
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Social Engineering Attack-Defense Strategies Based on Reinforcement Learning
1 School of Cyberspace Security, Beijing University of Posts and Telecommunications, Beijing, 100876, China
2 School of Computer Science, Beijing University of Technology, Beijing, 100124, China
* Corresponding Author: Rundong Yang. Email:
Computer Systems Science and Engineering 2023, 47(2), 2153-2170. https://doi.org/10.32604/csse.2023.038917
Received 04 January 2023; Accepted 20 April 2023; Issue published 28 July 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Social engineering attacks are considered one of the most hazardous cyberattacks in cybersecurity, as human vulnerabilities are often the weakest link in the entire network. Such vulnerabilities are becoming increasingly susceptible to network security risks. Addressing the social engineering attack defense problem has been the focus of many studies. However, two main challenges hinder its successful resolution. Firstly, the vulnerabilities in social engineering attacks are unique due to multistage attacks, leading to incorrect social engineering defense strategies. Secondly, social engineering attacks are real-time, and the defense strategy algorithms based on gaming or reinforcement learning are too complex to make rapid decisions. This paper proposes a multiattribute quantitative incentive method based on human vulnerability and an improved Q-learning (IQL) reinforcement learning method on human vulnerability attributes. The proposed algorithm aims to address the two main challenges in social engineering attack defense by using a multiattribute incentive method based on human vulnerability to determine the optimal defense strategy. Furthermore, the IQL reinforcement learning method facilitates rapid decision-making during real-time attacks. The experimental results demonstrate that the proposed algorithm outperforms the traditional Q-learning (QL) and deep Q-network (DQN) approaches in terms of time efficiency, taking 9.1% and 19.4% less time, respectively. Moreover, the proposed algorithm effectively addresses the non-uniformity of vulnerabilities in social engineering attacks and provides a reliable defense strategy based on human vulnerability attributes. This study contributes to advancing social engineering attack defense by introducing an effective and efficient method for addressing the vulnerabilities of human factors in the cybersecurity domain.Keywords
With the continuous development of network technology, communication is not limited by traditional distance or the various social networks, e-mail, or network communication methods that satisfy daily needs for communication and entertainment. The internet is becoming increasingly important, and we cannot live without it. However, there are also nefarious actors lurking in the network; they attack by taking advantage of users’ psychological weaknesses and inducing them to disclose sensitive information [1].
In the second quarter of 2022, the APWG (Anti-Phishing Working Group) observed 1,097,811 phishing attacks, a new record, and this was the worst quarter for phishing ever followed by the APWG. The number of phishing attacks reported to the APWG has quadrupled since the beginning of 2020, when the APWG started to keep phishing attacks. A total of 68,000 to 94,000 episodes per month were followed by the APWG in early 2020 [2].
Unlike traditional cyber attacks, social engineering attacks mainly exploit the psychological weaknesses of the target to execute the attack, and Reference [3] designed a general architecture for social engineering attacks. The main features of the structure are attack preparation, attack implementation, and attack gain. In the preparation stage, information and relationships are collected for the target, usually using web crawlers, social network information collection, etc. A social engineering script design is carried out in the attack preparation stage for the social engineering targets. In the attack gain stage, all information obtained is evaluated and judged on whether the attack was successful [4].
Network security has recently received increased attention, especially for social engineering attack defense strategies research. Many studies have focused on reinforcement learning, some based on game theory [4–7]. However, there are two problems with these technical approaches. First, social engineering attacks exploit human vulnerabilities to deceive and trick users into revealing sensitive information. The traditional social engineering defense strategy does not consider user vulnerability, leading to ineffective defense strategies. Therefore, we need to design a new model considering user vulnerability. Second, social engineering attacks are real-time, requiring real-time reactions to the attacks to avoid serious harm. Current game theory and reinforcement learning-based defense strategy responses are delayed because of their high time complexity [8,9].
A summary of the related work on reinforcement learning applied to cybersecurity, game-learning programs, and secure game-theoretic modeling are shown in Table 1.

In this paper, a new social engineering defense model is designed by combining the essential attributes of users to provide an optimal defense strategy with a low-computational-complexity social engineering defense. In addition, this paper presents a mechanism for quantifying user characteristics to model the vulnerability of users for the first time quantitatively, and a stochastic game is used to simulate the interaction between attackers and defenders. Finally, this paper applies Q-learning to stochastic games, constructs a reinforcement learning model for multiple intelligences, proposes a Q-learning algorithm based on user attributes, and optimizes the algorithm. Multiple attackers are treated as independent intelligence that can learn actively and independently to collect more information for the system proposes a proposed Q-learning (IQL) algorithm to reduce the algorithm’s complexity algorithm and improve its efficiency. The main research contributions of this paper are as follows.
This paper proposes a mechanism for quantifying user vulnerability based on target attributes that consider the interaction between user vulnerability and attackers and design a more comprehensive social engineering model approach to improve social engineering security.
This paper considers attackers and defenders as two sides of a game and designs a multi-intelligence reinforcement learning model using stochastic game theory combined with Q-learning. For the first time, this paper proposes a multiobjective attribute structure learning algorithm that can provide optimal decision strategies.
This paper proposes an optimization algorithm IQL. This paper can quickly obtain an optimal defense strategy by combining target attributes and user vulnerability information strategy. It is experimentally demonstrated that the algorithm performs better than QL and DQN.
This paper is composed of five sections. Following this introduction is Chapter 2, Problem Definition. In Chapter 3, Presenting the Model, an improved QL algorithm is proposed. This is followed by Chapter 4, Experimental Results and Analysis. Chapter 5 concludes the paper.
Usually, when attackers engineer user attacks, this paper considers the attack method, attack technique, attack detection, etc., however, all of these factors must be identified through human judgment. Therefore, the threat comes from combining these attacks and interaction with people during attack reinforcement. Existing social engineering attack defense models ignore the role of human attributes, so this paper proposes a new quantitative approach that combines human characteristics to quantitatively evaluate each attack node using the standard notation in Table 2.
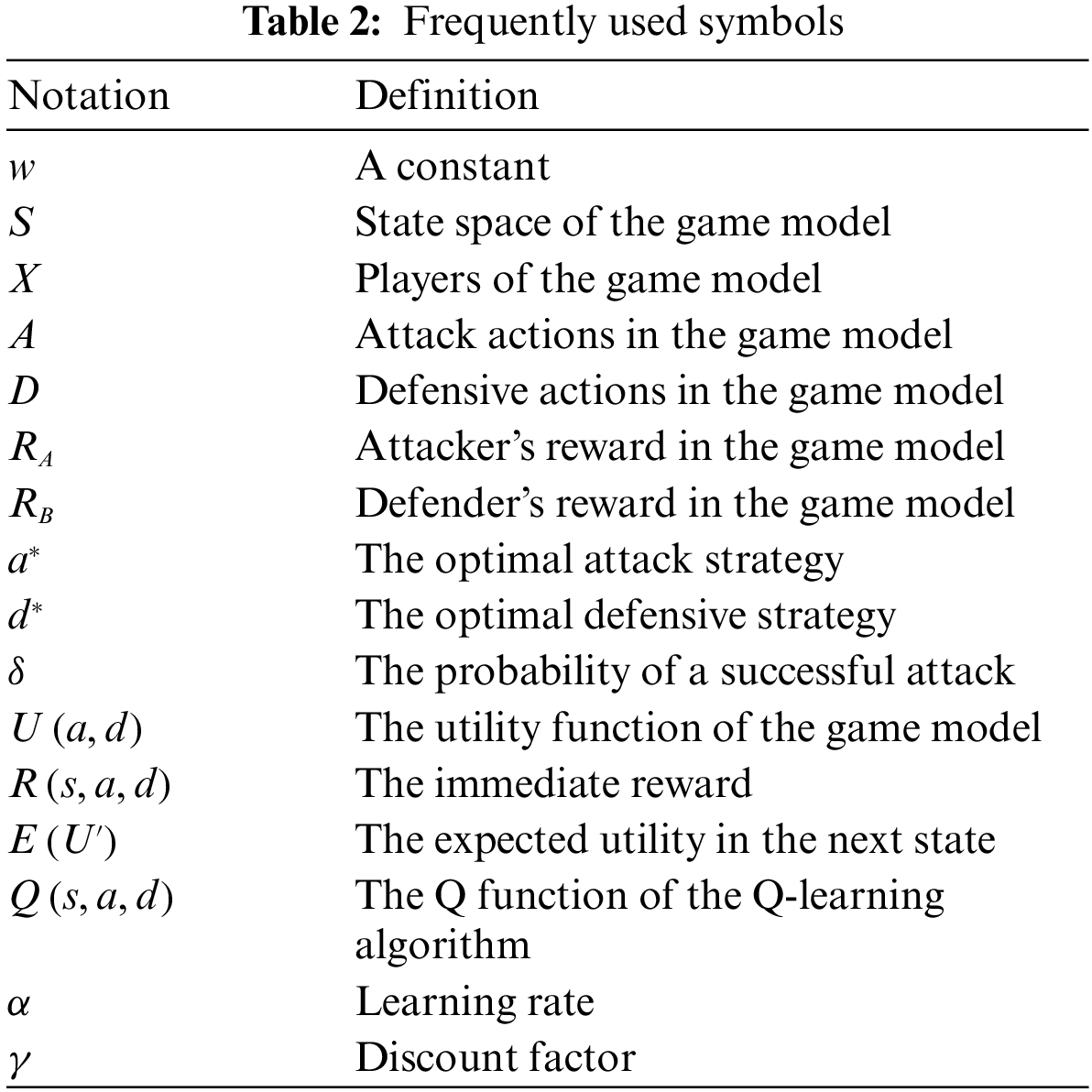
The attributes of the nodes are divided into two types: physical attributes and target attributes. A physical analysis mainly considers the impact size of the nodes in the entire system. Each node’s physical characteristics include the importance level of the node and the connection level in the node. The node’s target attributes mainly have the features of the target, security knowledge, character, and security awareness attributes. These attributes are directly related to the strength of the security defense.
Definition 1: The physical attributes mainly include the importance level and connection level of the node.
The importance level (IL) mainly indicates the node’s importance in the entire social engineering system. This importance level primarily three factors: the valid information that can be obtained, the impact on subsequent attacks, and whether trust is established [19].
The connection level (CL), which indicates the importance of the node’s associations in the social engineering system, is determined by the stage of the social engineering model in which the node is located and the number of other nodes connected to this node.
Definition 2: Target attributes (TA) mainly include defense technology, defense means, basic information of the target, security knowledge level, personality type, security awareness registration, and target cognitive paths [20]. The higher the target’s attributes value, the stronger its defense capability and the higher the node security. If the physical characteristics of the node are high, the assigned defense is enhanced accordingly [21].
The above values of the physical attributes and target attributes are set by the system administrator and mapped to a vector
In the above equation,
Attack resource consumption (AR): the consumption of attack resources in the attack preparation phase, the attack implementation phase, target information collection, scripting, trust building, and other actions that consume time [22].
Defense resource (DR) consumption: resource consumption in resisting social engineering attacks; time consumed in preventing attackers from obtaining protected information, detecting attacks, and identifying attacks for information collection [23].
Loss recovery consumption (LR): the time consumed in recovering from the loss caused by the attack, such as replacing a secret key, changing a password, or taking other actions to protect one’s property and information [24].
In the human vulnerability-based social engineering model, an attacker can use human vulnerabilities to perform social engineering attacks and obtain sensitive information. For the attacker, the greater the vulnerability found, the greater the harm and the greater the social engineering gain. Defense against social engineering focuses on the corresponding social engineering defenses for detected social engineering attacks. Ideally, the target has no exploitable vulnerabilities and is safe. However, in practice, the target attributes vary, the vulnerability performance ranges, the attacker can always find vulnerabilities to attack, and the defenses can lag and collapse when an attack occurs. The attacker and the defender are similar to the two sides of a game; the attacker tries to obtain the maximum reward, and the defender pursues the minimum loss. The two sides of the attacker and defender can be considered a stochastic game, and a stochastic game model can be used to analyze the best defense strategy for the defender. This paper design a new reward quantification method to quantify the role of vulnerability in the model, considering the properties of the target and the interaction between the vulnerability and the attack. The social engineering attack model is shown in Fig. 1 below.
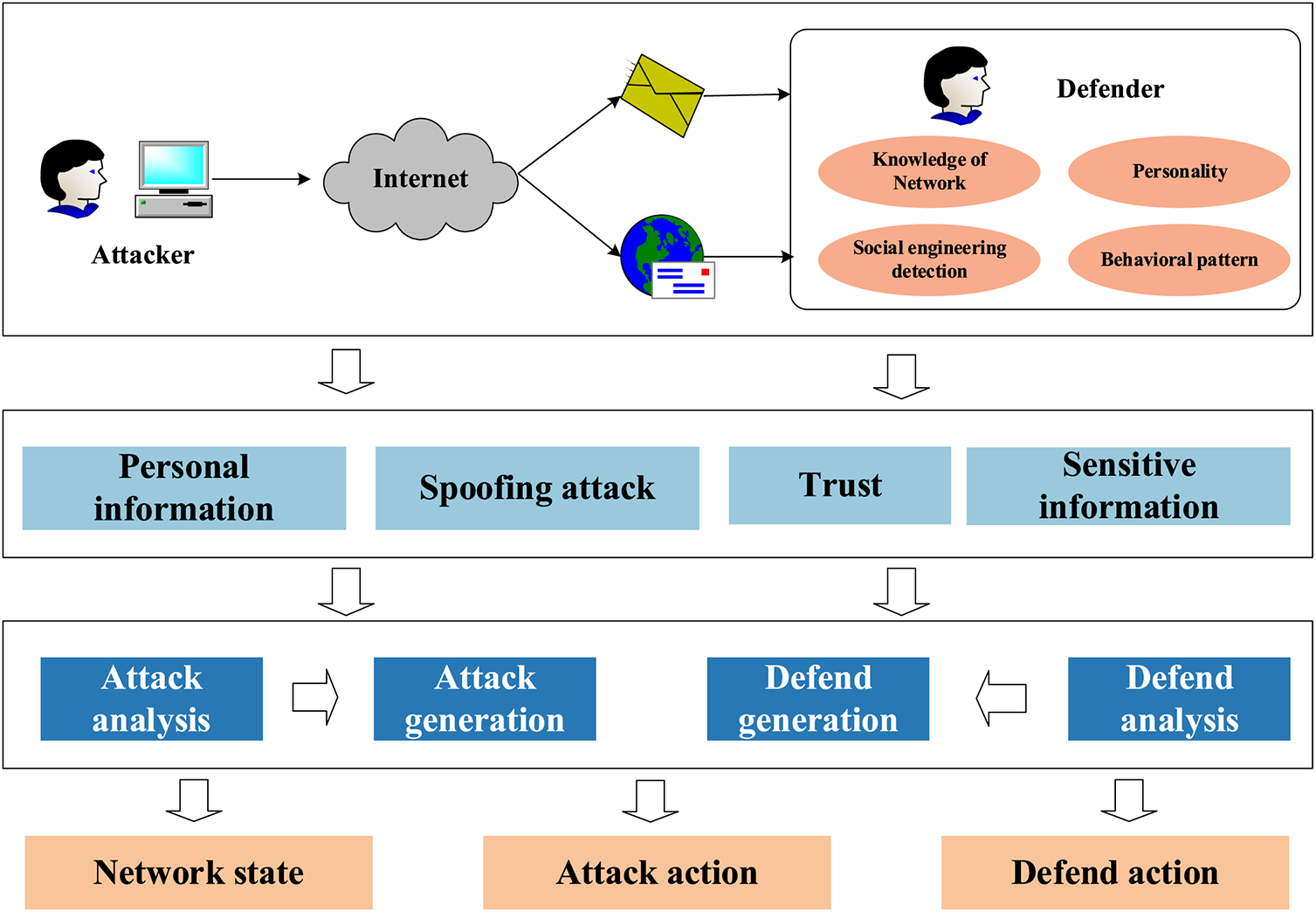
Figure 1: Social engineering attack model diagram
The structure of the social engineering system model is complex, with multiple stages. At each stage, the attacker does not have access to information about the entire system and takes random actions based on the information obtained at this stage. At the same time, neither the attacker nor the defender has access to the game information of the adversary or the gain of each action. This paper describes the game between the attacker and the defender in the social engineering system as a stochastic game model with incomplete information. The model is defined as follows.
where
The attacker’s utility consists of the attack gain and the period of the next state, and it can be expressed as
In the above equation,
Here, the SESM is an attribute-based social engineering security level indicator, and the SESM mainly reflects the node’s importance.
By formalizing the representations of the social engineering attack participants, the entire defined social engineering attack process is constructed as a game model
Definition 3: Social engineering defense security decision optimization problem: Using quantified rewards as input, the social engineering defense security decision optimization problem is to find the optimal attack strategy
The utility function in the entire social engineering system, mainly considering the interaction between the target vulnerability and attacker, is quantified by the attack utility function
3.2 Improved and Optimized Q-Learning Algorithm
In social engineering defense strategies, traditional approaches use Q-learning. This is because Q-learning algorithms converge quickly and can compute optimal policies. This method is widely used; however, as the system’s complexity increases, the system’s unstable and dynamic nature leads to an increase in the convergence time of the Q-learning method. Researchers have proposed relevant solutions combined with deep learning to improve the convergence speed of Q-learning algorithms. However, these solutions require a large amount of computation and often do not guarantee the algorithm’s convergence in computing the optimal policy. The traditional formulation of the Q algorithm can be expressed as
where s’ is the next state,
Theorem 1: The multi-attribute quantitative reinforcement learning model based on human weakness proposed in this paper is convergent, and the reward sequence {Q_t }_(t→∞) is the optimal rewards Q^*.
Proof:
According to Eqs. (6) and (7).
then it can be computed
In order to prove convergence, it is necessary to prove that the sequence
According to π(s) and π(sʹ), we have
If π (s) Q (s) − π (s^ʹ) Q^* (s^') ≥ 0
can get
According to the above proof, the model is convergent, where t he sequence
The Q-value update mechanism is also optimized to further improve the computation speed. Different learning processes can be updated simultaneously in parallel for the current state of the Q-value. There is no need to update after learning. All Q-learning procedures are performed simultaneously and synchronously to update the values, using the updated Q-values to update the previous Q-values. This is faster and more effective; the algorithm is shown in Algorithm 1.

According to Algorithm 1, this paper quantifies two global q variables,
4 Experimental Results and Analysis
In this chapter, we construct a simplenatural social engineering system and analyze the simulation results.
The social engineering system mainly simulates phishing attacks, and the ’ystem’s architecture is shown in Fig. 2. The whole structure includes the attack preparation, attack route, attack implementation, and attack gain stages. Attack preparation comprises collecting information from public resources, performing information system queries, collecting data from users, and writing scripts; attack target selection includes determining attack route nodes, such as phishing websites, phishing emails, and phishing SMSs; the attack implementation stage includes influencing the target, conducting psychological exploitation and script exploitation, assessing participant behavior, and building trust; and the attack gain stage mainly involves acquiring device permissions, obtaining sensitive information, and influencing target behavior.
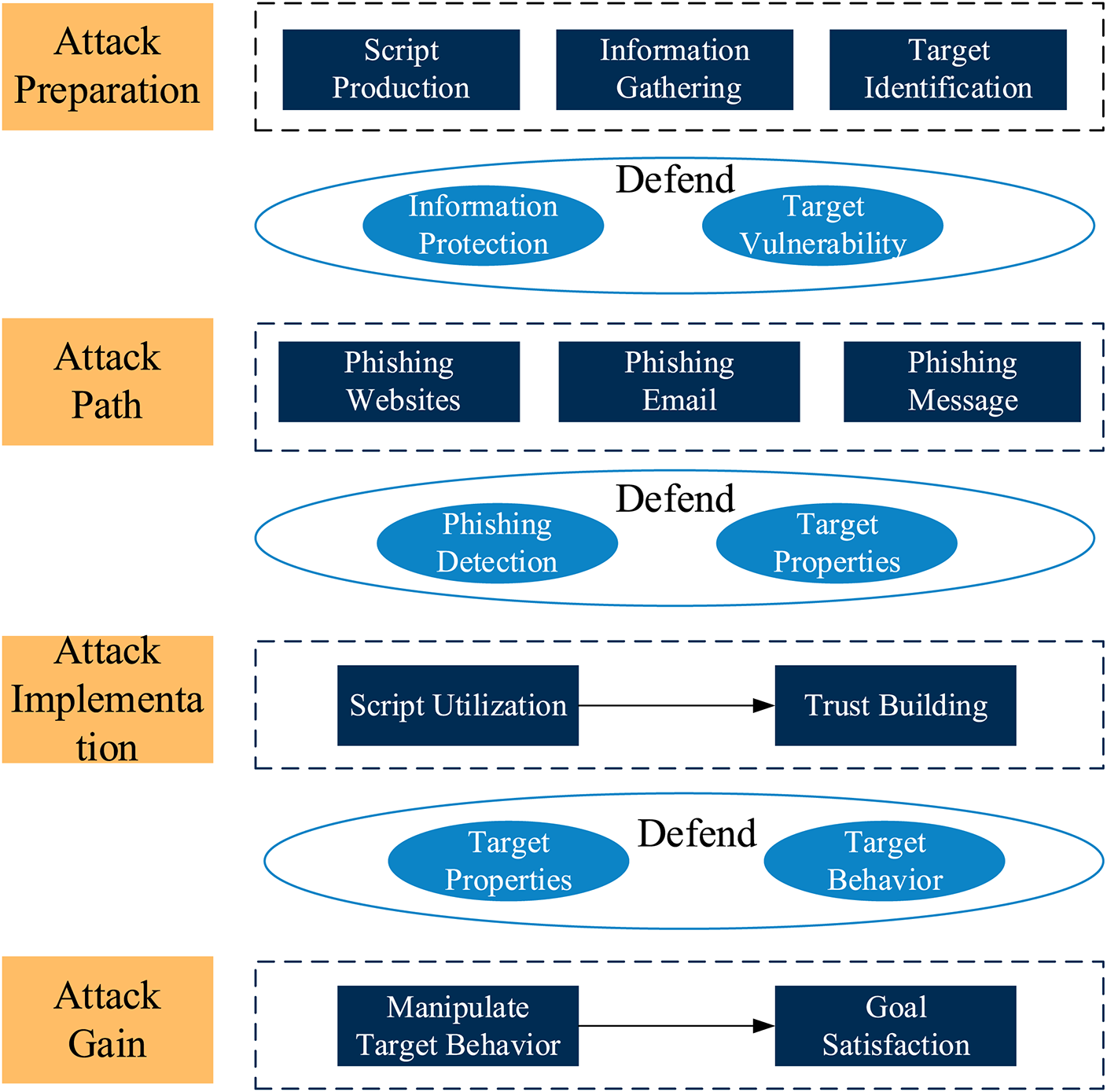
Figure 2: Experimental environment
The values of IL, CL, and TA for all nodes are shown in Table 3, where the three values of information search N1 are set to 2, 1, and 2; for the attack state N2, the three values are set to 1, 2, and 1; for gaining trust, N3, the three values are set to 2, 3, and 3; and for performing action N4, the three values are set to 3, 2, and 3.

The social engineering attacker, through the collection of target information, discovers the target attributes, finds the arget’s vulnerability, and executes an attack on the target, and the purpose of the attack is to obtain sensitive information or goods. The Common Attack Pattern Enumeration and Classification (CAPEC) database, developed and maintained by MITRE, records known cyber attack patterns [26]. The vulnerabilities are shown in Table 4.
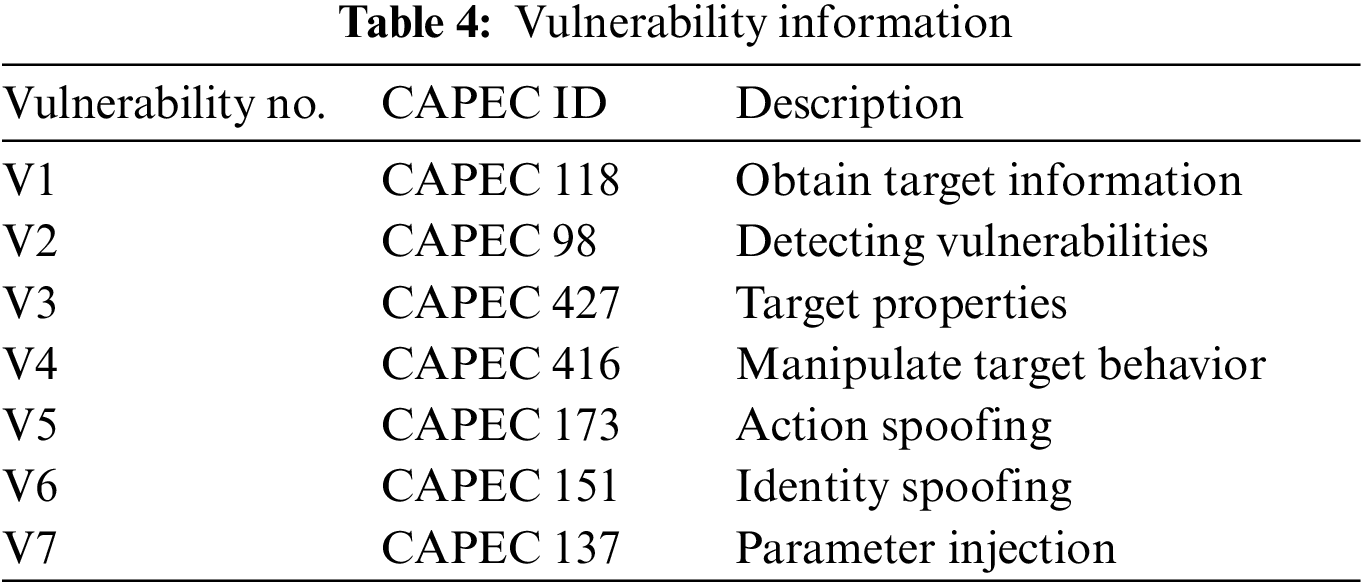
Table 5 lists all the states of the game; if the attacker discovers a vulnerability to an attack and exploits it, a state transition occurs. If the attacker does not find an attack state, the attacker takes no action. The attack actions are shown in Table 6, and the defense actions are shown in Table 7.

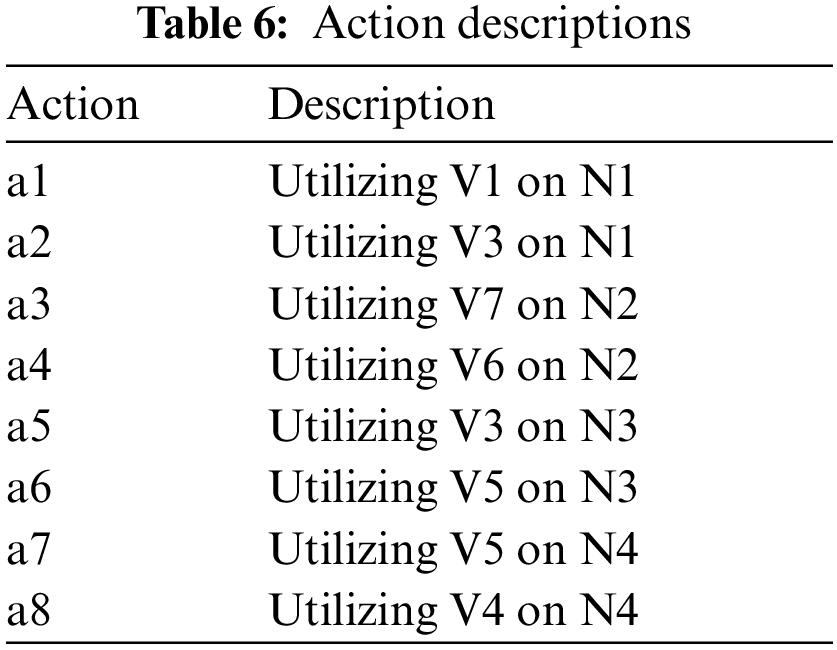
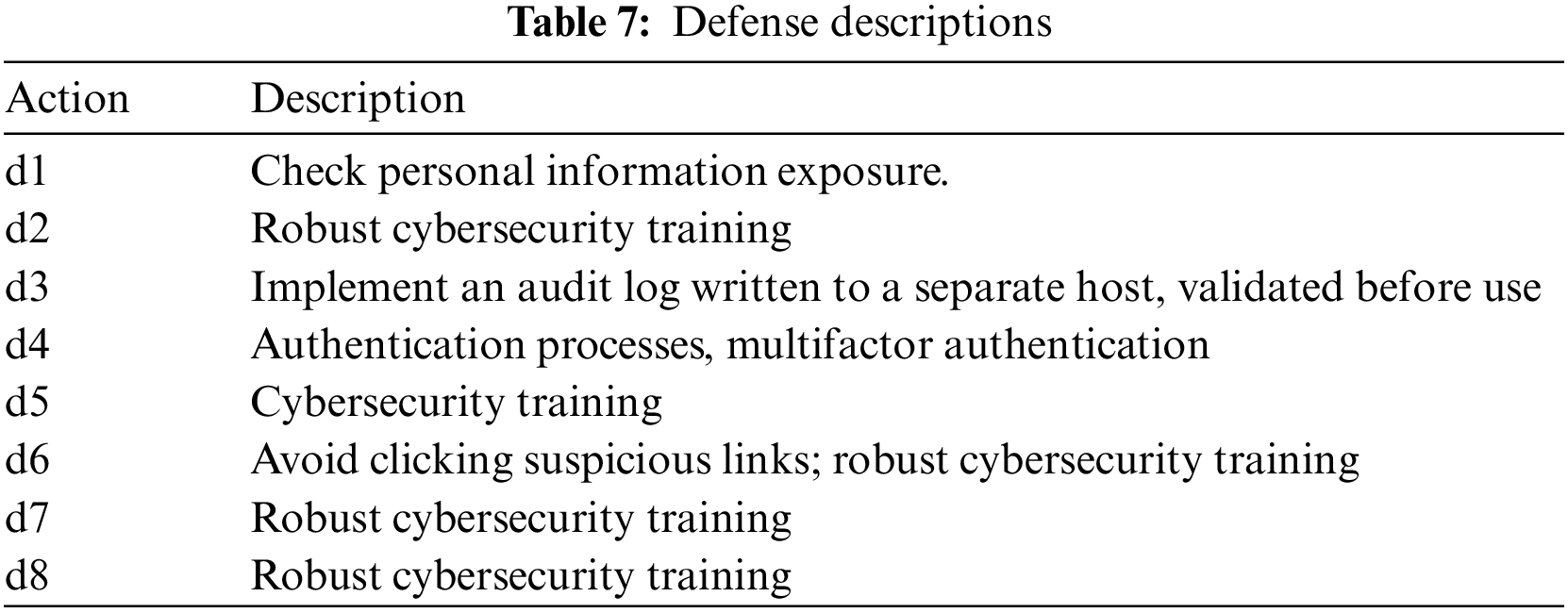
The corresponding sets of defense and attack strategies are shown in Table 9.
In this paper, we introduce the concepts of players and strategies and construct a model of reinforcement learning using players and strategies with a custom nature. In the game model of this paper, there are two players, and each player learns a new strategy. Each player’s strategy is formulated according to the player’s current state and the actions taken. The player’s probability is updated by observing the opponent’s behavior and changing the action accordingly. The best behavioral strategy is finally acquired through reinforcement learning for maximum benefit. The model in this paper has five states, and the reward of each state is shown in Fig. 3. As shown, the stochastic game reaches a Nash equilibrium after 2300 iterations. Table 8 lists the average rewards for the five states. According to the table, the rewards of S1 and S2 are essentially the same.
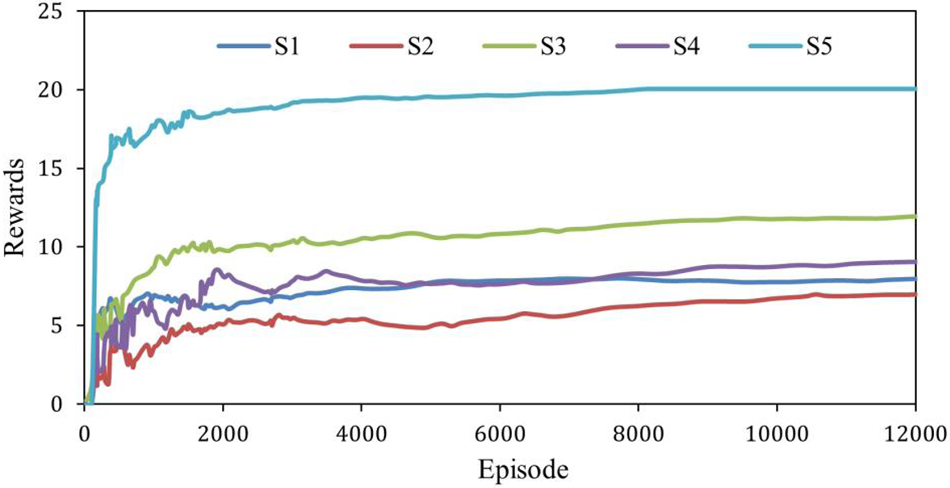
Figure 3: IQP process rewards in different states
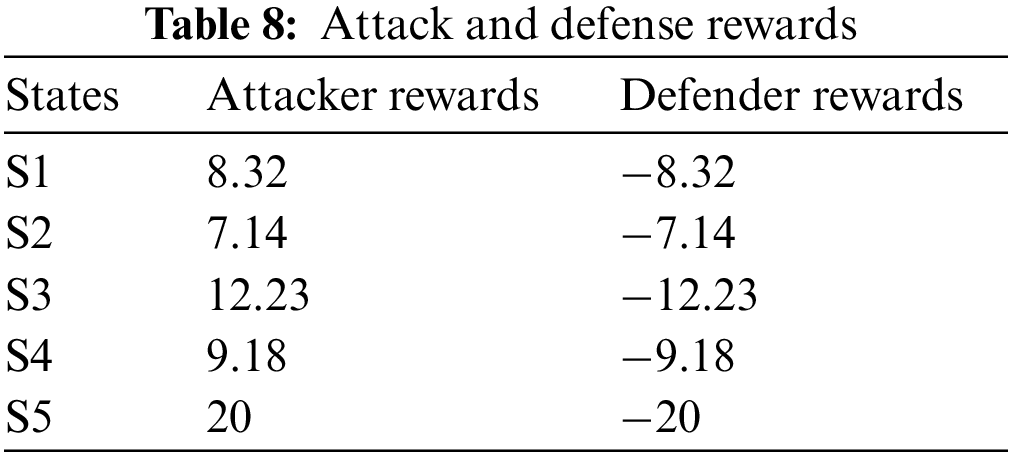
Table 9 lists the optimal strategies of the attackers and defenders in all states for each actual situation. It can be seen that in the initial stage of IQL, the probabilities of the players’ decisions are random. As the number of iterations of the overall tethered model increases, the agent can obtain information about the adversary, and the best defense strategies are finally accepted by using the solved game matrix. According to the IQL algorithm proposed in this paper, the optimal strategy for the attacker and the defender are solved. The implementation results show that the method proposed in this paper can effectively obtain the optimal defense strategies.
In this paper, we propose an improved Q-learning algorithm that utilizes parallel computing to improve the efficiency of the computation. We conducted experiments using 1, 10, 20, and 30 parallel learning states to verify the relationship between multiple parallel learning processes and decision-makingsimilar. The results are shown in Fig. 4. Increasing the number of learning processes within a specific range can effectively improve learning efficiency and lead to fast convergence. However, if 30 learning processes are set, the efficiency will be small, and the decision time will increase due to the overly complicated iterative process. The experiment shows that increasing the number of learning methods within a specific range can effectively reduce the strategy learning time, but using too many learning processes will increase the strategy learning time.
Figure 4: The decision duration of one iterative process for different numbers of learning processes
According to the literature survey, few studies apply game theory and reinforcement learning algorithms to the problem of social engineering defense strategy generation problem. Using different performance indicators and characteristics to compare and analyze the algorithm in this paper cannot prove the performance of the algorithm. Two commonly used reinforcement learning algorithms QL algorithm, and DQN algorithm [27], are used in this paper to compare and analyze the effectiveness and performance of the IQL algorithm proposed in this paper.
In this paper, the simulation experiment of social engineering defense strategy generation is carried out in the same network simulation environment, and the statistical analysis of the experimental data is carried out. The experimental results show that the simulation results obtained using Q-learning, DQN, and the algorithm in this paper in the social engineering random game scenario are shown in Fig. 5.
Figure 5: Comparison of simulation results obtained by using three different strategy-solving algorithms in social engineering attack-defense game
The above results show that in the social engineering random game scenario, the defender rewards obtained by the IQL solution are significantly greater than those obtained by the Q-Learning and DQN solutions. This experiment shows that defenders can reach their optimal defense strategy faster under the IQL reinforcement learning mechanism than other deep learning algorithms.
In a single iteration, the IQL algorithm can update different irrelevant states simultaneously, which can be considered an independent process. Therefore, the decision time of the IQL algorithm is always shorter than that of the QL algorithm. To prove this conclusion, we set up comparison experiments to calculate the policy learning time using the QL algorithm, the DQN algorithm, and the algorithm in this paper with different greedy values. The experimental results are shown in Fig. 6. The IQL algorithm has the shortest policy learning time for different greedy values. Under the condition ofe = 0.04, the IQL algorithm performs best on the minicamp testbed, with the highest number of states. QL runs for 15400 steps, DQN runs for 17400 steps, and IQL runs for only 14000.
Figure 6: Average completion times of the QL, DQN, and IQL algorithms with different discount factors
This is because the more states there are in the iterative process, the more computation is required and the higher the computational complexity. In general, the best performing iteration over the least is when e-0.04, and the completion time of the IQL algorithm can be reduced by 9.1% and 19.4% compared to the DQN and QL algorithms. The calculation formula is as follows:
In the above equation,
In this paper, we propose a reinforcement learning model based on game theory that can generate optimal social engineering defense strategies for social engineering attack models to enhance social engineering defenses and reduce losses. Since the traditional methods of social engineering defense strategy generation consider only the technical aspects of defense, humans are idealized and regarded as having consistent properties, which leads to an unsatisfactory defense strategy. Considering the interaction between target vulnerabilities and social engineering attacks, a quantification mechanism based on multiple target attributes is proposed. The attacker and defender are also modeled as a two-sided stochastic game. The optimal defense strategies of the defender are analyzed. To improve the real-time performance and effectiveness of the defense, a Q-learning algorithm based on the game is optimized, and a multistate independent parallel learning optimization method is proposed to improve the learning efficiency and to generate the optimal defense strategy quickly. According to the experimental simulation results, the average time needed to create the optimal policy is reduced by 12.5%~20% with the optimization method proposed in this paper compared with the QL and DQN algorithms. However, there are still some significant problems for the process in this paper; for example, the model construction could be more rough and sufficiently detailed for parallel task scheduling algorithm research, and the attack recovery method presented here could be improved.
Acknowledgement: Thanks are due to Kangfeng Zheng and Chunhua Wu for assistance with the experiments and to Xiujuan Wang and Bin Wu for valuable discussion. We are grateful for the assistance of the Beijing Natural Science Foundation (4202002).
Funding Statement: This research was funded by the Beijing Natural Science Foundation (4202002).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. APWG, Phishing Activity Trends Reports. 2022. [Online]. Available: https://apwg.org/trendsreports/ [Google Scholar]
2. Dmarcian, 2021 FBI Internet Crime Report. 2022. [Online]. Available: https://dmarcian.com/2021-fbi-internet-crime-report/ [Google Scholar]
3. K. Zheng, T. Wu, X. Wang, B. Wu and C. Wu, “A session and dialogue-based social engineering framework,” IEEE Access, vol. 7, pp. 67781–67794, 2019. [Google Scholar]
4. A. Yasin, L. Liu, T. Li, R. Fatima and W. Jianmin, “Improving software security awareness using a serious game,” IET Software, vol. 13, no. 2, pp. 159–169, 2019. [Google Scholar]
5. J. M. Hatfield, “Social engineering in cybersecurity: The evolution of a concept,” Computers & Security, vol. 73, pp. 102–113, 2018. [Google Scholar]
6. S. M. Albladi and G. R. S. Weir, “User characteristics that influence judgment of social engineering attacks in social networks,” Human-Centric Computing and Information Sciences, vol. 8, no. 1, pp. 5, 2018. [Google Scholar]
7. S. Seo and D. Kim, “SOD2G: A study on a social-engineering organizational defensive deception game framework through optimization of spatiotemporal MTD and decoy conflict,” Electronics, vol. 10, no. 23, pp. 3012, 2021. [Google Scholar]
8. Q. Zhu and T. Basar, “Game-theoretic methods for robustness, security, and resilience of cyberphysical control systems: Games-in-games principle for optimal cross-layer resilient control systems,” IEEE Control Systems Magazine, vol. 35, no. 1, pp. 46–65, 2015. [Google Scholar]
9. J. Pawlick, E. Colbert and Q. Zhu, “A game-theoretic taxonomy and survey of defensive deception for cybersecurity and privacy,” ACM Computing Surveys (CSUR), vol. 52, no. 4, pp. 1–28, 2019. [Google Scholar]
10. K. Zhong, Z. Yang, G. Xiao, X. Li, W. Yang et al., “An efficient parallel reinforcement learning approach to cross-layer defense mechanism in industrial control systems,” IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 11, pp. 2979–2990, 2022. [Google Scholar]
11. R. Elderman, L. J. J. Pater, A. S. Thie, M. M. Drugan and M. Wiering, “Adversarial reinforcement learning in a cyber security simulation,” in Proc. of the 8th Int. Conf. on Agents and Artificial Intelligence (ICAART), Rome, Italy, pp. 559–566, 2017. [Google Scholar]
12. K. Chung, C. A. Kamhoua, K. A. Kwiat, Z. T. Kalbarczyk and R. K. Iyer, “Game theory with learning for cyber security monitoring,” in Proc. of the 2016 IEEE 17th Int. Symp. on High Assurance Systems Engineering (HASE), Orlando, FL, USA, pp. 1–8, 2016. [Google Scholar]
13. K. Durkota, V. Lisy, B. Bošansky and C. Kiekintveld, “Optimal network security hardening using attack graph games,” in Proc. of the 24th Int. Conf. on Artificial Intelligence, Buenos Aires, Argentina, pp. 526–532, 2015. [Google Scholar]
14. K. Durkota, V. Lisý, B. Bošanský, C. Kiekintveld and M. Pěchouček, “Hardening networks against strategic attackers using attack graph games,” Computers & Security, vol. 87, pp. 101578, 2019. [Google Scholar]
15. A. Ridley, “Machine learning for autonomous cyber defense,” The Next Wave, vol. 22, no. 1, pp. 7–14, 2018. [Google Scholar]
16. M. L. Littman, “Markov games as a framework for multi-agent reinforcement learning,” in Proc. of the Eleventh Int. Conf. on Int. Conf. on Machine Learning, Rutgers University, New Brunswick, NJ, pp. 157–163, 1994. [Google Scholar]
17. J. Hu and M. P. Wellman, “Nash q-learning for general-sum stochastic games,” Journal of Machine Learning Research, vol. 4, pp. 1039–1069, 2003. [Google Scholar]
18. J. Heinrich and D. Silver, “Deep reinforcement learning from self-play in imperfect-information games,” arXiv preprint arXiv:1603.01121, 2016. [Google Scholar]
19. R. Yang, K. Zheng, B. Wu, D. Li, Z. Wang et al., “Predicting user susceptibility to phishing based on multidimensional features,” Computational Intelligence and Neuroscience, vol. 2022, pp. 7058972, 2022. [Google Scholar] [PubMed]
20. R. Yang, K. Zheng, B. Wu, C. Wu and X. Wang, “Prediction of phishing susceptibility based on a combination of static and dynamic features,” Mathematical Problems in Engineering, vol. 2022, pp. 2884769, 2022. [Google Scholar]
21. C. Liu, F. Tang, Y. Hu, K. Li, Z. Tang et al., “Distributed task migration optimization in MEC by extending multi-agent deep reinforcement learning approach,” IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 7, pp. 1603–1614, 2021. [Google Scholar]
22. F. Mouton, M. M. Malan, L. Leenen and H. S. Venter, “Social engineering attack framework,” in IEEE 2014 Information Security for South Africa, pp. 1–9, 2014. [Google Scholar]
23. A. Ghasempour, “Internet of things in smart grid: Architecture, applications, services, key technologies, and challenges,” Inventions, vol. 4, no. 1, pp. 22, 2019. [Google Scholar]
24. K. P. Mayfield, M. D. Petty, T. S. Whitaker, J. A. Bland and W. A. Cantrell, “Component-based implementation of cyberattack simulation models,” in Proc. of the 2019 ACM Southeast Conf., New York, NY, ACM, pp. 64–71, 2019. [Google Scholar]
25. M. S. Barnum, Common attack pattern enumeration and classification (CAPEC) schema. Department of Homeland Security, 2008. [Online]. Available:https://capec.mitre.org/ [Google Scholar]
26. R. Mitchell and R. Chen, “Modeling and analysis of attacks and counter defense mechanisms for cyber physical systems,” IEEE Transactions on Reliability, vol. 65, no. 1, pp. 350–358, 2015. [Google Scholar]
27. H. Van Hasselt, A. Guez and D. Silver, “Deep reinforcement learning with double q-learning,” in Proc. of the AAAI Conf. on Artificial Intelligence, Phoenix, Arizona, USA, pp. 2094–2100, 2016. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools