHODBN-EC approach under 30% of TS data
The training accuracy (TRA) and validation accuracy (VLA) gained by the DHODBN-EC methodology on the test dataset is shown in Fig. 7. The experimental outcome implicit in the DHODBN-EC algorithm has gained maximal values of TRA and VLA. Seemingly the VLA is greater than TRA.
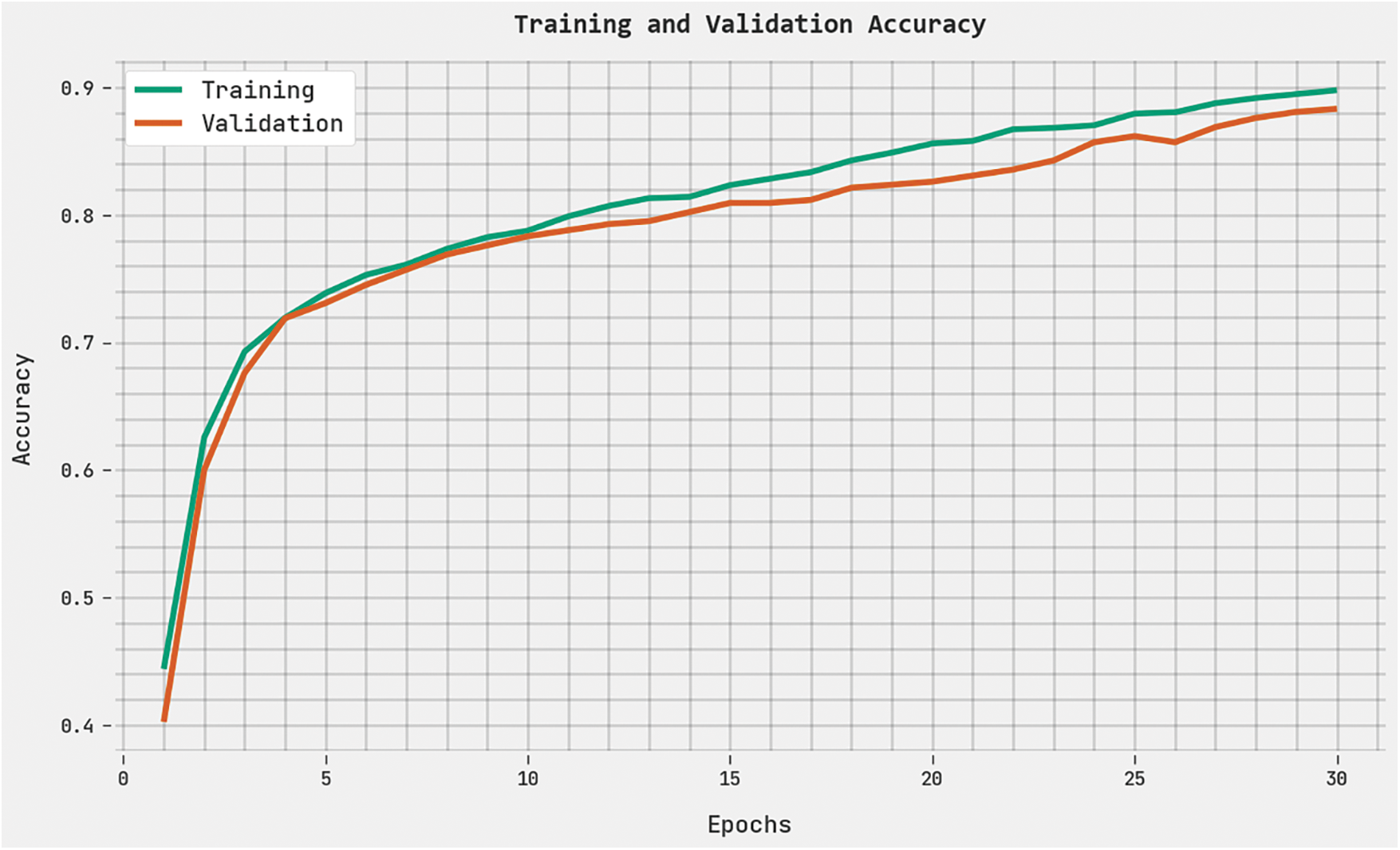
Figure 7: TRA and VLA analysis of the DHODBN-EC approach
The training loss (TRL) and validation loss (VLL) attained by the DHODBN-EC method on the test dataset are displayed in Fig. 8. The experimental outcome denoted the DHODBN-EC method has established the least values of TRL and VLL. Particularly, the VLL is lesser than TRL.
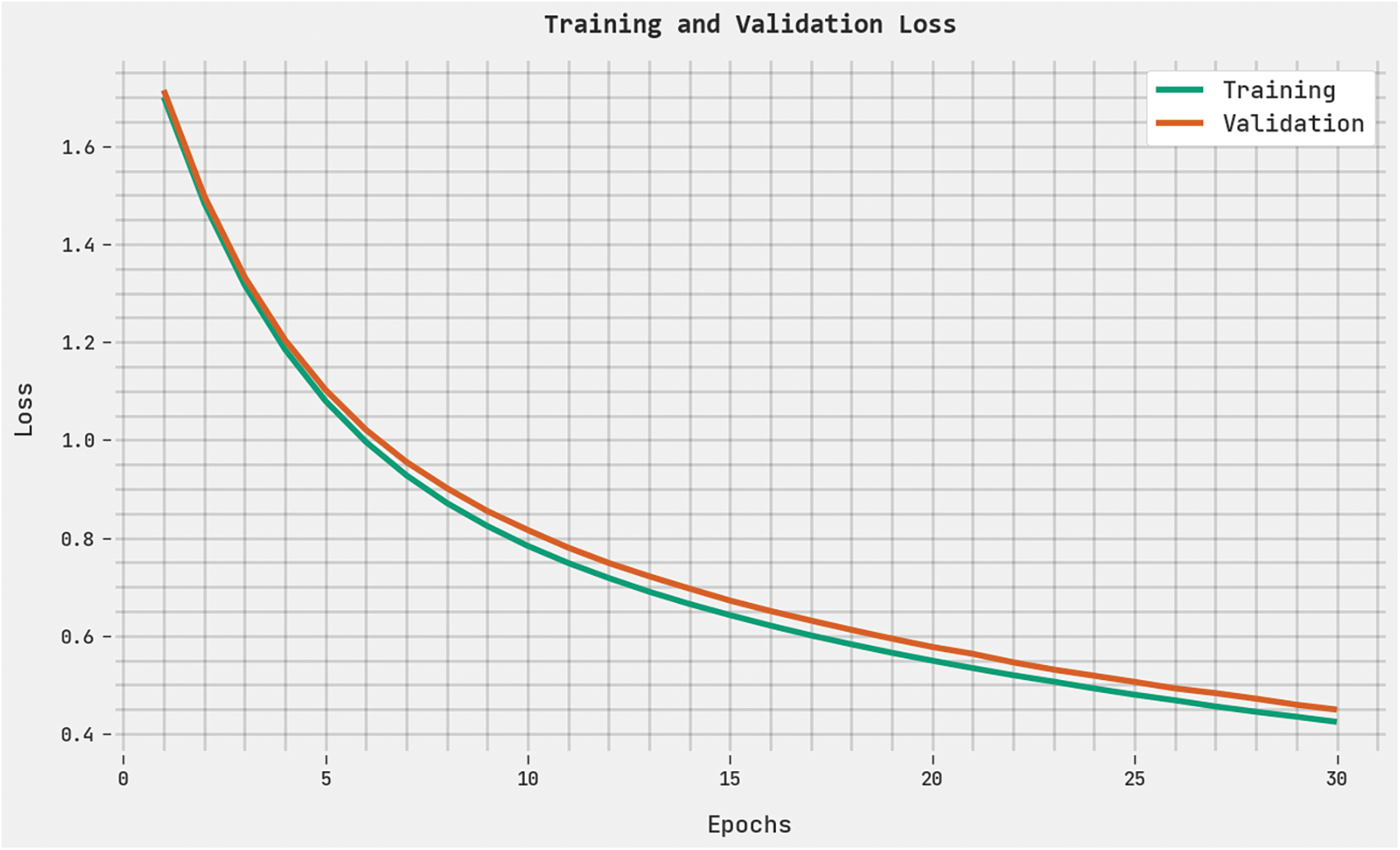
Figure 8: TRL and VLL analysis of the DHODBN-EC approach
A clear precision-recall analysis of the DHODBN-EC method on the test dataset is exhibited in Fig. 9. The figure denotes the DHODBN-EC technique has resulted in enhanced precision-recall values under all classes.
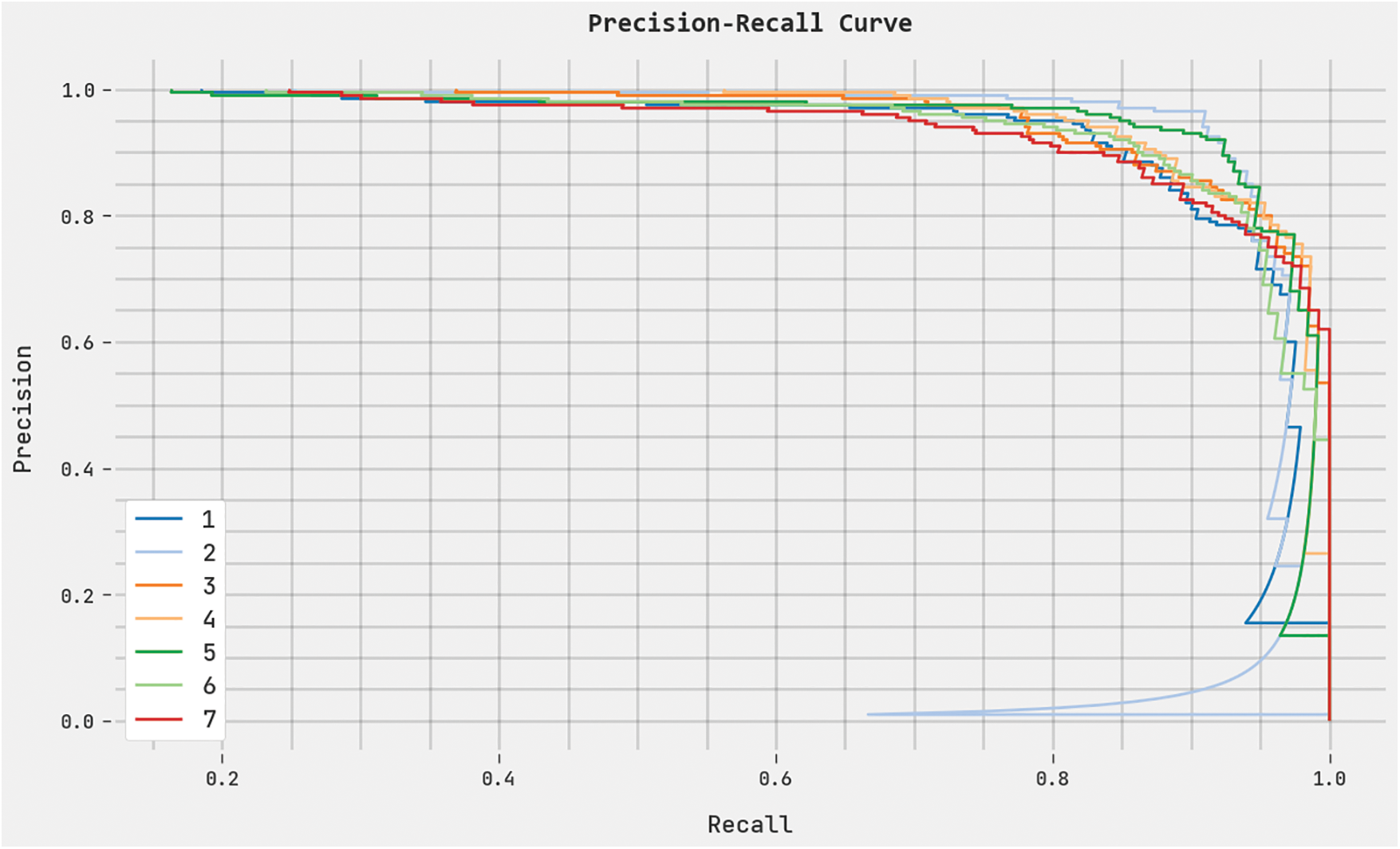
Figure 9: Precision-recall analysis of the DHODBN-EC approach
A complete ROC study of the DHODBN-EC algorithm on the test dataset is portrayed in Fig. 10. The results represented the DHODBN-EC method’s ability to categorise distinct classes on the test dataset.
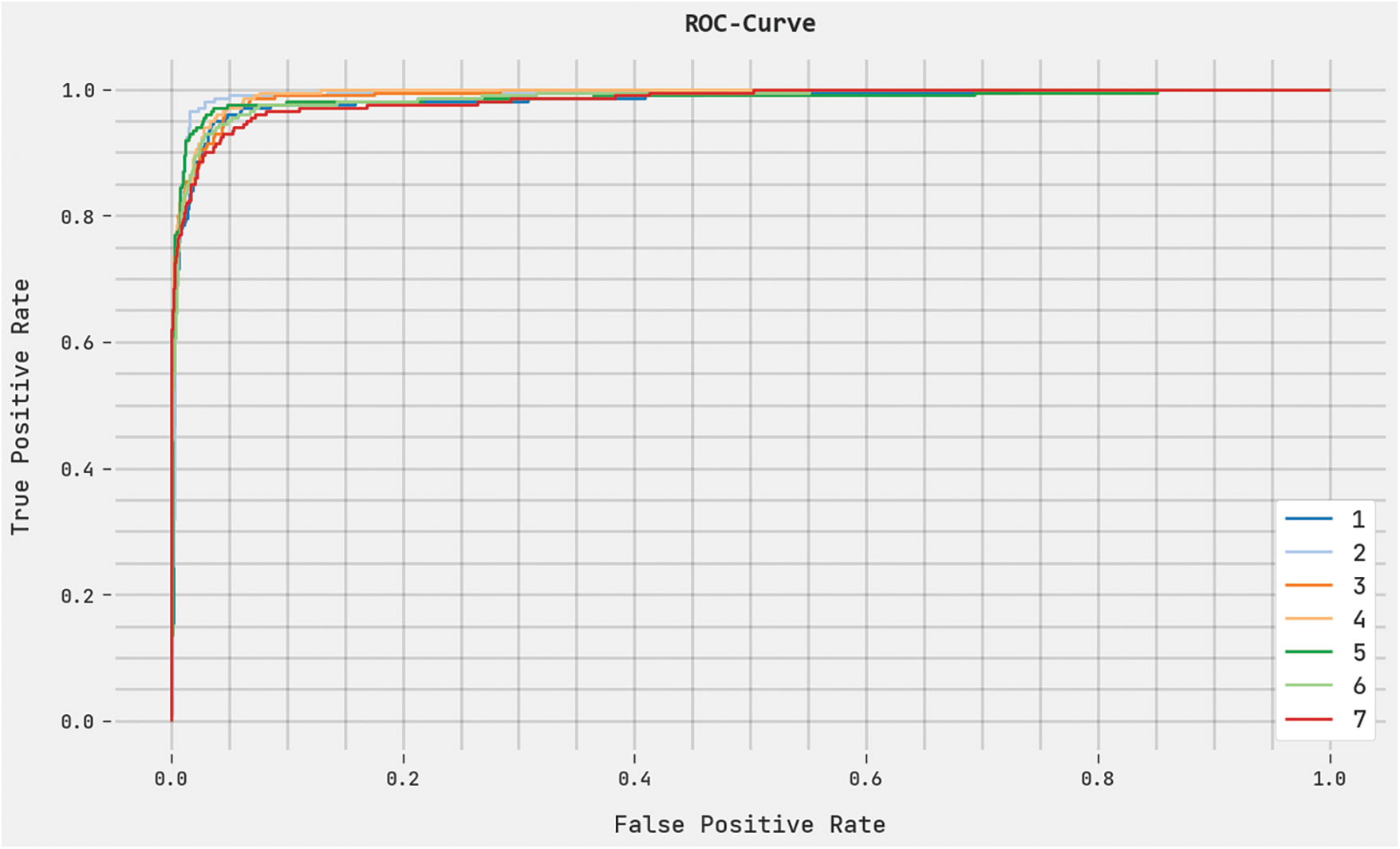
Figure 10: ROC analysis of DHODBN-EC approach
Table 3 portrays an extensive comparative study of the DHODBN-EC algorithm with contemporary techniques. Table 3 indicates a detailed
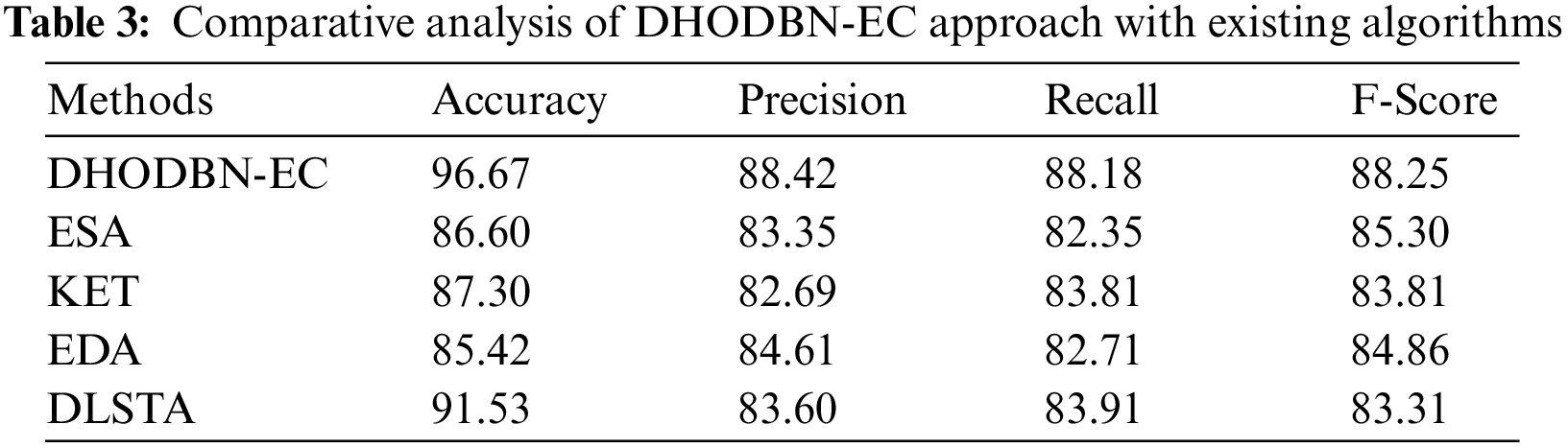
In this article, a new DHODBN-EC model was projected for English Twitter Data. The presented DHODBN-EC model aims to examine the existence of distinct emotion classes in tweets. The DHODBN-EC technique encompasses processing, DBN-based emotion detection, and DHO-based hyperparameter tuning. For emotion classification, the DHODBN-EC model utilizes the DBN model, which helps to determine distinct emotion class labels. Lastly, the DHO algorithm can be leveraged for optimal hyperparameter adjustment of the DBN technique. An extensive range of experimental analyses can be executed to demonstrate the enhanced performance of the DHODBN-EC approach. A comprehensive comparison study exhibited the improvements of the DHODBN-EC model over other approaches with maximum accuracy of 96.67%. In the future, a hybrid DL model can improve detection performance.
Acknowledgement: The authors extend their appreciation to the Princess Nourah bint Abdulrahman University Researchers Supporting Project Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia and the Deanship of Scientific Research at Umm Al-Qura University.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R281), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4340237DSR61).
Author Contributions: All authors contribute equally.
Availability of Data and Materials: Data sharing not applicable to this article as no datasets were generated during the current study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. I. Ameer, N. Ashraf, G. Sidorov and H. Gómez Adorno, “Multi-label emotion classification using content-based features in Twitter,” Computación y Sistemas, vol. 24, no. 3, pp. 1159–1164, 2020. [Google Scholar]
2. S. S. Baboo and M. Amirthapriya, “Comparison of machine learning techniques on twitter emotions classification,” SN Computer Science, vol. 3, no. 1, pp. 1–8, 2022. [Google Scholar]
3. A. Jain and V. Jain, “Sentiment classification of twitter data belonging to renewable energy using machine learning,” Journal of Information and Optimization Sciences, vol. 40, no. 2, pp. 521–533, 2019. [Google Scholar]
4. J. P. Pinto and V. Murari, “Real time sentiment analysis of political twitter data using machine learning approach,” International Research Journal of Engineering and Technology, vol. 6, no. 4, pp. 4124–4129, 2019. [Google Scholar]
5. H. Adamu, S. L. Lutfi, N. H. A. H. Malim, R. Hassan, A. di Vaio et al., “Framing twitter public sentiment on Nigerian government COVID-19 palliatives distribution using machine learning,” Sustainability, vol. 13, no. 6, pp. 3497, 2021. [Google Scholar]
6. C. P. D. Cyril, J. R. Beulah, N. Subramani, P. Mohan, A. Harshavardhan et al., “An automated learning model for sentiment analysis and data classification of Twitter data using balanced CA-SVM,” Concurrent Engineering, vol. 29, no. 4, pp. 386–395, 2021. [Google Scholar]
7. B. Venkateswarlu, V. V. Shenoi and P. Tumuluru, “CAViaR-WS-based HAN: Conditional autoregressive value at risk-water sailfish-based hierarchical attention network for emotion classification in COVID-19 text review data,” Social Network Analysis and Mining, vol. 12, no. 1, pp. 1–17, 2022. [Google Scholar]
8. E. R. Kumar, K. V. S. N. R. Rao, S. R. Nayak and R. Chandra, “Suicidal ideation prediction in twitter data using machine learning techniques,” Journal of Interdisciplinary Mathematics, vol. 23, no. 1, pp. 117–125, 2020. [Google Scholar]
9. H. Min, Y. Peng, M. Shoss and B. Yang, “Using machine learning to investigate the public’s emotional responses to work from home during the COVID-19 pandemic,” Journal of Applied Psychology, vol. 106, no. 2, pp. 214, 2021. [Google Scholar] [PubMed]
10. J. Xue, J. Chen, R. Hu, C. Chen, C. Zheng et al., “Twitter discussions and emotions about the COVID-19 pandemic: Machine learning approach,” Journal of Medical Internet Research, vol. 22, no. 11, pp. e20550, 2020. [Google Scholar] [PubMed]
11. M. Hasan, E. Rundensteiner and E. Agu, “Automatic emotion detection in text streams by analyzing twitter data,” International Journal of Data Science and Analytics, vol. 7, no. 1, pp. 35–51, 2019. [Google Scholar]
12. H. Çakar and A. Sengur, “Machine learning based emotion classification in the COVID-19 real world worry dataset,” Computer Science, vol. 6, no. 1, pp. 24–31, 2021. [Google Scholar]
13. M. Jabreel and A. Moreno, “A deep learning-based approach for multi-label emotion classification in tweets,” Applied Sciences, vol. 9, no. 6, pp. 1123, 2019. [Google Scholar]
14. S. M. Nagarajan and U. D. Gandhi, “Classifying streaming of Twitter data based on sentiment analysis using hybridization,” Neural Computing and Applications, vol. 31, no. 5, pp. 1425–1433, 2019. [Google Scholar]
15. M. Suhasini and S. Badugu, “Two step approach for emotion detection on Twitter data,” International Journal of Computer Applications, vol. 179, no. 53, pp. 12–19, 2018. [Google Scholar]
16. K. Tago and Q. Jin, “Influence analysis of emotional behaviors and user relationships based on Twitter data,” Tsinghua Science and Technology, vol. 23, no. 1, pp. 104–113, 2018. [Google Scholar]
17. M. A. Azim and M. H. Bhuiyan, “Text to emotion extraction using supervised machine learning techniques,” Telkomnika, vol. 16, no. 3, pp. 1394–1401, 2018. [Google Scholar]
18. B. Jang, I. Kim and J. W. Kim, “Word2vec convolutional neural networks for classification of news articles and tweets,” PLoS One, vol. 14, no. 8, pp. e0220976, 2019. [Google Scholar] [PubMed]
19. W. Almanaseer, M. Alshraideh and O. Alkadi, “A deep belief network classification approach for automatic diacritization of arabic text,” Applied Sciences, vol. 11, no. 11, pp. 5228, 2021. [Google Scholar]
20. G. Agarwal and H. Om, “Performance of deer hunting optimization based deep learning algorithm for speech emotion recognition,” Multimedia Tools and Applications, vol. 80, no. 7, pp. 9961–9992, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools