
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Multi-Versus Optimization with Deep Reinforcement Learning Enabled Affect Analysis on Arabic Corpus
1 Department of Computer Science, College of Sciences and Humanities-Aflaj, Prince Sattam bin Abdulaziz University, Aflaj, 16273, Saudi Arabia
2 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah Bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
3 Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Makkah, 24211, Saudi Arabia
4 Department of Computer Science, College of Computing and Information Technology, Shaqra University, Shaqra, Saudi Arabia
5 Research Centre, Future University in Egypt, New Cairo, 11845, Egypt
6 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Mesfer Al Duhayyim. Email:
Computer Systems Science and Engineering 2023, 47(3), 3049-3065. https://doi.org/10.32604/csse.2023.033836
Received 29 June 2022; Accepted 04 November 2022; Issue published 09 November 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Sentiment analysis (SA) of the Arabic language becomes important despite scarce annotated corpora and confined sources. Arabic affect Analysis has become an active research zone nowadays. But still, the Arabic language lags behind adequate language sources for enabling the SA tasks. Thus, Arabic still faces challenges in natural language processing (NLP) tasks because of its structure complexities, history, and distinct cultures. It has gained lesser effort than the other languages. This paper developed a Multi-versus Optimization with Deep Reinforcement Learning Enabled Affect Analysis (MVODRL-AA) on Arabic Corpus. The presented MVODRL-AA model majorly concentrates on identifying and classifying effects or emotions that occurred in the Arabic corpus. Firstly, the MVODRL-AA model follows data pre-processing and word embedding. Next, an n-gram model is utilized to generate word embeddings. A deep Q-learning network (DQLN) model is then exploited to identify and classify the effect on the Arabic corpus. At last, the MVO algorithm is used as a hyperparameter tuning approach to adjust the hyperparameters related to the DQLN model, showing the novelty of the work. A series of simulations were carried out to exhibit the promising performance of the MVODRL-AA model. The simulation outcomes illustrate the betterment of the MVODRL-AA method over the other approaches with an accuracy of 99.27%.Keywords
Arabic is a rapidly growing language on Twitter and the official language for twenty-two countries. But not much work has been done on analysing the Arabic language [1]. This can be because of various dialects and complications in the Arabic language that make it difficult to build a single mechanism for detecting emotions and sentiments in the Arabic language [2]. It can be divided into 2 major categories: Dialectical Arabic (DA) and Standard Arabic. Standard Arabic has 2 types they are Modern Standard Arabic (MSA) and Classical Arabic (CA) [3]. Even though MSA became the principal language of Arab countries and was printed in books and educated in schools [4], DA was spoken as a native language in individuals’ informal daily interaction and contains a robust existence in text and comments in emails or on microblogging networks. There exists only one MSA language for every Arabic speaker, but numerous dialects do not have formal written formats [5]. These results in the absence of lexicon sources for such dialects, and official grammar rulebooks do not work as proficiently with DA and MSA.
Twitter is a rich data bank full of opinions, sentiments, and emotions. Sentiment analysis (SA) is to classify a subjective text as negative, positive, or neutral [6]; emotion detection detects feelings types via the expression of texts, like sadness, anger, fear, and joy. Automated emotion recognition or affect detection focuses on identifying human affective states like sadness, joy, and love from several modalities, which include video, text, image, and audio [7]. Since a particular natural language processing (NLP) task, emotion identification from textual data has been a promising research matter for the past few years. Substantial attempts have been made to build a perfect automatic system that detects real human emotions from the text. A multilabel classifier challenge was assumed; more than one emotion was taken in a study [8]. Therefore, it provides more difficulties beyond multiclass or binary classifier issues. Automated text emotion recognition helps analyze user feelings, attitudes, and sentiments from online text like product reviews, tweets, comments, Facebook status, blogs, and news and maybe implied to several domains [9], i.e., customer services, chatbots, mental health monitoring, and e-learning mechanisms. Deep learning (DL) is described as a sub-field of machine learning (ML) which is made up of multiple hidden layers which were devised for feature extraction and complicated modelling [10]. DL has resulted in breakthroughs in several NLP applications, like affect analysis and Arabic sentiment.
This paper presents a Multi-versus Optimization with Deep Reinforcement Learning Enabled Affect Analysis (MVODRL-AA) on Arabic Corpus. The presented MVODRL-AA model majorly concentrates on identifying and classifying effects or emotions that occurred in the Arabic corpus. Firstly, the MVODRL-AA model follows data pre-processing and word embedding. Next, an n-gram model is utilized to generate word embeddings. A deep Q-learning network (DQLN) model is then exploited to identify and classify the effects on the Arabic corpus. At last, the MVO algorithm is used as a hyperparameter tuning approach to adjust the hyperparameters related to the DQLN model. A series of simulations were carried out to showcase the promising performance of the MVODRL-AA model.
The rest of the paper is organized as follows. Section 2 offers the related works, and Section 3 introduces the proposed model. Next, Section 4 gives an experimental validation, and Section 5 concludes the work.
AlGhamdi et al. [11] provided an intellectual mechanism for analysing Arabic tweets to detect suspicious messages. And needed Arabic tweet datasets from the microblog social network site Twitter through Twitter Streaming Application Programming Interface and saves in a desirable file format. The mechanism tokenizes and pre-processes tweet datasets. Manual labelling was conducted on the tweet dataset for not-suspicious (label 0) and suspicious (label 1) classes. The labelled tweet datasets can be utilized for training a classifier by using supervised ML systems to identify suspicious actions. At the testing stage, the system processes the unlabeled tweet datasets and identifies whether they belong to the not-suspicious or suspicious class. Alsayat et al. [12] introduced a complete strategy proposal for Arabic Language Sentiment Analysis (ALSA). The ALSA structure examines the feelings and opinions at every language level and the significance of framing an annotated corpus that helps understand an Arabic sentence from the phonetics level to the metonymy and rhetorical levels.
Alharbi et al. [13] suggested a SA with DL (SA-DL) related method for predicting the polarity of sentiments and opinions. Two kinds of recurrent neural networks (RNNs) were utilized for learning higher-level representations. Afterwards, mitigating the data dependency challenges and raising the forcefulness of the method, 3 distinct classifier techniques have been used for producing the concluding output. Ombabi et al. [14] suggested a new DL method for ALSA based on a single-layer convolutional neural network (CNN) structure for local feature extraction and 2 layers of long short-term memory (LSTM) for maintaining long-run dependences. The feature maps studied by LSTM and CNN were passed to the support vector machine (SVM) classifier for generating the concluding categorization. This method can be maintained by the FastText word embedding method. In [15], an efficient Bidirectional LSTM Network (BiLSTM) can be examined for enhancing ALSM by applying Forward-Backwards encapsulating context information from the Arabic feature series.
The authors in [16] introduced an optimized heterogeneous stacking ensemble technique to enhance the SA on Arabic text using three distinct pre-trained models. The proposed model enhances the SA and prediction outcomes. The authors in [17] developed an ML model for Arabic tweet analysis. Here, the Word2Vec approach is applied for word embedding with two pretrained continuous bag-of-words (CBOW) approaches examined. Finally, Naïve Bayes (NB) model is employed as a baseline classification model. The authors in [18] presented various DL models for Arabic SA. These models have been validated on the hybrid dataset, and the Arabic book reviews dataset (BRAD). The presented model investigated deep networks’ capability to detect discriminating features from data depicted at the character level.
In this paper, an MVODRL-AA technique was introduced to identify and classify effects or emotions that occurred in the Arabic corpus. Firstly, the MVODRL-AA model follows data pre-processing and word embedding. Next, the n-gram model is utilized to generate word embeddings. Then, the MVO with the DQLN model is exploited to identify and classify the effect on the Arabic corpus. Fig. 1 depicts the overall block diagram of the MVODRL-AA approach.
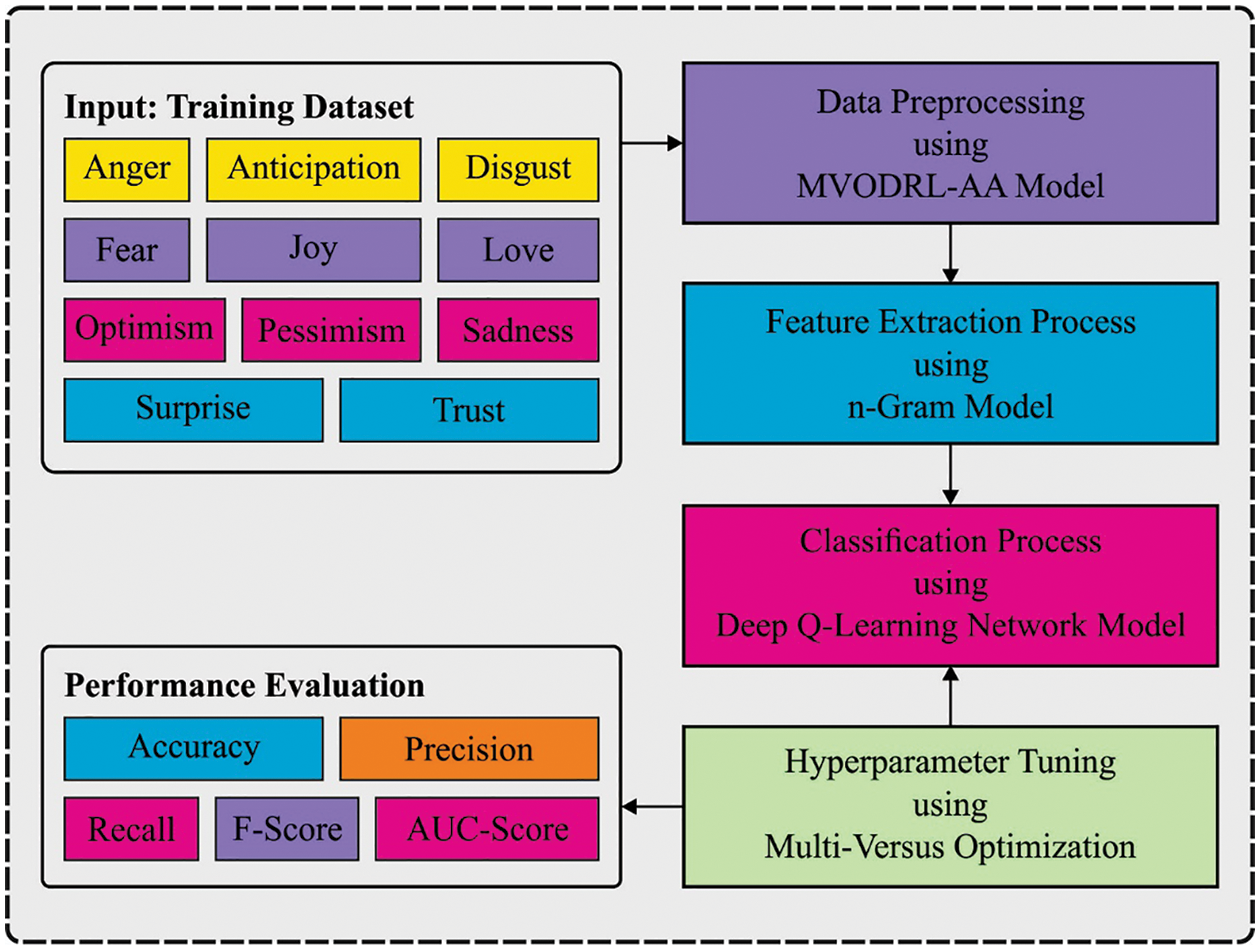
Figure 1: Overall block diagram of MVODRL-AA approach
3.1 Data Pre-Processing and Word Embedding
At the beginning level, the MVODRL-AA model follows data pre-processing and word embedding. Tweet pre-processing is the primary level in the suggested technique, transforming Arabic tweets to a form suitable and appropriate for the multilabel emotion classifier mechanism. Such pre-processing tasks encompass eliminating diacritics, punctuation, digits, stop words, and Latin characters and inspecting the process of tokenization, light stemming, and normalization. Moreover, improved the tweets by copying the embedded emoji in their respective Arabic words. Such language was used to reduce the tweets’ noisiness and ambiguity to increase the proposal’s effectiveness and accuracy.
Lexical n-gram methods were broadly utilized in NLP for syntax feature mapping & statistical analysis [19]. An advanced n-gram method for analyzing the generated corpus comprises tokenized words to find the word’s popularity or set of nearest terms. The probability of the existence of a series is computed by utilizing the probability chain rule:
For instance, it could assume a sentence as “Still COVID19 wave is running”. As per the probability chain rule, P (“Still Covid-19 wave is running”) = P(“Still”) × P(“Covid-19” | “Still”) × P(“wave” | “Still Covid-19”) × P(“is” | “Still Covid-19 wave”) × P(“running” | “Still Covid-19 wave is”).
The words probabilities in every sentence after applications of the probability chain rule:
The bigram method predicts the word probability a by utilizing the conditional probability
The expression for the probability can be:
The famous trigrams, unigrams, and bigrams are found in our corpus using the n-gram method.
3.2 DQLN-Based Affect Classification
At this stage, the model is exploited to identify and classify the effect on the Arabic corpus. Deep reinforcement learning (DRL) integrates three mechanisms such as reward, state, and action. The DRL agent aims to learn the mapping function from the state to action spaces. Next, the DRL agent obtains an award. The objective is to maximize the overall rewards. The classification method of the DQLN method is a function that receives the sample and returns the label probability [20].
The classifier agent’s goal is to recognize an instance in the trainable dataset correctly. Meanwhile, the classifier agent obtains a positive reward once it properly recognizes the instance; it accomplishes the objective by maximizing
In the RL technique, there exists a function that calculates the quality of state and action incorporation called as Q function:
According to the Bellman equation, the Q function is expressed by:
The classification agent maximizes the cumulative reward by solving the optimal
The table records the Q function in the lower dimension finite state space. However, in the higher dimension constant state space, the
In Eq. (13), y indicates the evaluated target of
In Eq. (14),
Now, the optimal
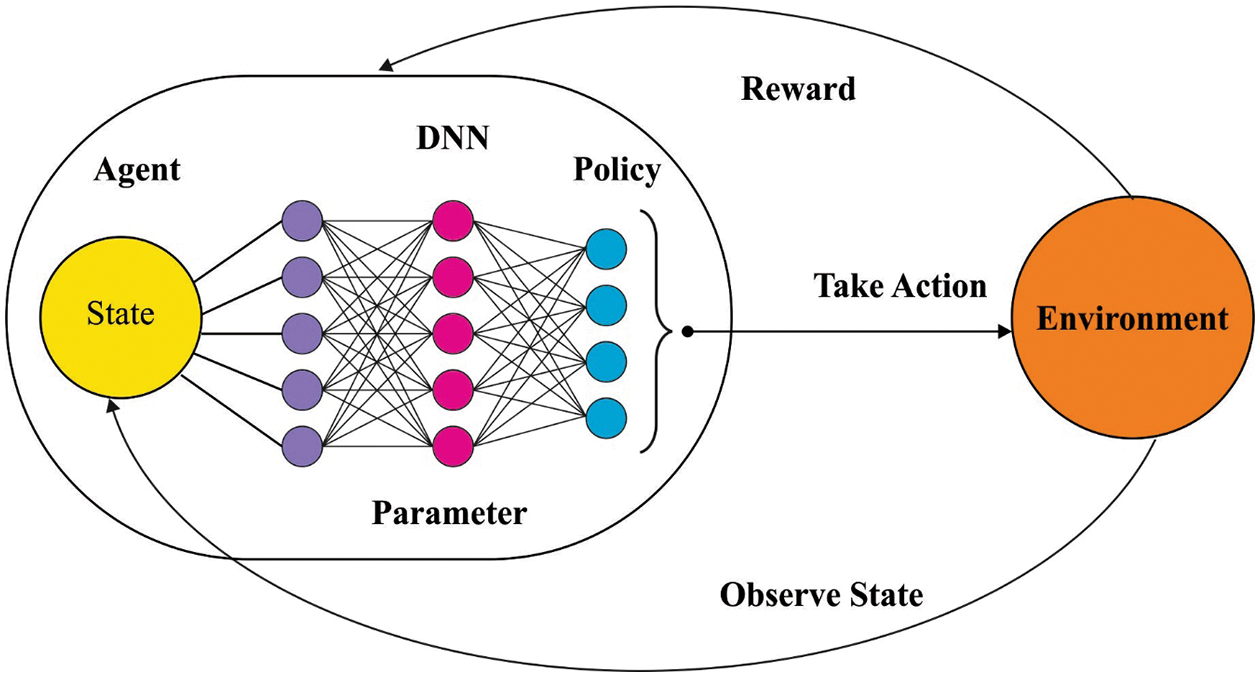
Figure 2: Structure of deep Q-networks
3.3 MVO-Based Hyperparameter Tuning
Finally, the MVO algorithm is used as a hyperparameter tuning approach to adjust the hyperparameters related to the DQLN model. MVO employs the black-and-white hole conception to explore the search space, where it employs a wormhole to exploit the search space [21]. Similar to each evolutionary algorithm, it initiates the optimization technique by initializing a population of solutions and trying to improve the solution through a predetermined iteration count. In the study, the individual development in every population is implemented according to the theory regarding the presence of a multi-universe. In this theory, every object in the universe can be regarded as a variable, and every solution to an optimizing issue is considered a universe. In the optimization technique, MVO follows the subsequent stages:
■ The high inflation rate is proportionate to the low probability of black holes.
■ The high inflation rate is proportionate to the high probability of white holes.
■ Object in the universe with low inflation rate tends to obtain further objects via black holes.
■ Object in the universe with high inflation rate moves from white to black holes.
■ Objects in each universe might face random motion toward the better universe nevertheless of the inflation rate.
In MVO, a wormhole tunnel is often determined among a universe, and the better universe formed solar.
In Eq. (16),
In Eq. (17),
In Eq. (18),
The proposed model is simulated using Python 3.6.5 tool. In this study, the effect analysis of the MVODRL-AA model on the Arabic language is examined on the SemEval2018-Ar Dataset comprising 10107 Arabic tweets under 11 class labels, as displayed in Table 1.
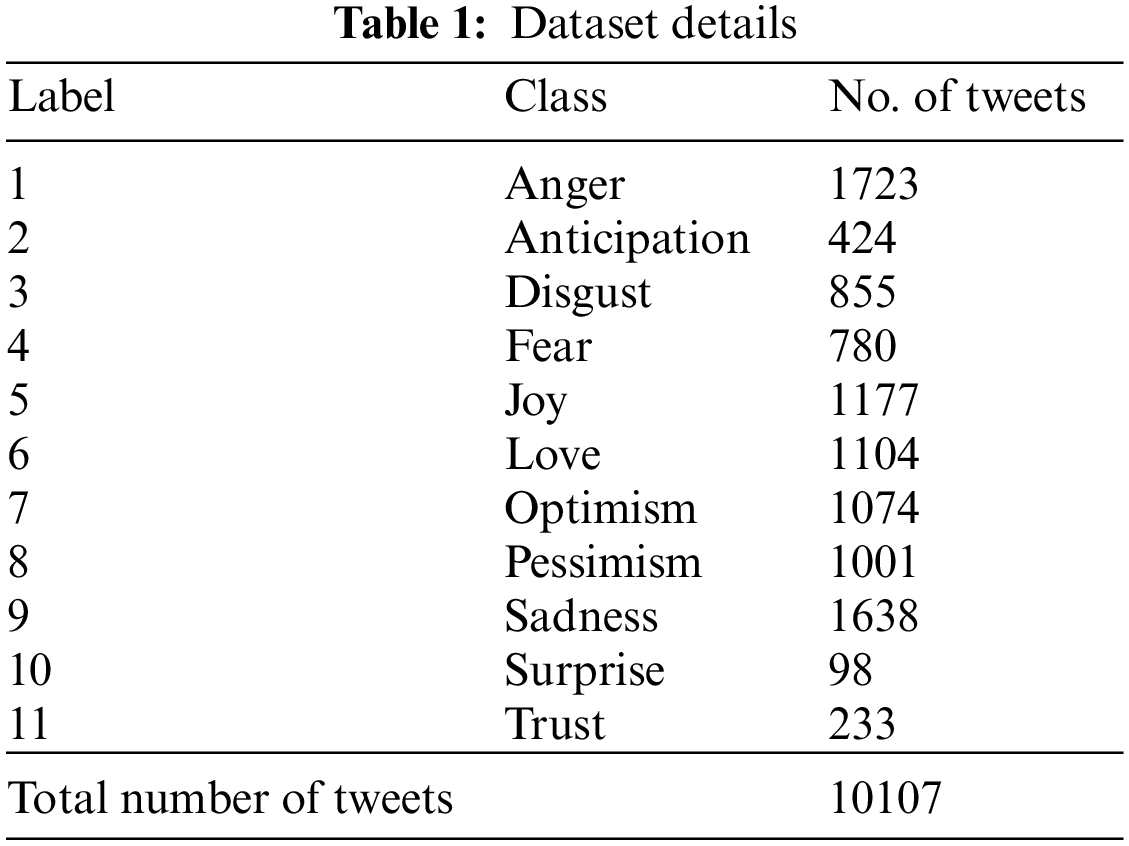
Fig. 3 illustrates the confusion matrix created by the MVODRL-AA model on the entire dataset. The figure implied that the MVODRL-AA model has properly identified 1689 samples under class 1, 392 samples under class 2, 815 samples under class 3, 754 samples under class 4, 1150 samples under class 5, 1060 samples under class 6, 1044 samples under class 7, 956 samples under class 8, 1594 samples under class 9, 56 samples under class 10, and 198 samples under class 11.
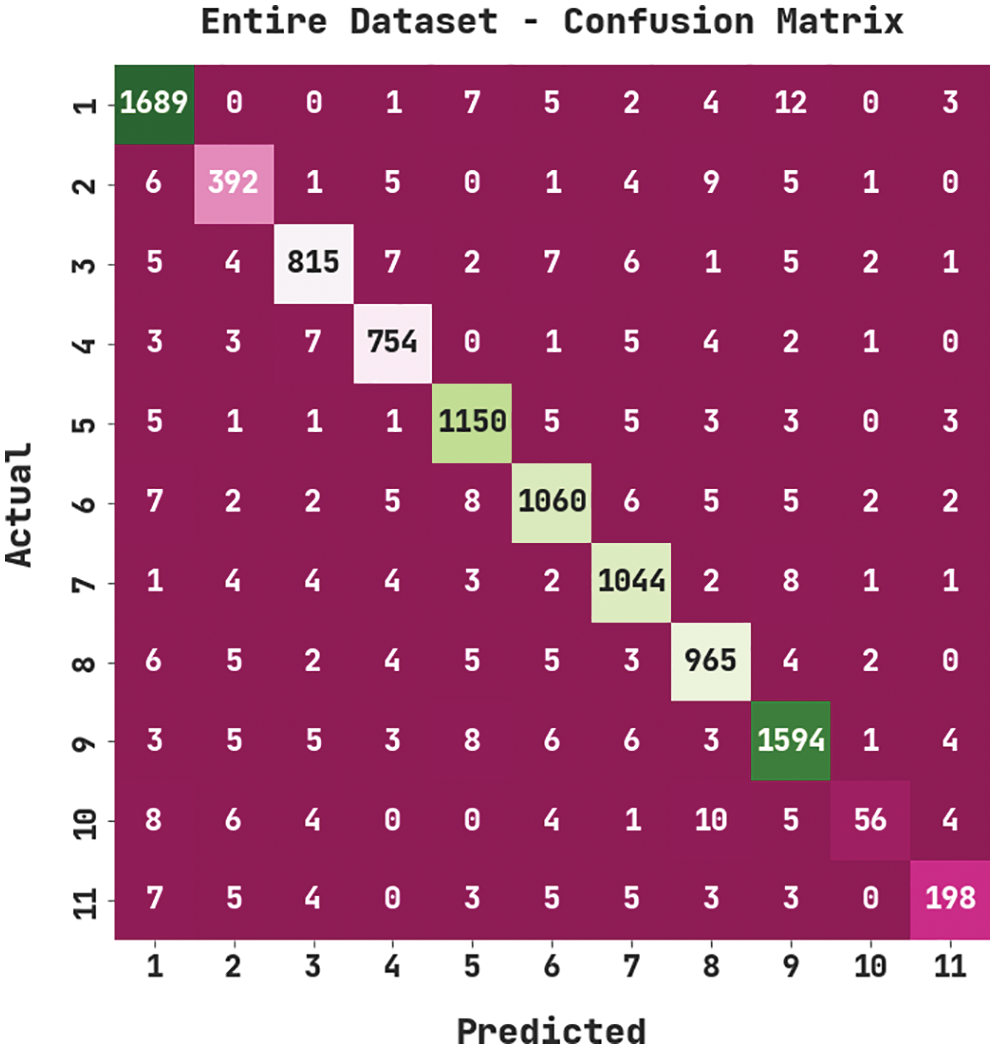
Figure 3: Confusion matrix of MVODRL-AA approach under the entire dataset
Table 2 and Fig. 4 indicate the affect analysis outcomes of the MVODRL-AA model on the entire dataset. The MVODRL-AA model has recognized Arabic tweets under class 1 with
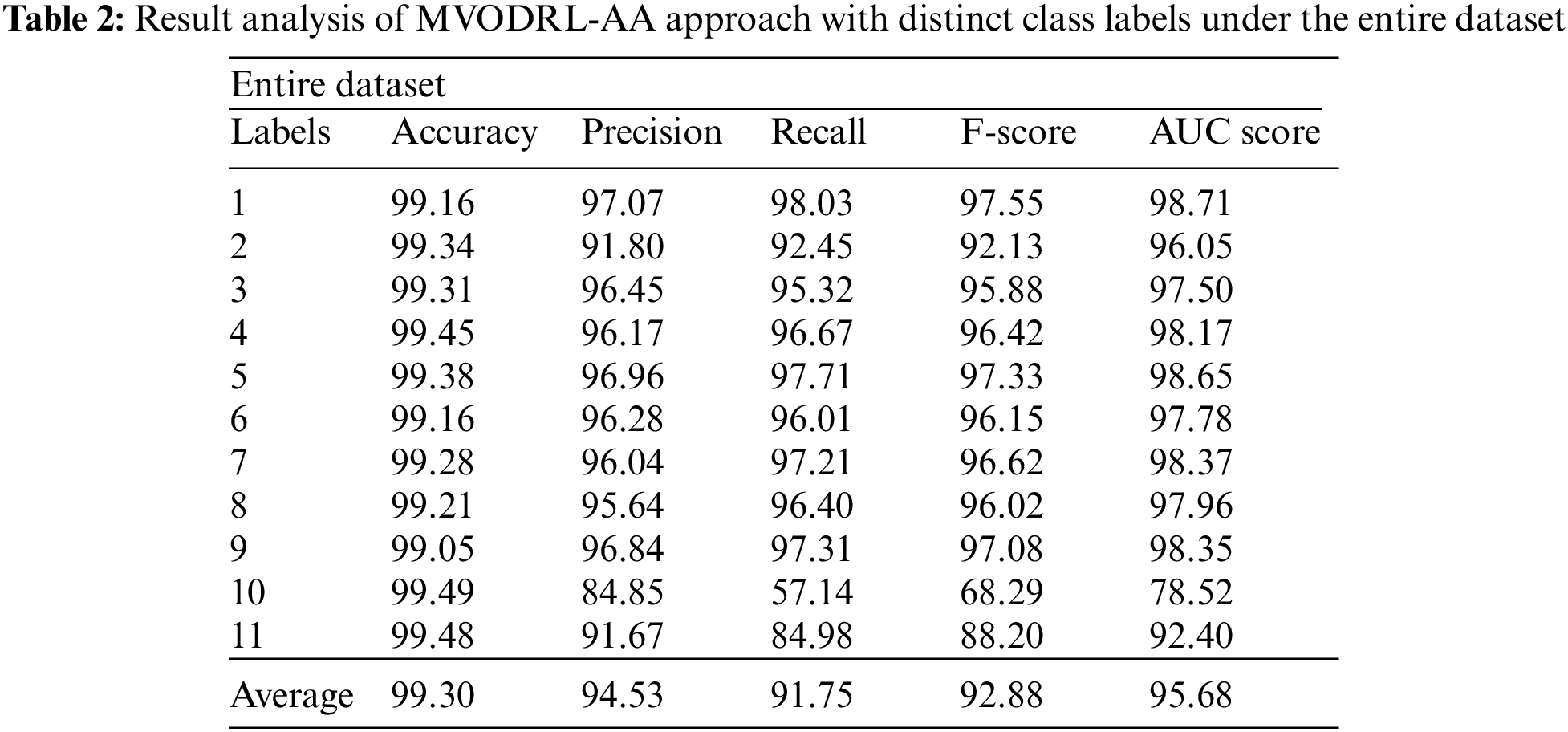
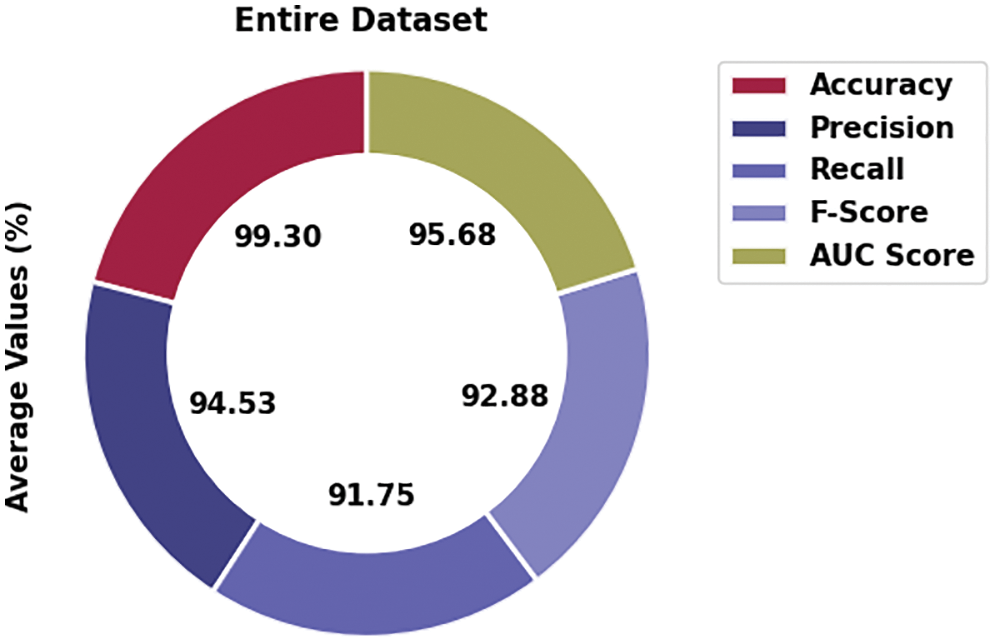
Figure 4: Average analysis of MVODRL-AA approach under the entire dataset
Fig. 5 demonstrates the confusion matrix created by the MVODRL-AA model on 70% of training (TR) data. The figure implied the MVODRL-AA technique has properly identified 1204 samples under class 1, 281 samples under class 2, 589 samples under class 3, 520 samples under class 4, 840 samples under class 5, 725 samples under class 6, 686 samples under class 7, 677 samples under class 8, 1118 samples under class 9, 39 samples under class 10, and 127 samples under class 11.
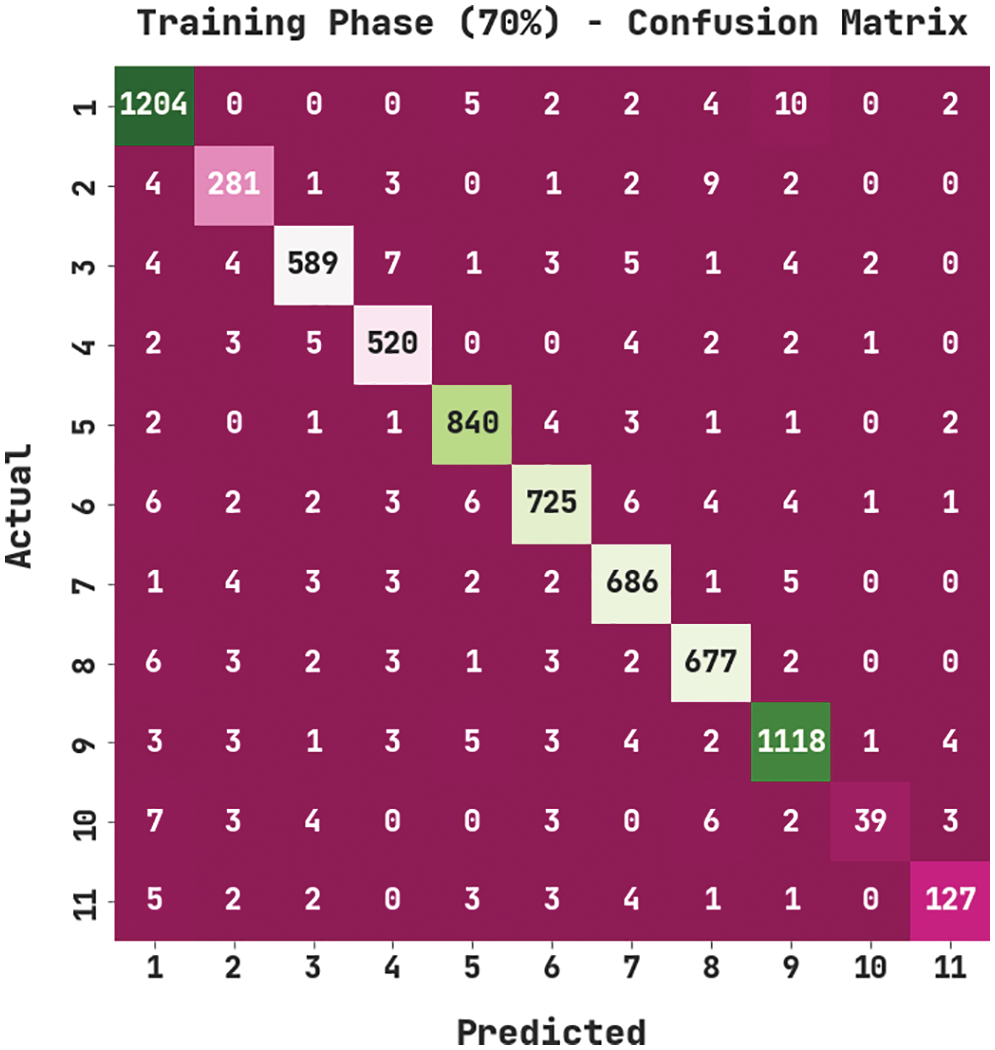
Figure 5: Confusion matrix of MVODRL-AA approach under 70% of TR data
Table 3 and Fig. 6 depict the affect analysis outcomes of the MVODRL-AA method on 70% of TR data. The MVODRL-AA model has recognized Arabic tweets under class 1 with
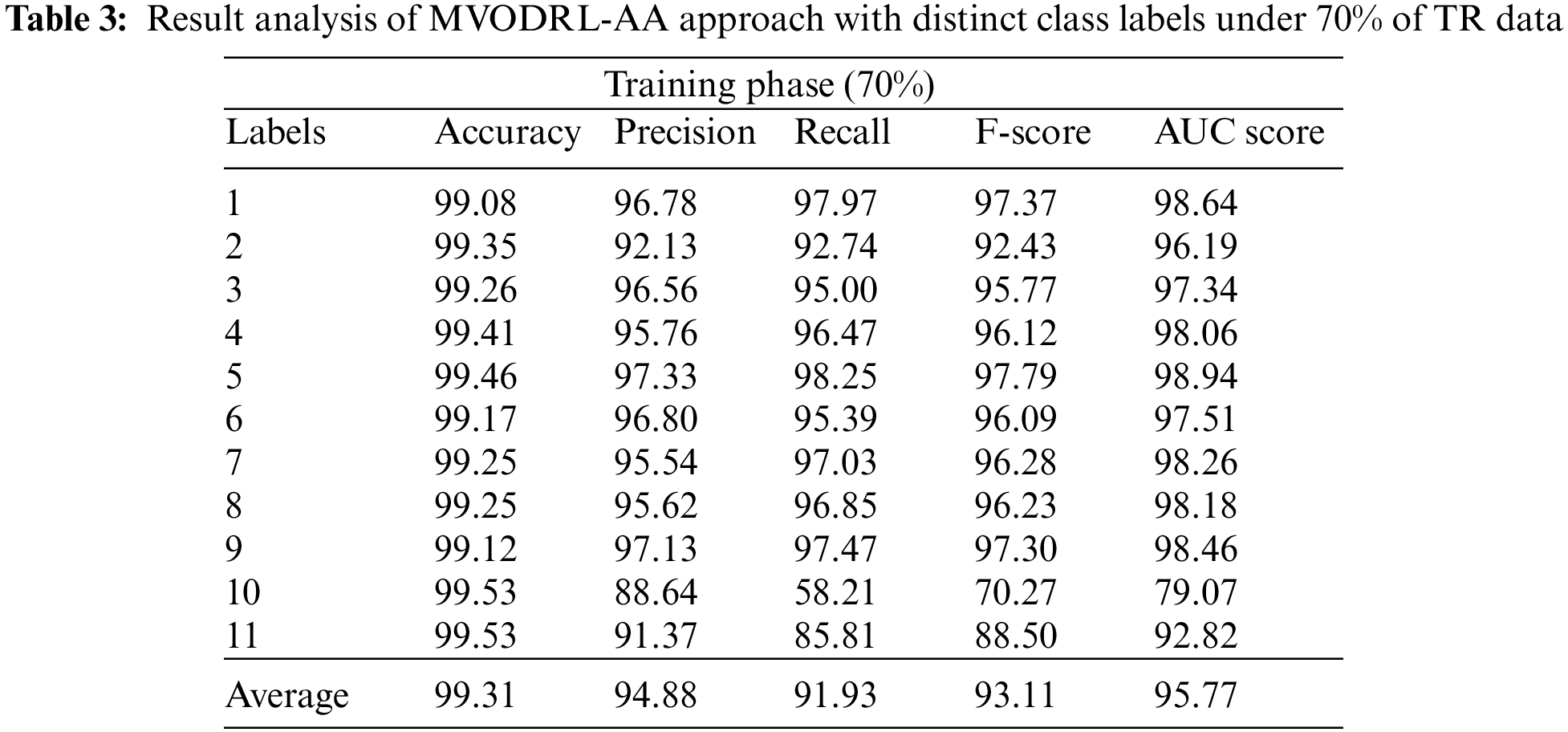
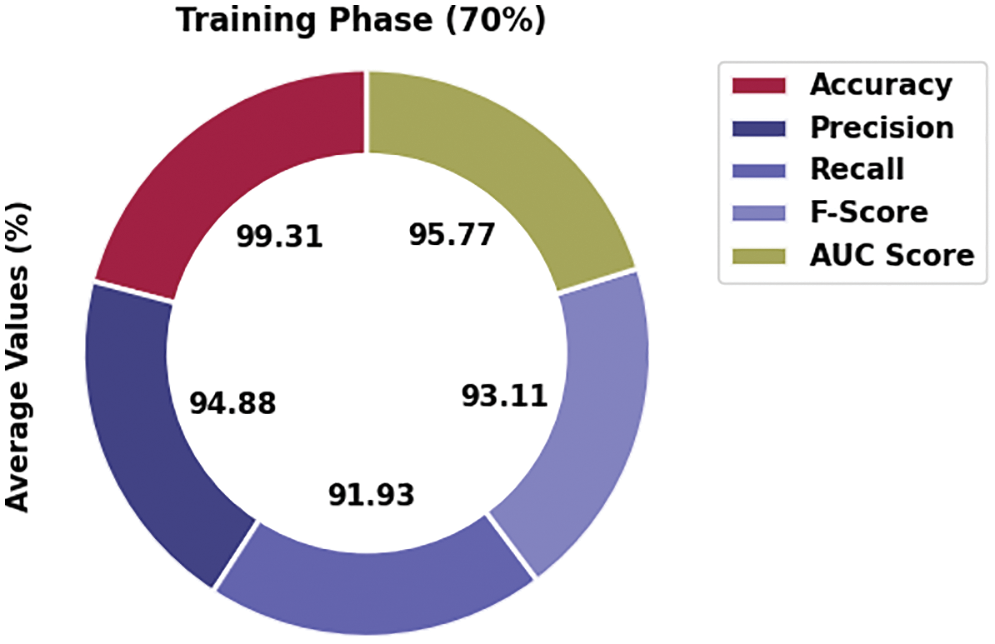
Figure 6: Average analysis of MVODRL-AA approach under 70% of TR data
Fig. 7 portrays the confusion matrix created by the MVODRL-AA method on 30% of testing (TS) data. The figure denoted the MVODRL-AA model has properly identified 485 samples under class 1, 111 samples under class 2, 226 samples under class 3, 234 samples under class 4, 310 samples under class 5, 335 samples under class 6, 358 samples under class 7, 288 samples under class 8, 476 samples under class 9, 17 samples under class 10, and 71 samples under class 11.
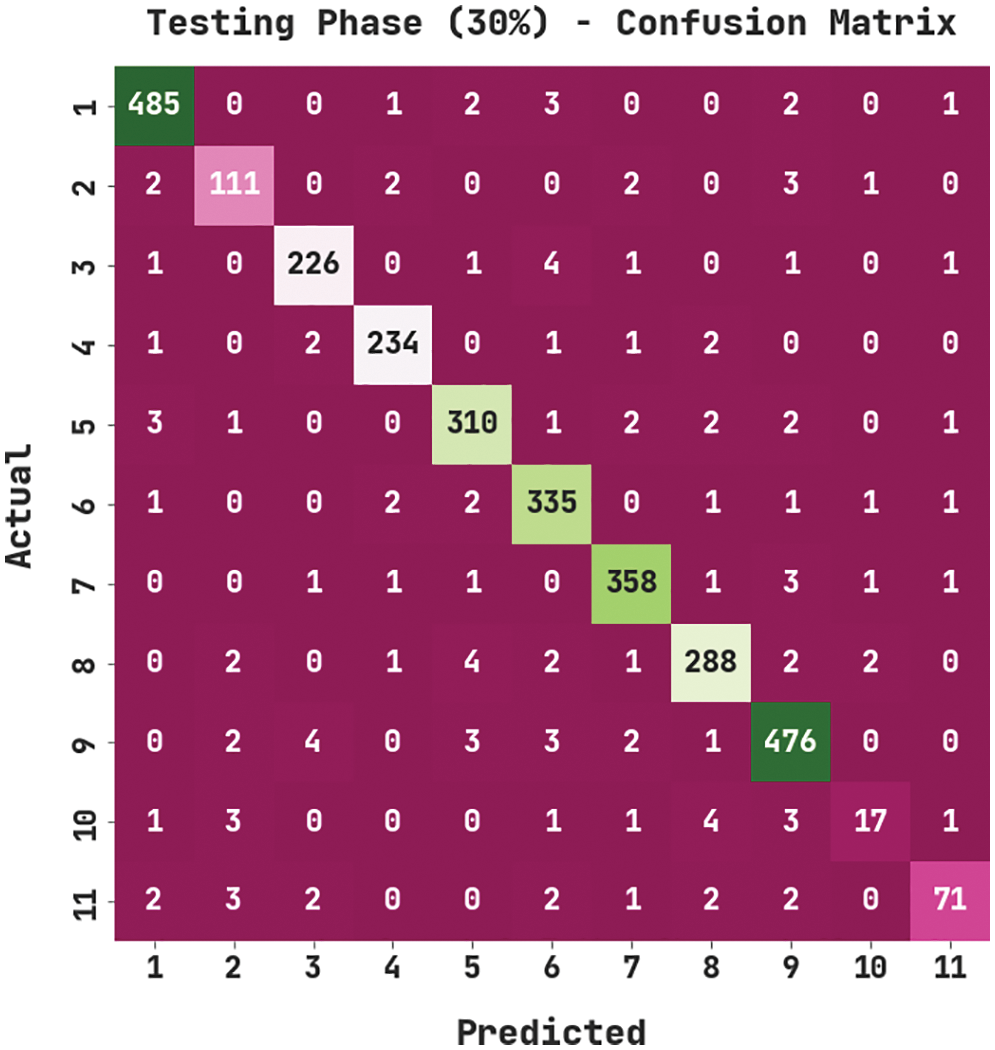
Figure 7: Confusion matrix of MVODRL-AA approach under 30% of TS data
Table 4 and Fig. 8 represent the affect analysis outcomes of the MVODRL-AA model on 30% of TS data. The MVODRL-AA model has recognized Arabic tweets under class 1 with
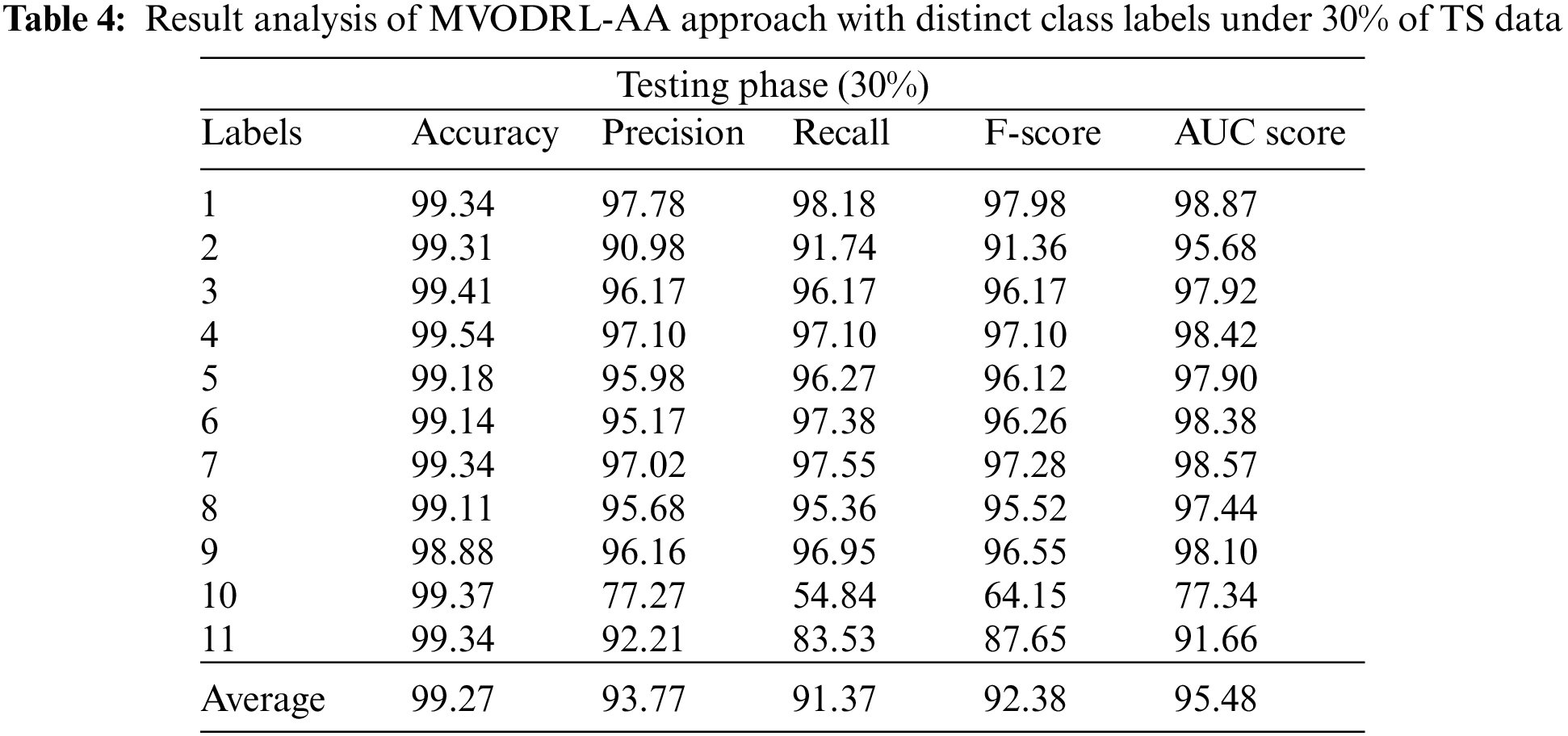
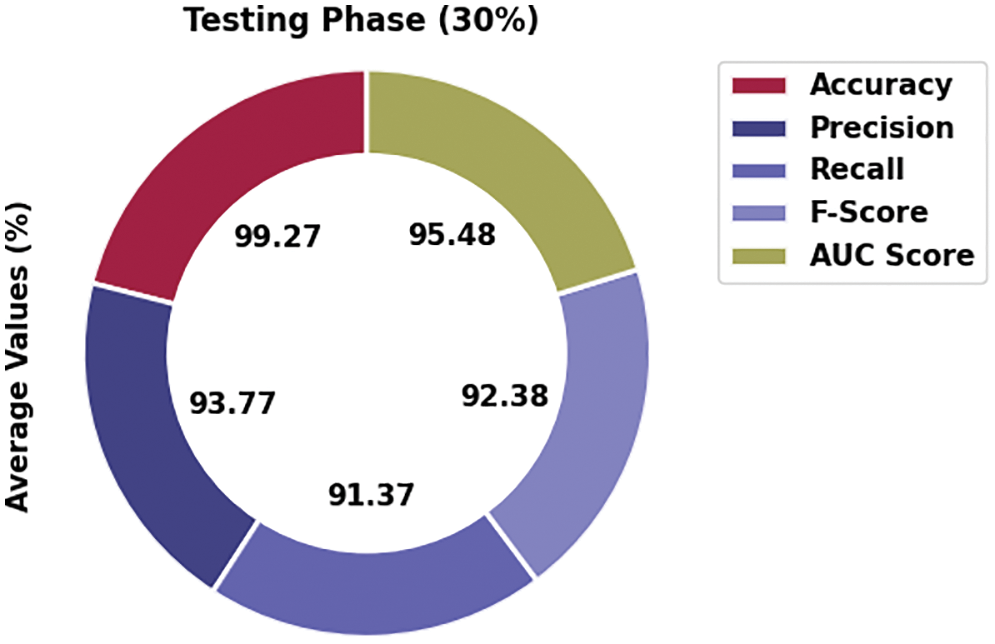
Figure 8: Average analysis of MVODRL-AA approach under 30% of TS data
The training accuracy (TA) and validation accuracy (VA) gained by the MVODRL-AA method on the test dataset is shown in Fig. 9. The experimental outcome denoted the MVODRL-AA technique has achieved maximal values of TA and VA. Particularly the VA is greater than TA.
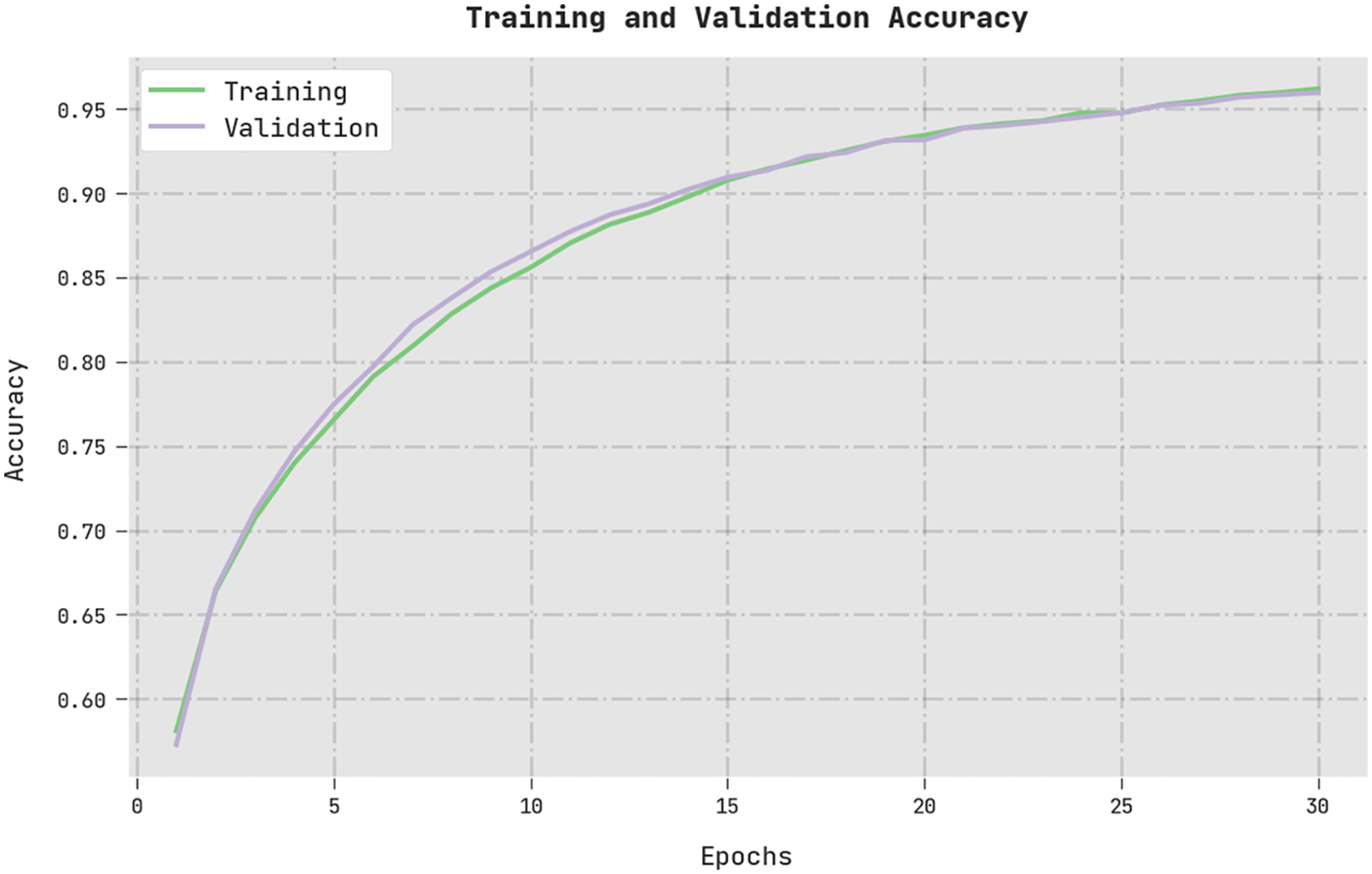
Figure 9: TA and VA analysis of MVODRL-AA methodology
The training loss (TL) and validation loss (VL) attained by the MVODRL-AA approach on the test dataset are displayed in Fig. 10. The experimental outcome implied the MVODRL-AA algorithm had exhibited the least values of TL and VL. In specific, the VL is lesser than TL.
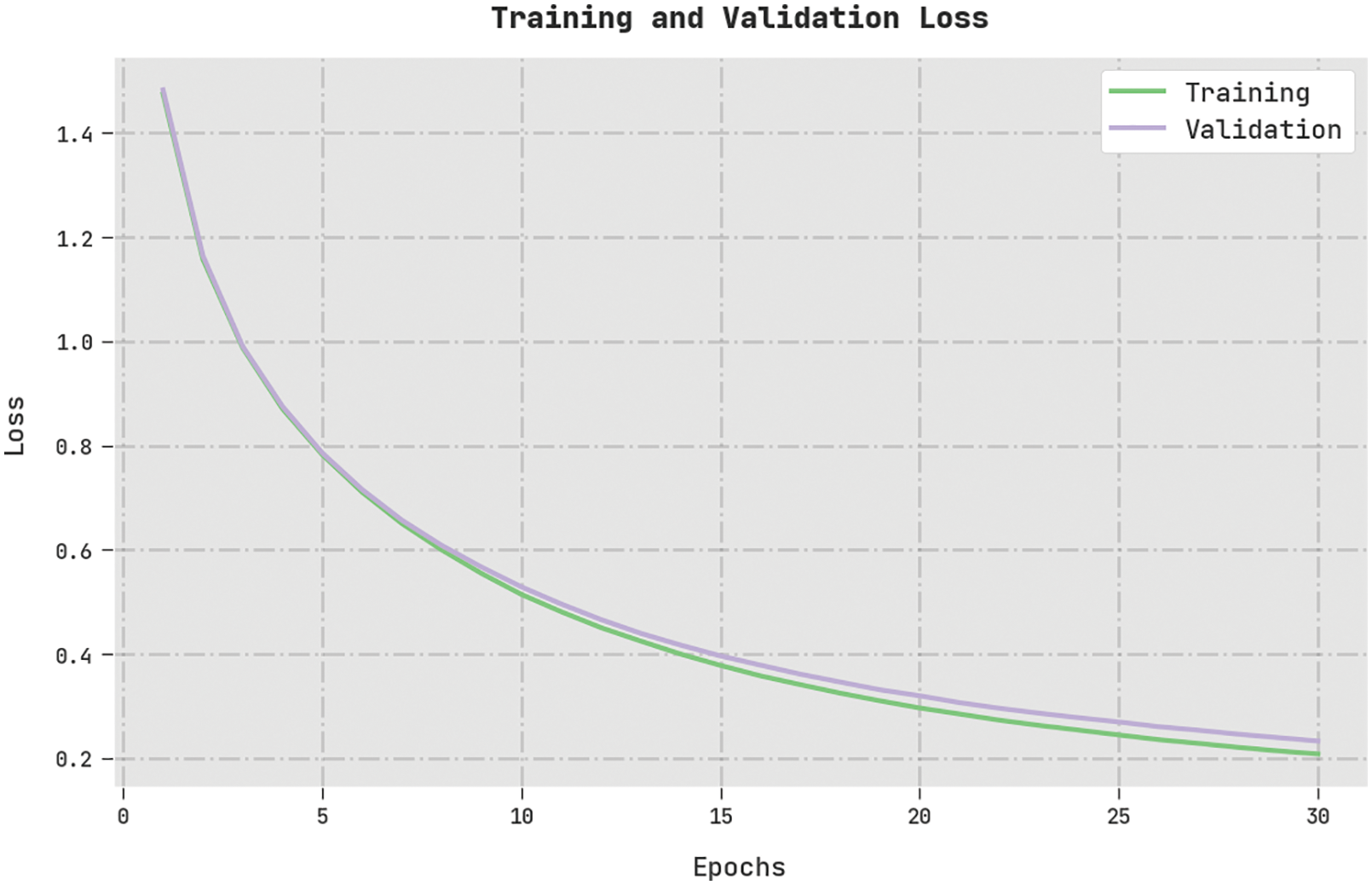
Figure 10: TL and VL analysis of MVODRL-AA methodology
A clear precision-recall analysis of the MVODRL-AA method on the test dataset is displayed in Fig. 11. The figure indicates the MVODRL-AA method has enhanced precision-recall values under all classes.
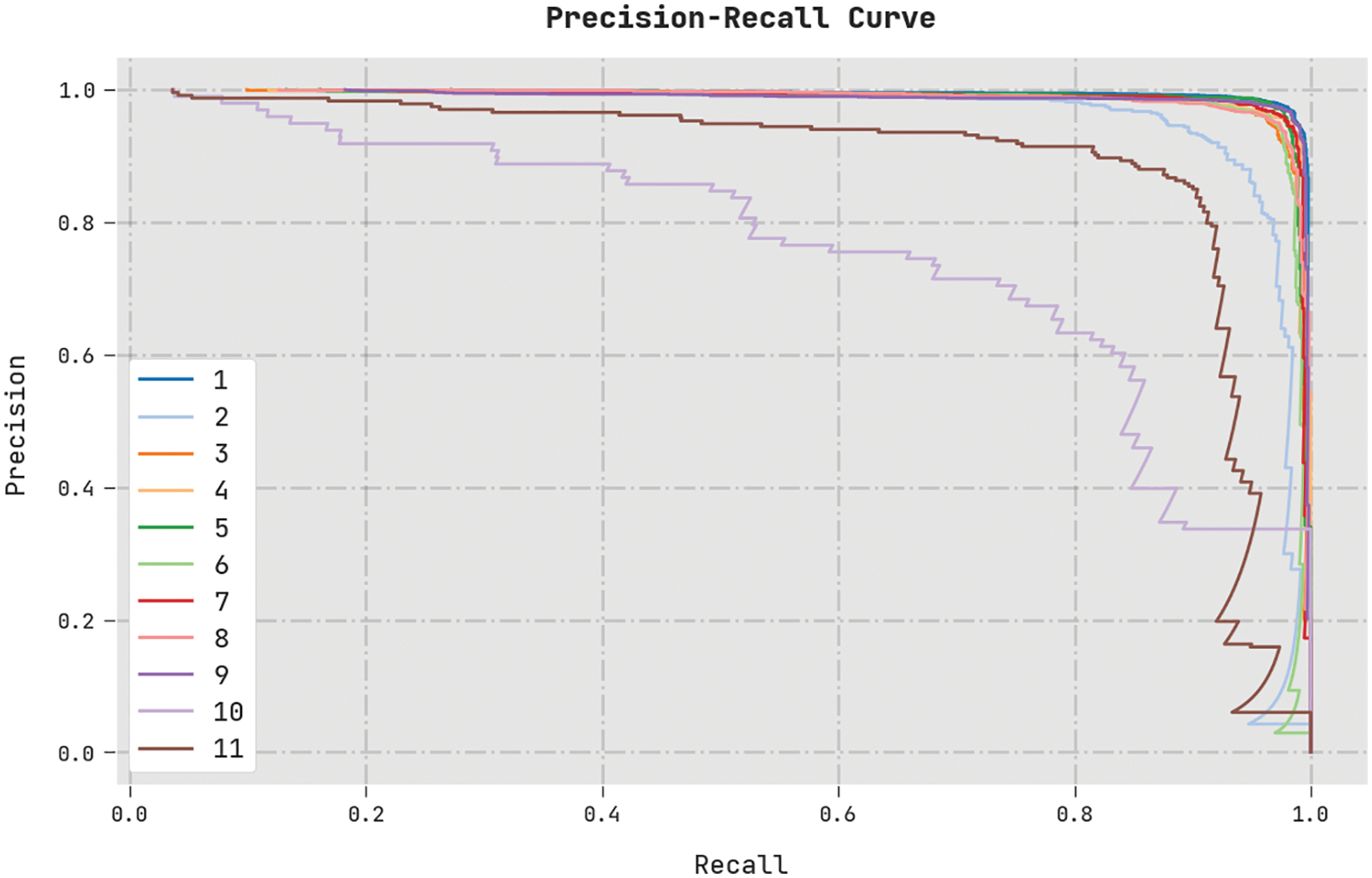
Figure 11: Precision-recall curve analysis of MVODRL-AA methodology
A brief ROC analysis of the MVODRL-AA method on the test dataset is illustrated in Fig. 12. The results indicated the MVODRL-AA approach had shown its ability to categorize distinct classes on the test dataset.
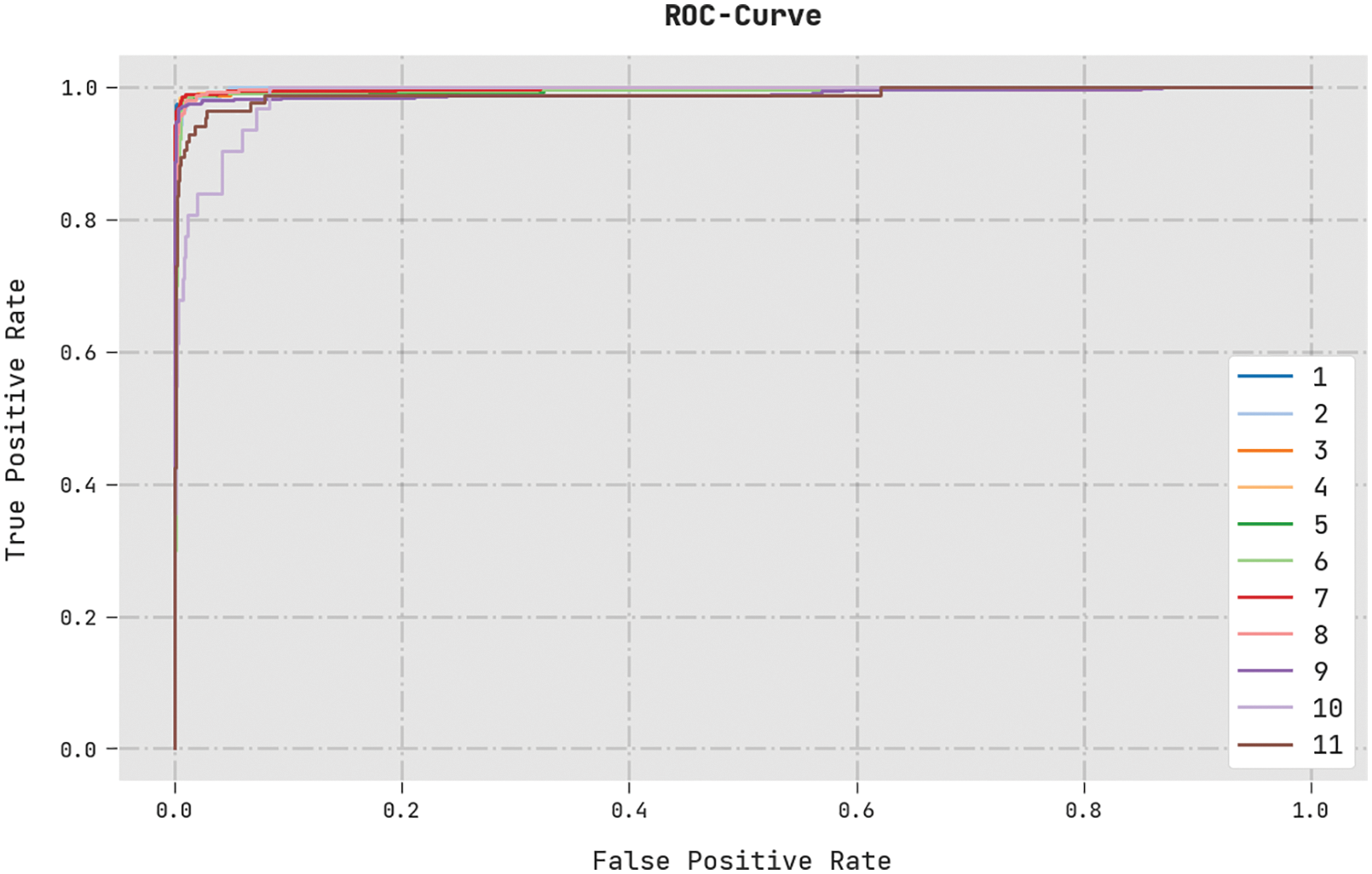
Figure 12: ROC curve analysis of MVODRL-AA methodology
To ensure the improvements of the MVODRL-AA model over other models, a comparative study is given in Table 5 and Fig. 13 [22]. The outcomes implied the supremacy of the MVODRL-AA model over other models. Based on
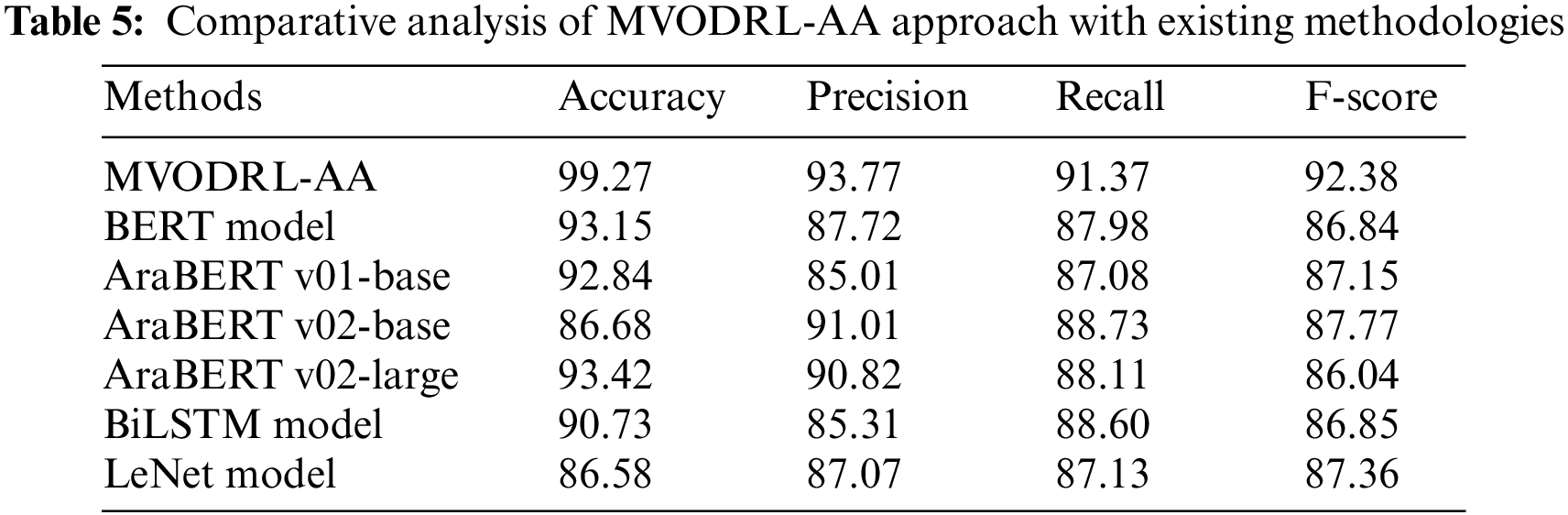
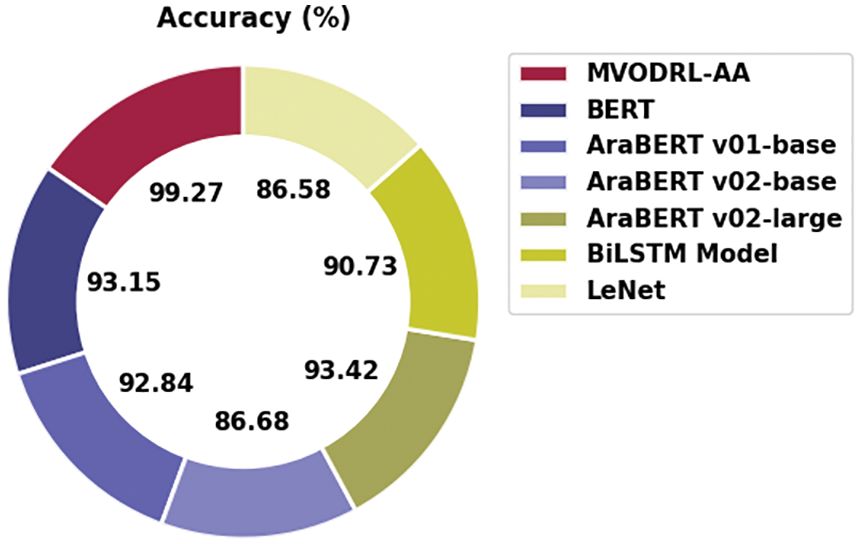
Figure 13: Comparative analysis of MVODRL-AA approach with existing methodologies
This paper introduces the MVODRL-AA technique to identify and classify effects or emotions in the Arabic corpus. Firstly, the MVODRL-AA model followed data pre-processing and the word embedding process. Next, the n-gram model is utilized to generate word embedding. The DQLN model is then exploited to identify and classify the effect on the Arabic corpus. At last, the MVO algorithm is used as a hyperparameter tuning approach to adjust the hyperparameters related to the DQLN model. A series of simulations were carried out to showcase the promising performance of the MVODRL-AA model. The simulation outcomes signify the betterment of the MVODRL-AA method over other approaches. In the future, the outcomes of the MVODRL-AA model can be extended to the use of hybrid metaheuristics. Besides, the proposed model can be employed in the fake news detection process.
Acknowledgement: None.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4340237DSR38.
Author Contributions: The manuscript was written through contributions of all authors. All authors have given approval to the final version of the manuscript. All authors have read and agreed to the final version of the manuscript.
Availability of Data and Materials: Data sharing not applicable to this article as no datasets were generated during the current study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. R. Alshalan, H. A. Khalifa, D. Alsaeed, H. Al-Baity and S. Alshalan, “Detection of hate speech in covid-19–Related tweets in the arab region: Deep learning and topic modeling approach,” Journal of Medical Internet Research, vol. 22, no. 12, pp. e22609, 2020. [Google Scholar] [PubMed]
2. E. A. H. Khalil, E. M. F. E. Houby and H. K. Mohamed, “Deep learning for emotion analysis in Arabic tweets,” Journal of Big Data, vol. 8, no. 1, pp. 136, 2021. [Google Scholar]
3. N. Al-Twairesh, “The evolution of language models applied to emotion analysis of Arabic tweets,” Information, vol. 12, no. 2, pp. 84, 2021. [Google Scholar]
4. M. Hegazi, Y. Al-Dossari, A. Al-Yahy, A. Al-Sumari and A. Hilal, “Preprocessing arabic text on social media,” Heliyon, vol. 7, no. 2, pp. e06191, 2021. [Google Scholar] [PubMed]
5. A. Alharbi, M. Taileb and M. Kalkatawi, “Deep learning in arabic sentiment analysis: An overview,” Journal of Information Science, vol. 47, no. 1, pp. 129–140, 2021. [Google Scholar]
6. A. Al-Laith and M. Alenezi, “Monitoring people’s emotions and symptoms from arabic tweets during the COVID-19 pandemic,” Information, vol. 12, no. 2, pp. 86, 2021. [Google Scholar]
7. R. Duwairi, A. Hayajneh and M. Quwaider, “A deep learning framework for automatic detection of hate speech embedded in Arabic tweets,” Arabian Journal for Science and Engineering, vol. 46, no. 4, pp. 4001–4014, 2021. [Google Scholar]
8. M. M. Fouad, A. Mahany, N. Aljohani, R. A. Abbasi and S. U. Hassan, “Arwordvec: Efficient word embedding models for Arabic tweets,” Soft Computing, vol. 24, no. 11, pp. 8061–8068, 2020. [Google Scholar]
9. A. Yadav and D. K. Vishwakarma, “Sentiment analysis using deep learning architectures: A review,” Artificial Intelligence Review, vol. 53, no. 6, pp. 4335–4385, 2020. [Google Scholar]
10. R. Alshalan and H. Al-Khalifa, “A deep learning approach for automatic hate speech detection in the Saudi twittersphere,” Applied Sciences, vol. 10, no. 23, pp. 8614, 2020. [Google Scholar]
11. M. A. AlGhamdi and M. A. Khan, “Intelligent analysis of Arabic tweets for detection of suspicious messages,” Arabian Journal for Science and Engineering, vol. 45, no. 8, pp. 6021–6032, 2020. [Google Scholar]
12. A. Alsayat and N. Elmitwally, “A comprehensive study for arabic sentiment analysis (challenges and applications),” Egyptian Informatics Journal, vol. 21, no. 1, pp. 7–12, 2020. [Google Scholar]
13. A. Alharbi, M. Kalkatawi and M. Taileb, “Arabic sentiment analysis using deep learning and ensemble methods,” Arabian Journal for Science and Engineering, vol. 46, no. 9, pp. 8913–8923, 2021. [Google Scholar]
14. A. H. Ombabi, W. Ouarda and A. M. Alimi, “Deep learning CNN–LSTM framework for Arabic sentiment analysis using textual information shared in social networks,” Social Network Analysis and Mining, vol. 10, no. 1, pp. 53, 2020. [Google Scholar]
15. H. Elfaik and E. H. Nfaoui, “Deep bidirectional lstm network learning-based sentiment analysis for Arabic text,” Journal of Intelligent Systems, vol. 30, no. 1, pp. 395–412, 2020. [Google Scholar]
16. H. Saleh, S. Mostafa, A. Alharbi, S. El-Sappagh and T. Alkhalifah, “Heterogeneous ensemble deep learning model for enhanced arabic sentiment analysis,” Sensors, vol. 22, no. 10, pp. 3707, 2022. [Google Scholar] [PubMed]
17. A. Al-Hashedi, B. Al-Fuhaidi, A. M. Mohsen, Y. Ali, H. A. Gamal Al-Kaf et al. “Ensemble classifiers for arabic sentiment analysis of social network (Twitter data) towards COVID-19-related conspiracy theories,” Applied Computational Intelligence and Soft Computing, vol. 2022, pp. 1–10, 2022. [Google Scholar]
18. E. Omara, M. Mousa and N. Ismail, “Character gated recurrent neural networks for arabic sentiment analysis,” Scientific Reports, vol. 12, no. 1, pp. 9779, 2022. [Google Scholar] [PubMed]
19. M. Ghiassi, J. Skinner and D. Zimbra, “Twitter brand sentiment analysis: A hybrid system using n-gram analysis and dynamic artificial neural network,” Expert Systems with Applications, vol. 40, no. 16, pp. 6266–6282, 2013. [Google Scholar]
20. X. Wang, Y. Wang, D. Shi, J. Wang and Z. Wang, “Two-stage wecc composite load modeling: A double deep Q-learning networks approach,” IEEE Transactions on Smart Grid, vol. 11, no. 5, pp. 4331–4344, 2020. [Google Scholar]
21. M. H. Lokman, I. Musirin, S. I. Suliman, H. Suyono, R. N. Hasanah et al., “Multi-verse optimization based evolutionary programming technique for power scheduling in loss minimization scheme,” IAES International Journal of Artificial Intelligence, vol. 8, no. 3, pp. 292, 2019. [Google Scholar]
22. H. Elfaik and E. H. Nfaoui, “Combining context-aware embeddings and an attentional deep learning model for arabic affect analysis on twitter,” IEEE Access, vol. 9, pp. 111214–111230, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools