
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Automatic Crop Expert System Using Improved LSTM with Attention Block
1 Computer Science Department, University of Engineering and Technology, Taxila, Pakistan
2 Department of Information Technology, College of Computer, Qassim University, Buraydah, Saudi Arabia
* Corresponding Author: Suliman Aladhadh. Email:
Computer Systems Science and Engineering 2023, 47(2), 2007-2025. https://doi.org/10.32604/csse.2023.037723
Received 14 November 2022; Accepted 18 April 2023; Issue published 28 July 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Agriculture plays an important role in the economy of any country. Approximately half of the population of developing countries is directly or indirectly connected to the agriculture field. Many farmers do not choose the right crop for cultivation depending on their soil type, crop type, and climatic requirements like rainfall. This wrong decision of crop selection directly affects the production of the crops which leads to yield and economic loss in the country. Many parameters should be observed such as soil characteristics, type of crop, and environmental factors for the cultivation of the right crop. Manual decision-making is time-taking and requires extensive experience. Therefore, there should be an automated system for the right crop recommendation to reduce human efforts and loss. An automated crop recommender system should take these parameters as input and suggest the farmer’s right crop. Therefore, in this paper, a long short-term memory Network with an attention block has been proposed. The proposed model contains 27 layers, the first of which is a feature input layer. There exist 25 hidden layers between them, and an output layer completes the structure. Through these levels, the proposed model enables a successful recommendation of the crop. Additionally, the dropout layer’s regularization properties aids in reduction of overfitting of the model. In this paper, a customized novel long short-term memory (LSTM) model is proposed with a residual attention block that recommends the right crop to farmers. Evaluation metrics used for the proposed model include f1-score, recall, precision, and accuracy attaining values as 95.69%, 96.56%, 96.9%, and 97.26% respectively.Keywords
Agriculture plays important role in the development and growth of the economy of the country but depending on the crop 26% to 80% [1] of the production is lost because of pests and the wrong choice of crop for cultivation [1,2]. The source of income for 43.5 percent of the rural population of Pakistan is agriculture. Agriculture contributes 20.9% to Pakistan’s Gross Domestic Product (GDP) Government of Pakistan (GOP, 2015) [3]. Similarly in India, 14%–18% of the GDP is dependent on agriculture, and Bangladesh as of 2016, contributes to the country’s GDP [4,5]. Major crops of Pakistan include maize, cotton, wheat, and sugarcane however some minor crops of Pakistan are tobacco, barely, jawar, bajra, sunflower, potato, etc. in the past few years due to excessive use of pesticides and industrialization the soil strength get effected which leads to loss of production in agriculture yield. Traditional methods of agriculture are not efficient to increase the productivity of agriculture [6]. Loss of production is also because of farmers’ wrong choice of crop cultivation and climatic changes.
Commonly farmers face difficulty regarding the suitable crop selection for cultivation based on soil, environment, and climatic requirements so which affects the productivity of agriculture yield. Currently, crop recommendation is based on the interaction between experts and farmers which is laborious. The traditional process of crop Recommendation is expensive and time-consuming and farmers don’t pay attention to the traditional crop recommendation system even though some farmers are not familiar with the recommendation system of the crop which leads to production loss in the agriculture field. Now researchers are paying attention to introducing the system for suitable crop recommendations to the farmers using past agriculture activities. Crop yield prediction methodologies help farmers with better decision-making in the agriculture field [7]. With the growing technologies, the concept of data mining, machine learning, and deep learning there exists a system that suggests the suitable crops to the farmer for cultivation that can increase the productivity in the agriculture field [8]. Data mining algorithms can be used for fertilizers and crop recommendation [9].
These techniques of fertilizer and crop recommendation can be implemented on smartphones. Crop recommendation is dependent on many features or parameters [10]. Potassium, nitrogen, phosphorus, rainfall, etc. are used for the process of crop recommendation. Nitrogen is very important in the production of crops like corn, yellowish leaves, and dwarfed seedling of corn because of low nitrogen in the soil [11]. Balance fertilizer and soil testing are important parameters for precision agriculture [12]. The agriculture field has embedded machine learning and deep learning algorithms to produce cost-effective, efficient, and fast solutions to difficulties that farmers faced. There exist many crop recommendations, fertilizer recommendations, and agriculture precision systems. The precision of agriculture includes the classification of soil, prediction of weather forecasting, monitoring crop, yield prediction, prediction of diseases, automatic irrigation systems, etc. The purpose of the [13] study was crop recommendation and pant disease detection using deep learning techniques. The plant village dataset was collected from the Kaggle website which consists of 38 categories of healthy and diseased plants for the detection of plant disease. The ‘Agriculture production in India’ dataset was collected from the Kaggle website for the recommendation of the crop. Data augmentation technique was performed to avoid mode from overfitting VGG16 as train d for pant disease detection that provides 97.53% accuracy and content-based filtering technique was used for crop recommendation system. The crop recommendation system uses location and season for cultivation as input features for crop suggestions.
Although, there exist various systems for crop recommendation based on machine learning and deep learning techniques. The major concern is to automate the process, however, in machine learning-based methods, a small size dataset is used, and therefore, they may fail on unseen environmental data and recommend the wrong crop causing the loss of millions. On the other side, the existing deep learning-based methods are more complex and require high computational resources. Thus, to overcome the above-mentioned challenges this article proposes a novel model based on LSTM with attention block.
The key contributions of this study are below:
• To propose a novel model that can recommend the most suitable crop for cultivation to farmers among twenty-two different crops such as watermelon, apple, rice, banana, pomegranate, black gram, papaya, chickpea, orange, coconut, coffee, muskmelon, cotton, grapes, moth beans, jute, mango, kidney beans, maize, and lentil.
• The algorithm is a modified form of a long short-term memory Network. The Proposed model has 27 layers including the first layer as a feature input layer, 25 hidden layers in between along with an output layer. This model makes possible an effective recommendation of the crop through these layers. Moreover, the dropout layer has regularization properties which help the model to minimize overfitting.
• To propose a novel LSTM, the concept of residual attention block is used to solve the problem of the vanishing and exploding gradient. The LSTM network simply consists of (1) The main branch with sequentially connected layers, and (2) a shortcut connection containing an LSMT layer. Shortcut connections enable the parameter of gradients to flow to the earlier layers of the network from the output layer more easily.
• To analyze the performance of the proposed model, the datasets i.e., crop recommendation Dataset after implication of data augmentation, comprising 5300 observations has been distributed into training, testing, and validation sets. The algorithm attained 97.26% accuracy for the recommendation of the suitable crop.
The rest of the study is arranged as follows: Section 2 is about the related work that describes the methods of crop recommendation that have been developed previously in the agriculture field. Section 3 described the methodology of the proposed LSTM and how the model is implemented for the crop recommendation system. Section 4 demonstrates the experimentation and results of our proposed LSTM. Section 5 is about the comparison of the proposed LSTM with existing techniques, and finally, Section 6 is about the conclusion and future work.
Authors of [14] research focus on the use of emerging technologies in the agriculture field to increase the productivity of crops by converting traditional techniques of farming into precision farming. Internet of things and data analysis techniques are included in new farming techniques. Soil characteristics such as temperature, soil moisture, PH, and humidity were used for the crop recommendation system. LM35 and DHT22 sensors were used for data collection of parameters such as PH, temperature, humidity, and moisture. Data pre-processing was performed to remove outliers and removal of noise. Feature scaling was also performed for normalizing the data. Temperature, humidity, pH, and rainfall parameters were used to train the machine learning model Naïve Bayes provides 96.89% accuracy however, this can be increased by using deep learning models. Although the proposed system was used to suggest the appropriate crop based on factors including temperature, soil moisture, PH, and humidity and offered 96.89% accuracy, the dataset utilized was too small, and the proposed system was very expensive because sensors were needed to gather the dataset. The purpose of this [15] study was to introduce the model that uses location, longitude, latitude, potassium, and ph., nitrogen and phosphorus as input features, and recommend rice, green peas, maize, sunflower and barley, etc. crops. Sapna Jaiswal proposed a system that helps farmers by providing periodic updates about the recent trend in agriculture and by answering farmer queries [16].
The goal of the [17] study was to assist the farmers in decision-making about which crop to grow depending on geographical location, environmental factors like rainfall, and temperature as well as soil characteristics. India’s agriculture and climate dataset has used that consists of a historical record of meteorological parameters and soil. The dataset consists of twenty crops and includes more than two hundred and seventy districts. Soil type, soil PH, thickness, location parameters, temperature, and precipitation features were used for model training. Data pre-processing was applied to eliminate the missing values. Decision tree, k nearest neighbor, random forest, and artificial neural network (ANN) models were trained and provided 90.2%, 89.78%, 90.43%, and 91.00% accuracy respectively. Although artificial neural network performs best among these models and provides 91% accuracy, however, this accuracy can further be increased by using other deep learning models. Additionally, additional elements like phosphorus, potassium, and humidity were not taken into account, despite the fact that all of these elements are required for a crop to be grown. The purpose of the [18] study was to introduce a crop recommendation system based on the parameters of soil like soil moisture, temperature, and humidity. A humidity sensor was used to detect the humidity and a temperature sensor was used to measure the water content in the soil. Evaluation measures are not included in the paper that shows the performance of the proposed model. However, this article only examined the recommendation system prototype, which operated on a modest dataset.
The purpose of [19] research was to bridge the gap between technology and farmers. In this research, the authors purposed a system for the recommendation of suitable cop and fertilizer based on the type of soil, geographical location, and potassium, nitrogen, and phosphorus content of the soil. K means clustering and random forest algorithms of machine learning were used for the recommendation of suitable crops and fertilizers. The performance of the model is not described in the paper which represents the accuracy of the proposed model. Akshatha et al. in [20] paper proposed a modern technique of farming that use crop yield data, soil type, and soil characteristics to recommend the farmer’s right crop for cultivation. This technique of farming increases productivity in the agriculture field and reduces the wrong choice of crop cultivation that results from loss of production. Groundnut, vegetables, millet, banana, cotton, sugarcane, paddy, coriander, and sorghum are the crops that were used in the dataset. Erosion, PH, texture, permeability, and depth features were used for crop recommendation. K nearest neighbor and naïve Bayes mode of machine learning were trained for the recommendation of these ten crops based on these features. However, this study used a tiny dataset and concentrated exclusively on the soil need. The effectiveness of the suggested model was not quantified, demonstrating its accuracy. The purpose of this [21] study was the recommendation suitable crops based on temperature, moisture, sunlight, intensity, humidity, and PH level. Support vector machine and naïve Bayes classifier were used to suggest a suitable crop for cultivation. The proposed system provides 90% accuracy on cop recommendations. However, this accuracy is not enough to rely on this system, this can be increased.
The goal of this [22] research was to purpose a system that takes three parameters i.e., crop yield data, soil type, and soil characteristics. These three parameters were used to recommend the farmer’s suitable crop for cultivation. The purpose system can increase the productivity of crops and prevent the farmer from taking the wrong crop for cultivation dataset was collected from Ramtak town India and compromises of vegetables, coriander, groundnut, sugarcane, paddy, cotton, and pluses crops. Soil color, PH, erosion, permeability, texture, drainage, depth, and water holding parameters were used for training four different models of machine learning that were random forest, decision tree, k nearest neighbor, and random tree for suitable crop recommendation of the crop, however, the accuracy of the proposed system was not tested and mentioned in the paper. The dataset solely includes soil-specific variables that were gathered from an Indian town. Because only soil characteristics from a particular country were considered, the suggested solution is only applicable to that particular region of India. The goal of [23] research was to purpose a system by using a support vector machine and random forest for the recommendation of suitable crops based on previous data. The purpose system predicts the suitable crop for cultivation in the future. Cotton, dry chili, sunflower, onion, jowar, wheat, rice, etc. crops were targeted for the recommendation. Support vector machine and random forest of machine learning models were trained for yield prediction however, model accuracy is not tested.
Manjula et al. select Nitrogen, Phosphorus, Sulphur, Magnesium, Iron, Potassium, Calcium, Zinc, and so forth, as input features, Decision Tree, and Naïve Bayes classifier as the recommender model [24]. Only the soil-specific parameters that were gathered from an Indian town were included in the dataset. The proposed method can only be employed in that particular region of India because only the soil characteristics of a certain country were utilised. Madhuri et al. in [25] research proposes a system for crop recommendation based on an artificial neural network. The proposed system of crop recommendation takes soil properties, climate parameters, and crop characteristics as input feature and suggest a suitable crop among rice, maize, sugarcane, and finger millet based on these input features. The suggestion of crops is predicted in terms of highly suitable, moderately suitable, marginally suitable, and not suitable using the dataset that was collected from Hadonahalli and Durgenahalli of doddabollapur district, Karnataka India. An artificial neural network was trained on the dataset and was tested for crop recommendation. ANN provides 96% accuracy on crop recommendation however, this can be increased by using the different options for training. Nevertheless, a proposed system was employed to suggest the best crop based on site-specific soil data and historical meteorological data. However, by taking into account market demand, the presence of market infrastructure, anticipated profit, post-harvest storage, and processing technologies, the proposed system can be expanded. A comparison of related work is listed in Table 1.
A Long short-term memory network is the modified version of a recurrent neural network that is mostly used in sequence prediction, LSTM extracts the temporal information from the data which is sequential. LSTM works on sequential data based on current input ct as well as LSTM uses the previous output of hidden state ht−1. Moreover, we have attached a residual attention block to select the most representative key features. To train our model, we used the data augmentation technique to increase the size of dataset for training.
Data augmentation is a method that increases the size of a training set by creating modified versions of an existing dataset, either through minor adjustments or the use of deep learning to produce new data points. The ACTGAN [33] model is employed in this study to augment the data. It builds on the well-known CTGAN model, a set of deep learning-based synthetic data generators for single table data that can learn from real data and produce highly accurate synthetic data. The crop recommendation dataset is employed to train the ACTGAN model, which starts from random weights. Following augmentation, the dataset consists of 5300 observations, with 4750 observations being used for training, 330 for validation, and 220 for testing.
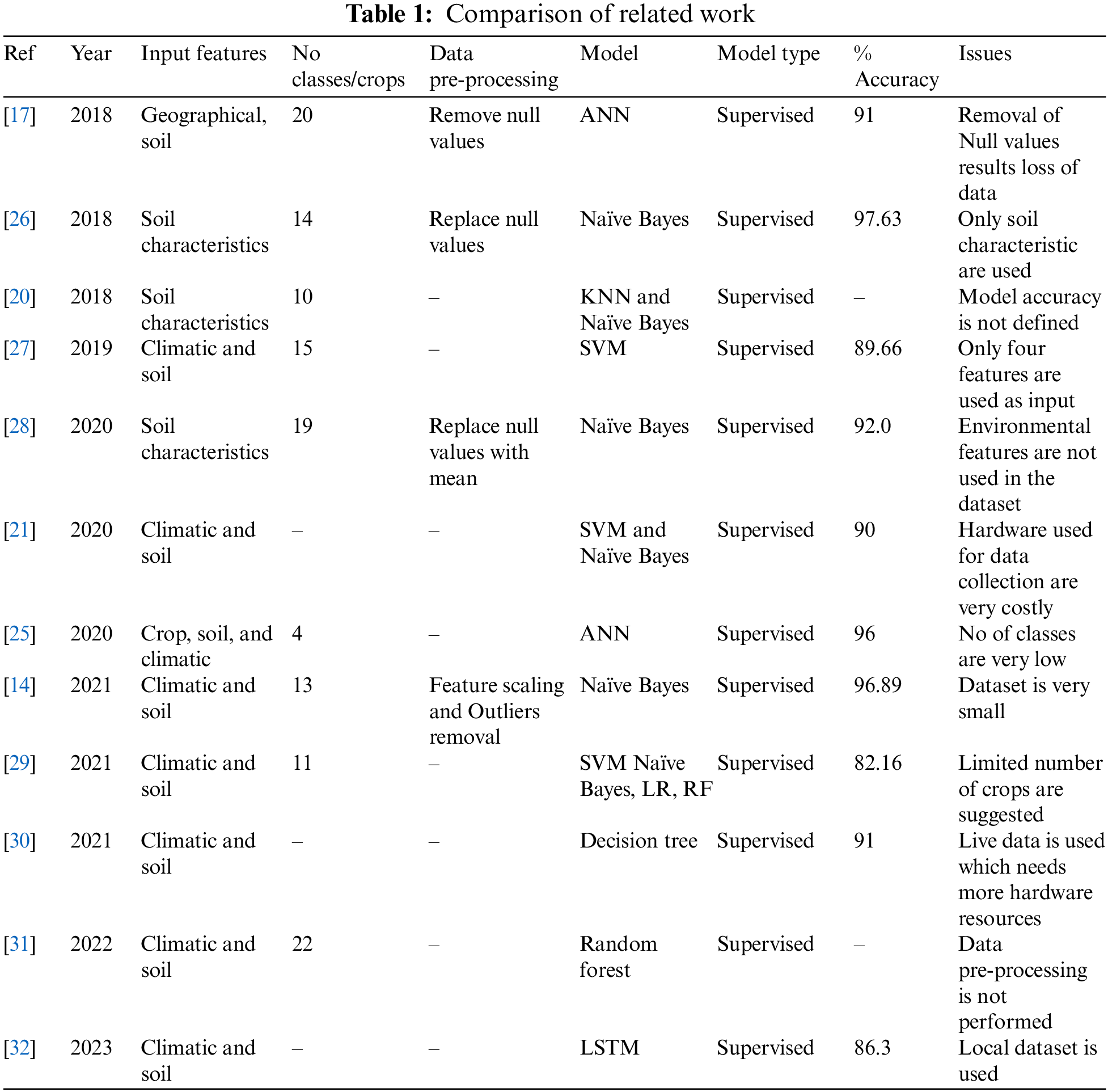
Standard recurrent neural network (RNN) becomes weak to learn dependencies hence the problem of exploding gradient and vanishing gradient arises when there is an increase in the time duration. State units, input gates, output gates and forget gates are introduced in LSTM to overcome the problem of vanishing gradient [34]. The Diagram of the input gate, output gate, and forget gate used in LSTM is shown in Fig. 1, Where tanh is the hyperbolic tangent function, “
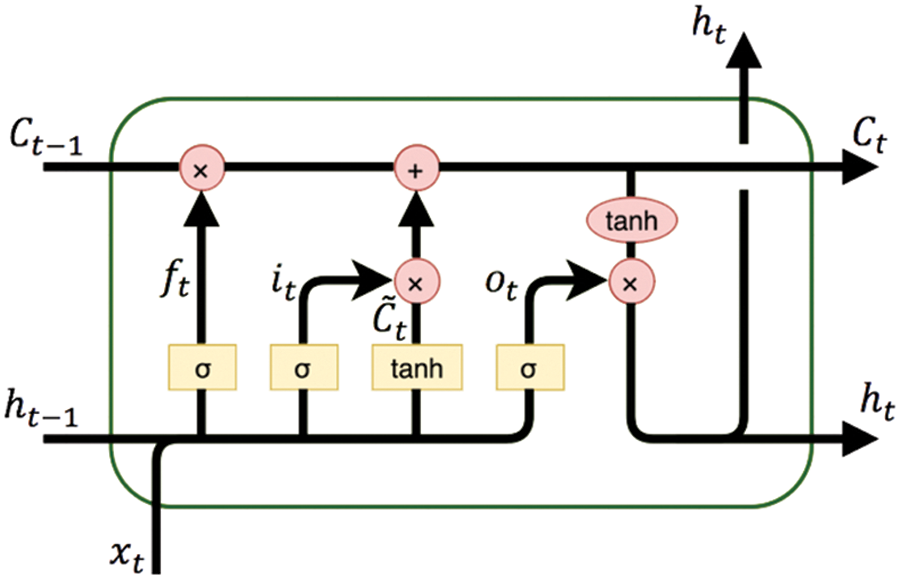
Figure 1: Gates of LSTM [35]
Long-distance time sequence information is stored in short term and long-term memory of the LSTM network. Long short-term memory minimizes the problem of vanishing gradient which occurs when the recurrent neural network (RNN) stops learning weights. Input gate, output gate and forget gate are used in LSTM to minimize the problem related to vanishing gradient. These gates are activation functions. Eq. (1) represents the input gate, Eq. (2) shows forget gate whereas Eq. (3) is used to represent the output gate. Eq. (4) represents the candidate for cell state, Eq. (5) is used to show the state of cell memory finally Eq. (6) shows the current output.
LSTM network compromises many hidden layers like the normalization layer, RELU layer, LSTM layer, fully connected, dropout layer, and classification layer. Long short-term memory outperforms the problems that are related to sequential data. In this paper, a novel LSTM is proposed that consists of 27 layers including the first layer as a feature input layer, and 25 hidden layers in between with an output layer. The proposed architecture is shown in Fig. 2. Attention block of the proposed LSTM is presented in Fig. 3. The proposed LSTM has an attention block that is used to solve the problem of the vanishing and exploding gradient. The Proposed LSTM network simply consists of (1) the main branch with sequentially connected layers, and (2) a shortcut connection containing an LSMT layer. Shortcut connections enable the parameter of gradients to flow to the earlier layers of the network from the output layer more easily. Initially, input features are provided to the feature input layer after that LSTM layers, Relu layer, and batch normalization layers are used to normalize the data. The Proposed LSTM has two branches main branch and a skips connection branch that is used to highlight only relevant activation during training. The attention block in the proposed LSTM reduces the computational resources that are wasted on irrelevant activations. There exist 22 classes in our dataset such as watermelon, apple, rice, banana, pomegranate, black gram, papaya, chickpea, orange, coconut, coffee, muskmelon, cotton, grapes, moth beans, jute, mango, kidney beans, maize, and lentil. The feature variables in dataset are seven for which our proposed LSTM-based method has been proposed.

Figure 2: Proposed LSTM
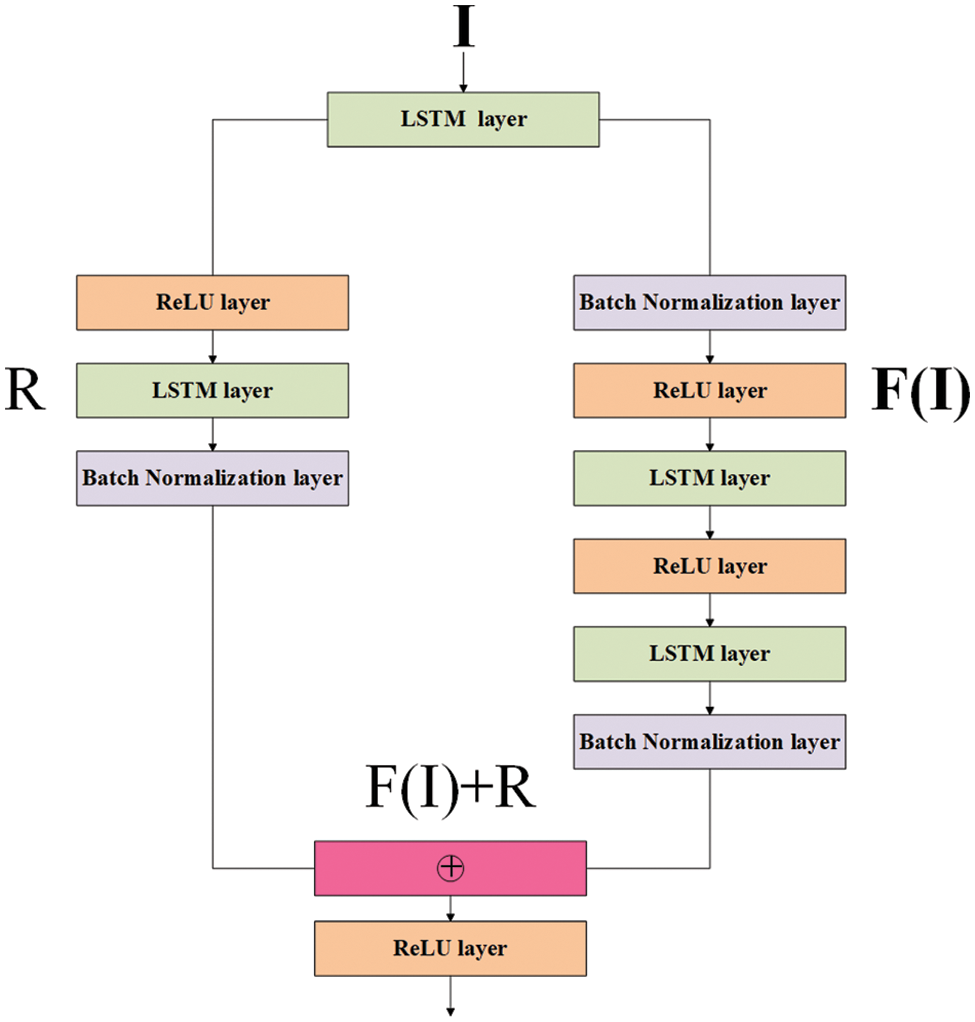
Figure 3: Attention block
In this research, we propose an effective expert crop system in which the residual attention block is embedded into the LSTM architecture. It is a simple idea that addresses the problem of substandard performance caused by the gradient diminishing as the model’s layer depth grows. It is a simple idea that takes the input as it is and adds it to the learned function as a method designed to solve the problem of inferior performance. In order to address the issue of performance deterioration of the model in this work, we used a residual block, which can aid the model in extracting additional features from each layer. It has 27 layers, and the attention modules were inserted between the eighth and nineteenth layers of the LSTM.
In a multi-layer LSTM structure, a residual connection can be used to address the degradation problem that can occur in deep neural networks. The residual connection involves adding the input to the output of the LSTM layer, and the original feature learned is denoted as H (I) = F (I) + R. The hope is to learn the feature residual F (I) = H (I) − R, which represents the part of the output that is not explained by the input.
The feature input layer gets the features as input for the network and passes these features to hidden layers of LSTM for the normalization of data. In this paper, seven input features are used that are humidity, Nitrogen, Potassium, Phosphorus, PH, temperature, and Rainfall. These seven features are provided as input to the feature input layer of the proposed LSTM for the recommendation of twenty-two different crops such as apple, chickpea, coconut, cotton, lentil, grapes, banana, maize, orange, rice, watermelon, papaya, moth beans, and coffee, etc.
Batch normalization layer speed up the training of the LSTM network [36]. Additional scaling and shifting operations are performed by inserting batch normalization layer to normalize the input of activation function and to overcome vanishing gradient before hidden layer like tanh/RELU/Sigmoid [37]. Normalization and affine transformation are Two channel-wise sequential operations that are performed with a batch normalization layer. Variance and mean of batch B are the two functions that are included in the normalization operation of data consisting of n features.
Eq. (7) shows the mean, and Eq. (8) represents variance finally Eq. (8) is used to calculate the normalization operation by using the mean and variance function.
Here B is the mini-batch with d-dimension input xi,
‘
β is the shift parameter and
RELU non-linear function RELU is applied to adjust the output to limit the output. tanh and sigmoid activation function can create the problem in backpropagation therefore, in this paper RELU has been used as an activation function. The definition of RELU in terms of gradient and term of function is represented in Eqs. (11) and (12), respectively.
RELU returns 0 if it gets negative input, and for any positive value of t, it returns that value. Therefore the output of RELU has a range from 0 to infinity.
An addition layer adds inputs element-wise from multiple neural network layers. The additional layer takes multiple inputs of the same shape and returns a single output.
Data is transformed into the one-dimensional vector and then provided to the fully connected layer. Bias value is added and connection weights are multiplied by previous data. Eq. (13) shows the operation performed by a fully connected layer.
Here W is the weight vector, b is the bias value, o is the input vector of the rth neuron, and f is an activation function.
The softmax layer is used for problems that are related to multiclass classification. Softmax is normally used as an output layer for most multiclass classification problems. The function of selection performed by the softmax layer is represented in Eq. (14).
S is a softmax function of input vector v, n shows the number of classes, evi is the standard exponential function for the input vector, and evj is the standard exponential function for the output vector. The detail of layers used in architecture is given in Table 2 where 5 [Batch Normalization] indicates that there are 5 layers of batch normalization employed. In a similar way, LSTM layers consist of 7 layers, while RELU layers include 8.

Precision agriculture is very important because its play important role in the economy of the country. Farmers get informed about the farming strategy and the right crop for cultivation with precision agriculture. The Dataset is collected from the Kaggle website and the name of the dataset is the ‘crop recommendation dataset’ [38]. The Dataset was created by using the data augmentation technique on sets of rainfall, fertilizer, and climate data available for India. Gathered over the period by the Indian council of food and agriculture (ICFA), India. Dataset is compromising of seven input features like N-the ratio of nitrogen content in the soil, humidity-relative humidity in %, K-the ratio of Potassium content in the soil, and ph.-ph. value of the soil, P-the ratio of Phosphorous content in the soil, temperature-the temperature in degrees Celsius, and rainfall-rainfall in mm. There exist 22 crops such as watermelon, apple, rice, banana, pomegranate, black gram, papaya, chickpea, orange, coconut, coffee, muskmelon, cotton, grapes, moth beans, jute, mango, kidney beans, maize, and lentil.
Data pre-processing is a very important step for the development of a good model. The accuracy of a model can be increased using data pre-processing techniques. Data pre-processing is performed and observed that there is no missing value in the dataset. The empirical distribution is compared with the theoretical values of the data and hence the distribution of sample data is accessed visually with the help of distribution plots. Expletory data analysis technique distribution plots are used in this paper for checking outliers and the results are shown in Fig. 4 below, it is observed that there are no outliers, and data is normally distributed.
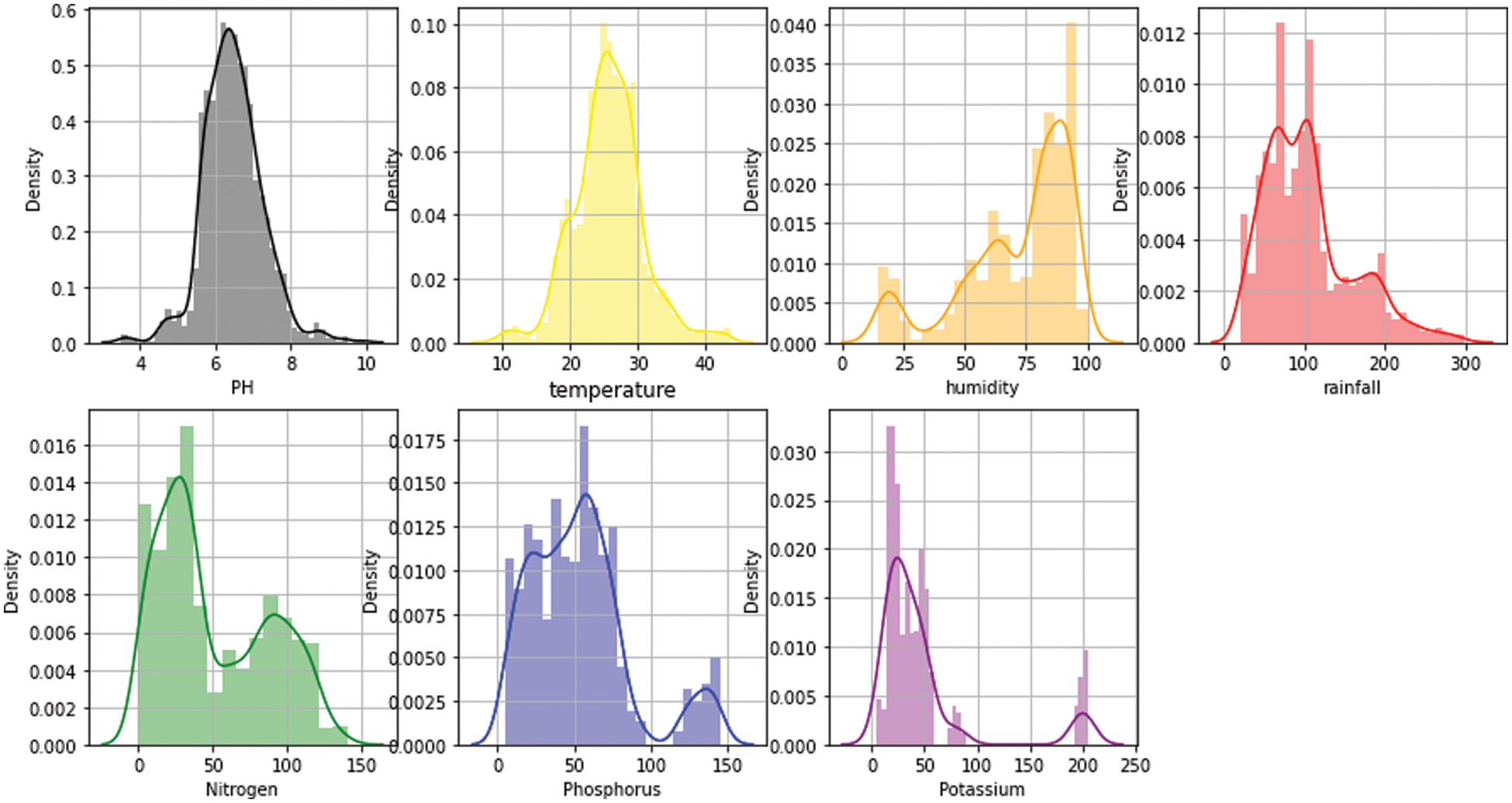
Figure 4: Exploratory data analysis
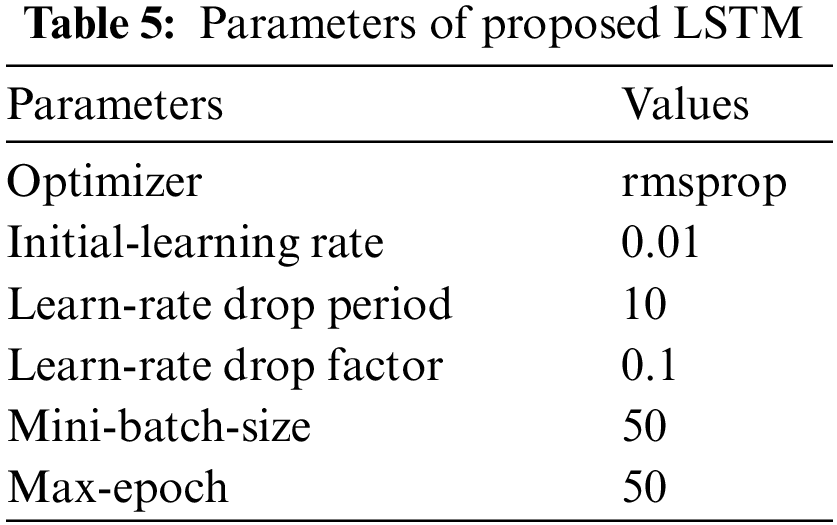
In this paper, rmsprop has been used as an optimizer with an initial-learning rate of 0.01, a learn-rate drop period of 10, and a Learn-rate drop factor of 0.1. Mini-batch-size is 50 and Max-epoch is set to 50. The training process with loss and accuracy of the model in MATLAB is presented in Fig. 5.
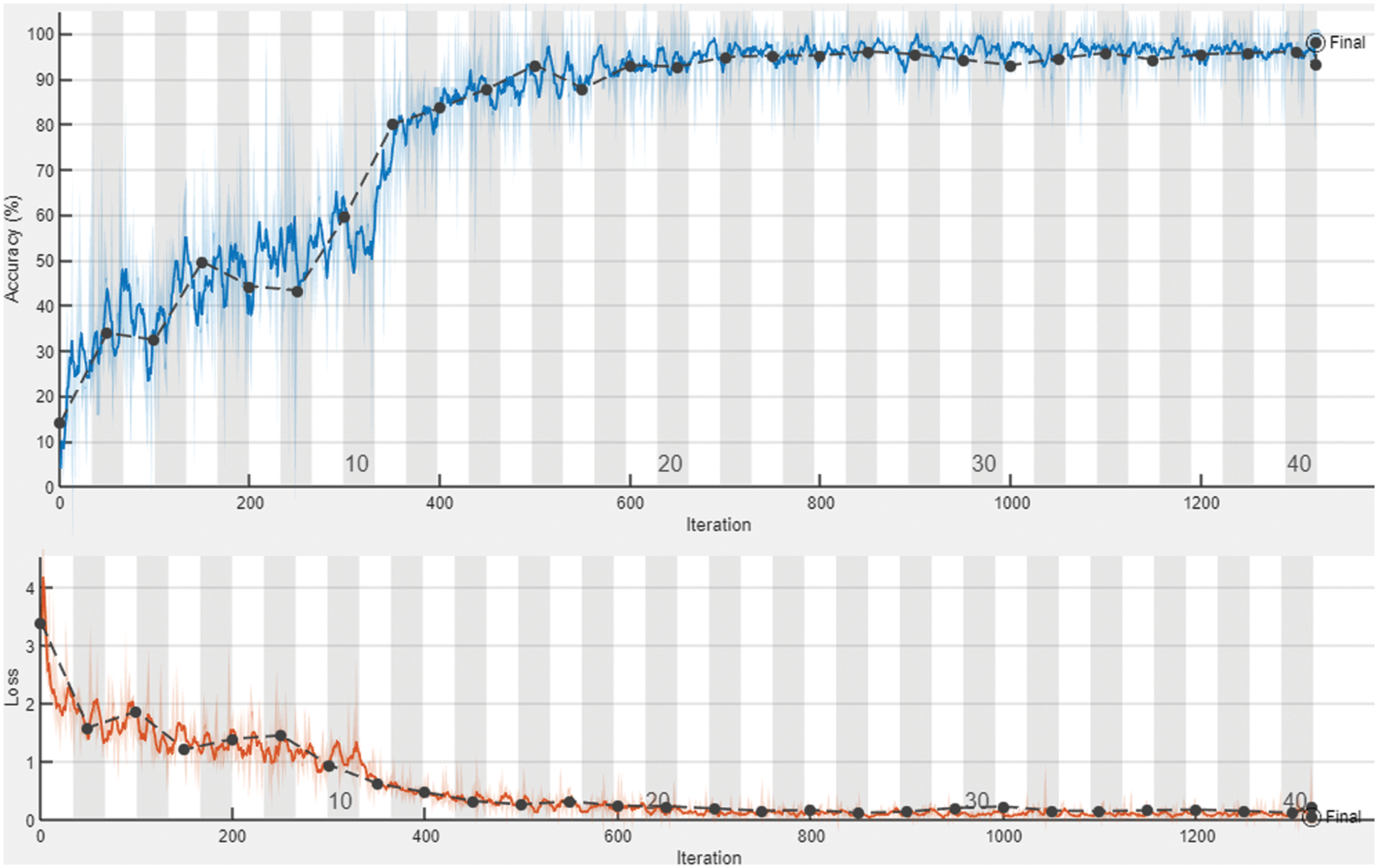
Figure 5: Accuracy and loss of proposed LSTM
The performance matrices used in this paper are Recall, Precision, F1_score, and accuracy of the proposed LSTM model. The recall is calculated as the fraction of the number of positive samples that are correctly classifieds into all positive samples and falsely classified positive samples Eq. (15) shows Recall.
The percentage of accurately classified samples is called the precision of a model. The number of truly positive samples divided by the total predicted positive samples is the precision of a model, and the formula of precision is shown in Eq. (16).
The Harmonic Mean of precision and Recall gives the F1-score, and Eq. (17) shows the formula of the F1-score.
The accuracy of a model is the total number of correct predictions. The number of correct predictions divided by all predictions provides the accuracy of the model, the accuracy of a model is calculated using Eq. (18).
Performance measures of the proposed model are listed in Table 3.
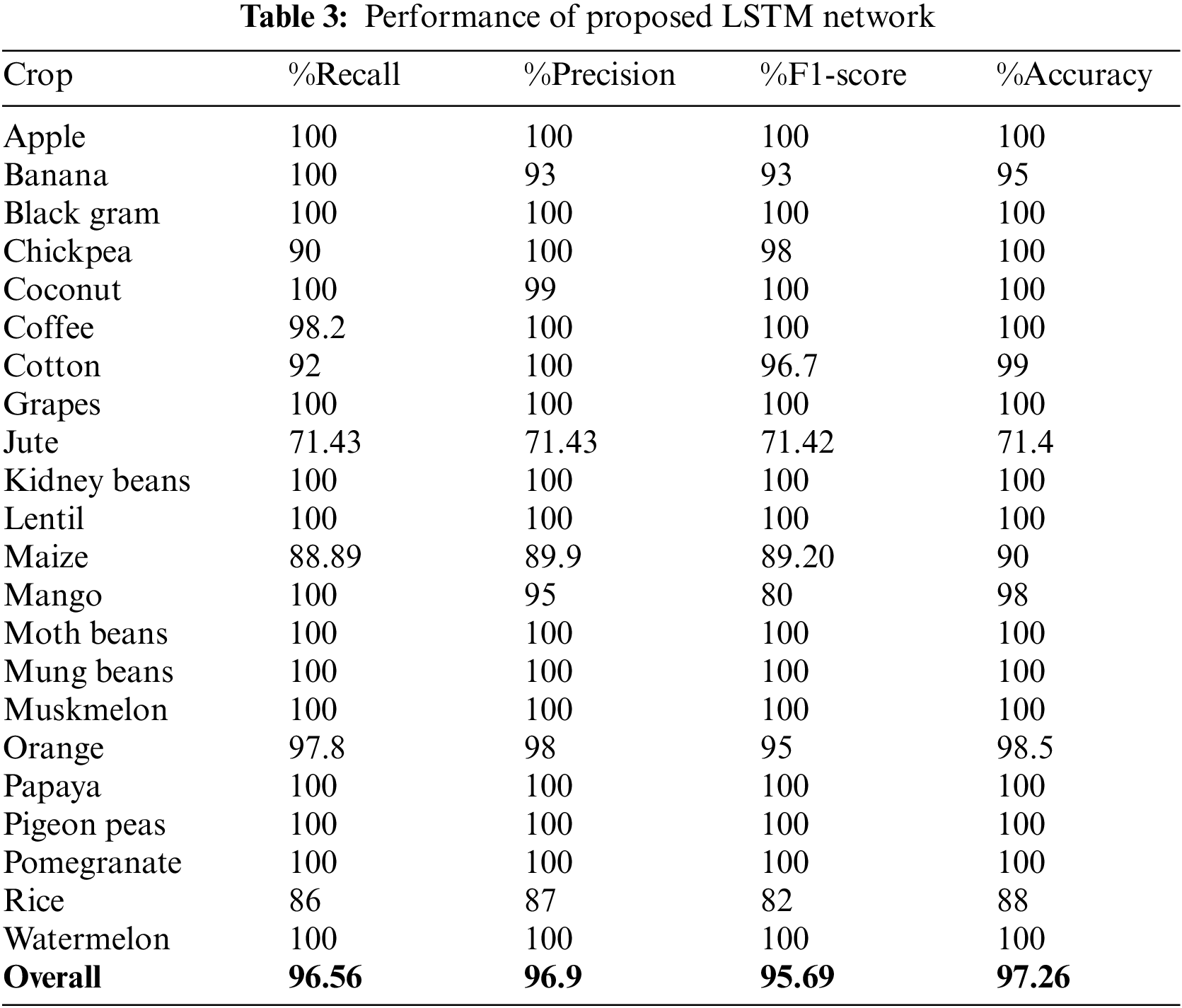
The precision of the model is the Percentage of all accurately classified crops [39]. F1-Score shows the accuracy of the model. The proposed LSTM provides 97.26% accuracy. The diagonal of the confusion matrix has high values so, it shows that the proposed LSTM provides high accuracy. The confusion matrix of the proposed LSTM is represented in Fig. 6.
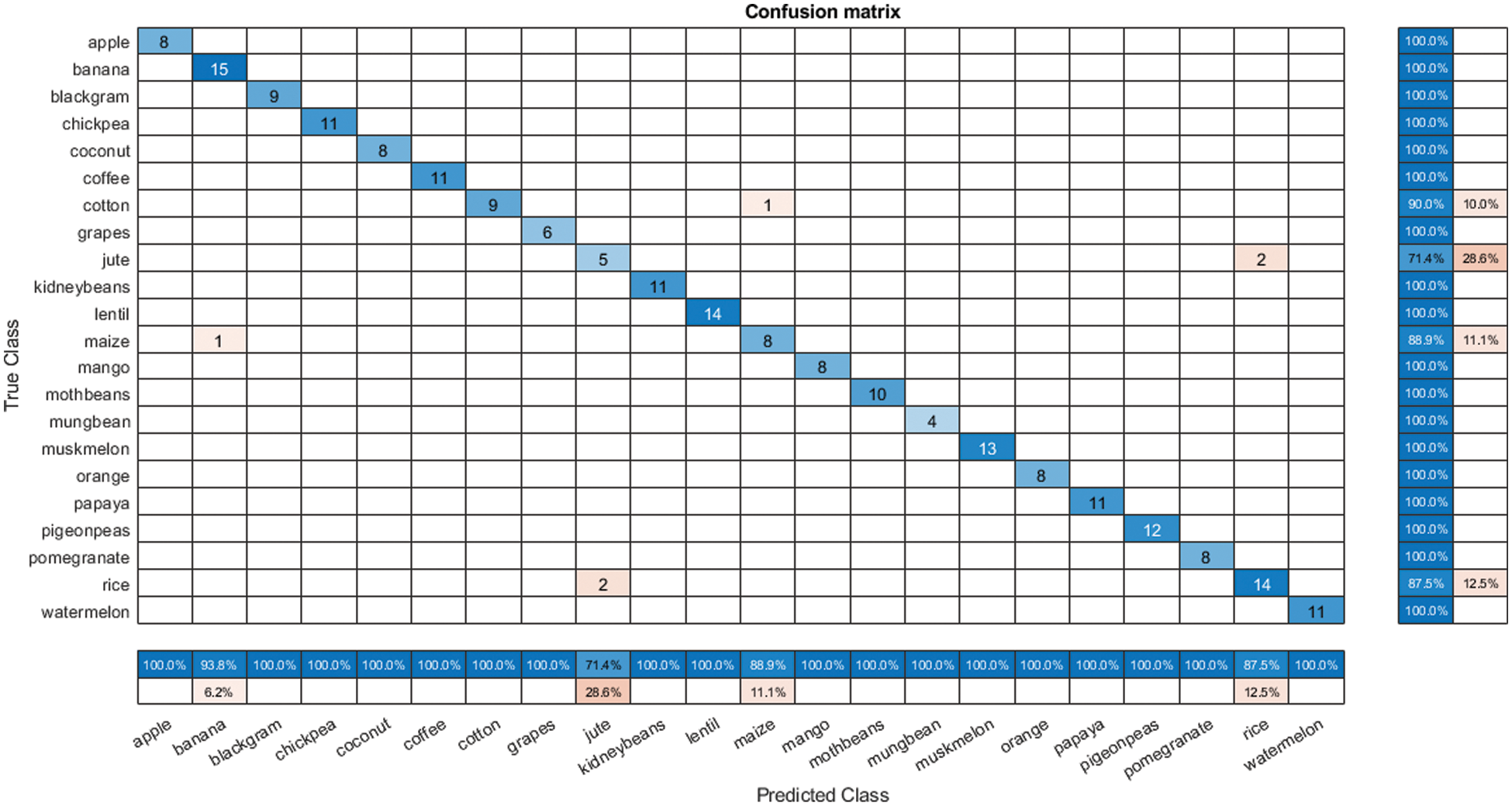
Figure 6: Confusion matrix of proposed LSTM
4.4 Comparison with Existing Techniques
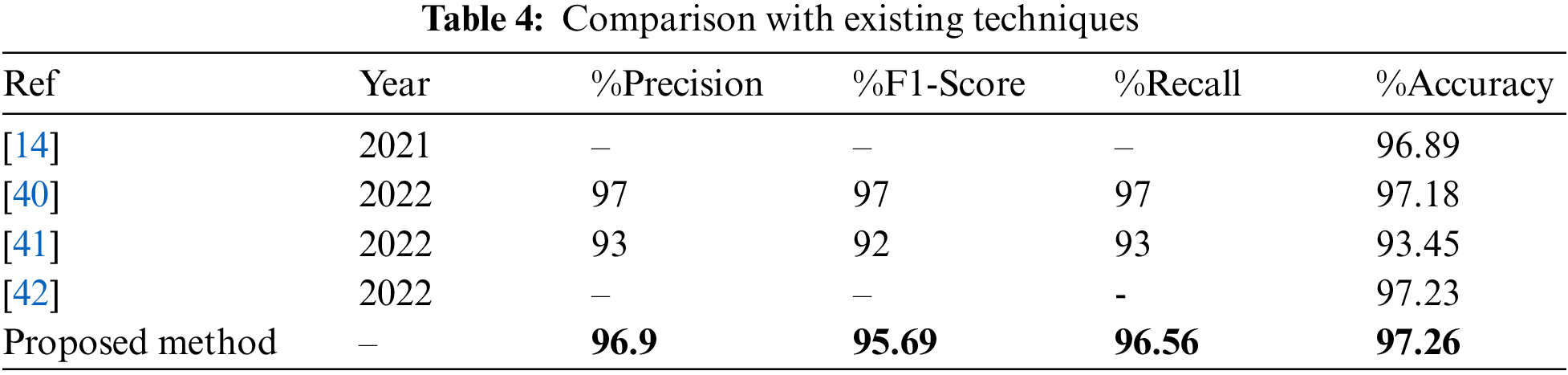
Precision farming using ML was demonstrated by Navod Neranjan in [40]. The crop recommendation platform was based on machine learning to assist farmers in selecting suitable crops based on local environmental conditions. The dataset was sourced from Kaggle and all features related to crop growth were selected during the feature selection process. Same dataset “crop recommendation” was used that contains twenty two different classes and seven input features. The authors conducted exploratory data analysis and used five ML models for predictive data analysis, with the Random Forest model being the most efficient, achieving an accuracy score of 97.18% and precision, recall, and F1 scores of 97%.
The aim of [41] study was to introduce a precise farming that helps to reduce manual labour and increased productivity. “Crop recommendation” dataset was used to train the model and the dataset included temperature, humidity, rainfall, soil pH, and ratios of nitrogen, potassium, and phosphorous as features and twenty-two different crops. Descriptive analytics were conducted to determine the optimum predictive model, giving insight into how the dataset appeared. Missing values were examined, and none were found for the crop suggestion dataset’s attributes. Multiple ML models were used, including SVM, Naive Baiye, KNN, Decision tree, lbgm, and Boost classifier. The lbgm classifier performed the best with 93.45% accuracy. Azmin et al. in [42], used the “crop recommendation” dataset that contains 22 different classes of crops. The features used in dataset are Nitrogen, Phosphorous, and Potassium content in soil, as well as temperature, humidity, and pH value and Rainfall. The data was in numerical form with continuous values and underwent pre-processing, revealing no missing values. Three models, Random Forest, KNN, and Naive Bayes classifier, were trained to predict the ideal crop, and Random Forest had the best performance, achieving 97.23% accuracy. The comparison of Proposed Long short-term memory in terms of precision, recall, f1-score, and accuracy is listed in Table 4.
Farmers should abandon traditional farming practices since they may result in a decline in crops yield. Therefore, farmers, today must accept the contemporary, and technological methods of agriculture. One of the most crucial methods for advising farmers on the growing of a crop that is appropriate for their environment is crop recommendation. In this article, an automatic crop expert system using improved LSTM with an attention block is introduced that will help farmers to grow the crop that is more suitable for their environment. Although there exist many deep learning and machine learning techniques that provide farmers the new technology for decision-making, however, they are less accurate and include fewer number of classes [43]. More particularly, Machine learning models may produce inaccurate results on unseen data due to their training set size. Moreover, machine learning models are difficult to customize, and challenging to change the parameters of machine learning models. The LSTM method has an attention block to overcome the problem of the vanishing and exploding gradient in the standard LSTM. The Proposed LSTM has two branches a main branch and a skip connection branch that is used to highlight only relevant activation during training. The attention block in the proposed LSTM reduces the computational resources that are wasted on irrelevant activations. LSTM is more tailored, and the parameters of the LSTM can easily be customized. The total number of parameters W in a standard LSTM network with one cell in each memory block and the learning computational complexity per time step is “O (W)”.Thus, twenty-two distinct crops are employed in this article, and seven input features are used to recommend the best crop for cultivation. However, more features, such as Sulphur, zinc, magnesium, boon, copper, nitrogen, and electric conductivity, can be included to improve the system’s accuracy for the system to be more effective [44]. The Following are the parameters used in the proposed LSTM during training Table 5.
Farmers should leave the traditional method of farming as the traditional method may cause a loss of production in the agriculture field. Now a day’s farmers need to adopt modern and technology-based ways of agriculture. There exist many deep learning and machine learning techniques that provide farmers the new technology for farming. Recommendation of a crop is one of the most important techniques that provide suggestions to farmers about the cultivation of a crop that is suitable for their environment. Geographical location, soil type, and cop type are some of the factors that are considered for the crop recommendation system. In this paper, we proposed a novel customized long short-term memory model based on a deep neural network for the recommendation of the most suitable crop using seven input features such as ph., humidity, rainfall, nitrogen, potassium, phosphorus, and temperature. Twenty-two different types of crops are recommended based on these 7 input features. Our proposed long short-term memory-based model outperforms the existing models for the recommendation of crops and provides 97.26% accuracy, 96.9% precision, 95.69% f1-score, and 96.56% recall. Therefore, our proposed system will help the farmers in the selection of the right crop according to their soil type and environmental features like temperature, rainfall, humidity, and soil characteristics like nitrogen, potassium, and phosphorus. In the future, we aim to provide mobile application and a web interface for the proposed system. Moreover, the farmer’s experience and consumer market are the two features that can be added to make this model more reliable.
Acknowledgement: The researchers would like to thank the Deanship of Scientific Research, Qassim University for funding the publication of this project.
Funding Statement: The researchers would like to thank the Deanship of Scientific Research, Qassim University for funding the publication of this project.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. N. H. Kulkarni, G. N. Srinivasan, B. M. Sagar and N. K. Cauvery, “Improving crop productivity through a crop recommendation system using ensembling technique,” in 2018 3rd Int. Conf. on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Bengaluru, India, pp. 114–119, 2018. [Google Scholar]
2. J. Lacasta, F. J. Lopez-Pellicer, B. Espejo-Garcı́a, J. Nogueras-Iso and F. J. Zarazaga-Soria, “Agricultural recommendation system for crop protection,” Computers and Electronics in Agriculture, vol. 152, no. 4, pp. 82–89, 2018. [Google Scholar]
3. A. A. Chandio, J. Yuansheng and H. Magsi, “Agricultural sub-sectors performance: An analysis of sector-wise share in agriculture GDP of Pakistan,” International Journal of Economics and Finance, vol. 8, no. 2, pp. 156–162, 2016. [Google Scholar]
4. S. S. Attaluri, N. K. Batcha and R. Mafas, “Crop plantation recommendation using feature extraction and machine learning techniques,” Journal of Applied Technology and Innovation (e-ISSN 2600-7304), vol. 4, pp. 1, 2020. [Google Scholar]
5. M. J. Mokarrama and M. S. Arefin, “RSF: A recommendation system for farmers,” in 2017 IEEE Region 10 Humanitarian Technology Conf. (R10-HTC), Dhaka, Bangladesh, pp. 843–850, 2017. [Google Scholar]
6. D. Dighe, H. Joshi, A. Katkar, S. Patil and S. Kokate, “Survey of crop recommendation systems,” in IRJET, India, vol. 5, pp. 476–481, 2018. [Google Scholar]
7. M. Garanayak, G. Sahu, S. N. Mohanty and A. K. Jagadev, “Agricultural recommendation system for crops using different machine learning regression methods,” International Journal of Agricultural and Environmental Information Systems (IJAEIS), vol. 12, pp. 1–20, 2021. [Google Scholar]
8. K. Shinde, J. Andrei and A. Oke, “Web based recommendation system for farmers,” International Journal on Recent and Innovation Trends in Computing and Communication, vol. 3, no. 3, pp. 41–52, 2015. [Google Scholar]
9. M. Shinde, K. Ekbote, S. Ghorpade, S. Pawar and S. Mone, “Crop recommendation and fertilizer purchase system,” International Journal of Computer Science and Information Technologies, vol. 7, pp. 665–667, 2016. [Google Scholar]
10. P. A. S. Chakraborty, A. Kumar and O. R. Pooniwala, “Intelligent crop recommendation system using machine learning,” in 2021 5th Int. Conf. on Computing Methodologies and Communication (ICCMC), Erode, India, IEEE, pp. 843–848, 2021. [Google Scholar]
11. Z. Jin, R. Prasad, J. Shriver and Q. Zhuang, “Crop model-and satellite imagery-based recommendation tool for variable rate N fertilizer application for the US corn system,” Precision Agriculture, vol. 18, no. 5, pp. 779–800, 2017. [Google Scholar]
12. H. Zhang, L. Zhang, Y. Ren, J. Zhang, X. Xu et al., “Design and implementation of crop recommendation fertilization decision system based on WEBGIS at village scale,” in Int. Conf. on Computer and Computing Technologies in Agriculture, Nanchang, China, pp. 357–364, 2010. [Google Scholar]
13. N. Patil, S. Kelkar, M. Ranawat and M. Vijayalakshmi, “Krushi Sahyog: Plant disease identification and crop recommendation using artificial intelligence,” in 2021 2nd Int. Conf. for Emerging Technology (INCET), Belagavi, India, pp. 1–6, 2021. [Google Scholar]
14. K. Anguraj, B. Thiyaneswaran, G. Megashree, J. P. Shri, S. Navya et al., “Crop recommendation on analyzing soil using machine learning,” Turkish Journal of Computer and Mathematics Education, vol. 12, no. 6, pp. 1784–1791, 2021. [Google Scholar]
15. G. Suresh, A. S. Kumar, S. Lekashri and R. Manikandan, “Efficient crop yield recommendation system using machine learning for digital farming,” International Journal of Modern Agriculture, vol. 10, pp. 906–914, 2021. [Google Scholar]
16. S. Jaiswal, T. Kharade, N. Kotambe, S. Shinde, M. D. Patil et al., “Collaborative recommendation system for agriculture sector,” ITM Web of Conferences, vol. 32, no. 3, pp. 3034, 2020. [Google Scholar]
17. Z. Doshi, S. Nadkarni, R. Agrawal and N. Shah, “AgroConsultant: Intelligent crop recommendation system using machine learning algorithms,” in 2018 Fourth Int. Conf. on Computing Communication Control and Automation (ICCUBEA), Pune, India, pp. 1–6, 2018. [Google Scholar]
18. T. Banavlikar, A. Mahir, M. Budukh and S. Dhodapkar, “Crop recommendation system using neural networks,” International Research Journal of Engineering and Technology (IRJET), vol. 5, pp. 1475–1480, 2018. [Google Scholar]
19. A. Chougule, V. K. Jha and D. Mukhopadhyay, “Crop suitability and fertilizers recommendation using data mining techniques,” in Progress in Advanced Computing and Intelligent Engineering, Berlin, Springer, pp. 205–213, 2019. [Google Scholar]
20. K. R. Akshatha and K. S. Shreedhara, “Implementation of machine learning algorithms for crop recommendation using precision agriculture,” International Journal of Research in Engineering, Science and Management (IJRESM), vol. 1, pp. 58–60, 2018. [Google Scholar]
21. P. Bandara, T. Weerasooriya, T. Ruchirawya, W. Nanayakkara, M. Dimantha et al., “Crop recommendation system,” International Journal of Computer Applications, vol. 975, pp. 8887, 2020. [Google Scholar]
22. D. A. Reddy, B. Dadore and A. Watekar, “Crop recommendation system to maximize crop yield in Ramtek region using machine learning,” International Journal of Scientific Research in Science and Technology, vol. 6, pp. 485–489, 2019. [Google Scholar]
23. D. A. Bondre and S. Mahagaonkar, “Prediction of crop yield and fertilizer recommendation using machine learning algorithms,” International Journal of Engineering Applied Sciences and Technology, vol. 4, no. 5, pp. 371–376, 2019. [Google Scholar]
24. R. K. Rajak, A. Pawar, M. Pendke, P. Shinde, S. Rathod et al., “Crop recommendation system to maximize crop yield using machine learning technique,” International Research Journal of Engineering and Technology, vol. 4, pp. 950–953, 2017. [Google Scholar]
25. J. Madhuri and M. Indiramma, “Artificial neural networks based integrated crop recommendation system using soil and climatic parameters,” Indian Journal of Science and Technology, vol. 14.19, pp. 1587–1597, 2021. [Google Scholar]
26. A. Arooj, M. Riaz and M. N. Akram, “Evaluation of predictive data mining algorithms in soil data classification for optimized crop recommendation,” in 2018 Int. Conf. on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, pp. 1–6, 2018. [Google Scholar]
27. A. Kumar, S. Sarkar and C. Pradhan, “Recommendation system for crop identification and pest control technique in agriculture,” in 2019 Int. Conf. on Communication and Signal Processing (ICCSP), Chennai, India, pp. 0185–0189, 2019. [Google Scholar]
28. K. Archana and K. G. Saranya, “Crop yield prediction, forecasting and fertilizer recommendation using voting based ensemble classifier,” SSRG International Journal of Computer Science and Engineering, vol. 7, pp. 1–4, 2020. [Google Scholar]
29. G. Dhruvi, C. Raval, R. Nayak and H. Jayswal, “Crop recommendation system using machine learning,” International Journal of Scientific Research in Computer Science, Engineering and Information Technology, vol. 7, pp. 558–569, 2021. [Google Scholar]
30. A. Gupta, D. Nagda, P. Nikhare and A. Sandbhor, “Smart crop prediction using IoT and machine learning,” International Journal of Engineering Research & Technology (IJERT), vol. 9, pp. 18–21, 2021. [Google Scholar]
31. M. Bouni, B. Hssina, K. Douzi and S. Douzi, “Towards an efficient recommender systems in smart agriculture: A deep reinforcement learning approach,” Procedia Computer Science, vol. 203, no. 5, pp. 825–830, 2022. [Google Scholar]
32. S. Iniyan, V. A. Varma and C. T. Naidu, “Crop yield prediction using machine learning techniques,” Advances in Engineering Software, vol. 175, no. 2, pp. 103326, 2023. [Google Scholar]
33. L. Bao, X. Liu, F. Wang and B. Fang, “ACTGAN: Automatic configuration tuning for software systems with generative adversarial networks,” in 2019 34th IEEE/ACM Int. Conf. on Automated Software Engineering (ASE), Piscataway, IEEE, pp. 465–476, 2019. [Google Scholar]
34. H. Huang and L. V. Yaming, “Short-term tie-line power prediction based on CNN-LSTM,” in 2020 IEEE 4th Conf. on Energy Internet and Energy System Integration (EI2), Wuhan, China, pp. 4118–4122, 2020. [Google Scholar]
35. R. Sharma, V. Agarwal, S. Sharma and M. S. Arya, “An LSTM-based fake news detection system using word embeddings-based feature extraction,” in ICT Analysis and Applications, Berlin, Springer, pp. 247–255, 2021. [Google Scholar]
36. Y. -S. Ting, Y. -F. Teng and T. -D. Chiueh, “Batch normalization processor design for convolution neural network training and inference,” in 2021 IEEE Int. Symp. on Circuits and Systems (ISCAS), Daegu, Korea, pp. 1–4, 2021. [Google Scholar]
37. W. Na, K. Liu, W. Zhang, H. Xie and D. Jin, “Deep neural network with batch normalization for automated modeling of microwave components,” in 2020 IEEE MTT-S Int. Conf. on Numerical Electromagnetic and Multiphysics Modeling and Optimization (NEMO), Hangzhou, China, pp. 1–3, 2020. [Google Scholar]
38. A. Ingle, “Crop recommendation dataset [Dataset],” 2022. [Google Scholar]
39. R. Mahum, H. Munir, Z. -U. -N. Mughal, M. Awais, F. Sher Khan et al., “A novel framework for potato leaf disease detection using an efficient deep learning model,” Human and Ecological Risk Assessment: An International Journal, vol. 29, pp. 1–24, 2022. [Google Scholar]
40. N. N. Thilakarathne, M. S. A. Bakar, P. E. Abas and H. Yassin, “A cloud enabled crop recommendation platform for machine learning-driven precision farming,” Sensors, vol. 22, no. 16, pp. 6299, 2022. [Google Scholar] [PubMed]
41. S. K. S. Durai and M. D. Shamili, “Smart farming using machine learning and deep learning techniques,” Decision Analytics Journal, vol. 3, pp. 100041, 2022. [Google Scholar]
42. S. N. F. L. M. Azmin and N. Arbaiy, “Soil classification based on machine learning for crop suggestion,” Journal of Soft Computing and Data Mining, vol. 3, pp. 79–91, 2022. [Google Scholar]
43. A. Priyadharshini, S. Chakraborty, A. Kumar and O. R. Pooniwala, “Intelligent crop recommendation system using machine learning,” in 2021 5th Int. Conf. on Computing Methodologies and Communication (ICCMC), Erode, India, pp. 843–848, 2021. [Google Scholar]
44. G. Banerjee, U. Sarkar and I. Ghosh, “A fuzzy logic-based crop recommendation system,” in Proc. of Int. Conf. on Frontiers in Computing and Systems, India, pp. 57–69, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools